Thank you for following along with another Security Week at Cloudflare. We’re extremely proud of the work our team does to make the Internet safer and to help meet the challenge of emerging threats. As our CISO Grant Bourzikas outlined in his kickoff post this week, security teams are facing a landscape of rapidly increasing complexity introduced by vendor sprawl, an “AI Boom”, and an ever-growing surface area to protect.
As we continuously work to meet new challenges, Innovation Weeks like Security Week give us an invaluable opportunity to share our point of view and engage with the wider Internet community. Cloudflare’s mission is to help build a better Internet. We want to help safeguard the Internet from the arrival of quantum supercomputers, help protect the livelihood of content creators from unauthorized AI scraping, help raise awareness of the latest Internet threats, and help find new ways to help reduce the reuse of compromised passwords. Solving these challenges will take a village. We’re grateful to everyone who has engaged with us on these issues via social media, contributed to our open source repositories, and reached out through our technology partner program to work with us on the issues most important to them. For us, that’s the best part.
We’re thrilled to announce that organizations can now protect their sensitive corporate network traffic against quantum threats by tunneling it through Cloudflare’s Zero Trust platform.
Cloudflare has made significant progress in boosting multi-factor authentication (MFA) adoption. With the addition of Apple and Google social logins, we’ve made secure access easier for our users.
We’re excited to announce that Cloudflare for Campaigns now includes Email Security, adding an extra layer of protection to email systems that power political campaigns.
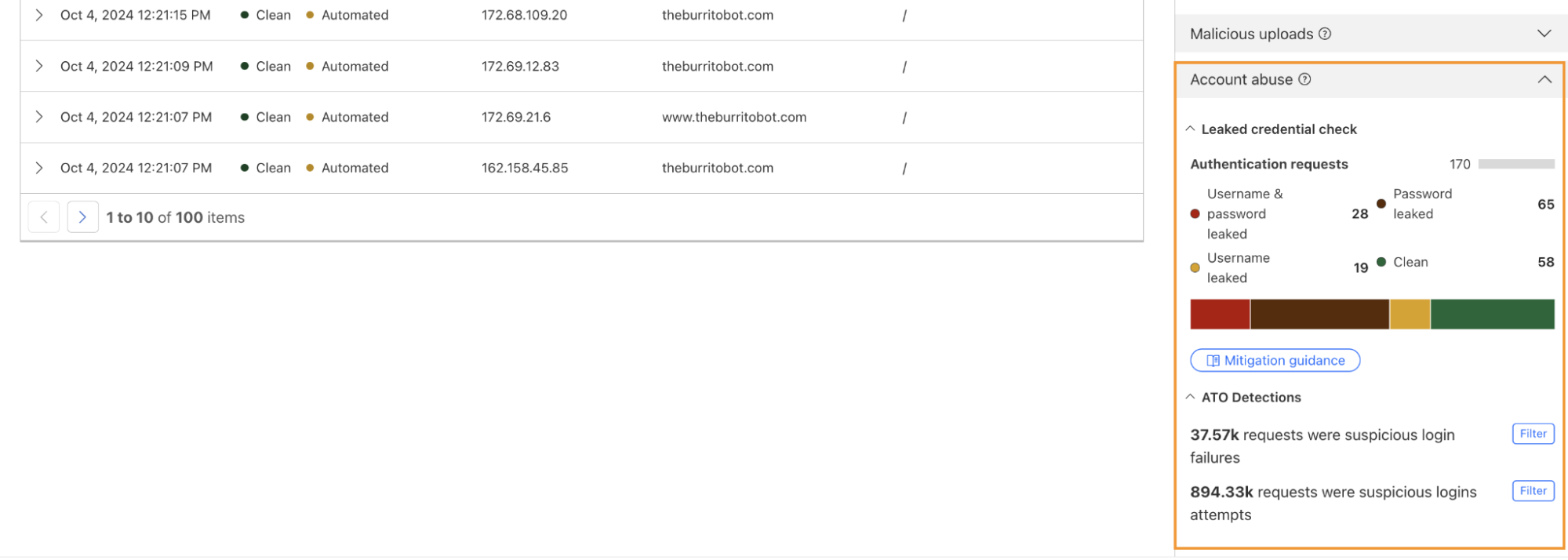
Nearly half of login attempts across websites protected by Cloudflare involved leaked credentials. The pervasive issue of password reuse is enabling automated bot attacks on a massive scale.
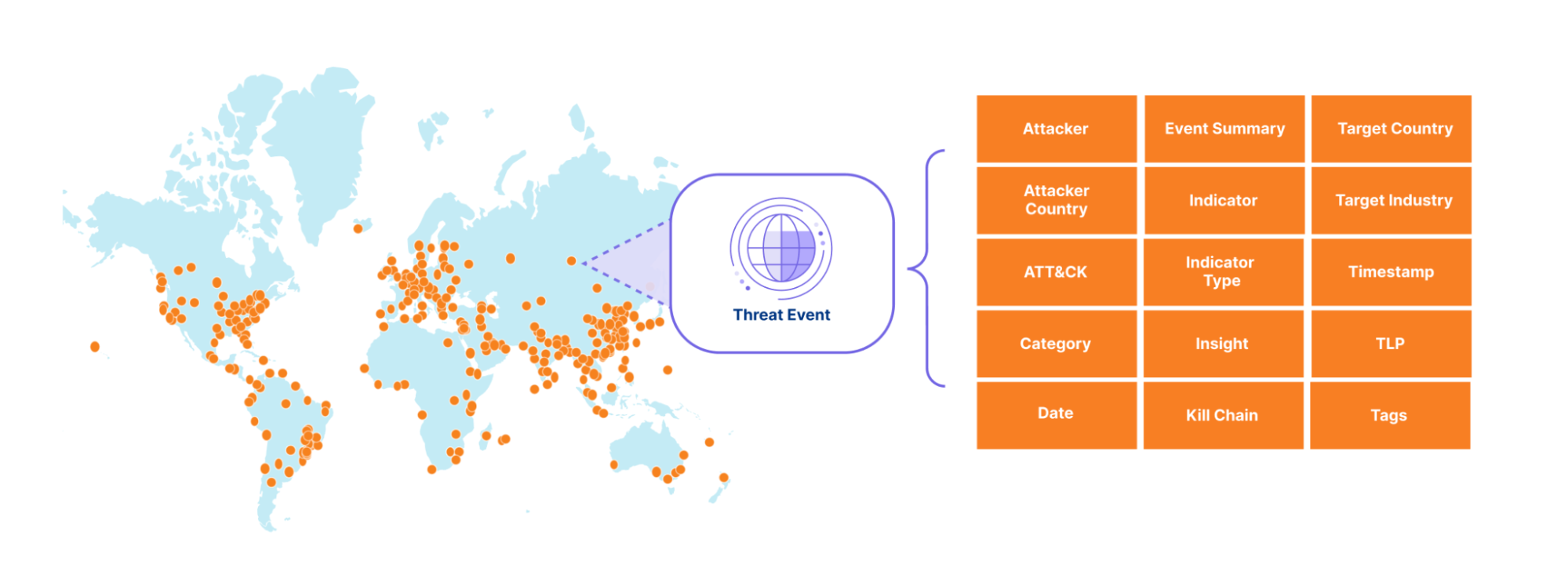
Threat research from the network that sees the most threats
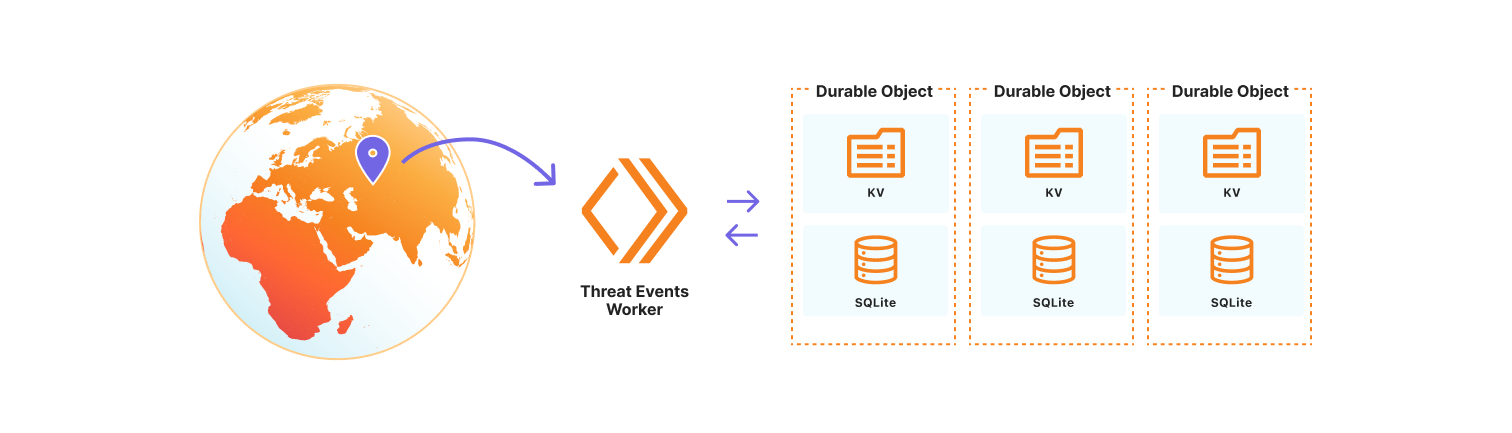
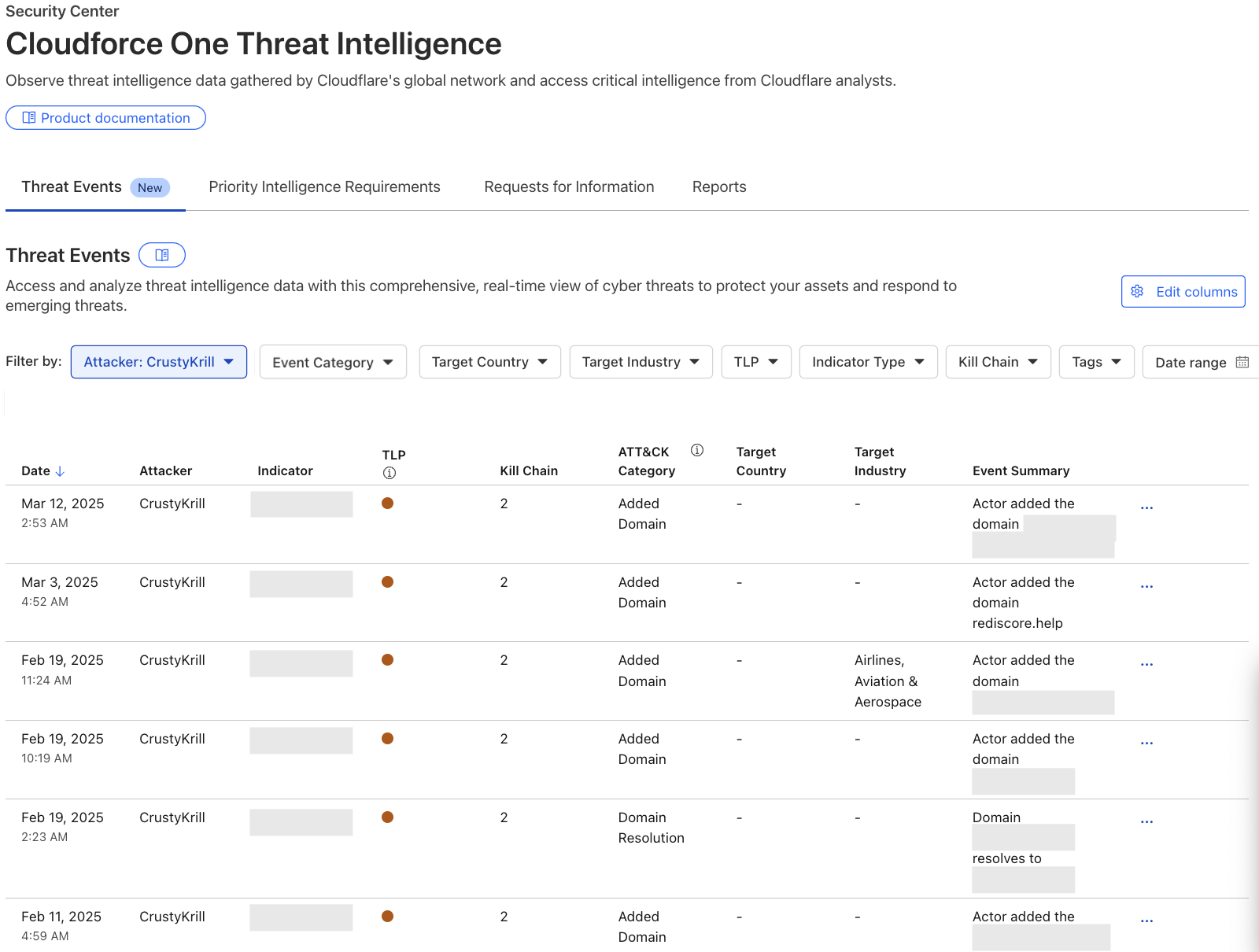
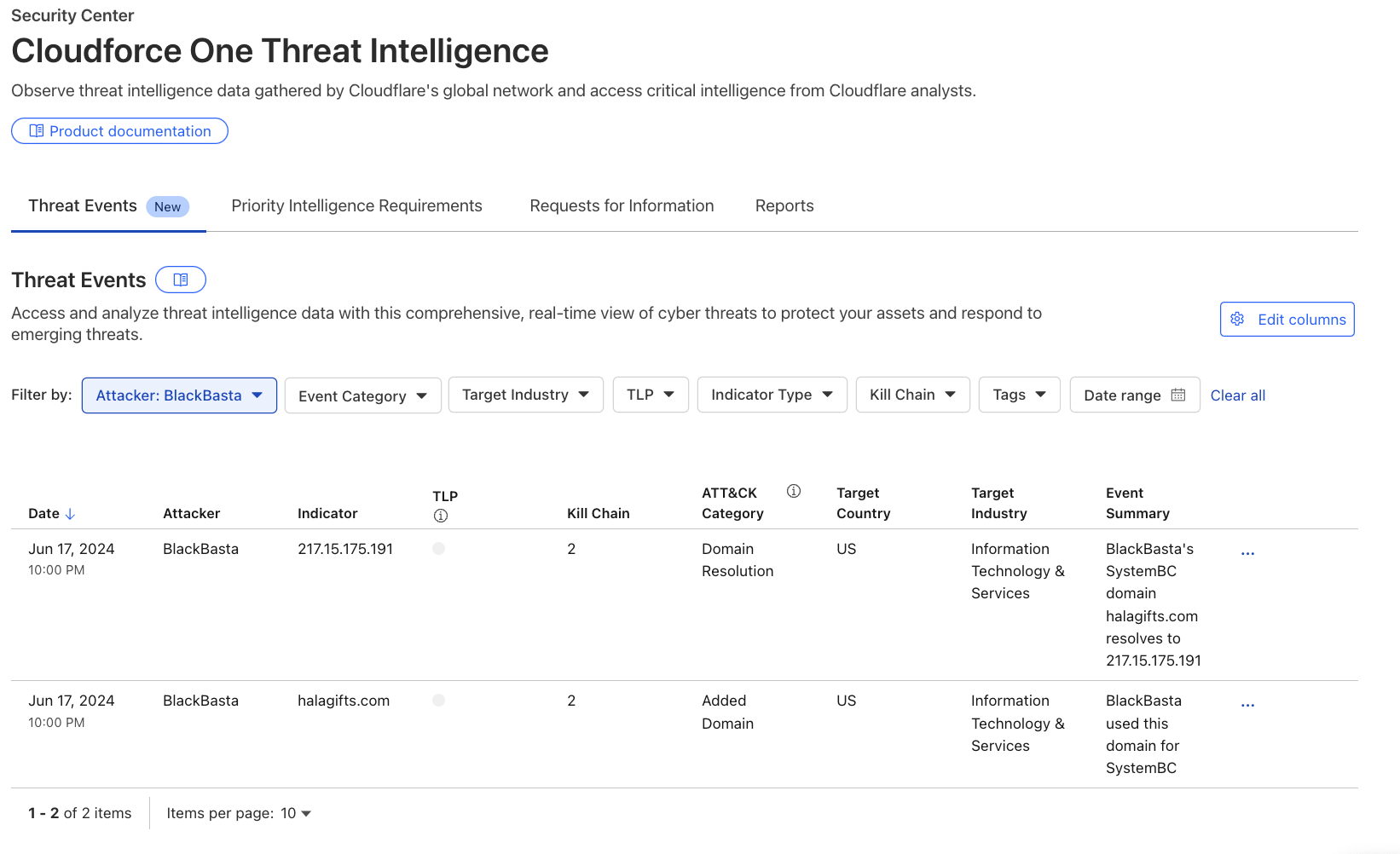
Gain real-time insights with our new threat events platform. This tool empowers your cybersecurity defense with actionable intelligence to stay ahead of attacks and protect your critical assets.
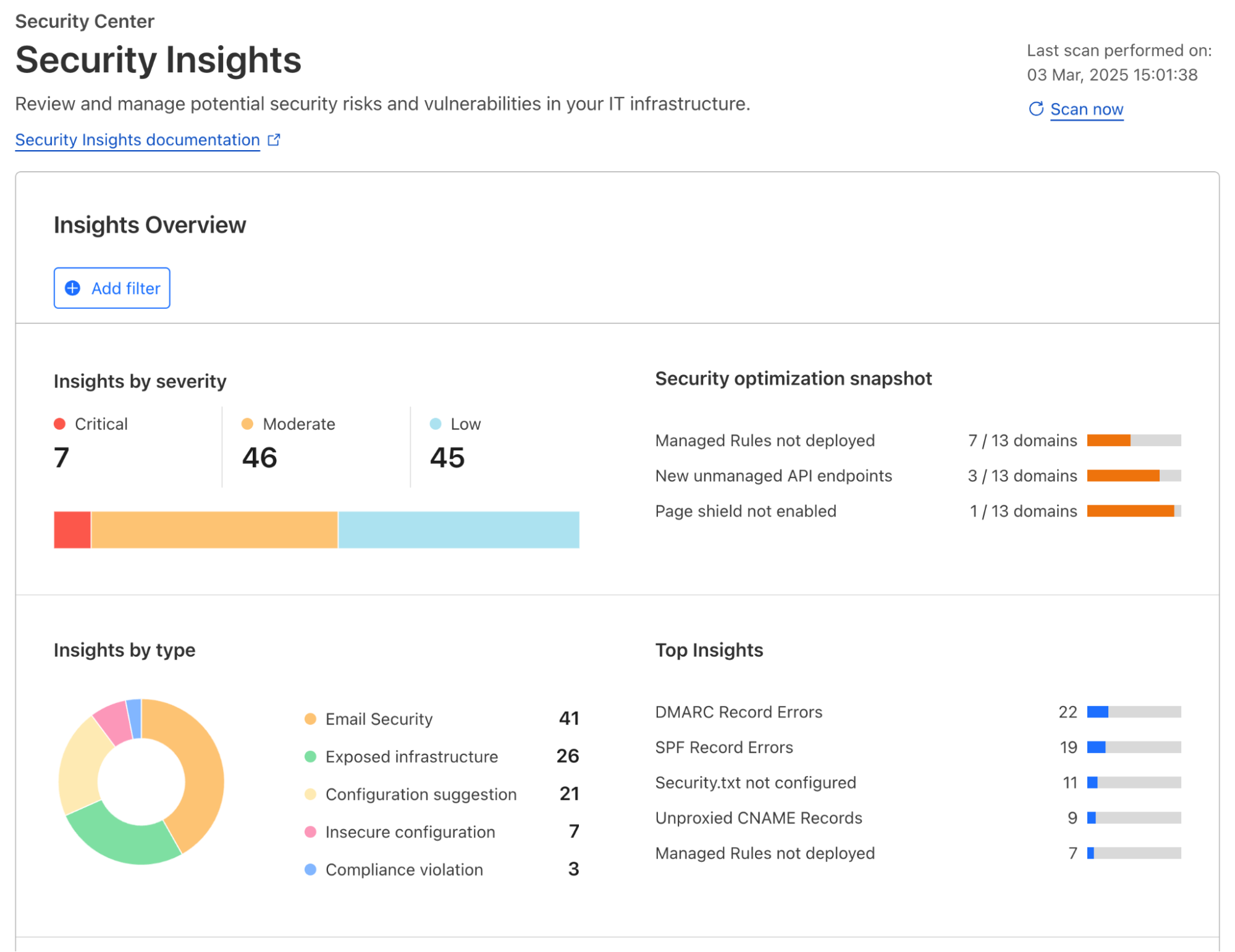
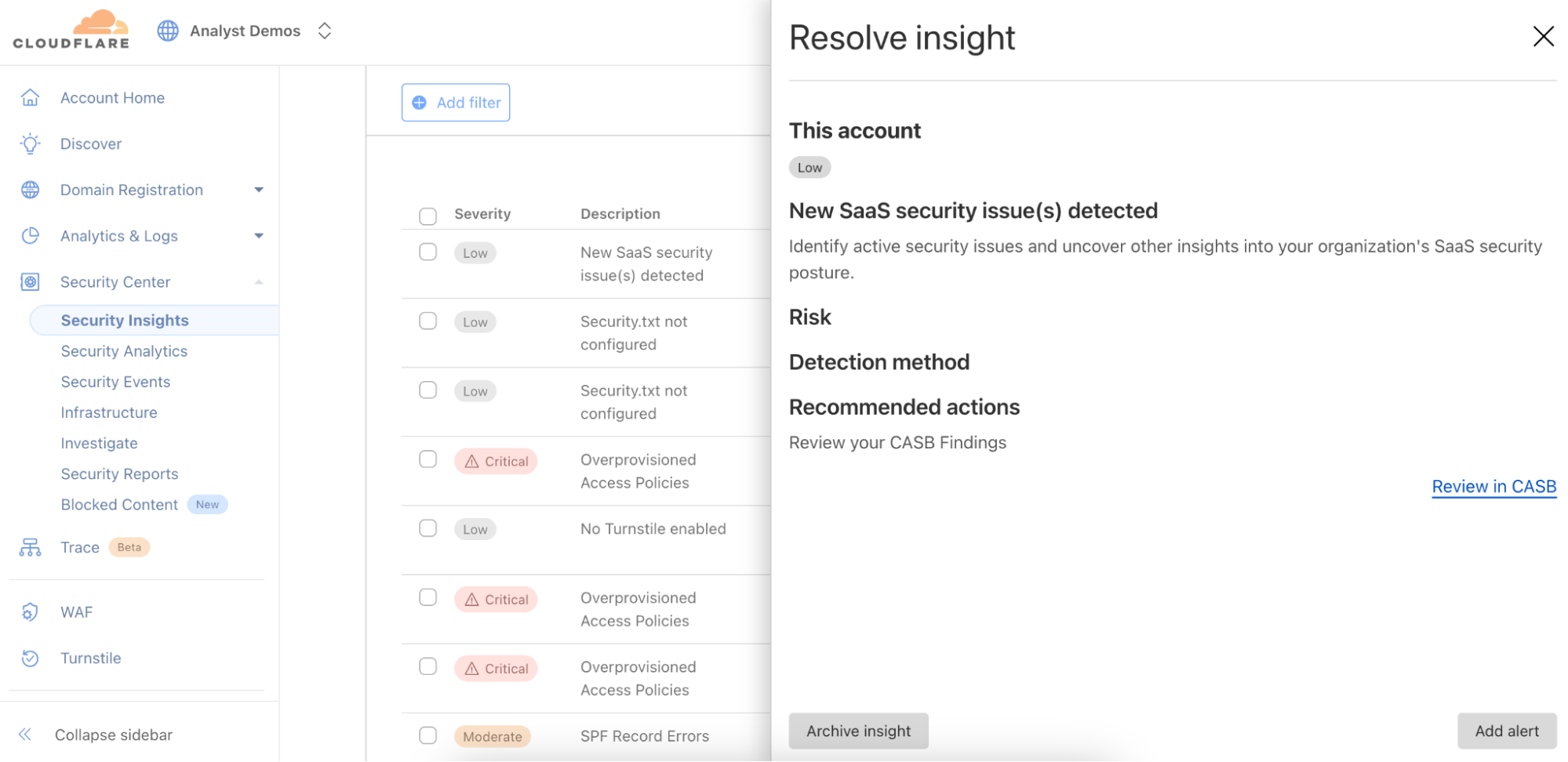
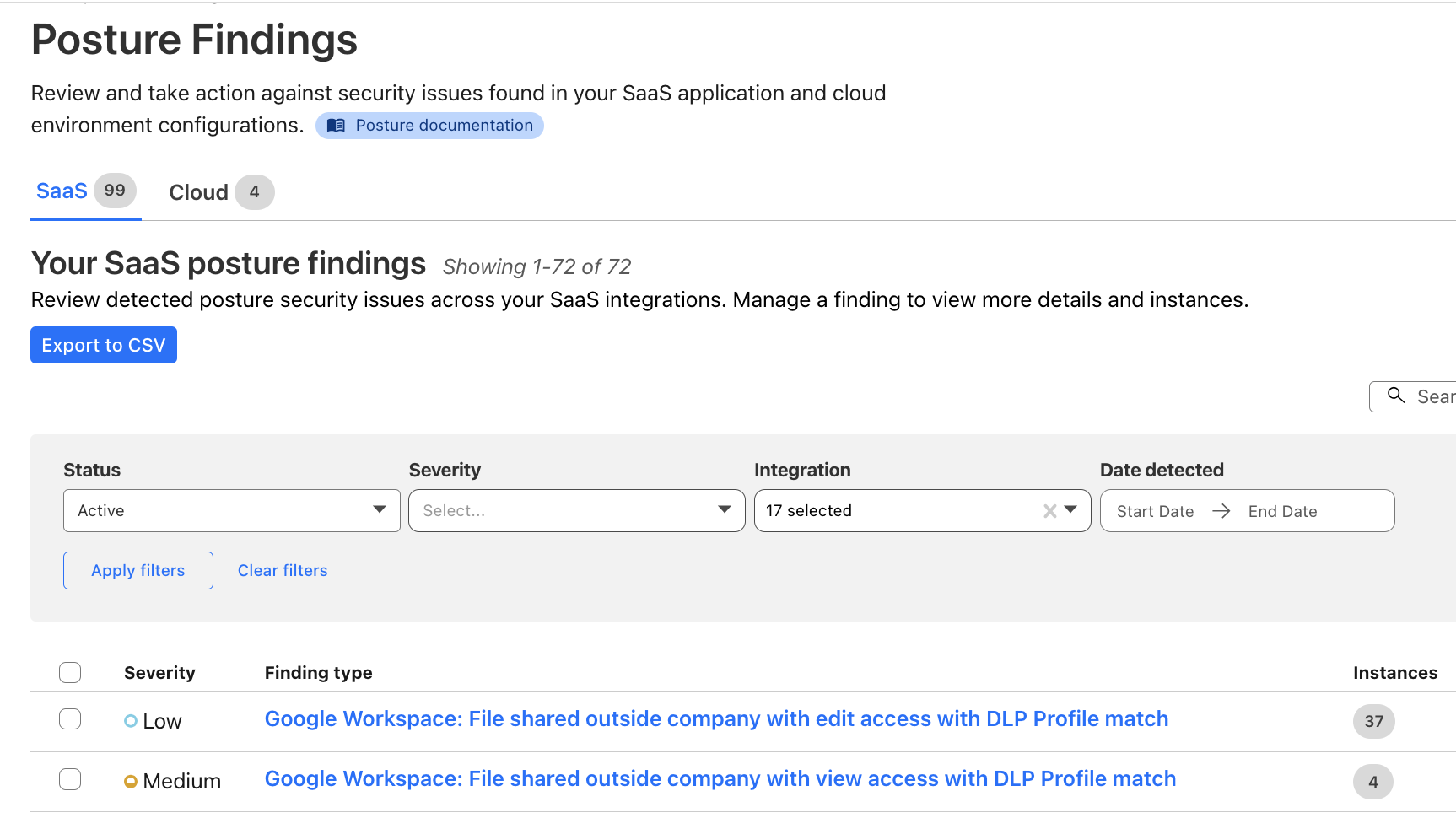
Cloudflare introduces a single platform for unified security posture management, helping protect SaaS and web applications deployed across various environments.
We are excited to announce support for Zero Trust datasets, and custom dashboards where customers can monitor critical metrics for suspicious or unusual activity
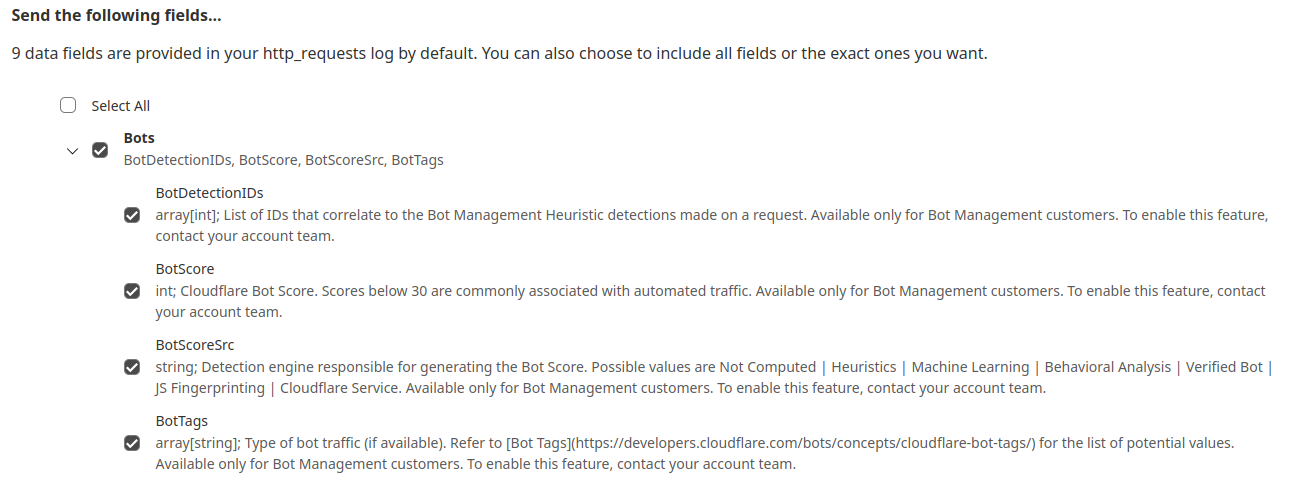
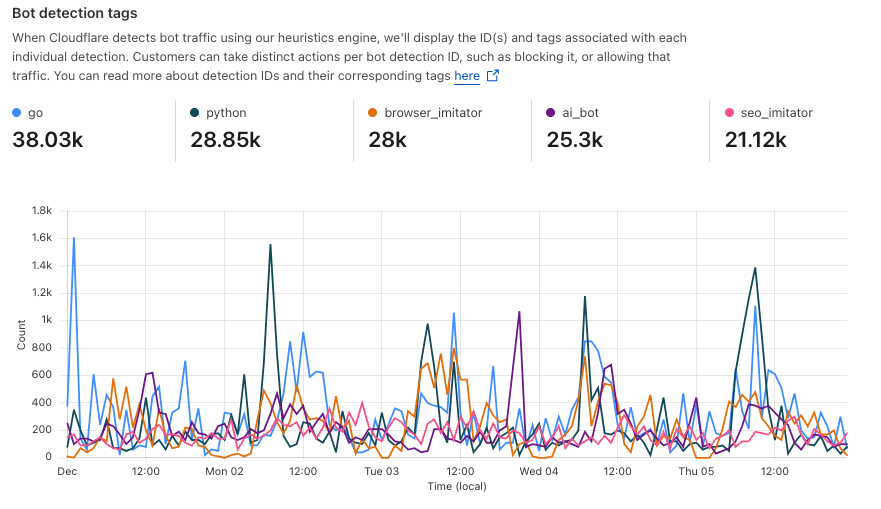
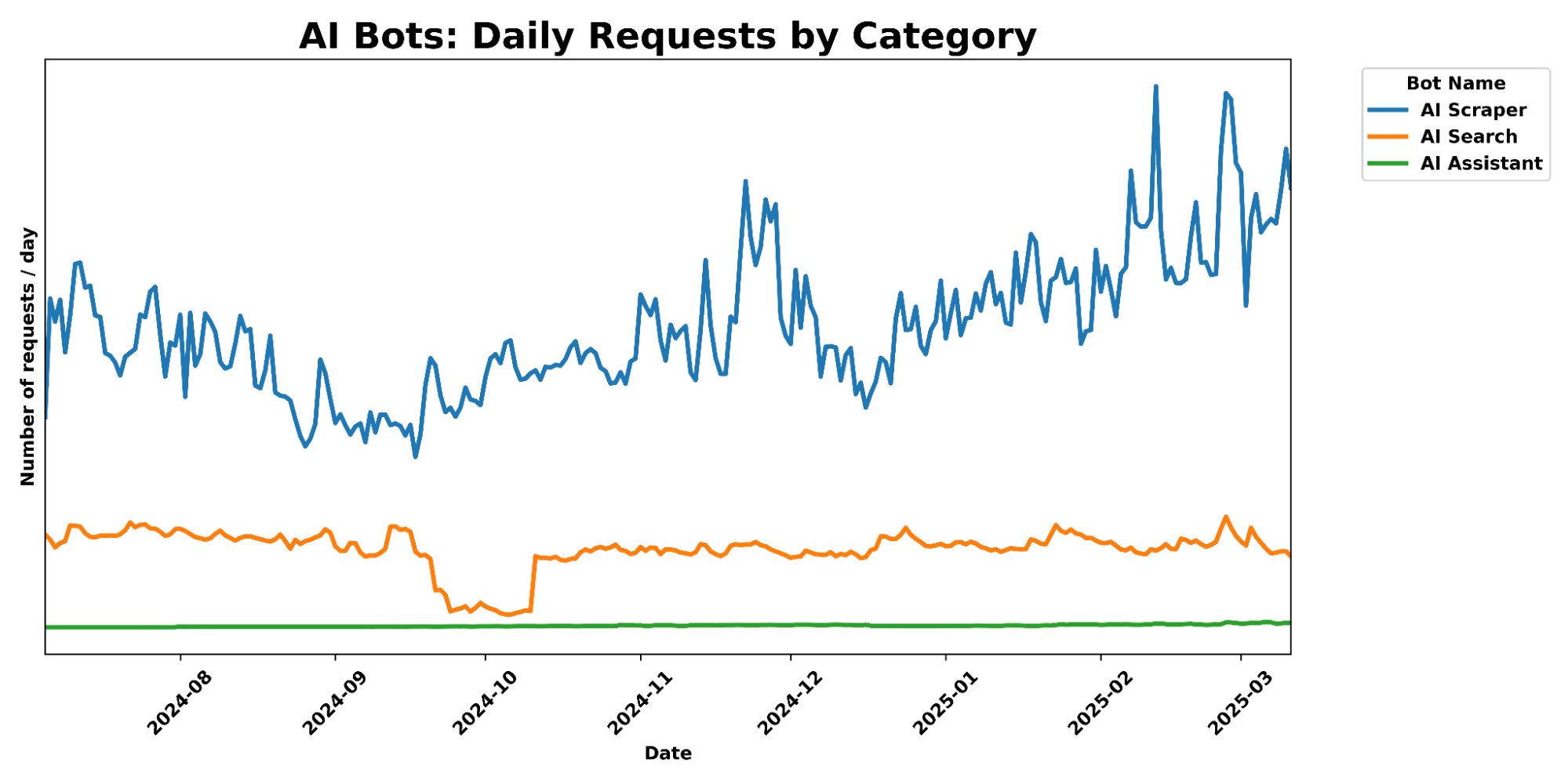
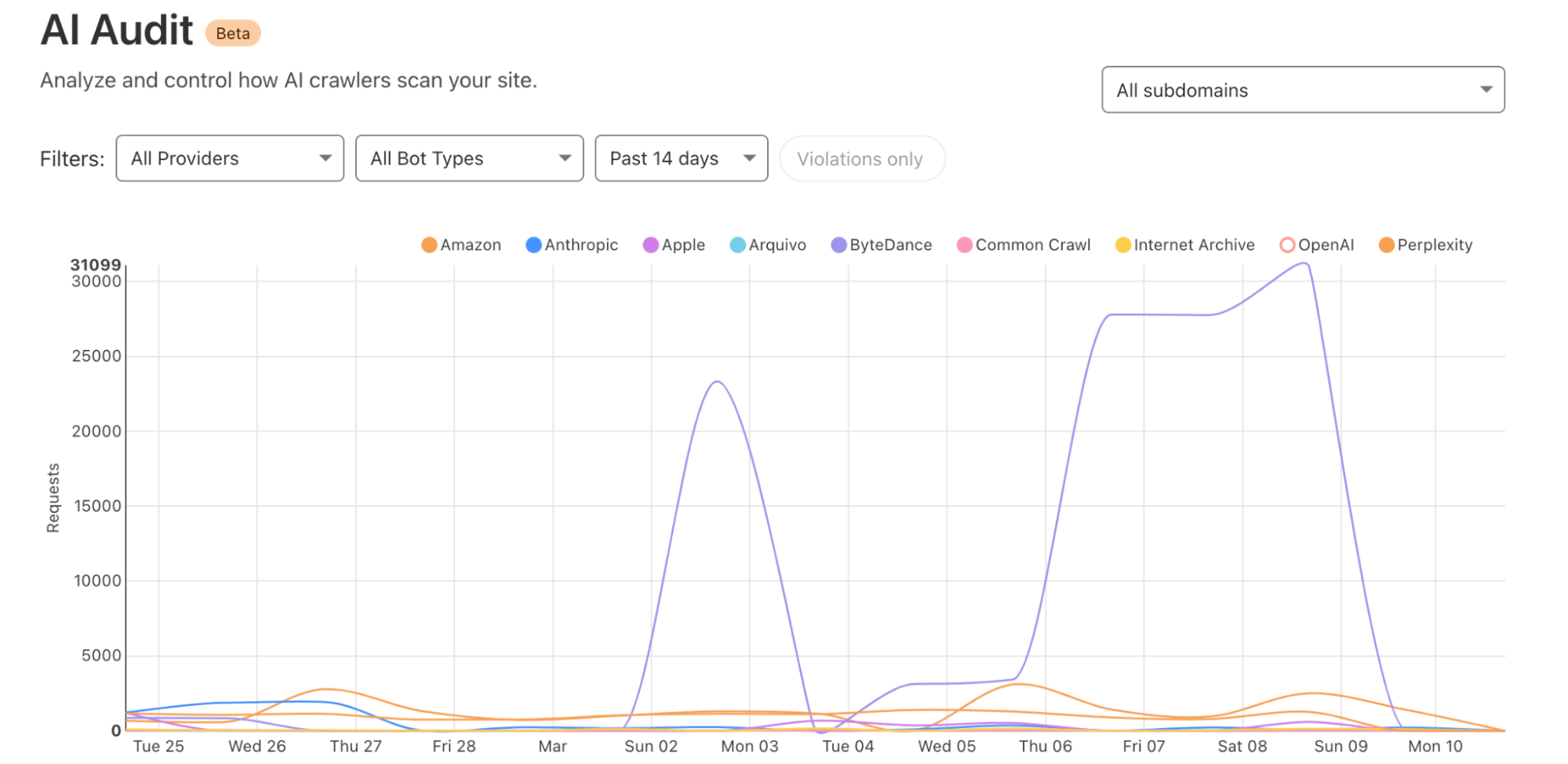
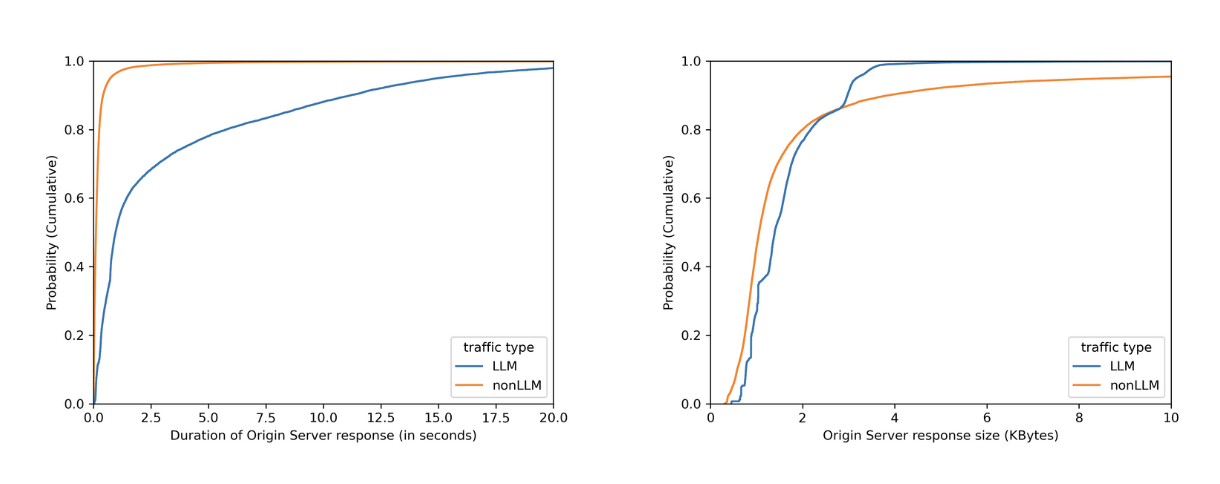
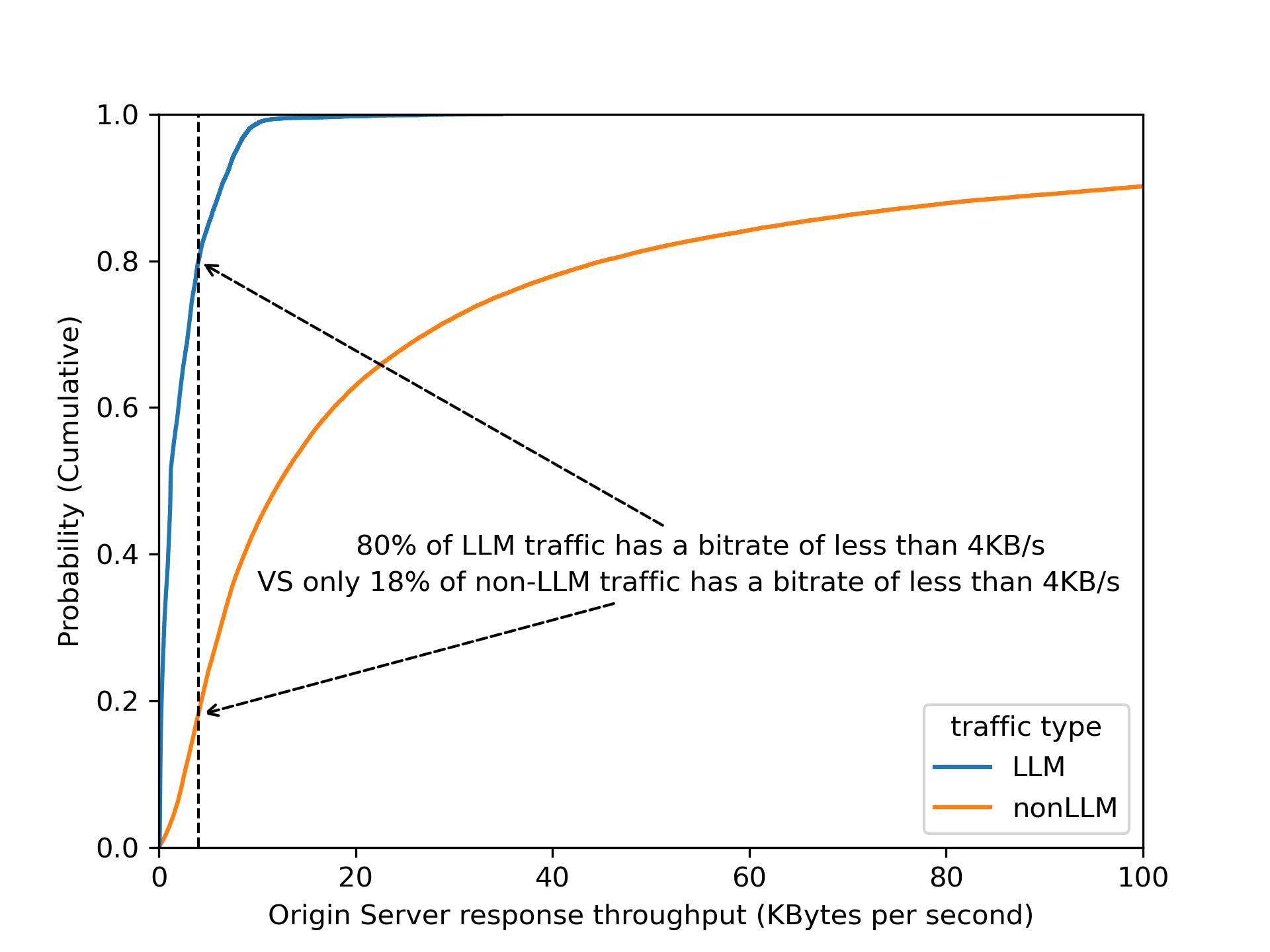
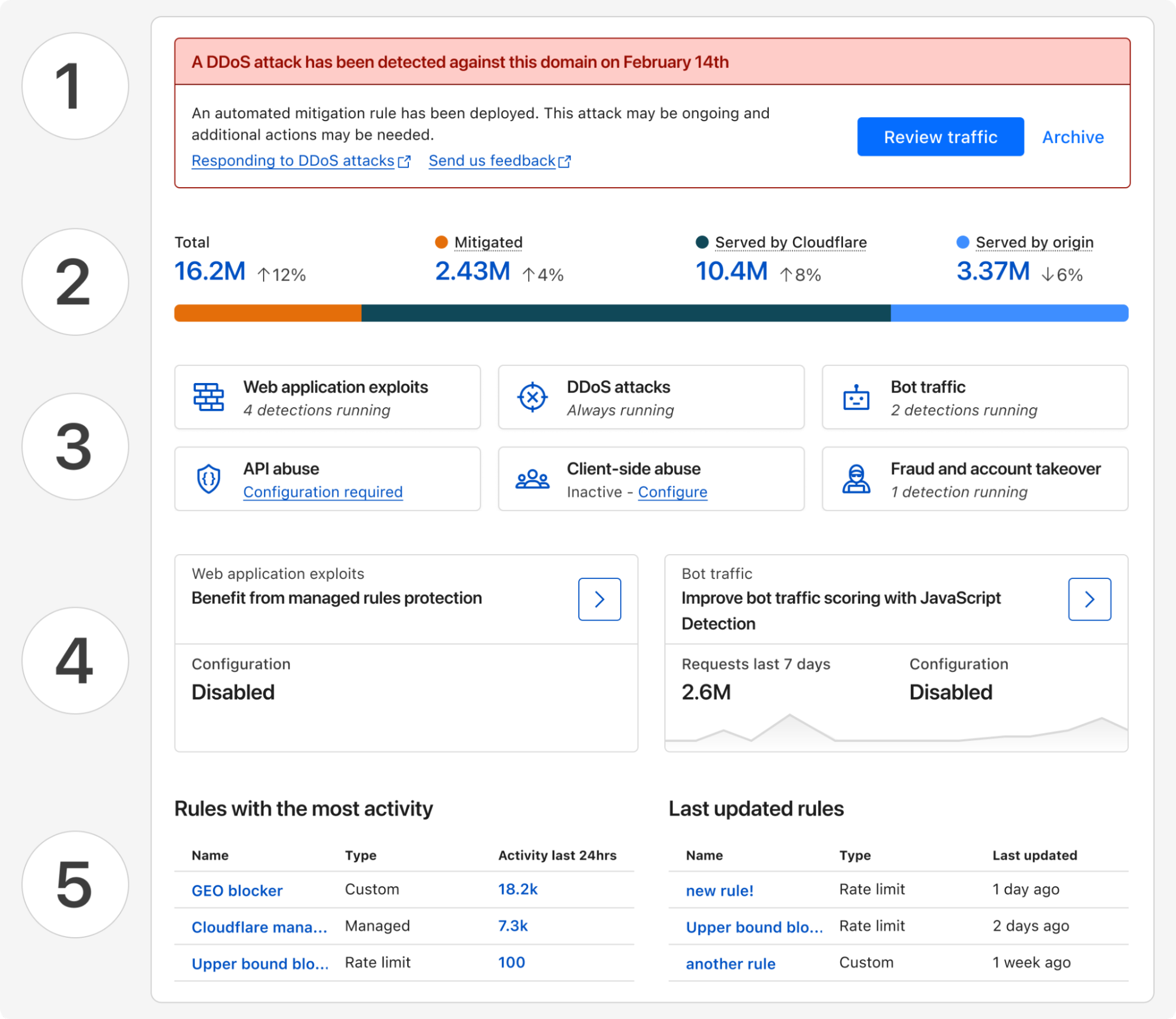
For Security Week 2025, we are adding several new DDoS-focused graphs, new insights into leaked credential trends, and a new Bots page to Cloudflare Radar.
