Linus has released the 7.1 kernel.
“So it’s only Sunday morning back home, but it’s Sunday afternoon where
I am right now, so I’m doing the 7.1 release at the regular time –
just not in the regular timezone.”
This is a current list of where and when I am scheduled to speak:
I’m giving a keynote at Cybernation 2026 in Berlin, Germany, on June 24, 2026.
I’m speaking at the Potsdam Conference on National Cybersecurity at the Hasso Plattner Institut in Potsdam, Germany. The event runs June 24–25, 2026, and my talk will be the evening of June 24.
I’m giving a fireside chat for Epicenter Works, to be held at Kaffee Alt Wien in Vienna, Austria, on Friday, June 26, 2026.
I’m participating (via Zoom) in a panel discussion at Quantum.Tech World in Boston, Massachusetts, USA, on Friday, June 26, 2026. The topic is “Q-Day’s Shortening Deadline: Immediate Solutions.”
Елисавета Белобрадова и Мариус Куркински влезли в един бар. По-точно, разминали се на входа, демонстрирайки удивителна симетрия.
Куркински първо се съгласи да участва в антипрайда „Шествие за семейството“ (да не се бърка с „Поход за семейството“, който тази година не се провежда, защото след разкола между евангелистите, които са в основата им, ресурсите отидоха при Шествието). После се отказа. Защо? Защото там, ти-ри-рам, ти-ри-рам.
Белобрадова пък предвождаше група депутатки от „Да, България“, които в навечерието на „София прайд“ внесоха в парламента предложения за промяна в Закона за предучилищното и училищното образование, между които беше и премахването на забраната на т.нар. ЛГБТ пропаганда. Това е нещо, което ПП–ДБ обещаха скоро след като забраната беше приета през август 2024 г. Няколко дни след внасянето на предложенията Белобрадова съобщи, че със съпартийците ѝ оттеглят тъкмо това от тях, свързано с ЛГБТ пропагандата (въпреки че и тази година подписа предизборната декларация на „София прайд“, с която се ангажира да се застъпва за „законови механизми за защита на ЛГБТИ хората от дискриминация във всички нейни форми“). Ама го направи завоалирано, без да споменава Това, за Което не Трябва да се Говори (ЛГБТ). Защо „Да, България“ оттегли точно това предложение? Защото там, ти-ри-рам, ти-ри-рам.
Или както се казва в една друга песен на Мариус от времето, преди той да се отдаде на традиционните ценности и да стане белобрад – „е, не, не мога такива неща да правя“.
Докато слушам тази песен, между другото, се замислих за разликата между частиците, междуметията и вметнатите части. Всъщност едва ли щях да направя тази асоциация, ако не бях прочела новата порция език на Павлина Върбанова. Този път тя е посветена, съвсем не между другото, на вметнатите части и на пунктуационните правила, на които се подчиняват те.
След вметката за вметнатите части се връщам към темата за „София прайд“ и „Шествие за семейството“. Тази година за първи път хомофобското шествие, което се провежда паралелно с прайда, е с на практика официален статус. То не само е под егидата на Българската православна църква (което не е било досега), а се радва на одобрението и на управляващите. От името на „Прогресивна България“ Слави Василев прочете в парламента декларация в подкрепа на Шествието. В нея се казва:
Във времена на ценностна дезориентация, социална фрагментация и тежка демографска криза, съхраняването на традиционното семейство не е просто въпрос на личен избор, а стълб на националната ни сигурност, идентичност и бъдеще. […] Избираме да застанем зад ценностите на мълчаливото мнозинство от хора, които се опитват да отстояват традициите, семейството и вярата, а не да ги деконструират, както е модерно напоследък.
