The new IRAP report includes four additional AWS services that are now assessed at the PROTECTED level under IRAP. This brings the total number of services assessed at the PROTECTED level to 168.
We have developed an IRAP documentation pack to help our Australian customers and their partners plan, architect, and assess risk for their workloads when they use AWS Cloud services.
The IRAP pack on AWS Artifact also includes newly updated versions of the AWS Consumer Guide and the whitepaper Reference Architectures for ISM PROTECTED Workloads in the AWS Cloud.
Reach out to your AWS representatives to let us know which additional services you would like to see in scope for upcoming IRAP assessments. We strive to bring more services into scope at the PROTECTED level under IRAP to support your requirements.
If you have feedback about this post, submit comments in the Comments section below.
Security threats demand swift action, which is why AWS Security Incident Response delivers AWS-native protection that can immediately strengthen your security posture. This comprehensive solution combines automated triage and evaluation logic with your security perimeter metadata to identify critical issues, seamlessly bringing in human expertise when needed. When Security Incident Response is integrated with Amazon GuardDuty and AWS Security Hub within a unified security environment, organizations gain 24/7 access to the AWS Customer Incident Response Team (CIRT) for rapid detection, expert analysis, and efficient threat containment—managed through one intuitive console. Security Incident Response is included with Amazon Managed Services (AMS), which helps organizations adopt and operate AWS at scale efficiently and securely.
In this post, we guide you through enabling Security Incident Response and executing a proof of concept (POC) to quickly enhance your security capabilities while realizing immediate benefits. We explore the service’s functionality, establish POC success criteria, define your configuration, prepare for deployment, enable the service, and optimize effectiveness from day one, helping your organization build confidence throughout the incident response lifecycle while improving recovery time.
Understanding the functionality of Security Incident Response
AWS Security Incident Response service provides comprehensive threat detection and response capabilities through a streamlined four-step process. It begins by ingesting security findings from GuardDuty and select Security Hub integrations with third-party tools. The service then automatically triages these findings using customer metadata and threat intelligence to identify anomalous behavior and suspicious activities. When potential threats are detected, CIRT members proactively investigate cases through the customer portal to determine whether they are true or false positives. For confirmed threats, the service escalates findings for immediate action, while false positives trigger updates to the auto-triage system and suppression rules for GuardDuty and Security Hub, continuously improving detection accuracy.
Comprehensive protection with minimal prerequisites
Security Incident Response delivers powerful security capabilities through seamless integration with both the AWS threat detection and incident response (TDIR) system and third-party security services such as CrowdStrike, Lacework, and TrendMicro. This solution provides a unified command center for end-to-end incident management—from planning and communication to resolution—while ingesting GuardDuty findings and integrating with external providers through Security Hub. With secure case management and an immutable activity timeline, it significantly enhances your security operations by augmenting your security operations center (SOC) and incident response (IR) teams with improved visibility and access to AWS-proven tools and personnel. The AWS CIRT works collaboratively with your responders during investigations and recovery, freeing your valuable resources for other priorities.
The service delivers continuous value through proactive monitoring and response capabilities. It constantly monitors your environment using GuardDuty and Security Hub findings, with service automation, triage, and analysis working diligently in the background to alert you only for genuine security concerns. This protection provides immediate value during potential incidents without demanding your constant attention.
Getting started is straightforward—the only prerequisite is having AWS Organizations enabled and making sure that you have established Organizations with a fundamental organizational unit (OU) structure encompassing member accounts. This foundation not only enables Security Incident Response deployment but also serves as the cornerstone for implementing a robust TDIR strategy across your organization.
Determine success criteria
Establishing success criteria helps benchmark the outcomes of the POC with the goals of the business. Some example criteria include:
Designate an incident response team: Identity and document internal team members and external resources responsible for incident response. As highlighted in AWS Well-Architected Security Pillar, having designated personnel reduces triage and response times during security incidents.
Develop a formal incident response framework: Develop a comprehensive incident response plan with detailed playbooks and regular table-top exercise protocols. AWS provides a reference library of playbooks on GitHub.
Run tabletop exercises: Consider implementing regular simulations that test incident response plans, identify gaps, and build muscle memory across security teams before a real crisis occurs. AWS provides context on various types of tabletop exercises.
Identify existing third-party security providers: Identify third-party security providers with Security Hub integrations that feed into Security Incident Response. AWS partners provide findings as documented at Detect and Analyze.
Implement GuardDuty: Configure GuardDuty according to best practices to monitor and detect threats across critical services. AWS maintains GuardDuty best practices in AWS Security Services Best Practices for GuardDuty.
Review your success criteria to make sure that your goals are realistic given your timeframe and potential constraints that are specific to your organization. For example, do you have full control over the configuration of AWS services that are deployed in an organization? Do you have resources that can dedicate time to implement and test? Is this time convenient for relevant stakeholders to evaluate the service?
Define your Security Incident Response configuration
After establishing your success criteria and timeline, it’s best practice to defineyour Security Incident Response configuration. Some important decisions include the following:
Select a delegated administrator account: Identify which account will serve as delegated administrator (DA) for Security Incident Response. This account and the AWS Region you select will host the Security Incident Response service and portal. AWS Security Reference Architecture (SRA) recommends using dedicated security tooling account. Review Important considerations and recommendations documentation before finalizing the DA.
Define the account scope: Security Incident Response is considered an organization-level service. Every account in every Region within your organization is entitled to coverage under a single subscription. Service coverage automatically adjusts as accounts are added or removed, providing complete protection across your entire AWS footprint.
Configure findings sources: Determine which security findings meet your organization’s needs. The service automatically ingests GuardDuty findings organization-wide and select Security Hub finding types from third-party partners. Evaluate which GuardDuty protection plans and Security Hub findings provide the most value for your security posture and incident response capabilities.
Develop an escalation framework: Establish clear escalation thresholds for different case types: self-managed, AWS-supported, and proactive cases. Define who has authority to determine case submission and type based on severity, impact, and resource requirements.
Implement analytics strategy: Determine whether to use native AWS analytics tools (such as Amazon Athena, Amazon OpenSearch, and Amazon Detective) or integrate with existing security information and event management (SIEM) solutions. These capabilities can enrich incident response with contextual data and deeper insights.
Prepare for deployment
After determining success criteria and Security Incident Response configuration, identify stakeholders, desired state, and timeframe. Prepare for deployment by completing:
Project plan and timeline: Develop a project plan with defined success criteria, scope boundaries, key milestones, and realistic implementation timelines. Suggested timeline of events:
Before enablement:
Configure GuardDuty and Security Hub third parties, perform resource planning
Request approvals for POC trial from the AWS account team or Service team
Day 0 – Enable the service
Week 1 – Open reactive CIRT cases
Week 2 – Connect to IT service management (ITSM) tools
Week 3 – Execute a tabletop exercise
Week 4 – Review the reporting provided by CIRT
Identify stakeholders: Identify CISO, information security teams, SOC personnel, incident response teams, security engineers, finance, legal, compliance, external MSSPs, and business unit representatives.
Develop a RACI matric: Create detailed RACI chart defining roles and responsibilities across incident response lifecycle, facilitating accountability and proper communication channels.
Set up IAM roles and permissions: Use AWS Identity and Access Management (IAM) roles to implement role-based access controls aligned with the RACI chart, including case management, escalation, and read-only roles using AWS managed policies. For more information, see AWS Managed Policies
Enable Security Incident Response
With preparations in place, you are ready to enable the service.
Access Security Incident Response in the management account:
Within the organization’s management account, go to the AWS Management Console and search for Security Incident Response in the console search bar.
Choose Sign Up.
Verify that Use delegated administrator account – Recommended is selected, enter the delegated administrator account number in the Account ID field, and choose Next.
Sign in to the delegated administrator account configured in step 3, search for Security Incident Response, and choose Sign up.
Complete setup in the delegated administrator account:
Define membership details:
Select your home region under Region selection.
For Membership name, enter a suitable name that follows your organization’s naming standards.
Under Membership contacts, enter the Primary and Secondary contact information.
Add Membership tags according to your organization’s tagging strategy.
Choose Next.
Configure permissions for proactive response:
Service permissions for proactive response is already enabled, but you can disable this feature if needed.
Select By choosing this option… and choose Next.
Review service permissions and choose Next.
Review the membership configuration and details, then choose Sign up.
The service-linked role created with proactive response cannot be created in the management account through this on-boarding process. See the AWS Security Incident Response User Guide for deploying the service-linked role to the management account.
Many organizations have well-established processes and application suites for IR and security threat management. To accommodate these pre-existing setups, AWS has developed integrations with popular ITSM and case management applications. Our initial releases enable complete bi-directional integration with both Jira and ServiceNow, with more on the way.
We have provided comprehensive instructions to guide you through the setup process in GitHub.
Optimize value on day one
Immediately after enabling the service, Security Incident Response begins to ingest your GuardDuty and Security Hub findings (from security partners). Your findings are automatically triaged and monitored using deterministic evaluation logic; based on your organization’s unique metadata and security perimeter, high-priority threats are escalated to your Security Incident Response command center for immediate investigation. While your organization receives 24/7 coverage from the start, implementing these recommended optimizations will significantly enhance threat detection accuracy, reduce false positives, accelerate response times, and strengthen your overall security posture through customized protection aligned with your specific business risks and compliance requirements.
To maximize immediate value from Security Incident Response, we suggest using its reactive capabilities beginning at day one. When your team encounters suspicious activities or requires expert investigation, you can create an AWS-supported case through the service portal to engage AWS CIRT specialists directly. These security experts effectively extend your team’s capabilities, providing specialized knowledge and guidance to help you quickly understand, contain, and remediate potential security concerns. This on-demand access to AWS CIRT can reduce your mean time to resolution, minimize potential impact, and make sure you have professional support even for complex security scenarios that might otherwise overwhelm internal resources.
Examples of reactive support queries include:
We noticed a suspicious IP address in our environment, performing various API calls. Can you help us investigate?
A new account was created two days ago, we were notified through an Amazon EventBridge rule and our endpoint detection and response (EDR) integrations, can you help us scope it and find out who created it? How was it created?
If you decide to move forward with AWS Security Incident Response and deploy a POC, we recommend the following action items:
Determine if you have the approval and budget to use Security Incident Response. Preferred pricing agreements, discounts, and performance-based trials are available.
Configure and deploy GuardDuty to help maintain comprehensive and relevant coverage across your management and member accounts, critical services, and workloads.
Verify that third-party security tools (such as CrowdStrike, Lacework, or Trend Micro) are properly integrated with Security Hub.
Communicate the security incident response tooling changes to the relevant organizational teams.
Conclusion
In this post, we showed you how to plan and implement an AWS Security Incident Response POC. You learned how to do so through phases, including defining success criteria, configuring Security Incident Response, and validating that Security Incident Response meets your business needs.
As a customer, this guide will help you run a successful POC with Security Incident Response. It guides you in assessing the value and factors to consider when deciding to implement the current features.
Amazon Web Services (AWS) is pleased to announce the successful renewal of the United Kingdom Cyber Essentials Plus certification. The Cyber Essentials Plus certificate is valid for one year until March 21, 2026.
Cyber Essentials Plus is a UK Government-backed, industry-supported certification scheme intended to help organizations demonstrate organizational cybersecurity against common cybersecurity threats. An independent third-party auditor certified by Information Assurance for Small and Medium Enterprises (IASME) completed the audit. The scope of our Cyber Essentials Plus certificate covers the AWS corporate network for the United Kingdom and Ireland.
AWS strives to continuously improve its compliance programs to help you meet your architectural and regulatory needs. Contact your AWS account team for questions.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Amazon Web Services (AWS) is excited to announce the successful completion of the Cloud Security Assurance Program (CSAP) low-tier certification for the AWS Seoul (ICN) Region for the very first time. The certification is valid for a period of five years, from March 28, 2025 to March 27, 2030.
