Post Syndicated from Justin Kwan original https://blog.cloudflare.com/performance-isolation-in-a-multi-tenant-database-environment/

Operating at Cloudflare scale means that across the technology stack we spend a great deal of time handling different load conditions. In this blog post we talk about how we solved performance difficulties with our Postgres clusters. These clusters support a large number of tenants and highly variable load conditions leading to the need to isolate activity to prevent tenants taking too much time from others. Welcome to real-world, large database cluster management!
As an intern at Cloudflare I got to work on improving how our database clusters behave under load and open source the resulting code.
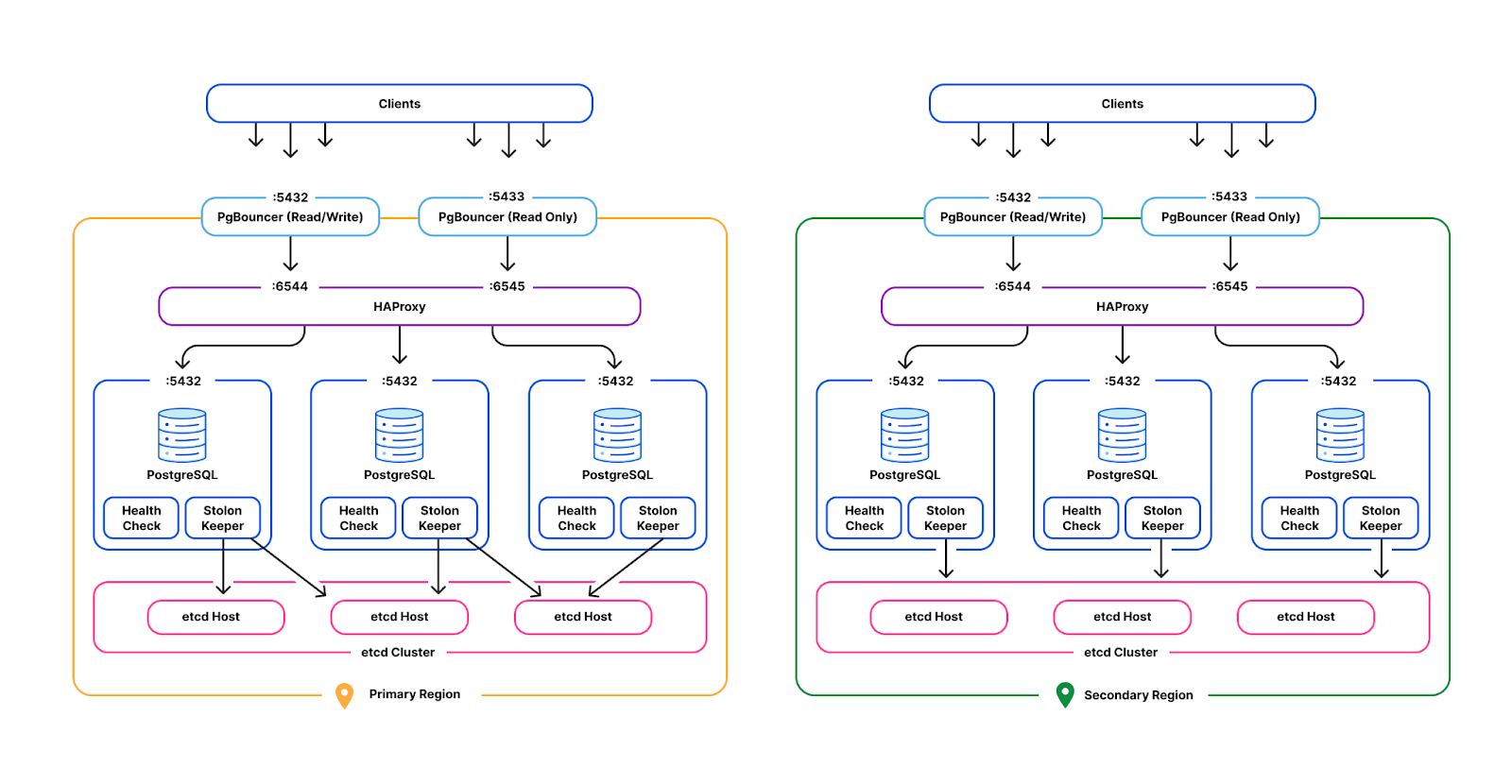
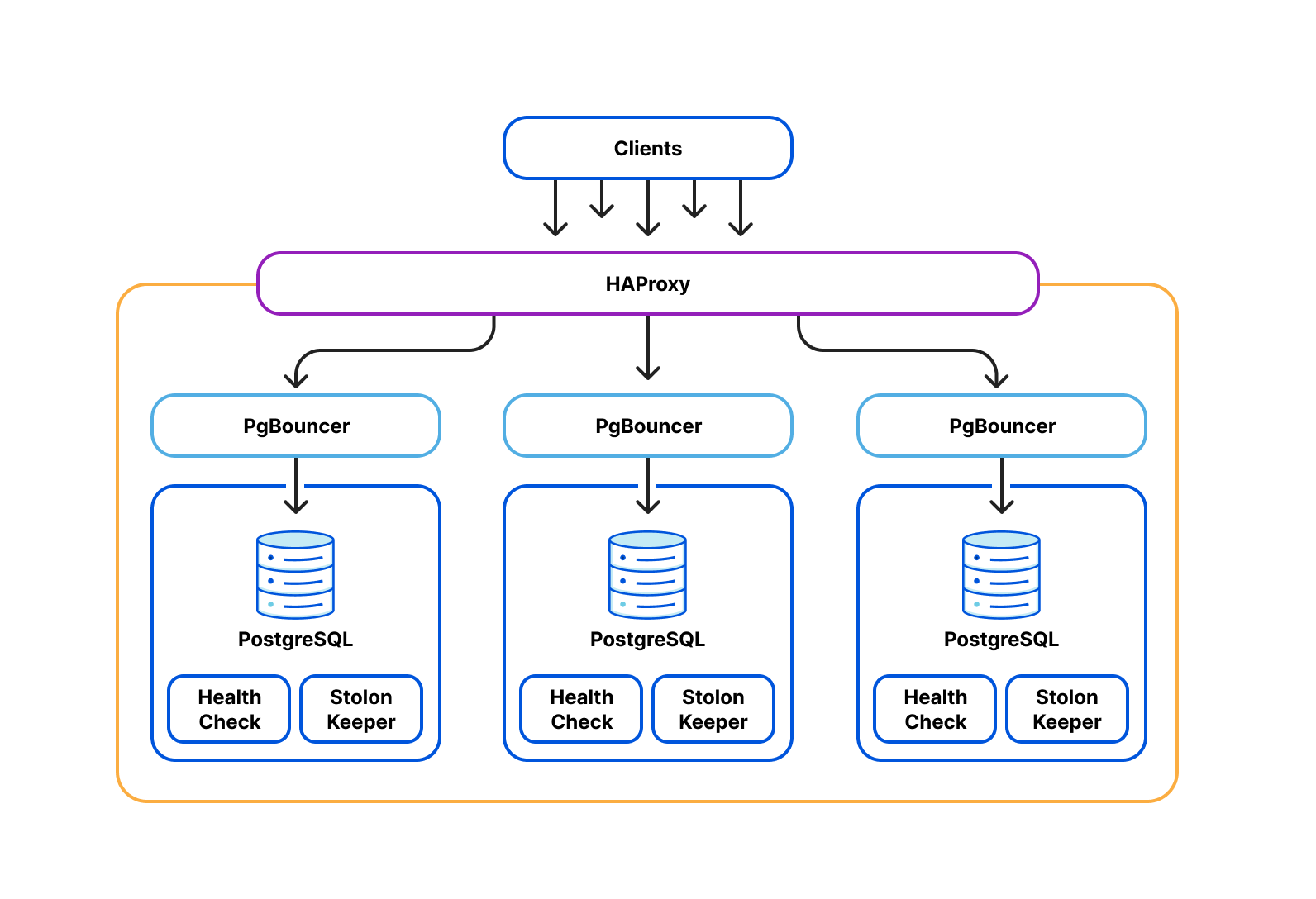
Cloudflare operates production Postgres clusters across multiple regions in data centers. Some of our earliest service offerings, such as our DNS Resolver, Firewall, and DDoS Protection, depend on our Postgres clusters’ high availability for OLTP workloads. The high availability cluster manager, Stolon, is employed across all clusters to independently control and replicate data across Postgres instances and elect Postgres leaders and failover under high load scenarios.
