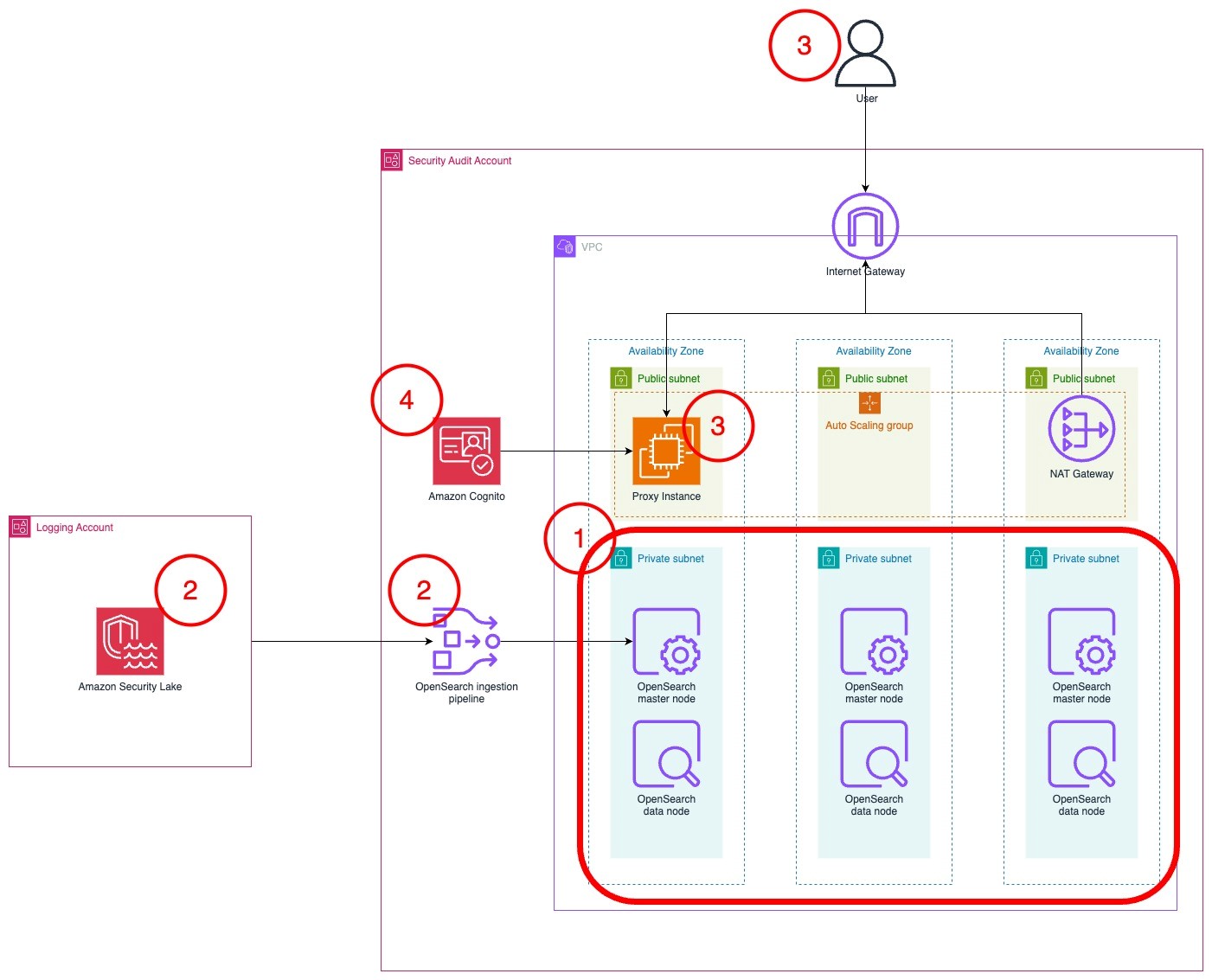
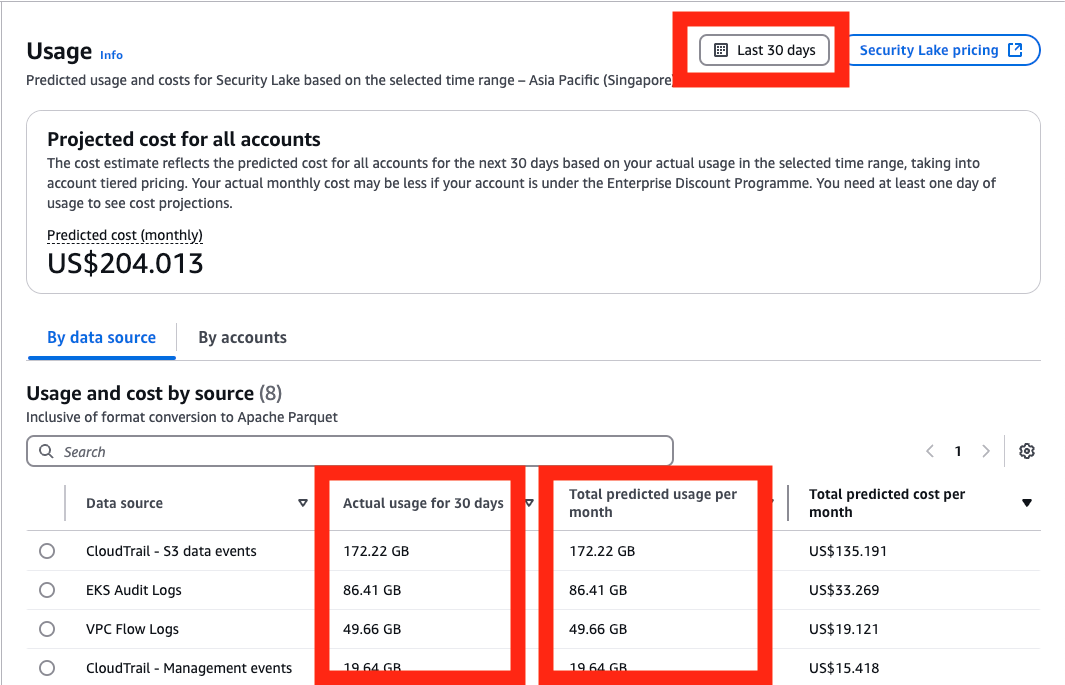
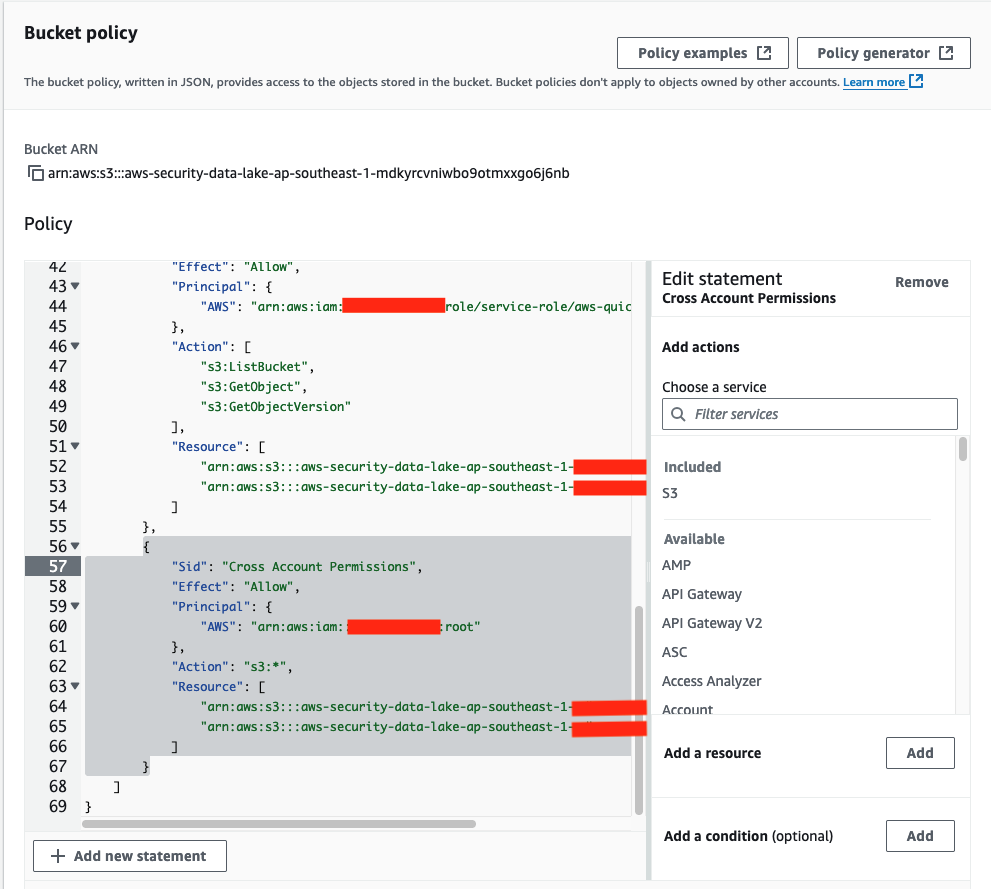
In this post, we introduce the AWS provider for the Secrets Store CSI Driver, a new AWS Secrets Manager add-on for Amazon Elastic Kubernetes Service (Amazon EKS) that you can use to fetch secrets from Secrets Manager and parameters from AWS Systems Manager Parameter Store and mount them as files in Kubernetes pods. The add-on is straightforward to install and configure, works on Amazon Elastic Compute Cloud (Amazon EC2) instances and hybrid nodes, and includes the latest security updates and bugfixes. It provides a secure and reliable way to retrieve your secrets in Kubernetes workloads.
Amazon EKS add-ons provide installation and management of a curated set of add-ons for EKS clusters. You can use these add-ons to help ensure that your EKS clusters are secure and stable and reduce the number of steps required to install, configure, and update add-ons.
Secrets Manager helps you manage, retrieve, and rotate database credentials, application credentials, OAuth tokens, API keys, and other secrets throughout their lifecycles. By using Secrets Manager to store credentials, you can avoid using hard-coded credentials in application source code, helping to avoid unintended or inadvertent access.
New EKS add-on: AWS provider for the Secrets Store CSI Driver
We recommend installing the provider as an Amazon EKS add-on instead of the legacy installation methods (Helm, kubectl) to reduce the amount of time it takes to install and configure the provider. The add-on can be installed in several ways: using eksctl—which you will use in this post—the AWS Management Console, the Amazon EKS API, AWS CloudFormation, or the AWS Command Line Interface (AWS CLI).
Security considerations
The open-source Secrets Store CSI Driver maintained by the Kubernetes community enables mounting secrets as files in Kubernetes clusters. The AWS provider relies on the CSI driver and mounts secrets as file in your EKS clusters. Security best practice recommends caching secrets in memory where possible. If you prefer to adopt the native Kubernetes experience, please follow the steps in this blog post. If you prefer to cache secrets in memory, we recommend using the AWS Secrets Manager Agent.
IAM principals require Secrets Manager permissions to get and describe secrets. If using Systems Manager Parameter Store, principals also require Parameter Store permissions to get parameters. Resource policies on secrets serve as another access control mechanism, and AWS principals must be explicitly granted permissions to access individual secrets if they’re accessing secrets from a different AWS account (see Access AWS Secrets Manager secrets from a different account). The Amazon EKS add-on provides security features including support for using FIPS endpoints. AWS provides a managed IAM policy, AWSSecretsManagerClientReadOnlyAccess, which we recommend using with the EKS add-on.
Solution walkthrough
In the following sections, you’ll create an EKS cluster, create a test secret in Secrets Manager, install the Amazon EKS add-on, and use it to retrieve the test secret and mount it as a file in your cluster.
Prerequisites
AWS credentials, which must be configured in your environment to allow AWS API calls and are required to allow access to Secrets Manager
With the prerequisites in place, you’re ready to run the commands in the following steps in your terminal:
Create an EKS cluster
Create a shell variable in your terminal with the name of your cluster:
CLUSTER_NAME="my-test-cluster”
Create an EKS cluster:
eksctl create cluster $CLUSTER_NAME
eksctl will automatically use a recent version of Kubernetes and create the resources needed for the cluster to function. This command typically takes about 15 minutes to finish setting up the cluster.
Create a test secret
Create a secret named addon_secret in Secrets Manager:
Create an AWS Identity and Access Management (IAM) role that the EKS Pod Identity service principal can assume and save it in a shell variable (replace <region> with the AWS Region configured in your environment):
Note: AWS provides a managed policy for client-side consumption of secrets through Secrets Manager: AWSSecretsManagerClientReadOnlyAccess. This policy grants access to get and describe secrets for the secrets in your account. If you want to further follow the principle of least privilege, create a custom policy scoped down to only the secrets you want to retrieve.
Attach the managed policy to the IAM role that you just created:
aws iam attach-role-policy \
--role-name nginx-deployment-role \
--policy-arn arn:aws:iam::aws:policy/AWSSecretsManagerClientReadOnlyAccess
Deploy your SecretProviderClass (make sure you’re in the same directory as the spc.yaml you just created):
kubectl apply -f spc.yaml
To learn more about the SecretProviderClass, see the GitHub readme for the provider.
Deploy your pod to your EKS cluster
For brevity, we’ve omitted the content of the Kubernetes deployment file. The following is an example deployment file for Pod Identity in the GitHub repository for the provider—use this file to deploy your pod:
In this post, you learned how to use the new Amazon EKS add-on for the AWS Secrets Store CSI Driver provider to securely retrieve your secrets and parameters and mount them as files in your Kubernetes clusters. The new EKS add-on provides benefits such as the latest security patches and bug fixes, tighter integration with Amazon EKS, and reduces the time it takes to install and configure the AWS Secrets Store CSI Driver provider. The add-on is validated by EKS to work with EC2 instances and hybrid nodes.
AWS re:Invent 2025, the premier cloud computing conference hosted by Amazon Web Services (AWS), returns to Las Vegas, Nevada, December 1–5, 2025. At AWS, security is our top priority, and re:Invent 2025 reflects this commitment with our most comprehensive security track to date. With more than 80 security aligned sessions spanning breakouts, workshops, chalk talks, and hands-on builders’ sessions, we’re bringing together the brightest minds to share insights, best practices, and innovative solutions. For security professionals, developers, and cloud architects, the event offers valuable insights into the latest security innovations at AWS, advanced threat protection capabilities, and defense strategies that scale. While attending re:Invent, you can visit the Security kiosk and AI Security kiosk at the expo hall to engage directly with AWS security experts about your specific needs.
The security track session selection process was driven by our extensive analysis of customer needs and real-world implementation challenges. We specifically focused on security areas where customers seek the most guidance and coalesced the sessions around four major themes: Securing and Leveraging AI, Architecting Security and Identity at scale,Building and scaling a Culture of Security, and Innovations in AWS Security. Our goal with the sessions is to address immediate security challenges and help you achieve broader business outcomes. In the following sections, we highlight a few key sessions in each of the four themes. You can visit the re:Invent catalog for a view of all sessions.
Securing and leveraging AI
Securing and using AI emerges as a dominant theme for the Security and Identity track, reflecting both the opportunities and challenges AI presents. From protecting AI workloads to harnessing AI for enhanced security operations, sessions span multiple AI topics to help organizations navigate this transformative technology safely and effectively. Here are a few key sessions on each of the AI topics.
Securing AI workloads
Breakout SEC410 – Advanced AI Security: Architecting Defense-in-Depth for AI Workloads: Dive deep into advanced security architectures for AI workloads, exploring how to protect your workload against sophisticated attack vectors. Through technical examples, we’ll implement secure architectures for AI workloads, covering identity, fine-grained access policies, and secure foundation model deployment patterns. Learn how to harden generative and agentic AI applications using AWS security capabilities, implementing least-privilege controls, and building secure architectures at scale.
Workshop SEC406 –Red teaming your generative AI and MCP applications at scale: Step into the shoes of an AI-powered red team adversary in the GenAI Red Team Challenge. In this intensive workshop, you’ll deploy an AI security agent to orchestrate sophisticated threat chains against Model Context Protocol (MCP) applications, systematically discovering vulnerabilities. Master countermeasures from prompt templating and guardrails to OAuth-enhanced MCP security configurations that prevent unauthorized access. This hands-on, gamified experience helps you think like a threat actor and equips you with practical skills in automated vulnerability testing and risk mitigation against common MITRE and OWASP vulnerabilities for LLM-based applications. You must bring your laptop to participate.
Security for Agentic AI
ChalkTalk SEC408 –Securing Agentic AI: OWASP, MAESTRO, and Real-World Defense Strategies: Explore the latest in Agentic AI security with OWASP’s updated Threats and Mitigations Guide and Agentic Security Initiative. We will also explore MAESTRO, a specialized threat modeling approach for AI systems, offering a layered methodology to identify and mitigate risks throughout the AI lifecycle. Through a real-world case study, we’ll demonstrate security best practices for agentic AI, including robust governance, continuous monitoring, and least-privilege access. Learn how to confidently deploy autonomous AI agents while minimizing risks. Gain practical insights for building secure, trustworthy, and resilient agentic AI applications that can transform industries safely.
Workshop SEC307 – Design authentication, authorization, and logging logic in Agentic AI apps: This hands-on workshop addresses the critical challenge of managing identities and permissions for generative AI agents. Learn to implement user and machine authentication, along with fine-grained authorization mechanisms, tailored for AI agents, tools, and LLMs. Explore consent management and permission delegation in AI contexts. Participants will gain practical experience using AWS’s latest services, including Strands SDK, Amazon Bedrock AgentCore Identity, Amazon Cognito for identity management, and Amazon Verified Permissions for authorization decisions. By the end, you’ll have the skills to enhance security and compliance in your AI operations using AWS’s cutting-edge identity and access management solutions.
Using AI for security
Builders SEC318– Strengthen your network security with generative AI: Transform how you manage network security using the power of generative AI. See how Amazon Q Developer helps you explore AWS Shield Network Security Director findings through natural language conversations. Learn to quickly identify misconfigured resources, understand security issues, and implement guided fixes across your AWS environment.
Chalktalk SEC304 – Building an AI-Powered security guardian for your Cognito applications: Elevate your application security with an intelligent AI-Powered security guardian to protect your Amazon Cognito-authenticated applications. In this interactive session, we’ll explore identity best practices and building an AI agent using Amazon Bedrock AgentCore to help verify best practices, perform detective analysis, and take automated preventative actions to mitigate risks. We’ll talk through how an AI agent can perform dynamic WAF rule adjustments, modify authentication flows, and perform security operations center (SOC) actions. Bring your questions and scenarios as we deep dive into how to implement AI-driven security controls for your Cognito protected applications.
Building and Scaling Culture of Security
This theme is woven throughout the re:Invent 2025 security track, reflecting the belief that technological solutions alone cannot ensure robust security outcomes. Enterprises with a Culture of Security become security-first organizations, after which they can accelerate secure digital transformations. Some of the sessions that showcase this theme are:
Breakout SEC319 – Climbing the AI Mountain With Your Security Team: Navigate the intersection of AI and security culture in this practical session. Learn how security teams can effectively embrace AI innovation through incremental steps and validation techniques. Using real-world examples, we’ll demonstrate how security practitioners can adapt their skills to AI challenges regardless of their level of specialized expertise and share strategies for building security-aware AI practices. From understanding generative and agentic AI-specific security risks to creating engaging team exercises, discover how to transform security from a potential bottleneck into an enabler of responsible AI innovation. Attendees will leave with actionable insights for building a security-first approach to AI adoption.
Chalktalk SEC343 – Fostering a Resilient Incident Response Culture: Discover how to combine human expertise with intelligent automation in security incident response. Learn how AWS Security Incident Response, auto-triaging capabilities, and generative AI work together to augment—not replace—your team’s decision-making. We’ll explore how integrating AWS Security Incident Response and generative AI into your workflows can reduce alert fatigue, accelerate accurate incident classification, and enable responders to focus on critical analysis. See how leading organizations balance automation with human oversight, creating more efficient and resilient incident response processes while maintaining the crucial elements of human judgment and institutional knowledge. Uncover practical strategies for integrating AI-driven insights with human expertise in your incident response culture.
Chalktalk SEC227 – Translating Security Metrics into Business Outcomes: Today CISOs face the challenge of translating complex security data into business value. This session reveals proven frameworks for transforming security metrics into strategic insights that drive boardroom decisions. Learn how leading organizations leverage AWS Security Hub, OpenSearch and Security Analytics and automation to build real-time risk dashboards that demonstrate security’s business impact. Walk away with practical strategies for evolving your security program from operational metrics to business outcomes, enabling data-driven investment decisions and measurable risk reduction that resonates with executives.
Architecting Security and Identity at scale
This theme explores how you can use the comprehensive toolset and proven patterns provided by AWS to implement enterprise-grade security controls that scale from individual workloads to global organizations. Some key sessions on this theme include:
ChalkTalk SEC333 – From Static to Dynamic: Modernizing AWS Access Management: Building a robust AWS identity foundation requires moving beyond static credentials. This session deep dives into proven patterns for implementing dynamic, temporary access across your AWS organization. We’ll explore real-world challenges of access key dependencies and share practical approaches to transition towards ephemeral credentials using IAM roles and SAML federation. Through practical examples and lessons learned, discover how to implement secure authentication patterns that scale while reducing operational overhead. Walk away with actionable strategies to strengthen your identity perimeter and modernize your access management approach.
Workshop SEC401 – Active defense strategies using AWS Al/ML services: This workshop will help you learn how to develop and deploy active defense strategies, such as deception, using Amazon Bedrock and Amazon SageMaker. Gain hands-on experience developing AI-driven responses for security operations. You will learn how to develop adaptive responses that mimic what an actor may be trying use against you. Discover implementation patterns for prompt engineering, deployment strategies, and monitoring methodologies. You must bring your laptop to participate.
Workshop SEC303 –Advanced AWS Network Security: Building Scalable Production Defenses: In this hands-on workshop, master AWS network security techniques to defend against today’s most critical threats. Learn to implement layer 7 capabilities and deep packet inspection using AWS Network Firewall and Route 53 Resolver DNS Firewall, securing both internet-bound and internal traffic flows. Gain practical experience in configuring scalable, reliable filtering to combat zero-day attacks and ransomware, while also implementing sophisticated east-west traffic controls to prevent lateral movement. Through real-world scenarios, you’ll learn to leverage IDS/IPS filtering, domain-based controls, and principle of least privilege using fully managed AWS services. Leave equipped to build resilient network defenses against modern cyber threats.
