Post Syndicated from Brendan Coll original https://blog.cloudflare.com/workers-vitest-integration
Today, we’re excited to announce a new Workers Vitest integration – allowing you to write unit and integration tests via the popular testing framework, Vitest, that execute directly in our runtime, workerd!
This integration provides you with the ability to test anything related to your Worker!
For the first time, you can write unit tests that run within the same runtime that Cloudflare Workers run on in production, providing greater confidence that the behavior of your Worker in tests will be the same as when deployed to production. For integration tests, you can now write tests for Workers that are triggered by Cron Triggers in addition to traditional fetch() events. You can also more easily test complex applications that interact with KV, R2, D1, Queues, Service Bindings, and more Cloudflare products.
For all of your tests, you have access to Vitest features like snapshots, mocks, timers, and spies.
In addition to increased testing and functionality, you’ll also notice other developer experience improvements like hot-module-reloading, watch mode on by default, and per-test isolated storage. Meaning that, as you develop and edit your tests, they’ll automatically re-run, without you having to restart your test runner.
Get started testing Workers with Vitest
The easiest way to get started with testing your Workers via Vitest is to start a new Workers project via our create-cloudflare tool:
npm create cloudflare@latest hello-world -- --type=hello-world
Running this command will scaffold a new project for you with the Workers Vitest integration already set up. An example unit test and integration test are also included.
Manual install and setup instructions
If you prefer to manually install and set up the Workers Vitest integration, begin by installing @cloudflare/vitest-pool-workers from npm:
$ npm install --save-dev @cloudflare/vitest-pool-workers
@cloudflare/vitest-pool-workers has a peer dependency on a specific version of vitest. Modern versions of npm will install this automatically, but we recommend you install it explicitly too. Refer to the getting started guide for the current supported version. If you’re using TypeScript, add @cloudflare/vitest-pool-workers to your tsconfig.json’s types to get types for the cloudflare:test module:
$ npm install --save-dev @cloudflare/vitest-pool-workers
@cloudflare/vitest-pool-workers has a peer dependency on a specific version of vitest. Modern versions of npm will install this automatically, but we recommend you install it explicitly too. Refer to the getting started guide for the current supported version. If you’re using TypeScript, add @cloudflare/vitest-pool-workers to your tsconfig.json’s types to get types for the cloudflare:test module:
{
"compilerOptions": {
"module": "esnext",
"moduleResolution": "bundler",
"lib": ["esnext"],
"types": [
"@cloudflare/workers-types/experimental",
"@cloudflare/vitest-pool-workers"
]
}
}
Then, enable the pool in your Vitest configuration file:
// vitest.config.js
import { defineWorkersConfig } from "@cloudflare/vitest-pool-workers/config";
export default defineWorkersConfig({
test: {
poolOptions: {
workers: {
wrangler: { configPath: "./wrangler.toml" },
},
},
},
});
After that, define a compatibility date after “2022-10-31” and enable the nodejs_compat compatibility flag in your wrangler.toml:
# wrangler.toml
main = "src/index.ts"
compatibility_date = "2024-01-01"
compatibility_flags = ["nodejs_compat"]
Test anything exported from a Worker
With the new Workers Vitest Integration, you can test anything exported from your Worker in both unit and integration-style tests. Within these tests, you can also test connected resources like R2, KV, and Durable Objects, as well as applications involving multiple Workers.
Writing unit tests
In a Workers context, a unit test imports and directly calls functions from your Worker then asserts on their return values. Let’s say you have a Worker that looks like this:
export function add(a, b) {
return a + b;
}
export default {
async fetch(request) {
const url = new URL(request.url);
const a = parseInt(url.searchParams.get("a"));
const b = parseInt(url.searchParams.get("b"));
return new Response(add(a, b));
}
}
After you’ve setup and installed the Workers Vitest integration, you can unit test this Worker by creating a new test file called index.spec.js with the following code:
import { env, createExecutionContext, waitOnExecutionContext, } from "cloudflare:test";
import { describe, it, expect } from "vitest";
import { add }, worker from "./src";
describe("Hello World worker", () => {
it(“adds two numbers”, async () => {
expect(add(2,3).toBe(5);
});
it("sends request (unit style)", async () => {
const request = new Request("http://example.com/?a=3&b=4");
const ctx = createExecutionContext();
const response = await worker.fetch(request, env, ctx);
await waitOnExecutionContext(ctx);
expect(await response.text()).toMatchInlineSnapshot(`"7"`);
});
});
Using the Workers Vitest integration, you can write unit tests like these for any of your Workers.
Writing integration tests
While unit tests are great for testing individual parts of your application, integration tests assess multiple units of functionality, ensuring that workflows and features work as expected. These are usually more complex than unit tests, but provide greater confidence that your app works as expected. In the Workers context, an integration test sends HTTP requests to your Worker and asserts on the HTTP responses.
With the Workers Vitest Integration, you can run integration tests by importing SELF from the new cloudflare:test utility like this:
// test/index.spec.ts
import { SELF } from "cloudflare:test";
import { it, expect } from "vitest";
import "../src";
// an integration test using SELF
it("sends request (integration style)", async () => {
const response = await SELF.fetch("http://example.com/?a=3&b=4");
expect(await response.text()).toMatchInlineSnapshot(`"7"`);
});
When using SELF for integration tests, your Worker code runs in the same context as the test runner. This means you can use mocks to control your Worker.
Testing different scenarios
Whether you’re writing unit or integration tests, if your application uses Cloudflare Developer Platform products (e.g. KV, R2, D1, Queues, or Durable Objects), you can test them. To demonstrate this, we have created a set of examples to help get you started testing.
Better testing experience === better testing
Having better testing tools makes it easier to test your projects right from the start, which leads to better overall quality and experience for your end users. The Workers Vitest integration provides that better experience, not just in terms of developer experience, but in making it easier to test your entire application.
The rest of this post will focus on how we built this new testing integration, diving into the internals of how Vitest works, the problems we encountered trying to get a framework to work within our runtime, and ultimately how we solved it and the improved DX that it unlocked.