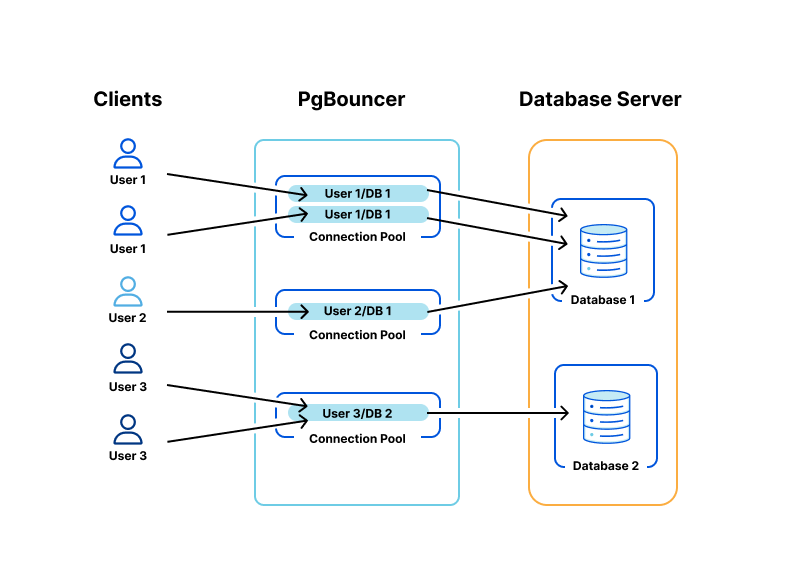
PgBouncer and HAProxy act as the gateway layer in each cluster. Each tenant acquires client-side connections from PgBouncer instead of Postgres directly. PgBouncer holds a pool of maximum server-side connections to Postgres, allocating those across multiple tenants to prevent Postgres connection starvation. From here, PgBouncer forwards queries to HAProxy, which load balances across Postgres primary and read replicas.
Problem
Our multi-tenant Postgres instances operate on bare metal servers in non-containerized environments. Each backend application service is considered a single tenant, where they may use one of multiple Postgres roles. Due to each cluster serving multiple tenants, all tenants share and contend for available system resources such as CPU time, memory, disk IO on each cluster machine, as well as finite database resources such as server-side Postgres connections and table locks. Each tenant has a unique workload that varies in system level resource consumption, making it impossible to enforce throttling using a global value.
This has become problematic in production affecting neighboring tenants:
- Throughput. A tenant may issue a burst of transactions, starving shared resources from other tenants and degrading their performance.
- Latency: A single tenant may issue very long or expensive queries, often concurrently, such as large table scans for ETL extraction or queries with lengthy table locks.
Both of these scenarios can result in degraded query execution for neighboring tenants. Their transactions may hang or take significantly longer to execute (higher latency) due to either reduced CPU share time, or slower disk IO operations due to many seeks from misbehaving tenant(s). Moreover, other tenants may be blocked from acquiring database connections from the database proxy level (PgBouncer) due to existing ones being held during long and expensive queries.
Previous solution
When database cluster load significantly increases, finding which tenants are responsible is the first challenge. Some techniques include searching through all tenants’ previous queries under typical system load and determining whether any new expensive queries have been introduced under the Postgres’ pg_stat_activity view.
Database concurrency throttling
Once the misbehaving tenants are identified, Postgres server-side connection limits are manually enforced using the Postgres query.
ALTER USER "some_bad-user" WITH CONNECTION LIMIT 123;This essentially restricts or “squeezes” the concurrent throughput for a single user, where each tenant will only be able to exhaust their share of connections.
