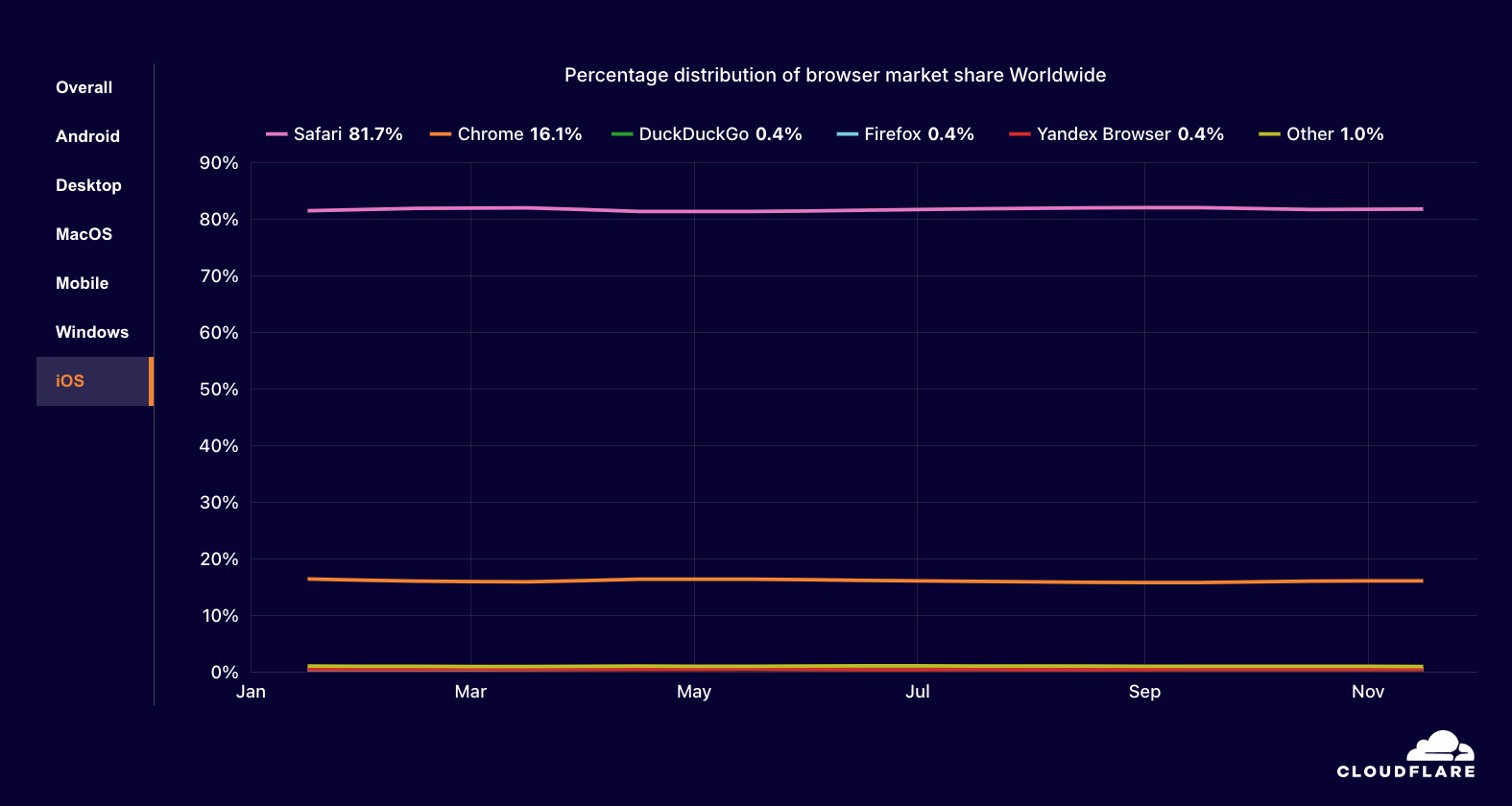
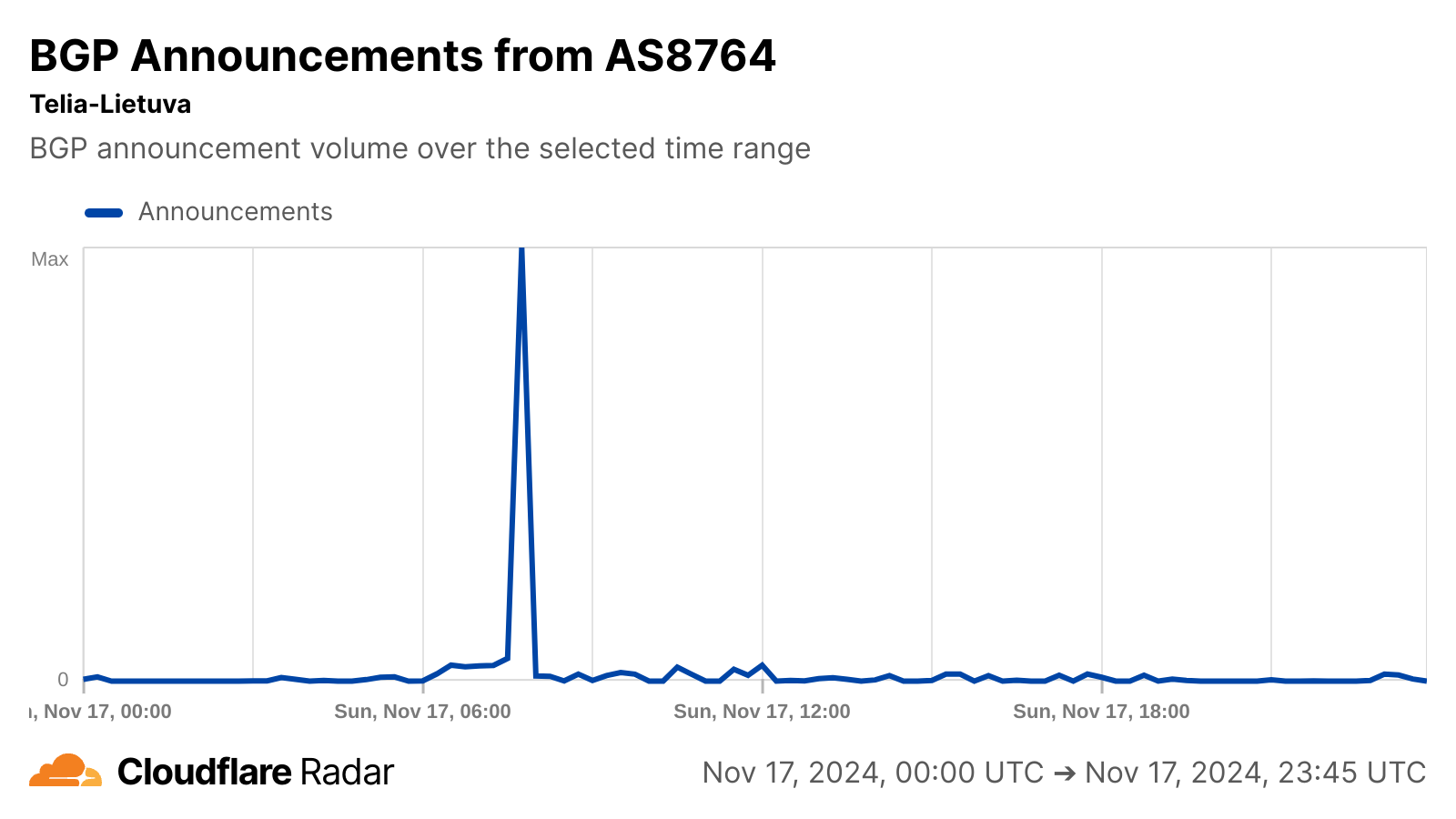
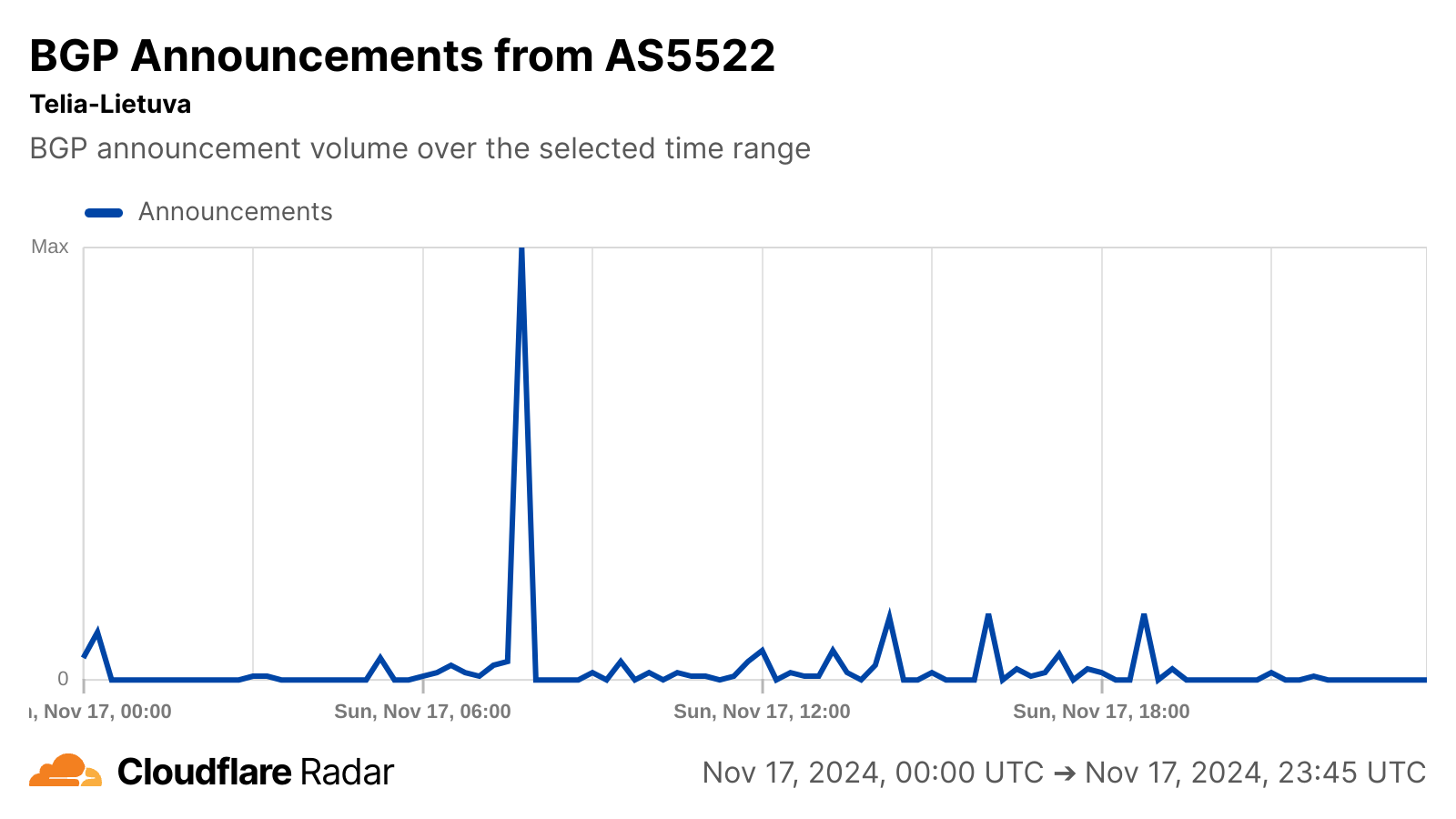
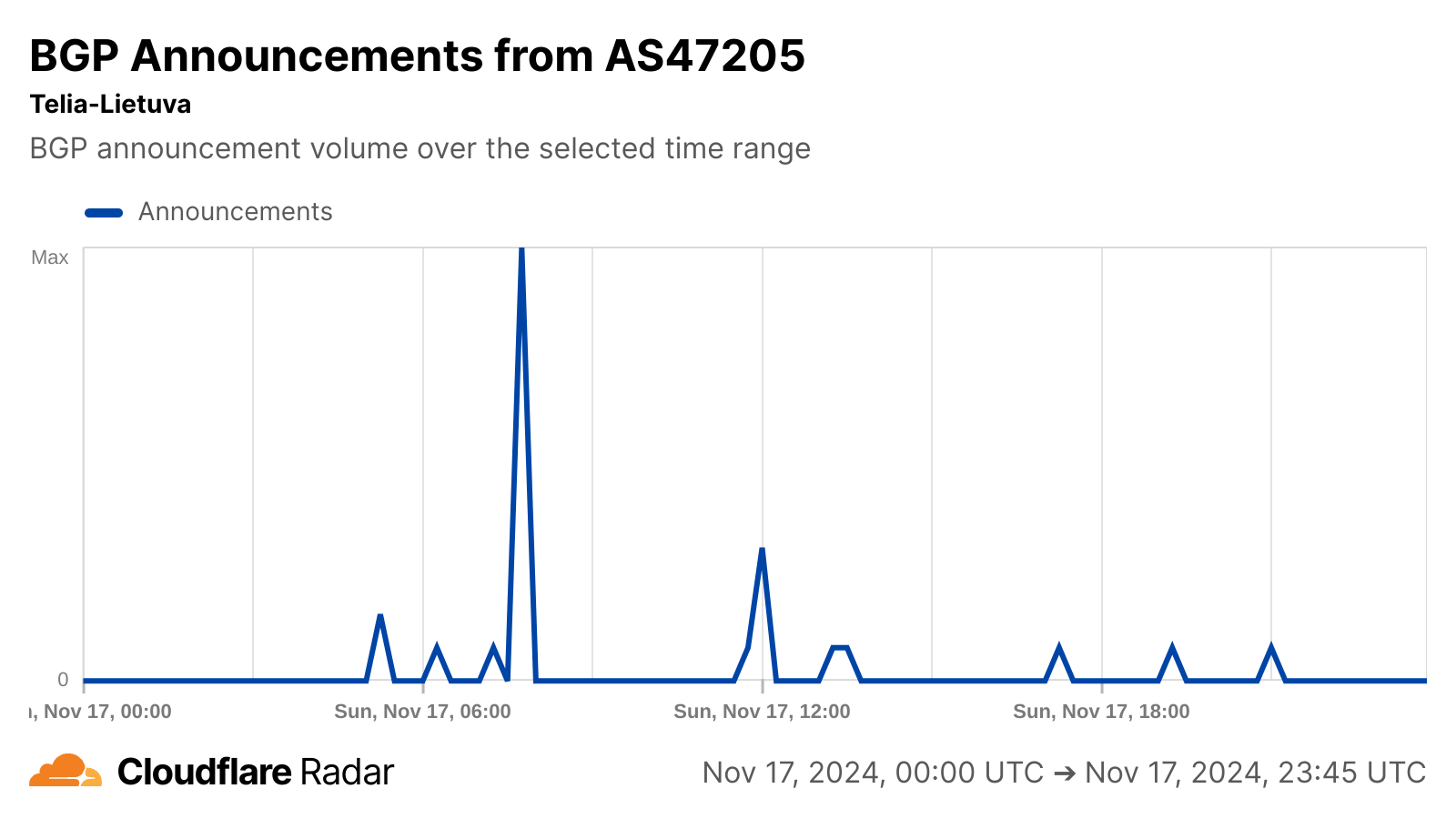
On 18 November 2025 at 11:20 UTC (all times in this blog are UTC), Cloudflare’s network began experiencing significant failures to deliver core network traffic. This showed up to Internet users trying to access our customers’ sites as an error page indicating a failure within Cloudflare’s network.
The issue was not caused, directly or indirectly, by a cyber attack or malicious activity of any kind. Instead, it was triggered by a change to one of our database systems’ permissions which caused the database to output multiple entries into a “feature file” used by our Bot Management system. That feature file, in turn, doubled in size. The larger-than-expected feature file was then propagated to all the machines that make up our network.
The software running on these machines to route traffic across our network reads this feature file to keep our Bot Management system up to date with ever changing threats. The software had a limit on the size of the feature file that was below its doubled size. That caused the software to fail.
After we initially wrongly suspected the symptoms we were seeing were caused by a hyper-scale DDoS attack, we correctly identified the core issue and were able to stop the propagation of the larger-than-expected feature file and replace it with an earlier version of the file. Core traffic was largely flowing as normal by 14:30. We worked over the next few hours to mitigate increased load on various parts of our network as traffic rushed back online. As of 17:06 all systems at Cloudflare were functioning as normal.
We are sorry for the impact to our customers and to the Internet in general. Given Cloudflare’s importance in the Internet ecosystem any outage of any of our systems is unacceptable. That there was a period of time where our network was not able to route traffic is deeply painful to every member of our team. We know we let you down today.
This post is an in-depth recount of exactly what happened and what systems and processes failed. It is also the beginning, though not the end, of what we plan to do in order to make sure an outage like this will not happen again.
The outage
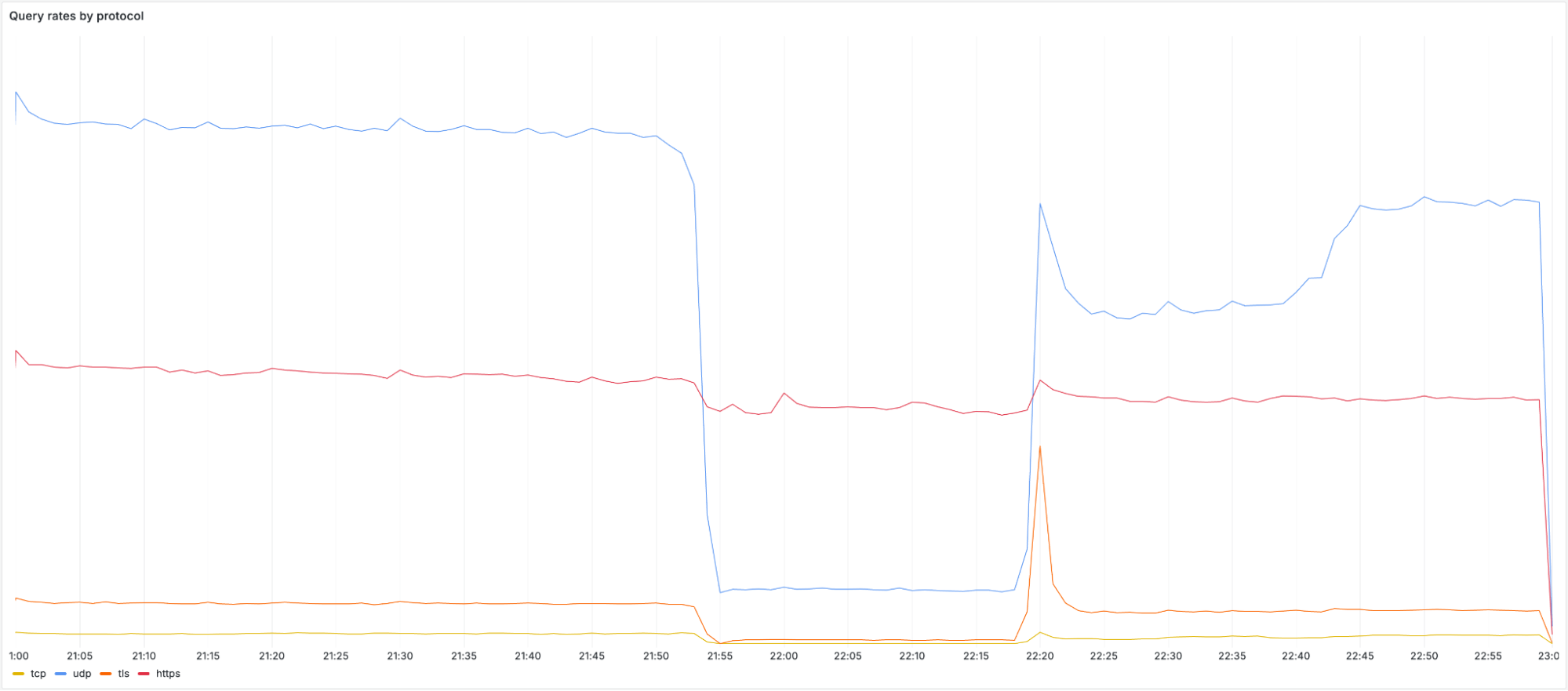
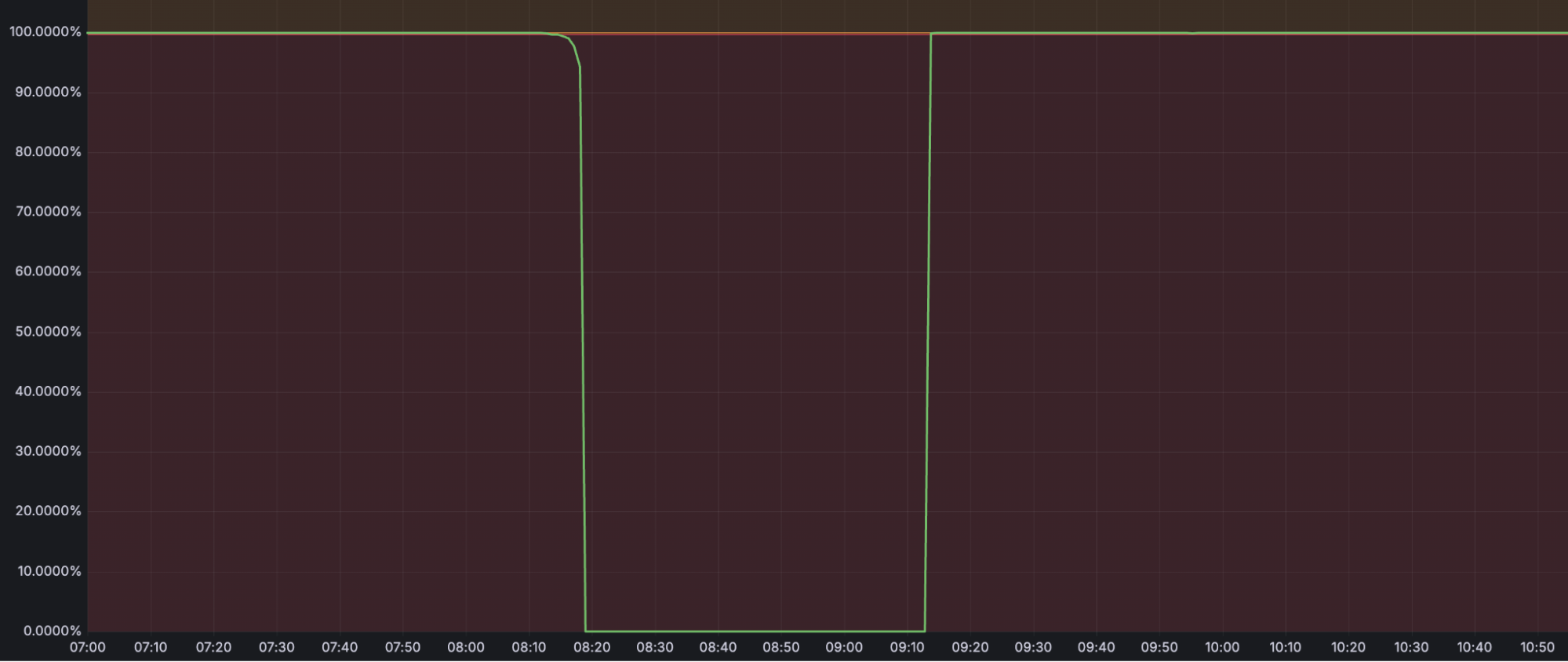
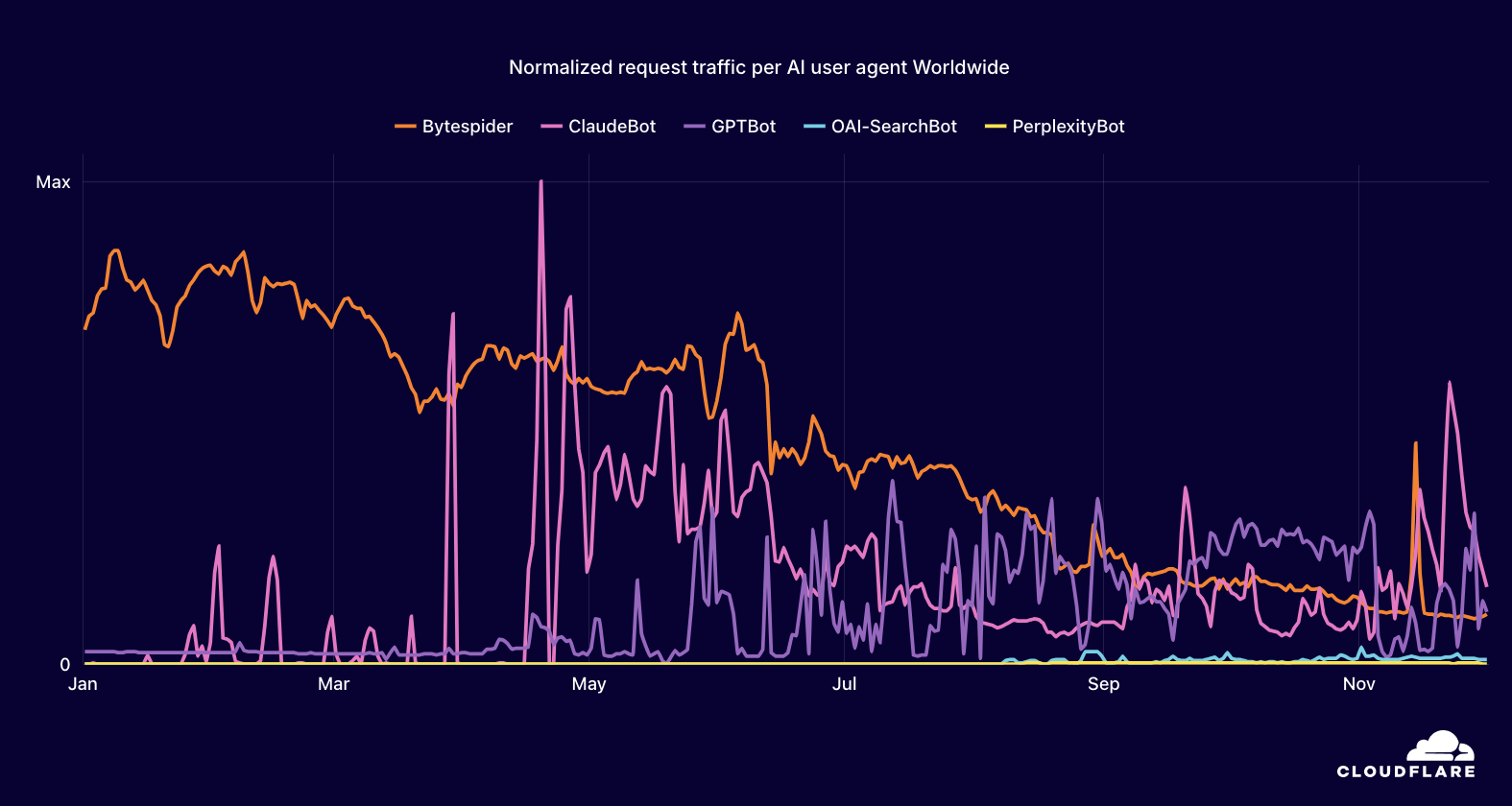
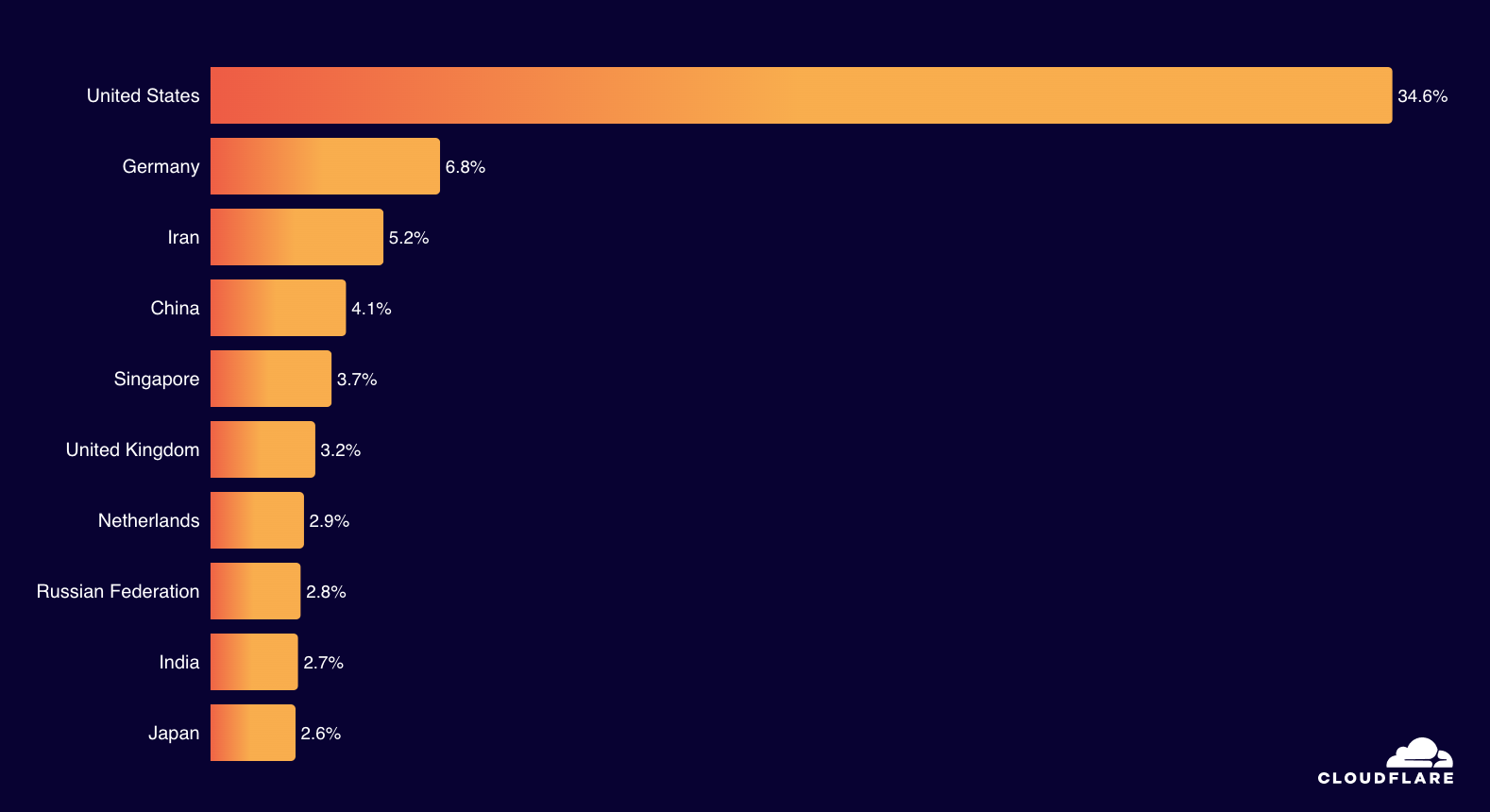
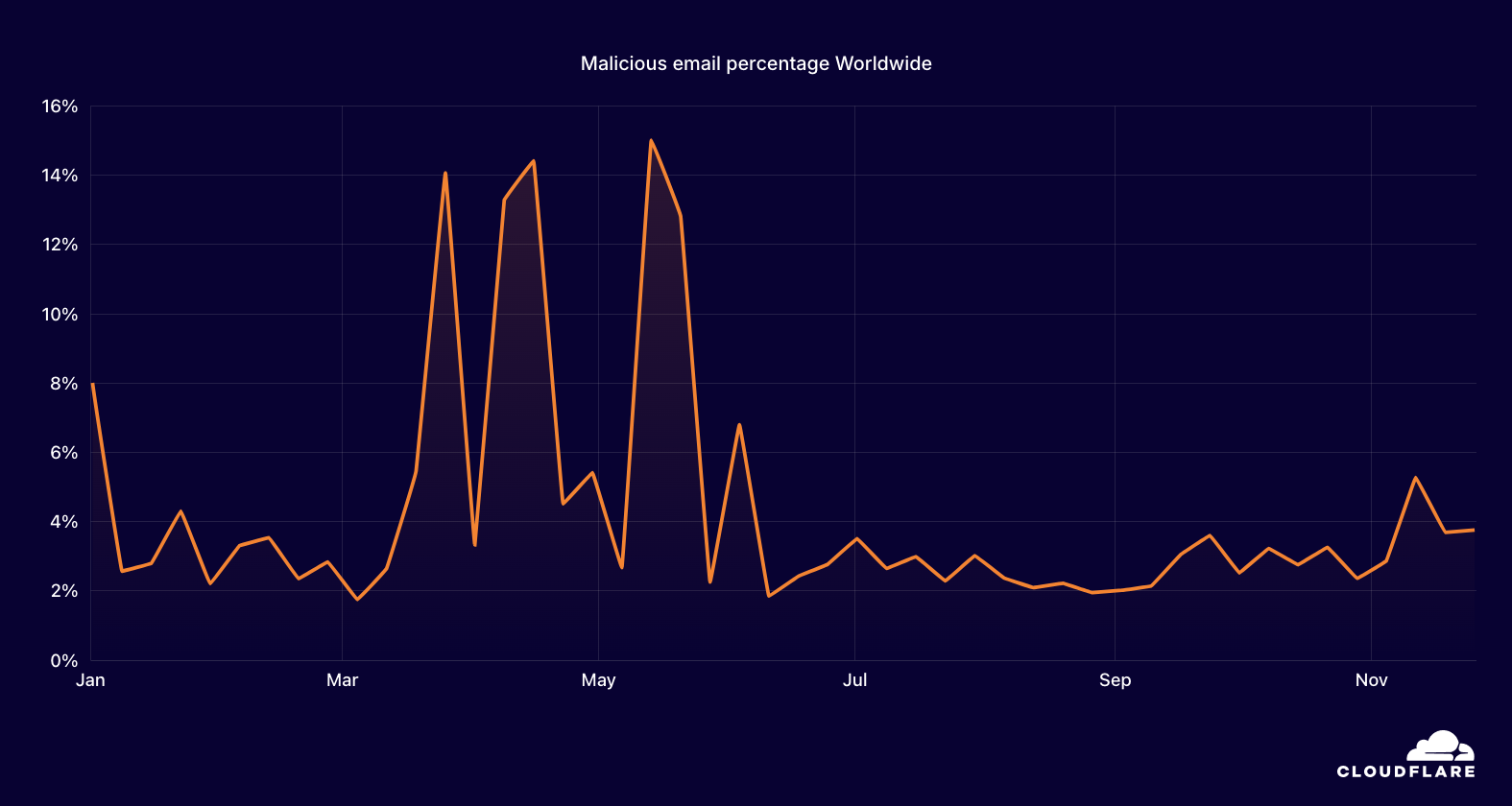
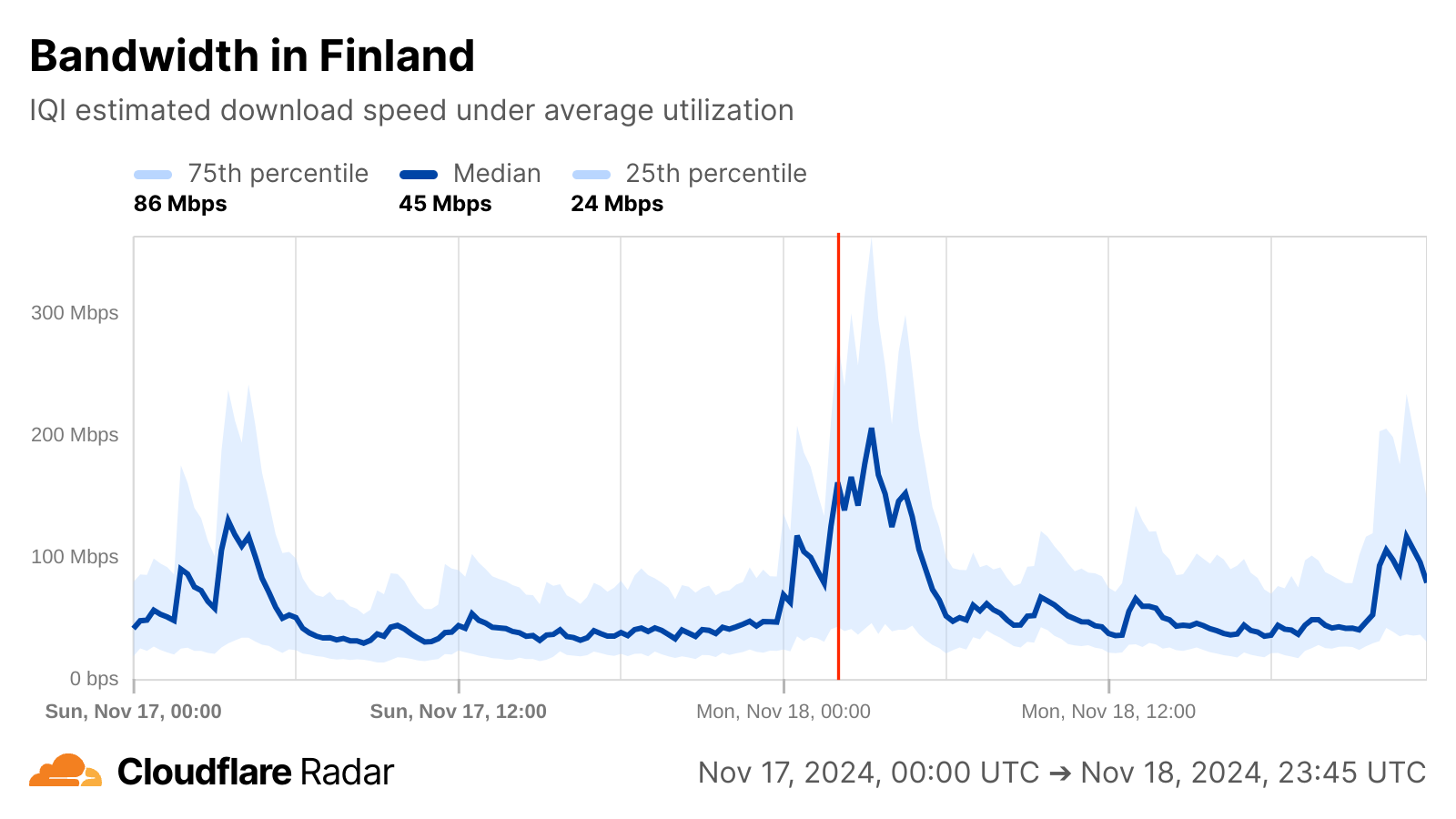
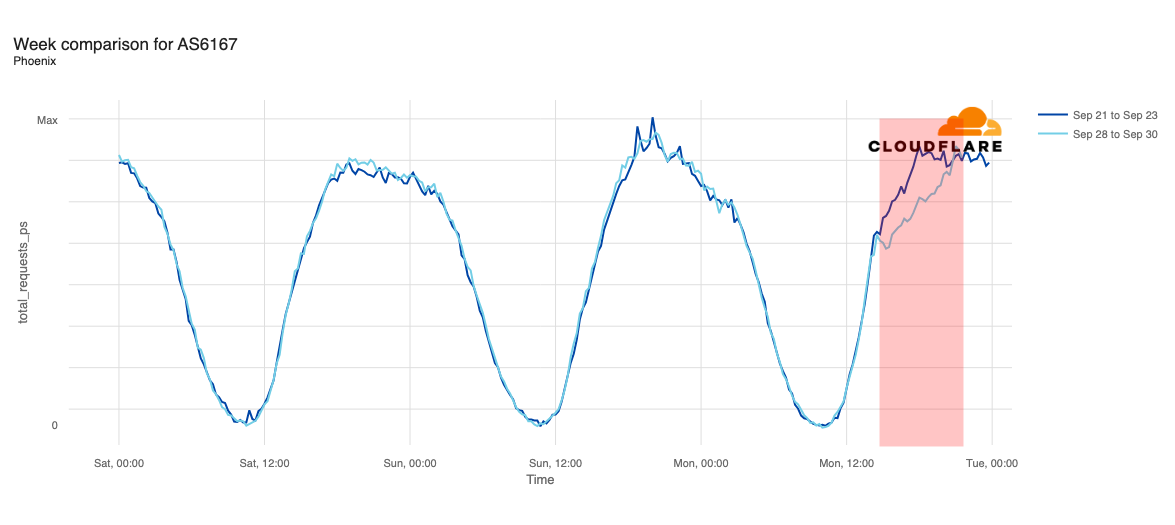
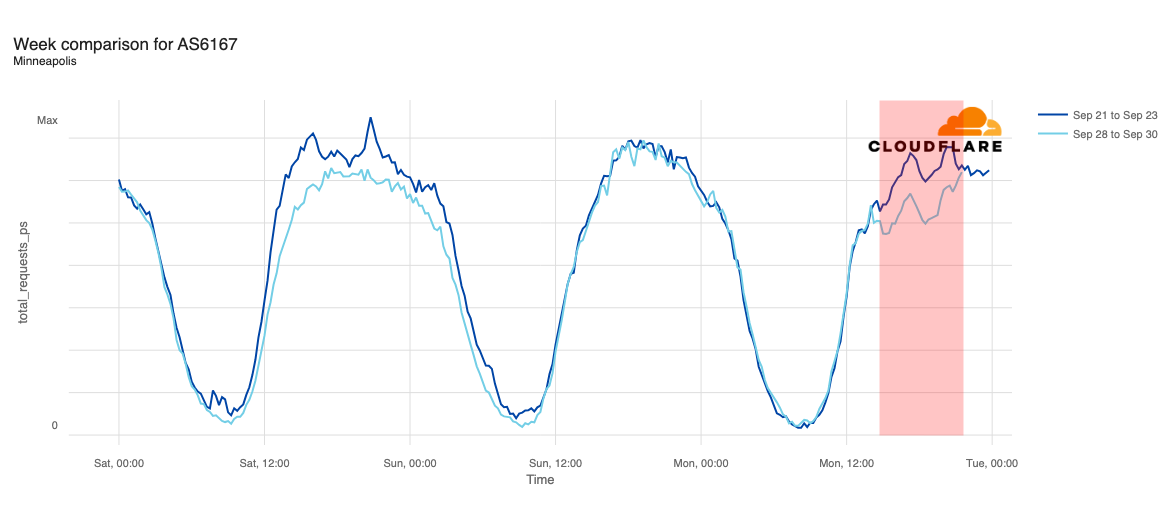
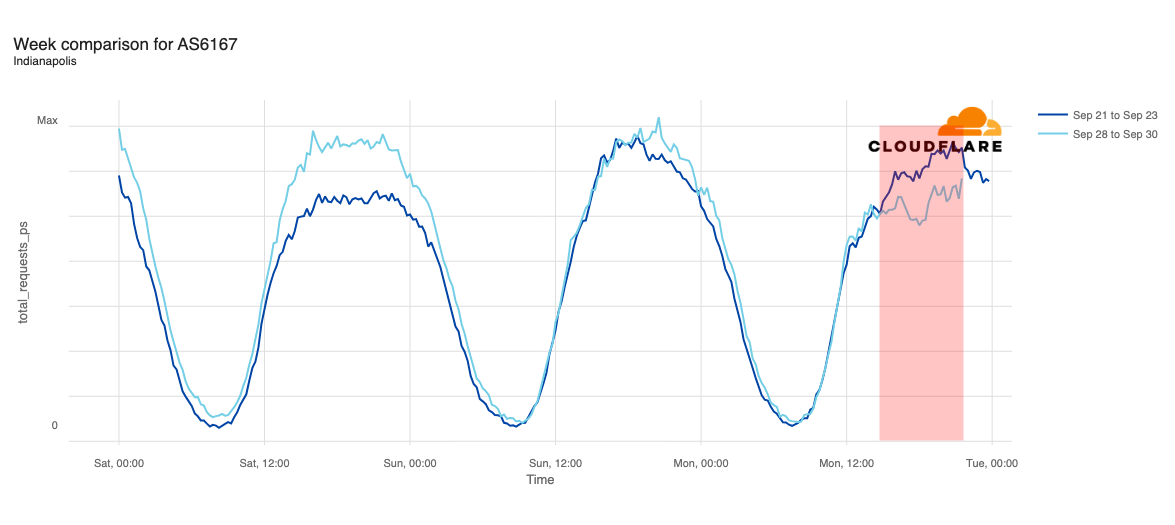
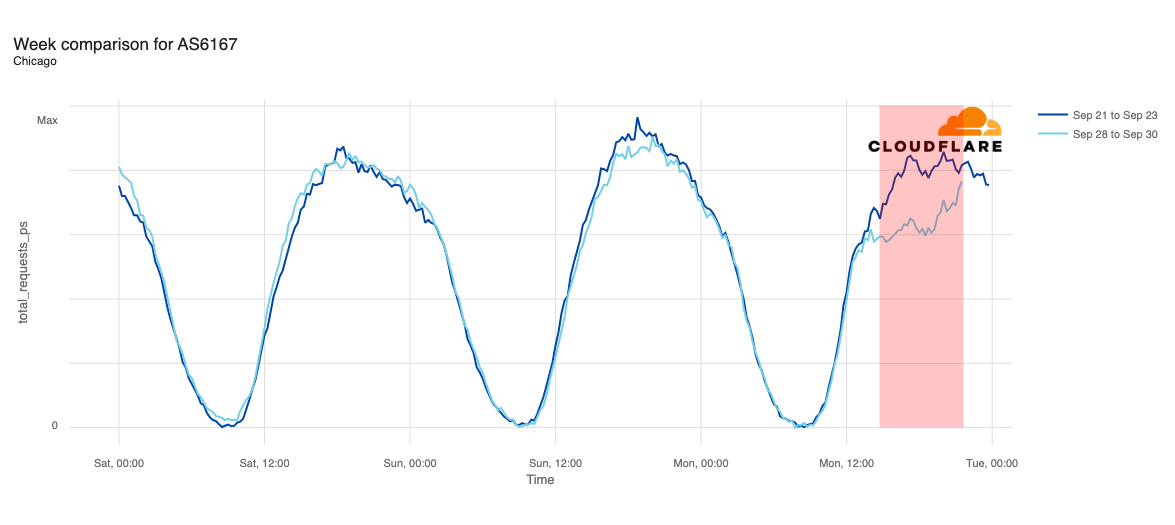
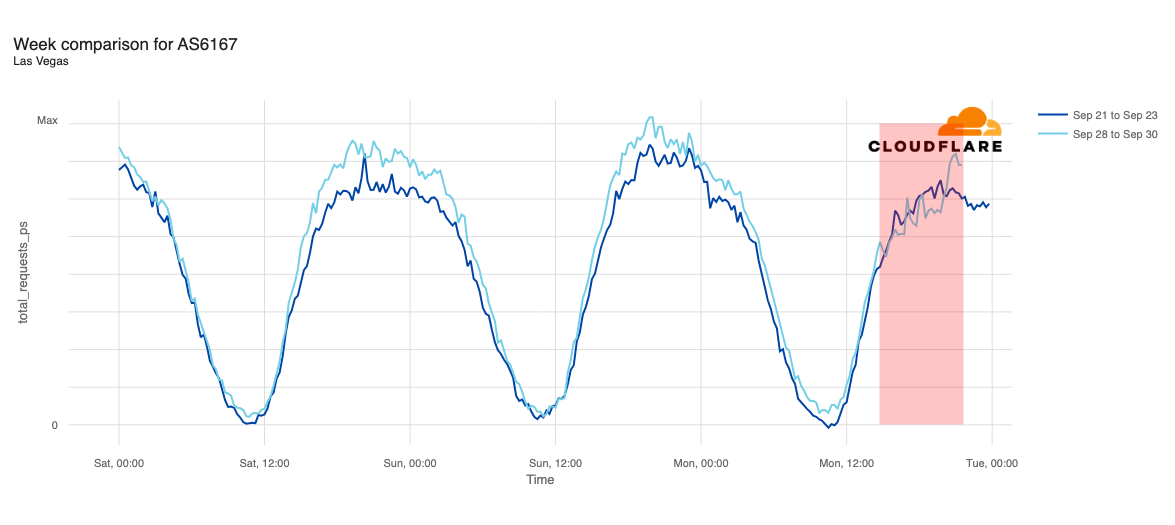
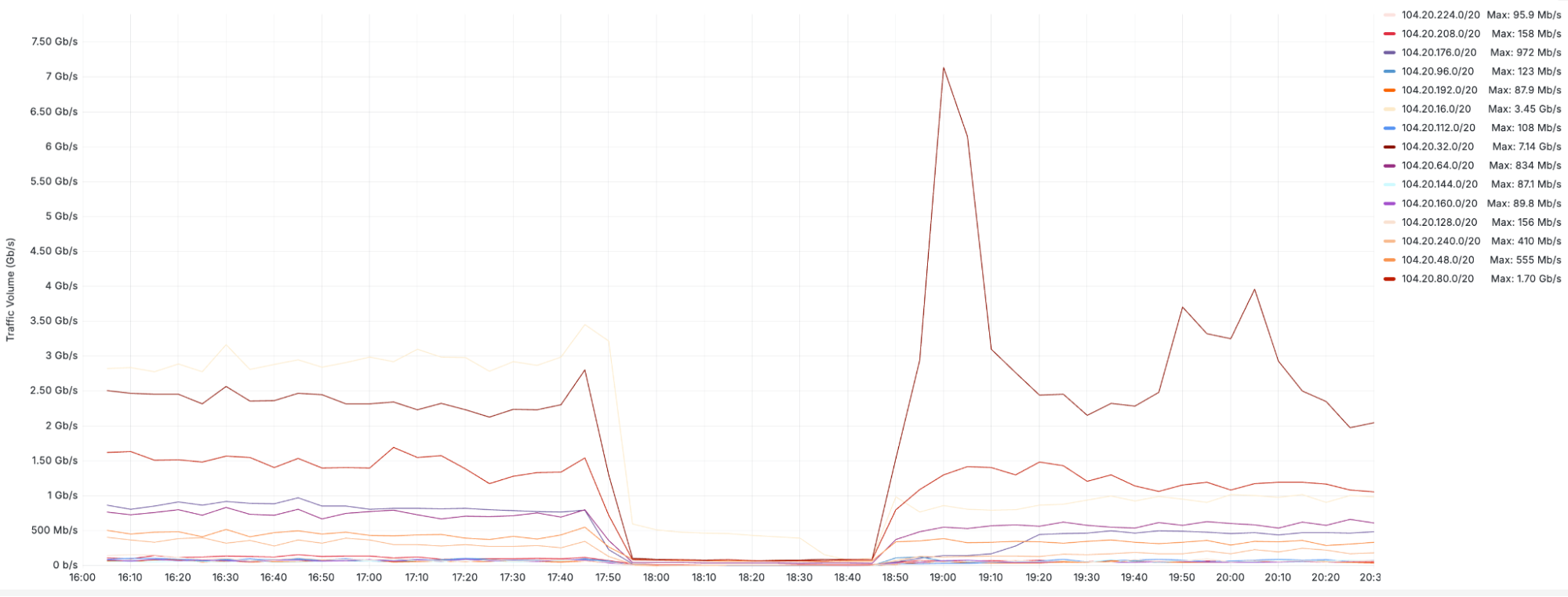
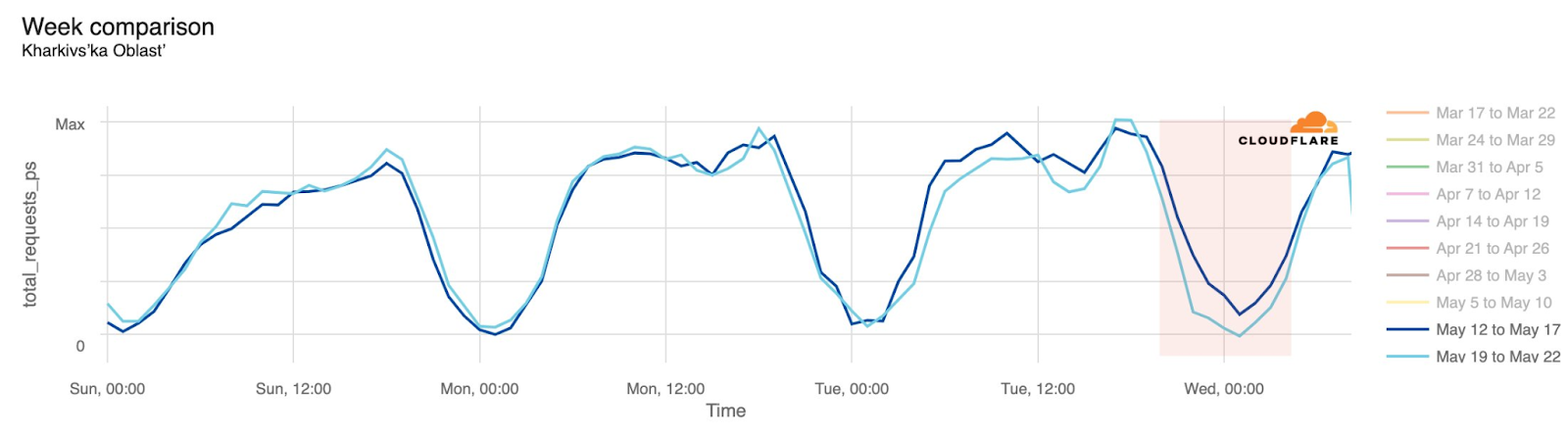
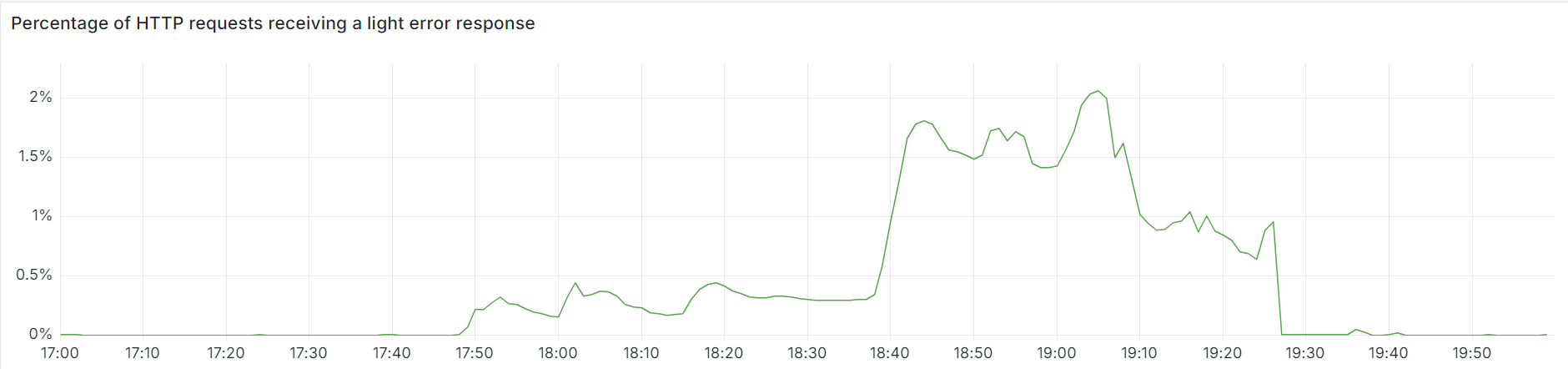
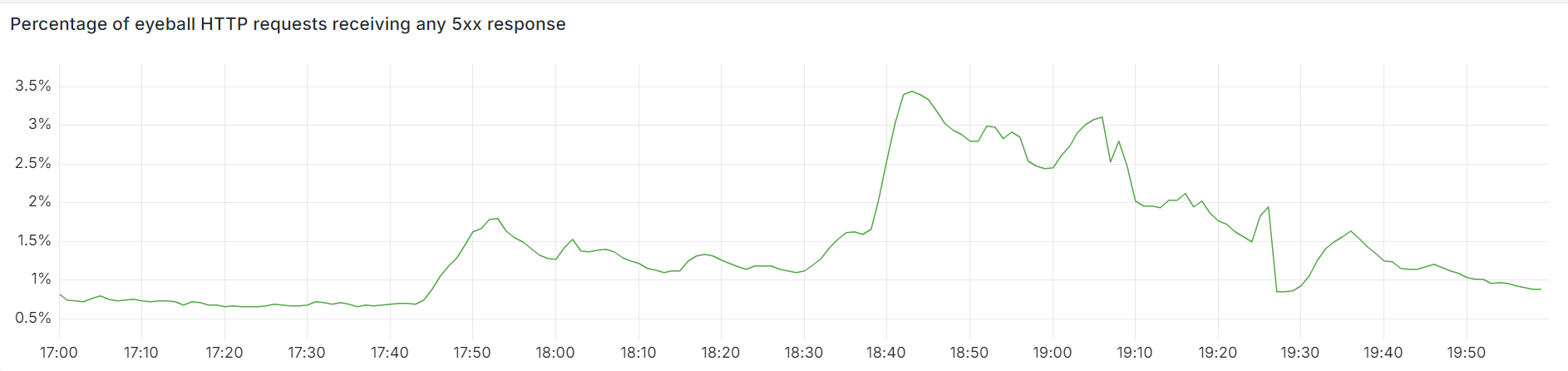
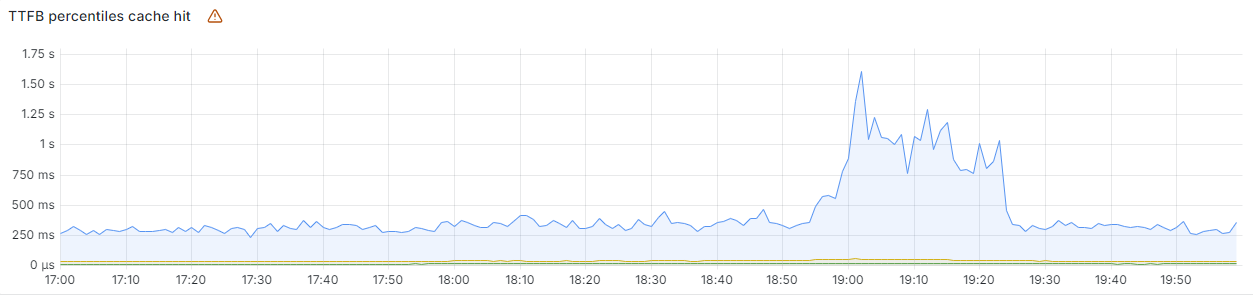
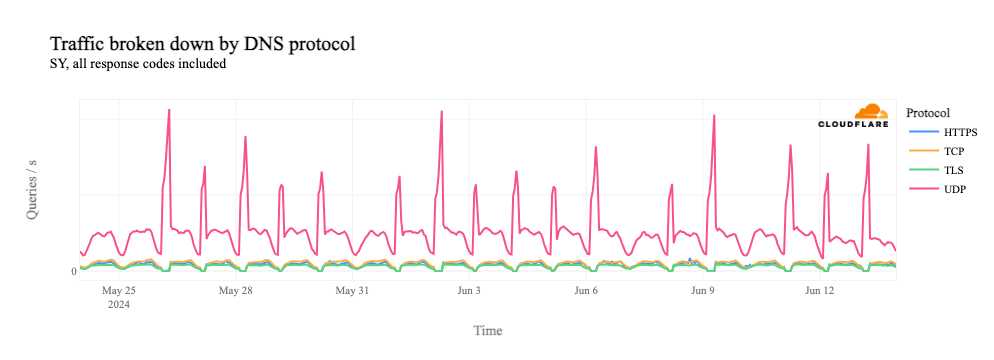
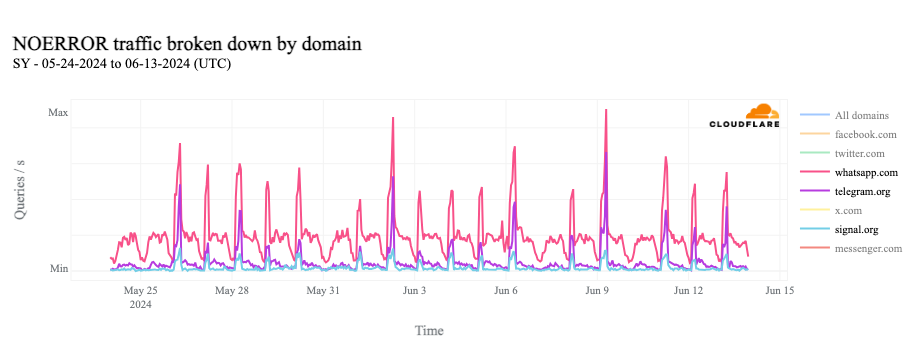
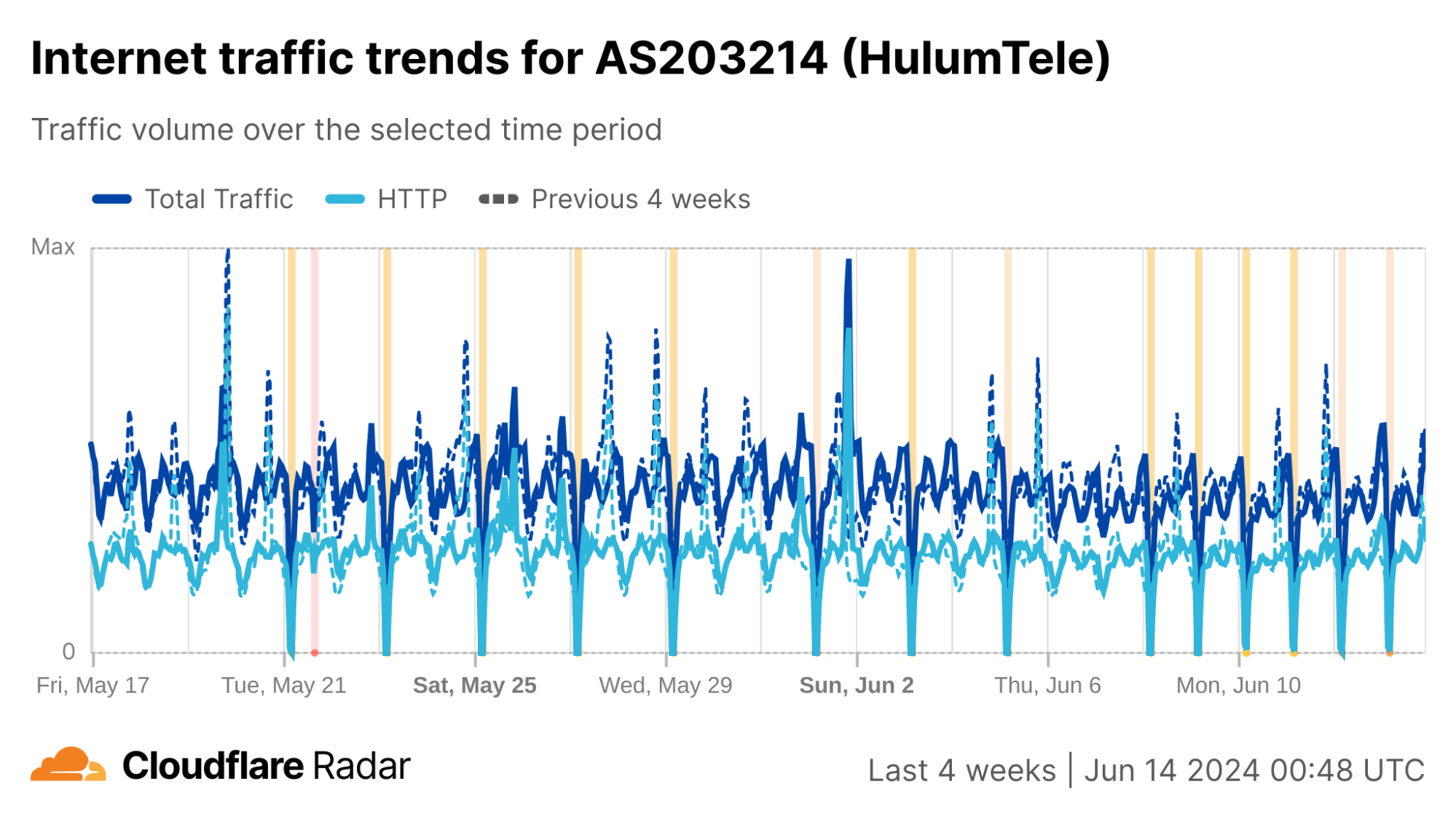
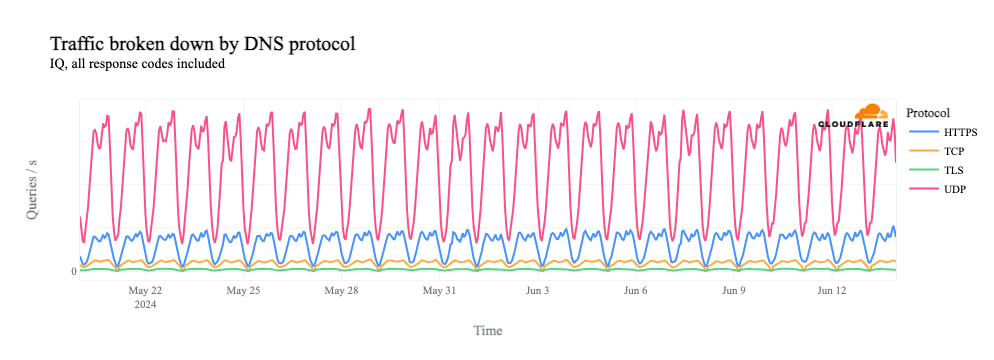
The chart below shows the volume of 5xx error HTTP status codes served by the Cloudflare network. Normally this should be very low, and it was right up until the start of the outage.
