R2 is an S3-compatible, globally distributed object storage, allowing developers to store large amounts of unstructured data without the costly egress bandwidth fees you commonly find with other providers.
To enjoy this egress freedom, you’ll have to start planning to send all that data you have somewhere else into R2. You might want to do it all at once, moving as much data as quickly as possible while ensuring data consistency. Or do you prefer moving the data to R2 slowly and gradually shifting your reads from your old provider to R2? And only then decide whether to cut off your old storage or keep it as a backup for new objects in R2?
There are multiple options for architecture and implementations for this movement, but taking terabytes of data from one cloud storage provider to another is always problematic, always involves planning, and likely requires staffing.
And that was hard. But not anymore.
Today we’re announcing the R2 Super Slurper, the feature that will enable you to move all your data to R2 in one giant slurp or sip by sip — all in a friendly, intuitive UI and API.
The first step: R2 Super Slurper Private Beta
One giant slurp
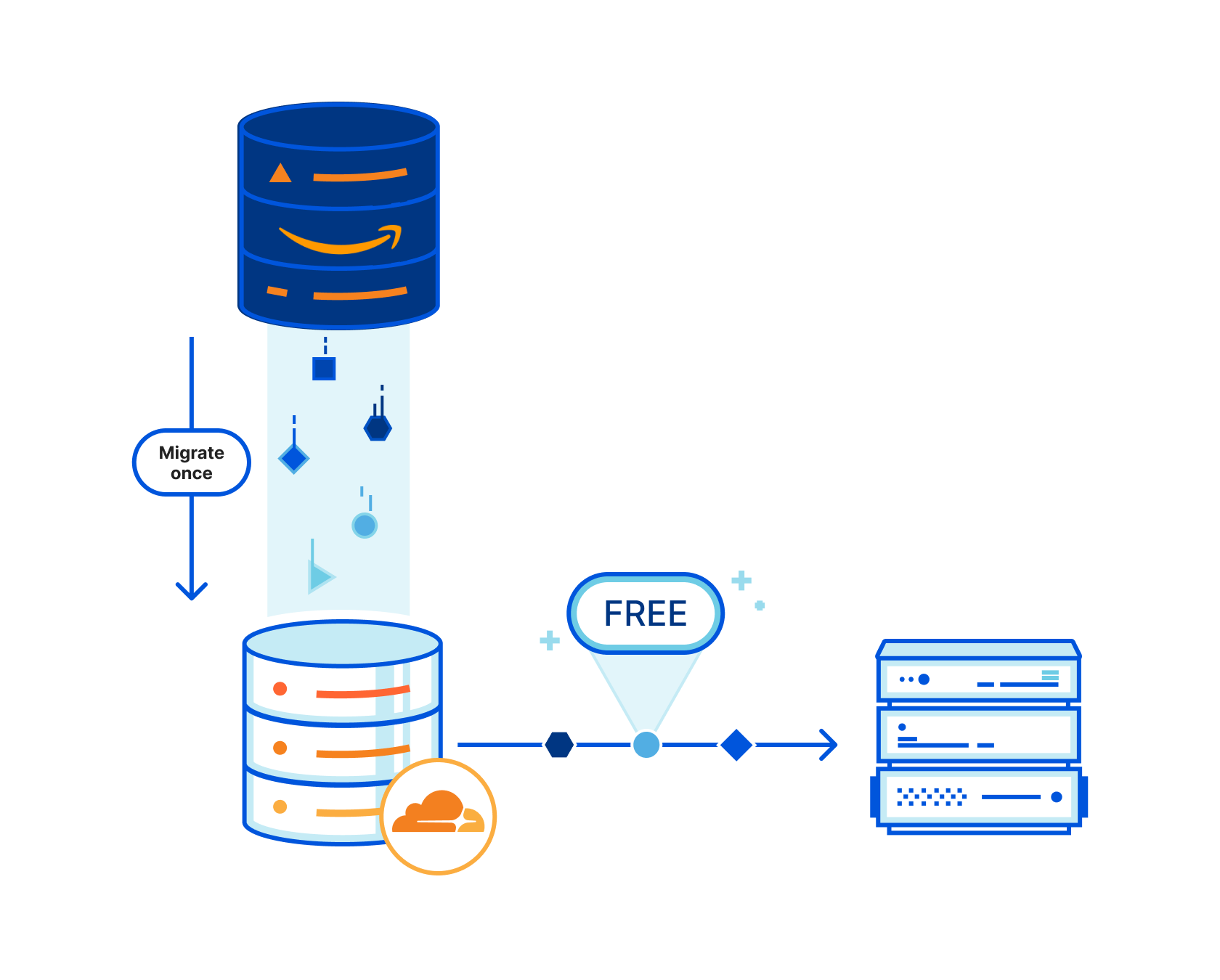
The very first iteration of the R2 Super Slurper allows you to target an S3 bucket and import the objects you have stored there into your R2 bucket. It’s a simple, one-time import that covers the most common scenarios. Point to your existing S3 source, grant the R2 Super Slurper permissions to read the objects you want to migrate, and an asynchronous job will take care of the rest.
You’ll also be able to save the definitions and credentials to access your source bucket, so you can migrate different folders from within the bucket, in new operations, without having to define URLs and credentials all over again. This operation alone will save you from scripting your way through buckets with many paths you’d like to validate for consistency. During the beta stages — with your feedback — we will evolve the R2 Super Slurper to the point where anyone can achieve an entirely consistent, super slurp, all with the click of just a few buttons.
Automatic sip by sip migration
Other future development includes automatic sip by sip migration, which provides a way to incrementally copy objects to R2 as they get requested from an end-user. It allows you to start serving objects from R2 as they migrate, saving you money immediately.
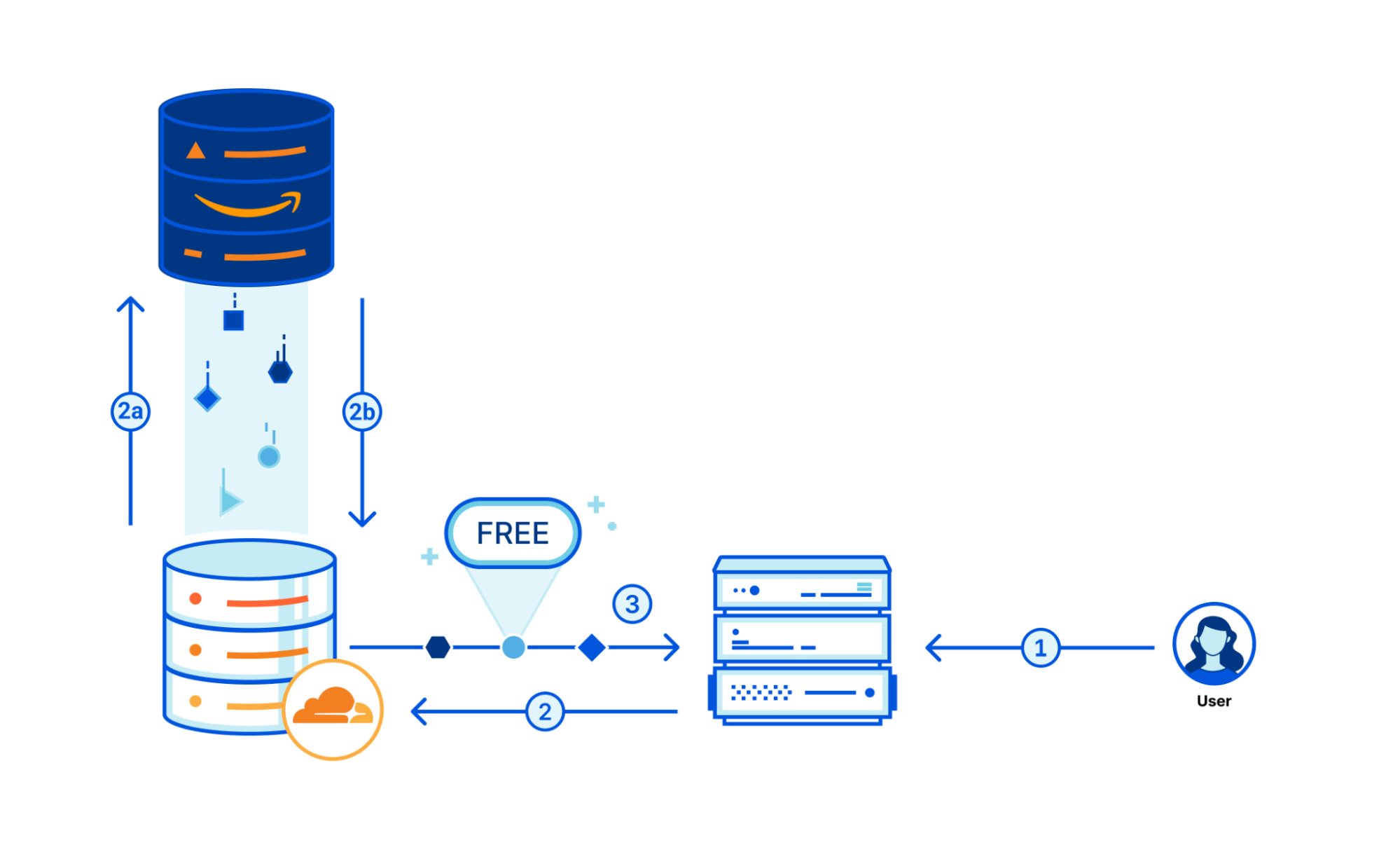
The flow of the requests and object migration will look like this:
Check for Object — A request arrives at Cloudflare (1), and we check the R2 bucket for the requested object (2). If the object exists, R2 serves it (3).