Войната е мир, свободата е робство, невежеството е сила, прогресивното е традиционно. Здравей, Оруел. А когато някой ЛГБТ тийнейджър отново се самоубие, защото не може да преживее тормоза (не искам да ви плаша, но такива трагедии ще продължат да се случват), институциите пак няма да разпознаят хомофобията като проблем. Традициите, които възпява новата власт, са опит да се върнат времената, когато ЛГБТ хората са живели в срам, страх, лъжи и неприемане на себе си. За ужасяващите измерения, до които може да доведе неприемането на себе си, препоръчвам новия сериал на Ричард Гад Half Man. Предупреждавам обаче, че не е лек за гледане.
Ала противоречията са, изглежда, основна характеристика за ПБ. И разорителният договор с „Боташ“, по който България трябва да плаща по над половин милион евро на ден, според новата власт се оказва суперизгоден. Ще потекат едни ми ти инфраструктурни проекти… Договорът може и да е такъв, обаче за Турция, която ще го използва като разменна монета за геополитическите си цели, пише Емилия Милчева в тазседмичната си статия „Машаллах, българи!“.
Освен стопляне на отношенията между България и Турция се наблюдава и завръщане на американско-китайската дружба, обръща ни внимание Искрен Иванов. Сприятеляването на две големи антидемократични сили може да произведе голямо чудовище, но авторът е оптимистичен. Според него възстановяването на добрите отношения между САЩ и Китай е
възможност балансът на силите в международната система да се върне отново към времето, когато политиците преговаряха с политици, а не с терористи.
Не знам как ще се развият отношенията между САЩ и Китай, но ще ви разкажа, че когато бях в пети клас, татко ми подари пиано и ме посрещна вкъщи с думите, че ми е взел „малко подаръче“. Влязох в детската стая и започнах да търся малкото подаръче – на бюрото, под леглото… А баща ми се заливаше от смях, понеже не виждах пианото, заемащо голяма част от стаята. Сетих се за тази случка, докато разсъждавах за избирателната обществена слепота във връзка със строежите в Баба Алино.
След като ви разказах историята за пианото, вече трябва да сте наясно, че от дете съм темерут. Част от темерутлъка ми е и че никога не развих интерес към компютърните игри. Но пък се възхищавам на хората, които ги правят – като Бисер Дянков, с когото разговаря игромислещата Миглена Николчина. Интервюто с него си струва, независимо дали харесвате компютърни игри, или сте като мен.
А ако ще ходите на „София прайд“, моля, пазете се. По възможност се движете на групи и се приберете бързо след края. Защото хомофобите вече имат благословията на държавата. И ако пострадате, властта едва ли ще прояви особено съчувствие.
As hard as we try to ensure that Metasploit is bug free, issues inevitably come up. Whether you’re running a module on an op or writing a new one, what we can do is make the debugging experience easier. To that end one of our two Google Summer of Code (GSoC) projects is here to deliver. Building on the previous pattern of HttpTrace comes two new options KerberosTicketTrace and CertificateTrace. These options, when enabled, will enable debugging output of Kerberos tickets and Certificates that are both sent and received by applicable modules. Now when things aren’t going quite right, users have new levers to reach for to inspect what’s happening under the hood.
For example, to inspect exactly what’s happening when using the auxiliary/admin/kerberos/get_ticket module:
Stay tuned for future enhancements like KerberosTicketTraceLevel which should have verbosity toggles such as meta, ticket, and full. We’d like to thank our GSoC contributors eve0805 and Pushpenderrathore for their hard work on this project.
Upcoming Evasion Module Changes
Metasploit is currently reconsidering the UX of evasion modules whereby users are currently required to use the module, set the payload, run it, then return to their exploit and copy the generated output from the evasion module into the exploit. This is a cumbersome process and we think we can do better but before we commit to a direction, we are soliciting feedback from the community on what they think would be the best path forward. To that end, we’ve published a writeup of the options we’re considering and a form through which we’re hoping to receive feedback. The form contains 3 questions and will be open until July 1st, 2026.
Description: Adds a new Metasploit exploit module exploit/multi/misc/clickfix_server that runs an HTTP server to deliver a “ClickFix”-style social-engineering page which copies a generated command payload to the victim’s clipboard that they are prompted execute.