The Cloud Security Assurance Program (CSAP) enables Korean public sector organizations to comply with national security standards and regulations, including the Act on the Development of Cloud Computing and Protection of its Users (also known as the Cloud Computing Act). By obtaining this certification, AWS can now provide secure cloud services that adhere to these standards, enabling domestic public sector organizations to safely innovate on AWS.
The Korea Internet and Security Agency (KISA, a government organization), under the Ministry of Science and ICT (MSIT), evaluated AWS in December 2024 and completed its re-assessment in March 2025. The CSAP scope includes 191 services that Korean customers can use in the AWS Seoul Region. For the full list of services, see the CSAP tab on the AWS Services in Scope by Compliance Program page. AWS strives to continuously bring as many services as possible into the scope of its compliance programs to help customers adhere to their architectural and regulatory needs.
If you have questions or feedback about CSAP, reach out to your AWS account team.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
AWS has been a proud participant in FedRAMP since 2013. As FedRAMP continues to modernize federal cloud security assessments, we are excited to support this transformation toward a more automated and efficient compliance framework. Today, we’re emphasizing our support for both APN partners and government customers through this evolution and sharing our perspective on these important changes.
On Monday, March 24, the General Services Administration announced a major overhaul of how it supports cloud service provider IT security authorizations as part of FedRAMP. AWS remains dedicated to maintaining support for existing FedRAMP authorizations while preparing for the new program framework, titled FedRAMP 20x (FR 20x). This means continuing to comply with all current processes, including continuous monitoring, as part of existing authorizations of our own services until government processes formally change.
Going forward, we intend to participate in industry working groups to help shape implementation standards. We are also investing in tools and services that will help both partner and agency customers adapt to the new compliance model in order to securely accelerate their cloud journeys. We look forward to supporting FedRAMP to “do once, and reuse many.”
Key updates for our partners and customers:
Adopting an automation-first approach. Automation accelerates the availability and use of the latest cloud services by federal customers. AWS continues to enhance our automated compliance verification capabilities to align with FR 20x’s vision.
Streamlining the authorization process. FedRAMP is moving toward a more efficient authorization process that leverages automation and continuous monitoring. AWS is well positioned to support this transition through our extensive suite of Cloud Governance services.
Enhancing security validation. The new framework will emphasize real-time compliance verification and automated control validation. AWS continues to invest in capabilities that will help customers meet these evolving requirements while maintaining the highest security standards.
Looking ahead: The modernization of FedRAMP represents an important step forward in federal cloud security. AWS remains committed to providing our government customers with the tools, resources, and support they need to succeed in this evolving landscape.
We encourage our customers to:
Continue operating under current FedRAMP guidelines
Stay informed about upcoming changes through AWS channels
Engage with their account manager for further guidance
Begin exploring automation capabilities for security compliance
As these changes roll out, AWS will continue to provide updates and guidance to help our customers navigate the transition successfully. For the latest information about AWS compliance offerings and FedRAMP authorizations, please visit our FedRAMP Compliance page.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
The new IRAP report includes an additional six AWS services that are now assessed at the PROTECTED level under IRAP. This brings the total number of services assessed at the PROTECTED level to 164.
The following are the six newly assessed services:
AWS has developed an IRAP documentation pack to help Australian customers and their partners plan, architect, and assess risk for their workloads when they use AWS Cloud services.
The IRAP pack on AWS Artifact also includes newly updated versions of the AWS Consumer Guide and the whitepaper Reference Architectures for ISM PROTECTED Workloads in the AWS Cloud.
Reach out to your AWS representatives to let us know which additional services you would like to see in scope for upcoming IRAP assessments. We strive to bring more services into scope at the PROTECTED level under IRAP to support your requirements.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
The IAR provides management and technical information security controls to help establish, implement, maintain, and continuously improve information assurance. AWS alignment with IAR requirements demonstrates our ongoing commitment to adhere to the heightened expectations for cloud service providers. As such, IAR-regulated customers can continue to use AWS services with confidence.
Independent third-party auditors from BDO evaluated AWS for the period of November 1, 2023, to October 31, 2024. The assessment report that illustrates the status of AWS compliance is available through AWS Artifact. AWS Artifact is a self-service portal for on-demand access to AWS compliance reports. Sign in to AWS Artifact in the AWS Management Console, or learn more at Getting Started with AWS Artifact.
AWS strives to continuously bring services into the scope of its compliance programs to help you meet your architectural and regulatory needs. If you have questions or feedback about IAR compliance, reach out to your AWS account team.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
This alignment with DESC requirements demonstrates our continued commitment to adhere to the heightened expectations for CSPs. Government customers of AWS can run their applications in AWS Cloud-certified Regions with confidence.
The independent third-party auditor (BSI) issued the Certificate of Compliance to AWS on behalf of DESC on January 23, 2025. The Certificate of Compliance that illustrates the compliance status of AWS is available through AWS Artifact. AWS Artifact is a self-service portal for on-demand access to AWS compliance reports. Sign in to AWS Artifact in the AWS Management Console, or learn more at Getting Started with AWS Artifact.
The certification includes 11 additional services in scope, for a total of 98 services. This is a 13% year-on-year increase in the number of services in the Middle East (UAE) Region that are in scope of the DESC CSP certification. For up-to-date information, including when additional services are added, see the AWS Services in Scope by Compliance Program webpage and choose DESC CSP.
AWS strives to continuously bring services into the scope of its compliance programs to help you adhere to your architectural and regulatory needs. If you have questions or feedback about DESC compliance, reach out to your AWS account team.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
The Finnish Transport and Communications Agency (Traficom) Cyber Security Centre published PiTuKri, which consists of 52 criteria that provide guidance across 11 domains for assessing the security of cloud service providers.
An independent third-party audit firm issued the report to assure customers that the AWS control environment is appropriately designed and operating effectively to demonstrate adherence with PiTuKri requirements. This attestation demonstrates the AWS commitment to adhere to security expectations for cloud service providers set by Traficom.
The latest report covers a 12-month period from October 1, 2023 to September 30, 2024. AWS has added the following 10 services to the current PiTuKri scope:
AWS strives to continuously bring new services into the scope of its compliance programs to help you meet your architectural and regulatory needs. Contact your AWS account team for questions about the PiTuKri report.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
The Swiss Financial Market Supervisory Authority (FINMA) has published several requirements and guidelines about engaging with outsourced services for the regulated financial services customers in Switzerland.
An independent third-party audit firm issued the report to assure customers that the AWS control environment is appropriately designed and operating effectively to support adherence with FINMA requirements.
The latest report covers the 12-month period from October 1, 2023 to September 30, 2024, for the following circulars:
2018/03 “Outsourcing – banks, insurance companies and selected financial institutions under FinIA”
2023/01 “Operational risks and resilience – banks”
Business Continuity Management (BCM) minimum standards proposed by the Swiss Insurance Association
AWS has added the following 10 services to the current FINMA scope:
AWS strives to continuously bring new services into the scope of its compliance programs to help you meet your architectural and regulatory needs. Contact your AWS account team for questions about the FINMA report.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Around the world, organizations are evaluating and embracing artificial intelligence (AI) and machine learning (ML) to drive innovation and efficiency. From accelerating research and enhancing customer experiences to optimizing business processes, improving patient outcomes, and enriching public services, the transformative potential of AI is being realized across sectors. Although using emerging technologies helps drive positive outcomes, leaders worldwide must balance these benefits with the need to maintain security, compliance, and resilience. Many organizations, including those in the public sector and regulated industries, are investing in generative AI applications powered by large language models (LLMs) and other foundation models (FMs) because these applications can transform and scale their work and provide better experiences for customers. Beyond computing power, unlocking this AI potential resides in the AI applications that organizations can create based on a variety of AI/ML development services, models, and data sources. Organizations must navigate the complexity of building AI applications in light of existing and emerging regulatory regimes while verifying that their AI applications and related data are secure, protected, and resilient to risks and threats.
AWS offers a wide range of AI/ML services and capabilities, built on our sovereign-by-design foundation, that are making it simpler for our customers to meet their digital sovereignty needs while getting the security, control, compliance, and resilience that they need. For example, Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, and Stability AI through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Amazon SageMaker provides tools and infrastructure to build, train, and deploy ML models at scale while supporting responsible AI with governance controls and access to pretrained models.
Innovating securely across the AI lifecycle
Security is and always has been our top priority at AWS. AWS customers benefit from our ongoing investment in data centers, networks, custom hardware, and secure software services, built to satisfy the requirements of the most security-sensitive organizations, including the government, healthcare, and financial services. We have always believed that it is essential that customers have control over their data and its location. That’s why we architected the AWS Cloud to be secure and sovereign-by-design from day one. We remain committed to giving our customers more control and choice so that they can use the full power of AWS while meeting their unique digital sovereignty needs.
As organizations develop and implement generative AI, they want to make sure that their data and applications are secured across the AI lifecycle, including data preparation, training, and inferencing. To help ensure the confidentiality and integrity of customer data, all of our Nitro-based Amazon Elastic Compute Cloud (Amazon EC2) instances that run ML accelerators such as AWS Inferentia and AWS Trainium, and graphics processing units (GPUs) such as P4, P5, G5, and G6, are backed by the industry-leading security capabilities of the AWS Nitro System. By design, there is no mechanism for anyone at AWS to access Nitro EC2 instances that customers use to run their workloads. The NCC Group, an independent cybersecurity firm, has validated the design of the Nitro System.
We take a secure approach to generative AI and make it practical for our customers to secure their generative AI workloads across the generative AI stack so that they can focus on building and scaling. All AWS services—including generative AI services—support encryption, and we continue to innovate and invest in controls and encryption features that allow our customers to encrypt everything everywhere.
For example, Amazon Bedrock uses encryption to protect data in transit and at rest, and data remains in the AWS Region where Amazon Bedrock is being used. Customer data, such as prompts, completions, custom models, and data used for fine-tuning or continued pre-training, is not used for Amazon Bedrock service improvement and is never shared with third-party model providers. When customers fine-tune a model in Amazon Bedrock, the data is never exposed to the public internet, never leaves the AWS network, is securely transferred through a customer’s virtual private cloud (VPN), and is encrypted in transit and at rest.
SageMaker protects ML model artifacts and other system artifacts by encrypting data in transit and at rest. Amazon Bedrock and SageMaker integrate with AWS Key Management Service (AWS KMS) so that customers can securely manage cryptographic keys. AWS KMS is designed so that no one—not even AWS employees—can retrieve plaintext keys from the service.
Developing responsibly
The responsible development and use of AI is a priority for AWS. We believe that AI should take a people-centric approach that makes AI safe, fair, secure, and robust. We are committed to supporting customers with responsible AI and helping them build fairer and more transparent AI applications to foster trust, meet regulatory requirements, and use AI to benefit their business and stakeholders. AWS is the first major cloud service provider to announce ISO/IEC 42001 accredited certification for AI services, covering Amazon Bedrock, Amazon Q Business, Amazon Textract, and Amazon Transcribe. ISO/IEC 42001 is an international management system standard that outlines requirements and controls for organizations to promote the responsible development and use of AI systems.
We take responsible AI from theory into practice by providing the necessary tools, guidance, and resources, including Amazon Bedrock Guardrails to help implement safeguards tailored to customer generative AI applications and aligned with their responsible AI policies, or Model Evaluation on Amazon Bedrock to evaluate, compare, and select the best FMs for specific use cases based on custom metrics, such as accuracy, robustness, and toxicity. Additionally, Amazon SageMaker Model Monitor automatically detects and alerts customers of inaccurate predictions from deployed models. We continue to publish AI Service Cards to enhance transparency by providing a single place to find information on the intended use cases and limitations, responsible AI design choices, and performance optimization best practices for our AI services and models.