Manual concurrency (connection) throttling has shown improvements in shedding load in Postgres during high production workloads:
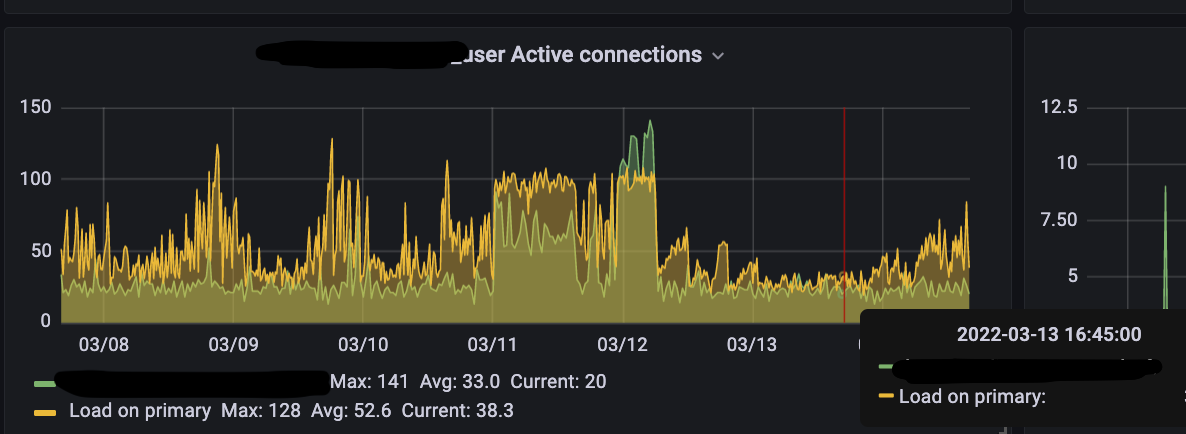
While we have seen success with this approach, it is not perfect and is horribly manual. It also suffers from the following:
- Postgres does not immediately kill existing tenant connections when a new user limit is set; the user may continue to issue bursty or expensive queries.
- Tenants may still issue very expensive, resource intensive queries (affecting neighboring tenants) even if their concurrency (connection pool size) is reduced.
- Manually applying connection limits against a misbehaving tenant is toil; an SRE could be paged to physically apply the new limit at any time of the day.
- Manually analyzing and detecting misbehaving tenants based on queries can be time-consuming and stressful especially during an incident, requiring production SQL analysis experience.
- Additionally, applying new throttling limits per user/pool, such as the allocated connection count, can be arbitrary and experimental while requiring extensive understanding of tenant workloads.
- Oftentimes, Postgres may be under so much load that it begins to hang (CPU starvation). SREs may be unable to manually throttle tenants through native interfaces once a high load situation occurs.
New solution
Gateway concurrency throttling
Typically, the system level resource consumption of a query is difficult to control and isolate once submitted to the server or database system for execution. However, a common approach is to intercept and throttle connections or queries at the gateway layer, controlling per user/pool traffic characteristics based on system resource consumption.
We have implemented connection throttling at our database proxy server/connection pooler, PgBouncer. Previously, PgBouncer’s user level connection limits would not kill existing connections, but only prevent exceeding it. We now support the ability to throttle and kill existing connections owned by each user or each user’s connection pool statically via configuration or at runtime via new administrative commands.
PgBouncer Configuration
[users]
dns_service_user = max_user_connections=60
firewall_service_user = max_user_connections=80
[pools]
user1.database1 = pool_size=90PgBouncer Runtime Commands
SET USER dns_service_user = ‘max_user_connections=40’;
SET POOL dns_service_user.dns_db = ‘pool_size=30’;This required major bug fixes, refactoring and implementation work in our fork of PgBouncer. We’ve also raised multiple pull requests to contribute all of our features to PgBouncer open source. To read about all of our work in PgBouncer, read this blog.
These new features now allow for faster and more granular “load shedding” against a misbehaving tenant’s concurrency (connection pool, user and database pair), while enabling stricter performance isolation.
Future solutions
We are continuing to build infrastructure components that monitor per-tenant resource consumption and detect which tenants are misbehaving based on system resource indicators against historical baselines. We aim to automate connection and query throttling against tenants using these new administrative commands.
We are also experimenting with various automated approaches to enforce strict tenant performance isolation.
Congestion avoidance
An adaptation of the TCP Vegas congestion avoidance algorithm can be employed to adaptively estimate and enforce each tenant’s optimal concurrency while still maintaining low latency and high throughput for neighboring tenants. This approach does not require resource consumption profiling, manual threshold tuning, knowledge of underlying system hardware, or expensive computation.
Traditionally, TCP Vegas converges to the initially unknown and optimal congestion window (max packets that can be sent concurrently). In the same spirit, we can treat the unknown congestion window as the optimal concurrency or connection pool size for database queries. At the gateway layer, PgBouncer, each tenant will begin with a small connection pool size, while we dynamically sample each tenant’s transaction’s round trip time (RTT) against Postgres. We gradually increase the connection pool size (congestion window) of a tenant so long as their transaction RTTs do not deteriorate.