Innovations in AWS Security
AWS innovation in security capabilities is designed to help organizations outpace evolving threats. From advanced threat detection powered by machine learning to revolutionary data protection mechanisms, these innovations demonstrate the AWS commitment to keeping customers secure in an evolving landscape. Some of the innovation-focused sessions are:
Breakout SEC203–State of the Art: AWS data protection in 2025 (ft. Vanguard): Join AWS Cryptography leaders for a comprehensive tour of 2025’s groundbreaking security innovations. Discover the latest launches across Cloudfront, KMS, Private CA, and Secrets Manager, showcasing AWS’s implementation of NIST-standardized post quantum cryptography. Learn how we’re revolutionizing cloud security through quantum-resistant algorithms, advanced certificate management, and automated secrets handling. Get an inside look at Vanguards enterprise-wide PQC migration and how they made it a strategic business priority. See firsthand how AWS continues raising the bar on data protection for your most sensitive workloads.
Breakout SEC323 – AWS detection and response innovations that drive security outcomes: Discover how the latest AWS detection and response capabilities can help secure your cloud environment more effectively. Learn practical ways to achieve integrated security outcomes through enhanced threat detection, automated vulnerability management, and streamlined response—all at scale. We’ll show you how to use AWS security services to protect workloads and data, centralize security monitoring, manage security posture continuously, and unify security data, while leveraging generative AI for security operations. Walk away with actionable insights for integrating AWS detection and response services to strengthen and simplify security across your AWS environment.
Breakout SEC310 – Innovations in Infrastructure Protection to strengthen your network: In this session, learn about new capabilities in infrastructure protection services like AWS Network Firewall, Amazon Route 53 DNS Firewall, AWS WAF, and AWS Shield, to simplify your application protection, streamline robust egress protections and gain insight into your network. Dive deep into how new visibility investments can give insight into misconfigurations, possible threats, and proactive identification of network configuration issues.
Conclusion
Don’t miss this opportunity to enhance your cloud security knowledge and connect with AWS security experts and industry peers. For a full view of the Security and Identity sessions, explore the AWS re:invent catalog where you can filter sessions by topic, areas of interest, role, and so on.
When you register, you’ll gain access to the session reservation system where you can reserve your seats. Popular security sessions, especially hands-on sessions, fill up quickly because of limited capacity, so we recommend reserving your preferred sessions as soon as scheduling opens. See you are re:Invent!
If you have feedback about this post, submit comments in the Comments section below.
Security and governance teams across all environments face a common challenge: translating abstract security and governance requirements into a concrete, integrated control framework. AWS services provide capabilities that organizations can use to implement controls across multiple layers of their architecture—from infrastructure provisioning to runtime monitoring. Many organizations deploy multi-account environments with AWS Control Tower, or Landing Zone Accelerator to implement a foundational baseline of controls and security architecture. Once their environment is provisioned, organizations typically look to add additional detective controls from services such as AWS Security Hub and AWS Config based on security, compliance, and operational requirements. While this sequence is a great start, there are more opportunities during this time to implement layered defense-in-depth coverage to enhance your security posture.
Highly regulated industries such as fintech and financial services are often viewed as the gold standard for governance and security controls. While these sectors have established robust frameworks, there’s consistently room for improvement and valuable lessons for other industries looking to enhance their control environments. However, many organizations struggle to move beyond a basic compliance-focused approach. In our experience working with customers across various sectors, this limited perspective often stems from multiple factors, including:
Immediate compliance pressures
Resource constraints
Limited understanding of control maturity pathways
Focus on detection rather than prevention
A tendency to prioritize technology-agnostic controls over bult-in AWS capabilities, leading to unnecessarily complex implementations
The good news? A more comprehensive approach that uses AWS preventative, proactive, detective, and responsive controls can significantly reduce risk while decreasing operational overhead through automation.
In this post, we outline a practical framework that you can adopt to evolve your security and governance controls strategy. We explore how your organization can mature from a detection-focused security posture to a multi-layered control framework, using real-world examples across the resource lifecycle, including infrastructure-as-code testing and preventative controls such as service control policies (SCPs), resource control policies (RCPs), and declarative policies (DPs).
Drawing from best practices in highly regulated industries while incorporating modern cloud capabilities through services such as AWS Organizations and AWS Control Tower, we provide a structured framework that you can use to elevate your organization’s control environment beyond basic compliance requirements.
Customer challenges in implementing controls
Organizations face several significant challenges when attempting to implement a comprehensive control framework in AWS. Let’s explore the main obstacles:
Resource constraints and expertise gaps
Security teams often find themselves caught between limited resources and expanding responsibilities in the cloud. With constrained budgets and personnel, teams typically gravitate toward quick wins through detective controls, which appear straightforward to implement initially. While this provides immediate visibility, it can leave critical gaps in security posture. Many teams lack comprehensive expertise across all control types, particularly in implementing preventative, proactive, and responsive controls effectively. The pressure to demonstrate immediate security improvements, combined with day-to-day operational demands, frequently results in tactical solutions rather than strategic, layered security approaches.
Analysis paralysis
Deciding which tools to prioritize can be a challenge; the breadth of options and extensive capabilities available across AWS security services and third-party tools can feel overwhelming at times. Security teams struggle to determine the optimal mix of controls for their environment and where to begin implementation. This challenge is compounded by the complexity of mapping technical compliance requirements to cloud-focused capabilities and maintaining visibility into emerging threats as the security landscape evolves. The layers of abstraction created by proliferating security controls can further obscure clear decision-making, leading teams to delay critical security improvements while seeking perfect solutions.
Misunderstanding of defense in depth
Defense in depth as a concept is good, but it can be misunderstood and difficult to achieve, leading to vulnerabilities in the security architecture. A common misconception is that a single strong control, separation of duties in AWS Identity and Access Management (IAM) roles, least permission in IAM policies, and so on, provide sufficient protection. This overlooks the crucial value of implementing controls at multiple points and how different control types can be combined to create a robust security posture. Teams often miss how organizational controls like SCPs can work in harmony with workload-specific controls to achieve greater protection. The role of preventative controls in guiding technical implementations is frequently under appreciated.
Maturity journey challenges
The path to security maturity presents numerous obstacles. Many organizations remain stuck in the early stages, implementing detective controls but never progressing to preventative measures. Security controls are often implemented in isolation, without consideration for the broader security landscape. Organizations struggle to create and follow a clear roadmap for evolving their security posture, and measuring improvement over time proves challenging.
Scale and consistency issues
As AWS environments grow, maintaining consistent governance and security becomes increasingly complex. Organizations face mounting challenges in managing exceptions and special cases across their expanding infrastructure. These interrelated challenges often result in controls implementations that fail to achieve their intended risk reduction goals. You need a structured approach to overcome these obstacles and implement comprehensive security controls, which we explore in the following sections.
Strategic investment in security
While implementing comprehensive controls requires an initial investment in time and resources, the long-term benefits fundamentally transform how organizations operate.
The foundation for this transformation begins with establishing baseline controls through proven starting points such as AWS Control Tower and its customization options. AWS Control Tower provides building blocks for secure multi-account architectures with hundreds of security capabilities and proactive controls already built in. Rather than trying to create baselines from scratch by wrangling vast amounts of account-level or resource-specific controls, you can use these accelerators to rapidly establish a strong security foundation. With these baseline controls in place, this transformation extends beyond security teams to enable the entire organization to operate more efficiently. Development and operations teams can deploy faster with confidence when security guardrails are in place. Security becomes an enabler rather than a bottleneck, so that teams across the organization can innovate while maintaining a strong security posture.
As you mature your organization’s control framework through automation and layered defenses, a security transformation occurs. Security teams shift from constant firefighting to proactive risk management. Automated policy enforcement replaces manual reviews, and the time previously spent on routine tasks can be redirected to strategic initiatives.
Preventative controls establish the foundation of a secure environment by defining the policies, standards, and requirements that guide security implementations. At their core, these controls encompass corporate security policies that outline acceptable resource configurations across the organization. They work in conjunction with compliance requirements and frameworks to help maintain regulatory alignment, while architectural standards and guidelines provide technical direction for implementations. Data classification policies play a crucial role by determining specific security requirements based on data sensitivity.
To illustrate how preventative controls work in practice, consider a common S3 bucket security requirement. A typical preventative control might establish a corporate policy stating All S3 buckets must be private by default, with public access granted only through an approved exception process. This simple but effective policy sets clear expectations and requirements before a technical implementation begins.
Organization level: SCPs blocking public S3 bucket creation.
Resource level:
RCPs enforcing network access controls, such as requiring authenticated access or limiting requests to your organization’s network range.
SCPs to stop malicious overwrites of S3 objects using SSE-C encryption by blocking s3:PutObject requests with customer-provided keys unless explicitly allowed, paired with AWS IAM Roles Anywhere for short-term credential enforcement.
Proactive controls act as an early warning system, identifying and addressing potential security issues before they manifest in your environment. These controls work by validating configurations and changes against established security requirements during the development and deployment phases. Through automated validation and policy enforcement at build and deploy time, proactive controls help prevent misconfigurations from reaching production environments, reducing the operational overhead of fixing security issues after the fact. Think of proactive controls as your first line of defense in maintaining a secure cloud environment. In AWS, these can be implemented at multiple levels:
Amazon S3 Block Public Access settings at the account level.
Policy-as-code checks in continuous integration and delivery (CI/CD) pipelines (such as CFN-Nag, or AWS Config proactive rules).
AWS CloudFormation hooks for pre-deployment validation and policy enforcement.
AWS Config rules in proactive mode to evaluate resources before creation.
At the resource level, you can use:
IAM policies restricting bucket policy modifications
CloudFormation Guard rules
#####################################
## Gherkin ##
#####################################
# Rule Identifier:
# S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED
# Description:
# Checks if your Amazon S3 bucket either has the Amazon S3 default encryption enabled or that the Amazon S3 bucket policy
# explicitly denies put-object requests without server side encryption that uses AES-256 or AWS Key Management Service.
# Reports on:
# AWS::S3::Bucket
# Evaluates:
# AWS CloudFormation
# Rule Parameters:
# NA
# Scenarios:
# a) SKIP: when there are no S3 resource present
# b) PASS: when all S3 resources Bucket Encryption ServerSideEncryptionByDefault is set to either "aws:kms" or "AES256"
# c) FAIL: when all S3 resources have Bucket Encryption ServerSideEncryptionByDefault is not set or does not have "aws:kms" or "AES256" configurations
# d) SKIP: when metadata includes the suppression for rule S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED
#
# Select all S3 resources from incoming template (payload)
#
let s3_buckets_server_side_encryption = Resources.*[ Type == 'AWS::S3::Bucket'
Metadata.cfn_nag.rules_to_suppress not exists or
Metadata.cfn_nag.rules_to_suppress.*.id != "W41"
Metadata.guard.SuppressedRules not exists or
Metadata.guard.SuppressedRules.* != "S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED"
]
rule S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED when %s3_buckets_server_side_encryption !empty {
%s3_buckets_server_side_encryption.Properties.BucketEncryption exists
%s3_buckets_server_side_encryption.Properties.BucketEncryption.ServerSideEncryptionConfiguration[*].ServerSideEncryptionByDefault.SSEAlgorithm in ["aws:kms","AES256"]
<<
Violation: S3 Bucket must enable server-side encryption.
Fix: Set the S3 Bucket property BucketEncryption.ServerSideEncryptionConfiguration.ServerSideEncryptionByDefault.SSEAlgorithm to either "aws:kms" or "AES256"
>>
}
Detective controls provide continuous visibility into your security posture by monitoring for and identifying potential security violations or unauthorized changes within your environment. While preventative controls aim to stop issues before they occur, detective controls help you maintain awareness of your security state and can identify when preventative controls have been bypassed or failed. These controls form a critical layer of defense by enabling rapid identification of security issues and providing the visibility needed for effective incident response and compliance reporting. While many organizations start and stop here, detective controls are only part of the solution:
AWS Config rules monitoring for public buckets
Security Hub findings to flag non-compliant resources
Responsive controls complete the security lifecycle by providing automated and manual mechanisms to address security issues after they’re detected. These controls define and implement the actions taken when security violations are identified, ranging from automated remediation of common misconfigurations to coordinated incident response procedures for complex security events. By establishing clear response patterns and using automation where appropriate, responsive controls help facilitate consistent and timely handling of security issues while reducing the mean time to remediation. Responsive controls address violations when they occur:
The power comes not from implementing these controls in isolation, but from using them together in a coordinated way. This layered approach begins with preventative controls to establish the requirements, followed by proactive controls to block most potential violations at the source. Issues that manage to slip through are caught by detective controls, while responsive controls automatically remediate identified problems. Throughout this process, comprehensive documentation tracks issues, remediation plans, and progress, such as through a plan of action and milestones (POAM), helping to make sure that compliance requirements are met and improvements can be measured over time.
Implementation lifecycles: Ideal compared to reality
You can follow one of two paths when implementing security controls: starting fresh with a comprehensive approach or evolving from an existing detective-focused implementation. Let’s examine both scenarios.
Starting fresh: The ideal approach
When starting from scratch, you have a unique opportunity to build your security and governance following an ideal approach. Your team can take advantage of this clean slate to architect controls and processes methodically, free from legacy constraints. The following steps offer guidance though establishing a strong foundation while maintaining the flexibility you need as your business grows.
Rationalize controls against requirements and risk profile:
Choose appropriate security frameworks (for example, CIS and NIST).
Map compliance, regulatory, legal, and contractual requirements to your base framework.
Define clear security objectives and success criteria for your security and compliance program.
Design a comprehensive control strategy:
Document control requirements across all four types (preventive, proactive, detective, and responsive controls). You can use the framework to decide which controls are best for each type of requirement.
Plan implementation phases and priorities.
Define metrics for measuring effectiveness.
Implement controls in layers:
Start with AWS Control Tower, which gives you foundational controls to mature from. You can add customizations if required.
Think about additional preventative controls that can help establish a stronger security and compliance posture.
Deploy proactive controls to stop violations.
Add detective controls as safeguards.
Implement responsive controls for automated or manual remediation.
Monitor and assess effectiveness
Evaluate control performance against defined metrics.
Identify gaps and areas for improvement.
Adjust controls based on emerging threats and changing requirements.
Implement continuous improvement feedback loop.
Evolution from detective controls: The common path
Most organizations find themselves starting with detective controls and face challenges in maturing from there:
Initial state:
Baseline detective controls through Security Hub and AWS Config
Manual remediation processes
Limited visibility into security posture
Maturation steps:
Analyze findings to identify patterns
Implement automated remediation for common issues
Add preventative and proactive controls based on recurring events
Periodically refine and update policies
Optimization:
Review control effectiveness
Identify gaps in coverage
Implement additional preventative, proactive, detective, and responsive measures
Automate processes where possible
The goal: Comprehensive and layered security controls
The goal of implementing security controls across multiple layers isn’t just about compliance or following best practices—it’s about creating a robust, resilient security posture that can effectively help prevent, detect, and respond to security issues. Let’s explore why this approach is crucial:
Why multiple control layers matter
Security controls shouldn’t exist in isolation. When implementing a security requirement, you should consider:
How can we prevent this issue from occurring?
How will we detect if our preventative controls fail?
What should happen when we detect a violation?
What policies and standards guide these decisions?
Moving beyond detection
While detective controls are important, they signal that a security violation has already occurred. A mature security posture requires:
Strong preventative controls to stop violations before they happen
Detective controls as a safety net if there is drift or a violation
Automated remediation where possible, to reduce exposure time
Clear policies to guide implementation and decisions
Measuring success
You should measure the effectiveness of your control framework through several key performance indicators. Success can be seen in the steady reduction of security findings over time, coupled with decreasing time-to-remediation metrics. The maturity of the framework becomes evident through an increasing percentage of automated remediation activities and a declining number of recurring issues. These improvements manifest in better audit outcomes, providing tangible evidence that the control framework is delivering its intended results.
Practical implementation: From theory to practice
Let’s examine how to implement a comprehensive control framework using a common security requirement: preventing exposure of sensitive data through public S3 buckets. This example demonstrates how different control types work together to create defense in depth. While not every control might be necessary for every situation, each should be carefully considered and evaluated based on various factors including system criticality, data sensitivity, operational overhead, and organizational risk tolerance. The decision to implement or omit specific controls should be deliberate and documented, rather than occurring by default.
The architecture will have layers and components like the following.
Preventative layer:
Service control policies (SCPs) or resource control policies (RCPs)
An effective security and compliance strategy includes all four types of security controls. While preventative controls are a first line of defense to help prevent unauthorized access or unwanted changes to your network, it’s important to make sure that you establish detective and responsive controls so that you know when an event occurs and can take immediate and appropriate action to remediate it. Using proactive controls adds another layer of security because it complements preventative controls, which are generally stricter in nature.
Begin by defining your security objectives, then establish clear policies to meet those objectives:
Define organizational and business objectives:
Identify data protection goals
Determine acceptable risk levels
Align with compliance requirements
Establish clear policies:
For example, document business requirements for external data sharing and access controls in security policies. These requirements will drive technical decisions around AWS storage configurations such as S3 bucket policies and public access settings.
Define permitted use cases for public access.
Establish exception processes.
Set clear ownership and responsibilities.
Deploy preventative guardrails:
Organization level:
SCPs to block public bucket creation at the organization level
Account-level S3 Block Public Access settings to enforce account-level restrictions
Resource level:
IAM policies restricting bucket policy modifications
S3 bucket policy templates with controlled deployment
RCPs to enforce rules on specific resource types across your organization
Deploy proactive guardrails:
Infrastructure as code:
Implement policy-as-code checks in CI/CD pipelines using:
Enable relevant optional AWS Control Tower guardrails
Add detective controls by creating a monitoring framework:
AWS CloudTrail for comprehensive API activity logging and auditing to enable investigation of unauthorized access attempts and configuration changes.
AWS Config rules for bucket configuration. AWS Config rules or AWS Config conformance packs deployed for the entire organization can monitor S3 bucket configurations for compliance.
Security Hub findings for continuous assessment by aggregating findings and flagging non-compliant resources.
Amazon EventBridge rules for policy changes to detect and route S3 bucket policy modifications.
IAM Access Analyzer for external access review.
Regular compliance reporting, which can be automated through AWS Audit Manager.
Implement responsive controls by automating remediation where possible:
Security Hub and Systems Manager integration to automate incident response workflows.
Custom Lambda functions for specific use cases.
Integration with ITSM for human review when needed.
The following table describes control types, what a basic implementation includes, and the services and methods used for advanced implementation.
Control type
Basic implementation
Advanced implementation
Preventative
Documentation, peer reviews
SCPs, RCPs, DPs, IAM policies, and S3 Block Public Access
Detective
Security Hub, AWS Config rules
Security Hub, AWS Config, and CloudWatch alerts
Responsive
Manual remediation
Auto-remediation through AWS Config, Systems Manager, EventBridge, and Lambda
Compliance
One-time checks
CIS/NIST mapping with Security Hub and automation of evidence collection and reporting using AWS Audit Manager
Automation
Limited
Full CI/CD Integration (for example, using CloudFormation or Terraform)
Cost optimization effort
High (manual effort)
Low (automation reduces overhead)
Scaling and management considerations
As your security and governance program matures, scaling these controls across a growing organization requires thoughtful management and automation. This section explores key considerations for effectively managing your security posture at scale, optimizing costs, and maintaining consistency across your AWS environment. Whether you’re expanding across multiple accounts, business units, or AWS Regions, these practices help you balance security requirements with operational efficiency and cost management.
Use AWS services effectively:
Consider deploying AWS Control Tower for consistent account setup and centrally deploying and managing controls at scale across multiple use cases and organizational units.
AWS Organizations can aid hierarchical policy management and the implementation of:
IAM policies for identity-based guardrails and permissions
SCPs for access guardrails
RCPs define permissions based on resource attributes
DPs to help facilitate consistent resource configurations across your organization
Tag policies for consistent resource categorization
Backup policies for data protection standards
AI service opt-out policies for data privacy requirements
Cost allocation tag policies to standardize cost attribution
Data residency policies to enforce regional restrictions
Implement resource governance through policy integration
For example, use Organizations tag policies to enforce a Confidential tag on S3 buckets storing personally identifiable information (PII). Combine this with SCPs that mandate AES-256 encryption for tagged buckets, overriding developer attempts to disable it.
Using backup policies to enforce retention rules (for example, Retention=7 years).
Use DPs to help maintain consistent security configurations across resources, such as enforcing encryption settings on Amazon Elastic Block Store (Amazon EBS) volumes or requiring specific security group rules.
Centralize logging and monitoring
Manage compliance exceptions:
Implement clear exception processes
Document and track approved exceptions
Establish regular periodic reviews of exceptions
Use time-bound approvals with automated expiration
Optimize costs:
Use periodic instead of continuous checking where appropriate
Implement targeted monitoring based on resource criticality
Implementing a comprehensive control framework is a journey, not a destination. Start from your organization’s current position, whether that’s with basic detective controls or a fresh implementation, and focus on progressive improvement rather than attempting to implement everything at once. Success comes from carefully documenting decisions about control implementation, regularly reviewing them, and using automation to reduce operational overhead while improving consistency. Progress can be measured through concrete metrics: reduced findings, faster remediation times, and increased automation.
Remember that the goal extends beyond better security—it’s about transforming security and governance from a reactive operation to a strategic enabler that provides real business value. This transformation manifests through reduced risk from systematic controls, improved operational efficiency through automation, and enhanced visibility and governance. Perhaps most importantly, it frees security teams to focus on strategic initiatives rather than routine operational tasks.
By following this approach, you can build a robust security and governance posture that not only protects your organization’s AWS environment but also supports business innovation and growth. The result is a security program that evolves alongside the business, enabling rather than hindering progress, while maintaining a strong approach that can scale with your organization’s needs.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Cloud adoption has fundamentally reshaped security operations, bringing flexibility and scalability, but also complexity. In this session from the Take Command 2025 Virtual Cybersecurity Summit, Rapid7’s product leaders discussed how today’s SOC and MDR capabilities must evolve to keep up. Hosted by Ellis Fincham, the panel featured Dan Martin and Tyler Terenzoni, who shared real-world insights on what cloud detection and response truly requires, what CNAPP can and can’t solve, and how to bridge the growing gap between alerts and actionable context.
The cloud has changed the rules
Traditional SOC tooling often struggles to keep up with cloud-native architectures. Dan Martin opened the discussion by highlighting a key shift:
“Detection doesn’t start at the endpoint anymore. It starts with understanding your architecture.”
The panel emphasized that while cloud offers flexibility and scale, it also introduces operational complexity. From short-lived containers to decentralized ownership, cloud environments require a different approach.
Visibility is the starting point
Tyler Terenzoni spoke to the importance of understanding what’s running and who owns it:
“There’s always a disconnect between what engineering thinks is in the environment and what security actually sees.”
He noted that cloud visibility isn’t just about logs, but also understanding user behavior, policy changes, and asset configuration in near real-time. Without this, SOC teams are often reacting to alerts without enough context.
This issue was reflected in the post-event survey, where 35% of respondents listed lack of visibility across the environment as a primary challenge in their threat detection efforts.
CNAPP isn’t the answer – but it helps
The panel clarified that Cloud-Native Application Protection Platforms (CNAPPs) are useful, but not a complete solution. According to Dan Martin:
“CNAPP is great for giving you coverage, but it doesn’t give you the operational context your SOC needs.”