Building resilience
Resilience plays a pivotal role in the development of any workload, and AI/ML workloads are no different. Customers need to know that their workloads in the cloud will continue to operate in the face of natural disasters, network disruptions, or disruptions due to geopolitical crises. AWS delivers the highest network availability of any cloud provider and is the only cloud provider to offer three or more Availability Zones (AZs) in all Regions, providing more redundancy. Understanding and prioritizing resilience is crucial for generative AI workloads to meet organizational availability and business continuity requirements. We have published guidance on designing generative AI workloads for resilience. To enable higher throughput and enhanced resilience during periods of peak demands in Amazon Bedrock, customers can use cross-region inference to distribute traffic across multiple Regions. For customers with specific European Union data sovereignty requirements, we are launching the AWS European Sovereign Cloud in 2025 to offer an additional layer of control and resilience.
Supporting choice and flexibility
It’s important that customers have access to diverse AI technologies, while having the freedom to choose the right solutions to meet their needs. AWS provides more diversity, choice, and flexibility so that customers can select the AI solution that best aligns with their specific requirements, whether that’s using open-source models, proprietary solutions, or their own custom AI models. For example, we understand the importance of open-source AI in fostering transparency, collaboration, and rapid innovation. Open-source models enable scrutiny of vulnerabilities, drive security improvements, and support research on AI safety. Amazon SageMaker JumpStart provides pretrained, open-source models for a wide range of common use cases. To provide practitioners and developers with the guidance and tools that they need to create secure-by-design AI systems, we are a founding member of the open-source initiative Coalition for Secure AI (CoSAI).
Also, our commitment to portability and interoperability helps ensure that customers can move easily between environments. For customers changing IT providers, we’ve taken concrete steps to lower costs, and AWS is actively engaged in efforts to facilitate switching between cloud providers, including through our support of the Cloud Infrastructure Service Providers in Europe (CISPE)Cloud Switching Framework, which lays out guidance to assist providers and customers in the switching process. This gives organizations the flexibility to adapt their cloud and AI strategies as their needs evolve.
We remain committed to providing customers with a choice of diverse AI technologies, along with secure and compliant ways to build their AI applications throughout the development lifecycle. Through this approach, customers can enhance the security, compliance, and resilience of their systems.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Welcome to the second post in our series on Security Guardians, a mechanism to distribute security ownership at Amazon Web Services (AWS) that trains, develops, and empowers builder teams to make security decisions about the software that they create. In the previous post, you learned the importance of building a culture of security ownership to scale security within your organization, and how AWS achieves this using the Security Guardians program. Since then, many customers have asked how they can build their own, similar program.
In this post, you will learn the steps to build your own Security Guardians program for your organization, including how to:
Set the vision, mission, and goals of your program
Identify developer teams that can pilot your new program
Define the expected behaviors for those teams
Develop training and create opportunities for career development to keep your teams engaged in the program
The guidance in this post is based on what we learned at AWS. Because every organization is different, the final version of the program you build is likely to look different from the one at AWS. Your program needs to reflect the current state of your organization’s culture of security and be designed to cultivate the security-related behaviors that are most important to your organization.
Security Guardians program mechanism
As discussed in the previous post, mechanisms form a key part of our business at AWS. Figure 1 demonstrates how a mechanism is a complete process, or virtuous cycle, that reinforces and improves itself as it operates. It takes controllable inputs and transforms them into ongoing outputs to address a recurring business challenge. In this case, the business challenge AWS faced was that security findings were being identified late in the development lifecycle, making it more expensive—in terms of time, money and effort—to remediate them. This led to bottlenecks in our security review process. The culture of security at AWS, specifically our culture of ownership, provides support to solve this challenge, but we needed the Security Guardians mechanism to actually do it.
Figure 1: AWS mechanism cycle
With most mechanisms, driving adoption is difficult, especially when the mechanism requires human participation to succeed. This is also true in the case of Security Guardians, and you can use our experience to help you avoid some of the challenges and growing pains of driving adoption.
Getting everyone aligned
“If I had an hour to solve a problem and my life depended on the solution, I would spend the first 55 minutes determining the proper question to ask, for once I know the proper question, I could solve the problem in less than five minutes.” – Albert Einstein
Getting alignment for the need to distribute security expertise starts with deeply understanding what problems need to be addressed. For example:
Is product delivery velocity being negatively impacted by delays in the security review process?
What business goal or metric are these delays negatively impacting?
Where in the security review process are those delays occurring?
What factors are contributing to those delays?
Is it a lack of time, people, or skills?
Thoroughly understanding the specific problems and their root causes, as identified by answering those questions, allows you to evaluate whether distributing security ownership is the appropriate solution. This in turn makes it easier to gain alignment and buy-in across the organization for the chosen approach.
A component of a culture of security
Building a strong culture of security requires support from executive leadership to set the direction for the rest of the organization. Executive support makes it easier for product leaders to secure the resources and finances needed for a Security Guardians program to be successful. To align with your organization’s leaders, you can reflect on the goals of your leaders and how the Security Guardians program can be built to meet those goals.
For example, if your business goal is to ship products 25 percent faster, understand how a particular resourcing effort from Security Guardians is going to help your organization meet that goal. AWS benefited from the program with a 26.9 percent reduction in the time to review a new service or feature when a Security Guardian was involved.
Our experience is that it’s challenging to establish a Security Guardians program without executive support. If you’re struggling to identify a business leader to sponsor the program and provide insight on the business problem, your AWS account team—including your account manager or solutions architect—can help. If you’re a business leader or executive reading this post, consider becoming that sponsor yourself.
One step at a time
A step-by-step approach to implementing the Security Guardians program helps overcome organizational challenges and avoid common pitfalls that could lead to failure. These steps, shown in Figure 2, are:
Set the vision
Choose innovators
Define behaviors
Maintain interest
Measure success
These steps support the activities that make a mechanism successful: adoption, inspection, and tools.
Figure 2: Steps for implementing a Security Guardians program
Set the vision
Now that you’ve identified the business problem or business goal, set the vision for the Security Guardians program by working backwards from this problem or goal to define the purpose of your program. For example, the vision of the AWS Security Guardians is “To nourish security ownership that consistently delights our customers with security-by-design throughout the development lifecycle.”
Craft an ambitious vision for your Security Guardians program. Think beyond easy wins and focus on bold, forward-thinking security outcomes for your organization. Make sure that each element of your vision aligns with a business problem or goal. The following table is an example of how the vision of the program is aligned with business goals:
Business goals
Security outcome
Long-term goals
Develop products faster and more efficiently.
To improve developer agility while reducing security risk.
Increase the number of threat models performed by Security Guardians (instead of by application security engineers). Over time, this goal could change to “increase the quality of threat models.”.
Decrease the average monthly security issue rate.
Train three new Security Guardians each quarter.
Reduce long-term security spend.
To identify and mitigate security risk as early as possible.
Increase customer trust.
To exceed customer security expectations by raising the security bar.
The next step is to define a clear mission that is supported with measurable goals. The mission and goals must be achievable and help to move the needle towards the long-term vision.
The final part is to name your program. We chose Security Guardians, like Marvel’s Guardians of the Galaxy. We’ve also heard customers using Security Champions, Security Advocates, Security Innovators, and Security Drivers. Have fun with it and make sure the name resonates with as many participants as possible.
After you’ve defined the vision, future state, mission, measurable goals, and name of the program, review them with your security and business leaders. It’s beneficial to include your innovators or Security Guardians who will be early adopters of the program in this review. In the next section, you’ll learn how to identify these innovators.
Choosing innovators
Just as you develop for and iterate with early adopters of the products you’re building, you should identify individuals and teams who will pilot the program with you. Before the AWS Security Guardians program, our application security engineering teams built relationships with product teams through security reviews.
This meant that they already knew which individuals within those product teams had an interest in security. This is where AWS started, but the success of your program isn’t dependent on whether you already know who these individuals are. Development teams will self-identify and nominate Security Guardians from their own teams. Figure 4 shows examples to help you get started understanding which development teams will be good early adopters for your program.
Figure 3: Example product teams for early program adopters
The examples in Figure 3 include:
Candidate A: Quick wins team
Early adopters typically share key traits, including existing security measures and a designated security role or team members with security expertise. Essentially, they already prioritize security at the team level.
Candidate B: High impact team
This is the team most impacted by the disparity between product development teams and security teams; the agility and time-related benefits of the Security Guardians program will be the highest for this team. For example, this team might be facing long delays in launching products because of the current security review process at your organization.
Candidate C: High risk team
This team owns a product that has a high security risk because of the nature of the product. This team will benefit the most from additional security scrutiny and from raising the security bar at your organization. For example, this team might be building a product that’s considered a critical asset, hosts sensitive data, or performs critical processes.
After you’ve identified one or more teams that could be good early adopters of the program, you need to identify at least one individual from each team to serve as the Security Guardian. Keep the vision and goals of your program in mind when selecting your Security Guardian. Your early Security Guardians should have at least the following characteristics:
Ability to exercise well-informed and decisive judgement
Maintain and showcase their knowledge
Not afraid to have their work be independently validated
Advocate for their security needs in internal discussions
Hold a high security bar
Thoughtful and assertive to make customer security a top priority on their team
In terms of time commitment, our experience is that each Security Guardian spends an average of 3.5 hours each month on activities such as answering general security questions, identifying security stories needed for sprints, diving deep into security related tasks and supporting security related tasks. Each application security review takes approximately 4 hours of effort.
The first post of this series contains even more details on the characteristics that make a good Security Guardian.
Defining behaviors
It’s important to set expectations on what behaviors you want Security Guardians, developers, and security teams to exhibit within the context of the program. These behaviors typically relate directly to the goals of the program. For example, if one of the goals is to increase the number of threat models created, then create threat modeling will be one of the defined behaviors. The behaviors need to be measurable with some flexibility for change as you improve the program.
At AWS, our Security Guardians have access to a runbook that lists the activities each Guardian should take when engaged as part of a review. With each of these activities understood, the program team will then make sure appropriate training is provided so that the Security Guardians are able to complete each of the activities. For example, AWS Security Guardians are asked to help develop threat models. To support this, the program team has developed and released training material to teach Security Guardians how to create a threat model.
With the defined behaviors, understand how the Security Guardian and product development team will engage with the security team. Although we’re clearly defining behaviors, the behaviors aren’t typically done in a silo for the successful launch of a secure product. At AWS, the Security Guardians and product developers engage with the security teams in key partnership areas. If you’re unsure of where to start in defining the behaviors of your program, Figure 4 shows an example of how teams interact at AWS, beginning with the creation of an initial threat model and going through review, remediation, and testing. Consider creating your own version of the model to help define the behaviors and key partnership areas at your organization.
Figure 4: Example behaviors and partnership areas at AWS
In the example of a threat model review, the Guardian and the central security team will jointly create and review the threat model. Specific activity examples include reviewing threats that have no documented mitigations and discussing additional threats that haven’t yet been considered.
As part of encouraging a culture of ownership, AWS recommends allowing Security Guardians to influence the role within a set of boundaries. An example of this is allowing the Security Guardians to be a part of recurring reviews of the program growth metrics, actively collecting their feedback, and encouraging them to host their own training sessions. Active Security Guardians are key to the success of the program and allowing them to influence the program will give them a sense of ownership and inclusion.
Maintaining interest
It’s important to not lose sight that a program like the AWS Security Guardians program is supported by volunteers. Most of your Security Guardians will be product developers who already have a full-time job developing products for your organization. The time and effort to find and onboard new Security Guardians will have a low return on investment if they stop engaging because the program owners didn’t keep them engaged. Keeping Security Guardians is just as important as finding them.
At AWS, we invest time to understand how to build trust with Security Guardians and provide value by working backwards from their wants and needs. Some Security Guardians joined the program to learn new skills and for career growth opportunities. AWS built training programs that were designed for Security Guardians and provide metrics that are used to document their impact to their managers and leaders.
AWS Security Guardians constantly tell us that they value recognition of their contributions by leadership. We work to build mechanisms to continuously surface the great work of our Security Guardians. We also recognize the contributions Security Guardians make through awards, gifts, and other incentives. For example, each quarter, the AWS Security Guardians team sends out a newsletter to senior leaders of the organization. This communication identifies the Guardians within their organization and highlights their contributions, including the number and impact of reviews they’ve completed.