Copy the Object — If the object does not exist in R2, a request for the object flows to the origin bucket (2a). Once there’s an answer with an object, we serve it and copy it into R2 (2b).
Serve the Object — R2 serves all future requests for the object (3).
With this capability you can copy your objects, previously scattered through one or even multiple buckets from other vendors, while ensuring that everything requested from the end-user side gets served from R2. And because you will only need to use the R2 Super Slurper to sip the object from elsewhere on the first request, you will start saving on those egress fees for any subsequent ones.
We are currently targeting S3-compatible buckets for now, but you can expect other sources to become available during 2023.
Join the waitlist for the R2 Super Slurper private beta
We will collaborate closely with many early users in the private beta stage to refine and test the service . Soon, we’ll announce an open beta where users can sign up for the service.
Make sure to join our Discord server and get in touch with a fantastic community of users and Cloudflare staff for all R2-related topics!
R2 gives developers object storage, without the egress fees. Before R2, cloud providers taught us to expect a data transfer tax every time we actually used the data we stored with them. Who stores data with the goal of never reading it? No one. Yet, every time you read data, the egress tax is applied. R2 gives developers the ability to access data freely, breaking the ecosystem lock-in that has long tied the hands of application builders.
In May 2022, we launched R2 into open beta. In just four short months we’ve been overwhelmed with over 12k developers (and rapidly growing) getting started with R2. Those developers came to us with a wide range of use cases from podcast applications to video platforms to ecommerce websites, and users like Vecteezy who was spending six figures in egress fees. We’ve learned quickly, gotten great feedback, and today we’re excited to announce R2 is now generally available.
We wouldn’t ask you to bet on tech we weren’t willing to bet on ourselves. While in open beta, we spent time moving our own products to R2. One such example, Cloudflare Images, proudly serving thousands of customers in production, is now powered by R2.
What can you expect from R2?
S3 Compatibility
R2 gives developers a familiar interface for object storage, the S3 API. WIth S3 Compatibility, you can easily migrate your applications and start taking advantage of what R2 has to offer right out of the gate.
Let’s take a look at some basic data operations in javascript. To try this out on your own, you’ll need to generate an Access Key.
// First we import our bindings as usual
import {
S3Client,
ListBucketsCommand,
} from "@aws-sdk/client-s3";
// Then we create a new client. Note that while R2 requires a region for S3 compatibility, only “auto” is supported
const S3 = new S3Client({
region: "auto",
endpoint: `https://${ACCOUNT_ID}.r2.cloudflarestorage.com`,
credentials: {
accessKeyId: ACCESS_KEY_ID, // fill in your own
secretAccessKey: SECRET_ACCESS_KEY, // fill in your own
},
});
// And now we can use our client to list associated buckets just like we would with any other S3 compatible object storage
console.log(
await S3.send(
new ListBucketsCommand('')
)
);
Regardless of the language, the S3 API offers familiarity. We have examples in Go, Java, PHP, and Ruby.
Region: Automatic
We don’t want to live in a world where developers are spending time looking into a crystal ball and predicting where application traffic might come from. Choosing a region as the first step in application development forces optimization decisions long before the first users show up.
While S3 compatibility requires you to specify a region, the only region we support is ‘auto’. Today, R2 automatically selects a bucket location in the closest available region to the create bucket request. If I create a bucket from my home in Austin, that bucket will live in the closest available R2 region to Austin.
In the future, R2 will use data access patterns to automatically optimize where data is stored for the best user experience.
Cloudflare Workers Integration
The Workers platform offers developers powerful compute across Cloudflare’s network. When you deploy on Workers, your code is deployed to Cloudflare’s 280+ locations across the globe, automatically. When paired with R2, Workers allows developers to add custom logic around their data without any performance overhead. Workers is built on isolates and not containers, and as a result you don’t have to deal with lengthy cold starts.
Let’s try creating a simple REST API for an R2 bucket! First, create your bucket and then add an R2 binding to your worker.
export default {
async fetch(request, env) {
const url = new URL(request.url);
const key = url.pathname.slice(1); // we’ll derive a key from the url path
switch (request.method) {
// For writes, we capture the request body and write that out to our bucket under the associated key
case 'PUT':
await env.MY_BUCKET.put(key, request.body);
return new Response(`Put ${key} successfully!`);
// For reads, we’ll use our key to perform a lookup
case 'GET':
const object = await env.MY_BUCKET.get(key);
// if we don’t find the given key we’ll return a 404 error
if (object === null) {
return new Response('Object Not Found', { status: 404 });
}
const headers = new Headers();
object.writeHttpMetadata(headers);
headers.set('etag', object.httpEtag);
return new Response(object.body, {
headers,
});
}
},
};
Through this Workers API, we can add all sorts of useful logic to the hot path of a R2 request.
Presigned URLs
Sometimes you’ll want to give your users permissions to specific objects in R2 without requiring them to jump through hoops. Through pre-signed URLs you can delegate your permissions to your users for any unique combination of object and action. Mint a pre-signed URL to let a user upload a file or share a file without giving access to the entire bucket.
import {
S3Client,
PutObjectCommand
} from "@aws-sdk/client-s3";
import { getSignedUrl } from "@aws-sdk/s3-request-presigner";
const S3 = new S3Client({
region: "auto",
endpoint: `https://${ACCOUNT_ID}.r2.cloudflarestorage.com`,
credentials: {
accessKeyId: ACCESS_KEY_ID,
secretAccessKey: SECRET_ACCESS_KEY,
},
});
// With getSignedUrl we can produce a custom url with a one hour expiration which will allow our end user to upload their dog pic
console.log(
await getSignedUrl(S3, new PutObjectCommand({Bucket: 'my-bucket-name', Key: 'dog.png'}), { expiresIn: 3600 })
)
Presigned URLs make it easy for developers to build applications that let end users safely access R2 directly.
Public buckets
Enabling public access for a R2 bucket allows you to expose that bucket to unauthenticated requests. While doing so on its own is of limited use, when those buckets are linked to a domain under your account on Cloudflare you can enable other Cloudflare features such as Access, Cache and bot management seamlessly on top of your data in R2.
Bottom line: public buckets help to bridge the gap between domain oriented Cloudflare features and the buckets you have in R2.
Transparent Pricing
R2 will never charge for egress. The pricing model depends on three factors alone: storage volume, Class A operations (writes, lists) and Class B operations (reads).
Storage is priced at $0.015 / GB, per month.
Class A operations cost $4.50 / million.
Class B operations cost $0.36 / million.
But before you’re ready to start paying for R2, we allow you to get up and running at absolutely no cost. The included usage is as follows:
10 GB-months of stored data
1,000,000 Class A operations, per month
10,000,000 Class B operations, per month
What’s next?
Making R2 generally available is just the beginning of our object storage journey. We’re excited to share what we plan to build next.
Object Lifecycles
In the future R2 will allow developers to set policies on objects. For example, setting a policy that deletes an object 60 days after it was last accessed. Object Lifecycles pushes object management down to the object store.
Jurisdictional Restrictions
While we don’t have plans to support regions explicitly, we know that data locality is important for a good deal of compliance use cases. Jurisdictional restrictions will allow developers to set a jurisdiction like the ‘EU’ that would prevent guarantee data from leavingwould not leave the jurisdiction.
Live Migration without Downtime
For large datasets, migrations are live and ongoing, as it takes time to move data over. Cache reserve is an easy way to quickly migrate your assets into a managed R2 instance to reduce your egress costs at the touch of a button. In the future, we’ll be extending this mechanism so that you can migrate any of your existing S3 object storage buckets to R2.
We invite everyone to sign up and get started with R2 today. Join the growing community of developers building on Cloudflare. If you have any feedback or questions, find us on our Discord server here! We can’t wait to see what you build.
All too often we are confronted with the choice to move quickly or act responsibly. Whether the topic is safety, security, or in this case sustainability, we’re asked to make the trade off of halting innovation to protect ourselves, our users, or the planet. But what if that didn’t always need to be the case? At Cloudflare, our goal is to bring sustainable computing to you without the need for any additional time, work, or complexity.
Enter Green Compute on Cloudflare Workers.
Green Compute can be enabled for any Cron triggered Workers. The concept is simple: when turned on, we’ll take your compute workload and run it exclusively on parts of our edge network located in facilities powered by renewable energy. Even though all of Cloudflare’s edge network is powered by renewable energy already, some of our data centers are located in third-party facilities that are not 100% powered by renewable energy. Green Compute takes our commitment to sustainability one step further by ensuring that not only our network equipment but also the building facility as a whole are powered by renewable energy. There are absolutely no code changes needed. Now, whether you need to update a leaderboard every five minutes or do DNA sequencing directly on our edge (yes, that’s a real use case!), you can minimize the impact of any scheduled work, regardless of how complex or energy intensive.