Integrating CNAPP data into SIEM, XDR, and MDR platforms enables richer investigations and tighter correlation across sources.
The shift from alerts to contextual action
Rather than focusing on the volume of alerts, the speakers urged security leaders to ask: can we act on this alert quickly and with confidence?
Dan Martin shared:
“It’s not about reducing alerts, it’s about giving your analysts the context to know what matters and what to do about it.”
Tyler Terenzoni added that turning alerts into action requires better integrations and unified telemetry. Without that foundation, even advanced detections can lead to noise and inefficiency.
AI will play a role, but not alone
While the session didn’t center on AI, the panel acknowledged its growing role in detection workflows. Dan Martin noted:
“AI helps with triage and correlation, but your success still depends on how well your tools talk to each other.”
The emphasis was on automation that supports analysts, not replaces them, especially in cloud environments where missteps can be costly.
Watch the full session on demand
If your team is looking to strengthen cloud detection, improve response times, or better align MDR with cloud operations, this session offers real-world insights and practical guidance.
RSA Conference (RSAC) 2025 drew 730 speakers, 650 exhibitors, and 44,000 attendees from across the globe to the Moscone Center in San Francisco, California from April 28 through May 1.
The keynote lineup was eclectic, with 37 presentations featuring speakers ranging from NBA Hall of Famer Earvin “Magic” Johnson to public and private-sector luminaries such as former US National Cyber Director Chris Inglis, U.S. Secretary of Homeland Security Kristi Noem, and cryptography experts Tal Rabin, Whitfield Diffie, and Adi Shamir.
Topics aligned with this year’s conference theme, “Many Voices. One Community,” and focused on the security industry’s shared drive to foresee risks, counter threats, and embrace new challenges.
Three themes caught our attention: agentic AI, cryptography, and public-private collaboration.
Agentic AI
The potential of agentic AI to augment human decision-making was a common thread among conversations at the conference. Numerous sessions touched on the topic, and the desire of attendees to understand the technology and learn how to balance its risks and opportunities was clear.
Separating hype from reality
An AI agent is a software program that can interact with its environment (as detailed in Figure 1), collect data, and use the data to perform self-determined tasks to meet predetermined goals.
Figure 1: Generative AI agents
Agentic systems offer a fundamentally different approach compared to traditional software, particularly in their ability to handle complex, dynamic, and domain-specific challenges. While traditional systems rely on rule-based automation and structured data, agentic systems use large language models (LLMs)—a subset of generative AI—to operate autonomously. Agents can learn from interactions with users, and make nuanced, context-aware decisions while keeping human analysts in the loop.
Numerous RSAC speakers alluded to AI agents as the next frontier in enterprise transformation. Gartner® predicts that: “By 2028, 33% of enterprise software applications will include agentic AI, up from less than 1% in 2024,” and “at least 15% of day-to-day work decisions will be made autonomously through agentic AI, up from zero percent in 2024.”
However, as organizations build AI agents, understanding the concerns that come with them is critical.
“Agentic AI presents tremendous opportunities to deliver business value and innovative security outcomes. Production deployments require a balance between its capabilities, and robust security and trust mechanisms.” —Hart Rossman, Global Services Security Vice President at AWS
In the RSAC keynote session The Five Most Dangerous New Attack Techniques…and What to Do for Each, Rob Lee, Chief of Research and Head of Faculty at SANS Institute noted that while security teams are embracing AI to amplify productivity, threat actors are doing the same. He pointed to MIT research that shows adversarial agent systems executing attack sequences are 47 times faster than human operators, with a 93 percent success rate in privilege escalation paths.
Safeguarding GenAI & Agentic Apps, Top 10 Risks in 2025, a half-day Open Worldwide Application Security Project (OWASP) event, focused on helping attendees distinguish real threats from hype. OWASP Gen AI Security Project team members and industry experts reviewed the 2025 OWASP Top 10 List for LLM and GenAI (shown in Figure 2), and introduced Agentic AI—Threats and Mitigations—the first in a series of guides from the OWASP Agentic Security Initiative (ASI) to provide a threat-model-based reference of emerging agentic threats and mitigations. Content feedback can be submitted to ASI in advance of the guide’s next release.
Figure 2: 2025 OWASP Top 10 for LLM Applications
Agentic AI wins Cybersecurity Startup Accelerator
The second annual AWS and CrowdStrike Cybersecurity Startup Accelerator, in collaboration with the NVIDIA Inception program, took place during RSAC. A panel of judges—including George Kurtz, Founder and CEO of CrowdStrike, CJ Moses, Chief Information Security Officer at Amazon, and David Reber Jr., Chief Security Officer at NVIDIA—evaluated startups on innovation, market relevance, and go-to-market potential. Terra Security, a provider of agentic AI-powered, continuous web application penetration testing, was selected from a group of 10 finalists who pitched live. Two runners-up, Kenzo Security and Rig Security, were also recognized for their standout approaches to agentic AI-driven security.
Addressing AI risks
The need to consider your security posture when assessing overall AI readiness was emphasized throughout the conference. A defense-in-depth architecture can help mitigate risks with multiple layers of protection across both traditional and AI software components. Innovative solutions such as AI red teaming, AI behavioral sandboxing, and advanced tracing and evaluation of generative AI agents can enhance your security strategy with a proactive approach to securing AI.
Encryption was another key topic. The FIDO Alliance hosted a half-day seminar that focused on developments in the global movement to passwordless technology such as passkeys—cryptographic keys designed to replace passwords by combining the power of public key cryptography with biometric authentication.
In Dude, Where’s My Password? The Challenges of Getting to Passwordless, Andy Ozment, Chief Technology Risk Officer and Executive Vice President at Capital One noted that 88 percent of data compromised in basic web application attacks reported in 2024 involved stolen credentials. Ozment pointed out that “going passwordless” through a combination of X.509 device certificates and FIDO2 passkeys presented Capital One with an opportunity to nearly eliminate entire classes of threats (as detailed in Figure 3), while increasing the quality of user experience.
Figure 3: Using passkeys to reduce risk while advancing user experience
Along the way, Ozment said, Capital One’s journey to passwordless was enabled by its transition from on-premises technology to going “all-in” on the public cloud. Watch the recording of his session or view the slides to learn more.
Post-quantum encryption
The state of post-quantum encryption was detailed in the popular Cryptographer’s Panel, moderated by Tal Rabin, Senior Principal Applied Scientist at AWS.
Panelist Vinod Vaikuntanathan, Professor at MIT underscored the impact of the quantum-resistant algorithm standardization process (Figure 4) started by the National Institute of Standards and Technology (NIST) in 2016. “We now have two public key encryption algorithms, and three new digital signature algorithms that are standardized,” he pointed out.
Figure 4: Post-quantum encryption algorithms
The panelists agreed that even though quantum computers aren’t here yet, the time to deploy these algorithms is now. NIST recommends phasing out existing encryption methods by 2030 in its Transition to Post-Quantum Cryptography Standards report. However, Vaikuntanathan and Adi Shamir, the “s” in the Rivest–Shamir–Adleman (RSA) public-key cryptosystem, advise organizations to take a hybrid approach that combines classic encryption algorithms such as RSA or Elliptic-curve Diffie–Hellman (ECDH) with post-quantum algorithms such as Module-Lattice-based Key Encapsulation Mechanism (ML-KEM). This approach, which is used by AWS and recommended by The European Commission, offers protection against both current and future threats.
RSAC Award for Excellence in the Field of Mathematics
Dr. Shai Halevi, Senior Principal Applied Scientist at AWS, was presented with the Award for Excellence in the Field of Mathematics for remarkable contributions to many areas of cryptography, including fundamental theory, advanced cryptographic primitives, secure multi-party computations, homomorphic encryption, and cryptographic code obfuscation.
Figure 5: Dr. Shai Halevi receives RSAC Award for Excellence in the Field of Mathematics
End-to-end encryption
Concerns about the recent US government group chat leak were also raised during the discussion. Public-key cryptography pioneer Whitfield Diffie noted that the use of an encrypted consumer messaging app to communicate classified information broke archiving laws. Because some commercial tools use 256-bit Advanced Encryption Standard (AES) encryption, which is “good enough” to protect communications, he predicted an increase in the use of consumer applications to protect sensitive information in unapproved ways.
The Cybersecurity and Infrastructure Security Agency (CISA) and the Federal Bureau of Investigation (FBI) recently advised individuals and organizations to start using encrypted messaging apps. However, as the role of these applications in business communication expands, it’s important not to lose sight of recordkeeping and compliance obligations. Organizations should consider solutions that offer administrative controls and data retention capabilities along with encryption.
AWS Wickr, for example, is a messaging and collaboration service that protects messaging, calling, file sharing, screen sharing, and location sharing with 256-bit end-to-end encryption. The data retention and administrative controls that it provides help customers meet regulatory requirements and manage user and device data remotely.
Wickr is Department of Defense Cloud Computing Security Requirements Guide Impact Level 5 (DoD CC SRG IL5) and Federal Risk and Authorization Management Program (FedRAMP) High authorized in the AWS GovCloud (US-West) Region. It also meets compliance programs and standards such as Health Insurance Portability and Accountability Act (HIPAA) eligibility, International Organization for Standardization (ISO) 27001, and System and Organization Controls (SOC) 1, 2, and 3.
Numerous sessions underlined the importance of collaboration to strengthening security. In his keynote, Johnson called attention to a lesson he learned on the basketball court—his peers made him stronger. “Larry Bird made me a better basketball player,” he said, relating his experience to the need for security teams to assist and learn from each other.
In Making America Safe Again Through Cyber Defense, Kristi Noem, U.S. Secretary of Homeland Security equated cybersecurity with national security, and insisted that building on public-private partnerships is “incredibly important.” “Our goal,” she said, “is to use our maximum effect of cooperation to make sure that we’re going after bad actors.”
After assuring attendees that CISA will continue to be America’s cyber defense agency, she urged congress to reauthorize the Cybersecurity Information Sharing Act of 2015. The law, which is set to expire in September, incentivizes businesses to share threat indicators with the Department of Homeland Security (DHS) and helps make sure that both the federal government and companies can take collaborative steps to address threats.
Panelists at an offsite threat intelligence discussion reiterated the ability of private industry to supplement government security capabilities. Adam Meyers, Senior VP, Counter Adversary Operations at CrowdStrike pointed out that technology companies often have more data and signals than governments. The CrowdStrike Falcon solution, he said, processes over 6 trillion events per day, and 55 million events per second at peak. This volume facilitates the detection of threat patterns that might otherwise go unnoticed.
Similarly, Moses noted that the size and scale of AWS infrastructure gives us unique visibility into internet traffic. Our global network of sensors and associated disruption tools observe over 700 million threat interactions every day, out of which 450 million can be classified as malicious. Internal threat intelligence tools such as MadPot, our sophisticated global honeypot system, produce high-fidelity findings (pieces of relevant information) that can be used to drive proactive intelligence sharing, and reduce investigative workloads.
“We’ll work together in order to be able to put a bow on a case and hand it to the FBI and DOJ, such that they don’t have to expend a great amount of resources in order to go forward and try to figure things out that we already know.” —CJ Moses, Chief Information Security Officer and VP of Security Engineering at Amazon
An example of this is the disruption of the cybercriminal group known as Anonymous Sudan. The group was responsible for tens of thousands of distributed denial-of-service (DDoS) attacks against critical infrastructure, corporate networks, and government agencies. With the help of tools like MadPot, AWS experts were able to identify the hosting provider infrastructure that the group used to launch the DDos attacks, and work with providers to disrupt them. Akamai SIRT, Cloudflare, CrowdStrike, DigitalOcean, Flashpoint, Google, Microsoft, PayPal, SpyCloud, and other private sector entities also assisted law enforcement, leading to the indictment of two Anonymous Sudan leaders.
If there’s one key takeaway, it’s a collective sense of transition. As we explore the benefits and risks of emerging AI technologies, encryption strategies, and information sharing, it’s important to remember that we cannot effectively combat threats in isolation. Security is a collective endeavor; only by working together can we adapt to evolving challenges and build cyber resilience.
For more information about cloud security, register to join AWS, Google Cloud, and Microsoft online at the SANS 2025 Cloud Security Exchange on August 21.
Wicked6 Cyber Games 2025 brought hundreds of women together worldwide from March 28–30. This dynamic virtual competition, sponsored by Amazon Web Services (AWS), helped attendees tackle real-world cybersecurity challenges through e-sports experiences. With 72 hours of women talking about cybersecurity, 11 cybersecurity games, and an attack and defense tournament streamed live, the weekend-long event highlighted the value of immersive learning while investing in the next generation of cybersecurity leaders.
Now in its sixth year, Wicked6 has established itself as more than just a competition—it’s become a cornerstone in building a collaborative security community. The Women’s Society of Cyberjutsu, a national 501(c)(3) nonprofit that promotes training, mentoring, and advancement of women and girls in cybersecurity careers, has co-hosted the event since its inception. This year’s theme was leveling up, and the virtual format enabled unprecedented global participation with 31 speakers and over 500 participants of all skill levels from 48 countries.
Keynotes and sessions
The event kicked off with an upbeat introduction from Wicked6 emcee Kristin Demoranville, founder and CEO of AnzenSage, Jessica Gulick, Executive Director of Wicked6 and founder of Cyber Esports Foundation, and Mari Galloway, CEO of Women’s Society of Cyberjutsu. The trio emphasized the importance of programs such as Wicked6 that provide women with space and opportunities to learn and grow, strengthen our confidence, and celebrate each other’s contributions to the cybersecurity community.
Keynotes featuring speakers from Africa, Australia, Japan, Saudi Arabia, and the US resonated with the multinational participants. Topics ranged from hacking and protecting AI in the age of large language models (LLMs) to drawing inspiration from science fiction novels, with an eye toward boosting skills.
In his introduction to keynote speaker Anna Collard, SVP of Content Strategy and Evangelist at KnowBe4 Africa, Hart Rossman, Global Security Services Vice President at AWS, noted the positive impact of time invested by Wicked6 participants and supporters. He pointed out that the opportunity the event provides to build relationships and practice both soft skills and technical skills is a great example of what it means to build strong security culture.
“At AWS, we recognize that security is a team sport. It’s about building community and raising the bar together, so we can overcome determined adversaries and make all of our customers, colleagues, and communities safer.” —Hart Rossman, Global Security Services Vice President at AWS
Technical sessions included a presentation focused on safeguarding Amazon Simple Storage Service (Amazon S3) buckets by two AWS women in security, Customer Incident Response Team (CIRT) Responder Jennifer Paz and Worldwide Specialist Security Solutions Architect Shahna Campbell. Paz and Campbell detailed an unusual increase of data encryption events in S3 buckets that used an encryption method known as server-side encryption using client-provided keys (SSE-C). This activity, which was recently detected by the AWS CIRT team and its automated security monitoring systems, has been attributed to malicious actors who obtained valid customer credentials and were using them to re-encrypt objects. Paz and Campbell demonstrated how collective security awareness and best practices can help prevent unauthorized access to S3 buckets and protect against ransomware events that abuse stolen credentials. Details of their investigation and prescriptive guidance for helping to prevent unintended encryption of Amazon S3 objects are available in a related AWS Security Blog post.
Gamified learning
A security-focused AWS Jam was integrated into Wicked6 for a unique, gamified learning experience. With AWS Jam, individuals and teams compete to solve a series of technical challenges in a lab-based cloud infrastructure that enhances practical understanding of AWS services and best practices. Additionally, Wicked6 participants had access to 11 different cybergame services, including Hack The Box, Haiku, InspireTech, and MetaCTF, fostering a collaborative learning environment where security practitioners at all levels could grow together.
An AWS GameDay during the event also focused on enhancing cloud security skills. Led by AWS ProServe Security and AWS Support experts Jonas Buecker, Hicham Terkiba, and Makendran Gunasekaran, the games focused on network security (including network log inspections), identity and access management (IAM) policies, and using application security techniques and AWS Web Application Firewall (AWS WAF) to help prevent SQL injections. One participant enthusiastically commented, “This was an amazing opportunity to practice hands-on AWS security learning,” underscoring the unique value of the experience.
Investing in tomorrow’s security leaders
AWS partnered to donate event tickets to South Africa’s MiDO Academy, which aims to create pathways out of poverty and meaningful employment opportunities for young people, while alleviating the pressures felt by business owners to upskill and integrate new cybersecurity talent. Dale Simons, CEO of MiDO Academy said, “The sponsored tickets from AWS didn’t just provide access to training—they gave our students entry into a global security community. Our young women now see themselves as part of a larger security mission, understanding that their contributions to cybersecurity can have worldwide impact.”
By combining technical challenges with mentorship and collaboration, Wicked6 helped participants work together to upskill and address tomorrow’s challenges. Gulick highlighted the event’s impact, stating “Wicked6 2025 was a success. Each year, women from all over the world join us for speakers, games, and networking. By learning to play cybersecurity games, these women can leverage games to learn new tech skills throughout their careers.”
No matter your role—whether you’re a seasoned professional or just starting your cybersecurity journey—continuous learning is key.
“It’s important as women and as cybersecurity professionals not to get comfortable with the status quo. Leveling up means stepping out of our comfort zones and doing things that scare us. Going to networking events, actively talking with people, connecting with people on LinkedIn, getting educated to improve skills, and putting ourselves out there. Wicked6 is the perfect place to do that this year and in the years to come!” —Mari Galloway, CEO of Women’s Society of Cyberjutsu
Pursuing the path to success
As cyber threats continue to evolve, AWS remains committed to strengthening global security culture through initiatives that promote active participation and partnership. This year’s Wicked6 Cyber Games exemplified how the security community can encourage and support future leaders with collaborative learning experiences and foster a more resilient and adaptable workforce.
If you have feedback about this blog post, submit comments in the Comments section below. You can also start a new thread on the AWS Security, Identity, and Compliance re:Post to get answers from the community.
As AI and machine learning (AI/ML) become increasingly accessible through cloud service providers (CSPs) such as Amazon Web Services (AWS), new security issues can arise that customers need to address. AWS provides a variety of services for AI/ML use cases, and developers often interact with these services through different programming languages. In this blog post, we focus on Python and its pickle module, which supports a process called pickling to serialize and deserialize object structures. This functionality simplifies data management and the sharing of complex data across distributed systems. However, because of potential security issues, it’s important to use pickling with care (see the warning note in pickle — Python object serialization). In this post, we’re going to show you ways to build secure AI/ML workloads that use this powerful Python module, ways to detect that it’s in use that you might not know about, and when it might be getting abused, and finally highlight alternative approaches that can help you avoid these issues.
Quick tips
Avoid unpickling data from untrusted sources
Use alternative serialization formats, when possible, such as Safetensors
Implement integrity checks for serialized data
Use static code analysis tools to detect unsafe pickling patterns, such as Semgrep
Understanding insecure pickle serialization and deserialization in Python
Effective data management is crucial in Python programming, and many developers turn to the pickle module for serialization. However, issues can arise when deserializing data from untrusted sources. The Python bytestream that pickling uses, is proprietary to Python. Until it’s unpickled, the data in the bytestream can’t be thoroughly evaluated. This is where security controls and validation become critical. Without proper validation, there’s a risk that an unauthorized user could inject unexpected code, potentially leading to arbitrary code execution, data tampering, or even unintended access to a system. In the context of AI model loading, secure deserialization is particularly important—it helps prevent outside parties from modifying model behavior, injecting backdoors, or causing inadvertent disclosure of sensitive data.
Throughout this post, we will refer to pickle serialization and deserialization collectively as pickling. Similar issues can be present in other languages (for example, Java and PHP) when untrusted data is used to recreate objects or data structures, resulting in potential security issues such as arbitrary code execution, data corruption, and unauthorized access.
Static code analysis compared to dynamic testing for detecting pickling
Security code reviews, including static code analysis, offer valuable early detection and thorough coverage of pickling-related issues. By examining source code (including third-party libraries and custom code) before deployment, teams can minimize security risks in a cost-effective way. Tools that provide static analysis can automatically flag unsafe pickling patterns, giving developers actionable insights to address issues promptly. Regular code reviews also help developers improve secure coding skills over time.
While static code analysis provides a comprehensive white-box approach, dynamic testing can uncover context-specific issues that only appear during runtime. Both methods are important. In this post, we focus primarily on the role of static code analysis in identifying unsafe pickling.
Tools like Amazon CodeGuru and Semgrep are effective at detecting security issues early. For open source projects, Semgrep is a great option to maintain consistent security checks.
The risks of insecure pickling in AI/ML
Pickling issues in AI/ML contexts can be especially concerning.
Invalidated object loading: AI/ML models are often serialized for future use. Loading these models from untrusted sources without validation can result in arbitrary code execution. Libraries such as pickle, joblib, and some yaml configurations allow serialization but must be handled securely.
For example: If a web application stores user input using pickle and unpickles it later with no validation, an unauthorized user could craft a harmful payload that executes arbitrary code on the server.
Data integrity: The integrity of pickled data is critical. Unexpectedly crafted data could corrupt models, resulting in incorrect predictions or behaviors, which is especially concerning in sensitive domains such as finance, healthcare, and autonomous systems.
For example: A team updates its AI model architecture or preprocessing steps but forgets to retrain and save the updated model. Loading the old pickled model under new code might trigger errors or unpredictable outcomes.
Exposure of sensitive information: Pickling often includes all attributes of an object, potentially exposing sensitive data such as credentials or secrets.
For example: An ML model might contain database credentials within its serialized state. If shared or stored without precautions, an unauthorized user who unpickles the file might gain unintended access to these credentials.
Insufficient data protection: When sent across networks or stored without encryption, pickled data can be intercepted, leading to inadvertent disclosure of sensitive information.
For example: In a healthcare environment, a pickled AI model containing patient data could be transmitted over an unsecured network, enabling an outside party to intercept and read sensitive information.
Performance overhead: Pickling can be slower than other serialization formats (such as, JSON or Protocol Buffers), which can affect ML and large language model (LLM) applications when inference speed is critical.
For example: In a real-time natural language processing (NLP) application using an LLM, heavy pickling or unpickling operations might reduce responsiveness and degrade the user experience.
Detecting unsafe unpickling with static code analysis tools
Static code analysis (SCA) is a valuable practice for applications dealing with pickled data, because it helps detect insecure pickling before deployment. By integrating SCA tools into the development workflow, teams can spot questionable deserialization patterns as soon as code is committed. This proactive approach reduces the risk of events involving unexpected code execution or unintended access due to unsafe object loading.
For instance, in a financial services application where objects are routinely pickled, a SCA tool can scan new commits to detect unvalidated unpickling. If identified, the development team can quickly address the issue, protecting both the integrity of the application and sensitive financial data.