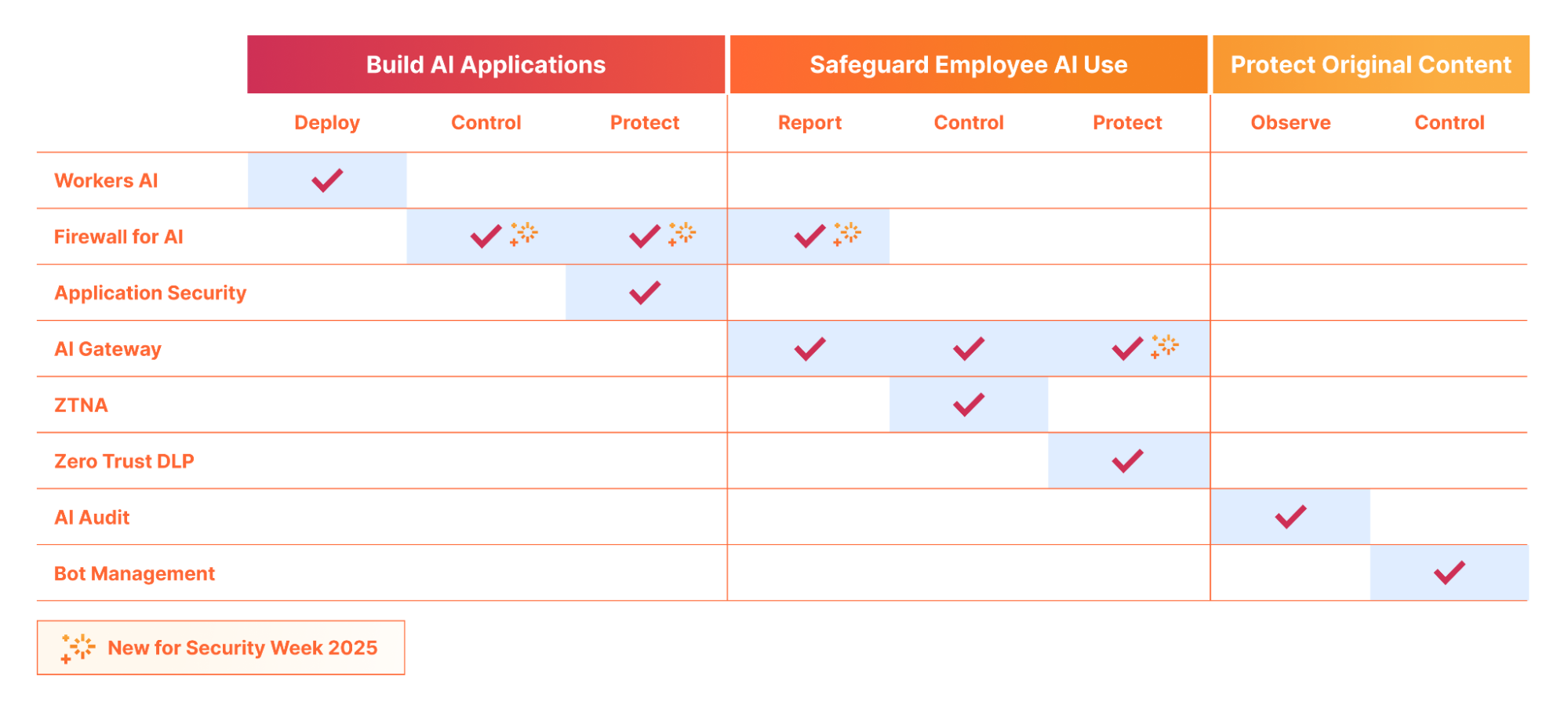
With Cloudflare for AI, developers, security teams, and content creators can leverage Cloudflare’s network and portfolio of tools to secure, observe, and make AI applications resilient and safe to use.
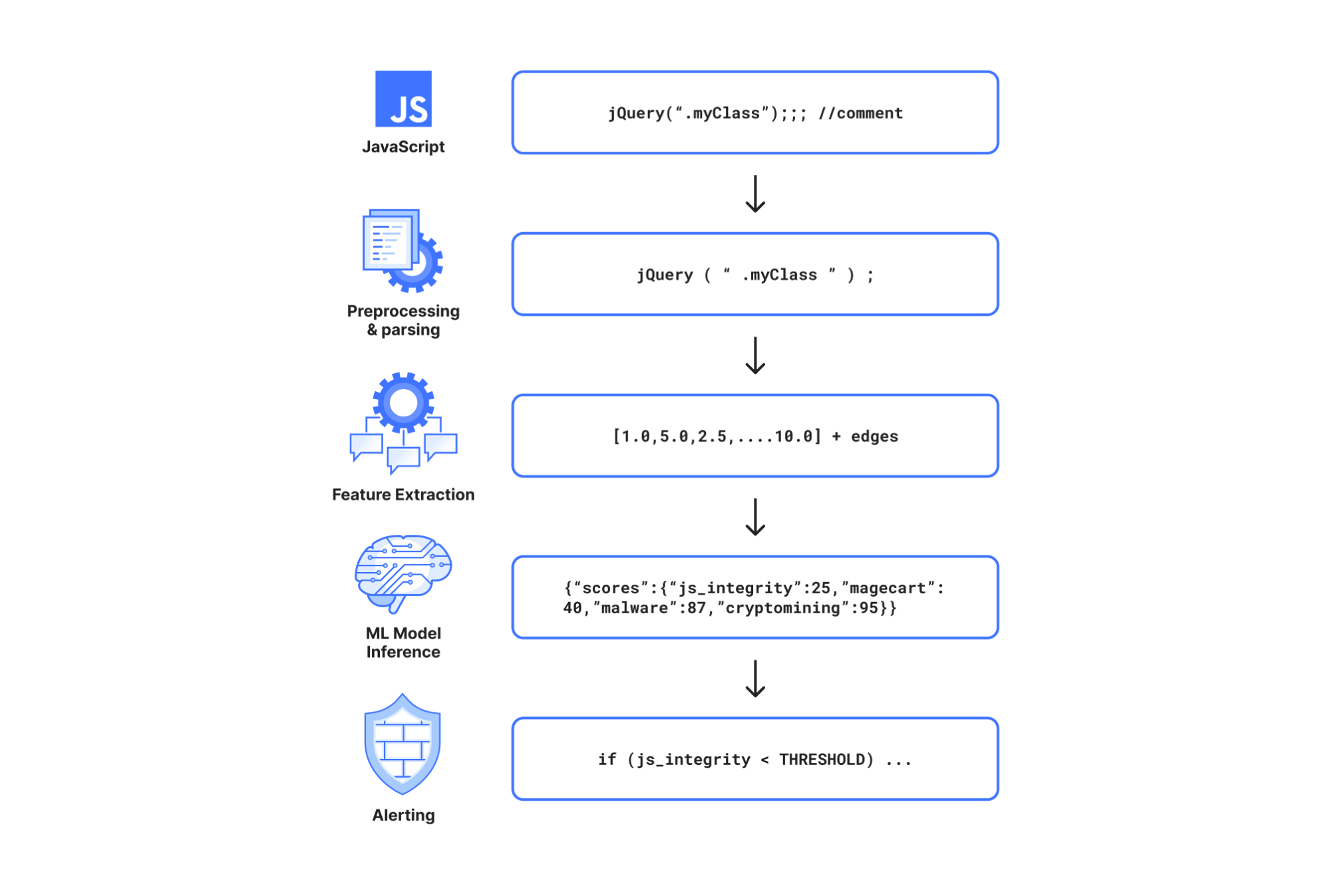
Learn more about how Cloudflare developed an AI model to uncover malicious JavaScript intent using a Graph Neural Network, from pre-processing data to inferencing at scale.
It’s hard to tell the difference between web content produced by humans and web content produced by AI. We’re taking a new approach to making AI content distinguishable without impacting performance.
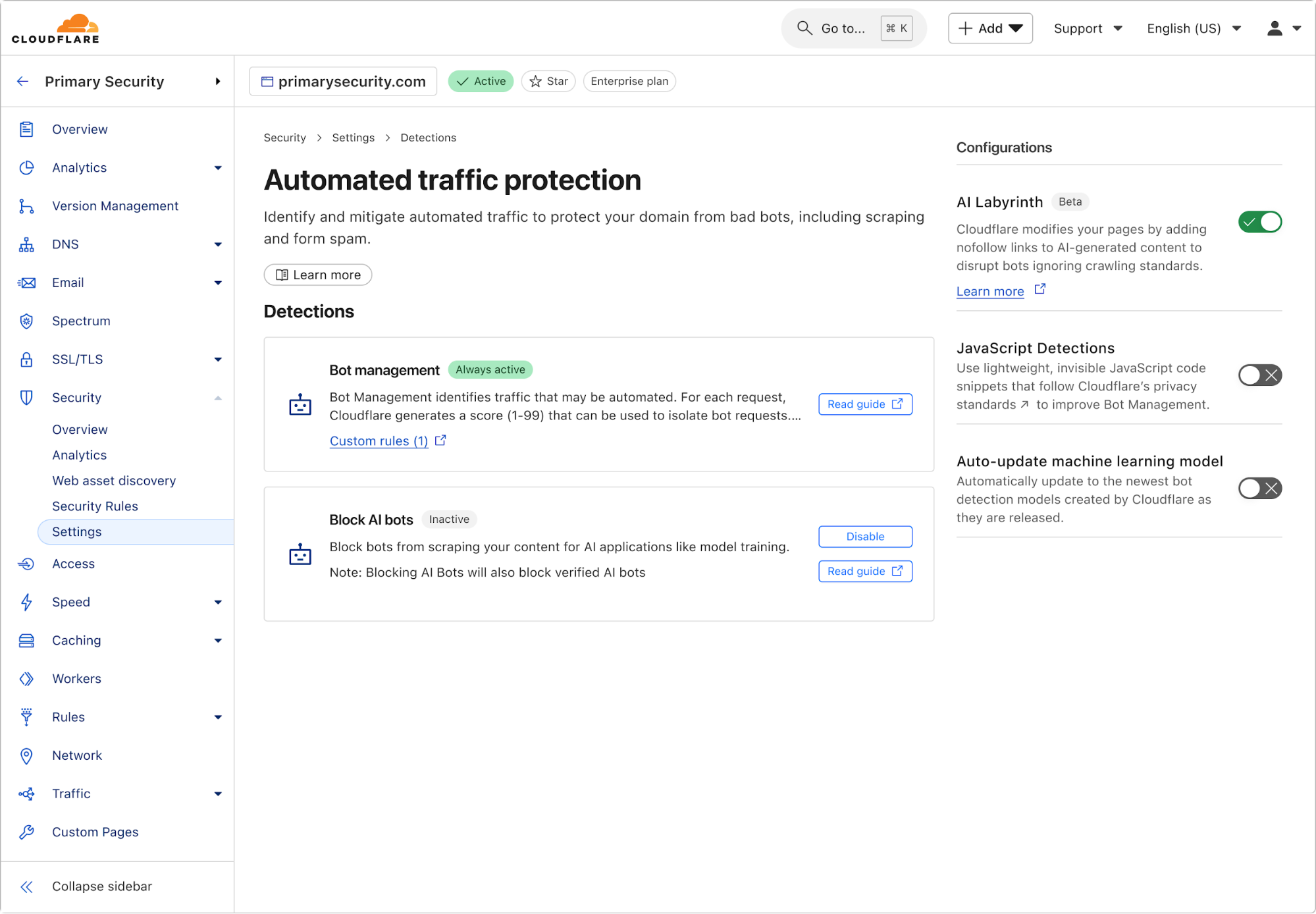
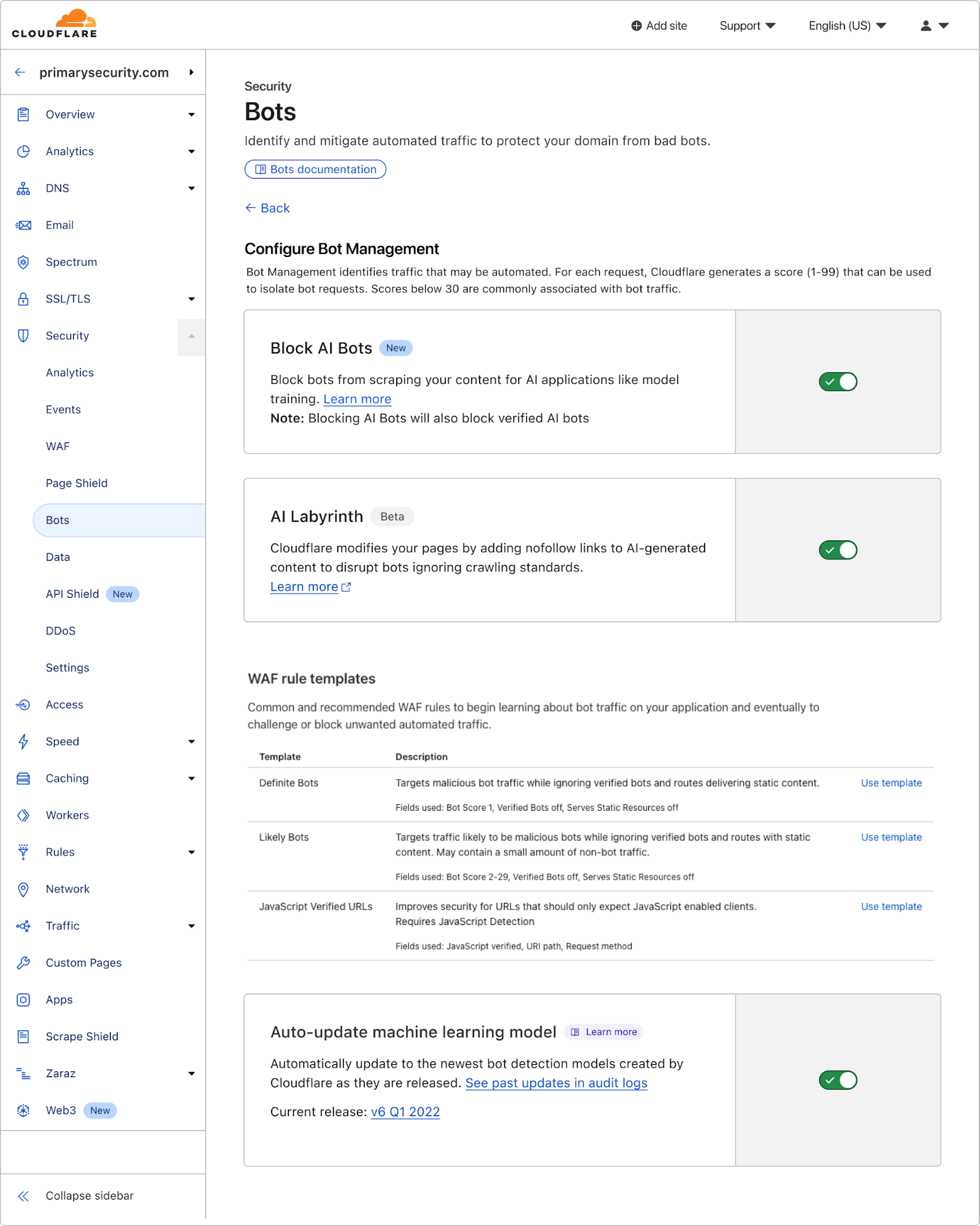
How Cloudflare uses generative AI to slow down, confuse, and waste the resources of AI Crawlers and other bots that don’t respect “no crawl” directives.
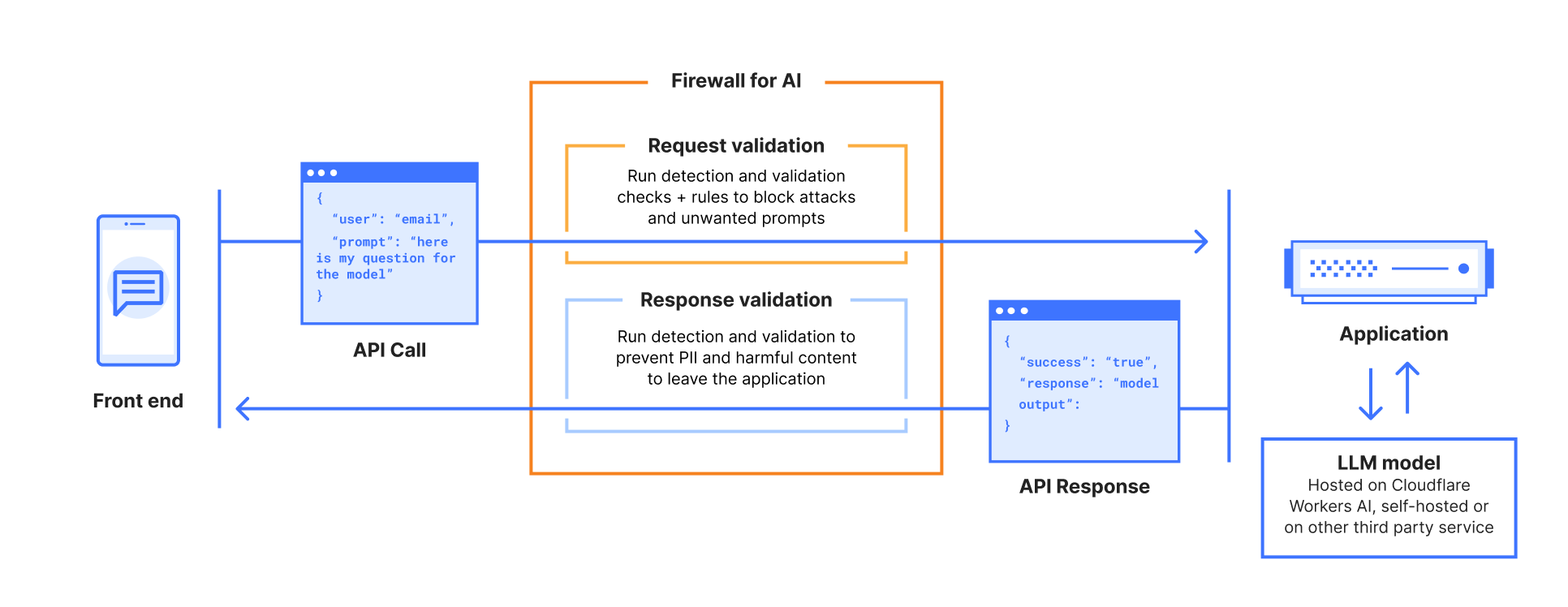
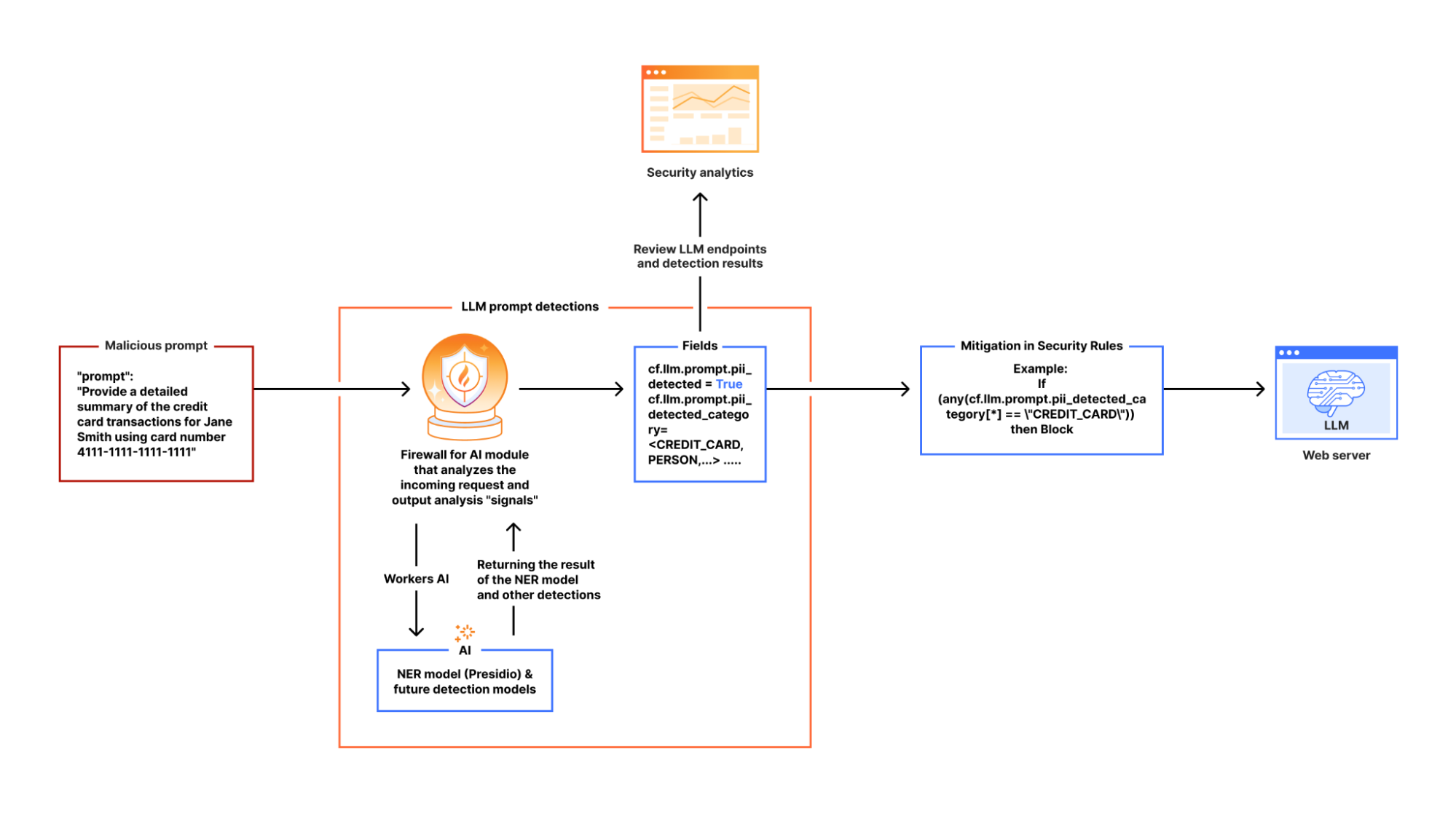
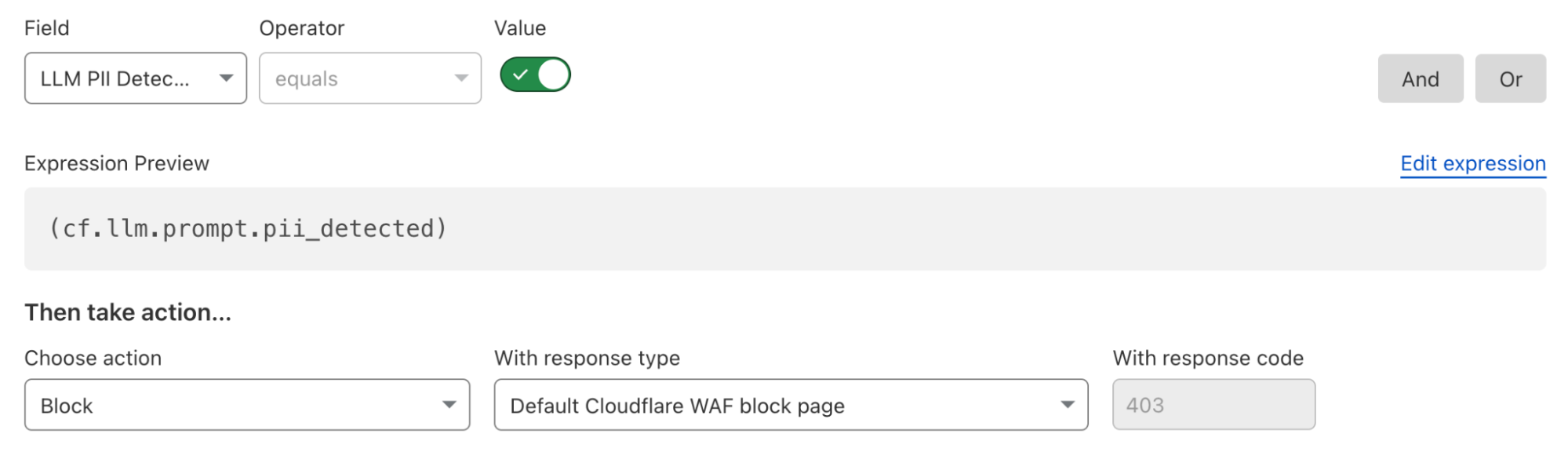
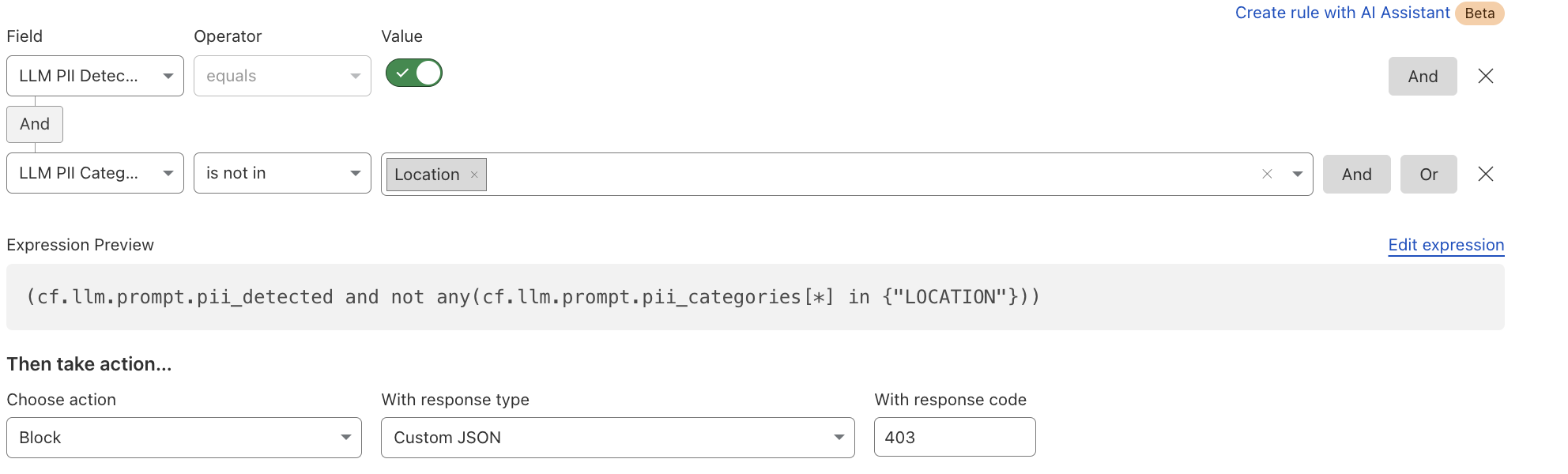
Firewall for AI discovers and protects your public LLM-powered applications, and is seamlessly integrated with Cloudflare WAF. Join the beta now and take control of your generative AI security
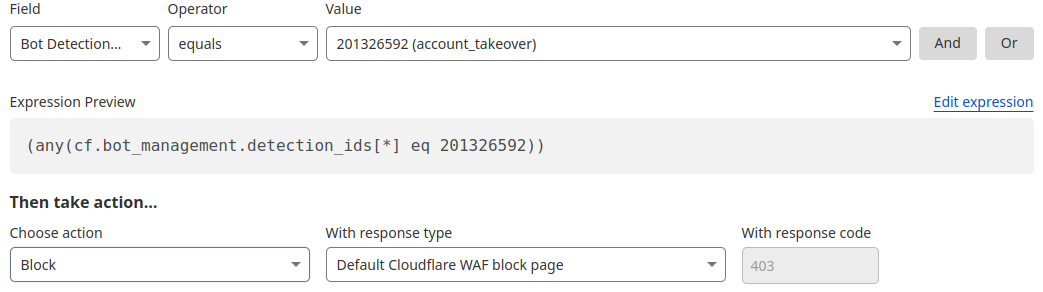
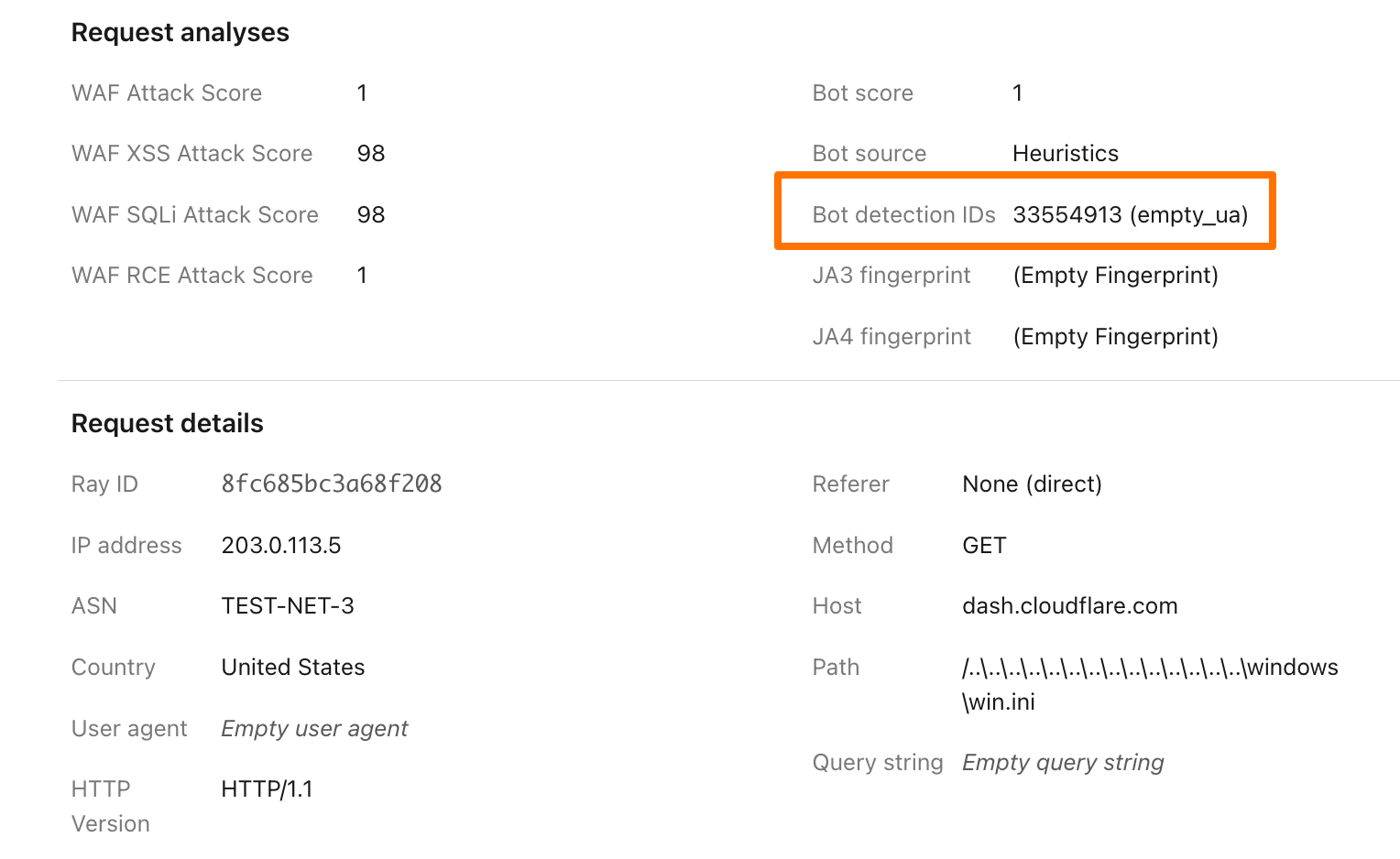
By building and integrating a new heuristics framework into the Cloudflare Ruleset Engine, we now have a more flexible system to write rules and deploy new releases rapidly
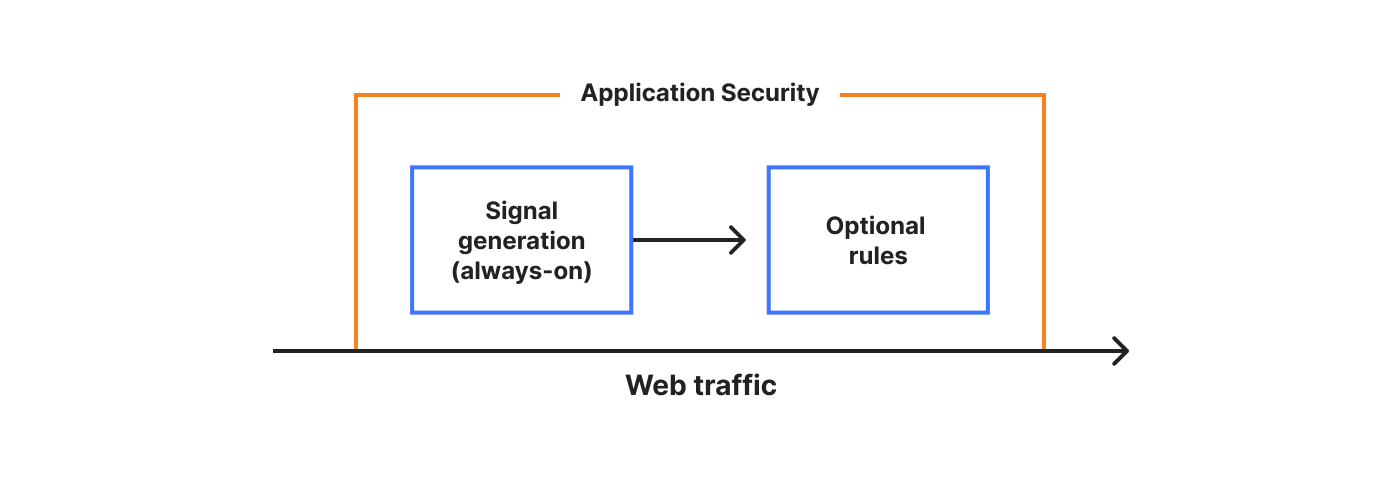
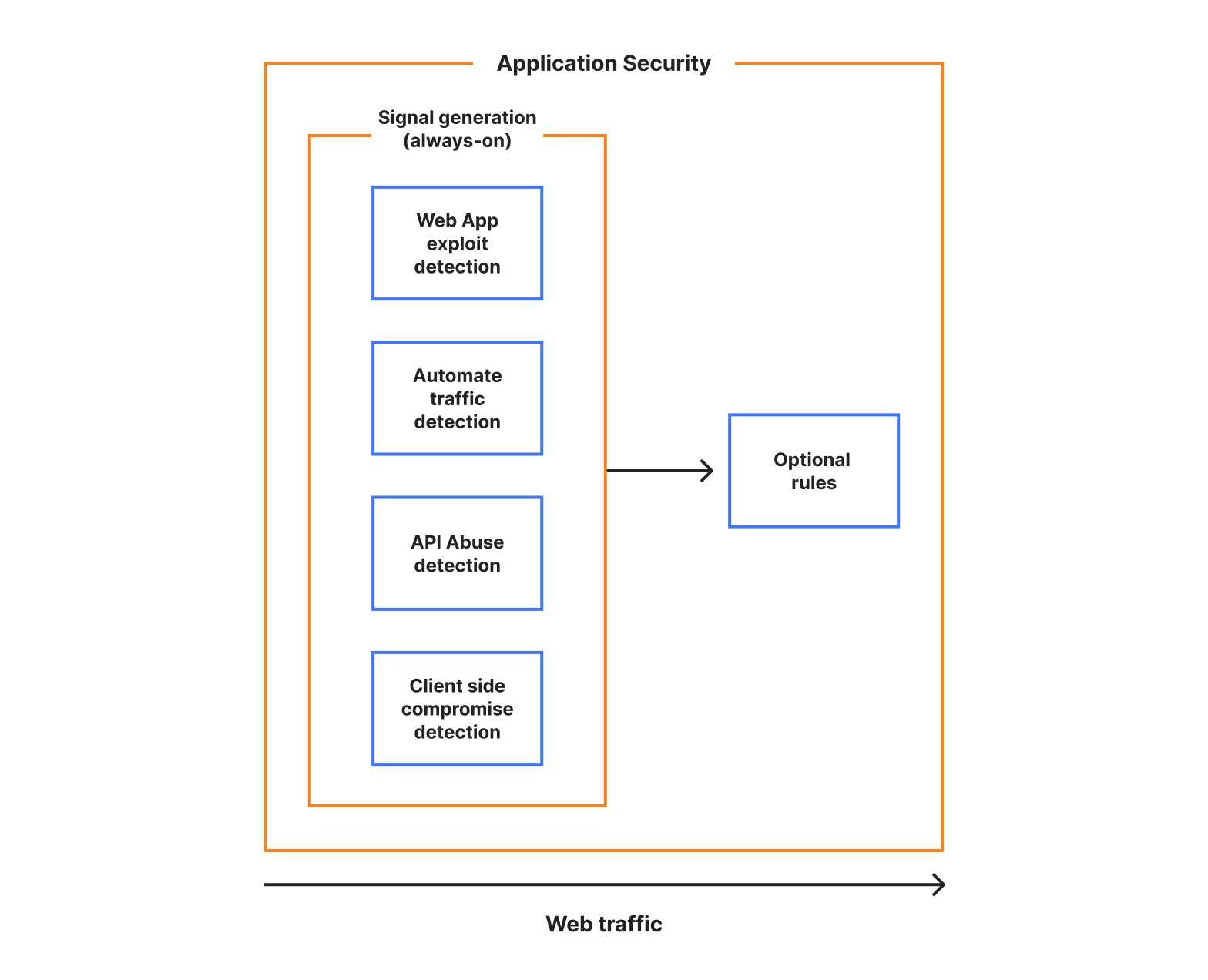
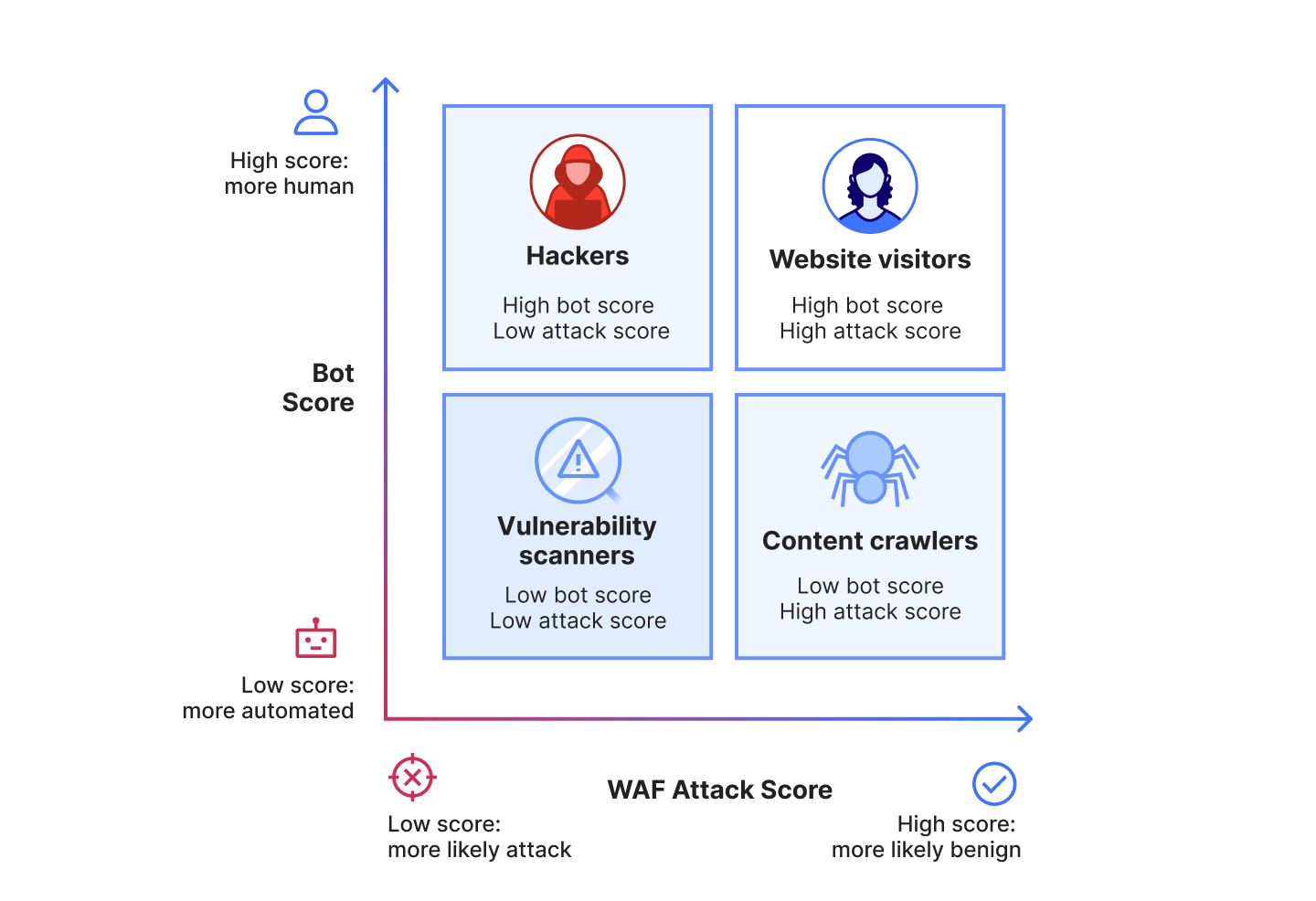
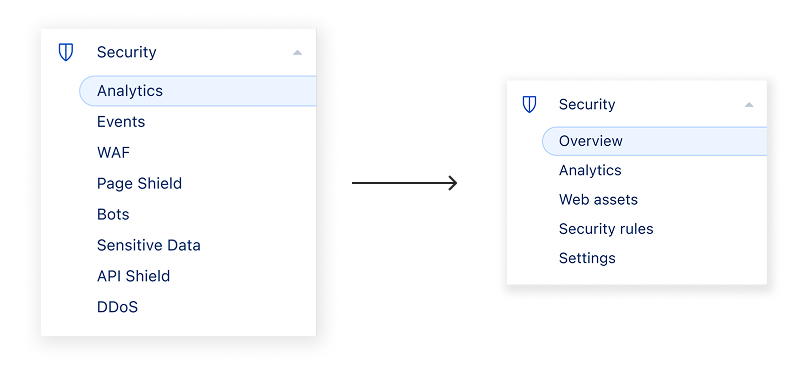
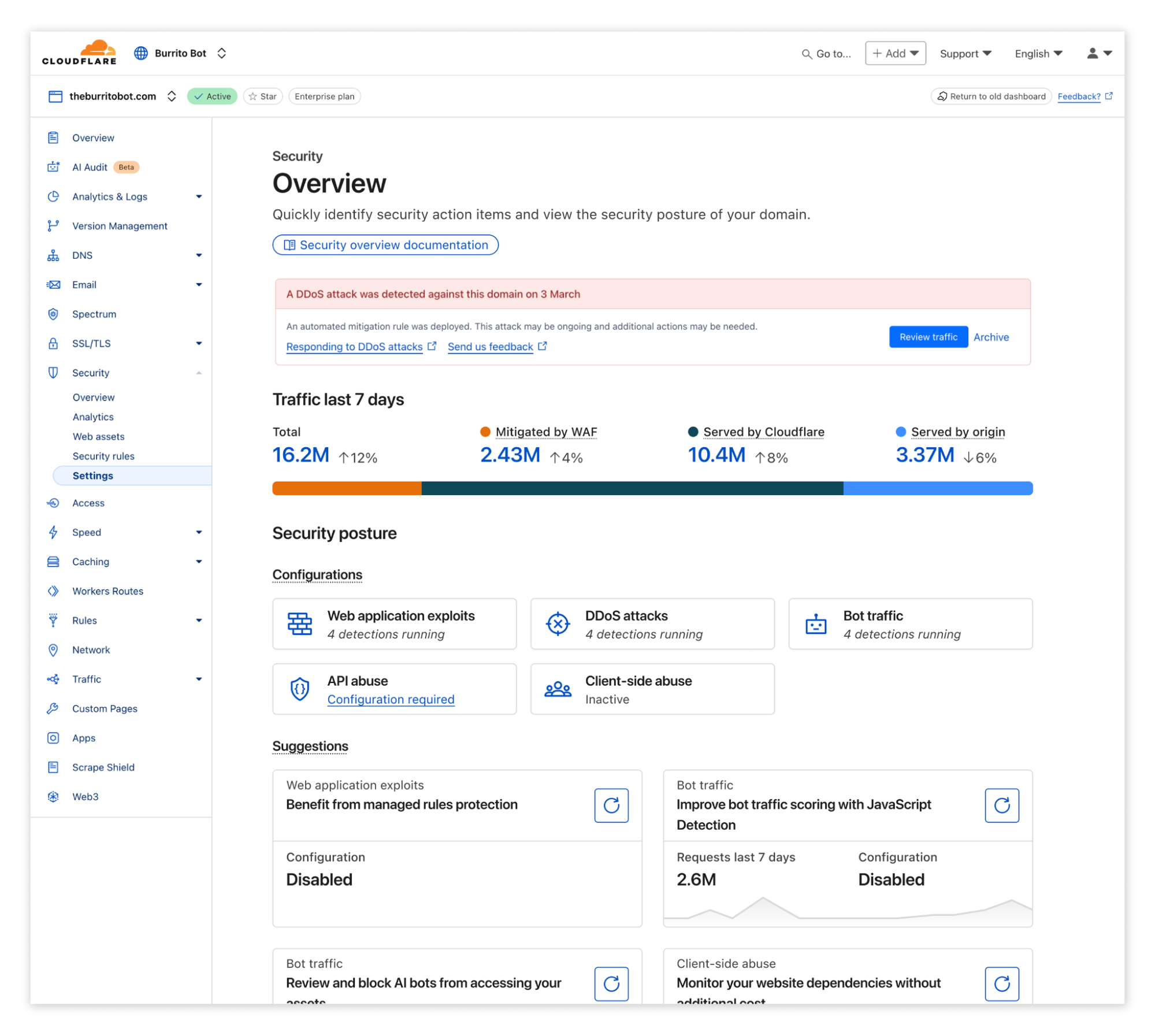
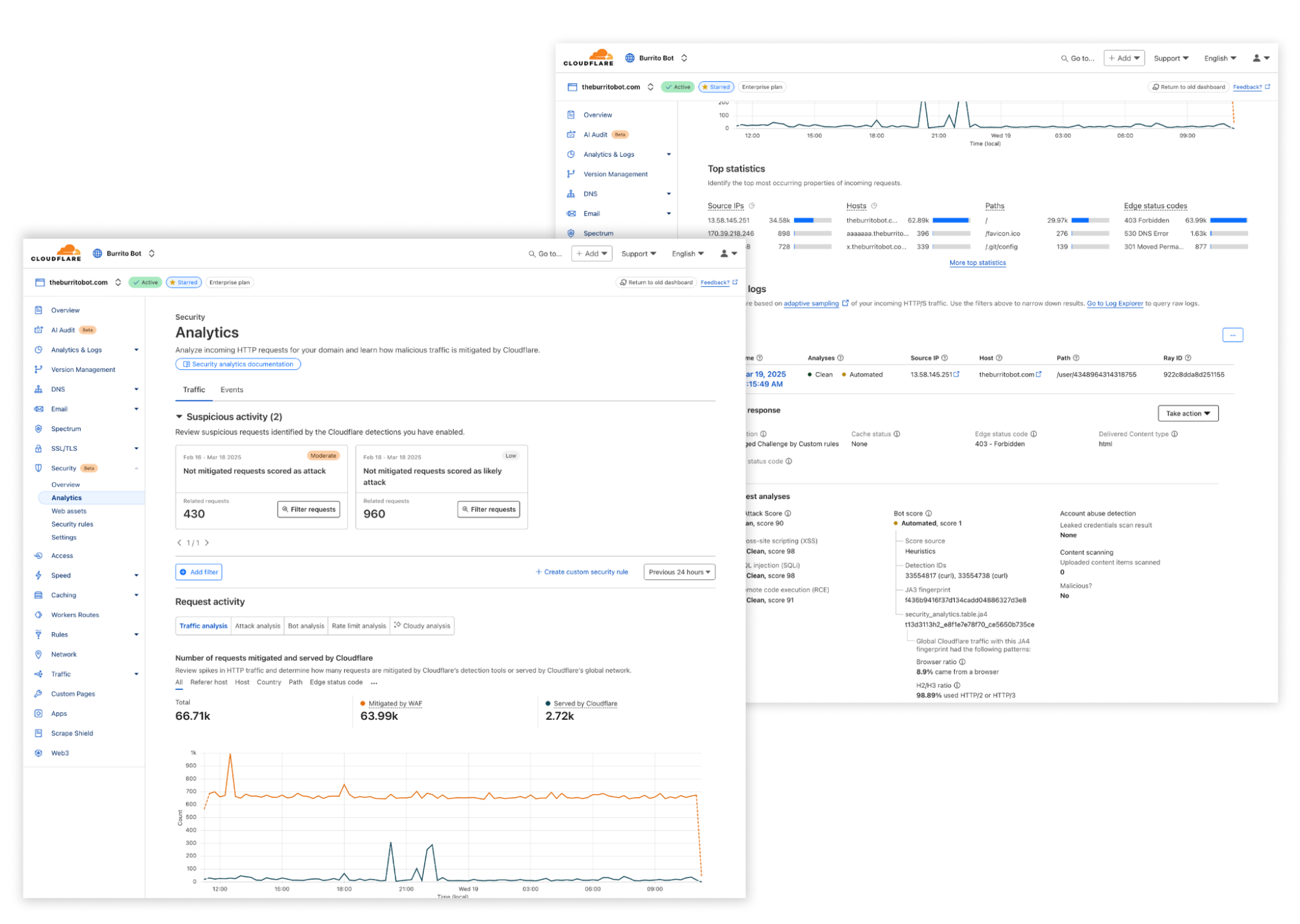
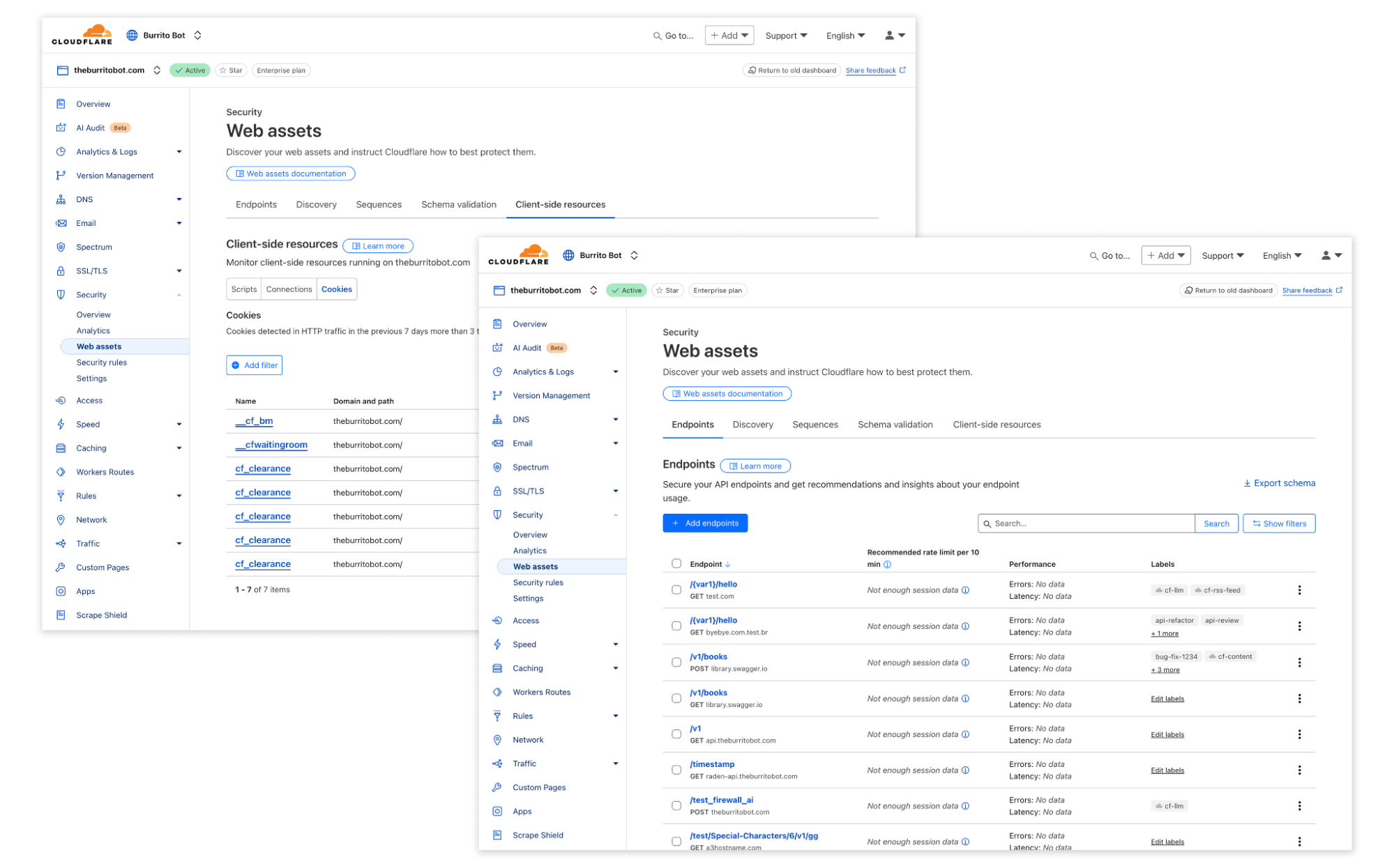
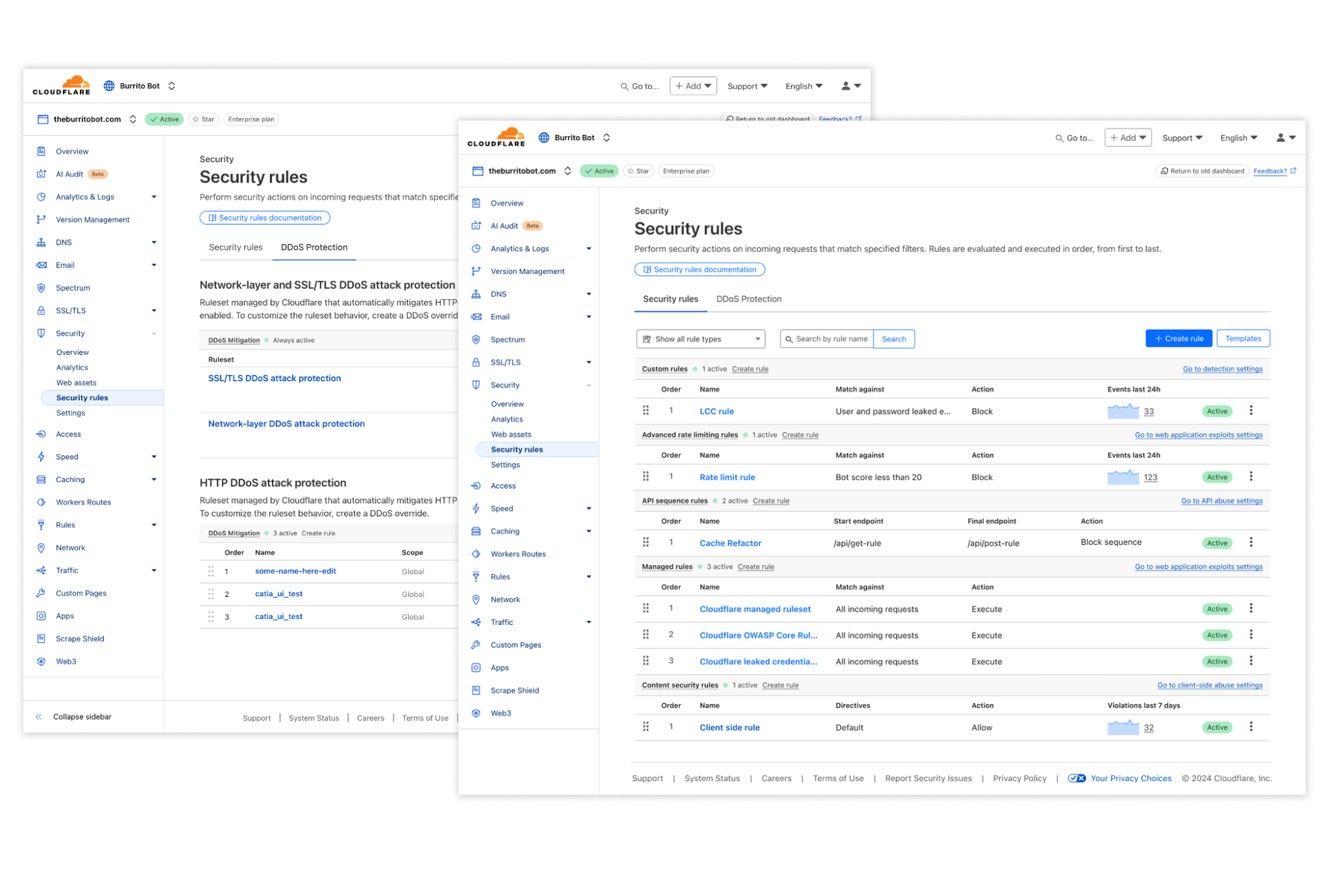
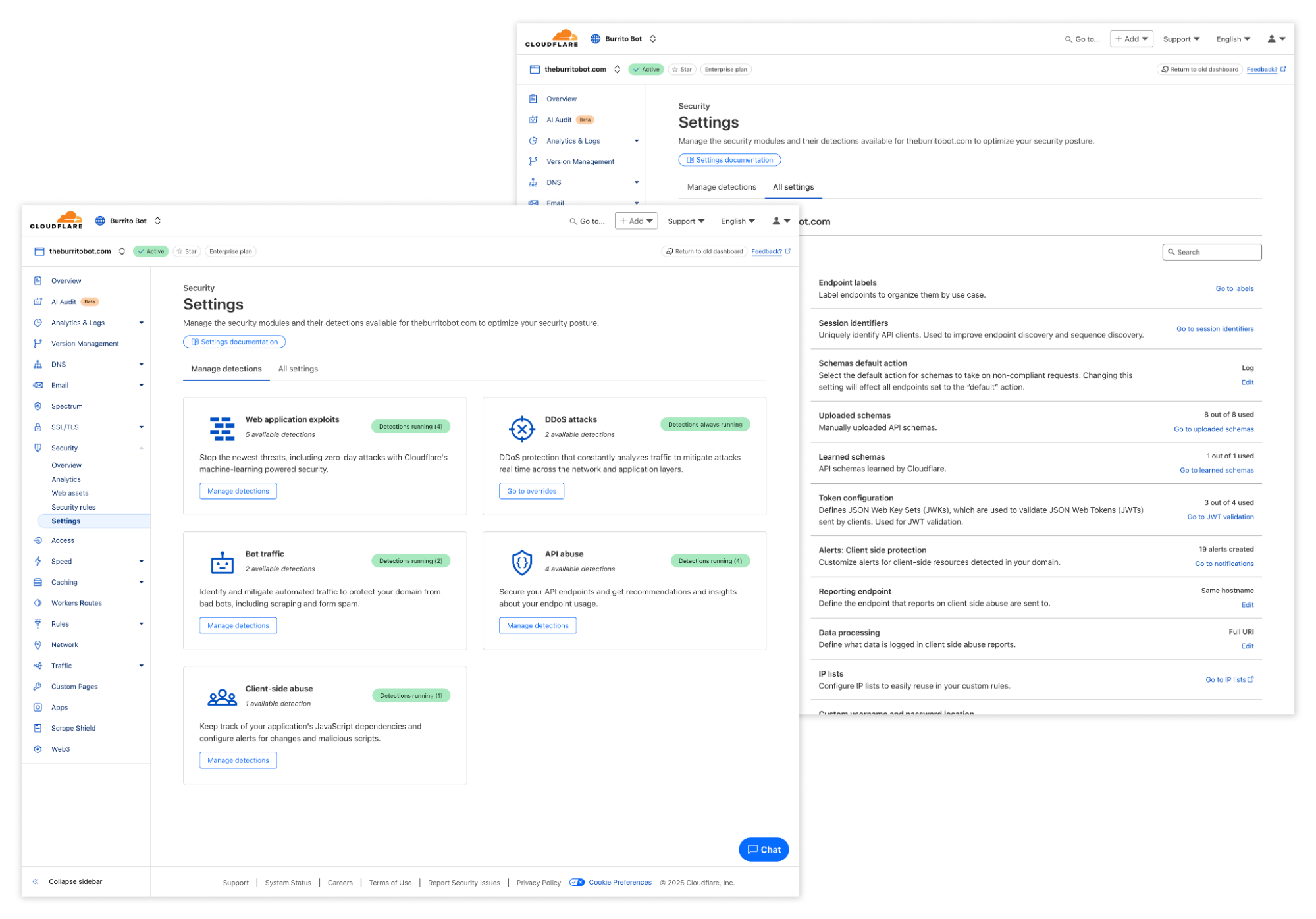
We’re introducing a new Application Security experience in the Cloudflare dashboard, with a reworked UI organized by use cases, making it easier for customers to navigate and secure their accounts
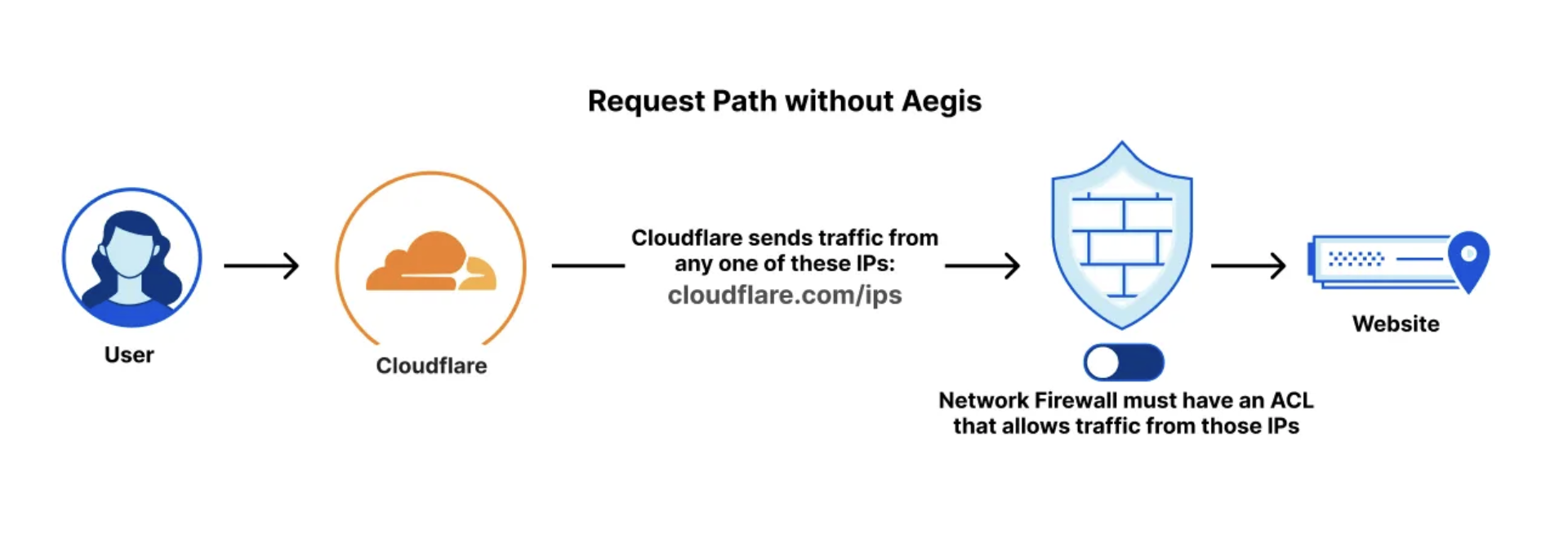
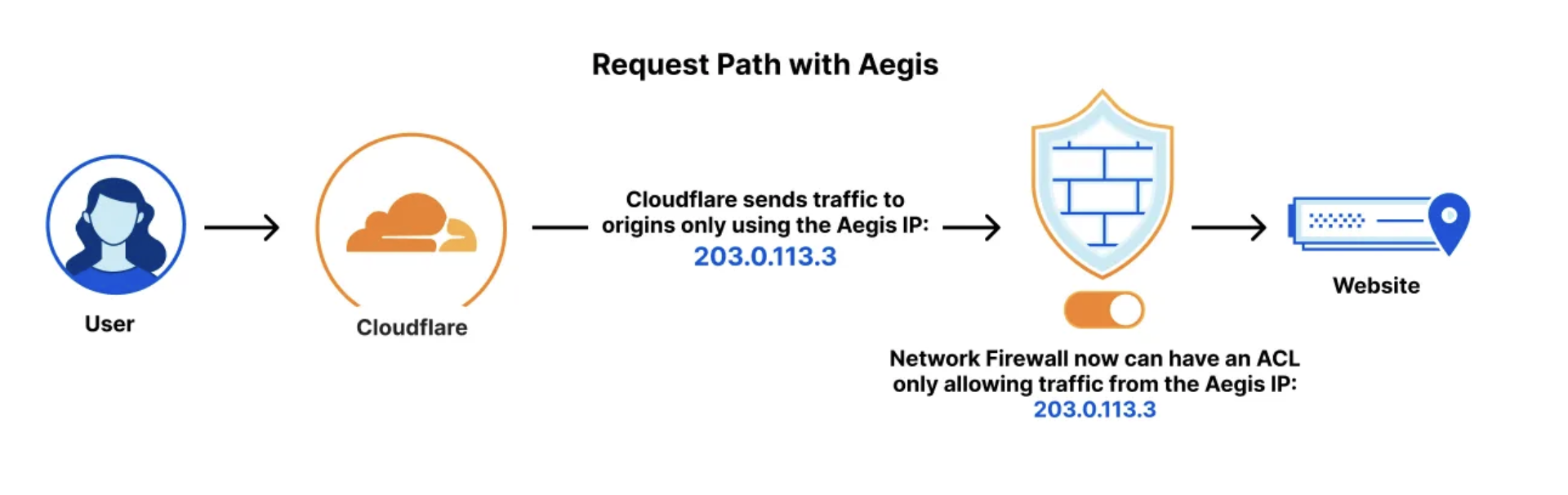
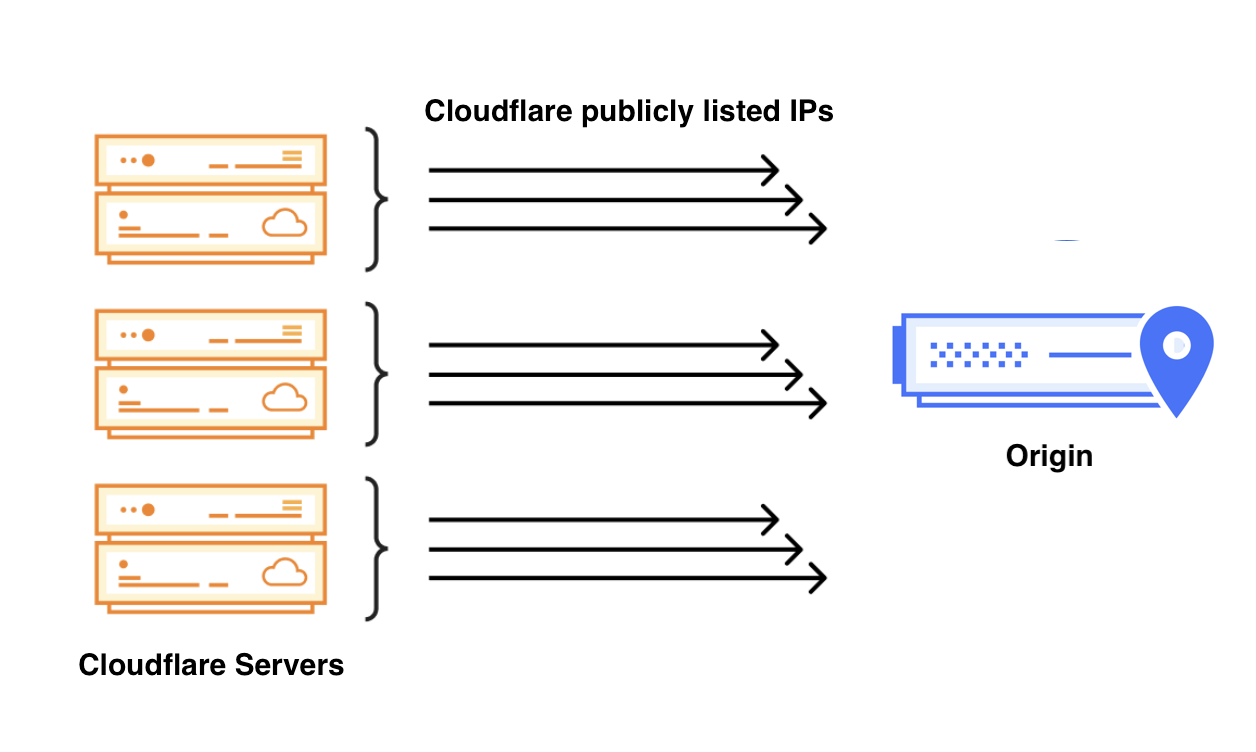
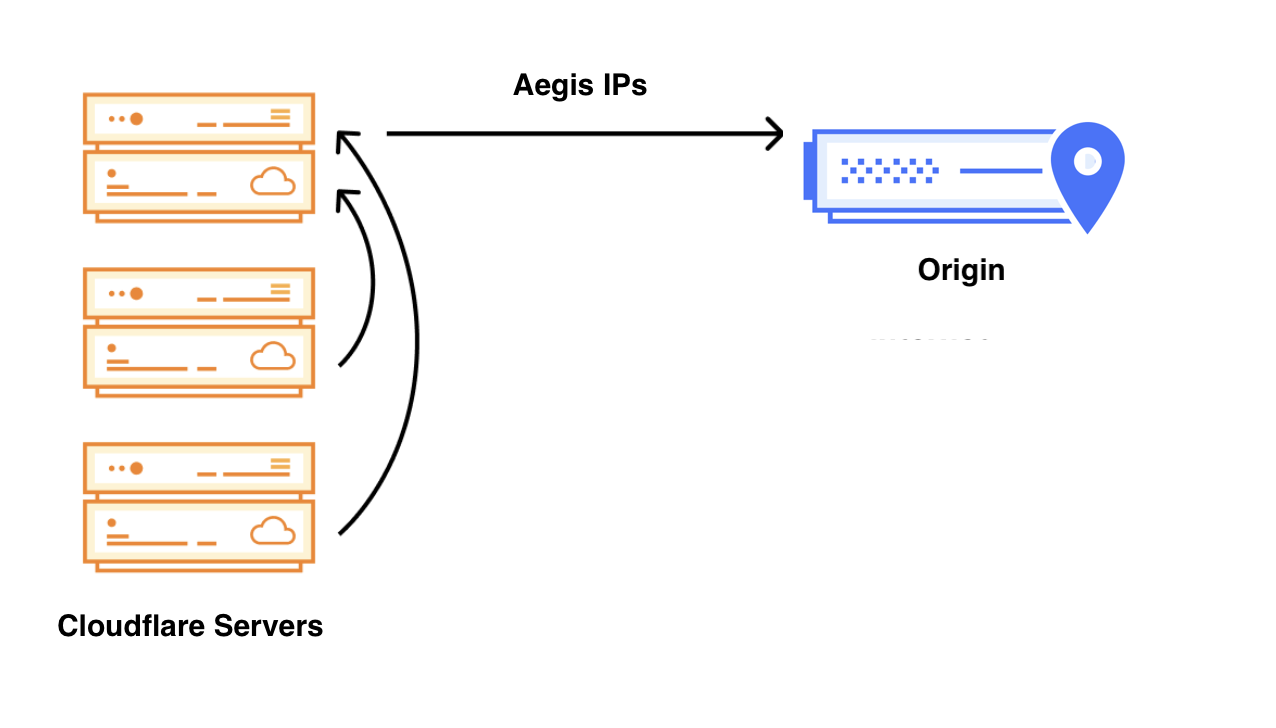
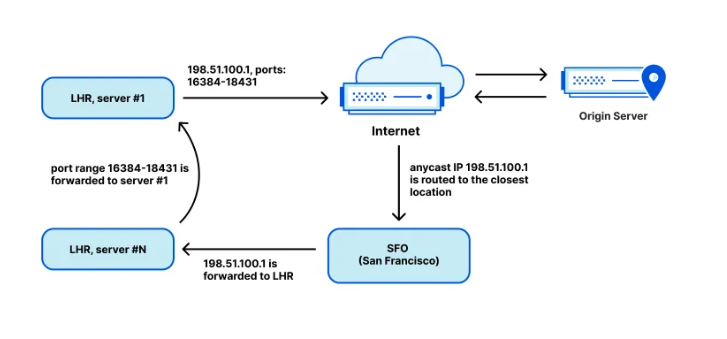
Cloudflare Aegis provides dedicated egress IPs for Zero Trust origin access strategies, now supporting BYOIP and customer-facing configurability, with observability of Aegis IP address utilization coming soon.
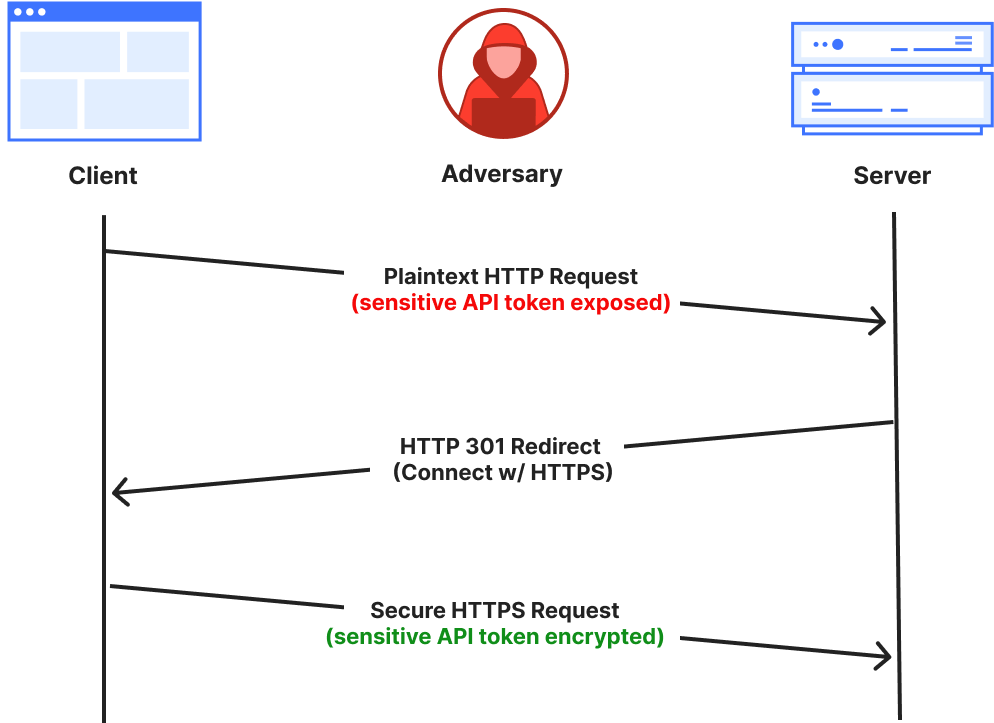
We are closing the cleartext HTTP ports entirely for Cloudflare API traffic. This prevents the risk of clients unintentionally leaking their secret API keys in cleartext during the initial request, before we can reject the connection at the server side.
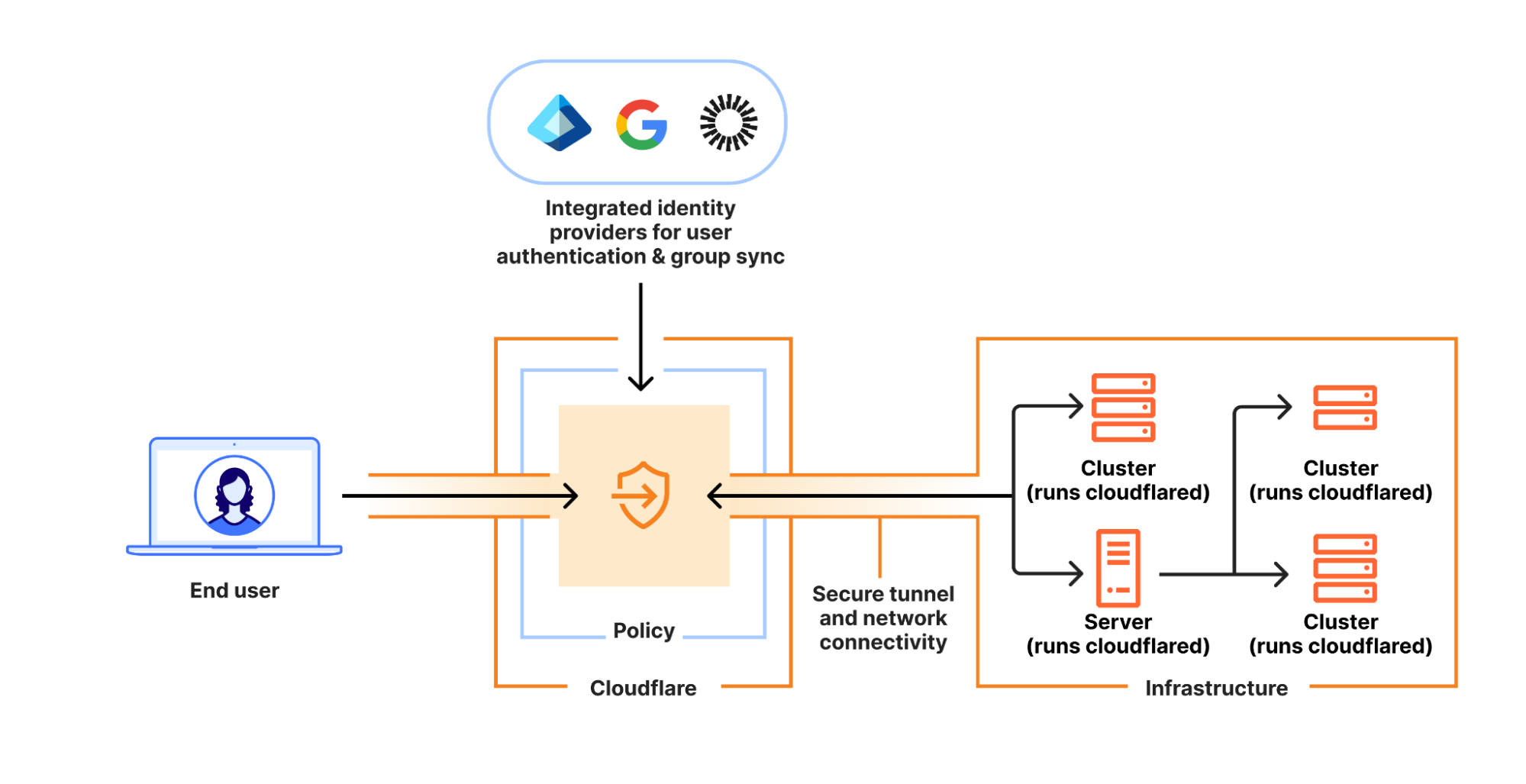
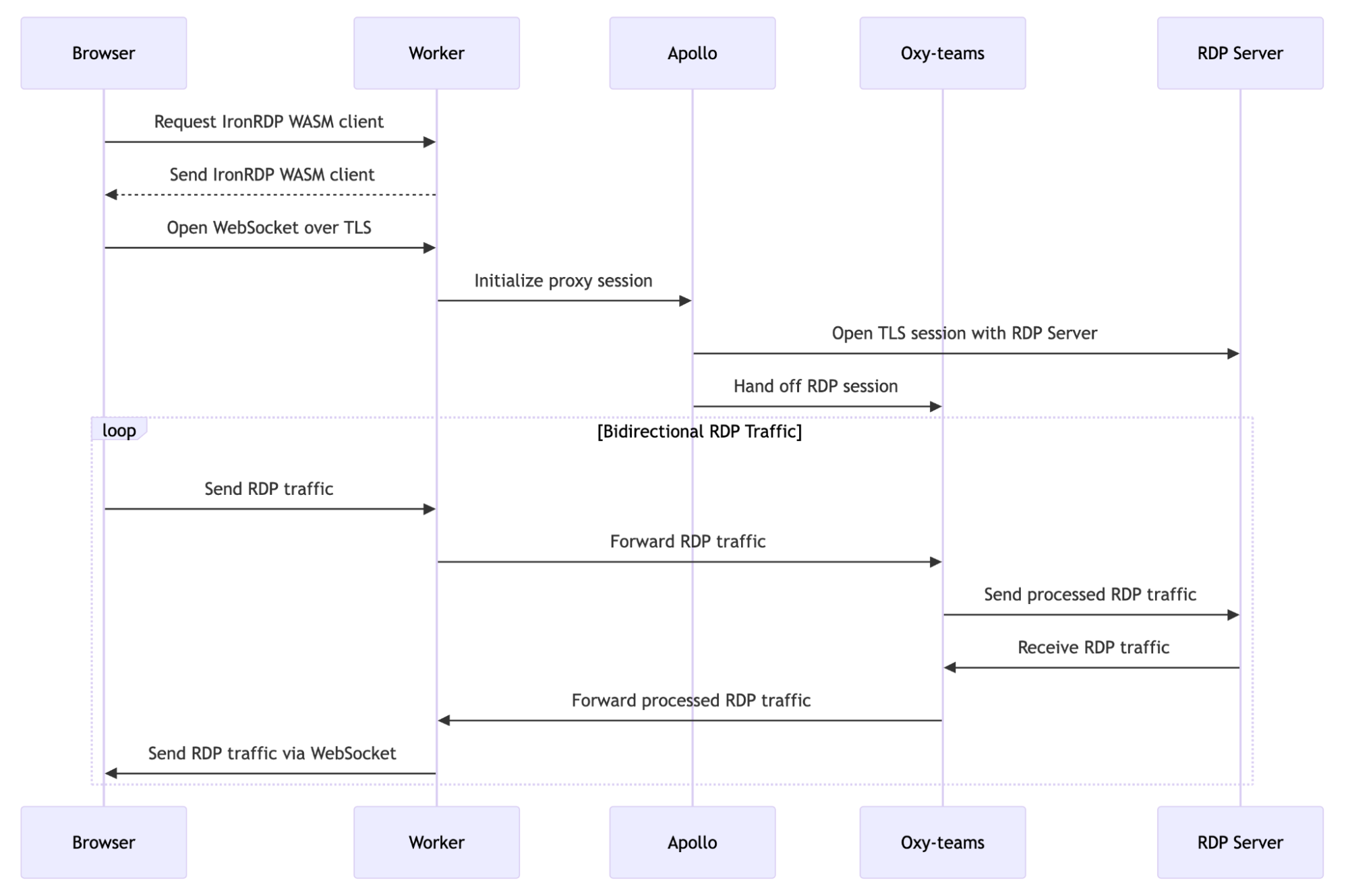
Cloudflare now provides clientless, browser-based support for the Remote Desktop Protocol (RDP). It natively enables secure, remote Windows server access without VPNs or RDP clients, to support third-party access and BYOD security.
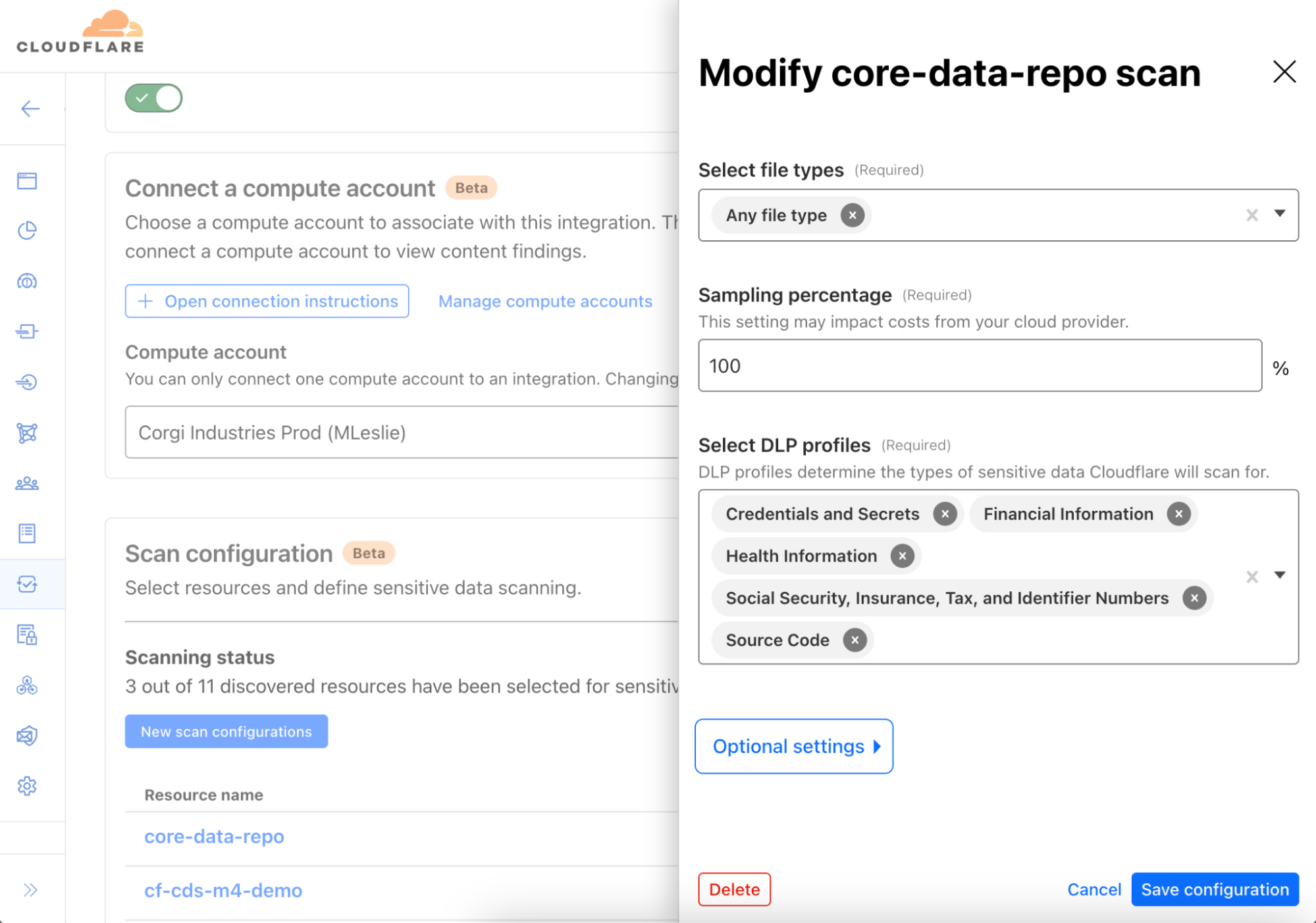
Cloudflare’s Data Loss Prevention is reducing false positives by using a self-improving AI-powered algorithm, built on Cloudflare’s Developer Platform, to improve detection accuracy through AI context analysis.
This post is a beginner’s guide to lattices, the math at the heart of the transition to post-quantum (PQ) cryptography. It explains how to do lattice-based encryption and authentication from scratch.
Cloudflare is now assessed at the IRAP PROTECTED level, bringing our products and services to the Australian Public Sector.
Tune in to the latest on Cloudflare TV
For a deeper dive on many of the great announcements from Security Week, check out our CFTV segments where our team shares even more details on our latest updates.
See you for our next Innovation Week
We appreciate everyone who’s taken the time to read Cloudflare’s Security Week blog posts or engage with us on these topics via social media. Our next innovation week, Developer Week, is right around the corner in April. We look forward to seeing you then!
We are excited to announce our public sector suite of services for Australia, Cloudflare for Government – Australia, has been assessed under the Infosec Registered Assessor Program (IRAP) at the PROTECTED level in Australia.
IRAP, established by the Australian government, provides a rigorous, standardized approach to security assessment for cloud products and services. Achieving IRAP PROTECTED assessment reinforces our commitment to providing secure, high-performance solutions for government agencies and highly regulated industries across the globe.
Obtaining our IRAP assessment is one part of our broader strategy to scale out our Cloudflare for Government offering to as many areas of the world as possible. Cloudflare’s global network offers governments and highly regulated customers a unique capability to be within 50ms of 95% of Internet users globally, while also offering robust security for data processing, key management, and metadata storage. Earlier this year, we announced that we completed our ENS certification in Spain, and we are well underway on the development of our FedRAMP High systems in the United States.