Enhancements and features (9)
#21008 from EclipseAditya – Adds kernel_rex_version to Msf::Post::Linux::Kernel, a new helper that extracts the upstream kernel version from uname -rand returns a Rex::Version. This eliminates an ArgumentError crash that occurred when 15+ Linux local exploit modules encountered distro-specific kernel version suffixes.
#21198 from Pushpenderrathore – This adds a CertificateTracePresenter, implementing certificate tracing using the presenter pattern aligned with existing Metasploit conventions. This can be enabled by setting the CertificateTrace datastore option when using modules like icpr_cert and get_ticket to see the X.509 certificates being sent and received.
#21222 from g0tmi1k – Standardizes the log output across many Metasploit modules to improve the host and port log details when IPv6 addresses are present.
#21266 from zeroSteiner – This improves how we log SMB services. If the service is detected but authentication fails, the client still logs what dialect was negotiated so we log the service even if we couldn’t authenticate to it.
#21383 from zeroSteiner – This bumps Ruby SMB to version 3.1.21 and closes a feature gap between Ruby SMB and the Rex SMB client. With the feature gap closed, modules/auxiliary/admin/smb/samba_symlink_traversal.rb can now be switched from Rex to the RubySMB client. One less module in the way of dropping the ancient Rex client.
#21466 from eve0805 – This adds introduces KerberosTicketTrace support as a datastore option for Metasploit’s Kerberos authentication flows. Enabling KerberosTicketTrace allows users to see the following requests and responses as they are sent and received: AS-REQ, AS-REP, TGS-REQ, TGS-REP, KRB-ERROR. Inbound messages are colored blue and outgoing messages are colored red to match the existing HttpTrace functionality. The coloring can be turned off and on with the KerberosTicketTraceColors datastore option.
#21528 from h00die – This PR updates Metasploit module metadata by adding Exploit-DB (EDB) reference IDs to existing modules that already have CVE references, improving cross-referencing for higher-fidelity vulnerability tracking.
#21535 from adfoster-r7 – Updates multiple HTTP login scanners to validate the remote target as a pre-requisite to running the login attempts.
#21554 from sjanusz-r7 – Make WebDAV upload PHP exploit checks less strict.
Bugs fixed (4)
#20618 from Aaditya1273 – Updates the MSSQL modules to no longer crash when running stored procedures like EXEC sp_linkedservers; against a remote host.
#21543 from sjanusz-r7 – Addresses a recent issue stemming from the recently-made changes to the webdav upload php module, where a false positive was being reported based on only the response code.
#21557 from adfoster-r7 – Fixes a db_import crash when importing zip files.
Documentation
You can find the latest Metasploit documentation on our docsite at docs.metasploit.com.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate and you can get more details on the changes since the last blog post from GitHub:
Data scientists and ML engineers often need to access raw data files in Amazon Simple Storage Service (Amazon S3) for machine learning training, data exploration, and generative AI workflows. However, when table-level access is governed by AWS Lake Formation, accessing the underlying S3 files has required maintaining separate permission mechanisms. S3 bucket policies or AWS Identity and Access Management (IAM) role policies create operational overhead and risk of permission drift.
Lake Formation now supports direct access to S3 data file locations for tables whose permissions it manages. Previously, data scientists with Lake Formation permissions on AWS Glue Data Catalog tables could query them using spark.sql(). Now, they can also read and write the underlying S3 data files using spark.read.parquet() or spark.read.csv() from Amazon EMR Spark jobs, Amazon SageMaker Unified Studio notebooks with EMR compute, and custom applications. All access is governed by the same Lake Formation permissions.
This capability is powered by the new GetTemporaryDataLocationCredentials() API, which vends temporary credentials scoped to registered S3 locations when callers have appropriate Lake Formation permissions on the corresponding Data Catalog tables. This eliminates the need to manage separate S3 bucket policies for file-level access while maintaining fine-grained access control in Lake Formation for table-based access. It enables your data scientists to explore S3 datasets securely, accelerate machine learning pipelines, and build generative AI workflows without compromising governance.
