Post Syndicated from Kyle Shields original https://aws.amazon.com/blogs/security/optimize-security-operations-with-aws-security-incident-response/
Security threats demand swift action, which is why AWS Security Incident Response delivers AWS-native protection that can immediately strengthen your security posture. This comprehensive solution combines automated triage and evaluation logic with your security perimeter metadata to identify critical issues, seamlessly bringing in human expertise when needed. When Security Incident Response is integrated with Amazon GuardDuty and AWS Security Hub within a unified security environment, organizations gain 24/7 access to the AWS Customer Incident Response Team (CIRT) for rapid detection, expert analysis, and efficient threat containment—managed through one intuitive console. Security Incident Response is included with Amazon Managed Services (AMS), which helps organizations adopt and operate AWS at scale efficiently and securely.
In this post, we guide you through enabling Security Incident Response and executing a proof of concept (POC) to quickly enhance your security capabilities while realizing immediate benefits. We explore the service’s functionality, establish POC success criteria, define your configuration, prepare for deployment, enable the service, and optimize effectiveness from day one, helping your organization build confidence throughout the incident response lifecycle while improving recovery time.
Understanding the functionality of Security Incident Response
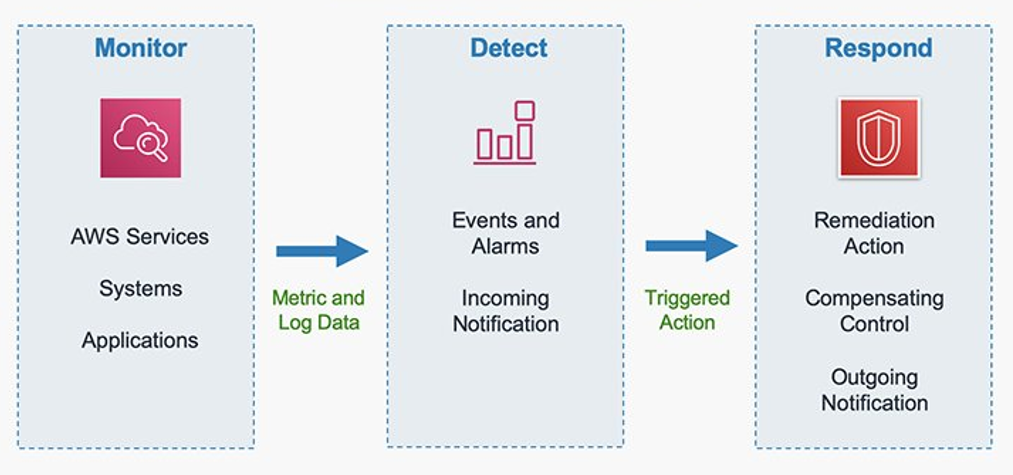
AWS Security Incident Response service provides comprehensive threat detection and response capabilities through a streamlined four-step process. It begins by ingesting security findings from GuardDuty and select Security Hub integrations with third-party tools. The service then automatically triages these findings using customer metadata and threat intelligence to identify anomalous behavior and suspicious activities. When potential threats are detected, CIRT members proactively investigate cases through the customer portal to determine whether they are true or false positives. For confirmed threats, the service escalates findings for immediate action, while false positives trigger updates to the auto-triage system and suppression rules for GuardDuty and Security Hub, continuously improving detection accuracy.
Comprehensive protection with minimal prerequisites
Security Incident Response delivers powerful security capabilities through seamless integration with both the AWS threat detection and incident response (TDIR) system and third-party security services such as CrowdStrike, Lacework, and TrendMicro. This solution provides a unified command center for end-to-end incident management—from planning and communication to resolution—while ingesting GuardDuty findings and integrating with external providers through Security Hub. With secure case management and an immutable activity timeline, it significantly enhances your security operations by augmenting your security operations center (SOC) and incident response (IR) teams with improved visibility and access to AWS-proven tools and personnel. The AWS CIRT works collaboratively with your responders during investigations and recovery, freeing your valuable resources for other priorities.
The service delivers continuous value through proactive monitoring and response capabilities. It constantly monitors your environment using GuardDuty and Security Hub findings, with service automation, triage, and analysis working diligently in the background to alert you only for genuine security concerns. This protection provides immediate value during potential incidents without demanding your constant attention.
Getting started is straightforward—the only prerequisite is having AWS Organizations enabled and making sure that you have established Organizations with a fundamental organizational unit (OU) structure encompassing member accounts. This foundation not only enables Security Incident Response deployment but also serves as the cornerstone for implementing a robust TDIR strategy across your organization.