Patterns in the source code
There are various ways to load a pickle object in Python. In this context, methods for detection can be tailored for secure coding habits and needed package dependencies. Many Python libraries include a function to load pickle objects. An effective approach can be to catalog all Python libraries used in the project, then create custom rules in your static code analysis tool to detect unsafe pickling or unpickling within those libraries.
CodeGuru and other static analysis tools continue to evolve their capability to detect unsafe pickling patterns. Organizations can use these tools and create custom rules to identify potential security issues in AI/ML pipelines.
Let’s define the steps for creating a safe process for addressing pickling issues:
Generate a list of all the Python libraries that are used in your repository or environment.
Check the static code analysis tool in your pipeline for current rules and the ability to add custom rules. If the tool is capable of discovering all the libraries used in your project, you can rely on it. However, if it’s not able to discover all the libraries used in your project, you should consider adding user-provided custom rules in your static code analysis tool.
Most of the issues can be identified with well-designed, context-driven patterns in the static code analysis tool. For addressing the pickling issues, you need to identify pickling and unpickling functions.
Implement and test the custom rules to verify full coverage of pickling and unpickling risks. Let’s identify patterns for a few libraries:
NumPy can efficiently pickle and unpickle arrays; useful for scientific computing workflows requiring serialized arrays. To catch potential unsafe pickle usage in NumPy, custom rules could target patterns like:
import numpy as np
data = np.load('data.npy', allow_pickle=True)
npyfile is a utility for loading NumPy arrays from pickled files. You can add the following patterns to your custom rules to discover potentially unsafe pickle object usage.
import npyfile
data = npyfile.load('example.pkl')
pandas can pickle and unpickle DataFrames using pickle, allowing for efficient storage and retrieval of tabular data. You can add the following patterns to your custom rules to discover potentially unsafe pickle object usage.
import pandas as pd
df = pd.read_pickle('dataframe.pkl')
joblib is often used for pickling and unpickling Python objects that involve large data, especially NumPy arrays, more efficiently than standard pickle. You can add the following patterns to your custom rules to discover potentially unsafe pickle object usage.
from joblib import load
data = load('large_data.pkl')
Scikit-learn provides joblib for pickling and unpickling objects and is particularly useful for models. You can add the following patterns to your custom rules to discover potentially unsafe pickle object usage.
from sklearn.externals import joblib
data = joblib.load('example.pkl')
PyTorch provides utilities for loading pickled objects that are especially useful for ML models and tensors. You can add the following patterns to your custom rule format to discover potentially unsafe pickle object usage.
import torch
data = torch.load('example.pkl')
By searching for these functions and parameters in code, you can set up targeted rules that highlight potential issues with pickling.
Effective mitigation
Addressing pickling issues requires not only detection, but also clear guidance on remediation. Consider recommending more secure formats or validations where possible as follows:
PyTorch
Use Safetensors to store tensors. If pickling remains necessary, add integrity checks (for example, hashing) for serialized data.
pandas
Verify data sources and integrity when using pd.read_pickle. Encourage safer alternatives (for example, CSV, HDF5, or Parquet) to help avoid pickling risks.
scikit-learn (via joblib)
Consider Skops for safer persistence. If switching formats isn’t feasible, implement strict validation checks before loading.
General advice
Identify safer libraries or methods whenever possible.
Switch to formats such as CSV or JSON for data, unless object-specific serialization is absolutely required.
Perform source and integrity checks before loading pickle files—even those considered trusted.
Example
The following is an example implementation that shows safe pickle implementation as a representation of the preceding information.
import io
import base64
import pickle
import boto3
import numpy as np
from cryptography.fernet import Fernet
###############################################################################
# 1) RESTRICTED UNPICKLER
###############################################################################
#
# By default, pickle can execute arbitrary code when loading. Here we implement
# a custom Unpickler that only allows certain safe modules/classes. Adjust this
# to your application's requirements.
#
class RestrictedUnpickler(pickle.Unpickler):
"""
Restricts unpickling to only the modules/classes we explicitly allow.
"""
allowed_modules = {
"numpy": set(["ndarray", "dtype"]),
"builtins": set(["tuple", "list", "dict", "set", "frozenset", "int", "float", "bool", "str"])
}
def find_class(self, module, name):
if module in self.allowed_modules:
if name in self.allowed_modules[module]:
return super().find_class(module, name)
# If not allowed, raise an error to prevent arbitrary code execution.
raise pickle.UnpicklingError(f"Global '{module}.{name}' is forbidden")
def restricted_loads(data: bytes):
"""Helper function to load pickle data using the RestrictedUnpickler."""
return RestrictedUnpickler(io.BytesIO(data)).load()
###############################################################################
# 2) AWS KMS & ENCRYPTION HELPERS
###############################################################################
def generate_data_key(kms_key_id: str, region: str = "us-east-1"):
"""
Generates a fresh data key using AWS KMS.
Returns (plaintext_key, encrypted_data_key).
"""
kms_client = boto3.client("kms", region_name=region)
response = kms_client.generate_data_key(KeyId=kms_key_id, KeySpec='AES_256')
# Plaintext data key (use to encrypt the pickle data locally)
plaintext_key = response["Plaintext"]
# Encrypted data key (store along with your ciphertext)
encrypted_data_key = response["CiphertextBlob"]
return plaintext_key, encrypted_data_key
def decrypt_data_key(encrypted_data_key: bytes, region: str = "us-east-1"):
"""
Decrypts the encrypted data key via AWS KMS, returning the plaintext key.
"""
kms_client = boto3.client("kms", region_name=region)
response = kms_client.decrypt(CiphertextBlob=encrypted_data_key)
return response["Plaintext"]
def build_fernet_key(plaintext_key: bytes) -> Fernet:
"""
Construct a Fernet instance from a 32-byte data key.
Fernet requires a 32-byte key *encoded* in URL-safe base64.
"""
if len(plaintext_key) < 32:
raise ValueError("Data key is smaller than 32 bytes; cannot build a Fernet key.")
fernet_key = base64.urlsafe_b64encode(plaintext_key[:32])
return Fernet(fernet_key)
###############################################################################
# 3) MAIN LOGIC
###############################################################################
def upload_pickled_data_s3(
numpy_obj: np.ndarray,
bucket_name: str,
s3_key: str,
kms_key_id: str,
region: str = "us-east-1"
):
"""
Pickle a numpy object, encrypt it locally, and upload the ciphertext +
encrypted data key to S3.
"""
# 1. Generate data key from KMS
plaintext_key, encrypted_data_key = generate_data_key(kms_key_id, region)
# 2. Build Fernet from plaintext data key
fernet = build_fernet_key(plaintext_key)
# 3. Serialize the numpy object with pickle
pickled_data = pickle.dumps(numpy_obj, protocol=pickle.HIGHEST_PROTOCOL)
# 4. Encrypt the pickled data
encrypted_data = fernet.encrypt(pickled_data)
# 5. Upload to S3 along with the encrypted data key (in metadata)
s3_client = boto3.client("s3", region_name=region)
s3_client.put_object(
Bucket=bucket_name,
Key=s3_key,
Body=encrypted_data,
Metadata={
"encrypted_data_key": base64.b64encode(encrypted_data_key).decode("utf-8")
}
)
print(f"Encrypted pickle uploaded to s3://{bucket_name}/{s3_key}")
def download_and_unpickle_data_s3(
bucket_name: str,
s3_key: str,
region: str = "us-east-1"
) -> np.ndarray:
"""
Download the ciphertext and the encrypted data key from S3. Decrypt the data
key with KMS, use it to decrypt the pickled data, then load with a restricted
unpickler for safety.
"""
s3_client = boto3.client("s3", region_name=region)
# 1. Get object from S3
response = s3_client.get_object(Bucket=bucket_name, Key=s3_key)
# 2. Extract the encrypted data key from metadata
metadata = response["Metadata"]
encrypted_data_key_b64 = metadata.get("encrypted_data_key")
if not encrypted_data_key_b64:
raise ValueError("Missing encrypted_data_key in S3 object metadata.")
encrypted_data_key = base64.b64decode(encrypted_data_key_b64)
# 3. Decrypt data key via KMS
plaintext_key = decrypt_data_key(encrypted_data_key, region)
fernet = build_fernet_key(plaintext_key)
# 4. Decrypt the pickled data
encrypted_data = response["Body"].read()
decrypted_pickled_data = fernet.decrypt(encrypted_data)
# 5. Use restricted unpickler to load the numpy object
numpy_obj = restricted_loads(decrypted_pickled_data)
return numpy_obj
###############################################################################
# DEMO USAGE
###############################################################################
if __name__ == "__main__":
# --- Replace with your actual values ---
KMS_KEY_ID = "arn:aws:kms:us-east-1:123456789012:key/your-kms-key-id"
BUCKET_NAME = "your-secure-bucket"
S3_OBJECT_KEY = "encrypted_npy_demo.bin"
AWS_REGION = "us-east-1" # or region of your choice
# Example numpy array
original_array = np.random.rand(2, 3)
print("Original Array:")
print(original_array)
# Upload (pickle + encrypt) to S3
upload_pickled_data_s3(
numpy_obj=original_array,
bucket_name=BUCKET_NAME,
s3_key=S3_OBJECT_KEY,
kms_key_id=KMS_KEY_ID,
region=AWS_REGION
)
# Download (decrypt + unpickle) from S3
retrieved_array = download_and_unpickle_data_s3(
bucket_name=BUCKET_NAME,
s3_key=S3_OBJECT_KEY,
region=AWS_REGION
)
print("\nRetrieved Array:")
print(retrieved_array)
# Verify integrity
assert np.allclose(original_array, retrieved_array), "Arrays do not match!"
print("\nSuccess! The retrieved array matches the original array.")
Conclusion
With the rapid expansion of cloud technologies, integrating static code analysis into your AI/ML development process is increasingly important. While pickling offers a powerful way to serialize objects for AI/ML and LLM applications, you can mitigate potential risks by applying manual secure code reviews, setting up automated SCA with custom rules, and following best practices such as using alternative serialization methods or verifying data integrity.
When working with ML models on AWS, see the AWS Well-Architected Framework’s Machine Learning Lens for guidance on secure architecture and recommended practices. By combining these approaches, you can maintain a strong security posture and streamline the AI/ML development lifecycle.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
On March 24, 2025, Kubernetes disclosed 5 new vulnerabilities affecting the Ingress NGINX Controller for Kubernetes. Successful exploitation could allow attackers access to all secrets stored across all namespaces in the Kubernetes cluster, which could result in cluster takeover.
CVE-2025-1974 (9.8 Critical): RCE escalation. An unauthenticated attacker with access to the pod network can achieve arbitrary code execution in the context of the ingress-nginx controller. This can lead to disclosure of Secrets accessible to the controller. (In the default installation, the controller can access all Secrets cluster-wide.)
CVE-2025-24514(8.8 High): Configuration injection via unsanitized auth-url annotation. In ingress-nginx, the `auth-url` Ingress annotation can be used to inject configuration into nginx. This can lead to arbitrary code execution in the context of the ingress-nginx controller, and disclosure of Secrets accessible to the controller.
CVE-2025-1097 (8.8 High): Configuration injection via unsanitized auth-tls-match-cn annotation. The `auth-tls-match-cn` Ingress annotation can be used to inject configuration into nginx. This can lead to arbitrary code execution in the context of the ingress-nginx controller, and disclosure of Secrets accessible to the controller.
CVE-2025-1098 (8.8 High): Configuration injection via unsanitized mirror annotations. The `mirror-target` and `mirror-host` Ingress annotations can be used to inject arbitrary configuration into nginx. This can lead to arbitrary code execution in the context of the ingress-nginx controller, and disclosure of Secrets accessible to the controller.
CVE-2025-24513 (4.8 Medium): Auth secret file path traversal vulnerability. Attacker-provided data is included in a filename by the ingress-nginx Admission Controller feature, resulting in directory traversal within the container. This could result in denial of service, or when combined with other vulnerabilities, limited disclosure of Secret objects from the cluster.
Of the 5 vulnerabilities disclosed, any one of the injection vulnerabilities (CVE-2025-24514, CVE-2025-1097, CVE-2025-1098) may be chained with CVE-2025-1974 to achieve unauthenticated RCE on the Kubernetes pod that is running a vulnerable Ingress NGINX Controller. Achieving RCE could allow an attacker to take over a Kubernetes cluster. As of March 25, 2025, none of the above CVEs is known to be exploited in the wild.
Ingress is a Kubernetes feature to route HTTP(S) traffic into a Kubernetes cluster. An Ingress Controller is an application responsible for performing the routing. While there are many Ingress Controllers available, the vulnerabilities disclosed on March 24 are specific to the Ingress NGINX Controller, which is an Ingress Controller based upon NGINX.
The original finders of all five vulnerabilities, Wiz, noted that 43% of cloud environments are vulnerable to the issues disclosed, and that they have identified 6,500 clusters with publicly exposed Ingress NGINX Controllers.
As of March 25, 2025 (14:00 pm GMT), there is now one known publicly available RCE exploit for CVE-2025-1974 (here). This exploit is unverified, but based on our understanding of the vulnerability, it appears viable.
Mitigation guidance
All 5 vulnerabilities are reported to affect the following versions of Ingress NGINX Controller:
Versions <= 1.11.4
Version 1.12.0
Notably, the Wiz advisory says that CVE-2025-24514 does not affect version 1.12.0, but the vendor indicates that the issue does affect 1.12.0.
Customers who use the Ingress NGINX Controller for Kubernetes are advised to update to the following versions immediately:
Version 1.11.5
Version 1.12.1
Rapid7 customers
With the latest Kubernetes Cluster Scanner (expected to be available Wednesday, March 26), InsightCloudSec customers will have the ability to discover Kubernetes workloads that have this vulnerability in their cluster. The discovery will be shown via the insights pack with a new insight called Publicly exposed vulnerable Ingress NGINX Admission. The insight will also include the remediation steps needed in order to resolve this vulnerability.
By implementing the PBHVA control overlay over a CCCS Medium baseline, you can better protect your organization’s most critical assets from potential threats and vulnerabilities, providing continuity of essential government operations and safeguarding sensitive information.
Understanding CCCS PBHVA overlay requirements
The CCCS PBHVA overlay consists of 137 controls designed to protect high-value assets, including 69 new controls and 68 controls from CCCS Medium. These controls provide enhanced data protection, particularly for integrity and availability, and are based on NIST SP 800-53 Revision 5.
Key findings from the Coalfire assessment
Coalfire’s assessment found that the LZA on AWS solution significantly supports CCCS PBHVA overlay compliance requirements:
71 percent of in-scope controls (97 of 137) are supported by the AWS contribution to compliance in the shared responsibility model
The solution uses over 35 AWS services to provide comprehensive security capabilities
Strong network segmentation is achieved through network account and network-boundary VPC design
Infrastructure-as-code (IaC) enables reliable build and deployment results
The 29 percent of controls not addressed by the LZA are on the customer side of the shared responsibility model. They are addressed in the customer’s application stack or as non-technical controls such as policies and procedures.
Key security capabilities
The LZA solution implements several critical security features:
While the LZA solution provides significant compliance support, organizations should note:
The solution alone does not guarantee compliance
Organizations must implement their own policies, standards, and procedures
A thorough understanding of the shared responsibility model is essential
The AWS Landing Zone Accelerator Verified Reference Architecture documentation is available for customer download in AWS Artifact. This resource can help organizations reduce the time and effort required to deploy an environment that aligns with CCCS PBHVA overlay requirements.
Conclusion
The Coalfire assessment confirms that the LZA on AWS solution provides effective support for CCCS PBHVA overlay compliance objectives. However, organizations should remember that compliance is an ongoing process that requires active management and cannot be achieved through technology alone.
For more information about implementing the Landing Zone Accelerator for CCCS PBHVA overlay requirements, contact your AWS account team or the AWS Public Sector team directly.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
If you’d like to skip directly to the detailed mapping between the CISA guidance and AWS security controls and best practices, visit our Github page.
Implementing CISA’s enhanced visibility and hardening guidance for communications infrastructure
In response to recent cybersecurity incidents attributed to actors from the People’s Republic of China, a number of cybersecurity agencies led by the U.S. Cybersecurity and Infrastructure Security Agency (CISA) have jointly released comprehensive guidance for securing communications infrastructure. As communications service providers (CSPs) migrate their workloads to the cloud, they must take steps to implement these security measures effectively in cloud environments.
This blog post describes how CSPs can use Amazon Web Services (AWS) capabilities to implement this guidance while benefiting from the advantages of the cloud.
The guidance focuses on two key domains:
Strengthening visibility: Enabling security teams to monitor, detect, and respond to potential threats through comprehensive visibility into digital assets
Hardening systems and devices: Implementing robust security controls and configurations to minimize vulnerabilities and help prevent unauthorized access
Overview of fundamental cloud concepts
Before exploring the specific guidance in this post, it’s important to understand how security recommendations apply differently to public cloud environments than to private infrastructure. A common tendency in the telecommunications industry is to treat public clouds as merely scaled-up versions of private clouds. This can result in a misunderstanding of security capabilities and underutilization of cloud-native security features of the public cloud.
The fundamental difference lies in how public clouds are architected—specifically for multi-tenancy, with strong tenant isolation as a cornerstone of their design. In AWS, virtual resources are isolated by default and require explicit configuration to interconnect. For example, when you create a virtual private cloud (VPC) with Amazon VPC, this logically isolated network does not permit inbound or outbound traffic until specific routes and ports are deliberately configured. Similarly, Amazon Simple Storage Service (Amazon S3) buckets are private by default, requiring explicit configuration to grant access. This isolation extends to the core of our virtualization infrastructure through the AWS Nitro System, which provides unprecedented workload isolation—even AWS operators with the highest privileges have no technical access to customer workloads. Furthermore, data moving between Nitro System based virtual machines or across our global backbone network is automatically encrypted, providing additional layers of protection beyond customer-implemented encryption.
This secure-by-design and secure-by-default philosophy permeates throughout AWS service design and operations. It isn’t merely a design choice—it’s a business imperative driven by the critical need for operational resilience and customer trust in the public cloud model. Our commitment to principles of this sort is reflected in our participation as a signatory to CISA’s Secure by Design Pledge.
When AWS customers operate in the public cloud, understanding the shared responsibility model is paramount. This model clearly delineates security responsibilities: AWS is responsible for security of the cloud, while customers are responsible for security in the cloud. This division of responsibilities significantly reduces your operational burden, because AWS assumes responsibility for securing everything about and inside the cloud services it provides, all the way down to the physical protection of data centers. As a result, you can concentrate your security resources where they matter most—protecting your applications and workloads—while AWS handles the undifferentiated heavy lifting of infrastructure security.
This shared responsibility model becomes even more advantageous when considering the economies of scale inherent to public cloud operations. The massive scale of AWS allows us to invest more in securing the foundations than a single enterprise could achieve independently, creating a security multiplier effect that benefits all customers. A compelling example of this scale advantage is our comprehensive threat intelligence program, which deploys honeypot sensors throughout our global network. These sensors observe more than 100 million potential threat interactions and probes daily. Using artificial intelligence and machine learning (AI/ML), we analyze this information and take swift, often automated actions to mitigate threats. In the first half of 2023 alone, this program enabled us to dismantle the sources of approximately 230,000 Layer 7 distributed denial of service (DDoS) events. We also provide this intelligence to customers through services like Amazon GuardDuty, extending the benefits of our scale to our customers.
The scale of AWS operations not only enables exemplary threat intelligence, but also necessitates extensive automation of our security operations. Several routine tasks, such as feature and patch deployments and configuration updates, are fully automated through deployment pipelines. Automation has the added benefit of taking humans out of the loop, thereby decreasing opportunities for mistakes.
Our scale also facilitates our comprehensive compliance with security standards across multiple industries and jurisdictions. Our global presence and diverse customer base necessitate adherence to the most stringent security requirements worldwide. Through the AWS Compliance Program, we’ve achieved 143 security standards and compliance certifications, ranging from ISO standards for cloud security and privacy to industry-specific regulations in finance and healthcare, as well as government security programs. This includes independent verification of our claims on the isolation properties of our Nitro System virtualization infrastructure. Consequently, you benefit from this scale-driven compliance, gaining access to a secure, certified infrastructure that implements state-of-the-art security systems.
These are a few reasons why, in a blog post titled Why cloud first is not a security problem, the UK’s National Cyber Security Centre concluded that “using the cloud securely should be your primary concern – not the underlying security of the public cloud.”
Private clouds, on the other hand, are typically within the control of a single organization and are single-tenanted, offering relatively weak workload isolation. Virtual resources in private clouds usually default to being interconnected upon creation, and so require explicit steps to increase isolation. Manual operations, with their opportunities for mistakes as well as potential involvement of threat actors, are often still a large part of private cloud workflows. Rarely do they undergo the level of security scrutiny that public clouds are routinely subjected to. These, and other differences, mean that security risks in each offering are inherently different, so correspondingly distinct security controls and solution architectures are needed to mitigate these risks.
Implementing hardening guidance with AWS
Your cloud resources and data are contained in an AWS account. An account acts as an identity and access management isolation boundary. When you need to share resources and data between two accounts, you must explicitly allow this access. This reduces the risk of lateral movement between accounts.
Designing your AWS environment correctly lays a strong foundation that can help you meet the CISA cybersecurity guidance. AWS Control Tower, working with AWS Organizations, enables you to establish a well-architected, multi-account environment based on security best practices.
For detailed guidance on creating a secure landing zone for telecom workloads, refer to our comprehensive blog post on this topic.
We’ve analyzed the recommendations in CISA’s guidance and grouped them into six categories across the two key domains. Refer to the GitHub page linked at the bottom of this post, which has further detailed guidance on the relevant AWS services that can assist your implementation of each individual security measure in the guidance.
Logging and monitoring
The guidance in this category emphasizes the importance of increasing visibility to understand network activity, which is essential for detecting anomalies and responding to incidents. Key security controls include the following: have a robust asset management capability, enable logging at various levels, centralize logging, protect the logging and monitoring infrastructure, and use security tools to detect anomalies and incidents.
Enhanced visibility is an inherent advantage of the public cloud model, particularly in AWS. This transparency is not just a bolted-on feature, but a fundamental necessity driven by the API-centric, pay-as-you-go business model. To accurately bill customers, AWS has built comprehensive tracking and logging capabilities into its core architecture. As a result, AWS provides robust tools that allow you to capture, centralize, and monitor logs across every layer of your network workload. This level of visibility extends far beyond what’s typically achievable in traditional infrastructure, offering you unprecedented insight into your IT assets and user activities.
Another key guidance is this area is to centralize security-related logging while isolating the logging infrastructure from other production environments. You can implement this guidance in AWS by using Amazon Security Lake together with OpenSearch implemented in separate accounts, with access restricted to just the security organization. Alternatively, this solution provides a best-practice implementation of creating collection and ingestion pipelines to allow for centralization and inspection of log sources across your AWS workloads without the use of Security Lake.