Cloudflare’s network spans more than 330 cities in over 120 countries, where we interconnect with approximately 13,000 network providers in order to provide a broad range of services to millions of customers. Our network is our greatest strength to provide resiliency, security, and performance. So, instead of creating a siloed government network that has limited access to our products and services, we decided to build the unique government compliance capabilities directly into our platform from the very beginning. We accomplished this by delivering critical controls in three key areas: traffic processing, management, and metadata storage.
The benefit of running the same software across our entire network is that it enables us to leverage our global footprint, and then make smart choices about how to handle traffic. For instance, Regional Services (our system that ensures that traffic is processed in the correct region) runs globally. Regional Services allows us to do global Layer 3 (network layer) DDoS attack prevention, while still only decrypting traffic inside our IRAP boundary, which includes both US and Australian facilities. This software-defined regionalization approach allows us to get the full benefits of the global network running anycast, while offering highly specific regionalization on the same hardware. We get similar advantages for key management and metadata storage locality.
Network and security services can dramatically improve user experiences, but only when they run as close to the user as possible, even if the user doesn’t live close to a major hub. Leveraging our global network of over 300 data centers to ingest traffic to our network, our private backbone can move traffic to the closest certified processing location that is within the scope of our IRAP system. This enables you to meet the most stringent controls of the IRAP assessment without trading off user experience.
Our single platform strategy enables almost every Cloudflare product and service across all of our solution areas to be included in scope with Cloudflare for Government – Australia. This includes our application security products like our CDN, WAF, API Shield, Rate Limiting, and Bot Management. Our Zero Trust Products like Secure Web Gateway, CASB, Magic Transit, Magic WAN, and Remote Browser Isolation are also in scope, as are developer platform components including Workers, R2, Durable Objects, Stream, and Cache Reserve.
We invite all of our Cloudflare for Government public and private partners to learn more about our capabilities and work with us to develop solutions to meet the security demands required in complex environments. Please reach out to us at [email protected] with any questions.
We are excited to announce our latest innovation to Cloudflare’s Data Loss Prevention (DLP) solution: a self-improving AI-powered algorithm that adapts to your organization’s unique traffic patterns to reduce false positives.
Many customers are plagued by the shapeshifting task of identifying and protecting their sensitive data as it moves within and even outside of their organization. Detecting this data through deterministic means, such as regular expressions, often fails because they cannot identify details that are categorized as personally identifiable information (PII) nor intellectual property (IP). This can generate a high rate of false positives, which contributes to noisy alerts that subsequently may lead to review fatigue. Even more critically, this less than ideal experience can turn users away from relying on our DLP product and result in a reduction in their overall security posture.
Built into Cloudflare’s DLP Engine, AI enables us to intelligently assess the contents of a document or HTTP request in parallel with a customer’s historical reports to determine context similarity and draw conclusions on data sensitivity with increased accuracy.
Understanding false positives and their impact on user confidence
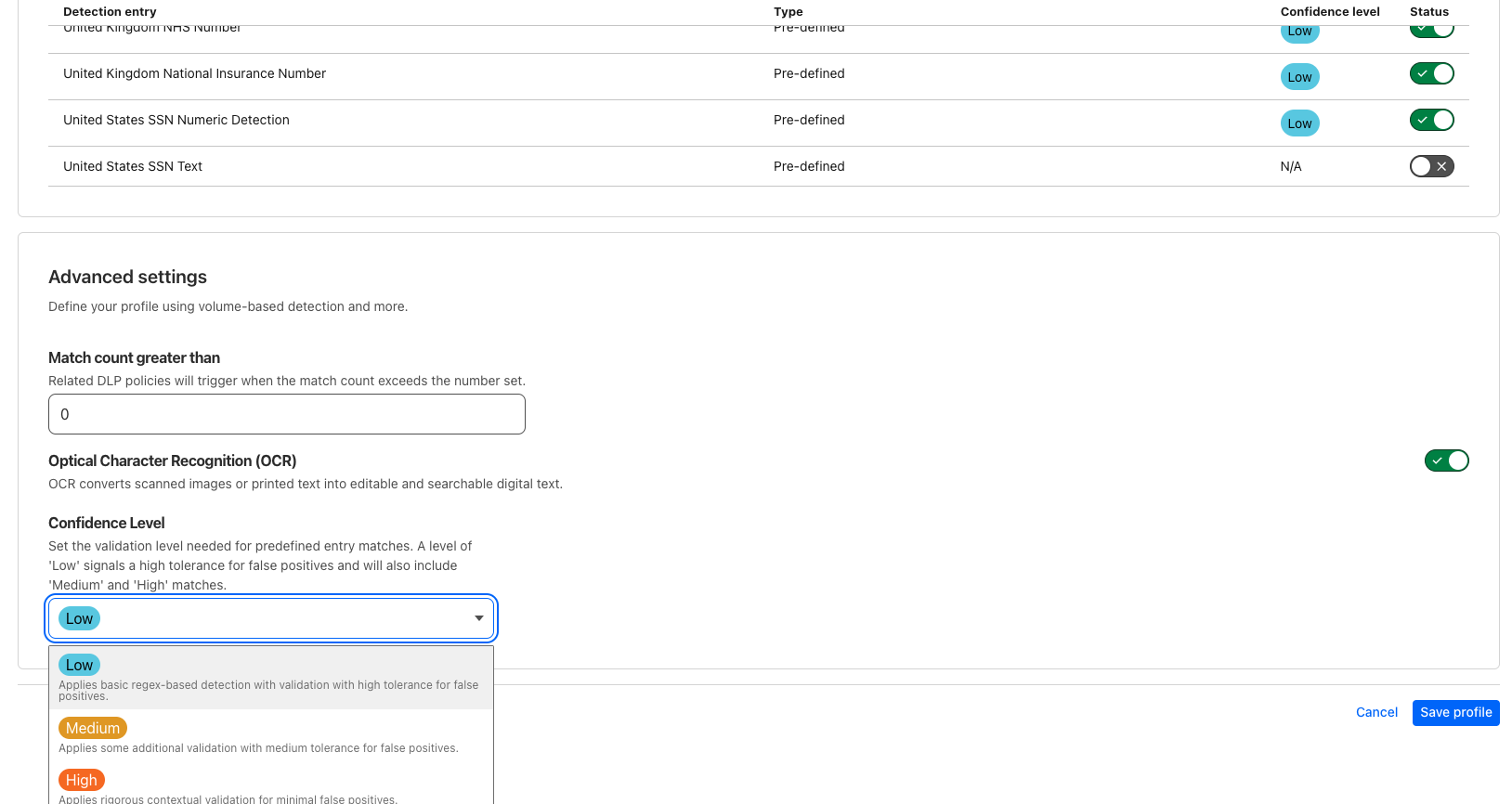
Data Loss Prevention (DLP) at Cloudflare detects sensitive information by scanning potential sources of data leakage across various channels such as web, cloud, email, and SaaS applications. While we leverage several detection methods, pattern-based methods like regular expressions play a key role in our approach. This method is effective for many types of sensitive data. However, certain information can be challenging to classify solely through patterns. For instance, U.S. Social Security Numbers (SSNs), structured as AAA-GG-SSSS, sometimes with dashes omitted, are often confused with other similarly formatted data, such as U.S. taxpayer identification numbers, bank account numbers, or phone numbers.