The volume prior to 11:20 is the expected baseline of 5xx errors observed across our network. The spike, and subsequent fluctuations, show our system failing due to loading the incorrect feature file. What’s notable is that our system would then recover for a period. This was very unusual behavior for an internal error.
The explanation was that the file was being generated every five minutes by a query running on a ClickHouse database cluster, which was being gradually updated to improve permissions management. Bad data was only generated if the query ran on a part of the cluster which had been updated. As a result, every five minutes there was a chance of either a good or a bad set of configuration files being generated and rapidly propagated across the network.
This fluctuation made it unclear what was happening as the entire system would recover and then fail again as sometimes good, sometimes bad configuration files were distributed to our network. Initially, this led us to believe this might be caused by an attack. Eventually, every ClickHouse node was generating the bad configuration file and the fluctuation stabilized in the failing state.
Errors continued until the underlying issue was identified and resolved starting at 14:30. We solved the problem by stopping the generation and propagation of the bad feature file and manually inserting a known good file into the feature file distribution queue. And then forcing a restart of our core proxy.
The remaining long tail in the chart above is our team restarting remaining services that had entered a bad state, with 5xx error code volume returning to normal at 17:06.
The following services were impacted:
Service / Product
Impact description
Core CDN and security services
HTTP 5xx status codes. The screenshot at the top of this post shows a typical error page delivered to end users.
Turnstile
Turnstile failed to load.
Workers KV
Workers KV returned a significantly elevated level of HTTP 5xx errors as requests to KV’s “front end” gateway failed due to the core proxy failing.
Dashboard
While the dashboard was mostly operational, most users were unable to log in due to Turnstile being unavailable on the login page.
Email Security
While email processing and delivery were unaffected, we observed a temporary loss of access to an IP reputation source which reduced spam-detection accuracy and prevented some new-domain-age detections from triggering, with no critical customer impact observed. We also saw failures in some Auto Move actions; all affected messages have been reviewed and remediated.
Access
Authentication failures were widespread for most users, beginning at the start of the incident and continuing until the rollback was initiated at 13:05. Any existing Access sessions were unaffected.
All failed authentication attempts resulted in an error page, meaning none of these users ever reached the target application while authentication was failing. Successful logins during this period were correctly logged during this incident.
Any Access configuration updates attempted at that time would have either failed outright or propagated very slowly. All configuration updates are now recovered.
As well as returning HTTP 5xx errors, we observed significant increases in latency of responses from our CDN during the impact period. This was due to large amounts of CPU being consumed by our debugging and observability systems, which automatically enhance uncaught errors with additional debugging information.
How Cloudflare processes requests, and how this went wrong today
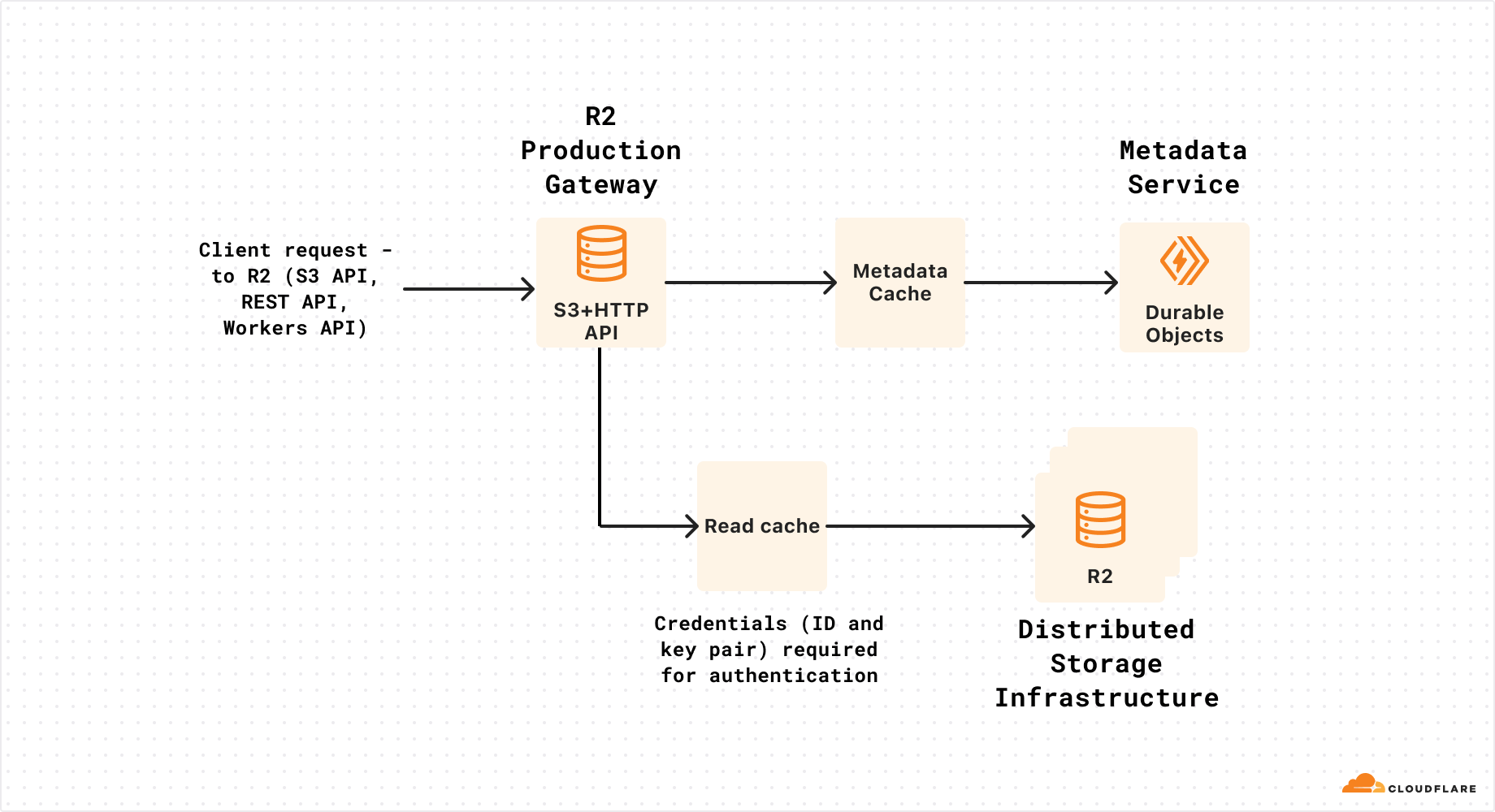
Every request to Cloudflare takes a well-defined path through our network. It could be from a browser loading a webpage, a mobile app calling an API, or automated traffic from another service. These requests first terminate at our HTTP and TLS layer, then flow into our core proxy system (which we call FL for “Frontline”), and finally through Pingora, which performs cache lookups or fetches data from the origin if needed.
We previously shared more detail about how the core proxy works here.
As a request transits the core proxy, we run the various security and performance products available in our network. The proxy applies each customer’s unique configuration and settings, from enforcing WAF rules and DDoS protection to routing traffic to the Developer Platform and R2. It accomplishes this through a set of domain-specific modules that apply the configuration and policy rules to traffic transiting our proxy.
One of those modules, Bot Management, was the source of today’s outage.
Cloudflare’s Bot Management includes, among other systems, a machine learning model that we use to generate bot scores for every request traversing our network. Our customers use bot scores to control which bots are allowed to access their sites — or not.
The model takes as input a “feature” configuration file. A feature, in this context, is an individual trait used by the machine learning model to make a prediction about whether the request was automated or not. The feature configuration file is a collection of individual features.
This feature file is refreshed every few minutes and published to our entire network and allows us to react to variations in traffic flows across the Internet. It allows us to react to new types of bots and new bot attacks. So it’s critical that it is rolled out frequently and rapidly as bad actors change their tactics quickly.
A change in our underlying ClickHouse query behaviour (explained below) that generates this file caused it to have a large number of duplicate “feature” rows. This changed the size of the previously fixed-size feature configuration file, causing the bots module to trigger an error.
As a result, HTTP 5xx error codes were returned by the core proxy system that handles traffic processing for our customers, for any traffic that depended on the bots module. This also affected Workers KV and Access, which rely on the core proxy.
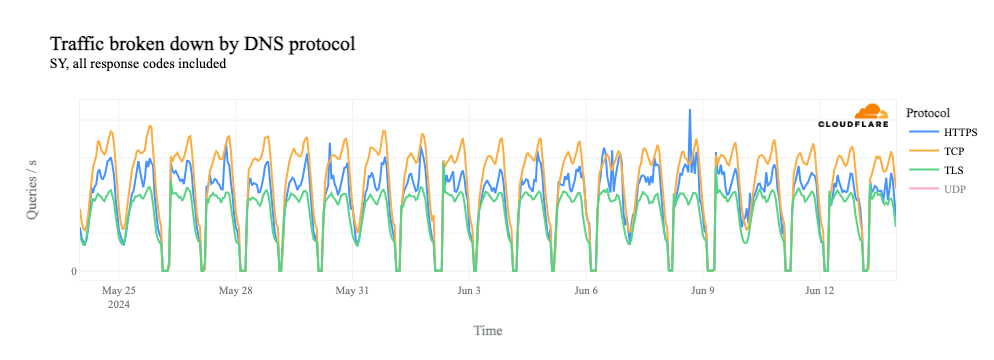
Unrelated to this incident, we were and are currently migrating our customer traffic to a new version of our proxy service, internally known as FL2. Both versions were affected by the issue, although the impact observed was different.
Customers deployed on the new FL2 proxy engine, observed HTTP 5xx errors. Customers on our old proxy engine, known as FL, did not see errors, but bot scores were not generated correctly, resulting in all traffic receiving a bot score of zero. Customers that had rules deployed to block bots would have seen large numbers of false positives. Customers who were not using our bot score in their rules did not see any impact.
Throwing us off and making us believe this might have been an attack was another apparent symptom we observed: Cloudflare’s status page went down. The status page is hosted completely off Cloudflare’s infrastructure with no dependencies on Cloudflare. While it turned out to be a coincidence, it led some of the team diagnosing the issue to believe that an attacker may be targeting both our systems as well as our status page. Visitors to the status page at that time were greeted by an error message:
In the internal incident chat room, we were concerned that this might be the continuation of the recent spate of high volume AisuruDDoS attacks:
The query behaviour change
I mentioned above that a change in the underlying query behaviour resulted in the feature file containing a large number of duplicate rows. The database system in question uses ClickHouse’s software.
For context, it’s helpful to know how ClickHouse distributed queries work. A ClickHouse cluster consists of many shards. To query data from all shards, we have so-called distributed tables (powered by the table engine Distributed) in a database called default. The Distributed engine queries underlying tables in a database r0. The underlying tables are where data is stored on each shard of a ClickHouse cluster.
Queries to the distributed tables run through a shared system account. As part of efforts to improve our distributed queries security and reliability, there’s work being done to make them run under the initial user accounts instead.
Before today, ClickHouse users would only see the tables in the default database when querying table metadata from ClickHouse system tables such as system.tables or system.columns.
Since users already have implicit access to underlying tables in r0, we made a change at 11:05 to make this access explicit, so that users can see the metadata of these tables as well. By making sure that all distributed subqueries can run under the initial user, query limits and access grants can be evaluated in a more fine-grained manner, avoiding one bad subquery from a user affecting others.
The change explained above resulted in all users accessing accurate metadata about tables they have access to. Unfortunately, there were assumptions made in the past, that the list of columns returned by a query like this would only include the “default” database:
SELECT
name,
type
FROM system.columns
WHERE
table = 'http_requests_features'
order by name;
Note how the query does not filter for the database name. With us gradually rolling out the explicit grants to users of a given ClickHouse cluster, after the change at 11:05 the query above started returning “duplicates” of columns because those were for underlying tables stored in the r0 database.
This, unfortunately, was the type of query that was performed by the Bot Management feature file generation logic to construct each input “feature” for the file mentioned at the beginning of this section.
The query above would return a table of columns like the one displayed (simplified example):
However, as part of the additional permissions that were granted to the user, the response now contained all the metadata of the r0 schema effectively more than doubling the rows in the response ultimately affecting the number of rows (i.e. features) in the final file output.
Memory preallocation
Each module running on our proxy service has a number of limits in place to avoid unbounded memory consumption and to preallocate memory as a performance optimization. In this specific instance, the Bot Management system has a limit on the number of machine learning features that can be used at runtime. Currently that limit is set to 200, well above our current use of ~60 features. Again, the limit exists because for performance reasons we preallocate memory for the features.
When the bad file with more than 200 features was propagated to our servers, this limit was hit — resulting in the system panicking. The FL2 Rust code that makes the check and was the source of the unhandled error is shown below:
This resulted in the following panic which in turn resulted in a 5xx error:
thread fl2_worker_thread panicked: called Result::unwrap() on an Err value
Other impact during the incident
Other systems that rely on our core proxy were impacted during the incident. This included Workers KV and Cloudflare Access. The team was able to reduce the impact to these systems at 13:04, when a patch was made to Workers KV to bypass the core proxy. Subsequently, all downstream systems that rely on Workers KV (such as Access itself) observed a reduced error rate.
The Cloudflare Dashboard was also impacted due to both Workers KV being used internally and Cloudflare Turnstile being deployed as part of our login flow.
Turnstile was impacted by this outage, resulting in customers who did not have an active dashboard session being unable to log in. This showed up as reduced availability during two time periods: from 11:30 to 13:10, and between 14:40 and 15:30, as seen in the graph below.
The first period, from 11:30 to 13:10, was due to the impact to Workers KV, which some control plane and dashboard functions rely upon. This was restored at 13:10, when Workers KV bypassed the core proxy system.
The second period of impact to the dashboard occurred after restoring the feature configuration data. A backlog of login attempts began to overwhelm the dashboard. This backlog, in combination with retry attempts, resulted in elevated latency, reducing dashboard availability. Scaling control plane concurrency restored availability at approximately 15:30.
Remediation and follow-up steps
Now that our systems are back online and functioning normally, work has already begun on how we will harden them against failures like this in the future. In particular we are:
Hardening ingestion of Cloudflare-generated configuration files in the same way we would for user-generated input
Enabling more global kill switches for features
Eliminating the ability for core dumps or other error reports to overwhelm system resources
Reviewing failure modes for error conditions across all core proxy modules
Today was Cloudflare’s worst outage since 2019. We’ve had outages that have made our dashboard unavailable. Some that have caused newer features to not be available for a period of time. But in the last 6+ years we’ve not had another outage that has caused the majority of core traffic to stop flowing through our network.
An outage like today is unacceptable. We’ve architected our systems to be highly resilient to failure to ensure traffic will always continue to flow. When we’ve had outages in the past it’s always led to us building new, more resilient systems.
On behalf of the entire team at Cloudflare, I would like to apologize for the pain we caused the Internet today.
Time (UTC)
Status
Description
11:05
Normal.
Database access control change deployed.
11:28
Impact starts.
Deployment reaches customer environments, first errors observed on customer HTTP traffic.
11:32-13:05
The team investigated elevated traffic levels and errors to Workers KV service.
The initial symptom appeared to be degraded Workers KV response rate causing downstream impact on other Cloudflare services.
Mitigations such as traffic manipulation and account limiting were attempted to bring the Workers KV service back to normal operating levels.
The first automated test detected the issue at 11:31 and manual investigation started at 11:32. The incident call was created at 11:35.
13:05
Workers KV and Cloudflare Access bypass implemented — impact reduced.
During investigation, we used internal system bypasses for Workers KV and Cloudflare Access so they fell back to a prior version of our core proxy. Although the issue was also present in prior versions of our proxy, the impact was smaller as described below.
13:37
Work focused on rollback of the Bot Management configuration file to a last-known-good version.
We were confident that the Bot Management configuration file was the trigger for the incident. Teams worked on ways to repair the service in multiple workstreams, with the fastest workstream a restore of a previous version of the file.
14:24
Stopped creation and propagation of new Bot Management configuration files.
We identified that the Bot Management module was the source of the 500 errors and that this was caused by a bad configuration file. We stopped automatic deployment of new Bot Management configuration files.
14:24
Test of new file complete.
We observed successful recovery using the old version of the configuration file and then focused on accelerating the fix globally.
14:30
Main impact resolved. Downstream impacted services started observing reduced errors.
A correct Bot Management configuration file was deployed globally and most services started operating correctly.
17:06
All services resolved. Impact ends.
All downstream services restarted and all operations fully restored.
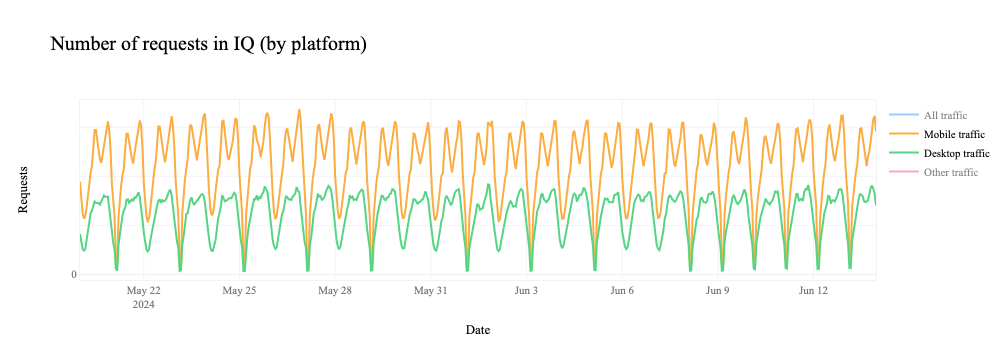
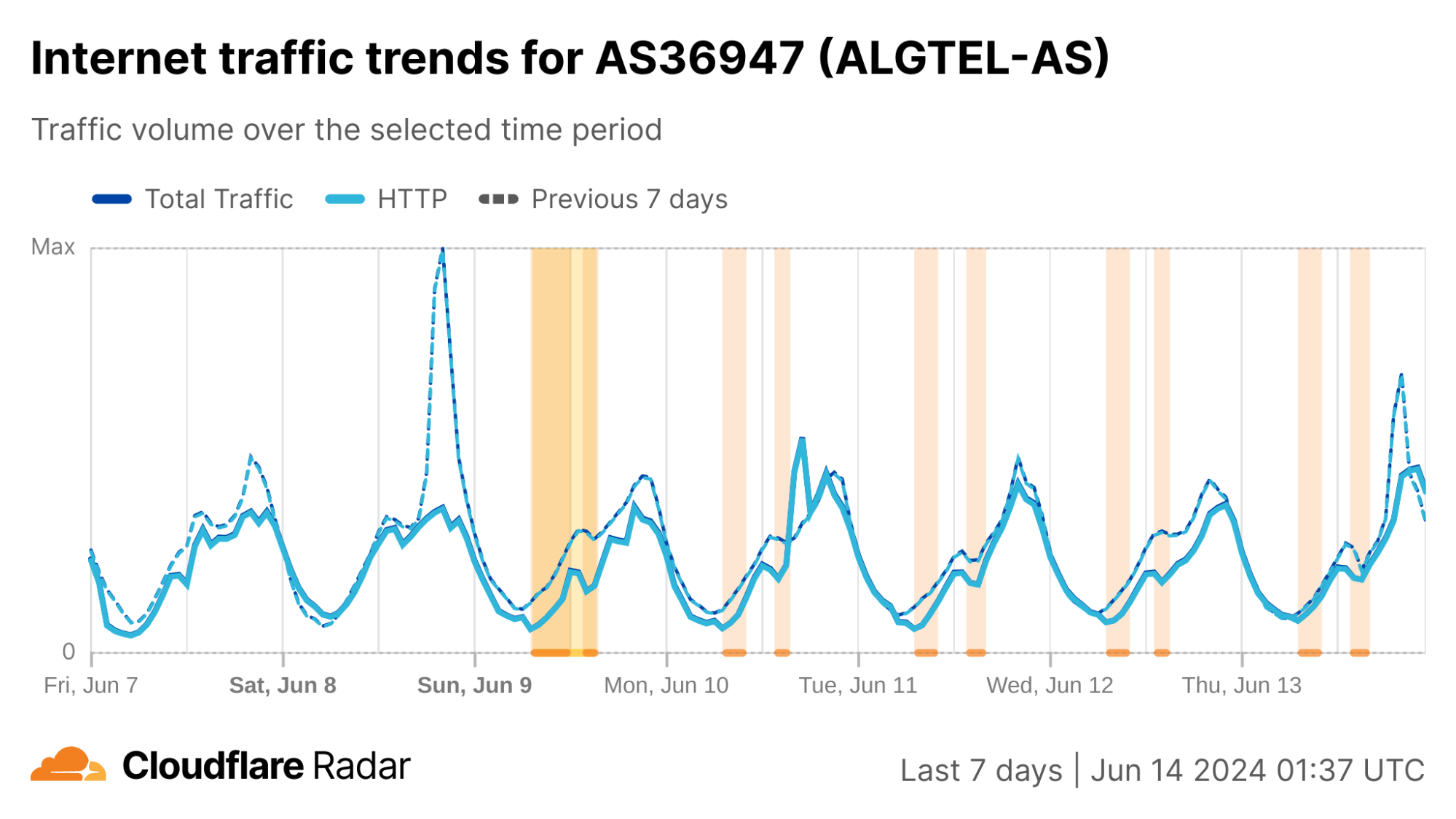
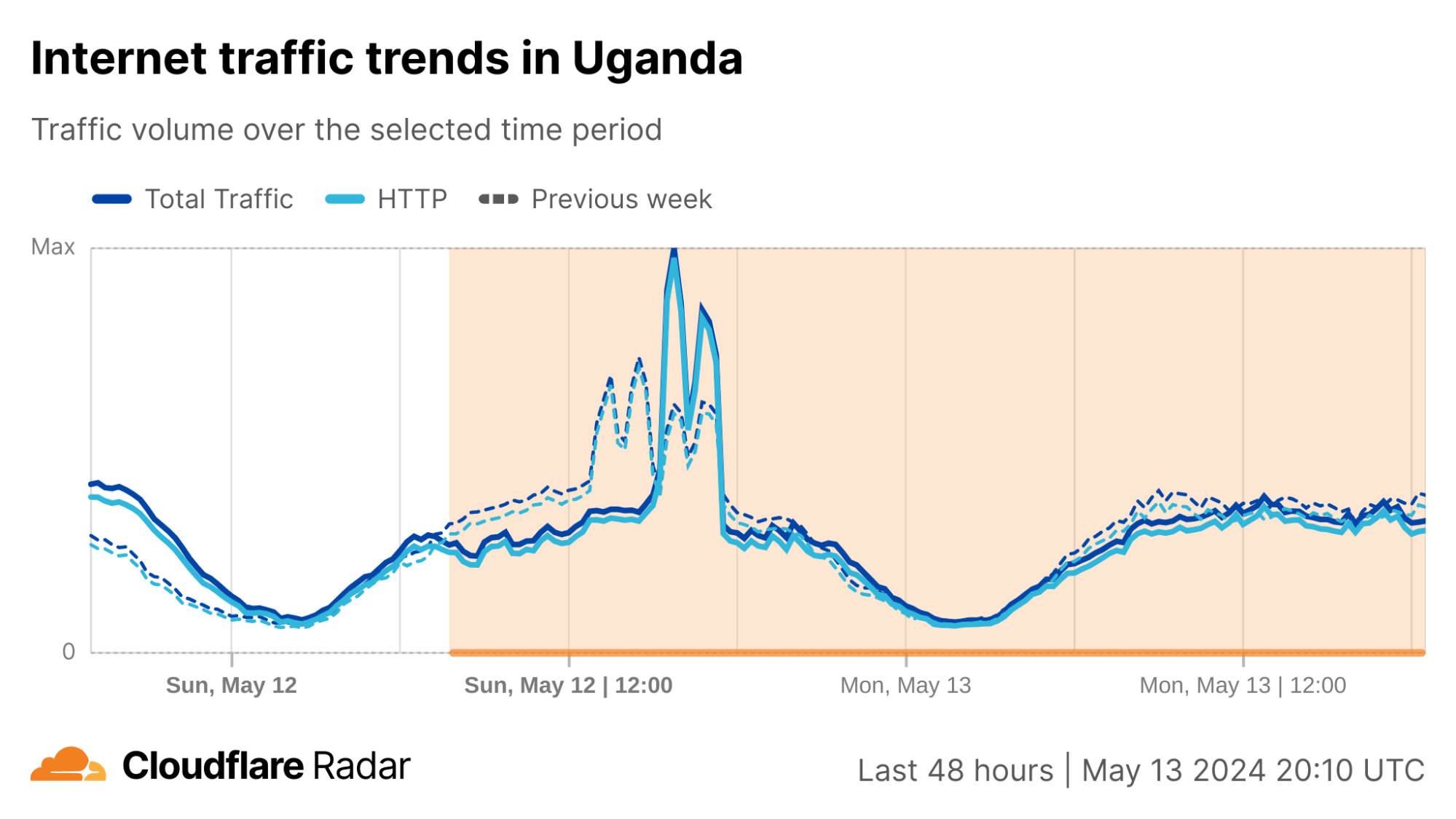
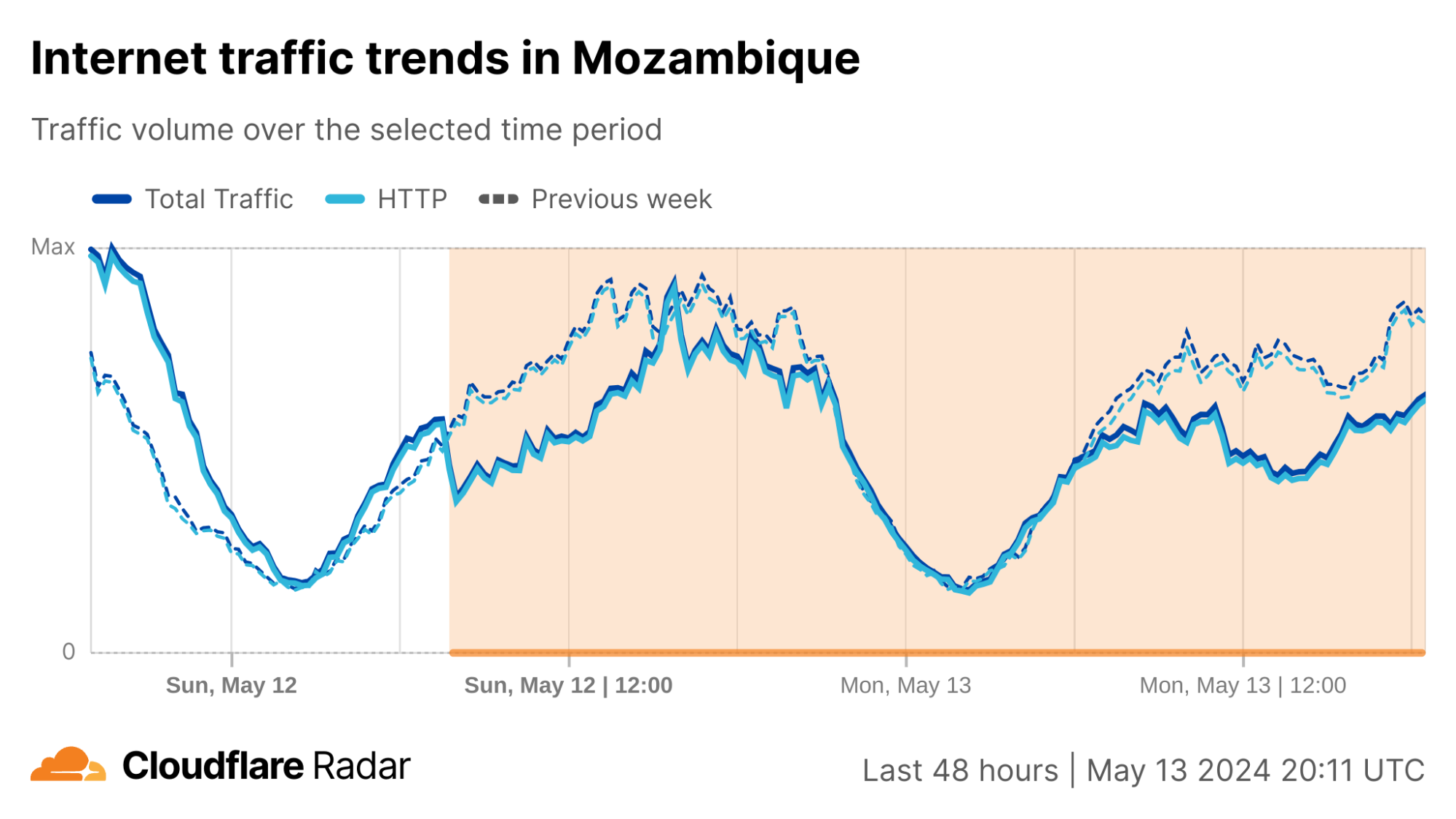
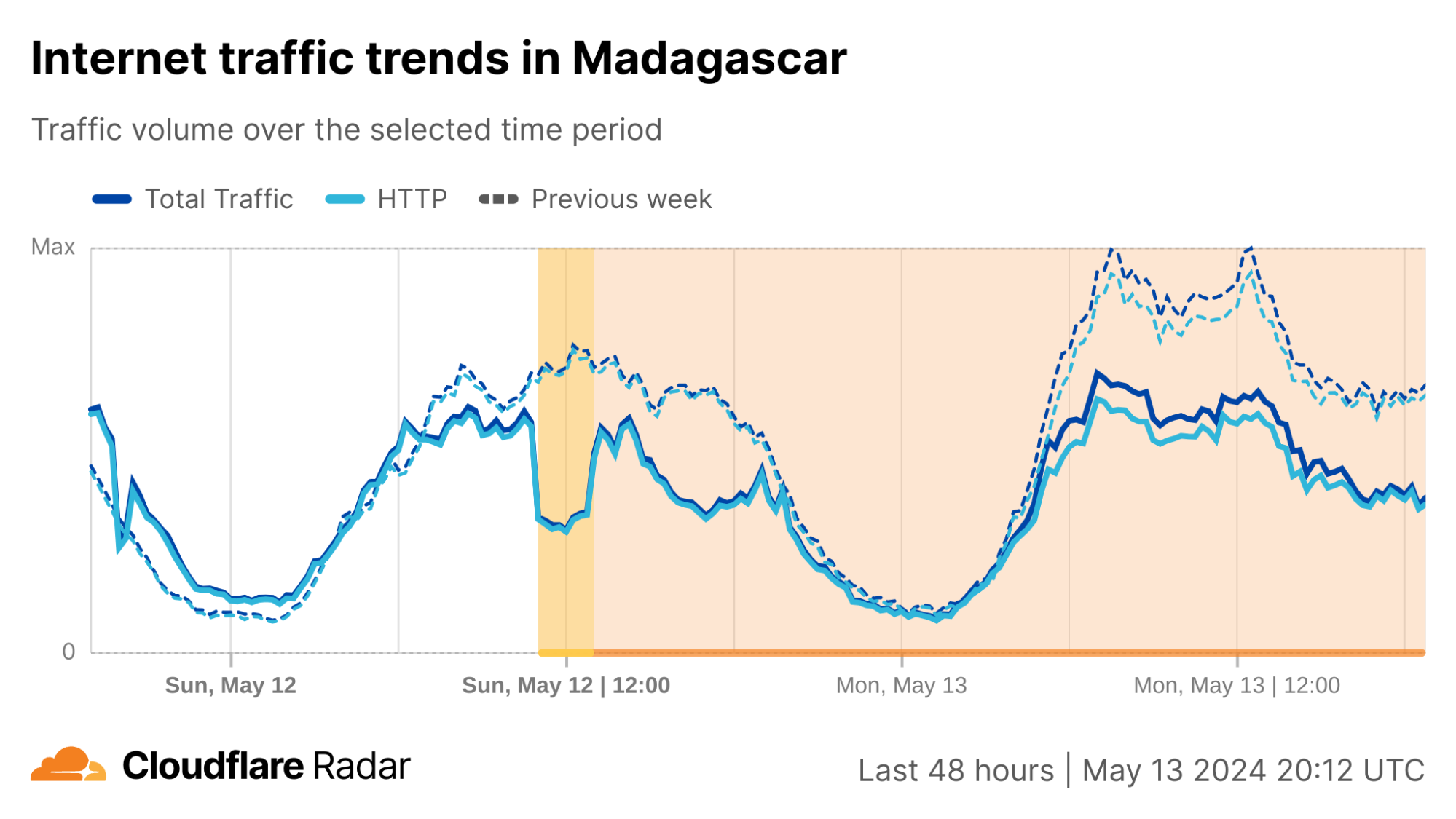
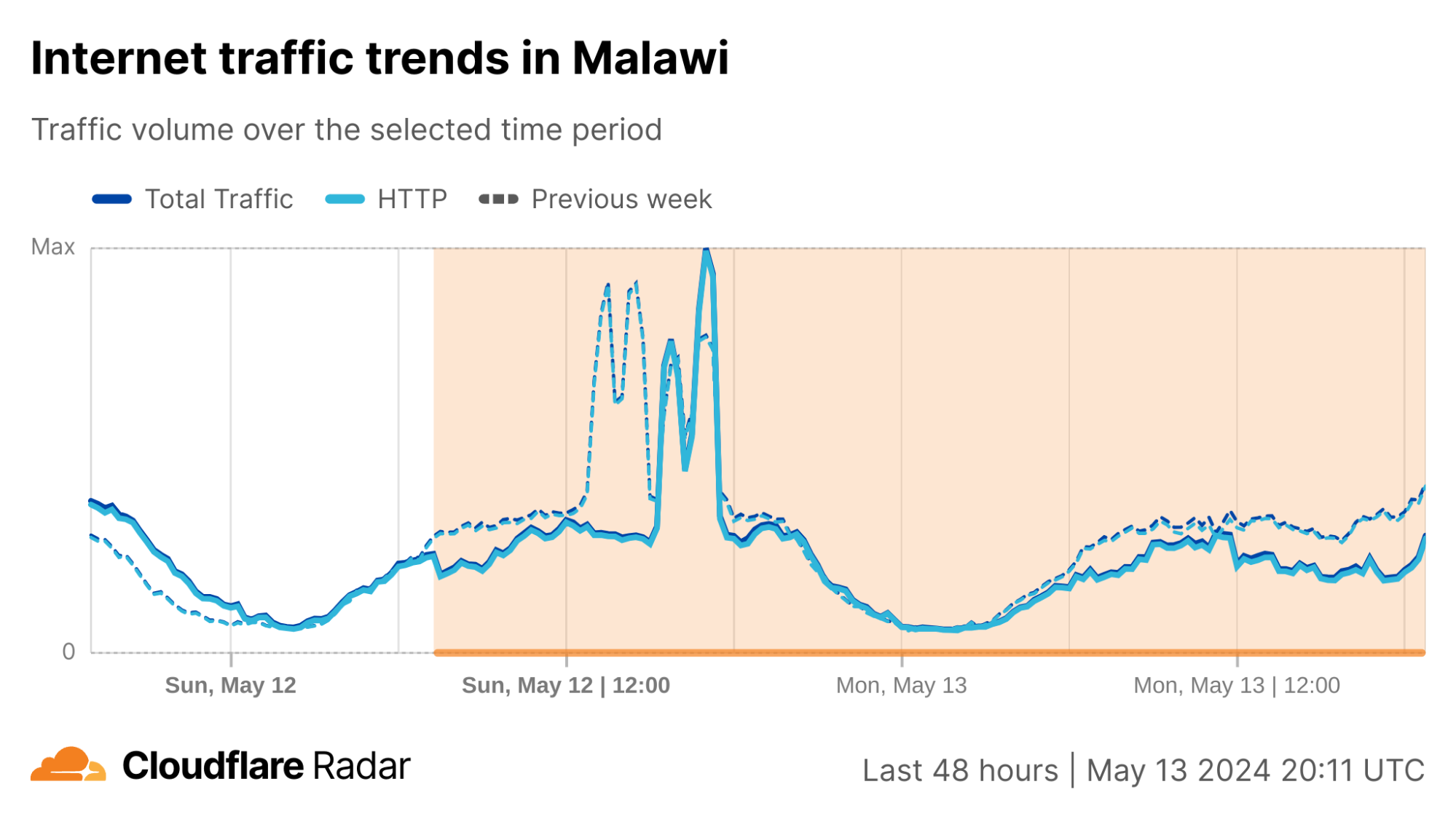
In the third quarter, we observed Internet disruptions with a wide variety of known causes, as well as several with no definitive or published cause. Once again, we unfortunately saw a number of government-directed shutdowns, including exam-related shutdowns in Sudan, Syria, and Iraq. Cable cuts, both submarine and terrestrial, caused Internet outages, including one caused by a stray bullet. A rogue contractor, among other events, caused power outages that impacted Internet connectivity. Damage from an earthquake and a fire caused service disruptions, as did a targeted cyberattack. And a myriad of technical issues, including issues with China’s Great Firewall, resulted in traffic losses across multiple countries.
As we have noted in the past, this post is intended as a summary overview of observed and confirmed disruptions, and is not an exhaustive or complete list of issues that have occurred during the quarter. A larger list of detected traffic anomalies is available in the Cloudflare Radar Outage Center. These anomalies are detected through significant deviations from expected traffic patterns observed across our network. Note that both bytes-based and request-based traffic graphs are used within the post to illustrate the impact of the observed disruptions — the choice of metric to include was generally made based on which better illustrated the impact of the disruption.
Government-directed shutdowns
Sudan
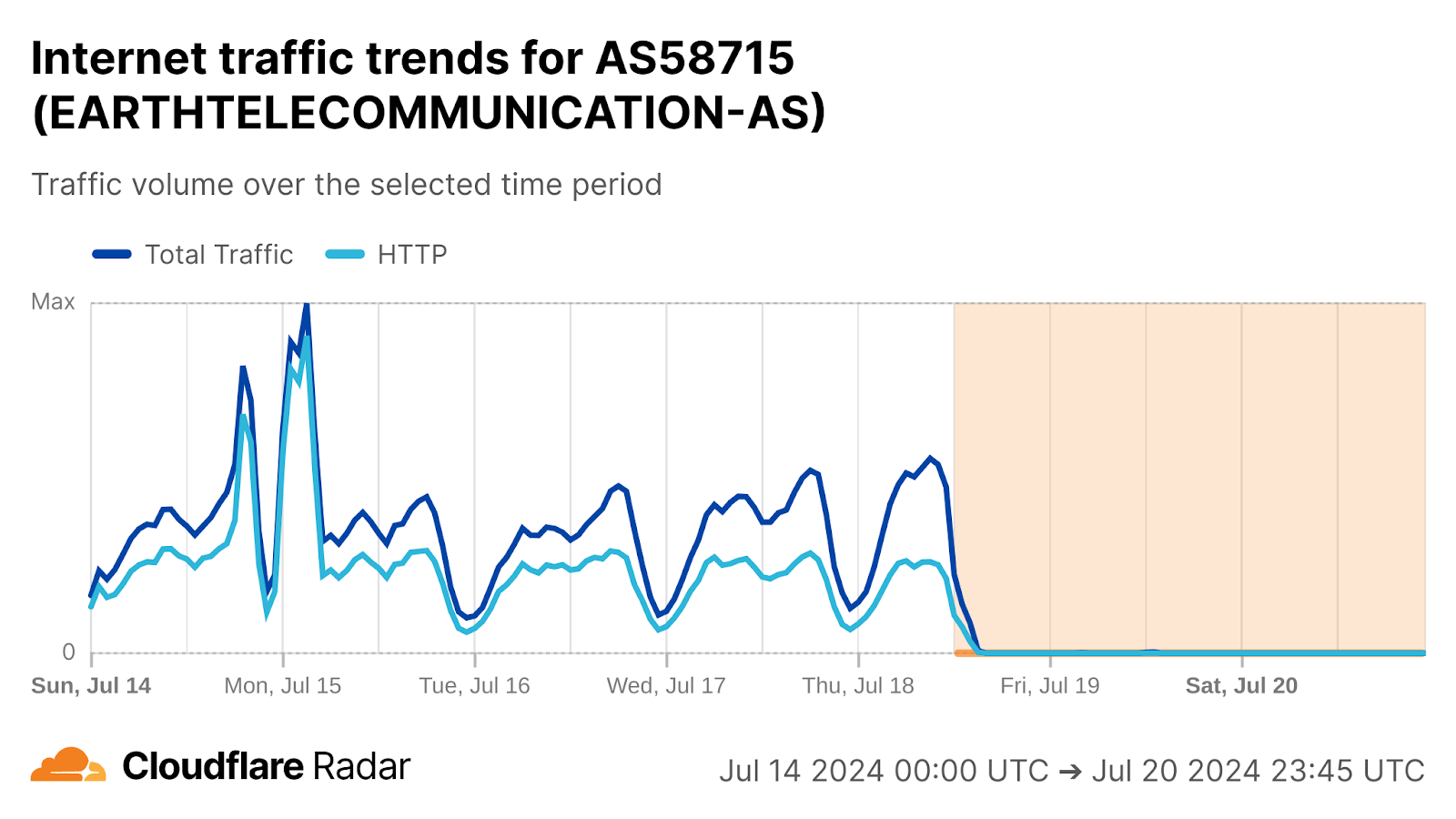
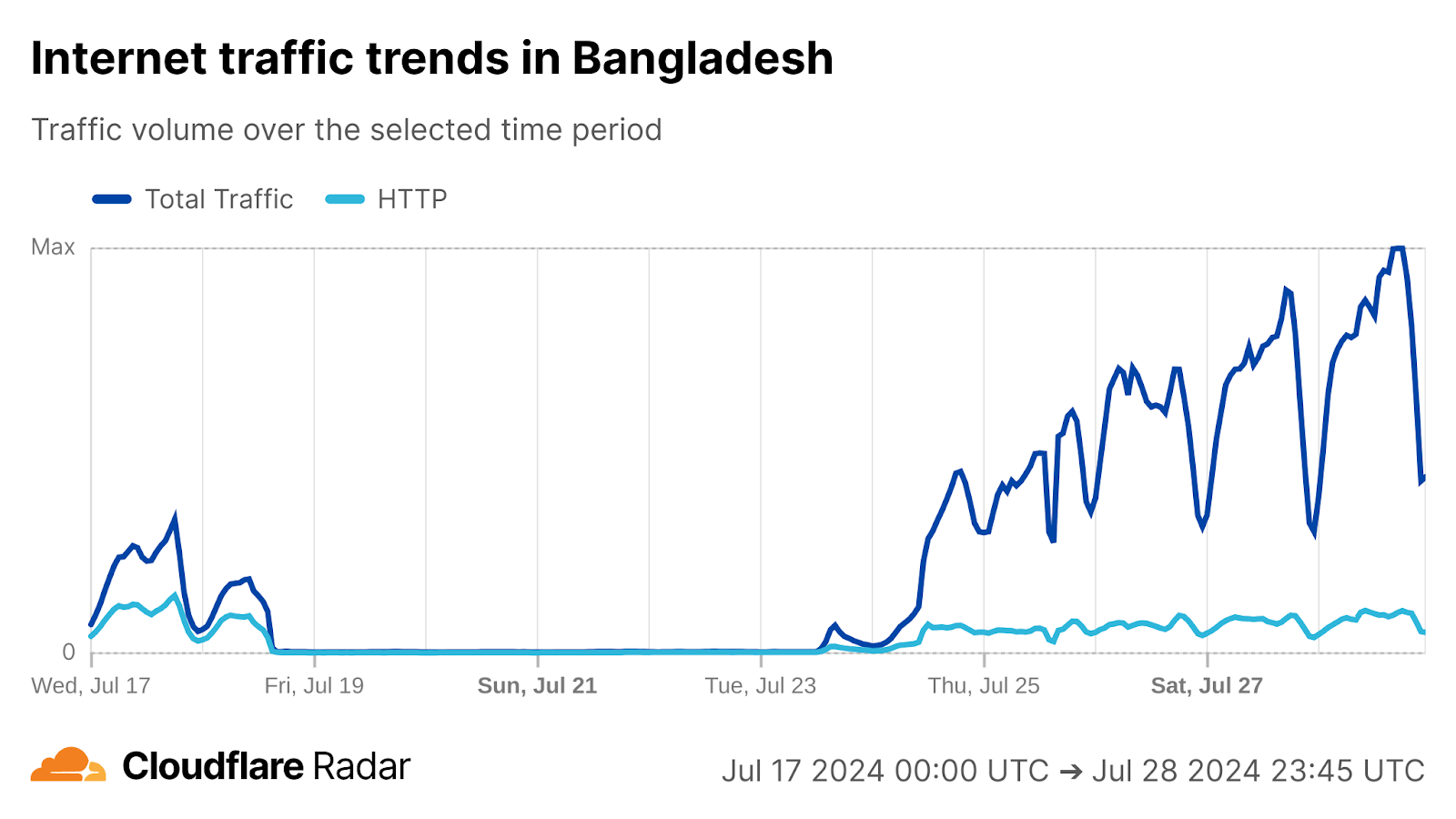
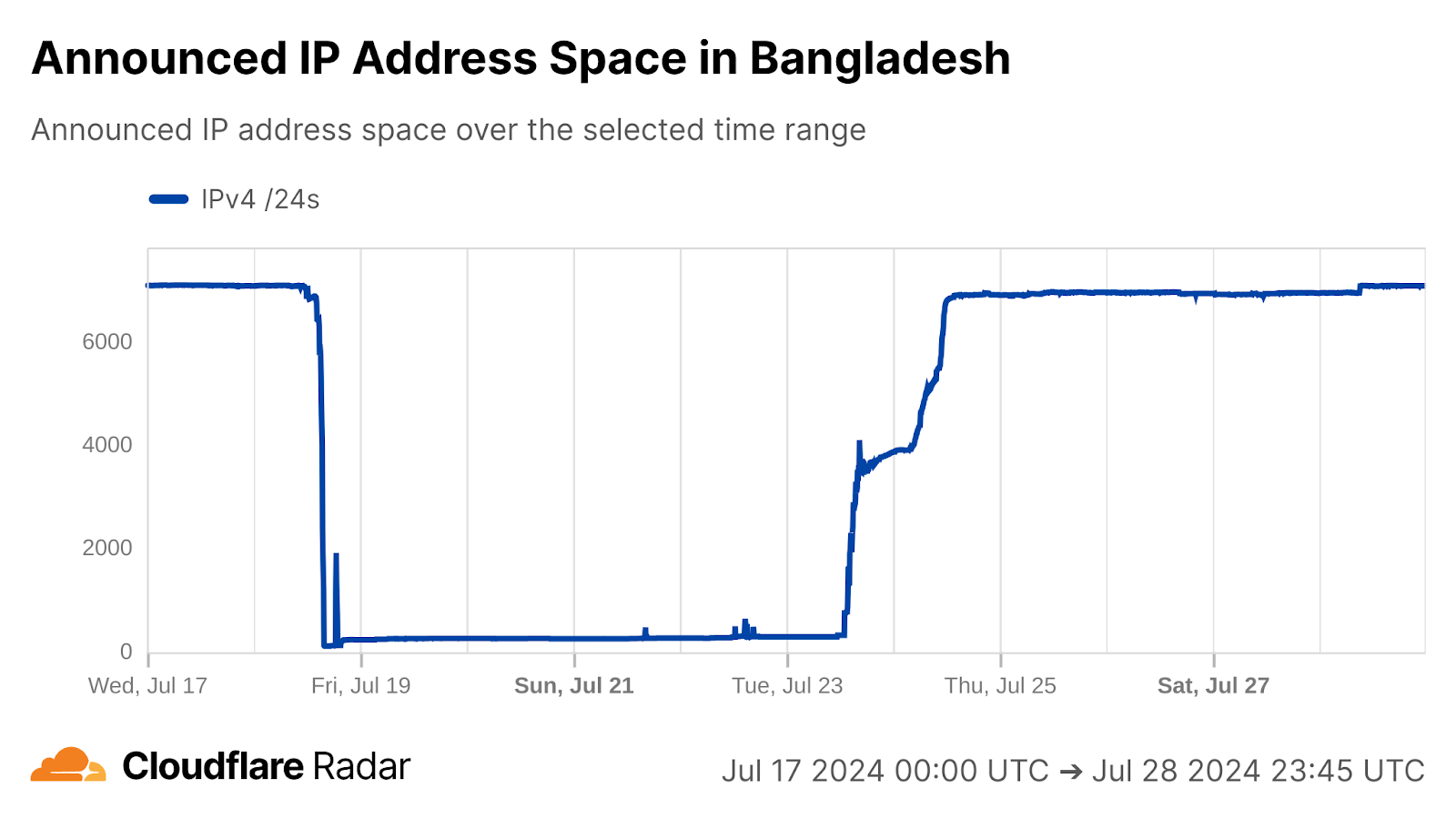
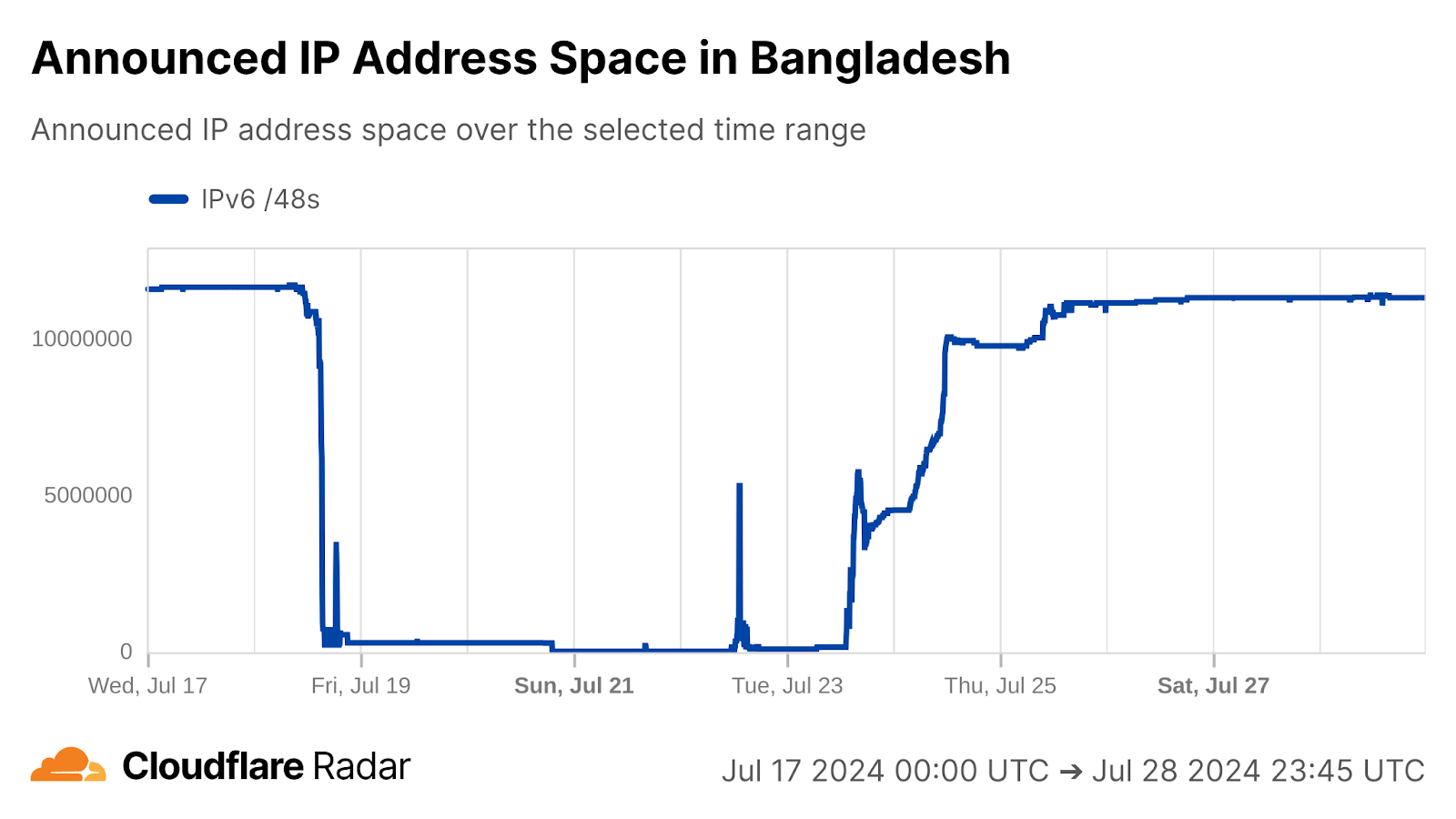
Regular drops in traffic from Sudan were observed between 12:00-15:00 UTC (14:00-17:00 local time) each day from July 7-10. Partial outages were observed at Sudatel (AS15706), and near-complete outages at SDN Mobitel (AS36998) and MTN Sudan (AS36972). Similar drops were also seen in traffic to our 1.1.1.1 DNS resolver from these impacted ASNs.
We have observed Sudan implementing government-directed Internet shutdowns in the past (2021, 2022), and given that the timing aligns with the last four days of postponed 2024 secondary school certificate examinations, in addition to fitting the pattern of short-duration disruptions repeating across multiple days, we believe that these drops in traffic were exam-related shutdowns as well.