How it works
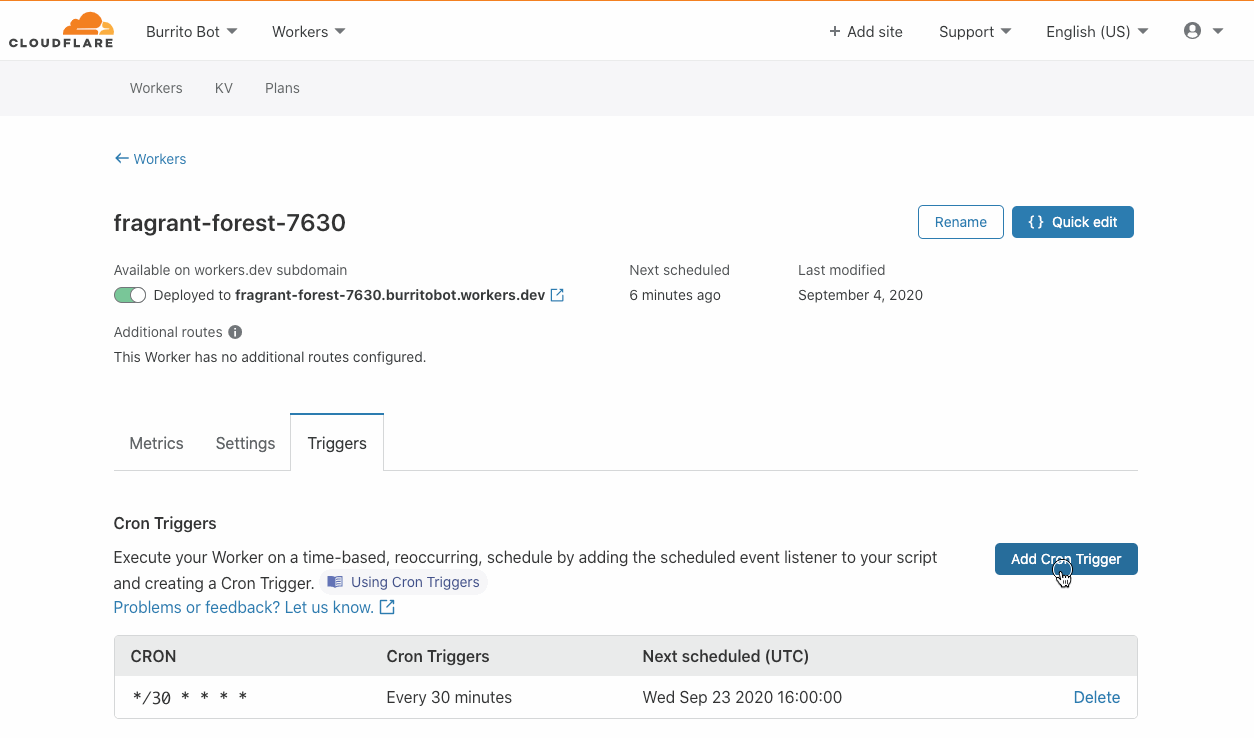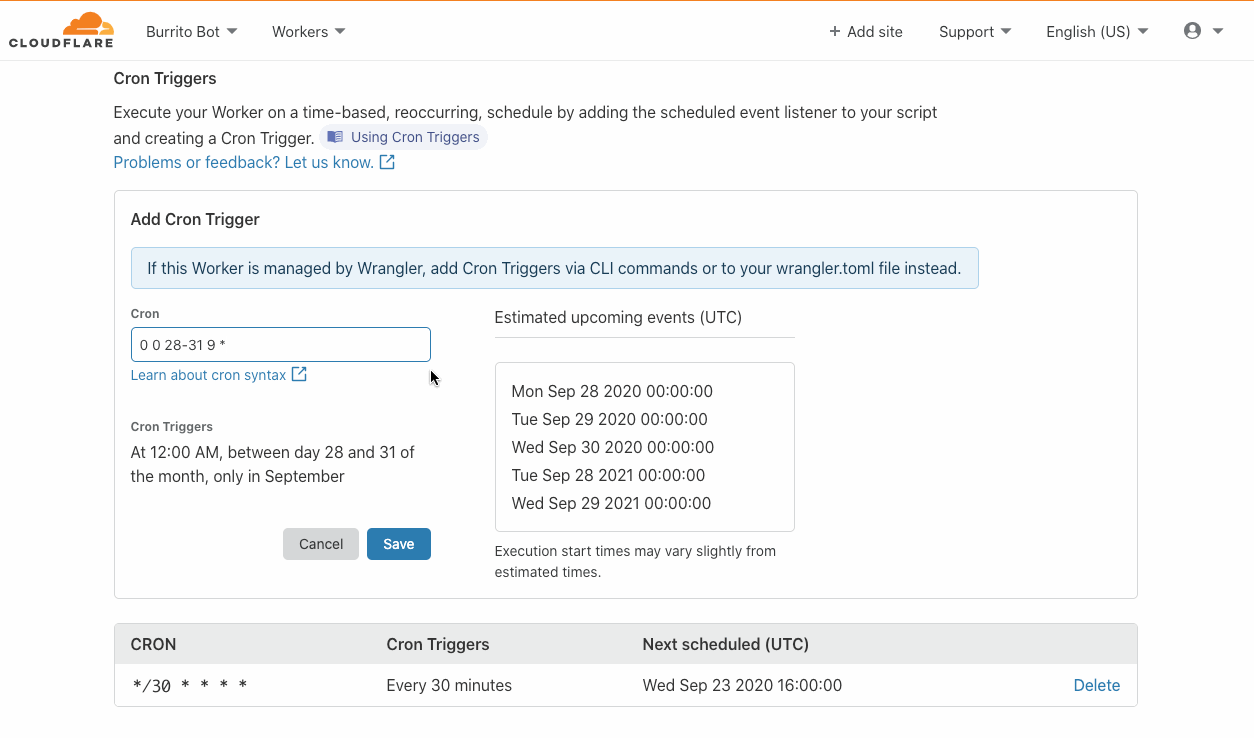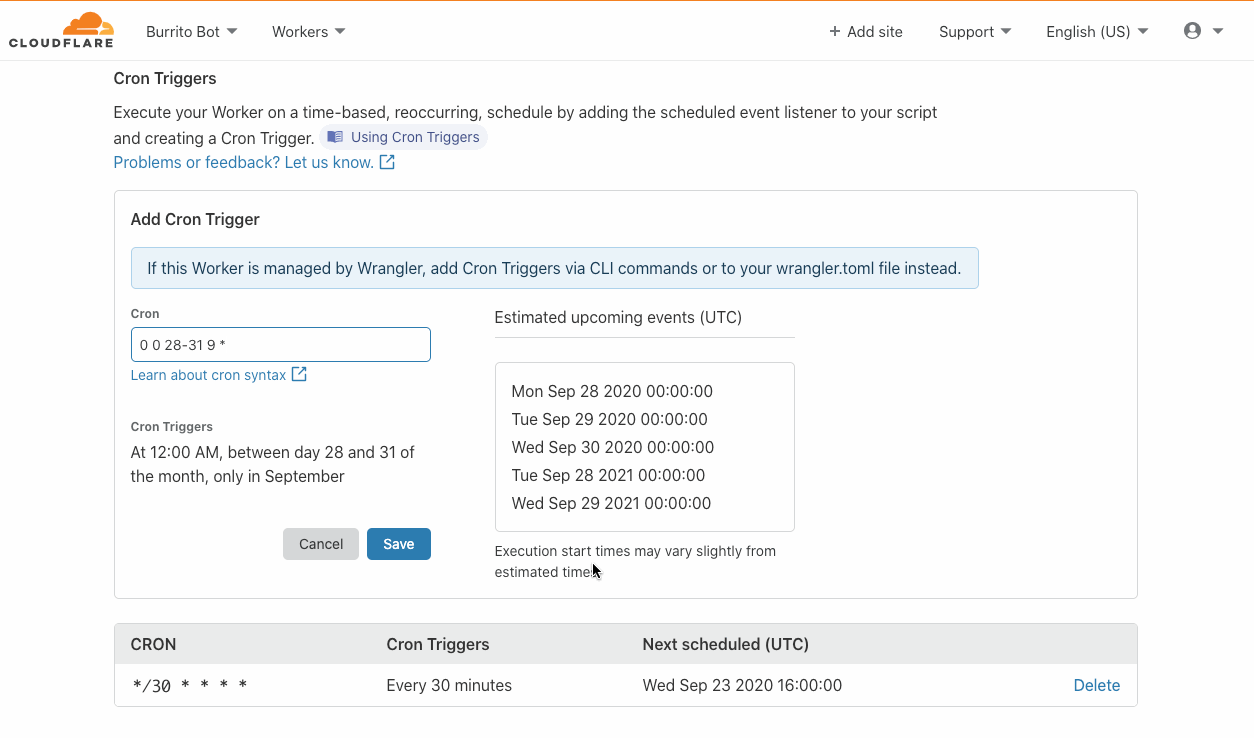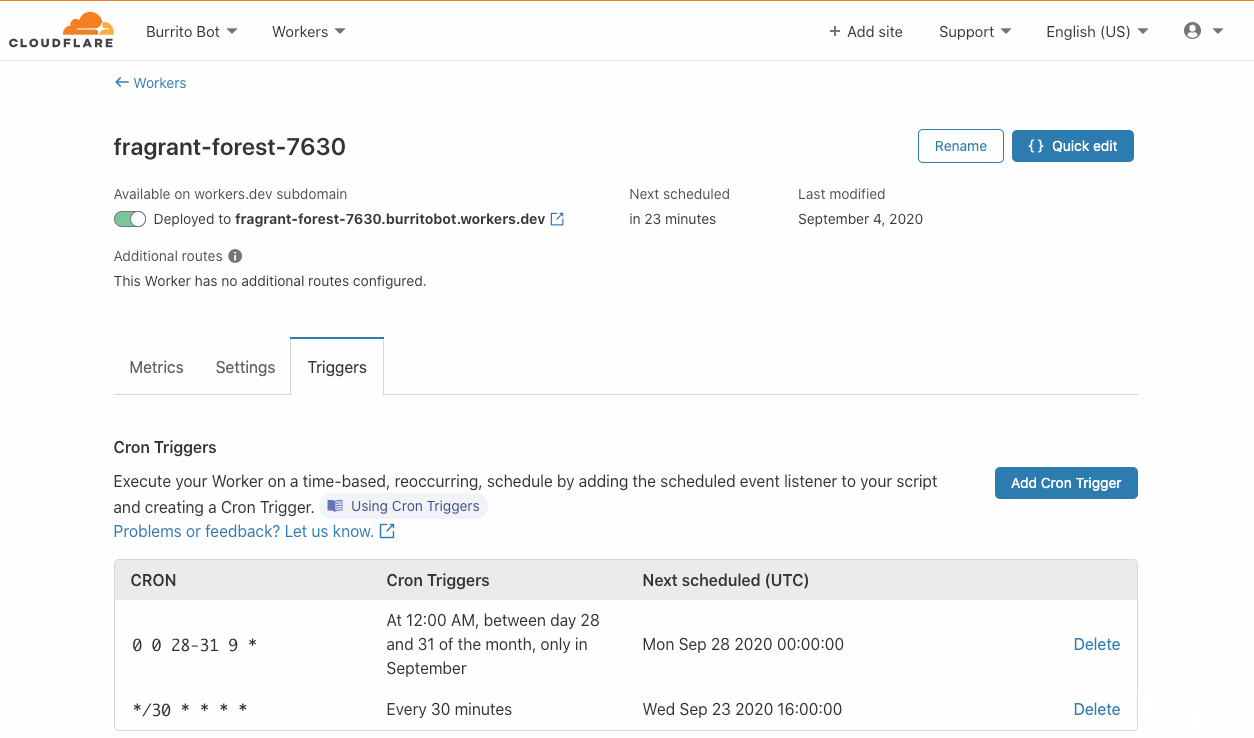
Cron triggers allow developers to set time-based invocations for their Workers. These Workers happen on a recurring schedule, as opposed to being triggered by application users via HTTP requests. Developers specify a job schedule in familiar cron syntax either through wrangler or within the Workers Dashboard. To set up a scheduled job, first create a Worker that performs a periodic task, then navigate to the ‘Triggers’ tab to define a Cron Trigger.
The great thing about cron triggered Workers is that there is no human on the other side waiting for a response in real time. There is no end user we need to run the job close to. Instead, these Workers are scheduled to run as (often computationally expensive) background jobs making them a no-brainer candidate to run exclusively on sustainable hardware, even when that hardware isn’t the closest to your user base.
Cloudflare’s massive global network is logically one distributed system with all the parts connected, secured, and trusted. Because our network works as a single system, as opposed to a system with logically isolated regions, we have the flexibility to seamlessly move workloads around the world keeping your impact goals in mind without any additional management complexity for you.
When you set up a Cron Trigger with Green Compute enabled, the Cloudflare network will route all scheduled jobs to green energy hardware automatically, without any application changes needed. To turn on Green Compute today, signup for our beta.
Real world use
If you haven’t ever had the pleasure of writing a cron job yourself, you might be wondering — what do you use scheduled compute for anyway?
There are a wide range of periodic maintenance tasks necessary to power any application. In my working life, I’ve built a scheduled job that ran every minute to monitor the availability of the system I was responsible for, texting me if any service was unavailable. In another instance, a job ran every five mins, keeping the core database and search feature in sync by pulling all new application data, transforming it, then inserting into a search database. In yet another example, a periodic job ran every half hour to iterate over all user sessions and cleanup sessions that were no longer active.
