Post Syndicated from Bryton Herdes original https://blog.cloudflare.com/route-leak-incident-january-22-2026/
On January 22, 2026, an automated routing policy configuration error caused us to leak some Border Gateway Protocol (BGP) prefixes unintentionally from a router at our data center in Miami, Florida. While the route leak caused some impact to Cloudflare customers, multiple external parties were also affected because their traffic was accidentally funnelled through our Miami data center location.
The route leak lasted 25 minutes, causing congestion on some of our backbone infrastructure in Miami, elevated loss for some Cloudflare customer traffic, and higher latency for traffic across these links. Additionally, some traffic was discarded by firewall filters on our routers that are designed to only accept traffic for Cloudflare services and our customers.
While we’ve written about route leaks before, we rarely find ourselves causing them. This route leak was the result of an accidental misconfiguration on a router in Cloudflare’s network, and only affected IPv6 traffic. We sincerely apologize to the users, customers, and networks we impacted yesterday as a result of this BGP route leak.
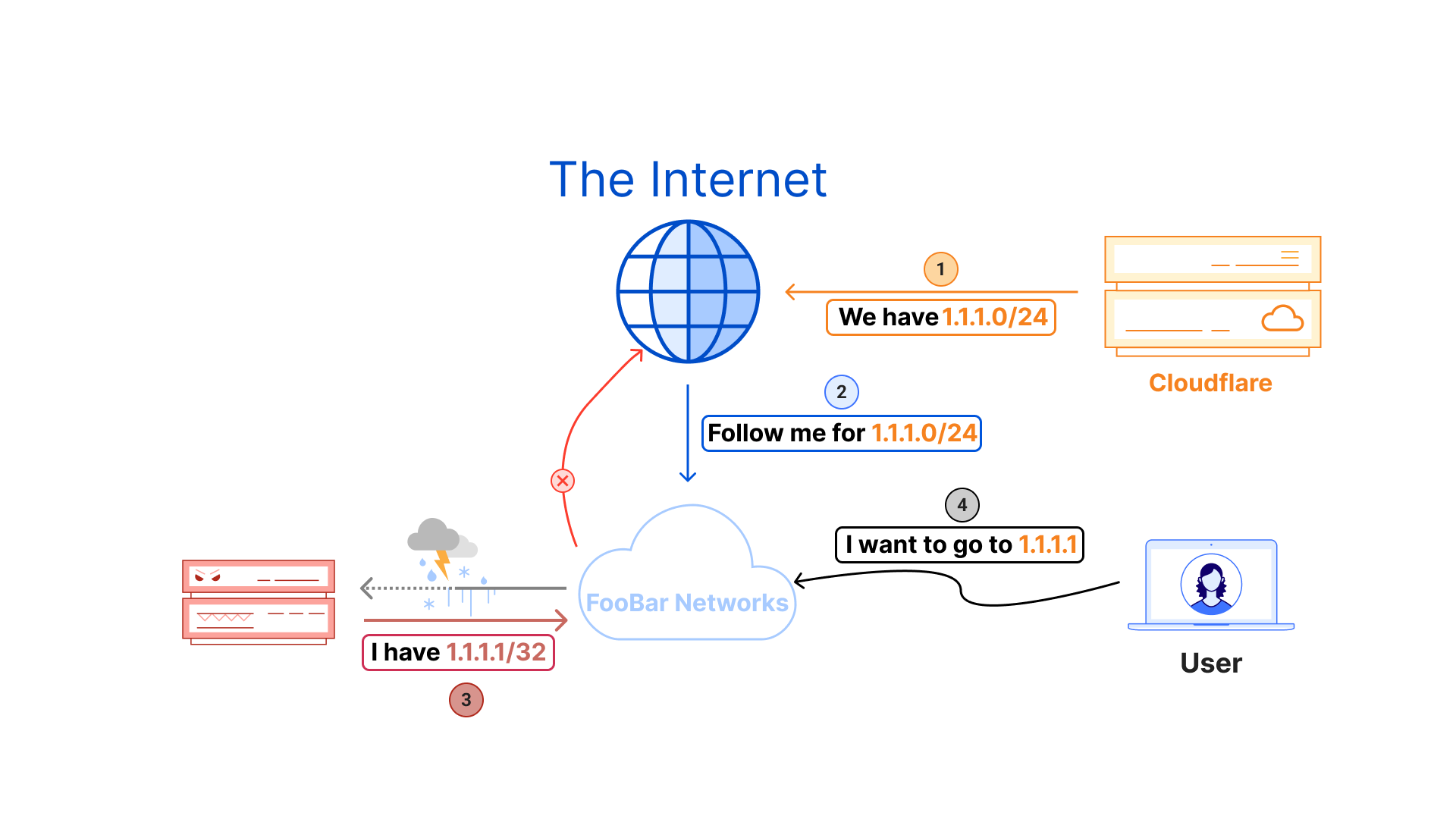
We have written multiple times about BGP route leaks, and we even record route leak events on Cloudflare Radar for anyone to view and learn from. To get a fuller understanding of what route leaks are, you can refer to this detailed background section, or refer to the formal definition within RFC7908.
