Post Syndicated from Elliott Sims original https://www.backblaze.com/blog/new-open-source-tool-for-consistency-in-cassandra-migrations/
Sometimes you find a problem because something breaks, and other times you find a problem the good way—by thinking it through before things break. This is a story about one of those bright, shining, lightbulb moments when you find a problem the good way.
On the Backblaze Site Reliability Engineering (SRE) team, we were thinking through an upcoming datacenter migration in Cassandra. We were running through all of the various types of queries we would have to do when we had the proverbial “aha” moment. We discovered an inconsistency in the way Cassandra handles lightweight transactions (LWTs).
If you’ve ever tried to do a datacenter migration in Cassandra and something got corrupted in the process but you couldn’t figure out why or how—this might be why. I’m going to walk through a short intro on Cassandra, how we use it, and the issue we ran into. Then, I’ll explain the workaround, which we open sourced.
Get the Open Source Code
You can download the open source code from our Git repository. We’d love to know how you’re using it and how it’s working for you—let us know in the comments.
How We Use Cassandra
First, if you’re not a Cassandra dev, I should mention that when we say “datacenter migration” it means something slightly different in Cassandra than what it sounds like. It doesn’t mean a data center migration in the physical sense (although you can use datacenter migrations in Cassandra when you’re moving data from one physical data center to another). In the simplest terms, it involves moving data between two Cassandra or Cassandra-compatible database replica sets within a cluster.
And, if you’re not familiar with Cassandra at all, it’s an open-source, NoSQL, distributed database management system. It was created to handle large amounts of data across many commodity servers, so it fits our use case—lots of data, lots of servers.
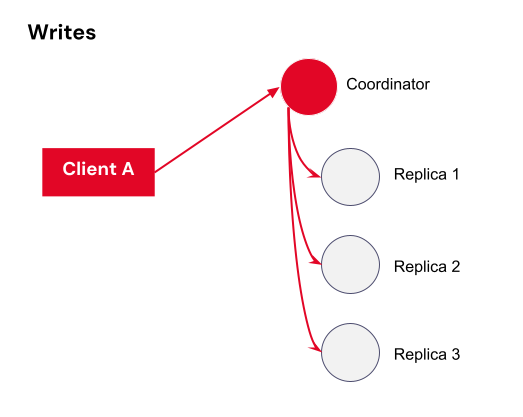
At Backblaze, we use Cassandra to index filename to location for data stored in Backblaze B2, for example. Because it’s customer data and not just analytics, we care more about durability and consistency than some other applications of Cassandra. We run with three replicas in a single datacenter and “batch” mode to require writes to be committed to disk before acknowledgement rather than the default “periodic.”
Datacenter migrations are an important aspect of running Cassandra, especially on bare metal. We do a few datacenter migrations per year either for physical data moves, hardware refresh, or to change certain cluster layout parameters like tokens per host that are otherwise static.
What Are LWTs and Why Do They Matter for Datacenter Migrations in Cassandra?
First of all, LWTs are neither lightweight nor transactions, but that’s neither here nor there. They are an important feature in Cassandra. Here’s why.
Cassandra is great at scaling. In something like a replicated SQL cluster, you can add additional replicas for read throughput, but not writes. Cassandra scales writes (as well as reads) nearly linearly with the number of hosts—into the hundreds. Adding nodes is a fairly straightforward and “automagic” process as well, with no need to do something like manual token range splits. It also handles individual down nodes with little to no impact on queries. Unfortunately, these properties come with a trade-off: a complex and often nonintuitive consistency model that engineers and operators need to understand well.
In a distributed database like Cassandra, data is replicated across multiple nodes for durability and availability.
Although databases generally allow multiple reads and writes to be submitted at once, they make it look to the outside world like all the operations are happening in order, one at a time. This property is known as serializability, and Cassandra is not serializable. Although it does have a “last write wins” system, there’s no transaction isolation and timestamps can be identical.
It’s possible, for example, to have a row that has some columns from one write and other columns from another write. It’s safe if you’re only appending additional rows, but mutating existing rows safely requires careful design. Put another way, you can have two transactions with different data that, to the system, appear to have equal priority.
How Do LWTs Solve This Problem?
As a solution for cases where stronger consistency is needed, Cassandra has a feature called “Lightweight Transactions” or LWTs. These are not really identical to traditional database transactions, but provide a sort of “compare and set” operation that also guarantees pending writes are completed before answering a read. This means if you’re trying to change a row’s value from “A” to “B”, a simultaneous attempt to change that row from “A” to “C” will return a failure. This is accomplished by doing a full—not at all lightweight—Paxos round complete with multiple round trips and slow expensive retries in the event of a conflict.