Scheduled jobs are the backbone of real world systems. Now, with Green Compute on Cloudflare Workers all these real world systems and their computationally expensive background maintenance tasks, can take advantage of running compute exclusively on machines powered by renewable energy.
The Green Network
Our mission at Cloudflare is to help you tackle your sustainability goals. Today, with the launch of the Carbon Impact Report we gave you visibility into your environmental impact. The collaboration with the Green Web Foundation gave green hosting certification for Cloudflare Pages. And our launch of Green Compute on Cloudflare Workers allows you to exclusively run on hardware powered by renewable energy. And the best part? No additional system complexity is required for any of the above.
Cloudflare is focused on making it easy to hit your ambitious goals. We are just getting started.
So you’ve built an application on the Workers platform. The first thing you might be wondering after pushing your code out into the world is “what does my production traffic look like?” How many requests is my Worker handling? How long are those requests taking? And as your production traffic evolves overtime it can be a lot to keep up with. The last thing you want is to be surprised by the traffic your serverless application is handling. But, you have a million things to do in your day job, and having to log in to the Workers dashboard every day to check usage statistics is one extra thing you shouldn’t need to worry about.
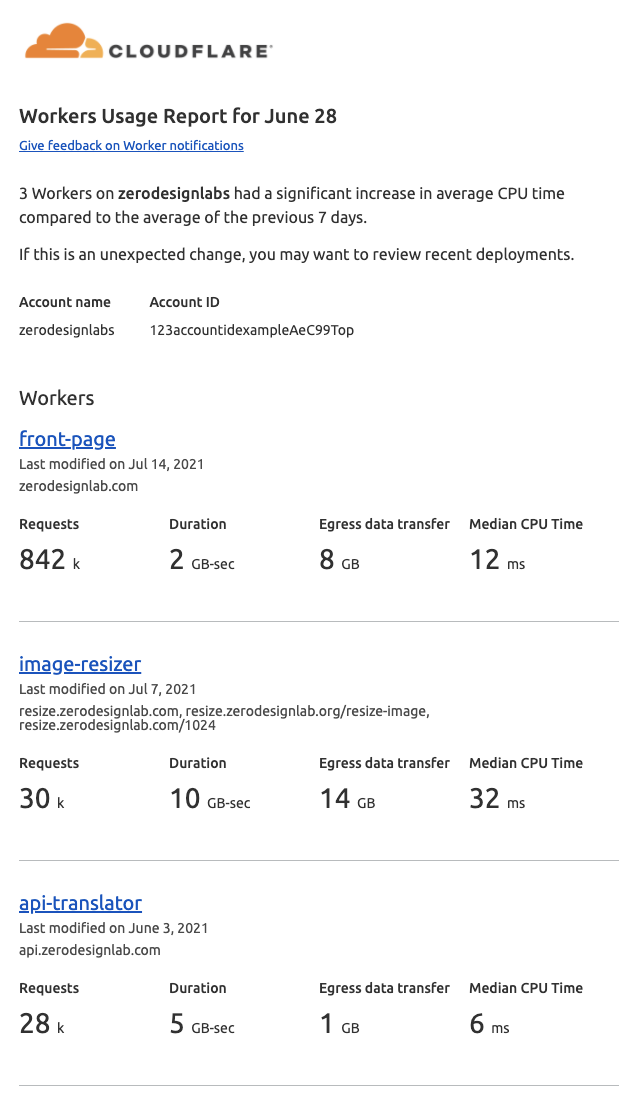
Today we’re excited to launch Workers usage notifications that proactively send relevant usage information directly to your inbox. Usage notifications come in two flavors. The first is a weekly summary of your Workers usage with a breakdown of your most popular Workers. The second flavor is an on-demand usage notification, triggered when a worker’s CPU usage is 25% above its average CPU usage over the previous seven days. This on-demand notification helps you proactively catch large changes in Workers usage as soon as those changes occur whether from a huge spike in traffic or a change in your code.
As of today, if you create a new free account with Workers, we’ll enable both the weekly summary and the CPU usage notification by default. All other account types will not have Workers usage notifications turned on by default, but the notifications can be enabled as needed. Once we collect substantial user feedback, our goal is to turn these notifications on by default for all accounts.