Essentially, a route leak occurs when a network tells the broader Internet to send it traffic that it’s not supposed to forward. Technically, a route leak occurs when a network, or Autonomous System (AS), appears unexpectedly in an AS path. An AS path is what BGP uses to determine the path across the Internet to a final destination. An example of an anomalous AS path indicative of a route leak would be finding a network sending routes received from a peer to a provider.
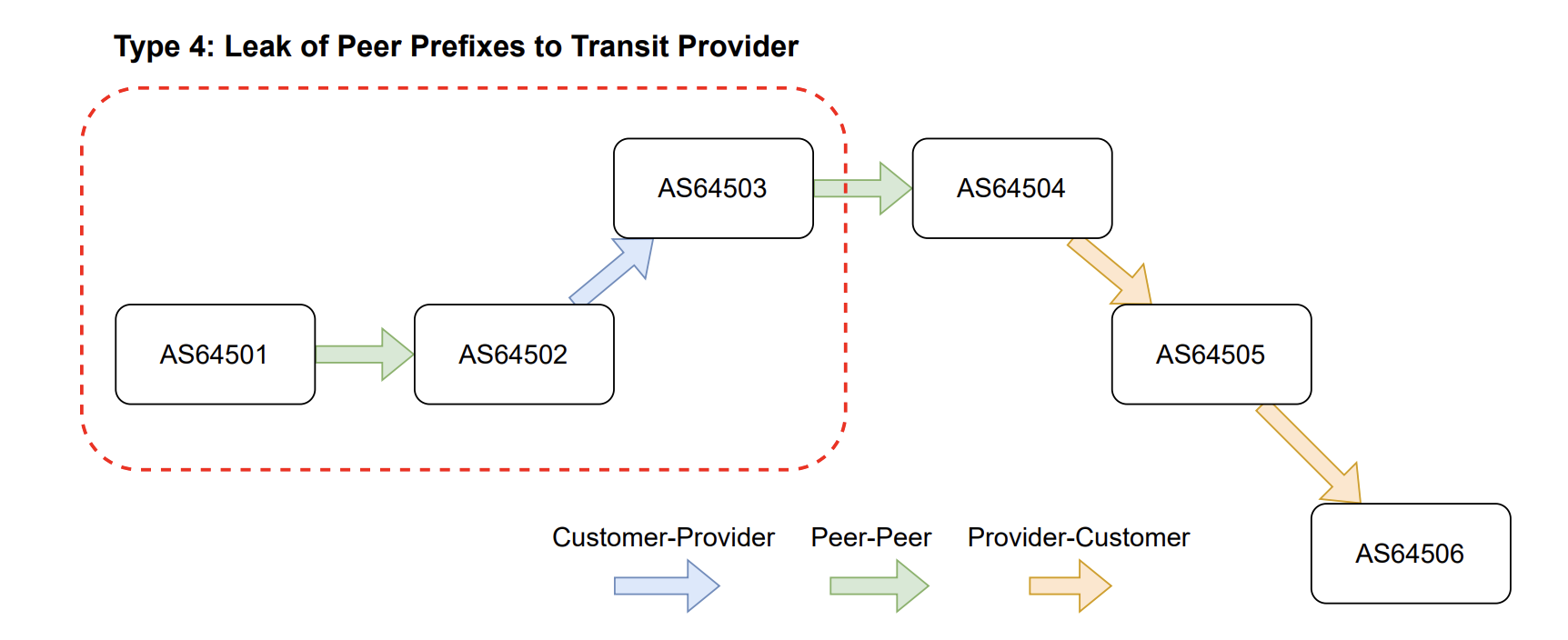
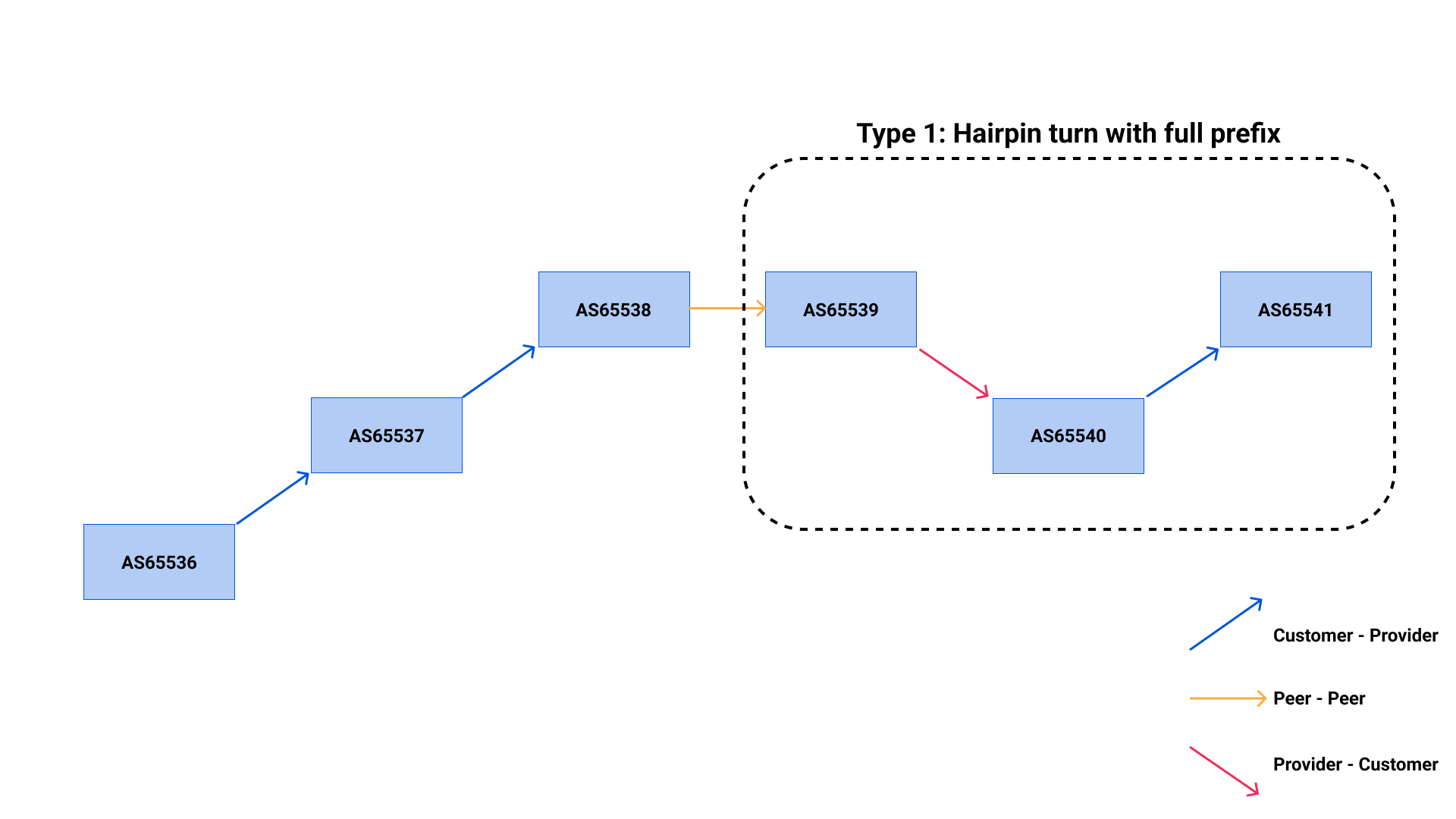
During this type of route leak, the rules of valley-free routing are violated, as BGP updates are sent from AS64501 to their peer (AS64502), and then unexpectedly up to a provider (AS64503). Oftentimes the leaker, in this case AS64502, is not prepared to handle the amount of traffic they are going to receive and may not even have firewall filters configured to accept all of the traffic coming in their direction. In simple terms, once a route update is sent to a peer or provider, it should only be sent further to customers and not to another peer or provider AS.