In Cassandra, the minimum consistency level for read and write operations is ONE, meaning that only a single replica needs to acknowledge the operation for it to be considered successful. This is fast, but in a situation where you have one down host, it could mean data loss, and later reads may or may not show the newest write depending on which replicas are involved and whether they’re received the previous write. For better durability and consistency, Cassandra also provides various quorum levels that require a response from multiple replicas, as well as an ALL consistency that requires responses from every replica.
Cassandra Is My Type of Database
Curious to know more about consistency limitations and LWTs in Cassandra? Christopher Batey’s presentation at the 2016 Cassandra Summit does a good job of explaining the details.
The Problem We Found With LWTs During Datacenter Migrations
Usually we use one datacenter in Cassandra, but there are circumstances where we sometimes stand up a second datacenter in the cluster and migrate to it, then tear down the original. We typically do this either to change num_tokens, to move data when we’re refreshing hardware, or to physically move to another nearby data center.
The TL:DR
We reasoned through the interaction between LWTs/serial and datacenter migrations and found a hole—there’s no guarantee of LWT correctness during a topology change (that is, a change to the number of replicas) large enough to change the number of replicas needed to satisfy quorum. It turns out that combining LWTs and datacenter migrations can violate consistency guarantees in subtle ways without some specific steps and tools to work around it.
The Long Version
Let’s say you are standing up a new datacenter, and you need to copy an existing datacenter to it. So, you have two datacenters—datacenter A, the existing datacenter, and datacenter B, the new datacenter. Let’s say datacenter A has three replicas you need to copy for simplicity’s sake, and you’re using quorum writes to ensure consistency.
Refresher: What is Quorum-Based Consistency in Cassandra?
Quorum consistency in Cassandra is based on the concept that a specific number of replicas must participate in a read or write operation to ensure consistency and availability—a majority (n/2 +1) of the nodes must respond before considering the operation as successful. This ensures that the data is durably stored and available even if a minority of replicas are unavailable.
You have different types of quorum you can choose from, and here’s how those defaults make a decision:
- Local quorum: Two out of the three replicas in the datacenter I’m talking to must respond in order to return success. I don’t care about the other datacenter.
- Global quorum: Four out of the six total replicas must respond in order to return success, and it doesn’t matter which datacenter they come from.
- Each quorum: Two out of the three replicas in each datacenter must respond in order to return success.
Most of these quorum types also have a serial equivalent for LWTs.
| Type of Quorum | Serial | Regular |
|---|---|---|
| Local | LOCAL_SERIAL |
LOCAL_QUORUM |
| Each | unsupported | EACH_QUORUM |
| Global | SERIAL |
QUORUM |
The problem you might run into, however, is that LWTs do not have an each_serial mode. They only have local and global. There’s no way to tell the LWT you want quorum in each datacenter.
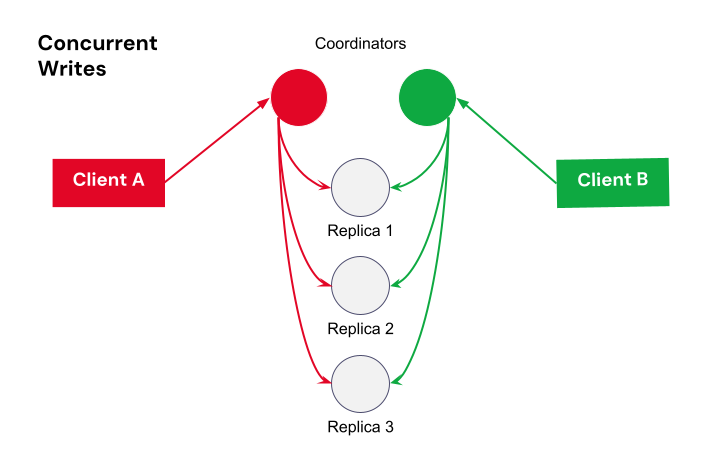
local_serial is good for performance, but transactions on different datacenters could overlap and be inconsistent. serial is more expensive, but normally guarantees correctness as long as all queries agree on cluster size. But what if a query straddles a topology change that changes quorum size?
Let’s use global quorum to show how this plays out. If a LWT starts when RF=3, at least two hosts must process it.
