Post Syndicated from Nick Sullivan original https://blog.cloudflare.com/cloudflare-research-two-years-in/

Great technology companies build innovative products and bring them into the world; iconic technology companies change the nature of the world itself.

Cloudflare’s mission reflects our ambitions: to help build a better Internet. Fulfilling this mission requires a multifaceted approach that includes ongoing product innovation, strategic decision-making, and the audacity to challenge existing assumptions about the structure and potential of the Internet. Two years ago, Cloudflare Research was founded to explore opportunities that leverage fundamental and applied computer science research to help change the playing field.
We’re excited to share five operating principles that guide Cloudflare’s approach to applying research to help build a better Internet and five case studies that exemplify these principles. Cloudflare Research will be all over the blog for the next several days, so subscribe and follow along!
Innovation comes from all places
Innovative companies don’t become innovative by having one group of people within the company dedicated to the future; they become that way by having a culture where new ideas are free-flowing and can come from anyone. Research is most effective when it is permitted to grow beyond or outside isolated lab environments, is deeply integrated into all facets of a company’s work, and connected with the world at large. We think of our research team as a support organization dedicated to identifying and nurturing ideas that are between three and five years away.
Cloudflare Research prioritizes strong collaboration to stay on top of big questions from our product, ETI, engineering teams and industry. Within Cloudflare, we learn about problems by embedding ourselves within other teams. Externally, we invite visiting researchers and academia, sit on boards and committees, contribute to open standards design and development, attend dozens of tech conferences a year, and publish papers in conferences.
Research engineering is truly full-stack. We incubate ideas from conception to prototype through to production code. Our team employs specialists from academic and industry backgrounds and generalists that help connect ideas across disciplines. We work closely with the product and engineering organizations on graduation plans where code ownership is critical. We also hire many research interns who help evaluate and de-risk new ideas before we help build them into production systems and eventually hand them off to other teams at the company.
Research questions can come from all parts of the company and even from customers. Our collaborative approach has led to many positive outcomes for Cloudflare and the Internet at large.
Case Study #1: Password security
Several years ago, a service called Have I Been Pwned, which lets people check if their password has been compromised in a breach, started using Cloudflare to keep the site up and running under load. However, the setup also highlighted a privacy issue: Have I Been Pwned would inevitably have access to every password submitted to the service, making it a juicy target for attackers. This insight raised the question: can such a service be offered in a privacy-preserving way?
Like much of the research team’s work, the kernel of a solution came from somewhere else at the company. The first work on the problem came from members of the support engineering organization, who developed a clever solution that mostly solved the problem. However, this initial investigation outlined a deep and complex problem space that could have applications far beyond passwords. At this point, the research team got involved and reached out to experts, including Thomas Ristenpart at Cornell Tech, to help study it more deeply.
This collaboration led us down a path to devise a new protocol and publish a paper entitled Protocols for Checking Compromised Credentials at ACM CCS 2019. The paper pointed us in a direction, but a desire to take this research and make it applicable to people led us to host our first visiting researcher to help build a prototype. We found even more inspiration and support internally when we learned that another team at Cloudflare was interested in adding capabilities to the Cloudflare Web Application Firewall to detect breached passwords for customers. This team ended up helping us build the prototype and integrate it into Cloudflare’s service.
This combination of customer insight, internal alignment, and external collaboration not only resulted in a powerful and unique customer feature, but it also helped advance the state of the art in privacy-preserving technology for an essential aspect of our online lives: Authentication. We’ll be making an exciting announcement around this technology on Thursday, so stay tuned.
A question-oriented approach leads to better products
To support Cloudflare’s fast-paced roadmap, the Research team takes a question-first approach. Focusing on questions is the essence of research itself, but it’s important to recognize what that means for an industry-leading company. We never stop asking big questions about the problems our products are already solving. Changes like the move from desktop to mobile computing or the transition from on-premise security solutions to the cloud happened within a decade, so it’s important to ask questions like:
- How will social and geopolitical forces changes impact the products we’re building today?