Another way that AWS recognizes the contributions of our Security Guardians is through the Guardians Belt Program. The Guardians Belt Program is designed to recognize Security Guardians for their contributions and support them as they work to advance their security skills and expand their scope of impact. Security Guardians earn Black, Green, Yellow, and White belts with each belt corresponding to significant accomplishments that require consistent commitment to raising the security bar.
To make sure that Security Guardians value the program, your organization should provide and actively facilitate benefits. The benefits must be accessible without requiring additional time or effort from the Security Guardians, promoting immediate and direct gains. Consider the following examples of benefits to maintain Security Guardian interest and support:
Specialized training: Workshops, game days, challenges and contests.
Impact opportunities: Ability to impact multiple products by working with other teams in the organization, ability to help define patterns, best practices, and automation for the program.
Community: Collaborate, connect, share and learn from experts and individuals with similar interests.
Ownership opportunities: Ability to accelerate certain steps in the process.
Leadership opportunities: Active involvement in recurring program or business reviews.
The best ways to maintain interest are determined by the culture of your organization. What does your organization value the most, and how will the program provide that to your Security Guardians? Sometimes, the best way to answer these questions is to ask your early or potential Security Guardians.
Measuring success
The final step of building a successful Security Guardians program is to measure program success. Measuring success is equivalent to the inspection step from Figure 1. This verifies that your desired outcomes are being achieved and provides a jumping off point for iteration. Measuring success also gives you the opportunity to audit the output or results of the Security Guardians program and perform corrections and improvements.
Earlier in this post, we covered identifying the business problem and creating the vision and measurable goals for your Security Guardians program. Example metrics include:
Average time to release features
Average number of security issues per team
Average time spent by Security Guardians and builders doing security work
Percentage of Security Guardians who have taken required and non-required training
Measuring success includes steps to collect feedback and tune the program over time, shown in Figure 5.
Figure 5: Feedback and tuning steps for Security Guardians program.
The cycle to gather feedback and tune the program includes:
Report on metrics
Communicate wins
Measure outcome and cycle time
Identify trends
Review goals
Gathering feedback from Security Guardians is as important as providing feedback to them. One of the ways AWS collects feedback from Security Guardians is through an annual survey that collects feedback on their experiences of program and tooling. To help both builders and Security Guardians improve over time, our security review tooling captures feedback from security engineers on the inputs from Security Guardians. Combined, the data gathered through these surveys helps our security ownership mechanism reinforce and improve itself over time.
Figure 6 summarizes the steps that you can take to develop your program.
Figure 6: Security Guardians program steps
The broad steps to develop a program include:
Set the vision: Set your vision for the program and metrics for success. Get sponsorship from leadership. Choose a name for your program.
Choose innovators: Identify innovators who have a passion for security and foster a community with continuous knowledge sharing.
Define behaviors: Redefine your RACI (responsible, accountable, consulted, informed) and be clear on expectations from your security advocates.
Maintain interest: Provide clear training and learning paths and opportunities for career advancement.
Measure success: Gather feedback and measure the program’s effectiveness.
Conclusion
This post and the previous post covered numerous concepts, considerations, and ideas, including:
The initial intention of the Security Guardians program is to focus on training developers in product teams. This improves early security-focused design thinking.
An alternative approach is to embed or align security engineers directly with product development teams. This can be more effective in organizations where reporting structures and accountability are key considerations.
Some organizations draw Security Guardians from all job types. The program can also be used to focus on uplifting developers and broad security culture.
You must regularly inspect the outcomes delivered by the Security Guardians program and use the information to make incremental improvements as the program matures.
For additional support building a Security Guardians program, contact your AWS account representative and they will get you in touch with a specialist who can help you develop your program.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
The new IRAP report includes an additional seven AWS services that are now assessed at the PROTECTED level under IRAP. This brings the total number of services assessed at the PROTECTED level to 158.
The following are the seven newly assessed services:
Many Australian customers are looking to experiment with how generative AI applications can help them better serve the Australian public. Customers can use two of the newly assessed services—Amazon Bedrock and Amazon DataZone—to help align with their governance, sovereignty, and security requirements up to the PROTECTED level:
Amazon Bedrock is a fully managed service that offers a choice of high-performing large language models (LLMs) and other foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, as well as Amazon through a single API. Amazon Bedrock also provides a broad set of capabilities customers need to build generative AI applications with security, privacy, and responsible AI.
Amazon DataZone is a data management service that makes it faster and simpler for customers to catalog, discover, share, and govern data stored across AWS, on premises, and third-party sources.
AWS has developed an IRAP documentation pack to help Australian customers and their partners to plan, architect, and assess risk for their workloads when they use AWS Cloud services.
The IRAP pack on AWS Artifact also includes newly updated versions of the AWS Consumer Guide and the whitepaper Reference Architectures for ISM PROTECTED Workloads in the AWS Cloud.
Reach out to your AWS representatives to let us know which additional services you would like to see in scope for upcoming IRAP assessments. We strive to bring more services into scope at the PROTECTED level under IRAP to support your requirements.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Amazon Web Services (AWS) announces that it has successfully renewed the Portuguese GNS (Gabinete Nacional de Segurança, National Security Cabinet) certification in the AWS Regions and edge locations in the European Union. This accreditation confirms that AWS cloud infrastructure, security controls, and operational processes adhere to the stringent requirements set forth by the Portuguese government for handling classified information at the National Reservado level (equivalent to the NATO Restricted level).
The GNS certification is based on the NIST SP800-53 Rev. 5 and CSA CCM v4 frameworks. It demonstrates the AWS commitment to providing the most secure cloud services to public-sector customers, particularly those with the most demanding security and compliance needs. By achieving this certification, AWS has demonstrated its ability to safeguard classified data up to the Reservado (Restricted) level, in accordance with the Portuguese government’s rigorous security standards.
AWS was evaluated by an authorized and independent third-party auditor, Adyta Lda, and by the Portuguese GNS itself. With the GNS certification, AWS customers in Portugal, including public sector organizations and defense contractors, can now use the full extent of AWS cloud services to handle national restricted information. This enables these customers to take advantage of AWS scalability, reliability, and cost-effectiveness, while safeguarding data in alignment with GNS standards.
The Agence du Numérique en Santé (ANS), the French governmental agency for health, introduced the HDS certification to strengthen the security and protection of personal health data. By achieving this certification, AWS demonstrates our continuous commitment to adhere to the heightened expectations for cloud service providers.
The following 24 Regions are in scope for this certification:
US East (N. Virginia)
US East (Ohio)
US West (N. California)
US West (Oregon)
Asia Pacific (Hong Kong)
Asia Pacific (Hyderabad)
Asia Pacific (Jakarta)
Asia Pacific (Mumbai)
Asia Pacific (Osaka)
Asia Pacific (Seoul)
Asia Pacific (Singapore)
Asia Pacific (Sydney)
Asia Pacific (Tokyo)
Canada (Central)
Europe (Frankfurt)
Europe (Ireland)
Europe (London)
Europe (Milan)
Europe (Paris)
Europe (Stockholm)
Europe (Zurich)
Middle East (UAE)
Israel (Tel Aviv)
South America (São Paulo)
The HDS certification demonstrates that AWS provides a framework for technical and governance measures to secure and protect personal health data according to HDS requirements. Our customers who handle personal health data can continue to manage their workloads in HDS-certified Regions with confidence.
For up-to-date information, including when additional Regions are added, visit the AWS Compliance Programs page and choose HDS.
AWS strives to continuously meet your architectural and regulatory needs. If you have questions or feedback about HDS compliance, reach out to your AWS account team.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
January 30, 2025: This post was republished to make the instructions clearer and compatible with OCSF 1.1.
Customers often require multiple log sources across their AWS environment to empower their teams to respond and investigate security events. In part one of this two-part blog post, I show you how you can use Amazon OpenSearch Service to ingest logs collected by Amazon Security Lake to facilitate near real-time monitoring.
Many customers use Security Lake to automatically centralize security data from Amazon Web Services (AWS) environments, software as a service (SaaS) providers, on-premises workloads, and cloud sources into a purpose-built data lake in their AWS environment. OpenSearch Service is a managed service that customers can use to deploy, operate, and scale OpenSearch clusters in the AWS Cloud. It natively integrates with Security Lake to enable customers to perform interactive log analytics and searches across large datasets, create enterprise visualization and dashboards, and perform analysis across disparate applications and logs. With Amazon OpenSearch Security Analytics, customers can also gain visibility into the security posture of their organization’s infrastructure, monitor for anomalous activity, detect potential security threats in near real time, and initiate alerts to pre-configured destinations.
Without using Amazon OpenSearch Service, customers would need to build, deploy and manage infrastructure for an analytics solution, such as an ELK stack.
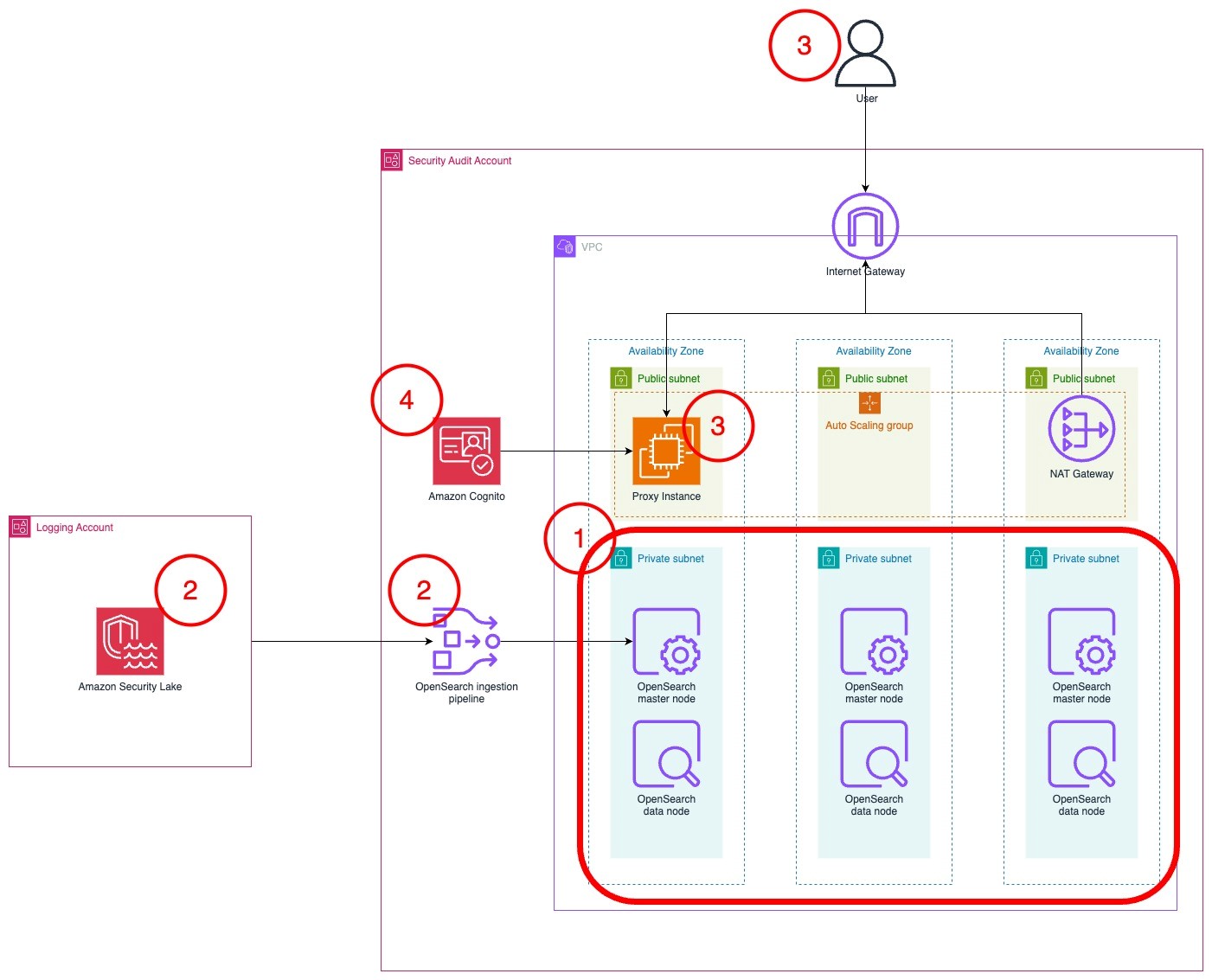
The architecture diagram in Figure 1 shows the completed architecture of the solution.
