Post Syndicated from Ashwini Rudra original https://aws.amazon.com/blogs/architecture/building-a-data-pipeline-for-tracking-sporting-events-using-aws-services/
In an evolving world that is increasingly connected, data-centric, and fast-paced, the sports industry is no exception. Amazon Web Services (AWS) has been helping customers in the sports industry gain real-time insights through analytics. You can re-invent and reimagine the fan experience by tracking sports actions and activities. In this blog post, we will highlight common architectural and design patterns for building a data pipeline to track sporting events in real time.
The sports industry is largely comprised of two subsegments: participatory and spectator sports. Participatory sports, for example fitness, golf, boating, and skiing, comprise the largest share of the market. Spectator sports, such as teams/clubs/leagues, individual sports, and racing, are expected to be the fastest growing segment. Sports teams/leagues/clubs comprise the largest share of the Spectator sports segment, and is growing most rapidly.
IoT data pipeline architecture overview
Let’s discuss the infrastructure in three parts:
- Infrastructure at the arena itself
- Processing data using AWS services
- Leveraging this analysis using a graphics overlay (this can be especially useful for broadcasters, OTT channels, and arena users)
Data-gathering devices
Radio-frequency identification (RFID) chips or IoT devices can be worn by players or embedded in the playing equipment. These devices emit 20–50 messages per second. These messages are collected and output using JSON. This information may include player coordinate positions, player speed, statistics, health information, or more. To process the game, leagues, coaches, or broadcasters can analyze this data using analytics tools and/or machine learning.

Figure 1. Data pipeline architecture using AWS Services
Processing data, feature engineering, and model training at AWS
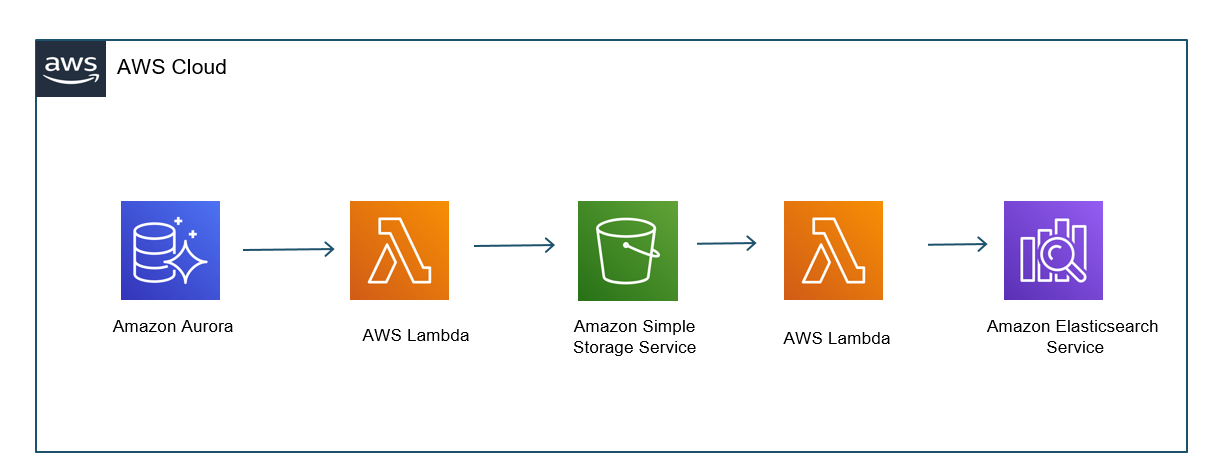
Use serverless services from AWS when possible in order to keep your solution scalable and cost-efficient. This also helps with operational overhead for teams. You can use the Kinesis family of services for stream ingestion and processing. The streaming data from hundreds to thousands of IoT sources (from equipment and clothing) can be fed to Amazon Kinesis Data Streams (KDS). KDS and Amazon Kinesis Data Firehose provide a buffering mechanism for streaming data before it lands on Amazon Simple Storage Service (S3). With Amazon Kinesis Data Analytics, you can process and analyze Kinesis stream data using powerful SQL, Apache Flink, or Beam. Kinesis Data Analytics also supports building applications in SQL, Java, Scala, and Python. With this service, you can quickly author and run powerful SQL code against Amazon Kinesis Streams as your source. This way you can perform time series analytics, feed real-time dashboards, and create real-time metrics. Read more about Amazon Kinesis Data Analytics for SQL Applications.