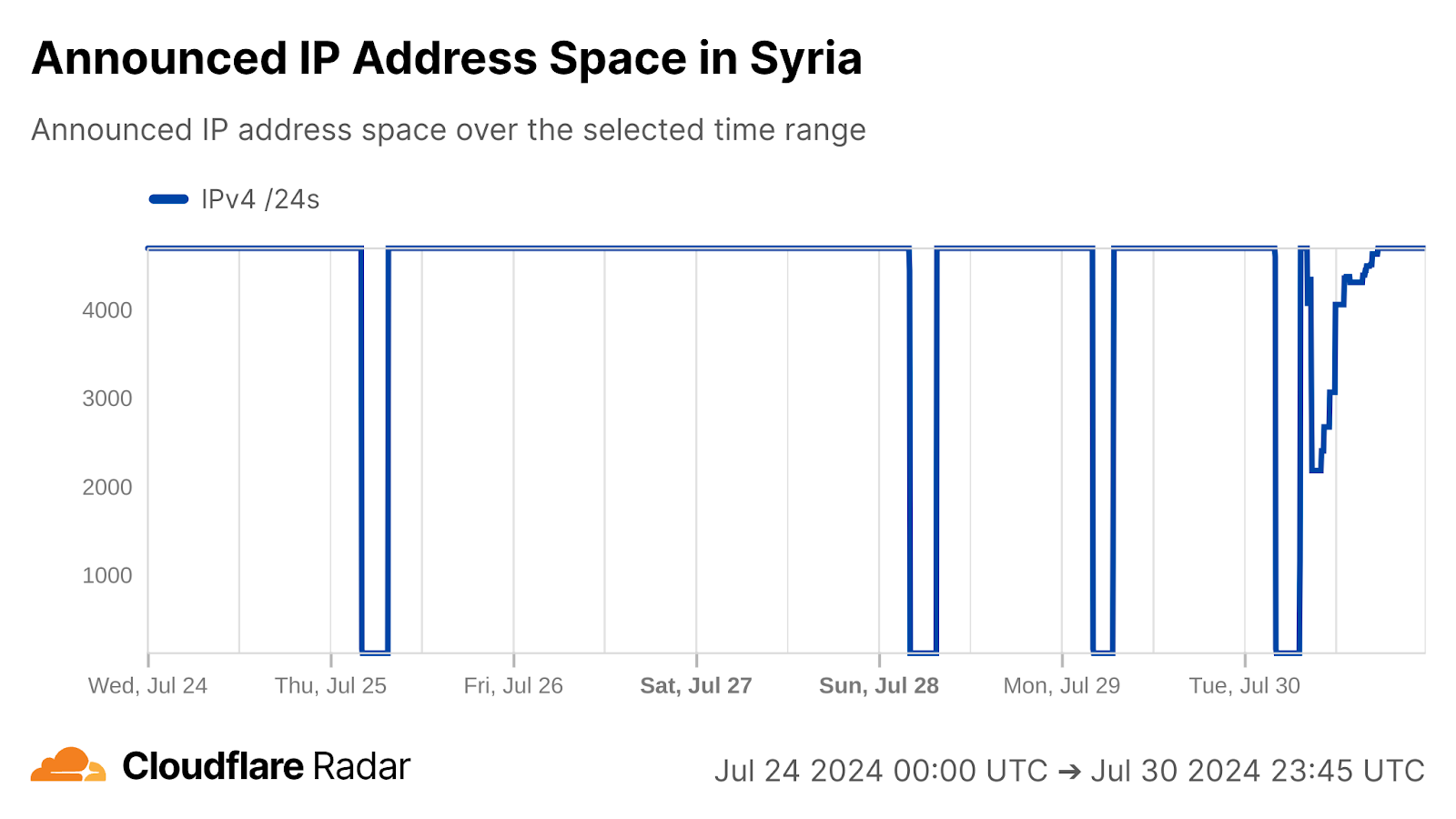
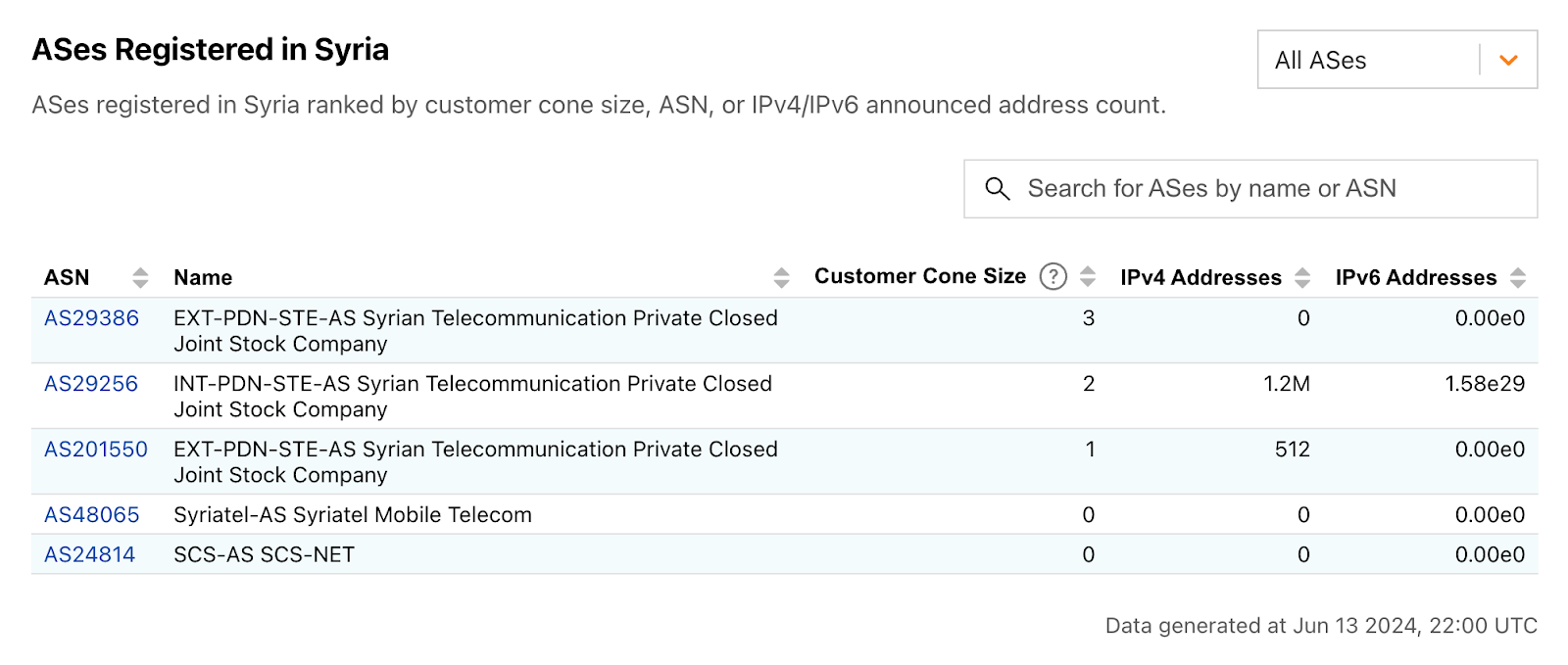
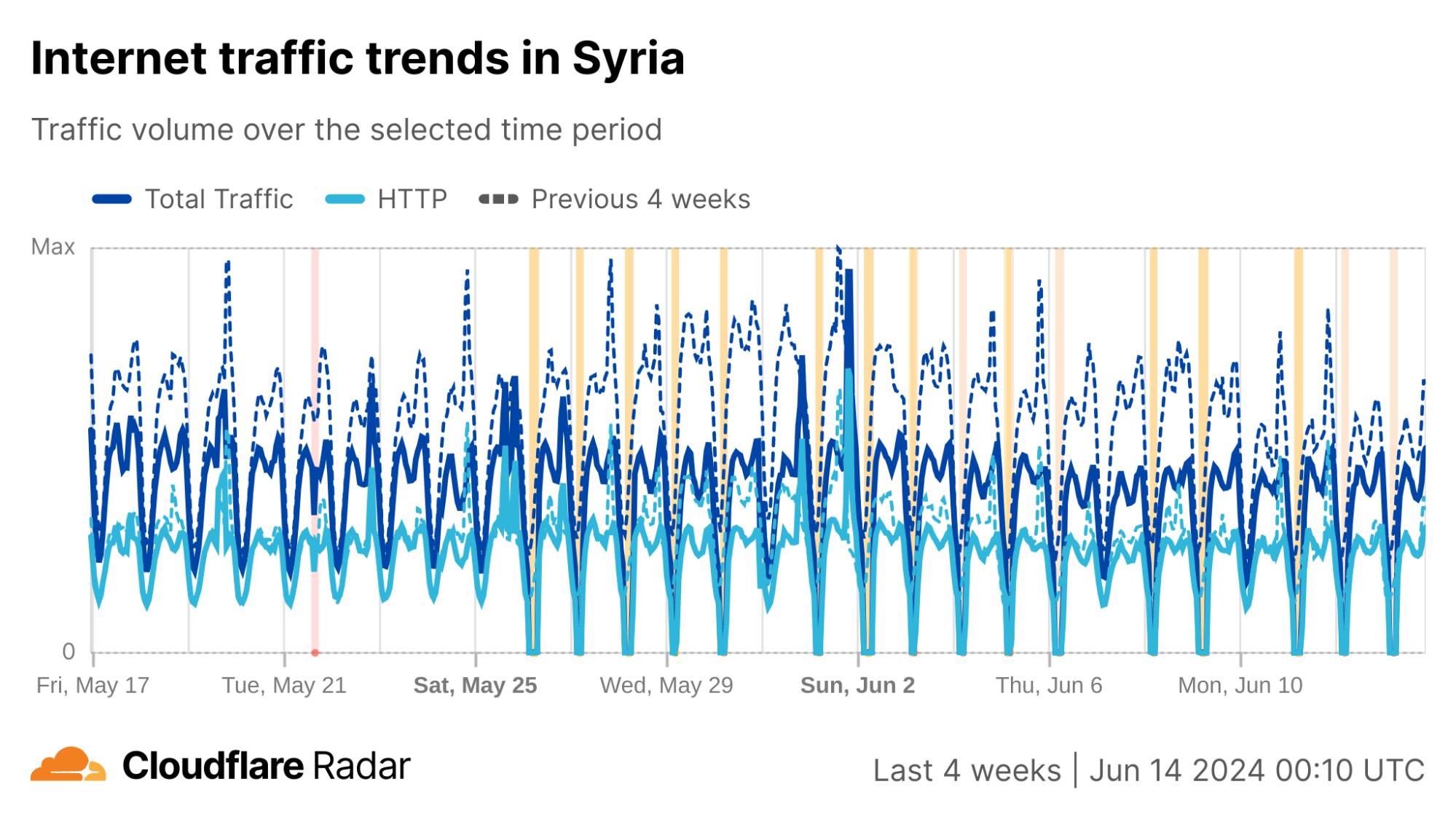
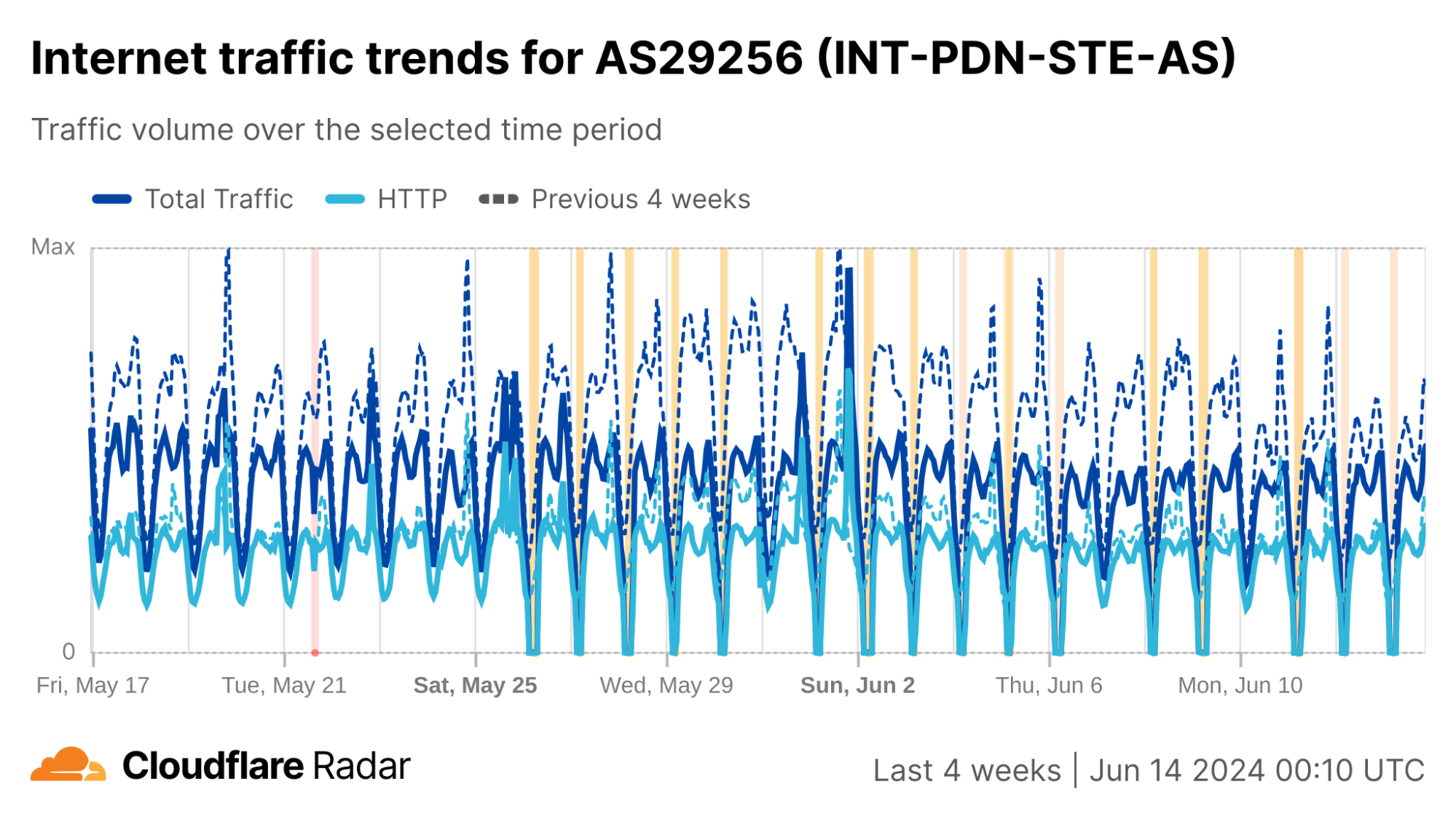
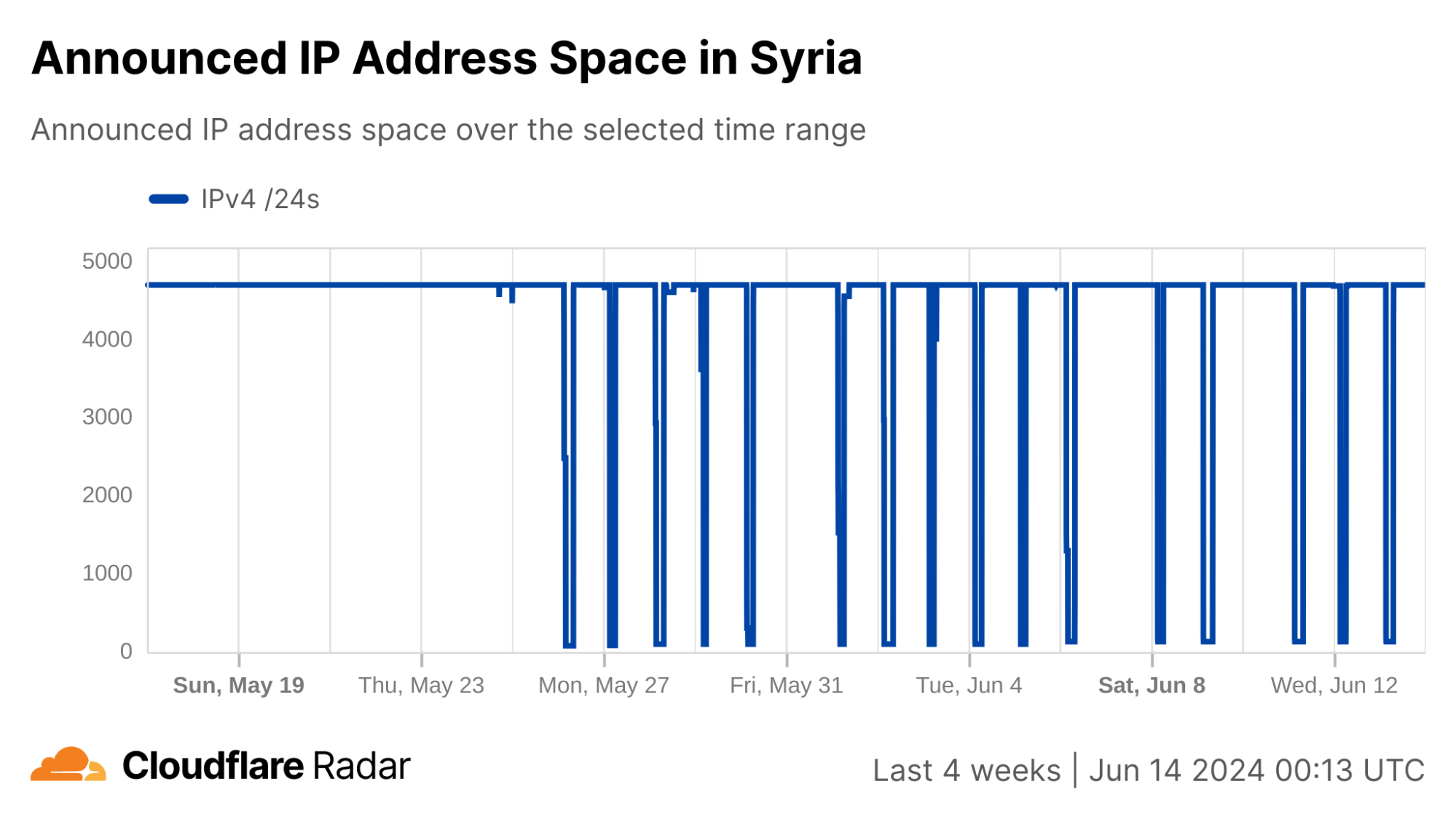
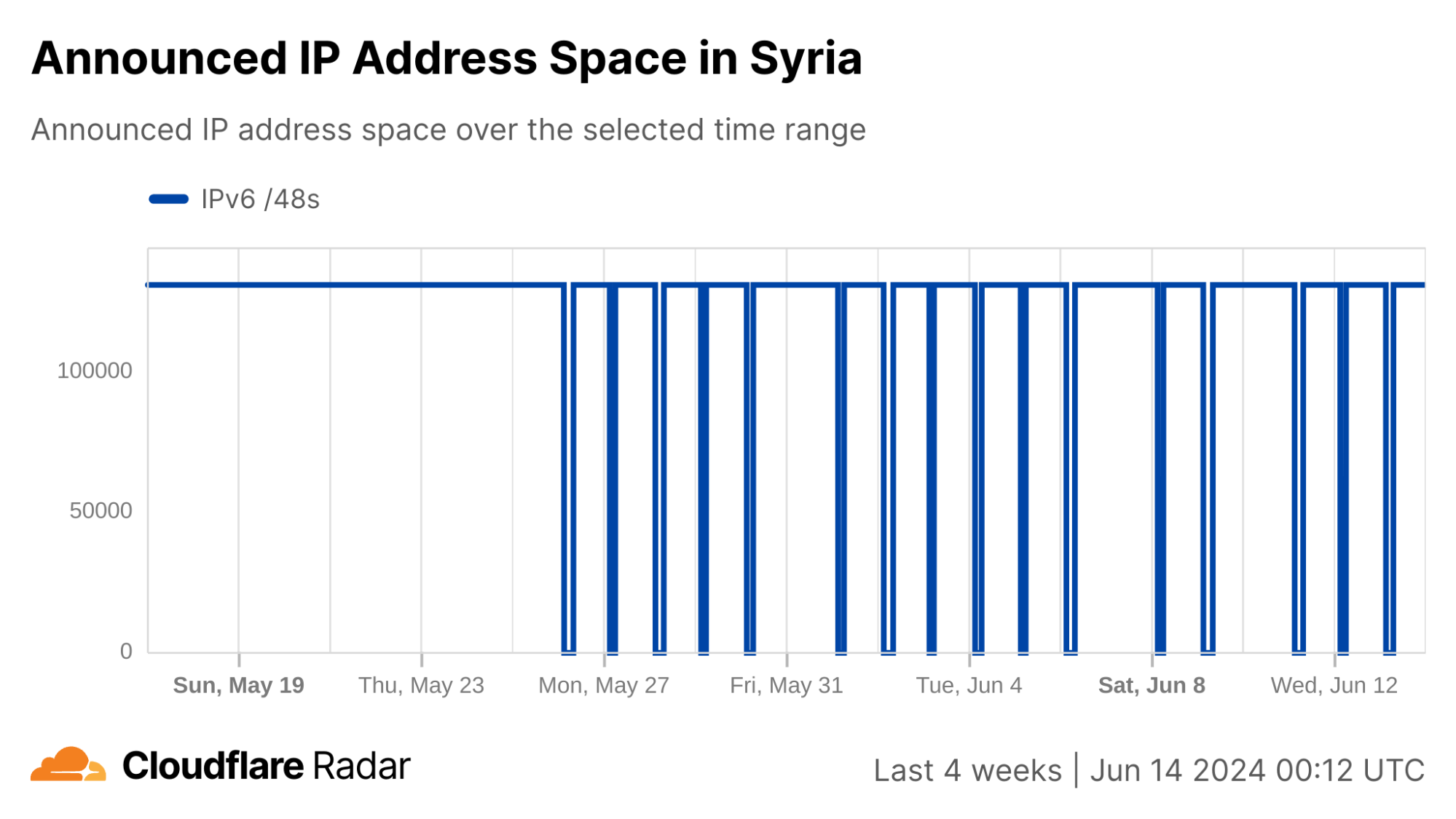
Syria
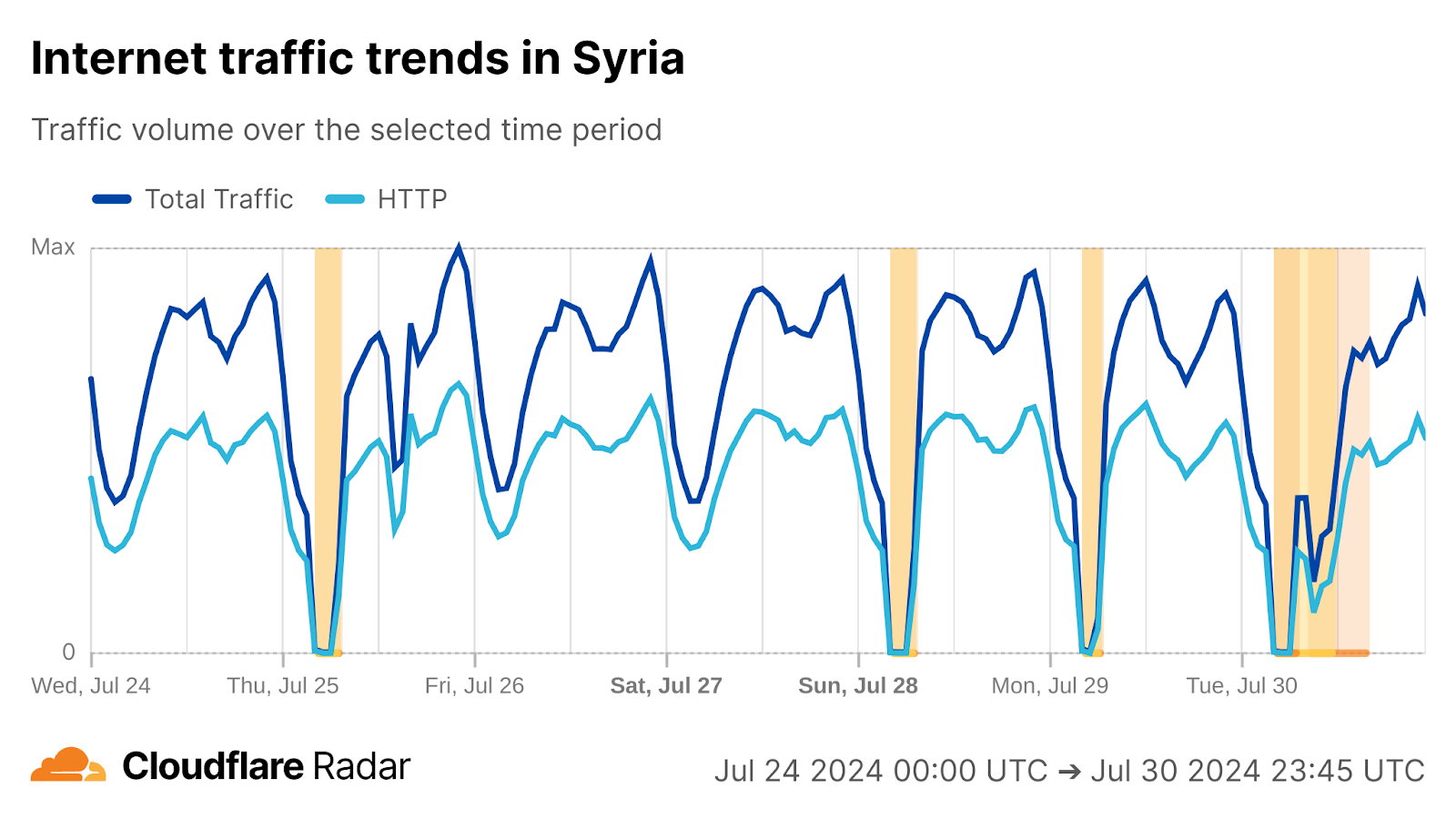
In our second quarter post, we covered the cellular connectivity-focused exam-related Internet shutdowns that Syria chose to implement this year in an effort to limit their impact. During the second quarter, the shutdowns associated with the “Basic Education Certificate” took place on June 21, 24, and 29 between 05:15 – 06:00 UTC (08:15 – 09:00 local time). Exams and associated shutdowns for the “Secondary Education Certificate” were scheduled to take place between July 12 and August 3, and during that period, we observed six additional Internet disruptions in Syria on July 12, 17, 21, 28, 31, and August 3, as shown in the graph below.
“As part of its efforts to ensure the integrity of the examination process, and in coordination with relevant authorities, the Ministry of Education was able to uncover organized exam cheating networks in three examination centers in Lattakia Governorate. These networks used advanced electronic technologies and devices in their attempt to manipulate the exam process.
The network was seized in cooperation with the Lattakia Education Directorate, following close monitoring and detection of suspicious attempts. It was found that members of the network used small earphones, wireless communication devices, and mobile phones equipped with advanced transmission and reception technologies, which contradict educational values and violate the integrity of the examination process and the principle of justice.”
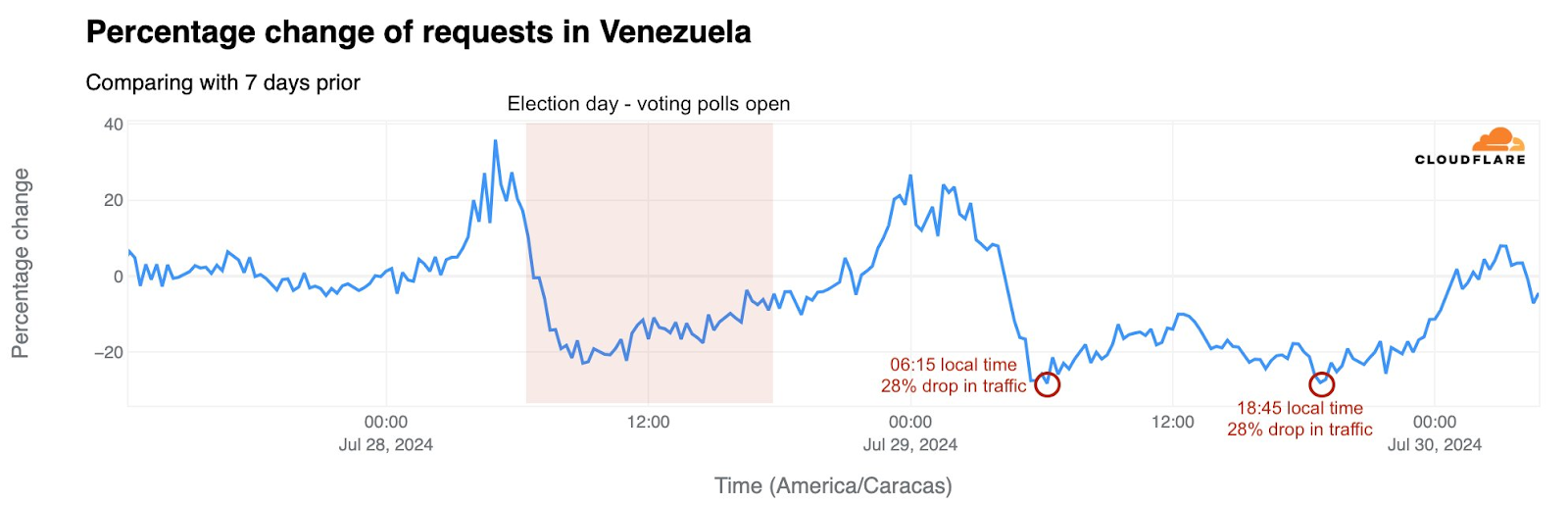
Venezuela
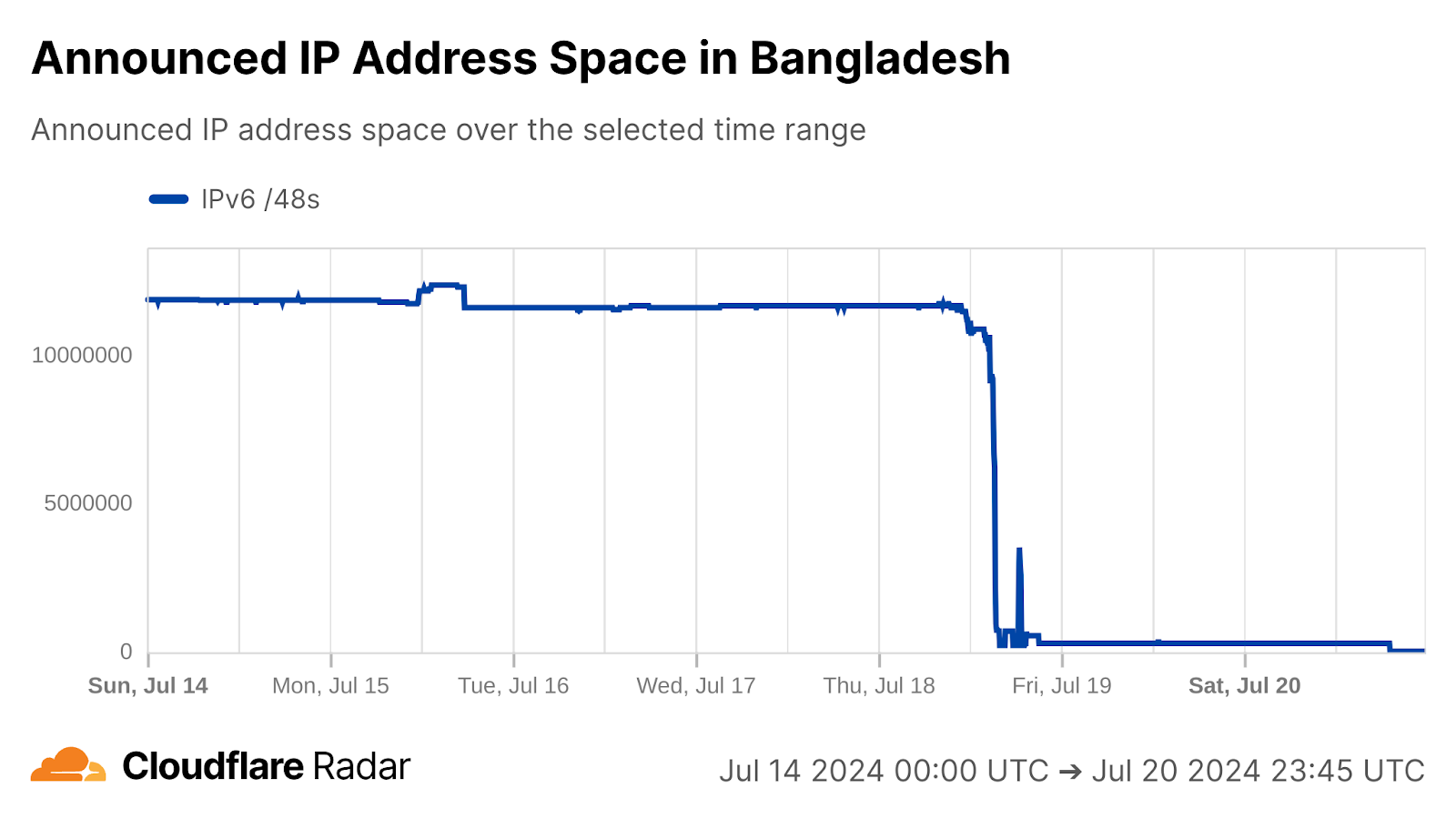
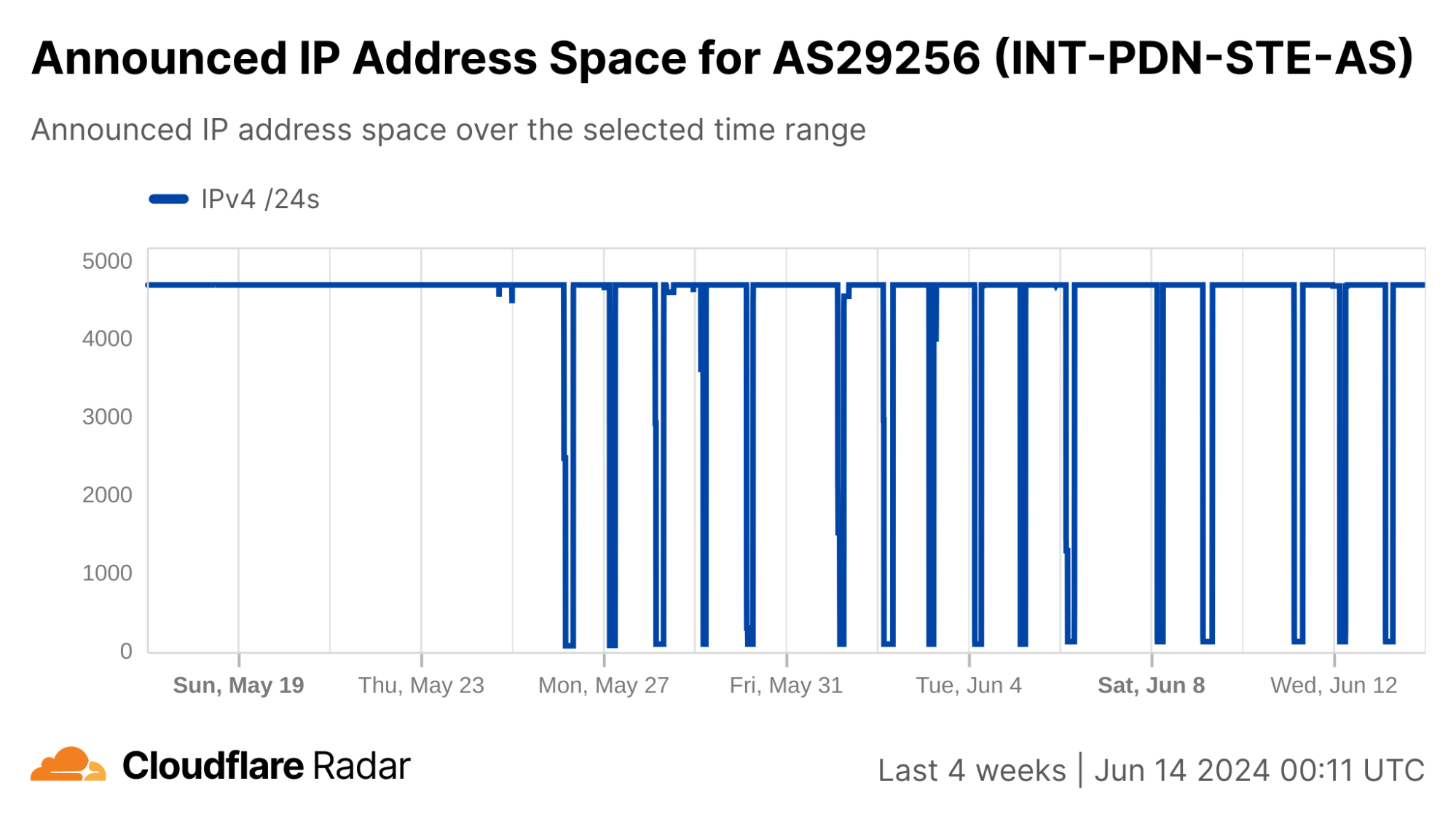
A slightly more unusual government directed shutdown took place in Venezuela on August 18 when Venezuelan provider SuperCable (AS22313) ceased service. An X post from Venezuelan industry watcher VE sin Filtro published a notification from CONATEL, the National Commission of Telecommunications in Venezuela, that notified SuperCable that as of March 14, 2025, its authority to operate in the country had been revoked, and established a 60 day transition period so that users could find another provider. Another X post from VE sin Filtro shared an email that SuperCable subscribers received from the company announcing the end of the service and, and noted that half an hour after the email was sent, subscribers were left without Internet connectivity. Traffic began to fall at 15:00 UTC (11:00 local time), and was gone after 15:30 UTC (11:30 local time). Connectivity remained shut down through the end of the quarter.
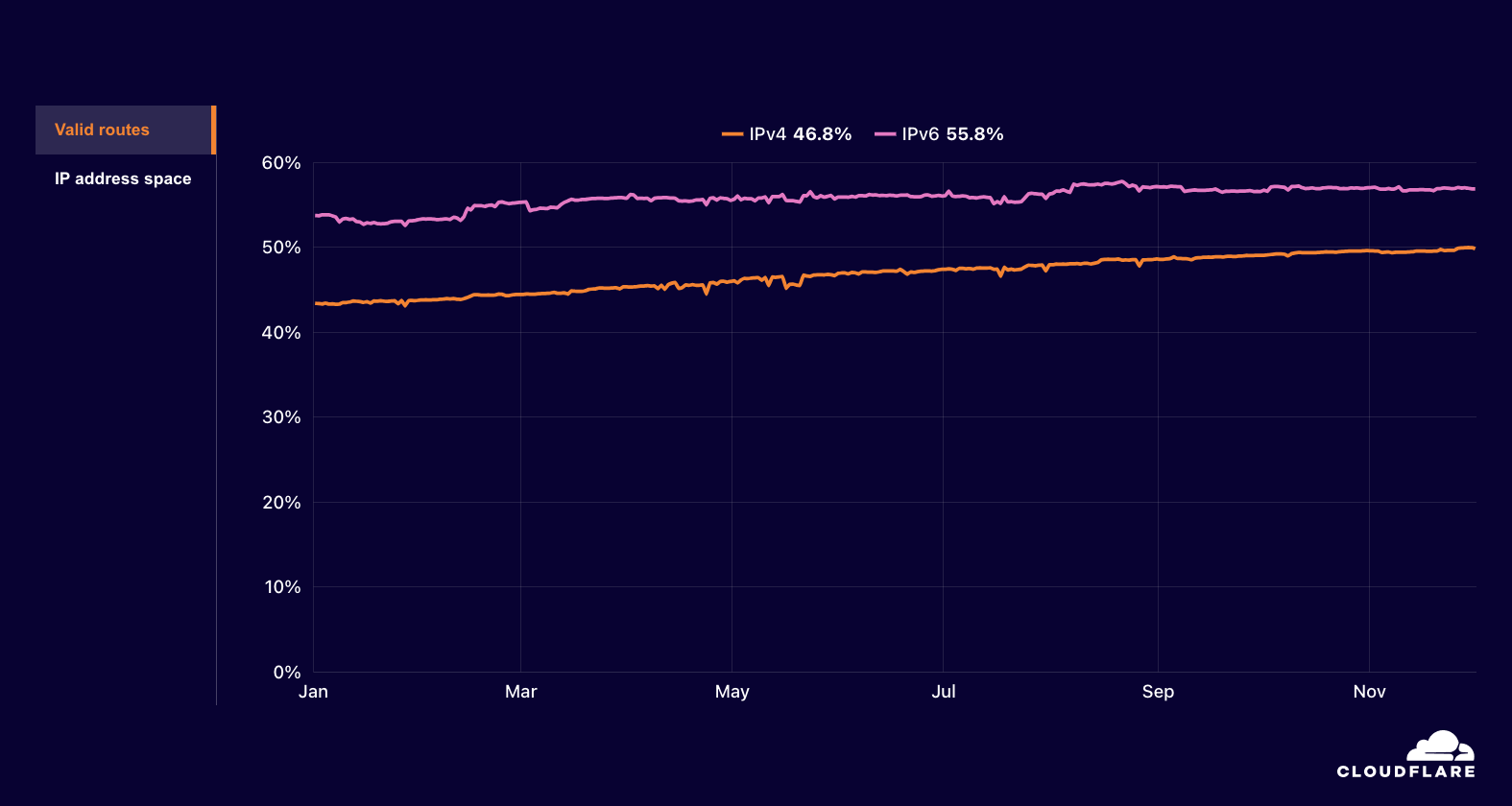
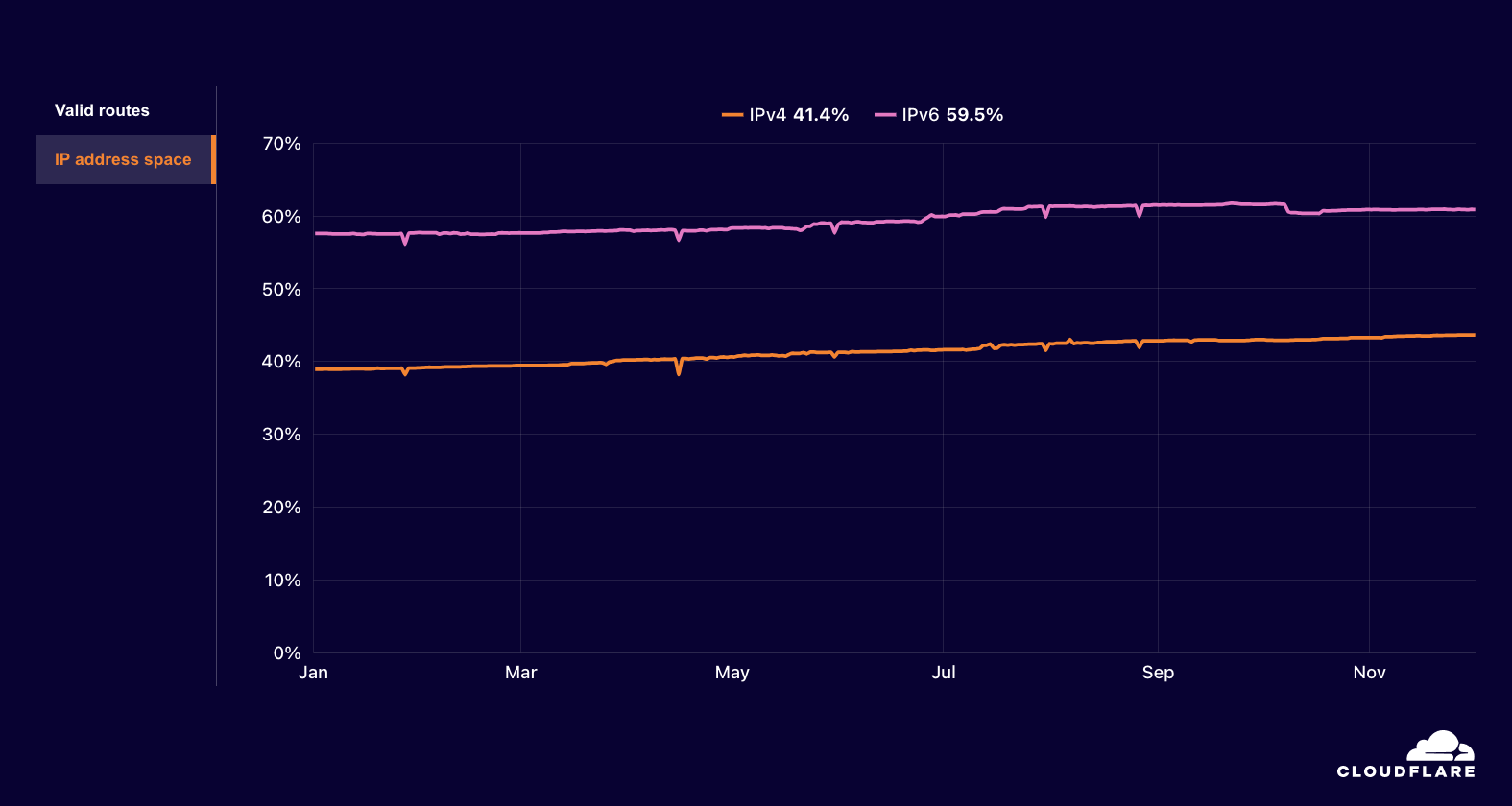
Interestingly, we did not see a corresponding full loss of announced IP address space when traffic disappeared. However, such full losses did occur between August 19-21, and again briefly on September 16. The number of announced /24s (blocks of 256 IPv4 addresses) fell from 95 to 63 on September 25, and remained at that level through the end of the quarter.
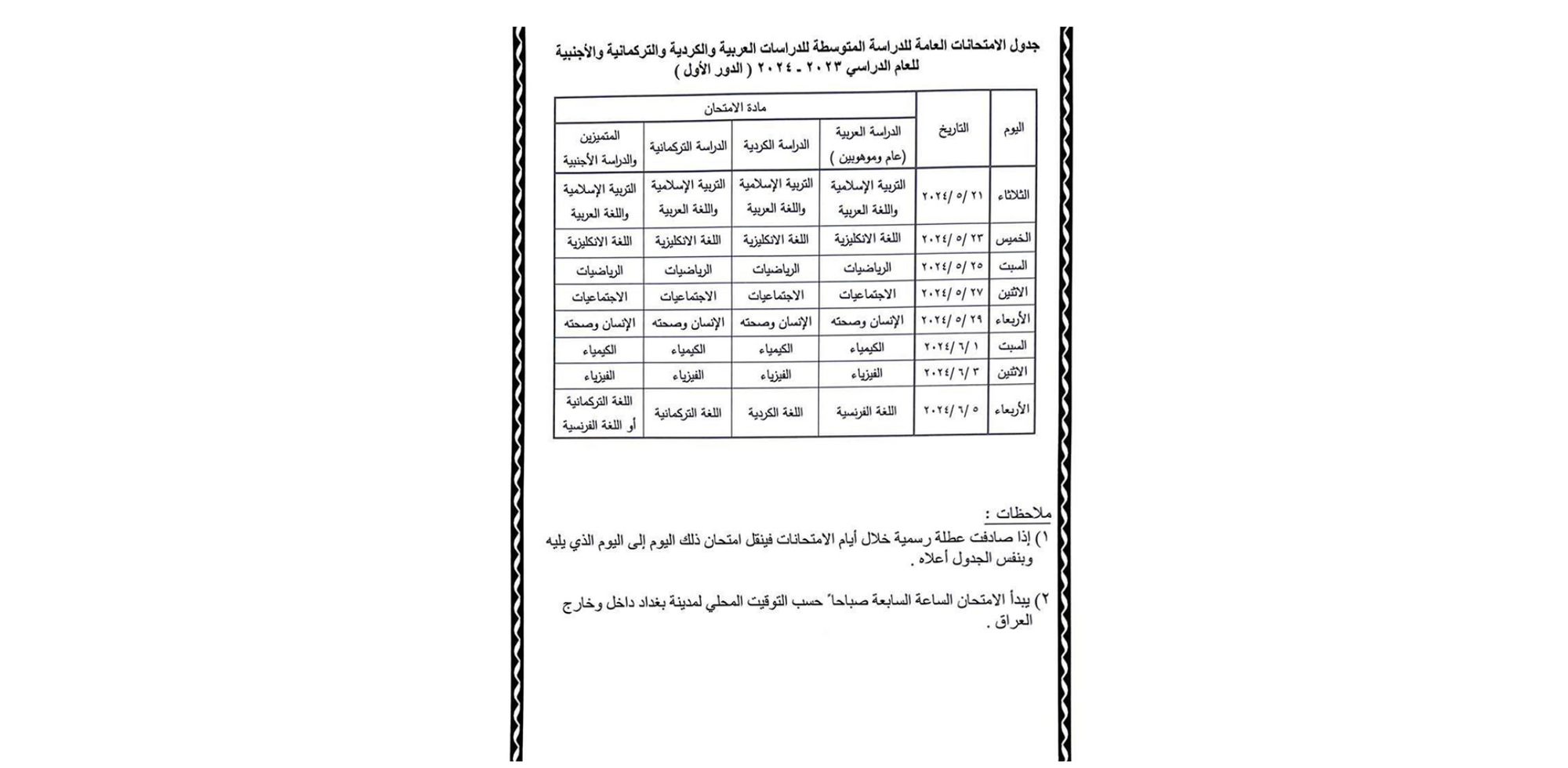
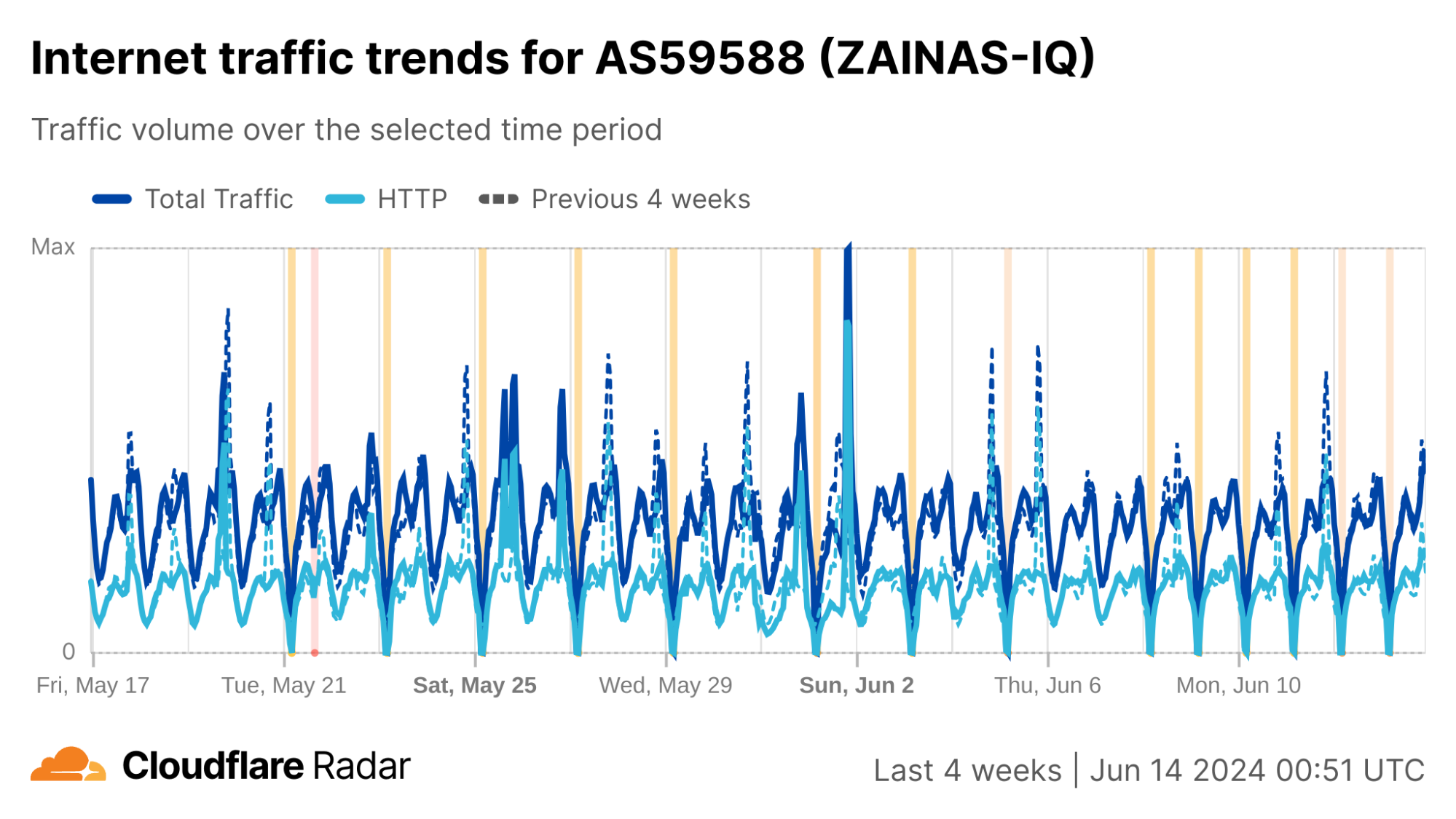
Iraq
Similar to Syria, we covered the latest rounds of exam-related Internet shutdowns in Iraq in our second quarter blog post. In that post, we noted that the shutdowns in the main part of the country ran until July 3 for preparatory school exams, and through July 6 in the Kurdistan region. These can be seen in the graph below.
In mid-September, the Taliban ordered the shutdown of fiber optic Internet connectivity in multiple provinces across Afghanistan, as part of a drive to “prevent immorality”. It was the first such ban issued since the Taliban took full control of the country in August 2021. As many as 15 provinces experienced shutdowns, and these regional shutdowns blocked Afghani students from attending online classes, impacted commerce and banking, and limited access to government agencies and institutions such as passport and registration offices, customs offices.
Less than two weeks later, just after 11:30 UTC (16:00 local time) on Monday, September 29, 2025, subscribers of wired Internet providers in Afghanistan experienced a brief service interruption, lasting until just before 12:00 UTC (16:30 local time). Mobile providers Afghan Wireless (AS38472) and Etisalat (AS131284) remained available during that period. However, just after 12:30 UTC (17:00 local time), the Internet was completely shut down, taking the country completely offline.
On July 7, a post on X from Claro alerted subscribers to a service disruption caused by damage to two fiber optic cables. According to a subsequent post, one was damaged by work being done by CORAAVEGA (La Vega Water And Sewerage Corporation) and the other by work being done by the Dominican Electric Transmission Company. As a result of the damage, traffic from Claro (AS6400) began to drop just before 16:00 UTC (12:00 local time), falling just over two-thirds compared to the prior week. Claro’s technicians were able to quickly locate the faults and repair them, with traffic recovering around 18:00 UTC (14:00 local time).
Angola
Between 12:45-15:45 UTC (13:45-16:45 local time) on July 19, users in Angola experienced an Internet disruption, with Unitel Angola (AS37119) experiencing as much as a 95% drop in traffic as compared to the previous week, and Connectis (AS327932) suffering a complete outage. According to an X post from Unitel Angola, it “was caused by a disruption at our partner Angola Cables, resulting from public road works that affected the national fiber optic interconnections.”
However, the timing of the disruption coincided with protests over the rise in diesel fuel prices, and local non-governmental organizations disputed Unitel Angola’s explanation, claiming that it was actually due to a government-directed Internet shutdown. Multiple Angolan network providers experienced a drop in announced IP address space during the period the Internet disruption occurred, and analysis of routing information for these networks finds that they share Angola Cables (AS37468) as an upstream provider, lending some credence to the explanation from Unitel Angola.
Haiti
Digicel Haiti (AS27653) is no stranger to Internet disruptions caused by damage to both terrestrial and submarine cables, experiencing such problems during the first and second quarters of 2025, as well as first, second, and third quarters of 2024. The most recent such disruption occurred on August 26, when they experienced two different cuts on their fiber optic infrastructure, according to an X post from the company’s Director General. Traffic dropped by approximately 80% during the disruption, which lasted from 19:30-23:00 UTC (15:30-19:00 UTC).
Pakistan & United Arab Emirates
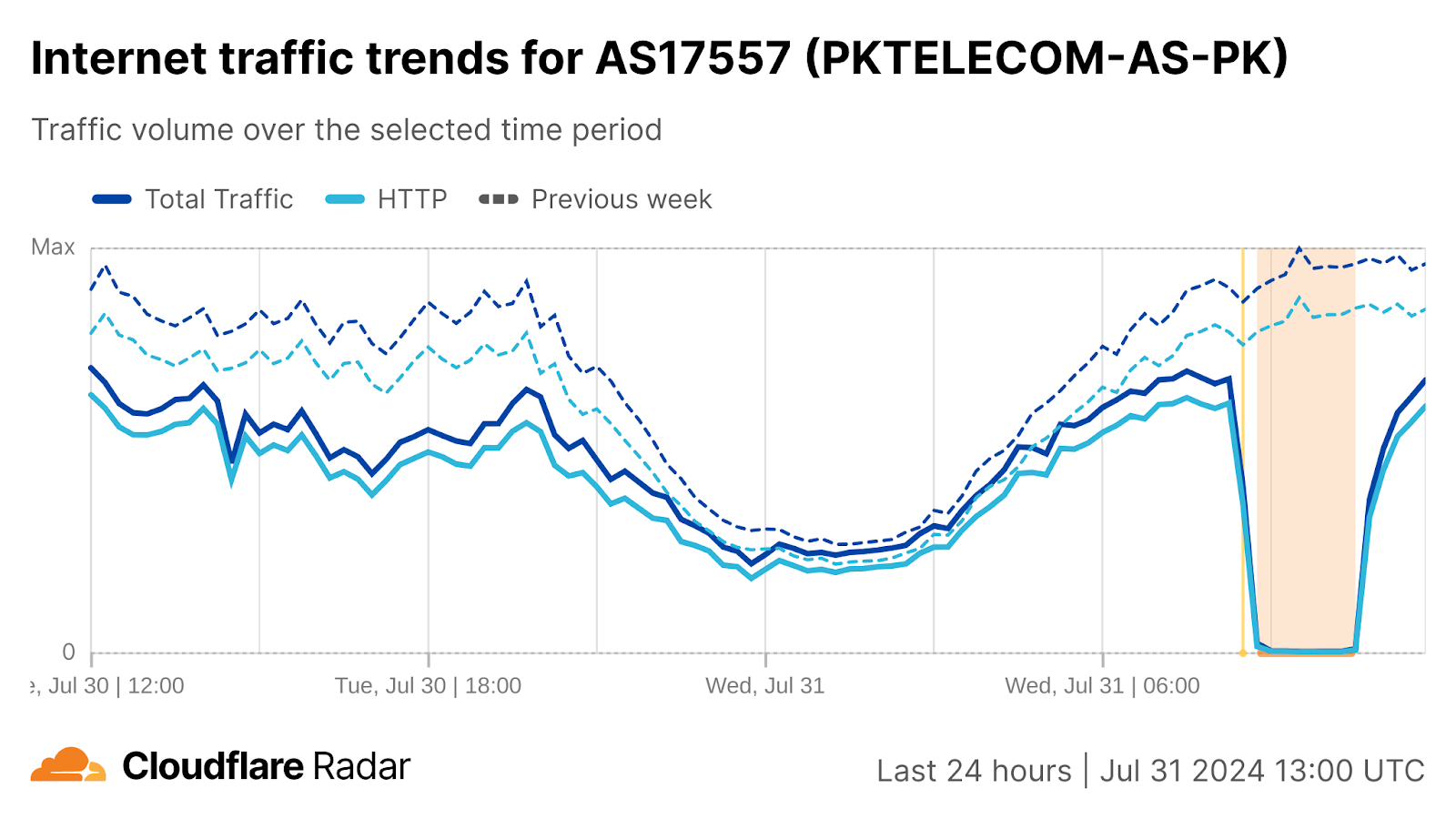
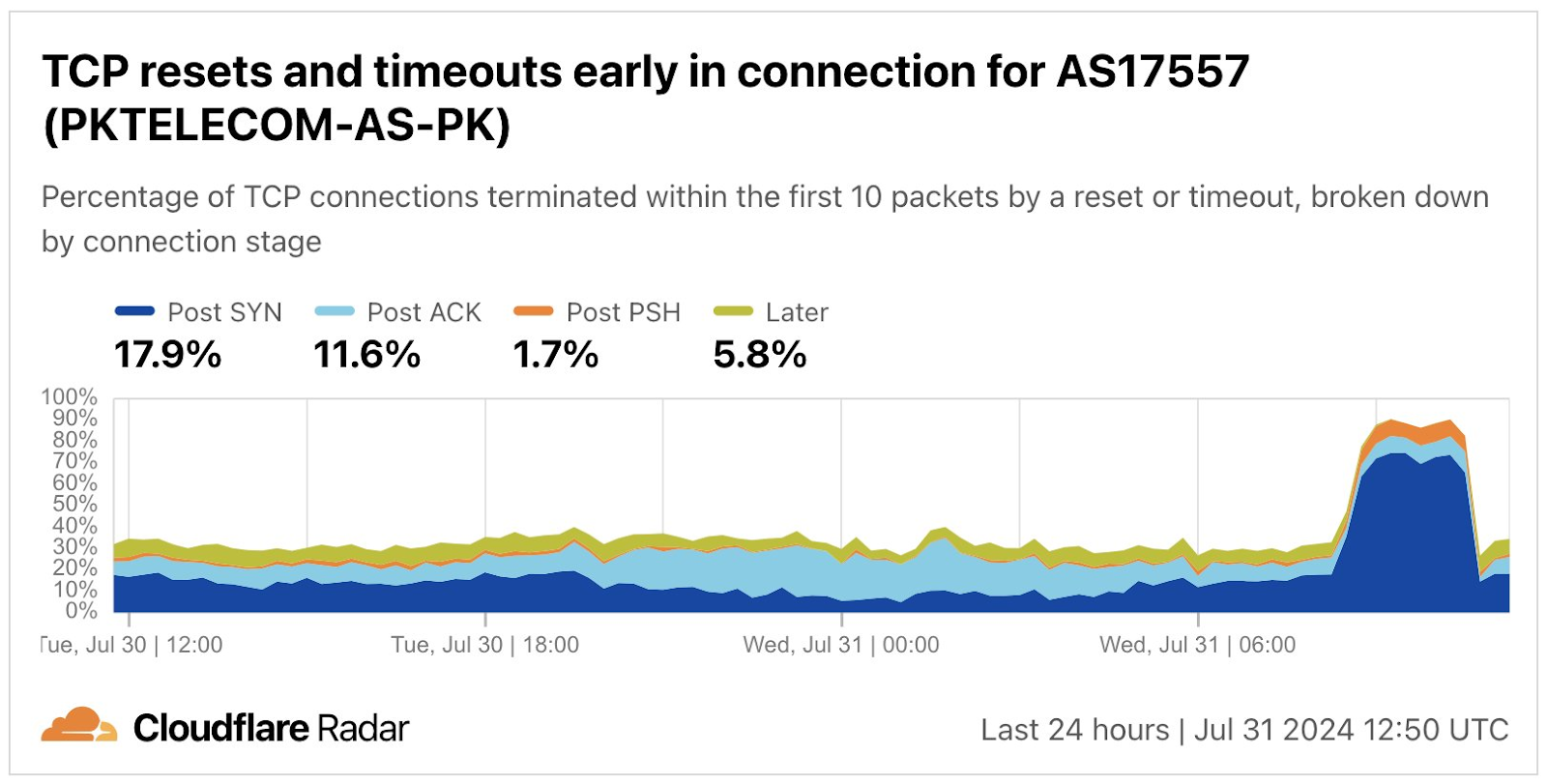
Telegeography’s Submarine Cable Map shows that the Red Sea has a high density of submarine cables that carry data between Europe, Africa, and Asia. Cuts to these cables can significantly impact connectivity, ranging from increased latency on international connections to complete outages. The impacts may only affect a single country, or they may disrupt multiple countries connected to a damaged cable. On September 6, Pakistan Telecom (AS17557)posted a message on X that stated “We would like to inform that submarine cable cuts have occurred in Saudi waters near Jeddah, impacting partial bandwidth capacity on SMW4 and IMEWE systems. As a result, internet users in Pakistan may experience some service degradation during peak hours.” (Initial reporting that the cable cuts occurred near Jeddah were apparently incorrect, as the damage occurred in Yemeni waters.)