How Vitest traditionally works
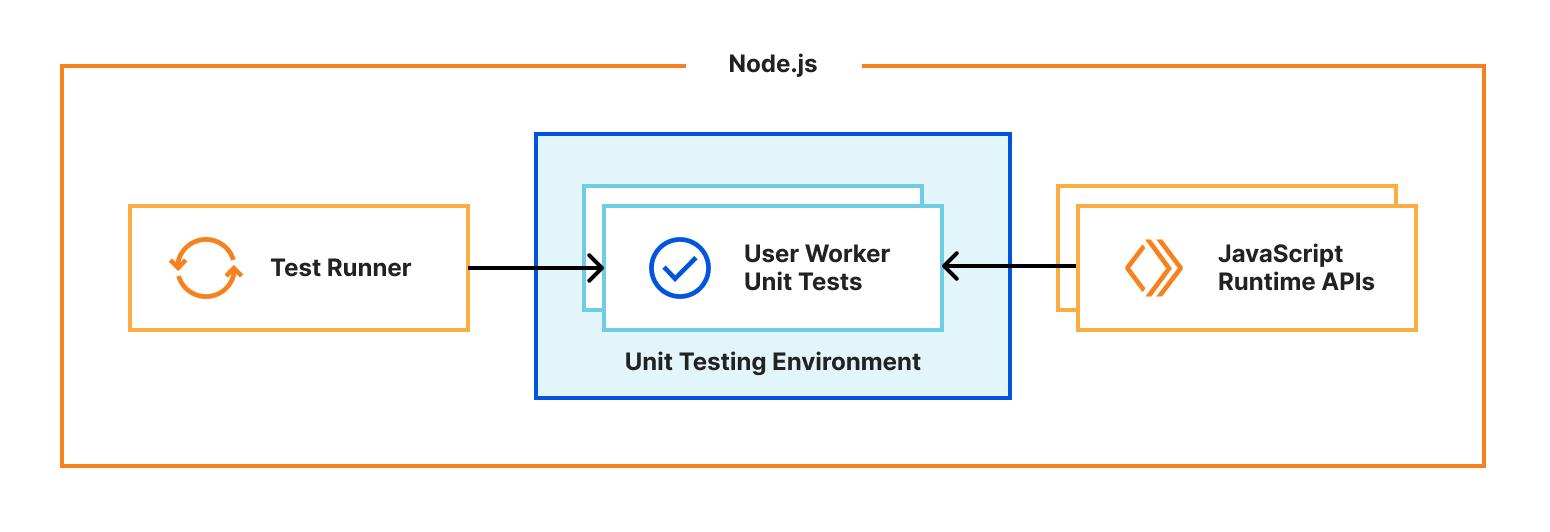
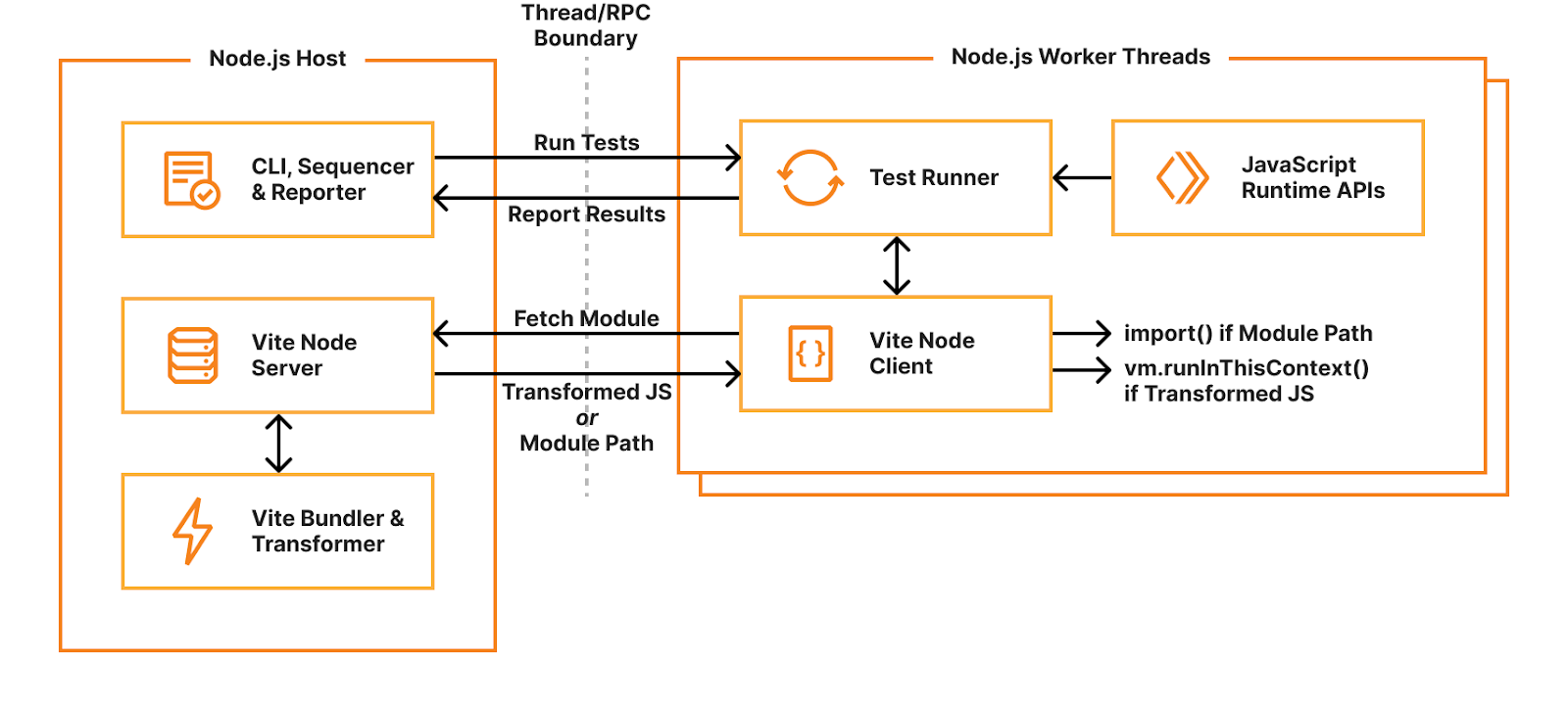
When you start Vitest’s CLI, it first collects and sequences all your test files. By default, Vitest uses a “threads” pool, which spawns Node.js worker threads for isolating and running tests in parallel. Each thread gets a test file to run, dynamically requesting and evaluating code as needed. When the test runner imports a module, it sends a request to the host’s “Vite Node Server” which will either return raw JavaScript code transformed by Vite, or an external module path. If raw code is returned, it will be executed using the node:vm runInThisContext() function. If a module path is returned, it will be imported using dynamic import(). Transforming user code with Vite allows hot-module-reloading (HMR) — when a module changes, it’s invalidated in the module cache and a new version will be returned when it’s next imported.
