As an organisation with global reach, translation and localisation have been part of the Raspberry Pi Foundation’s activities from the start. Code Clubs and educational partners all over the world are helping young people learn about computing in their own language. We’ve already published over 1,900 translated learning resources, covering up to 32 languages, thanks to the work of our talented localisation team and our amazing community of volunteer translators.
How our approach to translation considers design, process and people
English is seen by many as the language of computing, and in many countries, it’s also either the language of education or a language that young people aspire to learn. However, English is, in some instances, a barrier to learning: young people in many communities don’t have enough knowledge of English to use it to learn about digital technologies, or even if they do, the language of communication with other students, teachers, or volunteers may not be English.
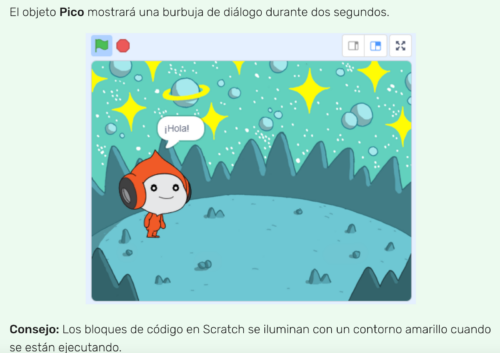
Our ‘Space Talk’ project in Latin American Spanish
In a world where browsers can instantly translate web pages and large language models can power seemingly perfect conversations in virtually any language, it’s easy to assume that translation just happens and that somehow, technology takes care of it. Unfortunately, that’s not the case. Technology is certainly crucial to translation, but there’s much more to it than that. Our approach to translation involves considering design, process, and people to ensure that localised materials truly help young people with their learning journey.
Localisation or translation?
Localisation and translation are similar terms that are often used interchangeably. Localisation normally refers to adapting a product to suit a local market, whereas translation is a subset of localisation that involves changing the language of the text. For instance, localisation includes currencies, measurements, formatting dates and numbers, and contextual references. Meanwhile, translation involves only changing the language of the text, such as from English to French.
At the Raspberry Pi Foundation, we see translation as an enabler. It enables volunteers to reach learners, learners to succeed in their educational goals, and the Foundation to achieve its mission all over the world.
Four key ways the Foundation maximises the impact and reach of our translated materials
1. Create with localisation in mind
Regardless of whether learning materials are intended for English-speaking or global audiences, it’s important to create and design them with localisation in mind. That way, they can be used in a variety of places, and any piece of content (text, graphics, or illustrations) can be modified to meet the needs of the target audience. Keeping localisation in mind might include allowing space for text expansion, being mindful of any text embedded in graphic elements, and even making sure the context is understandable for a variety of audiences. Making a piece of content localisable at the creation stage is virtually cost-free. Modifying fully built assets to translate them or to use them in other markets can be expensive and extremely time-consuming!
2. Always have user needs and priorities upfront
Before investing in localising or translating any materials, we seek to understand the needs and priorities of our users. In many countries where English is not the usual language of communication, materials in English are a barrier, even if some of the users have a working knowledge of English. Making materials available in local languages directly results in additional reach and enhanced learning outcomes. In other communities where English has a certain status, a more selective approach may be more appropriate. A full translation may not be expected, but translating or adapting elements within them, such as introductions, videos, infographics, or glossaries, can help engage new learners.
3. Maximise the use of technology
While it’s possible to translate with pen and paper, translation is only scalable with the use of technology. Computer-assisted translation tools, translation memories, terminology databases, machine translation, large language models, and so on are all technologies that play their part in making the translation process more efficient and scalable.
At the Foundation, we make use of a variety of translation technologies and also, crucially, work very closely with our content and development teams to integrate their tools and processes into the overall localisation workflow.
4. Take great care of the people
Even with the best technology and the smoothest integrations, there is a human element that is absolutely essential. Our amazing community of volunteers and partners work very closely with learners in their communities. They understand the needs of those learners and have a wealth of information and insights. We work with them to prioritise, translate, review and test the learning materials. They are key to ensuring that our learning materials help our users reach their learning goals.