The OpenSearch Service cluster is deployed within a virtual private cloud (VPC) across three Availability Zones for high availability.
The OpenSearch Service cluster ingests logs from Security Lake using an OpenSearch Ingestion pipeline.
The cluster is accessed by end users through a public-facing proxy hosted on an Amazon EC2 instance.
To reduce costs, the template doesn’t deploy a dead letter queue (DLQ) for the OpenSearch Ingestion pipeline. You can add one later if you want.
Instead of a public facing proxy, you can deploy a VPN to access your cluster.
Authentication to the cluster is managed with Amazon Cognito.
Figure 1: Solution architecture
Planning the deployment
This section will help you plan your OpenSearch service deployment, including what nodes you should choose, the amount of storage to allocate, and where to deploy the cluster.
Deciding instances for the OpenSearch Service master and data nodes
First, determine what instance type to use for the master and data nodes. If your workload generates less than 100 GB of Security Lake logs per day, we recommend using three m6g.large.search master nodes and three r6g.large.search data nodes. You can start small and scale up or scale out later. For more information about deciding the size and number of instances, see Get started with Amazon OpenSearch Service. Note the instance types that you have selected on a text editor because you will use this as an input for the AWS CloudFormation template that you will deploy later.
Configuring storage
To optimize your storage costs, you need to plan your data strategy. In this architecture, Security Lake is used for long-term log storage. Because Security Lake uses Amazon Simple Storage Service (Amazon S3), you can optimize long-term storage costs. You can configure OpenSearch Service to ingest priority logs based on the recent data that you can use for near-real time detection and alerting. Your team can query logs in Security Lake using its Zero-ETL integration with OpenSearch Service to analyze older logs.
Therefore, Security Lake should serve as your primary long-term log storage, with OpenSearch Service storing only the most recent logs.
The number of days of logs in OpenSearch Service will depend on how many days’ worth of data you need to investigate at a given time. I recommend storing 15 days of data in OpenSearch Service. This allows you to react to and investigate the most immediate security events while optimizing storage costs for older logs.
The next step is to determine the volume of logs generated by Security Lake.
Sign in to the Security Lake delegated administrator account.
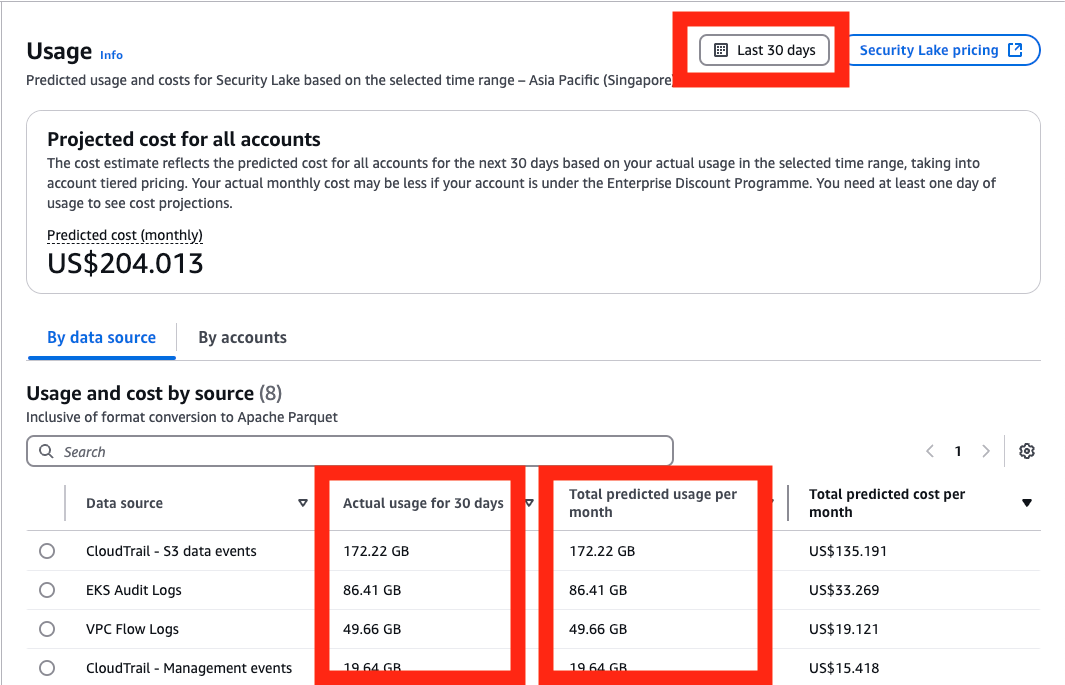
Go to the AWS Management Console for Security Lake. Choose Usage in the navigation pane.
On the Usage screen, select Last 30 days as the range of usage.
Add the total Actual usage for the last 30 days for the data sources that you intend to send to OpenSearch. If you have used Security Lake for less than 30 days, you can use the Total predicted usage per month. Divide this figure by 30 to get the daily data volume.
Figure 2: Select range of usage
To determine the total storage needed, multiply the data generated by Security Lake per day by the retention period you chose, then by 1.1 to account for the indexes, then multiply that number by 1.15 for overhead storage. For more information about calculating storage, see Get started with Amazon OpenSearch Service.
To determine the amount of Amazon Elastic Block Store (Amazon EBS) storage that you need per node, take the total amount of storage and divide it by the number of nodes that you have. Round that number up to the nearest whole number. You can increase the amount of storage after deployment when you have a better understanding of your workload. Make a note of this number in a text editor because you’ll use it as an input in the CloudFormation template later.
Example 1: 10 GB of Security Lake logs generated per day, stored for 30 days in OpenSearch Service in three nodes
10 GB of Security Lake logs stored for 30 days = 10 GB * 30 = 300 GB
Account for additional space for indexes and overhead space = 300 GB * 1.1 * 1.15 = 379.5 GB
Divide the storage required across three nodes, rounded up = 379.5/3 ≈ 127 GB per node
You would need 127 GB per node in OpenSearch Service
Example 2: 200 GB of Security Lake logs generated per day, stored for 15 days in OpenSearch Service across six nodes
200 GB of Security Lake logs stored for 15 days = 200 GB * 15 = 3000 GB
Account for additional space for indexes and overhead space = 3000 GB * 1.1 * 1.15 = 3795 GB
Divide the storage required across three nodes, rounded up = 3795/6 ≈ 633 GB per node
You would need 633 GB per node in OpenSearch Service
Where to deploy the cluster?
If you have an AWS Control Tower deployment or have a deployment modelled after the AWS Security Reference Architecture (AWS SRA), Security Lake should be deployed in the Log Archive account. Because security best practices recommend that the Log Archive account should not be frequently accessed, the OpenSearch Service cluster should be deployed into your Audit account or Security Tooling account.
You need to deploy your Security Lake subscriber in the same Region as your Security Lake roll-up Region. If you have more than one roll-up Region, choose the Region that collects logs from the Regions you want to monitor.
Your cluster needs to be deployed in the same Region as your Security Lake subscriber be able to access data.
Setting up the Security Lake subscriber
Before deploying the solution, create a Security Lake subscriber in your Security Lake roll-up Region so that OpenSearch Service can access data from Amazon Security Lake.
Access the Security Lake console in your Log Archive account.
Choose Subscribers in the navigation pane.
Choose Create subscriber.
On the Create subscriber page, enter a name, such as OpenSearch-subscriber.
Under Data Access, select Under S3 notification type, select SQS queue.
Under Subscriber credentials, enter the AWS account ID for the account you plan to deploy the OpenSearch cluster to, which should be your Security Tooling
Enter OpenSearchIngestion-<AWS account ID> under External ID.
Figure 3: Configuring the Security Lake subscriber
Leave All log and event sources selected and choose Create.
After the subscriber has been created, you will need to collect information to facilitate the deployment.
To gather necessary information:
Select the subscriber that you just created.
Derive the S3 bucket name from the S3 bucket ARN and store it in a text editor. The Amazon Resource Name (ARN) is formatted as arn:aws:s3:::<bucket name>. The bucket name should look like aws-security-data-lake-<region>-xxxxx.
Figure 4: Derive the S3 bucket name from the Subscriber details page
Go to the Amazon Simple Queue Service (Amazon SQS) console and select the SQS queue created as part of the Security Lake subscriber. It should look like AmazonSecurityLake-xxxxxxxxx-Main-Queue. Note the queue’s ARN and URL in your text editor.
Figure 5: Relevant details from the SQS queue
Deploy the solution
To deploy the solution in your Security Tooling account, use a CloudFormation template. This template deploys the OpenSearch Service cluster, OpenSearch Ingestion pipeline, and an AWS Lambda function to initialize the cluster.
To deploy the OpenSearch cluster:
To deploy the CloudFormation template that builds the OpenSearch service cluster, select the Launch Stack button.
In the CloudFormation console, make sure that you are in the correct AWS account. You should be in your Security Tooling account. Also make sure that you have selected the same Region as your Security Lake subscriber.
Enter a name for your stack. A name like os-stack-<day>-<month> can help you keep track of deployments.
Enter the instance types and Amazon EBS volume size that you noted earlier.
Enter the IP address range that you want to allow to access the proxy’s security group. You should limit this to your corporate IP range. You can set it as 0.0.0/0 if you want to expose it to the public internet.
Fill in the details of the Security Lake bucket and the subscriber Amazon SQS queue ARN, URL, and Region.
Figure 6: Add stack parameters
Check the acknowledgements in the Capabilities section.
Choose Create stack to begin deploying the resources.
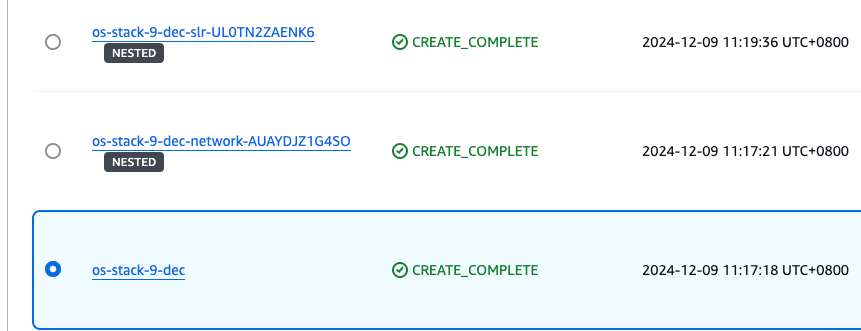
It will take 20–30 minutes to deploy the multiple nested templates. Wait for the main stack (not the nested ones) to achieve the CREATE_COMPLETE status before proceeding to the next step.
Note: If you encounter failures while deployment, you can download the CloudFormation file here and select Preserve successfully provisioned resources under Stack failure options while deploying. This will allow you to troubleshoot the stack deployment.
Go to the Outputs pane of the main CloudFormation stack. Save the DashboardsProxyURL, OpenSearchInitRoleARN, and PipelineRole values in a text editor to refer to later.
Figure 7: The stacks in the CREATE_COMPLETE state with the outputs panel shown
Open the DashboardsProxyURL value in a new tab.
