Post Syndicated from Sam Marsh original http://blog.cloudflare.com/ttfb-is-not-what-it-used-to-be/


Today, we’re making the case for why Time To First Byte (TTFB) is not a good metric for evaluating how fast web pages load. There are better metrics out there that give a more accurate representation of how well a server or content delivery network performs for end users. In this blog, we’ll go over the ambiguity of measuring TTFB, touch on more meaningful metrics such as Core Web Vitals that should be used instead, and finish on scenarios where TTFB still makes sense to measure.
Many of our customers ask what the best way would be to evaluate how well a network like ours works. This is a good question! Measuring performance is difficult. It’s easy to simplify the question to “How close is Cloudflare to end users?” The predominant metric that’s been used to measure that is round trip time (RTT). This is the time it takes for one network packet to travel from an end user to Cloudflare and back. We measure this metric and mention it from time to time: Cloudflare has an average RTT of 50 milliseconds for 95% of the Internet-connected population.
Whilst RTT is a relatively good indicator of the quality of a network, it doesn’t necessarily tell you that much about how good it is at actually delivering actual websites to end users. For instance, what if the web server is really slow? A user might be very close to the data center that serves the traffic, but if it takes a long time to actually grab the asset from disk and serve it the result will still be a poor experience.
This is where TTFB comes in. It measures the time it takes between a request being sent from an end user until the very first byte of the response being received. This sounds great on paper! However it doesn’t capture how a webpage or web application loads, and what happens after the first byte is received.
In this blog we’ll cover what TTFB is a good indicator of, what it's not great for, and what you should be using instead.
What is TTFB?
TTFB is a metric which reports the duration between sending the request from the client to a server for a given file, and the receipt of the first byte of said file. For example, if you were to download the Cloudflare logo from our website the TTFB would be how long it took to receive the first byte of that image. Similarly, if you were to measure the TTFB of a request to cloudflare.com the metric would return the TTFB of how long it took from request to receiving the first byte of the first HTTP response. Not how long it took for the image to be fully visible or for the web page to be loaded in a state that allowed a user to begin using it.
The simplest answer therefore is to look at the diametrically opposite measurement, Time to Last Byte (TTLB). TTLB, as you’d expect, measures how long it takes until the last byte of data is received from the server. For the Cloudflare logo file this would make sense, as until the image is fully downloaded it's not exactly useful. But what about for a webpage? Do you really need to wait until every single file is fully downloaded, even those images at the bottom of the page you can't immediately see? TTLB is fine for measuring how long it took to download a single file from a CDN / server. However for multi-faceted traffic, like web pages, it is too conservative, as it doesn’t tell you how long it took for the web page to be usable.
As an analogy we can look at measuring how long it takes to process an incoming airplane full of passengers. What's important is to understand how long it takes for those passengers to disembark, pass through passport control, collect their baggage and leave the terminal, if no onward journeys. TTFB would measure success as how long it took to get the first passenger off of the airplane. TTLB would measure how long it took the last passenger to leave the terminal, even if this passenger remained in the terminal for hours afterwards due to passport issues or getting lost. Neither are a good measure of success for the airline.
Why TTFB doesn't make sense
TTFB is a widely-used metric because it is easy-to-understand and it is a great signal for connection setup time, server time and network latency. It can help website owners identify when performance issues originate from their server. But is TTFB a good signal for how real users experience the loading speed of a web page in a browser?
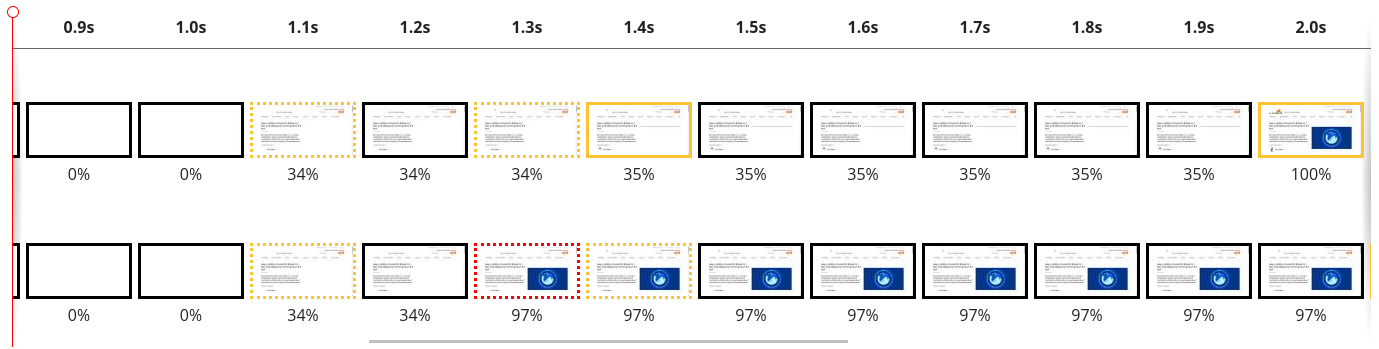
When a web page loads in a browser, the user’s perception of speed isn’t related to the moment the browser first receives bytes of data. It is related to when the user starts to see the page rendering on the screen.