In this post, we demonstrate reading from and writing to Lake Formation-managed S3 locations using Apache Spark jobs from EMR. Lake Formation credential vending for S3 location access is available in EMR release label 7.13 and later, Boto3 1.42.29 and later, AWS Java SDK 2.41.32 and later, and AWS Command Line Interface (AWS CLI) version 2.33.1 and later.
Key use cases for Lake Formation permissions to S3 locations
Unified permissions for Analytics and Machine Learning pipelines – Data scientists can access both structured tables through SQL queries and underlying data files through programmatic APIs for machine learning and AI workloads. They are empowered to use tools of their choice – for example, use Amazon Athena for SQL analytics with the table names while read and write to the underlying files in their SageMaker notebook or Spark application with spark.read.parquet(“s3://bucket/database_path/table_files/).
Enable AI ready data lakes – Machine learning pipelines can read training data directly from governed data lakes. Generative AI applications can access foundation model training datasets, and data exploration workflows to use native file APIs while maintaining centralized governance and compliance.
Reduced operational complexity – Operations teams don’t need to maintain separate permission policies – one in Lake Formation for table access and another in S3 bucket policies or AWS Identity and Access Management (IAM) roles for file access. This reduces the risk of permission mismatches and avoids inconsistent access control.
Unified audit capability – Auditors do not need to examine multiple log sources, such as S3 Access Logs, AWS CloudTrail events from different services, to understand who accessed what data and when. With this feature, you get a unified CloudTrail audit trail showing both table access through SQL engines and file access through direct APIs, with each access event linked to the Lake Formation permission grant.
What customers are saying
“Through our close collaboration with AWS, Lake Formation’s new S3 location-based permissions have transformed how we manage data governance at Intuit. By unifying two separate access mechanisms for the same data into one unified permission model, we’ve dramatically reduced complexity and streamlined our auditing process. This is exactly the kind of simplification that lets our teams move faster without compromising security, ensuring we maintain the strict compliance and governance standards our regulators expect.”
— Tapan Upadhyay, Group Engineering Manager, Intuit
Lake Formation Credential Vending Plugin for AWS SDK v2 for Java
Lake Formation has made available a specialized library AWS Lake Formation Credential Vending Plugin for AWS SDK V2 for Java. The Java plugin intercepts S3 requests for data, checks Lake Formation permissions for the requested location, and provides temporary scoped credentials to the client if permissions are granted in Lake Formation. If the S3 location access permissions are not managed by Lake Formation, the plugin checks for access in Amazon S3 Access Grants and lastly falls back to IAM permissions. The plugin is supported independently of Spark and comes as an enhancement to EMR Spark Full Table Access (FTA) mode, starting in EMR 7.13 and later. The plugin is integrated at the S3A level. Therefore, any client of S3A can enable it by setting the S3A configurations, in addition to the EMR Lake Formation Full Table Access (FTA) configuration as follows:
With the Java plugin, you can enable governance for data lake resources in your custom applications with Lake Formation permissions – managing both fine grained access for users requiring restricted access on Data Catalog tables while providing direct S3 object level access to use-cases that require them.
Note: (1) The principal that will be accessing direct S3 locations of the tables will require full table access. That is, Lake Formation SELECT permission on all columns and rows of the table is required. (2) The Spark cluster needs FTA configuration. (3) Currently, Apache Iceberg table format is not supported with this plugin.