- What assumptions may be present in existing systems based on the homogenous experiences of their creators?
- What changes are happening in the industry that will affect the way the Internet works?
- What opportunities do we see to leverage new and lower-cost hardware?
- How can we scale to meet growing needs?
- Are there new computing paradigms that need to be understood?
- How are user expectations shifting?
- Is there something we can build to help move the Internet in the right direction?
- Which security or privacy risks are likely to be exacerbated in the coming years?
By focusing on broader questions and being open to answers that don’t fit within the boundaries of existing solutions, we have the opportunity to see around corners. This type of foresight helps solve more than business problems; it can help improve products and the Internet at large. These types of questions are asked across the R&D functions of the company, but research focuses on the questions that aren’t easily answered in the short-term.
Case Study #2: SSL/TLS Recommender
When Cloudflare made SSL certificates free and automatic for all customers, it was a big step towards securing the web. One of the early criticisms of Cloudflare’s SSL offerings was the so-called “mullet” critique. Cloudflare offers a mode called “Flexible SSL,” which enables encryption between the browser and Cloudflare but keeps the connection between Cloudflare and the origin site unencrypted for backward compatibility. It’s called the mullet criticism because Flexible SSL provides encryption on the front half of the connection but none on the back half.
Most security risks for online communication occur between the user and Cloudflare (at the ISP or in the coffee shop, for example), not between Cloudflare and the origin server. The customers who couldn’t enable encryption on their servers had a much better security posture with Cloudflare.
In a few isolated instances, however, a customer did not take advantage of the most secure configuration possible, which resulted in unexpected and impactful security problems. Given the non-zero risk and acknowledging this valid product critique, we asked: what could we do to improve the security posture of millions of websites?
With the help of research interns with Internet scanning and measurement expertise, we built an advanced scanning/crawling tool to see how much things could be improved. It turned out we could do a lot, so we worked with various teams across the company to connect our scanning infrastructure to Cloudflare’s product. We now offer a service to all customers called the SSL/TLS recommender that has helped thousands of customers secure their sites and trim their mullets. The underlying reason that websites don’t use encryption for parts of their backends is complex, and what makes this project a good example of asking questions in a pragmatic way is that it not only gives Cloudflare an improved product, but it gives researcher set of tools to further explore the fundamental problem.
Build the tools today to deal with the issues of tomorrow
Another critical objective of research in the Cloudflare context is to help us prepare for the unknown. We identify and solve “what-if” scenarios based on how society is changing or may change. Thousands of companies rely on our infrastructure to serve their users and meet their business needs. We are continually improving their experience by future-proofing the technology that supports them during the best of times and the potential worst of times.
To prepare, we:
- Identify areas of future risk.
- Explore the fundamentals of the problem.
- Build expertise and validate that expertise in peer-reviewed venues.
- Build operating experience with prototypes and large-scale experiments.
- Build networks of relationships with those who can help in a crisis.
We would like to emulate the strategic thinking and planning required of the often unseen groups that support society — like the forestry service or a public health department. When the fire hits or the next virus arrives, we have the best chance to not only get through it but to innovate and flourish because of the mitigations put in place and the relationships built while thinking through impending challenges.
Case Study #3: IP Address Agility
One area of impending risk for the Internet is the exhaustion of IPv4 addresses. There are only around four billion potential IPv4 addresses, which is fewer than the number of humans globally, let alone the number of Internet-connected devices. We decided to examine this problem more deeply in the context of Cloudflare’s unique approach to networking.
Cloudflare’s architecture challenges several assumptions about how different aspects of the Internet relate to each other. Historically, a server IP address corresponds to a specific machine. Cloudflare’s anycast architecture and server design allow any server to serve any customer site. This architecture has allowed the service to scale in incredible ways with very little work.