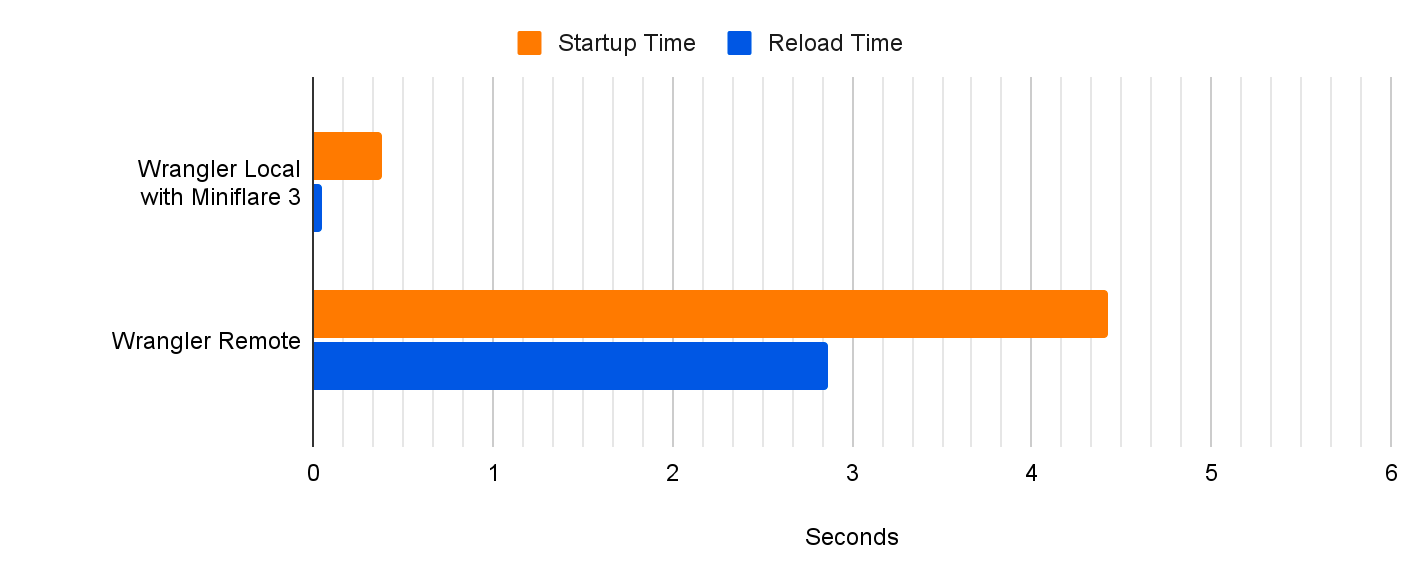
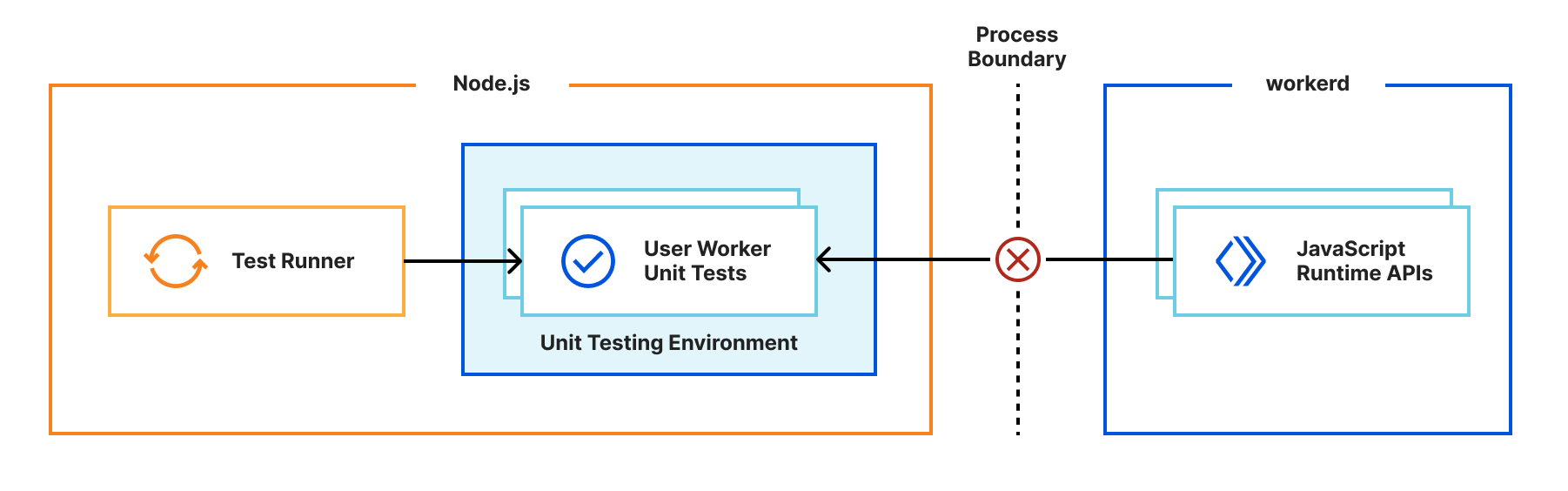
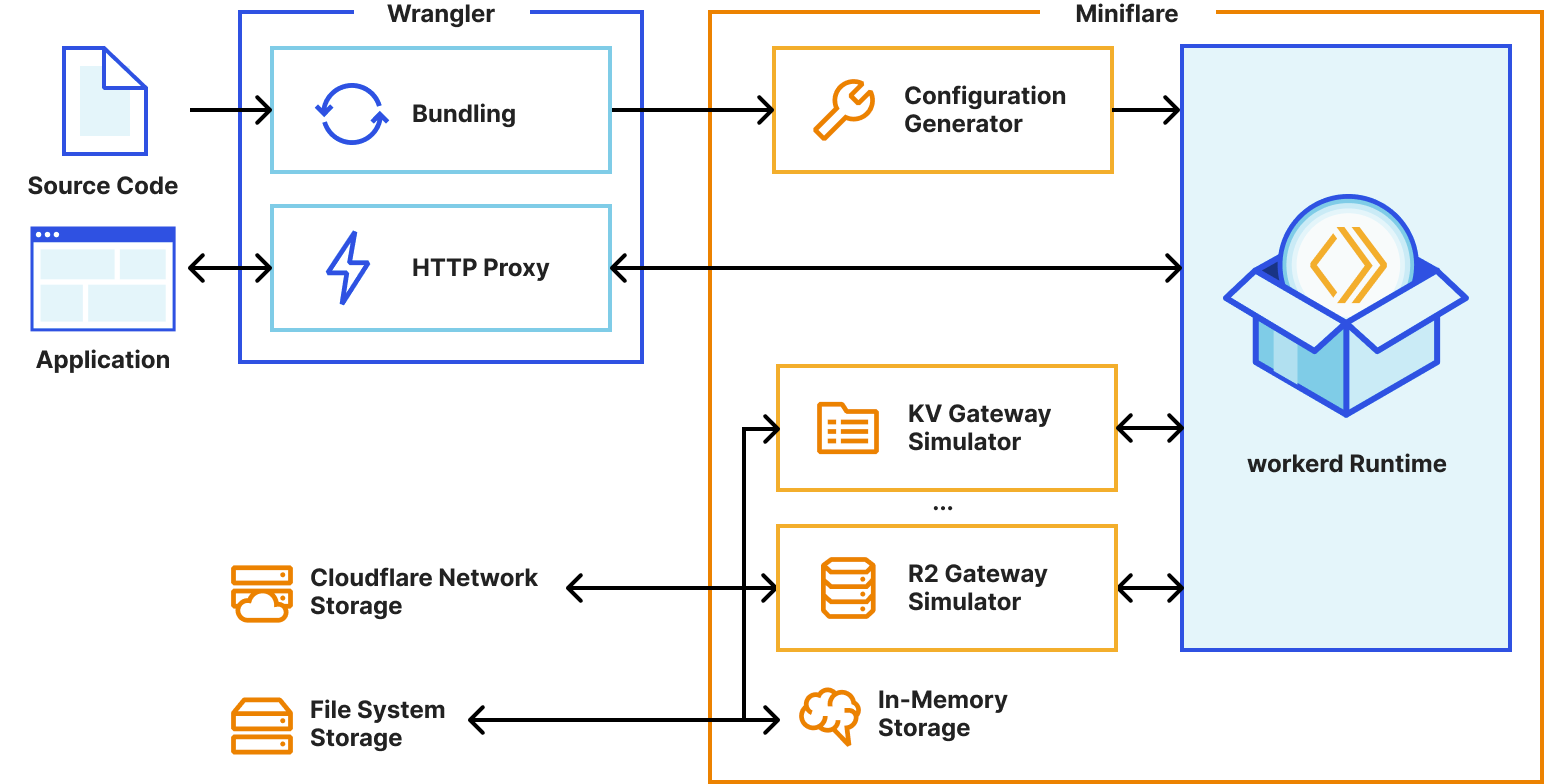
Miniflare is a fully-local simulator for Cloudflare’s Developer Platform. Miniflare v2 provided a custom environment for Vitest that allowed you to run your tests inside the Workers sandbox. This meant you could import and call any function using Workers runtime APIs in your tests. You weren’t restricted to integration tests that just sent and received HTTP requests. In addition, this environment provided per-test isolated storage, automatically undoing any changes made at the end of each test. In Miniflare v2, this environment was relatively simple to implement. We’d already reimplemented Workers Runtime APIs in a Node.js environment, and could inject them using Vitest’s APIs into the global scope of the test runner.