Since announcing our DLP product, we have introduced new capabilities like confidence thresholds to reduce the number of false positives users receive. This method involves examining the surrounding context of a pattern match to assess Cloudflare’s confidence in its accuracy. With confidence thresholds, users specify a threshold (low, medium, or high) to signify a preference for how tolerant detections are to false positives. DLP uses the chosen threshold as a minimum, surfacing only those detections with a confidence score that meets or exceeds the specified threshold.
However, implementing context analysis is also not a trivial task. A straightforward approach might involve looking for specific keywords near the matched pattern, such as “SSN” near a potential SSN match, but this method has its limitations. Keyword lists are often incomplete, users may make typographical errors, and many true positives do not have any identifying keywords nearby (e.g., bank accounts near routing numbers or SSNs near names).
Leveraging AI/ML for enhanced detection accuracy
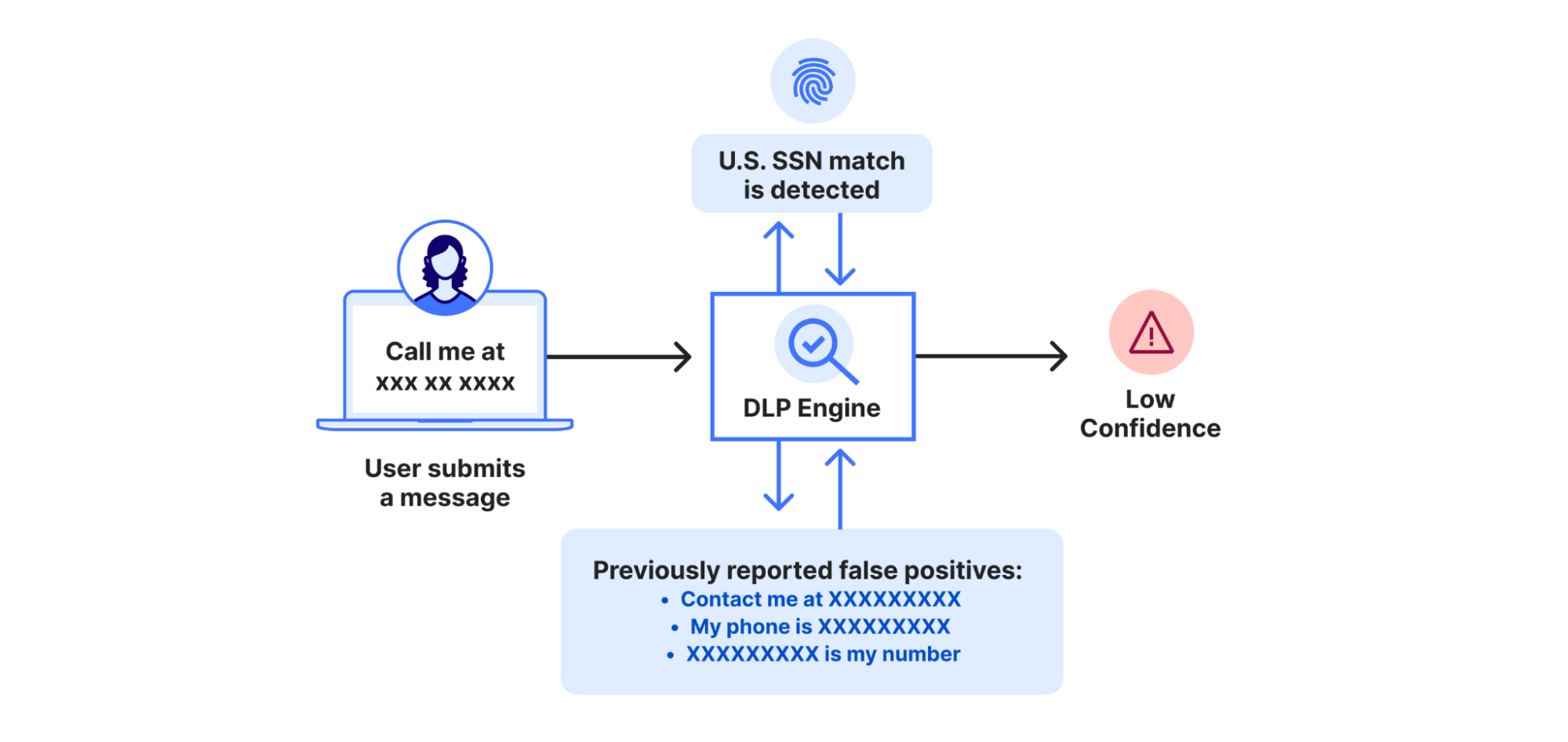
To address the limitations of a hardcoded strategy for context analysis, we have developed a dynamic, self-improving algorithm that learns from customer feedback to further improve their future experience. Each time a customer reports a false positive via decrypted payload logs, the system reduces its future confidence for hits in similar contexts. Conversely, reports of true positives increase the system’s confidence for hits in similar contexts.
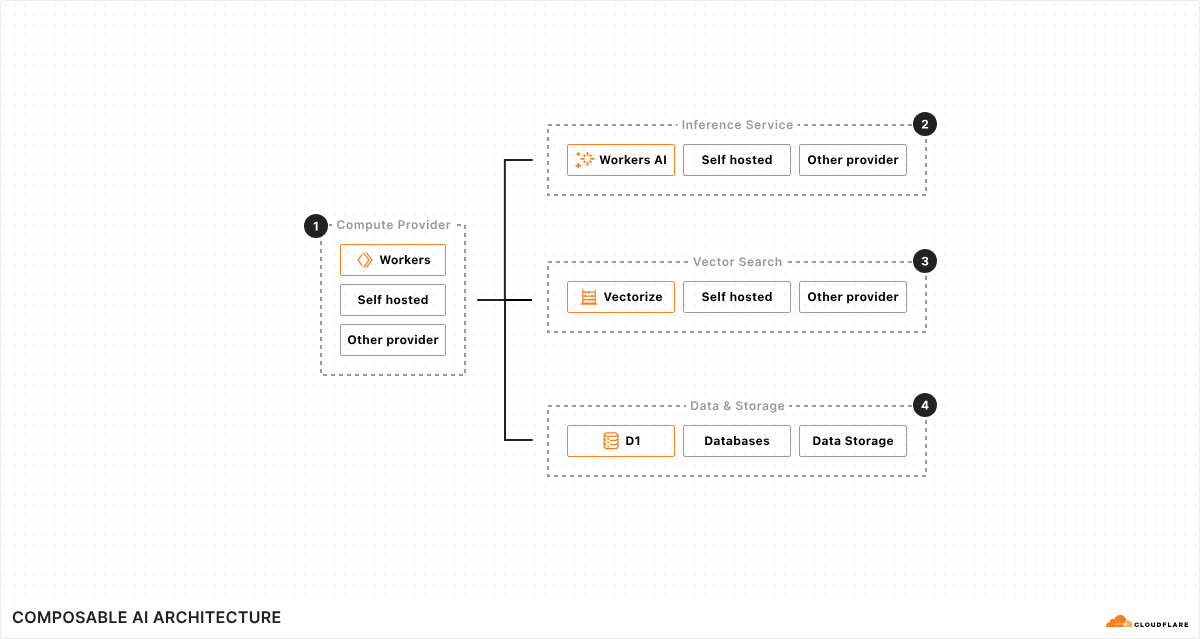
To determine context similarity, we leverage Workers AI. Specifically, a pretrained language model that converts the text into a high-dimensional vector (i.e. text embedding). These embeddings capture the meaning of the text, ensuring that two sentences with the same meaning but different wording map to vectors that are close to each other.
When a pattern match is detected, the system uses the AI model to compute the embedding of the surrounding context. It then performs a nearest neighbor search to find previously logged false or true positives with similar meanings. This allows the system to identify context similarities even if the exact wording differs, but the meaning remains the same.
In our experiments using Cloudflare employee traffic, this approach has proven robust, effectively handling new pattern matches it hadn’t encountered before. When the DLP admin reports false and true positives through the Cloudflare dashboard while viewing the payload log of a policy match, it helps DLP continue to improve, leading to a significant reduction in false positives over time.
Seamless integration with Workers AI and Vectorize
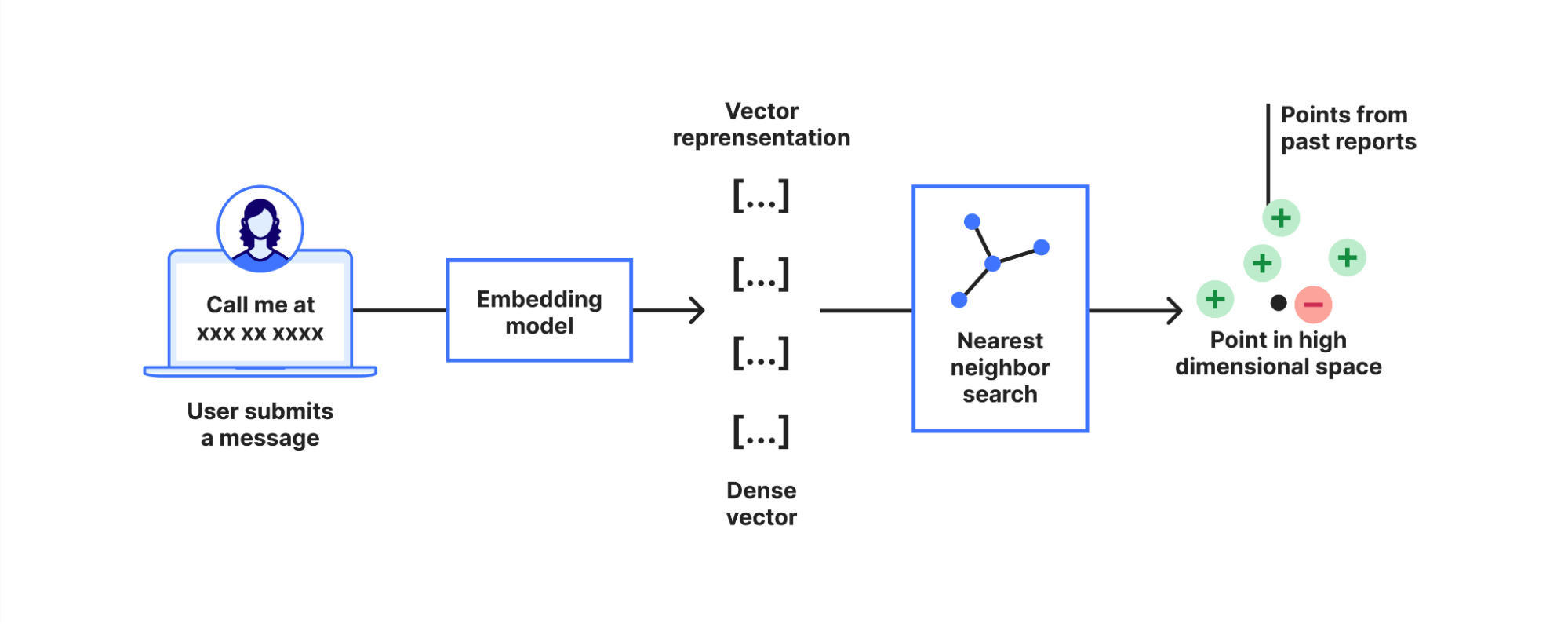
In developing this new feature, we used components from Cloudflare’s developer platform — Workers AI and Vectorize — which helps simplify our design. Instead of managing the underlying infrastructure ourselves, we leveraged Cloudflare Workers as the foundation, using Workers AI for text embedding, and Vectorize as the vector database. This setup allows us to focus on the algorithm itself without the overhead of provisioning underlying resources.
Thanks to Workers AI, converting text into embeddings couldn’t be easier. With just a single line of code we can transform any text into its corresponding vector representation.
const result = await env.AI.run(model, {text: [text]}).data;
This handles everything from tokenization to GPU-powered inference, making the process both simple and scalable.
The nearest neighbor search is equally straightforward. After obtaining the vector from Workers AI, we use Vectorize to quickly find similar contexts from past reports. In the meantime, we store the vector for the current pattern match in Vectorize, allowing us to learn from future feedback.
To optimize resource usage, we’ve incorporated a few more clever techniques. For example, instead of storing every vector from pattern hits, we use online clustering to group vectors into clusters and store only the cluster centroids along with counters for tracking hits and reports. This reduces storage needs and speeds up searches. Additionally, we’ve integrated Cloudflare Queues to separate the indexing process from the DLP scanning hot path, ensuring a robust and responsive system.
Privacy is a top priority. We redact any matched text before conversion to embeddings, and all vectors and reports are stored in customer-specific private namespaces across Vectorize, D1, and Workers KV. This means each customer’s learning process is independent and secure. In addition, we implement data retention policies so that vectors that have not been accessed or referenced within 60 days are automatically removed from our system.
Limitations and continuous improvements
AI-driven context analysis significantly improves the accuracy of our detections. However, this comes at the cost of some increase in latency for the end user experience. For requests that do not match any enabled DLP entries, there will be no latency increase. However, requests that match an enabled entry in a profile with AI context analysis enabled will typically experience an increase in latency of about 400ms. In rare extreme cases, for example requests that match multiple entries, that latency increase could be as high as 1.5 seconds. We are actively working to drive the latency down, ideally to a typical increase of 250ms or better.
Another limitation is that the current implementation supports English exclusively because of our choice of the language model. However, Workers AI is developing a multilingual model which will enable DLP to increase support across different regions and languages.
Looking ahead, we also aim to enhance the transparency of AI context analysis. Currently, users have no visibility on how the decisions are made based on their past false and true positive reports. We plan to develop tools and interfaces that provide more insight into how confidence scores are calculated, making the system more explainable and user-friendly.
With this launch, AI context analysis is only available for Gateway HTTP traffic. By the end of 2025, AI context analysis will be available in both CASB and Email Security so that customers receive the same AI enhancements across their entire data landscape.
Unlock the benefits: start using AI-powered detection features today
DLP’s AI context analysis is in closed beta. Sign up here for early access to experience immediate improvements to your DLP HTTP traffic matches. More updates are coming soon as we approach general availability!
To get access to DLP via Cloudflare One, contact your account manager.
The cryptography that secures the Internet is evolving, and it’s time to catch up. This post is a tutorial on lattice cryptography, the paradigm at the heart of the post-quantum (PQ) transition.
Twelve years ago (in 2013), the revelation of mass surveillance in the US kicked off the widespread adoption of TLS for encryption and authentication on the web. This transition was buoyed by the standardization and implementation of new, more efficient public-key cryptography based on elliptic curves. Elliptic curve cryptography was both faster and required less communication than its predecessors, including RSA and Diffie-Hellman over finite fields.
Today’s transition to PQ cryptography addresses a looming threat for TLS and beyond: once built, a sufficiently large quantum computer can be used to break all public-key cryptography in use today. And we continue to see advancements in quantum-computer engineering that bring us closer to this threat becoming a reality.
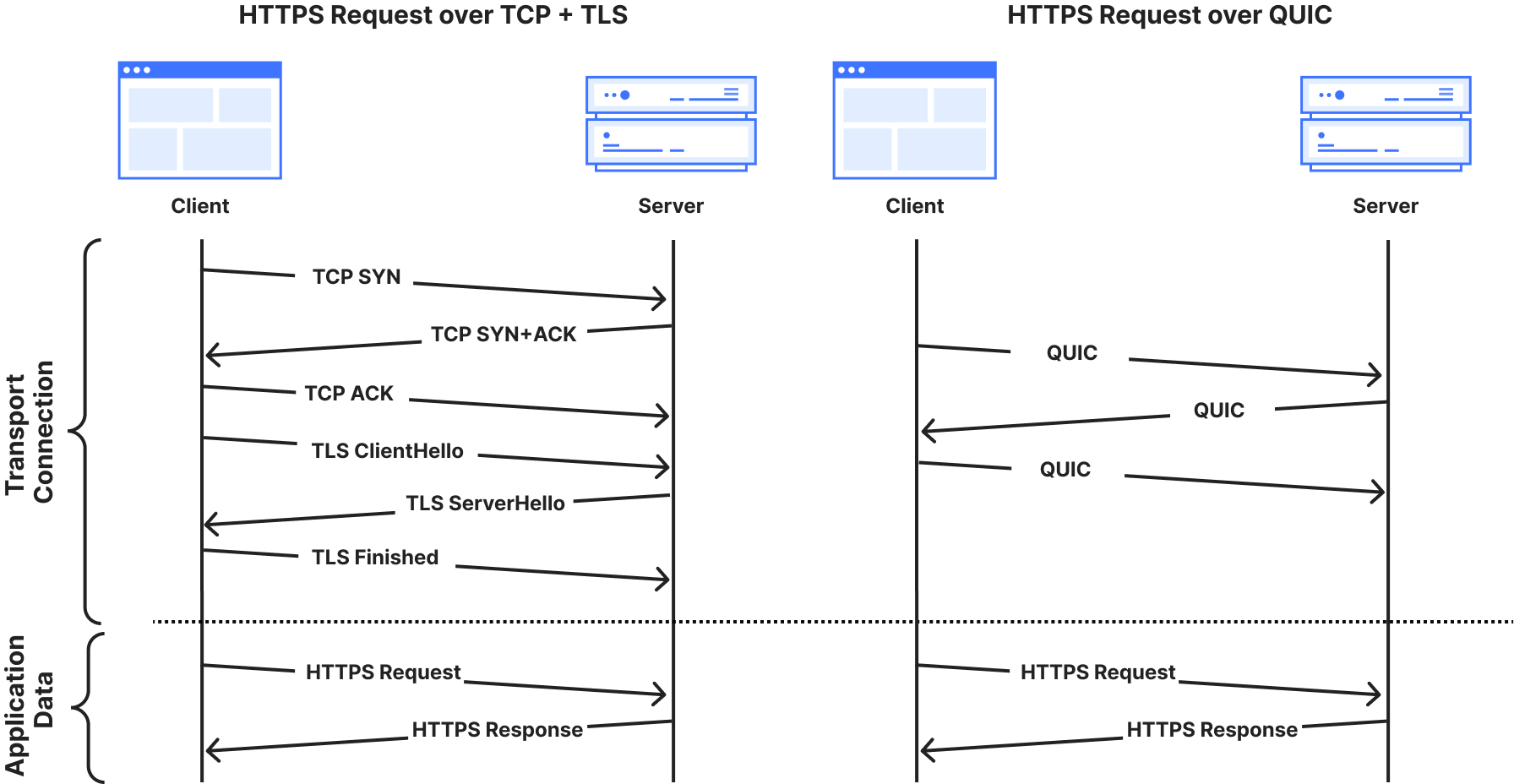
Fortunately, this transition is well underway. The research and standards communities have spent the last several years developing alternatives that resist quantum cryptanalysis. For its part, Cloudflare has contributed to this process and is an early adopter of newly developed schemes. In fact, PQ encryption has been available at our edge since 2022 and is used in over 35% of non-automated HTTPS traffic today (2025). And this year we’re beginning a major push towards PQ authentication for the TLS ecosystem.
Lattice-based cryptography is the first paradigm that will replace elliptic curves. Apart from being PQ secure, lattices are often as fast, and sometimes faster, in terms of CPU time. However, this new paradigm for public key crypto has one major cost: lattices require much more communication than elliptic curves. For example, establishing an encryption key using lattices requires 2272 bytes of communication between the client and the server (ML-KEM-768), compared to just 64 bytes for a key exchange using a modern elliptic-curve-based scheme (X25519). Accommodating such costs requires a significant amount of engineering, from dealing with TCP packet fragmentation, to reworking TLS and its public key infrastructure. Thus, the PQ transition is going to require the participation of a large number of people with a variety of backgrounds, not just cryptographers.
The primary audience for this blog post is those who find themselves involved in the PQ transition and want to better understand what’s going on under the hood. However, more fundamentally, we think it’s important for everyone to understand lattice cryptography on some level, especially if we’re going to trust it for our security and privacy.
We’ll assume you have a software-engineering background and some familiarity with concepts like TLS, encryption, and authentication. We’ll see that the math behind lattice cryptography is, at least at the highest level, not difficult to grasp. Readers with a crypto-engineering background who want to go deeper might want to start with the excellent tutorial by Vadim Lyubashevsky on which this blog post is based. We also recommend Sophie Schmieg’s blog on this subject.
While the transition to lattice cryptography incurs costs, it also creates opportunities. Many things we can build with elliptic curves we can also build with lattices, though not always as efficiently; but there are also things we can do with lattices that we don’t know how to do efficiently with anything else. We’ll touch on some of these applications at the very end.
We’re going to cover a lot of ground in this post. If you stick with it, we hope you’ll come away feeling empowered, not only to tackle the engineering challenges the PQ transition entails, but to solve problems you didn’t know how to solve before.
Strap in — let’s have some fun!
Encryption
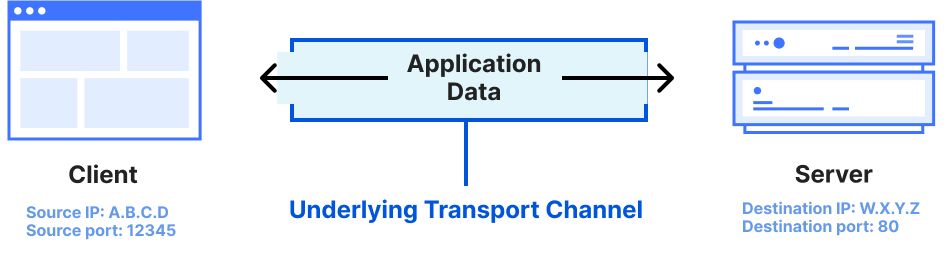
The most pressing problem for the PQ transition is to ensure that tomorrow’s quantum computers don’t break today’s encryption. An attacker today can store the packets exchanged between your laptop and a website you visit, and then, some time in the future, decrypt those packets with the help of a quantum computer. This means that much of the sensitive information transiting the Internet today — everything from API tokens and passwords to database encryption keys — may one day be unlocked by a quantum computer.
In fact, today’s encryption in TLS is mostly PQ secure: what’s at risk is the process by which your browser and a server establish an encryption key. Today this is usually done with elliptic-curve-based schemes, which are not PQ secure; our goal for this section is to understand how to do key exchange with lattices-based schemes, which are.
We will work through and implement a simplified version of ML-KEM, a.k.a. Kyber, the most widely deployed PQ key exchange in use today. Our code will be less efficient and secure than a spec-compliant, production-quality implementation, but will be good enough to grasp the main ideas.
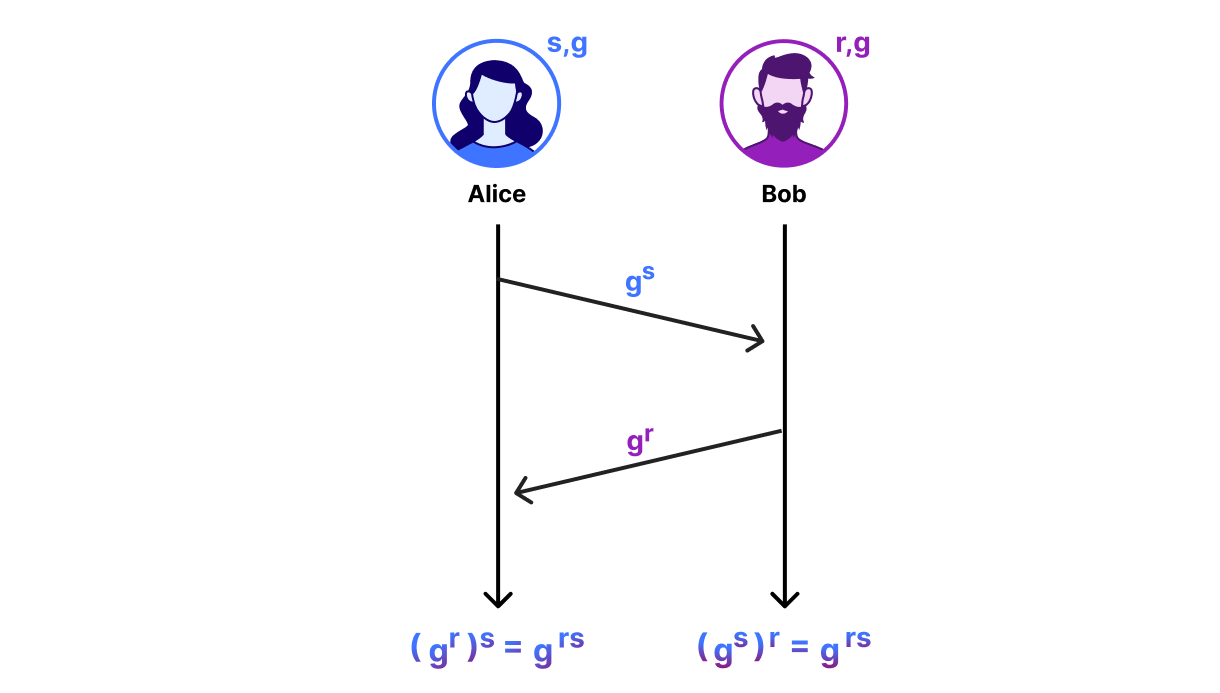
Our starting point is a protocol that looks an awful lot like Diffie-Hellman (DH) key exchange. For those readers unacquainted with DH, the goal is for Alice and Bob to establish a shared secret over an insecure network. To do so, each picks a random secret number, computes the corresponding “key share”, and sends the key share to the other:
Alice’s secret number is $s$ and her key share is $g^s$; Bob’s secret number is $r$ and his key share is $g^r$. Then given their secret and their peer’s key share, each can compute $g^{rs}$. The security of this protocol comes from how we choose $g$, $s$, and $r$ and how we do arithmetic. The most efficient instantiation of DH uses elliptic curves.
In ML-KEM we replace operations on elliptic curves with matrix operations. It’s not quite a drop-in replacement, so we’ll need a little linear algebra to make sense of it. But don’t worry: we’re going to work with Python so we have running code to play with, and we’ll use NumPy to keep things high level.
All the math we’ll need
A matrix is just a two-dimensional array of numbers. In NumPy, we can create a matrix as follows (importing numpy as np):
A = np.matrix([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
This defines A to be the 3-by-3 matrix with entries A[0,0]==1, A[0,1]==2, A[0,2]==3, A[1,0]==4, and so on.
For the purposes of this post, the entries of our matrices will always be integers. Furthermore, whenever we add, subtract, or multiply two integers, we then reduce the result, just like we do with hours on a clock, so that we end up with a number in range(Q) for some positive number Q, called the modulus. The exact value doesn’t really matter now, but for ML-KEM it’s Q=3329, so let’s go with that for now. (The modulus for a clock would be Q=12.)
In Python, we write multiplication of integers a and b modulo Q as c = a*b % Q. Here we compute a*b, divide the result by Q, then set c to the remainder. For example, 42*1337% Q is equal to 2890 rather than 56154. Modular addition and subtraction are done analogously. For the rest of this blog, we will sometimes omit “% Q” when it’s clear in context that we mean modular arithmetic.
Next, we’ll need three operations on matrices.
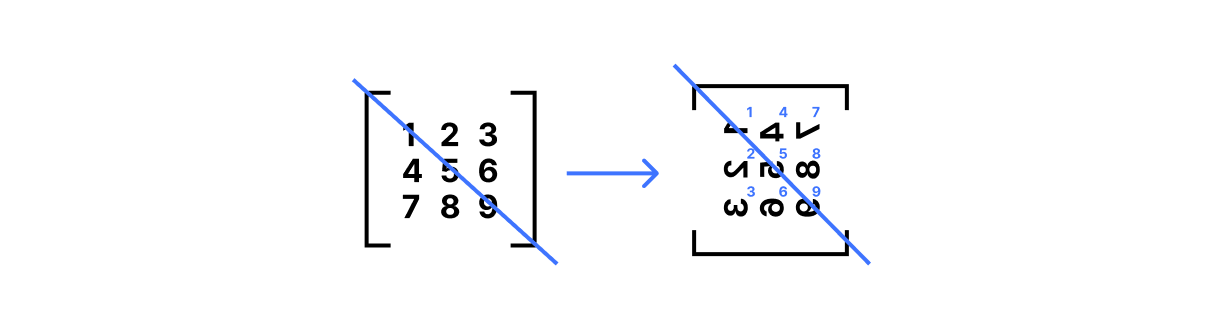
The first is matrix transpose, written A.T in NumPy. This operation flips the matrix along its diagonal so that A.T[j,i] == A[i,j] for all rows i and columns j:
print(A.T)
# [[1 4 7]
# [2 5 8]
# [3 6 9]]
To visualize this, imagine writing down a matrix on a translucent piece of paper. Draw a line from the top left corner to the bottom right corner of that paper, then rotate the paper 180° around that line:
The second operation we’ll need is matrix multiplication. Normally, we will multiply a matrix by a column vector, which is just a matrix with one column. For example, the following 3-by-1 matrix is a column vector:
s = np.matrix([[0],
[1],
[0]])
We can also write s more concisely as np.matrix([[0,1,0]]).T. To multiply a square matrix A by a column vector s, we compute the dot product of each row of A with s. That is, if t = A*s % Q, then t[i] == (A[i,0]*s[0,0] + A[i,1]*s[1,0] + A[i,2]*s[2,0]) % Q for each row i. The output will always be a column vector:
print(A*s % Q)
# [[2]
# [5]
# [8]]
The number of rows of this column vector is equal to the number of rows of the matrix on the left hand side. In particular, if we take our column vector s, transpose it into a 1-by-3 matrix, and multiply it by a 3-by-1 matrix r, then we end up with a 1-by-1 matrix:
r = np.matrix([[1,2,3]]).T
print(s.T*r % Q)
# [[2]]
The final matrix operation we’ll need is matrix addition. If A and B are both N-by-M matrices, then C = (A+B) % Q is the N-by-M matrix for which C[i,j] == (A[i,j]+B[i,j]) % Q. Of course, this only works if the matrices we’re adding have the same dimensions.
Warm up
Enough maths — let’s get to exchanging some keys. We start with the DH diagram from before and swap out the computations with matrix operations. Note that this protocol is not secure, but will be the basis of a secure key exchange mechanism we’ll develop in the next section:
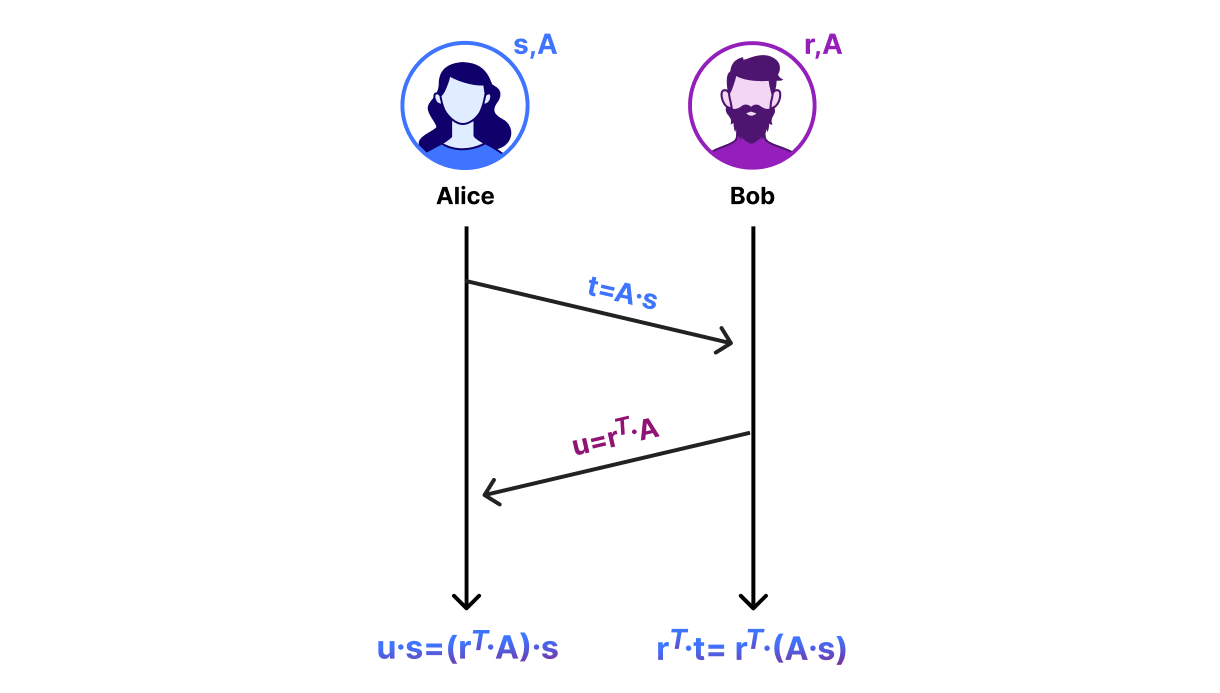
Alice and Bob agree on a public, N-by-N matrix A. This is analogous to the number $g$ that Alice and Bob agree on in the DH diagram.
Alice chooses a random length-N vector s and sends t = A*s % Q to Bob.
Bob chooses a random length-N vector r and sends u = r.T*A % Q to Alice. You can also compute this as (A.T*r).T % Q.
The vectors t and u are analogous to DH key shares. After the exchange of these key shares, Alice and Bob can compute a shared secret. Alice computes the shared secret as u*s % Q and Bob computes the shared secret as r.T*t % Q. To see why they compute the same key, notice that u*s == (r.T*A)*s == r.T*(A*s) == r.T*t.
In fact, this key exchange is essentially what happens in ML-KEM. However, we don’t use this directly, but rather as part of a public key encryption scheme. Public key encryption involves three algorithms:
key_gen(): The key generation algorithm that outputs a public encryption key pk and the corresponding secret decryption key sk.
encrypt(): The encryption algorithm that takes the public key and a plaintext and outputs a ciphertext.
decrypt(): The decryption algorithm that takes the secret key and a ciphertext and outputs the underlying plaintext. That is, decrypt(sk, encrypt(pk, ptxt)) == ptxt for any plaintext ptxt.
We’ll say the scheme is secure if, given a ciphertext and the public key used to encrypt it, no attacker can discern any information about the underlying plaintext without knowledge of the secret key. Once we have this encryption scheme, we then transform it into a key-encapsulation mechanism (the “KEM” in “ML-KEM”) in the last step. A KEM is very similar to encryption except that the plaintext is always a randomly generated key.
Our encryption scheme is as follows:
key_gen(): To generate a key pair, we choose a random, square matrix A and a random column vector s. We set our public key to (A,t=A*s % Q) and our secret key to s. Notice that t is Alice’s key share from the key exchange protocol above.
encrypt(): Suppose our plaintext ptxt is an integer in range(Q). To encrypt ptxt, Bob generates his key share u. He then derives the shared secret and adds it to ptxt. The ciphertext has two components:
u = r.T*A % Q
v = (r.T*t + m) % Q
Here m is a 1-by-1 matrix containing the plaintext, i.e., m = np.matrix([[ptxt]]), and r is a random column vector.
decrypt(): To decrypt, Alice computes the shared secret and subtracts it from v:
m = (v - u*s) % Q
Some readers will notice that this looks an awful lot like El Gamal encryption. This isn’t a coincidence. Good cryptographers roll their own crypto; great cryptographers steal from good cryptographers.
Let’s now put this together into code. The last thing we’ll need is a method of generating random matrices and column vectors. We call this function gen_mat() below. Take a crack at implementing this yourself. Our scheme has two parameters: the modulus Q; and the dimension of N of the matrix and column vectors. The choice of N matters for security, but for now feel free to pick whatever value you want.
def key_gen():
# Here `gen_mat()` returns an N-by-N matrix with entries
# randomly chosen from `range(0, Q)`.
A = gen_mat(N, N, 0, Q)
# Like above except the matrix is N-by-1.
s = gen_mat(N, 1, 0, Q)
t = A*s % Q
return ((A, t), s)
def encrypt(pk, ptxt):
(A, t) = pk
m = np.matrix([[ptxt]])
r = gen_mat(N, 1, 0, Q)
u = r.T*A % Q
v = (r.T*t + m) % Q
return (u, v)
def decrypt(sk, ctxt):
s = sk
(u, v) = ctxt
m = (v - u*s) % Q
return m[0,0]
# Test
assert decrypt(sk, encrypt(pk, 1)) == 1
Making the scheme secure (or “What is a lattice?”)
By now, you might be wondering what on Earth a lattice even is. We promise we’ll define it, but before we do, it’ll help to understand why our warm-up scheme is insecure and what it’ll take to fix it.
Readers familiar with linear algebra may already see the problem: in order for this scheme to be secure, it should be impossible for the attacker to recover the secret key s; but given the public (A,t), we can immediately solve for s using Gaussian elimination.
In more detail, if A is invertible, we can write the secret key as A-1*t == A-1*(A*s) == (A-1*A)*s == s, where A-1 is the inverse of A. (When you multiply a matrix by its inverse, you get the identity matrix I, which simply takes a column vector to itself, i.e., I*s == s.) We can use Gaussian elimination to compute this matrix. Intuitively, all we’re doing is solving a set of linear equations, where the entries of s are the unknown variables. (Note that this is possible even if A is not invertible.)
In order to make this encryption scheme secure, we need to make it a little… “messier”.
Let’s get messy
For starters, we need to make it hard to recover the secret key from the public key. Let’s try the following: generate another random vector e and add it into A*s. Our key generation algorithm becomes:
def key_gen():
A = gen_mat(N, N, 0, Q)
s = gen_mat(N, 1, 0, Q)
e = gen_mat(N, 1, 0, Q)
t = (A*s + e) % Q
return ((A, t), s)
Our formula for the column vector component of the public key, t, now includes an additive term e, which we’ll call the error. Like the secret key, the error is just a random vector.
Notice that the previous attack no longer works: since A-1*t == A-1*(A*s + e) == A-1*(A*s) + A-1*e == s + A-1*e, we need to know e in order to compute s.
Great, but this patch creates another problem. Take a second to plug in this new key generation algorithm into your implementation and test it out. What happens?
You should see that decrypt() now outputs garbage. We can see why using a little algebra:
(v - u*s) == (r.T*t + m) - (r.T*A)*s
== r.T*(A*s + e) + m - (r.T*A)*s
== r.T*(A*s) + r.T*e + m - r.T*(A*s)
== r.T*e + m
The entries of r and e are sampled randomly, so r.T*e is also uniformly random. It’s as if we encrypted m with a one-time pad, then threw away the one-time pad!
Handling decryption errors
What can we do about this? First, it would help if r.T*e were small so that decryption yields something that’s close to the plaintext. Imagine we could generate r and e in such a way that r.T*e were in range(-epsilon, epsilon+1) for some small epsilon. Then decrypt would output a number in range(ptxt-epsilon, ptxt+epsilon+1), which would be pretty close to the actual plaintext.
However, we need to do better than get close. Imagine your browser failing to load your favorite website one-third of the time because of a decryption error. Nobody has time for that.
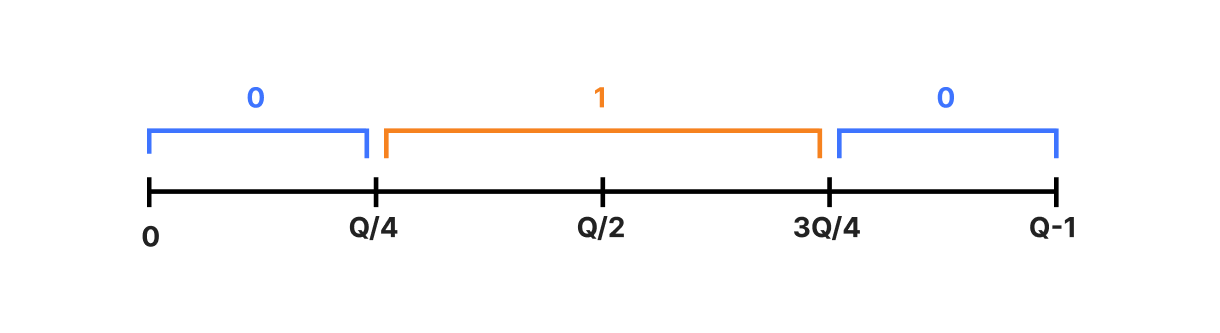
ML-KEM reduces the probability of decryption errors by being clever about how we encode the plaintext. Suppose all we want to do is encrypt a single bit, i.e., ptxt is either 0 or 1. Consider the numbers in range(Q), and split the number line into four chunks of roughly equal length:
Here we’ve labeled the region around zero (-Q/4 to Q/4 modulo Q) with ptxt=0 and the region far away from zero with ptxt=1. To encode the bit, we set it to the integer corresponding to the middle of its range, i.e., m = np.matrix([[ptxt * Q//2]]). (Note the double “//” — this denotes integer division in Python.) To decode, we choose the ptxt corresponding to whatever range m[0,0] is in. That way if the decryption error is small, then we’re highly likely to end up in the correct range.
Now all that’s left is to ensure the decryption error, r.T*e, is small. We do this by sampling short vectors r and e. By “short” we mean the entries of these vectors are sampled from a range that is much smaller than range(Q). In particular, we’ll pick some small positive integer beta and sample entries range(-beta,beta+1).
How do we choose beta? Well, it should be small enough that decryption succeeds with overwhelming probability, but not so small that r and e are easy to guess and our scheme is broken. Take a minute or two to play with this. The parameters we can vary are:
the modulus Q
the dimension of the column vectors N
the shortness parameter beta
For what ranges of these parameters is the decryption error low but the secret vectors are hard to guess? For what ranges is our scheme most efficient, in terms of runtime and communication cost (size of the public key plus the ciphertext)? We’ll give a concrete answer at the end of this section, but in the meantime, we encourage you to play with this a bit.
Gauss strikes back
At this point, we have a working encryption scheme that mitigates at least one key-recovery attack. We’ve come pretty far, but we have at least one more problem.
Take another look at our formula for the ciphertext ctxt = (u,v). What would happen if we managed to recover the random vector r? That would be catastrophic, since v == r.T*t + m, and we already know t (part of the public key) and v (part of the ciphertext).
Just as we were able to compute the secret key from the public key in our initial scheme, we can recover the encryption randomness r from the ciphertext component u using Gaussian elimination. Again, this is just because r is the solution to a system of linear equations.
We can mitigate this plaintext-recovery attack just as before, by adding some noise. In particular, we’ll generate a short vector according to gen_mat(N,1,-beta,beta+1) and add it into u. We also need to add noise to v in the same way, for reasons that we’ll discuss in the next section.
Once again, adding noise increases the probability of a decryption error, but this time the magnitude of the error also depends on the secret key s. To see this, recall that during decryption, we multiply u by s (to compute the shared secret), and the error vector is an additive term. We’ll therefore need s to be a short vector as well.
Let’s now put together everything we’ve learned into an updated encryption scheme. Our scheme now has three parameters, Q, N, and beta, and can be used to encrypt a single bit:
def key_gen():
A = gen_mat(N, N, 0, Q)
s = gen_mat(N, 1, -beta, beta+1)
e1 = gen_mat(N, 1, -beta, beta+1)
t = (A*s + e1) % Q
return ((A, t), s)
def encrypt(pk, ptxt):
(A, t) = pk
m = np.matrix([[ptxt*(Q//2) % Q]])
r = gen_mat(N, 1, -beta, beta+1)
e2 = gen_mat(N, 1, -beta, beta+1)
e3 = gen_mat(1, 1, -beta, beta+1)
u = (r.T*A + e2) % Q
v = (r.T*t + e3 + m) % Q
return (u, v)
def decrypt(sk, ctxt):
s = sk
(u, v) = ctxt
m = (v - u*s) % Q
if m[0,0] in range(Q//4, 3*Q//4):
return 1
return 0
# Test
assert decrypt(sk, encrypt(pk, 0)) == 0
assert decrypt(sk, encrypt(pk, 1)) == 1
Before moving on, try to find parameters for which the scheme works and for which the secret and error vectors seem hard to guess.
Learning with errors
So far we have a functioning encryption scheme for which we’ve mitigated two attacks, one a key-recovery attack and the other a plaintext-recovery attack. There seems to be no other obvious way of breaking our scheme, unless we choose parameters that are so weak that an attacker can easily guess the secret key s or ciphertext randomness r. Again, these vectors need to be short in order to prevent decryption errors, but not so short that they are easy to guess. (Likewise for the error terms.)
Still, there may be other attacks that require a little more sophistication to pull off. For instance, there might be some mathematical analysis we can do to recover, or at least make a good guess of, a portion of the ciphertext randomness. This raises a more fundamental question: in general, how do we establish that cryptosystems like this are actually secure?
As a first step, cryptographers like to try and reduce the attack surface. Modern cryptosystems are designed so that the problem of attacking the scheme reduces to solving some other problem that is easier to reason about.
Our public key encryption scheme is an excellent illustration of this idea. Think back to the key- and plaintext-recovery attacks from the previous section. What do these attacks have in common?
In both instances, the attacker knows some public vector that allowed it to recover a secret vector:
In the key-recovery attack, the attacker knew t for which A*s == t.
In the plaintext-recovery attack, the attacker knew u for which r.T*A == u (or, equivalently, A.T*r == u.T).
The fix in both cases was to construct the public vector in such a manner that it is hard to solve for the secret, namely, by adding an error term. However, ideally the public vector would reveal no information about the secret whatsoever. This ideal is formalized by the Learning With Errors (LWE) problem.
The LWE problem asks the attacker to distinguish between two distributions. Concretely, imagine we flip a coin, and if it comes up heads, we sample from the first distribution and give the sample to the attacker; and if the coin comes up tails, we sample from the second distribution and give the sample to the attacker. The distributions are as follows:
(A,t=A*s + e) where A is a random matrix generated with gen_mat(N,N,0,Q) and s and e are short vectors generated with gen_mat(N,1,-beta,beta+1).
