Post Syndicated from Mac Bowley original https://www.raspberrypi.org/blog/helping-young-people-navigate-ai-safely/
AI safety and Experience AI
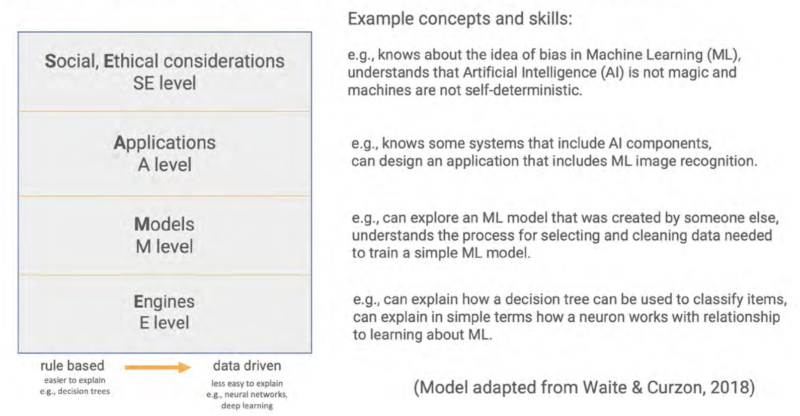
As our lives become increasingly intertwined with AI-powered tools and systems, it’s more important than ever to equip young people with the skills and knowledge they need to engage with AI safely and responsibly. AI literacy isn’t just about understanding the technology — it’s about fostering critical conversations on how to integrate AI tools into our lives while minimising potential harm — otherwise known as ‘AI safety’.

The UK AI Safety Institute defines AI safety as: “The understanding, prevention, and mitigation of harms from AI. These harms could be deliberate or accidental; caused to individuals, groups, organisations, nations or globally; and of many types, including but not limited to physical, psychological, social, or economic harms.”
As a result of this growing need, we’re thrilled to announce the latest addition to our AI literacy programme, Experience AI — ‘AI safety: responsibility, privacy, and security’. Co-developed with Google DeepMind, this comprehensive suite of free resources is designed to empower 11- to 14-year-olds to understand and address the challenges of AI technologies. Whether you’re a teacher, youth leader, or parent, these resources provide everything you need to start the conversation.
Linking old and new topics
AI technologies are providing huge benefits to society, but as they become more prevalent we cannot ignore the challenges AI tools bring with them. Many of the challenges aren’t new, such as concerns over data privacy or misinformation, but AI systems have the potential to amplify these issues.

Our resources use familiar online safety themes — like data privacy and media literacy — and apply AI concepts to start the conversation about how AI systems might change the way we approach our digital lives.
Each session explores a specific area:
- Your data and AI: How data-driven AI systems use data differently to traditional software and why that changes data privacy concerns
- Media literacy in the age of AI: The ease of creating believable, AI-generated content and the importance of verifying information
- Using AI tools responsibly: Encouraging critical thinking about how AI is marketed and understanding personal and developer responsibilities
Each topic is designed to engage young people to consider both their own interactions with AI systems and the ethical responsibilities of developers.
Designed to be flexible
Our AI safety resources have flexibility and ease of delivery at their core, and each session is built around three key components:
- Animations: Each session begins with a concise, engaging video introducing the key AI concept using sound pedagogy — making it easy to deliver and effective. The video then links the AI concept to the online safety topic and opens threads for thought and conversation, which the learners explore through the rest of the activities.
- Unplugged activities: These hands-on, screen-free activities — ranging from role-playing games to thought-provoking challenges — allow learners to engage directly with the topics.
- Discussion questions: Tailored for various settings, these questions help spark meaningful conversations in classrooms, clubs, or at home.
Experience AI has always been about allowing everyone — including those without a technical background or specialism in computer science — to deliver high-quality AI learning experiences, which is why we often use videos to support conceptual learning.

In addition, we want these sessions to be impactful in many different contexts, so we included unplugged activities so that you don’t need a computer room to run them! There is also advice on shortening the activities or splitting them so you can deliver them over two sessions if you want.
The discussion topics provide a time-efficient way of exploring some key implications with learners, which we think will be more effective in smaller groups or more informal settings. They also highlight topics that we feel are important but may not be appropriate for every learner, for example, the rise of inappropriate deepfake images, which you might discuss with a 14-year-old but not an 11-year-old.
A modular approach for all contexts
Our previous resources have all followed a format suitable for delivery in a classroom, but for these resources, we wanted to widen the potential contexts in which they could be used. Instead of prescribing the exact order to deliver them, educators are encouraged to mix and match activities that they feel would be effective for their context.

We hope this will empower anyone, no matter their surroundings, to have meaningful conversations about AI safety with young people.
The modular design ensures maximum flexibility. For example:
- A teacher might combine the video with an unplugged activity and follow-up discussion for a 60-minute lesson
- A club leader could show the video and run a quick activity in a 30-minute session
- A parent might watch the video and use the discussion questions during dinner to explore how generative AI shapes the content their children encounter
The importance of AI safety education
With AI becoming a larger part of daily life, young people need the tools to think critically about its use. From understanding how their data is used to spotting misinformation, these resources are designed to build confidence and critical thinking in an AI-powered world.
AI safety is about empowering young people to be informed consumers of AI tools. By using these resources, you’ll help the next generation not only navigate AI, but shape its future. Dive into our materials, start a conversation, and inspire young minds to think critically about the role of AI in their lives.
Ready to get started? Explore our AI safety resources today: rpf.io/aisafetyblog. Together, we can empower every child to thrive in a digital world.
The post Helping young people navigate AI safely appeared first on Raspberry Pi Foundation.