Post Syndicated from Igor Minar original https://blog.cloudflare.com/blazing-fast-development-with-full-stack-frameworks-and-cloudflare
Hello web developers! Last year we released a slew of improvements that made deploying web applications on Cloudflare much easier, and in response we’ve seen a large growth of Astro, Next.js, Nuxt, Qwik, Remix, SolidStart, SvelteKit, and other web apps hosted on Cloudflare. Today we are announcing major improvements to our integration with these web frameworks that makes it easier to develop sophisticated applications that use our D1 SQL database, R2 object store, AI models, and other powerful features of Cloudflare’s developer platform.
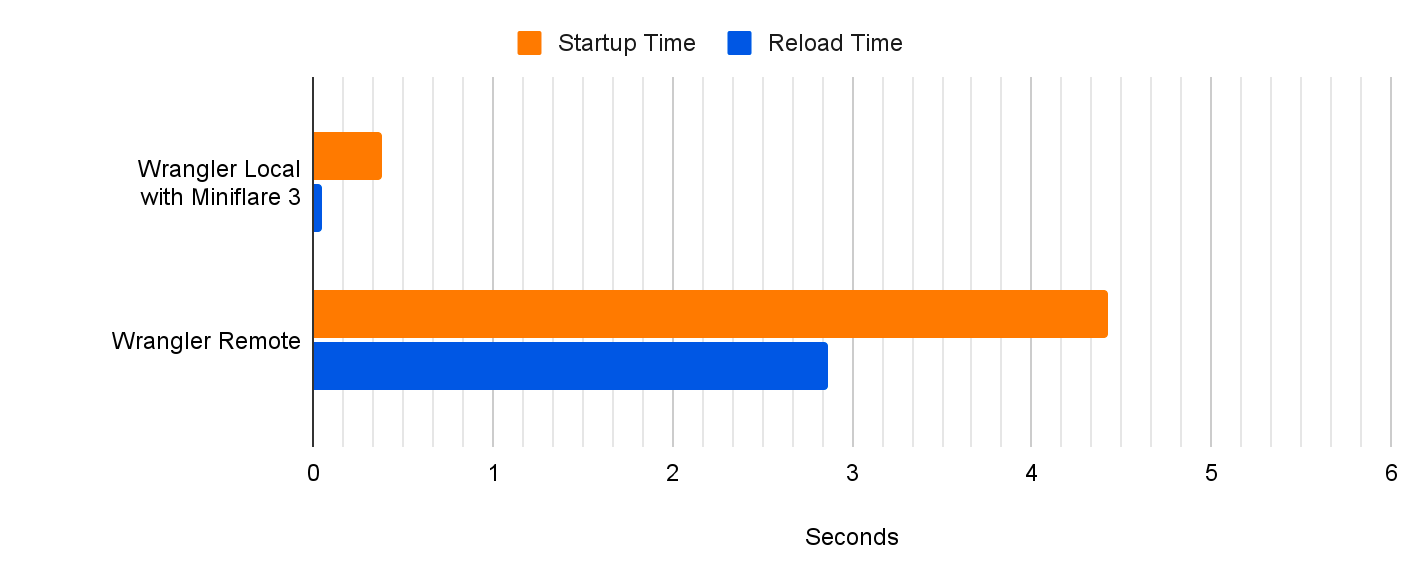
In the past, if you wanted to develop a web framework-powered application with D1 and run it locally, you’d have to build a production build of your application, and then run it locally using `wrangler pages dev`. While this worked, each of your code iterations would take seconds, or tens of seconds for big applications. Iterating using production builds is simply too slow, pulls you out of the flow, and doesn’t allow you to take advantage of all the DX optimizations that framework authors have put a lot of hard work into. This is changing today!
Our goal is to integrate with web frameworks in the most natural way possible, without developers having to learn and adopt significant workflow changes or custom APIs when deploying their app to Cloudflare. Whether you are a Next.js developer, a Nuxt developer, or prefer another framework, you can now keep on using the blazing fast local development workflow familiar to you, and ship your application on Cloudflare.
All full-stack web frameworks come with a local development server (dev server) that is custom tailored to the framework and often provides an excellent development experience, with only one exception — they don’t natively support some important features of Cloudflare’s development platform, especially our storage solutions.
So up until recently, you had to make a tough choice. You could use the framework-specific dev server to develop your application, but forgo access to many of Cloudflare’s features. Alternatively, you could take full advantage of Cloudflare’s platform including various resources like D1 or R2, but you would have to give up using the framework specific developer tooling. In that case, your iteration cycle would slow down, and it would take seconds rather than milliseconds for you to see results of your code changes in the browser. But not anymore! Let’s take a look.
Let’s build an application
Let’s create a new application using C3 — our create-cloudflare CLI. We could use any npm client of our choice (pnpm anyone?!?), but to keep things simple in this post, we’ll stick with the default npm client. To get started, just run:
$ npm create cloudflare@latest
Provide a name for your app, or stick with the randomly generated one. Then select the “Website or web app” category, and pick a full-stack framework of your choice. We support many: Astro, Next.js, Nuxt, Qwik, Remix, SolidStart, and SvelteKit.