In summary
Thinking about localisation from the moment we start creating learning materials, understanding the needs of users when creating our end goals, maximising the use of technology, and taking good care of our people and partners are the key principles that drive our translation effort.
If you’d like to find out more about translation at the Raspberry Pi Foundation or would like to contribute to the translation of our learning materials, feel free to contact us at [email protected].
A version of this article also appears in Hello World issue 23.
As COVID restrictions were fully lifted in 2023, the number of tourists grew dramatically. People began to explore the world again, frequently using the Grab app to make bookings outside of their home country. However, we noticed that communication posed a challenge for some users. Despite our efforts to integrate an auto-translation feature in the booking chat, we received feedback about occasional missed or inaccurate translations. You can refer to this blog for a better understanding of Grab’s chat system.
An example of a bad translation. The correct translation is: ‘ok sir’.
In an effort to enhance the user experience for travellers using the Grab app, we formed an engineering squad to tackle this problem. The objectives are as follows:
Ensure translation is provided when it’s needed.
Improve the quality of translation.
Maintain the cost of this service within a reasonable range.
Ensure translation is provided when it’s needed
Originally, we relied on users’ device language settings to determine if translation is needed. For example, if both the passenger and driver’s language setting is set to English, translation is not needed. Interestingly, it turned out that the device language setting did not reliably indicate the language in which a user would send their messages. There were numerous cases where despite having their device language set to English, drivers sent messages in another language.
Therefore, we needed to detect the language of user messages on the fly to make sure we trigger translation when it’s needed.
Language detection
Simple as it may seem, language detection is not that straightforward a task. We were unable to find an open-source language detector library that covered all Southeast Asian languages. We looked for Golang libraries as our service was written in Golang. The closest we could find were the following:
Whatlang: unable to detect Malay
Lingua: unable to detect Burmese and Khmer
We decided to choose Lingua over Whatlang as the base detector due to the following factors:
Overall higher accuracy.
Capability to provide detection confidence level.
We have more users using Malay than those using Burmese or Khmer.
When a translation request comes in, our first step is to use Lingua for language detection. If the detection confidence level falls below a predefined threshold, we fall back to call the third-party translation service as it can detect all Southeast Asian languages.
You may ask, why don’t we simply use the third-party service in the first place. It’s because:
The third-party service only has a translate API that also does language detection, but it does not provide a standalone language detection API.
Using the translate API is costly, so we need to avoid calling it when it’s unnecessary. We will cover more on this in a later section.
Another challenge we’ve encountered is the difficulty of distinguishing between Malay and Indonesian languages due to their strong similarities and shared vocabulary. The identical text might convey different meanings in these two languages, which the third-party translation service struggles to accurately detect and translate.
Differentiating Malay and Indonesian is a tough problem in general. However, in our case, the detection has a very specific context, and we can make use of the context to enhance our detection accuracy.
Making use of translation context
All our translations are for the messages sent in the context of a booking or order, predominantly between passenger and driver. There are two simple facts that can aid in our language detection:
Booking/order happens in one single country.
Drivers are almost always local to that country.
So, for a booking that happens in an Indonesian city, if the driver’s message is detected as Malay, it’s highly likely that the message is actually in Bahasa Indonesia.
Improve quality of translation
Initially, we were entirely dependent on a third-party service for translating our chat messages. While overall powerful, the third-party service is not perfect, and it does generate weird translations from time to time.
An example of a weird translation from a third-party service recorded on 19 Dec 2023.
Then, it came to us that we might be able to build an in-house translation model that could translate chat messages better than the third-party service. The reasons being:
The scope of our chat content is highly specific. All the chats are related to bookings or orders. There would not be conversations about life or work in the chat. Maybe a small Machine Learning (ML) model would suffice to do the job.