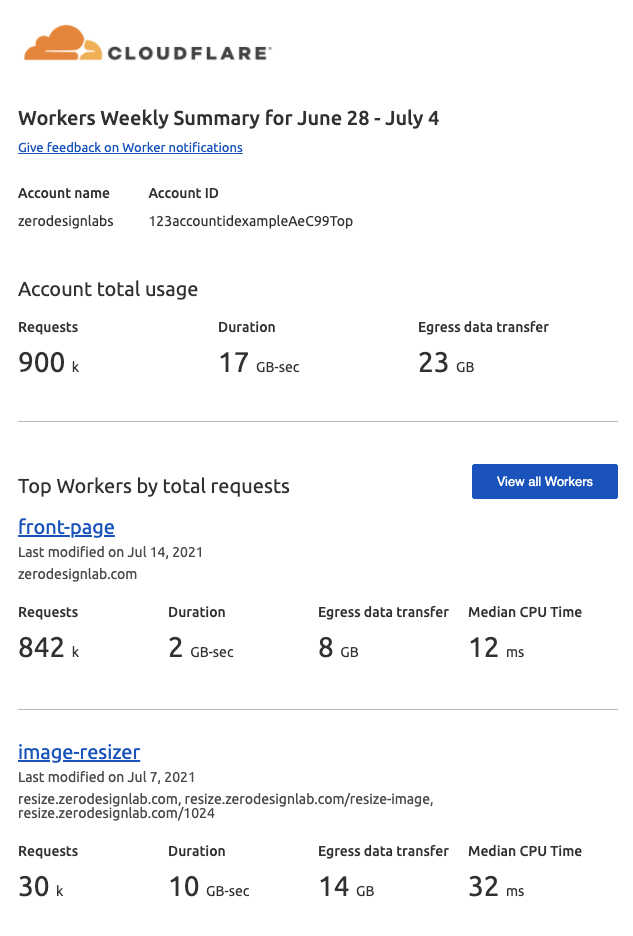
The Worker Weekly Summary
The mission of the Worker Weekly Summary is to give you a high-level view of your Workers usage automatically, in your inbox, without needing to sign in to the Worker’s dashboard. The summary includes valuable information such as total request counts, duration and egress data transfer, aggregated across your account, with breakouts for your most popular Workers that include median CPU time. Where duration accounts for the entire time your Worker spends responding to a request, CPU time is the time a script spends in computational work on the Cloudflare edge, discounting any time spent waiting on network requests, including requests to third-party APIs.
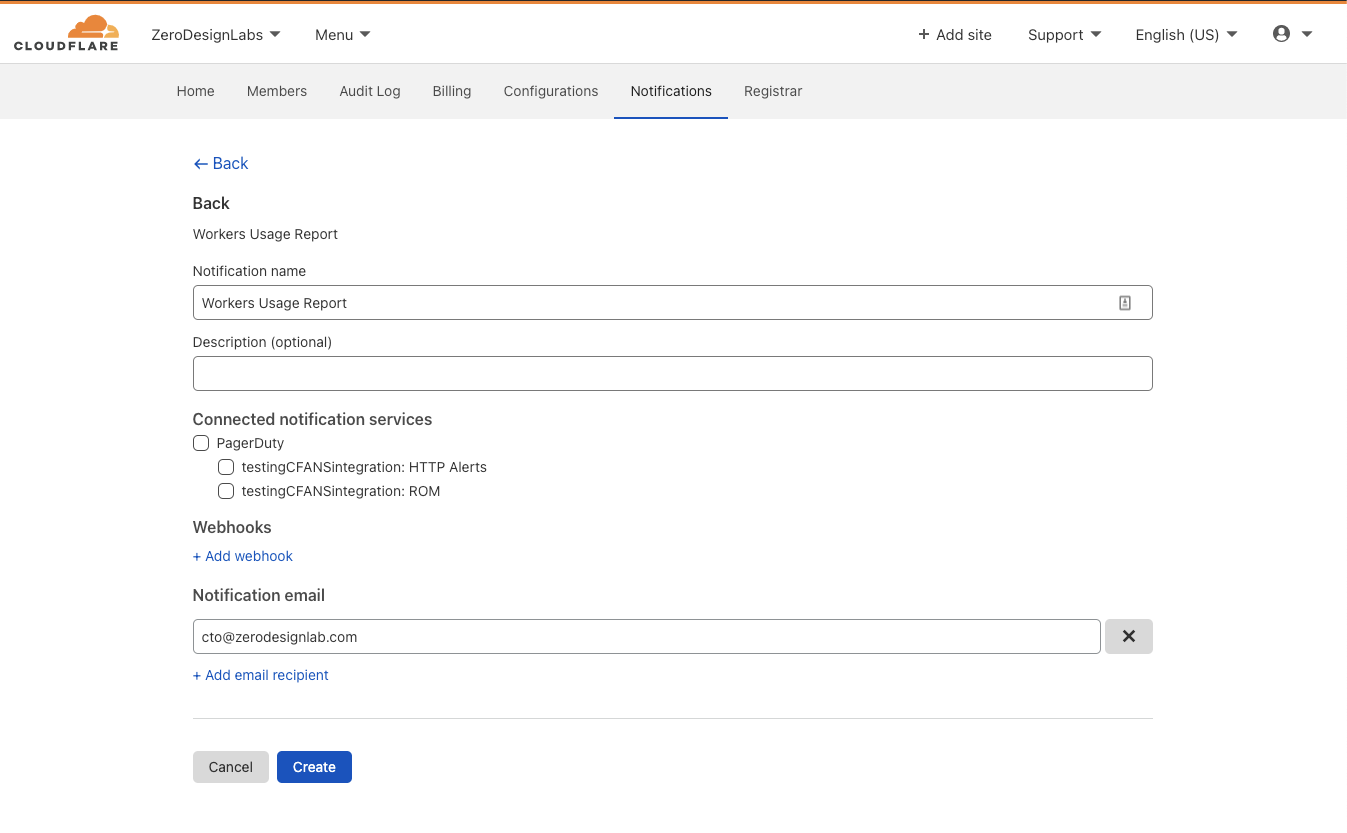
Workers Usage Report
Where the Workers Weekly Summary provides a high-level view of your account usage statistics, the Workers Usage Report is targeted, event-driven and potentially actionable. It identifies those Workers with greater than a 25% increase in CPU time compared to the average of the previous 7 days (i.e., those Workers taking significantly more CPU resources now than in the recent past).
While sometimes these increases may be no surprise, perhaps because you’ve recently pushed a new deployment that you expected to do more CPU heavy work, at other times they may indicate a bug or reveal that a script is unintentionally expensive. The Workers Usage Report gives us an opportunity to let you know when a noticeable change in your compute footprint occurs, so that you can remedy any potential problems right away.
Enabling Notifications
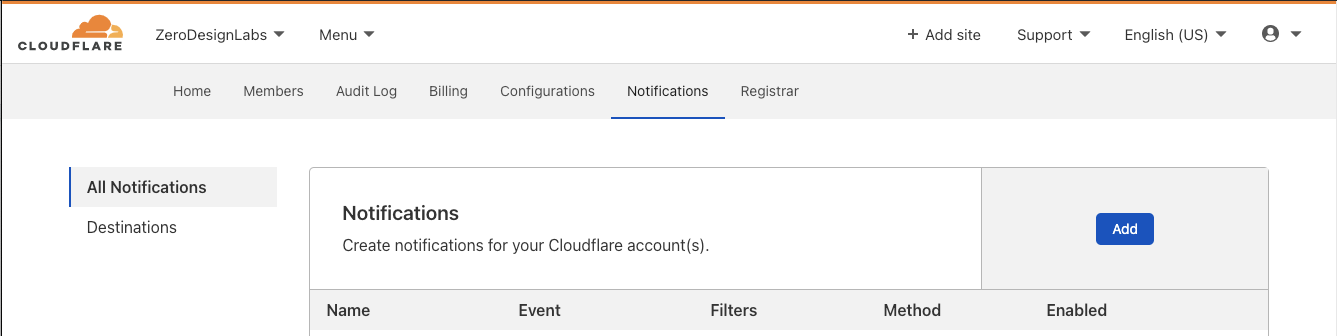
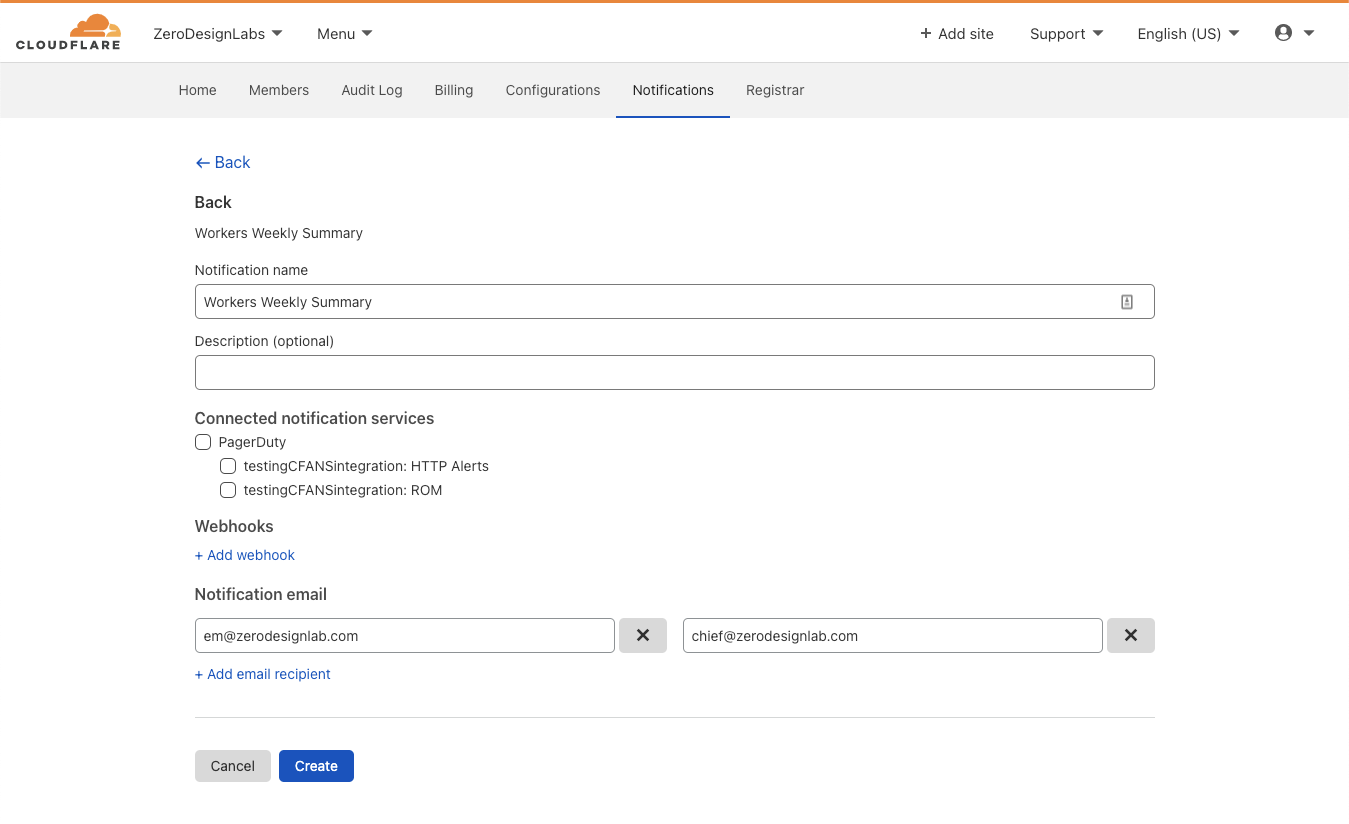
If you’d like to explicitly opt in to notifications, you can start off by clicking Add in the Notifications section of the Cloudflare zone dashboard.