Looking at the impact in Pakistan, we observed traffic drop by 25-30% in Sindh and Punjab between 12:00-20:00 UTC (17:00 – 01:00 local time).
In the United Arab Emirates, Etisalat alerted customers via a post on X that they “may experience slowness in data services due to an interruption in the international submarine cables.” Between 11:00-22:00 UTC (15:00-02:00 local time) on September 6, traffic from AS8966 (Etisalat)dropped as much as 28%.
Also in the UAE, service provider du (AS15802) told their customers via a post on X that “You may experience some slowness in our data services due to an International submarine cable cut.” This slowness is visible in Radar’s Internet quality metrics for the network between 11:00-22:00 UTC (15:00-02:00 local time) on September 6, with median bandwidth dropping by more than half, from 25 Mbps to as low as 9.8 Mbps, and median latency doubling from 30 ms to over 60 ms.
The graphs below provide another view of the impact of the cable cuts, based on Cloudflare network probes between New Delhi (del-c) to London (lhr-a) and Bombay (bom-c) to Frankfurt (fra-a). For the former pair of data centers, mean latency grew by approximately 20%, and for the latter pair, by approximately 30%, starting around 23:00 UTC on September 5. (The stable latency line at the bottom of both graphs represents probes going over the Cloudflare backbone, which was not impacted by the cable cuts.)
Texas, United States
Fiber optic cables are frequently damaged by errant ship anchors (submarine) or construction equipment (terrestrial), but on September 26, a stray bullet damaged a cable in the Dallas, Texas area, disrupting Internet connectivity for Spectrum (AS11427) customers. Spectrum acknowledged the service interruption in a post on X, followed by another post four and a half hours later stating that the issue had been resolved. Although neither post cited the bullet as the cause of the disruption, news reports attributed the claim to a Spectrum spokesperson. Overall, the disruption was fairly nominal, lasting for just two hours between 18:00-20:00 UTC (13:00-15:00 local time), with traffic dropping less than 25% as compared to the prior week.
South Africa
“Major cable breaks” disrupted Internet connectivity for customers of Telkom (AS37457) in South Africa on September 27. Although Telkom acknowledged the initial service disruption and its subsequent resolution in posts on X, it didn’t provide any information about the cause in these posts. However, it apparently later issued a statement, stating “Telkom confirms that mobile voice and data services, which were disrupted earlier on Saturday due to major cable breaks, have now been fully restored nationwide.” The disruption lasted six hours, from 08:00-14:00 UTC (10:00-16:00 local time), with traffic dropping as much as 50% as compared to the previous week.
Power outages cause Internet disruptions
Tanzania
A reported power outage at one of Airtel Tanzania’s data centers on July 1 resulted in a multi-hour disruption in connectivity for its mobile customers. The service interruption occurred between 11:30-18:00 UTC (14:30-21:00 local time), with traffic dropping on Airtel Tanzania (AS37133) by as much as 40% as compared to the previous week.
Czech Republic
According to the Industry and Trade Ministry in the Czech Republic, a fallen power cable caused a widespread power outage on July 4. This power outage impacted Internet connectivity within the country, with traffic dropping by as much as 32%. Traffic fell just after the power outage began at 10:00 UTC (12:00 local time), and although it was “nearly fully resolved” by 16:00 UTC (18:00 local time), traffic did not return to expected levels until closer to 20:00 UTC (22:00 local time). This trailing traffic recovery aligns with a published report that noted “While ČEPS, the national transmission system operator, restored full grid functionality by mid-afternoon, tens of thousands remained without electricity into the evening.”
St. Vincent and the Grenadines
On St. Vincent and the Grenadines, the St Vincent Electricity Services Limited (VINLEC) stated in a Facebook post that a “system failure” caused a power outage that affected customers on mainland St. Vincent. According to VINLEC, the system failed at approximately 11:30 local time on August 16 (03:30 UTC on August 17), and power was restored to all customers just after 04:00 local time on August 17 (08:00 UTC). During the four-hour power outage, which also disrupted Internet connectivity, traffic dropped by as much as 80% below expected levels.
Curaçao
In Curaçao, a series of Facebook posts from Aqualectra, the island’s water and power company, confirmed that there was a power outage, and provided updates on the progress towards restoration. The impact of the power outage to Internet connectivity was visible in traffic disruptions across several Internet service providers, including Flow (AS52233) and UTS (AS11081). The observed disruptions lasted for most of the day, with traffic dropping around 06:45 UTC (02:45 local time) and recovering to expected levels around 23:45 UTC (19:45 local time). During the disruption, the country’s traffic dropped by over 80% as compared to the previous week, with Flow experiencing a near complete outage.
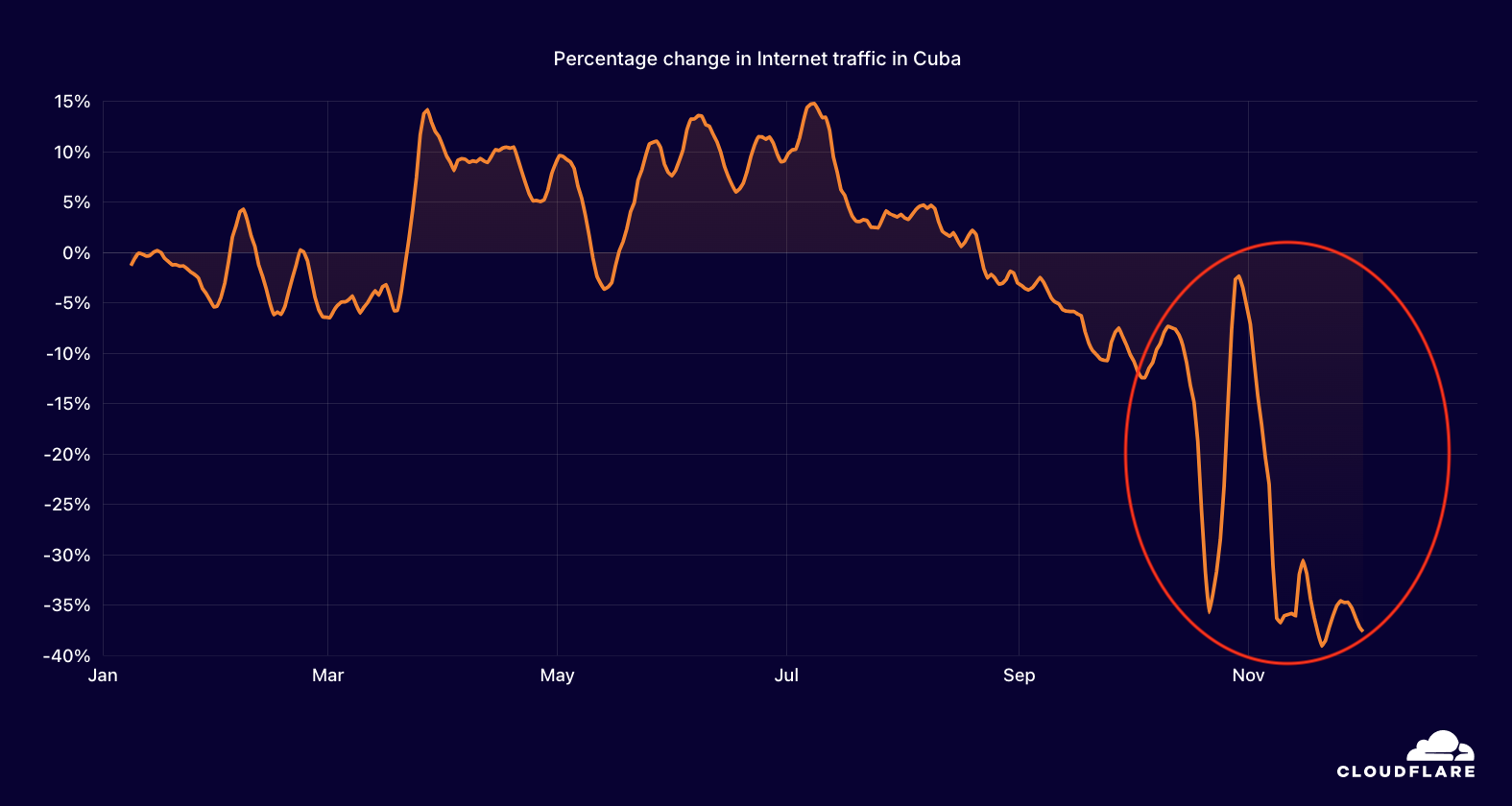
Cuba
Wide-scale power outages occur all too frequently in Cuba, and when power is lost, Internet connectivity follows. We have covered many such events in this series of blog posts over the last several years, and the latest occurred on September 10. That morning, an X post from the Unión Eléctrica de Cuba reported the collapse of the national electric power system at 09:14 local time (13:14 UTC) following the unexpected shutdown of the Antonio Guiteras Thermoelectric Power Plant (CTE). The island’s Internet traffic dropped by nearly 60% (as compared to expected levels) almost immediately, and remained lower than normal for over a day, returning to expected levels around 17:15 UTC on September 11 (13:15 local time) when the Ministerio de Energía y Minas de Cuba posted on X that the national electric system had been restored.
Gibraltar
A contractor cutting through three high voltage cables caused a nationwide power outage in Gibraltar on September 16, according to a Facebook post from the Gibraltar government. This power outage resulted in a disruption to Internet traffic between 11:15-18:30 UTC (13:15-20:30 local time), falling as low as 80% below the previous week.
Earthquake
Kamchatka Peninsula, Russia
A magnitude 8.8 earthquake struck the Kamchatka Peninsula in Russia at 23:24 UTC on July 29 (11:24 local time on July 30), and was powerful enough to trigger tsunami warnings for Japan, Alaska, Hawaii, Guam, and other Russian regions. The graphs below show that there was an immediate impact to Internet traffic across several networks in the region, including Rostelecom (AS12389) and InterkamService (AS42742), where traffic dropped by 75% or more. While traffic started to recover almost immediately across both providers, traffic on Rostelecom approached expected levels much more quickly than on InterkamService.
Targeted cyberattack
Yemen
A cyberattack targeting Houthi-controlled YemenNet(AS30873) on August 11 briefly disrupted connectivity across the network in Yemen. A significant drop in traffic occurred at around 14:15 UTC (17:15 local time), recovering by 15:00 UTC (18:00 local time). This observed drop in traffic aligns with the reported timing and duration of the attack, which was focused on YemenNet’s ADSL infrastructure.
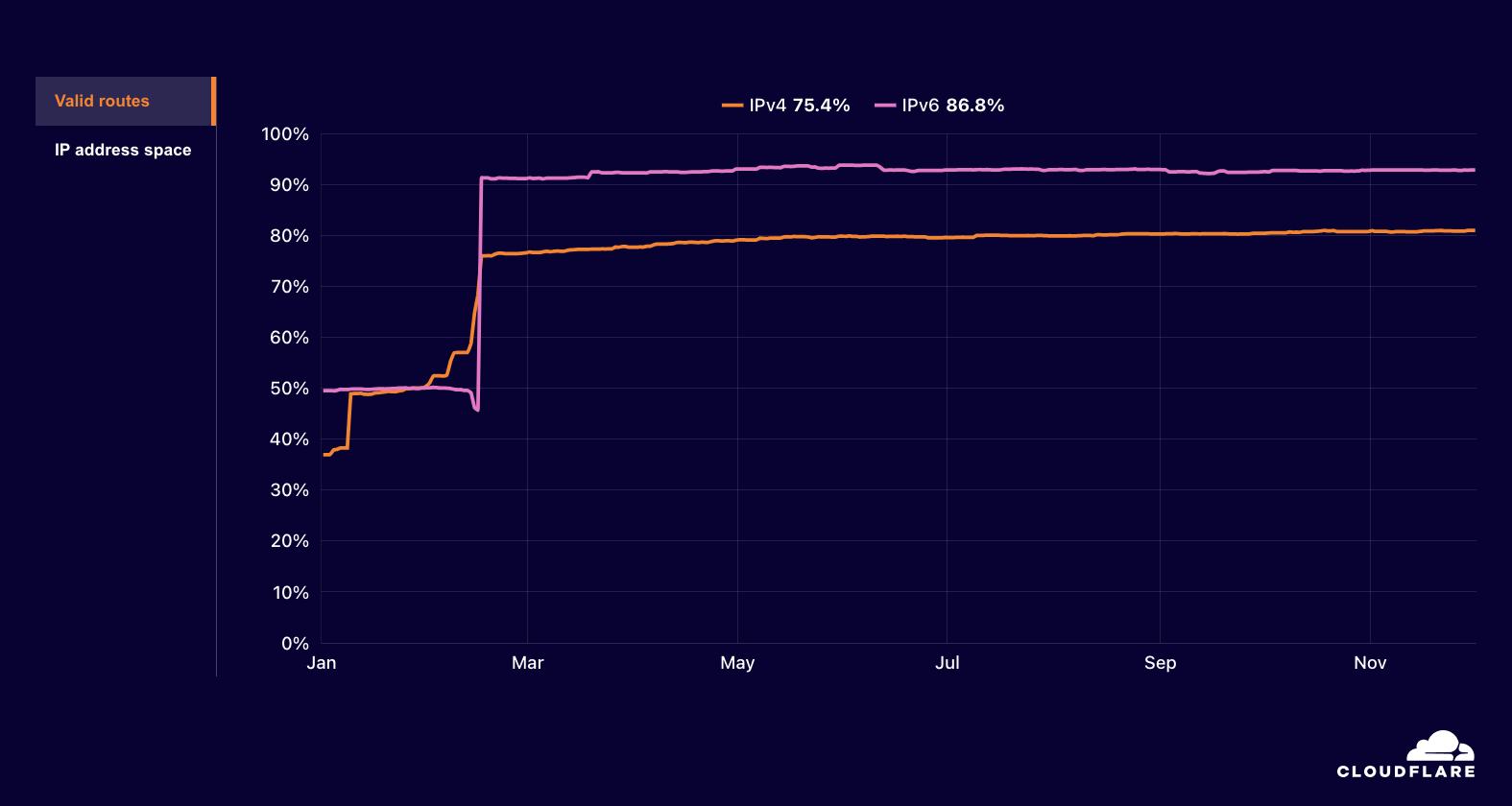
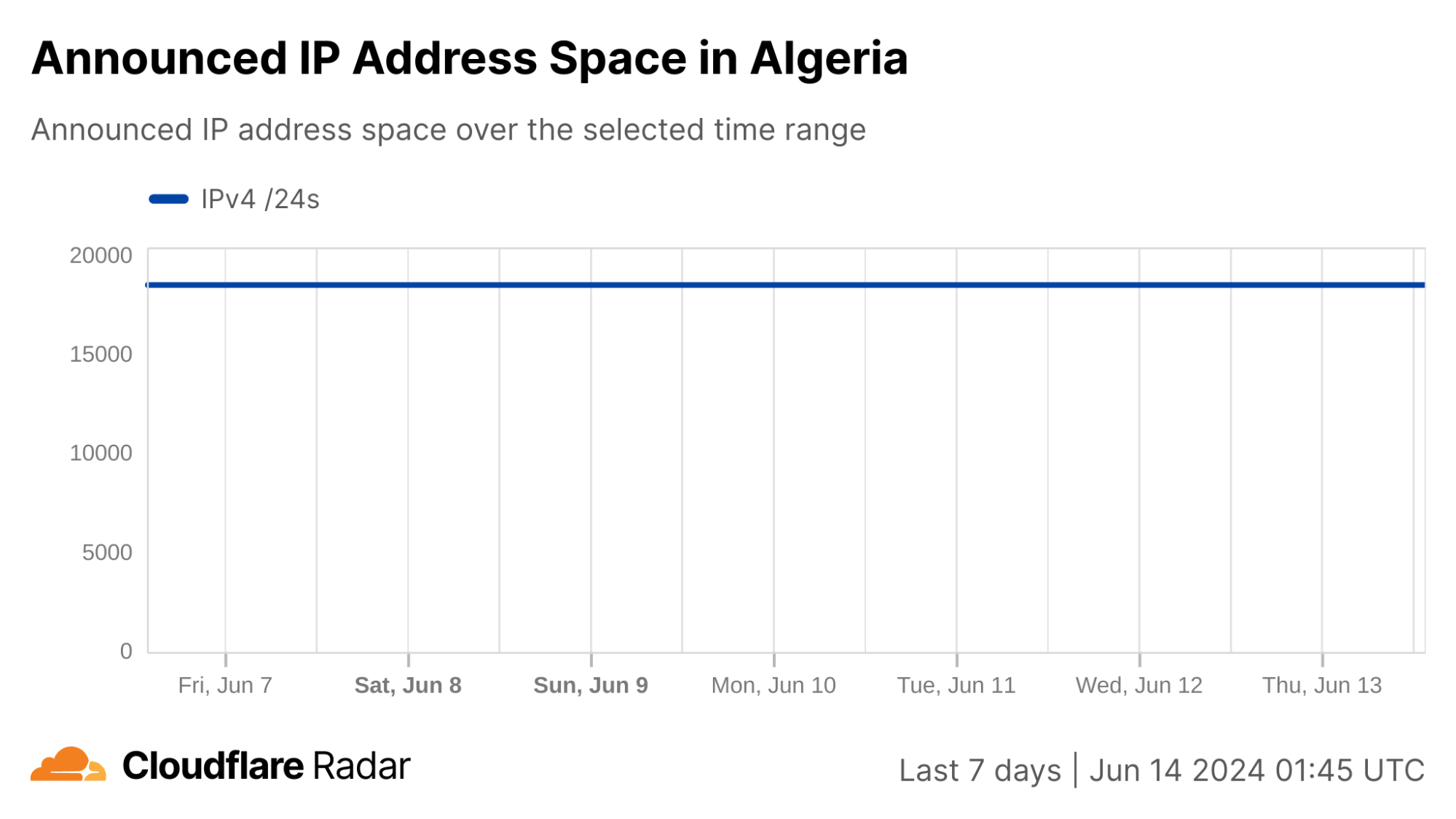
The attack also apparently impacted YemenNet’s routing, as announced IPv4 address space began to decline as the attack commenced. Although the attack ended within an hour after it started, announced address space remained depressed for approximately an additional hour, reaching as low as 510 /24s (blocks of 256 IPv4 addresses) being announced, down from a “steady state” of 870 /24s.
Fire causes infrastructure damage
Egypt
A fire at the Ramses Central Exchange in Cairo, Egypt on July 7 disrupted telecommunications services for a number of providers with infrastructure in the facility. The fire broke out in a Telecom Egypt equipment room, and impacted connectivity across multiple providers, including Etisalat (AS36992), Mobinil (AS37069), Orange Egypt (AS24863), and Vodafone Egypt (AS24835). Internet traffic across these providers initially dropped at 14:30 UTC (17:30 local time). Recovery to expected levels varied across the providers, with Etisalat recovering by July 9, Vodafone and Mobinil by July 10, and Orange Egypt on July 11.
On July 10, Telecom Egypt announced that services affected by the fire had been restored, after operations were transferred to alternative exchanges.
Technical problems
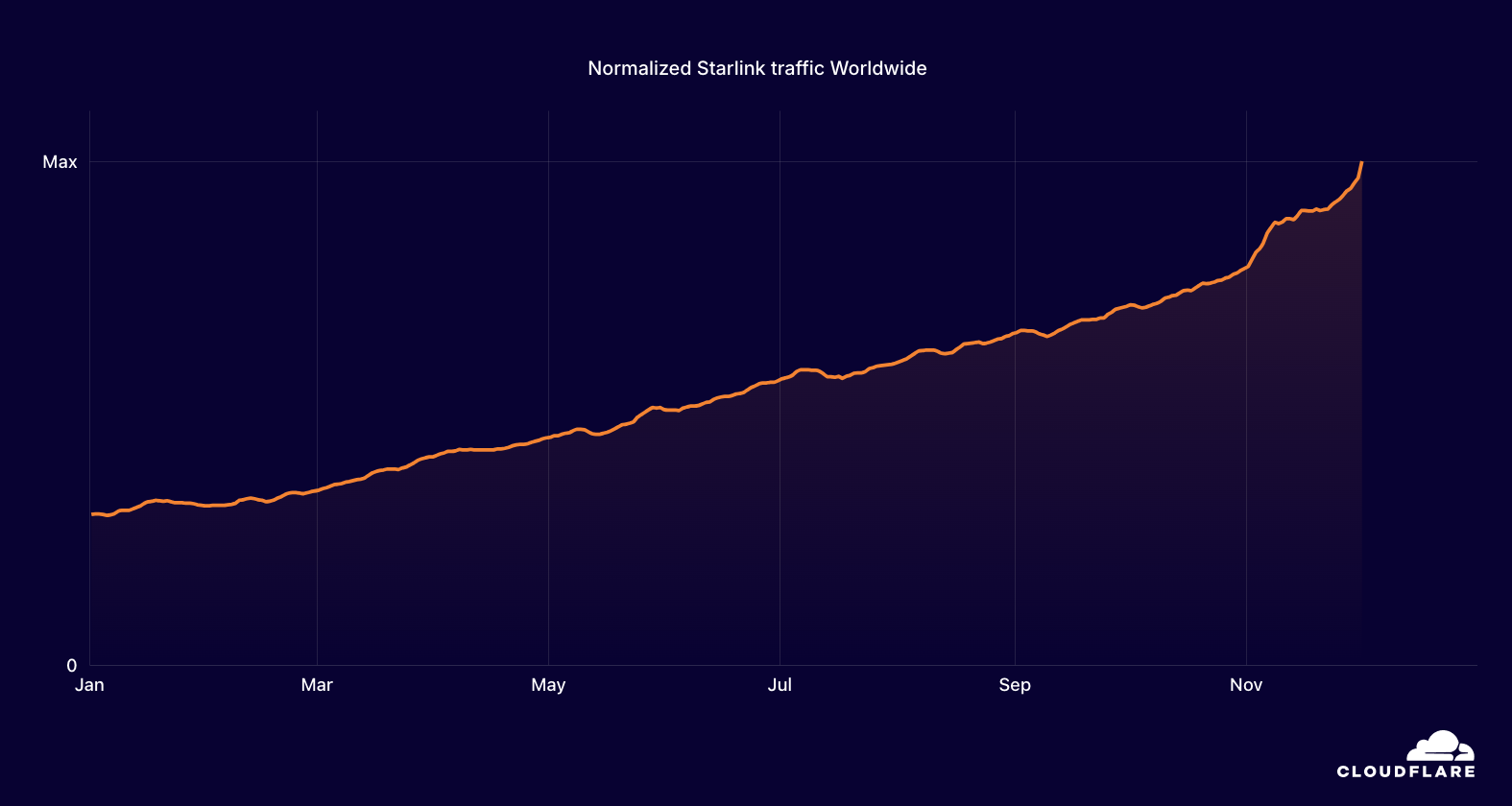
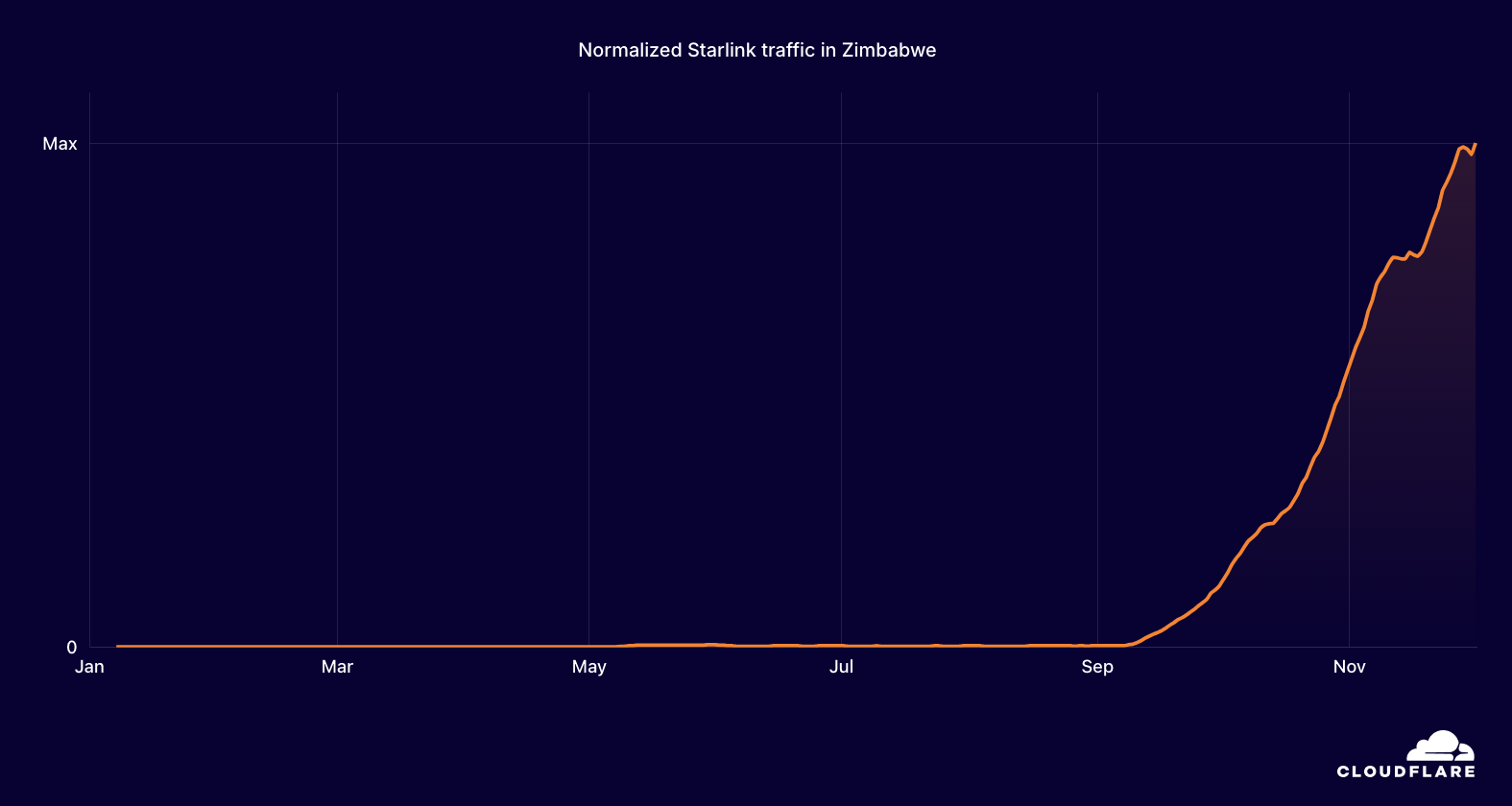
Starlink
Global satellite Internet service provider Starlink (AS14593) acknowledged a July 24 network outage through a post on X. The Vice President of Network Engineering at SpaceX explained, in a subsequent X post, that “The outage was due to failure of key internal software services that operate the core network.”
Traffic initially dropped around 19:15 UTC, and the disruption lasted approximately 2.5 hours. The impact of the Starlink outage was particularly noticeable in countries including Yemen and Sudan, where traffic dropped by approximately 50%, as well as in Zimbabwe, South Sudan, and Chad.
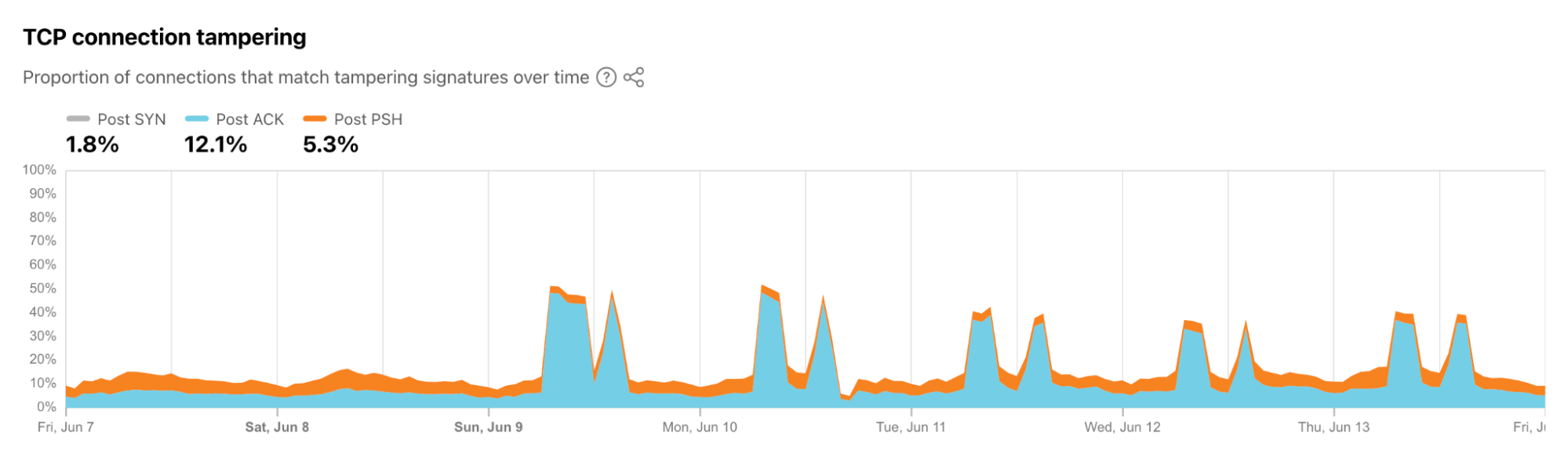
China
At around 16:30 UTC on August 19 (00:30 local time on August 20), we observed an anomalous 25% drop in China’s Internet traffic. Our analysis of related metrics found that this disruption caused a drop in the share of IPv4 traffic, as well as a spike in the share of HTTP traffic (meaning that HTTPS traffic share had fallen), as shown in the graphs below.
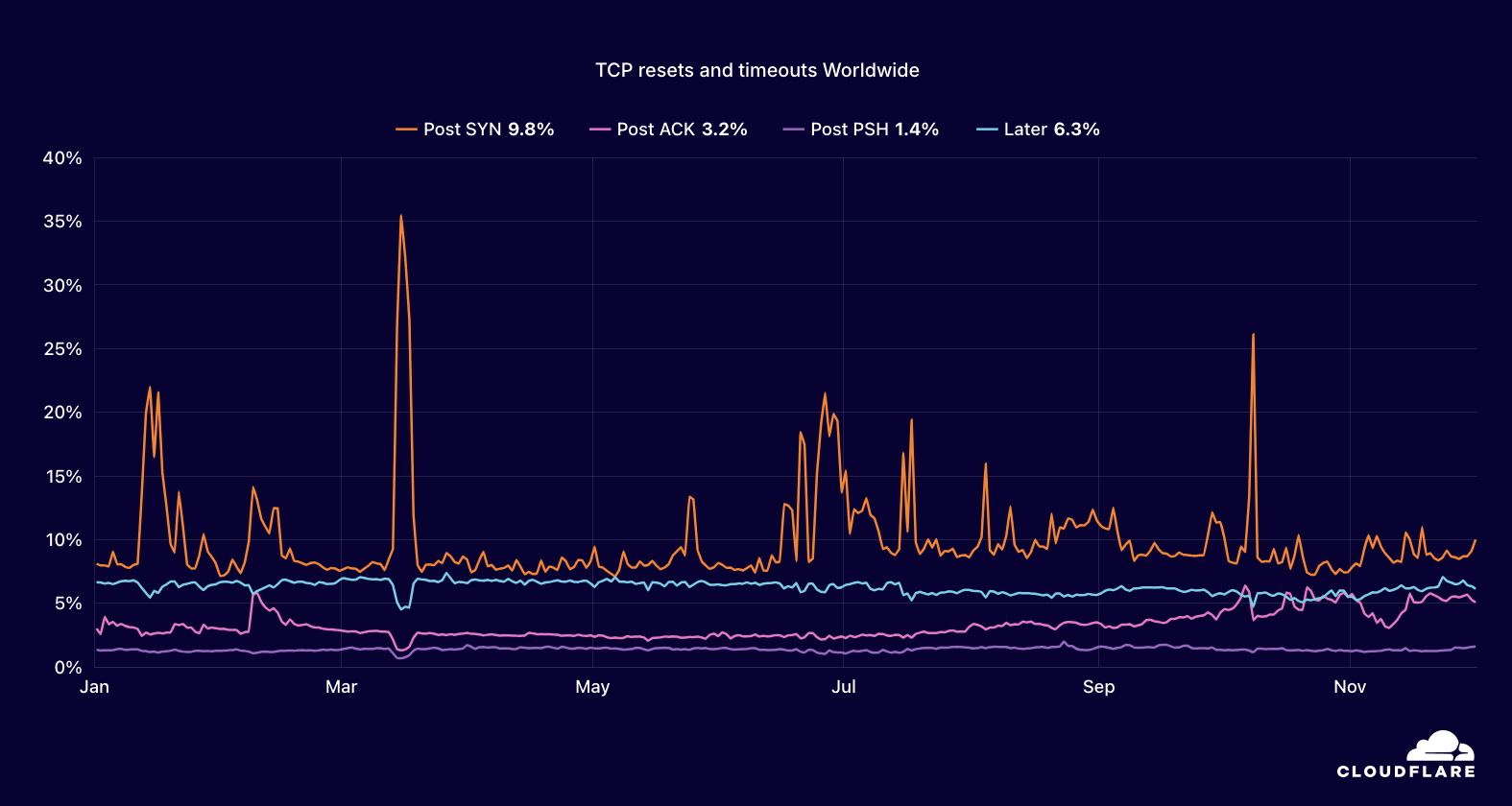
Further analysis also found the share of TCP connections terminated in the Post SYN stage doubled during the observed outage, from 39% to 78%, as shown below. The cause of these unusual observations was ultimately uncovered by a Great Firewall Report blog post, which stated, in part: “Between approximately 00:34 and 01:48 (Beijing Time, UTC+8) on August 20, 2025, the Great Firewall of China (GFW) exhibited anomalous behavior by unconditionally injecting forged TCP RST+ACK packets to disrupt all connections on TCP port 443. This incident caused massive disruption of the Internet connections between China and the rest of the world. … The responsible device does not match the fingerprints of any known GFW devices, suggesting that the incident was caused by either a new GFW device or a known device operating in a novel or misconfigured state.” This explanation is consistent with the anomalies visible in the Radar graphs.
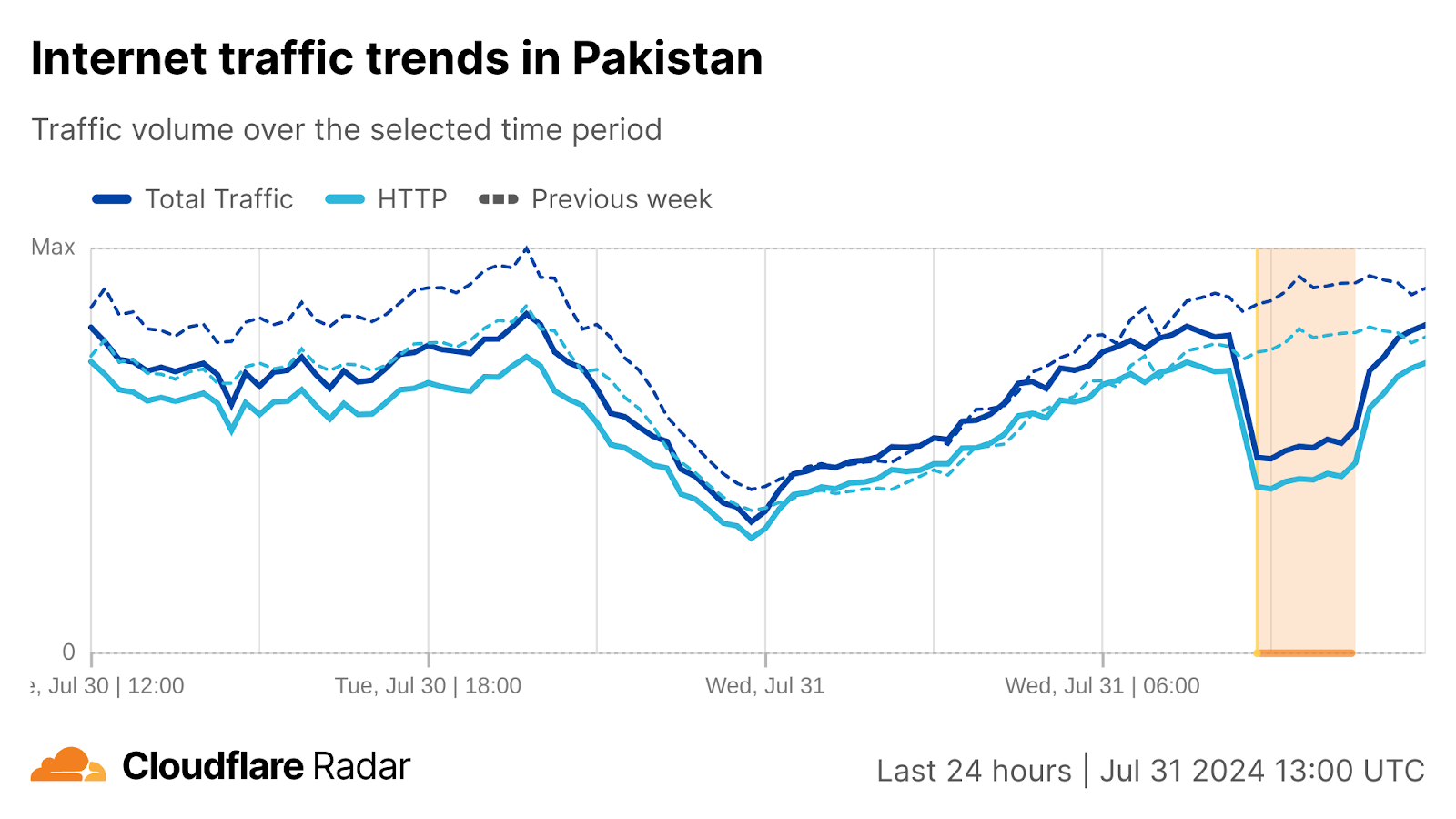
Pakistan
Subscribers of Nayatel (AS23674) experienced an approximately 90 minute disruption to Internet connectivity on September 24, due to a reported outage at an upstream provider. Traffic dropped as much as 57% between around 09:15-10:45 UTC (14:15-15:45 local). Transworld (AS38193) is one of several upstream providers to Nayatel, and a more significant drop in traffic is visible for that network, lasting from around 09:15-12:15 UTC (14:15-17:15 local time). The Nayatel disruption was likely less significant than the one seen at Transworld because Transworld is upstream of only a portion of the prefixes originated by Nayatel — traffic from other Nayatel prefixes was carried by other providers that remained available.
No definitive cause
Iran
Several weeks after experiencing a full Internet shutdown, Iran again experienced a sudden drop in Internet traffic around 21:00 UTC on July 5 (00:30 local time on July 6), with traffic falling 80% as compared to the prior week. While most of the “unknown” disruptions covered in this series of posts are observed but have no associated acknowledgement or explanation, this disruption had multiple competing explanations.
A published report noted “IRNA, Iran’s official news agency, cited the state-run Telecommunications Infrastructure Company, reporting a national-level disruption in international connectivity that affected most internet service providers Saturday night. Yet government officials have not publicly addressed the cause.” However, posts from civil society groups that follow Internet connectivity in Iran (net4people, FilterWatch) suggested that the disruption was again due to an intentional shutdown. And a post thread on X referenced, and disputed, a claim that the disruption was due to a DDoS attack. Unfortunately, no definitive root cause for this disruption could be found.
Colombia
Customers of Claro Colombia experienced an Internet disruption that lasted just over 30 minutes on August 6, with traffic falling two-thirds or more as compared to the prior week between 16:45 – 17:20 UTC. The disruption affected multiple ASNs owned by Claro, including AS10620, AS14080, and AS26611. (The Telmex Colombia and Comcel names shown in the graphs below are historical – Telmex and Comcel merged in 2012 and have operated under the Claro brand since then.) Claro did not acknowledge the disruption on social media, nor did it provide any explanation for it.
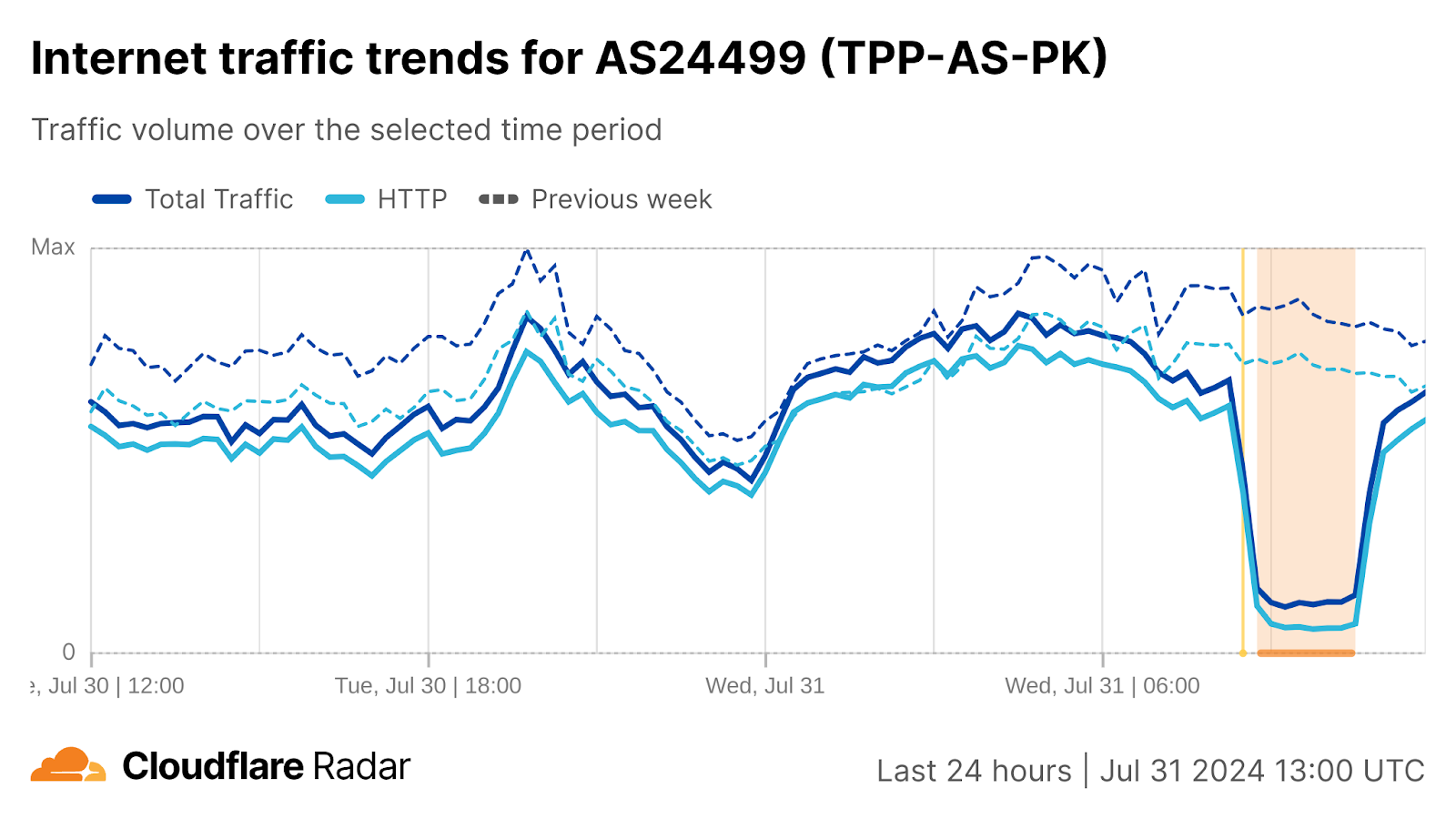
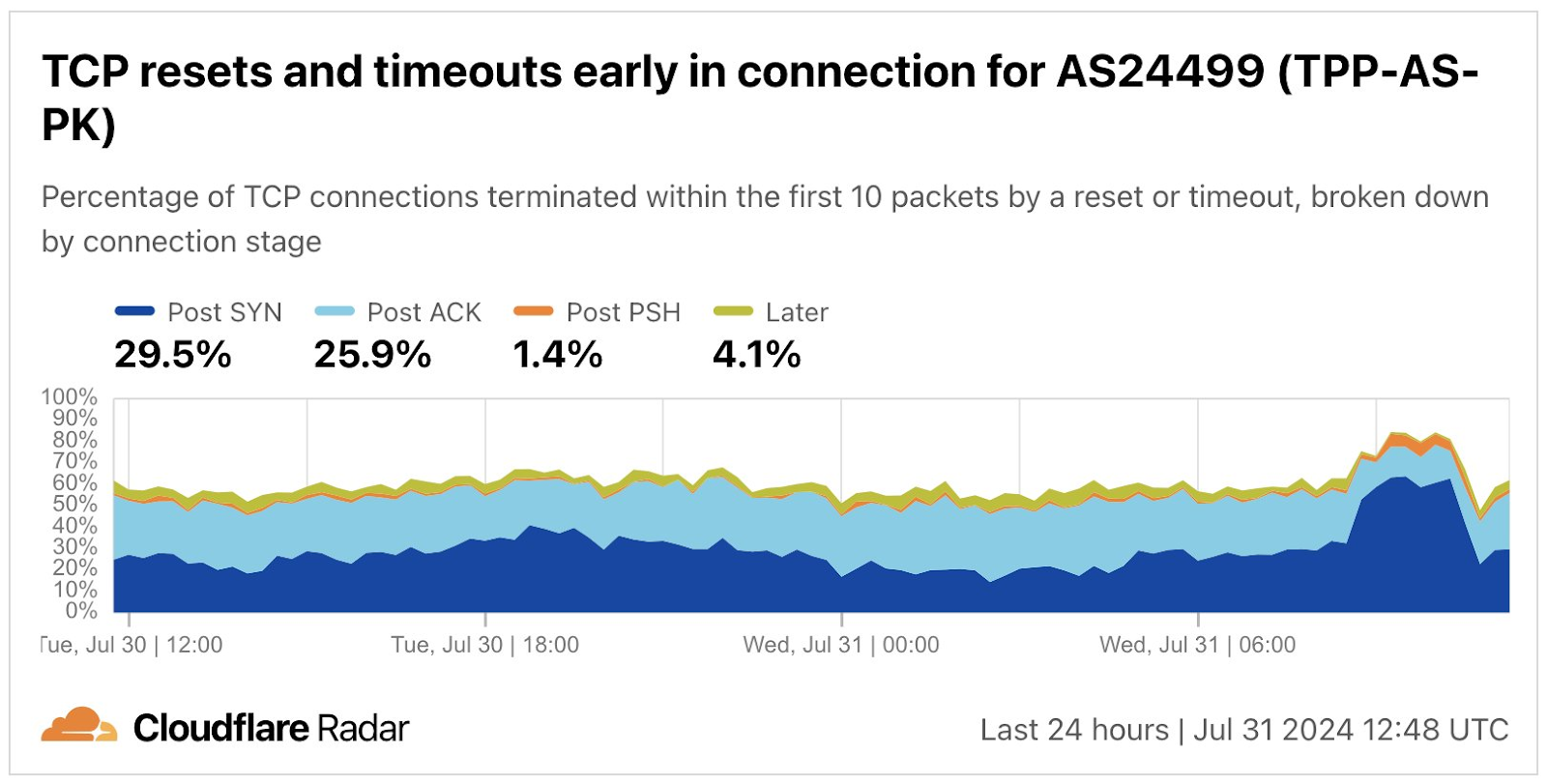
Pakistan
A near-complete outage at Pakistani backbone provider PTCL (AS17557) caused traffic from the network provider to drop 90% at 16:10 UTC (21:10 local time) on August 19. PTCL acknowledged the issue in a post on X, noting “We are currently facing data connectivity challenges on our PTCL and Ufone services.” Although they published a subsequent post several hours later after service was restored, they did not provide any additional information about the cause of the outage. However, one published report claimed “The disruption was primarily caused by a technical fault in PTCL’s fiber optic infrastructure.” while another report claimed “According to industry sources, the internet disruption in Pakistan may be connected to a technical fault in the fiber optic backbone or issues with main internet providers responsible for international online traffic.
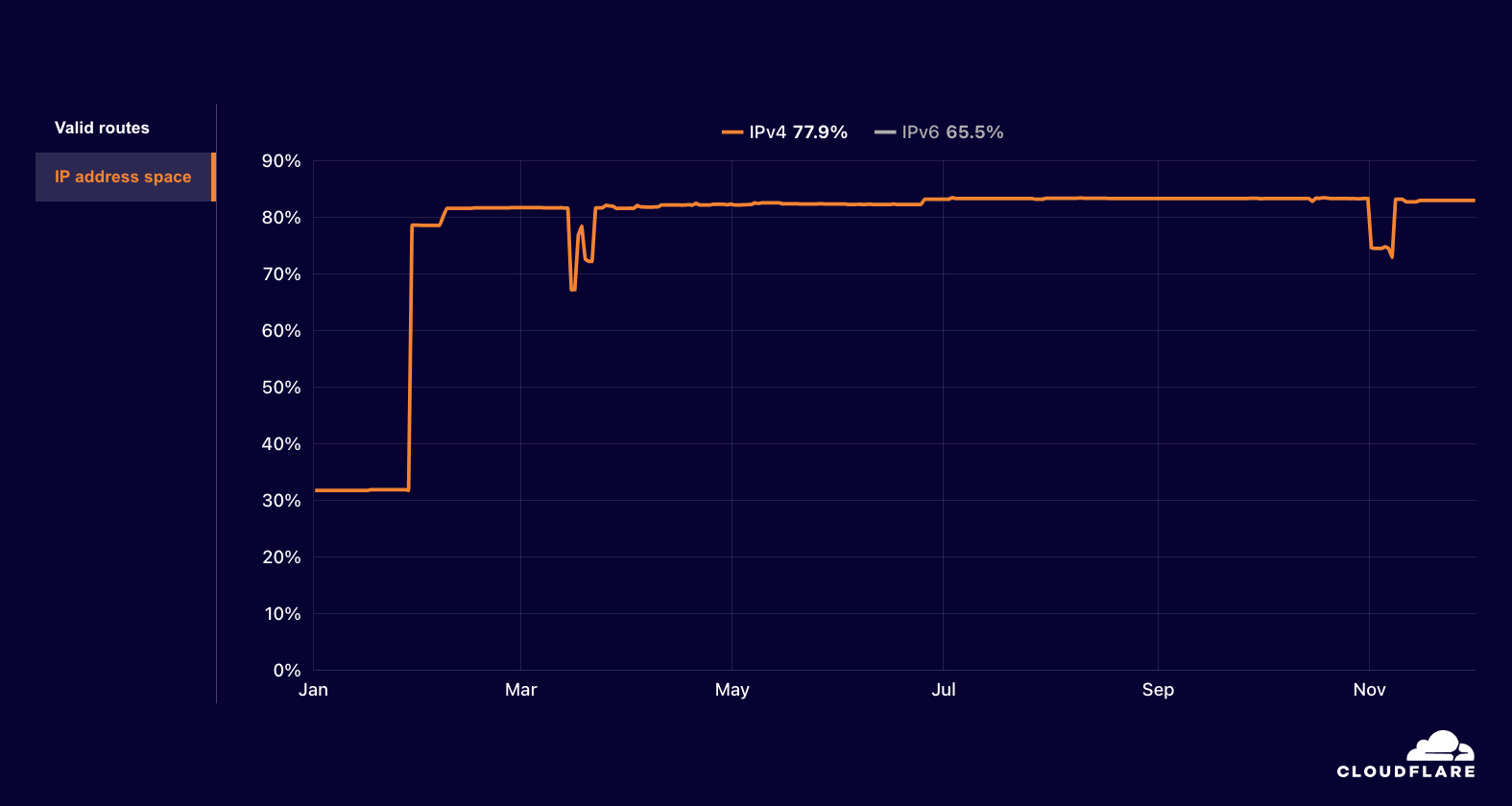
Interestingly, traffic from PTCL to Cloudflare’s 1.1.1.1 DNS resolver spiked as the outage began, and the share of requests made over UDP grew from 94% to 99%. In addition, routing data shows that there was also a small drop in announced IPv4 address space coincident with the outage. However, these additional observations do not necessarily confirm a “technical fault in PTCL’s fiber optic infrastructure” as the ultimate cause of the disruption.
South Africa
To their credit, South African provider RSAWEB (AS37053)quickly acknowledged an issue with their FTTx and Enterprise connectivity on September 10, but neither their initial post nor subsequent updates provided any information on the cause of the problem. Whatever the cause, it resulted in a near-complete loss of Internet traffic from RSAWEB between 15:00 and 16:30 UTC (17:00 – 18:30 local time).
Routing data also shows a loss of just two announced /24 address blocks concurrent with the outage, dropping from 470 to 468. Unless all of RSAWEB’s outbound traffic was flowing through this limited amount of IP address space, it seems unusual that the withdrawal of just 512 IPv4 addresses from the=e routing table would have such a significant impact on the network’s traffic.
SpaceX Starlink
After experiencing a brief disruption in July due to a software failure, Starlink (AS14593) suffered another short disruption between 04:00-05:00 UTC on September 15. Although Starlink generally acknowledges disruptions to their global network on their X account, and often providing a root cause, in this case they apparently published an acknowledgement on X, but deleted it after the issue was resolved. In addition to the drop in traffic, we observed a concurrent drop in announced IPv4 address space and spike in BGP announcements (likely withdrawals), suggesting that the disruption may have been caused by a network-related issue.
Conclusion
The recent launch of regional traffic insights on Radar brings yet another perspective to our ability to investigate observed Internet traffic anomalies. We can now drill down at regional and network levels, as well as exploring the impact across DNS traffic, connection bandwidth and latency, TCP connection tampering, and announced IP address space, helping us understand the impact of such events. And while these blog posts feature graphs from Radar and the Radar Data Explorer, the underlying data is available from our rich API. You can use the API to retrieve data to do your own local monitoring or analysis, or the Radar MCP server to incorporate Radar data into your AI tools.
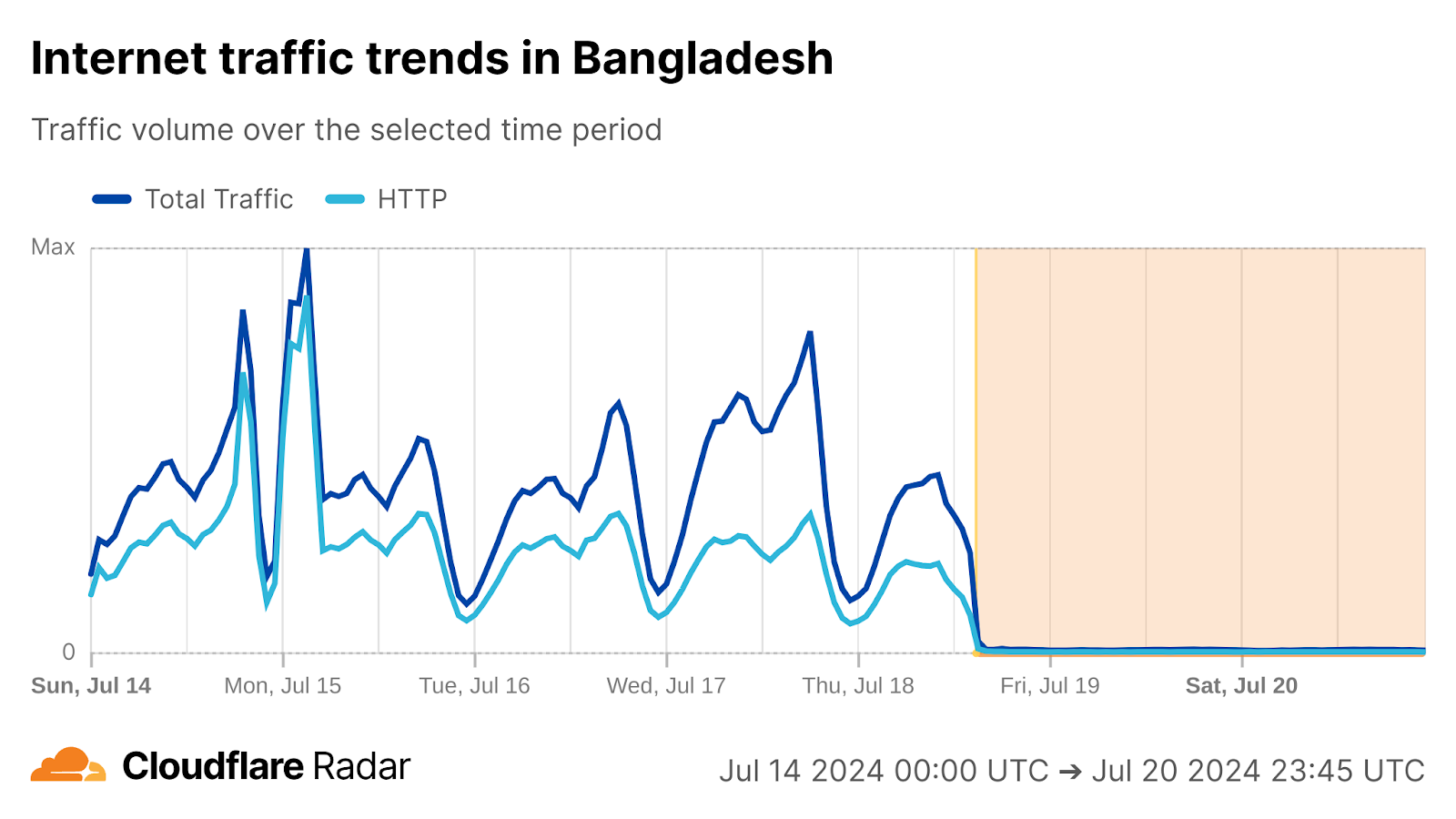
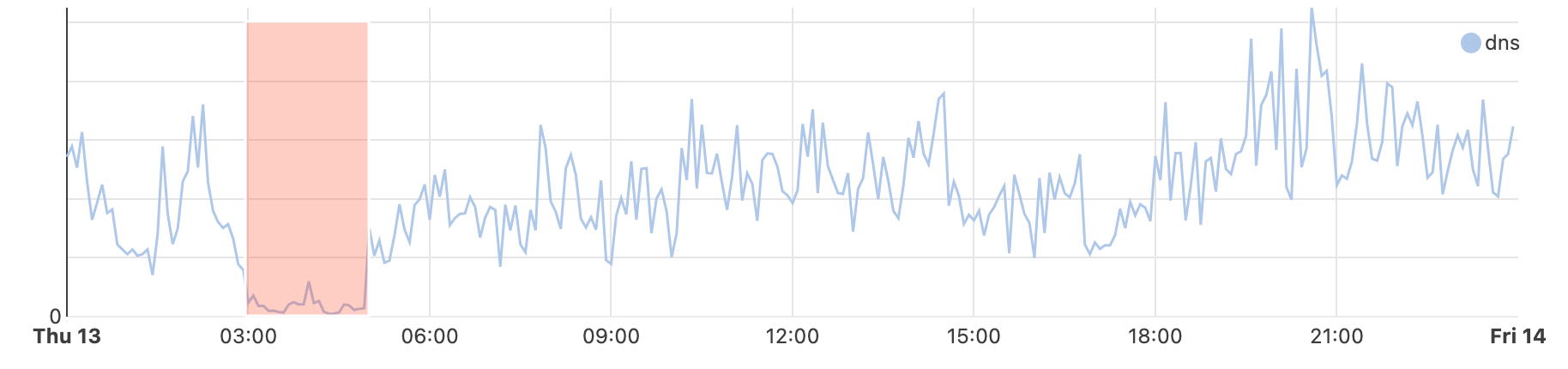
However, just after 12:30 UTC (17:00 local time), the Internet was completely shut down, with Afghani news outlet TOLOnews initially reporting in a post on X that “Sources have confirmed to TOLOnews that today (Monday), afternoon, fiber-optic Internet will be shut down across the country.” This shutdown is likely an extension of the regional shutdowns of fiber optic connections that took place earlier in September, and it will reportedly remain in force “until further notice”. (The earlier regional shutdowns are discussed in more detail below.)