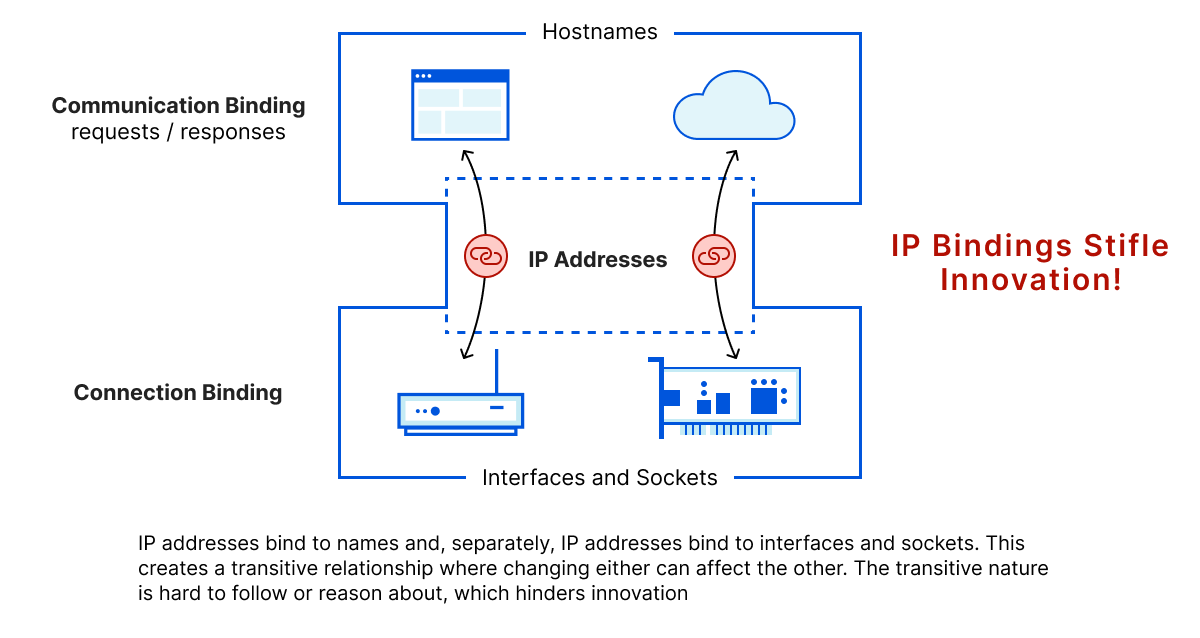
This insight led us to question other fundamental assumptions about how the Internet could potentially work. If an IP address doesn’t need to correspond with a specific server, what else could we decouple from it? Could we decouple hostnames from IPs? Maybe we could! We could also frame the question negatively: what do we lose if we don’t take advantage of this decoupling? It was worth an experiment, at least.
We decided to validate this assumption empirically. We ran an experiment serving all free customers from the same IP in an entire region in a cross-organizational effort that involved the DNS team, the IP addressing team, and the edge load balancing team. The experiment proved that using a single IP for millions of services was feasible, but it also highlighted some risks. The result was a paper published in ACM SIGCOMM 2021 and a project to re-architect our authoritative DNS system to be infinitely more flexible.
Going further together
The Internet is not simply a loose federation of companies and billions of dollars of deployed hardware; it’s a network of interconnected relationships with a global societal impact. These relationships and the technical standards that govern them are the connective tissue that allows us to build important aspects of modern society on the Internet.
Millions of Internet properties use Cloudflare’s network, which serves tens of millions of requests per second. The decisions we make, and the products we release, have significant implications on the industry and billions of people. For the majority of cases, we only control one side of the Internet connection. To serve billions of users and Internet-connected devices, we are governed by and need to support protocols such as DNS, BGP, TLS, and QUIC, defined by technical standards organizations like the Internet Engineering Task Force (IETF).