Note: Because the proxy relies on a self-signed certificate, you will get an insecure certificate warning. You can safely ignore this warning and proceed. For a production workload, you should issue a trusted private certificate from your internal public key infrastructure or use AWS Private Certificate Authority.
You will be presented with the Amazon Cognito sign-in page. Use administrator as the username.
Access Secrets Manager to find the password. Select the secret that was created as part of the stack.
Figure 8: The Cognito password in Secrets Manager
Choose Retrieve secret value to get the password.
Figure 9: Retrieve the secret value
After signing in, you will be prompted to change your password and will be redirected to the OpenSearch dashboard.
If you see a pop-up that states Start by adding your own data, select Explore on my own. On the next page, Introducing new OpenSearch Dashboards look & feel, choose Dismiss.
If you see a pop-up that states Select your tenant, select Global, and then choose Confirm.
Figure 10: Select and confirm your tenant
To initialize the OpenSearch cluster:
Choose the menu icon (three stacked horizontal lines) on the top left and select Security under the Management section.
Figure 11: Navigating to the Security page in the OpenSearch console
Select Roles. On the Roles page, search for the all_access role and select it.
Select Mapped users, and then select Manage mapping.
On the Map user screen, choose Add another backend role. Paste the value for the OpenSearchInitRoleARN from the list of CloudFormation outputs. Choose Map.
Figure 12: Mapping the role on the Security page in the OpenSearch console
Leave this tab open and return to the AWS Management console. Go to the AWS Lambda console and select the function named xxxxxx-OS_INIT.
In the function screen, choose Test, and then Create new test event.
Figure 13: Creating the test event in the Lambda console
Choose Invoke. The function should run for about 30 seconds. The execution results should show the component templates that have been created. This Lambda function creates the component and index templates to ingest Open Cybersecurity Framework (OCSF) formatted data, a set of indices and aliases that correspond with the OCSF classes generated by Security Lake, and a rollover policy that will rollover the index daily or if it becomes larger than 40 GB.
Figure 14: Invoking the Lambda function in the Lambda console
To set up the pipeline
Return to the Map user page on the OpenSearch console.
Choose Add another backend role. Paste the value of the PipelineRole from the CloudFormation template output. Choose This will allow the OpenSearch Ingestion to write to the cluster.
Figure 15: Mapping the OpenSearch Ingestion role
Access the Amazon S3 console in the Log Archive account where Security Lake is hosted.
Select the Security Lake bucket in your roll-up Region. It should look like aws-security-data-lake-region-xxxxxxxxxx.
Choose Permissions, then Edit under Bucket policy.
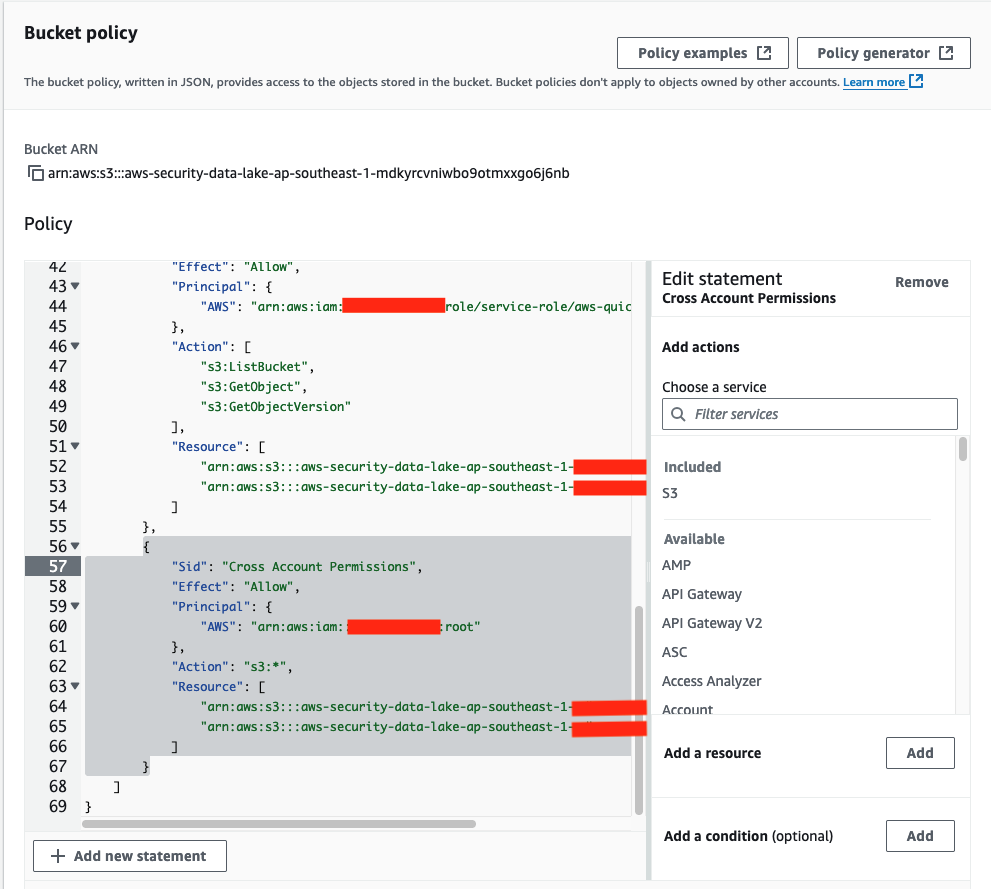
Add this policy to the end of the existing bucket policy. Replace the Principal with the ARN of the PipelineRole and the name of your Security Lake bucket in the Resource section.
{
"Sid": "Cross Account Permissions",
"Effect": "Allow",
"Principal": {
"AWS": "<Pipeline role ARN>"
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::<Security Lake bucket name>/*",
"arn:aws:s3:::<Security Lake bucket name>"
]
}
Figure 16: The modified S3 bucket access policy
Choose Save changes.
To upload the index patterns and dashboards
Download the Security-lake-objects.ndjson file by right-clicking on this link and selecting Save link as.
Access the Dashboards Management page through the navigation menu.
Choose Saved objects in the navigation pane.
On the Saved Objects page, choose Import on the right side of the screen.
Figure 17: Import saved objects
Choose Import and select the Security-lake-objects.ndjson file that you downloaded previously.
Leave Create new objects with unique IDs selected and choose Import.
You can now view the ingested logs on the Discover page and visualizations on the Dashboards page, which you can find on the navigation bar.
Figure 18: The Discover page displaying ingested logs
Clean up
To avoid unwanted charges, delete the main CloudFormation template, named os-stack-<day>-<month> (not the nested stacks).
Figure 19: Select the main stack in the CloudFormation console
Modify the Security Lake bucket policy in the logging account to remove the section you added that trusted the PipelineRole. Be careful not to modify the rest of the policy because it could impact the functioning of Security Lake and other subscribers.
Figure 20: The S3 bucket policy with the relevant sections that needed to be deleted
Conclusion
In this post, you learned how to plan an OpenSearch deployment with Amazon OpenSearch Service to ingest logs from Amazon Security Lake. With this solution, you’re able to aggregate and manage logs with Security Lake and visualize and monitor those logs with OpenSearch Service. After deployment, monitor the OpenSearch Service metrics to determine if you need to scale this up or out for improved performance. In part 2, I will show you how to set up the Security Analytics detector to generate alerts to security findings in near-real time.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Amazon Web Services (AWS) is pleased to announce the successful attestation of our conformance with the National Institute of Standards and Technology (NIST) Secure Software Development Framework (SSDF), Special Publication 800-218. This achievement underscores our ongoing commitment to the security and integrity of our software supply chain.
Executive Order (EO) 14028, Improving the Nation’s Cybersecurity (May 12, 2021) directs U.S. government agencies to take a variety of actions that “enhance the security of the software supply chain.” In accordance with the EO, NIST released the SSDF, and the Office and Management and Budget (OMB) issued Memorandum M-22-18, Enhancing the Security of the Software Supply Chain through Secure Software Development Practices, requiring U.S. government agencies to only use software provided by software producers who can attest to conformance with NIST guidance.
A FedRAMP certified Third Party Assessment Organization (3PAO) assessed AWS against the 42 security tasks in the SSDF. Our attestation form is available in the Cybersecurity and Infrastructure Security Agency (CISA) Repository for Software Attestations and Artifacts for our U.S. government agency customers to access and download. Per CISA guidance, agencies are encouraged to collect the AWS attestation directly from CISA’s repository.
As always, we value your feedback and questions. Reach out to the AWS Compliance team through the Contact Us page. To learn more about our other compliance and security programs, see AWS Compliance Programs.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
AWS Security Hub is a cloud security posture management (CSPM) service that performs security best practice checks across your Amazon Web Services (AWS) accounts and AWS Regions, aggregates alerts, and enables automated remediation. Security Hub is designed to simplify and streamline the management of security-related data from various AWS services and third-party tools. It provides a holistic view of your organization’s security state that you can use to prioritize and respond to security alerts efficiently.
Security Hub assigns a security score to your environment, which is calculated based on passed and failed controls. A control is a safeguard or countermeasure prescribed for an information system or an organization that’s designed to protect the confidentiality, integrity, and availability of the system and to meet a set of defined security requirements. You can use the security score as a mechanism to baseline the accounts. The score is displayed as a percentage rounded up or down to the nearest whole number.
In this blog post, we review the top four mechanisms that you can use to improve your security score, review the five controls in Security Hub that most often fail, and provide recommendations on how to remediate them. This can help you reduce the number of failed controls, thus improving your security score for the accounts.
What is the security score?
Security scores represent the proportion of passed controls to enabled controls. The score is displayed as a percentage rounded to the nearest whole number. It’s a measure of how well your AWS accounts are aligned with security best practices and compliance standards. The security score is dynamic and changes based on the evolving state of your AWS environment. As you address and remediate findings associated with controls, your security score can improve. Similarly, changes in your environment or the introduction of new Security Hub findings will affect the score.
Each check is a point-in-time evaluation of a rule against a single resource that results in a compliance status of PASSED, FAILED, WARNING, or NOT_AVAILBLE. A control is considered passed when the compliance status of all underlying checks for resources are PASSED or if the FAILED checks have a workflow status of SUPPRESSED. You can view the security score through the Security Hub console summary page—as shown in figure 1—to quickly gain insights into your security posture. The dashboard provides visual representations and details of specific findings contributing to the score. For more information about how scores are calculated, see determining security scores.
Figure. 1 Security Hub dashboard
How to improve the security score?
You can improve your security score in four ways:
Remediating failed controls: After the resources responsible for failed checks in a control are configured with compliant settings and the check is repeated, Security Hub marks the compliance status of the checks as PASSED and the workflow status as RESOLVED. This increases the number of passed controls, thus improving the score.
Suppressing findings associated with failed controls: When calculating the control status, Security Hub ignores findings in the ARCHIVED state as well as findings with a workflow status of SUPPRESSED, which will affect security scores. So if you suppress all failed findings for a control, the control status becomes passed.
If you determine that a Security Hub finding for a resource is an accepted risk, you can manually set the workflow status of the finding to SUPPRESSED from the Security Hub console or using the BatchUpdateFindings API. Suppression doesn’t stop new findings from being generated, but you can set up an automation rule to suppress all future new and updated findings that meet the filtering criteria.
Disabling controls that aren’t relevant: Security Hub provides flexibility by allowing administrators to customize and configure security controls. This includes the ability to disable specific controls or adjust settings to help align with organizational security policies. When a control is disabled, security checks are no longer performed and no additional findings are generated. Existing findings are set to ARCHIVED and the control is excluded from the security score calculations.
Use central configuration in Security Hub to tailor the security controls to help align with your organization’s specific requirements. You can fine-tune your security controls, focus on relevant issues, and improve the accuracy and relevance of your security score. Introducing new central configuration capabilities in AWS Security Hub provides an overview and the benefits of central configuration.
Suppression should be used when you want to tune control findings from specific resources whereas controls should be disabled only when the control is no longer relevant for your AWS environment.