While Monday’s first shutdown was only partial, with mobile connectivity apparently remaining available, the graphs below show that the second event took the country completely offline, with web and DNS traffic dropping to zero at a national level, as seen in the graphs below.
HTTP request traffic is traffic coming from web browsers, applications, and automated tools, and is a clear signal of the availability of Internet connectivity. The graph below shows this request volume dropping sharply as the shutdown was implemented.
HTTP request traffic from Afghanistan, September 29, 2025
Cloudflare sends bytes back in response to those HTTP requests (“HTTP bytes”), as well as sending bytes back in response to traffic associated with other services, such as our 1.1.1.1 DNS resolver, authoritative DNS, WARP, etc. (“total bytes”). Cloudflare stopped receiving client traffic from the services when the shutdown began, causing the bytes transferred in response to drop to zero.
Internet traffic from Afghanistan, September 29, 2025
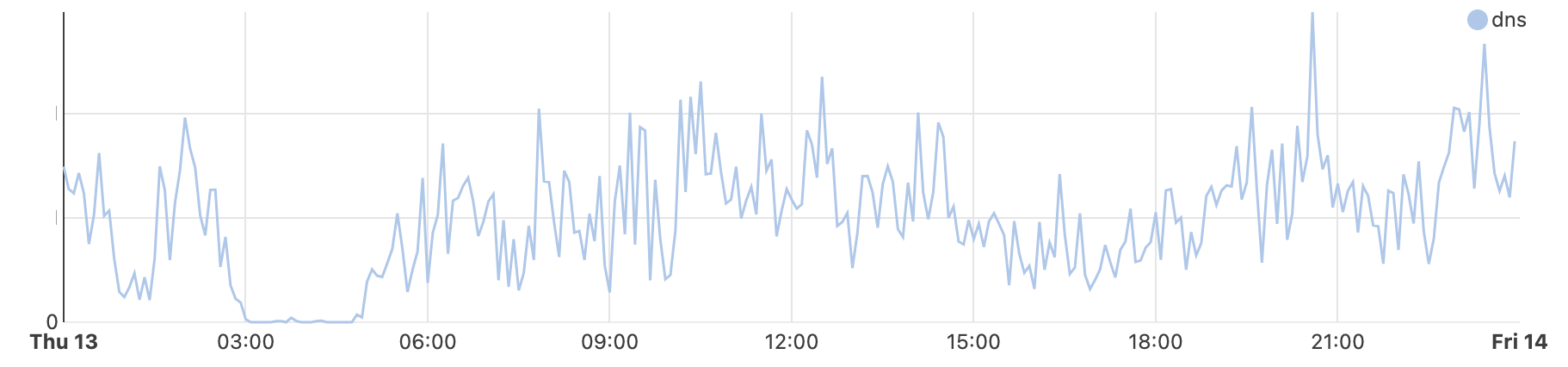
1.1.1.1 is Cloudflare’s privacy-focused DNS resolver, and processes DNS lookup requests from clients. As connectivity was cut, traffic to the service disappeared.
DNS query traffic to Cloudflare’s 1.1.1.1 resolver from Afghanistan, September 29, 2025
At a regional level, it appears that traffic from Kabul fell slightly later than traffic from the other regions, trailing them by approximately a half hour.
HTTP request traffic from the top five provinces in Afghanistan, September 29, 2025
The delay in traffic loss seen in Kabul may be associated with a more gradual loss of traffic seen at AS38742 (Afghan Wireless), which saw traffic approach zero just after 13:00 UTC (17:30 local time). This conjecture is supported by a published report that noted “Residents across Kabul and several provincial cities reported on Monday that fiber-optic services were no longer available, with only limited mobile data functioning briefly before signal towers stopped working altogether.”
Interestingly, it appears that as of 00:00 UTC (04:30 local time) on September 30, we continue to see a very small amount of traffic from this network. (This is in contrast to other networks, whose lines disappeared from the graph around 12:30 UTC (17:00 local time)).
HTTP request traffic from the top 10 ASNs in Afghanistan, September 29, 2025
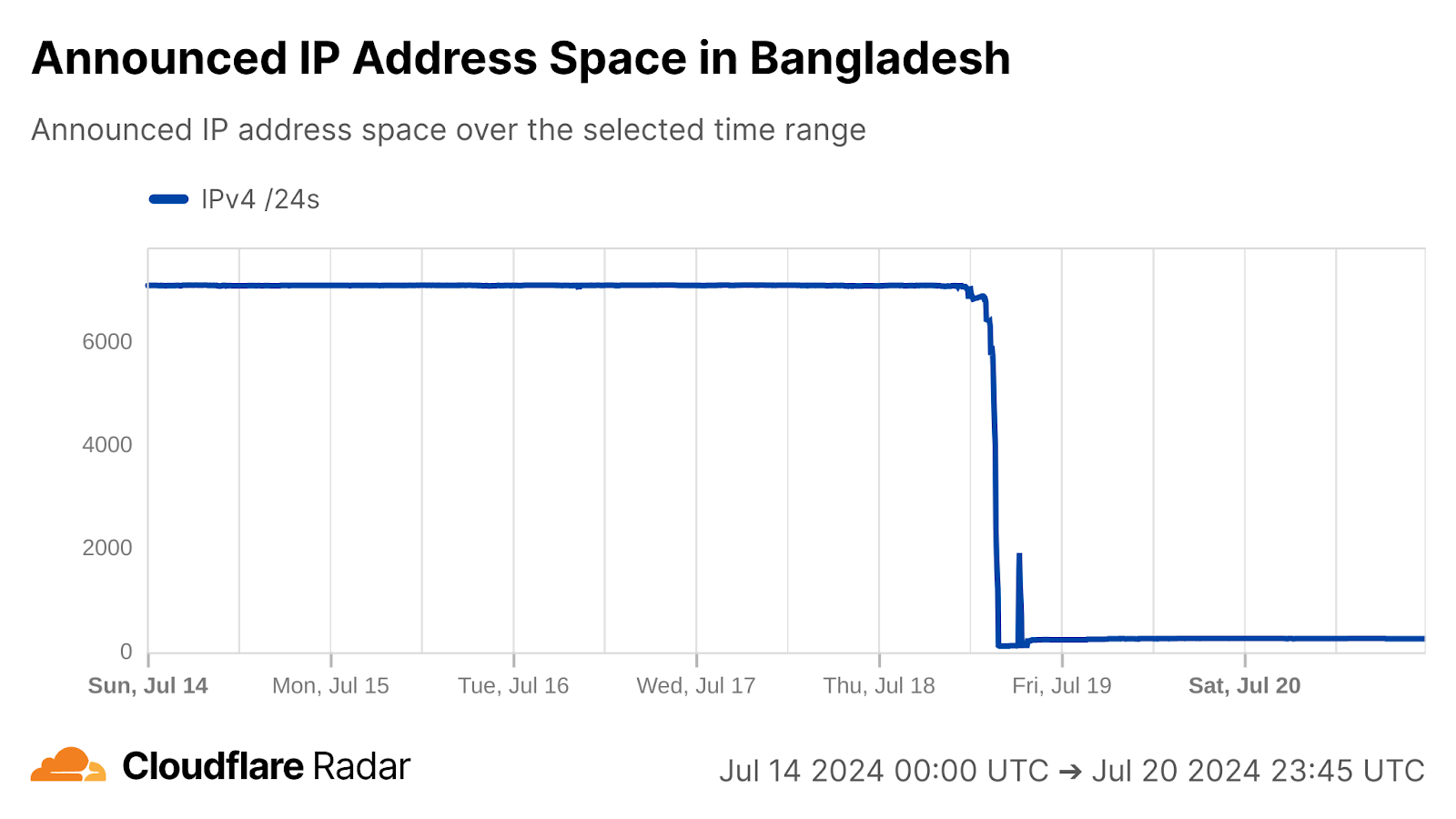
Network providers announce IP address space that they are responsible for to other networks, enabling the routing of traffic to and from those IP addresses. When these announcements are withdrawn, the resources in that address space, whether clients or servers, can no longer reach, or are no longer reachable from, the rest of the Internet.
In Afghanistan, announced IPv4 address space dropped rapidly as the shutdown was implemented, falling by two-thirds from 604 to 197 announced /24s (blocks of 256 IPv4 addresses) in the first 20 minutes, and then dropping further over the next 90 minutes. Through the end of the day, several networks continued to announce a small amount of IPv4 address space: four /24s from AS38742 (Afghan Wireless), two from AS149024 (Afghan Bawar ICT Services), and one each from AS138322 (Afghan Wireless) and AS136479 (Cyber Telecom).
Announced IPv4 address space from Afghanistan, September 29, 2025
Announced IPv6 address space fell as well, though not quite as catastrophically, dropping by three-fourths almost immediately, from 262,407 /48s (blocks of over 1.2 septillion IPv6 addresses) to 65,542.
Announced IPv6 address space from Afghanistan, September 29, 2025
Regional shutdowns by the Taliban to prevent “immoral activities”
In mid-September, the Taliban ordered the shutdown of fiber optic Internet connectivity in multiple provinces across Afghanistan, as part of a drive to “prevent immorality”. It was the first such ban issued since the Taliban took full control of the country in August 2021.
These regional shutdowns blocked Afghani students from attending online classes, impacted commerce and banking, and limited access to government agencies and institutions such as passport and registration offices, customs offices. As many as 15 provinces experienced shutdowns, and we review the observed impacts across several of them below, using the regional traffic data recently made available on Cloudflare Radar.
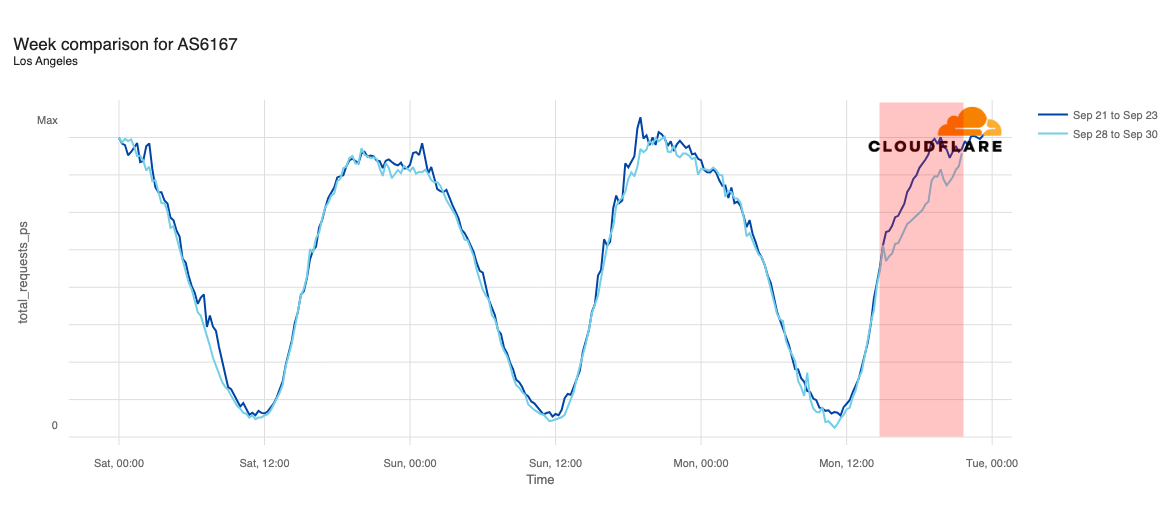
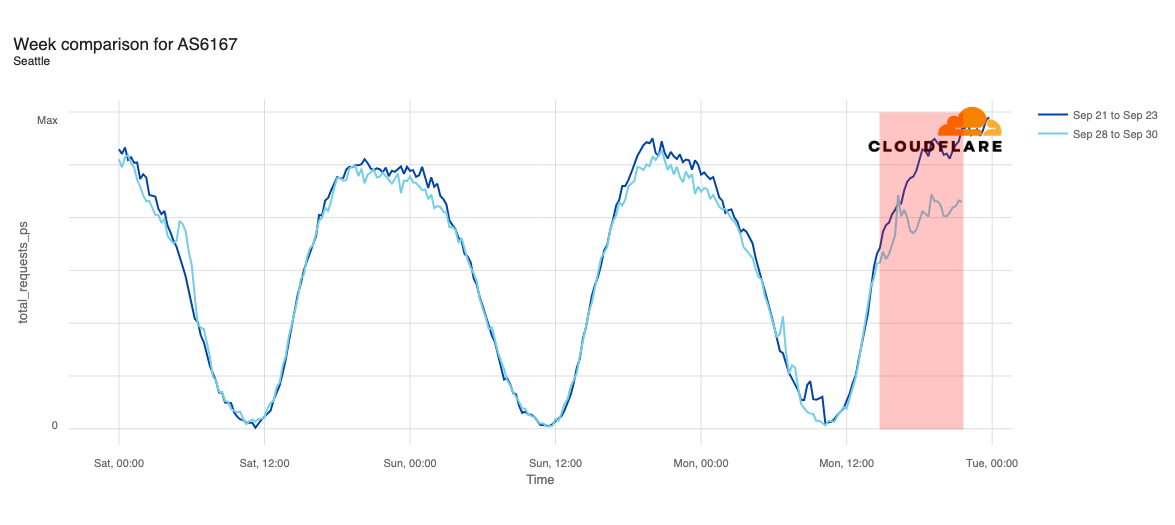
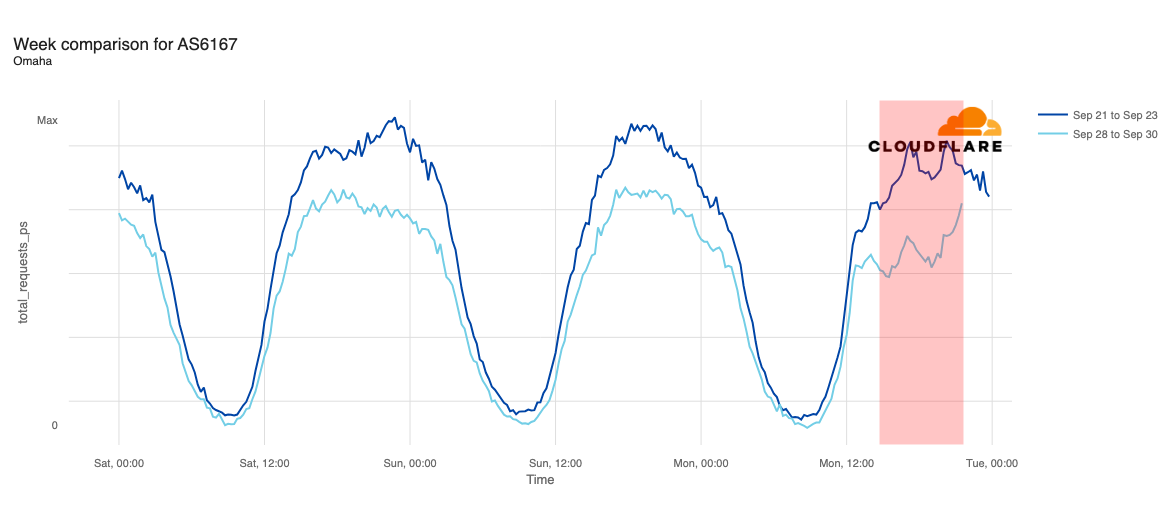
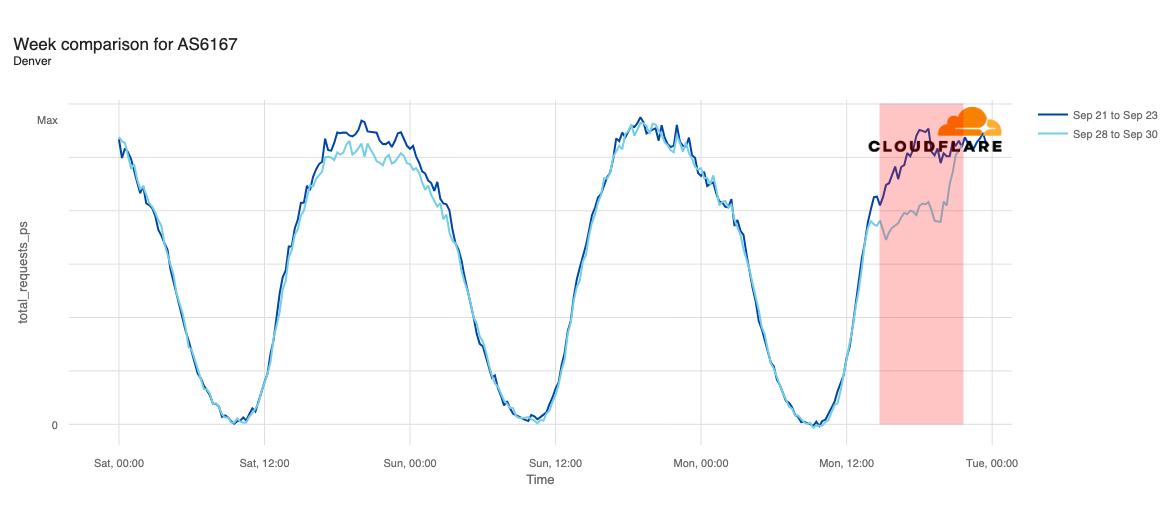
Balkh appeared to be one of the earliest targeted provinces, with traffic dropping midday (UTC) on September 15. While some nominal recovery occurred on September 23, traffic remained well below pre-shutdown levels.
Internet traffic from Balkh, Afghanistan, September 1-28, 2025
After several days of peak traffic levels double those seen in previous weeks, traffic in Takhar fell on September 16, remaining near zero until September 21, when a small amount of connectivity was apparently restored.
Internet traffic from Takhar, Afghanistan, September 1-28, 2025
In Kandahar, lower peak traffic volumes are visible between September 17 and September 21. The partial restoration of traffic is coincident with the restoration of Internet services highlighted in a published report, though it notes that “The restoration of services is limited to point-to-point connections for key government offices, including banks, customs offices, and the Directorate for National ID Cards.”
Internet traffic from Kandahar, Afghanistan, September 1-28, 2025
Baghlan experienced an anomalous spike in traffic on September 16, with total traffic spiking 3x higher than peaks seen during the previous weeks. However, on September 17, traffic dropped to a fraction of pre-shutdown levels. Except for a return to near-normal levels on September 21 & 22, the disruption remained in place through the end of the month.
Internet traffic from Baghlan, Afghanistan, September 1-28, 2025
Traffic in Nangarhar was disrupted between September 19-22, but quickly recovered to pre-shutdown levels once restored.
Internet traffic from Nangarhar, Afghanistan, September 1-28, 2025
After experiencing an apparent issue at the start of the month, Internet traffic in Oruzgan, again fell on September 19. After an apparent complete shutdown, on September 23, a small amount of traffic was again visible.
Internet traffic from Oruzgan, Afghanistan, September 1-28, 2025
Internet connectivity was also disrupted in the province of Herat, although differently. From September 22-25, partial Internet outages were implemented between 16:30-03:30 UTC (21:00-08:00 local time), with traffic volumes dropping to approximately half of those seen at the same time the prior weeks. The intent of these “Internet curfew” shutdowns is unclear, but Herat residents noted that they “severely disrupted their business and educational activities”.
Internet traffic from Herat, Afghanistan, September 16-29, 2025
While Internet shutdowns remain all too common around the world, most (though not all) are comparatively short-lived, and are generally in response to a local event, such as exams, unrest/riots, elections, etc. Given the broad impact of this shutdown across all facets of daily personal, social, and professional life in Afghanistan, analysts state that it “could deepen Afghanistan’s digital isolation, further damage its struggling economy and drive more Afghans out of work at a time when humanitarian needs are already severe.”
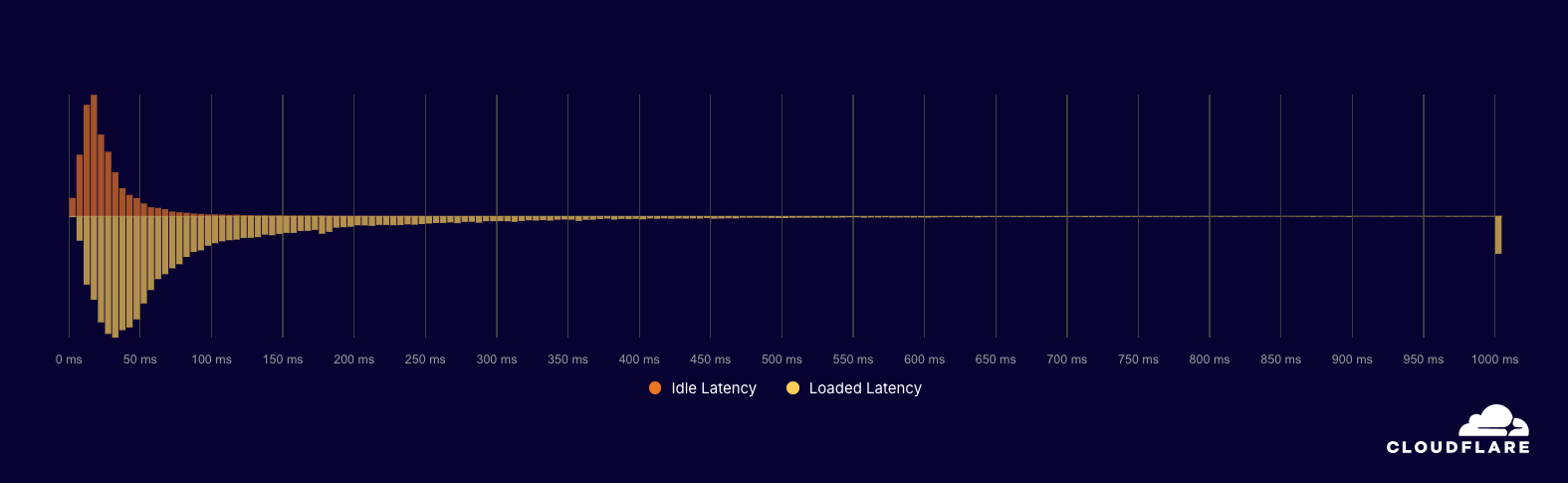
On August 21, 2025, an influx of traffic directed toward clients hosted in the Amazon Web Services (AWS) us-east-1 facility caused severe congestion on links between Cloudflare and AWS us-east-1. This impacted many users who were connecting to or receiving connections from Cloudflare via servers in AWS us-east-1 in the form of high latency, packet loss, and failures to origins.
Customers with origins in AWS us-east-1 began experiencing impact at 16:27 UTC. The impact was substantially reduced by 19:38 UTC, with intermittent latency increases continuing until 20:18 UTC.
This was a regional problem between Cloudflare and AWS us-east-1, and global Cloudflare services were not affected. The degradation in performance was limited to traffic between Cloudflare and AWS us-east-1. The incident was a result of a surge of traffic from a single customer that overloaded Cloudflare’s links with AWS us-east-1. It was a network congestion event, not an attack or a BGP hijack.
We’re very sorry for this incident. In this post, we explain what the failure was, why it occurred, and what we’re doing to make sure this doesn’t happen again.
Background
Cloudflare helps anyone to build, connect, protect, and accelerate their websites on the Internet. Most customers host their websites on origin servers that Cloudflare does not operate. To make their sites fast and secure, they put Cloudflare in front as a reverse proxy.
When a visitor requests a page, Cloudflare will first inspect the request. If the content is already cached on Cloudflare’s global network, or if the customer has configured Cloudflare to serve the content directly, Cloudflare will respond immediately, delivering the content without contacting the origin. If the content cannot be served from cache, we fetch it from the origin, serve it to the visitor, and cache it along the way (if it is eligible). The next time someone requests that same content, we can serve it directly from cache instead of making another round trip to the origin server.
When Cloudflare responds to a request with the cached content, it will send the response traffic over internal Data Center Interconnect (DCI) links through a series of network equipment and eventually reach the routers that represent our network edge (our “edge routers”) as shown below:
Our internal network capacity is designed to be larger than the available traffic demand in a location to account for failures of redundant links, failover from other locations, traffic engineering within or between networks, or even traffic surges from users. The majority of Cloudflare’s network links were operating normally, but some edge router links to an AWS peering switch had insufficient capacity to handle this particular surge.
What happened
At approximately 16:27 UTC on August, 21, 2025, a customer started sending many requests from AWS us-east-1 to Cloudflare for objects in Cloudflare’s cache. These requests generated a volume of response traffic that saturated all available direct peering connections between Cloudflare and AWS. This initial saturation became worse when AWS, in an effort to alleviate the congestion, withdrew some BGP advertisements to Cloudflare over some of the congested links. This action rerouted traffic to an additional set of peering links connected to Cloudflare via an offsite network interconnection switch, which subsequently also became saturated, leading to significant performance degradation. The impact became worse for two reasons: One of the direct peering links was operating at half-capacity due to a pre-existing failure, and the Data Center Interconnect (DCI) that connected Cloudflare’s edge routers to the offsite switch was due for a capacity upgrade. The diagram below illustrates this using approximate capacity estimates:
In response, our incident team immediately engaged with our partners at AWS to address the issue. Through close collaboration, we successfully alleviated the congestion and fully restored services for all affected customers.
Timeline
Time
Description
2025-08-21 16:27 UTC
Traffic surge for single customer begins, doubling total traffic from Cloudflare to AWS
IMPACT START
2025-08-21 16:37 UTC
AWS begins withdrawing prefixes from Cloudflare on congested PNI (Private Network Interconnect) BGP sessions
2025-08-21 16:44 UTC
Network team is alerted to internal congestion in Ashburn (IAD)
2025-08-21 16:45 UTC
Network team is evaluating options for response, but AWS prefixes are unavailable on paths that are not congested due to their withdrawals
2025-08-21 17:22 UTC
AWS BGP prefixes withdrawals result in a higher amount of dropped traffic
IMPACT INCREASE
2025-08-21 17:45 UTC
Incident is raised for customer impact in Ashburn (IAD)
2025-08-21 19:05 UTC
Rate limiting of single customer causing traffic surge decreases congestion
2025-08-21 19:27 UTC
Network team additional traffic engineering actions fully resolve congestion
IMPACT DECREASE
2025-08-21 19:45 UTC
AWS begins reverting BGP withdrawals as requested by Cloudflare
2025-08-21 20:07 UTC
AWS finishes normalizing BGP prefix announcements to Cloudflare over IAD PNIs
2025-08-21 20:18 UTC
IMPACT END
When impact started, we saw a significant amount of traffic related to one customer, resulting in congestion:
This was handled by manual traffic actions both from Cloudflare and AWS. You can see some of the attempts by AWS to alleviate the congestion by looking at the number of IP prefixes AWS is advertising to Cloudflare during the duration of the outage. The lines in different colors correspond to the number of prefixes advertised per BGP session with us. The dips indicate AWS attempting to mitigate by withdrawing prefixes from the BGP sessions in an attempt to steer traffic elsewhere:
The congestion in the network caused network queues on the routers to grow significantly and begin dropping packets. Our edge routers were dropping high priority packets consistently during the outage, as seen in the chart below, which shows the queue drops for our Ashburn routers during the impact period:
The primary impact to customers as a result of this congestion would have been latency, loss (timeouts), or low throughput. We have a set of latency Service Level Objectives defined which imitate customer requests back to their origins measuring availability and latency. We can see that during the impact period, the percentage of requests whose latency fails to meet the target SLO threshold dips below an acceptable level in lock step with the packet drops during the outage:
After the congestion was alleviated, there was a brief period where both AWS and Cloudflare were attempting to normalize the prefix advertisements that had been adjusted to attempt to mitigate the congestion. That caused a long tail of latency that may have impacted some customers, which is why you see the packet drops resolve before the customer latencies are restored.
Remediations and follow-up steps
This event has underscored the need for enhanced safeguards to ensure that one customer’s usage patterns cannot negatively affect the broader ecosystem. Our key takeaways are the necessity of architecting for better customer isolation to prevent any single entity from monopolizing shared resources and impacting the stability of the platform for others, and augmenting our network infrastructure to have sufficient capacity to meet demand.
To prevent a recurrence of this issue, we are implementing a multi-phased mitigation strategy. In the short and medium term:
We are developing a mechanism to selectively deprioritize a customer’s traffic if it begins to congest the network to a degree that impacts others.
We are expediting the Data Center Interconnect (DCI) upgrades which will provide network capacity significantly above what it is today.
We are working with AWS to make sure their and our BGP traffic engineering actions do not conflict with one another in the future.
Looking further ahead, our long-term solution involves building a new, enhanced traffic management system. This system will allot network resources on a per-customer basis, creating a budget that, once exceeded, will prevent a customer’s traffic from degrading the service for anyone else on the platform. This system will also allow us to automate many of the manual actions that were taken to attempt to remediate the congestion seen during this incident.
Conclusion
Customers accessing AWS us-east-1 through Cloudflare experienced an outage due to insufficient network congestion management during an unusual high-traffic event.
We are sorry for the disruption this incident caused for our customers. We are actively making these improvements to ensure improved stability moving forward and to prevent this problem from happening again.
On 14 July 2025, Cloudflare’s 1.1.1.1 Resolver service became unavailable to the Internet starting at 21:52 UTC and ending at 22:54 UTC. The majority of 1.1.1.1 users globally were affected. For many users, not being able to resolve names using the 1.1.1.1 Resolver meant that basically all Internet services were unavailable. This outage can be observed on Cloudflare Radar.
The outage occurred because of a misconfiguration of legacy systems used to maintain the infrastructure that advertises Cloudflare’s IP addresses to the Internet.
This was a global outage. During the outage, Cloudflare’s 1.1.1.1 Resolver was unavailable worldwide.
We’re very sorry for this outage. The root cause was an internal configuration error and not the result of an attack or a BGP hijack. In this blog, we’re going to talk about what the failure was, why it occurred, and what we’re doing to make sure this doesn’t happen again.
Background
Cloudflare introduced the 1.1.1.1 public DNS Resolver service in 2018. Since the announcement, 1.1.1.1 has become one of the most popular DNS Resolver IP addresses and it is free for anyone to use.
Almost all of Cloudflare’s services are made available to the Internet using a routing method known as anycast, a well-known technique intended to allow traffic for popular services to be served in many different locations across the Internet, increasing capacity and performance. This is the best way to ensure we can globally manage our traffic, but also means that problems with the advertisement of this address space can result in a global outage.
Cloudflare announces these anycast routes to the Internet in order for traffic to those addresses to be delivered to a Cloudflare data center, providing services from many different places. Most Cloudflare services are provided globally, like the 1.1.1.1 public DNS Resolver, but a subset of services are specifically constrained to particular regions.
These services are part of our Data Localization Suite (DLS), which allows customers to configure Cloudflare in a variety of ways to meet their compliance needs across different countries and regions. One of the ways in which Cloudflare manages these different requirements is to make sure the right service’s IP addresses are Internet-reachable only where they need to be, so your traffic is handled correctly worldwide. A particular service has a matching “service topology” – that is, traffic for a service should be routed only to a particular set of locations.
On June 6, during a release to prepare a service topology for a future DLS service, a configuration error was introduced: the prefixes associated with the 1.1.1.1 Resolver service were inadvertently included alongside the prefixes that were intended for the new DLS service. This configuration error sat dormant in the production network as the new DLS service was not yet in use, but it set the stage for the outage on July 14. Since there was no immediate change to the production network there was no end-user impact, and because there was no impact, no alerts were fired.
Incident Timeline
Time (UTC)
Event
2025-06-06 17:38
ISSUE INTRODUCED – NO IMPACT
A configuration change was made for a DLS service that was not yet in production. This configuration change accidentally included a reference to the 1.1.1.1 Resolver service and, by extension, the prefixes associated with the 1.1.1.1 Resolver service.
This change did not result in a change of network configuration, and so routing for the 1.1.1.1 Resolver was not affected.
Since there was no change in traffic, no alerts fired, but the misconfiguration lay dormant for a future release.
2025-07-14 21:48
IMPACT START
A configuration change was made for the same DLS service. The change attached a test location to the non-production service; this location itself was not live, but the change triggered a refresh of network configuration globally.
Due to the earlier configuration error linking the 1.1.1.1 Resolver’s IP addresses to our non-production service, those 1.1.1.1 IPs were inadvertently included when we changed how the non-production service was set up.
The 1.1.1.1 Resolver prefixes started to be withdrawn from production Cloudflare data centers globally.
2025-07-14 21:52
DNS traffic to 1.1.1.1 Resolver service begins to drop globally
2025-07-14 21:54
Related, non-causal event: BGP origin hijack of 1.1.1.0/24 exposed by withdrawal of routes from Cloudflare. This was not a cause of the service failure, but an unrelated issue that was suddenly visible as that prefix was withdrawn by Cloudflare.
2025-07-14 22:01
IMPACT DETECTED
Internal service health alerts begin to fire for the 1.1.1.1 Resolver
2025-07-14 22:01
INCIDENT DECLARED
2025-07-14 22:20
FIX DEPLOYED
Revert was initiated to restore the previous configuration. To accelerate full restoration of service, a manually triggered action is validated in testing locations before being executed.
2025-07-14 22:54
IMPACT ENDS
Resolver alerts cleared and DNS traffic on Resolver prefixes return to normal levels
2025-07-14 22:55
INCIDENT RESOLVED
Impact
Any traffic coming to Cloudflare via 1.1.1.1 Resolver services on these IPs was impacted. Traffic to each of these addresses were also impacted on the corresponding routes.
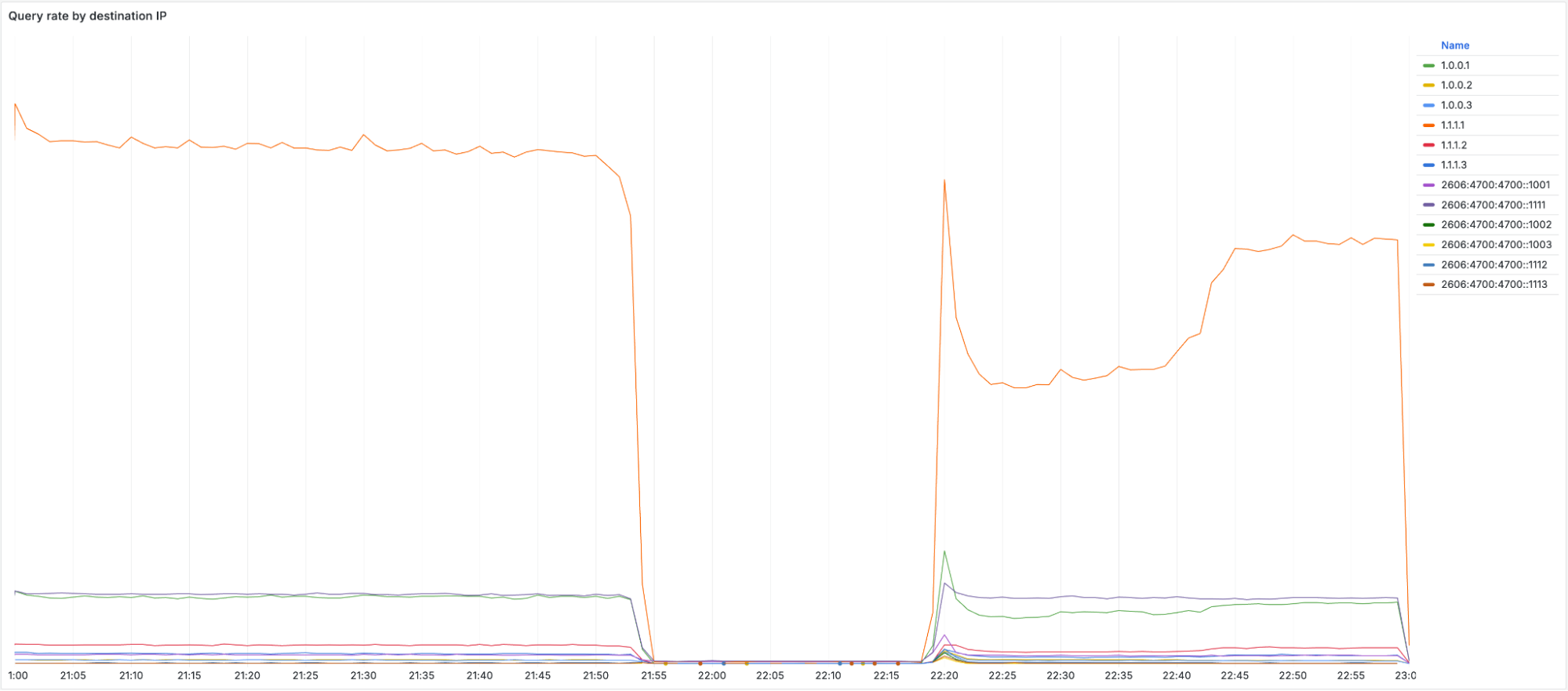
When the impact started we observed an immediate and significant drop in queries over UDP, TCP and DNS over TLS (DoT). Most users have 1.1.1.1, 1.0.0.1, 2606:4700:4700::1111, or 2606:4700:4700::1001 configured as their DNS server. Below you can see the query rate for each of the individual protocols and how they were impacted during the incident:
It’s worth noting that DoH (DNS-over-HTTPS) traffic remained relatively stable as most DoH users use the domain cloudflare-dns.com, configured manually or through their browser, to access the public DNS resolver, rather than by IP address. DoH remained available and traffic was mostly unaffected as cloudflare-dns.com uses a different set of IP addresses. Some DNS traffic over UDP that also used different IP addresses remained mostly unaffected as well.
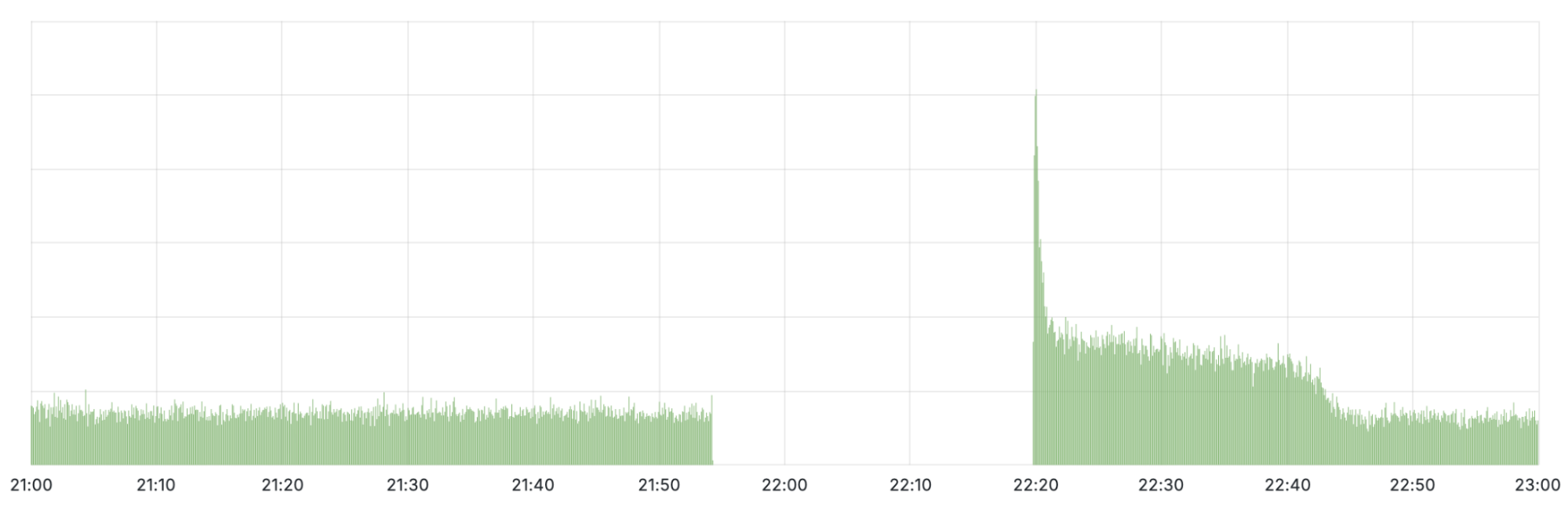
As the corresponding prefixes were withdrawn, no traffic sent to those addresses could reach Cloudflare. We can see this in the timeline for the BGP announcements for 1.1.1.0/24:
Pictured above is the timeline for BGP withdrawal and re-announcement of 1.1.1.0/24 globally
When looking at the query rate of the withdrawn IPs it can be observed that almost no traffic arrives during the impact window. When the initial fix was applied at 22:20 UTC, a large spike in traffic can be seen before it drops off again. This spike is due to clients retrying their queries. When we started announcing the withdrawn prefixes again, queries were able to reach Cloudflare once more. It took until 22:54 UTC before routing was restored in all locations and traffic returned to mostly normal levels.
Technical description of the error and how it happened
Failure of 1.1.1.1 Resolver Service
As described above, a configuration change on June 6 introduced an error in the service topology for a pre-production, DLS service. On July 14, a second change to that service was made: an offline data center location was added to the service topology for the pre-production DNS service in order to allow for some internal testing. This change triggered a refresh of the global configuration of the associated routes, and it was at this point that the impact from the earlier configuration error was felt. The service topology for the 1.1.1.1 Resolver’s prefixes was reduced from all locations down to a single, offline location. The effect was to trigger the global and immediate withdrawal of all 1.1.1.1 prefixes.
As routes to 1.1.1.1 were withdrawn, the 1.1.1.1 service itself became unavailable. Alerts fired and an incident was declared.
Technical Investigation and Analysis
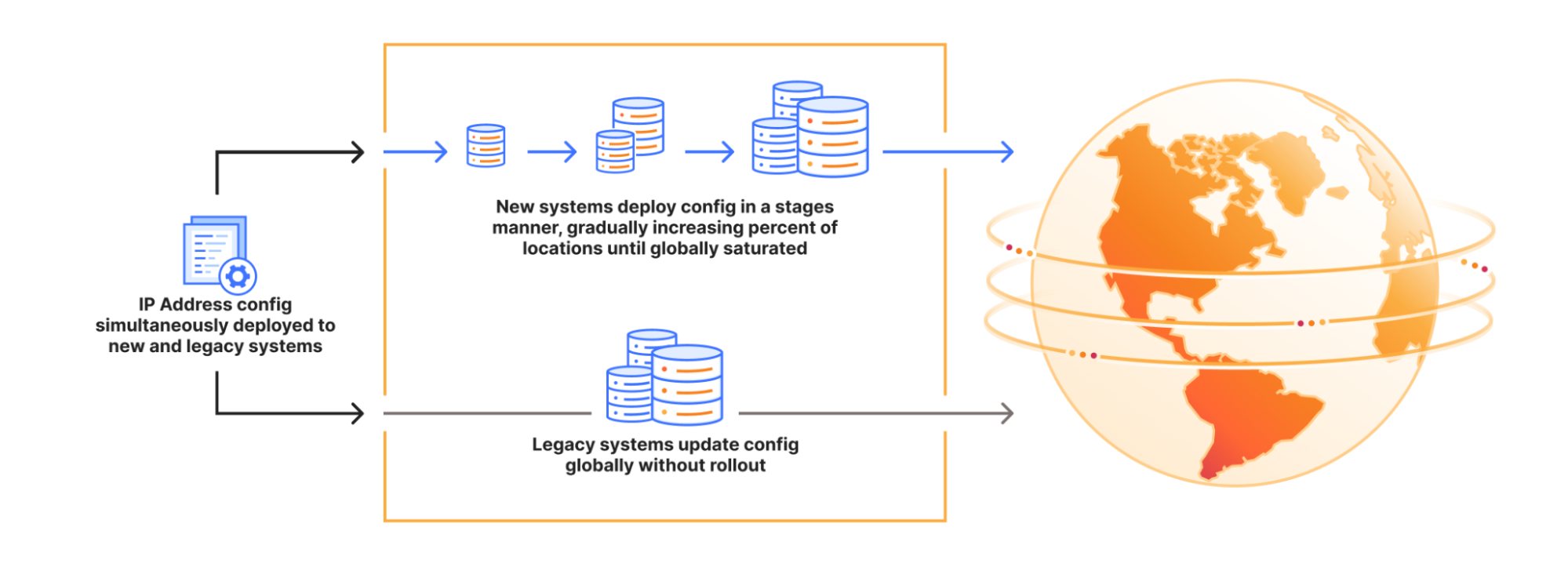
The way that Cloudflare manages service topologies has been refined over time and currently consist of a combination of a legacy and a strategic system that are synced. Cloudflare’s IP ranges are currently bound and configured across these systems that dictate where an IP range should be announced (in terms of datacenter location) on the edge network. The legacy approach of hard-coding explicit lists of data center locations and attaching them to particular prefixes has proved error-prone, since (for example) bringing a new data center online requires many different lists to be updated and synced consistently. This model also has a significant flaw in that updates to the configuration do not follow a progressive deployment methodology: Even though this release was peer-reviewed by multiple engineers, the change didn’t go through a series of canary deployments before reaching every Cloudflare data center. Our newer approach is to describe service topologies without needing to hard-code IP addresses, which better accommodate expansions to new locations and customer scenarios while also allowing for a staged deployment model, so changes can propagate slowly with health monitoring. During the migration between these approaches, we need to maintain both systems and synchronize data between them, which looks like this:
Initial alerts were triggered for the DNS Resolver at 22:01, indicating query, proxy, and data center failures. While investigating the alerts, we noted traffic toward the Resolver prefixes had drastically dropped and was no longer being received at our edge data centers. Internally, we use BGP to control route advertisements, and we found the Resolver routes from servers were completely missing.
Once our configuration error had been exposed and Cloudflare systems had withdrawn the routes from our routing table, all of the 1.1.1.1 routes should have disappeared entirely from the global Internet routing table. However, this isn’t what happened with the prefix 1.1.1.0/24. Instead, we got reports from Cloudflare Radar that Tata Communications India (AS4755) had started advertising 1.1.1.0/24: from the perspective of the routing system, this looked exactly like a prefix hijack. This was unexpected to see while we were troubleshooting the routing problem, but to be perfectly clear: this BGP hijack was not the cause of the outage. We are following up with Tata Communications.
Restoring the 1.1.1.1 Service
We reverted to the previous configuration at 22:20 UTC. Near instantly, we began readvertising the BGP prefixes which were previously withdrawn from the routers, including 1.1.1.0/24. This restored 1.1.1.1 traffic levels to roughly 77% of what they were prior to the incident. However, during the period since withdrawal, approximately 23% of the fleet of edge servers had been automatically reconfigured to remove required IP bindings as a result of the topology change. To add the configurations back, these servers needed to be reconfigured with our change management system which is not an instantaneous process by default for safety.
The process by which the IP bindings can be restored normally takes some time, as the network in individual locations is designed to be updated over a course of multiple hours. We implement a progressive rollout, rather than on all nodes at once to ensure we don’t introduce additional impact. However, given the severity of the incident, we accelerated the rollout of the fix after verifying the changes in testing locations to restore service as quickly and safely as possible. Normal traffic levels were observed at 22:54 UTC.
Remediation and follow-up steps
We take incidents like this seriously, and we recognise the impact that this incident had. Though this specific issue has been resolved, we have identified several steps we can take to mitigate the risk of a similar problem occurring in the future. We are implementing the following plan as a result of this incident:
Staging Addressing Deployments: Legacy components do not leverage a gradual, staged deployment methodology. Cloudflare will deprecate these systems which enables modern progressive and health mediated deployment processes to provide earlier indication in a staged manner and rollback accordingly.
Deprecating Legacy Systems: We are currently in an intermediate state in which current and legacy components need to be updated concurrently, so we will be migrating addressing systems away from risky deployment methodologies like this one. We will accelerate our deprecation of the legacy systems in order to provide higher standards for documentation and test coverage.
Conclusion
Cloudflare’s 1.1.1.1 DNS Resolver service fell victim to an internal configuration error.
We are sorry for the disruption this incident caused for our customers. We are actively making these improvements to ensure improved stability moving forward and to prevent this problem from happening again.
On June 12, 2025, Cloudflare suffered a significant service outage that affected a large set of our critical services, including Workers KV, WARP, Access, Gateway, Images, Stream, Workers AI, Turnstile and Challenges, AutoRAG, Zaraz, and parts of the Cloudflare Dashboard.
This outage lasted 2 hours and 28 minutes, and globally impacted all Cloudflare customers using the affected services. The cause of this outage was due to a failure in the underlying storage infrastructure used by our Workers KV service, which is a critical dependency for many Cloudflare products and relied upon for configuration, authentication and asset delivery across the affected services. Part of this infrastructure is backed by a third-party cloud provider, which experienced an outage today and directly impacted availability of our KV service.
We’re deeply sorry for this outage: this was a failure on our part, and while the proximate cause (or trigger) for this outage was a third-party vendor failure, we are ultimately responsible for our chosen dependencies and how we choose to architect around them.
This was not the result of an attack or other security event. No data was lost as a result of this incident. Cloudflare Magic Transit and Magic WAN, DNS, cache, proxy, WAF and related services were not directly impacted by this incident.
What was impacted?
As a rule, Cloudflare designs and builds our services on our own platform building blocks, and as such many of Cloudflare’s products are built to rely on the Workers KV service.
The following table details the impacted services, including the user-facing impact, operation failures, and increases in error rates observed:
Product/Service
Impact
Workers KV
Workers KV saw 90.22% of requests failing: any key-value pair not cached and that required to retrieve the value from Workers KV’s origin storage backends resulted in failed requests with response code 503 or 500.
The remaining requests were successfully served from Workers KV’s cache (status code 200 and 404) or returned errors within our expected limits and/or error budget.
This did not impact data stored in Workers KV.
Access
Access uses Workers KV to store application and policy configuration along with user identity information.
During the incident Access failed 100% of identity based logins for all application types including Self-Hosted, SaaS and Infrastructure. User Identity information was unavailable to other services like WARP and Gateway during this incident. Access is designed to fail closed when it cannot successfully fetch policy configuration or a user’s identity.
Active Infrastructure Application SSH sessions with command logging enabled failed to save logs due to a Workers KV dependency.
Access’ System for Cross Domain Identity (SCIM) service was also impacted due to its reliance on Workers KV and Durable Objects (which depended on KV) to store user information. During this incident, user identities were not updated due to Workers KV updates failures. These failures would result in a 500 returned to identity providers. Some providers may require a manual re-synchronization but most customers would have seen immediate service restoration once Access’ SCIM service was restored due to retry logic by the identity provider.
Service authentication based logins (e.g. service token, Mutual TLS, and IP-based policies) and Bypass policies were unaffected. No Access policy edits or changes were lost during this time.
Gateway
This incident did not affect most Gateway DNS queries, including those over IPv4, IPv6, DNS over TLS (DoT), and DNS over HTTPS (DoH).
However, there were two exceptions:
DoH queries with identity-based rules failed. This happened because Gateway couldn’t retrieve the required user’s identity information.
Authenticated DoH was disrupted for some users. Users with active sessions with valid authentication tokens were unaffected, but those needing to start new sessions or refresh authentication tokens could not.
Users of Gateway proxy, egress, and TLS decryption were unable to connect, register, proxy, or log traffic.
This was due to our reliance on Workers KV to retrieve up-to-date identity and device posture information. Each of these actions requires a call to Workers KV, and when unavailable, Gateway is designed to fail closed to prevent traffic from bypassing customer-configured rules.
WARP
The WARP client was impacted due to core dependencies on Access and Workers KV, which is required for device registration and authentication. As a result, no new clients were able to connect or sign up during the incident.
Existing WARP client users sessions that were routed through the Gateway proxy experienced disruptions, as Gateway was unable to perform its required policy evaluations.
Additionally, the WARP emergency disconnect override was rendered unavailable because of a failure in its underlying dependency, Workers KV.
Consumer WARP saw a similar sporadic impact as the Zero Trust version.
Dashboard
Dashboard user logins and most of the existing dashboard sessions were unavailable. This was due to an outage affecting Turnstile, DO, KV, and Access. The specific causes for login failures were:
Standard Logins (User/Password): Failed due to Turnstile unavailability.
Sign-in with Google (OIDC) Logins: Failed due to a KV dependency issue.
SSO Logins: Failed due to a full dependency on Access.
The Cloudflare v4 API was not impacted during this incident.
Challenges and Turnstile
The Challenge platform that powers Cloudflare Challenges and Turnstile saw a high rate of failure and timeout for siteverify API requests during the incident window due to its dependencies on Workers KV and Durable Objects.
We have kill switches in place to disable these calls in case of incidents and outages such as this. We activated these kill switches as a mitigation so that eyeballs are not blocked from proceeding. Notably, while these kill switches were active, Turnstile’s siteverify API (the API that validates issued tokens) could redeem valid tokens multiple times, potentially allowing for attacks where a bad actor might try to use a previously valid token to bypass.
There was no impact to Turnstile’s ability to detect bots. A bot attempting to solve a challenge would still have failed the challenge and thus, not received a token.
Browser Isolation
Existing Browser Isolation sessions via Link-based isolation were impacted due to a reliance on Gateway for policy evaluation.
New link-based Browser Isolation sessions could not be initiated due to a dependency on Cloudflare Access. All Gateway-initiated isolation sessions failed due its Gateway dependency.
Images
Uploads to Cloudflare Images were impacted during the incident window, with a 100% failure rate at the peak of the incident.
Overall image delivery dipped to around 97% success rate. Image Transformations were not significantly impacted, and Polish was not impacted.
Stream
Stream’s error rate exceeded 90% during the incident window as video playlists were unable to be served. Stream Live observed a 100% error rate.
Video uploads were not impacted.
Realtime
The Realtime TURN (Traversal Using Relays around NAT) service uses KV and was heavily impacted. Error rates were near 100% for the duration of the incident window.
The Realtime SFU service (Selective Forwarding Unit) was unable to create new sessions, although existing connections were maintained. This caused a reduction to 20% of normal traffic during the impact window.
Workers AI
All inference requests to Workers AI failed for the duration of the incident. Workers AI depends on Workers KV for distributing configuration and routing information for AI requests globally.
Pages & Workers Assets
Static assets served by Cloudflare Pages and Workers Assets (such as HTML, JavaScript, CSS, images, etc) are stored in Workers KV, cached, and retrieved at request time. Workers Assets saw an average error rate increase of around 0.06% of total requests during this time.
During the incident window, Pages error rate peaked to ~100% and all Pages builds could not complete.
AutoRAG
AutoRAG relies on Workers AI models for both document conversion and generating vector embeddings during indexing, as well as LLM models for querying and search. AutoRAG was unavailable during the incident window because of the Workers AI dependency.
Durable Objects
SQLite-backed Durable Objects share the same underlying storage infrastructure as Workers KV. The average error rate during the incident window peaked at 22%, and dropped to 2% as services started to recover.
Durable Object namespaces using the legacy key-value storage were not impacted.
D1
D1 databases share the same underlying storage infrastructure as Workers KV and Durable Objects.
Similar to Durable Objects, the average error rate during the incident window peaked at 22%, and dropped to 2% as services started to recover.
Queues & Event Notifications
Queues message operations including–pushing and consuming–were unavailable during the incident window.
Queues uses KV to map each Queue to underlying Durable Objects that contain queued messages.
Event Notifications use Queues as their underlying delivery mechanism.
AI Gateway
AI Gateway is built on top of Workers and relies on Workers KV for client and internal configurations. During the incident window, AI Gateway saw error rates peak at 97% of requests until dependencies recovered.
CDN
Automated traffic management infrastructure was operational but acted with reduced efficacy during the impact period. In particular, registration requests from Zero Trust clients increased substantially as a result of the outage.
The increase in requests imposed additional load in several Cloudflare locations, triggering response from automated traffic management. In response to these conditions, systems rerouted incoming CDN traffic to nearby locations, reducing impact to customers. There was a portion of traffic that was not rerouted as expected and is under investigation. CDN requests impacted by this issue would experience elevated latency, HTTP 499 errors, and / or HTTP 503 errors. Impacted Cloudflare service areas included São Paulo, Philadelphia, Atlanta, and Raleigh.
Workers / Workers for Platforms
Workers and Workers for Platforms rely on a third party service for uploads. During the incident window, Workers saw an overall error rate peak to ~2% of total requests. Workers for Platforms saw an overall error rate peak to ~10% of total requests during the same time period.
Workers Builds (CI/CD)
Starting at 18:03 UTC Workers builds could not receive new source code management push events due to Access being down.
100% of new Workers Builds failed during the incident window.
Browser Rendering
Browser Rendering depends on Browser Isolation for browser instance infrastructure.
Requests to both the REST API and via the Workers Browser Binding were 100% impacted during the incident window.
Zaraz
100% of requests were impacted during the incident window. Zaraz relies on Workers KV configs for websites when handling eyeball traffic. Due to the same dependency, attempts to save updates to Zaraz configs were unsuccessful during this period, but our monitoring shows that only a single user was affected.
Background
Workers KV is built as what we call a “coreless” service which means there should be no single point of failure as the service runs independently in each of our locations worldwide. However, Workers KV today relies on a central data store to provide a source of truth for data. A failure of that store caused a complete outage for cold reads and writes to the KV namespaces used by services across Cloudflare.
Workers KV is in the process of being transitioned to significantly more resilient infrastructure for its central store: regrettably, we had a gap in coverage which was exposed during this incident. Workers KV removed a storage provider as we worked to re-architect KV’s backend, including migrating it to Cloudflare R2, to prevent data consistency issues (caused by the original data syncing architecture), and to improve support for data residency requirements.
One of our principles is to build Cloudflare services on our own platform as much as possible, and Workers KV is no exception. Many of our internal and external services rely heavily on Workers KV, which under normal circumstances helps us deliver the most robust services possible, instead of service teams attempting to build their own storage services. In this case, the cascading impact from the failure from Workers KV exacerbated the issue and significantly broadened the blast radius.