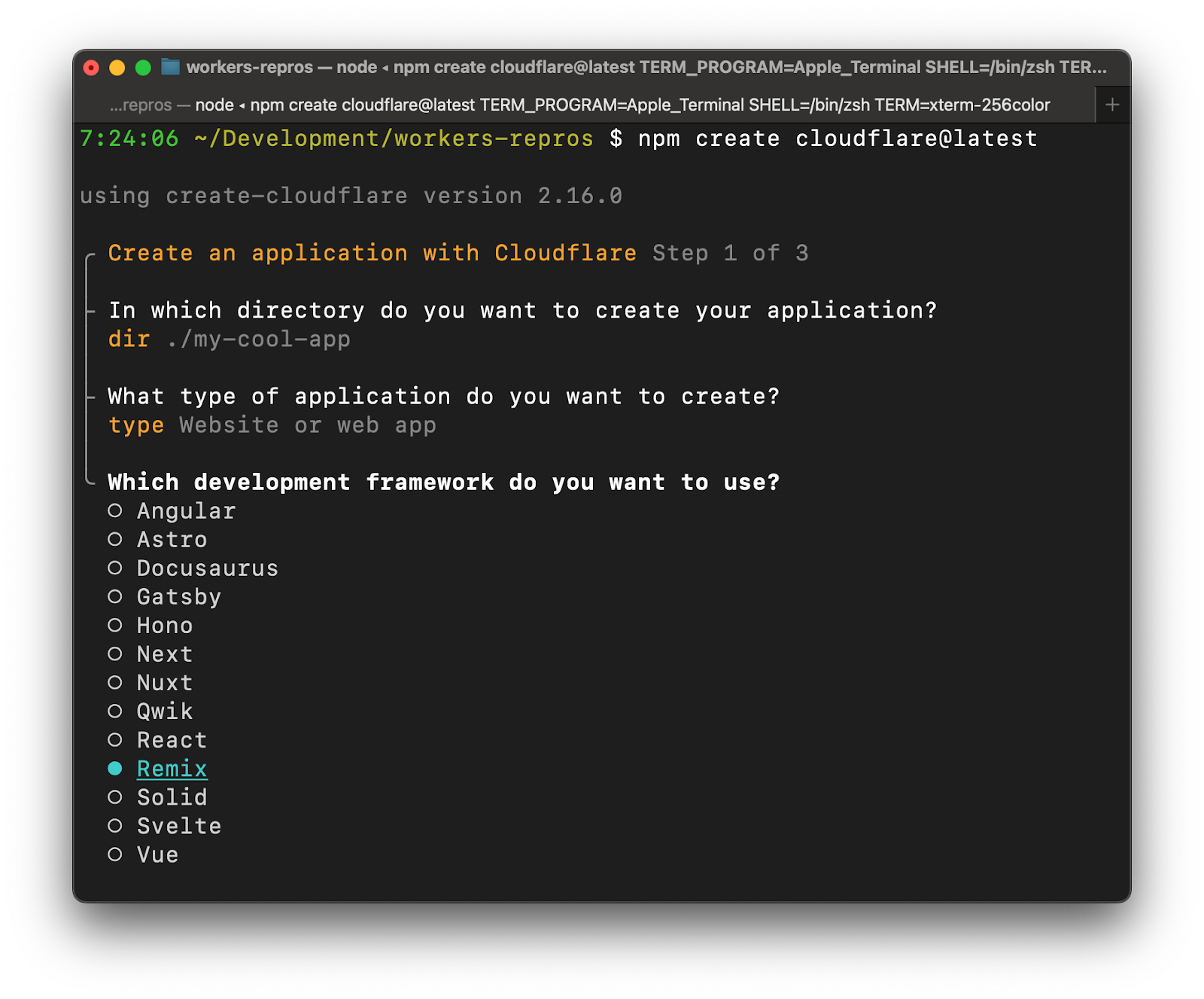
Since C3 delegates the application scaffolding to the latest version of the framework-specific CLI, you will scaffold the application exactly as the framework authors intended without missing out on any of the framework features or options. C3 then adds to your application everything necessary for integrating and deploying to Cloudflare so that you don’t have to configure it yourself.
With our application scaffolded, let’s get it to display a list of products stored in a database with just a few steps. First, we add the configuration for our database to our wrangler.toml config file:
[[d1_databases]]
binding = "DB"
database_name = "blog-products-db"
database_id = "XXXXXXXXXXXXXXXX"Yes, that’s right! You can now configure your bound resources via the wrangler.toml file, even for full-stack apps deployed to Pages. We’ll share much more about configuration enhancements to Pages in a dedicated announcement.
Now let’s create a simple schema.sql file representing our database schema:
CREATE TABLE products(product_id INTEGER PRIMARY KEY, name TEXT, price INTEGER);
INSERT INTO products (product_id, name, price) VALUES (1, 'Apple', 250), (2, 'Banana', 100), (3, 'Cherry', 375);
And initialize our database:
$ npx wrangler d1 execute blog-products-db --local --file schema.sql
Notice that we used the –local flag of wrangler d1 execute to apply the changes to our local D1 database. This is the database that our dev server will connect to.
