Post Syndicated from Pat Patterson original https://www.backblaze.com/blog/building-a-conversational-ai-chatbot-website-with-backblaze-b2-langchain/

In an earlier blog post, I explained how to build your own LLM with Backblaze B2 + Jupyter Notebook, implementing a simple conversational AI chatbot using the LangChain AI framework to implement retrieval-augmented generation (RAG). The notebook walks you through the process of loading PDF files from a Backblaze B2 Bucket into a vector store, running a local instance of a large language model (LLM) and combining those to form a chatbot that can answer questions on its specialist subject.
That article generated a lot of interest, and a few questions:
- “Could you make this into a web app, like ChatGPT?”
- “Could you use this with OpenAI? DeepSeek?”
- “Could I load multiple collections of documents into this?”
- “Could I run multiple LLMs and compare them?”
- “Can I add new documents to the vector store as they are uploaded to the bucket?”
The answer to all of these questions is “Yes!”
Today, I’ll present a simple conversational AI chatbot web app with a ChatGPT-style UI that you can easily configure to work with OpenAI, DeepSeek, or any of a range of other LLMs. In future blog posts, I’ll extend this to allow you to configure multiple LLMs and document collections, and integrate with Backblaze B2’s Event Notifications feature to load documents into the vector store within seconds of them being uploaded.
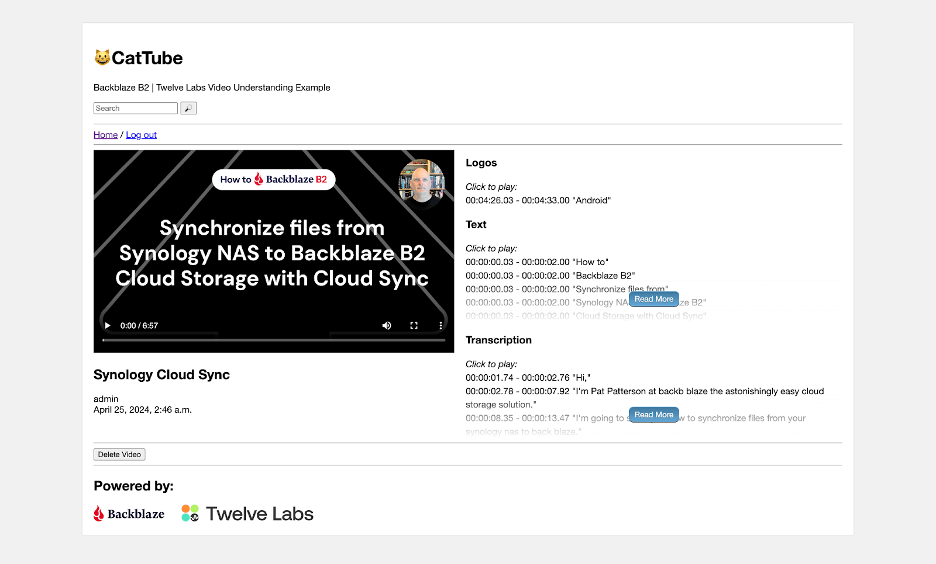
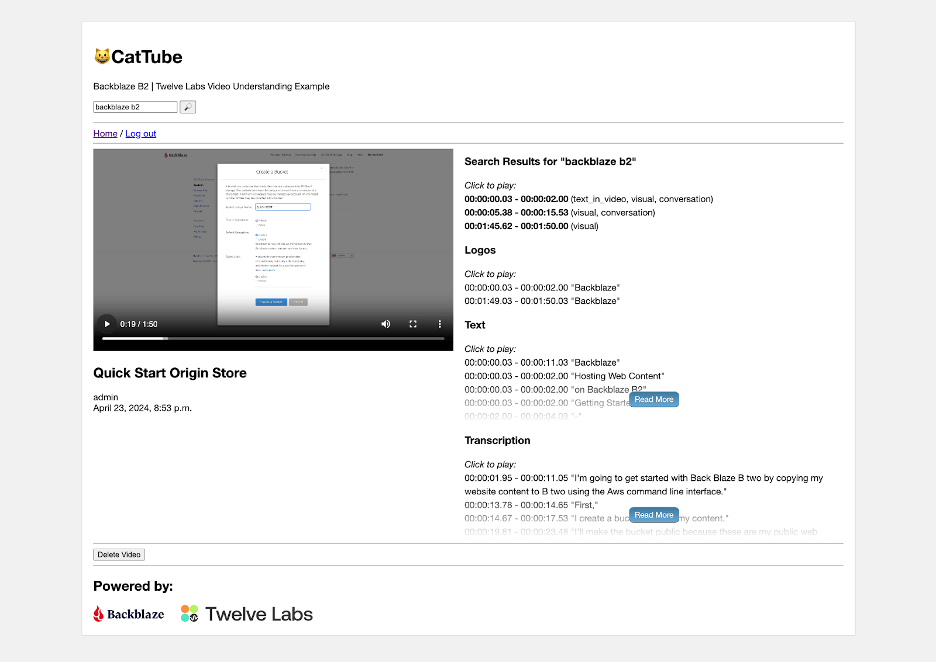
And, here’s a very short video of the chatbot in action:
RAG basics
Retrieval-augmented generation, or RAG for short, is a technique that applies the generative features of an LLM to a collection of documents, resulting in a chatbot that can effectively answer questions based on the content of those documents.