During the incident on January 22, we caused a similar kind of route leak, in which we took routes from some of our peers and redistributed them in Miami to some of our peers and providers. According to the route leak definitions in RFC7908, we caused a mixture of Type 3 and Type 4 route leaks on the Internet.
|
Time (UTC) |
Event |
|---|---|
|
2026-01-22 19:52 UTC |
A change that ultimately triggers the routing policy bug is merged in our network automation code repository |
|
2026-01-22 20:25 UTC |
Automation is run on single Miami edge-router resulting in unexpected advertisements to BGP transit providers and peers IMPACT START |
|
2026-01-22 20:40 UTC |
Network team begins investigating unintended route advertisements from Miami |
|
2026-01-22 20:44 UTC |
Incident is raised to coordinate response |
|
2026-01-22 20:50 UTC |
The bad configuration change is manually reverted by a network operator, and automation is paused for the router, so it cannot run again IMPACT STOP |
|
2026-01-22 21:47 UTC |
The change that triggered the leak is reverted from our code repository |
|
2026-01-22 22:07 UTC |
Automation is confirmed by operators to be healthy to run again on the Miami router, without the routing policy bug |
|
2026-01-22 22:40 UTC |
Automation is unpaused on the single router in Miami |
On January 22, 2026, at 20:25 UTC, we pushed a change via our policy automation platform to remove the BGP announcements from Miami for one of our data centers in Bogotá, Colombia. This was purposeful, as we previously forwarded some IPv6 traffic through Miami toward the Bogotá data center, but recent infrastructure upgrades removed the need for us to do so.
This change generated the following diff (a program that compares configuration files in order to determine how or whether they differ):
[edit policy-options policy-statement 6-COGENT-ACCEPT-EXPORT term ADV-SITELOCAL-GRE-RECEIVER from]
- prefix-list 6-BOG04-SITE-LOCAL;
[edit policy-options policy-statement 6-COMCAST-ACCEPT-EXPORT term ADV-SITELOCAL-GRE-RECEIVER from]
- prefix-list 6-BOG04-SITE-LOCAL;
[edit policy-options policy-statement 6-GTT-ACCEPT-EXPORT term ADV-SITELOCAL-GRE-RECEIVER from]
- prefix-list 6-BOG04-SITE-LOCAL;
[edit policy-options policy-statement 6-LEVEL3-ACCEPT-EXPORT term ADV-SITELOCAL-GRE-RECEIVER from]
- prefix-list 6-BOG04-SITE-LOCAL;
[edit policy-options policy-statement 6-PRIVATE-PEER-ANYCAST-OUT term ADV-SITELOCAL from]
- prefix-list 6-BOG04-SITE-LOCAL;
[edit policy-options policy-statement 6-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL from]
- prefix-list 6-BOG04-SITE-LOCAL;
[edit policy-options policy-statement 6-PUBLIC-PEER-OUT term ADV-SITELOCAL from]
- prefix-list 6-BOG04-SITE-LOCAL;
[edit policy-options policy-statement 6-TELEFONICA-ACCEPT-EXPORT term ADV-SITELOCAL-GRE-RECEIVER from]
- prefix-list 6-BOG04-SITE-LOCAL;
[edit policy-options policy-statement 6-TELIA-ACCEPT-EXPORT term ADV-SITELOCAL-GRE-RECEIVER from]
- prefix-list 6-BOG04-SITE-LOCAL;While this policy change looks innocent at a glance, only removing the prefix lists containing BOG04 unicast prefixes resulted in a policy that was too permissive:
policy-options policy-statement 6-TELIA-ACCEPT-EXPORT {
term ADV-SITELOCAL-GRE-RECEIVER {
from route-type internal;
then {
community add STATIC-ROUTE;
community add SITE-LOCAL-ROUTE;
community add MIA01;
community add NORTH-AMERICA;
accept;
}
}
}
The policy would now mark every prefix of type “internal” as acceptable, and proceed to add some informative communities to all matching prefixes. But more importantly, the policy also accepted the route through the policy filter, which resulted in the prefix — which was intended to be “internal” — being advertised externally. This is an issue because the “route-type internal” match in JunOS or JunOS EVO (the operating systems used by HPE Juniper Networks devices) will match any non-external route type, such as Internal BGP (IBGP) routes, which is what happened here.