Next, if you use TypeScript, let TypeScript know about your database by running:
$ npm run build-cf-types
This command is preconfigured for all full-stack applications created via C3 and executes wrangler types to update the interface of Cloudflare’s environment containing all configured bindings.
We can now start the dev server provided by your framework via a handy shortcut:
$ npm run dev
This shortcut will start your framework’s dev server, whether it’s powered by next dev, nitro, or vite.
Now to access our database and list the products, we can now use a framework specific approach. For example, in a Next.js application that uses the App router, we could update app/api/hello/route.ts with the following:
const db = getRequestContext().env.DB;
const productsResults = await db.prepare('SELECT * FROM products').all();
return Response.json(productsResults.results);
Or in a Nuxt application, we can create a server/api/hello.ts file and populate it with:
export default defineEventHandler(async ({ context }) => {
const db = context.cloudflare.env.DB;
const productsResults = await db.prepare('SELECT * FROM products').all();
return productsResults.results;
});
Assuming that the framework dev server is running on port 3000, you can test the new API route in either framework by navigating to http://localhost:3000/api/hello. For simplicity, we picked API routes in these examples, but the same applies to any UI-generating routes as well.
Each web framework has its own way to define routes and pass contextual information about the request throughout the application, so how you access your databases, object stores, and other resources will depend on your framework. You can read our updated full-stack framework guides to learn more:
Now that you know how to access Cloudflare’s resources in the framework of your choice, everything else you know about your framework remains the same. You can now develop your application locally, using the development server optimized for your framework, which often includes support for hot module replacement (HMR), custom dev tools, enhanced debugging support and more, all while still benefiting from Cloudflare-specific APIs and features. Win-win!
What has actually changed to enable these development workflows?
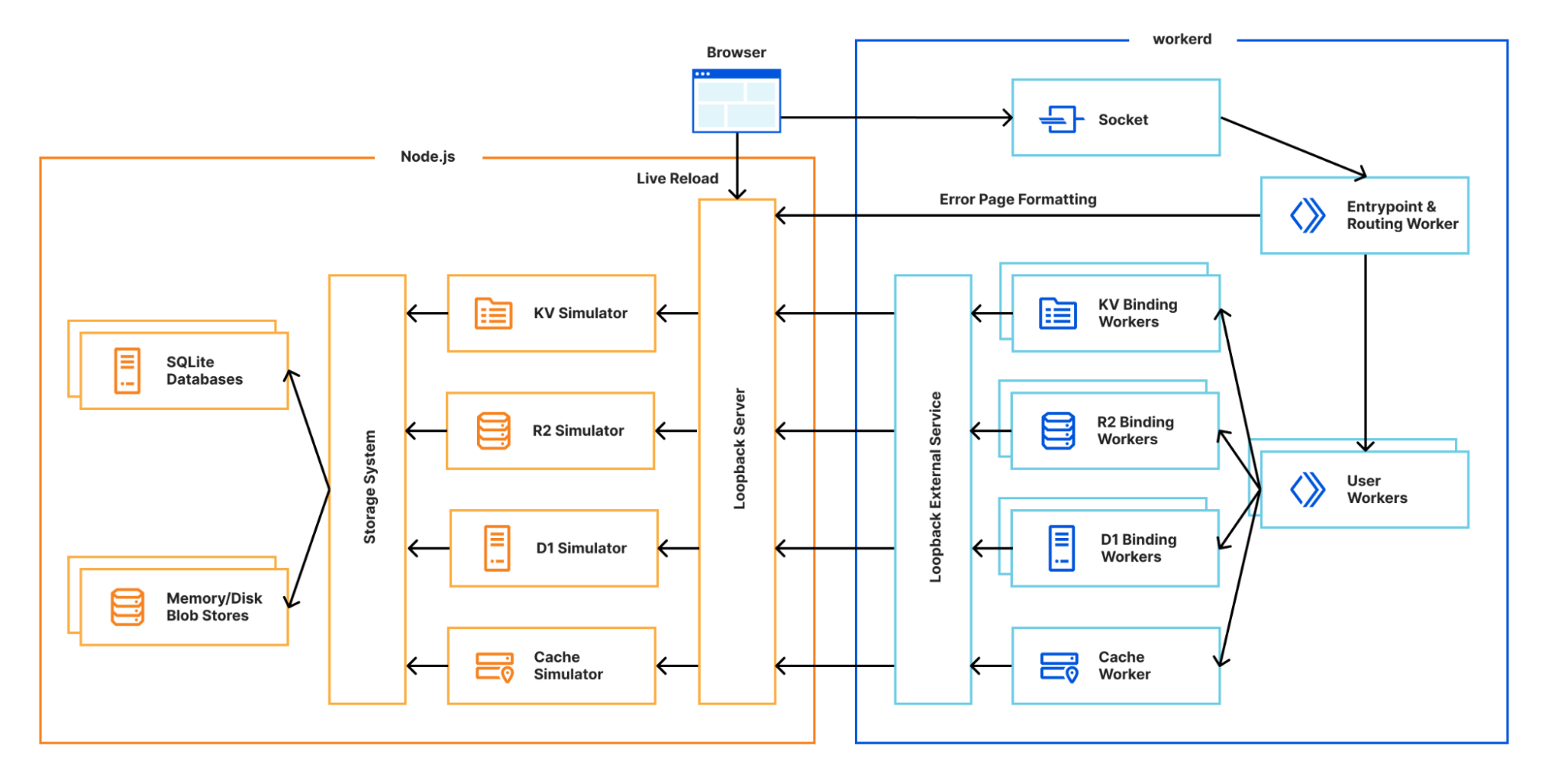
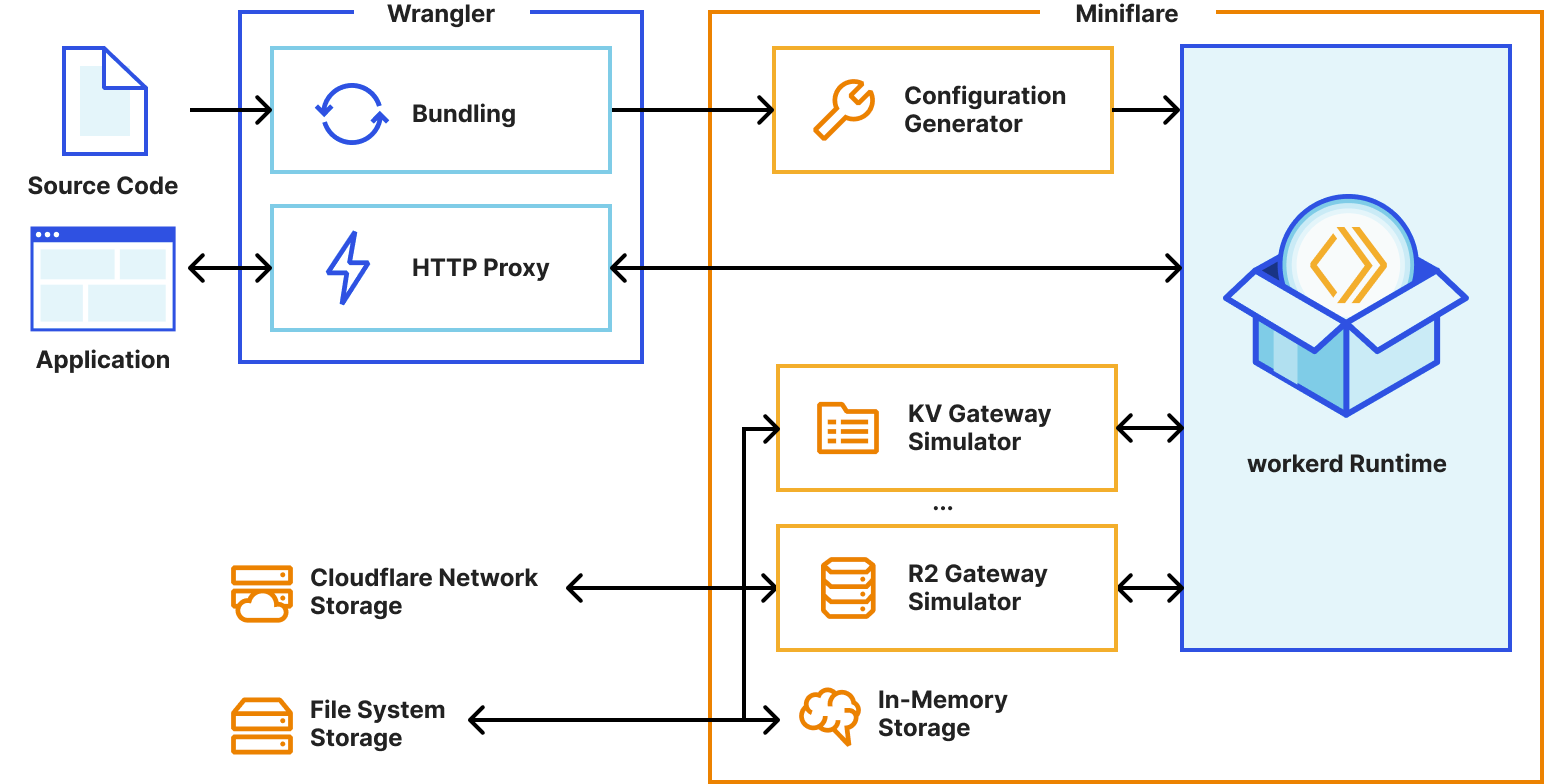
To decrease the development latency and preserve the custom framework-specific experiences, we needed to enable web frameworks and their dev servers to integrate with wrangler and miniflare in a seamless, almost invisible way.