Protocols evolve, and new protocols are constantly changing to serve the evolving needs of the Internet. An important part of our mission to help build a more secure, more private, more performant, and more available Internet involves taking a leadership role in shaping these protocols, deploying them at scale, and building the open-source software that implements them.
Case Study #4: Oblivious DNS
When Cloudflare launched the 1.1.1.1 recursive DNS service in 2019, privacy was again at the forefront. We offered 1.1.1.1 with a new encryption standard called DNS-over-HTTPS (DoH) to keep queries private as they travel over the Internet. However, even with DoH, a DNS query is associated with the IP address of the user who sent it. Cloudflare wrote a privacy policy and created technical measures to ensure that user IP data is only kept for a short amount of time and even engaged a top auditing firm to confirm this. But still, the question remained, could we offer the service without needing to have this privacy-sensitive information in the first place? We created the Onion Resolver to let users access the service over the Tor anonymity network, but it was extremely slow to use. Could we offer cryptographically private DNS with acceptable performance? It was an open problem.
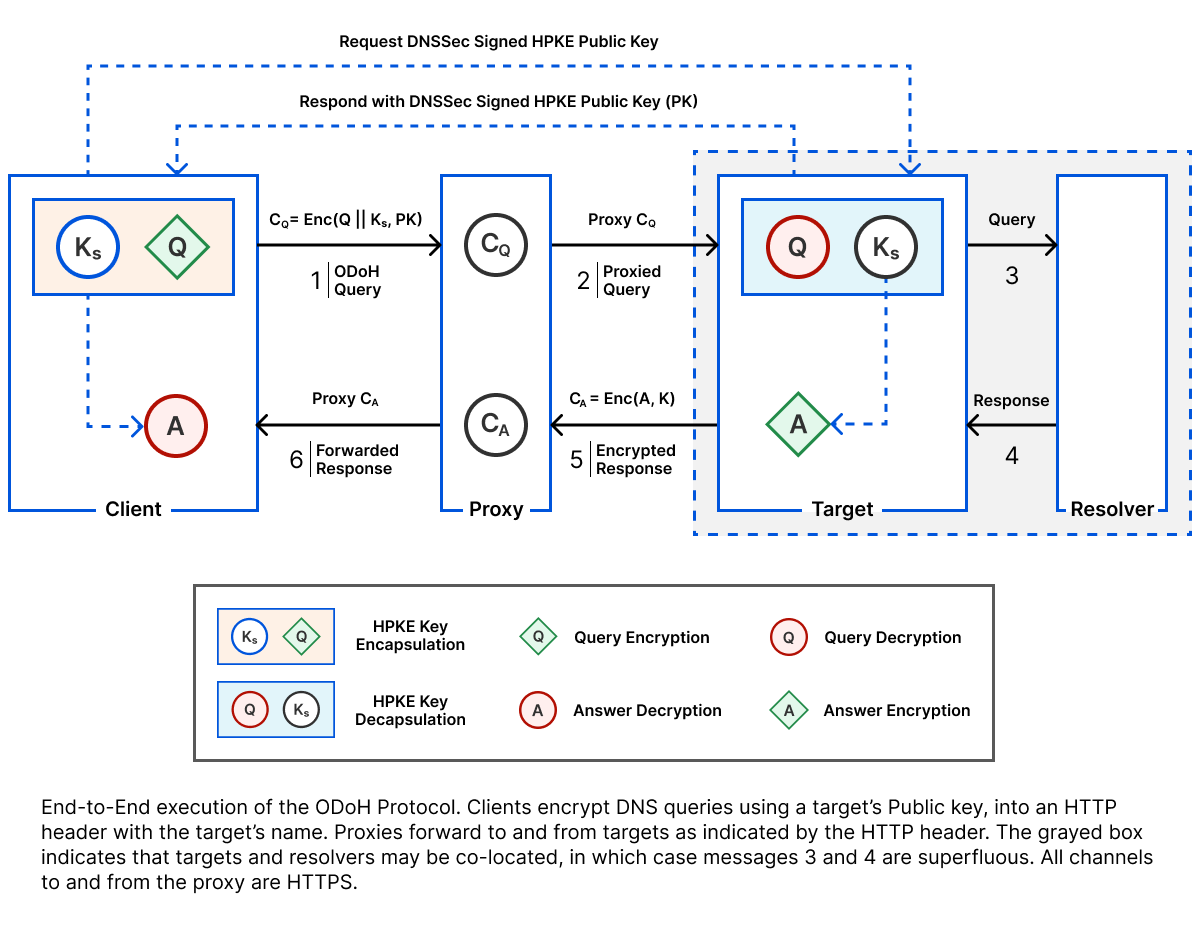
The breakthrough came through a combination of sources. We learned about new results out of academia describing a novel proxying technique called Oblivious DNS. We also found other folks in the industry from Apple and Fastly who were working on the same problem. The resulting proposal combined Oblivious DNS and DoH into an elegant protocol called Oblivious DoH (or ODoH). ODoH was published and discussed extensively at the IETF. DNS is an especially standards-dependent protocol since different parties operate so many components of the system. ODoH adds another participant to the equation, making careful interoperability standards even more critical.
The research team took an early draft of ODoH and, with the help of an intern (whose experience on the team you’ll hear from tomorrow), we built a prototype on Cloudflare Workers. With it, we measured the performance and confirmed the viability of a large-scale ODoH deployment, leading to this paper, published at PoPETS 2021.
The results of our experimentation gave us the confidence to build a production-quality implementation. Our research engineers worked with the engineers on the resolver team to implement and launch ODoH for 1.1.1.1. We also open-sourced ODoH-related code in Go, Rust, and a Cloudflare Workers-compatible implementation. We also worked with the open source community to land the protocol in widely available tools, like dnscrypt, to help further ODoH adoption. ODoH is just one example of cross-industry work to develop standards that you’ll learn more about in an upcoming post.