A typical RAG implementation splits each document in the collection into a number of roughly equal-sized, overlapping chunks, and generates an embedding for each chunk. Embeddings are vectors (lists) of floating point numbers with hundreds or thousands of dimensions. The distance between two vectors indicates their similarity. Small distances indicate high similarity and large distances indicate low similarity.
The RAG app then loads each chunk, along with its embedding, into a vector store. The vector store is a special-purpose database that can perform a similarity search–given a piece of text, the vector store can retrieve chunks ranked by their similarity to the query text by comparing the embeddings.
Let’s put the pieces together:
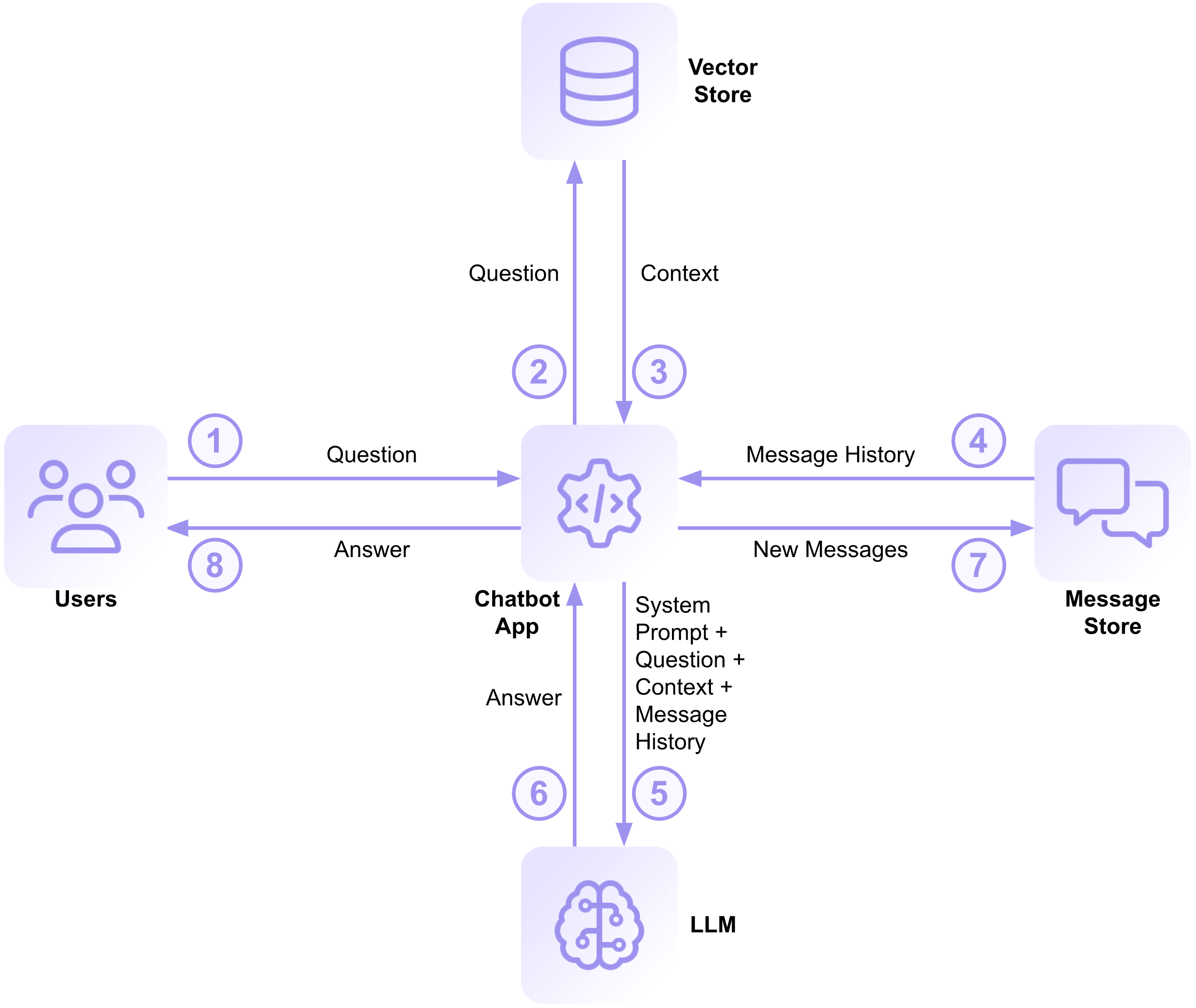
Given a question from the user (1), the RAG app can query the vector store for chunks of text that are similar to the question (2). This will be the context that helps the LLM answer the user’s question. Here’s a concrete example using the Backblaze documentation collection: Given the question, “Tell me about object lock,” the vector store returns four document chunks, each of about 170 words, to the app (3). Here is a link to the text of, and a short extract from, each chunk:
- Object Lock: With Object Lock Legal Hold, files are prevented from being changed or deleted, but the immutability does not have a defined retention period.
- Object Lock: You can enable Object Lock on a bucket when you create a new bucket or on an existing bucket.
- Object Lock: Object Lock in Backblaze B2 was designed with the Immutability feature in Veeam Backup & Replication in mind.
- Enable Object Lock with the S3 Compatible API: To enable Object Lock on an existing S3 compatible bucket, add the x-amz-bucket-object-lock-token header with a value of 1 to the S3 Put Object Lock Configuration API call.
Unsurprisingly, three of the four results are extracts from the main documentation article on Object Lock.
In order to provide a conversational experience, the RAG app maintains a chat history in a message store. The RAG app retrieves the message history (4) to form part of the query it will send to the LLM.
