Post Syndicated from Çağrı Çakır original https://aws.amazon.com/blogs/big-data/how-postnl-processes-billions-of-iot-events-with-amazon-managed-service-for-apache-flink/
This post is co-written with Çağrı Çakır and Özge Kavalcı from PostNL.
PostNL is the designated universal postal service provider for the Netherlands and has three main business units offering postal delivery, parcel delivery, and logistics solutions for ecommerce and cross-border solutions. With 5,800 retail points, 11,000 mailboxes, and over 900 automated parcel lockers, the company plays an important role in the logistics value chain. It aims to be the delivery organization of choice by making it as easy as possible to send and receive parcels and mail. With almost 34,000 employees, PostNL is at the heart of society. On a typical weekday, the company delivers an average of 1.1 million parcels and 6.9 million letters across Belgium, Netherlands, and Luxemburg.
In this post, we describe the legacy PostNL stream processing solution, its challenges, and why PostNL chose Amazon Managed Service for Apache Flink to help modernize their Internet of Things (IoT) data stream processing platform. We provide a reference architecture, describe the steps we took to migrate to Apache Flink, and the lessons learned along the way.
With this migration, PostNL has been able to build a scalable, robust, and extendable stream processing solution for their IoT platform. Apache Flink is a perfect fit for IoT. Scaling horizontally, it allows processing the sheer volume of data generated by IoT devices. With event time semantics, you can correctly handle events in the order they were generated, even from occasionally disconnected devices.
PostNL is excited about the potential of Apache Flink, and now plans to use Managed Service for Apache Flink with other streaming use cases and shift more business logic upstream into Apache Flink.
Apache Flink and Managed Service for Apache Flink
Apache Flink is a distributed computation framework that allows for stateful real-time data processing. It provides a single set of APIs for building batch and streaming jobs, making it straightforward for developers to work with bounded and unbounded data. Managed Service for Apache Flink is an AWS service that provides a serverless, fully managed infrastructure for running Apache Flink applications. Developers can build highly available, fault-tolerant, and scalable Apache Flink applications with ease and without needing to become an expert in building, configuring, and maintaining Apache Flink clusters on AWS.
The challenge of real-time IoT data at scale
Today, PostNL’s IoT platform, Roller Cages solution, tracks more than 380,000 assets with Bluetooth Low Energy (BLE) technology in near real time. The IoT platform was designed to provide availability, geofencing, and bottom state events of each asset by using telemetry sensor data such as GPS points and accelerometers that are coming from Bluetooth devices. Those events are used by different internal consumers to make logistical operations straightforward to plan, more efficient, and sustainable.

Tracking this high volume of assets emitting different sensor readings inevitably creates billions of raw IoT events for the IoT platform as well as for the downstream systems. Handling this load repeatedly both within the IoT platform and throughout the downstream systems was neither cost-efficient nor easy to maintain. To reduce the cardinality of events, the IoT platform uses stream processing to aggregate data over fixed time windows. These aggregations must be based on the moment when the device emitted the event. This type of aggregation based on event time becomes complex when messages may be delayed and arrive out of order, which may frequently happen with IoT devices that can get disconnected temporarily.