Determine success criteria
Establishing success criteria helps benchmark the outcomes of the POC with the goals of the business. Some example criteria include:
- Designate an incident response team: Identity and document internal team members and external resources responsible for incident response. As highlighted in AWS Well-Architected Security Pillar, having designated personnel reduces triage and response times during security incidents.
- Develop a formal incident response framework: Develop a comprehensive incident response plan with detailed playbooks and regular table-top exercise protocols. AWS provides a reference library of playbooks on GitHub.
- Run tabletop exercises: Consider implementing regular simulations that test incident response plans, identify gaps, and build muscle memory across security teams before a real crisis occurs. AWS provides context on various types of tabletop exercises.
- Identify existing third-party security providers: Identify third-party security providers with Security Hub integrations that feed into Security Incident Response. AWS partners provide findings as documented at Detect and Analyze.
- Implement GuardDuty: Configure GuardDuty according to best practices to monitor and detect threats across critical services. AWS maintains GuardDuty best practices in AWS Security Services Best Practices for GuardDuty.
Review your success criteria to make sure that your goals are realistic given your timeframe and potential constraints that are specific to your organization. For example, do you have full control over the configuration of AWS services that are deployed in an organization? Do you have resources that can dedicate time to implement and test? Is this time convenient for relevant stakeholders to evaluate the service?
Define your Security Incident Response configuration
After establishing your success criteria and timeline, it’s best practice to define your Security Incident Response configuration. Some important decisions include the following:
- Select a delegated administrator account: Identify which account will serve as delegated administrator (DA) for Security Incident Response. This account and the AWS Region you select will host the Security Incident Response service and portal. AWS Security Reference Architecture (SRA) recommends using dedicated security tooling account. Review Important considerations and recommendations documentation before finalizing the DA.
- Define the account scope: Security Incident Response is considered an organization-level service. Every account in every Region within your organization is entitled to coverage under a single subscription. Service coverage automatically adjusts as accounts are added or removed, providing complete protection across your entire AWS footprint.
- Configure findings sources: Determine which security findings meet your organization’s needs. The service automatically ingests GuardDuty findings organization-wide and select Security Hub finding types from third-party partners. Evaluate which GuardDuty protection plans and Security Hub findings provide the most value for your security posture and incident response capabilities.
- Develop an escalation framework: Establish clear escalation thresholds for different case types: self-managed, AWS-supported, and proactive cases. Define who has authority to determine case submission and type based on severity, impact, and resource requirements.
- Implement analytics strategy: Determine whether to use native AWS analytics tools (such as Amazon Athena, Amazon OpenSearch, and Amazon Detective) or integrate with existing security information and event management (SIEM) solutions. These capabilities can enrich incident response with contextual data and deeper insights.
Prepare for deployment
After determining success criteria and Security Incident Response configuration, identify stakeholders, desired state, and timeframe. Prepare for deployment by completing:
- Project plan and timeline: Develop a project plan with defined success criteria, scope boundaries, key milestones, and realistic implementation timelines. Suggested timeline of events:
- Before enablement:
- Configure GuardDuty and Security Hub third parties, perform resource planning
- Request approvals for POC trial from the AWS account team or Service team
- Day 0 – Enable the service
- Week 1 – Open reactive CIRT cases
- Week 2 – Connect to IT service management (ITSM) tools
- Week 3 – Execute a tabletop exercise
- Week 4 – Review the reporting provided by CIRT
- Before enablement:
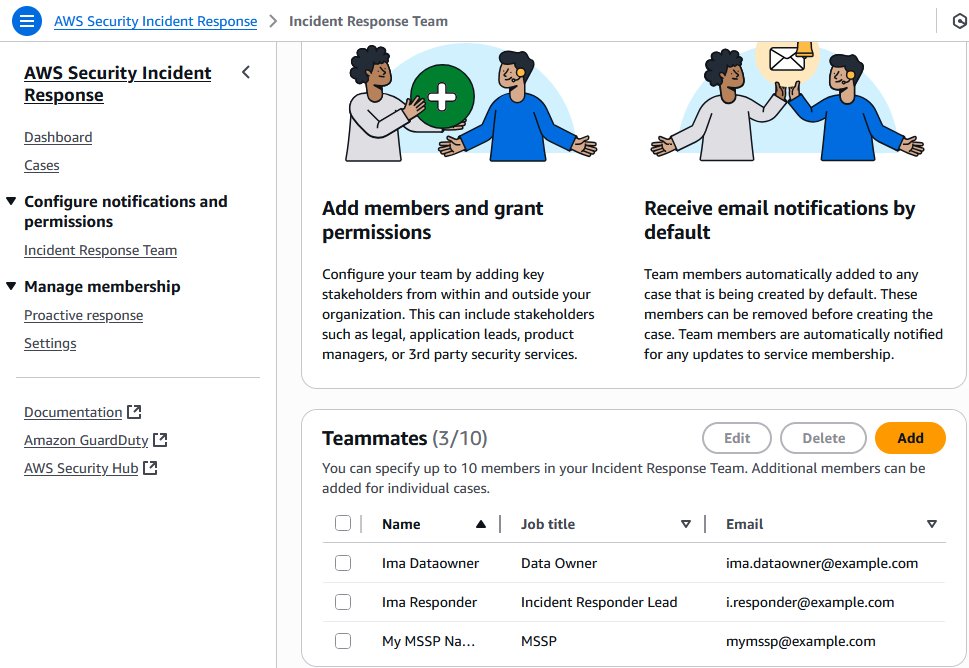
- Identify stakeholders: Identify CISO, information security teams, SOC personnel, incident response teams, security engineers, finance, legal, compliance, external MSSPs, and business unit representatives.