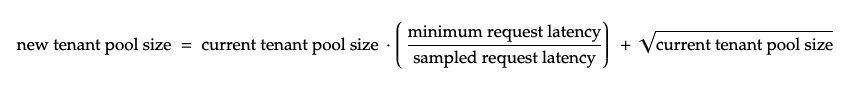
When a tenant’s sampled transaction latency increases, the formula’s minimum by sampled request latency ratio will decrease, naturally reducing the tenant’s available concurrency which reduces database load.
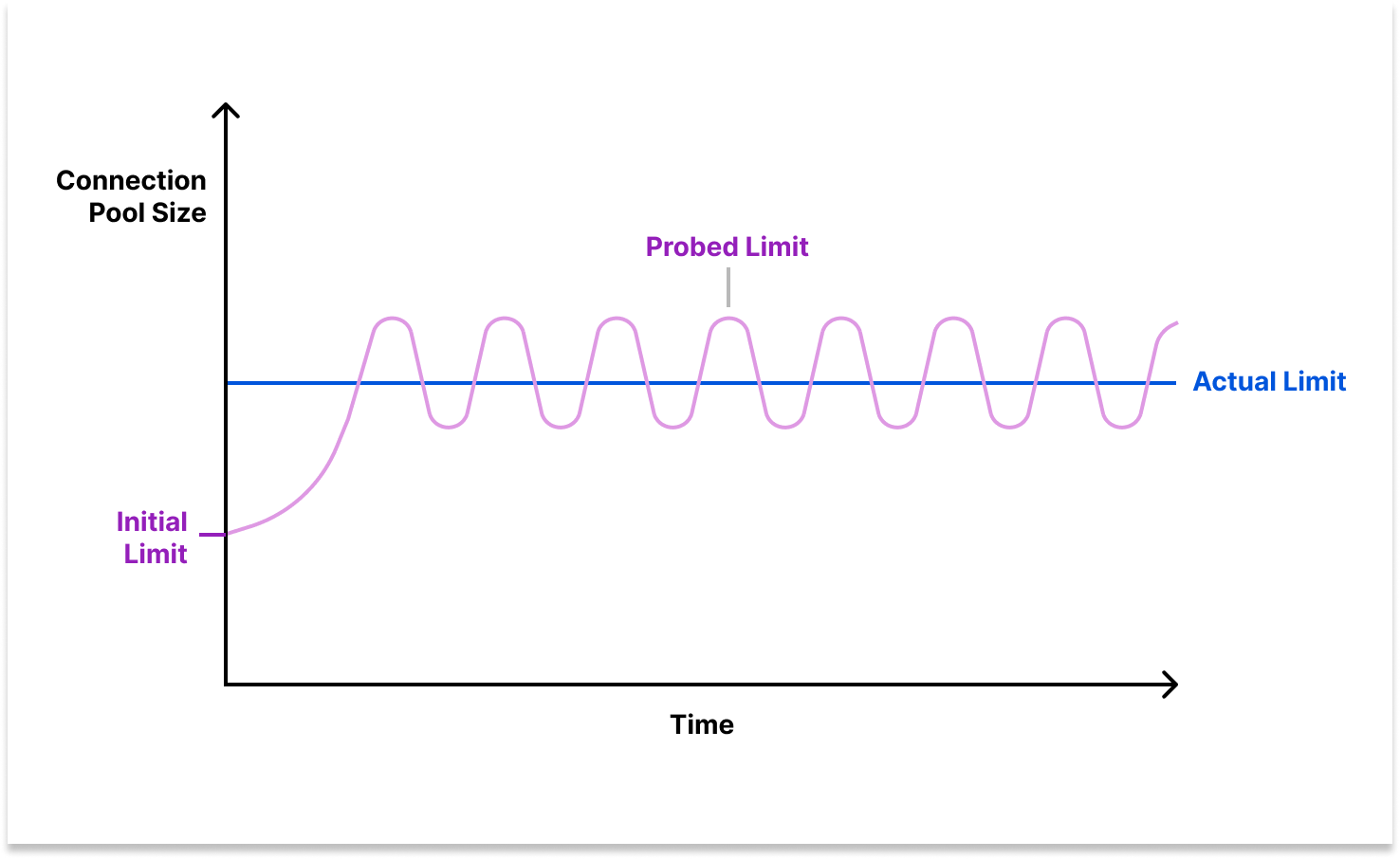
Essentially, this algorithm will “back off” when observing high query latencies as the indicator of high database load, regardless of whether the latency is due to CPU time or disk/network IO blocking, etc. This formula will converge to find the optimal concurrency limit (connection pool size) since the latency ratio always converges to 0 with sufficiently large sample request latencies. The square root of the current tenant pool size is chosen as a constant request “burst” headroom because of its fast growth and being relatively large for small pool sizes (when latencies are low) but converges when the pool size is reduced (when latencies are high).