A system prompt sets the guidelines for the LLM to generate responses. In a RAG, the system prompt typically specifies that the response should be based on retrieved document data rather than model memorization, and attempts to prevent hallucinations by ensuring that the model does not fabricate information if no relevant documents are found. Here is the system prompt from the RAG app:
Use the following pieces of context and the message history to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
The RAG submits the system prompt, the context, the last few messages in the conversation, and the user’s question to the LLM (5), which generates a, hopefully useful, response (6). Here’s the answer it provided to the above question:
Object Lock is a feature that allows users to enforce immutability on files stored in cloud storage, specifically in services like Backblaze B2 and AWS S3. Here are the key points about Object Lock:
- Immutability: Once a file is locked, it cannot be modified or deleted until a specified retention period expires or a legal hold is lifted.
- Retention Periods: Users can set a retention period when locking a file. During this time, the file remains immutable, meaning it cannot be changed or deleted.
- Legal Hold: Users can place files under a legal hold, which prevents modifications or deletions indefinitely until the hold is removed.
- Enabling Object Lock: Object Lock can be enabled for new buckets or existing ones, but it must be turned on at the bucket level before files are uploaded.
- Integrations: Some applications, like Veeam Backup & Replication, offer built-in support for Object Lock, making the process easier for users when they want to ensure file immutability during backups.
- No Extra Cost: There is no additional fee for using Object Lock; however, standard storage charges for the locked files still apply.
- Mistakes in Locking: If a user locks a file for longer than intended, they may need to contact support to resolve the situation, which could involve closing their storage account in some cases.