The third-party service is a general translation service. It doesn’t know the context of our messages. We, however, know the whole context. Having the right context gives us a great edge on generating the right translation.
Training steps
To create our own translation model, we took the following steps:
Perform topic modelling on Grab chat conversations.
Worked with the localisation team to create a benchmark set of translations.
Measured existing translation solutions against benchmarks.
Used an open source Large Language Model (LLM) to produce synthetic training data.
Used synthetic data to train our lightweight translation model.
Topic modelling
In this step, our aim was to generate a dataset which is both representative of the chat messages sent by our users and diverse enough to capture all of the nuances of the conversations. To achieve this, we took a stratified sampling approach. This involved a random sample of past chat conversation messages stratified by various topics to ensure a comprehensive and balanced representation.
Developing a benchmark
For this step we engaged Grab’s localisation team to create a benchmark for translations. The intention behind this step wasn’t to create enough translation examples to fully train or even finetune a model, but rather, it was to act as a benchmark for translation quality, and also as a set of few-shot learning examples for when we generate our synthetic data.
This second point was critical! Although LLMs can generate good quality translations, LLMs are highly susceptible to their training examples. Thus, by using a set of handcrafted translation examples, we hoped to produce a set of examples that would teach the model the exact style, level of formality, and correct tone for the context in which we plan to deploy the final model.
Benchmarking
From a theoretical perspective there are two ways that one can measure the performance of a machine translation system. The first is through the computation of some sort of translation quality score such as a BLEU or CHRF++ score. The second method is via subjective evaluation. For example, you could give each translation a score from 1 to 5 or pit two translations against each other and ask someone to assess which they prefer.
Both methods have their relative strengths and weaknesses. The advantage of a subjective method is that it corresponds better with what we want, a high quality translation experience for our users. The disadvantage of this method is that it is quite laborious. The opposite is true for the computed translation quality scores, that is to say that they correspond less well to a human’s subjective experience of our translation quality, but that they are easier and faster to compute.
To overcome the inherent limitations of each method, we decided to do the following:
Set a benchmark score for the translation quality of various translation services using a CHRF++ score.
Train our model until its CHRF++ score is significantly better than the benchmark score.
Perform a manual A/B test between the newly trained model and the existing translation service.
Synthetic data generation
To generate the training data needed to create our model, we had to rely on an open source LLM to generate the synthetic translation data. For this task, we spent considerable effort looking for a model which had both a large enough parameter count to ensure high quality outputs, but also a model which had the correct tokenizer to handle the diverse sets of languages which Grab’s customers speak. This is particularly important for languages which use non-standard character sets such as Vietnamese and Thai. We settled on using a public model from Hugging Face for this task.
We then used a subset of the previously mentioned benchmark translations to input as few-shot learning examples to our prompt. After many rounds of iteration, we were able to generate translations which were superior to the benchmark CHRF++ scores which we had attained in the previous section.
Model fine tuning
We now had one last step before we had something that was production ready! Although we had successfully engineered a prompt capable of generating high quality translations from the public Hugging Face model, there was no way we’d be able to deploy such a model. The model was far too big for us to deploy it in a cost efficient manner and within an acceptable latency. Our solution to this was to fine-tune a smaller bespoke model using the synthetic training data which was derived from the larger model.
These models were language specific (e.g. English to Indonesian) and built solely for the purpose of language translation. They are 99% smaller than the public model. With approximately 10 Million synthetic training examples, we were able to achieve performance which was 98% as effective as our larger model.
We deployed our model and ran several A/B tests with it. Our model performed pretty well overall, but we noticed a critical problem: sometimes, numbers got mutated in the translation. These numbers can be part of an address, phone number, price etc. Showing the wrong number in a translation can cause great confusion to the users. Unfortunately, an ML model’s output can never be fully controlled; therefore, we added an additional layer of programmatic check to mitigate this issue.
