Post Syndicated from Kari Rivas original https://www.backblaze.com/blog/the-truth-about-cloud-security-costs-why-high-costs-dont-always-mean-better-protection/

When evaluating cloud providers, cost is often the most visible factor—but in enterprise IT, information security (InfoSec), and compliance, security is always the first (and likely most important) concern. As a technology leader, you know that determining “acceptable” risk is a moving target, but you’re likely also regularly squeezed by budget pressures and a mandate to contribute to the company’s bottom line.
Taking a chance on providers with lower price tags might feel like too big of a risk—lower-cost providers must be sacrificing something, and all too often, that something is security. Right?
It’s a fair question, but the answer might surprise you. Today, we’re talking about how specialized cloud providers provide surprising value—and even provide security benefits—when compared with traditional, hyperscaler architectures. Let’s talk about what you need to know to evaluate a cloud provider’s security posture.
Want to hear from the experts?
Join our upcoming session to hear from Backblaze experts Troy Liljedahl, Sr. Director, Solutions Engineering, and Pat Patterson, Chief Technical Evangelist, about the knowledge and features you need to stay ahead of modern threats.
Join us to learn:
- Foundational controls: Master the best practices for using encryption, Object Lock, access keys, role-based access controls, and more to build a solid defense.
- Advanced threat detection: Get an exclusive look at Backblaze’s new feature, Anomaly Alerts, which helps detect irregular and potentially suspicious data access patterns.
- A unified approach: Understand how to integrate these powerful features to create a strong, easy-to-manage security strategy.

How specialized cloud providers provide security benefits
In theory, cloud architecture encourages redundancy. But in practice, many companies—even those using multi-cloud strategies—tend to consolidate key services like authentication and orchestration with a single vendor. When that vendor’s services go down, it doesn’t matter that your data is replicated across three availability zones in the same data center. If you can’t log in to access it, your redundancy becomes purely theoretical. This year alone, there have been major outages that had widespread consequences from the likes of Google, IBM cloud, and others.
Specialized cloud providers and multi-cloud strategies provide inherent benefits here.
- Vendor transparency: Open cloud providers publish clear, detailed practices around architecture, encryption, and compliance rather than burying them behind opaque marketing claims. This transparency allows your teams to independently validate security assurances.
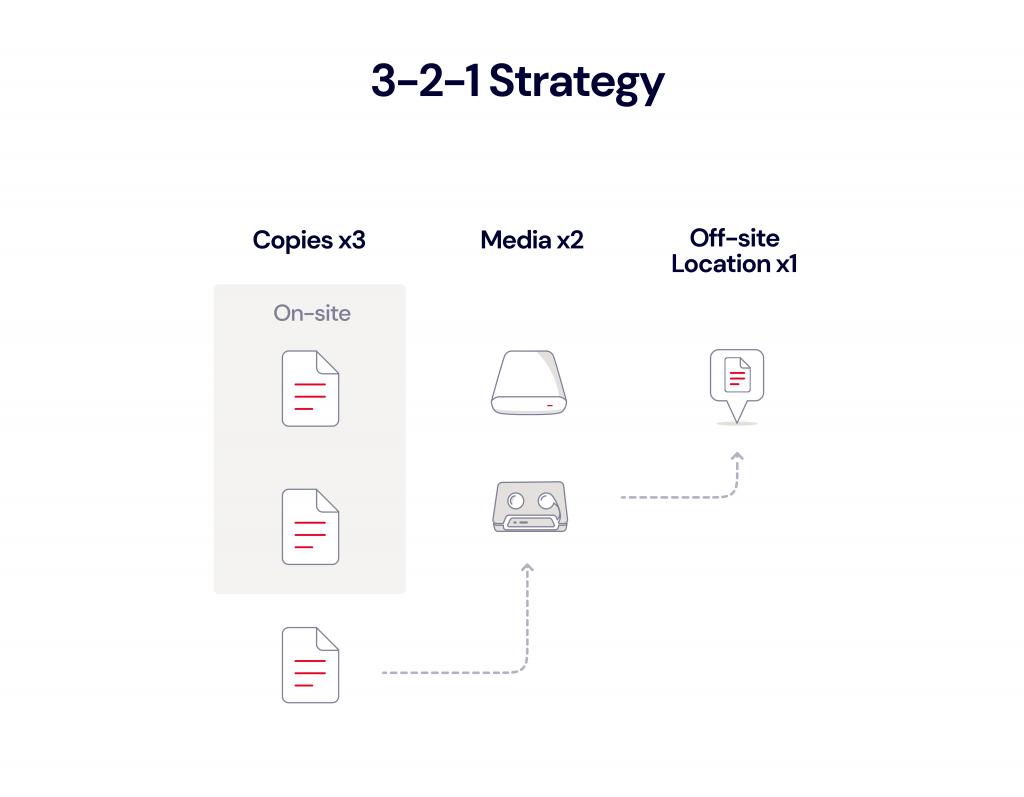
- Avoiding lock-in: Multi-cloud strategies ensure you’re not beholden to a single vendor’s security practices. If one provider falls short, data replication and redundancy across platforms can maintain both compliance and resilience.
