The International Association of Cryptologic Research—the academic cryptography association that’s been putting conferences like Crypto (back when “crypto” meant “cryptography”) and Eurocrypt since the 1980s—had to nullify an online election when trustee Moti Yung lost his decryption key.
For this election and in accordance with the bylaws of the IACR, the three members of the IACR 2025 Election Committee acted as independent trustees, each holding a portion of the cryptographic key material required to jointly decrypt the results. This aspect of Helios’ design ensures that no two trustees could collude to determine the outcome of an election or the contents of individual votes on their own: all trustees must provide their decryption shares.
Unfortunately, one of the three trustees has irretrievably lost their private key, an honest but unfortunate human mistake, and therefore cannot compute their decryption share. As a result, Helios is unable to complete the decryption process, and it is technically impossible for us to obtain or verify the final outcome of this election.
The group will redo the election, but this time setting a 2-of-3 threshold scheme for decrypting the results, instead of requiring all three
The Business of Secrets: Adventures in Selling Encryption Around the World by Fred Kinch (May 24, 2024)
From the vantage point of today, it’s surreal reading about the commercial cryptography business in the 1970s. Nobody knew anything. The manufacturers didn’t know whether the cryptography they sold was any good. The customers didn’t know whether the crypto they bought was any good. Everyone pretended to know, thought they knew, or knew better than to even try to know.
The Business of Secrets is the self-published memoirs of Fred Kinch. He was founder and vice president of—mostly sales—at a US cryptographic hardware company called Datotek, from company’s founding in 1969 until 1982. It’s mostly a disjointed collection of stories about the difficulties of selling to governments worldwide, along with descriptions of the highs and (mostly) lows of foreign airlines, foreign hotels, and foreign travel in general. But it’s also about encryption.
Datotek sold cryptographic equipment in the era after rotor machines and before modern academic cryptography. The company initially marketed computer-file encryption, but pivoted to link encryption—low-speed data, voice, fax—because that’s what the market wanted.
These were the years where the NSA hired anyone promising in the field, and routinely classified—and thereby blocked—publication of academic mathematics papers of those they didn’t hire. They controlled the fielding of strong cryptography by aggressively using the International Traffic in Arms regulation. Kinch talks about the difficulties in getting an expert license for Datotek’s products; he didn’t know that the only reason he ever got that license was because the NSA was able to break his company’s stuff. He had no idea that his largest competitor, the Swiss company Crypto AG, was owned and controlled by the CIA and its West German equivalent. “Wouldn’t that have made our life easier if we had known that back in the 1970s?” Yes, it would. But no one knew.
Glimmers of the clandestine world peek out of the book. Countries like France ask detailed tech questions, borrow or buy a couple of units for “evaluation,” and then disappear again. Did they break the encryption? Did they just want to see what their adversaries were using? No one at Datotek knew.
Kinch “carried the key generator logic diagrams and schematics” with him—even today, it’s good practice not to rely on their secrecy for security—but the details seem laughably insecure: four linear shift registers of 29, 23, 13, and 7 bits, variable stepping, and a small nonlinear final transformation. The NSA probably used this as a challenge to its new hires. But Datotek didn’t know that, at the time.
Kinch writes: “The strength of the cryptography had to be accepted on trust and only on trust.” Yes, but it’s so, so weird to read about it in practice. Kinch demonstrated the security of his telephone encryptors by hooking a pair of them up and having people listen to the encrypted voice. It’s rather like demonstrating the safety of a food additive by showing that someone doesn’t immediately fall over dead after eating it. (In one absolutely bizarre anecdote, an Argentine sergeant with a “hearing defect” could understand the scrambled analog voice. Datotek fixed its security, but only offered the upgrade to the Argentines, because no one else complained. As I said, no one knew anything.)
In his postscript, he writes that even if the NSA could break Datotek’s products, they were “vastly superior to what [his customers] had used previously.” Given that the previous devices were electromechanical rotor machines, and that his primary competition was a CIA-run operation, he’s probably right. But even today, we know nothing about any other country’s cryptanalytic capabilities during those decades.