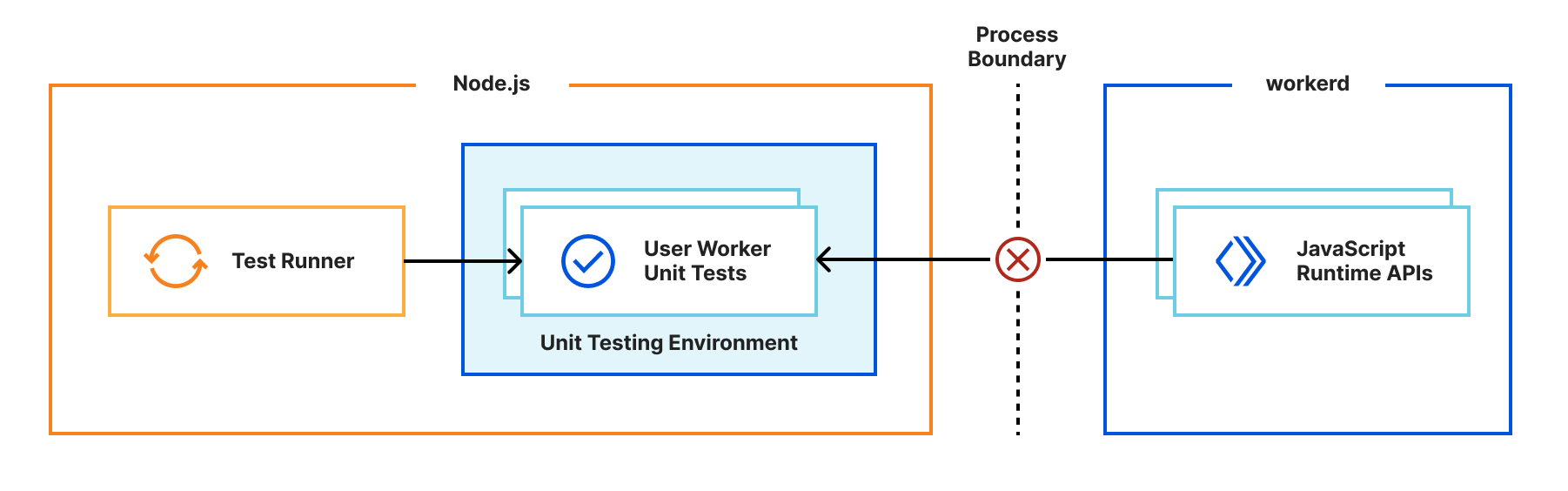
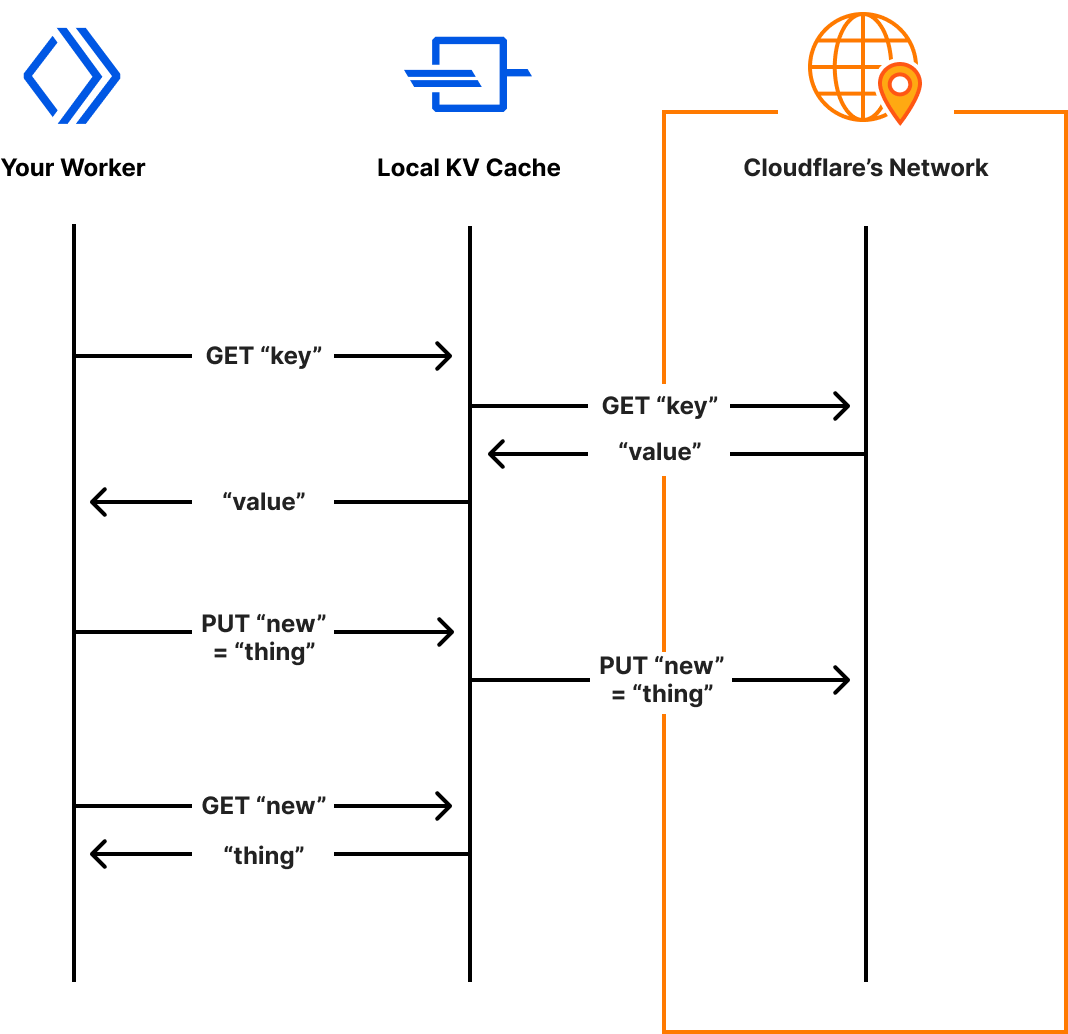
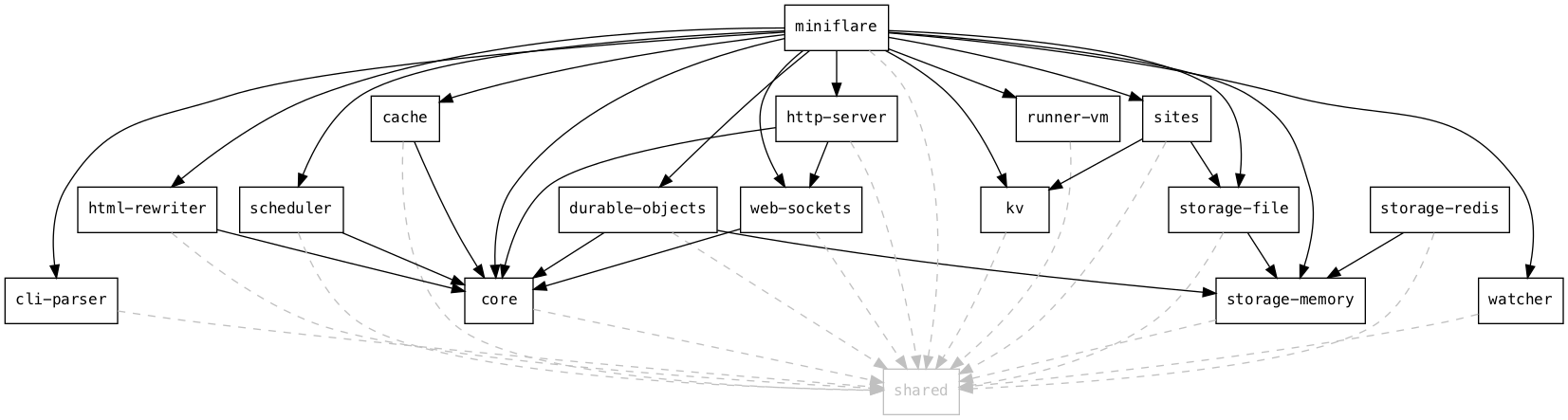
Miniflare is a key component in this puzzle. It is our local simulator for Cloudflare-specific resources, which is powered by workerd, our JavaScript (JS) runtime. By relying on workerd, we ensure that Cloudflare’s JavaScript APIs run locally in a way that faithfully simulates our production environment. The trouble is that framework dev servers already rely on Node.js to run the application, so bringing another JS runtime into the mix breaks many assumptions in how these dev servers have been architected.