From theory to practice at a global scale
There are thousands of papers published at dozens of venues every year on Internet technology. The ideas in academic research can change our fundamental understanding of the world scientifically but often haven’t impacted users yet. Innovation comes from all places, and it’s important to adopt ideas from the wider/outside community since we’re in a fortunate position to do so.
As an academic, you are rewarded for the breakthrough, not the follow-through. We value the ability to pursue, even drive, the follow-through because of the tangible improvements challenges offer to the Internet. We find that we can often learn much more about an idea by building and deploying it than by only thinking it up and writing it down. The smallest wrinkle in a lab environment or theoretical paper can become a large issue at Internet scale, and seemingly minor insights can unlock enormous potential.
We are grateful at Cloudflare to be in a rare position to leverage the diversity of the Internet to further existing research and study its real-world impact. We can bring the insights and solutions described in papers to reality because we have the insight into user behavior required to do it: right now, nearly every user on the Internet uses Cloudflare directly or indirectly.
We also have enough scale that problems that could have been solved conventionally must now use new tools. For example, cryptographic tools like identity-based encryption and zero-knowledge proofs have been around on paper for decades. They have only recently been deployed in a few live systems but are now emerging as valuable tools in the conventional Internet and have real-life impact.
Case Study #5: Cryptographic Attestation of Personhood
In Case Study #4, we explored a deep and fundamental networking question. As fun as exploring the plumbing can be, it’s also important to explore user experience questions because clients and customers can immediately feel them. A big part of Cloudflare’s value is protecting customers from bots, and one of the tools we use is the CAPTCHA. People hate CAPTCHAs. Few aspects of the web experience inspire more seething anger in the user experience than being stopped and asked to identify street signs and trucks in low-res images when trying to go to a site. Furthermore, the most common CAPTCHAs are inaccessible to many communities, including the blind and the visually impaired. The Bots team at Cloudflare has made great strides to reduce the number of CAPTCHAs shown on the server-side using machine learning (a challenging problem in itself). We decided to complement their work by asking if we could leverage accessibility on the client-side to provide equivalent protection to a CAPTCHA?