As a result, all IPv6 prefixes that Cloudflare redistributes internally across the backbone were accepted by this policy, and advertised to all our BGP neighbors in Miami. This is unfortunately very similar to the outage we experienced in 2020, on which you can read more on our blog.
When the policy misconfiguration was applied at 20:25 UTC, a series of unintended BGP updates were sent from AS13335 to peers and providers in Miami. These BGP updates are viewable historically by looking at MRT files with the monocle tool or using RIPE BGPlay.
➜ ~ monocle search --start-ts 2026-01-22T20:24:00Z --end-ts 2026-01-22T20:30:00Z --as-path ".*13335[ \d$]32934$*"
A|1769113609.854028|2801:14:9000::6:4112:1|64112|2a03:2880:f077::/48|64112 22850 174 3356 13335 32934|IGP|2801:14:9000::6:4112:1|0|0|22850:65151|false|||pit.scl
A|1769113609.854028|2801:14:9000::6:4112:1|64112|2a03:2880:f091::/48|64112 22850 174 3356 13335 32934|IGP|2801:14:9000::6:4112:1|0|0|22850:65151|false|||pit.scl
A|1769113609.854028|2801:14:9000::6:4112:1|64112|2a03:2880:f16f::/48|64112 22850 174 3356 13335 32934|IGP|2801:14:9000::6:4112:1|0|0|22850:65151|false|||pit.scl
A|1769113609.854028|2801:14:9000::6:4112:1|64112|2a03:2880:f17c::/48|64112 22850 174 3356 13335 32934|IGP|2801:14:9000::6:4112:1|0|0|22850:65151|false|||pit.scl
A|1769113609.854028|2801:14:9000::6:4112:1|64112|2a03:2880:f26f::/48|64112 22850 174 3356 13335 32934|IGP|2801:14:9000::6:4112:1|0|0|22850:65151|false|||pit.scl
A|1769113609.854028|2801:14:9000::6:4112:1|64112|2a03:2880:f27c::/48|64112 22850 174 3356 13335 32934|IGP|2801:14:9000::6:4112:1|0|0|22850:65151|false|||pit.scl
A|1769113609.854028|2801:14:9000::6:4112:1|64112|2a03:2880:f33f::/48|64112 22850 174 3356 13335 32934|IGP|2801:14:9000::6:4112:1|0|0|22850:65151|false|||pit.scl
A|1769113583.095278|2001:504:d::4:9544:1|49544|2a03:2880:f17c::/48|49544 1299 3356 13335 32934|IGP|2001:504:d::4:9544:1|0|0|1299:25000 1299:25800 49544:16000 49544:16106|false|||route-views.isc
A|1769113583.095278|2001:504:d::4:9544:1|49544|2a03:2880:f27c::/48|49544 1299 3356 13335 32934|IGP|2001:504:d::4:9544:1|0|0|1299:25000 1299:25800 49544:16000 49544:16106|false|||route-views.isc
A|1769113583.095278|2001:504:d::4:9544:1|49544|2a03:2880:f091::/48|49544 1299 3356 13335 32934|IGP|2001:504:d::4:9544:1|0|0|1299:25000 1299:25800 49544:16000 49544:16106|false|||route-views.isc
A|1769113584.324483|2001:504:d::19:9524:1|199524|2a03:2880:f091::/48|199524 1299 3356 13335 32934|IGP|2001:2035:0:2bfd::1|0|0||false|||route-views.isc
A|1769113584.324483|2001:504:d::19:9524:1|199524|2a03:2880:f17c::/48|199524 1299 3356 13335 32934|IGP|2001:2035:0:2bfd::1|0|0||false|||route-views.isc
A|1769113584.324483|2001:504:d::19:9524:1|199524|2a03:2880:f27c::/48|199524 1299 3356 13335 32934|IGP|2001:2035:0:2bfd::1|0|0||false|||route-views.isc
{trimmed}
In the monocle output seen above, we have the timestamp of our BGP update, followed by the next-hop in the announcement, the ASN of the network feeding a given route-collector, the prefix involved, and the AS path and BGP communities if any are found. At the end of the output per-line, we also find the route-collector instance.