Customize parameter values to fine tune controls: Some Security Hub controls use parameters that affect how the control is evaluated. Typically, these controls are evaluated against the default parameter values that Security Hub defines. However, for a subset of these controls, you can customize the parameter values. When you customize a parameter value for a control, Security Hub starts evaluating the control against the value that you specify. If the resource underlying the control satisfies the custom value, Security Hub generates a PASSED finding.
We will use these mechanisms to address the most commonly failed controls in the following sections.
Identifying the most commonly failed controls in Security Hub
You can use the AWS Management Console to identify the most commonly failed controls across your accounts in AWS Organizations:
Sign in to the delegated administrator account and open the Security Hub console.
On the navigation pain, choose Controls.
Here, you will see the status of your controls sorted by the severity of the failed controls. You will also see the associated number of failed checks with the failed controls in the Failed checks column on this page. A check is performed for each resource. If a column says 85 out of 124 for a control, it means 85 resources out of 124 failed the check for that control. You can sort this column in descending order to identify failed controls that have the most resources as shown in Figure 2.
Figure 2: Security Hub control status page
Addressing the most commonly failed controls
In this section we address remediation strategies for the most used Security Hub controls that have Critical and High severity and have a high failure rate amongst AWS customers. We review five such controls and provide recommended best practices, default settings for the resource type at deployment, guardrails, and compensating controls where applicable.
AutoScaling.3: Auto Scaling group launch configuration
An Auto Scaling group in AWS is a service that automatically adjusts the number of Amazon Elastic Compute Cloud (Amazon EC2) instances in a fleet based on user-defined policies, making sure that the desired number of instances are available to handle varying levels of application demand. A launch configuration is a blueprint that defines the configuration of the EC2 instances to be launched by the Auto Scaling group. The AutoScaling.3 control checks whether Instance Metadata Service Version 2 (IMDSv2) is enabled on the instances launched by EC2 Auto Scaling groups using launch configurations. The control fails if the Instance Metadata Service (IMDS) version isn’t included in the launch configuration, or if both Instance Metadata Service Version 1 (IMDSv1) and IMDSv2 are included. AutoScaling.3 aligns with best practice SEC06-BP02 Reduce attack surface of the well architected framework.
The IMDS is a service on Amazon EC2 that provides metadata about EC2 instances, such as instance ID, public IP address, AWS Identity and Access Management (IAM) role information, and user data such as scripts during launch. IMDS also provides credentials for the IAM role attached to the EC2 instance, which can be used by threat actors for privilege escalation. The existing instance metadata service (IMDSv1) is fully secure, and AWS will continue to support it. If your organization strategy involves using IMDSv1, then consider disabling AutoScaling.3 and EC2.8 Security Hub controls. EC2.8 is a similar control, but checks the IMDS configuration for each EC2 instance instead of the launch configuration.
IMDSv2 adds protection for four types of vulnerabilities that could be used to access the IMDS, including misconfigured or open website application firewalls, misconfigured or open reverse proxies, unpatched service-side request forgery (SSRF) vulnerabilities, and misconfigured or open layer 3 firewalls and network address translation. It does so by requiring the use of a session token using a PUT request when requesting instance metadata and using a Time to Live (TTL) default of 1 so the token cannot travel outside the EC2 instance. For more information on protections added by IMDSv2, see Add defense in depth against open firewalls, reverse proxies, and SSRF vulnerabilities with enhancements to the EC2 Instance Metadata Service.
The Autoscaling.3 control creates a failed check finding for every Amazon EC2 launch configuration that is out of compliance. An Auto Scaling group is associated with one launch configuration at a time. You cannot modify a launch configuration after you create it. To change the launch configuration for an Auto Scaling group, use an existing launch configuration as the basis for a new launch configuration with IMDSv2 enabled and then delete the old launch configuration. After you delete the launch configuration that’s out of compliance, Security Hub will automatically update the finding state to ARCHIVED. It’s recommended to use Amazon EC2 launch templates, which is a successor to launch configurations because you cannot create launch configurations with new EC2 instances released after December 31, 2022. See Migrate your Auto Scaling groups to launch templates for more information.
Amazon has taken a series of steps to make IMDSv2 the default. For example, Amazon Linux 2023 uses IMDSv2 by default for launches. You can also set the default instance metadata version at the account level to IMDSv2 for each Region. When an instance is launched, the instance metadata version is automatically set to the account level value. If you’re using the account-level setting to require the use of IMDSv2 outside of launch configuration, then consider using the central Security Hub configuration to disable AutoScaling.3 for these accounts. See the Sample Security Hub central configuration policy section for an example policy.
EC2.18: Security group configuration
AWS security groups act as virtual stateful firewalls for your EC2 instances to control inbound and outbound traffic and should follow the principle of least privileged access. In the Well-Architected Framework security pillar recommendation SEC05-BP01 Create network layers, it’s best practice to not use overly permissive or unrestricted (0.0.0.0/0) security groups because it exposes resources to misuse and abuse. By default, the EC2.18 control checks whether a security group permits unrestricted incoming TCP traffic on ports except for the allowlisted ports 80 and 443. It also checks if unrestricted UDP traffic is allowed on a port. For example, the check will fail if your security group has an inbound rule with unrestricted traffic to port 22. This control allows custom control parameters that can be used to edit the list of authorized ports for which unrestricted traffic is allowed. If you don’t expect any security groups in your organization to have unrestricted access on any port, then you can edit the control parameters and remove all ports from being allowlisted. You can use a central configuration policy as shown in Sample Security Hub central configuration policy to update the parameter across multiple accounts and Regions. Alternately, you can also add authorized ports to the list of ports you want to allowlist for the check to pass.
EC2.18 checks the rules in the security groups in accounts, whether the security groups are in use or not. You can use AWS Firewall Manager to identify and delete unused security groups in your organization using usage audit security group policies. Deleting unused security groups that have failed the checks will change the finding state of associated findings to ARCHIVED and exclude them from security score calculation. Deleting unused resources also aligns with SUS02-BP03 of the sustainability pillar of the Well-Architected Framework. You can create a Firewall Manager usage audit security group policy through the firewall manager using the following steps:
To configure Firewall Manager:
Sign in to the Firewall Manager administrator account and open the Firewall Manager console.
In the navigation pane, select Security policies.
Choose Create policy.
On Choose policy type and Region:
For Region, select the AWS Region the policy is meant for.
For Policy type, select Security group.
For Security group policy type, select Auditing and cleanup of unused and redundant security groups.
Choose Next.
On Describe policy:
Enter a Policy name and description.
For Policy rules, select Security groups within this policy scope must be used by at least one resource.
You can optionally specify how many minutes a security group can exist unused before it’s considered noncompliant, up to 525,600 minutes (365 days). You can use this setting to allow yourself time to associate new security groups with resources.
For Policy action, we recommend starting by selecting Identify resources that don’t comply with the policy rules, but don’t auto remediate. This allows you to assess the effects of your new policy before you apply it. When you’re satisfied that the changes are what you want, edit the policy and change the policy action by selecting Auto remediate any noncompliant resources.
Choose Next.
On Define policy scope:
For AWS accounts this policy applies to, select one of the three options as appropriate.
For Resource type, select Security Group.
For Resources, you can narrow the scope of the policy using tagging, by either including or excluding resources with the tags that you specify. You can use inclusion or exclusion, but not both.
Choose Next.
Review the policy settings to be sure they’re what you want, and then choose Create policy.
Firewall manager is a Regional service so these policies must be created in each Region you have services in.
You can also set up guardrails for security groups using Firewall Manager policies to remediate new or updated security groups that allow unrestricted access. You can create a Firewall Manager content audit security group policy through the Firewall Manager console:
To create a Firewall Manager security group policy:
Sign in to the Firewall Manager administrator account.
Open the Firewall Manager console.
In the navigation pane, select Security policies.
Choose Create policy.
On Choose policy type and Region:
For Region, select a Region.
For Policy type, select Security group.
For Security group policy type, select Auditing and enforcement of security group rules.
Choose Next.
On Describe policy:
Enter a Policy name and description.
For Policy rule options, select configure managed audit policy rules.
Configure the following options under Policy rules.
For the Security group rules to audit, select Inbound rules from the drop down.
Select Audit overly permissive security group rules.
Select Rule allows all traffic.
For Policy action, we recommend starting by selecting Identify resources that don’t comply with the policy rules, but don’t auto remediate. This allows you to assess the effects of your new policy before you apply it. When you’re satisfied that the changes are what you want, edit the policy and change the policy action by selecting Auto remediate any noncompliant resources.
Choose Next.
On Define policy scope:
For AWS accounts this policy applies to, select one of the three options as appropriate.
For Resource type, select Security Group.
For Resources, you can narrow the scope of the policy using tagging, by either including or excluding resources with the tags that you specify. You can use inclusion or exclusion, but not both.
Choose Next.
Review the policy settings to be sure they’re what you want, and then choose Create policy.
For use cases such as a bastion host where you might have unrestricted inbound access to port 22 (SSH), EC2.18 will fail. A bastion host is a server whose purpose is to provide access to a private network from an external network, such as the internet. In this scenario, you might want to suppress findings associated with the bastion host security groups instead of disabling the control. You can create a Security Hub automation rule in the Security Hub delegated administrator account based on a tag or resource ID to set the workflow status of future findings to SUPPRESSED. Note that an automation rule applies only in the Region in which it’s created. To apply a rule in multiple Regions, the delegated administrator must create the rule in each Region.
To create an automation rule:
Sign in to the delegated administrator account and open the Security Hub console.
In the navigation pane, select Automations, and then choose Create rule.
Enter a Rule Name and Rule Description.
For Rule Type, select Create custom rule.
In the Rule section, provide a unique rule name and a description for your rule.
For Criteria, use the Key, Operator, and Value drop down menus to select your rule criteria. Use the following fields in the criteria section:
Add key ProductName with operator Equals and enter the value Security Hub.
Add key WorkFlowStatus with operator Equals and enter the value NEW.
Add key ComplianceSecurityControlId with operator Equals and enter the value EC2.18.
Add key ResourceId with operator Equals and enter the Amazon Resource Name (ARN) of the bastion host security group as the value.
For Automated action:
Choose the drop down under Workflow Status and select SUPPRESSED.
Under Note, enter text such as EC2.18 exception.
For Rule status, select Enabled.
Choose Create rule.
This automation rule will set the workflow status of all future updated and new findings to SUPPRESSED.
IAM.6: Hardware MFA configuration for the root user
When you first create an AWS account, you begin with a single identity that has complete access to the AWS services and resources in the account. This identity is called the AWS account root user and is accessed by signing in with the email address and password that you used to create the account.
The root user has administrator level access to your AWS accounts, which requires that you apply several layers of security controls to protect this account. In this section, we walk you through:
What to do when the root account isn’t required on your Organizations member accounts and what to do when the root user is required.
We recommend using a layered approach and applying multiple best practices to secure your root account across these scenarios.
AWS root user best practices include recommendations from SEC02-BP01, which recommends multi-factor authentication (MFA) for the root user be enabled. IAM.6 checks whether your AWS account is enabled to use a hardware MFA device to sign in with root user credentials. The control fails if MFA isn’t enabled or if any virtual MFA devices are permitted for signing in with root user credentials. A finding is generated for every account that doesn’t meet compliance. To remediate, see General steps for enabling MFA devices, which describes how to set up and use MFA with a root account. Remember that the root account should be used only when absolutely necessary and is only required for a subset of tasks. As a best practice, for other tasks we recommend signing in to your AWS accounts using federation, which provides temporary access keys by assuming an IAM role instead of using long-lived static credentials.
The Organizations management account deploys universal security guardrails, and you can configure additional services that will affect the member accounts in the organization. So, you should restrict who can sign in and administer the root user in your management account and is why you should apply hardware MFA as an added layer of security.