(A,t) where A is a random matrix generated with gen_mat(N,N,0,Q) and t is a random vector generated with gen_mat(N,1,0,Q).
The first distribution corresponds to what we actually do in the encryption scheme; in the second, t is just a random vector, and no longer a secret vector at all. We say that the LWE problem is “hard” if no attacker is able to guess the coin flip with probability significantly better than one-half.
Our encryption is passively secure — meaning the ciphertext doesn’t leak any information about the plaintext — if the LWE problem is hard for the parameters we chose. To see why, notice that both the public key and ciphertext look like LWE instances; if we can replace each instance with an instance of the random distribution, then the ciphertext would be completely independent of the plaintext and therefore leak no information about it at all. Note that, for this argument to go through, we also have to add the error term e3 to the ciphertext component v.
Choosing the parameters
We’ve established that if solving the LWE problem is hard for parameters N, Q, and beta, then so is breaking our public key encryption scheme. What’s left for us to do is tune the parameters so that solving LWE is beyond the reach of any attacker we can think of. This is where lattices come in.
Lattices
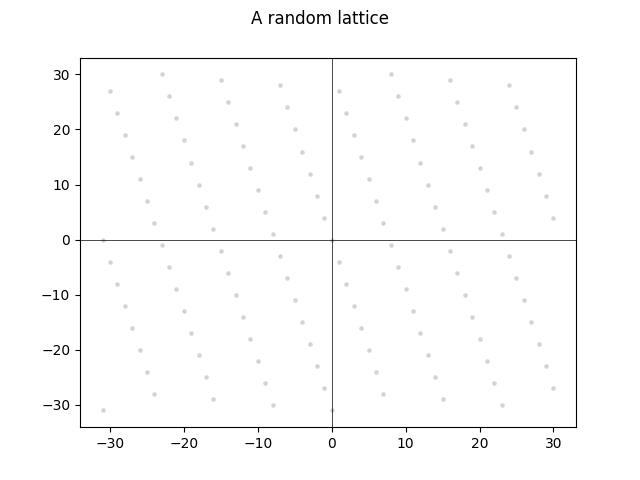
A lattice is an infinite grid of points in high-dimensional space. A two-dimensional lattice might look something like this:
The points always follow a clear pattern that resembles “lattice work” you might see in a garden:
For cryptography, we care about a special class of lattices, those defined by a matrix P that “recognizes” points in the lattice. That is, the lattice recognized by P is the set of vectors v for which P*v == 0, where “0” denotes the all-zero vector. The all-zero vector is np.zeros((N,1), dtype=int) in NumPy.
Readers familiar with linear algebra may have a different definition of lattices in mind: in general, a lattice is the set of points obtained by taking linear combinations of some basis. Our lattices can also be formulated in this way, i.e., for a matrix P that recognizes a lattice, we can compute the basis vectors that generate the lattice. However, we don’t much care about this representation here.
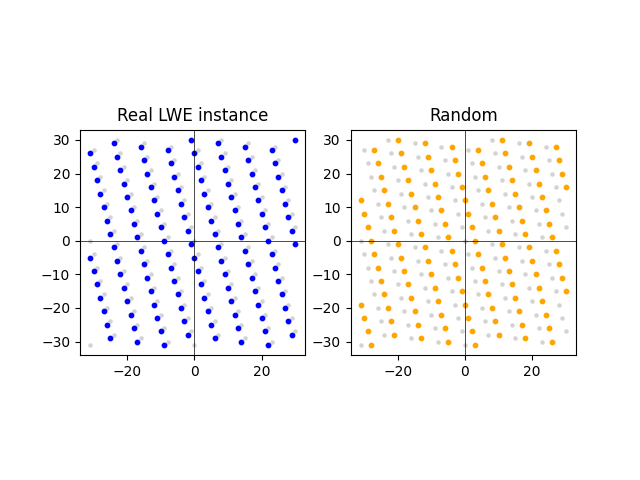
The LWE problem boils down to distinguishing a set of points that are “close to” the lattice from a set of points that are “far away from” the lattice. We construct these points from an LWE instance and a random (A,t) respectively. Here we have an LWE sample (left) and a sample from the random distribution (right):
What this shows is that the points of the LWE instance are much closer to the lattice than the random instance. This is indeed the case on average. However, while distinguishing LWE instances from random is easy in two dimensions, it gets harder in higher dimensions.
Let’s take a look at how we construct these points. First, let’s take an LWE instance (A,t=(A*s + e) % Q) and consider the lattice recognized by the matrix P we get by concatenating A with the identity matrix I. This might look something like this (N=3):
Let z denote this vector and consider the set of points v for which P*v == t. By definition, we say this set of points is “close to” the lattice because z is a short vector. (Remember: by “short” we mean its entries are bounded around 0 by beta.)
Now consider a random (A,t) and consider the set of points v for which P*v == t. We won’t prove it, but it is a fact that this set of points is likely to be “far away from” the lattice in the sense that there is no short vector z for which P*z == t.
Intuitively, solving LWE gets harder as z gets longer. Indeed, increasing the average length of z (by making beta larger) increases the average distance to the lattice, making it look more like a random instance:
On the other hand, making z too long creates another problem.
Breaking lattice cryptography by finding short vectors
Given a random matrix A, the Short Integer Solution (SIS) problem is to find short vectors (i.e., whose entries are bounded by beta) z1 and z2 for which (A*z1 + z2) % Q is zero. Notice that this is equivalent to finding a short vector z in the lattice recognized by P:
z = np.concatenate((z1, z2))
assert np.array_equal((A*z1 + z2) % Q, P*z % Q)
If we had a (quantum) computer program for solving SIS, then we could use this program to solve LWE as well: if (A,t) is an LWE instance, then z1.T*t will be small; otherwise, if (A,t) is random, then z1.T*t will be uniformly random. (You can convince yourself of this using a little algebra.) Therefore, in order for our encryption scheme to be secure, it must be hard to find short vectors in the lattice defined by those parameters.
Intuitively, finding long vectors in the lattice is easier than finding short ones, which means that solving the SIS problem gets easier as beta gets closer to Q. On the other hand, as beta gets closer to 0, it gets easier to distinguish LWE instances from random!
This suggests a kind of Goldilocks zone for LWE-based encryption: if the secret and noise vectors are too short, then LWE is easy; but if the secret and noise vectors are too long, then SIS is easy. The optimal choice is somewhere in the middle.
Enough math, just give me my parameters!
To tune our encryption scheme, we want to choose parameters for which the most efficient known algorithms (quantum or classical) for solving LWE are out of reach for any attacker with as many resources as we can imagine (and then some, in case new algorithms are discovered). But how do we know which attacks to look out for?
Fortunately, the community of expert lattice cryptographers and cryptanalysts maintains a tool called lattice-estimator that estimates the complexity of the best known (quantum) algorithms for lattice problems relevant to cryptography. Here’s what we get when we run this tool for ML-KEM (this requires Sage to run):
The number that we’re most interested in is “rop“, which estimates the amount of computation the attack would consume. Playing with this tool a bit, we eventually find some parameters for our scheme for which the “usvp” and “dual_hybrid” attacks have comparable complexity. However, lattice-estimator identifies an attack it calls “arora-gb” that applies to our scheme, but not to ML-KEM, that has much lower complexity. (N=600, Q=3329, and beta=4):
We’d have to bump the parameters even further to the scheme to a regime that has comparable security to ML-KEM.
Finally, a word of warning: when designing lattice cryptography, determining whether our scheme is secure requires a lot more than estimating the cost of generic attacks on our LWE parameters. In the absence of a mathematical proof of security in a realistic adversarial model, we can’t rule out other ways of breaking our scheme. Tread lightly, fair traveler, and bring a friend along for the journey.
Making the scheme efficient
Now that we understand how to encrypt with LWE, let’s take a quick look at how to make our scheme efficient.
The main problem with our scheme is that we can only encrypt a bit at a time. This is because we had to split the range(Q) into two chunks, one that encodes 1 and another that encodes 0. We could improve the bit rate by splitting the range into more chunks, but this would make decryption errors more likely.
Another problem with our scheme is that the runtime depends heavily on our security parameters. Encryption requires O(N2) multiplications (multiplication is the most expensive part of a secure implementation of modular arithmetic), and in order for our scheme to be secure, we need to make N quite large.
ML-KEM solves both of these problems by replacing modular arithmetic with arithmetic over a polynomial ring. This means the entries of our matrices will be polynomials rather than integers. We need to define what it means to add, subtract, and multiply polynomials, but once we’ve done that, everything else about the encryption scheme is the same.
In fact, you probably learned polynomial arithmetic in grade school. The only thing you might not be familiar with is polynomial modular reduction. To multiply two polynomials $f(X)$ and $g(X)$, we start by multiplying $f(X)\cdot g(X)$ as usual. Then we’re going to divide $f(X)\cdot g(X)$ by some special polynomial — ML-KEM uses $X^{256}+1$ — and take the remainder. We won’t try to explain this algorithm, but the takeaway is that the result is a polynomial with $256$ coefficients, each of which is an integer in range(Q).
The main advantage of using a polynomial ring for arithmetic is that we can pack more bits into the ciphertext. Our formula for the ciphertext is exactly the same (u=r.T*A + e2, v=r.T*t + e3 + m), but this time the plaintext m encodes a polynomial. Each coefficient of the polynomial encodes a bit, and we’ll handle decryption errors just as we did before, by splitting range(Q) into two chunks, one that encodes 1 and another that encodes 0. This allows us to reliably encrypt 256 bits (32 bytes) per ciphertext.
Another advantage of using polynomials is that it significantly reduces the dimension of the matrix without impacting security. Concretely, the most widely used variant of ML-KEM, ML-KEM-768, uses a 3-by-3 matrix A, so just 9 polynomials in total. (Note that $256 \cdot 3 = 768$, hence the name “ML-KEM-768”.) However, note that we have to be careful in how we choose the modulus: $X^{256}+1$ is special in that it does not exhibit any algebraic structure that is known to permit attacks.
The choices of Q=3329 for the coefficient modulus and $X^{256}+1$ for the polynomial modulus have one more benefit. They allow polynomial multiplication to be carried out using the NTT algorithm, which massively reduces the number of multiplications and additions we have to perform. In fact, this optimization is a major reason why ML-KEM is sometimes faster in terms of CPU time than key exchange with elliptic curves.
We won’t get into how NTT works here, except to say that the algorithm will look familiar to you if you’ve ever implemented RSA. In both cases we use the Chinese Remainder Theorem to split multiplication up into multiple, cheaper multiplications with smaller moduli.
From public key encryption to ML-KEM
The last step to build ML-KEM is to make the scheme secure against chosen ciphertext attacks (CCA). Currently, it’s only secure against chosen plaintext attacks (CPA), which basically means that the ciphertext leaks no information about the plaintext, regardless of the distribution of plaintexts. CCA security is stronger in that it gives the attacker access to decryptions of ciphertexts of its choosing. (Of course, it’s not allowed to decrypt the target ciphertext itself.) The specific transform used in ML-KEM results in a CCA-secure KEM (“Key-Encapsulation Mechanism”).
Chosen ciphertext attacks might seem a bit abstract, but in fact they formalize a realistic threat model for many applications of KEMs (and public key encryption for that matter). For example, suppose we use the scheme in a protocol in which the server authenticates itself to a client by proving it was able to decrypt a ciphertext generated by the client. In this kind of protocol, the server acts as a sort of “decryption oracle” in which its responses to clients depend on the secret key. Unless the scheme is CCA secure, this oracle can be abused by an attacker to leak information about the secret key over time, allowing it to eventually impersonate the server.
ML-KEM incorporates several more optimizations to make it as fast and as compact as possible. For example, instead of generating a random matrix A, we can derive it from a random, 32-byte string (called a “seed”) using a hash-based primitive called a XOF (“eXtendable Output Function”), in the case of ML-KEM this XOF is SHAKE128. This significantly reduces the size of the public key.
Another interesting optimization is that the polynomial coefficients (integers in range(Q)) in the ciphertext are compressed by rounding off the least significant bits of each coefficient, thereby reducing the overall size of the ciphertext.
All told, for the most widely deployed parameters (ML-KEM-768), the public key is 1184 bytes and the ciphertext is 1088 bytes. There’s no obvious way to reduce this, except by reducing the size of the encapsulated key or the size of the public matrix A. The former would make ML-KEM useful for fewer applications, and the latter would reduce the security margin.
Note that there are other lattice schemes that are smaller, but they are based on different hardness assumptions and are still undergoing analysis.
Authentication
In the previous section, we learned about ML-KEM, the algorithm already in use to make encryption PQ-secure. However, encryption is only one piece of the puzzle: establishing a secure connection also requires authenticating the server — and sometimes the client, depending on the application.
Authentication is usually provided by a digital signature scheme, which uses a secret key to sign a message and a public key to verify the signature. The signature schemes used today aren’t PQ-secure: a quantum computer can be used to compute the secret key corresponding to a server’s public key, then use this key to impersonate the server.
While this threat is less urgent than the threat to encryption, mitigating it is going to be more complicated. Over the years, we’ve bolted a number of signatures onto the TLS handshake in order to meet the evolving requirements of the web PKI. We have PQ alternatives for these signatures, one of which we’ll study in this section, but so far these signatures and their public keys are too large (i.e., take up too many bytes) to make comfortable replacements for today’s schemes. Barring some breakthrough in NIST’s ongoing standardization effort, we will have to re-engineer TLS and the web PKI to use fewer signatures.
For now, let’s dive into the PQ signature scheme we’re likely to see deployed first: ML-DSA, a.k.a. Dillithium. The design of ML-DSA follows a similar template as ML-KEM. We start by building some intermediate primitive, then we transform that primitive into the primitive we want, in this case a signature scheme.
ML-DSA is quite a bit more involved than ML-KEM, so we’re going to try to boil it down even further and just try to get across the main ideas.
Warm up
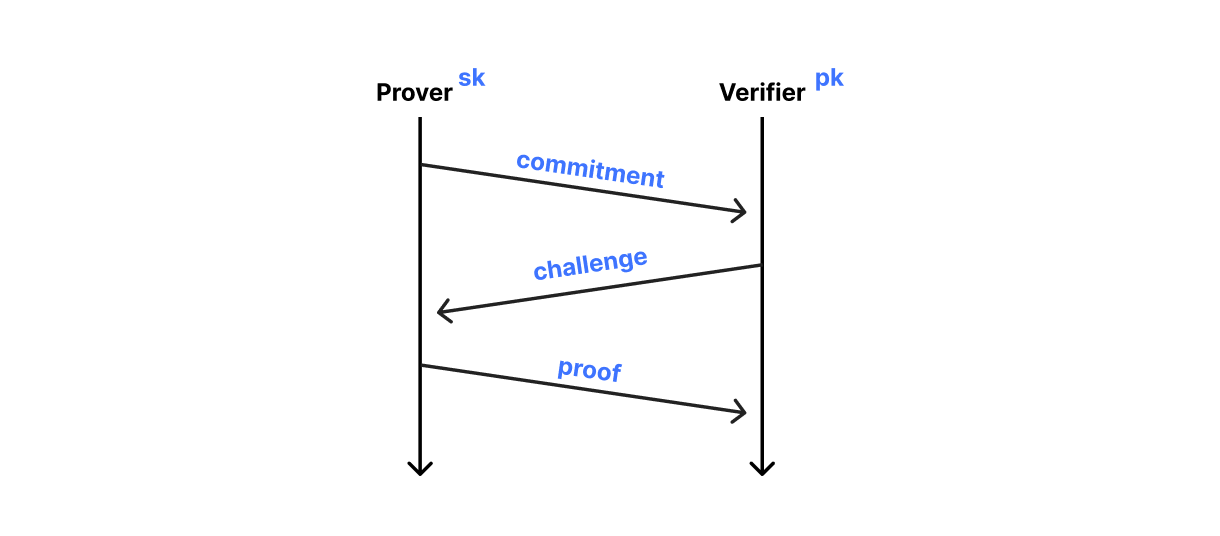
Whereas ML-KEM is basically El Gamal encryption with elliptic curves replaced with lattices, ML-DSA is basically the Schnorr identification protocol with elliptic curves replaced with lattices. Schnorr’s protocol is used by a prover to convince a verifier that it knows the secret key associated with its public key without revealing the secret key itself. The protocol has three moves and is executed with four algorithms:
initialize(): The prover initializes the protocol and sends a commitment to the verifier
challenge(): The verifier receives the commitment and sends the prover a challenge
finish(): The prover receives the challenge and sends the verifier the proof
verify(): Finally, the verifier uses the proof to decide whether the prover knows the secret key
We get the high-level structure of ML-DSA by making this protocol non-interactive. In particular, the prover derives the challenge itself by hashing the commitment together with the message to be signed. The signature consists of the commitment and proof: to verify the signature, the verifier recomputes the challenge from the commitment and message and runs verify()as usual.
Let’s jump right in to building Schnorr’s identification protocol from lattices. If you’ve never seen this protocol before, then this will look a little like black magic at first. We’ll go through it slowly enough to see how and why it works.
Just like for ML-KEM, our public key is an LWE instance (A,t=A*s1 + s2). However, this time our secret key is the pair of short vectors (s1,s2), i.e., it includes the error term. Otherwise, key generation is exactly the same:
To initialize the protocol, the prover generates another LWE instance (A,w=A*y1 + y2). You’ll see why in just a moment. The prover sends the hash of w as its commitment:
Here H is some cryptographic hash function, like SHA-3. The prover stores the secret vectors (y1,y2) for use in its next move.
Now it’s time for the verifier’s challenge. The challenge is just an integer, but we need to be careful about how we choose it. For now let’s just pick it at random:
def challenge():
return random.randrange(0, Q)
Remember: when we turn this protocol into a digital signature, the challenge is derived from the commitment, H(w), and the message. The range of this hash function must be the same as the set of outputs of challenge().
Now comes the fun part. The proof is a pair of vectors (z1,z2) satisfying A*z1 + z2 == c*t + w. We can easily produce this proof if we know the secret key:
z1 = (c*s1 + y1) % Q
z2 = (c*s2 + y2) % Q
Then A*z1 + z2 == A*(c*s1 + y1) + (c*s2 + y2) == c*(A*s1 + s2) + (A*y1 + y2) == c*t + w. Our goal is to design the protocol such that it’s hard to come up with (z1,z2) without knowing (s1,s2), even after observing many executions of the protocol.
Here are the finish() and verify() algorithms for completeness:
Notice that the verifier doesn’t actually check A*z1 + z2 == c*t + w directly; we have to rearrange the equation so that we can set the commitment to H(w) rather than w. We’ll explain the need for hashing in the next section.
Making this scheme secure
The question of whether this protocol is secure boils down to whether it’s possible to impersonate the prover without knowledge of the secret key. Let’s put our attacker hat on and poke around.
Perhaps there’s a way to compute the secret key, either from the public key directly or by eavesdropping on executions of the protocol with the honest prover. If LWE is hard, then clearly there’s no way we’re going to extract the secret key from the public key t. Likewise, the commitment H(w)doesn’t leak any information that would help us extract the secret key from the proof (z1,z2).
Let’s take a closer look at the proof. Notice that the vectors (y1,y2) “mask” the secret key vectors, sort of how the shared secret masks the plaintext in ML-KEM. However, there’s one big exception: we also scale the secret key vectors by the challenge c.
What’s the effect of scaling these vectors? If we squint at a few proofs, we start to see a pattern emerge. Let’s look at z1 first (N=3, Q=3329, beta=4):
Indeed, with enough proof samples, we should be able to make a pretty good guess of the value of s1. In fact, for these parameters, there is a simple statistical analysis we can do to compute s1 exactly. (Hint: Q is a prime number, which means c*pow(c,-1,Q)==1 whenever c>0.) We can also apply this analysis to s2, or compute it directly from t, s1, and A.
The main flaw in our protocol is that, although our secret vectors are short, scaling them makes them so long that they’re not completely masked by (y1,y2). Since c spans the entire range(Q), so do the entries of c*s1. and c*s2, which means in order to mask these entries, we need the entries of (y1,y2) to span range(Q) as well. However, doing this would make solving LWE for (A,w) easy, by solving SIS. We somehow need to strike a balance between the length of the vectors of our LWE instances and the leakage induced by the challenge.
Here’s where things get tricky. Let’s refer to the set of possible outputs of challenge() as the challenge space. We need the challenge space to be fairly large, large enough that the probability of outputting the same challenge twice is negligible.
Why would such a collision be a problem? It’s a little easier to see in the context of digital signatures. Let’s say an attacker knows a valid signature for a message m. The signature includes the commitment H(m), so the attacker also knows the challenge is c == H(H(w),m). Suppose it manages to find a different message m* for which c == H(H(w),m*). Then the signature is also valid for m! And this attack is easy to pull off if the challenge space, that is, the set of possible outputs of H, is too small.
Unfortunately, we can’t make the challenge space larger simply by increasing the size of the modulus Q: the larger the challenge might be, the more information we’d leak about the secret key. We need a new idea.
The best of both worlds
Remember that the hardness of LWE depends on the ratio between beta and Q. This means that y1 and y2 don’t need to be short in absolute terms, but short relative to random vectors.
With that in mind, consider the following idea. Let’s take a larger modulus, say Q=2**31 - 1, and we’ll continue to sample from the same challenge space, range(2**16).
First, notice that z1 is now “relatively” short, since its entries are now in range(-gamma, gamma+1), where gamma = beta*(2**16-1), rather than uniform over range(Q). Let’s also modify initialize() to sample the entries of (y1,y2) from the same range and see what happens:
This is definitely going in the right direction, since there are no obvious correlations between z1 and s1. (Likewise for z2 and s2.) However, we’re not quite there.
One problem is that the challenge space is still quite small. With only 2**16 challenges to choose from, we’re likely to see a collision even after only a handful of protocol executions. We need the challenge space to be much, much larger, say around 2**256. But then Q has to be an insanely large number in order for the beta to Q ratio to be secure.
ML-DSA is able to side step this problem due to its use of arithmetic over polynomial rings. It uses the same modulus polynomial as ML-KEM, so the challenge is a polynomial with 256 coefficients. The coefficients are chosen carefully so that the challenge space is large, but multiplication by the challenge scales the secret vector by a small amount. Note that we still end up using a slightly larger modulus (Q=8380417) for ML-DSA than for ML-KEM, but only by about twelve bits.
However, there is a more fundamental problem here, which is that we haven’t completely ruled out that signatures may leak information about the secret key.
Cause and effect
Suppose we run the protocol a number of times, and in each run, we happen to choose a relatively small value for some entry of y1. After enough runs, this would eventually allow us to reconstruct the corresponding entry of s1. To rule this out as a possibility, we need to make y1 even longer. (Likewise for y2.) But how long?
Suppose we know that the entries of z1 and z2 are always in range(-beta_loose,beta_loose+1) for some beta_loose > beta. Then we can simulate an honest run of the protocol as follows:
This procedure perfectly simulates honest runs of the protocol, in the sense that the output of simulate() is indistinguishable from the transcript of a real run of the protocol with the honest prover. To see this, notice that the w, c, z1, and z2 all have the same mathematical relationship (the verification equation still holds) and have the same distribution.
And here’s the punch line: since this procedure doesn’t use the secret key, it follows that the attacker learns nothing from eavesdropping on the honest prover that it can’t compute from the public key itself. Pretty neat!
What’s left to do is arrange for z1 and z2 to fall in this range. First, we modify initialize() by increasing the range of y1 and y2 by beta_loose:
This ensures the proof vectors z1 and z2 are roughly uniform over range(-beta_loose, beta_loose+1). However, they may fall slightly outside of this range, so need to modify finalize() to abort if not. Correspondingly, verify() should reject proof vectors that are out of range:
def finish(s1, s2, y1, y2, c):
z1 = (c*s1 + y1) % Q
z2 = (c*s2 + y2) % Q
if not in_range(z1, beta_loose) or not in_range(z2, beta_loose):
return (None, None)
return (z1, z2)
def verify(A, t, hw, c, z1, z2):
if not in_range(z1, beta_loose) or not in_range(z2, beta_loose):
return False
return H((A*z1 + z2 - c*t) % Q) == hw
If finish() returns (None,None), then the prover and verifier are meant to abort the protocol and retry until the protocol succeeds:
((A, t), (s1, s2)) = key_gen()
while True:
(hw, (y1, y2)) = initialize(A) # hw: prover -> verifier
c = challenge() # c: verifier -> prover
(z1, z2) = finish(s1, s2, y1, y2, c) # (z1, z2): prover -> verifier
if z1 is not None and z2 is not None:
break
assert verify(A, t, hw, c, z1, z2)
Interestingly, we should expect aborts to be quite common. The parameters of ML-DSA are tuned so that the protocol runs five times on average before it succeeds.
Another interesting point is that the security proof requires us to simulate not only successful protocol runs, but aborted protocol runs as well. More specifically, the protocol simulator must abort with the same probability as the real protocol, which implies that the rejection probability is independent of the secret key.
The simulator also needs to be able to produce realistic looking commitments for aborted transcripts. This is exactly why the prover commits to the hash of w rather than w itself: in the security proof, we can easily simulate hashes of random inputs.
Making this scheme efficient
ML-DSA benefits from many of the same optimizations as ML-KEM, including using polynomial rings, NTT for polynomial multiplication, and encoding polynomials with a fixed number of bits. However, ML-DSA has a few more tricks to make things smaller.
First, in ML-DSA, instead of the pair of short vectors z1 and z2, the proof consists of a single vector z=c*s1 + y, where y was committed to in the previous step. In turn, we only end up with a single proof vector z rather than two as before. Getting this to work requires a special encoding of the commitment so that we can’t compute y from it. ML-DSA uses a related trick to reduce the size of the t vector of the public key, but the details are more complicated.
For the parameters we expect to deploy first (ML-DSA-44), the public key is 1312 bytes long and the signature is a whopping 2420 bytes. In contrast to ML-KEM, it is possible to shave off some more bytes. This does not come for free and requires complicating the scheme. An example is HAETAE, which changes the distributions used. Falcon takes it a step further with even smaller signatures, using a completely different approach, which although elegant is also more complex to implement.
Wrap up
Lattice cryptography underpins the first generation of PQ algorithms to get widely deployed on the Internet. ML-KEM is already widely used today to protect encryption from quantum computers, and in the coming years we expect to see ML-DSA deployed to get ahead of the threat of quantum computers to authentication.
Lattices are also the basis of a new frontier for cryptography: computing on encrypted data.
Suppose you wanted to aggregate some metrics submitted by clients without learning the metrics themselves. With LWE-based encryption, you can arrange for each client to encrypt their metrics before submission, aggregate the ciphertexts, then decrypt to get the aggregate.
Suppose instead that a server has a database that it wants to provide clients access to without revealing to the server which rows of the database the client wants to query. LWE-based encryption allows the database to be encoded in a manner that permits encrypted queries.
These applications are special cases of a paradigm known as FHE (“Fully Homomorphic Encryption”), which allows for arbitrary computations on encrypted data. FHE is an extremely powerful primitive, and the only way we know how to build it today is with lattices. However, for most applications, FHE is far less practical than a special-purpose protocol would be (lattice-based or not). Still, over the years we’ve seen FHE get better and better, and for many applications it is already a decent option. Perhaps we’ll dig into this and other lattice schemes in a future blog post.
We hope you enjoyed this whirlwind tour of lattices. Thanks for reading!
Cloudflare Email Security customers using Microsoft Outlook can now enhance their data protection using our new DLP Assist capability. This application scans emails in real time as users compose them, identifying potential data loss prevention (DLP) violations, such as Social Security or credit card numbers. Administrators can instantly alert users of violations and take action downstream, whether by blocking or encrypting messages, to prevent sensitive information from leaking. DLP Assist is lightweight, easy to deploy, and helps organizations maintain compliance without disrupting workflow.
Making DLP more accessible
After speaking with our customers, we discovered a common challenge: many wanted to implement a data loss prevention policy for Outlook, but found existing solutions either too complex to set up or too costly to adopt.
That’s why we created DLP Assist to be a lightweight application that can be installed in minutes. Unlike other solutions, it doesn’t require changes to outbound email connectors or provide concerns about IP reputation to customers. By fully leveraging the Microsoft ecosystem, DLP Assist makes email DLP accessible to all organizations, whether they have dedicated IT teams or none at all.
We also recognized that traditional DLP solutions often demand significant financial investment in not just software but also in team members to configure and monitor them. DLP Assist aims to eliminate these barriers. Customers can use the application as part of our Email Security product, avoiding the need for additional purchases. Plus, with our DLP engine powered by optical character recognition (OCR), confidence levels, and other detection mechanisms, organizations don’t need a dedicated team to constantly oversee it.
By eliminating the complexities of legacy DLP and email systems, we allow customers to quickly begin preventing the unauthorized egress of sensitive data. With DLP Assist, organizations can be confident in controlling and protecting the information that leaves their environment.
How does it work?
Our DLP Assist is an application that integrates with the Desktop (Mac and Windows) and Web Outlook clients, passively scanning emails as they are composed. Running in the background within Microsoft Outlook, DLP Assist continuously monitors new text and attachments added to emails that users are drafting.
When a customer downloads and installs the application, Cloudflare creates a unique client ID specifically for emails read from the DLP Assist application, which serves as an identifier solely for use by DLP Assist within Cloudflare’s backend. When a user begins drafting a message, the DLP Assist application invokes several Microsoft Outlook APIs to gather information about how the message is changing. These APIs let the Cloudflare application continuously access different parts of the message like subject, body, attachments, etc. While the application is reading the changes within the message, it also establishes a secure, encrypted connection with a Cloudflare Worker.
As raw data about the email and attachments is sent to the Worker, the Worker relays the information to our DLP engine, which is at the heart of our scanning process. It leverages OCR technology to analyze attachments, extract text from images, and detect DLP violations across both email content and embedded data. It also examines raw text to ensure a comprehensive analysis of every part of the email and its attachments. While our engine supports most attachment types, it currently does not process video or audio files.
The DLP engine runs on all of our servers, and we also store the customer DLP profile configuration data on all of our servers. By keeping DLP policy configuration data on all servers alongside our analysis engine, we eliminate the need to reroute requests across our network allowing for low-latency, real-time DLP checks. The customer’s client ID enables us to find and apply their defined DLP profiles and accurately determine policy violations, delivering results directly to the Cloudflare Worker. If a violation is found, the Worker responds to the application to take action within Outlook.
Our architecture ensures real-time scanning with minimal latency, as end users are always near a Cloudflare Worker, regardless of their location. Additionally, this design provides built-in resilience — if a Cloudflare Worker becomes unavailable, another can take over, allowing for uninterrupted DLP enforcement. By scanning in real time, this allows us to provide immediate feedback to the user about any DLP violations that they have within their email, rather than the user having to wait till the message has been sent.
If a violation is detected, the application first displays an insight message — a ribbon notification at the top of the email — alerting the user to the issue. Administrators have full control over this message and can customize it to provide specific guidance or warnings. We find that most of our customers point users to documentation reminding them what is allowed to be sent outside of the organization.
When a DLP violation occurs, DLP Assist also injects a header into the EML file to indicate the violation. If the user removes the content that is in violation, the header is automatically removed as well.
If the violation remains unchanged, DLP Assist invokes a Microsoft Outlook API which prompts the user with a final warning, giving them another opportunity to revise the message before sending.
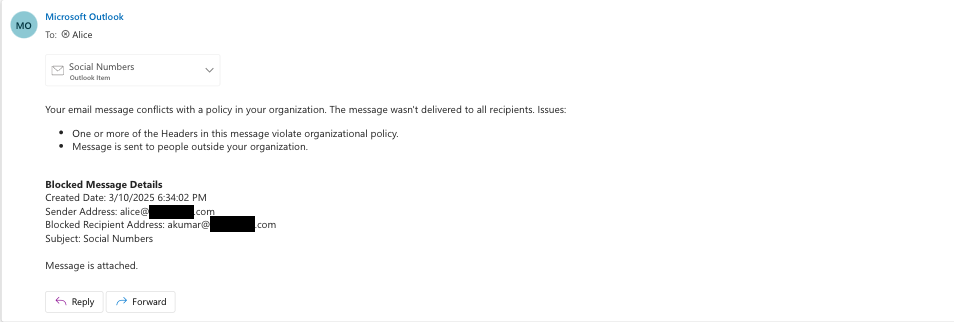
If the user proceeds without making changes, the email will be sent from the client with headers embedded into the EML showing that message contains a DLP violation. Organizations can configure their outbound mail transfer agent (MTA) to take appropriate action based on these headers. For those with Microsoft as their outbound MTA, Cloudflare’s DLP Assist integrates with Microsoft Purview, enabling organizations to block, encrypt, or require approval before sending.
For example, if an organization configures Purview to block the email, users will receive a notification similar to this one.
Violations detected by the DLP Assist application can also be sent externally through our Logpush feature. Customers have the flexibility to integrate this data with SIEM or SOAR platforms for deeper analysis, or store it in bucket storage solutions like Cloudflare R2. Additionally, customers can enhance their reporting capabilities by viewing block data directly within their outbound gateway.
As we continue to improve our DLP engine, we’re introducing more advanced ways to analyze messages. During Security Week 2025, we’re unveiling new AI methodologies that automatically fine-tune DLP confidence levels using machine learning models. Initially, these enhancements will be rolled out for Gateway violations, but we plan to extend them to email scanning in the near future. For more details, see the associated blog post.
Cloudflare One’s DLP Assist is designed for quick deployment, enabling organizations to implement a data loss prevention solution with minimal effort. It allows customers to immediately begin scanning emails for sensitive data and take action to prevent unauthorized sharing, ensuring compliance and security from day one.
How can I start using it?
To get started, navigate to the Zero Trust dashboard and click on the Email Security tab. From there, select the Outbound DLP tab.
To install DLP Assist, organizations can download the manifest file, which provides Microsoft with the necessary instructions to install the application within Outlook. Administrators can then upload this manifest file by going to Integrated Apps within the Microsoft 365 Admin Center and selecting Upload Custom Apps:
This application is best suited for use with OWA (Outlook Web Access) and the desktop (Mac and Windows) Outlook client. Due to Microsoft limitations, a stable experience on mobile devices is not yet available.
We’re continuously expanding our solutions to help organizations protect their data. Exciting new DLP and Email Security features are on the way throughout 2025, so stay tuned for upcoming announcements.
To learn more about our DLP and Email Security solutions, reach out to your Cloudflare representative. Want to see our detections in action? Run a free Retro Scan to uncover any potentially malicious messages hiding in your inbox.
Today is the final day of Security Week 2025, and after a great week of blog posts across a variety of topics, we’re excited to share the latest on Cloudflare’s data security products.
This announcement takes us to Cloudflare’s SASE platform, Cloudflare One, used by enterprise security and IT teams to manage the security of their employees, applications, and third-party tools, all in one place.
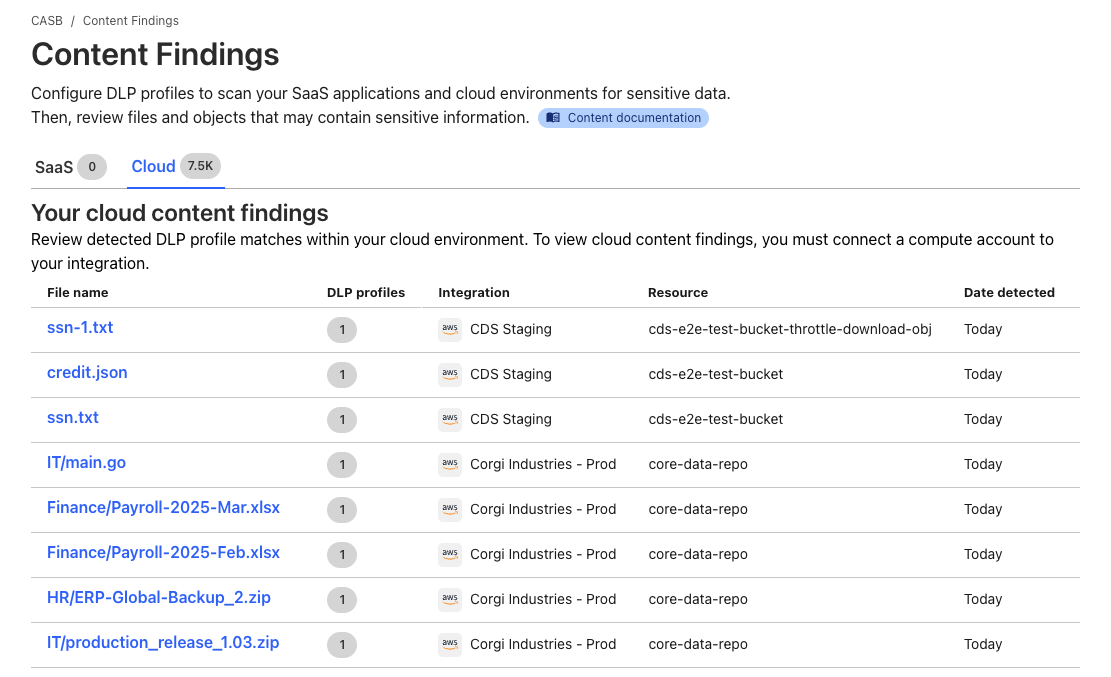
Starting today, Cloudflare One users can now use the CASB (Cloud Access Security Broker) product to integrate with and scan Amazon Web Services (AWS) S3 and Google Cloud Storage, for posture- and Data Loss Prevention (DLP)-related security issues. Create a free account to check it out.
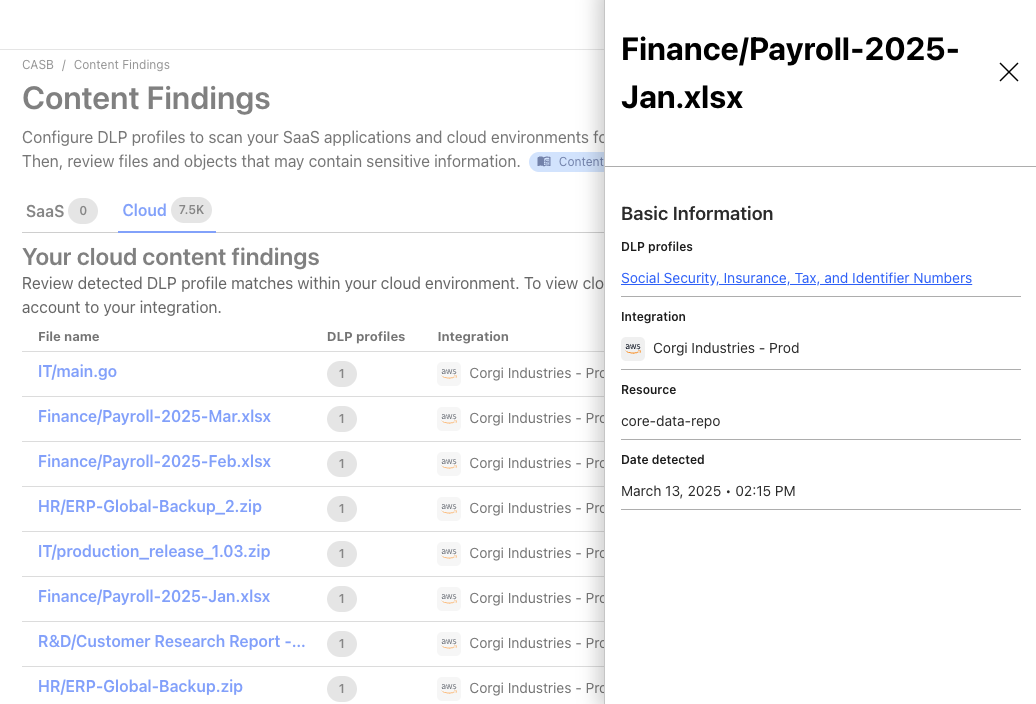
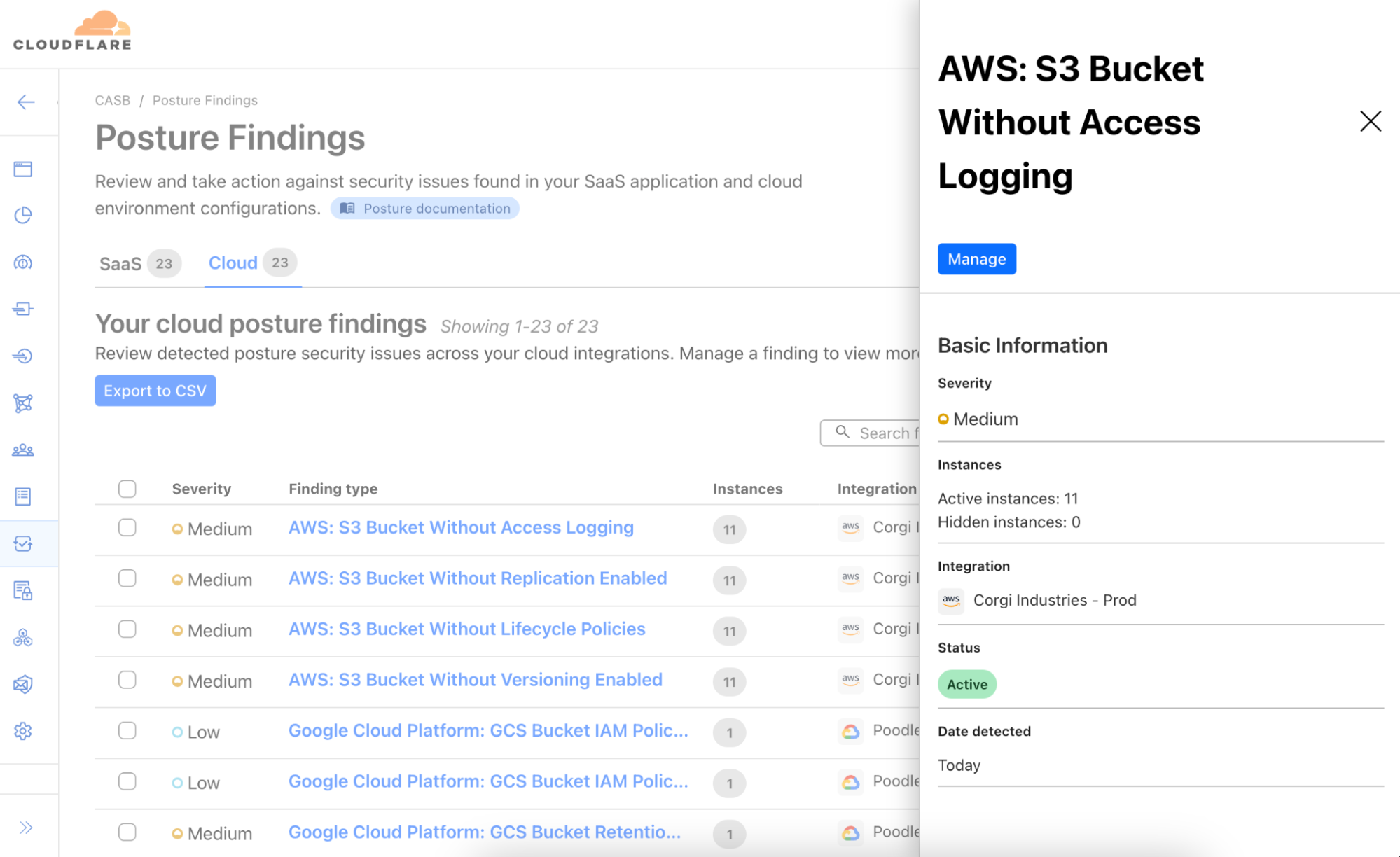
Scanning both point-in-time and continuously, users can identify misconfigurations in Identity and Access Management (IAM), bucket, and object settings, and detect sensitive information, like Social Security numbers, credit card numbers, or any other pattern using regex, in cloud storage objects.
Cloud DLP
Over the last few years, our customers — predominantly security and IT teams — have told us about their appreciation for CASB’s simplicity and effectiveness as a SaaS security product. Its number of supported integrations, its ease of setup, and speed in identifying critical issues across popular SaaS platforms, like files shared publicly in Microsoft 365 and exposed sensitive data in Google Workspace, has made it a go-to for many.
However, as we’ve engaged with customers, one thing became clear: the risks of unmonitored or exposed data at-rest go far beyond just SaaS environments. Sensitive information – whether intellectual property, customer data, or personal identifiers – can wreak havoc on an organization’s reputation and its obligations to its customers if it falls into the wrong hands. For many of our customers, the security of data stored in cloud providers like AWS and GCP is even more critical than the security of data in their SaaS tools.
That’s why we’ve extended Cloudflare CASB to include Cloud DLP (Data Loss Prevention) functionality, enabling users to scan objects in Amazon S3 buckets and Google Cloud Storage for sensitive data matches.
With Cloudflare DLP, you can choose from pre-built detection profiles that look for common data types (such as Social Security Numbers or credit card numbers) or create your own custom profiles using regular expressions. As soon as an object matching a DLP profile is detected, you can dive into the details, understanding the file’s context, seeing who owns it, and more. These capabilities provide the insight needed to quickly protect data and prevent exposure in real time.
And as with all CASB integrations, this new functionality also comes with posture management features, meaning whether you’re using AWS or GCP, we’ll help you identify misconfigurations and other cloud security issues that could leave your data vulnerable, like buckets that are publicly-accessible or have critical logging settings disabled, access keys needing rotation, or users without multi-factor authentication (MFA). It’s all included.
Simple by default, configurable where you want it
Cloudflare CASB and DLP are simple to use by default, making it easy to get started right away. But it’s also highly configurable, giving you the flexibility to fine-tune the scanning profiles to suit your specific needs.
For example, you can adjust which storage buckets or file types to scan, and even sample only a percentage of objects for analysis. The scanning also runs within your own cloud environment, so your data never leaves your infrastructure. This approach keeps your cloud storage secure and your costs managed while allowing you to tailor the solution to your organization’s unique compliance and security requirements.
Looking ahead, our roadmap also includes expanding support to additional cloud storage environments, such as Azure Blob Storage and Cloudflare R2, further extending our comprehensive, multi-cloud security strategy. Stay tuned for more on that!
How it works
From the start, we knew that to deliver DLP capabilities across cloud environments, it would require an efficient and scalable design to enable real-time detection of sensitive data exposure.
Serverless architecture for streamlined processing
An early design decision was made to leverage a serverless architecture approach to ensure sensitive data discovery is both efficient and scalable. Here’s how it works:
Compute Account: The entire process runs within a cloud account owned by your organization, known as a Compute Account. This design ensures your data remains within your boundaries, avoiding costly cloud egress fees. The Compute Account can be launched in under 15 minutes using a provided Terraform template.
Controller function: Every minute, a lightweight, serverless controller function in your cloud environment communicates with Cloudflare’s APIs, fetching the latest DLP configurations and security profiles from your Cloudflare One account.
Crawler process: The controller triggers an object discovery task, which is processed by a second serverless function known as the Crawler. The Crawler queries cloud storage accounts, like AWS S3 or Google Cloud Storage, via API to identify new objects. Redis is used within the Compute Account to track which objects have yet to be evaluated.
Scanning for sensitive data: Newly discovered objects are sent through a queue to a third serverless function called the Scanner. This function downloads the objects and streams their contents to the DLP engine in the Compute Account, which scans for matches against predefined or custom DLP Profiles.
Finding generation and alerts: If a DLP match is found, metadata about the object, such as context and ownership details, is published to a queue. This data is ingested by a Cloudflare-hosted service and presented in the Cloudflare Dashboard as findings, giving security teams the visibility needed to take swift action.