Solution overview
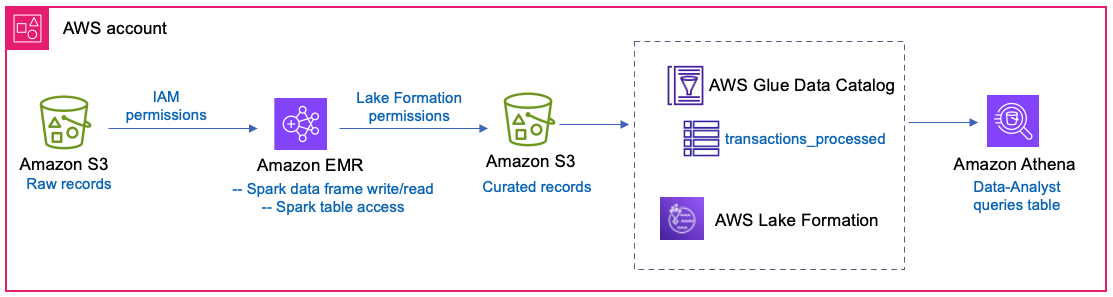
A financial services company runs daily ETL jobs using Spark in EMR. They process raw transaction records in S3 and store the processed records in another S3 location. The transformed Parquet data is registered with Lake Formation and cataloged as a table in Data Catalog. The ETL job will have direct IAM access to the raw data location, while it uses Lake Formation permissions to write to and read from the curated table location. Downstream, a data-analyst role will query the curated table, with restricted column access. The solution is shown in Figure 1.
Figure 1 – Architecture shows EMR Spark writing curated records to the S3 location of a table using Lake Formation permissions while Data-Analyst queries the same table with Lake Formation fine grained access control in Athena.
Prerequisites
To get started exploring this feature, we recommend you have the following setup.
To run the Spark code in EMR, you can choose to run the code in either SageMaker Unified Studio with EMR compute or use EMR cluster from EMR console. In the case of SageMaker Unified Studio domain and project, the Lake Formation permissions for the table location will be granted to the project execution role. In this post, we will illustrate using an EMR on EC2 cluster and a runtime role to submit the Spark script as a step to the cluster. For instructions to launch an EMR on EC2 cluster with Lake Formation full table access enabled, refer to instructions here – Lake Formation full table access for Amazon EMR on EC2 and Introducing runtime roles for Amazon EMR steps: Use IAM roles and AWS Lake Formation for access control with Amazon EMR. Fine Grained Access Control (FGAC) option is not supported for Spark on EMR with this feature since S3 location permission is full file path access.
First, we will get the setup ready with S3, sample database, table, and data. We will add a raw data set to S3 location, create a table with parquet data in another S3 location that represents the curated dataset for further downstream consumption. We will register the table data location with Lake Formation and grant permissions for the EMR run time role and Data-Analyst role.
Your S3 bucket will have the following structure.
Raw data – s3://<your-bucket-name>/raw/transactions/dt=2024-03-21/
Process data for table – s3://<your-bucket-name>/processed/transactions/
Spark script – s3://<your-bucket-name>/scripts/
Logs for the EMR cluster – s3://<your-bucket-name>/logs/
Step 1 – Create a parquet table in Data Catalog
From the Athena console query editor, create a table in Data Catalog.
-- Create a database
CREATE DATABASE finance_db;
-- Create an external table pointing to the S3 location
CREATE EXTERNAL TABLE IF NOT EXISTS finance_db.transactions_processed (
transaction_id STRING,
merchant_name STRING,
amount DECIMAL(18,2),
currency STRING,
account_number STRING,
card_type STRING,
status STRING,
region STRING
)
PARTITIONED BY (transaction_date DATE)
STORED AS PARQUET
LOCATION 's3:///processed/transactions/'
TBLPROPERTIES (
'parquet.compress'='SNAPPY'
);
Step 2 – Register S3 location and grant table permission to IAM roles in Lake Formation
2.1 Register the table data location s3://<your-bucket-name>/processed/transactions/ with Lake Formation in Lake Formation mode using the custom S3 registration IAM role. For details on how to register locations with Lake Formation, refer Adding an Amazon S3 location to your data lake.