Incident timeline and impact
The incident timeline, including the initial impact, investigation, root cause, and remediation, are detailed below.
Workers KV error rates to storage infrastructure. 91% of requests to KV failed during the incident window.
Cloudflare Access percentage of successful requests. Cloudflare Access relies directly on Workers KV and serves as a good proxy to measure Workers KV availability over time.
All timestamps referenced are in Coordinated Universal Time (UTC).
Time
Event
2025-06-12 17:52
INCIDENT START Cloudflare WARP team begins to see registrations of new devices fail and begin to investigate these failures and declares an incident.
2025-06-12 18:05
Cloudflare Access team received an alert due to a rapid increase in error rates.
Service Level Objectives for multiple services drop below targets and trigger alerts across those teams.
2025-06-12 18:06
Multiple service-specific incidents are combined into a single incident as we identify a shared cause (Workers KV unavailability). Incident priority upgraded to P1.
2025-06-12 18:21
Incident priority upgraded to P0 from P1 as severity of impact becomes clear.
2025-06-12 18:43
Cloudflare Access begins exploring options to remove Workers KV dependency by migrating to a different backing datastore with the Workers KV engineering team. This was proactive in the event the storage infrastructure continued to be down.
2025-06-12 19:09
Zero Trust Gateway began working to remove dependencies on Workers KV by gracefully degrading rules that referenced Identity or Device Posture state.
2025-06-12 19:32
Access and Device Posture force drop identity and device posture requests to shed load on Workers KV until third-party service comes back online.
2025-06-12 19:45
Cloudflare teams continue to work on a path to deploying a Workers KV release against an alternative backing datastore and having critical services write configuration data to that store.
2025-06-12 20:23
Services begin to recover as storage infrastructure begins to recover. We continue to see a non-negligible error rate and infrastructure rate limits due to the influx of services repopulating caches.
2025-06-12 20:25
Access and Device Posture restore calling Workers KV as third-party service is restored.
2025-06-12 20:28
IMPACT END Service Level Objectives return to pre-incident level. Cloudflare teams continue to monitor systems to ensure services do not degrade as dependent systems recover.
INCIDENT END Cloudflare team see all affected services return to normal function. Service level objective alerts are recovered.
Remediation and follow-up steps
We’re taking immediate steps to improve the resiliency of services that depend on Workers KV and our storage infrastructure. This includes existing planned work that we are accelerating as a result of this incident.
This encompasses several workstreams, including efforts to avoid singular dependencies on storage infrastructure we do not own, improving the ability for us to recover critical services (including Access, Gateway and WARP)
Specifically:
(Actively in-flight): Bringing forward our work to improve the redundancy within Workers KV’s storage infrastructure, removing the dependency on any single provider. During the incident window we began work to cut over and backfill critical KV namespaces to our own infrastructure, in the event the incident continued.
(Actively in-flight): Short-term blast radius remediations for individual products that were impacted by this incident so that each product becomes resilient to any loss of service caused by any single point of failure, including third party dependencies..
(Actively in-flight): Implementing tooling that allows us to progressively re-enable namespaces during storage infrastructure incidents. This will allow us to ensure that key dependencies, including Access and WARP, are able to come up without risking a denial-of-service against our own infrastructure as caches are repopulated.
This list is not exhaustive: our teams continue to revisit design decisions and assess the infrastructure changes we need to make in both the near (immediate) term and long term to mitigate the incidents like this going forward.
This was a serious outage, and we understand that organizations and institutions that are large and small depend on us to protect and/or run their websites, applications, zero trust and network infrastructure. Again we are deeply sorry for the impact and are working diligently to improve our service resiliency.
A massive power outage struck significant portions of Portugal and Spain at 10:34 UTC on April 28, grinding transportation to a halt, shutting retail businesses, and otherwise disrupting everyday activities and services. Parts of France were also reportedly impacted by the power outage. Portugal’s electrical grid operator blamed the outage on a “fault in the Spanish electricity grid”, and later stated that “due to extreme temperature variations in the interior of Spain, there were anomalous oscillations in the very high voltage lines (400 kilovolts), a phenomenon known as ‘induced atmospheric vibration’” and that “These oscillations caused synchronisation failures between the electrical systems, leading to successive disturbances across the interconnected European network.”
The breadth of Cloudflare’s network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the Internet impact of this power outage at both a local and national level, as well as at a network level, across traffic, network quality, and routing metrics.
Impacts in Portugal
Country level
In Portugal, Internet traffic dropped as the power grid failed, with traffic immediately dropping by half as compared to the previous week, falling to approximately 90% below the previous week within the next five hours.
Request traffic from users in Portugal to Cloudflare’s 1.1.1.1 DNS resolver also fell when the power went out, initially dropping by 40% as compared to the previous week, and falling further over the next several hours.
Network level
At a network level, the loss of Internet traffic from local providers including NOS, Vodafone, MEO, and NOWO was swift and significant. The Cloudflare Radar graphs below show that traffic from those networks effectively evaporated over the hours after the power outage began. The autonomous systems (ASNs) shown below for these providers may carry a mix of fixed and mobile broadband traffic. However, MEO breaks out at least some of their mobile traffic onto a separate ASN, and the graph below for MEO-MOVEL (AS42863) shows that request traffic from that network more than doubled after the power went out, as subscribers turned to their mobile devices for information about what was happening. However, despite the initial spike, this mobile traffic also fell over the next several hours, dropping to approximately half of the volume seen the prior week.
Regional level
In addition to looking at traffic at a national and network level, we can also look at traffic at a regional level. As noted above, the power outage did not impact every region of the country. The traffic graphs below show the changes in Internet traffic from the parts of Portugal where an impact was observed.
In Lisbon and Porto, a sharp, but limited drop in traffic was observed as the power outage began, with traffic recovering slightly almost as quickly. However, traffic gradually declined in the subsequent hours, in contrast to the other regions reviewed below.
The most significant immediate traffic drops were observed in Aveiro, Beja, Bragança, Castelo Branco, Évora, Faro, Guarda, Portalegre, Santarém, Viana do Castelo, Vila Real, and Viseu. In these areas, traffic fell and then quickly stabilized at very low volumes. In Braga and Setúbal, traffic declined more gradually after the initial drop.
Network quality
The power outage also impacted the quality of connectivity at a national level in Portugal. Prior to the loss of power, median download speeds across the country were around 40 Mbps, but within several hours after the state of the outage, fell as low as 15 Mbps. As expected, latency at a country level saw an opposite impact. Prior to the loss of power, median latency was around 20 ms. However, it gradually grew to as much as 50 ms. The lower download speeds and higher latency are likely due to the congestion of the network links that remained available.
Routing
Network infrastructure in Portugal was also impacted by the power outage, with the impact seen as a drop in announced IP address space. (This means that portions of Portuguese providers’ networks are no longer visible to the rest of the Internet.) The number of announced IPv4 /24s (blocks of 256 IPv4 addresses) dropped by ~300 (around 1.2%), and the number of announced IPv6 /48s (blocks of over 1.2 octillion IPv6 addresses) dropped from 17,928,551 to 16,355,607 (around 9%). Address space began to drop further after 16:00 UTC, possibly as a result of backup power being exhausted and associated network infrastructure falling offline.
Impacts in Spain
Country level
In Spain, Internet traffic dropped as the power grid failed, with traffic immediately dropping by around 60% as compared to the previous week, falling to approximately 80% below the previous week within the next five hours.
Request traffic from users in Spain to Cloudflare’s 1.1.1.1 DNS resolver also fell when the power went out, initially dropping by 54% as compared to the previous week, but quickly stabilizing.
Network level
At a network level, traffic volumes from the top five ASNs in Spain fell rapidly once power was lost, with most declining gradually over the next several hours. In contrast, traffic from Digi Spain Telecom (AS57269) fell quickly, but then stabilized at the lower level. In comparison to the previous week, traffic from these providers fell between 75% and 93% in the hours after the power outage began.
Regional level
In most of the impacted regions in Spain, traffic dropped off quickly and stabilized, or continued to fall further. However, some recovery in traffic is also evident, and can be seen in Navarre, La Rioja, Cantabria, and Basque Country. This traffic recovery is likely associated with an initial restoration of power in those regions, as an update from Red Eléctrica (operator of Spain’s national electricity grid) noted that “Electricity is now available in parts of Catalonia, Aragon, the Basque Country, Galicia, Asturias, Navarre, Castile and León, Extremadura, Andalusia, and La Rioja.”
Network quality
The power outage also impacted the quality of connectivity at a national level in Spain. Prior to the loss of power, median download speeds across the country were around 35 Mbps, but within several hours after the state of the outage, fell as low as 19 Mbps. Interestingly, the median bandwidth didn’t see the clean gradual decline as it did in Portugal, instead falling and recovering twice before gradually declining.
As expected, latency at a country level saw a significant increase. Prior to the loss of power, median latency was around 22 ms, but grew to as much as 40 ms. As in Portugal, the lower download speeds and higher latency are likely due to the congestion of the network links that remained available.
Routing
Similar to Portugal, network infrastructure in Spain was also impacted by the power outage, with the impact seen as a drop in announced IP address space. By 14:30 UTC, the number of announced IPv4 /24 address blocks had fallen by around 2.4%, and continued to drop further over the following hours. The number of announced IPv6 /48 address blocks fell by over 8% during that same time span, and also continued to drop in the following hours.
Impacts in other European countries
Parts of Andorra and France were also reportedly impacted by the power outage, with additional outages reported as far away as Belgium. At a national level, no traffic disruptions were evident in any of the countries.
Analysis of traffic at a regional level in France shows a slight decline concurrent with the power outage in several regions, but the drops were nominal in comparison to Spain and Portugal, and traffic volumes recovered to expected levels within 90 minutes. No impact was evident at a regional level in Andorra.
It appears that Morocco may have been impacted in some fashion by the power outage, or at least Orange Maroc was. In a post on X, the provider stated (translated) “Internet traffic has been disrupted following a massive power outage in Spain and Portugal, which is affecting international connections.” Cloudflare Radar shows that traffic from the network fell sharply around 12:00 UTC, 90 minutes after the power outage began, with a full outage beginning around 15:00 UTC.
Conclusion
Power restoration in Spain had already started as this post was being written, and full recovery will likely take hours to days. As power is restored, Internet traffic and other metrics will recover as well. The current state of Internet connectivity in Spain and Portugal can be tracked on Cloudflare Radar.
Multiple Cloudflare services, including R2 object storage, experienced an elevated rate of errors for 1 hour and 7 minutes on March 21, 2025 (starting at 21:38 UTC and ending 22:45 UTC). During the incident window, 100% of write operations failed and approximately 35% of read operations to R2 failed globally. Although this incident started with R2, it impacted other Cloudflare services including Cache Reserve, Images, Log Delivery, Stream, and Vectorize.
While rotating credentials used by the R2 Gateway service (R2’s API frontend) to authenticate with our storage infrastructure, the R2 engineering team inadvertently deployed the new credentials (ID and key pair) to a development instance of the service instead of production. When the old credentials were deleted from our storage infrastructure (as part of the key rotation process), the production R2 Gateway service did not have access to the new credentials. This ultimately resulted in R2’s Gateway service being able to authenticate with our storage backend. There was no data loss or corruption that occurred as part of this incident: any in-flight uploads or mutations that returned successful HTTP status codes were persisted.
Once the root cause was identified and we realized we hadn’t deployed the new credentials to the production R2 Gateway service, we deployed the updated credentials and service availability was restored.
This incident happened because of human error and lasted longer than it should have because we didn’t have proper visibility into which credentials were being used by the Gateway Worker to authenticate with our storage infrastructure.
We’re deeply sorry for this incident and the disruption it may have caused to you or your users. We hold ourselves to a high standard and this is not acceptable. This blog post exactly explains the impact, what happened and when, and the steps we are taking to make sure this failure (and others like it) doesn’t happen again.
What was impacted?
The primary incident window occurred between 21:38 UTC and 22:45 UTC.
The following table details the specific impact to R2 and Cloudflare services that depend on, or interact with, R2:
Product/Service
Impact
R2
All customers using Cloudflare R2 would have experienced an elevated error rate during the primary incident window. Specifically:
* Object write operations had a 100% error rate.
* Object reads had an approximate error rate of 35% globally. Individual customer error rate varied during this window depending on access patterns. Customers accessing public assets through custom domains would have seen a reduced error rate as cached object reads were not impacted.
* Operations involving metadata only (e.g., head and list operations) were not impacted.
There was no data loss or risk to data integrity within R2’s storage subsystem. This incident was limited to a temporary authentication issue between R2’s API frontend and our storage infrastructure.
Billing
Billing uses R2 to store customer invoices. During the primary incident window, customers may have experienced errors when attempting to download/access past Cloudflare invoices.
Cache Reserve
Cache Reserve customers observed an increase in requests to their origin during the incident window as an increased percentage of reads to R2 failed. This resulted in an increase in requests to origins to fetch assets unavailable in Cache Reserve during this period.
User-facing requests for assets to sites with Cache Reserve did not observe failures as cache misses failed over to the origin.
Email Security
Email Security depends on R2 for customer-facing metrics. During the primary incident window, customer-facing metrics would not have updated.
Images
All (100% of) uploads failed during the primary incident window. Successful delivery of stored images dropped to approximately 25%.
Key Transparency Auditor
All (100% of) operations failed during the primary incident window due to dependence on R2 writes and/or reads. Once the incident was resolved, service returned to normal operation immediately.
Log Delivery
Log delivery (for Logpush and Logpull) was delayed during the primary incident window, resulting in significant delays (up to 70 minutes) in log processing. All logs were delivered after incident resolution.
Stream
All (100% of) uploads failed during the primary incident window. Successful Stream video segment delivery dropped to 94%. Viewers may have seen video stalls every minute or so, although actual impact would have varied.
Stream Live was down during the primary incident window as it depends on object writes.
Vectorize
Queries and operations against Vectorize indexes were impacted during the incident window. During the incident window, Vectorize customers would have seen an increased error rate for read queries to indexes and all (100% of) insert and upsert operation failed as Vectorize depends on R2 for persistent storage.
Incident timeline
All timestamps referenced are in Coordinated Universal Time (UTC).
Time
Event
Mar 21, 2025 – 19:49 UTC
The R2 engineering team started the credential rotation process. A new set of credentials (ID and key pair) for storage infrastructure was created. Old credentials were maintained to avoid downtime during credential change over.
Mar 21, 2025 – 20:19 UTC
Set updated production secret (wrangler secret put) and executed wrangler deploy command to deploy R2 Gateway service with updated credentials.
Note: We later discovered the –env parameter was inadvertently omitted for both Wrangler commands. This resulted in credentials being deployed to the Worker assigned to the default environment instead of the Worker assigned to the production environment.
Mar 21, 2025 – 20:20 UTC
The R2 Gateway service Worker assigned to the default environment is now using the updated storage infrastructure credentials.
Note: This was the wrong Worker, the production environment should have been explicitly set. But, at this point, we incorrectly believed the credentials were updated on the correct production Worker.
Mar 21, 2025 – 20:37 UTC
Old credentials were removed from our storage infrastructure to complete the credential rotation process.
Mar 21, 2025 – 21:38 UTC
– IMPACT BEGINS –
R2 availability metrics begin to show signs of service degradation. The impact to R2 availability metrics was gradual and not immediately obvious because there was a delay in the propagation of the previous credential deletion to storage infrastructure.
Mar 21, 2025 – 21:45 UTC
R2 global availability alerts are triggered (indicating 2% of error budget burn rate).
The R2 engineering team began looking at operational dashboards and logs to understand impact.
Mar 21, 2025 – 21:50 UTC
Internal incident declared.
Mar 21, 2025 – 21:51 UTC
R2 engineering team observes gradual but consistent decline in R2 availability metrics for both read and write operations. Operations involving metadata only (e.g., head and list operations) were not impacted.
Given gradual decline in availability metrics, R2 engineering team suspected a potential regression in propagation of new credentials in storage infrastructure.
Mar 21, 2025 – 22:05 UTC
Public incident status page published.
Mar 21, 2025 – 22:15 UTC
R2 engineering team created a new set of credentials (ID and key pair) for storage infrastructure in an attempt to force re-propagation.
Continued monitoring operational dashboards and logs.
Mar 21, 2025 – 22:20 UTC
R2 engineering team saw no improvement in availability metrics. Continued investigating other potential root causes.
Mar 21, 2025 – 22:30 UTC
R2 engineering team deployed a new set of credentials (ID and key pair) to R2 Gateway service Worker. This was to validate whether there was an issue with the credentials we had pushed to gateway service.
Environment parameter was still omitted in the deploy and secret put commands, so this deployment was still to the wrong non-production Worker.
Mar 21, 2025 – 22:36 UTC
– ROOT CAUSE IDENTIFIED –
The R2 engineering team discovered that credentials had been deployed to a non-production Worker by reviewing production Worker release history.
Mar 21, 2025 – 22:45 UTC
– IMPACT ENDS –
Deployed credentials to correct production Worker. R2 availability recovered.
Mar 21, 2025 – 22:54 UTC
The incident is considered resolved.
Analysis
R2’s architecture is primarily composed of three parts: R2 production gateway Worker (serves requests from S3 API, REST API, Workers API), metadata service, and storage infrastructure (stores encrypted object data).
The R2 Gateway Worker uses credentials (ID and key pair) to securely authenticate with our distributed storage infrastructure. We rotate these credentials regularly as a best practice security precaution.
Our key rotation process involves the following high-level steps:
Create a new set of credentials (ID and key pair) for our storage infrastructure. At this point, the old credentials are maintained to avoid downtime during credential change over.
Set the new credential secret for the R2 production gateway Worker using the wrangler secret put command.
Set the new updated credential ID as an environment variable in the R2 production gateway Worker using the wrangler deploy command. At this point, new storage credentials start being used by the gateway Worker.
Remove previous credentials from our storage infrastructure to complete the credential rotation process.
Monitor operational dashboards and logs to validate change over.
The R2 engineering team uses Workers environments to separate production and development environments for the R2 Gateway Worker. Each environment defines a separate isolated Cloudflare Worker with separate environment variables and secrets.
Critically, both wrangler secret put and wrangler deploy commands default to the default environment if the –env command line parameter is not included. In this case, due to human error, we inadvertently omitted the –env parameter and deployed the new storage credentials to the wrong Worker (default environment instead of production). To correctly deploy storage credentials to the production R2 Gateway Worker, we need to specify --env production.
The action we took on step 4 above to remove the old credentials from our storage infrastructure caused authentication errors, as the R2 Gateway production Worker still had the old credentials. This is ultimately what resulted in degraded availability.
The decline in R2 availability metrics was gradual and not immediately obvious because there was a delay in the propagation of the previous credential deletion to storage infrastructure. This accounted for a delay in our initial discovery of the problem. Instead of relying on availability metrics after updating the old set of credentials, we should have explicitly validated which token was being used by the R2 Gateway service to authenticate with R2’s storage infrastructure.
Overall, the impact on read availability was significantly mitigated by our intermediate cache that sits in front of storage and continued to serve requests.
Resolution
Once we identified the root cause, we were able to resolve the incident quickly by deploying the new credentials to the production R2 Gateway Worker. This resulted in an immediate recovery of R2 availability.
Next steps
This incident happened because of human error and lasted longer than it should have because we didn’t have proper visibility into which credentials were being used by the R2 Gateway Worker to authenticate with our storage infrastructure.
We have taken immediate steps to prevent this failure (and others like it) from happening again:
Added logging tags that include the suffix of the credential ID the R2 Gateway Worker uses to authenticate with our storage infrastructure. With this change, we can explicitly confirm which credential is being used.
Related to the above step, our internal processes now require explicit confirmation that the suffix of the new token ID matches logs from our storage infrastructure before deleting the previous token.
Require that key rotation takes place through our hotfix release tooling instead of relying on manual wrangler command entry which introduces human error. Our hotfix release deploy tooling explicitly enforces the environment configuration and contains other safety checks.
While it’s been an implicit standard that this process involves at least two humans to validate the changes ahead as we progress, we’ve updated our relevant SOPs (standard operating procedures) to include this explicitly.
In Progress: Extend our existing closed loop health check system that monitors our endpoints to test new keys, automate reporting of their status through our alerting platform, and ensure global propagation prior to releasing the gateway Worker.
In Progress: To expedite triage on any future issues with our distributed storage endpoints, we are updating our observability platform to include views of upstream success rates that bypass caching to give clearer indication of issues serving requests for any reason.
The list above is not exhaustive: as we work through the above items, we will likely uncover other improvements to our systems, controls, and processes that we’ll be applying to improve R2’s resiliency, on top of our business-as-usual efforts. We are confident that this set of changes will prevent this failure, and related credential rotation failure modes, from occurring again. Again, we sincerely apologize for this incident and deeply regret any disruption it has caused you or your users.
Multiple Cloudflare services, including our R2 object storage, were unavailable for 59 minutes on Thursday, February 6th. This caused all operations against R2 to fail for the duration of the incident, and caused a number of other Cloudflare services that depend on R2 — including Stream, Images, Cache Reserve, Vectorize and Log Delivery — to suffer significant failures.
The incident occurred due to human error and insufficient validation safeguards during a routine abuse remediation for a report about a phishing site hosted on R2. The action taken on the complaint resulted in an advanced product disablement action on the site that led to disabling the production R2 Gateway service responsible for the R2 API.
Critically, this incident did not result in the loss or corruption of any data stored on R2.
We’re deeply sorry for this incident: this was a failure of a number of controls and we are prioritizing work to implement additional system-level controls related not only to our abuse processing systems, but so that we continue to reduce the blast radius of any system- or human- action that could result in disabling any production service at Cloudflare.
What was impacted?
All customers using Cloudflare R2 would have observed a 100% failure rate against their R2 buckets and objects during the primary incident window. Services that depend on R2 (detailed in the table below) observed heightened error rates and failure modes depending on their usage of R2.
The primary incident window occurred between 08:14 UTC to 09:13 UTC, when operations against R2 had a 100% error rate. Dependent services (detailed below) observed increased failure rates for operations that relied on R2.
From 09:13 UTC to 09:36 UTC, as R2 recovered and clients reconnected, the backlog and resulting spike in client operations caused load issues with R2’s metadata layer (built on Durable Objects). This impact was significantly more isolated: we observed a 0.09% increase in error rates in calls to Durable Objects running in North America during this window.
The following table details the impacted services, including the user-facing impact, operation failures, and increases in error rates observed:
Product/Service
Impact
R2
100% of operations against R2 buckets and objects, including uploads, downloads, and associated metadata operations were impacted during the primary incident window. During the secondary incident window, we observed a <1% increase in errors as clients reconnected and increased pressure on R2’s metadata layer.
There was no data loss within the R2 storage subsystem: this incident impacted the HTTP frontend of R2. Separation of concerns and blast radius management meant that the underlying R2 infrastructure was unaffected by this.
Stream
100% of operations (upload & streaming delivery) against assets managed by Stream were impacted during the primary incident window.
Images
100% of operations (uploads & downloads) against assets managed by Images were impacted during the primary incident window.
Impact to Image Delivery was minor: success rate dropped to 97% as these assets are fetched from existing customer backends and do not rely on intermediate storage.
Cache Reserve
Cache Reserve customers observed an increase in requests to their origin during the incident window as 100% of operations failed. This resulted in an increase in requests to origins to fetch assets unavailable in Cache Reserve during this period. This impacted less than 0.049% of all cacheable requests served during the incident window.
User-facing requests for assets to sites with Cache Reserve did not observe failures as cache misses failed over to the origin.
Log Delivery
Log delivery was delayed during the primary incident window, resulting in significant delays (up to an hour) in log processing, as well as some dropped logs.
Specifically:
Non-R2 delivery jobs would have experienced up to 4.5% data loss during the incident. This level of data loss could have been different between jobs depending on log volume and buffer capacity in a given location.
R2 delivery jobs would have experienced up to 13.6% data loss during the incident.
R2 is a major destination for Cloudflare Logs. During the primary incident window, all available resources became saturated attempting to buffer and deliver data to R2. This prevented other jobs from acquiring resources to process their queues. Data loss (dropped logs) occurred when the job queues expired their data (to allow for new, incoming data). The system recovered when we enabled a kill switch to stop processing jobs sending data to R2.
Durable Objects
Durable Objects, and services that rely on it for coordination & storage, were impacted as the stampeding horde of clients re-connecting to R2 drove an increase in load.
We observed a 0.09% actual) increase in error rates in calls to Durable Objects running in North America, starting at 09:13 UTC and recovering by 09:36 UTC.
Cache Purge
Requests to the Cache Purge API saw a 1.8% error rate (HTTP 5xx) increase and a 10x increase in p90 latency for purge operations during the primary incident window. Error rates returned to normal immediately after this.
Vectorize
Queries and operations against Vectorize indexes were impacted during the primary incident window. 75% of queries to indexes failed (the remainder were served out of cache) and 100% of insert, upsert, and delete operations failed during the incident window as Vectorize depends on R2 for persistent storage. Once R2 recovered, Vectorize systems recovered in full.
We observed no continued impact during the secondary incident window, and we have not observed any index corruption as the Vectorize system has protections in place for this.
Key Transparency Auditor
100% of signature publish & read operations to the KT auditor service failed during the primary incident window. No third party reads occurred during this window and thus were not impacted by the incident.
Workers & Pages
A small volume (0.002%) of deployments to Workers and Pages projects failed during the primary incident window. These failures were limited to services with bindings to R2, as our control plane was unable to communicate with the R2 service during this period.
Incident timeline and impact
The incident timeline, including the initial impact, investigation, root cause, and remediation, are detailed below.
All timestamps referenced are in Coordinated Universal Time (UTC).
Time
Event
2025-02-06 08:12
The R2 Gateway service is inadvertently disabled while responding to an abuse report.
2025-02-06 08:14
— IMPACT BEGINS —
2025-02-06 08:15
R2 service metrics begin to show signs of service degradation.
2025-02-06 08:17
Critical R2 alerts begin to fire due to our service no longer responding to our health checks.
2025-02-06 08:18
R2 on-call engaged and began looking at our operational dashboards and service logs to understand impact to availability.
2025-02-06 08:23
Sales engineering escalated to the R2 engineering team that customers are experiencing a rapid increase in HTTP 500’s from all R2 APIs.
2025-02-06 08:25
Internal incident declared.
2025-02-06 08:33
R2 on-call was unable to identify the root cause and escalated to the lead on-call for assistance.
2025-02-06 08:42
Root cause identified as R2 team reviews service deployment history and configuration, which surfaces the action and the validation gap that allowed this to impact a production service.
2025-02-06 08:46
On-call attempts to re-enable the R2 Gateway service using our internal admin tooling, however this tooling was unavailable because it relies on R2.
2025-02-06 08:49
On-call escalates to an operations team who has lower level system access and can re-enable the R2 Gateway service.
2025-02-06 08:57
The operations team engaged and began to re-enable the R2 Gateway service.
2025-02-06 09:09
R2 team triggers a redeployment of the R2 Gateway service.
2025-02-06 09:10
R2 began to recover as the forced re-deployment rolled out as clients were able to reconnect to R2.
2025-02-06 09:13
— IMPACT ENDS — R2 availability recovers to within its service-level objective (SLO). Durable Objects begins to observe a slight increase in error rate (0.09%) for Durable Objects running in North America due to the spike in R2 clients reconnecting.
2025-02-06 09:36
The Durable Objects error rate recovers.
2025-02-06 10:29
The incident is closed after monitoring error rates.
At the R2 service level, our internal Prometheus metrics showed R2’s SLO near-immediately drop to 0% as R2’s Gateway service stopped serving all requests and terminated in-flight requests.
The slight delay in failure was due to the product disablement action taking 1-2 minutes to take effect as well as our configured metrics aggregation intervals:
For context, R2’s architecture separates the Gateway service, which is responsible for authenticating and serving requests to R2’s S3 & REST APIs and is the “front door” for R2 — its metadata store (built on Durable Objects), our intermediate caches, and the underlying, distributed storage subsystem responsible for durably storing objects.
During the incident, all other components of R2 remained up: this is what allowed the service to recover so quickly once the R2 Gateway service was restored and re-deployed. The R2 Gateway acts as the coordinator for all work when operations are made against R2. During the request lifecycle, we validate authentication and authorization, write any new data to a new immutable key in our object store, then update our metadata layer to point to the new object. When the service was disabled, all running processes stopped.
While this means that all in-flight and subsequent requests fail, anything that had received a HTTP 200 response had already succeeded with no risk of reverting to a prior version when the service recovered. This is critical to R2’s consistency guarantees and mitigates the chance of a client receiving a successful API response without the underlying metadata and storage infrastructure having persisted the change.
Deep dive
Due to human error and insufficient validation safeguards in our admin tooling, the R2 Gateway service was taken down as part of a routine remediation for a phishing URL.
During a routine abuse remediation, action was taken on a complaint that inadvertently disabled the R2 Gateway service instead of the specific endpoint/bucket associated with the report. This was a failure of multiple system level controls (first and foremost) and operator training.
A key system-level control that led to this incident was in how we identify (or “tag”) internal accounts used by our teams. Teams typically have multiple accounts (dev, staging, prod) to reduce the blast radius of any configuration changes or deployments, but our abuse processing systems were not explicitly configured to identify these accounts and block disablement actions against them. Instead of disabling the specific endpoint associated with the abuse report, the system allowed the operator to (incorrectly) disable the R2 Gateway service.
Once we identified this as the cause of the outage, remediation and recovery was inhibited by the lack of direct controls to revert the product disablement action and the need to engage an operations team with lower level access than is routine. The R2 Gateway service then required a re-deployment in order to rebuild its routing pipeline across our edge network.
Once re-deployed, clients were able to re-connect to R2, and error rates for dependent services (including Stream, Images, Cache Reserve and Vectorize) returned to normal levels.
Remediation and follow-up steps
We have taken immediate steps to resolve the validation gaps in our tooling to prevent this specific failure from occurring in the future.
We are prioritizing several work-streams to implement stronger, system-wide controls (defense-in-depth) to prevent this, including how we provision internal accounts so that we are not relying on our teams to correctly and reliably tag accounts. A key theme to our remediation efforts here is around removing the need to rely on training or process, and instead ensuring that our systems have the right guardrails and controls built-in to prevent operator errors.
These work-streams include (but are not limited to) the following:
Actioned: deployed additional guardrails implemented in the Admin API to prevent product disablement of services running in internal accounts.
Actioned: Product disablement actions in the abuse review UI have been disabled while we add more robust safeguards. This will prevent us from inadvertently repeating similar high-risk manual actions.
In-flight: Changing how we create all internal accounts (staging, dev, production) to ensure that all accounts are correctly provisioned into the correct organization. This must include protections against creating standalone accounts to avoid re-occurrence of this incident (or similar) in the future.
In-flight: Further restricting access to product disablement actions beyond the remediations recommended by the system to a smaller group of senior operators.
In-flight: Two-party approval required for ad-hoc product disablement actions. Going forward, if an investigator requires additional remediations, they must be submitted to a manager or a person on our approved remediation acceptance list to approve their additional actions on an abuse report.
In-flight: Expand existing abuse checks that prevent accidental blocking of internal hostnames to also prevent any product disablement action of products associated with an internal Cloudflare account.
In-flight: Internal accounts are being moved to our new Organizations model ahead of public release of this feature. The R2 production account was a member of this organization but our abuse remediation engine did not have the necessary protections to prevent acting against accounts within this organization.
We’re continuing to discuss & review additional steps and effort that can continue to reduce the blast radius of any system- or human- action that could result in disabling any production service at Cloudflare.
Conclusion
We understand this was a serious incident and we are painfully aware of — and extremely sorry for — the impact it caused to customers and teams building and running their businesses on Cloudflare.
This is the first (and ideally, the last) incident of this kind and duration for R2, and we’re committed to improving controls across our systems and workflows to prevent this in the future.
The 2024 Cloudflare Radar Year in Review is our fifth annual review of Internet trends and patterns observed throughout the year at both a global and country/region level across a variety of metrics. In this year’s review, we have added several new traffic, adoption, connectivity, and email security metrics, as well as the ability to do year-over-year and geographic comparisons for selected metrics.
Below, we present a summary of key findings, and then explore them in more detail in subsequent sections.
Google maintained its position as the most popular Internet service overall. OpenAI remained at the top of the Generative AI category. Binance remained at the top of the Cryptocurrency category. WhatsApp remained the top Messaging platform, and Facebook remained the top Social Media site. 🔗
Global traffic from Starlink grew 3.3x in 2024, in line with last year’s growth rate. After initiating service in Malawi in July 2023, Starlink traffic from that country grew 38x in 2024. As Starlink added new markets, we saw traffic grow rapidly in those locations. 🔗
Googlebot, Google’s web crawler, was responsible for the highest volume of request traffic to Cloudflare in 2024, as it retrieved content from millions of Cloudflare customer sites for search indexing. 🔗
Traffic from ByteDance’s AI crawler (Bytespider) gradually declined over the course of 2024. Anthropic’s AI crawler (ClaudeBot) first started showing signs of ongoing crawling activity in April, then declined after an initial peak in May & June. 🔗
13.0% of TLS 1.3 traffic is using post-quantum encryption. 🔗
Adoption & Usage
Globally, nearly one-third of mobile device traffic was from Apple iOS devices. Android had a >90% share of mobile device traffic in 29 countries/regions; peak iOS mobile device traffic share was over 60% in eight countries/regions. 🔗
Globally, nearly half of web requests used HTTP/2, with 20.5% using HTTP/3. Usage of both versions was up slightly from 2023. 🔗
React, PHP, and jQuery were among the most popular technologies used to build websites, while HubSpot, Google, and WordPress were among the most popular vendors of supporting services and platforms. 🔗
Go surpassed NodeJS as the most popular language used for making automated API requests. 🔗
Google is far and away the most popular search engine globally, across all platforms. On mobile devices and operating systems, Baidu is a distant second. Bing is a distant second across desktop and Windows devices, with DuckDuckGo second most popular on macOS. Shares vary by platform and country/region. 🔗
Google Chrome is far and away the most popular browser overall. While this is also true on macOS devices, Safari usage is well ahead of Chrome on iOS devices. On Windows, Edge is the second most popular browser as it comes preinstalled and is the initial default. 🔗
Connectivity
225 major Internet disruptions were observed globally in 2024, with many due to government-directed regional and national shutdowns of Internet connectivity. Cable cuts and power outages were also leading causes. 🔗
Aggregated across 2024, 28.5% of IPv6-capable requests were made over IPv6. India and Malaysia were the strongest countries, at 68.9% and 59.6% IPv6 adoption respectively. 🔗
The top 10 countries ranked by Internet speed all had average download speeds above 200 Mbps. Spain was consistently among the top locations across the measured Internet quality metrics. 🔗
41.3% of global traffic comes from mobile devices. In nearly 100 countries/regions, the majority of traffic comes from mobile devices. 🔗
20.7% of TCP connections are unexpectedly terminated before any useful data can be exchanged. 🔗
Security
6.5% of global traffic was mitigated by Cloudflare’s systems as being potentially malicious or for customer-defined reasons. In the United States, the share of mitigated traffic grew to 5.1%, while in South Korea, it dropped slightly to 8.1%. In 44 countries/regions, over 10% of traffic was mitigated. 🔗
The United States was responsible for over a third of global bot traffic. Amazon Web Services was responsible for 12.7% of global bot traffic, and 7.8% came from Google. 🔗
Globally, Gambling/Games was the most attacked industry, slightly ahead of 2023’s most targeted industry, Finance. 🔗
Log4j, a vulnerability discovered in 2021, remains a persistent threat and was actively targeted throughout 2024. 🔗
Routing security, measured as the share of RPKI valid routes and the share of covered IP address space, continued to improve globally throughout 2024. We saw a 4.7% increase in RPKI valid IPv4 address space in 2024, and a 6.4% increase in RPKI valid routes in 2024. 🔗
Email Security
An average of 4.3% of emails were determined to be malicious in 2024, although this figure was likely influenced by spikes observed in March, April, and May. Deceptive links and identity deception were the two most common types of threats found in malicious email messages. 🔗
Over 99% of the email messages processed by Cloudflare Email Security from the .bar, .rest, and .uno top level domains (TLDs) were found to be either spam or malicious in nature. 🔗
Introduction
Over the last four years (2020, 2021, 2022, 2023), we have aggregated perspectives from Cloudflare Radar into an annual Year In Review, illustrating the Internet’s patterns across multiple areas over the course of that year. The Cloudflare Radar 2024 Year In Review microsite continues that tradition, featuring interactive charts, graphs, and maps you can use to explore and compare notable Internet trends observed throughout this past year.
Cloudflare’s network currently spans more than 330 cities in over 120 countries/regions, serving an average of over 63 million HTTP(S) requests per second for millions of Internet properties, in addition to handling over 42 million DNS requests per second on average. The resulting data generated by this usage, combined with data from other complementary Cloudflare tools, enables Radar to provide unique near-real time perspectives on the patterns and trends around security, traffic, performance, and usage that we observe across the Internet.
The 2024 Year In Review is organized into five sections: Traffic, Adoption & Usage, Connectivity, Security, and Email Security and covers the period from January 1 to December 1, 2024. We have incorporated several new metrics this year, including AI bot & crawler traffic, search engine and browser market share, connection tampering, and “most dangerous” top level domains (TLDs). To ensure consistency, we have kept underlying methodologies consistent with previous years’ calculations. Trends for 200 countries/regions are available on the microsite; smaller or less populated locations are excluded due to insufficient data. Some metrics are only shown worldwide, and are not displayed if a country/region is selected.
Below, we provide an overview of the content contained within the major Year In Review sections (Traffic, Adoption & Usage, Connectivity, Security, and Email Security), along with notable observations and key findings. In addition, we have also published a companion blog post that specifically explores trends seen across Top Internet Services.
The key findings and associated discussion within this post only provide a high-level perspective on the unique insights that can be found in the Year in Review microsite. Visit the microsite to explore the various datasets and metrics in more detail, including trends seen in your country/region, how these trends have changed as compared to 2023, and how they compare to other countries/regions of interest. Surveying the Internet from this vantage point provides insights that can inform decisions on everything from an organization’s security posture and IT priorities to product development and strategy.
Traffic trends
Global Internet traffic grew 17.2% in 2024.
An inflection point for Internet traffic arguably occurred thirty years ago. The World Wide Web went mainstream in 1994, thanks to the late 1993 release of the NCSA Mosaic browser for multiple popular operating systems, which included support for embedded images. In turn, “heavier” (in contrast to text-based) Internet content became the norm, and coupled with the growth in consumption through popular online services and the emerging consumer ISP industry, Internet traffic began to rapidly increase, and that trend has continued to the present.
To determine the traffic trends over time for the Year in Review, we use the average daily traffic volume (excluding bot traffic) over the second full calendar week (January 8-15) of 2024 as our baseline. (The second calendar week is used to allow time for people to get back into their “normal” school and work routines after the winter holidays and New Year’s Day. The percent change shown in the traffic trends chart is calculated relative to the baseline value — it does not represent absolute traffic volume for a country/region. The trend line represents a seven-day trailing average, which is used to smooth the sharp changes seen with data at a daily granularity. To compare 2024’s traffic trends with 2023 data and/or other locations, click the “Compare” icon at the upper right of the graph.
Throughout the first half of 2024, worldwide Internet traffic growth appeared to be fairly limited, within a percent or two on either side of the baseline value through mid-August. However, at that time growth clearly began to accelerate, climbing consistently through the end of November, growing 17.2% for the year. This trend is similar to those also seen in 2023 and 2022, as we discussed in the 2023 Year in Review blog post.
Internet traffic trends in 2024, worldwide
The West African country of Guinea experienced the most significant Internet traffic growth seen in 2024, reaching as much as 350% above baseline. Traffic growth didn’t begin in earnest until late February, and reached an initial peak in early April. It remained between 100% and 200% above baseline until September, when it experienced several multi-week periods of growth. While the September-November periods of traffic growth also occurred in 2023, they peaked at under 90% above baseline.
The impact of significant Internet outages is also clearly visible when looking at data across the year. Two significant Internet outages in Cuba are clearly visible as large drops in traffic in October and November. A reported “complete disconnection” of the national electricity system on the island occurred on October 18, lasting just over three days. Just a couple of weeks later, on November 6, damage from Hurricane Rafael caused widespread power outages in Cuba, resulting in another large drop in Internet traffic. Traffic has remained lower as Cuba’s electrical infrastructure continues to struggle.
Internet traffic trends in 2024, Cuba
As we frequently discuss in Cloudflare Radar blog and social media posts, government-directed Internet shutdowns occur all too frequently, and the impact of these actions are also clearly visible when looking at long-term traffic data. In Bangladesh, the government ordered the shutdown of mobile Internet connectivity on July 18, in response to student protests. Shortly after mobile networks were shut down, fixed broadband networks were taken offline as well, resulting in a near complete loss of Internet traffic from the country. Connectivity gradually returned over the course of several days, between July 23-28.
Internet traffic trends in 2024, Bangladesh
As we also noted last year, the celebration of major holidays can also have a visible impact on Internet traffic at a country level. For example, in Muslim countries including Indonesia and the United Arab Emirates, the celebration of Eid al-Fitr, the festival marking the end of the fast of Ramadan, is visible as a noticeable drop in traffic around April 9-10.
Internet traffic trends in 2024, Indonesia and United Arab Emirates
Google maintained its position as the most popular Internet service. OpenAI, Binance, WhatsApp, and Facebook led their respective categories.
Over the last several years, the Year In Review has ranked the most popular Internet services. These rankings cover an “overall” perspective, as well as a dozen more specific categories, based on analysis of anonymized query data of traffic to our 1.1.1.1 public DNS resolver from millions of users around the world. For the purposes of these rankings, domains that belong to a single Internet service are grouped together.
Google once again held the top spot overall, supported by its broad portfolio of services, as well as the popularity of the Android mobile operating system (more on that below). Meta properties Facebook, Instagram, and WhatsApp also held spots in the top 10.
Generative AI continued to grow in popularity throughout 2024, and in this category, OpenAI again held the top spot, building on the continued success and popularity of ChatGPT. Within Social Media, the top five remained consistent with 2023’s and 2022’s ranking, including Facebook, TikTok, Instagram, X, and Snapchat.
Global traffic from Starlink grew 3.3x in 2024, in line with last year’s growth rate. After initiating service in Malawi in July 2023, Starlink traffic from that country grew 38x in 2024.
SpaceX’s Starlink continues to be the leading satellite Internet service provider, bringing connectivity to unserved or underserved areas. In addition to opening up new markets in 2024, Starlink also announced relationships to provide in-flight connectivity to multiple airlines, and on cruise ships and trains, as well as enabling subscribers to roam with their subscription using the Starlink Mini.
We analyzed aggregate Cloudflare traffic volumes associated with Starlink’s primary autonomous system (AS14593) to track the growth in usage of the service throughout 2024. Similar to the traffic trends discussed above, the request volume shown on the trend line in the chart represents a seven-day trailing average. Comparisons with 2023 data can be shown by clicking the “Compare” icon at the upper right of the graph. Within comparative views, the lines are scaled to the maximum value shown.
On a worldwide basis, steady, consistent growth was seen across the year, though it accelerates throughout November. This acceleration may have been driven by traffic associated with customer-specific large software updates.
Starlink traffic growth worldwide in 2024
In many locations, there is pent-up demand for “alternative” connectivity providers such as Starlink, and in these countries/regions, we see rapid traffic growth when service becomes available, such as in Zimbabwe. Service availability was announced on September 7, and traffic from the country began to grow rapidly almost immediately thereafter.
Starlink traffic growth in Zimbabwe in 2024
In new markets, traffic growth continues after that initial increase. For example Starlink service became available in Malawi in July 2023, and throughout 2024, Starlink traffic from the country grew 38x. While Malawi’s 38x increase is impressive, other countries also experienced significant growth. In the Eastern European country of Georgia, service became available on November 1, 2023. After a slow ramp, traffic began to take off growing over 100x through 2024. In Paraguay, service availability was announced on December 21, and began to grow at the beginning of January, registering an increase of over 900x across the year.
Starlink traffic growth in Malawi in 2024
Googlebot was responsible for the highest volume of request traffic to Cloudflare in 2024 as it retrieved content from millions of Cloudflare customer sites for search indexing.
Cloudflare Radar shows users Internet traffic trends over a selected period of time, but at a country/region or network level. However, as we did in 2023, we again wanted to look at the traffic Cloudflare saw over the course of the full year from the entire IPv4 Internet. To do so, we can use Hilbert curves, which allow us to visualize a sequence of IPv4 addresses in a two-dimensional pattern that keeps nearby IP addresses close to each other, making them useful for surveying the Internet’s IPv4 address space.
Using a Hilbert curve, we can visualize aggregated IPv4 request traffic to Cloudflare from January 1 through December 1, 2024. Within the visualization, we aggregate IPv4 addresses at a /20 level, meaning that at the highest zoom level, each square represents traffic from 4,096 IPv4 addresses. This aggregation is done to keep the amount of data used for the visualization manageable. (While we would like to create a similar visualization for IPv6 traffic, the enormity of the full IPv6 address space would make associated traffic very hard to see in such a visualization, especially as such a small amount has been allocated for assignment by the Regional Internet Registries.)
Within the visualization, IP addresses are grouped by ownership, and for much of the IP address space shown there, a mouseover at the default zoom level will show the Regional Internet Registry (RIR) that the address block belongs to. However, there are also a number of blocks that were assigned prior to the existence of the RIR system, and for these, they are labeled with the name of the organization that owns them. Progressive zooming ultimately shows the autonomous system and country/region that the IP address block is associated with, as well as its share of traffic relative to the maximum. (If a country/region is selected, only the IP address blocks associated with that location are visible.) Overall traffic shares are indicated by shading based on a color scale, and although a number of large unshaded blocks are visible, this does not necessarily mean that the associated address space is unused, but rather that it may be used in a way that does not generate traffic to Cloudflare.
Hilbert curve showing aggregated 2024 traffic to Cloudflare across the IPv4 Internet
Warmer orange/red shading within the visualization represents areas of higher request volume, and buried within one of those areas is the IP address block that had the maximum request volume to Cloudflare during 2024. As it was in 2023, this address block was 66.249.64.0/20, which belongs to Google, and is one of several used by the Googlebot web crawler to retrieve content for search indexing. This use of that address space is a likely explanation for the high request volume, given the number of web properties on Cloudflare’s network.
Zoomed Hilbert curve view showing the IPv4 address block that generated the highest volume of requests
In addition to Google, owners of other prefixes in the top 20 include Alibaba, Microsoft, Amazon, and Apple. To explore the IPv4 Internet in more detail, we encourage you to go to the Year in Review microsite and explore it by dragging and zooming to move around IPv4 address space.
Among AI bots and crawlers, Bytespider (ByteDance) traffic gradually declined over the course of 2024, while ClaudeBot (Anthropic) was more active during the back half of the year.
AI bots and crawlers have been in the news throughout 2024 as they voraciously consume content to train ever-evolving models. Controversy has followed them, as not all bots and crawlers respect content owner directives to restrict crawling activity. In July, Cloudflare enabled customers to block these bots and crawlers with a single click, and during Birthday Week we introduced AI Audit to give website owners even more visibility into and control over how AI platforms access their content.
Tracking traffic trends for AI bots can help us better understand their activity over time — observing which are the most aggressive and have the highest volume of requests, which perform crawls on a regular basis, etc. The new AI bot & crawler traffic graph on Radar’s Traffic page, launched in September, provides insight into these traffic trends gathered over the selected time period for the top known AI bots.
Looking at traffic trends from two of those bots, we can see some interesting patterns. Bytespider is a crawler operated by ByteDance, the Chinese owner of TikTok, and is reportedly used to download training data for ByteDance’s Large Language Models (LLMs). Bytespider’s crawling activity trended generally downwards over the course of 2024, with end-of-November activity approximately 80-85% lower than that seen at the start of the year. ClaudeBot is Anthropic’s crawler, which downloads training data for its LLMs that power AI products like Claude. Traffic from ClaudeBot appeared to be mostly non-existent through mid-April, except for some small spikes that possibly represent test runs. Traffic became more consistently non-zero starting in late April, but after an early spike, trailed off through the remainder of the year.
Traffic trends for AI crawlers Bytespider and ClaudeBot in 2024
13.0% of TLS 1.3 traffic is using post-quantum encryption.
The term “post-quantum” refers to a new set of cryptographic techniques designed to protect data from adversaries that have the ability to capture and store current data for decryption by sufficiently powerful quantum computers in the future. The Cloudflare Research team has been exploring post-quantum cryptography since 2017.
In October 2022, we enabled post-quantum key agreement on our network by default, but use of it requires that browsers and clients support it as well. In 2024, Google’s Chrome 124 enabled it by default on April 17, and adoption grew rapidly following that release, increasing from just over 2% of requests to around 12% within a month, and ended November at 13%. We expect that adoption will continue to grow into and during 2025 due to support in other Chromium-based browsers, growing default support in Mozilla Firefox, and initial testing in Apple Safari.
Growth trends in post-quantum encrypted TLS 1.3 traffic during 2024
Adoption & Usage insights
Globally, nearly one-third of mobile device traffic was from Apple iOS devices. Android had a >90% share of mobile device traffic in 29 countries/regions; peak iOS mobile device traffic share was over 60% in eight countries/regions.
The two leading mobile device operating systems globally are Apple’s iOS and Google’s Android, and by analyzing information in the user agent reported with each request, we can get insight into the distribution of traffic by client operating system throughout the year. Again, we found that Android is responsible for the majority of mobile device traffic when aggregated globally, due to the wide distribution of price points, form factors, and capabilities.
Global distribution of mobile device traffic by operating system in 2024
In contrast, iOS adoption tops out in the 65% range in Jersey, the Faroe Islands, Guernsey, and Denmark. Adoption rates of 50% or more were seen in a total of 26 countries/regions, including Norway, Sweden, Australia, Japan, the United States, and Canada. These locations likely have a greater ability to afford higher priced devices, owing to their comparatively higher gross national income per capita.
Countries/regions with the largest share of iOS traffic in 2024
Globally, nearly half of web requests used HTTP/2, with 20.5% using HTTP/3.
HTTP (HyperText Transfer Protocol) is the core protocol that the web relies upon. HTTP/1.0 was first standardized in 1996, HTTP/1.1 in 1999, and HTTP/2 in 2015. The most recent version, HTTP/3, was completed in 2022, and runs on top of a new transport protocol known as QUIC. By running on top of QUIC, HTTP/3 can deliver improved performance by mitigating the effects of packet loss and network changes, as well as establishing connections more quickly. HTTP/3 also provides encryption by default, which mitigates the risk of attacks.
Current versions of desktop and mobile Google Chrome (and Chromium-based variants), Mozilla Firefox, and Apple Safari all support HTTP/3 by default. Cloudflare makes HTTP/3 available for free to all of our customers, although not every customer chooses to enable it.
Analysis of the HTTP version negotiated for each request provides insight into the distribution of traffic by the various versions of the protocol aggregated across the year. (“HTTP/1.x” aggregates requests made over HTTP/1.0 and HTTP/1.1.) At a global level, 20.5% of requests in 2024 were made using HTTP/3. Another 29.9% of requests were made over the older HTTP/1.x versions, while HTTP/2 remained dominant, accounting for the remaining 49.6%.
Global distribution of traffic by HTTP version in 2024
Looking at version distribution geographically, we found eight countries/regions sending more than a third of their requests over HTTP/3, with Reunion, Sri Lanka, Mongolia, Greece, and North Macedonia comprising the top five as shown below. Eight other countries/regions, including Iran, Ireland, Hong Kong, and China, sent more than half of their requests over HTTP/1.x throughout 2024. More than half of requests were made over HTTP/2 in a total of 147 countries/regions.
Countries/regions with the largest shares of HTTP/3 traffic in 2024
React, PHP, and jQuery were among the most popular technologies used to build websites, while Hubspot, Google, and WordPress were among the most popular vendors of supporting services and platforms.
Modern websites and applications are extremely complex, built on and integrating on a mix of frameworks, platforms, services, and tools. In order to deliver a seamless user experience, developers must ensure that all of these components happily coexist with each other. Using Cloudflare Radar’s URL Scanner, we again scanned websites associated with the top 5000 domains to identify the most popular technologies and services used across a dozen different categories.
In looking at core technologies used to build websites, React had a commanding lead over Vue.js and other JavaScript frameworks, PHP was the most popular programming technology, and jQuery’s share was 10x other popular JavaScript libraries.
Third-party services and platforms are also used by websites and applications to support things like analytics, content management, and marketing automation. Google Analytics remained the most widely used analytics provider, WordPress had a greater than 50% share among content management systems, and for marketing automation providers, category leader HubSpot had nearly twice the usage share of Marketo and MailChimp.
Top website technologies, JavaScript frameworks category in 2024
Go surpassed NodeJS as the most popular language used for making automated API requests.
Many dynamic websites and applications are built on automated API calls, and we can use our unique visibility into Web traffic to identify the top languages these API clients are written in. Applying heuristics to API-related requests determined to not be coming from a person using a browser or native mobile application helps us to identify the language used to build the API client.
Our analysis found that almost 12% of automated API requests are made by Go-based clients, with NodeJS, Python, Java, and .NET holding smaller shares. Compared to 2023, Go’s share increased by approximately 40%, allowing it to capture the top spot, while NodeJS’s share fell by just over 30%. Python and Java also saw their shares increase, while .NET’s fell.
Most popular API client languages in 2024
Google is the most popular search engine globally, across all platforms. On mobile devices/OS, Baidu is a distant second. Bing is a distant second across desktop and Windows devices, with DuckDuckGo second most popular on macOS.
Protecting and accelerating websites and applications for millions of customers, Cloudflare is in a unique position to measure search engine market share data. Our methodology uses HTTP’s referer header to identify the search engine sending traffic to customer sites and applications. The market share data is presented as an overall aggregate, as well as broken out by device type and operating system. (Device type and operating system data is derived from the User-Agent and Client Hints headers accompanying a content request.)
Aggregated at a global level, Google referred the most traffic to Cloudflare customers, with a greater than 88% share across 2024. Yandex, Baidu, Bing, and DuckDuckGo round out the top five, all with single digit percentage shares.
Overall worldwide search engine market share in 2024
However, when drilling down by location or platform, differences are apparent in the top search engines and their shares. For example, in South Korea, Google is responsible for only two-thirds of referrals, while local platform Naver drives 29.2%, with local portal Daum also in the top five at 1.3%.
Overall search engine market share in South Korea in 2024
Google’s dominance is also blunted a bit on Windows devices, where it drives only 80% of referrals globally. Unsurprisingly, Bing holds the second spot for Windows users, with a 10.4% share. Yandex, Yahoo, and DuckDuckGo round out the top 5, all with shares below 5%.
Overall worldwide search engine market share for Windows devices in 2024
For additional details, including search engines aggregated under “Other”, please refer to the quarterly Search Engine Referral Reports on Cloudflare Radar.
Google Chrome is the most popular browser overall. While also true on MacOS devices, Safari usage is well ahead of Chrome on iOS devices. On Windows, Edge is the second most popular browser.
Similar to our ability to measure search engine market share, Cloudflare is also in a unique position to measure browser market share. Our methodology uses information from the User-Agent and Client Hints headers to identify the browser making content requests, along with the associated operating system. Browser market share data is presented as an overall aggregate, as well as broken out by device type and operating system. Note that the shares of browsers available on both desktop and mobile devices, such as Chrome or Safari, are presented in aggregate.
Globally, we found that 65.8% of requests came from Google’s Chrome browser across 2024, and that just 15.5% came from Apple’s Safari browser. Microsoft Edge, Mozilla Firefox, and the Samsung Internet browser rounded out the top five, all with shares below 10%.
Overall worldwide web browser market share in 2024
Similar to the search engine statistics discussed above, differences are clearly visible when drilling down by location or platform. In some countries where iOS holds a larger market share than Android, Chrome remains the leading browser, but by a much lower margin. For example, in Sweden, Chrome’s share fell to 56.2%, while Safari’s increased to 22.5%. In Norway, Chrome fell to just 50%, while Safari grew to 25.6%.
Overall web browser market share in Norway in 2024
As the default browser on devices running iOS, Apple Safari was the most popular browser for iOS devices, commanding an 81.7% market share across the year, with Chrome at just 16.1%. And despite being the preinstalled default browser on Windows devices, Edge held just a 17.3% share, in comparison to Chrome’s 68.5%
Overall worldwide web browser market share for iOS devices in 2024
For additional details, including browsers aggregated under “Other”, please refer to the quarterly Browser Market Share Reports on Cloudflare Radar.
Connectivity
225 major Internet outages were observed around the world in 2024, with many due to government-directed regional and national shutdowns of Internet connectivity.
Throughout 2024, as we have over the last several years, we have written frequently about observed Internet outages, whether due to cable cuts, unspecified technical issues, government-directed shutdowns, or a number of other reasons covered in our quarterly summary posts (Q1, Q2, Q3). The impacts of these outages can be significant, including significant economic losses and severely limited communications. The Cloudflare Radar Outage Center tracks these Internet outages, and uses Cloudflare traffic data for insights into their scope and duration.
Some of the outages seen through the year were short-lived, lasting just a few hours, while others stretched on for days or weeks. In the latter category, an Internet outage in Haiti dragged on for eight days in September because repair crews were barred from accessing a damaged submarine cable due to a business dispute, while shutdowns of mobile and fixed Internet providers in Bangladesh lasted for approximately 10 days in July. In the former category, Iraq frequently experienced multi-hour nationwide Internet shutdowns intended to prevent cheating on academic exams — these contribute to the clustering visible in the timeline during June, July, August, and September.
Within the timeline on the Year in Review microsite, hovering over a dot will display metadata about that outage, and clicking on it will open a page with additional information. Below the map and timeline, we have added a bar graph illustrating the recorded reasons associated with the observed outages. In 2024, over half were due to government-directed shutdowns. If a country/region is selected, only outages and reasons for that country/region will be displayed.
Over 200 Internet outages were observed around the world during 2024
Aggregated across 2024, 28.5% of IPv6-capable requests were made over IPv6. India and Malaysia were the strongest countries, at 68.9% and 59.6% IPv6 adoption respectively.
The IPv4 protocol still used by many Internet-connected devices was developed in the 1970s, and was never meant to handle the vast and growing scale of the modern Internet. An initial specification for its successor, IPv6, was published in December 1995, evolving to a draft standard three years later, offering an expanded address space intended to better support the expected growth in the number of Internet-connected devices. At this point, available IPv4 space has long since been exhausted, and connectivity providers use solutions like Network Address Translation to stretch limited IPv4 resources. Hungry for IPv4 address space as their businesses and infrastructure grow, cloud and hosting providers are acquiring blocks of IPv4 address space for as much as \$30 – \$50 per address.
Cloudflare has been a vocal and active advocate for IPv6 since 2011, when we announced our Automatic IPv6 Gateway, which enabled free IPv6 support for all of our customers. In 2014, we enabled IPv6 support by default for all of our customers, but not all customers choose to keep it enabled for a variety of reasons. Note that server-side support is only half of the equation for driving IPv6 adoption, as end user connections need to support it as well. (In reality, it is a bit more complex than that, but server and client side support across applications, operating systems, and network environments are the two primary requirements. From a network perspective, implementing IPv6 also brings a number of other benefits.) By analyzing the IP version used for each request made to Cloudflare, aggregated throughout the year, we can get insight into the distribution of traffic by the various versions of the protocol.
At a global level, 28.5% of IPv6-capable (“dual-stack”) requests were made over IPv6, up from 26.4% in 2023. India was again the country with the highest level of IPv6 adoption, at 68.9%, carried in large part by 94% IPv6 adoption at Reliance Jio, one of the country’s largest Internet service providers. India was followed closely by Malaysia, where 59.6% of dual-stacked requests were made over IPv6 during 2024, thanks to strong IPv6 adoption rates across leading Internet providers within the country. IPv6 adoption in India was up from 66% in 2023, and in Malaysia, it was up from 57.3% last year. Saudi Arabia was the only other country with an IPv6 adoption rate above 50% this year, at 51.8%, whereas that list also included Vietnam, Greece, France, Uruguay, and Thailand in 2023. Thirty four countries/regions, including many in Africa, still have IPv6 adoption rates below 1%, while a total of 96 countries/regions have adoption rates below 10%.