The loading of a web page in a browser is a very complex process. Almost all of this process happens after TTFB is reported. After the first byte has been received, the browser still has to load the main HTML file. It also has to load fonts, stylesheets, javascript, images and other resources. Often these resources link to other resources that also must be downloaded. Often these resources entirely block the rendering of the page. Alongside all these downloads, the browser is also parsing the HTML, CSS and JavaScript. It is building data structures that represent the content of the web page as well as how it is styled. All of this is in preparation to start rendering the final page onto the screen for the user.
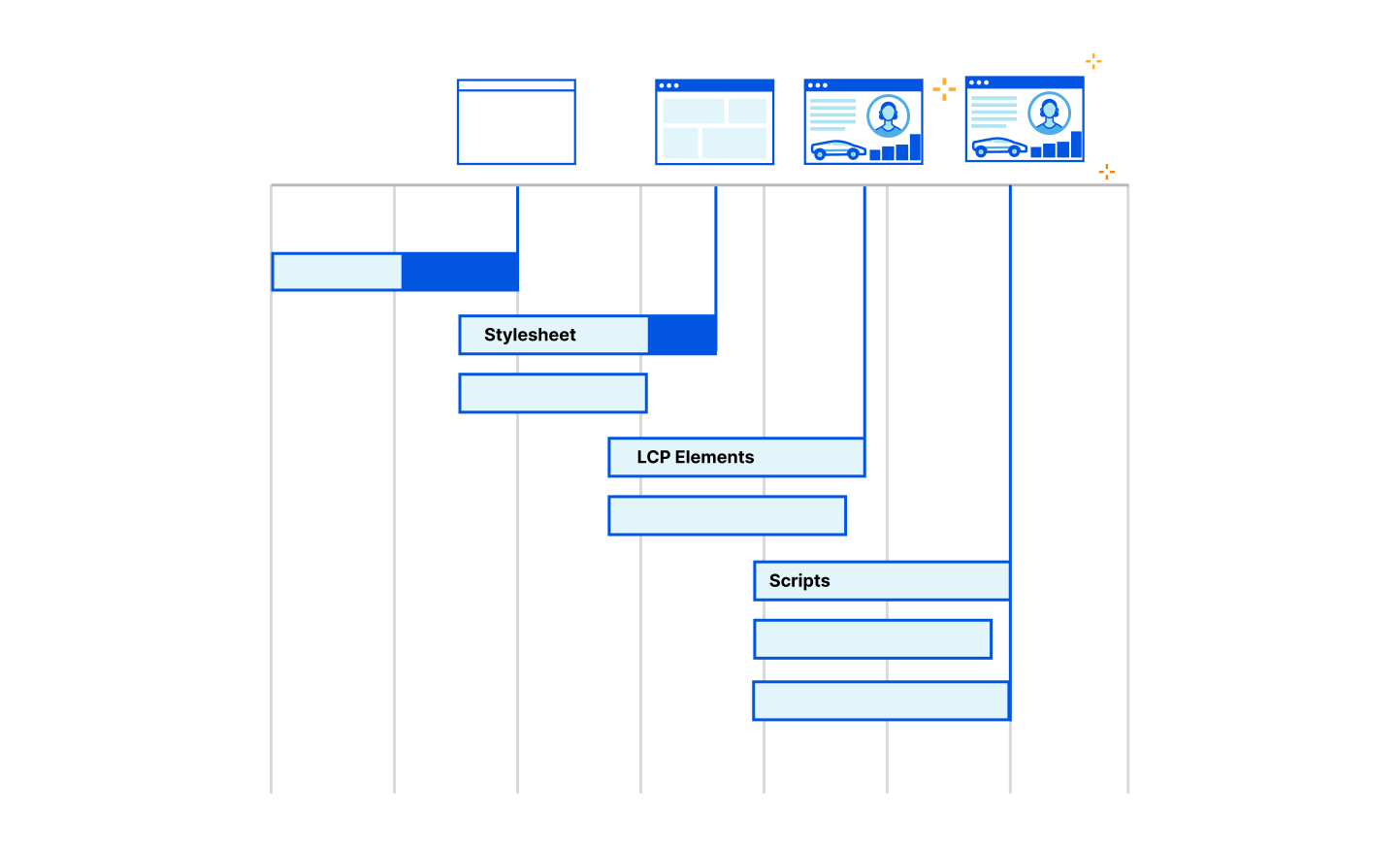
When the user starts seeing the web page actually rendered on the screen, TTFB has become a distant memory for the browser. For a metric that signals the loading speed as perceived by the user, TTFB falls dramatically short.