- Develop a RACI matric: Create detailed RACI chart defining roles and responsibilities across incident response lifecycle, facilitating accountability and proper communication channels.
- Configure management account access: Secure authorization to delegate administrative access. For more information, see Permissions required to designate a delegated Security Incident Response administrator account.
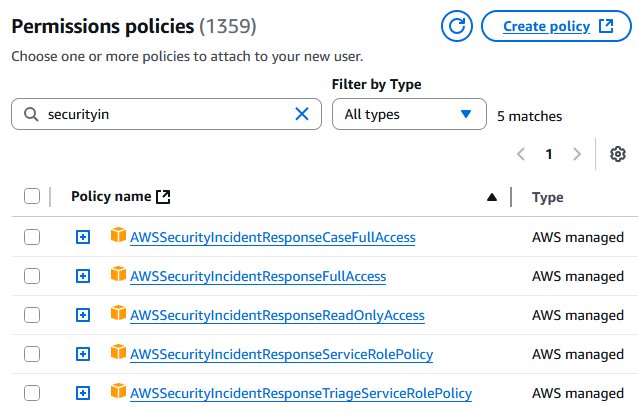
- Set up IAM roles and permissions: Use AWS Identity and Access Management (IAM) roles to implement role-based access controls aligned with the RACI chart, including case management, escalation, and read-only roles using AWS managed policies. For more information, see AWS Managed Policies
Enable Security Incident Response
With preparations in place, you are ready to enable the service.
Access Security Incident Response in the management account:
- Within the organization’s management account, go to the AWS Management Console and search for Security Incident Response in the console search bar.
- Choose Sign Up.
- Verify that Use delegated administrator account – Recommended is selected, enter the delegated administrator account number in the Account ID field, and choose Next.
- Sign in to the delegated administrator account configured in step 3, search for Security Incident Response, and choose Sign up.
Complete setup in the delegated administrator account:
- Define membership details:
- Select your home region under Region selection.
- For Membership name, enter a suitable name that follows your organization’s naming standards.
- Under Membership contacts, enter the Primary and Secondary contact information.
- Add Membership tags according to your organization’s tagging strategy.
- Choose Next.
- Configure permissions for proactive response:
- Service permissions for proactive response is already enabled, but you can disable this feature if needed.
- Select By choosing this option… and choose Next.
- Review service permissions and choose Next.
- Review the membership configuration and details, then choose Sign up.
- The service-linked role created with proactive response cannot be created in the management account through this on-boarding process. See the AWS Security Incident Response User Guide for deploying the service-linked role to the management account.
Detailed instructions can be found in the YouTube setup video.
Many organizations have well-established processes and application suites for IR and security threat management. To accommodate these pre-existing setups, AWS has developed integrations with popular ITSM and case management applications. Our initial releases enable complete bi-directional integration with both Jira and ServiceNow, with more on the way.
We have provided comprehensive instructions to guide you through the setup process in GitHub.
Optimize value on day one
Immediately after enabling the service, Security Incident Response begins to ingest your GuardDuty and Security Hub findings (from security partners). Your findings are automatically triaged and monitored using deterministic evaluation logic; based on your organization’s unique metadata and security perimeter, high-priority threats are escalated to your Security Incident Response command center for immediate investigation. While your organization receives 24/7 coverage from the start, implementing these recommended optimizations will significantly enhance threat detection accuracy, reduce false positives, accelerate response times, and strengthen your overall security posture through customized protection aligned with your specific business risks and compliance requirements.