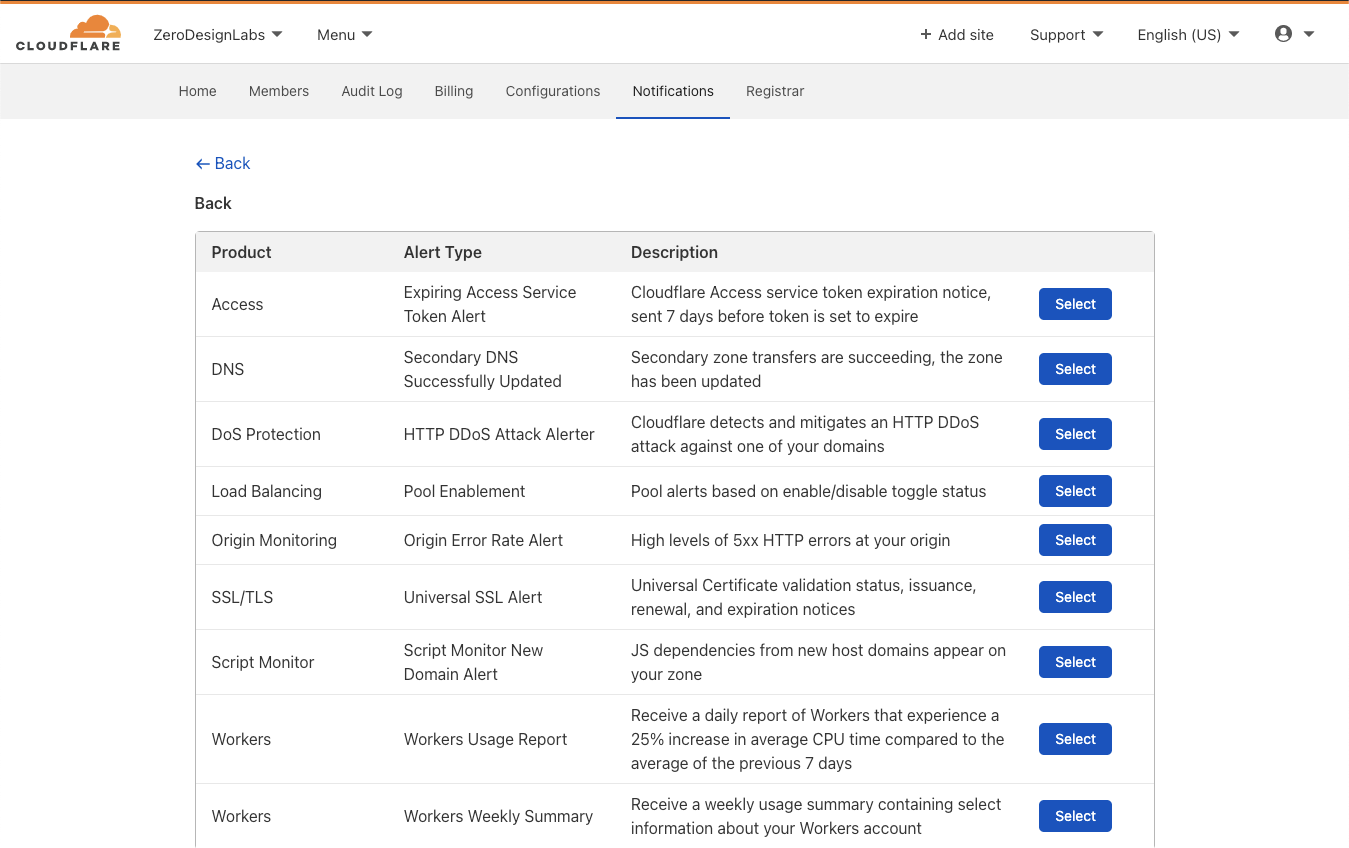
After clicking Add, note the two new entries below “Create Notifications” under the “Workers” Product:
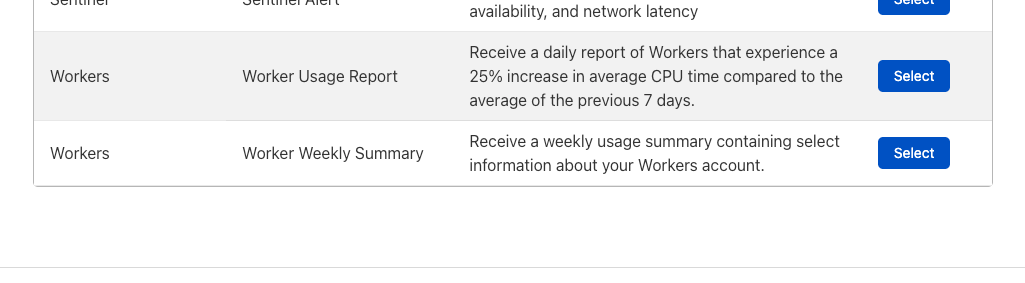
Click on the Select box in line with “ Weekly Summary” for the weekly roll-up, which will then allow you to configure email recipients, webhooks or connect the notification to PagerDuty.
Clicking Select next to “Usage Report” for CPU threshold notifications will send you to a similar configuration experience where you can customize email recipients and other integrations.
What’s next?
As mentioned above, we’re enabling notifications by default for all new free plans on Workers. Before rolling out these notifications by default to all our users, we want to hear from you. Let us know your experience with our Workers usage notifications by joining our Developer Community discord or by sending feedback via the survey in the email notifications.
Our Workers Weekly Summary and on-demand CPU usage notification are just the beginning of our journey to support a wide range of useful, relevant notifications that help you get visibility into your deployments. We want to surface the right usage information, exactly when you need it.
Cloudflare has always been about democratizing the Internet. For us, that means bringing the most powerful tools used by the largest of enterprises to the smallest development shops. Sometimes that looks like putting our global network to work defending against large-scale attacks. Other times it looks like giving Internet users simple and reliable privacy services like 1.1.1.1. Last week, it looked like Cloudflare Pages — a fast, secure and free way to build and host your JAMstack sites.
We see a huge opportunity with Cloudflare Pages. It goes beyond making it as easy as possible to deploy static sites, and extending that same ease of use to building full dynamic applications. By creating a seamless integration between Pages and Cloudflare Workers, we will be able to host the frontend and backend together, at the edge of the Internet and close to your users. The Linc team is joining Cloudflare to help us do just that.
Today, we’re excited to announce the acquisition of Linc, an automation platform to help front-end developers collaborate and build powerful applications. Linc has done amazing work with Frontend Application Bundles (FABs), making dynamic backends more accessible to frontend developers. Their approach offers a straightforward path to building end-to-end applications on Pages, with both frontend logic and powerful backend logic in one bundle. With the addition of Linc, we will accelerate Pages to enable richer and more powerful full-stack applications.
Combining Cloudflare’s edge network with Linc’s approach to server-side rendering, we’re able to set a new standard for performance on the web by delivering the speed of powerful servers close to users. Now, I’ll hand it over to Glen Maddern, who was the CTO of Linc, to share why they joined Cloudflare.
Linc and the Frontend Application Bundle (FAB) specification were designed with a single goal in mind: to give frontend developers the best possible tools to build, review, refine, and deploy their applications. An important piece of that is making server-side logic and rendering much more accessible, regardless of what type of app you’re building.