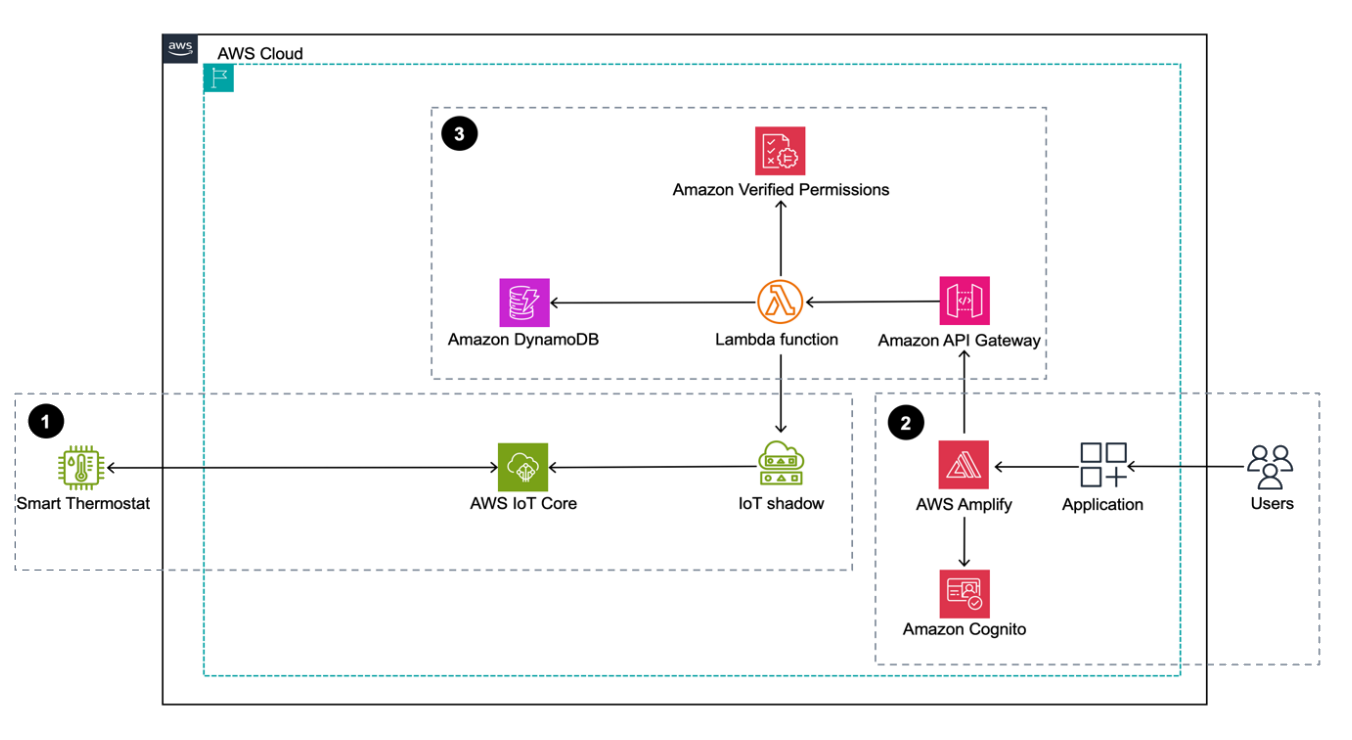
The following diagram illustrates the overall flow from edge to the downstream systems.

The workflow consists of the following components:
- The edge architecture includes IoT BLE devices that serve as sources of telemetry data, and gateway devices that connect these IoT devices to the IoT platform.
- Inlets contain a set of AWS services such as AWS IoT Core and Amazon API Gateway to collect IoT detections using MQTTS or HTTPS and deliver them to the source data stream using Amazon Kinesis Data Streams.
- The aggregation application filters IoT detections, aggregates them for a fixed time window, and sinks aggregations to the destination data stream.
- Event producers are the combination of different stateful services that generate IoT events such as geofencing, availability, bottom state, and in-transit.
- Outlets, including services such as Amazon EventBridge, Amazon Data Firehose, and Kinesis Data Streams, deliver produced events to consumers.
- Consumers, which are internal teams, interpret IoT events and build business logic based on them.
The core component of this architecture is the aggregation application. This component was originally implemented using a legacy stream processing technology. For several reasons, as we discuss shortly, PostNL decided to evolve this critical component. The journey of replacing the legacy stream processing with Managed Service for Apache Flink is the focus of the rest of this post.
The decision to migrate the aggregation application to Managed Service for Apache Flink
As the number of connected devices grows, so does the necessity for a robust and scalable platform capable of handling and aggregating massive volumes of IoT data. After thorough analysis, PostNL opted to migrate to Managed Service for Apache Flink, driven by several strategic considerations that align with evolving business needs:
- Enhanced data aggregation – Using Apache Flink’s strong capabilities in real-time data processing enables PostNL to efficiently aggregate raw IoT data from various sources. The ability to extend the aggregation logic beyond what was provided by the current solution can unlock more sophisticated analytics and more informed decision-making processes.
- Scalability – The managed service provides the ability to scale your application horizontally. This allows PostNL to handle increasing data volumes effortlessly as the number of IoT devices grows. This scalability means that data processing capabilities can expand in tandem with the business.