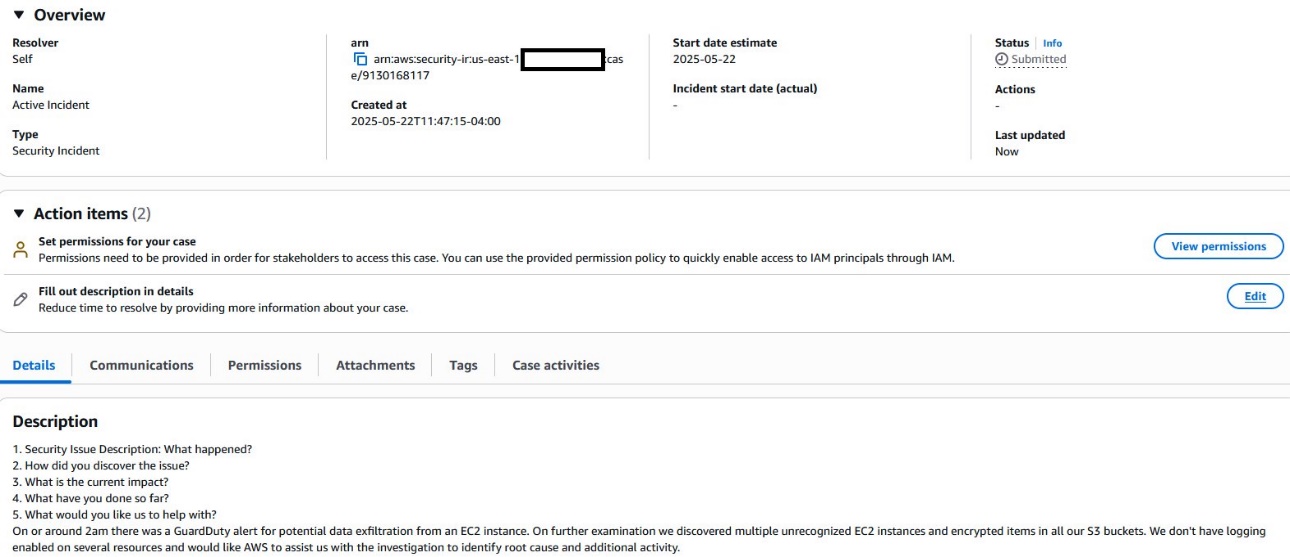
To maximize immediate value from Security Incident Response, we suggest using its reactive capabilities beginning at day one. When your team encounters suspicious activities or requires expert investigation, you can create an AWS-supported case through the service portal to engage AWS CIRT specialists directly. These security experts effectively extend your team’s capabilities, providing specialized knowledge and guidance to help you quickly understand, contain, and remediate potential security concerns. This on-demand access to AWS CIRT can reduce your mean time to resolution, minimize potential impact, and make sure you have professional support even for complex security scenarios that might otherwise overwhelm internal resources.
Examples of reactive support queries include:
- We noticed a suspicious IP address in our environment, performing various API calls. Can you help us investigate?
- A new account was created two days ago, we were notified through an Amazon EventBridge rule and our endpoint detection and response (EDR) integrations, can you help us scope it and find out who created it? How was it created?
- An AWS Identity and Access Management (IAM) user is making cross-Region API calls and creating resources in an unused Region.
- Our EDR solution detected unusual behavior on our production website, indicating a potential breach.
- Our EDR detected a suspicious web-shell upload and activity. We need help investigating and isolating this.
- An unauthorized user generated API activity above their authorization level, help us find privilege escalations.
- We need help analyzing security logs from our AWS WAF and Amazon Elastic Compute Cloud (Amazon EC2) instances. Are there any Indicators of compromise or suspicious patterns?
Next steps
If you decide to move forward with AWS Security Incident Response and deploy a POC, we recommend the following action items:
- Determine if you have the approval and budget to use Security Incident Response. Preferred pricing agreements, discounts, and performance-based trials are available.
- Configure and deploy GuardDuty to help maintain comprehensive and relevant coverage across your management and member accounts, critical services, and workloads.
- Verify that third-party security tools (such as CrowdStrike, Lacework, or Trend Micro) are properly integrated with Security Hub.
- Communicate the security incident response tooling changes to the relevant organizational teams.
Conclusion
In this post, we showed you how to plan and implement an AWS Security Incident Response POC. You learned how to do so through phases, including defining success criteria, configuring Security Incident Response, and validating that Security Incident Response meets your business needs.
As a customer, this guide will help you run a successful POC with Security Incident Response. It guides you in assessing the value and factors to consider when deciding to implement the current features.
Additional resources
- Security Incident Response – Getting Started Guide
- Configuring security tool integrations through Security Hub
- Managing Security Incident Response events with Amazon EventBridge
- Amazon GuardDuty best practices
- AWS Security Hub best practices
- AWS Security Incident Response Technical Guide (best practices)
- AWS Managed Services Offering
- AWS Security Incident Response Blog: The customer’s journey to accelerating the incident Response lifecycle
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.