Post Syndicated from Antony Prasad Thevaraj original https://aws.amazon.com/blogs/big-data/accelerate-onboarding-and-seamless-integration-with-thoughtspot-using-amazon-redshift-partner-integration/
Amazon Redshift is a fast, petabyte-scale cloud data warehouse that makes it simple and cost-effective to analyze all of your data using standard SQL. Tens of thousands of customers today rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the most widely used cloud data warehouse. You can run and scale analytics in seconds on all your data without having to manage your data warehouse infrastructure.
Today, we are excited to announce ThoughtSpot as a new BI partner available through Amazon Redshift partner integration. You can onboard with ThoughtSpot in minutes directly from the Amazon Redshift console and gain faster data-driven insights. Businesses typically look at ways to derive business insights. This is where modern analytics providers such as ThoughtSpot provide value. With its powerful AI-based search, live visualizations, and developer tools and APIs for sharing embedded analytics, ThoughtSpot democratizes access to data by providing self-service tools for all users.
In this post, you will learn how to integrate seamlessly with ThoughtSpot from the Amazon Redshift console. With the loosely coupled nature of the modern data stack, it’s simple to connect Amazon Redshift with ThoughtSpot. No data movement or replication is required.
ThoughtSpot: Live analytics for your modern data stack
Static dashboards cannot deliver consistent and reliable insights at the speed and global scale that customers demand. They lack the following:
- Opportunities for collaboration
- Discovery and reusability
- Secure remote data and insight access
- Rapid use case development with single-touch insight provisioning
ThoughtSpot empowers everyone to create, consume, and operationalize data-driven insights. ThoughtSpot consumer-grade search and AI technology delivers true self-service analytics that anyone can use, while its developer-friendly platform ThoughtSpot Everywhere makes it easy to build interactive data apps that integrate with your existing cloud provider.
As organizations increasingly move to the cloud, ThoughtSpot helps them quickly unlock value from their investment. ThoughtSpot’s simple search functionality enables you to easily ask and answer data questions in seconds to unearth impactful insights directly in Amazon Redshift. ThoughtSpot for AWS provides enterprises with more freedom and flexibility by eliminating the need to move data between cloud sources so that businesses can immediately benefit from data-driven decision-making.
ThoughtSpot is an AWS Data and Analytics Competency Partner with the Amazon Redshift Ready product designation. ThoughtSpot is also part of the Powered by Amazon Redshift program.
Integrate ThoughtSpot using Amazon Redshift partner integration
Complete the following steps to integrate ThoughtSpot with Amazon Redshift:
- On the Amazon Redshift console, choose Clusters in the navigation pane.
- Select your cluster and on the Actions menu, choose Add AWS Partner integration.

Alternatively, you can choose your individual cluster and on its details page, choose Add partner integration.

- Select ThoughtSpot as your desired BI partner.
- Choose Next.

- Choose Add partner.