- Focus on core business – By adopting a managed service, the IoT platform team can focus on implementing business logic and develop new use cases. The learning curve and overhead of operating Apache Flink at scale would have diverted valuable energies and resources of the relatively small team, slowing down the adoption process.
- Cost-effectiveness – Managed Service for Apache Flink employs a pay-as-you-go model that aligns with operational budgets. This flexibility is particularly beneficial for managing costs in line with fluctuating data processing needs.
Challenges of handling late events
Common stream processing use cases require aggregating events based on when they were generated. This is called event time semantics. When implementing this type of logic, you may encounter the problem of delayed events, in which events reach your processing system late, long after other events generated around the same time.
Late events are common in IoT due to reasons inherent to the environment, such as network delays, device failures, temporarily disconnected devices, or downtime. IoT devices often communicate over wireless networks, which can introduce delays in transmitting data packets. And sometimes they may experience intermittent connectivity issues, resulting in data being buffered and sent in batches after connectivity is restored. This may result in events being processed out of order—some events may be processed several minutes after other events that were generated around the same time.
Imagine you want to aggregate events generated by devices within a specific 10-second window. If events can be several minutes late, how can you be sure you have received all events that were generated in those 10 seconds?
A simple implementation may just wait for several minutes, allowing late events to arrive. But this method means that you can’t calculate the result of your aggregation until several minutes later, increasing the output latency. Another solution would be waiting a few seconds, and then dropping any events arriving later.
Increasing latency or dropping events that may contain critical information are not palatable options for the business. The solution must be a good compromise, a trade-off between latency and completeness.
Apache Flink offers event time semantics out of the box. In contrast to other stream processing frameworks, Flink offers multiple options for dealing with late events. We dive into how Apache Flink deal with late events next.
A powerful stream processing API
Apache Flink provides a rich set of operators and libraries for common data processing tasks, including windowing, joins, filters, and transformations. It also includes over 40 connectors for various data sources and sinks, including streaming systems like Apache Kafka and Amazon Managed Streaming for Apache Kafka, or Kinesis Data Streams, databases, and also file system and object stores like Amazon Simple Storage Service (Amazon S3).
But the most important characteristic for PostNL is that Apache Flink offers different APIs with different level of abstractions. You can start with a higher level of abstraction, SQL, or Table API. These APIs abstract streaming data as more familiar tables, making them easier to learn for simpler use cases. If your logic becomes more complex, you can switch to the lower level of abstraction of the DataStream API, where streams are represented natively, closer to the processing happening inside Apache Flink. If you need the finest-grained level of control on how each single event is handled, you can switch to the Process Function.
A key learning has been that choosing one level of abstraction for your application is not an irreversible architectural decision. In the same application, you can mix different APIs, depending on the level of control you need at that specific step.
Scaling horizontally
To process billions of raw events and grow with the business, the ability to scale was an essential requirement for PostNL. Apache Flink is designed to scale horizontally, distributing processing and application state across multiple processing nodes, with the ability to scale out further when the workload grows.
For this particular use case, PostNL had to aggregate the sheer volume of raw events with similar characteristics and over time, to reduce their cardinality and make the data flow manageable for the other systems downstream. These aggregations go beyond simple transformations that handle one event at a time. They require a framework capable of stateful stream processing. This is exactly the type of use case Apache Flink was designed for.
Advanced event time semantics
Apache Flink emphasizes event time processing, which enables accurate and consistent handling of data with respect to the time it occurred. By providing built-in support for event time semantics, Flink can handle out-of-order events and late data gracefully. This capability was fundamental for PostNL. As mentioned, IoT generated events may arrive late and out of order. However, the aggregation logic must be based on the moment the measurement was actually taken by the device—the event time—and not when it’s processed.
Resiliency and guarantees
PostNL had to make sure no data sent from the device is lost, even in case of failure or restart of the application. Apache Flink offers strong fault tolerance guarantees through its distributed snapshot-based checkpointing mechanism. In the event of failures, Flink can recover the state of the computations and achieve exactly-once semantics of the result. For example, each event from a device is never missed nor counted twice, even in the event of an application failure.