You might want to transform or enhance the streaming data before it is delivered to Amazon S3. Amazon Kinesis Data Firehose can be used with an AWS Lambda function to do the transformation. Let’s say you have a player prediction timestamp that you want to represent in a different time format to different ML algorithms. Lambda can process and transform this data. Kinesis Data Firehose will deliver the transformed and raw data to the destination (Amazon S3). This can occur after the specific buffering size or when the buffering interval is reached, whichever happens first.
For more complex transformations, AWS Glue can be used. For example, once the data lands in Amazon S3, you can start preparing and aggregating the training dataset using Amazon SageMaker Data Wrangler. As part of the feature engineering process, you can do the following:
- Transform the data
- Delete unneeded columns
- Impute missing values
- Perform label encoding
- Use the quick model option to get a sense of which features are adding predictive power as you progress with your data preparation
All the data preparation and feature engineering tasks can be performed from Data Wrangler’s single visual interface.
Once data is prepared in Amazon S3, Amazon SageMaker can be used for model training. In soccer, you can predict a goal percentage based on the player’s position, acceleration, and past performance history. SageMaker provides several built-in algorithms that can be trained. For real-time predictions, Amazon API Gateway provides an API layer to clients like an OTT, broadcasting service, or a web browser. API Gateway can invoke a Lambda function, with logic to call a SageMaker endpoint and persist the output to the database. This data can be used later on for further analysis or to fine-tune your models.

Figure 2. Deliver real-time prediction using Amazon SageMaker
Computer vision-based object detection techniques can be very useful in Sports. These techniques use deep learning algorithms to predict the pass probability, game player face-off, or win prediction. For the sports industry, object detection technology like these are crucial. They obviate the need for sensors. Real-time object identification can be used to:
- Generate new advanced analytics regarding player and team performance
- Aid game officials in making correct calls
- Provide fans an improved and more data-rich viewing experience