2.2 Grant DESCRIBE permission on the database finance_db and ALL permission on the table transactions_processed to your EMR runtime role.
2.3 Grant Data location permission to EMR runtime role on the curated table’s location. This is to allow writing to that location.
2.4 Grant DESCRIBE permission on the database finance_db and SELECT permission on the table transactions_processed to your Data-Analyst role. Exclude the columns transaction_id and account_number while granting SELECT permissions on the table to the Data-Analyst role.
3.2 Edit the S3 bucket name placeholder in the script (RAW_PATH and TABLE_PATH) to your resource names and upload to your S3 path s3://<your-bucket-name>/scripts/.
3.3 Make sure your EMR runtime role has access to the script location in its IAM policy permissions.
3.4 Submit and run the script as a step to the EMR cluster, following instructions at Add a Spark step.
What does the script do?
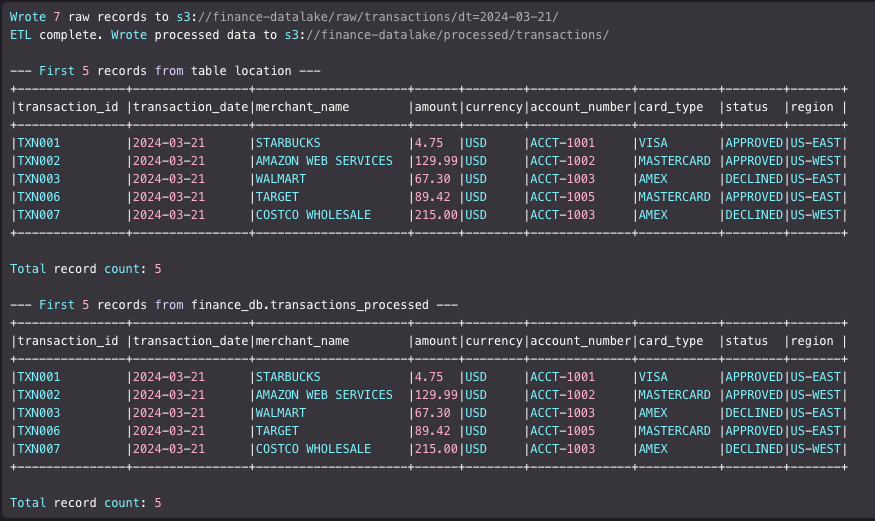
It populates raw records of transaction data into a Spark data frame, writes to the raw data bucket location using IAM permissions on the EMR runtime role. We apply some transformations and write directly to the S3 location of the table that is registered with Lake Formation, from the data frame using Spark’s native Parquet writer.
The following figure shows the stdout of the step.
The Java plugin integrated into EMR 7.13 automatically handles the access for the table’s data location registered with Lake Formation, so you don’t need to manually call the GetTemporaryDataLocationCredentials() API. In this example, the table data location s3://<your-bucket-name>/processed/transactions/ is registered with Lake Formation, for which EMR runtime role is granted ALL permissions. The direct S3 location access support by Lake Formation allows reading and writing to the location directly using Spark data frame.
Step 4 – Run query as Data-Analyst using Athena
Log in as the Data-Analyst role to the Athena console. Run a select query on the table as follows.
SELECT * FROM finance_db.transactions_processed WHERE status = 'DECLINED' AND transaction_date=DATE '2024-03-21';
The Data-Analyst role should see all but two columns of the table.
With these steps complete, we’ve read from and written to direct S3 locations using Spark data frames with the syntax s3://bucketname/prefix/, and accessed the same data using database_name.table_name syntax with Lake Formation permissions. This shows fine-grained access at table level and coarse-grained access at the file path level.
Clean up
To avoid incurring costs, clean up the resources you created for this post.
Delete the Data Catalog database and tables. This removes the related Lake Formation permissions too. Remove the S3 bucket registration from Lake Formation.
Delete the data files, logs, and the PySpark script of this post from your S3 bucket.