Post-translation quality check
Our goal is to ensure non-translatable content such as numbers, special symbols, and emojis in the original message doesn’t get mutated in the translation produced by our in-house model. We extract all the non-translatable content from the original message, count the occurrences of each, and then try to match the same in the translation. If it fails to match, we discard the in-house translation and fall back to using the third-party translation service.
Keep cost low
At Grab, we try to be as cost efficient as possible in all aspects. In the case of translation, we tried to minimise cost by avoiding unnecessary on-the-fly translations.
As you would have guessed, the first thing we did was to implement caching. A cache layer is placed before both the in-house translation model and the third-party translation. We try to serve translation from the cache first before hitting the underlying translation service. However, given that translation requests are in free text and can be quite dynamic, the impact of caching is limited. There’s more we need to do.
For context, in a booking chat, other than the users, Grab’s internal services can also send messages to the chat room. These messages are called system messages. For example,our food service always sends a message with information on the food order when an order is confirmed.
System messages are all fairly static in nature, however, we saw a very high amount of translation cost attributed to system messages. Taking a deeper look, we noticed the following:
Many system messages were not sent in the recipient’s language, thus requiring on-the-fly translation.
Many system messages, though having the same static structure, contain quite a few variants such as passenger’s name and food order item name. This makes it challenging to utilise our translation cache effectively as each message is different.
Since all system messages are manually prepared, we should be able to get them all manually translated into all the required languages, and avoid on-the-fly translations altogether.
Therefore, we launched an internal campaign, mandating all internal services that send system messages to chat rooms to get manual translations prepared, and pass in the translated contents. This alone helped us save roughly US$255K a year!
Next steps
At Grab, we firmly believe that our proprietary in-house translation models are not only more cost-effective but cater more accurately to our unique use cases compared to third-party services. We will focus on expanding these models to more languages and countries across our operating regions.
Additionally, we are exploring opportunities to apply learnings of our chat translations to other Grab content. This strategy aims to guarantee a seamless language experience for our rapidly expanding user base, especially travellers. We are enthusiastically looking forward to the opportunities this journey brings!
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
On 24 and 25 March, more than 140 members of the Code Club and CoderDojo communities joined us in Cambridge for our first-ever Clubs Conference.
At the Clubs Conference, volunteers and educators came together to celebrate their achievements and explore new ways to support young people to create with technology. The event included community display tables, interactive workshops, discussions,poster sessions, and talks.
For everyone who couldn’t join us in person, we recorded all of the talks that community members gave on the main stage. Here’s what you can learn from the speakers.
Running your club
Jane Waite from our team offered a taste of the research we do and how you can get insights from it to help you run your own coding club. Watch Jane’s talk to learn about the research that informs our projects for your club.
Rhodri Smith, who runs a Code Club, shared how you can use assistive technologies to open your club experience to more young people. Watch Rhodri’s talk for some fantastic tips on how assistive technology can make Code Club accessible to children of all ages and abilities.
Dave Morley, who volunteers at the CoderDojo at Royal Museums Greenwich, presented his way of using Scratch projects to keep engaging Dojo participants. Watch Dave’s talk for tips on how to create your own coding projects for young people.
Tim Duffey, who is part of the West Sound CoderDojo, shared how his Dojo ran successful online sessions during the coronavirus pandemic. Watch Tim’s talk for great advice on how to run successful coding clubs for young people online.
Steph Burton from our team presented new resources we’re working on to help clubs recruit and train volunteers. Watch Steph’s talk for tips on how to recruit new volunteers for your coding club.
Engaging young people in your club
Sophie Hudson, who runs a Code Club in rural Yorkshire, told us how her school’s Code Club turned taking part in Astro Pi Mission Zero into a cross-curricular activity, and how she partnered older learners with younger ones for peer mentoring that engaged new learners in coding. Watch Sophie’s talk to learn how you can get your school involved in Astro Pi, especially if you don’t have much adult support available.
We brought a replica of the Astro Pi computers to the Clubs Conference.