Global distribution of traffic by IP version in 2024
Countries/regions with the largest shares of IPv6 traffic in 2024
The top 10 countries ranked by Internet speed all had average download speeds above 200 Mbps. Spain was consistently among the top locations across measured Internet quality metrics.
As more and more of our everyday lives move online, including entertainment, work, education, finance, shopping, and even basic social and personal interaction, the quality of our Internet connections is arguably more important than ever, necessitating higher connection speeds and lower latency. Although Internet providers continue to evolve their service portfolios to offer increased connection speeds and reduced latency in order to support growth in use cases like videoconferencing, live streaming, and online gaming, consumer adoption is often mixed due to cost, availability, or other issues. By aggregating the results of speed.cloudflare.com tests taken during 2024, we can get a geographic perspective on connection quality metrics including average download and upload speeds, and average idle and loaded latencies, as well as the distribution of the measurements.
In 2024, Spain was a leader in download speed (292.6 Mbps) and upload speed (192.6 Mbps) metrics, and placed second globally for loaded latency (78.6 ms). (Loaded latency is the round-trip time when data-heavy applications are being used on the network.) Spain’s leadership in these connection quality metrics is supported by the strong progress that the country has made towards achieving the EU’s “Digital Decade” objectives, including fixed very high capacity network (VHCN) deployment, fiber-to-the-premises (FTTP) coverage, and 5G coverage with the latter two reaching 95.2% and 92.3% respectively. High speed fiber broadband connections are also relatively affordable, with research showing major providers offering 100 Mbps, 300 Mbps, 600 Mbps, and 1 Gbps packages, with the latter priced between €30 and €46 per month. The figures below for Spain show the largest clusters of speed measurements around the 100 Mbps mark, with slight bumps also visible around 300 Mbps, suggesting that the former package has the highest subscription rate, followed by the latter. Further, they show these connections are also relatively low latency, with 87% of idle latency measurements below 50 ms and 65% of loaded latency measurements below 100 ms, providing users with good gaming and videoconferencing/streaming experiences.
Measured download/upload speed distribution in Spain in 2024
Measured idle/loaded latency distribution in Spain in 2024
41.3% of global traffic comes from mobile devices. In nearly 100 countries/regions, the majority of traffic comes from mobile devices.
With approximately 70% of the world’s population using smartphones, and 91% of Americans owning a smartphone, these mobile devices have become an integral part of both our personal and professional lives, providing us with Internet access from nearly any place at any time. In some countries/regions, mobile devices primarily connect to the Internet via Wi-Fi, while other countries/regions are “mobile first”, where 4G/5G services are the primary means of Internet access.
Analysis of information contained with the user agent reported with each request to Cloudflare enables us to categorize it as coming from a mobile, desktop, or other type of device. Aggregating this categorization throughout the year at a global level, we found that 41.3% of traffic came from mobile devices, with 58.7% coming from desktop devices such as laptops and “classic” PCs. These traffic shares were in line with those measured in both 2023 and 2022, suggesting that mobile device usage has achieved a “steady state”. Over 77% of traffic came from mobile devices in Sudan, Cuba, and Syria, making them the countries/regions with the largest mobile device traffic share in 2024. Other countries/regions that had more than 50% of traffic come from mobile devices were concentrated in the Middle East/Africa, the Asia Pacific region, and South/Central America.
Global distribution of traffic by device type in 2024
Countries/regions with the largest shares of mobile device usage in 2024
20.7% of TCP connections are unexpectedly terminated before any useful data can be exchanged.
Cloudflare is in a unique position to help measure the health and behaviors of Internet networks around the world. One way we do this is passively measuring rates of connections to Cloudflare that appear anomalous, meaning that they are unexpectedly terminated before any useful data exchange occurs. The underlying causes of connection anomalies are varied and range from DoS attacks to quirky client behavior to third-party connection tampering (e.g., when a network monitors and selectively disrupts connections to filter content).
Connection anomalies are symptoms — visible signs that “something abnormal” is happening in a network, but the underlying root cause is not always clear from the outset. However, we can gain a better understanding by incorporating previously-reported network behaviors, active measurements and on-the-ground reports, and macro trends across networks. Additional details on such analysis can be found in the blog posts A global assessment of third-party connection tampering andBringing insights into TCP resets and timeouts to Cloudflare Radar.
Insights into TCP connection anomalies were launched on Cloudflare Radar in September, with the plot lines in the associated graph corresponding to the stage of the TCP connection in which the connection anomalously closed (using shorthand, the first three messages we typically receive from the client in a TCP connection are “SYN” and “ACK” packets to establish a connection, and then a “PSH” packet indicating the requested resource). In aggregate globally, over 20% of connections to Cloudflare were terminated unexpectedly, with the largest share (nearly half) being closed “Post SYN” — that is, after our server has received a client’s SYN packet, but before we have received a subsequent acknowledgement (ACK) from the client or any useful data that would follow the acknowledgement. These terminations can often be attributed to DoS attacks or Internet scanning. Post-ACK (3.1% globally) and Post-PSH (1.4% globally) anomalies are more often associated with connection tampering, especially when they occur at high rates in specific networks.
Trends in TCP connection anomalies by stage in 2024
Security
6.5% of global traffic was mitigated by Cloudflare’s systems as being potentially malicious or for customer-defined reasons.
To protect customers from threats posed by malicious bots used to attack websites and applications, Cloudflare mitigates this attack traffic using DDoS mitigation techniques or Web Application Firewall (WAF) Managed Rules. For a variety of other reasons, customers may also want Cloudflare to mitigate traffic using techniques like rate-limiting requests, or blocking all traffic from a given location, even if it isn’t malicious. Analyzing traffic to Cloudflare’s network throughout 2024, we looked at the overall share that was mitigated for any reason, as well as the share that was blocked as a DDoS attack or by WAF Managed Rules.
In 2024, 6.5% of global traffic was mitigated, up almost one percentage point from 2023. Just 3.2% was mitigated as a DDoS attack, or by WAF Managed Rules, a rate slightly higher than in 2023. More than 10% of the traffic originating from 44 countries/regions had mitigations generally applied, while DDoS/WAF mitigations were applied to more than 10% of the traffic originating from just seven countries/regions.
At a country/region level, Albania had one of the highest mitigated traffic shares throughout the year, at 42.9%, while Libya had one of the highest shares of traffic that was mitigated as a DDoS attack or by WAF Managed Rules, at 19.2%. In 2023’s Year in Review blog post, we highlighted the United States and Korea. This year, the share of mitigated traffic grew to 5.0% in the United States (up from 3.65% in 2023), while in South Korea, it dropped slightly to 8.1%, down from 8.36%.
Trends in mitigated traffic worldwide in 2024
The United States was responsible for over a third of global bot traffic. Amazon Web Services was responsible for 12.7% of global bot traffic, and 7.8% came from Google.
Bot traffic describes any non-human Internet traffic, and by monitoring traffic suspected to be from bots site and application owners can spot and, if necessary, block potentially malicious activity. However, not all bots are malicious — bots can also be helpful, and Cloudflare maintains a list of verified bots that includes those used for things like search engine indexing, performance testing, and availability monitoring. Regardless of intent, we analyzed where bot traffic was originating from in 2024, using the IP address of a request to identify the network (autonomous system) and country/region associated with the bot making the request. Cloud platforms remained among the leading sources of bot traffic due to a number of factors. These include the ease of using automated tools to quickly provision compute resources, the relatively low cost of using these compute resources in an ephemeral manner, the broadly distributed geographic footprint of cloud platforms, and the platforms’ high-bandwidth Internet connectivity.
Globally, we found that 68.5% of observed bot traffic came from the top 10 countries in 2024, with the United States responsible for half of that total, over 5x the share of second place Germany. (In comparison to 2023, the US share was up slightly, while Germany’s was down slightly.) Among cloud platforms that originate bot traffic, Amazon Web Services was responsible for 12.7% of global bot traffic, and 7.8% came from Google. Microsoft, Hetzner, Digital Ocean, and OVH all also contributed more than a percent each.
Global bot traffic distribution by source country in 2024
Global bot traffic distribution by source network in 2024
Globally, Gambling/Games was the most attacked industry, slightly ahead of 2023’s most targeted industry, Finance.
The industries targeted by attacks often shift over time, depending on the intent of the attackers. They may be trying to cause financial harm by attacking ecommerce sites during a busy shopping period, gain an advantage against opponents by attacking an online game, or make a political statement by attacking government-related sites. To identify industry-targeted attack activity during 2024, we analyzed mitigated traffic for customers that had an associated industry and vertical within their customer record. Mitigated traffic was aggregated weekly by source country/region across 19 target industries.
Companies in the Gambling/Games industry were, in aggregate, the most attacked during 2024, with 6.6% of global mitigated traffic targeting the industry. The industry was slightly ahead of Finance, which led 2023’s aggregate list. (Both industries are shown at 6.6% in the Summary view due to rounding.) Gambling/Games sites saw the largest shares of mitigated traffic in January and the first week of February, possibly related to National Football League playoffs in the United States, heading into the Super Bowl.
Attacks targeting Finance organizations were most active in May, reaching a peak of 15.3% of mitigated traffic the week of May 13. This is in line with the figure in our DDoS threat report for Q2 2024 that shows that Financial Services was the most attacked industry by request volume during the quarter in South America and the Middle East region.
As we have seen in the past, peak attack activity varied by industry on a weekly basis. The highest peaks for the year were seen in attacks targeting People & Society organizations (19.6% of mitigated traffic, week of January 1), the Autos & Vehicles industry (29.7% of mitigated traffic, week of January 15), and the Real Estate industry (27.5% of mitigated traffic, week of August 26).
Global mitigated traffic share by industry in 2024, summary view
Log4j remains a persistent threat and was actively targeted throughout 2024.
In December 2021, we published a series of blog posts about the Log4j vulnerability, highlighting the threat that it posed, our observations of attempted exploitation, and the steps we took to protect customers. Two years on, in our 2023 Year in Review, we noted that even as an older vulnerability, Log4j remained a top target for attacks during 2023, with related attack activity significantly higher than other commonly exploited vulnerabilities.
In 2024, three years after the initial Log4j disclosure, we found that Log4j remains an active threat. This year, we compared normalized daily attack activity for Log4j with attack activity for Atlassian Confluence Code Injection, a vulnerability we examined in the 2023 Year in Review, as well as aggregated daily attack activity for multiple CVEs related to Authentication Bypass and Remote Code Execution vulnerabilities published in 2024.
Log4j attack activity appeared to trend generally upwards across the year, with several significant spikes visible during the first half of the year, and then again in October and November. In terms of the difference in activity, Log4j ranges from approximately 4x to over 20x the activity seen for Atlassian Confluence Code Injection, and as much as 100x the aggregated activity seen for Authentication Bypass or Remote Code Injection vulnerabilities.
Global attack activity trends for commonly exploited vulnerabilities in 2024
Routing security, measured as the share of RPKI valid routes and the share of covered IP address space, continued to improve globally throughout 2024.
As the routing protocol that underpins the Internet, Border Gateway Protocol (BGP) communicates routes between networks, enabling traffic to flow between source and destination. BGP, however, relies on trust between networks, and incorrect information shared between peers, whether or not it was shared intentionally, can send traffic to the wrong place, potentially with malicious results. Resource Public Key Infrastructure (RPKI) is a cryptographic method of signing records that associate a BGP route announcement with the correct originating autonomous system (AS) number, providing a way of ensuring that the information being shared originally came from a network that is allowed to do so. (It is important to note that this is only half of the challenge of implementing routing security, because network providers also need to validate these signatures and filter out invalid announcements to prevent sharing them further.)
Cloudflare has long been an advocate for routing security, including being a founding participant in the MANRS CDN and Cloud Programme and providing a public tool that enables users to test whether their Internet provider has implemented BGP safely. Building on insights available in the Routing page on Cloudflare Radar, we analyzed data from RIPE NCC’s RPKI daily archive to determine the share of RPKI valid routes (as opposed to those route announcements that are invalid or whose status is unknown) and how that share has changed over the course of 2024, as well as determining the share of IP address space covered by valid routes. The latter metric is of interest because a route announcement covering a significant amount of IP address space (millions of IPv4 addresses, for example) has a greater potential impact than an announcement covering a small block of IP address space (hundreds of IPv4 addresses, for example).
At a global level during 2024, we saw a 6.4 percentage point increase (from 43.4% to 49.8%) in valid IPv4 routes, and a 3.2 percentage point increase (from 53.7% to 56.9%) in valid IPv6 routes. Given the trajectory, it is likely that over half of IPv4 routes will be RPKI valid by the end of calendar year 2024. Looking at the global share of IP address space covered by valid routes, we saw a 4.7 percentage point increase (from 38.9% to 43.6%) for IPv4, and a 3.3 percentage point increase (from 57.6% to 60.9%) for IPv6.
Shares of global RPKI valid routing entries by IP version in 2024
Shares of globally announced IP address space covered by RPKI valid routes in 2024
Spain started 2024 with less than half of its routes (both IPv4 and IPv6) RPKI valid. However, the share of valid routes grew significantly on February 15, when AS12479 (Orange Espagne) signed records associated with 98% of their IP address prefixes that were previously in an “unknown” (or NotFound) state of RPKI validity, thus converting these prefixes from unknown to valid. That drove an immediate increase for IPv4 to 76%, reaching 81% validity by December 1, and an immediate increase for IPv6 to 91%, reaching 92.9% validity by December 1. A notable change in covered IP address space was observed in Cameroon, where covered IPv4 space more than doubled at the end of January, growing from 32% to 82%. This was due to AS36912 (Orange Cameroun) signing records associated with all of their IPv4 address prefixes, changing the associated IP address space to RPKI valid.
IPv4 and IPv6 shares of RPKI valid routes for Spain in 2024
Share of IPv4 address space covered by RPKI valid routes for Cameroon in 2024
Email Security
An average of 4.3% of emails were determined to be malicious in 2024.
Despite the growing enterprise use of collaboration/messaging apps, email remains an important business application and is a very attractive entry point into enterprise networks for attackers. Attackers will send targeted malicious emails that attempt to impersonate an otherwise legitimate sender (such as a corporate executive), that try to get the user to click on a deceptive link, or that contain a dangerous attachment, among other types of threats. Cloudflare Email Security protects customers from email-based attacks, including those carried out through targeted malicious email messages. During 2024, an average of 4.3% of emails analyzed by Cloudflare were found to be malicious. Aggregated at a weekly level, spikes above 14% were seen in late March, early April, and mid-May. We believe that these spikes were related to targeted “backscatter” attacks, where the attacker flooded a target with undeliverable messages, which then bounced the messages to the victim, whose email had been set as the reply-to: address.
Global malicious email share trends in 2024
Deceptive links and identity deception were the two most common types of threats found in malicious email messages.
Attackers use a variety of techniques, which we refer to as threat categories, when they use malicious email messages as an attack vector. These categories are defined and explored in detail in our phishing threats report. In our analysis of malicious emails, we have found that such messages may contain multiple types of threats. In reviewing a weekly aggregation of threat activity trends for these categories, we found that, averaged across 2024, 42.9% of malicious email messages contained deceptive links, with the share reaching 70% at times throughout the year. Activity for this thread category was spiky, with low points seen in the March to May timeframe, and a general downward trend visible from July through November.
Identity deception was a similarly active threat category, with such threats also found in up to 70% of analyzed emails several weeks throughout the year. Averaged across 2024, 35.1% of emails contained attempted identity deception. The activity pattern for this threat category appears to be somewhat similar to deceptive links, with a number of the peaks and valleys occurring during the same weeks. At times, identity deception was a more prevalent threat in analyzed emails than deceptive links, as seen in the graph below.
Among other threat categories, extortion saw the most significant change throughout the year. After being found in 86% of malicious emails during the first week of January, its share gradually trended lower throughout the year, finishing November under 10%.
Global malicious email threat category trends for Deceptive Links and Identity Deception in 2024
Over 99% of the email messages processed by Cloudflare Email Security from the .bar, .rest, and .uno top level domains (TLDs) were found to be either spam or malicious in nature.
In March 2024, we launched a set of email security insights on Cloudflare Radar, including visibility into so-called “dangerous domains” — those top level domains (TLDs) that were found to be the sources of the most spam or malicious email among messages analyzed by Cloudflare Email Security. The analysis is based on the sending domain’s TLD, found in the From: header of an email message. For example, if a message came from [email protected], then example.com is the sending domain, and .com is the associated TLD.
In aggregate across 2024, we found that the .bar, .rest, and .uno TLDs were the “most dangerous”, each with over 99% of analyzed email messages characterized as either spam or malicious. (These TLDs are all at least a decade old, and each sees at least some usage, with between 20,000 and 60,000 registered domain names.) Sorting by malicious email share, the .ws ccTLD (country code top level domain) belonging to Western Samoa came out on top, with over 90% of analyzed emails categorized as malicious. Sorting by spam email share, .quest is the biggest offender, with over 88% of emails originating from associated domains characterized as spam.
TLDs originating the largest total shares of malicious and spam email in 2024
Conclusion
The Internet is an amazingly complex and dynamic organism, constantly changing, growing, and evolving.
With the Cloudflare Radar 2024 Year In Review, we are providing insights into the change, growth, and evolution that we have measured and observed throughout the year. Trend graphs, maps, tables, and summary statistics provide our unique perspectives on Internet traffic, Internet quality, and Internet security, and how key metrics across these areas vary around the world and over time.
We strongly encourage you to visit the Cloudflare Radar 2024 Year In Review microsite and explore the trends for your country/region, and to consider how they impact your organization so that you are appropriately prepared for 2025. In addition, for insights into the top Internet services across multiple industry categories, we encourage you to read the companion Year in Review blog post, From ChatGPT to Temu: ranking top Internet services in 2024.
As it is every year, it truly is a team effort to produce the data, microsite, and content for our annual Year in Review, and I’d like to acknowledge those team members that contributed to this year’s effort. Thank you to: Jorge Pacheco, Sabina Zejnilovic, Carlos Azevedo, Mingwei Zhang (Data Analysis); André Jesus, Nuno Pereira (Front End Development); João Tomé (Most popular Internet services); Jackie Dutton, Kari Linder, Guille Lasarte (Communications); Eunice Giles (Brand Design); Jason Kincaid (blog editing); and Paula Tavares (Engineering Management), as well as countless other colleagues for their answers, edits, support, and ideas.
When cable cuts occur, whether submarine or terrestrial, they often result in observable disruptions to Internet connectivity, knocking a network, city, or country offline. This is especially true when there is insufficient resilience or alternative paths — that is, when a cable is effectively a single point of failure. Associated observations of traffic loss resulting from these disruptions are frequently covered by Cloudflare Radar in social media and blog posts. However, two recent cable cuts that occurred in the Baltic Sea resulted in little-to-no observable impact to the affected countries, as we discuss below, in large part because of the significant redundancy and resilience of Internet infrastructure in Europe.
BCS East-West Interlink
Traffic volume indicators
On Sunday, November 17 2024, the BCS East-West Interlink submarine cable connecting Sventoji, Lithuania and Katthammarsvik, Sweden was reportedly damaged around 10:00 local (Lithuania) time (08:00 UTC). A Data Center Dynamics article about the cable cut quotes the CTO of Telia Lietuva, the telecommunications provider that operates the cable, and notes “The Lithuanian cable carried about a third of the nation’s Internet capacity, but capacity was carried via other routes.”
As the Cloudflare Radar graphs below show, there was no apparent impact to traffic volumes in either country at the time that the cables were damaged. The NetFlows graphs represent the number of bytes that Cloudflare sends to users and clients in response to their requests.
Internet quality
Internet quality metrics for both countries show changes in measured bandwidth and latency throughout the day on Sunday, but with no sudden anomalous shifts visible around the time of the cable cut. (The loss of connectivity associated with a cable cut potentially manifests itself as an increase in latency and concurrent decrease in bandwidth due to loss of capacity.) The latency graph for Sweden does show an increase in latency, but it began before the cable cut occurred, is similar to a pattern visible several hours earlier, and is matched by an increase in measured bandwidth, so it is unlikely to be related to the cable cut event.
Visibility in BGP events, announced IP address space unaffected
BGP announcements are a way for network providers to communicate routing information to other networks, and announcement activity observed on Telia Lietuva’s autonomous systems around the time of the cable cut may be related to the re-routing referenced in the article. No change in announced IP address space was visible for any of these autonomous systems, suggesting no loss of connectivity as the capacity was re-routed.
Telegeography’s submarinecablemap.com illustrates, at least in part, the resilience in connectivity enjoyed by these two countries. In addition to the damaged cable, it shows that Lithuania is connected to neighboring Latvia as well as to the Swedish mainland. Over 20 submarine cables land in Sweden, connecting it to multiple countries across Europe. In addition to the submarine resilience, network providers in both countries can take advantage of terrestrial fiber connections to neighboring countries, such as those illustrated in a European network map from Arelion (formerly Telia), which is only one of the large European backbone providers.
C-Lion1
Traffic volume indicators
Less than a day later, the C-Lion1 submarine cable, which connects Helsinki, Finland and Rostock Germany was reportedly damaged during the early morning hours of Monday, November 18. Cinia, the telecommunications company that owns the cable, said that the cable stopped working at about 02:00 UTC.
In this situation as well, as the Cloudflare Radar graphs below show, there was no apparent impact to traffic volumes in either country at the time that the cables were damaged. The Finland graphs, week-on-week, show fewer bytes transferred and fewer HTTP requests, but that difference is present before the cable cut at 02:00 UTC. However, the trend of the current line does not change after the cable cut, so the two events would appear unrelated.
Internet quality
By looking at volume-related metrics, alone, Internet connectivity would appear to be unaffected by the cable cut.
If, however, we change perspective and look at Internet quality, a brief yet interesting change is visible for Finland around the reported time of the cable damage, though it isn’t clear whether it is related in any way. Just after midnight, median measured bandwidth, previously consistent around 50 Mbps begins to grow, peaking just over 200 Mbps around 03:00 UTC. Around that same time, measured median latency also begins to drop, falling from around 30 ms to a low of 13 ms, also around 03:00 UTC. Median bandwidth returned to normal levels around 06:00 UTC, while latency took about two hours longer to return to normal levels. These observed improvements in bandwidth and latency could have been due to traffic being re-routed to along paths with better connectivity to measurement endpoints, but because the shifts began before the cable damage occurred, and recovered shortly thereafter, that is unlikely to be the root cause.
In Germany, a brief minor increase in median bandwidth peaked around 02:45 UTC, while no notable changes were observed in latency.
BGP business as usual
From a routing perspective, there was no notable BGP announcement activity observed for top autonomous systems in either Finland or Germany around 02:00 on November 18, and total announced IP address space aggregated at a country level also demonstrated no change.
Telegeography’s submarinecablemap.com shows that both Finland and Germany also have significant redundancy and resilience from a submarine cable perspective, with over 10 cables landing in Finland, and nearly 10 landing in Germany, including Atlantic Crossing-1 (AC-1), which connects to the United States over two distinct paths. Terrestrial fiber maps from Arelion and eunetworks (as just two examples) show multiple redundant fiber routes within both countries, as well as cross-border routes to other neighboring countries, enabling more resilient Internet connectivity.
Conclusion
As we have discussed in multiple prior blog posts (Jersey, 2016; AAE-1/SMW5, 2022; WACS/MainOne/SAT3/ACE, 2024; EASSy/Seacom, 2024), cable cuts often cause significant disruptions to Internet connectivity, in many cases because they represent a concentrated point of vulnerability, whether for an individual network provider, city/state, or country. These disruptions are often quite lengthy as well, due to the time needed to marshal repair resources, identify the location of the damage, etc. Although it is not always feasible due to financial or geographic constraints, building redundant and resilient network architecture, at multiple levels, is a best practice. This includes the sending traffic over multiple physical cables (both submarine and terrestrial), connecting to multiple peer and upstream network providers, and even avoiding single points of failure in core Internet resources like DNS servers.
On October 30, 2024, cloud hosting provider OVHcloud (AS16276) suffered a brief but significant outage. According to their incident report, the problem started at 13:23 UTC, and was described simply as “An incident is in progress on our backbone infrastructure.” OVHcloud noted that the incident ended 17 minutes later, at 13:40 UTC. As a major global cloud hosting provider, some customers use OVHcloud as an origin for sites delivered by Cloudflare — if a given content asset is not in our cache for a customer’s site, we retrieve the asset from OVHcloud.
We observed traffic starting to drop at 13:21 UTC, just ahead of the reported start time. By 13:28 UTC, it was approximately 95% lower than pre-incident levels. Recovery appeared to start at 13:31 UTC, and by 13:40 UTC, the reported end time of the incident, it had reached approximately 50% of pre-incident levels.
Traffic from OVHcloud (AS16276) to Cloudflare
Cloudflare generally exchanges most of our traffic with OVHcloud over peering links. However, as shown below, peered traffic volume during the incident fell significantly. It appears that some small amount of traffic briefly began to flow over transit links from Cloudflare to OVHcloud due to sudden changes in which Cloudflare data centers we were receiving OVHcloud requests. (Peering is a direct connection between two network providers for the purpose of exchanging traffic. Transit is when one network pays an intermediary network to carry traffic to the destination network.)
Because we peer directly, we exchange most traffic over our private peering sessions with OVHcloud. Instead, we found OVHcloud routing to Cloudflare dropped entirely for a few minutes, then switched to just a single Internet Exchange port in Amsterdam, and finally normalized globally minutes later.
As the graphs below illustrate, we normally see the largest amount of traffic from OVHcloud in our Frankfurt and Paris data centers, as OVHcloud has large data center presences in these regions. However, in that shift to transit, and the shift to an Amsterdam Internet Exchange peering point, we saw a spike in traffic routed to our Amsterdam data center. We suspect the routing shifts are the earliest signs of either internal BGP reconvergence, or general network recovery within AS12676, starting with their presence nearest our Amsterdam peering point.
The postmortem published by OVHcloud noted that the incident was caused by “an issue in a network configuration mistakenly pushed by one of our peering partner[s]” and that “We immediately reconfigured our network routes to restore traffic.” One possible explanation for the backbone incident may be a BGP route leak by the mentioned peering partner, where OVHcloud could have accepted a full Internet table from the peer and therefore overwhelmed their network or the peering partner’s network with traffic, or caused unexpected internal BGP route updates within AS12676.
Upon investigating what route leak may have caused this incident impacting OVHcloud, we found evidence of a maximum prefix-limit threshold being breached on our peering with Worldstream (AS49981) in Amsterdam.
Oct 30 13:16:53 edge02.ams01 rpd[9669]: RPD_BGP_NEIGHBOR_STATE_CHANGED: BGP peer 141.101.65.53 (External AS 49981) changed state from Established to Idle (event PrefixLimitExceeded) (instance master)
As the number of received prefixes exceeded the limits configured for our peering session with Worldstream, the BGP session automatically entered an idle state. This prevented the route leak from impacting Cloudflare’s network. In analyzing BGP Monitoring Protocol (BMP) data from AS49981 prior to the automatic session shutdown, we were able to confirm Worldstream was sending advertisements with AS paths that contained their upstream Tier 1 transit provider.
During this time, we also detected over 500,000 BGP announcements from AS49981, as Worldstream was announcing routes to many of their peers, visible on Cloudflare Radar.
Worldsteam later posted a notice on their status page, indicating that their network experienced a route leak, causing routes to be unintentionally advertised to all peers:
“Due to a configuration error on one of the core routers, all routes were briefly announced to all our peers. As a result, we pulled in more traffic than expected, leading to congestion on some paths. To address this, we temporarily shut down these BGP sessions to locate the issue and stabilize the network. We are sorry for the inconvenience.”
We believe Worldstream also leaked routes on an OVHcloud peering session in Amsterdam, which caused today’s impact.
Conclusion
Cloudflare has written aboutimpactful route leaks before, and there are multiple methods available to prevent BGP route leaks from impacting your network. One is setting max prefix-limits for a peer, so the BGP session is automatically torn down when a peer sends more prefixes than they are expected to. Other forward-looking measures areAutonomous System Provider Authorization (ASPA) for BGP, where Resource Public Key Infrastructure (RPKI) helps protect a network from accepting BGP routes with an invalid AS path, orRFC9234, which prevents leaks by tying strict customer and provider relationships to BGP updates. For improved Internet resilience, we recommend that network operators follow recommendations defined withinMANRS for Network Operators.
Cloudflare’s network spans more than 330 cities in over 120 countries, where we interconnect with over 13,000 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions. Thanks to Cloudflare Radar functionality released earlier this year, we can explore the impact from a routing perspective, as well as a traffic perspective, at both a network and location level.
As we have noted in the past, this post is intended as a summary overview of observed and confirmed disruptions, and is not an exhaustive or complete list of issues that have occurred during the quarter.
Over the past several years, we have seen multiple governments around the world implement Internet shutdowns in response to protests within their countries. Some shutdowns are more targeted, affecting only (a subset of) mobile Internet providers, while others are more aggressive, effectively cutting off Internet connectivity at a national level. In addition, we all too frequently see governments implement nationwide multi-hour Internet shutdowns in an effort to prevent students from cheating on national exams. Unfortunately, governments were active in both respects during the third quarter, as we observed multiple government directed Internet shutdowns. Several were covered in our August 1 blog post, A recent spate of Internet disruptions.
Bangladesh
Violent student protests in Bangladesh against quotas in government jobs and rising unemployment rates led the government to order the nationwide shutdown of mobile Internet connectivity on July 18, reportedly to “ensure the security of citizens.” This government-directed shutdown ultimately became a near-complete Internet outage for the country, as broadband networks were taken offline as well. At a country level, Internet traffic in Bangladesh dropped to near zero just before 21:00 local time (15:00 UTC). Announced IP address space from the country dropped to near zero at that time as well, meaning that nearly every network in the country was disconnected from the Internet.
Traffic and announced IP address space at a national level began to recover around 18:00 local time (12:00 UTC) on July 23, and continued over the next several days, as fixed broadband connectivity was restored, with mobile connectivity returning on July 28. The initial restoration was characterized as a “trial run”, prioritizing banking, commercial sectors, technology firms, exporters, outsourcing providers and media outlets, according to the state minister for post, telecommunication and information technology.
Ahead of this nationwide shutdown, we observed outages across several Bangladeshi network providers, perhaps foreshadowing what was to come. At AS24389 (Grameenphone), a complete Internet outage started at 01:30 local time on July 18 (19:30 UTC on July 17), with a total loss of both Internet traffic and announced IP address space.
These mobile connectivity outages lasted from July 18 through July 28. Just a few days after connectivity was restored, additional clashes between police and protestors drove the government to order mobile Internet connectivity to be shut down again. As shown in the graphs below, traffic on these mobile network providers dropped between 13:30 and 14:15 local time (07:30 to 08:15 UTC) on Sunday, August 4.
These protests ultimately led the government to order a full Internet shutdown in the country, with both traffic and announced IP address space dropping precipitously around 10:30 local time (04:30 UTC) on Monday, August 5. However, the shutdown appeared to be short-lived, as broadband connectivity began to recover around 13:20 local time (07:20 UTC), with mobile connectivity being restored around 14:00 local time (08:00 UTC).
Iraqi Kurdistan
Both Iraq and Iraqi Kurdistan (the autonomous Kurdistan region in the northern part of the country) regularly implement government directed Internet shutdowns to prevent cheating on secondary and baccalaureate exams. Within Iraqi Kurdistan, we observed two sets of exam-related Internet shutdowns during the third quarter. The impacts of the shutdowns are visible on traffic from networks that operate within the region, as well as on the country-level graphs for Iraq.
The first round of shutdowns occurred in July, impacting AS59625 (KorekTel), AS21277 (Newroz Telecom), AS48492 (IQ Online), and AS206206 (KNET) between 06:00 – 08:00 local time (03:00 – 05:00 UTC) on July 3, 7, 10, and 14. This is consistent with shutdowns observed in the second quarter, as well as in June 2023. None of the impacted networks experienced a drop in announced IP address space during these shutdowns.
The second set of shutdowns in Iraqi Kurdistan took place across multiple days during the back half of August. On August 17, 19, 21, 24, 26, 28, and 31, all four network providers were again impacted, as seen in the graphs below, with traffic dropping between 06:00 – 08:00 local time (03:00 – 05:00 UTC).
Iraq
In Iraq, a second round of exams for 12th graders resulted in over two weeks of regular Internet shutdowns across the country occurring between 06:00 – 08:00 local time (03:00 – 05:00 UTC) on multiple days between August 29 and September 16, intended to prevent cheating on second ministerial exams for secondary education. Both HTTP traffic and announced IP address space from Iraq dropped during these shutdowns, as seen in the graphs below.
(Note that the red annotation bar visible on September 11 & 12 on both the country and network-level graphs below highlights an internal data pipeline issue, and is not associated with an Internet shutdown in Iraq.)
This round of government-directed shutdowns impacted multiple local network providers, including AS58322 (Halasat), AS51684 (AsiaCell), AS203214 (HulumTele), AS199739 (Earthlink), and AS59588 (ZAINAS). In reviewing the distribution of mobile device and desktop traffic at a network level, gaps were observed during the shutdowns on AS58322 and AS199739, and to a lesser extent, AS203214, suggesting that these networks were completely offline, while AS56184 and AS59588 remained at least partially online. (This is also corroborated by complete or partial loss of announced IP address space across these networks during the shutdowns.)
The length of the shutdowns varied by day — they all began at 07:00 local time (04:00 UTC), but the end times ranged between 09:45 -10:30 local time (06:45 – 07:30 UTC). The graphs below show the impact at a country level, as well as to AS29256 (Syrian Telecom), the primary telecommunications provider within the country.
On August 12, a round of baccalaureate exams began in Mauritania, and in an effort to prevent student cheating on the exams, the government instituted multiple Internet shutdowns that impacted several major mobile providers. Two shutdowns were observed on August 12, between 08:00 – 12:00 local time (08:00 – 12:00 UTC) and between 15:00 – 19:00 local time (15:00 – 19:00 UTC), and an additional one was observed on August 13, between 08:00 – 12:30 local time (08:00 – 12:30 UTC). Impacted network providers included AS37508 (Mattel), AS37541 (Chinguitel), and AS29544 (Mauritel). Announced IP address space for these networks remained unchanged during the shutdown periods, suggesting that that mobile subscriber connectivity was disabled, as opposed to the networks effectively being disconnected from the Internet, as we have seen in other countries.
Exam-related Internet shutdowns are, unfortunately, not new to Mauritania, as authorities in the country also implemented them between 2017 and 2020.
Cable cuts
Eswatini (Swaziland)
On July 14, MTN Eswatini (AS327765) informed customers via a post on X that “connection to the internet and data services is currently intermittent, because of fiber cable breaks resulting from wildfires.” This apparent connection disruption was visible in Cloudflare Radar between 19:30 and 20:15 local time (17:30 and 18:15 UTC).
Cameroon
In Cameroon, a fiber cut that occurred on August 4 during sanitation work disrupted mobile connectivity for Cameroon Telecommunications (AS15964 (Camtel)) customers for over half a day. According to a (translated) post on X from Camtel, “We inform you that due to the sanitation work carried out in the city of Yaoundé, at the place called Cradat, our Voice and Data services have been temporarily interrupted on the entire mobile network.” The observed disruption occurred between 03:00 – 16:30 local time (02:00 – 15:30 UTC). Although it initially started during a time when traffic was lower overnight anyway, both request and bytes traffic remained lower than the same time a week prior during the duration of the disruption.
Liberia
The Liberia Telecommunications Authority posted an announcement to their Facebook page on August 21 noting that “We have been informed by the CCL that the ACE Cable is experiencing interruptions.” (The Africa Coast to Europe (ACE) submarine cable connects multiple countries along the West Coast of Africa to Portugal and Europe.) The announcement further noted that the first signs of interruption occurred at 01:00 local time (and UTC), and that Lonestar Cell MTN (AS37410) was among the providers that had been “gravely affected” by the cut.
We observed traffic on Lonestar Cell MTN dropping just after 01:00, in line with the announcement. The network experienced a complete outage lasting over a day and a half, before traffic started to recover at 14:00 local time (and UTC) on August 22. In a Facebook post on August 22, Lonestar Cell MTN confirmed that Internet service had been restored, and that customer accounts would be credited with 500 MB of data for free.
Niger
A September 7 post on X from Airtel Niger alerted customers to Internet service disruptions caused by cuts on international fiber optic cables. As a land-locked country, Niger is dependent on terrestrial connections to networks in neighboring countries, but it isn’t clear which connection or country Airtel Niger’s post was referencing.
Two significant Internet disruptions were observed around the time of Airtel Niger’s post that we believe are related to the referenced fiber cuts. The first occurred between 18:00 – 21:00 local time (17:00 – 20:00 UTC) on September 6, visible at a country level and at a network level as well on AS37531 (Airtel Niger) and AS37233 (Orange Niger / Zamani Telecom). The second disruption occurred between 10:45 – 12:00 local time (09:45 – 11:00 UTC) on September 7, visible at a country level as well as on those two networks.
Haiti
Internet disruptions related to submarine cable failures often take a significant amount of time to resolve because of the challenges repair crews face in getting to, and accessing, the damaged portion of the cable, as it is frequently located deep underwater in the middle of an ocean. A September 14 submarine cable failure that impacted Digicel Haiti (AS27653) lasted for over a week for a similar, but slightly different, reason.
A significant loss of traffic on Digicel Haiti was first observed at 08:00 local time (12:00 UTC) on September 14. On September 16, Digicel Haiti posted a press release confirming that since September 14, a failure had been detected on an international submarine cable belonging to Cable and Wireless, and that the cable damage occurred at Kaliko Beach Club (the property is reportedly used as a cable entry point). Digicel noted that their technicians went to the scene of the damage immediately, but were denied access, apparently because of a business dispute dating back to 2021. The release also explained that technical teams had taken temporary steps to ensure the continuity of essential services, which prevented the incident from resulting in a complete loss of connectivity. On September 22, a subsequent press release posted by Digicel Haiti announced the restoration of Internet services as of 02:00 local time (06:00 UTC), and referenced vandalism as the cause of the cable damage.
The outage lasted for only an hour, between 15:45 and 16:45 local time (09:45 – 10:45 UTC), dropping both traffic and announced IP address space to zero. At a country level, traffic dropped as much as 72% as compared to the previous week. Given the complete loss of both traffic and IP address space, the damage likely occurred on the connection between Megacom and Rostelecom.
Severe weather
An active hurricane season during July, August, and September resulted in infrastructure damage caused by multiple hurricanes disrupting Internet connectivity in multiple places across the Caribbean and Southeastern United States.
Grenada & Saint Vincent and the Grenadines
At the start of the third quarter, Grenada and Saint Vincent and the Grenadines both suffered significant damage from Hurricane Beryl, reportedly causing destruction of infrastructure, buildings, agriculture, and the natural environment.
On July 1, traffic from Grenada dropped significantly at 10:00 local time (14:00 UTC), just ahead of landfall on Grenada’s Carriacou Island. The most significant impacts to traffic were seen for approximately the first 24 hours, though traffic did not return to expected pre-storm levels until around 10:00 local time (14:00 UTC) on July 5.
Internet traffic in Saint Vincent and the Grenadines was also disrupted by Hurricane Beryl, also falling at 10:00 local time (14:00 UTC). Similar to Grenada, the most significant impact was seen in the first 24 hours, with consistent gradual recovery seen after that time. However, traffic did not return to expected pre-storm levels until July 11.
Jamaica
As Hurricane Beryl continued across the Caribbean, it passed Jamaica on July 3. The associated damage that it caused impacted Internet connectivity on the island, with traffic dropping significantly around 14:00 local time (19:00 UTC). As the graph below shows, the disruption was preceded by higher than normal traffic volumes, presumably due to residents looking for information about Beryl. The disruption lasted nearly a week, with traffic returning to expected levels on July 10.
U.S. Virgin Islands
The following month, damage from Tropical Storm Ernesto caused power outages across the U.S. Virgin Islands, resulting in disruptions to Internet connectivity. Traffic from the islands dropped precipitously at 22:00 local time on August 13 (02:00 UTC on August 14) and remained lower for over two days, before returning to expected pre-storm levels around 11:00 local time (15:00 UTC) on August 16.
Bermuda
Over the course of the following few days, Ernesto strengthened from a tropical storm into a hurricane, but had weakened by the time it hit Bermuda on August 16/17. In this case, damage was reportedly limited to power outages, downed trees, and flooding, but even this limited damage disrupted Internet connectivity on the island. As the storm made landfall on the island, traffic levels dropped over 80% at 22:00 local time on August 16 (01:00 UTC on August 17). Traffic levels remained depressed for about two and a half days, recovering to expected levels around 09:00 local time (12:00 UTC) on August 19.
Nepal
Heavy rains in Nepal at the end of September resulted in flooding and landslides across much of the country, which in turn resulted in power outages and Internet disruptions. One such disruption believed to be associated with the impacts of the storm was observed on September 28, when AS23752 (Nepal Telecom), AS45650 (Vianet), AS139922 (Dishhome), and AS17501 (Worldlink) all saw traffic drop 50 – 70% between 14:15 – 16:00 local time (08:30 – 10:15 UTC).
United States
A disruption to traffic from AS11427 (Charter Communications/Spectrum) in Texas that occurred between 12:30 and 19:30 local time on July 9 (17:30 – 00:30 UTC) was caused by “a third-party infrastructure issue caused by the impact of Hurricane Beryl”, according to a July 9 post on X from the provider. Spectrum acknowledged the issue shortly after it began, and followed up again after service had been restored.
Hurricane Helene made landfall in northern Florida as a Category 4 storm late in the evening (local time) on September 26, and over the following hours and days, continued north through Georgia, South Carolina, and North Carolina, and into Tennessee. Even as it weakened, it caused historic flooding and damage to roads, homes, power lines, and telecommunications infrastructure. Below, we review the traffic impacts observed at a state level in three of the most impacted states, as well as exploring the impact at a network level for selected providers. (Doug Madory at Kentik published an excellent blog post exploring the impact of Helene from the perspective of their data, and the networks referenced below were informed by that post.)
Georgia
Helene entered Georgia early morning on Friday, September 27, and by midday (local time), peak traffic was approximately 20% lower than peak levels seen in the days ahead of the storm. (The lower peaks on September 28 & 29 are likely due to it being a weekend.) At a state level, peak traffic remained lower over the following week, with more recovery seen heading into the week of October 6.
One of the most significantly impacted network providers in Georgia was AS11240 (ATC Broadband), which saw traffic start to drop around 22:00 local time on September 26 (02:00 UTC on September 27). Subscribers and customers experienced a near complete outage until around 08:00 local time on September 30 (12:00 UTC), when traffic volumes slowly started to recover. The normal diurnal traffic pattern became more clear in the following days, with peak traffic levels continuing to increase over the next week as well.
The midday traffic peak on September 27 in South Carolina was just 65% of the preceding days, with the peaks remaining lower over the following two weekend days. Traffic remained somewhat lower during the week following Helene, with peak increases becoming more evident the week of October 6.
At AS19212 (Piedmont Rural Telephone) in South Carolina, traffic began to fall rapidly around midnight local time on September 27 (04:00 UTC), reaching a state of near complete outage over the next eight hours. A gradual recovery is visible over the following several days, with a more regular pattern becoming evident on October 1, with rapid growth over the following week, accelerating towards the end of the week.
Although a drop in traffic is visible in the graph for North Carolina on September 27, it occurs after a midday peak in line with previous days, and the magnitude is not as significant as that seen in South Carolina and Georgia. Traffic peaks over the following week are in line with the week preceding Helene’s arrival, with higher peaks seen the week of October 6.
North Carolina providers AS53488 (Morris Broadband) and AS53274 (Skyrunner) both experienced multi-day disruptions, likely related to damage from Helene. However, these disruptions took Morris Broadband completely offline several times over the course of a week — the announced IP address space graph below shows three distinct drops to zero, aligning with outages visible in the traffic graph, when the network was effectively disconnected from the Internet. A similar but less severe pattern was seen at Skyrunner, which lost 75-80% of announced IP address space for a two-day period covering September 27-29, aligning with an outage visible in the associated traffic graph.
A nationwide power outage in Venezuela on August 30 was, according to President Nicolás Maduro, the result of an attack on the Guri Reservoir, Venezuela’s largest hydroelectric project. A published report indicated that all 24 of the country’s states reported a total or partial loss of electricity supply. The loss of power unsurprisingly caused an Internet disruption, with country-level traffic dropping 82%, starting around 04:45 local time (08:45 UTC). Traffic began to increase as electricity returned to various parts of the country throughout the day, and returned to expected levels just after midnight local time on August 31 (04:00 UTC).
Kenya
On August 30, Kenya Power Care posted a Customer Alert on its Facebook page, issued at 21:57 local time (18:57 UTC), stating that “We have lost power supply to various parts of the country except North Rift region and sections of Western region.” Approximately a half hour before that alert, Kenya’s Internet traffic began to drop, falling as much as 61%. Just two hours later, Kenya Power Care posted a follow up, stating “Following the partial outage affecting several parts of the country this evening, we are pleased to report that power supply has now been restored to the entire Western region, as well as parts of Central Rift, South Nyanza, and Nairobi regions.” However, traffic did not return to expected levels for several more hours, taking until 06:00 local time (03:00 UTC).
A week later, on September 6, Kenya Power Care posted another similar Customer Alert, noting that “We are experiencing a power outage affecting several parts of the country, except sections of North Rift and Western regions.” This alert was issued at 09:20 local time (06:20 UTC), and follows a drop in Internet traffic that started around 09:00 local time (06:00 UTC). Traffic dropped approximately 45% during this power outage, and returned to expected levels around 16:00 local time (13:00 UTC). Traffic recovery aligns with a subsequent Customer Alert posted on Facebook, where Kenya Power Care stated “We are glad to report that normal electricity supply was restored across the country as at 3:49pm”.
A statement from Energy and Petroleum Cabinet Secretary Opiyo Wandayi, shared on Facebook by Kenya Power Care, explained the cause of the power outage: “Today, Friday 6th September 2024 at 8.56 am, the 220kV High Voltage Loiyangalani transmission line tripped at Suswa substation while evacuating 288MW from Lake Turkana Wind Power (LTWP) plant. This was followed by a trip on the Ethiopia – Kenya 500kV DC interconnector that was then carrying 200MW, resulting to a total loss of 488MW…”
Ecuador
According to a (translated) September 7 post on X from CENACE, the national electricity operator in Ecuador, “We inform the public that due to a fault in the Molino substation bar, which is connected to the Paute generation, there has been a power outage in some provinces of the country. Cenace’s technical team, in coordination with the distribution companies, is working to gradually restore electrical service. It is estimated that it will take 3 to 4 hours maximum for the supply to return to normal.” The post was published at 09:53 local time (14:53 UTC), approximately an hour after Internet traffic from the country began to drop. Traffic returned to expected levels just under four hours later, at around 12:30 local time (17:30 UTC), in line with CENACE’s predicted time for power to be fully restored.
On September 18/19, the first of several planned nightly power outages to enable needed grid maintenance in Ecuador disrupted Internet connectivity. Traffic dropped by over 60% as compared to the same time the prior week starting around 21:30 local (02:30 UTC), with the power outages reportedly scheduled for 22:00 – 06:00 local time. Internet traffic recovered to expected levels around 06:00 local time (11:00 UTC) as power was restored. Similar power cuts were reportedly planned from September 23 to September 27, but these power outages did not appear to impact traffic levels in Ecuador as compared to the previous week.
Senegal
Senegal’s power company, Senelec, posted a communiqué on X on September 12 that stated (translated) “Senelec informs its valued customers that an incident that occurred this morning at the Hann substation resulted in the loss of the OMVS interconnected network and disruptions to electricity distribution.” This disruption to electricity distribution also resulted in a disruption to Internet traffic, which dropped sharply at 13:00 local time (13:00 UTC), falling as much as 80%. Traffic recovered to expected levels by 20:00 local time (20:00 UTC) around the same time that Senelec posted a followup about the incident that stated (translated) “Effective restoration of electricity supply in all localities.”
Maintenance
Syria
As we discussed above, Internet users in Syria were impacted by an exam-related Internet shutdown from 07:00 – 10:15 local time (04:00 – 07:15 UTC) on July 30. However, just an hour after connectivity was restored, another disruption occurred, as seen in both the traffic and announced IP address space graphs below. According to a (translated) Facebook post from Syrian Telecom, “…during the periodic maintenance of one of the air conditioners in one of the technical halls, an explosion occurred, which caused the internet circuits to be temporarily out of service.” Traffic remained depressed for approximately eight hours, recovering to expected levels around 19:00 local time (16:00 UTC).
Cyberattack
Russia
Roskomnadzor, Russia’s Internet regulate, blamed a brief disruption in traffic observed in Russia and on AS12389 (Rostelecom) on August 21 on a distributed denial-of-service (DDoS) attack that targeted Russian telecommunications operators. The disruption was brief, lasting from around 13:45 until 14:30 Moscow time (10:45 – 11:30 UTC). Roskomnadzor subsequently stated “As of 3 PM Moscow time, the attack has been repelled, and services are operating normally.” The disruption reportedly impacted messaging services Telegram and WhatsApp, as well as Wikipedia, Yandex, VKontakte, telecom support services, and mobile banking apps. Some experts questioned the official explanation, suggesting instead that the disruption was due to centralized interference from Roskomnadzor.
Military action
Palestine
We have covered Internet disruptions related to the ongoing conflict in Gaza multiple times since October 2023, both on Cloudflare Radar’s presence on X, and on the Cloudflare blog (1, 2, 3). In many of these cases, Paltel (AS12975) has posted notices on social media regarding service disruptions and outages. On September 8, Paltel posted a message on its Facebook page, stating (translated) “We regret to announce the suspension of home internet services in the central and southern areas of the Gaza Strip, due to the ongoing aggression.”
Within the Gaza, Rafah, Deir al-Balah Governorates, we observed a sharp drop in traffic at 18:00 local time (16:00 UTC). The impact appeared to be most significant in Rafah and Deir al-Balah. Traffic returned to expected levels around 23:00 local time (21:00 UTC), and Paltel confirmed the service restoration in a subsequent Facebook post, stating (translated) “We would like to announce the return of home Internet services in central and southern Gaza Strip to the way it was before it was interrupted hours ago.”
Lebanon
Israeli airstrikes targeting the Lebanese capital of Beirut on September 28 likely knocked local network provider Solidere (AS42852) offline for several hours. The graph below shows a loss of traffic starting around 12:15 local time (10:15 UTC), at the same time a complete loss of announced IP address space occurred. Most of Solidere’s IP address space started to get announced again at 14:45 local time (12:45 UTC), and a slight increase in traffic was seen at that time as well. Traffic levels fully recovered just after 18:00 local time (16:00 UTC), and announced IP address space had stabilized by that time as well.
Fire
Algeria
A fire near a data center in Blida Province, Algeria disrupted connectivity on AS327931 (Djezzy) at 13:00 and local time (12:00 UTC) on July 24. According to a (translated) X post from Djezzy, “Djezzy announced fluctuations in its services in some areas of the country, as it was a victim of a fire that broke out on Wednesday, July 24, 2024, in a warehouse of one of the companies located near its technical center in the state of Blida.” The post from Djezzy predicted that “97% of the sites will be restored by around 3 am [July 25]”, but traffic did not return to expected levels until the end of the day on July 25.
Unknown
United States
On Monday, September 30, customers on Verizon’s mobile network in multiple cities across the United States reported experiencing a loss of connectivity. Impacted phones showed “SOS” instead of the usual bar-based signal strength indicator, and customers complained of an inability to make or receive calls on their mobile devices. Although initial reports of connectivity problems started around 09:00 ET (13:00 UTC), we didn’t see a noticeable change in request volume at an ASN level until about two hours later. AS6167 (CELLCO) is the autonomous system used by Verizon for its mobile network.
Just before 12:00 ET (16:00 UTC), Verizon published a social media post acknowledging the problem, stating “We are aware of an issue impacting service for some customers. Our engineers are engaged, and we are working quickly to identify and solve the issue.” As the graph below shows, a slight decline (-5%) in HTTP traffic as compared to traffic at the same time a week prior is first visible around 11:00 ET (15:00 UTC), and request volume fell as much as 9% below expected levels at 13:45 ET (17:45 UTC).
Media reports listed cities including Chicago, Indianapolis, New York City, Atlanta, Cincinnati, Omaha, Phoenix, Denver, Minneapolis, Seattle, Los Angeles, and Las Vegas as being most impacted. Traffic graphs illustrating the impacts seen in these cities can be found in our Impact of Verizon’s September 30 outage on Internet traffic blog post.
Traffic appeared to return to expected levels around 17:15 ET (21:15 UTC). At 19:18 ET (23:18 UTC), a social media post from Verizon noted “Verizon engineers have fully restored today’s network disruption that impacted some customers. Service has returned to normal levels.”
Pakistan
On July 31, Pakistan experienced a wide-scale Internet disruption that lasted approximately two hours, between 13:30 – 15:30 local time (08:30 – 10:30 UTC). Traffic only dropped ~45% at a country level, but AS17557 (PTCL) experienced a near complete loss of traffic, while traffic at AS24499 (Telenor Pakistan) dropped nearly 90%. Together, the two network providers serve an estimated nine million users, and are among the top five Internet service providers in the country.
The actual cause of the disruption is disputed. It was reported that the Pakistan Telecommunication Authority (PTA) attributed the disruptions to a technical glitch in the international submarine cable affecting the Pakistan Telecommunication Company Limited (PTCL) network. However, another published report noted “According to our sources, the government’s latest firewall edition to block the content was misconfigured, resulting in Internet connectivity disruption.” Additional details can be found in our August 1 blog post, A recent spate of Internet disruptions.
United Kingdom
On August 14, subscribers of UK service provider Vodafone (AS25135)reported problems accessing both mobile and landline Internet connections. Starting around 11:00 local time (10:00 UTC), we observed traffic starting to drop, ultimately falling 43% below the same time the prior week. The disruption was fairly short-lived, as traffic returned to expected levels by 13:30 local time (12:30 UTC). Vodafone did not acknowledge the issue on social media, nor did it provide a public explanation for what caused the disruption.
Conclusion
Although Internet disruptions observed during the third quarter had a variety of underlying causes, those caused by power outages due to aging or insufficiently maintained electrical infrastructure are worth highlighting. Of course, widespread power outages always create a massive inconvenience for impacted populations, but over the last several years, as communication, entertainment, commerce, and more have become increasingly reliant on the Internet, the impact of these outages has become even more significant, because losing electrical power largely means losing Internet connectivity. Although mobile connectivity may still be available in some cases, it is decidedly not a complete replacement, not to mention that mobile devices will eventually need to be recharged. While addressing the underlying infrastructure issues require non-trivial amounts of time, resources, and money, governments appear to be taking steps towards doing so.
On Monday, September 30, customers on Verizon’s mobile network in multiple cities across the United States reported experiencing a loss of connectivity. Impacted phones showed “SOS” instead of the usual bar-based signal strength indicator, and customers complained of an inability to make or receive calls on their mobile devices.
AS6167 (CELLCO) is the autonomous system used by Verizon for its mobile network. To better understand how the outage impacted Internet traffic on Verizon’s network, we took a look at HTTP request volume from AS6167 independent of geography, as well as traffic from AS6167 in various cities that were reported to be the most significantly impacted.
Although initial reports of connectivity problems started around 09:00 ET (13:00 UTC), we didn’t see a noticeable change in request volume at an ASN level until about two hours later. Just before 12:00 ET (16:00 UTC), Verizon published a social media post acknowledging the problem, stating “We are aware of an issue impacting service for some customers. Our engineers are engaged and we are working quickly to identify and solve the issue.”
As the Cloudflare Radar graph below shows, a slight decline (-5%) in HTTP traffic as compared to traffic at the same time a week prior is first visible around 11:00 ET (15:00 UTC). Request volume fell as much as 9% below expected levels at 13:45 ET (17:45 UTC).
Just after 17:00 ET (21:00 UTC), Verizon published a second social media post noting, in part, “Verizon engineers are making progress on our network issue and service has started to be restored.” Request volumes returned to expected levels around the same time, surpassing the previous week’s levels at 17:15 ET (21:15 UTC). At 19:18 ET (23:18 UTC), a social media post from Verizon noted “Verizon engineers have fully restored today’s network disruption that impacted some customers. Service has returned to normal levels.”
Media reports listed cities including Chicago, Indianapolis, New York City, Atlanta, Cincinnati, Omaha, Phoenix, Denver, Minneapolis, Seattle, Los Angeles, and Las Vegas as being most impacted. In addition to looking at comparative traffic trends across the whole Verizon Wireless network, we also compared request volumes in the listed cities to the same time a week prior (September 23).
Declines in request traffic starting around 11:00 ET (15:00 UTC) are clearly visible in cities including Los Angeles, Seattle, Omaha, Denver, Phoenix, Minneapolis, Indianapolis, and Chicago. In contrast to other cities, Omaha’s request volume was already trending lower than last week heading into today’s outage, but its graph clearly shows the impact of today’s disruption as well. Omaha’s difference in traffic was the most significant, down approximately 30%, while other cities saw declines in the 10-20% range.
Request traffic from Las Vegas initially appeared to exhibit a bit of volatility around 11:00 ET (15:00 UTC), but continues to track fairly closely to last week’s levels before exceeding them starting at 16:00 ET (20:00 UTC). Cincinnati was tracking slightly above last week’s request volume before the outage began, and tracked closely to the prior week during the outage period.
We observed week-over-week traffic increases during the outage period in New York and Atlanta. However, in both cities, traffic was already slightly above last week’s levels, and that trend continued throughout the day.
Based on our observations, it appears that voice services on Verizon’s network may have been more significantly impacted than data services, as we saw some declines in request traffic across impacted cities, but none experienced full outages.
As of this writing (19:15 ET, 23:15 UTC), no specific information has been made available by Verizon regarding the root cause of the network problems.
On September 17, 2024, during routine maintenance, Cloudflare inadvertently stopped announcing fifteen IPv4 prefixes, affecting some Business plan websites for approximately one hour. During this time, IPv4 traffic for these customers would not have reached Cloudflare, and users attempting to connect to websites assigned addresses within those prefixes would have received errors.
We’re very sorry for this outage.
This outage was the result of an internal software error and not the result of an attack. In this blog post, we’re going to talk about what the failure was, why it occurred, and what we’re doing to make sure this doesn’t happen again.
Background
Cloudflare assembled a dedicated Addressing team in 2019 to simplify the ways that IP addresses are used across Cloudflare products and services. The team builds and maintains systems that help Cloudflare conserve and manage its own network resources. The Addressing team also manages periodic changes to the assignment of IP addresses across infrastructure and services at Cloudflare. In this case, our goal was to reduce the number of IPv4 addresses used for customer websites, allowing us to free up addresses for other purposes, like deploying infrastructure in new locations. Since IPv4 addresses are a finite resource and are becoming more scarce over time, we carry out these kinds of “renumbering” exercises quite regularly.
Renumbering in Cloudflare is carried out using internal processes that move websites between sets of IP addresses. A set of IP addresses that no longer has websites associated with it is no longer needed, and can be retired. Once that has happened, the associated addresses are free to be used elsewhere.
Back in July 2024, a batch of Business plan websites were moved from their original set of IPv4 addresses to a new, smaller set, appropriate to the forecast requirements of that particular plan. On September 17, after confirming that all of the websites using those addresses had been successfully renumbered, the next step was to be carried out: detach the IPv4 prefixes associated with those addresses from Cloudflare’s network and to withdraw them from service. That last part was to be achieved by removing those IPv4 prefixes from the Internet’s global routing table using the Border Gateway Protocol (BGP), so that traffic to those addresses is no longer routed towards Cloudflare. The prefixes concerned would then be ready to be deployed for other purposes.
What was released and how did it break?
When we migrated customer websites out of their existing assigned address space in July, we used a one time migration template that cycles through all the websites associated with the old IP addresses and moves them to new ones. This calls a function that updates the IP assignment mechanism to synchronize the IP address-to-website mapping.
A couple of months prior to the July migration, the relevant function code was updated as part of a separate project related to legacy SSL configurations. That update contained a fix that replaced legacy code to synchronize two address pools with a call to an existing synchronization function. The update was reviewed, approved, merged, and released.