Overall, Object Lock is a crucial feature for organizations that need to ensure data integrity and compliance with regulations concerning data retention.
The RAG app adds the user’s question and the LLM’s response to the message store (7), returns the answer to the user (8), and awaits the next question.
A quick tour of the sample app
The sample app is on GitHub at https://github.com/backblaze-b2-samples/ai-rag-app. The app is open source, under the MIT license, so you can use it as a basis for your own experimentation without any restrictions. The app was originally written to demonstrate RAG with Backblaze B2 Cloud Storage, but it works with any S3 compatible object store.
The README file covers configuration and deployment in some detail; in this blog post, I’ll just give you a high-level overview. The sample app is written in Python using the Django web framework. API credentials and related settings are configured via environment variables, while the LLM and vector store are configured via Django’s settings.py file:
CHAT_MODEL: ModelSpec = {
'name': 'OpenAI',
'llm': {
'cls': ChatOpenAI,
'init_args': {
'model': "gpt-4o-mini",
}
},
}
# Change source_data_location and vector_store_location to match your environment
# search_k is the number of results to return when searching the vector store
DOCUMENT_COLLECTION: CollectionSpec = {
'name': 'Docs',
'source_data_location': 's3://blze-ev-ai-rag-app/pdfs',
'vector_store_location': 's3://blze-ev-ai-rag-app/vectordb/docs/openai',
'search_k': 4,
'embeddings': {
'cls': OpenAIEmbeddings,
'init_args': {
'model': "text-embedding-3-large",
},
},
}
The sample app is configured to use OpenAI GPT-4o mini, but the README explains how to use different online LLMs such as DeepSeek V3 or Google Gemini 2.0 Flash, or even a local LLM such as Meta Llama 3.1 via the Ollama framework. If you do run a local LLM, be sure to pick a model that fits your hardware. I tried running Meta’s Llama 3.3, which has 70 billion parameters (70B), on my MacBook Pro with the M1 Pro CPU. It took nearly three hours to answer a single question! Llama 3.1 8B was a much better fit, answering questions in less than 30 seconds.
Notice that the document collection is configured with the location of a vector store containing the Backblaze documentation as a sample dataset. The README file contains an application key with read-only access to the PDFs and vector store so you can try the application without having to load your own set of documents.
If you want to use your own document collection, a pair of custom commands allow you to load them from a Backblaze B2 Bucket into the vector store and then query the vector store to test that it all worked.
First, you need to load your data:
% python manage.py load_vector_store
Deleting existing LanceDB vector store at s3://blze-ev-ai-rag-app/vectordb/docs
Creating LanceDB vector store at s3://blze-ev-ai-rag-app/vectordb/docs
Loading data from s3://blze-ev-ai-rag-app/pdfs in pages of 1000 results
Successfully retrieved page 1 containing 618 result(s) from s3://blze-ev-ai-rag-app/pdfs
Skipping pdfs/.bzEmpty
Skipping pdfs/cloud_storage/.bzEmpty
Loading pdfs/cloud_storage/cloud-storage-about-backblaze-b2-cloud-storage.pdf
Loading pdfs/cloud_storage/cloud-storage-add-file-information-with-the-native-api.pdf
Loading pdfs/cloud_storage/cloud-storage-additional-resources.pdf
...
Loading pdfs/v1_api/s3-put-object.pdf
Loading pdfs/v1_api/s3-upload-part-copy.pdf
Loading pdfs/v1_api/s3-upload-part.pdf
Loaded batch of 614 document(s) from page
Split batch into 2758 chunks
[2025-02-28T01:26:11Z WARN lance_table::io::commit] Using unsafe commit handler. Concurrent writes may result in data loss. Consider providing a commit handler that prevents conflicting writes.
Added chunks to vector store
Added 614 document(s) containing 2758 chunks to vector store; skipped 4 result(s).
Created LanceDB vector store at s3://blze-ev-ai-rag-app/vectordb/docs. "vectorstore" table contains 2758 rows
Now you can verify that the data is stored by querying the vector store. Notice how the raw results from the vector store include an S3 URI identifying the source document:
% python manage.py search_vector_store 'Which B2 native APIs would I use to upload large files?'