The journey of choosing the right Apache Flink API
A key requirement of the migration was reproducing exactly the behavior of the legacy aggregation application, as expected by the downstream systems that can’t be modified. This introduced several additional challenges, in particular around windowing semantics and late event handling.
As we have seen, in IoT, events may be out of order by several minutes. Apache Flink offers two high-level concepts for implementing event time semantics with out-of-order events: watermarks and allowed lateness.
Apache Flink provides a range of flexible APIs with different levels of abstraction. After some initial research, Flink-SQL and the Table API were discarded. These higher levels of abstraction provide advanced windowing and event time semantics, but couldn’t provide the fine-grained control PostNL needed to reproduce exactly the behavior of the legacy application.
The lower level of abstraction of the DataStream API also offers windowing aggregation capabilities, and allows you to customize the behaviors with custom triggers, evictors, and handling late events by setting an allowed lateness.
Unfortunately, the legacy application was designed to handle late events in a peculiar way. The result was a hybrid event time and processing time logic that couldn’t be easily reproduced using high-level Apache Flink primitives.
Fortunately, Apache Flink offers a further lower level of abstraction, the ProcessFunction API. With this API, you have the finest-grained control on application state, and you can use timers to implement virtually any custom time-based logic.
PostNL decided to go in this direction. The aggregation was implemented using a KeyedProcessFunction that provides a way to perform arbitrary stateful processing on keyed streams—logically partitioned streams. Raw events from each IoT device are aggregated based on their event time (the timestamp written on the event by the source device) and the results of each window is emitted based on processing time (the current system time).
This fine-grained control finally allowed PostNL to reproduce exactly the behavior expected by the downstream applications.
The journey to production readiness
Let’s explore the journey of migrating to Managed Service for Apache Flink, from the start of the project to the rollout to production.
Identifying requirements
The first step of the migration process focused on thoroughly understanding the existing system’s architecture and performance metrics. The goal was to provide a seamless transition to Managed Service for Apache Flink with minimal disruption to ongoing operations.
Understanding Apache Flink
PostNL needed to familiarize themselves with the Managed Service for Apache Flink application and its streaming processing capabilities, including built-in windowing strategies, aggregation functions, event time vs. processing time differences, and finally KeyProcessFunction and mechanisms for handling late events.
Different options were considered, using primitives provided by Apache Flink out of the box, for event time logic and late events. The biggest requirement was to reproduce exactly the behavior of the legacy application. The ability to switch to using a lower level of abstraction helped. Using the finest-grained control allowed by the ProcessFunction API, PostNL was able to handle late events exactly as the legacy application.
Designing and implementing ProcessFunction
The business logic is designed using ProcessFunction to emulate the peculiar behavior of the legacy application in handling late events without excessively delaying the initial results. PostNL decided to use Java for the implementation, because Java is the primary language for Apache Flink. Apache Flink allows you to develop and test your application locally, in your preferred integrated development environment (IDE), using all the available debug tools, before deploying it to Managed Service for Apache Flink. Java 11 with Maven compiler was used for implementation. For more information about IDE requirements, refer to Getting started with Amazon Managed Service for Apache Flink (DataStream API).
Testing and validation
The following diagram shows the architecture used to validate the new application.

To validate the behavior of the ProcessFunction and late event handling mechanisms, integration tests were designed to run both the legacy application and the Managed Service for Flink application in parallel (Steps 3 and 4). This parallel execution allowed PostNL to directly compare the results generated by each application under identical conditions. Multiple integration test cases push data to the source stream (2) in parallel (7) and wait until their aggregation window is complete, then they pull the aggregated results from the destination stream to compare (8). Integration tests are automatically triggered by the CI/CD pipeline after deployment of the infrastructure is complete. During the integration tests, the primary focus was on achieving data consistency and processing accuracy between the legacy application and the Managed Service for Flink application. The output streams, aggregated data, and processing latencies were compared to validate that the migration didn’t introduce any unexpected discrepancies. For writing and running the integration tests, Robot Framework, an open source automation framework, was utilized.