Terminate the EMR cluster.
Conclusion
In this post, we showed how to use Lake Formation’s direct S3 location access to read and write data files using Spark data frames from Amazon EMR, while maintaining unified governance through Lake Formation permissions. We walked through the GetTemporaryDataLocationCredentials() API and the AWS Lake Formation Credential Vending Plugin for AWS SDK v2 for Java, which is integrated into EMR release labels 7.13 and later.
This capability unifies permission management for both fine-grained table-based access and direct S3 file path access in Lake Formation. Your data scientists can now use spark.read.parquet() and spark.write alongside spark.sql(), governed by the same permissions, audited in the same CloudTrail logs, and managed from a single console.
To get started, launch an EMR 7.13 cluster and start exploring the feature. Here are some additional resources:
Acknowledgements: We would like to thank all the team members who worked to launch this feature successfully – Rajas Bhate, Akhil Yendluri, Kunal Parikh, Sharda Khubchandani, Dhananjay Badaya, Santhosh Padmanabhan, Nitin Agrawal and Sandeep Adwankar.
Преди време намерих данните на европейската обсерватория Copernicus, но така и не ми е оставало време да ги прегледам. Съдържат безценни данни за земеделската земя, горите, крайбрежните зони, рискове от наводнения и пожари. Тази седмица седнах да погледна един от слоевете – за изкуствено покрита земя. Разбирайте асфалт и бетон, който изцяло покрива кварталите ни.
В миналото съм критикувалдоста прилагането на изискванията за озеленяване специално в София и ролята му в презастрояването. Докато един бивш главен архитект ги наричаше безсмислени, а доста строители – прекомерни, всъщност са далеч не достатъчно изискващи и отчасти трудни за прилагане. Не, че някой се е опитвал да ги наложи истински дори в сегашния им вид. На практика се позволява бетонирането на цели парцели стига строителят да може да покаже няколко кашпи с дървета и няколко квадрата чима с трева. В този смисъл вече избилата мухъл по стените се брои към озеленяването за целите на акт 16. Не защото нормативно е позволено, а защото има добре установена практика с ревностно пазена документация. Заради последното заведох тази седмица няколко дела.