By contrast, Miniflare v3 runs your Worker code inside the same workerd runtime that Cloudflare uses in production. Running tests directly in workerd presented a challenge — workerd runs in its own process, separate from the Node.js worker thread, and it’s not possible to reference JavaScript classes across a process boundary.
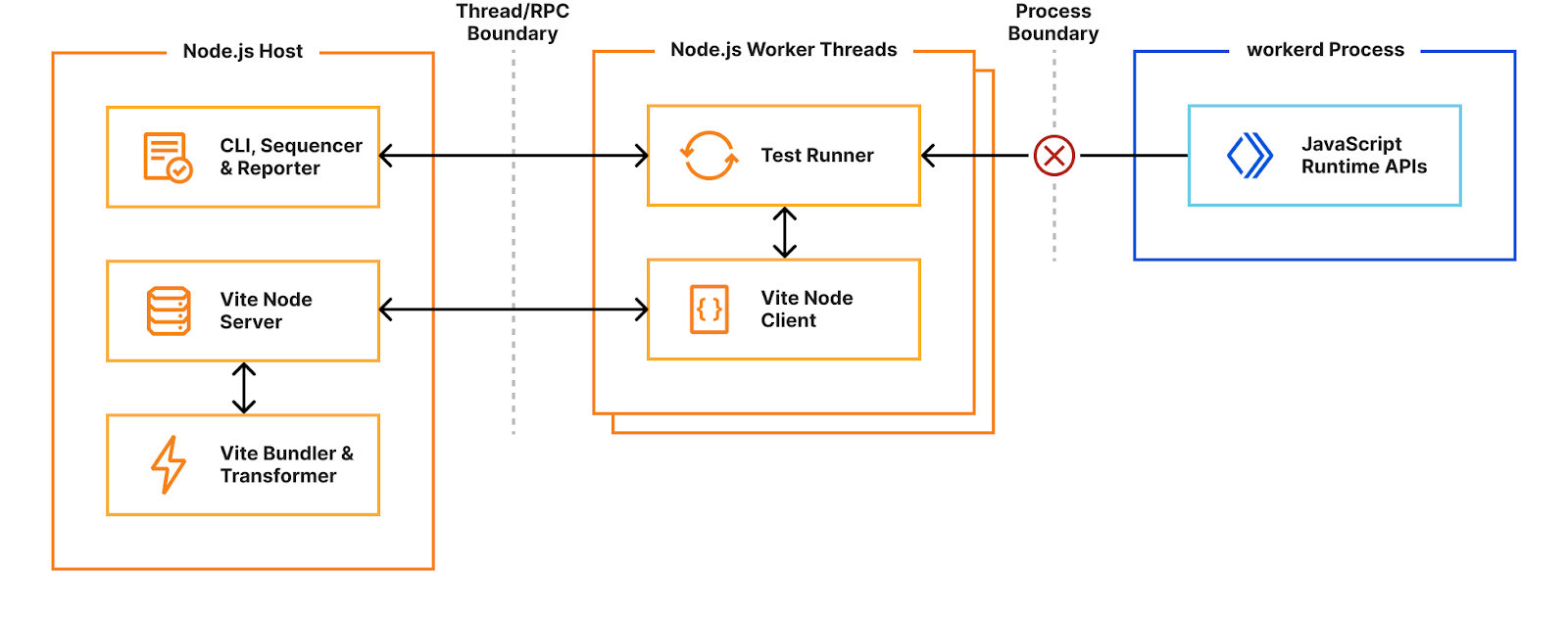
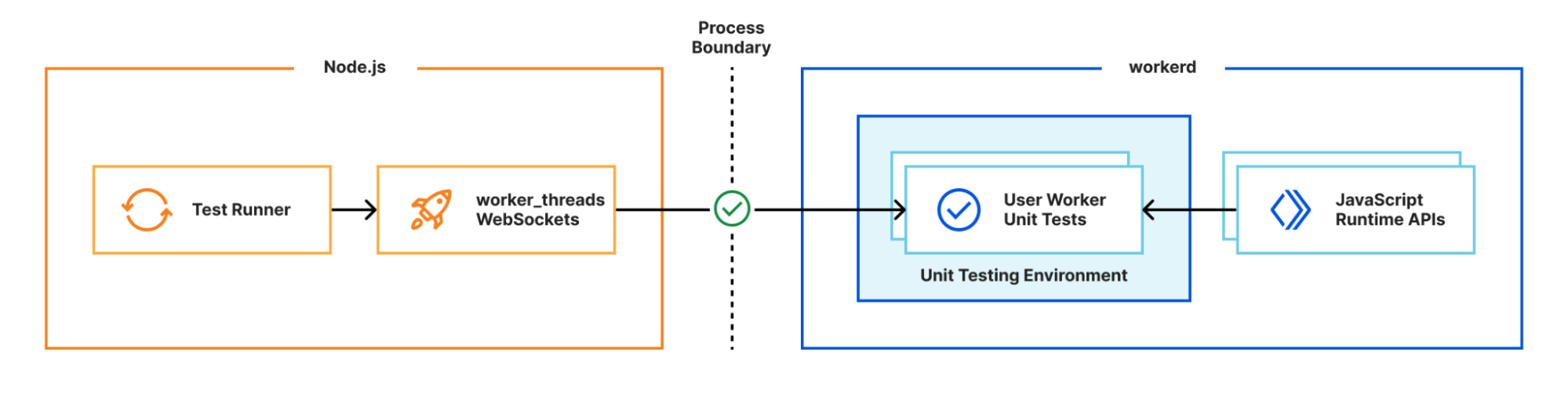
Solving the problem with custom pools
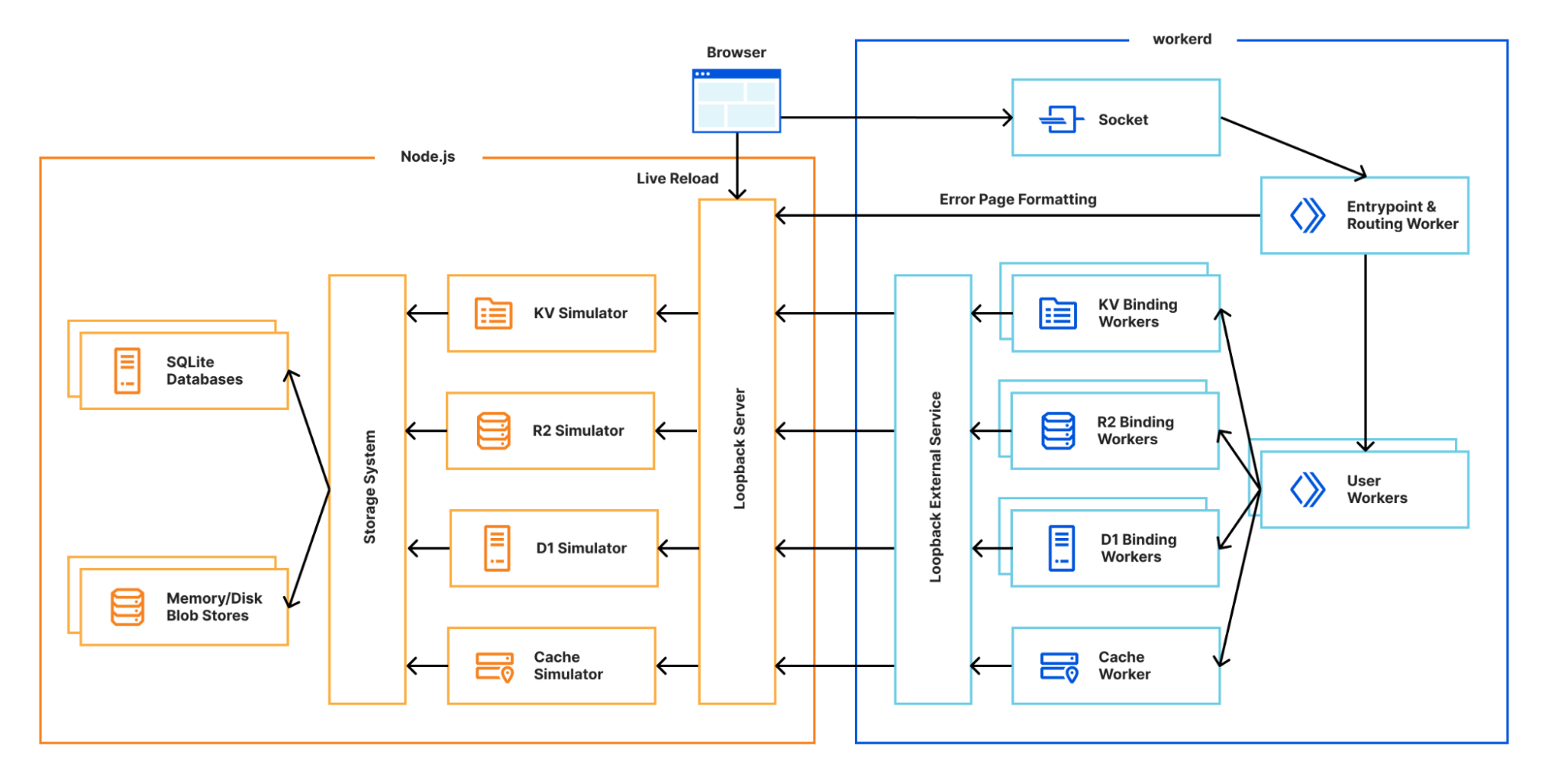
Instead, we use Vitest’s custom pools feature to run the test runner in Cloudflare Workers running locally with workerd. A pool receives test files to run and decides how to execute them. By executing the runner inside workerd, tests have direct access to Workers runtime APIs as they’re