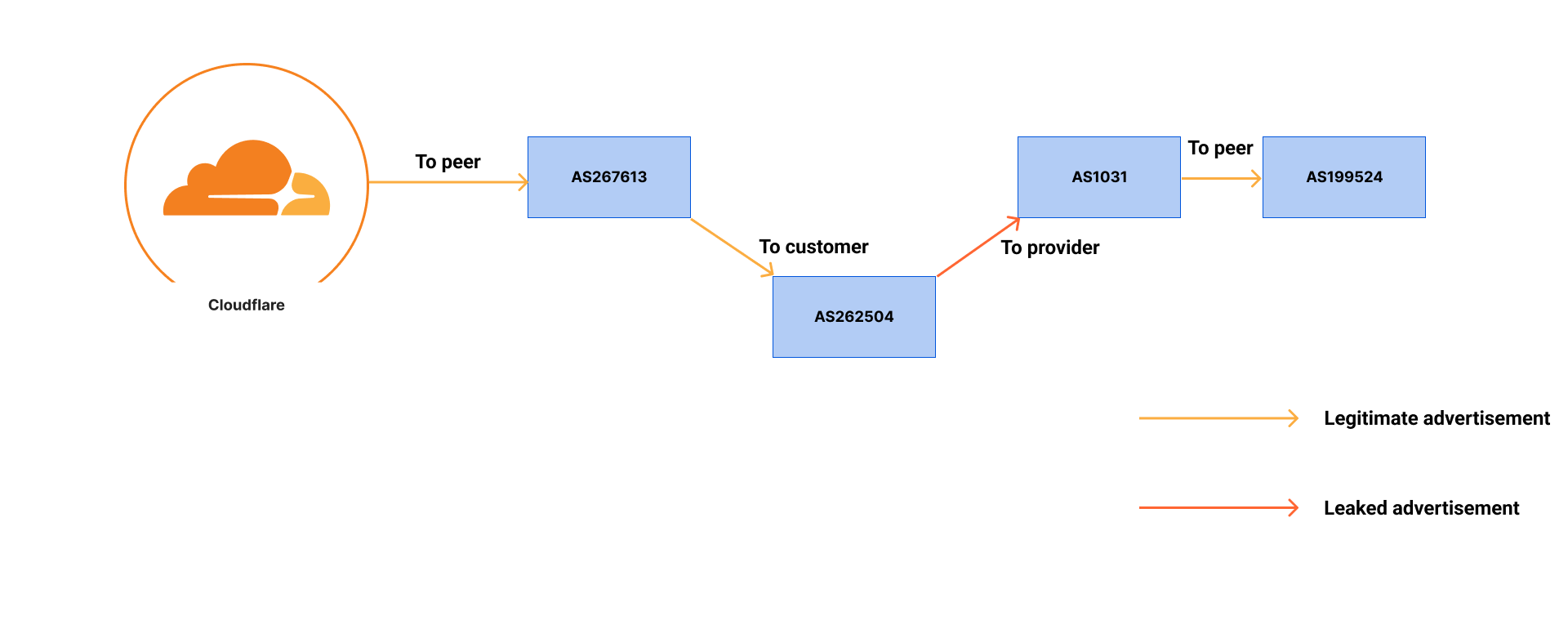
Looking at the first update for prefix 2a03:2880:f077::/48, the AS path is 64112 22850 174 3356 13335 32934. This means we (AS13335) took the prefix received from Meta (AS32934), our peer, and then advertised it toward Lumen (AS3356), one of our upstream transit providers. We know this is a route leak as routes received from peers are only meant to be readvertised to downstream (customer) networks, not laterally to other peers or up to providers.