Many customers manage hundreds of AWS accounts across their organization and managing hardware MFA devices for each root account can be a challenge. While it’s a best practice to use MFA, an alternative approach might be necessary. This includes mapping out and identifying the most critical AWS accounts. This analysis should be done carefully—consider if this is a production environment, what type of data is present, and the overall criticality of the workloads running in that account.
This subset of your most critical AWS accounts should be configured with MFA. For other accounts, consider that in most cases the root account isn’t required and you can disable the use of the root account across the Organizations member accounts using Organizations service control policies (SCP). The following is an example:
If you’re using AWS Control Tower, use the disallow actions as a root user guardrail. If you’re using an SCP for organizations or the AWS Control Tower guardrail to restrict root use in member accounts, consider disabling the IAM.6 control in those member accounts. However, do not disable IAM.6 in the management account. See the Sample Security Hub central configuration policy section for an example policy.
If root account use is required within a member account, confirmed as a valid root-user-task, then perform the following steps:
Another consideration and best practice is to make sure that all AWS accounts have updated contact information, including the email attached to the root user. This is important for several reasons. For example, you must have access to the email associated with the root user to reset the root user’s password. See how to update the email address associated with the root user. AWS uses account contact information to notify and communicate with the AWS account administrators on several important topics including security, operations, and billing related information. Consider using an email distribution list to make sure these email addresses are mapped to a common internal mailbox restricted to your cloud or security team. See how to update your AWS primary and secondary account contact details.
EC2.2: Default security groups configuration
Each Amazon Virtual Private Cloud (Amazon VPC) comes with a default security group. We recommend that you create security groups for EC2 instances or groups of instances instead of using the default security group. If you don’t specify a security group when you launch an instance, the service associates the instance with the default security group for the VPC. In addition, the default security group cannot be deleted because it’s the default security group assigned to an EC2 instance if another security group is not created or assigned.
The default security group allows outbound and inbound traffic from network interfaces (and their associated instances) that are assigned to the same security group. EC2.2 checks whether the default security group of a VPC allows inbound or outbound traffic, and the control fails if the security group allows inbound or outbound traffic. This control doesn’t check if the default security group is in use. A finding is generated for each default VPC security group that’s out of compliance. The default security group doesn’t adhere to least privilege and therefore the following steps are recommended. If no EC2 instance is attached to the default security group, delete the inbound and outbound rules of the default security group. However, if you’re not certain that the default security group is in use, use the following AWS Command Line Interface (AWS CLI) command across each account and Region. If the command returns a list of EC2 instance IDs, then the default security group is in use by these instances. If it returns an empty list, then the default security group isn’t used in that account. Use the ‐‐region option to change Regions.
For these instances, replace the default security group with a new security group using similar rules and work with the owners of those EC2 instances to determine a least privilege security group and ruleset that could be applied. After the instances are moved to the replacement security group, you can remove the inbound and outbound rules of the default security group. You can use an AWS Config rule in each account and Region to remove the inbound and outbound rules of the default security group.
Under the Resource ID Parameter dropdown, select GroupId.
Under Parameter, enter the ARN of the automation service role you copied in step 1.
Choose Save.
It’s important to verify that changes and configurations are clearly communicated to all users of an environment. We recommend that you take the opportunity to update your company’s central cloud security requirements and governance guidance and notify users in advance of the pending change.
ECS.5: ECS container access configuration
An Amazon Elastic Container Service (Amazon ECS) task definition is a blueprint for running Docker containers within an ECS cluster. It defines various parameters required for launching containers, such as Docker image, CPU and memory requirements, networking configuration, container dependencies, environment variables, and data volumes. An ECS task definition is to containers is what a launch configuration is to EC2 instances. ECS.5 is a control related to ECS and ensures that the ECS task definition has read-only access to mounted root filesystem enabled. This control is important and great for defense in depth because it helps prevent containers from making changes to the container’s root file system, prevents privilege escalation if a container is compromised, and can improve security and stability. This control fails if the readonlyRootFilesystem parameter doesn’t exist or is set to false in the ECS task definition JSON.
If you’re using the console to create the task definition, then you must select the read-only box against the root file system parameter in the console as show in Figure 3. If you are using JSON for task definition, then the parameter readonlyRootFilesystem must be set to true and supplied with the container definition or updated in order for this check to pass. This control creates a failed check finding for every ECS task definition that is out of compliance.
Figure 3: Using the ECS console to set readonlyRootFilesystem to true
Follow the steps in the remediation section of the control user guide to fix the resources identified by the control. Consider using infrastructure as code (IaC) tools such as AWS CloudFormation to define your task definitions as code, with the read-only root filesystem set to true to help prevent accidental misconfigurations. If you use continuous integration and delivery (CI/CD) to create your container task definitions, then consider adding a check that looks for the existence of the readonlyRootFilesystem parameter in the task definition and that its set to true.
If this is expected behavior for certain task definitions, you can use Security Hub automation rules to suppress the findings by matching on the ComplianceSecurityControlID and ResourceId filters in the criteria section.
To create the automation rule:
Sign in to the delegated administrator account and open the Security Hub console.
In the navigation pane, select Automations.
Choose Create rule. For Rule Type, select Create custom rule.
Enter a Rule Name and Rule Description.
In the Rule section, enter a unique rule name and a description for your rule.
For Criteria, use the Key, Operator, and Value drop down menus to specify your rule criteria. Use the following fields in the criteria section:
Add key ProductName with operator Equals and enter the value Security Hub.
Add key WorkFlowStatus with operator Equals and enter the value NEW.
Add key ComplianceSecurityControlId with operator Equals and enter the value ECS.5.
Add key ResourceId with operator Equals and enter the ARN of the ECS task definition as the value.
For Automated action,
Choose the dropdown under Workflow Status and select SUPPRESSED.
Under note, enter a description such as ECS.5 exception.
For Rule status, select Enabled
Choose Create rule.
Sample Security Hub central configuration policy
In this section, we cover a sample policy for the controls reviewed in this post using central configuration. To use central configuration, you must integrate Security Hub with Organizations and designate a home Region. The home Region is also your Security Hub aggregation Region, which receives findings, insights, and other data from linked Regions. If you use the Security Hub console, these prerequisites are included in the opt-in workflow for central configuration. Remember that an account or OU can only be associated with one configuration policy at a given time as to not have conflicting configurations. The policy should also provide complete specifications of settings applied to that account. Review the policy considerations document to understand how central configuration policies work. Follow the steps in the Start using central configuration to get started.
If you want to disable controls and update parameters as described in this post, then you must create two policies in the Security Hub delegated administrator account home Region. One policy applies to the management account and another policy applies to the member accounts.
First, create a policy to disable IAM.6, Autoscaling.3, and update the ports for the EC2.18 control to identify security groups with unrestricted access on the ports. Apply this policy to all member accounts. Use the Exclude organization units or accounts section to enter the account ID of the AWS management account.
To create a policy to disable IAM.6, Autoscaling.3 and update the ports:
Open the Security Hub console in the Security Hub delegated administrator account home Region.
In the navigation pane, select Configuration and then the Policies tab. Then, choose Create policy. If you already have an existing policy that applies to all member accounts, then select the policy and choose Edit.
For Controls, select Disable specific controls.
For Controls to disable, select IAM.6 and AutoScaling.3.
Select Customize controls parameters.
From the Select a Control dropdown, select EC2.18.
Edit the cell under List of authorized TCP ports, and add ports that are allow listed for unrestricted access. If no ports should be allow listed for unrestricted access then delete the text in the cell.
For Accounts, select All accounts.
Choose Exclude organizational units or accounts and enter the account ID of the management account.
For Policy details, enter a policy name and description.
Choose Next.
On the Review and apply page, review your configuration policy details. Choose Create policy and apply.
Create another policy in the Security Hub delegated administrator account home Region to disable Autoscaling.3 and update the ports for the EC2.18 control to fail the check for security groups with unrestricted access on any port. Apply this policy to the management account. Use the Specific accounts option for the Accounts section and then the Enter organization unit or accounts tab to enter the account ID of the management account.
To disable Autoscaling.3 and update the ports:
Open the AWS Security Hub console in the Security Hub delegated administrator account home Region.
In the navigation pane, select Configuration and the Policies tab.
Choose Create policy. If you already have an existing policy that applies to the management account only, then select the policy and choose Edit.
For Controls, choose Disable specific controls.
For Controls to disable, select AutoScaling.3.
Select Customize controls parameters.
From the Select a Control dropdown, select EC2.18.
Edit the cell under List of authorized TCP ports and add ports that are allow listed for unrestricted access. If no ports should be allow listed for unrestricted access then delete the text in the cell.
For Accounts, select Specific accounts.
Select the Enter Organization units or accounts tab and enter the Account ID of the management account.
For Policy details, enter a policy name and description.
Choose Next.
On the Review and apply page, review your configuration policy details. Choose Create policy and apply.
Conclusion
In this post, we reviewed the importance of the Security Hub security score and the four methods that you can use to improve your score. The methods include remediation of non-complaint resources, managing controls using Security Hub central configuration, suppressing findings using Security Hub automation rules, and using custom parameters to customize controls. You saw ways to address the five most commonly failed controls across Security Hub customers, including remediation strategies and guardrails for each of these controls.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Amazon Web Services (AWS) is pleased to announce the successful renewal of the United Kingdom Cyber Essentials Plus certification. The Cyber Essentials Plus certificate is valid for one year until March 22, 2025.
Cyber Essentials Plus is a UK Government–backed, industry-supported certification scheme intended to help organizations demonstrate controls against common cyber security threats. An independent third-party auditor certified by Information Assurance for Small and Medium Enterprises (IASME) completed the audit. The scope of our Cyber Essentials Plus certificate covers the AWS corporate network for the United Kingdom, Ireland, and Germany.
As always, we value your feedback and questions. Reach out to the AWS Compliance team through the Contact Us page. If you have feedback about this post, submit a comment in the Comments section below. To learn more about our other compliance and security programs, see AWS Compliance Programs.
Amazon Web Services (AWS) has recently renewed the Esquema Nacional de Seguridad (ENS) High certification, upgrading to the latest version regulated under Royal Decree 311/2022. The ENS establishes security standards that apply to government agencies and public organizations in Spain and service providers on which Spanish public services depend.
This security framework has gone through significant updates since the Royal Decree 3/2010 to the latest Royal Decree 311/2022 to adapt to evolving cybersecurity threats and technologies. The current scheme defines basic requirements and lists additional security reinforcements to meet the bar of the different security levels (Low, Medium, High).
Achieving the ENS High certification for its 311/2022 version underscores AWS commitment to maintaining robust cybersecurity controls and highlights our proactive approach to cybersecurity.
We are happy to announce the addition of 14 services to the scope of our ENS certification, for a new total of 172 services in scope. The certification now covers 31 Regions. Some of the additional services in scope for ENS High include the following:
Amazon Bedrock – This fully managed service offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Amazon EventBridge – Use this service to easily build loosely coupled, event-driven architectures. It creates point-to-point integrations between event producers and consumers without needing to write custom code or manage and provision servers.
AWS HealthOmics – This service helps healthcare and life science organizations and their software partners store, query, and analyze genomic, transcriptomic, and other omics data and then uses that data to generate insights to improve health.
AWS Signer – This is a fully managed code-signing service to ensure the trust and integrity of your code. AWS Signer manages the code-signing certificate’s public and private keys and enables central management of the code-signing lifecycle.
AWS Wickr – This service encrypts messages, calls, and files with a 256-bit end-to-end encryption protocol. Only the intended recipients and the customer organization can decrypt these communications, reducing the risk of adversary-in-the-middle attacks.
AWS achievement of the ENS High certification is verified by BDO Auditores S.L.P., which conducted an independent audit and confirmed that AWS continues to adhere to the confidentiality, integrity, and availability standards at its highest level as described in Royal Decree 311/2022.
As always, we are committed to bringing new services into the scope of our ENS High program based on your architectural and regulatory needs. If you have questions about the ENS program, reach out to your AWS account team or contact AWS Compliance.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us onTwitter.