Една от основните роли на изискванията за озеленяване е не само чистота на въздуха и намаляване на шумовото замърсяване, но и задържане на водата от проливните дъждове, за да не се получават наводнения и пропускането ѝ надолу, за да захранва подпочвените води. За съжаление, последните са под огромен риск не само, защото масово и често нелегално се използват за миене на коли в автомивки и сгради без право да се вържат към ВИК, но защото все по-голяма част от София е практически запечатана.
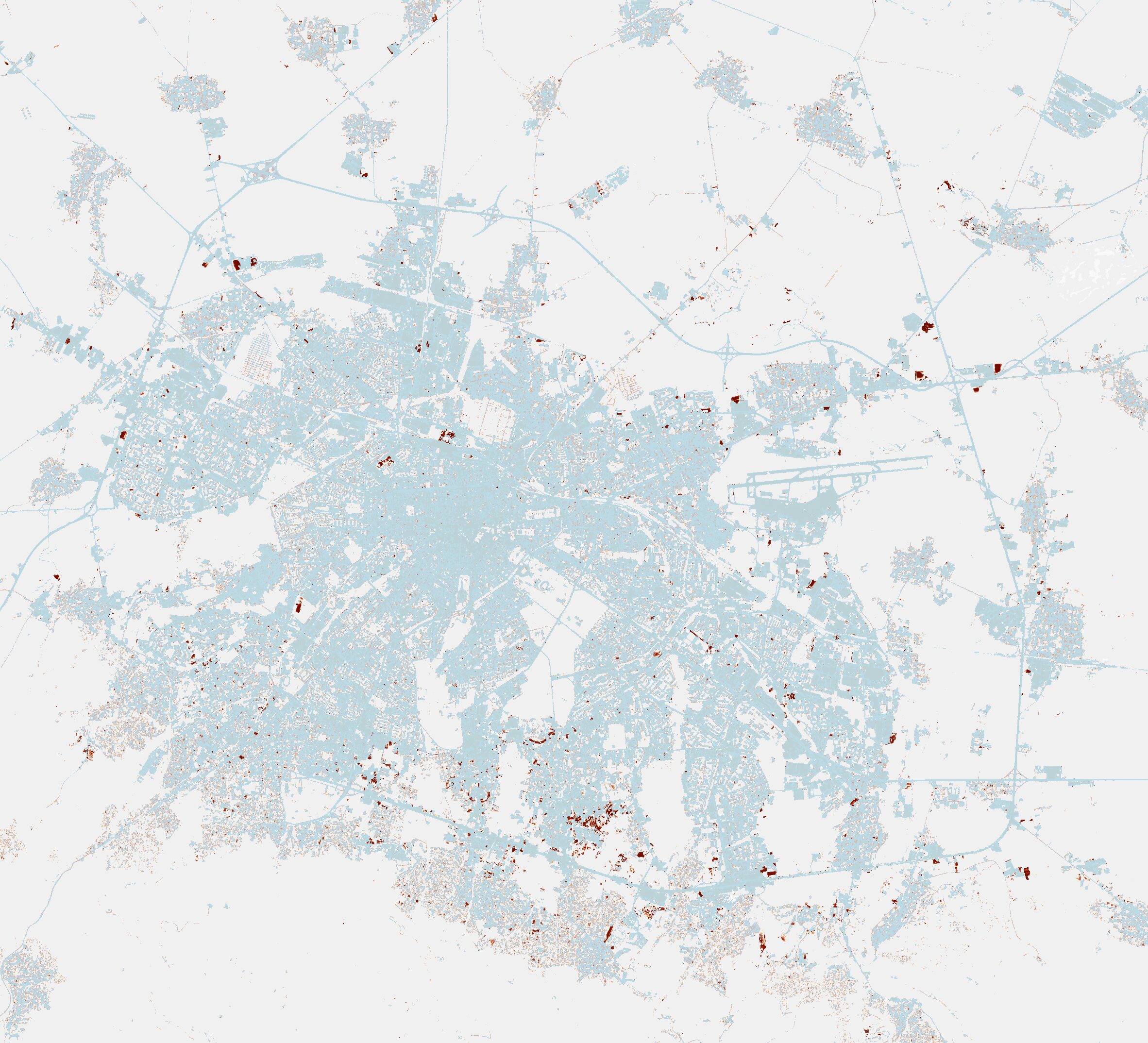
Виждаме го при всеки следващ строеж и това се позволява от ЗУТ и изискванията за озеленяване в София. Исках да разбера колко точно. Copernicus предоставя такива данни. Имат слоевете за 2018, 2021 и 2024-та. Следващото заснемане ще е догодина та ще може да сравним какво се е случило покрай бума на влезли в експлоатация имоти след многото разрешения за и започнати строежи преди това.
Интерактивна карта със слоевете може да видите на сайта на обсерваторията. Тук показвам изгледа през трите години. За съжаление, тази през 2018-та е направена по различен модел и не пасва на следващите. Вижда се ясно обаче как липсват сградите от източната страна на горния край на Самоковско шосе, в Манастирски ливади, на север от централна гара и на юг от Бизнес парка. В последната снимка показвам сравнението между 2021-ва и 2024-та. В червено се виждат новите „запечатани“ части на София. Това не означава, че не се е строяло другаде преди това, а че там вече е имало ниски сгради, производства и друго, макар и далеч не с такава интензивност на застрояване.
2018
2021
2024
Разликата между 2021 и 2024
Може сменяте галерията със стрелката надясно или да ги видите и тук на цял екран: 2018, 2021, 2024, промяна при 2024.
Тепърва ще разглеждам данните на Copernicus. Има интересни показатели за озеленяването.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.