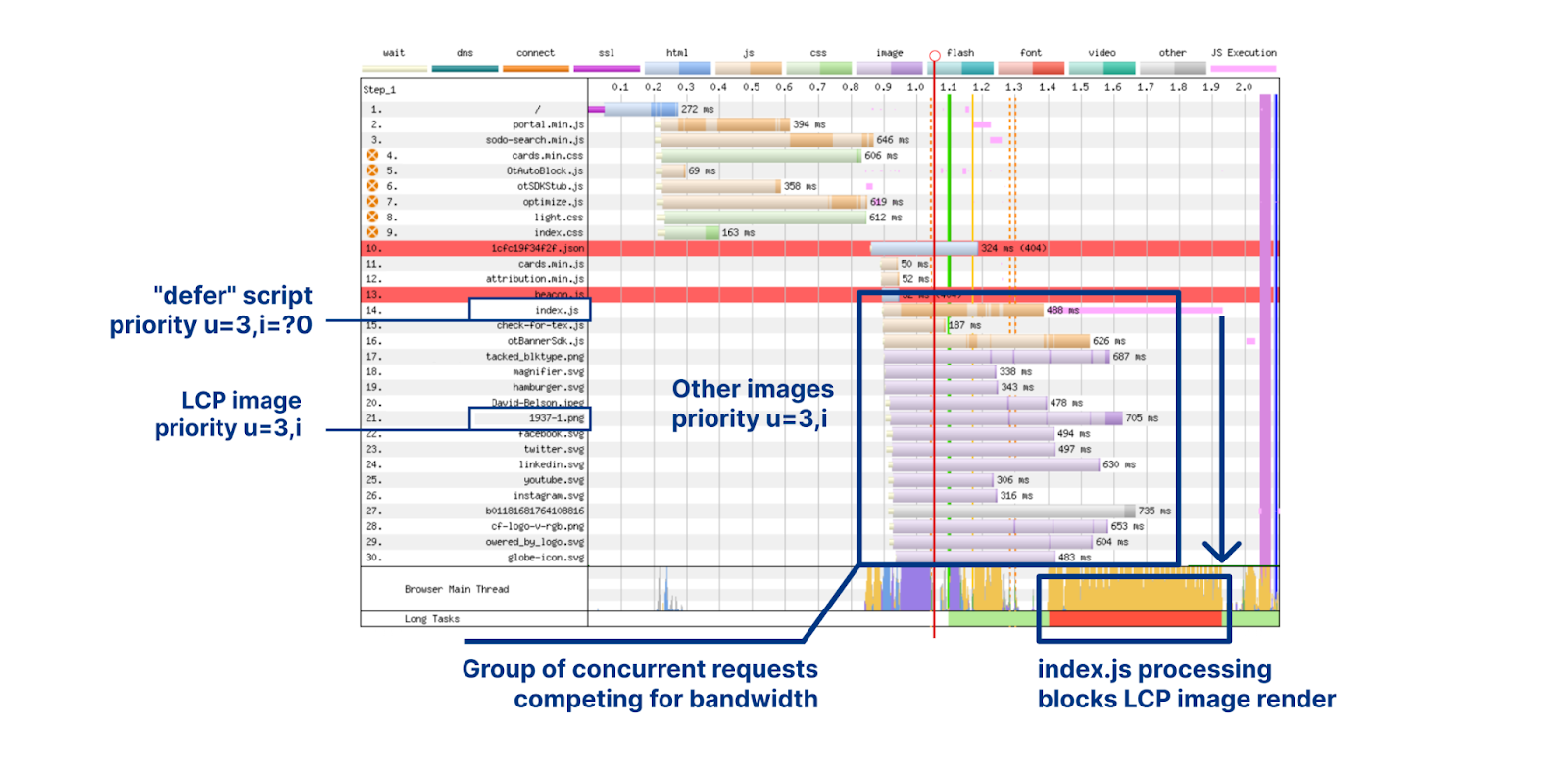
Receiving the first byte isn't sufficient to determine a good end user experience as most pages have additional render blocking resources that get loaded after the initial document request. Render-blocking resources are scripts, stylesheets, and HTML imports that prevent a web page from loading quickly. From a TTFB perspective it means the client could stop the ‘TTFB clock’ on receipt of the first byte of one of these files, but the web browser is blocked from showing anything to the user until the remaining critical assets are downloaded.