Configuration and change management
The guidance in this category emphasizes the centralization, security, and protection of configurations. It highlights the importance of detecting and providing alerts for unauthorized modifications, auditing configurations for compliance, and a change management process that automates routine changes to minimize unintended drift.
In AWS, you can implement infrastructure and configuration as code, which allows for central storage of configuration in repositories, tracking changes through version control, and implementing changes through approved change management processes. You can use code repositories and continuous integration and continuous delivery (CI/CD) pipelines to automate the implementation of these configurations, helping you increase deployment speed, maintain consistency, simplify management, and implement a rigorous and auditable change control process.
Regardless of how infrastructure is deployed and managed, you can use the AWS Config service to automatically track the current state and history of a wide set of configuration information across more than 100 AWS services and hundreds of their resource types. You can also write custom AWS Config rules to take automatic actions whenever sensitive resources are modified, or take advantage of more than 400 AWS managed rules in AWS Config that send alerts or create automatic remediations when critical resources change state.
Identity and access management
The guidance in this category emphasizes the importance of active account and permissions management, use of phishing-resistant authentication methods, implementing least privilege through role-based access controls, managing emergency access, and limiting sessions.
Authentication and authorization, which are critical components of access control, are managed through AWS Identity and Access Management (IAM), AWS IAM Identity Center, and AWS Organizations. AWS provides you with capabilities to manage permissions at scale across identities, resources, and services, including mandating the use of multi-factor authentication (MFA) for logins. Furthermore, these capabilities support customers adhering to the principle of least privilege by encouraging time-bound, session-based credential management by using AWS Security Token Service (AWS STS).
The guidance in this category emphasizes segmenting workloads and networks to limit the potential for lateral movement and exposure to the internet, monitoring and regulating traffic flows by using policies, and securing unused ports.
You can achieve network micro-segmentation, a critical aspect of modern security architecture, through VPCs and subnets. You can, for example, segregate internet-facing components of your application from those that don’t require such access by placing them in separate VPCs and enabling internet access only on the VPC that requires it. You can control traffic flows within and between segments by using a variety of network services—routing tables, internet gateways, transit gateways, and firewall services, to name a few. This segmentation minimizes your risk from unauthorized activity that originates from the internet and limits the potential for lateral movement in the event of a breach.
To implement the guidance regarding out-of-band management, you can architect your network connections to separate management traffic from network signaling traffic by using subnets—for example, a single EC2 instance can have multiple elastic network interfaces (ENIs) attached to different subnets or even different VPCs: one that permits only management traffic and another that permits only signaling traffic.
Strong cryptography to encrypt data at rest and in traffic
The guidance in this category emphasizes using strong cipher suites, secure versions of encryption protocols, and PKI-based certificates to protect data at rest and in transit.
Encryption, a cornerstone of data protection, is comprehensively addressed in AWS offerings. API endpoints of AWS services support TLS 1.3 (and a minimum of TLS 1.2) with secure standards-based cipher suites, encryption keys, and advanced security features like HKDF (HMAC-based extract-and-expand key derivation function) for added security. AWS services that manage customer secrets sent over the wire also support post-quantum cryptography. For example, AWS Key Management Service (AWS KMS), AWS Certificate Manager, and AWS Secrets Manager support a hybrid post-quantum key exchange option for the TLS network encryption protocol. In its use of the Border Gateway Protocol (BGP), AWS uses Resource Public Key Infrastructure (RPKI) and Route Origin Authorization (ROA) to protect the Amazon IP address space and routes from misconfigurations and hijacking.
You can also use AWS cryptographic services such as AWS KMS, AWS CloudHSM, and AWS Certificate Manager to help secure your data in transit and at rest. Keys that you create in AWS KMS are protected by FIPS 140-2 Level 3 validated hardware security modules (HSMs), and there is no mechanism for anyone, including AWS service operators, to view, access, or export plaintext key material.
AWS Secrets Manager helps you securely manage, retrieve, and rotate database credentials, application credentials, OAuth tokens, API keys, and other secrets throughout their lifecycles. For more details on AWS cryptography solutions and best practices, refer to Encryption best practices for AWS services.
Vulnerability management
This guidance emphasizes minimizing exploitation risks through proper lifecycle management, regular patching, and elimination of insecure protocols. AWS helps address these requirements through both shared responsibility and innovative architectural approaches.
Under the shared responsibility model, AWS manages the security of underlying infrastructure. This includes maintaining up-to-date systems and services, disabling insecure protocols and unused ports, and providing Security Bulletins for timely vulnerability notifications. AWS services are supported through contractually defined terms, so that you don’t need to worry about end-of-life infrastructure components.
For your applications, AWS enables a transformative approach to vulnerability management through ephemeral resources and immutable infrastructure. Instead of maintaining long-lived instances that require continuous patching, you can maintain a single, hardened, and frequently updated Amazon Machine Image (AMI) as your golden image. When updates are needed, rather than patching running instances, you simply deploy new instances with your application code installed from an updated AMI. Similar approaches also apply to container-based workloads. Workloads based on AWS Lambda reduce your patching responsibility even further, because only the code that contains your business logic (and any supporting layers you have chosen) needs to be updated—AWS patches the underlying hypervisors, operating systems, and containers automatically. This approach enables you to keep your systems in a known, secure state while reducing both the threat surface and operational overhead. You can further enhance security by using AWS networking features like security groups to disable insecure protocols, such as enforcing HTTPS rather than HTTP.
Conclusion
The comprehensive guidance from cybersecurity agencies provides a crucial framework for securing telecommunications infrastructure. As demonstrated throughout this post, AWS offers a robust set of native services and capabilities that align with the recommendations from CISA and allied governments. From enhanced visibility through logging and monitoring, to strong identity management, network segmentation, encryption, and vulnerability management, AWS provides the tools you need to implement these security controls effectively while maintaining operational efficiency. The shared responsibility model, combined with AWS continuous innovation in security, enables telecommunications companies to build and maintain resilient, secure cloud environments.
We continue to expand the scope of our assurance programs at Amazon Web Services (AWS) and are pleased to announce the successful completion of our first ever Protected B High Value Assets (PBHVA) assessment with 149 assessed services and features. Completion of this assessment effective October 4, 2024, makes AWS the first cloud service provider (CSP) in Canada to meet this high security bar and provide assurance to our valued customers. This assessment also re-affirms our commitment to helping public and commercial customers achieve and maintain the highest-grade security standard for workloads with increased sensitivity.
What is the PBHVA assessment and why is it important?
The Protected B High Value Asset (PBHVA) overlay seeks to enhance the integrity and availability of customer organizational workloads that are considered to have an increased level of sensitivity. These are systems that the Government of Canada (GC) and its service providers use to support delivery of services at a national scale or that are determined to be significant for handling sensitive information. The overlay is a set of 117 controls from the ITSG-33 security control catalogue (baselined against NIST 800-53), which augments the security safeguards to enhance integrity and availability.
As of October 4, 2024, there are a total of 149 AWS services and features that were assessed by the Canadian Centre for Cyber Security (CCCS) under PBHVA assessment criteria. The assessment covers services and features that are available in both the Canada (Central) and Canada West (Calgary) AWS Regions.
How can you access the assessment?
The summary assessment is available through AWS Artifact. You can also learn more about the PBHVA assessment on our AWS PBHVA webpage.
AWS strives to continuously bring services into scope of its compliance programs to help you meet your architectural and regulatory needs. Please reach out to your AWS account team if you have questions or feedback about the PBHVA assessment.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
The cloud has become the backbone of modern innovation, powering everything from AI to remote work. But as organizations embrace the cloud, they also face an ever-expanding and increasingly complex attack surface. With purpose-built harvesting technology providing real-time visibility into everything running across multi-cloud environments, Exposure Command from Rapid7 ensures teams have an up-to-date inventory, mapping their cloud attack surface and enriching asset data with risk and business context.
To ensure teams can keep up with the torrid pace of innovation and overcome increased complexity, Rapid7 remains dedicated to investing in advancing the cloud security capabilities available within Exposure Command. To that end, we’ve made a few significant updates across AI resource coverage, third-party CNAPP enrichment and more. Let’s dive right in.
Extending coverage for securing AI/ML development in the cloud
AI and machine learning (ML) are transforming industries, but the speed of adoption can often leave organizations vulnerable. AI/ML workloads often process sensitive or proprietary data, requiring robust protections to ensure compliance with ever-evolving regulations. Safeguarding these environments isn’t just about securing the infrastructure; it’s about understanding the unique workflows and ensuring compliance at every step.
These workloads also introduce unique risks, such as model poisoning attacks or vulnerabilities in APIs, creating new vectors for data exfiltration and service disruption. Additionally, the dynamic nature of cloud-hosted AI services presents challenges in maintaining secure configurations as resources scale elastically, potentially exposing sensitive endpoints or misconfigured setups.
To that end, Exposure Command has expanded support for critical AI services like Amazon Comprehend and Polly, AWS’s natural language processing and text-to-speech services.This provides comprehensive visibility across an organization’s attack surface, aligning AI-specific risks with broader enterprise priorities.
Shifting left and securing the software supply chain
Developers are at the forefront of modern cloud environments, making “shift-left” strategies essential for effective security. By addressing risks during development rather than after deployment, teams can eliminate vulnerabilities before they become costly issues.
Exposure Command now offers more robust Infrastructure-as-Code (IaC) scanning and deeper CI/CD integration, with Terraform and CloudFormation support across hundreds of resource types. For development teams, integrations like GitLab, GitHub Actions, AWS CloudFormation, and Azure DevOps bring security checks directly into their workflows. Whether it’s identifying misconfigurations in AWS Glue Catalogs or assessing risks in SES configurations, these tools help teams secure their code without breaking their stride.
Bridging the hybrid cloud gap with native and third-party CNAPP connectors
For many organizations, the challenge isn’t just securing the cloud – it’s securing everything holistically. Hybrid environments that span on-prem systems and multiple cloud providers can create silos, leading to gaps in visibility and risk management. To tackle this, we’ve integrated InsightCloudSec data directly into Surface Command, empowering security teams with a unified view of their entire attack surface in one place.
But we didn’t stop at consolidating our own native CNAPP capabilities. Teams now get out-of-the-box integrations with popular cloud security tools like Wiz and Orca as well as CSP-native services like AWS Inspector, all making it easier than ever to identify risks across cloud-native and hybrid environments. Everything can now be seen in one place – from endpoint vulnerabilities to cloud misconfigurations and overly permissive roles – allowing for faster action with clarity and precision.
Tackling virtual desktop risks with custom registry keys
With the rise of remote work, virtual desktop infrastructures (VDIs) like AWS Workspaces have become essential. Yet, their dynamic nature makes tracking vulnerabilities a challenge. Exposure Command addresses this with features like custom registry keys for golden images, ensuring you can trace a risk back to its source and effectively prioritize remediation.
Commanding the cloud attack surface
The challenges of securing modern environments aren’t going away. Attack surfaces will continue to expand, threats will grow more sophisticated, and organizations will face increasing pressure to innovate securely.
Keep an eye out for more updates coming soon as we continue to invest in helping organizations effectively manage exposures from endpoint to cloud.
Around the world, organizations are evaluating and embracing artificial intelligence (AI) and machine learning (ML) to drive innovation and efficiency. From accelerating research and enhancing customer experiences to optimizing business processes, improving patient outcomes, and enriching public services, the transformative potential of AI is being realized across sectors. Although using emerging technologies helps drive positive outcomes, leaders worldwide must balance these benefits with the need to maintain security, compliance, and resilience. Many organizations, including those in the public sector and regulated industries, are investing in generative AI applications powered by large language models (LLMs) and other foundation models (FMs) because these applications can transform and scale their work and provide better experiences for customers. Beyond computing power, unlocking this AI potential resides in the AI applications that organizations can create based on a variety of AI/ML development services, models, and data sources. Organizations must navigate the complexity of building AI applications in light of existing and emerging regulatory regimes while verifying that their AI applications and related data are secure, protected, and resilient to risks and threats.
AWS offers a wide range of AI/ML services and capabilities, built on our sovereign-by-design foundation, that are making it simpler for our customers to meet their digital sovereignty needs while getting the security, control, compliance, and resilience that they need. For example, Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, and Stability AI through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Amazon SageMaker provides tools and infrastructure to build, train, and deploy ML models at scale while supporting responsible AI with governance controls and access to pretrained models.
Innovating securely across the AI lifecycle
Security is and always has been our top priority at AWS. AWS customers benefit from our ongoing investment in data centers, networks, custom hardware, and secure software services, built to satisfy the requirements of the most security-sensitive organizations, including the government, healthcare, and financial services. We have always believed that it is essential that customers have control over their data and its location. That’s why we architected the AWS Cloud to be secure and sovereign-by-design from day one. We remain committed to giving our customers more control and choice so that they can use the full power of AWS while meeting their unique digital sovereignty needs.
As organizations develop and implement generative AI, they want to make sure that their data and applications are secured across the AI lifecycle, including data preparation, training, and inferencing. To help ensure the confidentiality and integrity of customer data, all of our Nitro-based Amazon Elastic Compute Cloud (Amazon EC2) instances that run ML accelerators such as AWS Inferentia and AWS Trainium, and graphics processing units (GPUs) such as P4, P5, G5, and G6, are backed by the industry-leading security capabilities of the AWS Nitro System. By design, there is no mechanism for anyone at AWS to access Nitro EC2 instances that customers use to run their workloads. The NCC Group, an independent cybersecurity firm, has validated the design of the Nitro System.
We take a secure approach to generative AI and make it practical for our customers to secure their generative AI workloads across the generative AI stack so that they can focus on building and scaling. All AWS services—including generative AI services—support encryption, and we continue to innovate and invest in controls and encryption features that allow our customers to encrypt everything everywhere.
For example, Amazon Bedrock uses encryption to protect data in transit and at rest, and data remains in the AWS Region where Amazon Bedrock is being used. Customer data, such as prompts, completions, custom models, and data used for fine-tuning or continued pre-training, is not used for Amazon Bedrock service improvement and is never shared with third-party model providers. When customers fine-tune a model in Amazon Bedrock, the data is never exposed to the public internet, never leaves the AWS network, is securely transferred through a customer’s virtual private cloud (VPN), and is encrypted in transit and at rest.
SageMaker protects ML model artifacts and other system artifacts by encrypting data in transit and at rest. Amazon Bedrock and SageMaker integrate with AWS Key Management Service (AWS KMS) so that customers can securely manage cryptographic keys. AWS KMS is designed so that no one—not even AWS employees—can retrieve plaintext keys from the service.
Developing responsibly
The responsible development and use of AI is a priority for AWS. We believe that AI should take a people-centric approach that makes AI safe, fair, secure, and robust. We are committed to supporting customers with responsible AI and helping them build fairer and more transparent AI applications to foster trust, meet regulatory requirements, and use AI to benefit their business and stakeholders. AWS is the first major cloud service provider to announce ISO/IEC 42001 accredited certification for AI services, covering Amazon Bedrock, Amazon Q Business, Amazon Textract, and Amazon Transcribe. ISO/IEC 42001 is an international management system standard that outlines requirements and controls for organizations to promote the responsible development and use of AI systems.
We take responsible AI from theory into practice by providing the necessary tools, guidance, and resources, including Amazon Bedrock Guardrails to help implement safeguards tailored to customer generative AI applications and aligned with their responsible AI policies, or Model Evaluation on Amazon Bedrock to evaluate, compare, and select the best FMs for specific use cases based on custom metrics, such as accuracy, robustness, and toxicity. Additionally, Amazon SageMaker Model Monitor automatically detects and alerts customers of inaccurate predictions from deployed models. We continue to publish AI Service Cards to enhance transparency by providing a single place to find information on the intended use cases and limitations, responsible AI design choices, and performance optimization best practices for our AI services and models.
Building resilience
Resilience plays a pivotal role in the development of any workload, and AI/ML workloads are no different. Customers need to know that their workloads in the cloud will continue to operate in the face of natural disasters, network disruptions, or disruptions due to geopolitical crises. AWS delivers the highest network availability of any cloud provider and is the only cloud provider to offer three or more Availability Zones (AZs) in all Regions, providing more redundancy. Understanding and prioritizing resilience is crucial for generative AI workloads to meet organizational availability and business continuity requirements. We have published guidance on designing generative AI workloads for resilience. To enable higher throughput and enhanced resilience during periods of peak demands in Amazon Bedrock, customers can use cross-region inference to distribute traffic across multiple Regions. For customers with specific European Union data sovereignty requirements, we are launching the AWS European Sovereign Cloud in 2025 to offer an additional layer of control and resilience.
Supporting choice and flexibility
It’s important that customers have access to diverse AI technologies, while having the freedom to choose the right solutions to meet their needs. AWS provides more diversity, choice, and flexibility so that customers can select the AI solution that best aligns with their specific requirements, whether that’s using open-source models, proprietary solutions, or their own custom AI models. For example, we understand the importance of open-source AI in fostering transparency, collaboration, and rapid innovation. Open-source models enable scrutiny of vulnerabilities, drive security improvements, and support research on AI safety. Amazon SageMaker JumpStart provides pretrained, open-source models for a wide range of common use cases. To provide practitioners and developers with the guidance and tools that they need to create secure-by-design AI systems, we are a founding member of the open-source initiative Coalition for Secure AI (CoSAI).
Also, our commitment to portability and interoperability helps ensure that customers can move easily between environments. For customers changing IT providers, we’ve taken concrete steps to lower costs, and AWS is actively engaged in efforts to facilitate switching between cloud providers, including through our support of the Cloud Infrastructure Service Providers in Europe (CISPE)Cloud Switching Framework, which lays out guidance to assist providers and customers in the switching process. This gives organizations the flexibility to adapt their cloud and AI strategies as their needs evolve.
We remain committed to providing customers with a choice of diverse AI technologies, along with secure and compliant ways to build their AI applications throughout the development lifecycle. Through this approach, customers can enhance the security, compliance, and resilience of their systems.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Developing secure products and services is imperative for organizations that are looking to strengthen operational resilience and build customer trust. However, system design often prioritizes performance, functionality, and user experience over security. This approach can lead to vulnerabilities across the supply chain.
As security threats continue to evolve, the concept of Secure by Design (SbD) is gaining importance in the effort to mitigate vulnerabilities early, minimize risks, and recognize security as a core business requirement. We’re excited to share a whitepaper we recently authored with SANS Institute called Building Security from the Ground up with Secure by Design, which addresses SbD strategy and explores the effects of SbD implementations.
The whitepaper contains context and analysis that can help you take a proactive approach to product development that facilitates foundational security. Key considerations include the following:
Integrating SbD into the software development lifecycle (SDLC)
Supporting SbD with automation
Reinforcing defense-in-depth
Applying SbD to artificial intelligence (AI)
Identifying threats in the design phase with threat modeling
Using SbD to simplify compliance with requirements and standards
Planning for the short and long term
Establishing a culture of security
While the journey to a Secure by Design approach is an iterative process that is different for every organization, the whitepaper details five key action items that can help set you on the right path. We encourage you to download the whitepaper and gain insight into how you can build secure products with a multi-layered strategy that meaningfully improves your technical and business outcomes. We look forward to your feedback and to continuing the journey together.
January 30, 2025: This post was republished to make the instructions clearer and compatible with OCSF 1.1.
Customers often require multiple log sources across their AWS environment to empower their teams to respond and investigate security events. In part one of this two-part blog post, I show you how you can use Amazon OpenSearch Service to ingest logs collected by Amazon Security Lake to facilitate near real-time monitoring.
Many customers use Security Lake to automatically centralize security data from Amazon Web Services (AWS) environments, software as a service (SaaS) providers, on-premises workloads, and cloud sources into a purpose-built data lake in their AWS environment. OpenSearch Service is a managed service that customers can use to deploy, operate, and scale OpenSearch clusters in the AWS Cloud. It natively integrates with Security Lake to enable customers to perform interactive log analytics and searches across large datasets, create enterprise visualization and dashboards, and perform analysis across disparate applications and logs. With Amazon OpenSearch Security Analytics, customers can also gain visibility into the security posture of their organization’s infrastructure, monitor for anomalous activity, detect potential security threats in near real time, and initiate alerts to pre-configured destinations.
Without using Amazon OpenSearch Service, customers would need to build, deploy and manage infrastructure for an analytics solution, such as an ELK stack.
The architecture diagram in Figure 1 shows the completed architecture of the solution.
The OpenSearch Service cluster is deployed within a virtual private cloud (VPC) across three Availability Zones for high availability.
The OpenSearch Service cluster ingests logs from Security Lake using an OpenSearch Ingestion pipeline.
The cluster is accessed by end users through a public-facing proxy hosted on an Amazon EC2 instance.
To reduce costs, the template doesn’t deploy a dead letter queue (DLQ) for the OpenSearch Ingestion pipeline. You can add one later if you want.
Instead of a public facing proxy, you can deploy a VPN to access your cluster.
Authentication to the cluster is managed with Amazon Cognito.
Figure 1: Solution architecture
Planning the deployment
This section will help you plan your OpenSearch service deployment, including what nodes you should choose, the amount of storage to allocate, and where to deploy the cluster.
Deciding instances for the OpenSearch Service master and data nodes
First, determine what instance type to use for the master and data nodes. If your workload generates less than 100 GB of Security Lake logs per day, we recommend using three m6g.large.search master nodes and three r6g.large.search data nodes. You can start small and scale up or scale out later. For more information about deciding the size and number of instances, see Get started with Amazon OpenSearch Service. Note the instance types that you have selected on a text editor because you will use this as an input for the AWS CloudFormation template that you will deploy later.
Configuring storage
To optimize your storage costs, you need to plan your data strategy. In this architecture, Security Lake is used for long-term log storage. Because Security Lake uses Amazon Simple Storage Service (Amazon S3), you can optimize long-term storage costs. You can configure OpenSearch Service to ingest priority logs based on the recent data that you can use for near-real time detection and alerting. Your team can query logs in Security Lake using its Zero-ETL integration with OpenSearch Service to analyze older logs.
Therefore, Security Lake should serve as your primary long-term log storage, with OpenSearch Service storing only the most recent logs.
The number of days of logs in OpenSearch Service will depend on how many days’ worth of data you need to investigate at a given time. I recommend storing 15 days of data in OpenSearch Service. This allows you to react to and investigate the most immediate security events while optimizing storage costs for older logs.
The next step is to determine the volume of logs generated by Security Lake.
Sign in to the Security Lake delegated administrator account.
Go to the AWS Management Console for Security Lake. Choose Usage in the navigation pane.
On the Usage screen, select Last 30 days as the range of usage.
Add the total Actual usage for the last 30 days for the data sources that you intend to send to OpenSearch. If you have used Security Lake for less than 30 days, you can use the Total predicted usage per month. Divide this figure by 30 to get the daily data volume.
Figure 2: Select range of usage
To determine the total storage needed, multiply the data generated by Security Lake per day by the retention period you chose, then by 1.1 to account for the indexes, then multiply that number by 1.15 for overhead storage. For more information about calculating storage, see Get started with Amazon OpenSearch Service.