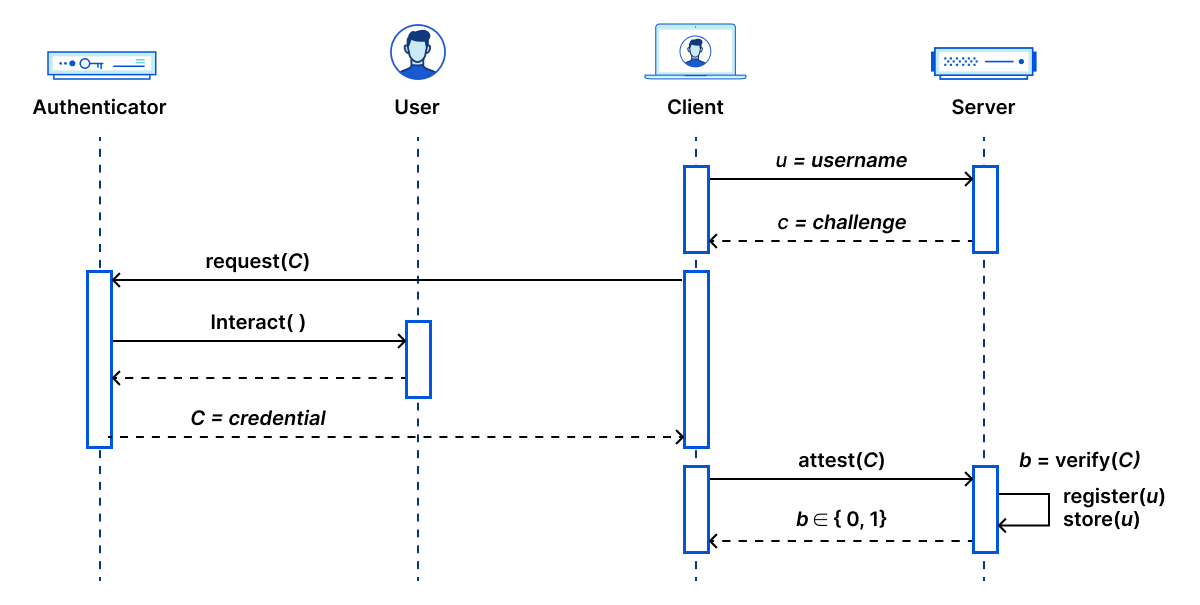
This question led us down the path to developing a new technique we call the Cryptographic Attestation of Personhood (CAP). Instead of users proving to Cloudflare that they are human by performing a human task, we could ask them to prove that they have trusted physical hardware. We identified the widely deployed WebAuthn standard to do this so that millions of users could leverage their hard security keys or the hardware biometric system built into their phones and laptops.
This project raised several exciting and profound privacy and user experience questions. With the help of a research intern experienced in anonymous authentication, we published a paper at SAC 2021 that leveraged and improved upon zero-knowledge cryptography systems to add additional privacy features to our solution. Cloudflare’s ubiquity allows us to expose millions of users to this new idea and understand how it’s understood: for example, do users think sites can collect biometrics from their users this way? We have an upcoming paper submission (with the user research team) about these user experience questions.
Some answers to these research-shaped questions are surprising, some weren’t, but in all cases, the outcome of taking a questions-oriented approach was tools for solving problems.
What to expect from the blog
As mentioned above, Cloudflare Research will be all over the Cloudflare blog in the next several days to make several announcements and share technical explainers, including:
- A new landing page where you can read our research and find additional resources.
- Technical deep dives into research papers and standards, including the projects referenced above (and MANY more).
- Insights into our process and ways to collaborate with us.
Happy reading!