After the integration tests are passed, there is one more validation layer: end-to-end tests. Similar to the integration tests, end-to-end tests are automatically invoked by the CI/CD pipeline after the deployment of the platform infrastructure is complete. This time, multiple end-to-end test cases send data to AWS IoT Core (1) in parallel (9) and check the aggregated results from the destination S3 bucket (5, 6) dumped from the output stream to compare (10).
Deployment
PostNL decided to run the new Flink application on shadow mode. The new application ran for some time in parallel with the legacy application, consuming exactly the same inputs, and sending output from both applications to a data lake on Amazon S3. This allowed them to compare the results of the two applications using real production data, and also to test the stability and performance of the new one.
Performance optimization
During migration, the PostNL IoT platform team learned how the Flink application can be fine-tuned for optimal performance, considering factors such as data volume, processing speed, and efficient late event handling. A particularly interesting aspect was to verify that the state size wasn’t increasing unbounded over the long term. A risk of using the finest-grained control of ProcessFunction is state leak. This happens when your implementation, directly controlling the state in the ProcessFunction, misses some corner cases where a state is never deleted. This causes the state to grow unbounded. Because streaming applications are designed to run continuously, an expanding state can degrade performance and eventually exhaust memory or local disk space.
With this phase of testing, PostNL found the right balance of application parallelism and resources—including compute, memory, and storage—to process the normal daily workload profile without lag, and handle occasional peaks without over-provisioning, optimizing both performance and cost-effectiveness.
Final switch
After running the new application in shadow mode for some time, the team decided the application was stable and emitting the expected output. The PostNL IoT platform finally switched over to production and shut down the legacy application.
Key takeaways
Among the several learnings gathered in the journey of adopting Managed Service for Apache Flink, some are particularly important, and proving key when expanding to new and diverse use cases:
- Understand event time semantics – A deep understanding of event time semantics is crucial in Apache Flink for accurately implementing time-dependent data operations. This knowledge makes sure events are processed correctly relative to when they actually occurred.
- Use the powerful Apache Flink API – Apache Flink’s API allows for the creation of complex, stateful streaming applications beyond basic windowing and aggregations. It’s important to fully grasp the extensive capabilities offered by the API to tackle sophisticated data processing challenges.
- With power comes more responsibility – The advanced functionality of Apache Flink’s API brings significant responsibility. Developers must make sure applications are efficient, maintainable, and stable, requiring careful resource management and adherence to best practices in coding and system design.
- Don’t mix event time and processing time logic – Combining event time and processing time for data aggregation presents unique challenges. It prevents you from using higher-level functionalities provided out of the box by Apache Flink. The lowest level of abstractions among Apache Flink APIs allow for implementing custom time-based logic, but require a careful design to achieve accuracy and timely results, alongside extensive testing to validate good performance.
Conclusion
In the journey of adopting Apache Flink, the PostNL team learned how the powerful Apache Flink APIs allow you to implement complex business logic. The team came to appreciate how Apache Flink can be utilized to solve several and diverse problems, and they are now planning to extend it to more stream processing use cases.
With Managed Service for Apache Flink, the team was able to focus on the business value and implementing the required business logic, without worrying about the heavy lifting of setting up and managing an Apache Flink cluster.
To learn more about Managed Service for Apache Flink and choosing the right managed service option and API for your use case, see What is Amazon Managed Service for Apache Flink. To experience hands-on how to develop, deploy, and operate Apache Flink applications on AWS, see the Amazon Managed Service for Apache Flink Workshop.
About the Authors
 Çağrı Çakır is the Lead Software Engineer for the PostNL IoT platform, where he manages the architecture that processes billions of events each day. As an AWS Certified Solutions Architect Professional, he specializes in designing and implementing event-driven architectures and stream processing solutions at scale. He is passionate about harnessing the power of real-time data, and dedicated to optimizing operational efficiency and innovating scalable systems.
Çağrı Çakır is the Lead Software Engineer for the PostNL IoT platform, where he manages the architecture that processes billions of events each day. As an AWS Certified Solutions Architect Professional, he specializes in designing and implementing event-driven architectures and stream processing solutions at scale. He is passionate about harnessing the power of real-time data, and dedicated to optimizing operational efficiency and innovating scalable systems.