Static vs Dynamic frontends
One of the biggest problems in frontend web development today is the dramatic difference in complexity when moving from generating static sites (e.g. building a directory full of HTML, JS, and CSS files) to hosting a full application (traditionally using NodeJS and a web server like Express). While you gain the flexibility of being able to render everything on-demand and customised for the current user, you increase your maintenance cost — you now have servers that you need to keep running. And unless you’re operating at a global scale already, you’ll often see worse end-user performance as your requests are only being served from one or maybe a couple of locations worldwide.
While serverless platforms have arisen to solve these problems for backend services and can be brought to bear on frontend apps, they’re much less cost-effective than using static hosting, especially if the bulk of your frontend assets are static. As such, we’ve seen a rise of technologies under the umbrella term of “JAMstack”; they aim at making static sites more powerful (like rebuilding based off CMS updates), or at making it possible to deploy small pieces of server-side APIs as “cloud functions”, along with each update of your app. But it’s still fundamentally a limited architecture — you always have a static layer between you and your users, so the more dynamic your needs, the more complex your build pipeline becomes, or the more you’re forced to rely on client-side logic.
FABs took a different approach: a deployment artefact that could support the full range of server-side needs, from entirely static sites, apps with some API routes or cloud functions, all the way to full server-side streaming rendering. We also made it compatible with all the cloud hosting providers you might want, so that deploying becomes as easy as uploading a ZIP file. Then, as your needs change, as dynamic content becomes more important, as new frameworks arise that offer increasing performance or you look at moving which provider you’re hosting with, you never need to change your tooling and deployment processes.
The FAB approach
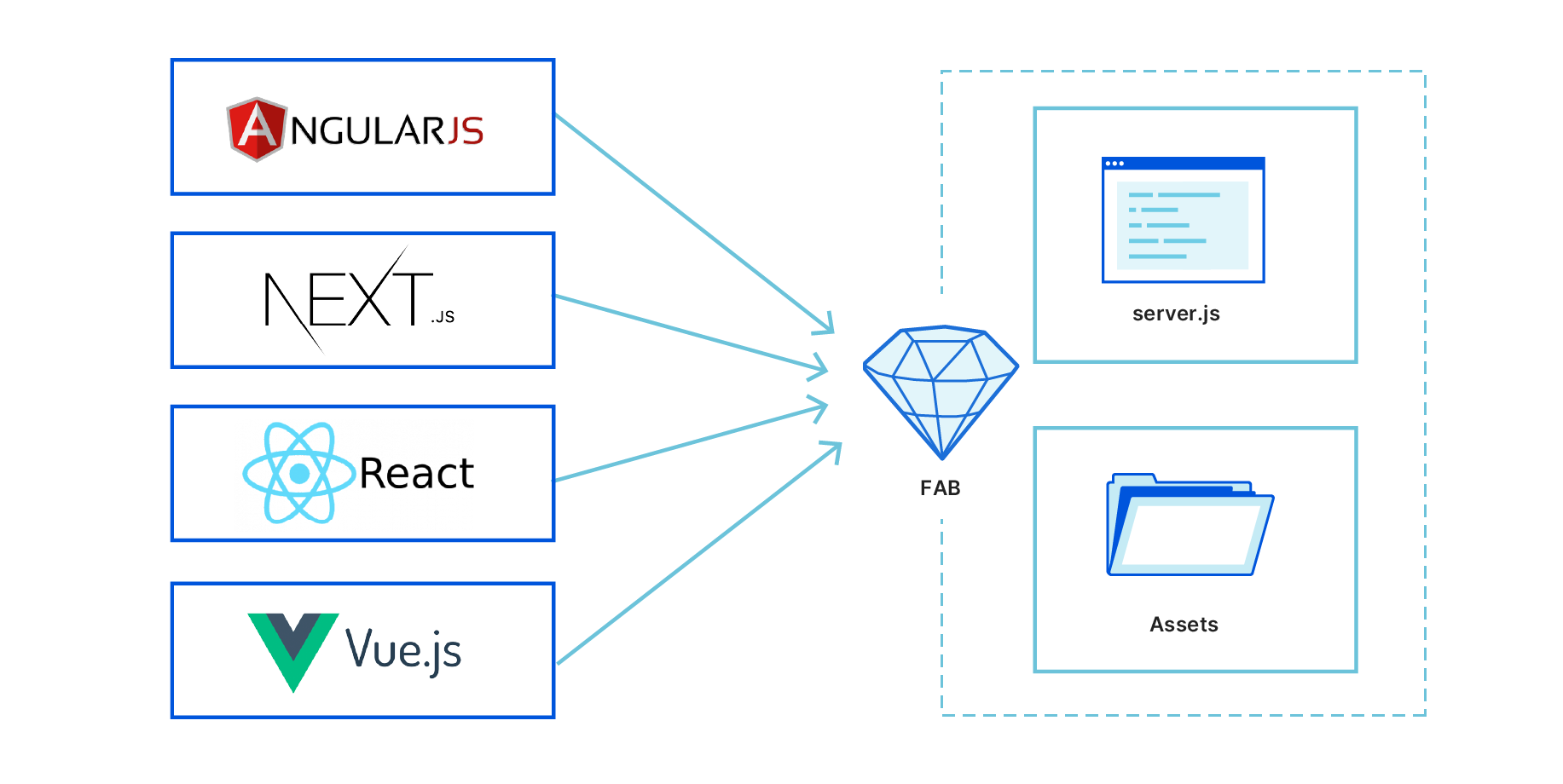
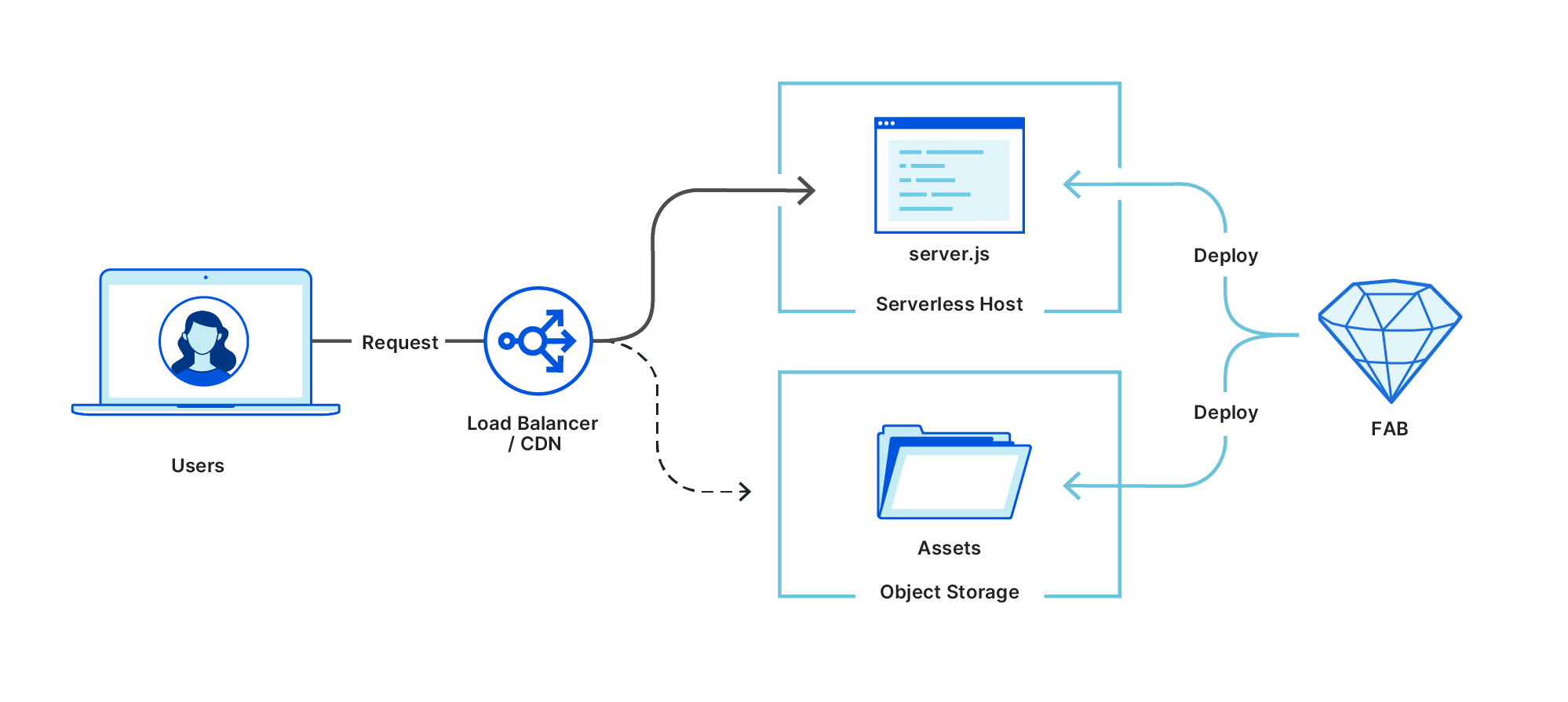
Regardless of what framework you’re working with, the FAB compiler generates a fab.zip file that has two components: a server.js file that acts as a server-side entry point, and an _assets directory that stores the HTML, CSS, JS, images, and fonts that are sent to the client.
This simple structure gives us enough flexibility to handle all kinds of apps. For example, a static site will have a server.js of only a few auto-generated lines of server-side code, just enough to add redirects for any files outside the _assets directory. On the other end of the spectrum, an app with full server rendering looks and works exactly the same. It just has a lot more code inside its server.js file.