This is because browsers need instructions for what to render and what resources need to be fetched to complete “painting” a given web page. These instructions come from a server response. But the servers sending these responses often need time to compile these resources — this is known as “server think time.” While the servers are busy during this time… browsers sit idle and wait. And the TTFB counter goes up.
There have been a number of attempts over the years to benefit from this “think time”. First came Server Push, which was superseded last year by Early Hints. Early Hints take advantage of “server think time” to asynchronously send instructions to the browser to begin loading resources while the origin server is compiling the full response. By sending these hints to a browser before the full response is prepared, the browser can figure out what it needs to do to load the webpage faster for the end user. It also stops the TTFB clock, meaning a lower TTFB. This helps ensure the browser gets the critical files sooner to begin loading the webpage, and it also means the first byte is delivered sooner as there is no waiting on the server for the whole dataset to be prepared and ready to send. Even with Early Hints, though, TTFB doesn’t accurately define how long it took the web page to be in a usable state.
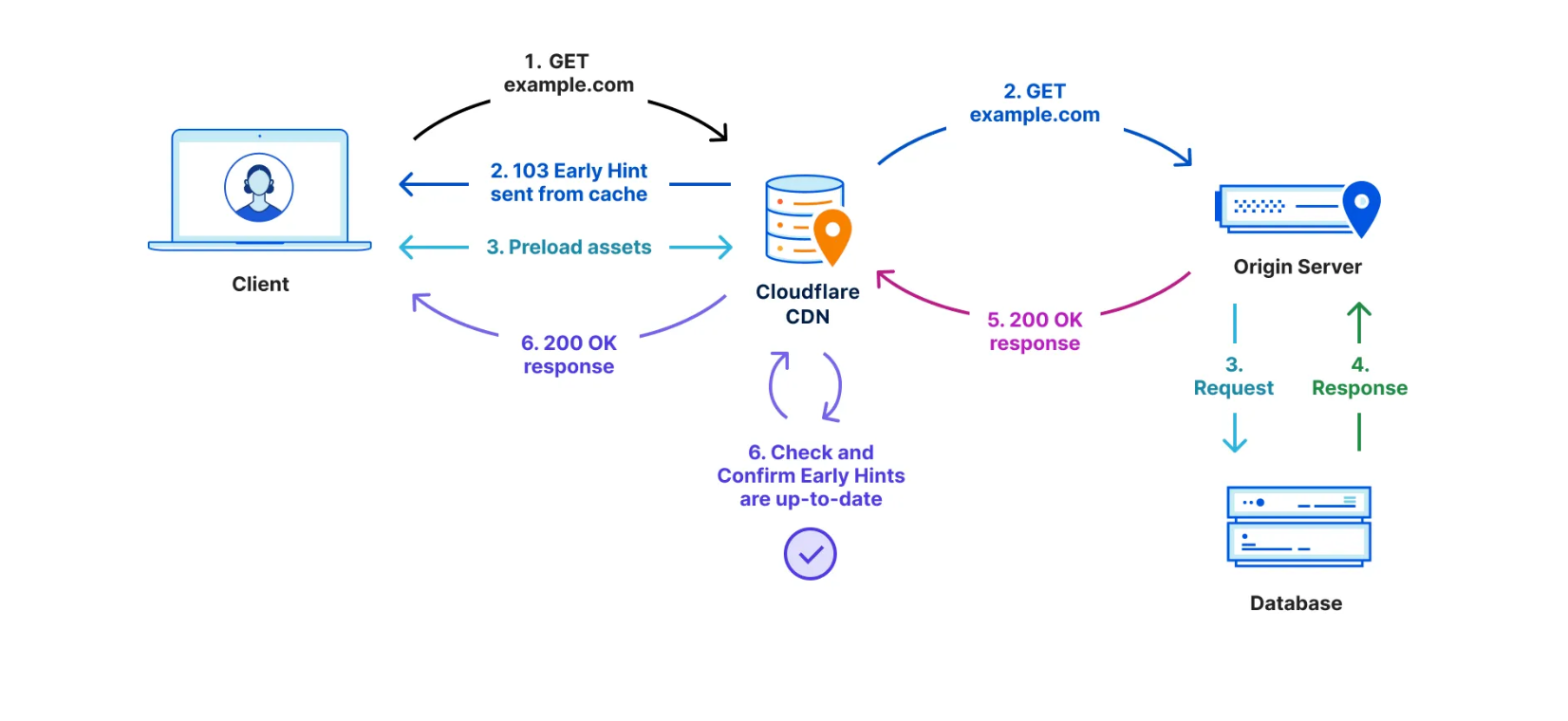
TTFB also does not take into account multiplexing benefits of HTTP/2 and HTTP/3 which allow browsers to load files in parallel. It also doesn't take into account compression on the origin, which would result in a higher TTFB but a quicker page load overall due to the time the server took to compress the assets and send them in a small format over the network.