 Özge Kavalcı works as Senior Solution Engineer for the PostNL IoT platform and loves to build cutting-edge solutions that integrate with the IoT landscape. As an AWS Certified Solutions Architect, she specializes in designing and implementing highly scalable serverless architectures and real-time stream processing solutions that can handle unpredictable workloads. To unlock the full potential of real-time data, she is dedicated to shaping the future of IoT integration.
Özge Kavalcı works as Senior Solution Engineer for the PostNL IoT platform and loves to build cutting-edge solutions that integrate with the IoT landscape. As an AWS Certified Solutions Architect, she specializes in designing and implementing highly scalable serverless architectures and real-time stream processing solutions that can handle unpredictable workloads. To unlock the full potential of real-time data, she is dedicated to shaping the future of IoT integration.
 Amit Singh works as a Senior Solutions Architect at AWS with enterprise customers on the value proposition of AWS, and participates in deep architectural discussions to make sure solutions are designed for successful deployment in the cloud. This includes building deep relationships with senior technical individuals to enable them to be cloud advocates. In his free time, he likes to spend time with his family and learn more about everything cloud.
Amit Singh works as a Senior Solutions Architect at AWS with enterprise customers on the value proposition of AWS, and participates in deep architectural discussions to make sure solutions are designed for successful deployment in the cloud. This includes building deep relationships with senior technical individuals to enable them to be cloud advocates. In his free time, he likes to spend time with his family and learn more about everything cloud.
 Lorenzo Nicora works as Senior Streaming Solutions Architect at AWS helping customers across EMEA. He has been building cloud-centered, data-intensive systems for several years, working in the finance industry both through consultancies and for fintech product companies. He has used open-source technologies extensively and contributed to several projects, including Apache Flink.
Lorenzo Nicora works as Senior Streaming Solutions Architect at AWS helping customers across EMEA. He has been building cloud-centered, data-intensive systems for several years, working in the finance industry both through consultancies and for fintech product companies. He has used open-source technologies extensively and contributed to several projects, including Apache Flink.


 Ashok Padmanabhan is a Sr. IoT Data Architect with AWS Professional Services. Ashok primarily works with manufacturing and automotive customers to design and build Industry 4.0 solutions.
Ashok Padmanabhan is a Sr. IoT Data Architect with AWS Professional Services. Ashok primarily works with manufacturing and automotive customers to design and build Industry 4.0 solutions.






 Lorenzo Nicora works as Senior Streaming Solution Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open-source technologies extensively and contributed to several projects, including Apache Flink, and is the maintainer of the Flink Prometheus connector.
Lorenzo Nicora works as Senior Streaming Solution Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open-source technologies extensively and contributed to several projects, including Apache Flink, and is the maintainer of the Flink Prometheus connector. Francisco Morillo is a Senior Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon MSK and Amazon Managed Service for Apache Flink. He is also a main contributor to the Flink Prometheus connector.
Francisco Morillo is a Senior Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon MSK and Amazon Managed Service for Apache Flink. He is also a main contributor to the Flink Prometheus connector.


 Steven Carpenter is a Senior Solution Developer on the AWS Industries Prototyping and Customer Engineering (PACE) team, helping AWS customers bring innovative ideas to life through rapid prototyping on the AWS platform. He holds a master’s degree in Computer Science from Wayne State University in Detroit, Michigan.
Steven Carpenter is a Senior Solution Developer on the AWS Industries Prototyping and Customer Engineering (PACE) team, helping AWS customers bring innovative ideas to life through rapid prototyping on the AWS platform. He holds a master’s degree in Computer Science from Wayne State University in Detroit, Michigan.  Aravindharaj Rajendran is a Senior Solution Developer within the AWS Industries Prototyping and Customer Engineering (PACE) team, based in Herndon, VA. He helps AWS customers materialize their innovative ideas by rapid prototyping using the AWS platform. Outside of work, he loves playing PC games, Badminton and Traveling.
Aravindharaj Rajendran is a Senior Solution Developer within the AWS Industries Prototyping and Customer Engineering (PACE) team, based in Herndon, VA. He helps AWS customers materialize their innovative ideas by rapid prototyping using the AWS platform. Outside of work, he loves playing PC games, Badminton and Traveling.