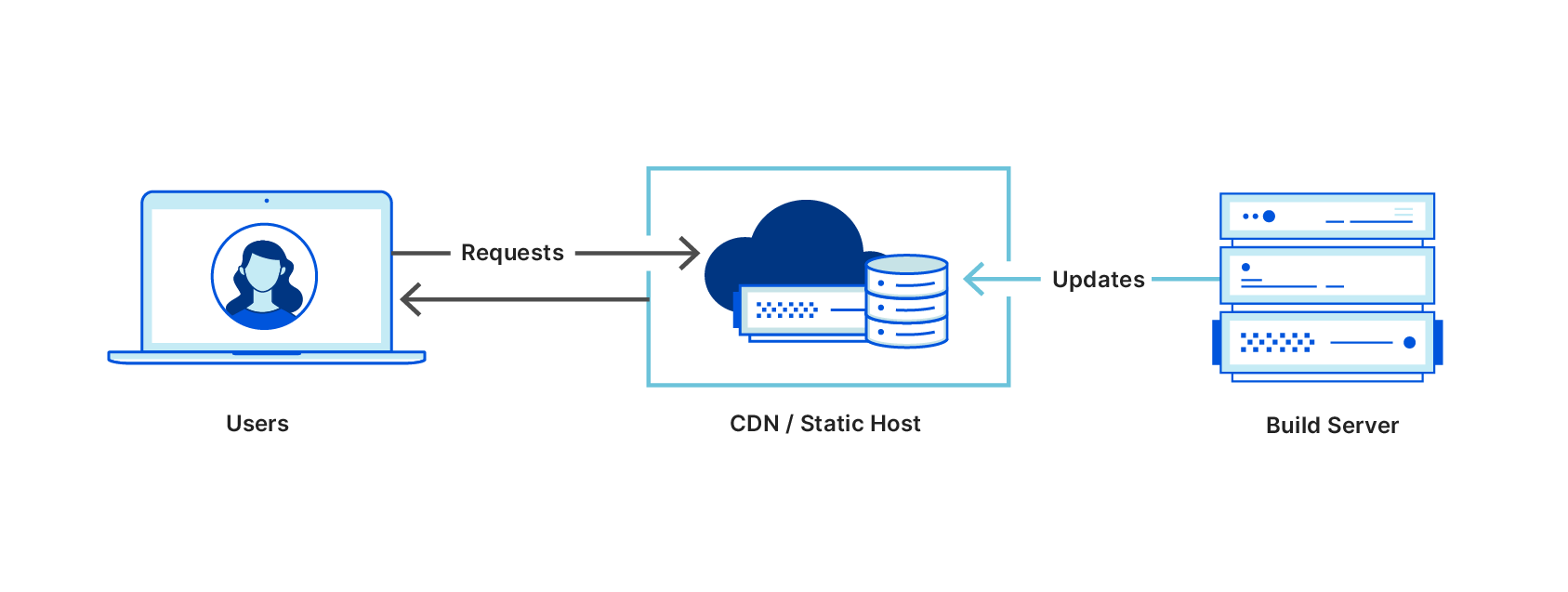
On a server running NodeJS, serving a compiled FAB is as easy as fab serve fab.zip, but FABs are really designed with production class hosting in mind. They make use of world-class CDNs and the best serverless hosting platforms around.
When a FAB is deployed, it’s often split into these component parts and deployed separately. Assets are sent to a low-cost object storage platform with a CDN in front of it, and the server component is sent to dedicated serverless hosting. It’s all deployed in an atomic, idempotent manner that feels as simple as uploading static files, but completely unlocks dynamic server-side code as part of your architecture.
That generic architecture works great and is compatible with virtually every hosting platform around, but it works slightly differently on Cloudflare Workers.
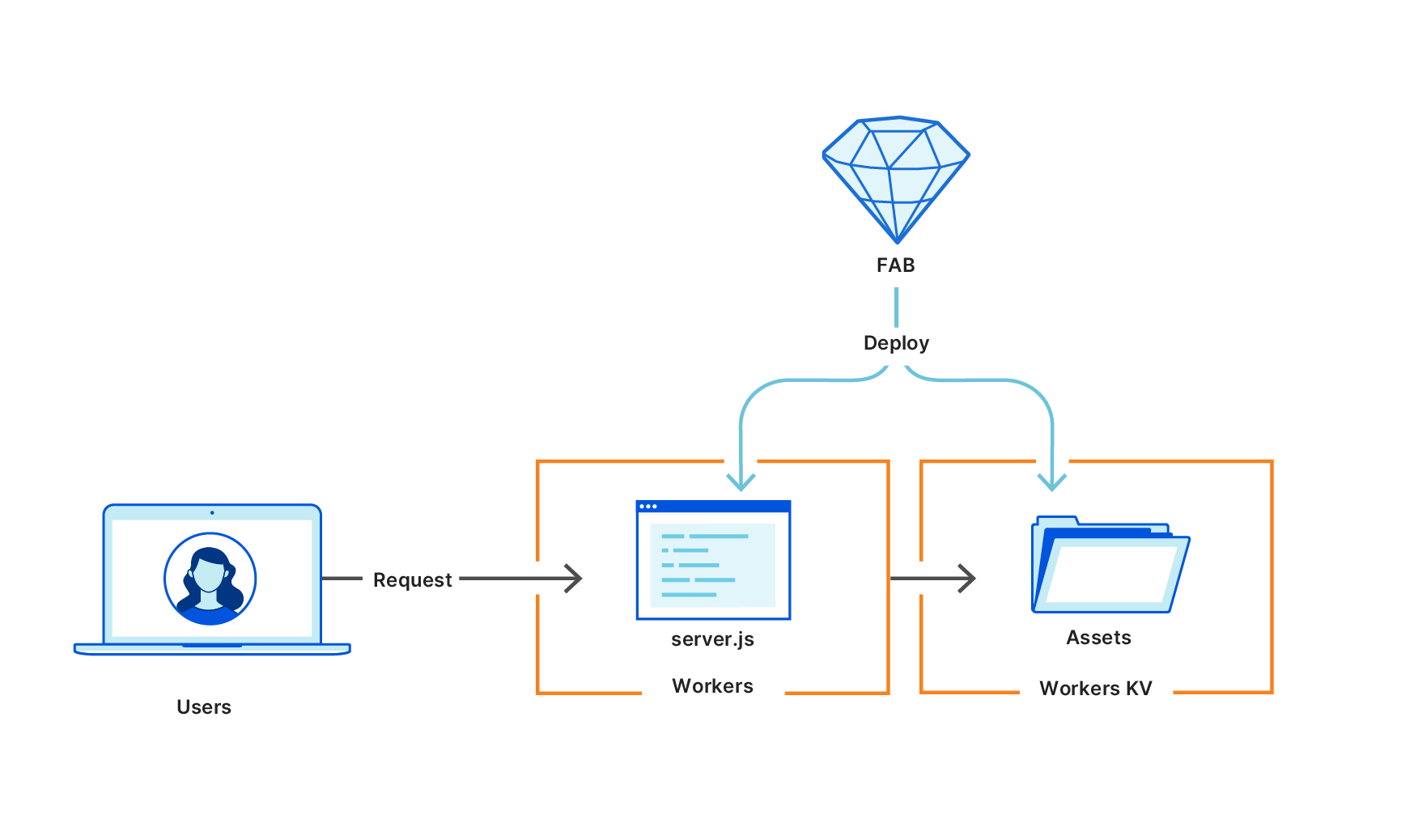
Workers, unlike other serverless platforms, truly runs at the edge: there is no CDN or load balancer in front of it to split off /_assets routes and send them directly to the Assets storage. This means that every request hits the worker, whether it’s triggering a full page render or piping through the bytes for an image file. It might feel like a downside, but with Workers’ performance and cost profile, it’s quite the opposite — it actually gives us much more flexibility in what we end up building, and gets us closer to the goal of fully unlocking server-side code.
To give just one example, we no longer need to store our asset files on a dedicated static file host — instead, we can use Cloudflare’s global key-value storage: Workers KV. Our server.js running inside a Worker can then map /_assets requests directly into the KV store and stream the result to the user. This results in significantly better performance than proxying to a third-party asset host.
What we’ve found is that Cloudflare offered the most “FAB-native” hosting option, and so it’s very exciting to have the opportunity to further develop what they can do.
Linc + Cloudflare
As we stated above, Linc’s goal was to give frontend developers the best tooling to build and refine their apps, regardless of which hosting they were using. But we started to notice an important trend — if a team had a free choice for where to host their frontend, they inevitably chose Cloudflare Workers. In some cases, for a period, teams even used Linc to deploy a FAB to Workers alongside their existing hosting to demonstrate the performance improvement before migrating permanently.
At the same time, we started to see more and more opportunities to fully embrace edge-rendering and make global serverless hosting more powerful and accessible. But the most exciting ideas required deep integration with the hosting providers themselves. Which is why, when we started talking to Cloudflare, everything fell into place.
We’re so excited to join the Cloudflare effort and work on expanding Cloudflare Pages to cover the full spectrum of applications. Not only do they share our goal of bringing sophisticated technology to every development team, but with innovations like Durable Objects starting to offer new storage paradigms, the potential for a truly next-generation deployment, review & hosting platform is tantalisingly close.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.