- Log in on the ThoughtSpot landing page.
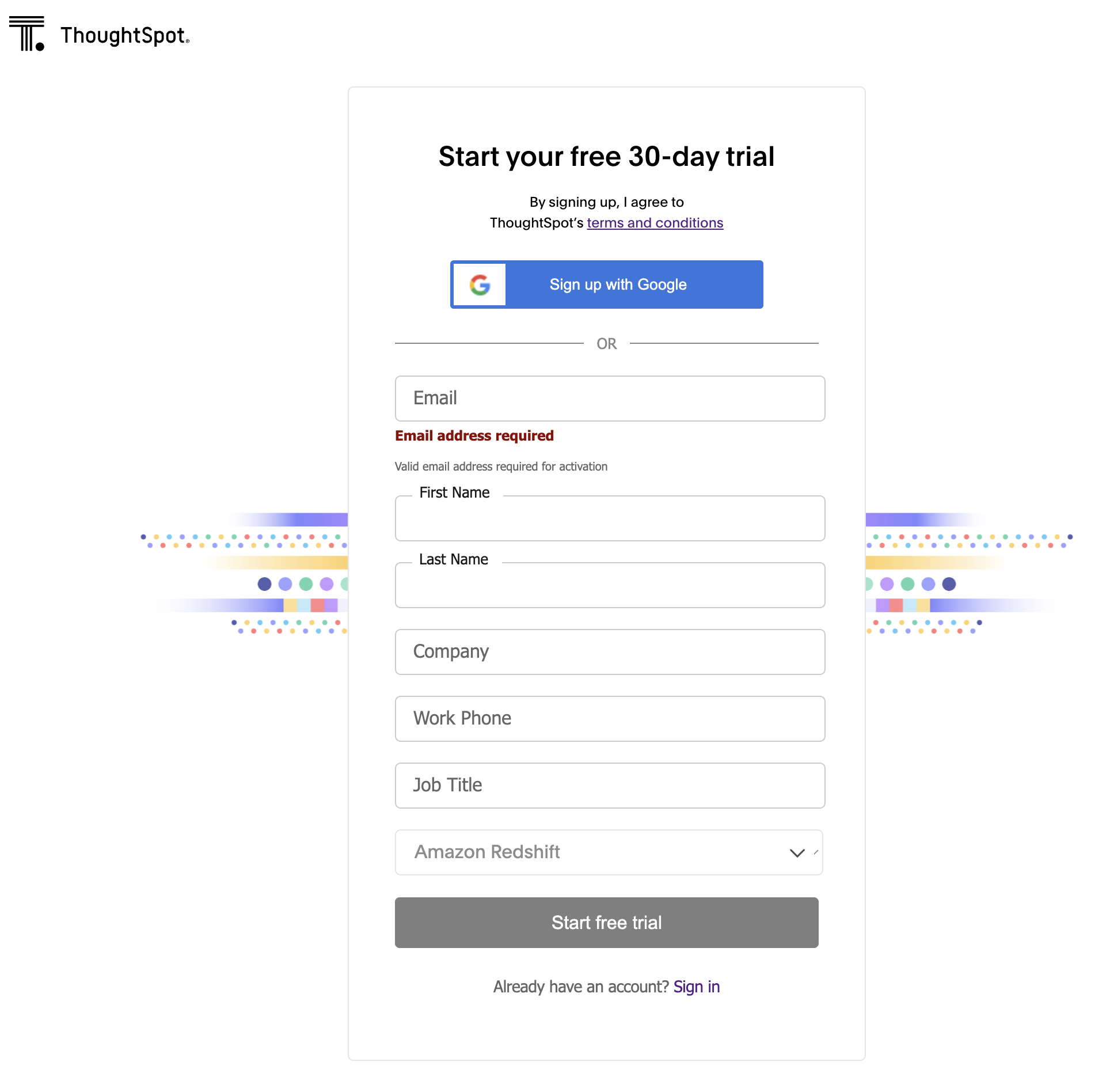
- Select Continue to Setup.

- On the Amazon Redshift connection details page, enter your Amazon Redshift database password for Password.
- Choose Continue.
To connect to your Amazon Redshift cluster, make sure to enable the Publicly accessible option and allow list the ThoughtSpot IP in your Amazon Redshift cluster’s security group.

- Select your desired tables and choose Update.
- If a prompt appears, choose Update again.
After you have successfully integrated with ThoughtSpot, you will see an Active status in the Integrations section on the Amazon Redshift console.

Congratulations! You’re now ready to start visualizing data using ThoughtSpot. The following example shows you trends in sales growth YTD, current sales trends across regions, and a comparison between product type sales between the current year and the previous year. You can slice and dice the dataset based on the granularity defined by the user.

Partner feedback
“ThoughtSpot is thrilled to expand our long-time cooperation with AWS with the announcement of our Amazon Redshift partner integration. Leading organizations are already extracting value from their data using AI-powered analytics on Amazon Redshift, and today we are making it even more frictionless for Amazon Redshift users to launch ThoughtSpot’s free trial to solve real problems quickly.”
– Kuntal Vahalia, SVP of WW Partners & APAC
Conclusion
In this post, we discussed how Amazon Redshift partner integration provides a fast-onboarding experience and allows you to create valuable business insights by integrating with ThoughtSpot. ThoughtSpot enables you to unlock the value of your modern data stack by empowering your entire organization with live analytics and data search, while Amazon Redshift provides a modern data warehouse experience for you to manage analytics at scale.
If you’re an AWS Partner and would like to integrate your product into the Amazon Redshift console, contact [email protected] for additional information and guidance. This console partner integration functionality is available to new and existing customers at no additional cost. To get started and learn more, see Integrating Amazon Redshift with an AWS Partner.
About the Authors
 Antony Prasad Thevaraj is a Sr. Partner Solutions Architect in Data and Analytics at AWS. He has over 12 years of experience as a Big Data Engineer, and has worked on building complex ETL and ELT pipelines for various business units.
Antony Prasad Thevaraj is a Sr. Partner Solutions Architect in Data and Analytics at AWS. He has over 12 years of experience as a Big Data Engineer, and has worked on building complex ETL and ELT pipelines for various business units.
 Maneesh Sharma is a Senior Database Engineer at AWS with more than a decade of experience designing and implementing large-scale data warehouse and analytics solutions. He collaborates with various Amazon Redshift Partners and customers to drive better integration.
Maneesh Sharma is a Senior Database Engineer at AWS with more than a decade of experience designing and implementing large-scale data warehouse and analytics solutions. He collaborates with various Amazon Redshift Partners and customers to drive better integration.