running in a Worker. WebSockets are used to send and receive serialisable RPC messages between the Node.js host and workerd process. Note we’re running the exact same test runner code originally designed for a Node-context inside a Worker here. This means our Worker needs to provide Node’s built-in modules, support for dynamic code evaluation, and loading of arbitrary modules from disk with Node-resolution behavior. The nodejs_compat compatibility flag provides support for some of Node’s built-in modules, but does not solve our other problems. For that, we had to get creative…
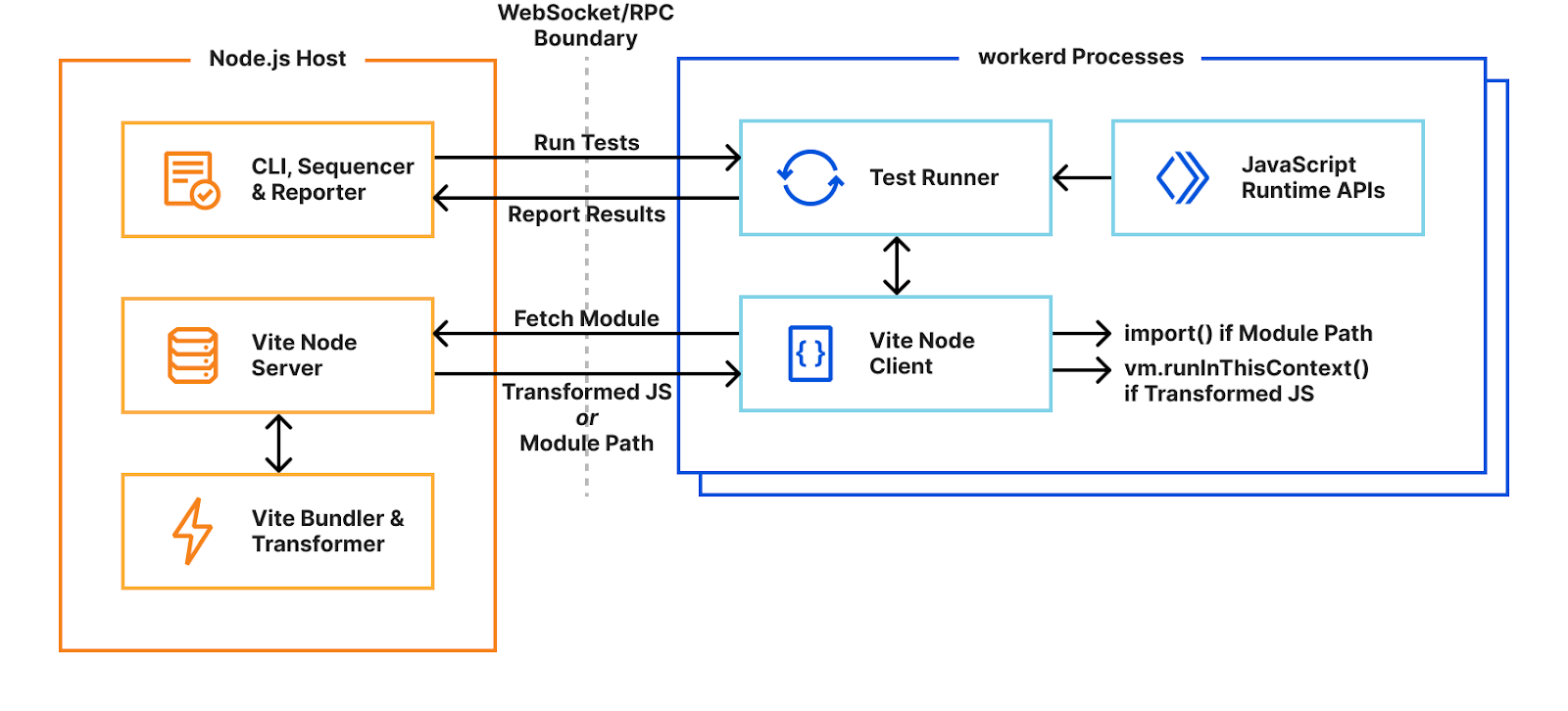
Dynamic code evaluation
For security reasons, the Cloudflare Workers runtime does not allow dynamic code evaluation via eval() or new Function(). It also requires all modules to be defined ahead-of-time before execution starts. The test runner doesn’t know what code to run until we start executing tests, so without lifting these restrictions, we have no way of executing the raw JavaScript code transformed by Vite nor importing arbitrary modules from disk. Fortunately, code that is only meant to run locally – like tests – has a much more relaxed security model than deployed code. To support local testing and other development-specific use-cases such as Vite’s new Runtime API, we added “unsafe-eval bindings” and “module-fallback services” to workerd.
Unsafe-eval bindings provide local-only access to the eval() function, and new Function()/new AsyncFunction()/new WebAssembly.Module() constructors. By exposing these through a binding, we retain control over which code has access to these features.