- Risk distribution: By spreading workloads across providers, organizations mitigate the risk of a single point of failure, outage, or vendor breach.
- Compliance flexibility: Different providers may align more strongly with specific frameworks (SOC 2, HIPAA, GDPR, etc.), giving enterprises options to meet evolving regulatory demands.
This means that organizations don’t have to choose between cost efficiency and security—they can and should get both.
How to evaluate a cloud provider’s security posture
Choosing the right cloud provider isn’t just about price, features, or performance—it’s about knowing they can safeguard your data and prove it. Here are key areas to assess:
- Architecture & physical security
- Does the provider operate its own infrastructure or rely on generic colocation facilities?
- What physical safeguards (biometrics, restricted access, surveillance) protect the data centers?
- Encryption & data protection
- Is data encrypted both in transit (TLS/SSL) and at rest (AES-256 or equivalent)?
- Are key management options available, including customer-managed keys?
- Is immutability (Object Lock or write once, read many (WORM) storage) supported for ransomware defense?
- Access & identity controls
- Are granular permissioning and role-based access (RBAC) controls available?
- Does the provider support single sign on (SSO), multi-factor authentication (MFA), and integration with enterprise identity systems?
- Can admins maintain clear audit logs of all access and changes?
- Compliance & certifications
- Which third-party attestations does the provider maintain (SOC 2, HIPAA, PCI-DSS, GDPR, ISO)?
- Can they provide signed agreements (such as Business Associate Agreements (BAAs)) as needed for regulated industries?
- Resilience & multi-cloud strategy
- Do they offer replication across regions or the ability to integrate into a multi-cloud strategy?
- How quickly can you move workloads or data out if you need to change vendors or access data in case of emergency?
By using this evaluation framework, IT leaders can look past marketing promises and price tags, focusing on verifiable controls and independent certifications.
The hyperscaler tax for cloud security
Many enterprises assume that higher cloud storage costs from hyperscalers like AWS, Azure, or Google Cloud translate directly into better security. In reality, much of that premium is a “hyperscaler tax” driven by complex business models, bundled services, and legacy infrastructure—not inherently superior protection. Specialized cloud providers can often deliver the same enterprise-grade security controls—encryption, compliance certifications, access management—without the inflated price tag, proving that security and affordability are not mutually exclusive.
Building a better mousetrap: The innovation behind Backblaze B2
From the beginning, Backblaze has architected its storage solution to be both performant and cost-effective. And, by specializing in storage (as opposed to the myriad of solutions offered by, say, Amazon Web Services and other hyperscalers), Backblaze is able to optimize for the economics of storage and storage alone.
To help you get past the price tag and into the technical details, let’s break down the pillars of Backblaze B2 security and compliance.
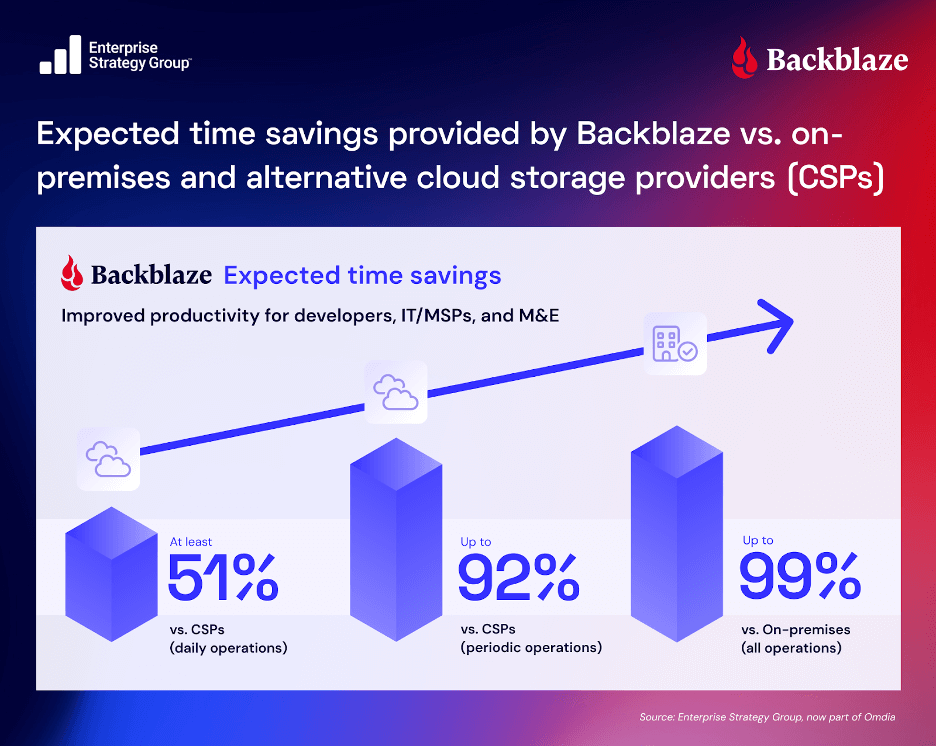
Compliance? We’ve got a visual for that.