To determine the amount of Amazon Elastic Block Store (Amazon EBS) storage that you need per node, take the total amount of storage and divide it by the number of nodes that you have. Round that number up to the nearest whole number. You can increase the amount of storage after deployment when you have a better understanding of your workload. Make a note of this number in a text editor because you’ll use it as an input in the CloudFormation template later.
Example 1: 10 GB of Security Lake logs generated per day, stored for 30 days in OpenSearch Service in three nodes
10 GB of Security Lake logs stored for 30 days = 10 GB * 30 = 300 GB
Account for additional space for indexes and overhead space = 300 GB * 1.1 * 1.15 = 379.5 GB
Divide the storage required across three nodes, rounded up = 379.5/3 ≈ 127 GB per node
You would need 127 GB per node in OpenSearch Service
Example 2: 200 GB of Security Lake logs generated per day, stored for 15 days in OpenSearch Service across six nodes
200 GB of Security Lake logs stored for 15 days = 200 GB * 15 = 3000 GB
Account for additional space for indexes and overhead space = 3000 GB * 1.1 * 1.15 = 3795 GB
Divide the storage required across three nodes, rounded up = 3795/6 ≈ 633 GB per node
You would need 633 GB per node in OpenSearch Service
Where to deploy the cluster?
If you have an AWS Control Tower deployment or have a deployment modelled after the AWS Security Reference Architecture (AWS SRA), Security Lake should be deployed in the Log Archive account. Because security best practices recommend that the Log Archive account should not be frequently accessed, the OpenSearch Service cluster should be deployed into your Audit account or Security Tooling account.
You need to deploy your Security Lake subscriber in the same Region as your Security Lake roll-up Region. If you have more than one roll-up Region, choose the Region that collects logs from the Regions you want to monitor.
Your cluster needs to be deployed in the same Region as your Security Lake subscriber be able to access data.
Setting up the Security Lake subscriber
Before deploying the solution, create a Security Lake subscriber in your Security Lake roll-up Region so that OpenSearch Service can access data from Amazon Security Lake.
Access the Security Lake console in your Log Archive account.
Choose Subscribers in the navigation pane.
Choose Create subscriber.
On the Create subscriber page, enter a name, such as OpenSearch-subscriber.
Under Data Access, select Under S3 notification type, select SQS queue.
Under Subscriber credentials, enter the AWS account ID for the account you plan to deploy the OpenSearch cluster to, which should be your Security Tooling
Enter OpenSearchIngestion-<AWS account ID> under External ID.
Figure 3: Configuring the Security Lake subscriber
Leave All log and event sources selected and choose Create.
After the subscriber has been created, you will need to collect information to facilitate the deployment.
To gather necessary information:
Select the subscriber that you just created.
Derive the S3 bucket name from the S3 bucket ARN and store it in a text editor. The Amazon Resource Name (ARN) is formatted as arn:aws:s3:::<bucket name>. The bucket name should look like aws-security-data-lake-<region>-xxxxx.
Figure 4: Derive the S3 bucket name from the Subscriber details page
Go to the Amazon Simple Queue Service (Amazon SQS) console and select the SQS queue created as part of the Security Lake subscriber. It should look like AmazonSecurityLake-xxxxxxxxx-Main-Queue. Note the queue’s ARN and URL in your text editor.
Figure 5: Relevant details from the SQS queue
Deploy the solution
To deploy the solution in your Security Tooling account, use a CloudFormation template. This template deploys the OpenSearch Service cluster, OpenSearch Ingestion pipeline, and an AWS Lambda function to initialize the cluster.
To deploy the OpenSearch cluster:
To deploy the CloudFormation template that builds the OpenSearch service cluster, select the Launch Stack button.
In the CloudFormation console, make sure that you are in the correct AWS account. You should be in your Security Tooling account. Also make sure that you have selected the same Region as your Security Lake subscriber.
Enter a name for your stack. A name like os-stack-<day>-<month> can help you keep track of deployments.
Enter the instance types and Amazon EBS volume size that you noted earlier.
Enter the IP address range that you want to allow to access the proxy’s security group. You should limit this to your corporate IP range. You can set it as 0.0.0/0 if you want to expose it to the public internet.
Fill in the details of the Security Lake bucket and the subscriber Amazon SQS queue ARN, URL, and Region.
Figure 6: Add stack parameters
Check the acknowledgements in the Capabilities section.
Choose Create stack to begin deploying the resources.
It will take 20–30 minutes to deploy the multiple nested templates. Wait for the main stack (not the nested ones) to achieve the CREATE_COMPLETE status before proceeding to the next step.
Note: If you encounter failures while deployment, you can download the CloudFormation file here and select Preserve successfully provisioned resources under Stack failure options while deploying. This will allow you to troubleshoot the stack deployment.
Go to the Outputs pane of the main CloudFormation stack. Save the DashboardsProxyURL, OpenSearchInitRoleARN, and PipelineRole values in a text editor to refer to later.
Figure 7: The stacks in the CREATE_COMPLETE state with the outputs panel shown
Open the DashboardsProxyURL value in a new tab.
Note: Because the proxy relies on a self-signed certificate, you will get an insecure certificate warning. You can safely ignore this warning and proceed. For a production workload, you should issue a trusted private certificate from your internal public key infrastructure or use AWS Private Certificate Authority.
You will be presented with the Amazon Cognito sign-in page. Use administrator as the username.
Access Secrets Manager to find the password. Select the secret that was created as part of the stack.
Figure 8: The Cognito password in Secrets Manager
Choose Retrieve secret value to get the password.
Figure 9: Retrieve the secret value
After signing in, you will be prompted to change your password and will be redirected to the OpenSearch dashboard.
If you see a pop-up that states Start by adding your own data, select Explore on my own. On the next page, Introducing new OpenSearch Dashboards look & feel, choose Dismiss.
If you see a pop-up that states Select your tenant, select Global, and then choose Confirm.
Figure 10: Select and confirm your tenant
To initialize the OpenSearch cluster:
Choose the menu icon (three stacked horizontal lines) on the top left and select Security under the Management section.
Figure 11: Navigating to the Security page in the OpenSearch console
Select Roles. On the Roles page, search for the all_access role and select it.
Select Mapped users, and then select Manage mapping.
On the Map user screen, choose Add another backend role. Paste the value for the OpenSearchInitRoleARN from the list of CloudFormation outputs. Choose Map.
Figure 12: Mapping the role on the Security page in the OpenSearch console
Leave this tab open and return to the AWS Management console. Go to the AWS Lambda console and select the function named xxxxxx-OS_INIT.
In the function screen, choose Test, and then Create new test event.
Figure 13: Creating the test event in the Lambda console
Choose Invoke. The function should run for about 30 seconds. The execution results should show the component templates that have been created. This Lambda function creates the component and index templates to ingest Open Cybersecurity Framework (OCSF) formatted data, a set of indices and aliases that correspond with the OCSF classes generated by Security Lake, and a rollover policy that will rollover the index daily or if it becomes larger than 40 GB.
Figure 14: Invoking the Lambda function in the Lambda console
To set up the pipeline
Return to the Map user page on the OpenSearch console.
Choose Add another backend role. Paste the value of the PipelineRole from the CloudFormation template output. Choose This will allow the OpenSearch Ingestion to write to the cluster.
Figure 15: Mapping the OpenSearch Ingestion role
Access the Amazon S3 console in the Log Archive account where Security Lake is hosted.
Select the Security Lake bucket in your roll-up Region. It should look like aws-security-data-lake-region-xxxxxxxxxx.
Choose Permissions, then Edit under Bucket policy.
Add this policy to the end of the existing bucket policy. Replace the Principal with the ARN of the PipelineRole and the name of your Security Lake bucket in the Resource section.
{
"Sid": "Cross Account Permissions",
"Effect": "Allow",
"Principal": {
"AWS": "<Pipeline role ARN>"
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::<Security Lake bucket name>/*",
"arn:aws:s3:::<Security Lake bucket name>"
]
}
Figure 16: The modified S3 bucket access policy
Choose Save changes.
To upload the index patterns and dashboards
Download the Security-lake-objects.ndjson file by right-clicking on this link and selecting Save link as.
Access the Dashboards Management page through the navigation menu.
Choose Saved objects in the navigation pane.
On the Saved Objects page, choose Import on the right side of the screen.
Figure 17: Import saved objects
Choose Import and select the Security-lake-objects.ndjson file that you downloaded previously.
Leave Create new objects with unique IDs selected and choose Import.
You can now view the ingested logs on the Discover page and visualizations on the Dashboards page, which you can find on the navigation bar.
Figure 18: The Discover page displaying ingested logs
Clean up
To avoid unwanted charges, delete the main CloudFormation template, named os-stack-<day>-<month> (not the nested stacks).
Figure 19: Select the main stack in the CloudFormation console
Modify the Security Lake bucket policy in the logging account to remove the section you added that trusted the PipelineRole. Be careful not to modify the rest of the policy because it could impact the functioning of Security Lake and other subscribers.
Figure 20: The S3 bucket policy with the relevant sections that needed to be deleted
Conclusion
In this post, you learned how to plan an OpenSearch deployment with Amazon OpenSearch Service to ingest logs from Amazon Security Lake. With this solution, you’re able to aggregate and manage logs with Security Lake and visualize and monitor those logs with OpenSearch Service. After deployment, monitor the OpenSearch Service metrics to determine if you need to scale this up or out for improved performance. In part 2, I will show you how to set up the Security Analytics detector to generate alerts to security findings in near-real time.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
AWS Security Hub is a cloud security posture management (CSPM) service that performs security best practice checks across your Amazon Web Services (AWS) accounts and AWS Regions, aggregates alerts, and enables automated remediation. Security Hub is designed to simplify and streamline the management of security-related data from various AWS services and third-party tools. It provides a holistic view of your organization’s security state that you can use to prioritize and respond to security alerts efficiently.
Security Hub assigns a security score to your environment, which is calculated based on passed and failed controls. A control is a safeguard or countermeasure prescribed for an information system or an organization that’s designed to protect the confidentiality, integrity, and availability of the system and to meet a set of defined security requirements. You can use the security score as a mechanism to baseline the accounts. The score is displayed as a percentage rounded up or down to the nearest whole number.
In this blog post, we review the top four mechanisms that you can use to improve your security score, review the five controls in Security Hub that most often fail, and provide recommendations on how to remediate them. This can help you reduce the number of failed controls, thus improving your security score for the accounts.
What is the security score?
Security scores represent the proportion of passed controls to enabled controls. The score is displayed as a percentage rounded to the nearest whole number. It’s a measure of how well your AWS accounts are aligned with security best practices and compliance standards. The security score is dynamic and changes based on the evolving state of your AWS environment. As you address and remediate findings associated with controls, your security score can improve. Similarly, changes in your environment or the introduction of new Security Hub findings will affect the score.
Each check is a point-in-time evaluation of a rule against a single resource that results in a compliance status of PASSED, FAILED, WARNING, or NOT_AVAILBLE. A control is considered passed when the compliance status of all underlying checks for resources are PASSED or if the FAILED checks have a workflow status of SUPPRESSED. You can view the security score through the Security Hub console summary page—as shown in figure 1—to quickly gain insights into your security posture. The dashboard provides visual representations and details of specific findings contributing to the score. For more information about how scores are calculated, see determining security scores.
Figure. 1 Security Hub dashboard
How to improve the security score?
You can improve your security score in four ways:
Remediating failed controls: After the resources responsible for failed checks in a control are configured with compliant settings and the check is repeated, Security Hub marks the compliance status of the checks as PASSED and the workflow status as RESOLVED. This increases the number of passed controls, thus improving the score.
Suppressing findings associated with failed controls: When calculating the control status, Security Hub ignores findings in the ARCHIVED state as well as findings with a workflow status of SUPPRESSED, which will affect security scores. So if you suppress all failed findings for a control, the control status becomes passed.
If you determine that a Security Hub finding for a resource is an accepted risk, you can manually set the workflow status of the finding to SUPPRESSED from the Security Hub console or using the BatchUpdateFindings API. Suppression doesn’t stop new findings from being generated, but you can set up an automation rule to suppress all future new and updated findings that meet the filtering criteria.
Disabling controls that aren’t relevant: Security Hub provides flexibility by allowing administrators to customize and configure security controls. This includes the ability to disable specific controls or adjust settings to help align with organizational security policies. When a control is disabled, security checks are no longer performed and no additional findings are generated. Existing findings are set to ARCHIVED and the control is excluded from the security score calculations.
Use central configuration in Security Hub to tailor the security controls to help align with your organization’s specific requirements. You can fine-tune your security controls, focus on relevant issues, and improve the accuracy and relevance of your security score. Introducing new central configuration capabilities in AWS Security Hub provides an overview and the benefits of central configuration.
Suppression should be used when you want to tune control findings from specific resources whereas controls should be disabled only when the control is no longer relevant for your AWS environment.
Customize parameter values to fine tune controls: Some Security Hub controls use parameters that affect how the control is evaluated. Typically, these controls are evaluated against the default parameter values that Security Hub defines. However, for a subset of these controls, you can customize the parameter values. When you customize a parameter value for a control, Security Hub starts evaluating the control against the value that you specify. If the resource underlying the control satisfies the custom value, Security Hub generates a PASSED finding.
We will use these mechanisms to address the most commonly failed controls in the following sections.
Identifying the most commonly failed controls in Security Hub
You can use the AWS Management Console to identify the most commonly failed controls across your accounts in AWS Organizations:
Sign in to the delegated administrator account and open the Security Hub console.
On the navigation pain, choose Controls.
Here, you will see the status of your controls sorted by the severity of the failed controls. You will also see the associated number of failed checks with the failed controls in the Failed checks column on this page. A check is performed for each resource. If a column says 85 out of 124 for a control, it means 85 resources out of 124 failed the check for that control. You can sort this column in descending order to identify failed controls that have the most resources as shown in Figure 2.
Figure 2: Security Hub control status page
Addressing the most commonly failed controls
In this section we address remediation strategies for the most used Security Hub controls that have Critical and High severity and have a high failure rate amongst AWS customers. We review five such controls and provide recommended best practices, default settings for the resource type at deployment, guardrails, and compensating controls where applicable.
AutoScaling.3: Auto Scaling group launch configuration
An Auto Scaling group in AWS is a service that automatically adjusts the number of Amazon Elastic Compute Cloud (Amazon EC2) instances in a fleet based on user-defined policies, making sure that the desired number of instances are available to handle varying levels of application demand. A launch configuration is a blueprint that defines the configuration of the EC2 instances to be launched by the Auto Scaling group. The AutoScaling.3 control checks whether Instance Metadata Service Version 2 (IMDSv2) is enabled on the instances launched by EC2 Auto Scaling groups using launch configurations. The control fails if the Instance Metadata Service (IMDS) version isn’t included in the launch configuration, or if both Instance Metadata Service Version 1 (IMDSv1) and IMDSv2 are included. AutoScaling.3 aligns with best practice SEC06-BP02 Reduce attack surface of the well architected framework.
The IMDS is a service on Amazon EC2 that provides metadata about EC2 instances, such as instance ID, public IP address, AWS Identity and Access Management (IAM) role information, and user data such as scripts during launch. IMDS also provides credentials for the IAM role attached to the EC2 instance, which can be used by threat actors for privilege escalation. The existing instance metadata service (IMDSv1) is fully secure, and AWS will continue to support it. If your organization strategy involves using IMDSv1, then consider disabling AutoScaling.3 and EC2.8 Security Hub controls. EC2.8 is a similar control, but checks the IMDS configuration for each EC2 instance instead of the launch configuration.
IMDSv2 adds protection for four types of vulnerabilities that could be used to access the IMDS, including misconfigured or open website application firewalls, misconfigured or open reverse proxies, unpatched service-side request forgery (SSRF) vulnerabilities, and misconfigured or open layer 3 firewalls and network address translation. It does so by requiring the use of a session token using a PUT request when requesting instance metadata and using a Time to Live (TTL) default of 1 so the token cannot travel outside the EC2 instance. For more information on protections added by IMDSv2, see Add defense in depth against open firewalls, reverse proxies, and SSRF vulnerabilities with enhancements to the EC2 Instance Metadata Service.
The Autoscaling.3 control creates a failed check finding for every Amazon EC2 launch configuration that is out of compliance. An Auto Scaling group is associated with one launch configuration at a time. You cannot modify a launch configuration after you create it. To change the launch configuration for an Auto Scaling group, use an existing launch configuration as the basis for a new launch configuration with IMDSv2 enabled and then delete the old launch configuration. After you delete the launch configuration that’s out of compliance, Security Hub will automatically update the finding state to ARCHIVED. It’s recommended to use Amazon EC2 launch templates, which is a successor to launch configurations because you cannot create launch configurations with new EC2 instances released after December 31, 2022. See Migrate your Auto Scaling groups to launch templates for more information.
Amazon has taken a series of steps to make IMDSv2 the default. For example, Amazon Linux 2023 uses IMDSv2 by default for launches. You can also set the default instance metadata version at the account level to IMDSv2 for each Region. When an instance is launched, the instance metadata version is automatically set to the account level value. If you’re using the account-level setting to require the use of IMDSv2 outside of launch configuration, then consider using the central Security Hub configuration to disable AutoScaling.3 for these accounts. See the Sample Security Hub central configuration policy section for an example policy.
EC2.18: Security group configuration
AWS security groups act as virtual stateful firewalls for your EC2 instances to control inbound and outbound traffic and should follow the principle of least privileged access. In the Well-Architected Framework security pillar recommendation SEC05-BP01 Create network layers, it’s best practice to not use overly permissive or unrestricted (0.0.0.0/0) security groups because it exposes resources to misuse and abuse. By default, the EC2.18 control checks whether a security group permits unrestricted incoming TCP traffic on ports except for the allowlisted ports 80 and 443. It also checks if unrestricted UDP traffic is allowed on a port. For example, the check will fail if your security group has an inbound rule with unrestricted traffic to port 22. This control allows custom control parameters that can be used to edit the list of authorized ports for which unrestricted traffic is allowed. If you don’t expect any security groups in your organization to have unrestricted access on any port, then you can edit the control parameters and remove all ports from being allowlisted. You can use a central configuration policy as shown in Sample Security Hub central configuration policy to update the parameter across multiple accounts and Regions. Alternately, you can also add authorized ports to the list of ports you want to allowlist for the check to pass.
EC2.18 checks the rules in the security groups in accounts, whether the security groups are in use or not. You can use AWS Firewall Manager to identify and delete unused security groups in your organization using usage audit security group policies. Deleting unused security groups that have failed the checks will change the finding state of associated findings to ARCHIVED and exclude them from security score calculation. Deleting unused resources also aligns with SUS02-BP03 of the sustainability pillar of the Well-Architected Framework. You can create a Firewall Manager usage audit security group policy through the firewall manager using the following steps:
To configure Firewall Manager:
Sign in to the Firewall Manager administrator account and open the Firewall Manager console.
In the navigation pane, select Security policies.
Choose Create policy.
On Choose policy type and Region:
For Region, select the AWS Region the policy is meant for.
For Policy type, select Security group.
For Security group policy type, select Auditing and cleanup of unused and redundant security groups.
Choose Next.
On Describe policy:
Enter a Policy name and description.
For Policy rules, select Security groups within this policy scope must be used by at least one resource.
You can optionally specify how many minutes a security group can exist unused before it’s considered noncompliant, up to 525,600 minutes (365 days). You can use this setting to allow yourself time to associate new security groups with resources.
For Policy action, we recommend starting by selecting Identify resources that don’t comply with the policy rules, but don’t auto remediate. This allows you to assess the effects of your new policy before you apply it. When you’re satisfied that the changes are what you want, edit the policy and change the policy action by selecting Auto remediate any noncompliant resources.
Choose Next.
On Define policy scope:
For AWS accounts this policy applies to, select one of the three options as appropriate.
For Resource type, select Security Group.
For Resources, you can narrow the scope of the policy using tagging, by either including or excluding resources with the tags that you specify. You can use inclusion or exclusion, but not both.
Choose Next.
Review the policy settings to be sure they’re what you want, and then choose Create policy.
Firewall manager is a Regional service so these policies must be created in each Region you have services in.
You can also set up guardrails for security groups using Firewall Manager policies to remediate new or updated security groups that allow unrestricted access. You can create a Firewall Manager content audit security group policy through the Firewall Manager console:
To create a Firewall Manager security group policy:
Sign in to the Firewall Manager administrator account.
Open the Firewall Manager console.
In the navigation pane, select Security policies.
Choose Create policy.
On Choose policy type and Region:
For Region, select a Region.
For Policy type, select Security group.
For Security group policy type, select Auditing and enforcement of security group rules.
Choose Next.
On Describe policy:
Enter a Policy name and description.
For Policy rule options, select configure managed audit policy rules.
Configure the following options under Policy rules.
For the Security group rules to audit, select Inbound rules from the drop down.
Select Audit overly permissive security group rules.
Select Rule allows all traffic.
For Policy action, we recommend starting by selecting Identify resources that don’t comply with the policy rules, but don’t auto remediate. This allows you to assess the effects of your new policy before you apply it. When you’re satisfied that the changes are what you want, edit the policy and change the policy action by selecting Auto remediate any noncompliant resources.
Choose Next.
On Define policy scope:
For AWS accounts this policy applies to, select one of the three options as appropriate.
For Resource type, select Security Group.
For Resources, you can narrow the scope of the policy using tagging, by either including or excluding resources with the tags that you specify. You can use inclusion or exclusion, but not both.
Choose Next.
Review the policy settings to be sure they’re what you want, and then choose Create policy.
For use cases such as a bastion host where you might have unrestricted inbound access to port 22 (SSH), EC2.18 will fail. A bastion host is a server whose purpose is to provide access to a private network from an external network, such as the internet. In this scenario, you might want to suppress findings associated with the bastion host security groups instead of disabling the control. You can create a Security Hub automation rule in the Security Hub delegated administrator account based on a tag or resource ID to set the workflow status of future findings to SUPPRESSED. Note that an automation rule applies only in the Region in which it’s created. To apply a rule in multiple Regions, the delegated administrator must create the rule in each Region.
To create an automation rule:
Sign in to the delegated administrator account and open the Security Hub console.
In the navigation pane, select Automations, and then choose Create rule.
Enter a Rule Name and Rule Description.
For Rule Type, select Create custom rule.
In the Rule section, provide a unique rule name and a description for your rule.
For Criteria, use the Key, Operator, and Value drop down menus to select your rule criteria. Use the following fields in the criteria section:
Add key ProductName with operator Equals and enter the value Security Hub.
Add key WorkFlowStatus with operator Equals and enter the value NEW.
Add key ComplianceSecurityControlId with operator Equals and enter the value EC2.18.
Add key ResourceId with operator Equals and enter the Amazon Resource Name (ARN) of the bastion host security group as the value.