// Type signature for unsafe-eval bindings
interface UnsafeEval {
eval(script: string, name?: string): unknown;
newFunction(script: string, name?: string, ...args: string[]): Function;
newAsyncFunction(script: string, name?: string, ...args: string[]): AsyncFunction;
newWasmModule(src: BufferSource): WebAssembly.Module;
}
Using the unsafe-eval binding eval() method, we were able to implement a polyfill for the required vm.runInThisContext() function. While we could also implement loading of arbitrary modules from disk using unsafe-eval bindings, this would require us to rebuild workerd’s module resolution system in JavaScript. Instead, we allow workers to be configured with module fallback services. If enabled, imports that cannot be resolved by workerd become HTTP requests to the fallback service. These include the specifier, referrer, and whether it was an import or require. The service may respond with a module definition, or a redirect to another location if the resolved location doesn’t match the specifier. Requests originating from synchronous requires will block the main thread until the module is resolved. The Workers Vitest pool’s fallback service implements Node-like resolution with Node-style interoperability between CommonJS and ES modules.
Durable Objects as test runners
Now that we can run and import arbitrary code, the next step is to get Vitest’s thread worker running inside workerd. Every incoming request has its own request context. To improve overall performance, I/O objects such as streams, request/response bodies and WebSockets created in one request context cannot be used from another. This means if we want to use a WebSocket for RPC between the pool and our workerd processes, we need to make sure the WebSocket is only used from one request context. To coordinate this, we define a singleton Durable Object for accepting the RPC connection and running tests from. Functions using RPC such as resolving modules, reporting results and console logging will always use this singleton. We use Miniflare’s “magic proxy” system to get a reference to the singleton’s stub in Node.js, and send a WebSocket upgrade request directly to it. After adding a few more Node.js polyfills, and a basic cloudflare:test module to provide access to bindings and a function for creating ExecutionContexts, we’re able to write basic Workers unit tests! 🎉
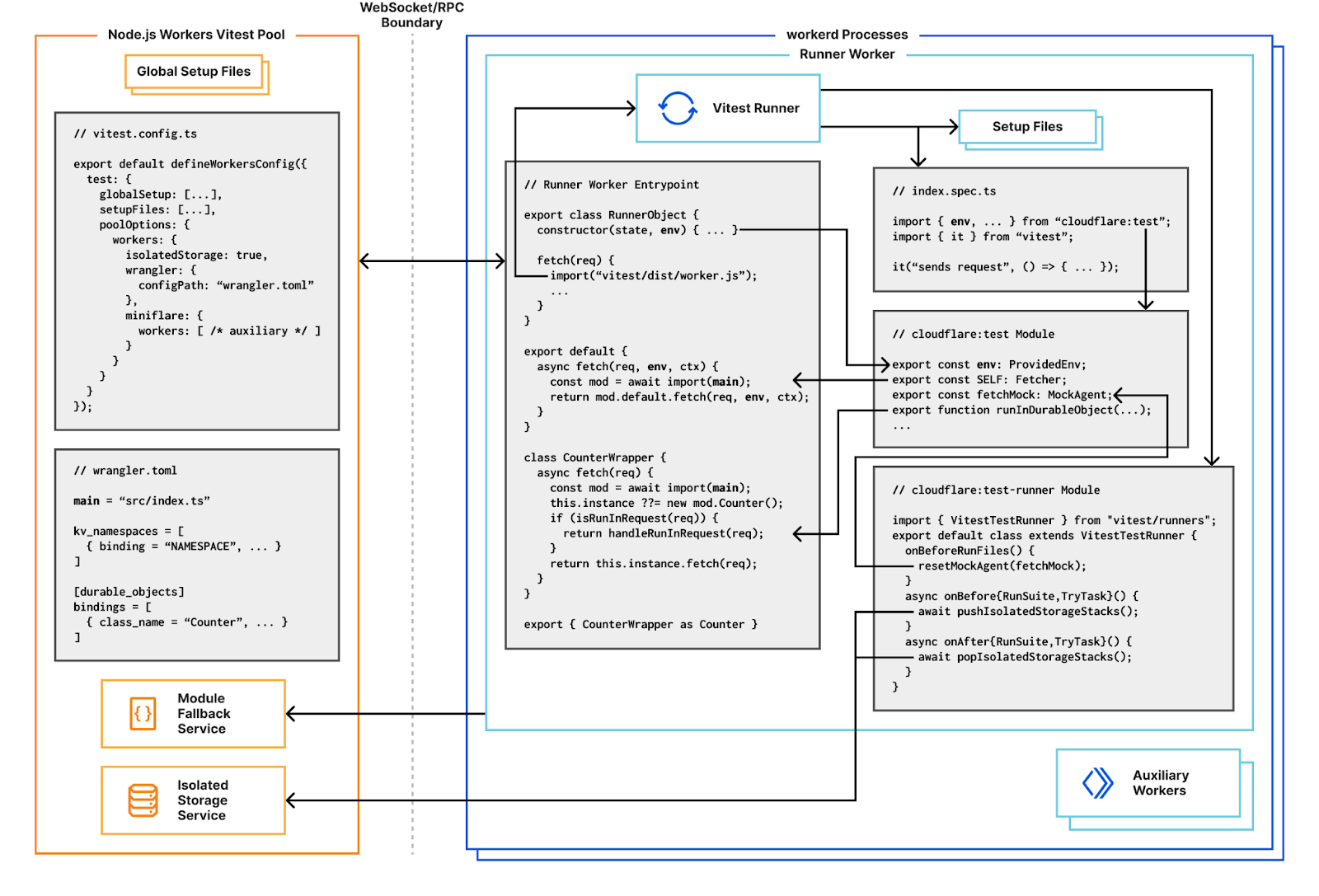
Integration tests with hot-module-reloading
In addition to unit tests, we support integration testing with a special SELF service binding in the cloudflare:test module. This points to a special export default { fetch(...) {...} } handler which uses Vite to import your Worker’s main module.
Using Vite’s transformation pipeline here means your handler gets hot-module-reloading (HMR) for free! When code is updated, the module cache is invalidated, tests are rerun, and subsequent requests will execute with new code. The same approach of wrapping user code handlers applies to Durable Objects too, providing the same HMR benefits.
Integration tests can be written by calling SELF.fetch(), which will dispatch a fetch() event to your user code in the same global scope as your test, but under a different request context. This means global mocks apply to your Worker’s execution, as do request context lifetime restrictions. In particular, if you forget to call ctx.waitUntil(), you’ll see an appropriate error message. This wouldn’t be the case if you called your Worker’s handler directly in a unit test, as you’d be running under the runner singleton’s Durable Object request context, whose lifetime is automatically extended.