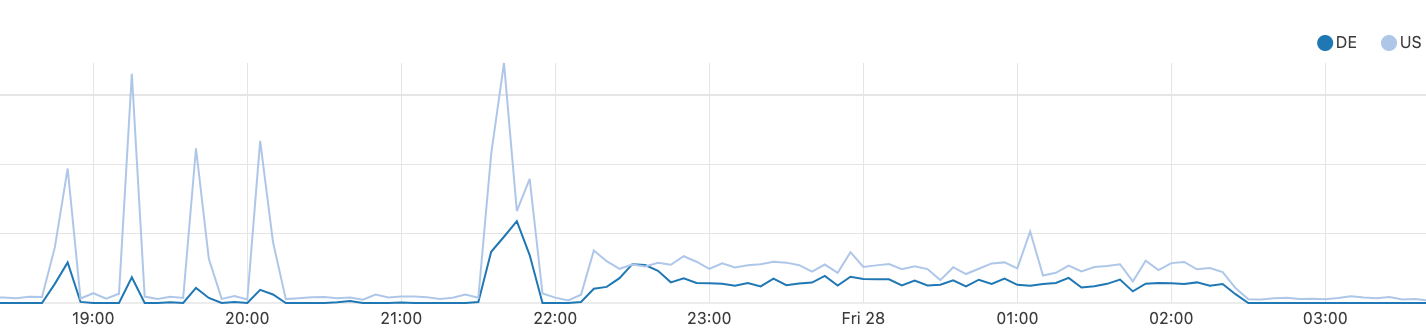
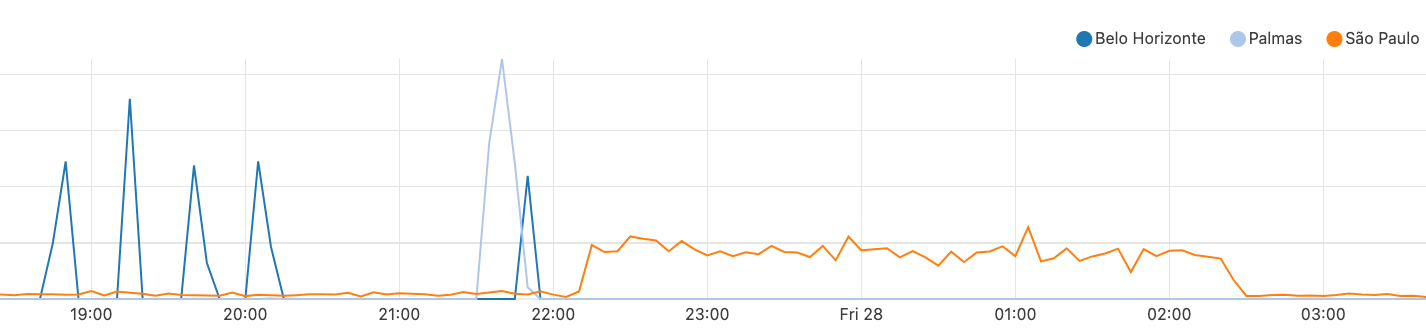
As a result of the leak and the forwarding of unintended traffic into our Miami router from providers and peers, we experienced congestion on our backbone between Miami and Atlanta, as you can see in the graph below.

This would have resulted in elevated loss for some Cloudflare customer traffic, and higher latency than usual for traffic traversing these links. In addition to this congestion, the networks whose prefixes we leaked would have had their traffic discarded by firewall filters on our routers that are designed to only accept traffic for Cloudflare services and our customers. At peak, we discarded around 12Gbps of traffic ingressing our router in Miami for these non-downstream prefixes.

We are big supporters and active contributors to efforts within the IETF and infrastructure community that strengthen routing security. We know firsthand how easy it is to cause a route leak accidentally, as evidenced by this incident.
Preventing route leaks will require a multi-faceted approach, but we have identified multiple areas in which we can improve, both short- and long-term.
In terms of our routing policy configurations and automation, we are:
-
Patching the failure in our routing policy automation that caused the route leak, and will mitigate this potential failure and others like it immediately
-
Implementing additional BGP community-based safeguards in our routing policies that explicitly reject routes that were received from providers and peers on external export policies
-
Adding automatic routing policy evaluation into our CI/CD pipelines that looks specifically for empty or erroneous policy terms
-
Improve early detection of issues with network configurations and the negative effects of an automated change
To help prevent route leaks in general, we are:
-
Validating routing equipment vendors’ implementation of RFC9234 (BGP roles and the Only-to-Customer Attribute) in preparation for our rollout of the feature, which is the only way independent of routing policy to prevent route leaks caused at the local Autonomous System (AS)
-
Encouraging the long term adoption of RPKI Autonomous System Provider Authorization (ASPA), where networks could automatically reject routes that contain anomalous AS paths
Most importantly, we would again like to apologize for the impact we caused users and customers of Cloudflare, as well as any impact felt by external networks.