Scalable and secure design
The DLP pipeline ensures that sensitive data never leaves your cloud environment — a privacy-first approach. All communication between the Compute Account and Cloudflare’s APIs are initiated by the controller, also meaning there is no need to perform any extra configuration to allow ingress traffic.
How to get started
To get started, reach out to your account team to learn more about this new data security functionality and our roadmap. If you want to try this out on your own, you can login to the Cloudflare One dashboard (create a free account here if you don’t have one) and navigate to the CASB page to set up your first integration.
Short-lived SSH access made its debut on Cloudflare’s SASE platform in October 2024. Leveraging the knowledge gained through the BastionZero acquisition, short-lived SSH access enables organizations to apply Zero Trust controls in front of their Linux servers. That was just the beginning, however, as we are thrilled to announce the release of a long-requested feature: clientless, browser-based support for the Remote Desktop Protocol (RDP). Built on top of Cloudflare’s modern proxy architecture, our RDP proxy offers a secure and performant solution that, critically, is also easy to set up, maintain, and use.
Security challenges of RDP
Remote Desktop Protocol (RDP) was born in 1998 with Windows NT 4.0 Terminal Server Edition. If you have never heard of that Windows version, it’s because, well, there’s been 16 major Windows releases since then. Regardless, RDP is still used across thousands of organizations to enable remote access to Windows servers. It’s a bit of a strange protocol that relies on a graphical user interface to display screen captures taken in very close succession in order to emulate the interactions on the remote Windows server. (There’s more happening here beyond the screen captures, including drawing commands, bitmap updates, and even video streams. Like we said — it’s a bit strange.) Because of this complexity, RDP can be computationally demanding and poses a challenge for running at high performance over traditional VPNs.
Beyond its quirks, RDP has also had a rather unsavory reputation in the security industry due to early vulnerabilities with the protocol. The two main offenders are weak user sign-in credentials and unrestricted port access. Windows servers are commonly protected by passwords, which often have inadequate security to start, and worse still, may be shared across multiple accounts. This leaves these RDP servers open to brute force or credential stuffing attacks.
Bad actors have abused RDP’s default port, 3389, to carry out on-path attacks. One of the most severe RDP vulnerabilities discovered is called BlueKeep. Officially known as CVE-2019-0708, BlueKeep is a vulnerability that allows remote code execution (RCE) without authentication, as long as the request adheres to a specific format and is sent to a port running RDP. Worse still, it is wormable, meaning that BlueKeep can spread to other machines within the network with no user action. Because bad actors can compromise RDP to gain unauthorized access, attackers can then move laterally within the network, escalating privileges, and installing malware. RDP has also been used to deploy ransomware such as Ryuk, Conti, and DoppelPaymer, earning it the nickname “Ransomware Delivery Protocol.”
This is a subset of vulnerabilities in RDP’s history, but we don’t mean to be discouraging. Thankfully, due to newer versions of Windows, CVE patches, improved password hygiene, and better awareness of privileged access, many organizations have reduced their attack surface. However, for as many secured Windows servers that exist, there are still countless unpatched or poorly configured systems online, making them easy targets for ransomware and botnets.
The need for a browser-based RDP solution
Despite its security risks, RDP remains essential for many organizations, particularly those with distributed workforces and third-party contractors. It provides value for compute-intensive tasks that require high-powered Windows servers with CPU/GPU resources greater than users’ machines can offer. For security-focused organizations, RDP grants better visibility into who is accessing Windows servers and what actions are taken during those sessions.
Because issuing corporate devices to contractors is costly and cumbersome, many organizations adopt a bring-your-own-device (BYOD) policy. This decision instead requires organizations to provide contractors with a means to RDP to a Windows server with the necessary corporate resources to fulfill their role.
Traditional RDP requires client software on user devices, so this is not an appropriate solution for contractors (or any employees) using personal machines or unmanaged devices. Previously, Cloudflare customers had to rely on self-hosted third-party tools like Apache Guacamole or Devolutions Gateway to enable browser-based RDP access. This created several operational pain points:
Infrastructure complexity: Deploying and maintaining RDP gateways increases operational overhead.
Maintenance burden: Commercial and open-source tools may require frequent updates and patches, sometimes even necessitating custom forks.
Compliance challenges: Third-party software requires additional security audits and risk management assessments, particularly for regulated industries.
Redundancy, but not the good kind – Customers come to Cloudflare to reduce the complexity of maintaining their infrastructure, not add to it.
We’ve been listening. Cloudflare has architectured a high-performance RDP proxy that leverages the modern security controls already part of our Zero Trust Network Access (ZTNA) service. We feel that the “security/performance tradeoff” the industry commonly touts is a dated mindset. With the right underlying network architecture, we can help mitigate RDP’s most infamous challenges.
Introducing browser-based RDP with Access
Cloudflare’s browser-based RDP solution is the newest addition to Cloudflare Access alongside existing clientless SSH and VNC offerings, enabling secure, remote Windows server access without VPNs or RDP clients. Built natively within Cloudflare’s global network, it requires no additional infrastructure.
Our browser-based RDP access combines the power of self-hosted Access applications with the additional flexibility of targets, introduced with Access for Infrastructure. Administrators can enforce:
Authentication: Control how users authenticate to your internal RDP resources with SSO, MFA, and device posture.
Authorization: Use policy-based access control to determine who can access what target and when.
Auditing: Provide Access logs to support regulatory compliance and visibility in the event of a security breach.
Users only need a web browser — no native RDP client is necessary! RDP servers are accessed through our app connector, Cloudflare Tunnel, using a common deployment model of existing Access customers. There is no need to provision user devices to access particular RDP servers, making for minimal setup to adopt this new functionality.
How it works
The client
Cloudflare’s implementation leverages IronRDP, a high-performance RDP client that runs in the browser. It was selected because it is a modern, well-maintained, RDP client implementation that offers an efficient and responsive experience. Unlike Java-based Apache Guacamole, another popular RDP client implementation, IronRDP is built with Rust and integrates very well with Cloudflare’s development ecosystem.
While selecting the right tools can make all the difference, using a browser to facilitate an RDP session faces some challenges. From a practical perspective, browsers just can’t send RDP messages. RDP relies directly on the Layer 4 Transmission Control Protocol (TCP) for communication, and while browsers can use TCP as the underlying protocol, they do not expose APIs that would let apps build protocol support directly on raw TCP sockets.
Another challenge is rooted in a security consideration: the username and password authentication mechanism that is native to RDP leaves a lot to be desired in the modern world of Zero Trust.
In order to tackle both of these challenges, the IronRDP client encapsulates the RDP session in a WebSocket connection. Wrapping the Layer 4 TCP traffic in HTTPS enables the client to use native browser APIs to communicate with Cloudflare’s RDP proxy. Additionally, it enables Cloudflare Access to secure the entire session using identity-aware policies. By attaching a Cloudflare Access authorization JSON Web Token (JWT) via cookie to the WebSocket connection, every inter-service hop of the RDP session is verified to be coming from the authenticated user.
A brief aside into how security and performance is optimized: in conventional client-based RDP traffic, the client and server negotiate a TLS connection to secure and verify the session. However, because the browser WebSocket connection is already secured with TLS to Cloudflare, we employ IronRDP’s RDCleanPath protocol extension to eliminate this second encapsulation of traffic. Removing this redundancy avoids unnecessary performance degradation and increased complexity during session handshakes.
The server
The IronRDP client initiates a WebSocket connection to a dedicated WebSocket proxy, which is responsible for authenticating the client, terminating the WebSocket connection, and proxying tunneled RDP traffic deeper into Cloudflare’s infrastructure to facilitate connectivity. The seemingly simple task of determining how this WebSocket proxy should be built turned out to be the most challengingdecision in the development process.
Our initial proposal was to develop a new service that would run on every server within our network. While this was feasible, operating a new service would introduce a non-trivial maintenance burden, which ultimately turned out to be more overhead than value-add in this case. The next proposal was to build it into Front Line (FL), one of Cloudflare’s oldest services that is responsible for handling tens of millions of HTTP requests per second. This approach would have sidestepped the need to expose new IP addresses and benefitted from the existing scaffolding to let the team move quickly. Despite being promising at first, this approach was decided against because FL is undergoing significant investment, and the team didn’t want to build on shifting sands.
Finally, we identified a solution that implements the proxy service using Cloudflare Workers! Fortunately, Workers automatically scales to massive request rates, which eliminates some of the groundwork we’d lay if we had chosen to build a new service. Candidly, this approach was not initially preferred due to some ambiguities around how Workers communicates with internal Cloudflare services, but with support from the Workers team, we found a path forward.
From the WebSocket proxy Worker, the tunneled RDP connection is sent to the Apollo service, which is responsible for routing traffic between on-ramps and off-ramps for Cloudflare Zero Trust. Apollo centralizes and abstracts these complexities to let other services focus on application-specific functionality. Apollo determines which Cloudflare colo is closest to the target Cloudflare Tunnel and establishes a connection to an identical Apollo instance running in that colo. The egressing Apollo instance can then facilitate the final connection to the Cloudflare Tunnel. By using Cloudflare’s global network to traverse the distance between the ingress colo and the target Cloudflare Tunnel, network disruptions and congestion is managed.
Apollo connects to the RDP server and passes the ingress and egress connections to Oxy-teams, the service responsible for inspecting and proxying the RDP traffic. It functions as a pass-through (strictly enabling traffic connectivity) as the web client authenticates to the RDP server. Our initial release makes use of NT Lan Manager (NTLM) authentication, a challenge-response authentication protocol requiring username and password entry. Once the client has authenticated with the server, Oxy-teams is able to proxy all subsequent RDP traffic!
This may sound like a lot of hops, but every server in our network runs every service. So believe it or not, this complex dance takes place on a single server and by using UNIX domain sockets for communication, we also minimize any performance impact. If any of these servers become overloaded, experience a network fault, or have a hardware problem, the load is automatically shifted to a neighboring server with the help of Unimog, Cloudflare’s L4 load balancer.
Putting it all together
User initiation: The user selects an RDP server from Cloudflare’s App Launcher (or accesses it via a direct URL). Each RDP server is associated with a public hostname secured by Cloudflare.
Ingress: This request is received by the closest data center within Cloudflare’s network.
Authentication: Cloudflare Access authenticates the session by validating that the request contains a valid JWT. This token certifies that the user is authorized to access the selected RDP server through the specified domain.
Web client delivery:Cloudflare Workers serves the IronRDP web client to the user’s browser.
Secure tunneling: The client tunnels RDP traffic from the user’s browser over a TLS-secured WebSocket to another Cloudflare Worker.
Traffic routing: The Worker that receives the IronRDP connection terminates the WebSocket and initiates a connection to Apollo. From there, Apollo creates a connection to the RDP server.
Authentication relay: With a connection established, Apollo relays RDP authentication messages between the web client and the RDP server.
Connection establishment: Upon successful authentication, Cloudflare serves as an RDP proxy between the web browser and the RDP server, connecting the user to the RDP server with free-flowing traffic.
Policy enforcement: Cloudflare’s secure web gateway, Oxy-teams, applies Layer 4 policy enforcement and logging of the RDP traffic.
Key benefits of this architecture:
No additional software: Access Windows servers directly from a browser.
Low latency: Cloudflare’s global network minimizes performance overhead.
Enhanced security: RDP access is protected by Access policies, preventing lateral movement.
Integrated logging and monitoring: Administrators can observe and control RDP traffic.
To learn more about Cloudflare’s proxy capabilities, take a look at our related blog post explaining our proxy framework.
Selective, modern RDP authentication
Cloudflare’s browser-based RDP solution exclusively supports modern RDP authentication mechanisms, enforcing best practices for secure access. Our architecture ensures that RDP traffic using outdated or weak legacy security features from older versions of the RDP standard, such as unsecured password-based authentication or RC4 encryption, are never allowed to reach customer endpoints.
Cloudflare supports secure session negotiation using the following principles:
TLS-based WebSocket connection for transport security.
Fine-grained policies that enforce single sign on (SSO), multi-factor authentication (MFA), and dynamic authorization.
Integration with enterprise identity providers via SAML (Security Assertion Markup Language) and OIDC (OpenID Connect).
Every RDP session that passes through Cloudflare’s network is encrypted and authenticated.
What’s next?
This is only the beginning for our browser-based RDP solution! We have already identified a few areas for continued focus:
Enhanced visibility and control for administrators: Because RDP traffic passes through Cloudflare Workers and proxy services, browser-based RDP will expand to include session monitoring. We are also evaluating data loss prevention (DLP) support, such as restricting actions like file transfers and clipboard use, to prevent unauthorized data exfiltration without compromising performance.
Advanced authentication: Long-lived credentials are a thing of the past. Future iterations of browser-based RDP will include passwordless functionality, eliminating the need for end users to remember passwords and administrators from having to manage them. To that end, we are evaluating methods such as client certificate authentication, passkeys and smart cards, and integration with third-party authentication providers via Access.
Compliance and FedRAMP High certification
We plan to include browser-based RDP in our FedRAMP High offering for enterprise and government organizations, a high-priority initiative we announced in early February. This certification will validate that our solution meets the highest standards for:
Data protection
Identity and access management
Continuous monitoring
Incident response
Seeking FedRAMP High compliance demonstrates Cloudflare’s commitment to securing sensitive environments, such as those in the federal government, healthcare, and financial sectors.
By enforcing a modern, opinionated, and secure implementation of RDP, Cloudflare provides a secure, scalable, and compliant solution tailored to the needs of organizations with critical security and compliance mandates.
Get started today
At Cloudflare, we are committed to providing the most comprehensive solution for ZTNA, which now also includes privileged access to sensitive infrastructure like Windows servers over browser-based RDP. Cloudflare’s browser-based RDP solution is in closed beta with new customers being onboarded each week. You can request access here to try out this exciting new feature.
In the meantime, check out ourAccess for Infrastructure documentation to learn more about how Cloudflare protects privileged access to sensitive infrastructure. Access for Infrastructure is currently available free to teams of under 50 users, and at no extra cost to existing pay-as-you-go and Contract plan customers through an Access or Zero Trust subscription. Stay tuned as we continue to natively rebuild BastionZero’s technology into Cloudflare’s Access for Infrastructure service!
Forrester Research has recognized Cloudflare as a Leader in it’s The Forrester Wave™: Web Application Firewall Solutions, Q1 2025 report. This market analysis helps security and risk professionals select the right solution for their needs. According to Forrester:
“Cloudflare is a strong option for customers that want to manage an easy-to-use, unified web application protection platform that will continue to innovate.”
In this evaluation, Forrester assessed 10 Web Application Firewall (WAF) vendors across 22 criteria, including product security and vision. We believe this recognition is due to our continued investment in our product offering. Get a complimentary copy of the report here.
Since introducing our first WAF in 2013, Cloudflare has transformed it into a robust, enterprise-grade Application Security platform. Our fully integrated suite includes WAF, bot mitigation, API security, client-side protection, and DDoS mitigation, all built on our expansive global network. By leveraging AI and machine learning, we deliver industry-leading security while enhancing application performance through our content delivery and optimization solutions.
According to the Forrester report, “Cloudflare stands out with features that help customers work more efficiently.” Unlike other solutions in the market, Cloudflare’s WAF, API Security, bot detection, client-side security, and DDoS protection are natively integrated within a single platform, running on a unified engine. Our integrated solution empowers a seamless user experience and enables advanced threat detection across multiple vectors to meet the most demanding security requirements.
Cloudflare: a standout in Application Security
Forrester’s evaluation of Web Application Firewall solutions is one of the most comprehensive assessments in the industry. We believe this report highlights Cloudflare’s integrated global cloud platform and our ability to deliver enterprise-grade security without added complexity. We don’t just offer a WAF — we provide a flexible, customizable security toolkit designed to address your unique application security challenges.
Cloudflare continuously leads the WAF market through our strategic vision and the breadth of our capabilities. We center our approach on relentless innovation, delivering industry-leading security features, and ensuring a seamless management experience with enterprise processes and tools such as Infrastructure as Code (IaC) and DevOps. Our predictable cadence of major feature releases, powered by annual initiatives like Security Week and Birthday Week, ensures that customers always have access to the latest security advancements.
We believe Forrester also highlighted Cloudflare’s extensive security capabilities, with particular recognition of the significant improvements in our API security offerings.
Cloudflare’s top-ranked criteria
In the report, Cloudflare received the highest possible scores in 15 out of 22 criteria, reinforcing, in our opinion, our commitment to delivering the most advanced, flexible and easy-to-use web application protection in the industry. Some of the key criteria include:
Detection models: Advanced AI and machine learning models that continuously evolve to detect new threats.
Layer 7 DDoS protection: Industry-leading mitigation of sophisticated application-layer attacks.
Rule creation and modification: Simple, easy to use rule creation experience, propagating within seconds globally.
Management UI: An intuitive and efficient user interface that simplifies security management.
Product security: A robust architecture that ensures enterprise-grade security.
Infrastructure-as-code support: Seamless integration with DevOps workflows for automated security policy enforcement.
Innovation: A forward-thinking approach to security, consistently pushing the boundaries of what’s possible.
What sets Cloudflare apart?
First, Cloudflare’s WAF goes beyond traditional rule-based protections, offering a comprehensive suite of detection mechanisms to identify attacks and vulnerabilities across web and API traffic while also safeguarding client environments. We leverage AI and machine learning to detect threats such as attacks, automated traffic, anomalies, and compromised JavaScript, among others. Our industry-leading application-layer DDoS protection makes volumetric attacks a thing of the past.
Second, Cloudflare has also made significant strides in API security. Our WAF can be supercharged with features such as: API discovery, schema validation & sequence mitigation, volumetric detection, and JWT authentication.
Third, Cloudflare simplifies security management with an intuitive dashboard that is easy to use while still offering powerful configurations for advanced practitioners. All features are Terraform-supported, allowing teams to manage the entire Cloudflare platform as code. With Security Analytics, customers gain a comprehensive view of all traffic, whether mitigated or not, and can run what-if scenarios to test new rules before deployment. This analytic capability ensures that businesses can dynamically adapt their security posture while maintaining high performance. To make security management even more seamless, our AI agent, powered by Natural Language Processing (NLP), helps users craft and refine custom rules and create powerful visualizations within our analytics engine.
Cloudflare: the clear choice for modern security
We are confident that Forrester’s report validates what our customers already know: Cloudflare is a leading WAF vendor, offering unmatched security, innovation, and ease of use. As threats continue to evolve, we remain committed to pushing the boundaries of web security to protect organizations worldwide.
If you’re looking for a powerful, scalable, and easy-to-manage web application firewall, Cloudflare is the best choice for securing your applications, APIs, and infrastructure.
Ready to enhance your security?
Learn more about Cloudflare WAF by creating an account today and see why Forrester has recognized us as a leader in the market.
Forrester does not endorse any company, product, brand, or service included in its research publications and does not advise any person to select the products or services of any company or brand based on the ratings included in such publications. Information is based on the best available resources. Opinions reflect judgment at the time and are subject to change. For more information, read about Forrester’s objectivity here .
Connections made over cleartext HTTP ports risk exposing sensitive information because the data is transmitted unencrypted and can be intercepted by network intermediaries, such as ISPs, Wi-Fi hotspot providers, or malicious actors on the same network. It’s common for servers to either redirect or return a 403 (Forbidden) response to close the HTTP connection and enforce the use of HTTPS by clients. However, by the time this occurs, it may be too late, because sensitive information, such as an API token, may have already been transmitted in cleartext in the initial client request. This data is exposed before the server has a chance to redirect the client or reject the connection.
A better approach is to refuse the underlying cleartext connection by closing the network ports used for plaintext HTTP, and that’s exactly what we’re going to do for our customers.
Today we’re announcing that we’re closing all of the HTTP ports on api.cloudflare.com. We’re also making changes so that api.cloudflare.com can change IP addresses dynamically, in line with on-going efforts to decouple names from IP addresses, and reliably managing addresses in our authoritative DNS. This will enhance the agility and flexibility of our API endpoint management. Customers relying on static IP addresses for our API endpoints will be notified in advance to prevent any potential availability issues.
In addition to taking this first step to secure Cloudflare API traffic, we’ll release the ability for customers to opt-in to safely disabling all HTTP port traffic for their websites on Cloudflare. We expect to make this free security feature available in the last quarter of 2025.
We have consistentlyadvocated for strong encryption standards to safeguard users’ data and privacy online. As part of our ongoing commitment to enhancing Internet security, this blog post details our efforts to enforce HTTPS-only connections across our global network.
Understanding the problem
We already provide an “Always Use HTTPS” setting that can be used to redirect all visitor traffic on our customers’ domains (and subdomains) from HTTP (plaintext) to HTTPS (encrypted). For instance, when a user clicks on an HTTP version of the URL on the site (http://www.example.com), we issue an HTTP 3XX redirection status code to immediately redirect the request to the corresponding HTTPS version (https://www.example.com) of the page. While this works well for most scenarios, there’s a subtle but important risk factor: What happens if the initial plaintext HTTP request (before the redirection) contains sensitive user information?
Initial plaintext HTTP request is exposed to the network before the server can redirect to the secure HTTPS connection.
Third parties or intermediaries on shared networks could intercept sensitive data from the first plaintext HTTP request, or even carry out a Monster-in-the-Middle (MITM) attack by impersonating the web server.
One may ask if HTTP Strict Transport Security (HSTS) would partially alleviate this concern by ensuring that, after the first request, visitors can only access the website over HTTPS without needing a redirect. While this does reduce the window of opportunity for an adversary, the first request still remains exposed. Additionally, HSTS is not applicable by default for most non-user-facing use cases, such as API traffic from stateless clients. Many API clients don’t retain browser-like state or remember HSTS headers they’ve encountered. It is quite common practice for API calls to be redirected from HTTP to HTTPS, and hence have their initial request exposed to the network.
Therefore, in line with our culture of dogfooding, we evaluated the accessibility of the Cloudflare API (api.cloudflare.com) over HTTP ports (80, and others). In that regard, imagine a client making an initial request to our API endpoint that includes their secret API key. While we outright reject all plaintext connections with a 403 Forbidden response instead of redirecting for API traffic — clearly indicating that “Cloudflare API is only accessible over TLS” — this rejection still happens at the application layer. By that point, the API key may have already been exposed over the network before we can even reject the request. We do have a notification mechanism in place to alert customers and rotate their API keys accordingly, but a stronger approach would be to eliminate the exposure entirely. We have an opportunity to improve!
A better approach to API security
Any API key or token exposed in plaintext on the public Internet should be considered compromised. We can either address exposure after it occurs or prevent it entirely. The reactive approach involves continuously tracking and revoking compromised credentials, requiring active management to rotate each one. For example, when a plaintext HTTP request is made to our API endpoints, we detect exposed tokens by scanning for ‘Authorization’ header values.
In contrast, a preventive approach is stronger and more effective, stopping exposure before it happens. Instead of relying on the API service application to react after receiving potentially sensitive cleartext data, we can preemptively refuse the underlying connection at the transport layer, before any HTTP or application-layer data is exchanged. The preventative approach can be achieved by closing all plaintext HTTP ports for API traffic on our global network. The added benefit is that this is operationally much simpler: by eliminating cleartext traffic, there’s no need for key rotation.
The transport layer carries the application layer data on top.
To explain why this works: an application-layer request requires an underlying transport connection, like TCP or QUIC, to be established first. The combination of a port number and an IP address serves as a transport layer identifier for creating the underlying transport channel. Ports direct network traffic to the correct application-layer process — for example, port 80 is designated for plaintext HTTP, while port 443 is used for encrypted HTTPS. By disabling the HTTP cleartext server-side port, we prevent that transport channel from being established during the initial “handshake” phase of the connection — before any application data, such as a secret API key, leaves the client’s machine.
Both TCP and QUIC transport layer handshakes are a pre-requisite for HTTPS application data exchange on the web.
Therefore, closing the HTTP interface entirely for API traffic gives a strong and visible fast-failure signal to developers that might be mistakenly accessing http://… instead of https://… with their secret API keys in the first request — a simple one-letter omission, but one with serious implications.
In theory, this is a simple change, but at Cloudflare’s global scale, implementing it required careful planning and execution. We’d like to share the steps we took to make this transition.
Understanding the scope
In an ideal scenario, we could simply close all cleartext HTTP ports on our network. However, two key challenges prevent this. First, as shown in the Cloudflare Radar figure below, about 2-3% of requests from “likely human” clients to our global network are over plaintext HTTP. While modern browsers prominently warn users about insecure HTTP connections and offer features to silently upgrade to HTTPS, this protection doesn’t extend to the broader ecosystem of connected devices. IoT devices with limited processing power, automated API clients, or legacy software stacks often lack such safeguards entirely. In fact, when filtering on plaintext HTTP traffic that is “likely automated”, the share rises to over 16%! We continue to see a wide variety of legacy clients accessing resources over plaintext connections. This trend is not confined to specific networks, but is observable globally.
Closing HTTP ports, like port 80, across our entire IP address space would block such clients entirely, causing a major disruption in services. While we plan to cautiously start by implementing the change on Cloudflare’s API IP addresses, it’s not enough. Therefore, our goal is to ensure all of our customers’ API traffic benefits from this change as well.
Breakdown of HTTP and HTTPS for ‘human’ connections
The second challenge relates to limitations posed by the longstanding BSD Sockets API at the server-side, which we have addressed using Tubular, a tool that inspects every connection terminated by a server and decides which application should receive it. Operators historically have faced a challenging dilemma: either listen to the same ports across many IP addresses using a single socket (scalable but inflexible), or maintain individual sockets for each IP address (flexible but unscalable). Luckily, Tubular has allowed us to resolve this using ‘bindings’, which decouples sockets from specific IP:port pairs. This creates efficient pathways for managing endpoints throughout our systems at scale, enabling us to handle both HTTP and HTTPS traffic intelligently without the traditional limitations of socket architecture.
Step 0, then, is about provisioning both IPv4 and IPv6 address space on our network that by default has all HTTP ports closed. Tubular enables us to configure and manage these IP addresses differently than others for our endpoints. Additionally, Addressing Agility and Topaz enable us to assign these addresses dynamically, and safely, for opted-in domains.
Moving from strategy to execution
In the past, our legacy stack would have made this transition challenging, but today’s Cloudflare possesses the appropriate tools to deliver a scalable solution, rather than addressing it on a domain-by-domain basis.
Using Tubular, we were able to bind our new set of anycast IP prefixes to our TLS-terminating proxies across the globe. To ensure that no plaintext HTTP traffic is served on these IP addresses, we extended our global iptables firewall configuration to reject any inbound packets on HTTP ports.
As a result, any connections to these IP addresses on HTTP ports are filtered and rejected at the transport layer, eliminating the need for state management at the application layer by our web proxies.
The next logical step is to update the DNS assignments so that API traffic is routed over the correct IP addresses. In our case, we encoded a new DNS policy for API traffic for the HTTPS-only interface as a declarative Topaz program in our authoritative DNS server:
The above policy encodes that for any DNS query targeting the ‘API traffic’ class, we return the respective HTTPS-only interface IP addresses. Topaz’s safety guarantees ensure exclusivity, preventing other DNS policies from inadvertently matching the same queries and misrouting plaintext HTTP expected domains to HTTPS-only IPs
api.cloudflare.com is the first domain to be added to our HTTPS-only API traffic class, with other applicable endpoints to follow.
Opting-in your API endpoints
As we said above, we’ve started with api.cloudflare.com and our internal API endpoints to thoroughly monitor any side effects on our own systems before extending this feature to customer domains. We have deployed these changes gradually across all data centers, leveraging Topaz’s flexibility to target subsets of traffic, minimizing disruptions, and ensuring a smooth transition.
To monitor unencrypted connections for your domains, before blocking access using the feature, you can review the relevant analytics on the Cloudflare dashboard. Log in, select your account and domain, and navigate to the “Analytics & Logs” section. There, under the “Traffic Served Over SSL” subsection, you will find a breakdown of encrypted and unencrypted traffic for your site. That data can help provide a baseline for assessing the volume of plaintext HTTP connections for your site that will be blocked when you opt in. After opting in, you would expect no traffic for your site will be served over plaintext HTTP, and therefore that number should go down to zero.
Snapshot of ‘Traffic Served Over SSL’ section on Cloudflare dashboard
Towards the last quarter of 2025, we will provide customers the ability to opt in their domains using the dashboard or API (similar to enabling the Always Use HTTPS feature). Stay tuned!
Wrapping up
Starting today, any unencrypted connection to api.cloudflare.com will be completely rejected. Developers should not expect a 403 Forbidden response any longer for HTTP connections, as we will prevent the underlying connection to be established by closing the HTTP interface entirely. Only secure HTTPS connections will be allowed to be established.
We are also making updates to transition api.cloudflare.com away from its static IP addresses in the future. As part of that change, we will be discontinuing support for non-SNI legacy clients for Cloudflare API specifically — currently, an average of just 0.55% of TLS connections to the Cloudflare API do not include an SNI value. These non-SNI connections are initiated by a small number of accounts. We are committed to coordinating this transition and will work closely with the affected customers before implementing the change. This initiative aligns with our goal of enhancing the agility and reliability of our API endpoints.
Beyond the Cloudflare API use case, we’re also exploring other areas where it’s safe to close plaintext traffic ports. While the long tail of unencrypted traffic may persist for a while, it shouldn’t be forced on every site.
In the meantime, a small step like this can allow us to have a big impact in helping make a better Internet, and we are working hard to reliably bring this feature to your domains. We believe security should be free for all!
Over the years, we have framed our Application Security features against market-defined product groupings such as Web Application Firewall (WAF), DDoS Mitigation, Bot Management, API Security (API Shield), Client Side Security (Page Shield), and so forth. This has led to unnecessary artificial separation of what is, under the hood, a well-integrated single platform.
This separation, which has sometimes guided implementation decisions that have led to different systems being built for the same purpose, makes it harder for our users to adopt our features and implement a simple effective security posture for their environment.
Today, following user feedback and our drive to constantly innovate and simplify, we are going back to our roots by breaking these artificial product boundaries and revising our dashboard, so it highlights our strengths. The ultimate goal remains: to make it shockingly easy to secure your web assets.
Introducing a new unified Application Security experience.
If you are a Cloudflare Application Security user, log in to the dashboard today and try out the updated dashboard interface. To make the transition easier, you can toggle between old and new interfaces.
Security, simplified
Modern applications are built using a variety of technologies. Your app might include a web interface and a mobile version, both powered by an API, each with its own unique security requirements. As these technologies increasingly overlap, traditional security categories like Web, API, client-side, and bot protection start to feel artificial and disconnected when applied to real-world application security.
Consider scenarios where you want to secure your API endpoints with proper authentication, or prevent vulnerability scanners from probing for weaknesses. These tasks often require switching between multiple dashboards, creating different policies, and managing disjointed configurations. This fragmented approach not only complicates workflows but also increases the risk of overlooking a critical vulnerability. The result? A security posture that is harder to manage and potentially less effective.
When you zoom out, a pattern emerges. Whether it’s managing bots, securing APIs, or filtering web traffic, these solutions ultimately analyze incoming traffic looking for specific patterns, and the resulting signal is used to perform actions. The primary difference between these tools is the type of signal they generate, such as identifying bots, enforcing authorization, or flagging suspicious requests.
At Cloudflare, we saw an opportunity to address this complexity by unifying our application security tools into a single platform with one cohesive UI. A unified approach means security practitioners no longer have to navigate multiple interfaces or piece together different security controls. With a single UI, you can configure policies more efficiently, detect threats faster, and maintain consistent protection across all aspects of your application. This simplicity doesn’t just save time, it ensures that your applications remain secure, even as threats evolve.
At the end of the day, attackers won’t care which product you’re using. But by unifying application security, we ensure they’ll have a much harder time finding a way in.
Many products, one common approach
To redefine the experience across Application Security products, we can start by defining three concepts that commonly apply:
Web traffic (HTTP/S), which can be generalised even further as “data”
Signals and detections, which provide intelligence about the traffic. Can be generalised as “metadata”
Security rules that let you combine any signal or detection (metadata), to block, challenge or otherwise perform an action on the web traffic (data)
We can diagram the above as follows:
Using these concepts, all the product groupings that we offer can be converted to different types of signals or detections. All else remains the same. And if we are able to run and generate our signals on all traffic separately from the rule system, therefore generating all the metadata, we get what we call always-on detections, another vital benefit of a single platform approach. Also note that the order in which we generate the signals becomes irrelevant.
In diagram form:
The benefits are twofold. First, problem spaces (such as account takeover or web attacks) become signal groupings, and therefore metadata that can be queried to answer questions about your environment.
For example, let’s take our Bot Management signal, the bot score, and our WAF Attack Score signal, the attack score. These already run as always-on detections at Cloudflare. By combining these two signals and filtering your traffic against them, you can gain powerful insights on who is accessing your application*:
Second, as everything is just a signal, the mitigation layer, driven by the optional rules, becomes detection agnostic. By providing the same signals as fields in a unified rule system, writing high level policies becomes a breeze. And as we said earlier, given the detection is always-on and fully separated from the mitigation rule system, exploring the data can be thought of as a powerful rule match preview engine. No need to deploy a rule in LOG mode to see what it matches!
We can now design a unified user experience that reflects Application Security as a single product.
* note: the example here is simplistic, and the use cases become a lot more powerful once you expand to the full set of potential signals that the platform can generate. Take, for example, our ability to detect file uploads. If you run a job application site, you may want to let crawlers access your site, but you may *not* want crawlers to submit applications on behalf of applicants. By combining the bot score signal with the file upload signal, you can ensure that rule is enforced.
Introducing a unified Application Security experience
As signals are always-on, the user journey can now start from our new overview page where we highlight security suggestions based on your traffic profile and configurations. Alternatively, you can jump straight into analytics where you can investigate your traffic using a combination of all available signals.
When a specific traffic pattern seems malicious, you can jump into the rule system to implement a security policy. As part of our new design, given the simplicity of the navigation, we also took advantage of the opportunity to introduce a new web assets page, where we highlight discovery and attack surface management details.
Of course, reaching the final design required multiple iterations and feedback sessions. To best understand the balance of maintaining flexibility in the UI whilst reducing complexity, we focused on customer tasks to be done and documenting their processes while trying to achieve their intended actions in the dashboard. Reducing navigation items and using clear naming was one element, but we quickly learned that the changes needed to support ease of use for tasks across the platform.
Here is the end result:
To recap, our new dashboard now includes:
One overview page where misconfigurations, risks, and suggestions are aggregated
Simplified and redesigned security analytics that surfaces security signals from all Application Security capabilities, so you can easily identify and act on any suspicious activity
A new web assets page, where you can manage your attack surfaces, helping improve detection relevance
A single Security Rules page that provides a unified interface to manage, prioritise, and customise all mitigation rules in your zone, significantly streamlining your security configuration
A new settings page where advanced control is based on security needs, not individual products
Let’s dive into each one.
Overview
With the unified security approach, the new overview page aggregates and prioritizes security suggestions across all your web assets, helping you maintain a healthy security posture. The suggestions span from detected (ongoing) attacks if there are any, to risks and misconfigurations to further solidify your protection. This becomes the daily starting point to manage your security posture.
Analytics
Security Analytics and Events have been redesigned to make it easier to analyze your traffic. Suspicious activity detected by Cloudflare is surfaced at the top of the page, allowing you to easily filter and review related traffic. From the Traffic Analytics Sampled Log view, further below in the page, new workflows enable you to take quick action to craft a custom rule or review related security events in context.
Web assets
Web assets is a new concept introduced to bridge your business goals with threat detection capabilities. A web asset is any endpoint, file, document, or other related entity that we normally would act on from a security perspective. Within our new web asset page, you will be able to explore all relevant discovered assets by our system.
With our unified security platform, we are able to rapidly build new use-case driven threat detections. For example, to block automated actions across your e-commerce website, you can instruct Cloudflare’s system to block any fraudulent signup attempts, while allowing verified crawlers to index your product pages. This is made possible by labelling your web assets, which, where possible, is automated by Cloudflare, and then using those labels to power threat detections to protect your assets.
Security rules
The unified Security rules interface brings all mitigation rule types — including WAF custom rules, rate limiting rules, API sequence rules, and client side rules — together in one centralized location, eliminating the need to navigate multiple dashboards.
The new page gives you visibility into how Cloudflare mitigates both incoming traffic and blocks potentially malicious client side resources from loading, making it easier to understand your security posture at a glance. The page allows you to create customised mitigation rules by combining any detection signals, such as Bot Score, Attack Score, or signals from Leaked Credential Checks, enabling precise control over how Cloudflare responds to potential threats.
Settings
Balancing guidance and flexibility was the key driver for designing the new Settings page. As much as Cloudflare guides you towards the optimal security posture through recommendations and alerts, customers that want the flexibility to proactively adjust these settings can find all of them here.
Experience it today
This is the first of many enhancements we plan to make to the Application Security experience in the coming months. To check out the new navigation, log in to the Cloudflare dashboard, click on “Security” and choose “Check it out” when you see the message below. You will still have the option of opting out, if you so prefer.
Let us know what you think either by sharing feedback in our community forum or by providing feedback directly in the dashboard (you will be prompted if you revert to the old design).
Today, we’re taking a deep dive into Aegis, Cloudflare’s origin protection product, to help you understand what the product is, how it works, and how to take full advantage of it for locking down access to your origin. We’re excited to announce the availability of Bring Your Own IPs (BYOIP) for Aegis, a customer-accessible Aegis API, and a gradual rollout for observability of Aegis IP utilization.
If you are new to Cloudflare Aegis, let’s take a step back and understand the product’s purpose and security benefits, process, and how it came to be.
Origin protection then…
Allowlisting a specific set of IP addresses has long existed as one of the simplest ways of restricting access to a server. This firewall mechanism is a starting state that just about every server supports. As we built Cloudflare’s network, one of the first features that customers requested was the ability to restrict access to their origin, so only Cloudflare could make requests to it. Back then, the most natural way to support this was to tell our customers which IP addresses belong to us, so they could allowlist those in their origin firewall. To that end, we have published our IP address ranges, providing an easy configuration to ensure that all traffic accessing your origin comes from Cloudflare’s network.
However, Cloudflare’s IP ranges are used across multiple Cloudflare services and customers, so restricting access to the full list doesn’t necessarily give customers the security benefit they need. With the frequency and scale of IP-based and DDoS attacks every day, origin protection is absolutely paramount. Some customers have the need for more stringent security precautions to ensure that traffic is only coming from Cloudflare’s network and, more specifically, only coming from their zones within Cloudflare.
Origin protection now…
Cloudflare has built out additional services to lock down access to your origin, like authenticated origin pulls (mTLS) and Cloudflare Tunnels, that no longer rely on IP addresses as an indicator of identity. These are part of a global effort towards Zero Trust security: whereas the Internet used to operate under a trust-but-verify model, we aim to operate as nothing is trusted, and everything is verified.
Having non-ephemeral IP addresses — upon which the firewall allowlist mechanism relies — does not quite fit the Zero Trust system. Although mTLS and similar solutions present a more modern approach to origin security, they aren’t always feasible for customers, depending on their hardware or system architecture.
We launched Cloudflare Aegis in March 2023 for customers seeking an intermediary security solution. Aegis provides a dedicated IP address, or set of addresses, from which Cloudflare sends requests, allowing you to further lock down your origin’s layer 3 firewall. Aegis also simplifies management by only requiring you to allowlist a small number of IP addresses.
Normally, Cloudflare’s publicly listed IP ranges are used to egress from Cloudflare’s network to the customer origin. With these IP addresses distributed across Cloudflare’s network, the customer traffic can egress from many servers to the customer origin.
With Aegis, a customer does not necessarily have an Aegis IP address on every server if they are using IPv4. That means requests must be routed through Cloudflare’s network to a server where Aegis IP addresses are present before the traffic can egress to the customer origin.
How requests are routed with Aegis
A few terms, before we begin:
Anycast: a technology where each of our data centers “announces” and can handle the same IP address ranges
Unicast: a technology where each server is given its own, unique unicast IP address
Dedicated egress Aegis IPs are located in a particular set of specific data centers. This list is handpicked by the customer, in conversation with Cloudflare, to be geographically close to their origin servers for optimal security and performance in tandem.
Aegis relies on a technology called soft-unicasting, which allows us to share a /32 egress IPv4 amongst many servers, thereby enabling us to spread a single subnet across many data centers. Then, the traffic going back from the origin servers (the return path) is routed to their closest data center. Once in Cloudflare’s network, our in-house L4 XDP-based load balancer, Unimog, ensures that the return packets make it back to the machine that connected to the origin servers at the start.
This supports fast, local, and reliable egress from Cloudflare’s network. With this configuration, we essentially use Anycast at the BGP layer before using an IP and port range to reach a specific machine in the correct data center. Across Cloudflare’s network, we use a significant range of egress IPs to cover all data centers and machines. Since Aegis customers only have a few IPv4 addresses, the range is limited to a few data centers rather than Cloudflare’s entire egress IP range.
The capacity issue
Every IP address has 65,535 ports. A request egresses from exactly one port on the Aegis IP address to exactly one port on the origin IP address.
Each TCP request consists of a 4-way tuple that contains:
Source IP address
Source port
Destination IP address
Destination port
A UDP request can also consist of a 4-way tuple (if it’s connected) or a 2-way tuple (if it’s unconnected), simply including a bind IP address and port. Aegis supports both TCP and UDP traffic — in either case, the requests rely upon IP:port pairings between the source and destination.
When a request reaches the origin, it opens a connection, through which data can pass between the source and destination. One source port can sustain multiple connections at a time, only if the destination ip:ports are different.
Normally at Cloudflare, an IP address establishes connections to a variety of different destination IP ports or addresses to support high traffic volumes. With Aegis, that is no longer the case. The challenge with Aegis IP capacity is exactly that: all the traffic is egressing to the same (or a small set of) origin IP address(es) from the same (or a small set of) source IP address(es). That means Aegis IP addresses have capacity constraints associated with them.
The number of concurrent connections is the number of simultaneous connections for a given 4-way tuple. Between one client and one server, the volume of concurrent connections is inherently limited by the number of ports on an IP address to 65,535 — each source ip:port can only support a single outbound connection per destination IP:port. In practice, that maximum number of concurrent connections is often lower due to assignments of port ranges across many servers and imperfect load distribution.
For planning purposes, we use an estimate of ~80% of the IP capacity (the volume of concurrent connections a source IP address can support to a destination IP address) to protect against overload, in case of traffic spikes. If every port on an IP address is maintaining a concurrent connection, that address would reach and exceed capacity — it would be overloaded with port usage exhaustion. Requests may then be dropped since no new connections can be established. To build in resiliency, we only plan to support 40k concurrent connections per Aegis IP address per origin.
Aegis with IPv6
Each customer who onboards with Cloudflare Aegis receives two /64 prefixes to be globally allocated and announced. That means, outside of Cloudflare’s China Network, every Cloudflare data center has hundreds or even thousands of addresses reserved for egressing your traffic directly to your origin. Without Aegis, any data center in Cloudflare’s Anycast network can serve as a point of egress – so we built Aegis with IPv6 to preserve that level of resiliency and performance. The sheer scale of IPv6, with its available address space, allows us to cushion Aegis’ capacity to a point far beyond any reasonable concern. Globally allocating and announcing your Aegis IPv6 addresses maintains all of Cloudflare’s functionality as a reverse proxy without inducing additional friction.
Aegis with IPv4
Although using IPv6 with Aegis facilitates the best possible speed and resiliency for your traffic, we recognize the transition from IPv4 to IPv6 can be challenging for some customers. Moreover, some customers prefer Aegis IPv4 for granular control over their traffic’s physical egress locations. Still, IPv4 space is more limited and more expensive — while all Cloudflare Aegis customers simply receive two dedicated /64s for IPv6, enabling Aegis with IPv4 requires a touch more tailoring. When you onboard to Aegis, we work with you to determine the ideal number of IPv4 addresses for your Aegis configuration to maintain optimal performance and resiliency, while also ensuring cost efficiency.
Naturally, this introduces a bottleneck — whereas every Cloudflare data center can serve as a point of egress with Aegis IPv6, only a small fraction will have that capability with Aegis IPv4. We aim to mitigate this impact by careful provisioning of the IPv4 addresses.
Now that BYOIP for Aegis is supported, you can also onboard an entire IPv4 /24 prefix or IPv6 /64 for Aegis, allowing for a cost-effective configuration with a much higher volume of capacity.
When we launched Aegis, each IP address was allocated to one data center, requiring at least two IPv4 addresses for appropriate resiliency. To reduce the number of IP addresses necessary in your layer 3 firewall allowlist, and to manage the cost to the customer of leasing IPs, we expanded our Aegis functionality so that one address can be announced from up to four data centers. To do this, we essentially slice the available IP port range into four subsets and provision each at a unique data center.
A quick refresher: when a request travels through Cloudflare, it first hits our network via an ingress data center. The ingress data center is generally near the eyeball, who is sending the request. Then, the request is routed following BGP – or Argo Smart Routing, when enabled – to an exit, or egress, data center. The exit data center will generally fall in close geographic proximity to the request’s destination, which is the customer origin. This mitigates latency induced by the final hop from Cloudflare’s network to your origin.
With Aegis, the possible exit data centers are limited to the data centers in which an Aegis IP address has been allocated. For IPv6, this is a non-issue, since every data center outside our China Network is covered. With IPv4, however, the exit data centers are limited to a much smaller number (4 x the number of Aegis IPs). Aegis IP addresses are allocated, then, to data centers in close geographic proximity to your origin(s). This maximizes the likelihood that whichever data centers would ordinarily have been selected as the egress data center are already announcing Aegis IP addresses. Theoretically, no extra hop is necessary from the optimal exit data center to an Aegis-enabled data center – they are one and the same. In practice, this cannot be guaranteed 100% of the time because optimal routes are ever-changing. We recommend IPv6 to ensure optimal performance because of this possibility of an extra hop with IPv4.
A brief comparison, to summarize:
Aegis IPv4
Aegis IPv6
Physical points of egress
4 physical data center sites (1-2 cities near origin) per IP address
All 300+ Cloudflare locations (excluding China network)
Capacity
One IPv4 address per 40,000 concurrent connections per origin
Two /64 prefixes for all Aegis customers (>36 quintillion IP addresses)
~50,000x capacity of IPv4 config
Pricing model
Monthly fee based on IPv4 leases or BYOIP for Aegis prefix fees
Included with product purchase or BYOIP for Aegis prefix fees
Now, with Aegis analytics coming soon, customers can monitor and manage their IP address usage by Cloudflare data centers in aggregate. Every Cloudflare data center will now run a service with the sole purpose of calculating and reporting Aegis usage for each origin IP:port at regular intervals. Written to an internal database, these reports will be aggregated and exposed to customers via Cloudflare’s GraphQL Analytics API. Several aggregation functions will be available, such as average usage over a period of time, or total summed usage.
This will allow customers to track their own IP address usage to further optimize the distribution of traffic and addresses across different points of presence for IPv4. Additionally, the improved observability will support customer-created notifications via RSS feeds such that you can design your own notification thresholds for port usage.
How Aegis benefits from connection reuse & coalescence
As we mentioned earlier, requests egress from the source IP address to the destination IP address only when a connection has been established between the two. In early Internet protocols, requests and connections were 1:1. Now, once that connection is open, it can remain open and support hundreds or thousands of requests between that source and destination via connection reuse and connection coalescing.
Connection reuse, implemented by HTTP/1.1, allows for requests with the same source ip:port and destination IP:port to pass through the same connection to the origin. A “simple” website by modern standards can send hundreds of requests just to load initially; by streamlining these into a single origin connection, connection reuse reduces the latency derived from constantly opening and closing new connections between two endpoints. Still, any request from a different domain would need to create a new, unique connection to communicate with the origin.