// test/index.spec.ts
import { SELF } from "cloudflare:test";
import { it, expect } from "vitest";
import "../src/index";
it("sends request", async () => {
const response = await SELF.fetch("https://example.com");
expect(await response.text()).toMatchInlineSnapshot(`"body"`);
});
Isolated per-test storage
Most Workers applications will have at least one binding to a Cloudflare storage service, such as KV, R2 or D1. Ideally, tests should be self-contained and runnable in any order or on their own. To make this possible, writes to storage need to be undone at the end of each test, so reads by other tests aren’t affected. Whilst it’s possible to do this manually, it can be tricky to keep track of all writes and undo them in the correct order. For example, take the following two functions:
// helpers.ts
interface Env {
NAMESPACE: KVNamespace;
}
// Get the current list stored in a KV namespace
export async function get(env: Env, key: string): Promise<string[]> {
return await env.NAMESPACE.get(key, "json") ?? [];
}
// Add an item to the end of the list
export async function append(env: Env, key: string, item: string) {
const value = await get(env, key);
value.push(item);
await env.NAMESPACE.put(key, JSON.stringify(value));
}
If we wanted to test these functions, we might write something like below. Note we have to keep track of all the keys we might write to, and restore their values at the end of tests, even if those tests fail.
// helpers.spec.ts
import { env } from "cloudflare:test";
import { beforeAll, beforeEach, afterEach, it, expect } from "vitest";
import { get, append } from "./helpers";
let startingList1: string | null;
let startingList2: string | null;
beforeEach(async () => {
// Store values before each test
startingList1 = await env.NAMESPACE.get("list 1");
startingList2 = await env.NAMESPACE.get("list 2");
});
afterEach(async () => {
// Restore starting values after each test
if (startingList1 === null) {
await env.NAMESPACE.delete("list 1");
} else {
await env.NAMESPACE.put("list 1", startingList1);
}
if (startingList2 === null) {
await env.NAMESPACE.delete("list 2");
} else {
await env.NAMESPACE.put("list 2", startingList2);
}
});
beforeAll(async () => {
await append(env, "list 1", "one");
});
it("appends to one list", async () => {
await append(env, "list 1", "two");
expect(await get(env, "list 1")).toStrictEqual(["one", "two"]);
});
it("appends to two lists", async () => {
await append(env, "list 1", "three");
await append(env, "list 2", "four");
expect(await get(env, "list 1")).toStrictEqual(["one", "three"]);
expect(await get(env, "list 2")).toStrictEqual(["four"]);
});
This is slightly easier with the recently introduced onTestFinished() hook, but you still need to remember which keys were written to, or enumerate them at the start/end of tests. You’d also need to manage this for KV, R2, Durable Objects, caches and any other storage service you used. Ideally, the testing framework should just manage this all for you.
That’s exactly what the Workers Vitest pool does with the isolatedStorage option which is enabled by default. Any writes to storage performed in a test are automagically undone at the end of the test. To support seeding data in beforeAll() hooks, including those in nested describe()-blocks, a stack is used. Before each suite or test, a new frame is pushed to the storage stack. All writes performed by the test or associated beforeEach()/afterEach() hooks are written to the frame. After each suite or test, the top frame is popped from the storage stack, undoing any writes.

Miniflare implements simulators for storage services on top of Durable Objects with a separate blob store. When running locally, workerd uses SQLite for Durable Object storage. To implement isolated storage, we implement an on-disk stack of .sqlite database files by backing up the databases when “pushing”, and restoring backups when “popping”. Blobs stored in the separate store are retained through stack operations, and cleaned up at the end of each test run. Whilst this works, it involves copying lots of .sqlite files. Looking ahead, we’d like to explore using SQLite SAVEPOINTS for a more efficient solution.
Declarative request mocking
In addition to storage, most Workers will make outbound fetch() requests. For tests, it’s often useful to mock responses to these requests. Miniflare already allows you to specify an undici MockAgent to route all requests through. The MockAgent class provides a declarative interface for specifying requests to mock and the corresponding responses to return. This API is relatively simple, whilst being flexible enough for advanced use cases. We provide an instance of MockAgent as fetchMock in the cloudflare:test module.
import { fetchMock } from "cloudflare:test";
import { beforeAll, afterEach, it, expect } from "vitest";
beforeAll(() => {
// Enable outbound request mocking...
fetchMock.activate();
// ...and throw errors if an outbound request isn't mocked
fetchMock.disableNetConnect();
});
// Ensure we matched every mock we defined
afterEach(() => fetchMock.assertNoPendingInterceptors());
it("mocks requests", async () => {
// Mock the first request to `https://example.com`
fetchMock
.get("https://example.com")
.intercept({ path: "/" })
.reply(200, "body");
const response = await fetch("https://example.com/");
expect(await response.text()).toBe("body");
});
To implement this, we bundled a stripped down version of undici containing just the MockAgent code. We then built a custom undici Dispatcher that used the Worker’s global fetch() function instead of undici’s built-in HTTP implementation based on llhttp and node:net.
Testing Durable Objects directly
Finally, Miniflare v2’s custom Vitest environment provided support for accessing the instance methods and state of Durable Objects in tests directly. This allowed you to unit test Durable Objects like any other JavaScript class—you could mock particular methods and properties, or immediately call specific handlers like alarm(). To implement this in workerd, we rely on our existing wrapping of user Durable Objects for Vite transforms and hot-module reloading. When you call the runInDurableObject(stub, callback) function from cloudflare:test, we store callback in a global cache and send a special fetch() request to stub which is intercepted by the wrapper. The wrapper executes the callback in the request context of the Durable Object, and stores the result in the same cache. runInDurableObject() then reads from this cache, and returns the result.
Note that this assumes the Durable Object is running in the same isolate as the runInDurableObject() call. While this is true for same-Worker Durable Objects running locally, it means Durable Objects defined in auxiliary workers can’t be accessed directly.
Try it out!
We are excited to release the @cloudflare/vitest-pool-workers package on npm, and to provide an improved testing experience for you.
Make sure to read the Write your first test guide and begin writing unit and integration tests today! If you’ve been writing tests using one of our previous options, our unstable_dev migration guide or our Miniflare 2 migration guide should explain key differences and help you move your tests over quickly.
If you run into issues or have suggestions for improvements, please file an issue in our GitHub repo or reach out via our Developer Discord.