Helen Gardner from our team shared how you can motivate and inspire your coders by supporting them to share their projects in the Coolest Projects showcase — even their very first Scratch animation. Watch Helen’s talk if you’re looking for something new for your club.
The benefits of Code Club and CoderDojo for your community
Fiona Lindsay, who leads a Code Club, presented her insights into the skills beyond coding that young people learn at Code Club, and she shared some wonderful videos of her coders talking about their experience. Watch Fiona’s talk to hear young girls talk about how to get more girls into coding, and for evidence of why every school should have a Code Club.
Last year, Fiona’s Code Club held a special event to celebrate the tenth birthday of Code Club.
Bruce Harms, who is involved in AruCoderDojo, shared how he and his team are making the CoderDojo model part of their wider work to bring digital skills and infrastructure to Aruba. Watch Bruce’s talk to learn how his team has tailored their coding clubs for their local community.
What is volunteering for CoderDojo and Code Club like?
Marcus Davage, who volunteers at a Code Club, shared his journey as a volunteer translator of our resources, and how he engaged colleagues at his workplace in also supporting translations to make coding skills available to more young people across the world. Watch Marcus’s talk if you speak more than one language.
To end the day, we hosted a group of community members onstage to have a chat about their journeys with CoderDojo and Code Club, what they’ve learned, and how they see the future of their clubs. Watch the panel conversation if you want inspiration and advice for getting involved in helping kids create with tech.
Thank you to everyone who gave talks, ran workshops, presented posters, and had conversations to share their questions and insights. It was wonderful to meet all of you, and we came away from the Clubs Conference feeling super inspired by the amazing work Code Club and CoderDojo volunteers all over the world do to help young people learn to create with digital technologies.
We learned so much from listening to you, and we will take the lessons into our work to support you and your clubs in the best way we can.
We meet many young people with an astounding passion for tech, and we also meet the incredible volunteers and educators who help them find their feet in the digital world. Our series of community stories is one way we share their journeys with you.
Today we’re introducing you to Nadia from Maysan, Iraq. Nadia’s achievements speak for themselves, and we encourage you to watch her video to see some of the remarkable things she has accomplished.
Say hello to Nadia
Nadia’s journey with the Raspberry Pi Foundation started when she moved to England to pursue a PhD at Brunel University. As an international student, she wanted to find a way to be part of the local community and make the most of her time abroad. Through her university’s volunteer department, she was introduced to Code Club and began supporting club sessions for children in her local library. The opportunity to share her personal passion for all things computer science and coding with young people felt like the perfect fit.
“[Code Club] added to my skills. And at the same time, I was able to share my expertise with the young children and to learn from them as well.”
Nadia Al-Aboody
Soon, Nadia saw that the skills young people learned at her Code Club weren’t just technical, but included team building and communication as well. That’s when she realised she needed to take Code Club with her when she moved back home to Iraq.
A Code Club in every school in Iraq
With personal awareness of just how important it is to encourage girls to engage with computing and digital technologies, Nadia set about training the Code Club network’s first female-only training team. Her group of 15 trainers now runs nine clubs — and counting— throughout Iraq, with their goal being to open a club in every single school in the country.
Reaching new areas can be a challenge, one that Nadia is addressing by using Code Club resources offline:
“Not every child has a smartphone or a device, and that was one of the biggest challenges. The [Raspberry Pi] Foundation also introduced the unplugged activities, which was amazing. It was very important to us because we can teach computer science without the need for a computer or a smart device.”
Nadia Al-Aboody
Nadia also works with a team of other volunteers to translate our free resources related to Code Club and other initiatives for young people into Arabic, making them accessible to many more young people around the world.
Tamasin Greenough Graham, Head of Code Club here at the Foundation, shares just how important volunteers like Nadia are in actively pushing our shared mission forwards.