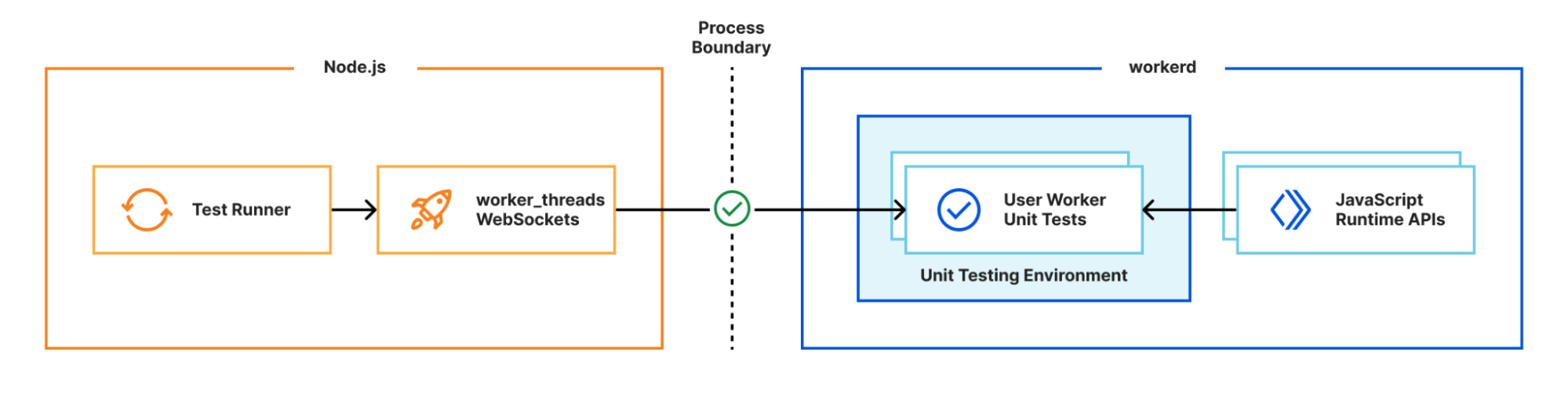
Our team however came up with an interesting approach to bridging the gap between these two JS runtimes. We call it the getPlatformProxy() API, which is now part of wrangler and is super-powered by miniflare’s magic proxy. This API exposes a JS proxy object that behaves just like the usual Workers env object containing all bound resources. The proxy object enables code from Node.js to transparently invoke JavaScript code running in workerd, as well access Cloudflare-specific runtime APIs.