For Automated action:
Choose the drop down under Workflow Status and select SUPPRESSED.
Under Note, enter text such as EC2.18 exception.
For Rule status, select Enabled.
Choose Create rule.
This automation rule will set the workflow status of all future updated and new findings to SUPPRESSED.
IAM.6: Hardware MFA configuration for the root user
When you first create an AWS account, you begin with a single identity that has complete access to the AWS services and resources in the account. This identity is called the AWS account root user and is accessed by signing in with the email address and password that you used to create the account.
The root user has administrator level access to your AWS accounts, which requires that you apply several layers of security controls to protect this account. In this section, we walk you through:
What to do when the root account isn’t required on your Organizations member accounts and what to do when the root user is required.
We recommend using a layered approach and applying multiple best practices to secure your root account across these scenarios.
AWS root user best practices include recommendations from SEC02-BP01, which recommends multi-factor authentication (MFA) for the root user be enabled. IAM.6 checks whether your AWS account is enabled to use a hardware MFA device to sign in with root user credentials. The control fails if MFA isn’t enabled or if any virtual MFA devices are permitted for signing in with root user credentials. A finding is generated for every account that doesn’t meet compliance. To remediate, see General steps for enabling MFA devices, which describes how to set up and use MFA with a root account. Remember that the root account should be used only when absolutely necessary and is only required for a subset of tasks. As a best practice, for other tasks we recommend signing in to your AWS accounts using federation, which provides temporary access keys by assuming an IAM role instead of using long-lived static credentials.
The Organizations management account deploys universal security guardrails, and you can configure additional services that will affect the member accounts in the organization. So, you should restrict who can sign in and administer the root user in your management account and is why you should apply hardware MFA as an added layer of security.
Many customers manage hundreds of AWS accounts across their organization and managing hardware MFA devices for each root account can be a challenge. While it’s a best practice to use MFA, an alternative approach might be necessary. This includes mapping out and identifying the most critical AWS accounts. This analysis should be done carefully—consider if this is a production environment, what type of data is present, and the overall criticality of the workloads running in that account.
This subset of your most critical AWS accounts should be configured with MFA. For other accounts, consider that in most cases the root account isn’t required and you can disable the use of the root account across the Organizations member accounts using Organizations service control policies (SCP). The following is an example:
If you’re using AWS Control Tower, use the disallow actions as a root user guardrail. If you’re using an SCP for organizations or the AWS Control Tower guardrail to restrict root use in member accounts, consider disabling the IAM.6 control in those member accounts. However, do not disable IAM.6 in the management account. See the Sample Security Hub central configuration policy section for an example policy.
If root account use is required within a member account, confirmed as a valid root-user-task, then perform the following steps:
Another consideration and best practice is to make sure that all AWS accounts have updated contact information, including the email attached to the root user. This is important for several reasons. For example, you must have access to the email associated with the root user to reset the root user’s password. See how to update the email address associated with the root user. AWS uses account contact information to notify and communicate with the AWS account administrators on several important topics including security, operations, and billing related information. Consider using an email distribution list to make sure these email addresses are mapped to a common internal mailbox restricted to your cloud or security team. See how to update your AWS primary and secondary account contact details.
EC2.2: Default security groups configuration
Each Amazon Virtual Private Cloud (Amazon VPC) comes with a default security group. We recommend that you create security groups for EC2 instances or groups of instances instead of using the default security group. If you don’t specify a security group when you launch an instance, the service associates the instance with the default security group for the VPC. In addition, the default security group cannot be deleted because it’s the default security group assigned to an EC2 instance if another security group is not created or assigned.
The default security group allows outbound and inbound traffic from network interfaces (and their associated instances) that are assigned to the same security group. EC2.2 checks whether the default security group of a VPC allows inbound or outbound traffic, and the control fails if the security group allows inbound or outbound traffic. This control doesn’t check if the default security group is in use. A finding is generated for each default VPC security group that’s out of compliance. The default security group doesn’t adhere to least privilege and therefore the following steps are recommended. If no EC2 instance is attached to the default security group, delete the inbound and outbound rules of the default security group. However, if you’re not certain that the default security group is in use, use the following AWS Command Line Interface (AWS CLI) command across each account and Region. If the command returns a list of EC2 instance IDs, then the default security group is in use by these instances. If it returns an empty list, then the default security group isn’t used in that account. Use the ‐‐region option to change Regions.
For these instances, replace the default security group with a new security group using similar rules and work with the owners of those EC2 instances to determine a least privilege security group and ruleset that could be applied. After the instances are moved to the replacement security group, you can remove the inbound and outbound rules of the default security group. You can use an AWS Config rule in each account and Region to remove the inbound and outbound rules of the default security group.
Under the Resource ID Parameter dropdown, select GroupId.
Under Parameter, enter the ARN of the automation service role you copied in step 1.
Choose Save.
It’s important to verify that changes and configurations are clearly communicated to all users of an environment. We recommend that you take the opportunity to update your company’s central cloud security requirements and governance guidance and notify users in advance of the pending change.
ECS.5: ECS container access configuration
An Amazon Elastic Container Service (Amazon ECS) task definition is a blueprint for running Docker containers within an ECS cluster. It defines various parameters required for launching containers, such as Docker image, CPU and memory requirements, networking configuration, container dependencies, environment variables, and data volumes. An ECS task definition is to containers is what a launch configuration is to EC2 instances. ECS.5 is a control related to ECS and ensures that the ECS task definition has read-only access to mounted root filesystem enabled. This control is important and great for defense in depth because it helps prevent containers from making changes to the container’s root file system, prevents privilege escalation if a container is compromised, and can improve security and stability. This control fails if the readonlyRootFilesystem parameter doesn’t exist or is set to false in the ECS task definition JSON.
If you’re using the console to create the task definition, then you must select the read-only box against the root file system parameter in the console as show in Figure 3. If you are using JSON for task definition, then the parameter readonlyRootFilesystem must be set to true and supplied with the container definition or updated in order for this check to pass. This control creates a failed check finding for every ECS task definition that is out of compliance.
Figure 3: Using the ECS console to set readonlyRootFilesystem to true
Follow the steps in the remediation section of the control user guide to fix the resources identified by the control. Consider using infrastructure as code (IaC) tools such as AWS CloudFormation to define your task definitions as code, with the read-only root filesystem set to true to help prevent accidental misconfigurations. If you use continuous integration and delivery (CI/CD) to create your container task definitions, then consider adding a check that looks for the existence of the readonlyRootFilesystem parameter in the task definition and that its set to true.
If this is expected behavior for certain task definitions, you can use Security Hub automation rules to suppress the findings by matching on the ComplianceSecurityControlID and ResourceId filters in the criteria section.
To create the automation rule:
Sign in to the delegated administrator account and open the Security Hub console.
In the navigation pane, select Automations.
Choose Create rule. For Rule Type, select Create custom rule.
Enter a Rule Name and Rule Description.
In the Rule section, enter a unique rule name and a description for your rule.
For Criteria, use the Key, Operator, and Value drop down menus to specify your rule criteria. Use the following fields in the criteria section:
Add key ProductName with operator Equals and enter the value Security Hub.
Add key WorkFlowStatus with operator Equals and enter the value NEW.
Add key ComplianceSecurityControlId with operator Equals and enter the value ECS.5.
Add key ResourceId with operator Equals and enter the ARN of the ECS task definition as the value.
For Automated action,
Choose the dropdown under Workflow Status and select SUPPRESSED.
Under note, enter a description such as ECS.5 exception.
For Rule status, select Enabled
Choose Create rule.
Sample Security Hub central configuration policy
In this section, we cover a sample policy for the controls reviewed in this post using central configuration. To use central configuration, you must integrate Security Hub with Organizations and designate a home Region. The home Region is also your Security Hub aggregation Region, which receives findings, insights, and other data from linked Regions. If you use the Security Hub console, these prerequisites are included in the opt-in workflow for central configuration. Remember that an account or OU can only be associated with one configuration policy at a given time as to not have conflicting configurations. The policy should also provide complete specifications of settings applied to that account. Review the policy considerations document to understand how central configuration policies work. Follow the steps in the Start using central configuration to get started.
If you want to disable controls and update parameters as described in this post, then you must create two policies in the Security Hub delegated administrator account home Region. One policy applies to the management account and another policy applies to the member accounts.
First, create a policy to disable IAM.6, Autoscaling.3, and update the ports for the EC2.18 control to identify security groups with unrestricted access on the ports. Apply this policy to all member accounts. Use the Exclude organization units or accounts section to enter the account ID of the AWS management account.
To create a policy to disable IAM.6, Autoscaling.3 and update the ports:
Open the Security Hub console in the Security Hub delegated administrator account home Region.
In the navigation pane, select Configuration and then the Policies tab. Then, choose Create policy. If you already have an existing policy that applies to all member accounts, then select the policy and choose Edit.
For Controls, select Disable specific controls.
For Controls to disable, select IAM.6 and AutoScaling.3.
Select Customize controls parameters.
From the Select a Control dropdown, select EC2.18.
Edit the cell under List of authorized TCP ports, and add ports that are allow listed for unrestricted access. If no ports should be allow listed for unrestricted access then delete the text in the cell.
For Accounts, select All accounts.
Choose Exclude organizational units or accounts and enter the account ID of the management account.
For Policy details, enter a policy name and description.
Choose Next.
On the Review and apply page, review your configuration policy details. Choose Create policy and apply.
Create another policy in the Security Hub delegated administrator account home Region to disable Autoscaling.3 and update the ports for the EC2.18 control to fail the check for security groups with unrestricted access on any port. Apply this policy to the management account. Use the Specific accounts option for the Accounts section and then the Enter organization unit or accounts tab to enter the account ID of the management account.
To disable Autoscaling.3 and update the ports:
Open the AWS Security Hub console in the Security Hub delegated administrator account home Region.
In the navigation pane, select Configuration and the Policies tab.
Choose Create policy. If you already have an existing policy that applies to the management account only, then select the policy and choose Edit.
For Controls, choose Disable specific controls.
For Controls to disable, select AutoScaling.3.
Select Customize controls parameters.
From the Select a Control dropdown, select EC2.18.
Edit the cell under List of authorized TCP ports and add ports that are allow listed for unrestricted access. If no ports should be allow listed for unrestricted access then delete the text in the cell.
For Accounts, select Specific accounts.
Select the Enter Organization units or accounts tab and enter the Account ID of the management account.
For Policy details, enter a policy name and description.
Choose Next.
On the Review and apply page, review your configuration policy details. Choose Create policy and apply.
Conclusion
In this post, we reviewed the importance of the Security Hub security score and the four methods that you can use to improve your score. The methods include remediation of non-complaint resources, managing controls using Security Hub central configuration, suppressing findings using Security Hub automation rules, and using custom parameters to customize controls. You saw ways to address the five most commonly failed controls across Security Hub customers, including remediation strategies and guardrails for each of these controls.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
AI-TRiSM – Trust, Risk and Security Management in the Age of AI
Co-authored by Lara Sunday and Pojan Shahrivar
As artificial intelligence (AI) and machine learning (ML) technologies continue to advance and proliferate, organizations across industries are investing heavily in these transformative capabilities. According to Gartner, by 2027, spending on AI software will grow to $297.9 billion at a compound annual growth rate of 19.1%. Generative AI (GenAI) software spend will rise from 8% of AI software in 2023 to 35% by 2027.
With the promise of enhanced efficiency, personalization, and innovation, organizations are increasingly turning to cloud environments to develop and deploy these powerful AI and ML technologies. However, this rapid innovation also introduces new security risks and challenges that must be addressed proactively to protect valuable data, intellectual property, and maintain the trust of customers and stakeholders.
Benefits of Cloud Environments for AI Development
Cloud platforms offer unparalleled scalability, allowing organizations to easily scale their computing resources up or down to meet the demanding requirements of training and deploying complex AI models.
“The ability to spin up and down resources on-demand has been a game-changer for our AI development efforts,” says Stuart Millar, Principal AI Engineer at Rapid7. “We can quickly provision the necessary compute power during peak training periods, then scale back down to optimize costs when those resources are no longer needed.”
Cloud environments also provide a cost-effective way to develop AI models, with usage-based pricing models that avoid large upfront investments in hardware and infrastructure. Additionally, major cloud providers offer access to cutting-edge AI hardware and pre-built tools and services, such as Amazon SageMaker, Azure Machine Learning, and Google Cloud AI Platform, which can accelerate development and deployment cycles.
Challenges and Risks of Cloud-Based AI Development
While the cloud offers numerous advantages for AI development, it also introduces unique challenges that organizations must navigate. Limited visibility into complex data flows and model updates can create blind spots for security teams, leaving them unable to effectively monitor for potential threats or anomalies.
In their AI Threat Landscape Report, HiddenLayer highlighted that 98% of all the companies surveyed identified that elements of their AI models were crucial to their business success, and 77% identified breaches to their AI in the past year. Additionally, multi-cloud and hybrid deployments bring monitoring, governance, and reporting challenges, making it difficult to assess AI/ML risk in context across different cloud environments.
New Attack Vectors and Risk Types
Developing AI in the cloud also exposes organizations to new attack vectors and risk types that traditional security tools may not be equipped to detect or mitigate. Some examples include:
Prompt Injection (LLM01): Imagine a large language model used for generating marketing copy. An attacker could craft a special prompt that tricks the model into generating harmful or offensive content, damaging the company’s brand and reputation.
Training Data Poisoning (LLM03, ML02): Adversaries can tamper with training data to compromise the integrity and reliability of cloud-based AI models. In the case of an AI model used for image recognition in a security surveillance system, poisoned training data containing mislabeled images could cause the model to generate incorrect classifications, potentially missing critical threats.
Model Theft (LLM10, ML05): Unauthorized access to proprietary AI models deployed in the cloud poses risks to intellectual property and competitive advantage. If a competitor were to steal a model trained on a company’s sensitive data, they could potentially replicate its functionality and gain valuable insights.
Supply Chain Vulnerabilities (LLM05, ML06): Compromised libraries, datasets, or services used in cloud AI development pipelines can lead to widespread security breaches. A malicious actor might introduce a vulnerability into a widely used open-source library for AI, which could then be exploited to gain access to AI models deployed by multiple organizations.
Developing Best Practices for Securing AI Development
To address these challenges and risks, organizations need to develop and implement best practices and standards tailored to their specific business needs, striking the right balance between enabling innovation and introducing risk.
While guidelines like NCSC Secure AI System Development and The Open Standard for Responsible AI provide a valuable starting point, organizations must also develop their own customized best practices that align with their unique business requirements, risk appetite, and AI/ML use cases. For instance, a financial institution developing AI models for fraud detection might prioritize best practices around data governance and model explainability to ensure compliance with regulations and maintain transparency in decision-making processes.
Key considerations when developing these best practices include:
Ensuring secure data handling and governance throughout the AI lifecycle
Implementing robust access controls and identity management for AI/ML resources
Validating and monitoring AI models for potential biases, vulnerabilities, or anomalies
Establishing incident response and remediation processes for AI-specific threats
Maintaining transparency and explainability to understand and audit AI model behavior
Rapid7’s Approach to Securing AI Development
“At Rapid7, our InsightCloudSec solution offers real-time visibility into AI/ML resources running across major cloud providers, allowing security teams to continuously monitor for potential risks or misconfigurations,” says Aniket Menon, VP, Product Management. “Visibility is the foundation for effective security in any environment, and that’s especially true in the complex world of AI development. Without a clear view into your AI/ML assets and activities, you’re essentially operating blind, leaving your organization vulnerable to a range of threats.”
Here at Rapid7 our AI TRiSM (Trust, Risk, and Security Management) framework empowers our teams. The framework provides us with confidence not only in our operations but also in driving innovation. In their recent blog outlining the company’s AI principles, Laura Ellis and Sabeen Malik shared how Rapid7 tackles and addresses AI challenges. Centering on transparency, fairness, safety, security, privacy, and accountability, these principles are not just guidelines; they are integral to how Rapid7 builds, deploys, and manages AI systems.
Security and compliance are two key InsightCloudSec capabilities. Compliance Packs are out-of-the-box collections of related Insights focused on industry requirements and standards for all of your resources. Compliance packs may focus on security, costs, governance, or combinations of these across a variety of frameworks, e.g., HIPAA, PCI DSS, GDPR, etc.
Last year Rapid7 launched the Rapid7 AI/ML Security Best Practices compliance pack, the pack allows for real-time and continuous visibility into AI/ML resources running across your clouds with support for GenAI services across AWS, Azure and GCP. To empower you to assess this data in the context of your organizational requirements and priorities, you can then automatically prioritize AI/ML-related risk with Layered Context based on exploitability and potential business impact.
You can also leverage Identity Analysis in InsightCloudSec to collect and present the actions executed by a given user or role within a certain time period. These logged actions are collected and analyzed, providing you with a view across your organization of who can access AI/ML resources and automatically rightsize in accordance with the least privilege access (LPA) concept. This enables you to strategically inform your policies moving forward. Native automation allows you to then act on your assessments to alert on compliance drift, remediate AI/ML risk, and enact prevention mechanisms.
Rapid7’s Continued Dedication to AI Innovation
As an inaugural signer of the CISA Secure by Design Pledge, and through our partnership with Queen’s University Belfast Centre for Secure Information Technologies (CSIT), Rapid7 remains dedicated to collaborating with industry leaders and academic institutions to stay ahead of emerging threats and develop cutting-edge solutions for securing AI development.
As the adoption of AI and ML capabilities continues to accelerate, it’s imperative that organizations have the knowledge and tools to make informed decisions and build with confidence. By implementing robust best practices and leveraging advanced security tools like InsightCloudSec, organizations can harness the power of AI while mitigating the associated risks and ensuring their valuable data and intellectual property remain protected.
To learn more about how Rapid7 can help your organization develop and implement best practices for securing AI development, visit our website to request a demo.
Gartner, Forecast Analysis: Artificial Intelligence Software, 2023-2027, Worldwide, Alys Woodward, et al, 07 November 2023
RSA Conference 2024 drew 650 speakers, 600 exhibitors, and thousands of security practitioners from across the globe to the Moscone Center in San Francisco, California from May 6 through 9.
The keynote lineup was diverse, with 33 presentations featuring speakers ranging from WarGames actor Matthew Broderick, to public and private-sector luminaries such as Cybersecurity and Infrastructure Security Agency (CISA) Director Jen Easterly, U.S. Secretary of State Antony Blinken, security technologist Bruce Schneier, and cryptography experts Tal Rabin, Whitfield Diffie, and Adi Shamir.
Topics aligned with this year’s conference theme, “The art of possible,” and focused on actions we can take to revolutionize technology through innovation, while fortifying our defenses against an evolving threat landscape.
This post highlights three themes that caught our attention: artificial intelligence (AI) security, the Secure by Design approach to building products and services, and Chief Information Security Officer (CISO) collaboration.
AI security
Organizations in all industries have started building generative AI applications using large language models (LLMs) and other foundation models (FMs) to enhance customer experiences, transform operations, improve employee productivity, and create new revenue channels. So it’s not surprising that AI dominated conversations. Over 100 sessions touched on the topic, and the desire of attendees to understand AI technology and learn how to balance its risks and opportunities was clear.
“Discussions of artificial intelligence often swirl with mysticism regarding how an AI system functions. The reality is far more simple: AI is a type of software system.” — CISA
FMs and the applications built around them are often used with highly sensitive business data such as personal data, compliance data, operational data, and financial information to optimize the model’s output. As we explore the advantages of generative AI, protecting highly sensitive data and investments is a top priority. However, many organizations aren’t paying enough attention to security.
A joint generative AI security report released by Amazon Web Services (AWS) and the IBM Institute for Business Value during the conference found that 82% of business leaders view secure and trustworthy AI as essential for their operations, but only 24% are actively securing generative AI models and embedding security processes in AI development. In fact, nearly 70% say innovation takes precedence over security, despite concerns over threats and vulnerabilities (detailed in Figure 1).
Figure 1: Generative AI adoption concerns, Source: IBM Security
Because data and model weights—the numerical values models learn and adjust as they train—are incredibly valuable, organizations need them to stay protected, secure, and private, whether that means restricting access from an organization’s own administrators, customers, or cloud service provider, or protecting data from vulnerabilities in software running in the organization’s own environment.
There is no silver AI-security bullet, but as the report points out, there are proactive steps you can take to start protecting your organization and leveraging AI technology to improve your security posture:
Establish a governance, risk, and compliance (GRC) foundation. Trust in gen AI starts with new security governance models (Figure 2) that integrate and embed GRC capabilities into your AI initiatives, and include policies, processes, and controls that are aligned with your business objectives.
Figure 2: Updating governance, risk, and compliance models, Source: IBM Security
Strengthen your security culture. When we think of securing AI, it’s natural to focus on technical measures that can help protect the business. But organizations are made up of people—not technology. Educating employees at all levels of the organization can help avoid preventable harms such as prompt-based risks and unapproved tool use, and foster a resilient culture of cybersecurity that supports effective risk mitigation, incident detection and response, and continuous collaboration.
“You’ve got to understand early on that security can’t be effective if you’re running it like a project or a program. You really have to run it as an operational imperative—a core function of the business. That’s when magic can happen.” — Hart Rossman, Global Services Security Vice President at AWS
Engage with partners. Developing and securing AI solutions requires resources and skills that many organizations lack. Partners can provide you with comprehensive security support—whether that’s informing and advising you about generative AI, or augmenting your delivery and support capabilities. This can help make your engineers and your security controls more effective.
While many organizations purchase security products or solutions with embedded generative AI capabilities, nearly two-thirds, as detailed in Figure 3, report that their generative AI security capabilities come through some type of partner.
Figure 3: Most security gen AI capabilities are coming from third-party products or partners, Source: IBM Security
Tens of thousands of customers are using AWS, for example, to experiment and move transformative generative AI applications into production. AWS provides AI-powered tools and services, a Generative AI Innovation Center program, and an extensive network of AWS partners that have demonstrated expertise delivering machine learning (ML) and generative AI solutions. These resources can support your teams with hands-on help developing solutions mapped to your requirements, and a broader collection of knowledge they can use to help you make the nuanced decisions required for effective security.
Building secure software was a popular and related focus at the conference. Insecure design is ranked as the number four critical web application security concern on the Open Web Application Security Project (OWASP) Top 10.
The concept known as Secure by Design is gaining importance in the effort to mitigate vulnerabilities early, minimize risks, and recognize security as a core business requirement. Secure by Design builds off of security models such as Zero Trust, and aims to reduce the burden of cybersecurity and break the cycle of constantly creating and applying updates by developing products that are foundationally secure.
More than 60 technology companies—including AWS—signed CISA’s Secure by Design Pledge during RSA Conference as part of a collaborative push to put security first when designing products and services.