Cloudflare offers many features that can improve the loading speed of a website, but don’t necessarily impact the TTFB score. These features include Zaraz, Rocket Loader, HTTP/2 and HTTP/3 Prioritization, Mirage, Polish, Image Resizing, Auto Minify and Cache. These features improve the loading time of a webpage, ensuring they load optimally through a series of enhancements from image optimization and compression to render blocking elimination by optimizing the sending of assets from the server to the browser in the best possible order.
More comprehensive metrics are required to illustrate the full loading process of a web page, and the benefit provided by these features. This is where Real User Monitoring helps. At Cloudflare we are all-in on Real User Monitoring (RUM) as the future of website performance. We’re investing heavily in it: both from an observation point of view and from an optimization one also.
For those unfamiliar with RUM, we typically optimize websites for three main metrics – known as the “Core Web Vitals”. This is a set of key metrics which are believed to be the best and most accurate representation of a poorly performing website vs a well performing one. These key metrics are Largest Contentful Paint, First Input Delay and Cumulative Layout Shift.

LCP measures loading performance; typically how long it takes to load the largest image or text block visible in the browser. FID measures interactivity. For example, the time between when a user clicks or taps on a button to when the browser responds and starts doing something. Finally, CLS measures visual stability. A good, or bad example of CLS is when you go to a website on your mobile phone, tap on a link and the page moves at the last second meaning you tap something you didn't want to. That would be a lower CLS score as its poor user experience.
Looking at these metrics gives us a good idea of how the end user is truly experiencing your website (RUM) vs. how quickly the first byte of the file was retrieved from the nearest Cloudflare data center (TTFB).
Good TTFB, bad user experience
One of the “sub parts” that comprise LCP is TTFB. That means a poor TTFB is very likely to result in a poor LCP. If it takes you 20 seconds to retrieve the first byte of the first image, your user isn't going to have a good experience – regardless of your outlook on TTFB vs RUM.
Conversely, we found that a good TTFB does not always mean a good LCP score, or FID or CLS. We ran a query to collect RUM metrics of web pages we served which had a good TTFB score. Good is defined as a TTFB as less than 800ms. This allowed us to ask the question: TTFB says these websites are good. Does the RUM data support that?
We took four distinct samples from our RUM data in June. Each sample had a different date-range and sample-rate combination. In each sample we queried for 200,000 page views. From these 200,000 page views we filtered for only the page views that reported a 'Good' TTFB. Across the samples, of all page views that have a good TTFB, about 21% of them did not have a “good” LCP score. 46% of them did not have a “good” FID score. And 57% of them did not have a good CLS score.
This clearly shows the disparity between measuring the time it takes to receive the first byte of traffic, vs the time it takes for a webpage to become stable and interactive. In summary, LCP includes TTFB but also includes other parts of the loading experience. LCP is a more comprehensive, user-centric metric.
TTFB is not all bad
Reading this post and others from Speed Week 2023 you may conclude we really don't like TTFB and you should stop using it. That isn't the case.
There are a few situations where TTFB does matter. For starters, there are many applications that aren’t websites. File servers, APIs and all sorts of streaming protocols don’t have the same semantics as web pages and the best way to objectively measure performance is to in fact look at exactly when the first byte is returned from a server.
To help optimize TTFB for these scenarios we are announcing Timing Insights, a new analytics tool to help you understand what is contributing to "Time to First Byte" (TTFB) of Cloudflare and your origin. Timing Insights breaks down TTFB from the perspective of our servers to help you understand what is slow, so that you can begin addressing it.