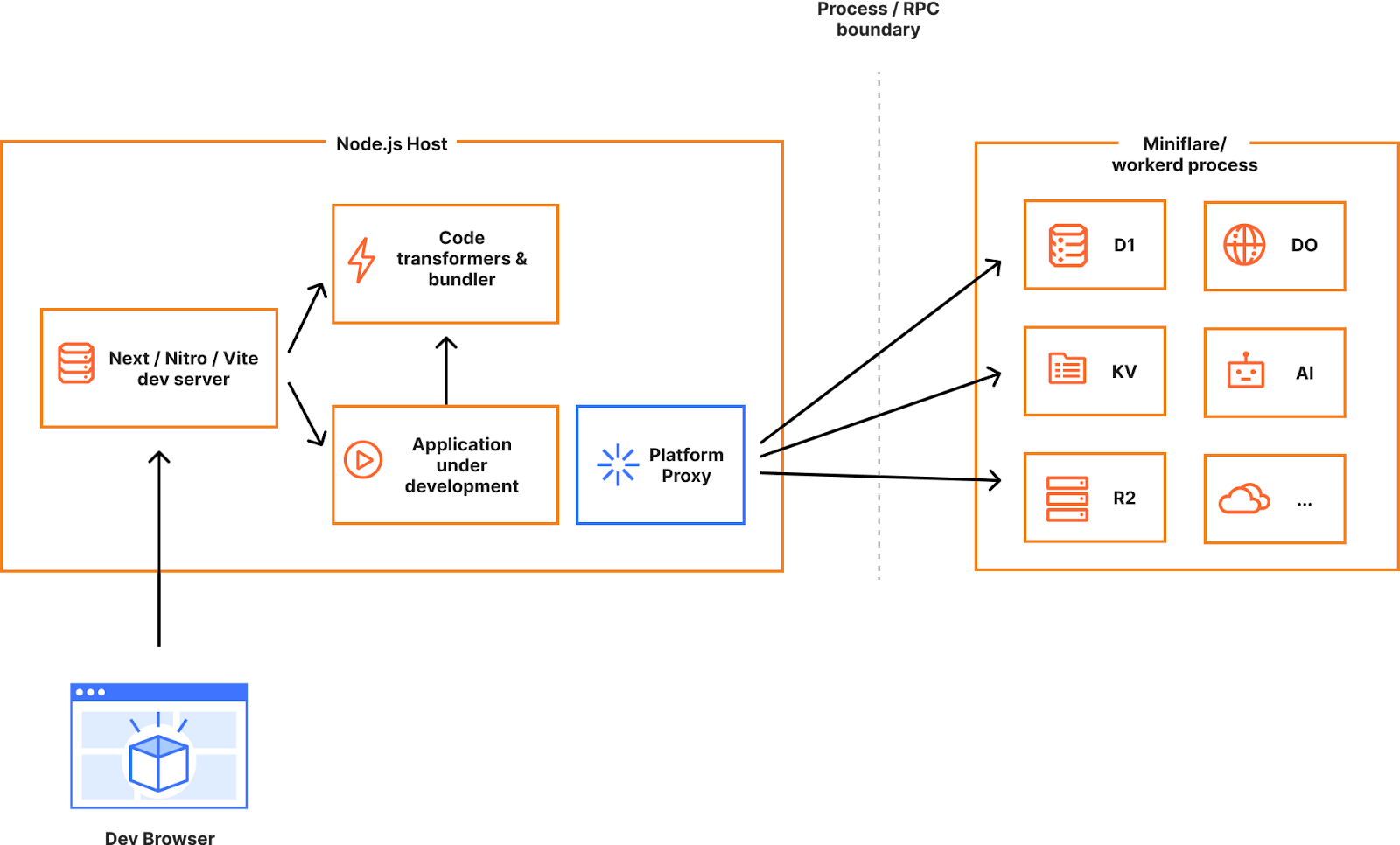
With this bridge between the Node.js and workerd runtimes, your application can now access Cloudflare simulators for D1, R2, KV and other storage solutions directly while running in a dev server powered by Node.js. Or you could even write an Node.js script to do the same:
import {getPlatformProxy} from 'wrangler';
const {env} = getPlatformProxy();
console.dir(env);
const db = env.DB;
// Now let’s execute a DB query that runs in a local D1 db
// powered by miniflare/workerd and access the result from Node.js
const productsResults = await db.prepare('SELECT * FROM products').all();
console.log(productsResults.results);With the getPlatformProxy() API available, the remaining work was all about updating all framework adapters, plugins, and in some cases frameworks themselves to make use of this API. We are grateful for the support we received from framework teams on this journey, especially Alex from Astro, pi0 from Nuxt, Pedro from Remix, Ryan from Solid, Ben and Rich from Svelte, and our collaborator on the next-on-pages project, James Anderson.
Future improvements to development workflows with Vite
While the getPlatformProxy() API is a good solution for many scenarios, we can do better. If we could run the entire application in our JS runtime rather than Node.js, we could even more faithfully simulate the production environment and reduce developer friction and production surprises.