Read Football tracking in the NFL with Amazon SageMaker for more information on how to track using broadcast video data. Using SageMaker, you can train object detection models that analyze thousands of images. You can then locate and classify the football itself, and distinguish it from background objects.
Creating a graphics overlay
When you have the ML inference data and video ingestion ready, you may want to represent this data on your broadcasted video. The graphic overlay feature lets you insert an image (a BMP, PNG, or TGA file) at a specified time. It is displayed as a static overlay on the underlying video for a specified duration. The motion graphic overlay feature lets you insert an animation (a MOV or SWF file, or a series of PNG files) on the underlying video. This can be displayed at a specified time for a specified duration.
For example, a player’s motion prediction can be inserted on video during a game, through a RESTful API call of ML inferences. You can use AWS Elemental Live to achieve this. Read about AWS Elemental Live Graphic Overlay at AWS documentation.
Reducing latency
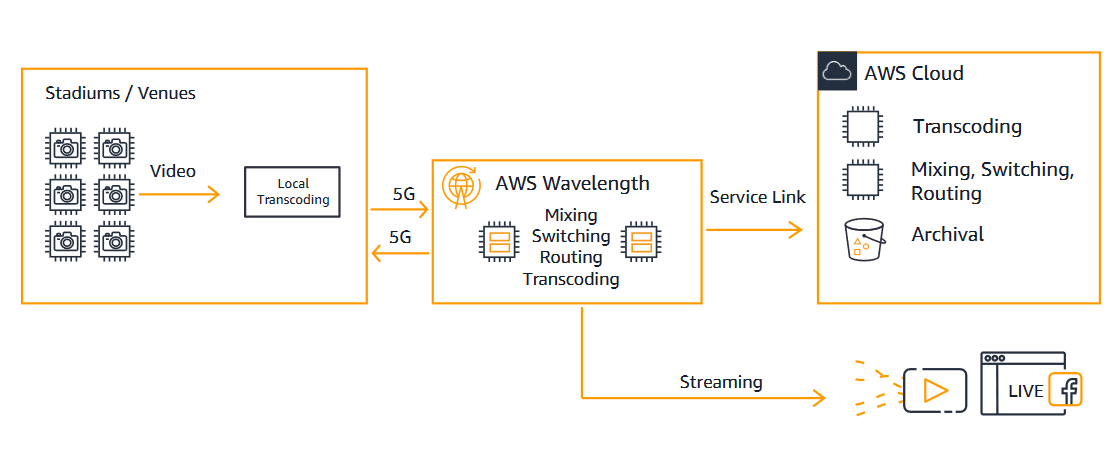
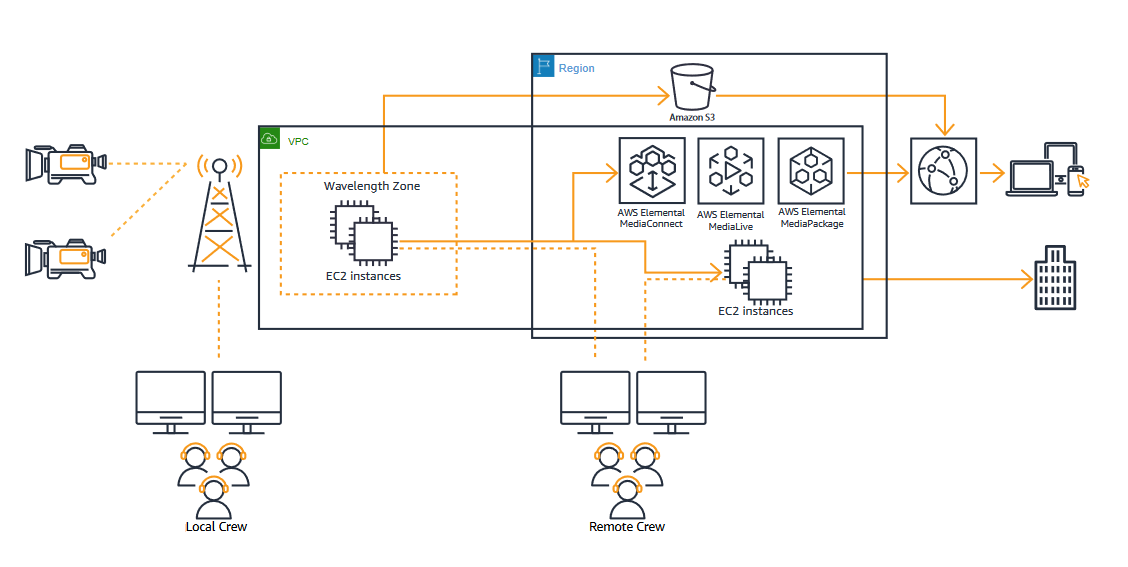
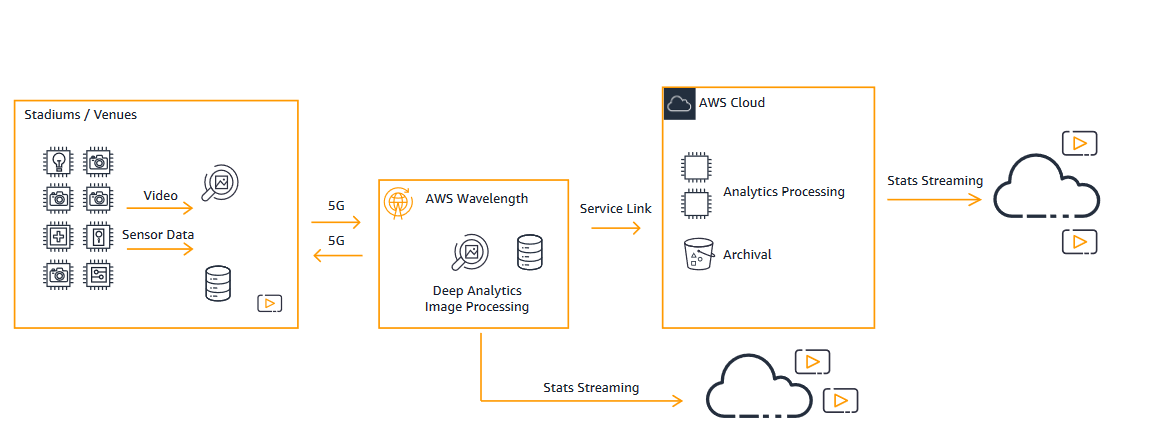
You may want to reduce latency for analytics such as for player health and safety. Use video, data, or machine learning processing at the arena using AWS Outposts. You can also use AWS Wavelength along with 5G infrastructure. For more information, read Catch Important Moments in Sports with 5G and AWS Wavelength.
Summary
In this blog, we’ve highlighted how customers in the sports industry are using AWS to increase the quality of the game, and enhance the sports fan’s experience. The following benefits can be achieved by building a data pipeline for tracking sporting events using AWS services:
- Amazon Kinesis collects, processes, and analyzes in-game streaming data in real time. This way both teams and fans get timely insights and can react quickly to new information.
- The serverless nature of this architecture enables a cost-effective, scalable, and operationally efficient environment for customers.
- Amazon Machine Learning services like Amazon SageMaker can be used to enrich the fan viewing experience. It presents in-game predictions such as who will score next, or which team will win the game.
Visit our AWS Sports Partnerships page for more information on how AWS is changing the game.