“Volunteers like Nadia really show us why we do the work we do. Our Code Club team exists to support volunteers who are out there on the ground, making a real difference to young people. Nadia is a true champion for Code Club, and goes out of her way to help give more children access to learning about computing. By translating resources, alongside overseeing a growing network of clubs, she helps to support more volunteers and, in turn, reach more young people. Having Nadia as a member of the community is really valuable.”
Tamasin Greenough Graham, Head of Code Club
If you are interested in becoming a Code Club volunteer, visit codeclub.org for all the information you need to get started.
Help us celebrate Nadia and her commendable commitment to growing the Code Club community in Iraq by sharing her story on Twitter, LinkedIn, and Facebook.
All young people deserve meaningful opportunities to learn how to create with digital technologies. But according to UNESCO, as much as 40% of people around the world don’t have access to education in a language they speak or understand. At the Raspberry Pi Foundation, we offer more than 200 free online projects that people all over the world use to learn about computing, coding, and creating things with digital technologies. To make these projects more accessible, we’ve published over 1700 translated versions so far, in 32 different languages. You can check out these translated resources by visiting projects.raspberrypi.org and choosing your language from the drop-down menu.
Two young children in Uganda code on a laptop at a CoderDojo session.
Most of this translation work was completed by an amazing community of volunteer translators. In 2021 alone, learners engaged in more than 570,000 learning experiences in languages other than English using our projects.
So how do we know it’s important to put in the effort to make our projects available in many different languages? Various studies show that learning in one’s first language leads to better educational and social outcomes.
Improved access and attainment for girls
Education policy specialists Chloe O’Gara and Nancy Kendall describe in a USAID-funded guide document (1996, p. 100) that girls living in multilingual communities are less likely to know the official language of school instruction than boys, because girls’ lives tend to be more restricted to home and family, where they have fewer opportunities to become proficient in a second language. These restrictions limit their access to education, and if they go to school, they are more likely to have a limited understanding of the dominant language, and therefore learn less. Observations in research studies (Hovens, 2002; Benson 2002a, 2002b) suggest that making education available in a local language greatly increases female students’ opportunities for educational access and attainment.
In rural India, a group of girls cluster around a computer.
Improved self-efficacy
Research studies conducted in Guinea and Senegal (Clemons & Yerende, 2009) suggest that education in a local language, which is more likely to focus on the learner’s circumstances, community, and learning and development needs, increases the learner’s belief in their abilities and skills, compared to education in a dominant language.
Young people program in Scratch on a Raspberry Pi, at Co-creation Hub, Nigeria.
Improved test scores
Learning in a language other than one’s own has a negative effect on learning outcomes, especially for learners living in poverty. For example, a UNESCO-funded case study in Honduras showed that 94% of pupils learned reading skills if their home language was the same as the language of assessment. In contrast, among pupils who spoke a different language at home, this proportion dropped to 62%. Similarly, a UNESCO-funded case study in Guatemala showed that when students were able to learn in a bilingual environment, attendance and promotion rates increased, while rates of repetition and dropout rates decreased. Moreover, students attained higher scores in all subjects and skills, including the mastery of the dominant language (UNESCO Global Education Monitoring Report, Policy Paper 24, February 2016).
Three girls in Brazil code on a laptop in a Code Club session.
Improved acquisition of programming concepts
A survey conducted by a researcher from the University of California San Diego showed that non-native English speakers found it challenging to learn programming languages when the majority of instructional materials and technical communications were only available in English (Guo, 2018). Moreover, a computing education research study of the association between local language use and the rate at which young people learn to program showed that beginners who learned to program in a programming language with keywords and environment localised into their primary language demonstrated new programming concepts at a faster rate, compared with beginners from the same language group who learned using a programming interface in English (Dasgupta & Hill, 2017).
You can help with translations and empower young people
It is clear from these studies that in order to achieve the most impact and to benefit disadvantaged and underserved communities, educational initiatives must work to make learning resources available in the language that learners are most familiar with.
By translating our learning resources, we not only support people who have English as a second language, we also make the resources useful for people who don’t speak any English — estimated as four out of every five people on Earth.