In the ideal world, we’d like you to develop against the same runtime that you deploy to in production, and this can only be achieved by integrating workerd directly into the dev servers of all frameworks, which is not a small feat considering the number of frameworks out there and the differences between them.
We however got a bit lucky. As we kicked off this effort, we quickly realized that Vite, a popular dev server used by many full-stack frameworks, was gaining increasingly greater adoption. In fact, Remix switched over to Vite just recently and confirmed the popularity of Vite as the common foundation for web development today.
If Vite had first-class support for running a full-stack application in an alternative JavaScript runtime, we could enable anyone using Vite to develop their applications locally with complete access to the Cloudflare developer platform. No more framework specific custom integrations and workarounds — all the features of a full-stack framework, Vite, and Cloudflare accessible to all developers.
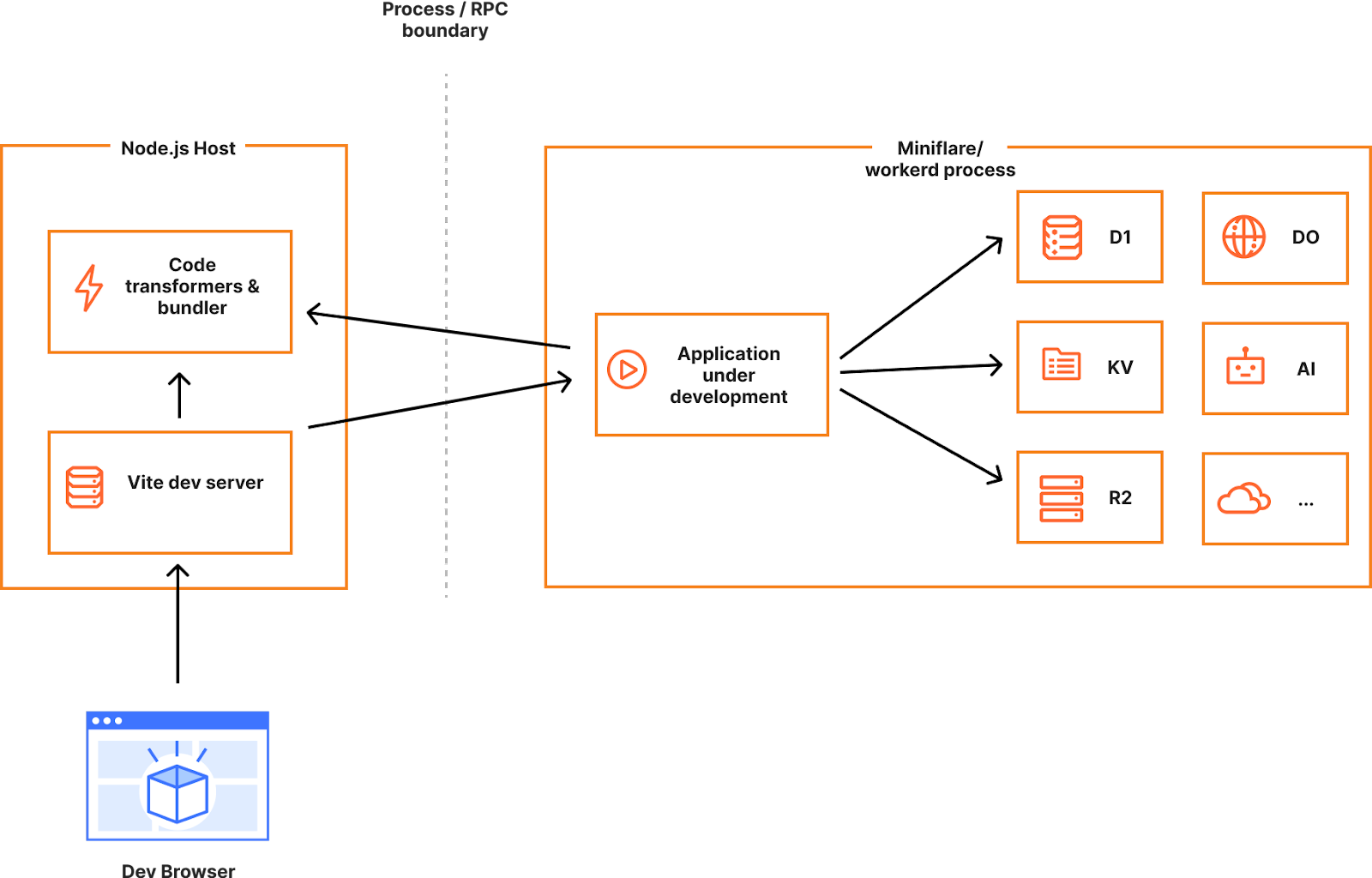
Sounds too good to be true? Maybe. We are very stoked to be working with the Vite team on the Vite environments proposal, which could enable just that. This proposal is still evolving, so stay tuned for updates.
What will you build today?
We aim to make Cloudflare the best development platform for web developers. Making it quick and easy to develop your application with frameworks and tools you are already familiar with is a big part of our story. Start your journey with us by running a single command:
$ npm create cloudflare@latest