Want a quick glance on how Backblaze compares to other cloud storage providers on key security and compliance elements? Check out our comparison matrices.
Architecture and physical security: The foundation of trust
Our security starts with our physical infrastructure. Our data centers are designed for 11 nines of data durability and are staffed 24/7/365. They feature:
- Best-in-class security features: Biometric security, ID checks, and multi-layered access controls.
- A purpose-built infrastructure: From Backblaze Storage Pods to projects like Shard Stash and ongoing feature releases, the Backblaze platform is designed for maximum data durability and security.
This physical and architectural security is the bedrock of our service, and it’s backed by industry-standard certifications like SOC 2 Type 2 certification.
Data storage security: Protecting data at rest and in transit
Data security is a core tenet of our platform. From the moment your data leaves your system until it is stored on our pods, it is protected by multiple layers of encryption.
- Encryption in transit: All files are transmitted to Backblaze B2 using an encrypted TLS connection.
- Encryption at rest: Your data is encrypted before it is stored on disk. We offer two options for server-side encryption with 256-bit Advanced Encryption Standard (AES-256):
- Server-side encryption (SSE) with Backblaze managed keys (SSE-B2): We handle the key management for you, providing seamless, built-in protection.
- SSE with customer managed keys (SSE-C): For organizations with strict compliance requirements, you can manage your own keys, giving you complete control over your data’s access.
- Object Lock for immutability: Our Object Lock feature provides a powerful layer of ransomware protection. Using a write-once, read-many (WORM) model, it prevents files from being modified, manipulated, or deleted for a customer-determined retention period. This is an essential tool for compliance and disaster recovery.
- Cloud Replication: For businesses with high-availability or geographical redundancy requirements, Backblaze B2 supports automatic replication of data across different regions, ensuring your data is always available and safe from regional outages or other incidents.
Access management security: Granting control and ensuring accountability
Controlling who can access your data is paramount. We provide granular, enterprise-grade access management controls that give you full command over your storage:
- Fine-grained API key control: Create and manage accounts, groups, and specific data access permissions with robust API key control.
- Multi-factor authentication (MFA) & single sign-on (SSO): We offer multiple account authentication options, including MFA and SSO via providers like Google Workspace and Office 365, to prevent unauthorized access.
- Comprehensive logging: Backblaze provides detailed logs and reports on all activities within your account, so you can maintain a clear audit trail.
Compliance: Demonstrating our commitment to best practices
Security is not just a feature; it’s a commitment that’s verified by independent third parties. Backblaze has achieved a number of security and compliance attestations, including:
- SOC 2, Type 2: We have been independently audited and certified for SOC 2, Type 2 compliance, demonstrating our commitment to protecting customer data.
- HIPAA: For business customers who are Covered Entities under the Health Insurance Portability and Accountability Act (HIPAA), we can provide a Business Associate Agreement (BAA) upon request.
- PCI-DSS: Backblaze’s adherence to the Payment Card Industry Data Security Standard (PCI-DSS) is supported by our use of Stripe to handle card information and our internal security controls.
- GDPR: We adhere to General Data Protection Regulation (GDPR) privacy policies and provide Data Processing Agreement Addendums (DPAs) for EEA/EU and UK residents.
While some competitors may also offer these certifications, Backblaze’s pricing model is built to ensure you don’t have to pay a premium for them. Our efficiencies mean that we can pass the savings directly to you without compromising on the security and compliance that your business demands.
Specialized cloud storage: Enabling enterprises to evaluate their best options
In the end, our goal is to free you from the false choice between security and affordability. The reality is that the high cost of some cloud providers is a result of their complex, multi-tiered business models—not a reflection of superior security. Backblaze’s commitment to building a focused, innovative, and transparent cloud storage solution allows us to deliver on our promise: enterprise-grade security and compliance, at a fraction of the cost.
The post The Truth About Cloud Security Costs: Why High Costs Don’t Always Mean Better Protection appeared first on Backblaze Blog | Cloud Storage & Cloud Backup