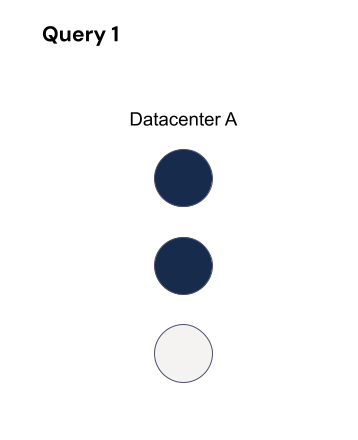
While it’s running, the topology changes to two datacenters (A and B) each with RF=3 (so six replicas total) with a quorum of four. There’s a chance that a query affecting the same partition could then run without overlapping nodes, which means consistency guarantees are not maintained for those queries. For that query, quorum is four out of six where those four could be the three replicas in datacenter B and the remaining replica in datacenter A.
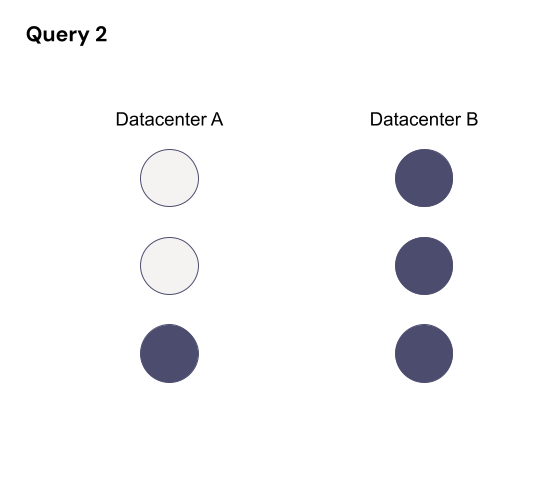
Those two queries are on the same partition, but they’re not overlapping any hosts, so they don’t know about each other. It violates the LWT guarantees.
The Solution to LWT Inconsistency
What we needed was a way to make sure that the definition of “quorum” didn’t change too much in the middle of a LWT running. Some change is okay, as long as old and new are guaranteed to overlap.
To account for this, you need to change the replication factor one level at a time and make sure there are no transactions still running that started before the previous topology change before you make the next. Three replicas with a quorum of two can only change to four replicas with a quorum of three. That way, at least one replica must overlap. The same thing happens when you go from four to five replicas or five to six replicas. This also applies when reducing the replication factor, such as when tearing down the old datacenter after everything has moved to the new one.
Then, you just need to make sure no LWT overlaps multiple changes. You could just wait long enough that they’ve timed out, but it’s better to be sure. This requires querying the internal-only system.paxos table on each host in the cluster between topology changes.
We built a tool that checks to see whether there are still transactions running from before we made a topology change. It reads system.paxos on each host, ignoring any rows with proposal_ballot=null, and records them. Then after a short delay, it re-reads system.paxos, ignoring any rows that weren’t present in the previous run, or any with proposal_ballot=null in either read, or any where in_progress_ballot has changed. Any remaining rows are potentially active transactions.
This worked well the first few times that we used it, on 3.11.6. To our surprise, when we tried to migrate a cluster running 3.11.10 the tool reported hundreds of thousands of long-running LWTs. After a lot of digging, we found a small (but fortunately well-commented) performance optimization added as part of a correctness fix (CASSANDRA-12126), which means proposal_ballot does not get set to null if the proposal is empty/noop. To work around this, we had to actually parse the proposal field. Fortunately all we need is the is_empty flag in the third field, so no need to reimplement the full parsing code. A big impact to us for a seemingly small and innocuous change piggy-backed onto a correctness fix, but that’s the risk of directly reading internal-only tables.
We’ve used the tool several times now for migrations with good results, but it’s still relatively basic and limited. It requires running repeatedly until all transactions are complete, and sometimes manual intervention to deal with incomplete transactions. In some cases we’ve been able to force-commit a long-pending LWT by doing a SERIAL read of the partition affected, but in a couple of cases we actually ended up running across LWTs that still didn’t seem to complete. Fortunately in every case so far it was in a temporary table and a little work allowed us to confirm that we no longer needed the partition at all and could just delete it.
Most people who use Cassandra may never run across this problem, and most of those who do will likely never track down what caused the small mystery inconsistency around the time they did a datacenter migration. If you rely on LWTs and are doing a datacenter migration, we definitely recommend going through the extra steps to guarantee consistency until and unless Cassandra implements an EACH_SERIAL consistency level.
Using the Tool
If you want to use the tool for yourself to help maintain consistency through datacenter migrations, you can find it here. Drop a note in the comments to let us know how it’s working for you and if you think of any other ways around this problem—we’re all ears!
If You’ve Made It This Far
You might be interested in signing up for our Developer Newsletter where our resident Chief Technical Evangelist, Pat Patterson, shares the latest and greatest ways you can use B2 Cloud Storage in your applications.
The post New Open Source Tool for Consistency in Cassandra Migrations appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.











 ︎
︎