Get started with RUM today
To help you understand the real user experience of your website we have today launched Cloudflare Observatory – the new home of performance at Cloudflare.
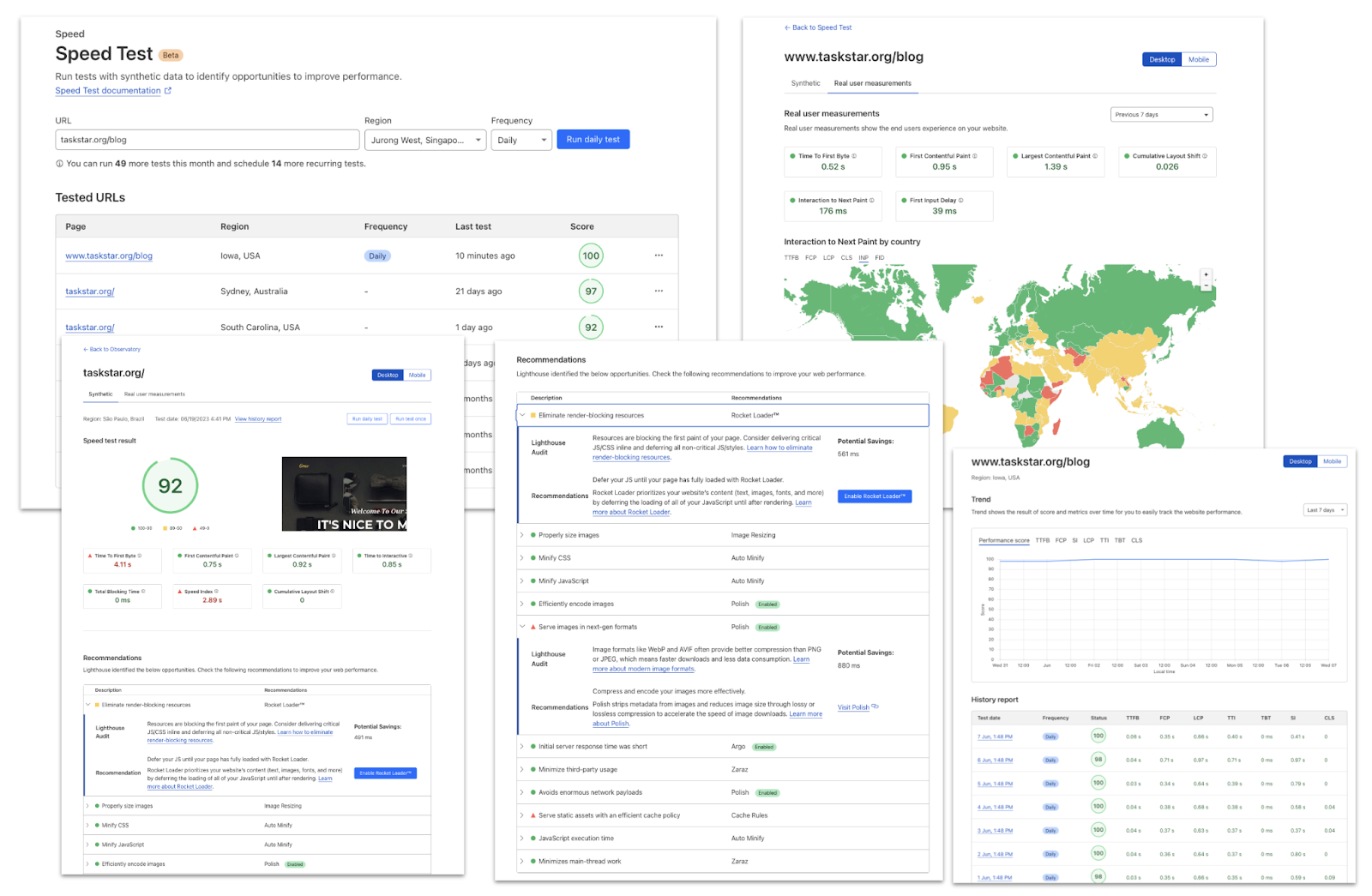
Cloudflare users can now easily monitor website performance using Real User Monitoring (RUM) data along with scheduled synthetic tests from different regions in a single dashboard. This will identify any performance issues your website may have. The best bit? Once we’ve identified any issues, Observatory will highlight customized recommendations to resolve these issues, all with a single click.
Start making your website faster today with Observatory.