As of HTTP/2, connection coalescing can group requests from different domains into one connection if the requests have the same destination IP address and the server certificate is authoritative for both domains. Depending on the traffic patterns routing from the eyeball to an Aegis IP address, the volume of connection reuse & coalescence can vary. One connection most likely facilitates the traffic of many requests, but each connection requires at least one request to open it in the first place. Therefore, the worst possible ratio between concurrent connections and concurrent requests is 1:1.
In practice, a 1:1 ratio between connections and requests almost never happens. Connection reuse and connection coalescence are very common but highly variable, due to sporadic traffic patterns. We size our Aegis IP address allocations accordingly, erring on the conservative side to minimize risk of capacity overload. With the proper number of dedicated egress IP addresses and optimal allocation to Cloudflare points of presence, we are able to lock down your origin with IPv4 addresses to block malicious layer 7 traffic and reduce overall load to your origin.
Connection reuse and coalescence pairs well with Aegis to reduce load on the origin’s side as well. Because a request can be reused if it comes from the same source IP:port and shares a destination IP:port, routing traffic from a reduced number of source IP addresses (Aegis addresses, in this case) to your origin facilitates a smaller number of total connections. Not only does this improve security by limiting open connection access, but also it reduces latency since fewer connections need to be opened. Maintaining fewer connections is also less resource intensive — more connections means more CPU and more memory handling the inbound requests. By reducing the number of connections to the origin through reuse and coalescence, HTTP/2 lowers the overall cost of operation by optimizing resource usage.
Recap and recommendations
Cloudflare Aegis locks down your origin by restricting access via your origin’s layer 3 firewall. By routing traffic from Cloudflare’s network to your origin through dedicated egress IP addresses, you can ensure that requests coming from Cloudflare are legitimate customer traffic. With a simple flip-switch configuration — allow listing your Aegis IP addresses in your origin’s firewall — you can block excessive noise and bad actors from access. So, to help you take full advantage of Aegis, let’s recap:
Concurrent connections can be, at worst, a 1:1 ratio to concurrent requests.
Cloudflare bases our IP address usage recommendations on 40,000 concurrent connections to minimize risk of capacity overload.
Each Aegis IP address supports an estimated 40,000 concurrent connections per origin IP address.
Customer-facing Aegis observability (coming soon via gradual rollout)
For customers leasing Cloudflare-owned Aegis IP addresses, the Aegis API will allow you to enable and disable Aegis on zones within your parent account (parent being the account which owns the IP lease). If you deploy your Aegis IP addresses across multiple accounts, you’ll still rely on Cloudflare’s account team to enable and disable Aegis on zones within those additional accounts.
For customers who leverage BYOIP for Aegis, the Aegis API will allow you to enable and disable Aegis on zones within your parent account and within any accounts to which you delegate prefix permissions. We recommend BYOIP for Aegis for improved configurability and cost efficiency.
BYOIP
Cloudflare-owned IPs
Enable Aegis on zones on parent account
✓
✓
Enable Aegis on zones beyond parent account
✓
✗
Disable Aegis on zones on parent account
✓
✓
Disable Aegis on zones beyond parent account
✓
✗
Access Aegis analytics via the API
✓
✓
With the improved Aegis observability, all Aegis customers will be able to monitor their port usage by IP address, account, zone, and data centers in aggregate via the API. You will also be able to ingest these metrics to configure your own, customizable alerts based on certain port usage thresholds. Alongside the new configurability of Aegis, this visibility will better equip customers to manage their Aegis deployments themselves and alert us to any changes, rather than the other way around.
We also have a few adjacent recommendations to optimize your Aegis configuration. We generally encourage the following best practices for security hygiene for your origin and traffic as well.
IPv6 Compatibility: if your origin(s) support IPv6, you will experience even better resiliency, performance, and availability with your dedicated egress IP addresses at a lower overall cost.
HTTP/2 or HTTP/3 adoption: by supporting connection reuse and coalescence, you will reduce overall load to your origin and latency in the path of your request.
Multi-level origin protection: while Aegis protects your origin at the application level, it pairs well with Access and CNI, Authenticated Origin Pulls, and/or other Cloudflare products to holistically protect, verify, and facilitate your traffic from edge to origin.
If you or your organization want to enhance security and lock down your origin with dedicated egress IP addresses reach out to your account team to onboard today.
For years, Cloudflare has helped organizations modernize their access to internal resources by delivering identity-aware access controls through our Zero Trust Network Access (ZTNA) service, Cloudflare Access. Our customers have accelerated their ZTNA implementations for web-based applications in particular, using our intuitive workflows for Access applications tied to public hostnames.
However, given our architecture design, we have primarily handled private network application access (applications tied to private IP addresses or hostnames) through the network firewall component of our Secure Web Gateway (SWG) service, Cloudflare Gateway. We provided a small wrapper from Access to connect the two experiences. While this implementation technically got the job done, there were some clear downsides, and our customers have frequently cited the inconsistency.
Today, we are thrilled to announce that we have redesigned the self-hosted private application administrative experience within Access to match the experience for web-based apps on public hostnames. We are introducing support for private hostname and IP address-defined applications directly within Access, as well as reusable access policies. Together, these updates make ZTNA even easier for our customers to deploy and streamline ongoing policy management.
A private application in this context, is any application that is only accessible through a private IP address or hostname.
Private IP addresses
Private IP addresses, often referred to as RFC 1918 IP addresses, are scoped to a specific network and can only be reached by users on that network. While public IP addresses must be unique across the entire Internet, private IP addresses can be reused across networks. Any device or virtual machine will have a private IP address. For example, if I run ipconfig on my own Windows machine, I can see an address of 192.168.86.172.
This is the address that any other machine on my own network can use to reference and communicate with this specific machine. Private IP addresses are useful for applications and ephemeral infrastructure (systems that spin up and down dynamically) because they can be reused and only have to be unique within their specific network. This is much easier to manage than issuing a public IPv4 address to resources – we’ve actually run out of available public IPv4 address space!
In order to host an application on a machine in my network, I need to make that application available to other machines in the network. Typically, this is done by assigning the application to a specific port. A request to that application might then look something like this: http://10.128.0.6:443 which in plain English is saying “Using the hypertext transfer protocol, reach out to the machine at an address of 10.128.0.6 in my network, and connect to port 443.” Connecting to an application can be done in a browser, over SSH, over RDP, through a thick client application, or many other methods of accessing a resource over an IP address.
In this case, we have an Apache2 example web server, running at that address and port combination.
If I attempt to access this IP address outside of the same network as this machine running the web server, then I will either get no result, or a completely different application, if I have something else running on that IP address/port combination in that other network.
Private hostnames
We don’t want to remember 10.128.0.6 every time we want to access this application. Just like the Internet, we can use DNS in our private network. While public DNS serves as the phone book for the entire Internet, private DNS is more like a school directory that is only valid for phone numbers within the campus.
For a private application, I can configure a DNS record, very similar to how I might expose a public website to the world. But instead, I will map my DNS record to a private IP address that is only accessible within my own network. Additionally, private DNS does not require registering a domain with a registrar or adhering to defined top level domains. I can host an application on application.mycompany, and it is a valid internal DNS record.
In this example, I am running my web server on Google Cloud and will call the application kennyapache.local. In my local DNS, kennyapache.local has an A record mapping it to an IPv4 address within my private network on Google Cloud (GCP).
This means that any machine within my network can use https://kennyapache.local instead of having to remember the explicit IP address.
Accessing private applications outside the private network
Private networks require your machine, or virtual machine, to be connected directly to the same network as the target private IP address or hostname. This is a helpful property to keep unauthorized users from accessing applications, but presents a challenge if the application you want to use is outside your local network.
Virtual Private Networks (VPNs), forward proxies, and proxy protocols (aka “PAC files”) are all methods to enable a machine outside your private network to reach a private IP address/hostname within the private network. These tools work by adding an additional network interface to the machine and specifying that certain requests need to be routed through a remote private network, not the local network the machine is currently connected to, or out to the public Internet.
When I connect my machine to a forward proxy, in this case Cloudflare’s device client, WARP, and run ipconfig I can see a new network interface and IP address added to the list:
This additional network interface will take control of specific network requests and route those to an external private network instead of the default behavior of my machine, which would be to route to that IP address on my own local network.
A look back: protecting private applications with Cloudflare Zero Trust before Access Private IP Address and Hostname support
We will continue to use our Apache2 server hosted on a GCP private domain as an example private application. We will briefly touch on how Cloudflare Zero Trust was previously used to protect private applications and why this new feature is a huge step forward. Cloudflare Zero Trust has two primary components used to protect application traffic: Cloudflare Access and Gateway.
Cloudflare Access
Cloudflare Access is designed to protect internal applications and resources without the need for a traditional VPN. Access allows organizations to authenticate and authorize users through identity providers — such as Okta, Azure AD, or Google Workspace — before granting them entry to internal systems or web-based applications.
Until now, Access required that an application had to be defined using a public DNS record. This means that a user had to expose their application to the Internet in order to leverage Access and use all of its granular security features. This isn’t quite as scary as it sounds, because Access allows you to enforce strong user, device, and network security controls. In fact, NIST and many other major security organizations support this model.
In practice, an administrator would map their internal IP address or hostname to a public URL using our app connector, Cloudflare Tunnel.
Then, the administrator would create an Access application corresponding to that public URL. Cloudflare then sends a user through a single sign-on flow for any request made to that application.
However, this approach does not work for organizations that have strict requirements to never expose an application over public DNS. Additionally, this does not work for applications outside the browser like SSH, RDP, FTP and other thick client applications, which are all options to connect to private applications.
If I tried to SSH to my Access-protected public hostname, I would get an error message with no way to authenticate, since there is no easy way to do a single sign-on through the browser in conjunction with SSH.
Access Private Network applications
Until now, because Access operated using public hostnames, we have handled private network access for our customers using the network firewall piece of Cloudflare Gateway. A few years ago, we launched Access Private Network applications, which automatically generate the required Gateway block policies. However, this was a limited approach that was ultimately just a wrapper in front of two Gateway policies.
Cloudflare Gateway
Cloudflare Gateway is a secure web gateway that protects users from threats on the public Internet by filtering and securing DNS and web traffic. Gateway acts as a protective layer between end users and online resources by enforcing security controls, like blocking malicious domains, restricting access to risky categories of sites, and preventing data exfiltration.
Gateway is also used to route user traffic into private networks and acts as a forward proxy. It allows customers to create policies for private IP addresses and hostnames. This is because Gateway relies on traffic being proxied from the user’s machine to the Gateway service itself. This is most commonly done with the Cloudflare WARP client. WARP enables the configuration of which IP addresses and hostnames to send to Gateway for filtering and routing.
Once connected to a private network, through Gateway, a user can directly connect to private IP addresses and hostnames that are configured for that network.
I can then configure specific network firewall policies to allow or block traffic destined to private IP addresses.
Great! Looks like we’ve solved protecting private applications using Gateway. Not quite, unfortunately, as there are a few components of Gateway that are not an ideal model for an application-focused security model. While not discussed above, a few of the challenges we encountered when using Gateway for application access control included:
Private applications were mixed in with general Gateway network firewall rules, complicating configuration and maintenance
Defining and managing private applications was not possible in Terraform
Application access logs were buried in general network firewall logs (these logs can contain all Internet traffic for an organization!)
Enforcement within Gateway relied on specific WARP client sessions, which lacked granular identity details
Administrators couldn’t use Access Rule Groups or other Access features built specifically for managing application access controls
We knew we could do better.
A unified approach to application access
Knowing these limitations, we set out to extend Access to support any application, regardless of whether it is public or private. This principle guided our efforts to create a unified application definition in Cloudflare Access. Any self-hosted application, regardless of whether it is public or privately routable, should be defined in a single application type. The result is quite straightforward: Access Applications now support private IP addresses and hostnames.
However, the engineering work was not as simple as adding a private IP address and hostname option to Cloudflare Access. Given our platform’s architecture, Access does not have any way to route private requests by itself. We still have to rely on Gateway and the WARP client for that component.
An application-aware firewall
This meant that we needed to add an application-specific phase to Gateway’s firewall. The new phase detects whether a user’s traffic matches a defined application, and if so it sends the traffic to Access for authentication and authorization of a user and their session. This required extending Gateway’s network firewall to have knowledge of which private IP addresses and hostnames are defined as applications.
Thanks to this new firewall phase, now an administrator can configure exactly where they want their private applications to be evaluated in their overall network firewall.
Private application sessions
The other component we had to solve was per-application session management. In an Access public application, we issue a JSON Web Token (JWT) as a cookie which conveniently has an expiration associated. That acts as a session expiration. For private applications, we do not always have the ability to store a cookie. If the request is not over a browser, there is nowhere to put a cookie.
For browser-based private applications, we follow the exact same pattern as a public application and issue a JWT as a means to track the session. App administrators get the additional benefit of being able to do JWT validation for these apps as well. Non-browser based applications required adding a new per-application session to Gateway’s firewall. These application sessions are bound to a specific device and track the next time a user has to authenticate before accessing the application.
Access private applications
Once we solved application awareness and session management in Gateway’s firewall, we could extend Access to support private IP address- and hostname-defined applications. Administrators can now directly define Access applications using private IP addresses and hostnames:
You can see that private hostname and private IP address are now configuration options when defining an Access application.
If it is a non-HTTPS application (whether HTTP or non-browser), the user will receive a client pop-up prompting a re-authentication:
HTTPS applications will behave exactly the same as an Access application with a public hostname. The user will be prompted to log in via single sign-on, and then a JWT will be issued to that specific domain.
Then we see a JWT issued to the application itself.
Introducing Reusable Policies
As part of this work, we were able to address another long-standing pain point in Access —– managing policies across multiple applications was a time-consuming and error-prone process. Policies were nested objects under individual applications, requiring administrators to either rely heavily on Access Groups or repeat identical configurations for each application.
With Reusable Policies, administrators can now create standardized policies — such as high, medium, or low risk — and assign them across multiple applications. A single change to a reusable policy will propagate to all associated applications, significantly simplifying management. With this new capability, we anticipate that many of our customers will be able to move from managing hundreds of access policies to a small handful. We’ve also renamed “Access Groups” to “Rule Groups,” aligning with their actual function and reducing confusion with identity provider (IdP) groups.
A redesigned user interface
Alongside these functional updates, we’ve launched a significant UI refresh based on years of user feedback. The new interface offers more information at a glance and provides consistent, intuitive workflows for defining and managing applications.
Looking ahead
While today’s release is a major step forward, there’s more to come. Currently, private hostname support is limited to port 443 with TLS inspection enabled. Later in 2025, we plan to extend support to arbitrary private hostnames on any port and protocol, further broadening Access’s capabilities.
Get started today
These new Access features are live and ready for you to explore. If you haven’t yet started modernizing remote access at your organization, sign up for a free account to test it out. Whether you’re securing private resources or simplifying policy management, we’re excited to see how these updates enhance your Zero Trust journey. As always, we’re here to help — reach out to your account team with any questions or feedback.
Within the Cloudflare Application Security team, every machine learning model we use is underpinned by a rich set of static rules that serve as a ground truth and a baseline comparison for how our models are performing. These are called heuristics. Our Bot Management heuristics engine has served as an important part of eight global machine learning (ML) models, but we needed a more expressive engine to increase our accuracy. In this post, we’ll review how we solved this by moving our heuristics to the Cloudflare Ruleset Engine. Not only did this provide the platform we needed to write more nuanced rules, it made our platform simpler and safer, and provided Bot Management customers more flexibility and visibility into their bot traffic.
Bot detection via simple heuristics
In Cloudflare’s bot detection, we build heuristics from attributes like software library fingerprints, HTTP request characteristics, and internal threat intelligence. Heuristics serve three separate purposes for bot detection:
Bot identification: If traffic matches a heuristic, we can identify the traffic as definitely automated traffic (with a bot score of 1) without the need of a machine learning model.
Train ML models: When traffic matches our heuristics, we create labelled datasets of bot traffic to train new models. We’ll use many different sources of labelled bot traffic to train a new model, but our heuristics datasets are one of the highest confidence datasets available to us.
Validate models: We benchmark any new model candidate’s performance against our heuristic detections (among many other checks) to make sure it meets a required level of accuracy.
While the existing heuristics engine has worked very well for us, as bots evolved we needed the flexibility to write increasingly complex rules. Unfortunately, such rules were not easily supported in the old engine. Customers have also been asking for more details about which specific heuristic caught a request, and for the flexibility to enforce different policies per heuristic ID. We found that by building a new heuristics framework integrated into the Cloudflare Ruleset Engine, we could build a more flexible system to write rules and give Bot Management customers the granular explainability and control they were asking for.
The need for more efficient, precise rules
In our previous heuristics engine, we wrote rules in Lua as part of our openresty-based reverse proxy. The Lua-based engine was limited to a very small number of characteristics in a rule because of the high engineering cost we observed with adding more complexity.
With Lua, we would write fairly simple logic to match on specific characteristics of a request (i.e. user agent). Creating new heuristics of an existing class was fairly straight forward. All we’d need to do is define another instance of the existing class in our database. However, if we observed malicious traffic that required more than two characteristics (as a simple example, user-agent and ASN) to identify, we’d need to create bespoke logic for detections. Because our Lua heuristics engine was bundled with the code that ran ML models and other important logic, all changes had to go through the same review and release process. If we identified malicious traffic that needed a new heuristic class, and we were also blocked by pending changes in the codebase, we’d be forced to either wait or rollback the changes. If we’re writing a new rule for an “under attack” scenario, every extra minute it takes to deploy a new rule can mean an unacceptable impact to our customer’s business.
More critical than time to deploy is the complexity that the heuristics engine supports. The old heuristics engine only supported using specific request attributes when creating a new rule. As bots became more sophisticated, we found we had to reject an increasing number of new heuristic candidates because we weren’t able to write precise enough rules. For example, we found a Golang TLS fingerprint frequently used by bots and by a small number of corporate VPNs. We couldn’t block the bots without also stopping the legitimate VPN usage as well, because the old heuristics platform lacked the flexibility to quickly compile sufficiently nuanced rules. Luckily, we already had the perfect solution with Cloudflare Ruleset Engine.
Our new heuristics engine
The Ruleset Engine is familiar to anyone who has written a WAF rule, Load Balancing rule, or Transform rule, just to name a few. For Bot Management, the Wireshark-inspired syntax allows us to quickly write heuristics with much greater flexibility to vastly improve accuracy. We can write a rule in YAML that includes arbitrary sub-conditions and inherit the same framework the WAF team uses to both ensure any new rule undergoes a rigorous testing process with the ability to rapidly release new rules to stop attacks in real-time.
Writing heuristics on the Cloudflare Ruleset Engine allows our engineers and analysts to write new rules in an easy to understand YAML syntax. This is critical to supporting a rapid response in under attack scenarios, especially as we support greater rule complexity. Here’s a simple rule using the new engine, to detect empty user-agents restricted to a specific JA4 fingerprint (right), compared to the empty user-agent detection in the old Lua based system (left):
--- Adds heuristic to be used for inference in `detect` method
-- @param heuristic schema.Heuristic table
function EmptyUserAgentHeuristic:add(heuristic)
self.heuristic = heuristic
end
--- Detect runs empty user agent heuristic detection
-- @param ctx context of request
-- @return schema.Heuristic table on successful detection or nil otherwise
function EmptyUserAgentHeuristic:detect(ctx)
local ua = ctx.user_agent
if not ua or ua == '' then
return self.heuristic
end
end
return _M
ref: empty-user-agent
description: Empty or missing
User-Agent header
action: add_bot_detection
action_parameters:
active_mode: false
expression: http.user_agent eq
"" and cf.bot_management.ja4 = "t13d1516h2_8daaf6152771_b186095e22b6"
The Golang heuristic that captured corporate proxy traffic as well (mentioned above) was one of the first to migrate to the new Ruleset engine. Before the migration, traffic matching on this heuristic had a false positive rate of 0.01%. While that sounds like a very small number, this means for every million bots we block, 100 real users saw a Cloudflare challenge page unnecessarily. At Cloudflare scale, even small issues can have real, negative impact.
When we analyzed the traffic caught by this heuristic rule in depth, we saw the vast majority of attack traffic came from a small number of abusive networks. After narrowing the definition of the heuristic to flag the Golang fingerprint only when it’s sourced by the abusive networks, the rule now has a false positive rate of 0.0001% (One out of 1 million). Updating the heuristic to include the network context improved our accuracy, while still blocking millions of bots every week and giving us plenty of training data for our bot detection models. Because this heuristic is now more accurate, newer ML models make more accurate decisions on what’s a bot and what isn’t.
New visibility and flexibility for Bot Management customers
While the new heuristics engine provides more accurate detections for all customers and a better experience for our analysts, moving to the Cloudflare Ruleset Engine also allows us to deliver new functionality for Enterprise Bot Management customers, specifically by offering more visibility. This new visibility is via a new field for Bot Management customers called Bot Detection IDs. Every heuristic we use includes a unique Bot Detection ID. These are visible to Bot Management customers in analytics, logs, and firewall events, and they can be used in the firewall to write precise rules for individual bots.
Detections also include a specific tag describing the class of heuristic. Customers see these plotted over time in their analytics.
To illustrate how this data can help give customers visibility into why we blocked a request, here’s an example request flagged by Bot Management (with the IP address, ASN, and country changed):
Before, just seeing that our heuristics gave the request a score of 1 was not very helpful in understanding why it was flagged as a bot. Adding our Detection IDs to Firewall Events helps to paint a better picture for customers that we’ve identified this request as a bot because that traffic used an empty user-agent.
In addition to Analytics and Firewall Events, Bot Detection IDs are now available for Bot Management customers to use in Custom Rules, Rate Limiting Rules, Transform Rules, and Workers.
Account takeover detection IDs
One way we’re focused on improving Bot Management for our customers is by surfacing more attack-specific detections. During Birthday Week, we launched Leaked Credentials Check for all customers so that security teams could help prevent account takeover (ATO) attacks by identifying accounts at risk due to leaked credentials. We’ve now added two more detections that can help Bot Management enterprise customers identify suspicious login activity via specific detection IDs that monitor login attempts and failures on the zone. These detection IDs are not currently affecting the bot score, but will begin to later in 2025. Already, they can help many customers detect more account takeover events now.
Detection ID 201326592 monitors traffic on a customer website and looks for an anomalous rise in login failures (usually associated with brute force attacks), and ID 201326593 looks for an anomalous rise in login attempts (usually associated with credential stuffing).
Protect your applications
If you are a Bot Management customer, log in and head over to the Cloudflare dashboard and take a look in Security Analytics for bot detection IDs 201326592 and 201326593.
These will highlight ATO attempts targeting your site. If you spot anything suspicious, or would like to be protected against future attacks, create a rule that uses these detections to keep your application safe.
Modern websites rely heavily on JavaScript. Leveraging third-party scripts accelerates web app development, enabling organizations to deploy new features faster without building everything from scratch. However, supply chain attacks targeting third-party JavaScript are no longer just a theoretical concern — they have become a reality, as recent incidents have shown. Given the vast number of scripts and the rapid pace of updates, manually reviewing each one is not a scalable security strategy.
Cloudflare provides automated client-side protection through Page Shield. Until now, Page Shield could scan JavaScript dependencies on a web page, flagging obfuscated script content which also exfiltrates data. However, these are only indirect indicators of compromise or malicious intent. Our original approach didn’t provide clear insights into a script’s specific malicious objectives or the type of attack it was designed to execute.
Taking things a step further, we have developed a new AI model that allows us to detect the exact malicious intent behind each script. This intelligence is now integrated into Page Shield, available to all Page Shield add-on customers. We are starting with three key threat categories: Magecart, crypto mining, and malware.
Screenshot of Page Shield dashboard showing results of three types of analysis.
With these improvements, Page Shield provides deeper visibility into client-side threats, empowering organizations to better protect their users from evolving security risks. This new capability is available to all Page Shield customers with the add-on. Head over to the dashboard, and you can find the new malicious code analysis for each of the scripts monitored.
In the following sections, we take a deep dive into how we developed this model.
Training the model to detect hidden malicious intent
We built this new Page Shield AI model to detect the intent of JavaScript threats at scale. Training such a model for JavaScript comes with unique challenges, including dealing with web code written in many different styles, often obfuscated yet benign. For instance, the following three snippets serve the same function.
With such a variance of styles (and many more), our machine learning solution needs to balance precision (low false positive rate), recall (don’t miss an attack vector), and speed. Here’s how we do it:
Using syntax trees to classify malicious code
JavaScript files are parsed into syntax trees (connected acyclic graphs). These serve as the input to a Graph Neural Network (GNN). GNNs are used because they effectively capture the interdependencies (relationships between nodes) in executing code, such as a function calling another function. This contrasts with treating the code as merely a sequence of words — something a code compiler, incidentally, does not do. Another motivation to use GNNs is the insight that the syntax trees of malicious versus benign JavaScript tend to be different. For example, it’s not rare to find attacks that consist of malicious snippets inserted into, but otherwise isolated from, the rest of a benign base code.
To parse the files, the tree-sitter library was chosen for its speed. One peculiarity of this parser, specialized for text editors, is that it parses out concrete syntax trees (CST). CSTs retain everything from the original text input, including spacing information, comments, and even nodes attempting to repair syntax errors. This differs from abstract syntax trees (AST), the data structures used in compilers, which have just the essential information to execute the underlying code while ignoring the rest. One key reason for wanting to convert the CST to an AST-like structure, is that it reduces the tree size, which in turn reduces computation and memory usage. To do that, we abstract and filter out unnecessary nodes such as code comments. Consider for instance, how the following snippet
x = `result: ${(10+5) * 3}`;;; //this is a comment
… gets converted to an AST-like representation:
Abstract Syntax Tree (AST) representation of the sample code above. Unnecessary elements get removed (e.g. comments, spacing) whereas others get encoded in the tree structure (order of operations due to parentheses).
One benefit of working with parsed syntax trees is that tokenization comes for free! We collect and treat the node leaves’ text as our tokens, which will be used as features (inputs) for the machine learning model. Note that multiple characters in the original input, for instance backticks to form a template string, are not treated as tokens per se, but remain encoded in the graph structure given to the GNN. (Notice in the sample tree representations the different node types, such as “assignment_expression”). Moreover, some details in the exact text input become irrelevant in the executing AST, such as whether a string was originally written using double quotes vs. single quotes.
We encode the node tokens and node types into a matrix of counts. Currently, we lowercase the nodes’ text to reduce vocabulary size, improving efficiency and reducing sparsity. Note that JavaScript is a case-sensitive language, so this is a trade-off we continue to explore. This matrix and, importantly, the information about the node edges within the tree, is the input to the GNN.
How do we deal with obfuscated code? We don’t treat it specially. Rather, we always parse the JavaScript text as is, which incidentally unescapes escape characters too. For instance, the resulting AST shown below for the following input exemplifies that:
Abstract Syntax Tree (AST) representation of the sample code above. JavaScript escape characters are unescaped.
Moreover, our vocabulary contains several tokens that are commonly used in obfuscated code, such as double escaped hexadecimal-encoded characters. That, together with the graph structure information, is giving us satisfying results — the model successfully classifies malicious code whether it’s obfuscated or not. Analogously, our model’s scores remain stable when applied to plain benign scripts compared to obfuscating them in different ways. In other words, the model’s score on a script is similar to the score on an obfuscated version of the same script. Having said that, some of our model’s false positives (FPs) originate from benign but obfuscated code, so we continue to investigate how we can improve our model’s intelligence.
Architecting the Graph Neural Network
We train a message-passing graph convolutional network (MPGCN) that processes the input trees. The message-passing layers iteratively update each node’s internal representation, encoded in a matrix, by aggregating information from its neighbors (parent and child nodes in the tree). A pooling layer then condenses this matrix into a feature vector, discarding the explicit graph structure (edge connections between nodes). At this point, standard neural network layers, such as fully connected layers, can be applied to progressively refine the representation. Finally, a softmax activation layer produces a probability distribution over the four possible classes: benign, magecart, cryptomining, and malware.
We use the TF-GNN library to implement graph neural networks, with Keras serving as the high-level frontend for model building and training. This works well for us with one exception: TF-GNN does not support sparse matrices / tensors. (That lack of support increases memory consumption, which also adds some latency.) Because of this, we are considering switching to PyTorch Geometric instead.
Graph neural network architecture, transforming the input tree with features down to the 4 classification probabilities.
The model’s output probabilities are finally inverted and scaled into scores (ranging from 1 to 99). The “js_integrity” score aggregates the malicious classes (magecart, malware, cryptomining). A low score means likely malicious, and a high score means likely benign. We use this output format for consistency with other Cloudflare detection systems, such as Bot Management and the WAF Attack Score. The following diagram illustrates the preprocessing and feature analysis pipeline of the model down to the inference results.
Model inference pipeline to sniff out and alert on malicious JavaScript.
Tackling unbalanced data: malicious scripts are the minority
Finding malicious scripts is like finding a needle in a haystack; they are anomalies among plenty of otherwise benign JavaScript. This naturally results in a highly imbalanced dataset. For example, our Magecart-labeled scripts only account for ~6% of the total dataset.
Not only that, but the “benign” category contains an immense variance (and amount) of JavaScript to classify. The lengths of the scripts are highly diverse (ranging from just a few bytes to several megabytes), their coding styles vary widely, some are obfuscated whereas others are not, etc. To make matters worse, malicious payloads are often just small, carefully inserted fragments within an otherwise perfectly valid and functional benign script. This all creates a cacophony of token distributions for an ML model to make sense of.
Still, our biggest problem remains finding enough malevolent JavaScript to add to our training dataset. Thus, simplifying it, our strategy for data collection and annotation is two-fold:
Malicious scripts are about quantity → the more, the merrier (for our model, that is 😉). Of course, we still care about quality and diversity. But because we have so few of them (in comparison to the number of benign scripts), we take what we can.
Benign scripts are about quality → the more variance, the merrier. Here we have the opposite situation. Because we can collect so many of them easily, the value is in adding differentiated scripts.
Learning key scripts only: reduce false positives with minimal annotation time
To filter out semantically-similar scripts (mostly benign), we employed the latest advancements in LLM for generating code embeddings. We added those scripts that are distant enough from each other to our dataset, as measured by vector cosine similarity. Our methodology is simple — for a batch of potentially new scripts:
Call an LLM to generate its embedding. We’ve had good results with starcoder2, and most recently qwen2.5-coder.
Search in the database for the top-1 closest other script’s vectors.
If the distance > threshold (0.10), select it and add it to the database.
Else, discard the script (though we consider it for further validations and tests).
Although this methodology has an inherent bias in gradually favoring the first seen scripts, in practice we’ve used it for batches of newly and randomly sampled JavaScript only. To review the whole existing dataset, we could employ other but similar strategies, like applying HDBSCAN to identify an unknown number of clusters and then selecting the medoids, boundary, and anomaly data points.
We’ve successfully employed this strategy for pinpointing a few highly varied scripts that were relevant for the model to learn from. Our security researchers save a tremendous amount of time on manual annotation, while false positives are drastically reduced. For instance, in a large and unlabeled bucket of scripts, one of our early evaluation models identified ~3,000 of them as malicious. That’s too many to manually review! By removing near duplicates, we narrowed the need for annotation down to only 196 samples, less than 7% of the original amount (see the t-SNE visualization below of selected points and clusters). Three of those scripts were actually malicious, one we could not fully determine, and the rest were benign. By just re-training with these new labeled scripts, a tiny fraction of our whole dataset, we reduced false positives by 50% (as gauged in the same bucket and in a controlled test set). We have consistently repeated this procedure to iteratively enhance successive model versions.
2D visualization of scripts projected onto an embedding space, highlighting those sufficiently dissimilar from one another.
From the lab, to the real world
Our latest model in evaluation has both a macro accuracy and an overall malicious precision nearing 99%(!) on our test dataset. So we are done, right? Wrong! The real world is not the same as the lab, where many more variances of benign JavaScript can be seen. To further assure minimum prediction changes between model releases, we follow these three anti-fool measures:
Evaluate metrics uncertainty
First, we thoroughly estimate the uncertainty of our offline evaluation metrics. How accurate are our accuracy metrics themselves? To gauge that, we calculate the standard error and confidence intervals for our offline metrics (precision, recall, F1 measure). To do that, we calculate the model’s predicted scores on the test set once (the original sample), and then generate bootstrapped resamples from it. We use simple random (re-)sampling as it offers us a more conservative estimate of error than stratified or balanced sampling.
We would generate 1,000 resamples, each a fraction of 15% resampled from the original test sample, then calculate the metrics for each individual resample. This results in a distribution of sampled data points. We measure its mean, the standard deviation (with Bessel’s correction), and finally the standard error and a confidence interval (CI) (using the percentile method, such as the 2.5 and 97.5 percentiles for a 95% CI). See below for an example of a bootstrapped distribution for precision (P), illustrating that a model’s performance is a continuum rather than a fixed value, and that might exhibit subtly (left-)skewed tails. For some of our internally evaluated models, it can easily happen that some of the sub-sampled metrics decrease by up to 20 percentage points within a 95% confidence range. High standard errors and/or confidence ranges signal needs for model improvement and for improving and increasing our test set.
An evaluation metric, here precision (P), might change significantly depending on what’s exactly tested. We thoroughly estimate the metric’s standard error and confidence intervals.
Benchmark against massive offline unlabeled dataset
We run our model on the entire corpus of scripts seen by Cloudflare’s network and temporarily cached in the last 90 days. By the way, that’s nearly 1 TiB and 26 million different JavaScript files! With that, we can observe the model’s behavior against real traffic, yet completely offline (to ensure no impact to production). We check the malicious prediction rate, latency, throughput, etc. and sample some of the predictions for verification and annotation.
Review in staging and shadow mode
Only after all the previous checks were cleared, we then run this new tentative version in our staging environment. For major model upgrades, we also deploy them in shadow mode (log-only mode) — running on production, alongside our existing model. We study the model’s behavior for a while before finally marking it as production ready, otherwise we go back to the drawing board.
AI inference at scale
At the time of writing, Page Shield sees an average of 40,000 scripts per second. Many of those scripts are repeated, though. Everything on the Internet follows a Zipf’s law distribution, and JavaScript seen on the Cloudflare network is no exception. For instance, it is estimated that different versions of the Bootstrap library run on more than 20% of websites. It would be a waste of computing resources if we repeatedly re-ran the AI model for the very same inputs — inference result caching is needed. Not to mention, GPU utilization is expensive!
The question is, what is the best way to cache the scripts? We could take an SHA-256 hash of the plain content as is. However, any single change in the transmitted content (comments, spacing, or a different character set) changes the SHA-256 output hash.
A better caching approach? Since we need to parse the code into syntax trees for our GNN model anyway, this tree structure and content is what we use to hash the JavaScript. As described above, we filter out nodes in the syntax tree like comments or empty statements. In addition, some irrelevant details get abstracted out in the AST (escape sequences are unescaped, the way of writing strings is normalized, unnecessary parentheses are removed for the operations order is encoded in the tree, etc.).
Using such a tree-based approach to caching, we can conclude that at any moment over 99.9% of reported scripts have already been seen in our network! Unless we deploy a new model with significant improvements, we don’t re-score previously seen JavaScript but just return the cached score. As a result, the model only needs to be called fewer than 10 times per minute, even during peak times!
Let AI help ease PCI DSS v4 compliance
One of the most popular use cases for deploying Page Shield is to help meet the two new client-side security requirements in PCI DSS v4 — 6.4.3 and 11.6.1. These requirements make companies responsible for approving scripts used in payment pages, where payment card data could be compromised by malicious JavaScript. Both of these requirements become effective on March 31, 2025.
Page Shield with AI malicious JavaScript detection can be deployed with just a few clicks, especially if your website is already proxied through Cloudflare. Sign up here to fast track your onboarding!
Generative AI is reshaping many aspects of our lives, from how we work and learn, to how we play and interact. Given that it’s Security Week, it’s a good time to think about some of the unintended consequences of this information revolution and the role that we play in bringing them about.
Today’s web is full of AI-generated content: text, code, images, audio, and video can all be generated by machines, normally based on a prompt from a human. Some models have become so sophisticated that distinguishing their artifacts — that is, the text, audio, and video they generate — from everything else can be quite difficult, even for machines themselves. This difficulty creates a number of challenges. On the one hand, those who train and deploy generative AI need to be able to identify AI-created artifacts they scrape from websites in order to avoid polluting their training data. On the other hand, the origin of these artifacts may be intentionally misrepresented, creating myriad problems for society writ large.
Part of the solution to this problem might be watermarking. The basic idea of watermarking is to modify the training process, the inference process, or both so that an artifact of the model embeds some identifying information of the model from which it originates. This way a model operator, or potentially the consumer of the content themselves, can determine whether some artifact came from the model by checking for the presence of the watermark.
Watermarking shares many of the same goals as the C2PA initiative. C2PA seeks to add provenance of media from a variety of sources, not just AI. Think of it as a chain of digital signatures, where each link in the chain corresponds to some modification of the artifact. For example, if you’re a Cloudflare customer using Images to serve C2PA-tagged content, you can opt in to preserve the provenance by extending this signature chain, even after the image is compressed on our network.
The challenge of this approach is that it requires participation by each entity in the chain of custody of the artifact. Watermarking has the potential to make C2PA more robust by preserving the origin of the artifact even after unattributed modification. Whereas the C2PA signature is encoded in an image’s metadata, a watermark is embedded in the pixels of the image itself.
In this post, we’re going to take a look at an emerging paradigm for AI watermarking. Based on cryptography, these new watermarks aim to provide rigorous, mathematical guarantees of quality preservation and robustness to modification of the content. This field is, as of 2025, only a couple of years old, and we don’t yet know if it will yield schemes that are practical to deploy. Nevertheless, we believe this is a promising area of research, and we hope this post inspires someone to come up with the next big idea.
The case for cryptography
It’s often said that cryptography is necessary but not sufficient for security. In other words, cryptographers make certain assumptions about the state of the system, like that a key is kept secret from the attacker, or that some computational puzzle is hard to solve. When these assumptions hold, a good cryptosystem provides a mathematical proof of security against the class of attacks it is designed to prevent.
Artifact watermarking usually has three security goals:
Robustness: Users of the model should not be able to easily misrepresent the origin of its artifacts. The watermark should be verifiable even after the artifact is modified to some extent.
Undetectability: Watermarking should have negligible impact on the quality of the model output. In particular, watermarked artifacts should be indistinguishable from non-watermarked artifacts of the same model.
Unforgeability: It should be impossible for anyone but the model operator to produce watermarked artifacts. No one should be able to convince the model operator that an artifact was generated by the model when it wasn’t.
Today’s state-of-the-art watermarks, including Google’s SynthID and Meta’s Video Seal, are often based on deep learning. These schemes involve training a machine learning model, typically one with an encoder–decoder architecture where the encoder encodes a signature into an artifact and the decoder decodes the signature:
Figure 1: Illustration of the process of training an encoder-decoder watermarking model.
The training process involves subjecting the watermarked artifact to a series of known attacks. The more attacks the model thwarts, the higher the model quality. For example, the trainer would alter the artifact in various ways and run the decoder on the outputs: the model scores high if the decoder manages to correctly output the signature most of the time.
This idea is quite beautiful. It’s like a scaled up version of penetration testing, an essential practice of security engineering whereby the system is subjected to a suite of known attacks until all known vulnerabilities are patched. Of course, there will always be new attack variants or new attack strategies that the model was not trained on and that may evade the model.
And so ensues the proverbial game of cat-and-mouse that consumes so much time in security engineering. Coping with new attacks on robustness, undetectability, or unforgeability of deep-learning based watermarks requires continual intelligence gathering and re-training of deployed models to keep up with attackers.
The promise of cryptography is that it helps us break out of these kinds of cat-and-mouse games. Cryptography reduces the attack surface by focusing the attacker’s attention on breaking some narrow aspect of the system that is easier to reason about. This might be gaining access to some secret key, or solving some (seemingly unrelated) computational puzzle that is believed to be impossible to solve.
Pseudorandom codes
To the best of our knowledge, the first cryptographic AI watermark was proposed by Scott Aaronson in the summer of 2022 while he was working at OpenAI. Tailored specifically for chatbots, Aaronson’s simple scheme was both undetectable and unforgeable. However, it was susceptible to some simple attacks on robustness.
Figure 2: The “emoji attack”: Ask the chatbot to embed a simple pattern in its response, then remove the pattern manually. This is sufficient to remove some cryptographic watermarks from the model output.
In the year or so that followed, other cryptographic watermarks were proposed, all making different trade-offs between detectability and robustness. Two years later, in a paper that appeared at CRYPTO 2024, Miranda Christ and Sam Gunn articulated a new framework for watermarks that, if properly instantiated, would provide all three properties simultaneously.
Along with the prompt provided by the user, generative AI models typically take as input some randomness generated by the model operator. For many such models, it is often possible to run the model “in reverse” such that, given an artifact of the model, one can recover an approximation of the initial randomness used to generate it. We’ll see why this is important in a moment.
The starting point for Christ-Gunn-2024 is a mathematical tool called an error correcting code. These codes are normally used to transmit messages over noisy channels and are found in just about every system we rely on, including fiber optics, satellites, the data bus on your motherboard, and even quantum computers.
To transmit a message m, one first encodes it into a codewordc=encode(m). Then the receiver attempts to decode the codeword as decode(c). Error correcting codes are designed to tolerate some fraction of the codeword bits being flipped: if too many bits are flipped, then decoding will fail.
Now, ignoring undetectability and unforgeability for a moment, we can use an error correcting code to make a robust watermark as follows:
Generate the initial randomness.
Embed a codeword c=encode(m) into the randomness in some manner, by overwriting bits of randomness with bits of c. The message m can be whatever we want, for example a short string identifying the version of our model.
Run the model with the modified randomness.
To verify the watermark, we:
Run the model “in reverse” on the artifact, obtaining an approximation of the initial randomness.
Extract the codeword c* from the randomness.
If decode(c*) succeeds, then the watermark is present.
Why does this work? Since c is a codeword, we can verify the watermark even if our approximation of the initial randomness isn’t perfect. Some of the bits will be flipped, but the error correcting property of the code allows us to compensate for this. In fact, this is also what makes the watermark robust, since we can also tolerate bit flips caused by an attacker munging the artifact. Of course, the better our approximation of the initial randomness, the more robust our watermark will be, since we’ll be able to correct for more bit flips.
To see why this watermark is detectable, notice that overwriting bits of the randomness with a fixed codeword (c=encode(m)) biases the randomness and thereby the output of the model. Thus, the distribution of watermarked artifacts will be slightly different from unwatermarked artifacts, perhaps even noticeably so. This watermark is also forgeable, since the encoding algorithm is public and can be run by anyone.
The challenge then is to design error-correcting codes for which codewords look random, and generating codewords requires knowledge of a secret key held by the model operator. Christ-Gunn-2024 names these pseudorandom error-correcting codes, or simply pseudorandom codes.
A pseudorandom code consists of three algorithms:
k = key_gen(): the key generation algorithm. Let’s call k the watermarking key.
c = encode(k,m): the encoding algorithm takes in a message m and outputs a codeword c.
m = decode(k,c): the decoding algorithm takes in a codeword c and outputs the underlying message m, or an indication that decoding failed.
The term “pseudorandom” refers to the fact that codewords aren’t technically random bit strings. Intuitively, an attacker can distinguish a codeword from a random string if it manages to guess the watermarking key. Thus, our goal is to choose parameters for the code such that distinguishing codewords from random — for example, by guessing the watermarking key — is hard for any computationally bounded attacker.
To use a pseudorandom code for watermarking, the operator first generates a watermarking key k. Then each time it gets a prompt from a user, it generates the initial randomness, embeds c=encode(k,m) into the initial randomness, and runs the model. To verify the watermark, the operator runs the model in reverse to get the inverted randomness, extracts the inverted codeword, c*, and computes decode(k,c*): if decoding succeeds, then the watermark is present.
In order for this watermark to be undetectable, we need to pick an embedding of the codeword that doesn’t change the distribution of the initial randomness. The details of this embedding depend on the model. Let’s take a look at Stable Diffusion as an example.
A watermark for Stable Diffusion
Stable Diffusion is a model used for image generation that takes as input a tensor of normally distributed floating point numbers called a latent. The model uses the user’s prompt to “denoise” the latent tensor over a number of iterations, then converts the final version of the latent to an image.
Approximating the initial latent
Diffusion inversion is an iterative process that returns an exact or approximate initial latent by reversing the sampling process that generated an image. Inversion for text to image diffusion models is a relatively new area of research. A common application of diffusion inversion is editing images by text prompts.
Denoising Diffusion Implicit Models (DDIMs) are iterative, implicit probabilistic models that can generate high quality images using a faster sampling process than other approaches, as it only requires a relatively small number of timesteps to generate a sample. This makes DDIM Inversion a popular inversion technique because it is computationally fast, as it requires only a few timesteps to return an approximate initial latent of a generated image. Despite its popularity, it has some known limitations and can be problematic to use for tasks where exact image reproduction is required. These limitations have led researchers to explore techniques that produce exact initial latents. However, since watermarks based on pseudorandom codes can tolerate errors, it’s worth investigating whether DDIM Inversion suffices for our purposes.
Before we can generate an approximate initial latent, we need a generated image. To do this we use a pretrained Stable Diffusion model that uses a DDIM scheduler. The scheduler performs the “denoising” process that generates an image from a random noise seed (initial latent). By default, the pipeline computes random latents; when embedding a watermark we will generate this latent ourselves as described in the next section. The Stable Diffusion pipelines in the code snippets below sets the number of inference steps to 50. This parameter controls the number of steps the denoising process takes. 50 steps provides a nice balance between speed and image quality.
from stable_diffusion.utils import build_stable_diffusion_pipeline
from stable_diffusion.schedulers import ddim_scheduler
# Instantiate Stable Diffusion pipeline
model_cache_path = './model_cache'
model = 'stabilityai/stable-diffusion-2-1-base'
scheduler, _ = ddim_scheduler()
pipe, device = build_stable_diffusion_pipeline(model, model_cache_path, scheduler)
# Generate image
prompt = 'grainy photo of a UFO at night'
image, _ = pipe(prompt, num_inference_steps=50, return_dict=False)
To compute the approximate initial latent for the image we generated, we run the sampling process backwards. We could include the prompt, but in the case of verifying a watermark, we will usually not know the initial prompt, so we instead just set it to the empty string:
from PIL import Image
from stable_diffusion.utils import build_stable_diffusion_pipeline,
convert_pil_to_latents
from stable_diffusion.schedulers import ddim_inverse_scheduler
# Load image
img = Image.open(image_path)
# Instantiate Stable Diffusion pipeline with DDIM Inverse scheduler
model_cache_path = './model_cache'
model = 'stabilityai/stable-diffusion-2-1-base'
scheduler, _= ddim_inverse_scheduler()
pipe, _ = build_stable_diffusion_pipeline(model, model_cache_path, scheduler)
# Convert the input image to latent space
image_latent = convert_pil_to_latents(pipe, img)
# Invert the sampling process that generated the image with an empty prompt
inverted_latent, _ = pipe('', output_type='latent', latents=image_latent,
num_inference_steps=50, return_dict=False)
Embedding the code
The initial latent used for stable diffusion consists of a bunch of floating point numbers, each independently and normally distributed with a mean of zero.
The following observation is from a recent evaluation of the watermark of Christ and Gunn for stable diffusion. (There they used a more sophisticated but expensive inversion method than DDIM.) Observe that the probability that each number is negative is equal to the probability that the number is positive. Likewise, if the code is indeed pseudorandom, then each bit of the codeword is computationally indistinguishable from a bit that is one with probability ½ and zero with probability ½.