If you’re interested in helping us translate our learning resources, which are completely free, you can find out more at rpf.io/translate.
Since the inception of Code Club in 2012, teachers in Wales have been part of the Code Club community, running extracurricular Code Club sessions for learners in their schools. As of late 2021, there are 84 active clubs in Wales. With our new Code Club Community Coordinator for Wales, Sarah Eve Roberts, on board, we are thrilled to be able to offer more dedicated support to the community in Wales.
Support and engagement for Welsh Code Clubs
Sarah introduced herself to the Welsh education community by running a Code Club training workshop for teachers. Educators from 32 Welsh schools joined her to learn how to start their own Code Club and then tried one of the free coding projects we provide for club sessions for themselves.
The Welsh Code Club network had a chance to meet Sarah at a country-wide online codealong on 11 March, just in time to kick off British Science Week 2022. In this one-hour codealong event, we took beginner coders through the first project of our new ‘Introduction to Scratch’ pathway, Space Talk. Space Talk is a fantastic project for Code Clubs: it provides beginners with a simple introduction to coding in Scratch, and also gives plenty of opportunity for more experienced learners to get creative and make the project their own.
The codealong was fantastically popular, with 90 teachers and 2900 learners from 59 schools participating. Several of the schools shared their excitement with us on Twitter, posting pictures and videos of their Space Talk projects.
Tamasin Greenough Graham, Head of Code Club, says: “It was wonderful to see so many children and teachers from Wales coding with us. I really loved the creativity they showed in all their projects!”
Welsh translations of Code Club learning materials
Although the codealong took place in English, Space Talk and the whole ‘Introduction to Scratch’ pathway are available in the Welsh language. The pathway includes a total of six projects, bringing the total number of Welsh-language coding projects we offer to 37. It’s really important to us to offer our learning materials in Welsh, especially because we know it helps young people engage with our free coding activities.
The translation of learning materials is a collaborative effort at the Raspberry Pi Foundation: we work with a team of 1465 volunteer translators, who translate our materials into 33 languages, making them accessible for more children and educators around the world.
Two of these translators, Marcus and Julia Davage, are based in Wales. They help to make our projects accessible to Welsh-speaking learners. Marcus and Julia have been part of the community for 6 years, volunteering at Code Club and running their own club:
“I started volunteering for Code Club in 2016 when my daughter was in a Welsh-medium primary school and her teacher had started a Code Club. This lasted until 2019. Last year I started my own Code Club at the Welsh-medium primary school at which my wife Julia teaches. Since helping out, she has taught Scratch in her own lessons!”
– Marcus Davage, Code Club volunteer & Welsh translation volunteer
Marcus and Julia have translated numerous learning resources and communications for our Welsh community. Marcus describes the experience of translating:
“I noticed that several of the projects hadn’t been completely translated into Welsh, so when my company, BMC Software, promoted a Volunteering Day for all of its staff, I jumped at the opportunity to spend the whole day finishing off many of the missing translations! I must admit, I did laugh at a few terms, like ’emoji’ (which has no official translation), ’emoticon’ (‘gwenoglun’ or ‘smiley face’), and ‘wearable tech’ (‘technoleg gwisgadwy’).”
– Marcus Davage, Code Club volunteer & Welsh translation volunteer
We’re thankful to Marcus and Julia and to all the teachers and volunteers in Wales who bring coding skills to the young people in their schools.
Get involved in Code Club, in Wales or elsewhere
Keen readers may have noticed that this year marks the tenth anniversary of Code Club! We have lots of celebrations planned for the worldwide community of volunteers and learners, in long-running clubs as well as in brand-new ones.
So now is an especially great time to get involved by starting a Code Club at your school, or by signing up to volunteer at an up-and-running club. Find out more at codeclub.org.
And if you’re interested in learning more about Code Club in Wales, email us at [email protected] so Sarah can get in touch.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.