The pledge demonstrates a commitment to making measurable progress towards seven goals within a year:
Broaden the use of multi-factor authentication (MFA)
Reduce default passwords
Enable a significant reduction in the prevalence of one or more vulnerability classes
Increase the installation of security patches by customers
Publish a vulnerability disclosure policy (VDP)
Demonstrate transparency in vulnerability reporting
Strengthen the ability of customers to gather evidence of cybersecurity intrusions affecting products
“From day one, we have pioneered secure by design and secure by default practices in the cloud, so AWS is designed to be the most secure place for customers to run their workloads. We are committed to continuing to help organizations around the world elevate their security posture, and we look forward to collaborating with CISA and other stakeholders to further grow and promote security by design and default practices.” — Chris Betz, CISO at AWS
The need for security by design applies to AI like any other software system. To protect users and data, we need to build security into ML and AI with a Secure by Design approach that considers these technologies to be part of a larger software system, and weaves security into the AI pipeline.
Since models tend to have very high privileges and access to data, integrating an AI bill of materials (AI/ML BOM) and Cryptography Bill of Materials (CBOM) into BOM processes can help you catalog security-relevant information, and gain visibility into model components and data sources. Additionally, frameworks and standards such as the AI RMF 1.0, the HITRUST AI Assurance Program, and ISO/IEC 42001 can facilitate the incorporation of trustworthiness considerations into the design, development, and use of AI systems.
CISO collaboration
In the RSA Conference keynote session CISO Confidential: What Separates The Best From The Rest, Trellix CEO Bryan Palma and CISO Harold Rivas noted that there are approximately 32,000 global CISOs today—4 times more than 10 years ago. The challenges they face include staffing shortages, liability concerns, and a rapidly evolving threat landscape. According to research conducted by the Information Systems Security Association (ISSA), nearly half of organizations (46%) report that their cybersecurity team is understaffed, and more than 80% of CISOs recently surveyed by Trellix have experienced an increase in cybersecurity threats over the past six months. When asked what would most improve their organizations’ abilities to defend against these threats, their top answer was industry peers sharing insights and best practices.
Building trusted relationships with peers and technology partners can help you gain the knowledge you need to effectively communicate the story of risk to your board of directors, keep up with technology, and build success as a CISO.
AWS CISO Circles provide a forum for cybersecurity executives from organizations of all sizes and industries to share their challenges, insights, and best practices. CISOs come together in locations around the world to discuss the biggest security topics of the moment. With NDAs in place and the Chatham House Rule in effect, security leaders can feel free to speak their minds, ask questions, and get feedback from peers through candid conversations facilitated by AWS Security leaders.
“When it comes to security, community unlocks possibilities. CISO Circles give us an opportunity to deeply lean into CISOs’ concerns, and the topics that resonate with them. Chatham House Rule gives security leaders the confidence they need to speak openly and honestly with each other, and build a global community of knowledge-sharing and support.” — Clarke Rodgers, Director of Enterprise Strategy at AWS
At RSA Conference, CISO Circle attendees discussed the challenges of adopting generative AI. When asked whether CISOs or the business own generative AI risk for the organization, the consensus was that security can help with policies and recommendations, but the business should own the risk and decisions about how and when to use the technology. Some attendees noted that they took initial responsibility for generative AI risk, before transitioning ownership to an advisory board or committee comprised of leaders from their HR, legal, IT, finance, privacy, and compliance and ethics teams over time. Several CISOs expressed the belief that quickly taking ownership of generative AI risk before shepherding it to the right owner gave them a valuable opportunity to earn trust with their boards and executive peers, and to demonstrate business leadership during a time of uncertainty.
Embrace the art of possible
There are many more RSA Conference highlights on a wide range of additional topics, including post-quantum cryptography developments, identity and access management, data perimeters, threat modeling, cybersecurity budgets, and cyber insurance trends. If there’s one key takeaway, it’s that we should never underestimate what is possible from threat actors or defenders. By harnessing AI’s potential while addressing its risks, building foundationally secure products and services, and developing meaningful collaboration, we can collectively strengthen security and establish cyber resilience.
Join us to learn more about cloud security in the age of generative AI at AWS re:Inforce 2024 June 10–12 in Pennsylvania. Register today with the code SECBLOfnakb to receive a limited time $150 USD discount, while supplies last.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Imagine the following scenario: You’re about to enjoy a strategic duel on chess.com or dive into an intense battle in Fortnite, but as you log in, you find your hard-earned achievements, ranks, and reputation have vanished into thin air. This is not just a hypothetical scenario but a real possibility in today’s cloud gaming landscape, where a single security breach can undo years of dedication and achievement.
Cloud gaming, powered by giants like AWS, is transforming the gaming industry, offering unparalleled accessibility and dynamic gaming experiences. Yet, with this technological leap forward comes an increase in cyber threats. The gaming world has already witnessed significant security breaches, such as the GTA5 code theft and Activision’s consistent data challenges, highlighting the lurking dangers in this digital arena.
In such a scenario, securing cloud-based games isn’t just an additional feature; it’s an absolute necessity. As we examine the intricate world of cloud gaming, the role of comprehensive security solutions becomes increasingly vital. In the subsequent sections, we will explore how Rapid7’s InsightCloudSeccan be instrumental in securing cloud infrastructure and CI/CD processes in game development, thereby safeguarding the integrity and continuity of our virtual gaming experiences.
Challenges in Cloud-Based Game Development
Picture this: You’re a game developer, immersed in creating the next big title in cloud gaming. Your team is buzzing with creativity, coding, and testing. But then, out of the blue, you’re hit by a cyberattack, much like the one that rocked CD Projekt Red in 2021. Imagine the chaos – months of hard work (e.g. Cyberpunk 2077 or The Witcher 3) locked up by ransomware, with all sorts of confidential data floating in the wrong hands. This scenario is far from fiction in today’s digital gaming landscape.
What Does This Kind of Attack Really Mean for a Game Development Team?
The Network Weak Spot: It’s like leaving the back door open while you focus on the front; hackers can sneak in through network gaps we never knew existed. That’s what might have happened with CD Projekt Red. A more fortified network could have been their digital moat.
When Data Gets Held Hostage: It’s one thing to secure your castle, but what about safeguarding the treasures inside? The CD Projekt Red incident showed us how vital it is to keep our game codes and internal documents under lock and key, digitally speaking.
A Safety Net Missing: Imagine if CD Projekt Red had a robust backup system. Even after the attack, they could have bounced back quicker, minimizing the damage. It’s like having a safety net when you’re walking a tightrope. You hope you won’t need it, but you’ll be glad it’s there if you do.
This is where a solution like Rapid7’s InsightCloudSeccomes into play. It’s not just about building higher walls; it’s about smarter, more responsive defense systems. Think of it as having a digital watchdog that’s always on guard, sniffing out threats, and barking alarms at the first sign of trouble.
With tools that watch over your cloud infrastructure, monitor every digital move in real time, and keep your compliance game strong, you’re not just creating games; you’re also playing the ultimate game of digital security – and winning.
Navigating Cloud Security in Game Development: An Artful Approach
In the realm of cloud-based game development, mastering AWS services’ security nuances transcends mere technical skill – it’s akin to painting a masterpiece. Let’s embark on a journey through the essential AWS services like EC2, S3, Lambda, CloudFront, and RDS, with a keen focus on their security features – our guardians in the digital expanse.
Consider Amazon EC2 as the infrastructure’s backbone, hosting the very servers that breathe life into games. Here, Security Groups act as discerning gatekeepers, meticulously managing who gets in and out. They’re not just gatekeepers but wise ones, remembering allowed visitors and ensuring a seamless yet secure flow of traffic.
Amazon S3 stands as our digital vault, safeguarding data with precision-crafted bucket policies. These policies aren’t just rules; they’re declarations of trust, dictating who can glimpse or alter the stored treasures. History is littered with tales of those who faltered, so precision here is paramount.
Lambda functionsemerge as the silent virtuosos of serverless architecture, empowering game backends with their scalable might. Yet, their power is wielded judiciously, guided by the principle of least privilege through meticulously assigned roles and permissions, minimizing the shadow of vulnerability.
Amazon CloudFront, our swift courier, ensures game content flies across the globe securely and at breakneck speed. Coupled with AWS Shield (Advanced), it stands as a bulwark against DDoS onslaughts, guaranteeing that game delivery remains both rapid and impregnable.
Amazon RDS, the fortress for player data, automates the mundane yet crucial tasks – backups, patches, scaling – freeing developers to craft experiences. It whispers secrets only to those meant to hear, guarding data with robust encryption, both at rest and in transit.
Visibility and vigilance form the bedrock of our security ethos. With tools like AWS CloudTrail and CloudWatch, our gaze extends across every corner of our domain, ever watchful for anomalies, ready to act with precision and alacrity.
Encryption serves as our silent sentinel, a protective veil over data, whether nestled in S3’s embrace or traversing the vastness to and from EC2 and RDS. It’s our unwavering shield against the curious and the malevolent alike.
In weaving the security measures of these AWS services into the fabric of game development, we engage not in mere procedure but in the creation of a secure tapestry that envelops every facet of the development journey. In the vibrant, ever-evolving landscape of game creation, fortifying our cloud infrastructure with a security-first mindset is not just a technical endeavor – it’s a strategic masterpiece, ensuring our games are not only a source of joy but bastions of privacy and security in the cloud.
Automated Cloud Security with InsightCloudSec
When it comes to deploying a game in the cloud, understanding and implementing automated security is paramount. This is where Rapid7’s InsightCloudSec takes center stage, revolutionizing how game developers secure their cloud environments with a focus on automation and real-time monitoring.
Data Harvesting Strategies
InsightCloudSec differentiates itself through its innovative approach to data collection and analysis, employing two primary methods: API harvesting and Event Driven Harvesting (EDH). Initially, InsightCloudSec utilizes the API method, where it directly calls cloud provider APIs to gather essential platform information. This process enables InsightCloudSec to populate its platform with critical data, which is then unified into a cohesive dataset. For example, disparate storage solutions from AWS, Azure, and GCP are consolidated under a generic “Storage” category, while compute instances are unified as “Instances.” This normalization allows for the creation of universal compliance packs that can be applied across multiple cloud environments, enhancing the platform’s efficiency and coverage.
However, the real game-changer is Rapid7’s implementation of EDH. Unlike the traditional API pull method, EDH leverages serverless functions within the customer’s cloud environment to ingest security event data and configuration changes in real-time. This data is then pushed to the InsightCloudSec platform, significantly reducing costs and increasing the speed of data acquisition. For AWS environments, this means event information can be updated in near real-time, within 60 seconds, and within 2-3 minutes for Azure and GCP. This rapid update capability is a stark contrast to the hourly or daily updates provided by other cloud security platforms, setting InsightCloudSec apart as a leader in real-time cloud security monitoring.
Automated Remediation with InsightCloudSec Bots
The integration of near-to-real-time event information through Event Driven Harvesting (EDH) with InsightCloudSec’s advanced bot automation features equips developers with a formidable toolset for safeguarding cloud environments. This unique combination not only flags vulnerable configurations but also facilitates automatic remediation within minutes, a critical capability for maintaining a pristine cloud ecosystem. InsightCloudSec’s bots go beyond mere detection; they proactively manage misconfigurations and vulnerabilities across virtual machines and containers, ensuring the cloud space is both secure and compliant.
The versatility of these bots is remarkable. Developers have the flexibility to define the scope of the bot’s actions, allowing changes to be applied across one or multiple accounts. This granular control ensures that automated security measures are aligned with the specific needs and architecture of the cloud environment.
Moreover, the timing of these interventions can be finely tuned. Whether responding to a set schedule or reacting to specific events – such as the creation, modification, or deletion of resources – the bots are adept at addressing security concerns at the most opportune moments. This responsiveness is especially beneficial in dynamic cloud environments where changes are frequent and the security landscape is constantly evolving.
The actions undertaken by InsightCloudSec’s bots are diverse and impactful. According to the extensive list of sample bots provided by Rapid7, these automated guardians can, for example:
Automatically tag resources lacking proper identification, ensuring that all elements within the cloud are categorized and easily manageable
Enforce compliance by identifying and rectifying resources that do not adhere to established security policies, such as unencrypted databases or improperly configured networks
Remediate exposed resources by adjusting security group settings to prevent unauthorized access, a crucial step in safeguarding sensitive data
Monitor and manage excessive permissions, scaling back unnecessary access rights to adhere to the principle of least privilege, thereby reducing the risk of internal and external threats
And much more…
This automation, powered by InsightCloudSec, transforms cloud security from a reactive task to a proactive, streamlined process.
By harnessing the power of EDH for real-time data harvesting and leveraging the sophisticated capabilities of bots for immediate action, developers can ensure that their cloud environments are not just reactively protected but are also preemptively fortified against potential vulnerabilities and misconfigurations. This shift towards automated, intelligent cloud security management empowers developers to focus on innovation and development, confident in the knowledge that their infrastructure is secure, compliant, and optimized for the challenges of modern cloud computing.
Infrastructure as Code (IaC) Enhanced: Introducing mimInsightCloudSec
In the dynamic arena of cloud security, particularly in the bustling sphere of game development, the wisdom of “an ounce of prevention is worth a pound of cure” holds unprecedented significance. This is where the role of Infrastructure as Code (IaC) becomes pivotal, and Rapid7’s innovative tool, mimInsightCloudSec, elevates this approach to new heights.
mimInsightCloudSec, a cutting-edge component of the InsightCloudSec platform, is specifically designed to integrate seamlessly into any development pipeline, whether you prefer working with executable binaries or thrive in a containerized ecosystem. Its versatility allows it to be a perfect fit for various deployment strategies, making it an indispensable tool for developers aiming to embed security directly into their infrastructure deployment process.
The primary goal of mimInsightCloudSec is to identify vulnerabilities before the infrastructure is even created, thus embodying the proactive stance on security. This foresight is crucial in the realm of game development, where the stakes are high, and the digital landscape is constantly shifting. By catching vulnerabilities at this nascent stage, developers can ensure that their games are built on a foundation of security, devoid of the common pitfalls that could jeopardize their work in the future.
Figure 2: Shift Left – Infrastructure as Code (IaC) Security
Upon completion of its analysis, mimInsightCloudSec presents its findings in a variety of formats suitable for any team’s needs, including HTML, SARIF, and XML. This flexibility ensures that the results are not just comprehensive but also accessible, allowing teams to swiftly understand and address any identified issues. Moreover, these results are pushed to the InsightCloudSec platform, where they contribute to a broader overview of the security posture, offering actionable insights into potential misconfigurations.
But the capabilities of the InsightCloudSec platform extend even further. Within this sophisticated environment, developers can craft custom configurations, tailoring the security checks to fit the unique requirements of their projects. This feature is particularly valuable for teams looking to go beyond standard security measures, aiming instead for a level of infrastructure hardening that is both rigorous and bespoke. These custom configurations empower developers to establish a static level of security that is robust, nuanced, and perfectly aligned with the specific needs of their game-development projects.
By leveraging mimInsightCloudSec within the InsightCloudSec ecosystem, game developers not only can anticipate and mitigate vulnerabilities before they manifest but also refine their cloud infrastructure with precision-tailored security measures. This proactive and customized approach ensures that the gaming experiences they craft are not only immersive and engaging but also built on a secure, resilient digital foundation.
Figure 3: Misconfigurations and recommended remediations in the InsightCloudSec platform
In summary, Rapid7’s InsightCloudSec offers a comprehensive and automated approach to cloud security, crucial for the dynamic environment of game development. By leveraging both API harvesting and innovative Event Driven Harvesting – along with robust support for Infrastructure as Code – InsightCloudSec ensures that game developers can focus on what they do best: creating engaging and immersive gaming experiences with the knowledge that their cloud infrastructure is secure, compliant, and optimized for performance.
In a forthcoming blog post, we’ll explore the unique security challenges that arise when operating a game in the cloud. We’ll also demonstrate how InsightCloudSec can offer automated solutions to effortlessly maintain a robust security posture.
You can use Amazon Security Lake to simplify log data collection and retention for Amazon Web Services (AWS) and non-AWS data sources. To make sure that you get the most out of your implementation requires proper planning.
In this post, we will show you how to plan and implement a proof of concept (POC) for Security Lake to help you determine the functionality and value of Security Lake in your environment, so that your team can confidently design and implement in production. We will walk you through the following steps:
Understand the functionality and value of Security Lake
Determine success criteria for the POC
Define your Security Lake configuration
Prepare for deployment
Enable Security Lake
Validate deployment
Understand the functionality of Security Lake
Figure 1 summarizes the main features of Security Lake and the context of how to use it:
Figure 1: Overview of Security Lake functionality
As shown in the figure, Security Lake ingests and normalizes logs from data sources such as AWS services, AWS Partner sources, and custom sources. Security Lake also manages the lifecycle, orchestration, and subscribers. Subscribers can be AWS services, such as Amazon Athena, or AWS Partner subscribers.
There are four primary functions that Security Lake provides:
Centralize visibility to your data from AWS environments, SaaS providers, on-premises, and other cloud data sources — You can collect log sources from AWS services such as AWS CloudTrail management events, Amazon Simple Storage Service (Amazon S3) data events, AWS Lambda data events, Amazon Route 53 Resolver logs, VPC Flow Logs, and AWS Security Hub findings, in addition to log sources from on-premises, other cloud services, SaaS applications, and custom sources. Security Lake automatically aggregates the security data across AWS Regions and accounts.
Normalize your security data to an open standard — Security Lake normalizes log sources in a common schema, the Open Security Schema Framework (OCSF), and stores them in compressed parquet files.
Use your preferred analytics tools to analyze your security data — You can use AWS tools, such as Athena and Amazon OpenSearch Service, or you can utilize external security tools to analyze the data in Security Lake.
Optimize and manage your security data for more efficient storage and query — Security Lake manages the lifecycle of your data with customizable retention settings with automated storage tiering to help provide more cost-effective storage.
Determine success criteria
By establishing success criteria, you can assess whether Security Lake has helped address the challenges that you are facing. Some example success criteria include:
I need to centrally set up and store AWS logs across my organization in AWS Organizations for multiple log sources.
I need to more efficiently collect VPC Flow Logs in my organization and analyze them in my security information and event management (SIEM) solution.
I want to use OpenSearch Service to replace my on-premises SIEM.
I want to collect AWS log sources and custom sources for machine learning with Amazon Sagemaker.
I need to establish a dashboard in Amazon QuickSight to visualize my Security Hub findings and a custom log source data.
Review your success criteria to make sure that your goals are realistic given your timeframe and potential constraints that are specific to your organization. For example, do you have full control over the creation of AWS services that are deployed in an organization? Do you have resources that can dedicate time to implement and test? Is this time convenient for relevant stakeholders to evaluate the service?
The timeframe of your POC will depend on your answers to these questions.
Important: Security Lake has a 15-day free trial per account that you use from the time that you enable Security Lake. This is the best way to estimate the costs for each Region throughout the trial, which is an important consideration when you configure your POC.
Define your Security Lake configuration
After you establish your success criteria, you should define your desired Security Lake configuration. Some important decisions include the following:
Determine AWS log sources — Decide which AWS log sources to collect. For information about the available options, see Collecting data from AWS services.
Determine third-party log sources — Decide if you want to include non-AWS service logs as sources in your POC. For more information about your options, see Third-party integrations with Security Lake; the integrations listed as “Source” can send logs to Security Lake.
Note: You can add third-party integrations after the POC or in a second phase of the POC. Pre-planning will be required to make sure that you can get these set up during the 15-day free trial. Third-party integrations usually take more time to set up than AWS service logs.
Select a delegated administrator – Identify which account will serve as the delegated administrator. Make sure that you have the appropriate permissions from the organization admin account to identify and enable the account that will be your Security Lake delegated administrator. This account will be the location for the S3 buckets with your security data and where you centrally configure Security Lake. The AWS Security Reference Architecture (AWS SRA) recommends that you use the AWS logging account for this purpose. In addition, make sure to review Important considerations for delegated Security Lake administrators.
Select accounts in scope — Define which accounts to collect data from. To get the most realistic estimate of the cost of Security Lake, enable all accounts across your organization during the free trial.
Determine analytics tool — Determine if you want to use native AWS analytics tools, such as Athena and OpenSearch Service, or an existing SIEM, where the SIEM is a subscriber to Security Lake.
Define log retention and Regions — Define your log retention requirements and Regional restrictions or considerations.
Prepare for deployment
After you determine your success criteria and your Security Lake configuration, you should have an idea of your stakeholders, desired state, and timeframe. Now you need to prepare for deployment. In this step, you should complete as much as possible before you deploy Security Lake. The following are some steps to take:
Create a project plan and timeline so that everyone involved understands what success look like and what the scope and timeline is.
Define the relevant stakeholders and consumers of the Security Lake data. Some common stakeholders include security operations center (SOC) analysts, incident responders, security engineers, cloud engineers, finance, and others.
Define who is responsible, accountable, consulted, and informed during the deployment. Make sure that team members understand their roles.
Consider other technical prerequisites that you need to accomplish. For example, if you need roles in addition to what Security Lake creates for custom extract, transform, and load (ETL) pipelines for custom sources, can you work with the team in charge of that process before the POC?
Enable Security Lake
The next step is to enable Security Lake in your environment and configure your sources and subscribers.
Deploy Security Lake across the Regions, accounts, and AWS log sources that you previously defined.
Configure custom sources that are in scope for your POC.
Configure analytics tools in scope for your POC.
Validate deployment
The final step is to confirm that you have configured Security Lake and additional components, validate that everything is working as intended, and evaluate the solution against your success criteria.
Validate log collection — Verify that you are collecting the log sources that you configured. To do this, check the S3 buckets in the delegated administrator account for the logs.
Validate analytics tool — Verify that you can analyze the log sources in your analytics tool of choice. If you don’t want to configure additional analytics tooling, you can use Athena, which is configured when you set up Security Lake. For sample Athena queries, see Amazon Security Lake Example Queries on GitHub and Security Lake queries in the documentation.
Obtain a cost estimate — In the Security Lake console, you can review a usage page to verify that the cost of Security Lake in your environment aligns with your expectations and budgets.
Assess success criteria — Determine if you achieved the success criteria that you defined at the beginning of the project.
Next steps
Next steps will largely depend on whether you decide to move forward with Security Lake.
Determine if you have the approval and budget to use Security Lake.
Expand to other data sources that can help you provide more security outcomes for your business.
Configure S3 lifecycle policies to efficiently store logs long term based on your requirements.
Let other teams know that they can subscribe to Security Lake to use the log data for their own purposes. For example, a development team that gets access to CloudTrail through Security Lake can analyze the logs to understand the permissions needed for an application.
Conclusion
In this blog post, we showed you how to plan and implement a Security Lake POC. You learned how to do so through phases, including defining success criteria, configuring Security Lake, and validating that Security Lake meets your business needs.
As a customer, this guide will help you run a successful proof of value (POV) with Security Lake. It guides you in assessing the value and factors to consider when deciding to implement the current features.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.