To embed the codeword in the latent, we just set the sign of each number according to the corresponding bit of the codeword:
from stable_diffusion.utils import build_stable_diffusion_pipeline
from stable_diffusion.schedulers import ddim_scheduler
import numpy as np
import torch
# Generate a normally distributed latent. For the default image
# size of 512x512 pixels, the latent shape is `[1, 4, 64, 64]`.
initial_latent = np.abs(np.random.randn(*LATENTS_SHAPE))
with np.nditer(initial_latent, op_flags=['readwrite']) as it:
codeword = encode(k, m)
for (i, x) in enumerate(it):
# `codeword[i]` is a `bool` representing the `i`-th bit of
# the codeword.
x *= 1 if codeword[i] else -1
watermarked_latent = torch.from_numpy(initial_latent).to(dtype=torch.float32)
# Instantiate Stable Diffusion pipeline
model_cache_path = './model_cache'
model = 'stabilityai/stable-diffusion-2-1-base'
scheduler, _ = ddim_scheduler()
pipe, _ = build_stable_diffusion_pipeline(model, model_cache_path, scheduler)
# Generate watermarked image
prompt = 'grainy photo of a UFO at night'
watermarked_image, _ = pipe(prompt, num_inference_steps=50,
latents=watermarked_latent,
return_dict=False)
To verify this watermark, we compute the inverted latent, extract the codeword, and attempt to decode:
from PIL import Image
from stable_diffusion.utils import build_stable_diffusion_pipeline,
convert_pil_to_latents
from stable_diffusion.schedulers import ddim_inverse_scheduler
import numpy as np
# Load image
img = Image.open(image_path)
# Instantiate Stable Diffusion pipeline with DDIM Inverse scheduler
model_cache_path = './model_cache'
model = 'stabilityai/stable-diffusion-2-1-base'
scheduler, _ = ddim_inverse_scheduler()
pipe, _ = build_stable_diffusion_pipeline(model, model_cache_path, scheduler)
# Convert the input image to latent space
image_latent = convert_pil_to_latents(pipe, img)
# Invert the sampling process that generated the image
inverted_latent, _ = pipe('', output_type='latent', latents=image_latent,
num_inference_steps=50, return_dict=False)
watermark_verified = False
with np.nditer(inverted_latent.cpu().numpy()) as it:
inverted_codeword = []
for x in it:
inverted_codeword.append(x > 0)
if decode(k, inverted_codeword) == m:
watermark_verified = True
This should work in theory given the error-correcting properties of the code. But does it work in practice?
Evaluation
A good approximate initial latent is one that is very similar to the original latent that generated an image. Given our embedding of a codeword into the latent, we define similarity as latents that have a high percentage of overlapping or matching signs.
To get a feel for this difference, we can visualize it by comparing a generated image to the same image, but with the inverted latent (these images are unwatermarked):
Figure 3: Image generated with prompt ‘grainy photo of a UFO at night’ (left) and the same image generated using the inverted latent (right).
To evaluate how good the approximate latents are for preserving the robustness of watermarks, we randomly sampled 1,000 prompts from the PartiPrompts benchmark dataset. For each of these prompts we generated initial latent and inverted latent pairs. We then computed our similarity metric for each pair. We found that on average, 82% of the signs matched for all initial latent and inverted latent pairs, and at least 75% of signs matched for 90% of the pairs.
We were pleasantly surprised with how accurate the approximation was on average. If 75% of the signs are preserved, then this gives us a decent margin for correcting for errors introduced by an attacker attempting to remove the watermark. Of course a better approximation would give us a better robustness margin. More study is required to fully understand the strengths and limitations of using DDIM Inversion for watermark decoding.
Candidate pseudorandom codes
Now that we have a feel for how to apply pseudorandom codes, let’s take a look at how we actually build them. Although the field is barely a year old, we already have a handful of candidates.
One obvious idea to try is to compose a plain error-correcting code with some cryptographic primitive to make the code pseudorandom. For instance, we might use some standard authenticated encryption scheme, like AES-GCM-SIV, to encrypt m, then apply an error correcting code to the ciphertext. (The watermarking key would be the encryption key.) This “encrypt-then-encode” composition seems natural because encryption schemes are already designed so that their ciphertexts are pseudorandom. Unfortunately, error correcting codes are generally highly structured, and this structure would be betrayed by the codeword, even when applied to a (pseudo)random input.
The dual composition, “encode-then-encrypt”, also doesn’t work. If the ciphertext is non-malleable, as in AES-GCM-SIV, then we wouldn’t be able to tolerate any number of bit flips. On the other hand, if the ciphertext were malleable, as in AES-CTR, then the attacker would be able to forge codewords by manipulating a known codeword in a targeted manner.
The strategy of Christ-Gunn-2024 is to modify an existing error-correcting code to make it pseudorandom.
Pseudorandom LDPC codes
Their starting point is the widely used Low-Density Parity-Check (LDPC) code. This code is defined by a parity check matrix P with and a corresponding generator matrix G. The parity check matrix has bit entries and might look something like this:
This matrix is used to check if a given bit string is a codeword. By definition, a codeword is any bit string c for which the weight of P*c (the number ones in the output of P*c) is small. (Note that arithmetic is modulo 2 here.) The generator matrix G is constructed from P so that it can be used as the encoder. In particular, for any bit string m, c=G*m is a codeword. The performance of this code depends in large part on the sparsity of the parity check matrix: roughly speaking, the more zero entries the matrix has, the more the bit flips the code can tolerate.
The main idea of Christ-Gunn-2024 is to tune the parameters of the LDPC code (the dimensions of the parity check matrix and its density) so that when the parity-check matrix P is chosen at random, the generator matrix G is pseudorandom. This means that, intuitively, when we encode a random input m as c=G*m, the codeword c is also pseudorandom. (There is a bit more that goes into constructing the input m, but this is roughly the idea.)
It’s easy to see that a watermark based on this construction is robust, as it follows immediately from the capacity of LDPC to tolerate bit flips. Ensuring the watermark remains undetectable is more delicate, as it relies on relatively strong and understudied computational assumptions. As a result, it’s not clear today for what parameter ranges this scheme is concretely secure. (There has been some progress here: a recent preprint by Surendra Ghentiyala and Venkatesan Guruswami showed that the pseudorandomness of Christ-Gunn-2024 can be proved with slightly weaker assumptions.)
To get a feel for how things might go wrong, consider what happens if the attacker manages to guess one of the rows of the parity check matrix P. When we take the dot product of this row with a codeword, then the output will be 0 with high probability. (By definition, c is a codeword if the sum of the dot products of c with each row of P is small.) But if we take the dot product of this row with a random bit string, then we should expect to see 0 with probability roughly ½. This gives us a way of distinguishing codewords from random bit strings.
Guessing a row of P is easy if the matrix is too sparse. In the extreme case, if each row has only one bit set, then there are only n possible values for that row, where n is the number of columns of P. On the other hand, making P too dense will degrade the code’s ability to detect bit flips.
Similarly, it may be easy to guess a row of P if the length of the codeword itself (n) is too small. Thus, in order for this code to be pseudorandom, it is necessary (but not sufficient) for the number of possible parity check matrices to be so large that exhaustively searching for P is not feasible. This can be done by increasing the size of the codeword or tolerating fewer bit flips.
Pseudorandom codes from PRFs
Another approach to constructing pseudorandom codes comes from a 2024 preprint from Noah Golowich and Ankur Moitra. Their starting point is a common cryptographic primitive called a pseudorandom function (PRF). They require a PRF that takes as input a key k, a bit string x of length m and outputs a bit, denoted F(k,m).
Suppose our codewords are x1, w1=F(k,x1), …, xn, wn=F(k,xn) where x1, …, xn are random m-bit strings. (Notice that the codeword length is (m+1)*n.) To verify if a string is a codeword, we parse the codeword into x1, w1, …, xn, wnand check if wi = F(k,xi) for all i. If the number of checks that pass is sufficiently high, then the string is likely a codeword.
It’s easy to see that this code is pseudorandom if the output of F is pseudorandom. However, it’s not very robust: to make the i-th check fail, we just need to flip a single bit, wi. The attacker just needs to flip a sufficient number of these bits to cause verification to fail. To defeat this attack, the encoder permutes the bits of the codeword with a secret, random permutation. That way the attacker has to guess the position of a sufficient number of wis in the permuted bit string. (A bit more is required to make this scheme provably robust, but this is the idea.)
Note that the number of bit flips we can tolerate with this scheme depends significantly on the number of PRF checks. This in turn determines the length of the codeword, so we may only get a reasonable degree of robustness for longer codewords. Note that we can increase the number of PRF checks by decreasing the length m of the xis, but making these strings too short is detrimental for pseudorandomness. (What happens if we happen to randomly pick xi==xjfor i!=j?)
Are these schemes practical?
In our own experiments with Stable Diffusion, we were able to tune the LDPC code to tolerate up to 33% of the codeword bits being mangled, which is likely more than sufficient for robustness in practice. However, achieving this required making the parity check matrix so sparse that the code is not strongly pseudorandom. Thus, the resulting watermark cannot be considered cryptographically undetectable. Among the parameter sets for which the code is plausibly pseudorandom, we didn’t find any for which the code tolerates more than 5% bit flips.
Our findings were similar for the PRF-based code: with plausibly pseudorandom parameters, we couldn’t tune the code to tolerate more than 1% bit flips. Like the LDPC code, we can crank this higher by sacrificing pseudorandomness, but we weren’t able to crack 5% with any parameters we tried.
There are a few ways to think about this.
First, for both codes, robustness improves as the codeword gets larger. In particular, if the latent space for Stable Diffusion were larger, then we’d expect to be able to tolerate more bit flips. In general, cryptographic watermarks of all kinds perform better when there is more randomness to work with. For example, short responses produced by chatbots are especially hard for any watermarking strategy, including pseudorandom codes.
Another takeaway is that we need a better approximation of the initial latent than provided by DDIM. Indeed, in their own evaluation of the LDPC-based code, Sam Gunn, Xuandong Zhao, and Dawn Song chose a much more sophisticated inversion method, which exhibited better results, albeit at a higher computational cost.
A third view is that, as a practical matter, cryptographic undetectability might not be all that important for some applications. For instance, we might decide the watermark is good enough on the basis of statistical tests to check for biases within, or correlations across, codewords. Of course, such tests can’t rule out the possibility of perceptible differences between watermarked and unwatermarked artifacts.
Figure 4: Images with verified LDPC watermarks generated with prompt ‘grainy photo of a UFO at night’.
Conclusion
The sign of a good abstraction boundary is that it allows folks to collaborate across disciplines. With pseudorandom codes, it seems like we’ve landed on the right abstraction for AI watermarking: it’s up to cryptography experts to figure out how to instantiate them; and it’s up to AI/ML experts to figure out how to embed them in their applications. We believe this separation of concerns has the potential to make watermarking easier to deploy, especially for operators like Cloudflare’s Workers AI, who don’t train and maintain the models themselves.
After spending a few weeks playing around with this stuff, we’re excited by the potential of pseudorandom codes to make strong watermarks for generative AI. However, we feel it will take some time for this field to yield practical schemes.
Existing candidates will require further study to determine the parameter ranges for which they provide good security. It is also worthwhile to investigate new approaches to building pseudorandom codes, perhaps starting with some other error correcting code besides LDPC. We should also examine what is even theoretically possible in this space: perhaps there is a fundamental tension between detectability and robustness that can’t be resolved for some parameter regimes.
It’s also going to be important for watermarks based on pseudorandom codes to be publicly verifiable, as some other cryptographic watermarks are. Concretely, the LDPC code is sort of analogous to public key encryption, where the ciphertext corresponds to a codeword. It might be possible to flip this paradigm around and make a digital signature where the signature is a codeword. Of course, this only works when the weights of the model are also publicly available.
On the AI/ML side, we need to look closer at methods of approximating the initial randomness for different types of models. This blog looked at what is perhaps the simplest possible method for Stable Diffusion, and while this seems to work pretty well, it’s obvious that we can do a lot better. It’s just a matter of keeping costs low. A good rule of thumb might be that verifying the watermark should not be more expensive than watermarked inference.
Pseudorandom codes may also have applications beyond watermarking. When we circulated this blog post internally, an idea that came up a lot was to somehow apply this technology to non-AI content, to embed in the content its provenance. Indeed, this is the idea behind the C2PA integration. Pseudorandom codes aren’t immediately applicable, but may be in the future. Wherever you have a source of randomness in the process of generating some artifact, like digital photography, you can embed in that randomness a codeword.
Thanks for reading! We hope we’ve managed to pique your interest in this field. We certainly will be following along. If you’d like to play with the code we used to produce the numbers in this blog, or just make some cool watermarked AI content, you can find our demo on GitHub.
Today, we’re excited to announce AI Labyrinth, a new mitigation approach that uses AI-generated content to slow down, confuse, and waste the resources of AI Crawlers and other bots that don’t respect “no crawl” directives. When you opt in, Cloudflare will automatically deploy an AI-generated set of linked pages when we detect inappropriate bot activity, without the need for customers to create any custom rules.
AI Labyrinth is available on an opt-in basis to all customers, including the Free plan.
Using Generative AI as a defensive weapon
AI-generated content has exploded, reportedly accounting for four of the top 20 Facebook posts last fall. Additionally, Medium estimates that 47% of all content on their platform is AI-generated. Like any newer tool it has both wonderful and malicious uses.
At the same time, we’ve also seen an explosion of new crawlers used by AI companies to scrape data for model training. AI Crawlers generate more than 50 billion requests to the Cloudflare network every day, or just under 1% of all web requests we see. While Cloudflare has several tools for identifying and blocking unauthorized AI crawling, we have found that blocking malicious bots can alert the attacker that you are on to them, leading to a shift in approach, and a never-ending arms race. So, we wanted to create a new way to thwart these unwanted bots, without letting them know they’ve been thwarted.
To do this, we decided to use a new offensive tool in the bot creator’s toolset that we haven’t really seen used defensively: AI-generated content. When we detect unauthorized crawling, rather than blocking the request, we will link to a series of AI-generated pages that are convincing enough to entice a crawler to traverse them. But while real looking, this content is not actually the content of the site we are protecting, so the crawler wastes time and resources.
As an added benefit, AI Labyrinth also acts as a next-generation honeypot. No real human would go four links deep into a maze of AI-generated nonsense. Any visitor that does is very likely to be a bot, so this gives us a brand-new tool to identify and fingerprint bad bots, which we add to our list of known bad actors. Here’s how we do it…
How we built the labyrinth
When AI crawlers follow these links, they waste valuable computational resources processing irrelevant content rather than extracting your legitimate website data. This significantly reduces their ability to gather enough useful information to train their models effectively.
To generate convincing human-like content, we used Workers AI with an open source model to create unique HTML pages on diverse topics. Rather than creating this content on-demand (which could impact performance), we implemented a pre-generation pipeline that sanitizes the content to prevent any XSS vulnerabilities, and stores it in R2 for faster retrieval. We found that generating a diverse set of topics first, then creating content for each topic, produced more varied and convincing results. It is important to us that we don’t generate inaccurate content that contributes to the spread of misinformation on the Internet, so the content we generate is real and related to scientific facts, just not relevant or proprietary to the site being crawled.
This pre-generated content is seamlessly integrated as hidden links on existing pages via our custom HTML transformation process, without disrupting the original structure or content of the page. Each generated page includes appropriate meta directives to protect SEO by preventing search engine indexing. We also ensured that these links remain invisible to human visitors through carefully implemented attributes and styling. To further minimize the impact to regular visitors, we ensured that these links are presented only to suspected AI scrapers, while allowing legitimate users and verified crawlers to browse normally.
A graph of daily requests over time, comparing different categories of AI Crawlers.
What makes this approach particularly effective is its role in our continuously evolving bot detection system. When these links are followed, we know with high confidence that it’s automated crawler activity, as human visitors and legitimate browsers would never see or click them. This provides us with a powerful identification mechanism, generating valuable data that feeds into our machine learning models. By analyzing which crawlers are following these hidden pathways, we can identify new bot patterns and signatures that might otherwise go undetected. This proactive approach helps us stay ahead of AI scrapers, continuously improving our detection capabilities without disrupting the normal browsing experience.
By building this solution on our developer platform, we’ve created a system that serves convincing decoy content instantly while maintaining consistent quality – all without impacting your site’s performance or user experience.
How to use AI Labyrinth to stop AI crawlers
Enabling AI Labyrinth is simple and requires just a single toggle in your Cloudflare dashboard. Navigate to the bot management section within your zone, and toggle the new AI Labyrinth setting to on:
Once enabled, the AI Labyrinth begins working immediately with no additional configuration needed.
AI honeypots, created by AI
The core benefit of AI Labyrinth is to confuse and distract bots. However, a secondary benefit is to serve as a next-generation honeypot. In this context, a honeypot is just an invisible link that a website visitor can’t see, but a bot parsing HTML would see and click on, therefore revealing itself to be a bot. Honeypots have been used to catch hackers as early as the late 1986 Cuckoo’s Egg incident. And in 2004, Project Honeypot was created by Cloudflare founders (prior to founding Cloudflare) to let everyone easily deploy free email honeypots, and receive lists of crawler IPs in exchange for contributing to the database. But as bots have evolved, they now proactively look for honeypot techniques like hidden links, making this approach less effective.
AI Labyrinth won’t simply add invisible links, but will eventually create whole networks of linked URLs that are much more realistic, and not trivial for automated programs to spot. The content on the pages is obviously content no human would spend time-consuming, but AI bots are programmed to crawl rather deeply to harvest as much data as possible. When bots hit these URLs, we can be confident they aren’t actual humans, and this information is recorded and automatically fed to our machine learning models to help improve our bot identification. This creates a beneficial feedback loop where each scraping attempt helps protect all Cloudflare customers.
What’s next
This is only the first iteration of using generative AI to thwart bots for us. Currently, while the content we generate is convincingly human, it won’t conform to the existing structure of every website. In the future, we’ll continue to work to make these links harder to spot and make them fit seamlessly into the existing structure of the website they’re embedded in. You can help us by opting in now.
While we are still early in what is likely going to be a substantial shift in how the world operates, two things are clear: the Internet, and how we interact with it, will change, and the boundaries of security and data privacy have never been more difficult to trace, making security an important topic in this shift.
At Cloudflare, we have a mission to help build a better Internet. And while we can only speculate on what AI will bring in the future, its success will rely on it being reliable and safe to use.
Today, we are introducing Cloudflare for AI: a suite of tools aimed at helping businesses, developers, and content creators adopt, deploy, and secure AI technologies at scale safely.
Cloudflare for AI is not just a grouping of tools and features, some of which are new, but also a commitment to focus our future development work with AI in mind.
Let’s jump in to see what Cloudflare for AI can deliver for developers, security teams, and content creators…
For developers
If you are building an AI application, whether a fully custom application or a vendor-provided hosted or SaaS application, Cloudflare can help you deploy, store, control/observe, and protect your AI application from threats.
Build & deploy: Workers AI and our new AI Agents SDK facilitates the scalable development & deployment of AI applications on Cloudflare’s network. Cloudflare’s network enhances user experience and efficiency by running AI closer to users, resulting in low-latency and high-performance AI applications. Customers are also using Cloudflare’s R2 to store their AI training data with zero egress fees, in order to develop the next-gen AI models.
We are continually investing in not only our serverless AI inference infrastructure across the globe, but also in making Cloudflare the best place to build AI Agents. Cloudflare’s composable AI architecture has all the primitives that enable AI applications to have real time communications, persist state, execute long-running tasks, and repeat them on a schedule.
Protect and control: Once your application is deployed, be it directly on Cloudflare, using Workers AI, or running on your own infrastructure (cloud or on premise), Cloudflare’s AI Gateway lets you gain visibility into the cost, usage, latency, and overall performance of the application.
Additionally, Firewall for AI lets you layer security on top by automatically ensuring every prompt is clean from injection, and that personally identifiable information (PII) is neither submitted to nor (coming soon) extracted from, the application.
For security teams
Security teams have a growing new challenge: ensure AI applications are used securely, both in regard to internal usage by employees, as well as by users of externally-facing AI applications the business is responsible for. Ensuring PII data is handled correctly is also a growing major concern for CISOs.
Discover applications: You can’t protect what you don’t know about. Firewall for AI’s discovery capability lets security teams find AI applications that are being used within the organization without the need to perform extensive surveys.
Control PII flow and access: Once discovered, via Firewall for AI or other means, security teams can leverage Zero Trust Network Access (ZTNA) to ensure only authorized employees are accessing the correct applications. Additionally, using Firewall for AI, they can ensure that, even if authorised, neither employees nor potentially external users, are submitting or extracting personally identifiable information (PII) to/from the application.
Protect against exploits: Malicious users are targeting AI applications with novel attack vectors, as these applications are often connected to internal data stores. With Firewall for AI and the broader Application Security portfolio, you can protect against a wide number of exploits highlighted in the OWASP Top 10 for LLM applications, including, but not limited to, prompt injection, sensitive information disclosure, and improper output handling.
Safeguarding conversations: With Llama Guard integrated into both AI Gateway and Firewall for AI, you can ensure both input and output of your AI application is not toxic, and follows topic and sentiment rules based on your internal business policies.
Observe who is accessing your content: With our AI Audit dashboard, you gain visibility (who, what, where and when) into the AI platforms crawling your site to retrieve content to use for AI training data. We are constantly classifying and adding new vendors as they create new crawlers.
Block access: If AI crawlers do not follow robots.txt or other relevant standards, or are potentially unwanted, you can block access outright. We’ve provided a simple “one click” button for customers using Cloudflare on our self-serve plans to protect their website. Larger organizations can build fine tune rules using our Bot Management solution allowing them to target individual bots and create custom filters with ease.
Cloudflare for AI: making AI security simple
If you are using Cloudflare already, or the deployment and security of AI applications is top of mind, reach out, and we can help guide you through our suite of AI tools to find the one that matches your needs.
Ensuring AI is scalable, safe and resilient, is a natural extension of Cloudflare’s mission, given so much of our success relies on a safe Internet.
Imagine building an LLM-powered assistant trained on your developer documentation and some internal guides to quickly help customers, reduce support workload, and improve user experience. Sounds great, right? But what if sensitive data, such as employee details or internal discussions, is included in the data used to train the LLM? Attackers could manipulate the assistant into exposing sensitive data or exploit it for social engineering attacks, where they deceive individuals or systems into revealing confidential details, or use it for targeted phishing attacks. Suddenly, your helpful AI tool turns into a serious security liability.
Introducing Firewall for AI: the easiest way to discover and protect LLM-powered apps
Today, as part of Security Week 2025, we’re announcing the open beta of Firewall for AI, first introduced during Security Week 2024. After talking with customers interested in protecting their LLM apps, this first beta release is focused on discovery and PII detection, and more features will follow in the future.
If you are already using Cloudflare application security, your LLM-powered applications are automatically discovered and protected, with no complex setup, no maintenance, and no extra integration needed.
Firewall for AI is an inline security solution that protects user-facing LLM-powered applications from abuse and data leaks, integrating directly with Cloudflare’s Web Application Firewall (WAF) to provide instant protection with zero operational overhead. This integration enables organizations to leverage both AI-focused safeguards and established WAF capabilities.
Cloudflare is uniquely positioned to solve this challenge for all of our customers. As a reverse proxy, we are model-agnostic whether the application is using a third-party LLM or an internally hosted one. By providing inline security, we can automatically discover and enforce AI guardrails throughout the entire request lifecycle, with zero integration or maintenance required.
Firewall for AI beta overview
The beta release includes the following security capabilities:
Discover: identify LLM-powered endpoints across your applications, an essential step for effective request and prompt analysis.
Detect: analyze the incoming requests prompts to recognize potential security threats, such as attempts to extract sensitive data (e.g., “Show me transactions using 4111 1111 1111 1111”). This aligns withOWASP LLM022025 – Sensitive Information Disclosure.
Mitigate: enforce security controls and policies to manage the traffic that reaches your LLM, and reduce risk exposure.
Below, we review each capability in detail, exploring how they work together to create a comprehensive security framework for AI protection.
Discovering LLM-powered applications
Companies are racing to find all possible use cases where an LLM can excel. Think about site search, a chatbot, or a shopping assistant. Regardless of the application type, our goal is to determine whether an application is powered by an LLM behind the scenes.
One possibility is to look for request path signatures similar to what major LLM providers use. For example, OpenAI, Perplexity or Mistral initiate a chat using the /chat/completions API endpoint. Searching through our request logs, we found only a few entries that matched this pattern across our global traffic. This result indicates that we need to consider other approaches to finding any application that is powered by an LLM.
Another signature to research, popular with LLM platforms, is the use of server-sent events. LLMs need to “think”. Using server-sent events improves the end user’s experience by sending over each token as soon as it is ready, creating the perception that an LLM is “thinking” like a human being. Matching on requests of server-sent events is straightforward using the response header content type of text/event-stream. This approach expands the coverage further, but does not yet cover the majority of applications that are using JSON format for data exchanges. Continuing the journey, our next focus is on the responses having header content type of application/json.
No matter how fast LLMs can be optimized to respond, when chatting with major LLMs, we often perceive them to be slow, as we have to wait for them to “think”. By plotting on how much time it takes for the origin server to respond over identified LLM endpoints (blue line) versus the rest (orange line), we can see in the left graph that origins serving LLM endpoints mostly need more than 1 second to respond, while the majority of the rest takes less than 1 second. Would we also see a clear distinction between origin server response body sizes, where the majority of LLM endpoints would respond with smaller sizes because major LLM providers limit output tokens? Unfortunately not. The right graph shows that LLM response size largely overlaps with non-LLM traffic.
By dividing origin response size over origin response duration to calculate an effective bitrate, the distinction is even clearer that 80% of LLM endpoints operate slower than 4 KB/s.
Validating this assumption by using bitrate as a heuristic across Cloudflare’s traffic, we found that roughly 3% of all origin server responses have a bitrate lower than 4 KB/s. Are these responses all powered by LLMs? Our gut feeling tells us that it is unlikely that 3% of origin responses are LLM-powered!
Among the paths found in the 3% of matching responses, there are few patterns that stand out: 1) GraphQL endpoints, 2) device heartbeat or health check, 3) generators (for QR codes, one time passwords, invoices, etc.). Noticing this gave us the idea to filter out endpoints that have a low variance of response size over time — for instance, invoice generation is mostly based on the same template, while conversations in the LLM context have a higher variance.
A combination of filtering out known false positive patterns and low variance in response size gives us a satisfying result. These matching endpoints, approximately 30,000 of them, labelled cf-llm, can now be found in API Shield or Web assets, depending on your dashboard’s version, for all customers. Now you can review your endpoints and decide how to best protect them.
Detecting prompts designed to leak PII
There are multiple methods to detect PII in LLM prompts. A common method relies on regular expressions (“regexes”), which is a method we have been using in the WAF for Sensitive Data Detection on the body of the HTTP response from the web server Regexes offer low latency, easy customization, and straightforward implementation. However, regexes alone have limitations when applied to LLM prompts. They require frequent updates to maintain accuracy, and may struggle with more complex or implicit PII, where the information is spread across text rather than a fixed format.
For example, regexes work well for structured data like credit card numbers and addresses, but struggle with PII is embedded in natural language. For instance, “I just booked a flight using my Chase card, ending in 1111” wouldn’t trigger a regex match as it lacks the expected pattern, even though it reveals a partial credit card number and financial institution.
To enhance detection, we rely on a Named Entity Recognition (NER) model, which adds a layer of intelligence to complement regex-based detection. NER models analyze text to identify contextual PII data types, such as names, phone numbers, email addresses, and credit card numbers, making detection more flexible and accurate. Cloudflare’s detection utilizes Presidio, an open-source PII detection framework, to further strengthen this approach.
Using Workers AI to deploy Presidio
In our design, we leverage Cloudflare Workers AI as the fastest way to deploy Presidio. This integration allows us to process LLM app requests inline, ensuring that sensitive data is flagged before it reaches the model.
Here’s how it works:
When Firewall for AI is enabled on an application and an end user sends a request to an LLM-powered application, we pass the request to Cloudflare Workers AI which runs the request through Presidio’s NER-based detection model to identify any potential PII from the available entities. The output includes metadata like “Was PII found?” and “What type of PII entity?”. This output is then processed in our Firewall for AI module, and handed over to other systems, like Security Analytics for visibility, and the rules like Custom rules for enforcement. Custom rules allow customers to take appropriate actions on the requests based on the provided metadata.
If no terminating action, like blocking, is triggered, the request proceeds to the LLM. Otherwise, it gets blocked or the appropriate action is applied before reaching the origin.
Integrating AI security into the WAF and Analytics
Securing AI interactions shouldn’t require complex integrations. Firewall for AI is seamlessly built into Cloudflare’s WAF, allowing customers to enforce security policies before prompts reach LLM endpoints. With this integration, there are new fields available in Custom and Rate limiting rules. The rules can be used to take immediate action, such as blocking or logging risky prompts in real time.
For example, security teams can filter LLM traffic to analyze requests containing PII-related prompts. Using Cloudflare’s WAF rules engine, they can create custom security policies tailored to their AI applications.
Here’s what a rule to block detected PII prompts looks like:
Alternatively, if an organization wants to allow certain PII categories, such as location data, they can create an exception rule:
In addition to the rules, users can gain visibility into LLM interactions, detect potential risks, and enforce security controls using Security Analytics and Security Events. You can find more details in our documentation.
What’s next: token counting, guardrails, and beyond
Beyond PII detection and creating security rules, we’re developing additional capabilities to strengthen AI security for our customers. The next feature we’ll release is token counting, which analyzes prompt structure and length. Customers can use the token count field in Rate Limiting and WAF Custom rules to prevent their users from sending very long prompts, which can impact third party model bills, or allow users to abuse the models. This will be followed by using AI to detect and allow content moderation, which will provide more flexibility in building guardrails in the rules.
If you’re an enterprise customer, join the Firewall for AI beta today! Contact your customer team to start monitoring traffic, building protection rules, and taking control of your LLM traffic.
Today, one of the greatest challenges that cyber defenders face is analyzing detection hits from indicator feeds, which provide metadata about specific indicators of compromise (IOCs), like IP addresses, ASNs, domains, URLs, and hashes. While indicator feeds have proliferated across the threat intelligence industry, most feeds contain no contextual information about why an indicator was placed on the feed. Another limitation of most feeds today is that they focus solely on blockable indicators and cannot easily accommodate more complex cases, such as a threat actor exploiting a CVE or an insider threat. Instead, this sort of complex threat intelligence is left for long form reporting. However, long-form reporting comes with its own challenges, such as the time required for writing and editing, which can lead to significant delays in releasing timely threat intelligence.
To help address these challenges, we are excited to launch our threat events platform for Cloudforce One customers. Every day, Cloudflare blocks billions of cyber threats. This new platform contains contextual data about the threats we monitor and mitigate on the Cloudflare network and is designed to empower security practitioners and decision makers with actionable insights from a global perspective.
On average, we process 71 million HTTP requests per second and 44 million DNS queries per second. This volume of traffic provides us with valuable insights and a comprehensive view of current (real-time) threats. The new threat events platform leverages the insights from this traffic to offer a comprehensive, real-time view of threat activity occurring on the Internet, enabling Cloudforce One customers to better protect their assets and respond to emerging threats.
How we built the threat events platform leveraging Cloudflare’s traffic insights
The sheer volume of threat activity observed across Cloudflare’s network would overwhelm any system or SOC analyst. So instead, we curate this activity into a stream of events that include not only indicators of compromise (IOCs) but also context, making it easier to take action based on Cloudflare’s unique data. To start off, we expose events related to denial of service (DOS) attacks observed across our network, along with the advanced threat operations tracked by our Cloudforce One Intelligence team, like the various tools, techniques, and procedures used by the threat actors we are tracking. We mapped the events to the MITRE ATT&CK framework and to the cyber kill chain stages. In the future, we will add events related to traffic blocked by our Web Application Firewall (WAF), Zero Trust Gateway, Zero Trust Email Security Business Email Compromise, and many other Cloudflare-proprietary datasets. Together, these events will provide our customers with a detailed view of threat activity occurring across the Internet.
Each event in our threat events summarizes specific threat activity we have observed, similar to a STIX2 sighting object and provides contextual information in its summary, detailed view and via the mapping to the MITRE ATT&Ck and KillChain stages. For an example entry, please see the API documentation.
Our goal is to empower customers to better understand the threat landscape by providing key information that allows them to investigate and address both broad and specific questions about threats targeting their organization. For example:
Who is targeting my industry vertical?
Who is targeting my country?
What indicators can I use to block attacks targeting my verticals?
What has an adversary done across the kill chain over some period of time?
Each event has a unique identifier that links it to the identified threat activity, enabling our Cloudforce One threat intelligence analysts to provide additional context in follow-on investigations.
How we built the threat events platform using Cloudflare Workers
We chose to use the Cloudflare Developer Platform to build out the threat events platform, as it allowed us to leverage the versatility and seamless integration of Cloudflare Workers. At its core, the platform is a Cloudflare Worker that uses SQLite-backed Durable Objects to store events observed on the Cloudflare network. We opted to use Durable Objects over D1, Cloudflare’s serverless SQL database solution, because it permits us to dynamically create SQL tables to store uniquely customizable datasets. Storing datasets this way allows threat events to scale across our network, so we are resilient to surges in data that might correlate with the unpredictable nature of attacks on the Internet. It also permits us to control events by data source, share a subset of datasets with trusted partners, or restrict access to only authorized users. Lastly, the metadata for each individual threat event is stored in the Durable Object KV so that we may store contextual data beyond our fixed, searchable fields. This data may be in the form of requests-per-second for our denial of service events, or sourcing information so Cloudforce One analysts can tie the event to the exact threat activity for further investigation.
How to use threat events
Cloudforce One customers can access threat events through the Cloudflare Dashboard in Security Center or via the Cloudforce One threat events API. Each exposes the stream of threat activity occurring across the Internet as seen by Cloudflare, and are customizable by user-defined filters.
In the Cloudflare Dashboard, users have access to an Attacker Timelapse view, designed to answer strategic questions, as well as a more granular events table for drilling down into attack details. This approach ensures that users have the most relevant information at their fingertips.
Events Table
The events table is a detailed view in the Security Center where users can drill down into specific threat activity filtered by various criteria. It is here that users can explore specific threat events and adversary campaigns using Cloudflare’s traffic insights. Most importantly, this table will provide our users with actionable Indicators of Compromise and an event summary so that they can properly defend their services. All of the data available in our events table is equally accessible via the Cloudforce One threat events API.
To showcase the power of threat events, let’s explore a real-world case:
Recently leaked chats of the Black Basta criminal enterprise exposed details about their victims, methods, and infrastructure purchases. Although we can’t confirm whether the leaked chats were manipulated in any way, the infrastructure discussed in the chats was simple to verify. As a result, this threat intelligence is now available as events in the threat events, along with additional unique Cloudflare context.
Analysts searching for domains, hosts, and file samples used by Black Basta can leverage the threat events to gain valuable insight into this threat actor’s operations. For example, in the threat events UI, a user can filter the “Attacker” column by selecting ‘BlackBasta’ in the dropdown, as shown in the image below. This provides a curated list of verified IP addresses, domains, and file hashes for further investigation. For more detailed information on Cloudflare’s unique visibility into Black Basta threat activity see Black Basta’s blunder: exploiting the gang’s leaked chats.
Why we are publishing threat events
Our customers face a myriad of cyber threats that can disrupt operations and compromise sensitive data. As adversaries become increasingly sophisticated, the need for timely and relevant threat intelligence has never been more critical. This is why we are introducing threat events, which provides deeper insights into these threats.
The threat events platform aims to fill this gap by offering a more detailed and contextualized view of ongoing threat activity. This feature allows analysts to self-serve and explore incidents through customizable filters, enabling them to identify patterns and respond effectively. By providing access to real-time threat data, we empower organizations to make informed decisions about their security strategies.
To validate the value of our threat events platform, we had a Fortune 20 threat intelligence team put it to the test. They conducted an analysis against 110 other sources, and we ranked as their #1 threat intelligence source. They found us “very much a unicorn” in the threat intelligence space. It’s early days, but the initial feedback confirms that our intelligence is not only unique but also delivering exceptional value to defenders.
What’s next
While Cloudforce One customers now have access to our API and dashboard, allowing for seamless integration of threat intelligence into their existing systems, they will also soon have access to more visualisations and analytics for the threat events in order to better understand and report back on their findings. This upcoming UI will include enhanced visualizations of attacker timelines, campaign overviews, and attack graphs, providing even deeper insights into the threats facing your organization. Moreover, we’ll add the ability to integrate with existing SIEM platforms and share indicators across systems.
Read more about the threat intelligence research our team publishes here or reach out to your account team about how to leverage our new threat events to enhance your cybersecurity posture.
In today’s fast-paced digital landscape, companies are managing an increasingly complex mix of environments — from SaaS applications and public cloud platforms to on-prem data centers and hybrid setups. This diverse infrastructure offers flexibility and scalability, but also opens up new attack surfaces.
To support both business continuity and security needs, “security must evolve from being reactive to predictive”. Maintaining a healthy security posture entails monitoring and strengthening your security defenses to identify risks, ensure compliance, and protect against evolving threats. With our newest capabilities, you can now use Cloudflare to achieve a healthy posture across your SaaS and web applications. This addresses any security team’s ultimate (daily) question: How well are our assets and documents protected?
A predictive security posture relies on the following key components:
Real-time discovery and inventory of all your assets and documents
Continuous asset-aware threat detection and risk assessment
Prioritised remediation suggestions to increase your protection
Today, we are sharing how we have built these key components across SaaS and web applications, and how you can use them to manage your business’s security posture.
Your security posture at a glance
Regardless of the applications you have connected to Cloudflare’s global network, Cloudflare actively scans for risks and misconfigurations associated with each one of them on a regular cadence. Identified risks and misconfigurations are surfaced in the dashboard under Security Center as insights.
Insights are grouped by their severity, type of risks, and corresponding Cloudflare solution, providing various angles for you to zoom in to what you want to focus on. When applicable, a one-click resolution is provided for selected insight types, such as setting minimum TLS version to 1.2 which is recommended by PCI DSS. This simplicity is highly appreciated by customers that are managing a growing set of assets being deployed across the organization.
To help shorten the time to resolution even further, we have recently added role-based access control (RBAC) to Security Insights in the Cloudflare dashboard. Now for individual security practitioners, they have access to a distilled view of the insights that are relevant for their role. A user with an administrator role (a CSO, for example) has access to, and visibility into, all insights.
In addition to account-wide Security Insights, we also provide posture overviews that are closer to the corresponding security configurations of your SaaS and web applications. Let’s dive into each of them.
Securing your SaaS applications
Without centralized posture management, SaaS applications can feel like the security wild west. They contain a wealth of sensitive information – files, databases, workspaces, designs, invoices, or anything your company needs to operate, but control is limited to the vendor’s settings, leaving you with less visibility and fewer customization options. Moreover, team members are constantly creating, updating, and deleting content that can cause configuration drift and data exposure, such as sharing files publicly, adding PII to non-compliant databases, or giving access to third party integrations. With Cloudflare, you have visibility across your SaaS application fleet in one dashboard.
Posture findings across your SaaS fleet
From the account-wide Security Insights, you can review insights for potential SaaS security issues:
You can choose to dig further with Cloud Access Security Broker (CASB) for a thorough review of the misconfigurations, risks, and failures to meet best practices across your SaaS fleet. You can identify a wealth of security information including, but not limited to:
Publicly available or externally shared files
Third-party applications with read or edit access
Unknown or anonymous user access
Databases with exposed credentials
Users without two-factor authentication
Inactive user accounts
You can also explore the Posture Findings page, which provides easy searching and navigation across documents that are stored within the SaaS applications.
Additionally, you can create policies to prevent configuration drift in your environment. Prevention-based policies help maintain a secure configuration and compliance standards, while reducing alert fatigue for Security Operations teams, and these policies can prevent the inappropriate movement or exfiltration of sensitive data. Unifying controls and visibility across environments makes it easier to lock down regulated data classes, maintain detailed audit trails via logs, and improve your security posture to reduce the risk of breaches.
How it works: new, real-time SaaS documents discovery
Delivering SaaS security posture information to our customers requires collecting vast amounts of data from a wide range of platforms. In order to ensure that all the documents living in your SaaS apps (files, designs, etc.) are secure, we need to collect information about their configuration — are they publicly shared, do third-party apps have access, is multi-factor authentication (MFA) enabled?
We previously did this with crawlers, which would pull data from the SaaS APIs. However, we were plagued with rate limits from the SaaS vendors when working with larger datasets. This forced us to work in batches and ramp scanning up and down as the vendors permitted. This led to stale findings and would make remediation cumbersome and unclear – for example, Cloudflare would be reporting that a file is still shared publicly for a short period after the permissions were removed, leading to customer confusion.
To fix this, we upgraded our data collection pipeline to be dynamic and real-time, reacting to changes in your environment as they occur, whether it’s a new security finding, an updated asset, or a critical alert from a vendor. We started with our Microsoft asset discovery and posture findings, providing you real-time insight into your Microsoft Admin Center, OneDrive, Outlook, and SharePoint configurations. We will be rapidly expanding support to additional SaaS vendors going forward.
Listening for update events from Cloudflare Workers
Cloudflare Workers serve as the entry point for vendor webhooks, handling asset change notifications from external services. The workflow unfolds as follows:
Webhook listener: An initial Worker acts as the webhook listener, receiving asset change messages from vendors.
Data storage & queuing: Upon receiving a message, the Worker uploads the raw payload of the change notification to Cloudflare R2 for persistence, and publishes it to a Cloudflare Queue dedicated to raw asset changes.
Transformation Worker: A second Worker, bound as a consumer to the raw asset change queue, processes the incoming messages. This Worker transforms the raw vendor-specific data into a generic format suitable for CASB. The transformed data is then:
Stored in Cloudflare R2 for future reference.
Published on another Cloudflare Queue, designated for transformed messages.
CASB Processing: Consumers & Crawlers
Once the transformed messages reach the CASB layer, they undergo further processing:
Polling consumer: CASB has a consumer that polls the transformed message queue. Upon receiving a message, it determines the relevant handler required for processing.
Crawler execution: The handler then maps the message to an appropriate crawler, which interacts with the vendor API to fetch the most up-to-date asset details.
Data storage: The retrieved asset data is stored in the CASB database, ensuring it is accessible for security and compliance checks.
With this improvement, we are now processing 10 to 20 Microsoft updates per second, or 864,000 to 1.72 million updates daily, giving customers incredibly fast visibility into their environment. Look out for expansion to other SaaS vendors in the coming months.
Securing your web applications
A unique challenge of securing web applications is that no one size fits all. An asset-aware posture management bridges the gap between a universal security solution and unique business needs, offering tailored recommendations for security teams to protect what matters.
Posture overview from attacks to threats and risks
Starting today, all Cloudflare customers have access to Security Overview, a new landing page customized for each of your onboarded domains. This page aggregates and prioritizes security suggestions across all your web applications:
Any (ongoing) attacks detected that require immediate attention
Disposition (mitigated, served by Cloudflare, served by origin) of all proxied traffic over the last 7 days
Summary of currently active security modules that are detecting threats
Suggestions of how to improve your security posture with a step-by-step guide
And a glimpse of your most active and lately updated security rules
These tailored security suggestions are surfaced based on your traffic profile and business needs, which is made possible by discovering your proxied web assets.
Discovery of web assets
Many web applications, regardless of their industry or use case, require similar functionality: user identification, accepting payment information, etc. By discovering the assets serving this functionality, we can build and run targeted threat detection to protect them in depth.
As an example, bot traffic towards marketing pages versus login pages have different business impacts. Content scraping may be happening targeting your marketing materials, which you may or may not want to allow, while credential stuffing on your login page deserves immediate attention.
Web assets are described by a list of endpoints; and labelling each of them defines their business goals. A simple example can be POST requests to path /portal/login, which likely describes an API for user authentication. While the GET requests to path /portal/login denote the actual login webpage.
To describe business goals of endpoints, labels come into play. POST requests to the /portal/login endpoint serving end users and to the /api/admin/login endpoint used by employees can both can be labelled using the same cf-log-inmanaged label, letting Cloudflare know that usernames and passwords would be expected to be sent to these endpoints.
API Shield customers can already make use of endpoint labelling. In early Q2 2025, we are adding label discovery and suggestion capabilities, starting with three labels, cf-log-in, cf-sign-up, and cf-rss-feed. All other customers can manually add these labels to the saved endpoints. One example, explained below, is preventing disposable emails from being used during sign-ups.
Always-on threat detection and risk assessment
Use-case driven threat detection
Customers told us that, with the growing excitement around generative AI, they need support to secure this new technology while not hindering innovation. Being able to discover LLM-powered services allows fine-tuning security controls that are relevant for this particular technology, such as inspecting prompts, limit prompting rates based on token usage, etc. In a separate Security Week blog post, we will share how we build Cloudflare Firewall for AI, and how you can easily protect your generative AI workloads.
Account fraud detection, which encompasses multiple attack vectors, is another key area that we are focusing on in 2025.
On many login and signup pages, a CAPTCHA solution is commonly used to only allow human beings through, assuming only bots perform undesirable actions. Put aside that most visual CAPTCHA puzzles can be easily solved by AI nowadays, such an approach cannot effectively solve the root cause of most account fraud vectors. For example, human beings using disposable emails to sign up single-use accounts to take advantage of signup promotions.
To solve this fraudulent sign up issue, a security rule currently under development could be deployed as below to block all attempts that use disposable emails as a user identifier, regardless of whether the requester was automated or not. All existing or future cf-log-in and cf-sign-up labelled endpoints are protected by this single rule, as they both require user identification.
Our fast expanding use-case driven threat detections are all running by default, from the first moment you onboarded your traffic to Cloudflare. The instant available detection results can be reviewed through security analytics, helping you make swift informed decisions.
API endpoint risk assessment
APIs have their own set of risks and vulnerabilities, and today Cloudflare is delivering seven new risk scans through API Posture Management. This new capability of API Shield helps reduce risk by identifying security issues and fixing them early, before APIs are attacked. Because APIs are typically made up of many different backend services, security teams need to pinpoint which backend service is vulnerable so that development teams may remediate the identified issues.
Our new API posture management risk scans do exactly that: users can quickly identify which API endpoints are at risk to a number of vulnerabilities, including sensitive data exposure, authentication status, Broken Object Level Authorization (BOLA) attacks, and more.
Authentication Posture is one risk scan you’ll see in the new system. We focused on it to start with because sensitive data is at risk when API authentication is assumed to be enforced but is actually broken. Authentication Posture helps customers identify authentication misconfigurations for APIs and alerts of their presence. This is achieved by scanning for successful requests against the API and noting their authentication status. API Shield scans traffic daily and labels API endpoints that have missing and mixed authentication for further review.
For customers that have configured session IDs in API Shield, you can find the new risk scan labels and authentication details per endpoint in API Shield. Security teams can take this detail to their development teams to fix the broken authentication.
We’re launching today with scans for authentication posture, sensitive data, underprotected APIs, BOLA attacks, and anomaly scanning for API performance across errors, latency, and response size.
Simplify maintaining a good security posture with Cloudflare
Achieving a good security posture in a fast-moving environment requires innovative solutions that can transform complexity into simplicity. Bringing together the ability to continuously assess threats and risks across both public and private IT environments through a single platform is our first step in supporting our customers’ efforts to maintain a healthy security posture.
To further enhance the relevance of security insights and suggestions provided and help you better prioritize your actions, we are looking into integrating Cloudflare’s global view of threat landscapes. With this, you gain additional perspectives, such as what the biggest threats to your industry are, and what attackers are targeting at the current moment. Stay tuned for more updates later this year.
If you haven’t done so yet, onboard your SaaS and web applications to Cloudflare today to gain instant insights into how to improve your business’s security posture.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.