 Ayush Agrawal is a Startups Solutions Architect from Gurugram, India with 11 years of experience in Cloud Computing. With a keen interest in AI, ML, and Cloud Security, Ayush is dedicated to helping startups navigate and solve complex architectural challenges. His passion for technology drives him to constantly explore new tools and innovations. When he’s not architecting solutions, you’ll find Ayush diving into the latest tech trends, always eager to push the boundaries of what’s possible.
Ayush Agrawal is a Startups Solutions Architect from Gurugram, India with 11 years of experience in Cloud Computing. With a keen interest in AI, ML, and Cloud Security, Ayush is dedicated to helping startups navigate and solve complex architectural challenges. His passion for technology drives him to constantly explore new tools and innovations. When he’s not architecting solutions, you’ll find Ayush diving into the latest tech trends, always eager to push the boundaries of what’s possible. Fraser Sequeira is a Solutions Architect with AWS based in Mumbai, India. In his role at AWS, Fraser works closely with startups to design and build cloud-native solutions on AWS, with a focus on analytics and streaming workloads. With over 10 years of experience in cloud computing, Fraser has deep expertise in big data, real-time analytics, and building event-driven architecture on AWS.
Fraser Sequeira is a Solutions Architect with AWS based in Mumbai, India. In his role at AWS, Fraser works closely with startups to design and build cloud-native solutions on AWS, with a focus on analytics and streaming workloads. With over 10 years of experience in cloud computing, Fraser has deep expertise in big data, real-time analytics, and building event-driven architecture on AWS.


 Çağrı Çakır is the Lead Software Engineer for the PostNL IoT platform, where he manages the architecture that processes billions of events each day. As an AWS Certified Solutions Architect Professional, he specializes in designing and implementing event-driven architectures and stream processing solutions at scale. He is passionate about harnessing the power of real-time data, and dedicated to optimizing operational efficiency and innovating scalable systems.
Çağrı Çakır is the Lead Software Engineer for the PostNL IoT platform, where he manages the architecture that processes billions of events each day. As an AWS Certified Solutions Architect Professional, he specializes in designing and implementing event-driven architectures and stream processing solutions at scale. He is passionate about harnessing the power of real-time data, and dedicated to optimizing operational efficiency and innovating scalable systems. Özge Kavalcı works as Senior Solution Engineer for the PostNL IoT platform and loves to build cutting-edge solutions that integrate with the IoT landscape. As an AWS Certified Solutions Architect, she specializes in designing and implementing highly scalable serverless architectures and real-time stream processing solutions that can handle unpredictable workloads. To unlock the full potential of real-time data, she is dedicated to shaping the future of IoT integration.
Özge Kavalcı works as Senior Solution Engineer for the PostNL IoT platform and loves to build cutting-edge solutions that integrate with the IoT landscape. As an AWS Certified Solutions Architect, she specializes in designing and implementing highly scalable serverless architectures and real-time stream processing solutions that can handle unpredictable workloads. To unlock the full potential of real-time data, she is dedicated to shaping the future of IoT integration. Amit Singh works as a Senior Solutions Architect at AWS with enterprise customers on the value proposition of AWS, and participates in deep architectural discussions to make sure solutions are designed for successful deployment in the cloud. This includes building deep relationships with senior technical individuals to enable them to be cloud advocates. In his free time, he likes to spend time with his family and learn more about everything cloud.
Amit Singh works as a Senior Solutions Architect at AWS with enterprise customers on the value proposition of AWS, and participates in deep architectural discussions to make sure solutions are designed for successful deployment in the cloud. This includes building deep relationships with senior technical individuals to enable them to be cloud advocates. In his free time, he likes to spend time with his family and learn more about everything cloud. Lorenzo Nicora works as Senior Streaming Solutions Architect at AWS helping customers across EMEA. He has been building cloud-centered, data-intensive systems for several years, working in the finance industry both through consultancies and for fintech product companies. He has used open-source technologies extensively and contributed to several projects, including Apache Flink.
Lorenzo Nicora works as Senior Streaming Solutions Architect at AWS helping customers across EMEA. He has been building cloud-centered, data-intensive systems for several years, working in the finance industry both through consultancies and for fintech product companies. He has used open-source technologies extensively and contributed to several projects, including Apache Flink.