Unfortunately, the fix had consequences for the subsequent renumbering work. Upon closer inspection (we’ve done some very close post-incident inspection), a side effect of the change was to suppress updates in cases where there was no linked reference to a legacy SSL certificate. Since not all websites use legacy certificates, the effect was that not all websites were renumbered — 1,661 customer websites remained linked to old addresses in the address pools that were intended to be withdrawn. This was not noticed during the renumbering work in July, which had concluded with the assumption that every website linked to the old addresses had been renumbered, and that assumption was not checked.
At 2024-09-17 17:51 UTC, fifteen IPv4 prefixes corresponding to the addresses that were thought to be safely unused were withdrawn using BGP. Cloudflare operates a global network with hundreds of data centers, and there was some variation in the precise time when the prefixes were withdrawn from particular parts of the world. In the following ten minutes, we observed an aggregate 10 Gbps drop in traffic to the 1,661 affected websites network-wide.
The graph above shows traffic volume (in bits per second) for each individual prefix that was affected by the incident.
Incident timeline and impact
All timestamps are UTC on 2024-09-17.
At 17:41, the Addressing engineering team initiated the release that disabled prefixes in production.
At 17:51, BGP announcements began to be withdrawn and traffic to Cloudflare on the impacted prefixes started to drop.
At 17:57, the SRE team noticed alerts triggered by an increase in unreachable IP address space and began investigating. The investigation ended shortly afterwards, since it is generally expected that IP addresses will become unreachable when they are being removed from service, and consequently the alerts did not seem to indicate an abnormal situation.
At 18:36, Cloudflare received escalations from two customers, and an incident was declared. A limited deployment window was quickly implemented once the severity of the incident was assessed.
At 18:46, Addressing team engineers confirmed that the change introduced in the renumbering release triggered the incident and began preparing the rollback procedure to revert changes.
At 18:50, the release was rolled back, prefixes were re-announced in BGP to the Internet, and traffic began flowing back through Cloudflare.
At 18:50:27, the affected routes were restored and prefixes began receiving traffic again.
There was no impact to IPv6 traffic. 1,661 customer websites that were associated with addresses in the withdrawn IPv4 prefixes were affected. There was no impact to other customers or services.
How did we fix it?
The immediate fix to the problem was to roll back the release that was determined to be the proximal cause. Since all approved changes have tested roll back procedures, this is often a pragmatic first step to fix whatever has just been found to be broken. In this case, as in many, it was an effective way to resolve the immediate impact and return things to normal.
Identifying the root cause took more effort. The code mentioned above that had been modified earlier this year is quite old, and part of a legacy system that the Addressing team has been working on moving away from since the team’s inception. Much of the engineering effort during that time has been on building the modern replacement, rather than line-level dives into the legacy code.
We have since fixed the specific bug that triggered this incident. However, to address the more general problem of relying on old code that is not as well understood as the code in modern systems, we will do more. Sometimes software has bugs, and sometimes software is old, and these are not useful excuses; they are just the way things are. It’s our job to maintain the agility and confidence in our release processes while living in this reality, maintaining the level of safety and stability that our customers and their customers rely on.
What are we doing to prevent this from happening again?
We take incidents like this seriously, and we recognise the impact that this incident had. Though this specific bug has been resolved, we have identified several steps we can take to mitigate the risk of a similar problem occurring in the future. We are implementing the following plan as a result of this incident:
Test: The Addressing Team is adding tests that check for the existence of outstanding assignments of websites to IP addresses as part of future renumbering exercises. These tests will verify that there are no remaining websites that inadvertently depend on the old addresses being in service. The changes that prompted this incident made incorrect assumptions that all websites had been renumbered. In the future, we will avoid making assumptions like those, and instead do explicit checks to make sure.
Process: The Addressing team is improving the processes associated with the withdrawal of Cloudflare-owned prefixes, regardless of whether the withdrawal is associated with a renumbering event, to include automated and manual verification of traffic levels associated with the addresses that are intended to be withdrawn. Where traffic is attached to a service that provides more detailed logging, service-specific request logs will be checked for signs that the addresses thought to be unused are not associated with active traffic.
Implementation: The Addressing Team is reviewing every use of stored procedures and functions associated with legacy systems. Where there is doubt, functionality will be re-implemented with present-day standards of documentation and test coverage.
We are sorry for the disruption this incident caused for our customers. We are actively making these improvements to ensure improved stability moving forward and to prevent this problem from happening again.
Cloudflare Radar is constantly monitoring the Internet for widespread disruptions. In mid-July, we published our Q2 2024 Internet Disruption Summary, and here we examine recent several noteworthy disruptions detected in the first month of Q3, including traffic anomalies observed in Bangladesh, Syria, Pakistan, and Venezuela.
Bangladesh
Violent student protests in Bangladesh against quotas in government jobs and rising unemployment rates led the government to order the nationwide shutdown of mobile Internet connectivity on July 18, reportedly to “ensure the security of citizens.” This government-directed shutdown ultimately became a near-complete Internet outage for the country, as broadband networks were taken offline as well. At a country level, Internet traffic in Bangladesh dropped to near zero just before 21:00 local time (15:00 UTC). Announced IP address space from the country dropped to near zero at that time as well, meaning that nearly every network in the country was disconnected from the Internet.
However, ahead of this nationwide shutdown, we observed outages across several Bangladeshi network providers, perhaps foreshadowing what was to come. At AS24389 (Grameenphone), a complete Internet outage started at 01:30 local time on July 18 (19:30 UTC on July 17), with a total loss of both Internet traffic and announced IP address space.
In the days before the shutdown, both median bandwidth and latency at a country level for Bangladesh were fairly stable. However, Cloudflare Radar’s Internet Quality measurements at a country level show a clear increase in median bandwidth and a concurrent drop in median latency, both likely due to the loss of measurements from mobile network providers as they disconnected from the Internet.
Five days after the full Internet shutdown started, broadband Internet services providers in Bangladesh began to restore connectivity on July 23. The initial restoration was characterized as a “trial run”, prioritizing banking, commercial sectors, technology firms, exporters, outsourcing providers and media outlets, according to the state minister for post, telecommunication and information technology. Announced IP address space began to increase around 19:00 local time (13:00 UTC), with traffic volumes beginning to trend upwards at that same time, as selected networks reconnected to the Internet.
Unfortunately, Syria is no stranger to Internet shutdowns, as they occur yearly during nationwide exams, implemented with the intent of preventing cheating on those exams. Our recent blog post titled Exam-ining recent Internet shutdowns in Syria, Iraq, and Algeria examined the first round of 2024 exams, which took place between May 26 and June 13.
A second round of exams, and with them, multi-hour Internet shutdowns, began on July 25, and seen in the schedules below, published by Syrian Telecom on its Facebook page (English translation via Google Lens).
The Internet shutdowns implemented for the first four days of tests are clearly visible in the graph below, occurring on July 25, 28, 29, and 30.
However, you will also note another disruption is visible in both Syria’s Internet traffic and announced IP address space shortly after the planned shutdown on July 30. According to a (translated) Facebook post from Syrian Telecom, “while performing regular maintenance on one of the air conditioners located in one of the technical halls [data centers], an explosion occurred, causing the Internet circuits to temporarily go out of service.” This issue resulted in a disruption lasting approximately eight hours, between 11:00 – 19:00 local time (08:00 – 16:00 UTC) seen in both traffic and announced IP address space graphs for AS29256 (Syrian Telecom).
Pakistan
Closing out the month, on July 31, Pakistan experienced a wide-scale Internet disruption that lasted approximately two hours, between 13:30 – 15:30 local time (08:30 – 10:30 UTC). Traffic only dropped ~45% at a country level, but AS17557 (PTCL) experienced a near complete loss of traffic, while traffic at AS24499 (Telenor Pakistan) dropped nearly 90%. Together, the two network providers serve an estimated nine million users, and are among the top five Internet service providers in the country.
It was reported that the Pakistan Telecommunication Authority (PTA) attributed the disruptions to a technical glitch in the international submarine cable affecting the Pakistan Telecommunication Company Limited (PTCL) network. However, another published report noted “According to our sources, the government’s latest firewall edition to block the content was misconfigured, resulting in Internet connectivity disruption.” (Some additional information about the firewall can be found in this article.) The graphs below are from forthcoming TCP reset/timeout data on Cloudflare Radar, and show increased numbers of connections terminating immediately after the initial synchronization (SYN) packet used to establish new TCP connections (“Post SYN”) between 13:30 – 15:30 local time (08:30 – 10:30 UTC) on PTCL and Telenor Pakistan, coincident with the observed disruption. In other words, the rate of SYN packets arriving at Cloudflare was mostly consistent during the disruption, but there was a drop in other TCP packets, suggesting that the firewall explanation may be plausible.
A Facebook post from the Pakistan Telecommunication Authority (PTA) simply highlighted that the issue had been resolved, and that “The exact issue is being investigated by PTA to avoid such instances in future.”
Regardless of the actual cause, the disruption had a clear impact on the country’s financial markets, with a published report stating “The KSE-100 index suffered a sharp decline on Wednesday, plummeting over 740 points in the final hour of trading amid a nationwide internet outage. Analysts attributed the sudden drop to panic selling as investors struggled with limited market data.”
Venezuela
In the past, some countries have implemented government-directed Internet shutdowns as a means of limiting communication about or organizing of protests and demonstrations associated with contested elections. Although such protests and demonstrations sprang up in the wake of a contested presidential election in Venezuela that took place on July 28, Internet shutdowns did not follow. However, in monitoring Internet traffic in Venezuela during the days around the election, the Cloudflare Radar team did observe several notable drops in traffic, as compared to the same times the week prior.
After surging 35% at 05:00 local time (09:00 UTC) on Sunday, July 28 (election day), traffic dropped after the polls opened, down by as much as 23% at 09:00 local time (13:00 UTC). On July 29, the day following the election, traffic was as much as 28% lower than the same time the previous week at 06:15 local time (10:15 UTC) and 18:45 local time (22:45 UTC).
And while the observed drops in traffic appeared to be organic, and not caused by an Internet shutdown, it is worth noting that multiple websites are being blocked in Venezuela. An Internet Society Pulse blog post, published two days ahead of the election, reports that “Around 60 websites are currently blocked in Venezuela, including eight media sites and three that fact-check news and misinformation.”, citing data from the Open Observatory of Network Interference (OONI).
Cloudflare’s network spans more than 320 cities in over 120 countries, where we interconnect with over 13,000 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions. Thanks to Cloudflare Radar functionality released earlier this year, we can explore the impact from a routing perspective, as well as a traffic perspective, at both a network and location level.
As we have seen in previous years, nationwide exams take place across several MENA countries in the second quarter, and with them come government directed Internet shutdowns. Cable cuts, both terrestrial and submarine, caused Internet outages across a number of countries, with the ACE submarine cable being a particular source of problems. Maintenance, power outages, and technical problems also disrupted Internet connectivity, as did unknown issues. And as we have frequently seen in the two-plus years since the conflict began, Internet connectivity in Ukraine suffers as a result of Russian attacks.
As we have noted in the past, this post is intended as a summary overview of observed disruptions, and is not an exhaustive or complete list of issues that have occurred during the quarter.
Government directed
Syria, Algeria, Iraq
Each spring, governments in several countries in the Middle East and North Africa (MENA) region order local telecommunications providers to shut down or disrupt Internet connectivity across the country in an effort to prevent students from cheating on national secondary and high school exams. These shutdowns/disruptions generally occur for several hours per day over a multi-week period. We covered such events in 2023, 2022, and 2021, as they occurred in locations including Syria, Sudan, Algeria, and Iraq.
In June, we published Exam-ining recent Internet shutdowns in Syria, Iraq, and Algeria, which examined the daily Internet shutdowns that took place in Iraq and Syria, as well as the two multi-hour daily disruptions in Algeria, which appeared to be pursuing a content blocking strategy, rather than a full nationwide shutdown. The post examined the impact that these shutdowns have on Internet traffic, and also analyzed routing information and traffic from other Cloudflare services in an effort to better understand how these shutdowns are being implemented.
In addition to the shutdowns covered in the previously referenced blog post, Iraq implemented a second round of shutdowns that started on June 23, and ran through at least July 14. Some of these shutdowns impacted the same set of networks seen in the first round, and some impacted networks in the autonomous Kurdistan region in the north.
Both sets of shutdowns reviewed above appeared to have followed the same approach as the first round covered in the earlier blog post.
Kenya, Burundi, Uganda, Rwanda, Tanzania
Concerns over a potential Internet shutdown during planned protests against tax increases proposed in “Finance Bill 2024” by the Kenyan government led to the publication of a joint statement signed by multiple organizations. The statement strongly urged the Kenyan government to refrain from enforcing any
Internet shutdowns or information controls, and highlighted the “disastrous economic effects” such a move could have. In response, the Communications Authority of Kenya issued a press release stating that “For the avoidance of doubt, the Authority has no intention whatsoever to shut down Internet traffic or interfere with the quality of connectivity. Such actions would be a betrayal of the Constitution as a whole, the freedom of expression in particular and our own ethos.”
As protests escalated on June 25, Internet traffic in Kenya dropped at 16:30 local time (13:30 UTC). Initially, this outage was thought to be due to issues with one or more undersea cables that provide international connectivity to the country, with the potential cause supported by social media posts from Safaricom and Airtel.
Similar concurrent drops in Internet traffic were observed in Burundi, Uganda, Rwanda, and Tanzania, as shown below. Issues with submarine cables connected to one country can impact Internet connectivity in other countries if there is a dependency on that country/cable for upstream Internet connectivity. As such, the observed disruptions in those four countries were not that unusual. To that end, a (subsequently deleted) post on X from MTN Uganda noted: “Our esteemed customers, We are experiencing a degraded service on all our internet services due to an outage caused by our connectivity supply through Kenya. Our technical teams and partners are working jointly to resolve the issue in the shortest time possible. In the interim, we kindly advise our customers to use *165# to access Mobile Money and other app based services. Thank you.“
However, other participants in the Internet infrastructure community in Africa called the undersea cable outage explanation into question. Kyle Spencer, Executive Director of the Uganda Internet eXchange Point, posted on X that “I am told the Kenyan government ordered sea cable landing stations to disconnect circuits.” Ben Roberts, Group CTIO at Liquid Intelligent Technologies (a pan-African network infrastructure provider), posted “No cables are damaged this week.” In addition, outages on undersea cables are rarely, if ever, resolved in a matter of hours, as this disruption was – they frequently last for days or weeks.
On June 26, Safaricom’s CEO claimed “This outage was occasioned by reduced bandwidth on some cables that carry Internet traffic”, contradicting the company’s original claim. No additional information was forthcoming from Airtel or the Communications Authority of Kenya, but as noted above, some within the industry believe that the disruption that impacted connectivity in Kenya, Burundi, Uganda, Rwanda, and Tanzania was directed by the government of Kenya, and was not caused by submarine cable outages.
Cable cuts
Haiti
At 17:36 local time (21:36 UTC) on April 28, Digicel Haiti posted an “important note” on X that stated in part (translated) “On April 27, 2024, the company suffered several attacks on its international optical infrastructure in the Drouya area on National Road #1. The optical fiber was damaged by the impact of cartridges after the armed clashes in the area for a few days. It affected several services such as internet (data), SMS, MonCash and international calling. For now, we are happy to inform the population that all services are restored to 100%.” The graph below shows the impact of the fiber damage, with AS27653 (Digicel Haiti) suffering an Internet outage lasting nearly 24 hours, from around 17:30 local time (21:30 UTC) on April 27 through approximately 16:00 local time (20:00 UTC) on April 28, after which traffic quickly recovered.
Then on May 3, The Director General of Digicel Haiti posted on X that (translated) “Digicel is informing the general public that it suffered two more damages to its international fiber infrastructure at 2am this morning. We have restored Moncash services, SMS, and Fiber Optic connections. Our crews are already on their way to address the apparent landslide in the Canaan area.” The disruption caused by this fiber damage lasted for approximately eight hours, between 02:15 – 10:30 local time (06:15 – 14:30 UTC), and as seen in the graph below, appeared to have a nominal impact on traffic.
On Sunday, May 12, issues with the EASSy and Seacom submarine cables again disrupted connectivity to East Africa, impacting a number of countries previously affected by a set of cable cuts that occurred nearly three months earlier. Insight into these earlier cable cuts and the initial impact of May’s cable damage was covered in our East African Internet connectivity again impacted by submarine cable cuts blog post.
Traffic levels across a number of the impacted countries dropped just before 11:00 local time (08:00 UTC). The magnitude of the initial impact varied by country, with traffic initially dropping by 10-25% in Kenya, Uganda, Madagascar, and Mozambique, while traffic in Rwanda, Malawi, and Tanzania dropped by one-third or more than compared to the previous week. The overall impact was most significant in Tanzania, Madagascar, and Rwanda, as seen in the graphs below. Traffic returned to expected levels at various times over the following week, ranging from a day and a half later (May 13) in Kenya to a week later (May 19) in Rwanda.
Repairs to the EASSy and Seacom cables were completed on May 31. Repairs to the cables damaged in February were ongoing as of July 9, as their location in a war zone complicates repair efforts.
Chad
A reported fiber optic cable cut in Cameroon disrupted Internet connectivity for customers of Moov Africa TChad on May 25. The outage lasted three hours, between 15:15 -18:15 local time (14:15 – 17:15 UTC), with the impact visible at a country level as well. Routing was disrupted too, as the number of IPv4 /24 prefixes (256 IPv4 addresses) announced by Moov Africa Tchad fell from eight to three during the disruption.
The event was similar to one that occurred on January 10, when Moov Africa Tchad and country-level traffic was disrupted for over 12 hours “due to a cut in the optical fiber coming from Cameroon through which Chad has access to the Internet”. During that event, significant volatility was also observed from a routing perspective, as the volume of announced IPv4 address space shifted frequently at a network and country level during the disruption. As we noted last quarter, as a landlocked country, Chad is dependent on terrestrial Internet connections to/through neighboring countries, and the AfTerFibre cable map illustrates Chad’s reliance on limited cable paths through Cameroon and Sudan.
Gambia, Mauritania, Senegal
A reported “network interruption” on the Africa Coast to Europe (ACE) submarine cable disrupted traffic across networks in the Gambia, Mauritania, and Senegal on June 5. AS25250 (Gamtel), AS29544 (Mauritel), and AS37649 (Free/Tigo) all saw traffic drop around 23:00 local time (23:00 UTC). As seen in the graphs below, the outage lasted for nearly 11 hours, with traffic recovering just 10:00 local time on June 6 (10:00 UTC). Mauritel saw a near complete outage, while Gamtel and Free/Tigo saw less severe impacts, possibly because they were able to shift traffic to back up links.
Maintenance
Guinea, Gambia, Sierra Leone, Liberia
Above, we discussed an unexpected network interruption on the ACE submarine cable that caused outages across multiple countries on June 5. However, two months earlier, a planned outage for repair work on the cable also disrupted connectivity across multiple African countries. A communiqúe issued by the Ministry of Posts, Telecommunications and the Digital Economy in Guinea noted in part (translated) “…the ACE (Africa Coast to Europe) network will undergo a planned outage on April 8, 2024, between midnight and 2:00 a.m. morning in the following countries: Guinea, Senegal, Gambia, Sierra Leone and Liberia. This total outage of approximately 2 hours will affect Internet traffic and international calls.”
The graphs below show the impact to traffic in the listed countries for the planned two-hour repair window, though it appears that traffic did not return fully to expected levels after the repair window concluded – it is unclear why it remained slightly depressed. In addition, despite being listed as one of the impacted countries, no impact to traffic was observed in Senegal.
Guinea
Rounding out a trifecta of entries about the ACE submarine cable, planned maintenance work on the cable by GUILAB reportedly caused a multi-hour outage at AS37461 (Orange Guinea) and at a country level as well, lasting from 12:15 – 15:45 local time (12:15 – 15:45 UTC). (GUILAB is the company in charge of managing the capacity allocated to Guinea on the ACE submarine cable.) The maintenance work was reported by Orange Guinea in two X posts (1, 2), although these posts were subsequently deleted.
Power outage
Kenya
At 18:30 local time (15:30 UTC) on May 2, Kenya Power posted a “Power Outage Alert” on X that stated “At 5:40 PM (EAT) today, Thursday, 2nd May 2024, we experienced a system disturbance on the grid, resulting in power supply disruption in most parts of the country.” The graph below shows the resultant impact on Internet connectivity in the country, with traffic dropping sharply between 17:30 – 17:45 local time (14:30 – 14:45 UTC). The drop in traffic lasted until approximately 21:30 local time (18:30 UTC), the same time that Kenya Power posted a “Power Supply Restoration” notice on X, highlighting the restoration of power to parts of the country. Although the post-outage spike seen in the graph would suggest pent-up demand for online content, a longer-term view of Kenya’s Internet traffic shows traffic peaks at the same time (22:00 local time, 19:00 UTC) during the preceding two days as well.
Ecuador
A nationwide power outage in Ecuador on June 19 impacted hospitals, homes, and the subway, in addition to causing a major disruption to Internet connectivity. The graph below shows Ecuador’s Internet traffic dropping sharply just after 15:00 local time (20:00 UTC). A post on X from Public Works Minister Roberto Luque explained (translated) “The immediate report that we received from CENACE is that there is a failure in the transmission line that caused a cascade disconnection, so there is no energy service on a national scale.” A subsequent post pointed at a lack of investment in the underlying systems, and noted that as of 18:41 pm local time (23:41 UTC), “95% of the energy has already been restored”. After the initial sharp drop, traffic began to recover fairly quickly, and was effectively back to expected levels by the stated time.
Albania, Bosnia, Montenegro
A sudden increase in power consumption related to increased usage due to high temperatures, as well electrical systems being impacted by the heat, caused a widespread power outage across Montenegro, Bosnia, and Montenegro on June 21. The outage reportedly originated in Montenegro after a 400-kilowatt transmission line exploded. While power outages are generally more localized to a single country, or region within a country, power distribution systems are linked across Balkan countries as part of the Trans-Balkan Electricity Corridor.
Published reports (MSN, Reuters) noted that electrical networks went down 12:00 – 13:00 local time (10:00 – 11:00 UTC), and that electricity suppliers in the impacted countries started restoring power by mid-afternoon, and had it largely restored by the evening. The graphs below show traffic from Albania, Bosnia, and Montenegro starting to drop around 12:00 local time (10:00 UTC), reaching its nadir in Albania and Bosnia at 12:30 local time (10:30 UTC) and at 13:00 local time (11:00 UTC) in Montenegro. Traffic recovered gradually over the next several hours as power was restored, returning to expected levels by 15:30 local time (13:30 UTC).
Croatia was reportedly impacted by the power outage as well, but no adverse impact to traffic at a country level is visible during the timeframe that connectivity in the other countries was disrupted.
Military action
Ukraine
During the two-plus years of the Russia-Ukraine conflict, Ukraine’s power grid has been a frequent target for Russian air attacks. When damage to Ukraine’s electrical power infrastructure occurs as a result of these attacks, Internet connectivity is also disrupted. Attacks on May 21 caused power outages across a number of areas in Ukraine. The most significant impact was in Sumy, where traffic dropped as low as 82% below the previous week at 00:00 on May 22 local time (21:00 UTC). As the graphs below illustrate, traffic was also lower than the previous week for several hours in Kyiv, Kharkiv, and Vinnytsia, with traffic returning to expected levels by around 08:00 local time (05:00 UTC) on May 22.
\
Technical problems
Malaysia
As we’ve covered in previous quarterly posts, Internet outages and disruptions aren’t always due to significant wide-scale events like severe weather, power outages, or cable cuts. Sometimes more mundane technical issues can cause problems when users try to access the Internet. One example of this occurred on April 15 in Malaysia, when customers of Time Internet experienced a network outage for nearly two hours. The company explained the reason for the outage in a contrite post on their Facebook page, stating in part “This Internet service outage was by far the worst in our history – affecting approximately 40% of our customers. … At 5.38pm today, both our primary and secondary Secure DNS servers became unreachable. This means that any browser or service requiring a DNS address resolution was not able to reach its intended site.” Because subscribers could not reach Time Internet’s DNS resolvers, they were unable to resolve hostnames for Internet services, sites, and applications, including those delivered by Cloudflare. This resulted in the drop in traffic seen in the graph below, which started just after 17:00 local time (05:00 UTC), and began to recover approximately an hour later. The company did not provide any additional information on what caused the DNS servers to fail.
Nepal
In Nepal, a number of local Internet service providers including AS45650 (Vianet) and AS139922 (Dishhome) rely on Indian provider Bharti Airtel for upstream connectivity, enabling them to reach the rest of the Internet. A published report underscores the reliance, noting “Nepali ISPs buy 70 percent of their internet from Airtel.”
On April 25, these ISPs warned that their services could be interrupted because the Nepali government had not provided them with foreign exchange services that would enable them to pay bandwidth vendors such as Airtel, whom they reportedly owed USD $30 million to. On May 1, Airtel informed the delinquent Nepali providers that Internet services may be interrupted at any time due to the overdue payment, and on May 2, Airtel took that step. The graphs below show Vianet’s traffic dropping to near zero at 16:15 local time (10:30 UTC), recovering to expected levels six hours later. An hour later, at 17:15 local time (11:30 UTC), Dishhome’s traffic dropped significantly, though not as severely as Vianet’s. Dishhome’s traffic also recovered approximately six hours later.
A month later, on June 3, AS45650 (Vianet) and AS17501 (Worldlink) in Nepal experienced Internet disruptions that were reportedly caused by routing issues on Bharti Airtel’s network. On Worldlink, a drop in traffic occurred between 12:15 – 14:00 local time (06:30 – 08:15 UTC), while on Vianet, the loss of traffic took place between 12:15 – 13:15 local time (06:30 – 07:30 local time).
Unknown
Most of the Internet disruptions covered in this blog post series have a known root cause, whether admitted/stated by the impacted provider(s) or closely associated with a real world event (severe weather, power outage, etc.) However, other disruptions are observed and even publicized by the impacted provider, but no underlying reason for the outage is ever made public.
Malaysia
On May 21, CelcomDigi (AS10030)posted on X that it was experiencing an outage on its network, and that it was working to resolve the issue as soon as possible. However. just 12 minutes later, it published a second post stating that it had fully restored Celcom Internet service. These posts were made at 21:35 and 21:47 local time (13:35 and 13:47) respectively. However, as the graph below shows, traffic volumes had returned to expected levels over an hour earlier, as the observed Internet disruption on Celcom’s network lasted between 18:00 – 20:15 local time (10:00 – 12:15 UTC). (Note that the second disruption shown in the graph below was due to an internal Cloudflare data pipeline issue, and not any sort of problem with Celcom’s network.)
Starlink
SpaceX Starlink’s satellite Internet service is unique in that it has an international subscriber base, so outages on its network have a more wide-reaching impact than issues with an ISP that covers a single country. At 01:59 UTC on May 29, Starlinkshared on X that it was currently experiencing a network outage, and that it was actively implementing a solution. Twenty-eight minutes later, it posted “The network issue has been fully resolved.” This brief outage is visible in the graph below as a slight dip in traffic. However, what is particularly interesting is the spike in traffic to Cloudflare from Starlink’s network following the resolution of the outage. The sharp increase and rapid decline of the traffic curve after service was restored suggests that it may be related to an automated connectivity check of some kind, rather than pent-up user demand for content.
Chad
A near-complete Internet outage was observed in Chad on June 5 between 08:15 – 12:00 local time (07:15 – 11:00 UTC), as seen in the graph below. Routing was also impacted, as the number of IPv4 /24 address blocks (256 IPv4 addresses) announced by network providers in the country dropped by as much as 75% during the outage.
A news item covering the outage noted that only Starlink subscribers retained Internet access during the outage. It also noted that Chad has faced recurring Internet disruptions since 2016, either because of problems with fiber-optic cables, or due to government directed shutdowns in the name of national security. It is unclear what ultimately caused this particular outage.
India
With an estimated subscriber base in excess of over 460 million, any Internet disruption affecting Reliance Jio’s network (AS55836) is going to have a widespread impact across India. On June 18, Reliance Jio experienced two disruptions that occurred between 13:15 – 17:15 local time (07:45 – 11:45 UTC). Each disruption lasted less than an hour, and dropped traffic levels to approximately half of those seen at the same time a week prior. Both mobile and fiber connectivity was affected, and no additional information has been provided by Reliance Jio regarding the root cause of the connectivity issues.
Conclusion
As we become increasingly dependent on reliable Internet connectivity, we must recognize that that connectivity is itself reliant on a complex and interconnected foundation of physical, technical, and political factors. A failure in any one of these foundational components, whether due to a cable cut, power outage, misconfiguration, or government action, can have a significant impact, disrupting Internet connectivity for millions of users, potentially across multiple countries. While the resilience and reliability of the physical and technical components can be improved through redundancy and best practices, political factors have arguably proven to be the hardest to address. However, organizations like AccessNow, through their #KeepItOn campaign, mobilize people, communities, and civil society actors globally to fight against government-directed Internet shutdowns, which can have significant financial consequences.
On Thursday, June 20, 2024, two independent events caused an increase in latency and error rates for Internet properties and Cloudflare services that lasted 114 minutes. During the 30-minute peak of the impact, we saw that 1.4 – 2.1% of HTTP requests to our CDN received a generic error page, and observed a 3x increase for the 99th percentile Time To First Byte (TTFB) latency.
A new Distributed Denial-of-Service (DDoS) mitigation mechanism deployed between 14:14 and 17:06 UTC triggered a latent bug in our rate limiting system that allowed a specific form of HTTP request to cause a process handling it to enter an infinite loop between 17:47 and 19:27 UTC
Impact from these events were observed in many Cloudflare data centers around the world.
With respect to the backbone congestion event, we were already working on expanding backbone capacity in the affected data centers, and improving our network mitigations to use more information about the available capacity on alternative network paths when taking action. In the remainder of this blog post, we will go into more detail on the second and more impactful of these events.
As part of routine updates to our protection mechanisms, we created a new DDoS rule to prevent a specific type of abuse that we observed on our infrastructure. This DDoS rule worked as expected, however in a specific suspect traffic case it exposed a latent bug in our existing rate-limiting component. To be absolutely clear, we have no reason to believe this suspect traffic was intentionally exploiting this bug, and there is no evidence of a breach of any kind.
We are sorry for the impact and have already made changes to help prevent these problems from occurring again.
Background
Rate-limiting suspicious traffic
Depending on the profile of an HTTP request and the configuration of the requested Internet property, Cloudflare may protect our network and our customer’s origins by applying a limit to the number of requests a visitor can make within a certain time window. These rate limits can activate through customer configuration or in response to DDoS rules detecting suspicious activity.
Usually, these rate limits will be applied based on the IP address of the visitor. As many institutions and Internet Service Providers (ISPs) can have many devices and individual users behind a single IP address, rate limiting based on the IP address is a broad brush that can unintentionally block legitimate traffic.
Balancing traffic across our network
Cloudflare has several systems that together provide continuous real-time capacity monitoring and rebalancing to ensure we serve as much traffic as we can as quickly and efficiently as we can.
The first of these is Unimog, Cloudflare’s edge load balancer. Every packet that reaches our anycast network passes through Unimog, which delivers it to an appropriate server to process that packet. That server may be in a different location from where the packet originally arrived into our network, depending on the availability of compute capacity. Within each data center, Unimog aims to keep the CPU load uniform across all active servers.
For a global view of our network, we rely on Traffic Manager. Across all of our data center locations, it takes in a variety of signals, such as overall CPU utilization, HTTP request latency, and bandwidth utilization to instruct rebalancing decisions. It has built-in safety limits to prevent causing outsized traffic shifts, and also considers the expected resulting load in destination locations when making any decisions.
Incident timeline and impact
All timestamps are UTC on 2024-06-20.
14:14 DDoS rule gradual deployment starts
17:06 DDoS rule deployed globally
17:47 First HTTP request handling processe is poisoned
18:04 Incident declared automatically based on detected high CPU load
18:34 Service restart shown to recover on a server, full restart tested in one data center
18:44 CPU load normalized in data center after service restart
18:51 Continual global reloads of all servers with many stuck processes begin
19:05 Global eyeball HTTP error rate peaks at 2.1% service unavailable / 3.45% total
19:05 First Traffic Manager actions recovering service
19:11 Global eyeball HTTP error rate halved to 1% service unavailable / 1.96% total
19:27 Global eyeball HTTP error rate reduced to baseline levels
19:29 DDoS rule deployment identified as likely cause of process poisoning
19:34 DDoS rule is fully disabled
19:43 Engineers stop routine restarts of services on servers with many stuck processes
20:16 Incident response stood down
Below, we provide a view of the impact from some of Cloudflare’s internal metrics. The first graph illustrates the percentage of all eyeball (inbound from external devices) HTTP requests that were served an error response because the service suffering poisoning could not be reached. We saw an initial increase to 0.5% of requests, and then later a larger one reaching as much as 2.1% before recovery started due to our service reloads.
For a broader view of errors, we can see all 5xx responses our network returned to eyeballs during the same window, including those from origin servers. These peaked at 3.45%, and you can more clearly see the gradual recovery between 19:25 and 20:00 UTC as Traffic Manager finished its re-routing activities. The dip at 19:25 UTC aligns with the last large reload, with the error increase afterwards primarily consisting of upstream DNS timeouts and connection limits which are consistent with high and unbalanced load.
And here’s what our TTFB measurements looked like at the 50th, 90th and 99th percentiles, showing an almost 3x increase in latency at p99:
Technical description of the error and how it happened
Global percentage of HTTP Request handling processes that were using excessive CPU during the event
Earlier on June 20, between 14:14 – 17:06 UTC, we gradually activated a new DDoS rule on our network. Cloudflare has recently been building a new way of mitigating HTTP DDoS attacks. This method is using a combination of rate-limits and cookies in order to allow legitimate clients that were falsely identified as being part of an attack to proceed anyway.
With this new method, an HTTP request that is considered suspicious runs through these key steps:
Check for the presence of a valid cookie, otherwise block the request
If a valid cookie is found, add a rate-limit rule based on the cookie value to be evaluated at a later point
Once all the currently applied DDoS mitigation are run, apply rate-limit rules
We use this “asynchronous” workflow because it is more efficient to block a request without a rate-limit rule, so it gives a chance for other rule types to be applied.
So overall, the flow can be summarized with this pseudocode:
for (rule in active_mitigations) {
// ... (ignore other rule types)
if (rule.match_current_request()) {
if (!has_valid_cookie()) {
// no cookie: serve error page
return serve_error_page();
} else {
// add a rate-limit rule to be evaluated later
add_rate_limit_rule(rule);
}
}
}
evaluate_rate_limit_rules();
When evaluating rate-limit rules, we need to make a key for each client that is used to look up the correct counter and compare it with the target rate. Typically, this key is the client IP address, but other options are available, such as the value of a cookie as used here. We actually reused an existing portion of the rate-limit logic to achieve this. In pseudocode, it looks like:
function get_cookie_key() {
// Validate that the cookie is valid before taking its value.
// Here the cookie has been checked before already, but this code is
// also used for "standalone" rate-limit rules.
if (!has_valid_cookie_broken()) { // more on the "broken" part later
return cookie_value;
} else {
return parent_key_generator();
}
}
This simple key generation function had two issues that, combined with a specific form of client request, caused an infinite loop in the process handling the HTTP request:
The rate-limit rules generated by the DDoS logic are using internal APIs in ways that haven’t been anticipated. This caused the parent_key_generator in the pseudocode above to point to the get_cookie_key function itself, meaning that if that code path was taken, the function would call itself indefinitely
As these rate-limit rules are added only after validating the cookie, validating it a second time should give the same result. The problem is that the has_valid_cookie_broken function used here is actually different and both can disagree if the client sends multiple cookies where some are valid but not others
So, combining these two issues: the broken validation function tells get_cookie_key that the cookie is invalid, causing the else branch to be taken and calling the same function over and over.
A protection many programming languages have in place to help prevent loops like this is a run-time protection limit on how deep the stack of function calls can get. An attempt to call a function once already at this limit will result in a runtime error. When reading the logic above, an initial analysis might suggest we were reaching the limit in this case, and so requests eventually resulted in an error, with a stack containing those same function calls over and over.
However, this isn’t the case here. Some languages, including Lua, in which this logic is written, also implement an optimization called proper tail calls. A tail call is when the final action a function takes is to execute another function. Instead of adding that function as another layer in the stack, as we know for sure that we will not be returning execution context to the parent function afterwards, nor using any of its local variables, we can replace the top frame in the stack with this function call instead.
The end result is a loop in the request processing logic which never increases the size of the stack. Instead, it simply consumes 100% of available CPU resources, and never terminates. Once a process handling HTTP requests receives a single request on which the action should be applied and has a mixture of valid and invalid cookies, that process is poisoned and is never able to process any further requests.
Every Cloudflare server has dozens of such processes, so a single poisoned process does not have much of an impact. However, then some other things start happening:
The increase in CPU utilization for the server causes Unimog to lower the amount of new traffic that server receives, moving traffic to other servers, so at a certain point, more new connections are directed away from servers with a subset of their processes poisoned to those with fewer or no poisoned processes, and therefore lower CPU utilization.
The gradual increase in CPU utilization in the data center starts to cause Traffic Manager to redirect traffic to other data centers. As this movement does not fix the poisoned processes, CPU utilization remains high, and so Traffic Manager continues to redirect more and more traffic away.
The redirected traffic in both cases includes the requests that are poisoning processes, causing the servers and data centers to which this redirected traffic was sent to start failing in the same way.
Within a few minutes, multiple data centers had many poisoned processes, and Traffic Manager had redirected as much traffic away from them as possible, but was restricted from doing more. This was partly due to its built-in automation safety limits, but also because it was becoming more difficult to find a data center with sufficient available capacity to use as a target.
The first case of a poisoned process was at 17:47 UTC, and by 18:09 UTC – five minutes after the incident was declared – Traffic Manager was re-routing a lot of traffic out of Europe:
A summary map of Traffic Manager capacity actions as of 18:09 UTC. Each circle represents a data center that traffic is being re-routed towards or away from. The color of the circle indicates the CPU load of that data center. The orange ribbons between them show how much traffic is re-routed, and where from/to.
It’s obvious to see why, if we look at the percentage of the HTTP request service’s processes that were saturating their CPUs. 10% of our capacity in Western Europe was already gone, and 4% in Eastern Europe, during peak traffic time for those timezones:
Percentage of all the HTTP request handling processes saturating their CPU, by geographic region
Partially poisoned servers in many locations struggled with the request load, and the remaining processes could not keep up, resulting in Cloudflare returning minimal HTTP error responses.
Cloudflare engineers were automatically notified at 18:04 UTC, once our global CPU utilization reached a certain sustained level, and started to investigate. Many of our on-duty incident responders were already working on the open incident caused by backbone network congestion, and in the early minutes we looked into likely correlation with the network congestion events. It took some time for us to realize that locations where the CPU was highest is where traffic was the lowest, drawing the investigation away from a network event being the trigger. At this point, the focus moved to two main streams:
Evaluating if restarting poisoned processes allowed them to recover, and if so, instigating mass-restarts of the service on affected servers
Identifying the trigger of processes entering this CPU saturation state
It was 25 minutes after the initial incident was declared when we validated that restarts helped on one sample server. Five minutes after this, we started executing wider restarts – initially to entire data centers at once, and then as the identification method was refined, on servers with a large number of poisoned processes. Some engineers continued regular routine restarts of the affected service on impacted servers, whilst others moved to join the ongoing parallel effort to identify the trigger. At 19:36 UTC, the new DDoS rule was disabled globally, and the incident was declared resolved after executing one more round of mass restarts and monitoring.
At the same time, conditions presented by the incident triggered a latent bug in Traffic Manager. When triggered, the system would attempt to recover from the exception by initiating a graceful restart, halting its activity. The bug was first triggered at 18:17 UTC, then numerous times between 18:35 and 18:57 UTC. During two periods in this window (18:35-18:52 UTC and 18:56-19:05 UTC) the system did not issue any new traffic routing actions. This meant whilst we had recovered service in the most affected data centers, almost all traffic was still being re-routed away from them. Alerting notified on-call engineers of the issue at 18:34 UTC. By 19:05 UTC the Traffic team had written, tested, and deployed a fix. The first actions following restoration showed a positive impact on restoring service.
Remediation and follow-up steps
To resolve the immediate impact to our network from the request poisoning, Cloudflare instigated mass rolling restarts of the affected service until the change that triggered the condition was identified and rolled back. The change, which was the activation of a new type of DDoS rule, remains fully rolled back, and the rule will not be reactivated until we have fixed the broken cookie validation check and are fully confident this situation cannot recur.
We take these incidents very seriously, and recognize the magnitude of impact they had. We have identified several steps we can take to address these specific situations, and the risk of these sorts of problems from recurring in the future.
Design: The rate limiting implementation in use for our DDoS module is a legacy component, and rate limiting rules customers configure for their Internet properties use a newer engine with more modern technologies and protections.
Design: We are exploring options within and around the service which experienced process poisoning to limit the ability to loop forever through tail calls. Longer term, Cloudflare is entering the early implementation stages of replacing this service entirely. The design of this replacement service will allow us to apply limits on the non-interrupted and total execution time of a single request.
Process: The activation of the new rule for the first time was staged in a handful of production data centers for validation, and then to all data centers a few hours later. We will continue to enhance our staging and rollout procedures to minimize the potential change-related blast radius.
Conclusion
Cloudflare experienced two back-to-back incidents that affected a significant set of customers using our CDN and network services. The first was network backbone congestion that our systems automatically remediated. We mitigated the second by regularly restarting the faulty service whilst we identified and deactivated the DDoS rule that was triggering the fault. We are sorry for any disruption this caused our customers and to end users trying to access services.
The conditions necessary to activate the latent bug in the faulty service are no longer possible in our production environment, and we are putting further fixes and detections in place as soon as possible.
The practice of cheating on exams (or at least attempting to) is presumably as old as the concept of exams itself, especially when the results of the exam can have significant consequences for one’s academic future or career. As access to the Internet became more ubiquitous with the growth of mobile connectivity, and communication easier with an assortment of social media and messaging apps, a new avenue for cheating on exams emerged, potentially facilitating the sharing of test materials or answers. Over the last decade, some governments have reacted to this perceived risk by taking aggressive action to prevent cheating, ranging from targeted DNS-based blocking/filtering to multi-hour nationwide shutdowns across multi-week exam periods.
Syria and Iraq are well-known practitioners of the latter approach, and we have covered past exam-related Internet shutdowns in Syria (2021, 2022, 2023) and Iraq (2022, 2023) here on the Cloudflare blog. It is now mid-June 2024, and exams in both countries took place over the last several weeks, and with those exams, regular nationwide Internet shutdowns. In addition, Baccalaureate exams also took place in Algeria, and we have written about related Internet disruptions there in the past (2022, 2023). However, in contrast to the single daily shutdowns in Syria and Iraq, the Algerian government opted instead for two multi-hour disruptions each day – one in the morning, one in the afternoon – and appears to be pursuing a content blocking strategy, rather than a full nationwide shutdown.
As we have done in past year’s posts, we will examine the impact that these shutdowns have on Internet traffic, but also analyze routing information and traffic from other Cloudflare services in an effort to better understand how these shutdowns are being implemented.
Syria
The Syrian Telecom Company, to their credit, publishes an exam schedule on social media, with the image below published to their Facebook page. The English version was created by applying Google Translate to the image. The schedule shows the date & time of each Internet shutdown (“disconnection”), in addition to the subject(s) of that day’s exam(s). In 2024, exams started on May 26, and went through June 13.
In Syria, AS29256 (Syrian Telecom) is effectively the Internet, as shown in the table below. While there are a few other autonomous systems (ASNs/ASes) registered in Syria, there are only two that currently announce IP address space to the public Internet. As such, the trends seen at a country level for Syria reflect those seen for AS29256, and this is clearly evident in the traffic graphs below.
Nationwide Internet shutdowns in Syria began on May 26, taking place for varying multi-hour periods from Sunday to Thursday for three consecutive weeks. The graphs below show Internet traffic from the country, as well as AS29256, dropping to zero during the scheduled shutdowns.
In addition, graphs from the Cloudflare Radar Routing pages for Syria and AS29256 show the number of IPv4 and IPv6 prefixes being announced country-wide and by AS29256 dropping to at or near zero during each shutdown. This ultimately means that there is no Internet path back to systems (IP addresses) connected to Syrian Telecom. Below, we explore why this is important and problematic.
As has been observed in the past, the shutdowns in Syria are asymmetrical. That is, traffic can exit the country (via AS29256), but there are no paths for responses to return. The impact of this approach is clearly evident in traffic to Cloudflare’s 1.1.1.1 DNS Resolver. We continue to see traffic to the resolver when the shutdowns take place, and in fact, we see the traffic spike during the shutdowns, as the graph below shows.
If we dig into traffic to 1.1.1.1 by protocol, we can see that it is driven by requests over UDP port 53, the standard port used for DNS requests over UDP and TCP. (Given the request pattern, that also appears to be the primary way that we see traffic to the resolver from Syria.)
If we remove the UDP line from the graph, we see that request volume for DNS over TCP port 53, as well as DNS over HTTPS (DoH) and DNS over TLS (DoT), all drops to zero during the shutdowns.
Similarly, we can clearly see the shutdowns in HTTP(S) request-based traffic graphs as well, since HTTP(S) is also a TCP-based protocol.
Why do we see this impact? With DNS over UDP, the client simply makes a request to the resolver – no multi-step handshake is involved, as with TCP. So in this case, 1.1.1.1 is receiving these requests, but as shown above, there’s no path for the response to reach the client. Because it hasn’t received a response, the client retries the request, and this flood of retries is manifested as the spike seen in the graphs above.
However, as we see above, request volume for DNS over TCP, as well as DoH, DoT, and HTTP(S) (which all use TCP), falls to zero during the shutdowns. The lack of a path back to the client means that the TCP 3-way handshake can’t complete, and thus we don’t see DNS requests over these protocols.
In looking at 1.1.1.1 Resolver request volume from Syria for popular social media and messaging applications, we can see traffic for facebook.com most closely matches the spikes shown above. Removing facebook.com from the graph, we can also see similar, though more limited, increases for domains used by popular messaging applications WhatsApp, Signal, and Telegram. Facebook and WhatsApp are reportedly the most popular social media and messaging applications in Syria.
Although we have focused on the analysis of traffic to Cloudflare’s DNS resolver, and the patterns seen within that traffic, it is also worth highlighting an interesting pattern observed in traffic to Cloudflare’s Authoritative DNS platform. (DNS resolvers act as a middleman between clients, such as a laptop or phone, and an authoritative DNS server. Authoritative DNS servers contain information specific to the domain names they serve, including IP addresses and other types of records.)
The graph below shows bits/second traffic from Syria for Cloudflare’s authoritative DNS service on June 13. (Similar patterns were observed during the other days when shutdowns occurred, but data volume limits the ability to create a graph showing an extended period of time.) In this graph, we can see that at the start of the shutdown (03:00 UTC), traffic rises sharply, effectively plateaus for the duration of the shutdown, and then returns to normal levels. We believe that the traffic pattern illustrated here could be the result of some local resolvers in Syria having the IP addresses for our authoritative DNS servers cached, and are making requests to them. The increased traffic level could be because they are retrying their queries after not receiving responses, but in a less aggressive fashion than the client applications driving the resolver traffic spikes shown above.
In summary, Syria appears to be implementing their Internet shutdowns not through filtering, but rather by simply not announcing their IP address space for the duration of the shutdown, thereby preventing any responses from returning to the originating requestor, whether client application, web browser, or local DNS resolver.
Iraq
On May 19, the Iraqi Ministry of Communication posted an update that stated (translated) “The Ministry of Communications would like to note that the Internet service will be cut off for two hours during the general exams for intermediate studies, from six in the morning until eight in the morning, based on higher directives and at the request of the Ministry of Education.” The post came nearly a year after the Iraqi Ministry of Communication refused a request from the Ministry of Education to shut down the Internet during the baccalaureate exams as part of efforts to prevent cheating. On May 20, the Iraqi Ministry of Education posted the schedule for the upcoming set of exams to its Facebook page.
Iraq has a much richer network service provider environment than Syria does, with over 150autonomous systems (ASNs) registered in the country and announcing IP address space, compared to just two ASNs (both Syrian Telecom) in Syria announcing IP address space. Although traffic in Iraq is generally concentrated among the larger providers, shutdowns are rarely “complete” at a country level because not every autonomous system (network provider) in the country implements a shutdown. (This is due in part to the autonomous Kurdistan region in the north, which often implements similar shutdowns on their own schedule. Network providers in this region are included in Iraq’s country-level graphs.)
We can see this in a Cloudflare Radar traffic graph that shows the shutdowns at a country level, where traffic is dropping by around 87% during each multi-hour shutdown. In addition to the five networks also shown here (AS203214 (HulumTele), AS199739 (Earthlink), AS58322 (Halasat), AS51684 (Asiacell), and AS59588 (Zainas)), further analysis finds more than 30 where we observed a complete loss of traffic during the shutdowns, with a number of them downstream of these providers.
In contrast to Syria, the changes to announced IP address space during the shutdowns are much less severe in Iraq. Several of the shutdowns are correlated with a drop of ~20-25% in announced IPv4 address space, while a few others saw a drop closer to just 2%.
Similar to Syria, we can also look at 1.1.1.1 resolver traffic data to better understand how the shutdowns are being implemented. The country-level graphs below suggest that UDP traffic patterns are not visibly changing, suggesting that responses from the resolver are, in fact, getting back to the clients. However, this likely isn’t the case, and such a conclusion is at least in part an artifact of the graph’s time frame and hourly granularity, as well as the inclusion of resolver traffic from Kurdish network providers (ASNs). The shutdowns are more clearly evident in the DNS-over-TCP and DNS-over-HTTPS graphs below, as well as in the graph for HTTP(S) request traffic (both mobile & desktop), which is also TCP-based. In these graphs, the troughs on days that shutdowns occurred generally dip lower than those on the days that the Internet remained available.
In looking at authoritative DNS traffic from Iraq during a shutdown (for June 13 as an example day, as above), we see evidence of a decline in traffic during the time the shutdown occurs.
The decline in authoritative DNS traffic is more evident at an ASN level, such as in the graph below for AS203214 (Hulum), effectively confirming that UDP traffic is not getting through here either.
Considering the traffic, 1.1.1.1 Resolver, and authoritative DNS observations reviewed here, it suggests that the Internet shutdowns taking place in Iraq are more complex than Syria’s, as it appears that both UDP and TCP traffic are unable to egress from impacted network providers. As not all impacted network providers are showing a complete loss of announced IP address space during the shutdowns, Iraq is taking a different approach to disrupting Internet connectivity. Although analysis of our data doesn’t provide a definitive conclusion, there are several likely options, and network providers in the country may be combining several. These options revolve around:
IP: Block packets from reaching IP addresses. This may be done by withdrawing prefix announcements from the routing table (a brute force approach) or by blocking access to specific IP addresses, such as those associated with a specific application or service (a more surgical approach).
Connection: Block connections based on SNI/HTTP headers, or other application data. If a network or on-path device is able to observe the server name (or other relevant headers/data), then the connection can be terminated.
DNS: Operators of private or ‘internal’ DNS resolvers, offered by ISPs and enterprise environments for use by their own users, can apply content restrictions, blocking the resolution of hostnames associated with websites and other applications.
The consequences of these options are covered in more detail in a blog post. In addition, applying them at common network chokepoints, such as AS212330 (IRAQIXP) or AS208293 (AlSalam State Company, associated with the Iraqi Ministry of Communications), can disrupt connectivity at multiple downstream ISPs, without those providers necessarily having to take action themselves.
Algeria
As we noted in blog posts in 2022 and 2023, Algeria has a history of disrupting Internet connectivity during Baccalaureate exams. This has been taking place since 2018, following widespread cheating in 2016 that saw questions leaked online both before and during tests. On March 13, the Algerian Ministry of Education announced that the Baccalaureate exams would be held June 9-13. As expected, Internet disruptions were observed both country-wide and at a network level. Similar to previous years, two disruptions were observed each day. The first one began at 08:00 local time (07:00 UTC), and except for June 9, lasted three hours, ending at 11:00 local time (10:00 UTC). (On June 9, it lasted until 13:00 local time (12:00 UTC).) The second one began between 14:00-14:30 local time (13:00-13:30 UTC), and lasted until 16:00-17:00 local time (15:00-16:00 UTC) – the end time varied by day.
As seen in the graphs below, the impact to traffic was fairly nominal, suggesting that wide scale Internet shutdowns similar to those seen in Syria were not being implemented. While this is in line with 2023’s pronouncement by the Minister of Education that there would be no Internet shutdown on exam days, a number of posts on X complained of broader cuts to Internet connectivity.
Similar to the analysis above of the shutdowns in Syria and Iraq, we can also review changes to announced IP address space to better understand how connectivity was being disrupted. In this case, as the graphs below show, no meaningful changes to announced IPv4 address space were observed during the days the Baccalaureate exams were given. As such, the observed drops in traffic were not caused by routing changes.
In the HTTP(S) request traffic graph below, the twice-daily disruptions are highlighted, with the morning one appearing as a nominal drop in traffic, and the afternoon one causing a more severe decline. (The graph shows request traffic aggregated at a country level, but the graphs for the ASNs listed above also show similar patterns.)
In addition, similar patterns are observed in 1.1.1.1 resolver traffic at a country and ASN level, but only for DNS over TCP, DNS over TLS, and DNS over HTTPS, all of which leverage TCP. In the graph below showing only resolver traffic over UDP, there’s no clear evidence of disruptions. However, in the graph that shows resolver traffic over HTTPS, TCP, and TLS, a slight perturbation is visible in the morning, as traffic begins to rise for the day, and a sharper decrease is visible in the afternoon, with both disruptions aligning with the twice daily drops in traffic discussed above.
These observations support the conjecture that the Algerian government is likely taking a more nuanced approach to restricting access to content, interfering in some fashion with TCP-based traffic. The conjecture is also supported by an internal tool that helps to understand connection tampering that is based on research co-designed and developed by members of the Cloudflare Research team. We will be launching insights into TCP connection tampering on Cloudflare Radar later in 2024 and, in the meantime, technical details can be found in the peer-reviewed paper titled Global, Passive Detection of Connection Tampering.
The graph below, taken from the internal tool, highlights observed TCP connection tampering in connections from Algeria during the week that the Baccalaureate exams took place. While some baseline level of post-ACK and post-PSH tampering is consistently visible, we see significant increases in post-ACK twice a day during the exam period, at the times that align with the shifts in traffic discussed above. Technical descriptions of post-ACK and post-PSH tampering can be found in the Cloudflare Radar glossary, but in short, tampering post-ACK means an established TCP connection to Cloudflare’s server has been abruptly ended by one or more RST packets before the server sees data packets. Although clients do use RSTs, clients are more likely to close connections with a FIN (as specified by the RFC). The RST method can also be used by middleboxes that (i) sees the data packet, then (ii) drops the data packet, then (iii) sends an RST to the server to force the server to close the connection (and very likely another RST to the client too for the same reason). Tampering post-PSH means that something on the path, like a middlebox, (i) saw something it didn’t like on an established connection, then (ii) permitted the data to pass but then, (iii) it sends the RST to force endpoints to close the connection.
Looking beyond Cloudflare-sourced data, aggregated test results from the Open Observatory of Network Interference (OONI) also show evidence of anomalous behavior. Using OONI Probe, a mobile and desktop app, can probe for potential blocking of websites, instant messaging apps, and censorship circumvention tools. Examining test results from users in Algeria for popular messaging platforms WhatsApp, Telegram, Signal, and Facebook Messenger for the first two weeks of June, we clearly see the appearance of test results marked as “Anomaly” starting on June 9. (OONI defines “Anomaly” results as “Measurements that provided signs of potential blocking”.) OONI Tor testresults also show a similar “Anomaly” pattern. Anomalous traffic patterns are also visible for Google Web Search, YouTube, and GMail.
Although the analysis of these observations and data sets doesn’t provide us with specific details around exactly how the observed Internet disruptions are being implemented, it strongly supports the supposition that network providers in Algeria are, in some fashion, interfering with TCP connections, but not blocking them outright nor shutting down their networks completely. Given that popular messaging platforms, Google properties, Cloudflare’s 1.1.1.1 DNS resolver, and some number of Cloudflare customer sites all appear to be impacted, it suggests that a list of hostnames are being targeted for disruption/interference, either by the SNI or the destination IP address.
Conclusion
Perhaps recognizing the broad negative impact that brute-force nationwide Internet shutdowns have as a response to cheating on exams, some governments appear to be turning to more nuanced techniques, such as content blocking or connection tampering. However, because these are widely applied as well, they are arguably just as disruptive as a full nationwide Internet shutdown. The cause of full shutdowns, such as those seen in Syria, are arguably easier to diagnose than the disruptions to connectivity seen in Iraq and Algeria, which appear to use approaches that are hard to specifically identify from the outside.
On Sunday, May 12, issues with the ESSAy and Seacom submarine cables again disrupted connectivity to East Africa, impacting a number of countries previously affected by a set of cable cuts that occurred nearly three months earlier.
Already suffering from reduced capacity due to the February cable cuts, these countries were impacted by a second set of cable cuts that occurred on Sunday, May 12. According to a social media post from Ben Roberts, Group CTIO at Liquid Intelligent Technologies in Kenya, faults on the EASSy and Seacom cables again disrupted connectivity to East Africa, as he noted “All sub sea capacity between East Africa and South Africa is down.” A BBC article citing Roberts stated that the EASSy cable had been cut approximately 45km (28 miles) north of the South African port city of Durban. A subsequent press release issued by the Communications Authority of Kenya stated that the cut had occurred at the Mtunzini teleport station (in South Africa). As seen in the map below, both the EASSy and Seacom cables land in Mtunzini.
Map of African undersea cables, April 2024. Source: https://manypossibilities.net/african-undersea-cables/
Impacts to country-level Internet traffic
Cloudflare Radar saw traffic levels across a number of the impacted countries drop just before 11:00 local time (08:00 UTC). As seen in the graphs below, the magnitude of impact varied by country, with traffic initially dropping by 10-25% in Kenya, Uganda, Madagascar, and Mozambique, while traffic in Rwanda, Malawi, and Tanzania dropped by one-third or more as compared to the previous week.
In Kenya and Uganda, the overall impact appeared to be low, with traffic generally remaining just below expected levels in the day and a half following the cable faults. In the other countries, the overnight trough of the diurnal traffic patterns remained consistent with the previous week’s traffic levels, but otherwise traffic remains significantly lower than expected.
The importance of redundancy
In Kenya, the impact may have been nominal due to steps taken by providers like Safaricom and Airtel Kenya. In a May 12 social media post, Safaricom noted “…We have since activated redundancy measures to minimise service interruption and keep you connected as we await the full restoration of the cable.” In a subsequent social media post on May 13, Safaricom noted “Thanks to our redundancy plans and capacity investment across multiple undersea cables our services continue to be available, however some customers may experience slow connectivity and speeds.” Similarly, a social media post from Airtel Kenya noted “Following yesterday’s undersea fiber cut that has impacted internet connectivity, we would like to update you that we have taken measures to improve your browsing experience through additional capacity enhancement.”
Similarly, the previously referenced press release from the Communications Authority of Kenya talked about actions being taken, stating “Meanwhile, the Authority has directed service providers to take proactive steps to secure alternative routes for their traffic and is monitoring the situation closely to ensure that incoming and outbound internet connectivity is available. The East Africa Marine System (TEAMS) cable, which has not been affected by the cut, is currently being utilised for local traffic flow while redundancy on the South Africa route has been activated to minimize the impact.”
What’s next?
Once the necessary permits are secured and the cable faults are located, repairs can often be completed in several days. However, because cable repair ships are something of a scarce resource, there is often a delay to both engage a vessel and for it to travel to the area where the cable damage occurred, whether from its baseport or the location of a previous repair. However, in this case that delay may be comparatively short, as submarine cable industry observer @philBE2 predicts “Expecting the usual suspect, CS Leon Thevenin, now moored in Cape Town, to be swiftly mobilized for an expeditious repair mission…”
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.