Rather than reactively shedding load, congestion avoidance preventatively or “smoothly” throttles traffic before load induced performance degradation becomes an issue. This algorithm aims to prevent database server resource starvation which causes other queries to hang.
Theoretically, if one tenant misbehaves and causes load induced latency for others, this TCP congestion algorithm may incorrectly blindly throttle all tenants. Hence why it may be necessary to apply this adaptive throttling only against tenants with high CPU to latency correlation when the system performance is degrading.
Tenant resource quotas
Configurable resource quotas can be introduced per each tenant. Upstream application service tenants are restricted to their allocated share of resources expressed as CPU % utilized per second and max memory. If a tenant overuses their share, the database gateway (PgBouncer) should throttle their concurrency, queries per second and ingress bytes to force consumption within their allocated slice.
Resource throttling a tenant must not “spillover” or affect other tenants accessing the same cluster. This could otherwise reduce the availability of other customer-facing applications and violate SLO (service-level objectives). Resource restriction must be isolated to each tenant.
If traffic is low against Postgres instances, tenants should be permitted to exceed their allocation limit. However, when load against the cluster degrades the entire performance of the system (latency), the tenant’s limit must be re-enforced at the gateway layer, PgBouncer. We can make deductions around the health of the entire database server based on indicators such as average query latency’s rate of change against a predefined threshold. All tenants should agree that a surplus in resource consumption may result in query throttling of any pattern.
Each tenant has a unique and variable workload, which may degrade multi tenant performance at any time. Quick detection requires profiling the baseline resource consumption of each tenant’s (or tenant’s connection pooled) workload against each local Postgres server (backend pids) in near real-time. From here, we can correlate the “baseline” traffic characteristics with system level resource consumption per database instance.
Taking an average or generalizing statistical measures across distributed nodes (each tenant’s resource consumption on Postgres instances in this case) can be inaccurate due to high variance in traffic against leader vs replica instances. This would lead to faulty throttling decisions applied against users. For instance, we should not throttle a user’s concurrency on an idle read replica even if the user consumes excessive resources on the primary database instance. It is preferable to capture tenant consumption on a per Postgres instance level, and enforce throttling per instance rather than across the entire cluster.
Multivariable regression can be employed to model the relationship between independent variables (concurrency, queries per second, ingested bytes) against the dependent variables (system level resource consumption). We can calculate and enforce the optimal independent variables per tenant under high load scenarios. To account for workload changes, regression adaptability vs accuracy will need to be tuned by adjusting the sliding window size (amount of time to retain profiled data points) when capturing workload consumption.
Gateway query queuing
User queries can be prioritized for submission to Postgres at the gateway layer (PgBouncer). Within a one or multiple global priority queues, query submissions by all tenants are ordered based on the current resource consumption of the tenant’s connection pool or the tenant itself. Alternatively, ordering can be based on each query’s historical resource consumption, where each query is independently profiled. Based on changes in tenant resource consumption captured from each Postgres instance’s server, all queued queries can be reordered every time the scheduler forwards a query to be submitted.
To prevent priority queue starvation (one tenant’s query is at the end of the queue and is never executed), the gateway level query queuing can be configured to only enable when there is peak load/traffic against the Postgres instance. Or, the time of enqueueing a query can be factored into the priority ordering.
This approach would isolate tenant performance by allowing non-offending tenants to continue reserving connections and executing queries (such as critical health monitoring queries). Higher latency would only be observed from the tenants that are utilizing more resources (from many/expensive transactions). This approach is straightforward to understand, generic in application (can queue transactions based on other input metrics), and non-destructive as it does not kill client/server connections, and should only drop queries when the in-memory priority queue reaches capacity.
Conclusion
Performance isolation in our multi-tenant storage environment continues to be a very interesting challenge that touches areas including OS resource management, database internals, queueing theory, congestion algorithms and even statistics. We’d love to hear how the community has tackled the “noisy neighbor” problem by isolating tenant performance at scale!