2025-03-01 02:38:07,740 ai_rag_app.management.commands.search INFO Opening vector store at s3://blze-ev-ai-rag-app/vectordb/docs/openai
2025-03-01 02:38:07,740 ai_rag_app.utils.vectorstore DEBUG Populating AWS environment variables from the b2 profile
Found 4 docs in 2.30 seconds
2025-03-01 02:38:11,074 ai_rag_app.management.commands.search INFO
page_content='Parts of a large file can be uploaded and copied in parallel, which can significantly reduce the time it takes to upload terabytes of data. Each part can be anywhere from 5 MB to 5 GB, and you can pick the size that is most convenient for your application. For best upload performance, Backblaze recommends that you use the recommendedPartSize parameter that is returned by the b2_authorize_account operation. To upload larger files and data sets, you can use the command-line interface (CLI), the Native API, or an integration, such as Cyberduck. Usage for Large Files Generally, large files are treated the same as small files. The costs for the API calls are the same. You are charged for storage for the parts that you uploaded or copied. Usage is counted from the time the part is stored. When you call the b2_finish_large_file' metadata={'source': 's3://blze-ev-ai-rag-app/pdfs/cloud_storage/cloud-storage-large-files.pdf'}
...
The core of the sample application is the RAG class. There are several methods that create the basic components of the RAG, but here we’ll look at how the _create_chain() method brings together the system prompt, vector store, message history, and LLM.
First, we define the system prompt, which includes a placeholder for the context—those chunks of text that the RAG will retrieve from the vector store:
# These are the basic instructions for the LLM
system_prompt = (
"Use the following pieces of context and the message history to "
"answer the question at the end. If you don't know the answer, "
"just say that you don't know, don't try to make up an answer. "
"\n\n"
"Context: {context}"
)
Then we create a prompt template that brings together the system prompt, message history, and the user’s question:
# The prompt template brings together the system prompt, context, message history and the user's question
prompt_template = ChatPromptTemplate(
[
("system", system_prompt),
MessagesPlaceholder(variable_name="history", optional=True, n_messages=10),
("human", "{question}"),
]
)
Now we use LangChain Expression Language (LCEL) to bring the various components together to form a chain. LCEL allows us to define a chain of components declaratively; that is, we provide a high-level representation of the chain we want, rather than specifying how the components should fit together.
Notice the log_data() helper method—it simply logs its input and passes it on to the next component in the chain.
# Create the basic chain
# When loglevel is set to DEBUG, log_input will log the results from the vector store
chain = (
{
"context": (
itemgetter("question")
| retriever
| log_data('Documents from vector store', pretty=True)
),
"question": itemgetter("question"),
"history": itemgetter("history"),
}
| prompt_template
| model
| log_data('Output from model', pretty=True)
)
Assigning a name to the chain allows us to add instrumentation when we invoke it:
# Give the chain a name so the handler can see it
named_chain: Runnable[Input, Output] = chain.with_config(run_name="my_chain")
Now, we use LangChain’s RunnableWithMessageHistory class to manage adding and retrieving messages from the message store:
# Add message history management
return RunnableWithMessageHistory(
named_chain,
lambda session_id: RAG._get_session_history(store, session_id),
input_messages_key="question",
history_messages_key="history",
)
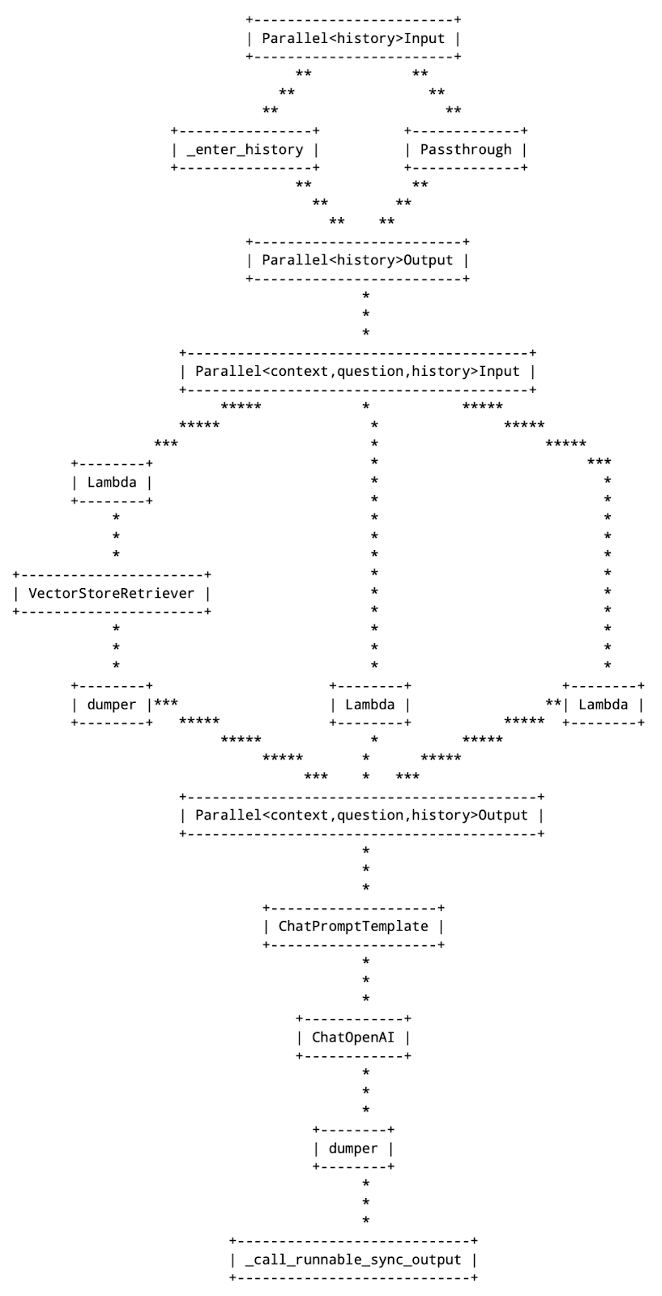
Finally, the log_chain() function prints an ASCII representation of the chain to the debug log:
log_chain(history_chain, logging.DEBUG, {"configurable": {'session_id': 'dummy'}})
This is the output:
The RAG class’ invoke() function, in contrast, is very simple. Here is the key section of code:
response = self._chain.invoke(
{"question": question},
config={
"configurable": {
"session_id": session_key
},
"callbacks": [
ChainElapsedTime("my_chain")
]
},
)
The input to the chain is a Python dictionary containing the question, while the config argument configures the chain with the Django session key and a callback that annotates the chain output with its execution time. Since the chain output contains Markdown formatting, the API endpoint that handles requests from the front end uses the open source markdown-it library to render the output to HTML for display.
The remainder of the code is mostly concerned with rendering the web UI. One interesting facet is that the Django view, responsible for rendering the UI as the page loads, uses the RAG’s message store to render the conversation, so if you reload the page, you don’t lose your context.
Take this code and run it!
The sample AI RAG application is open source under the MIT license, and I encourage you to use it as the basis for your own RAG exploration. The README file suggests a few ways you could extend it, and I also draw your attention to conclusion of the README if you are thinking of running the app in production:
[…] in order to get you started quickly, we streamlined the application in several ways. There are a few areas to attend to if you wish to run this app in a production setting:
- The app does not use a database for user accounts, or any other data, so there is no authentication. All access is anonymous. If you wished to have users log in, you would need to restore Django’s AuthenticationMiddleware class to the MIDDLEWARE configuration and configure a database.
- Sessions are stored in memory. As explained above, you can use Gunicorn to scale the application to multiple threads, but you would need to configure a Django session backend to run the app in multiple processes or on multiple hosts.
- Similarly, conversation history is stored in memory, so you would need to use a persistent message history implementation, such as RedisChatMessageHistory to run the app in multiple processes or on multiple hosts.
Above all, have fun! AI is a rapidly evolving technology, with vendors and open source projects releasing new capabilities every day. I hope you find this app a useful way of jumping in.
The post Building a Conversational AI Chatbot Website with Backblaze B2 + LangChain appeared first on Backblaze Blog | Cloud Storage & Cloud Backup






























{kind=link}