A lot of this book has a “you had to be there” vibe. And it’s mostly tone-deaf. There is no real acknowledgment of the human-rights-abusing countries on Datotek’s customer list, and how their products might have assisted those governments. But it’s a fascinating artifact of an era before commercial cryptography went mainstream, before academic cryptography became approved for US classified data, before those of us outside the triple fences of the NSA understood the mathematics of cryptography.
Ultimately, the architects settled on a creative solution. Rather than bolt KEM onto the existing double ratchet, they allowed it to remain more or less the same as it had been. Then they used the new quantum-safe ratchet to implement a parallel secure messaging system.
Now, when the protocol encrypts a message, it sources encryption keys from both the classic Double Ratchet and the new ratchet. It then mixes the two keys together (using a cryptographic key derivation function) to get a new encryption key that has all of the security of the classical Double Ratchet but now has quantum security, too.
The Signal engineers have given this third ratchet the formal name: Sparse Post Quantum Ratchet, or SPQR for short. The third ratchet was designed in collaboration with PQShield, AIST, and New York University. The developers presented the erasure-code-based chunking and the high-level Triple Ratchet design at the Eurocrypt 2025 conference. At the Usenix 25 conference, they discussed the six options they considered for adding quantum-safe forward secrecy and post-compromise security and why SPQR and one other stood out. Presentations at the NIST PQC Standardization Conference and the Cryptographic Applications Workshop explain the details of chunking, the design challenges, and how the protocol had to be adapted to use the standardized ML-KEM.
Jacomme further observed:
The final thing interesting for the triple ratchet is that it nicely combines the best of both worlds. Between two users, you have a classical DH-based ratchet going on one side, and fully independently, a KEM-based ratchet is going on. Then, whenever you need to encrypt something, you get a key from both, and mix it up to get the actual encryption key. So, even if one ratchet is fully broken, be it because there is now a quantum computer, or because somebody manages to break either elliptic curves or ML-KEM, or because the implementation of one is flawed, or…, the Signal message will still be protected by the second ratchet. In a sense, this update can be seen, of course simplifying, as doubling the security of the ratchet part of Signal, and is a cool thing even for people that don’t care about quantum computers.
We pointed a commercial-off-the-shelf satellite dish at the sky and carried out the most comprehensive public study to date of geostationary satellite communication. A shockingly large amount of sensitive traffic is being broadcast unencrypted, including critical infrastructure, internal corporate and government communications, private citizens’ voice calls and SMS, and consumer Internet traffic from in-flight wifi and mobile networks. This data can be passively observed by anyone with a few hundred dollars of consumer-grade hardware. There are thousands of geostationary satellite transponders globally, and data from a single transponder may be visible from an area as large as 40% of the surface of the earth.
Today’s world requires us to make complex and nuanced decisions about our digital security. Evaluating when to use a secure messaging app like Signal or WhatsApp, which passwords to store on your smartphone, or what to share on social media requires us to assess risks and make judgments accordingly. Arriving at any conclusion is an exercise in threat modeling.
In security, threat modeling is the process of determining what security measures make sense in your particular situation. It’s a way to think about potential risks, possible defenses, and the costs of both. It’s how experts avoid being distracted by irrelevant risks or overburdened by undue costs.
We threat model all the time. We might decide to walk down one street instead of another, or use an internet VPN when browsing dubious sites. Perhaps we understand the risks in detail, but more likely we are relying on intuition or some trusted authority. But in the U.S. and elsewhere, the average person’s threat model is changing—specifically involving how we protect our personal information. Previously, most concern centered on corporate surveillance; companies like Google and Facebook engaging in digital surveillance to maximize their profit. Increasingly, however, many people are worried about government surveillance and how the government could weaponize personal data.
Since the beginning of this year, the Trump administration’s actions in this area have raised alarm bells: The Department of Government Efficiency (DOGE) tookdata from federal agencies, Palantir combined disparate streams of government data into a single system, and Immigration and Customs Enforcement (ICE) used social media posts as a reason to deny someone entry into the U.S.
These threats, and others posed by a techno-authoritarian regime, are vastly different from those presented by a corporate monopolistic regime—and different yet again in a society where both are working together. Contending with these new threats requires a different approach to personal digital devices, cloud services, social media, and data in general.
What Data Does the Government Already Have?
For years, most public attention has centered on the risks of tech companies gathering behavioral data. This is an enormous amount of data, generally used to predict and influence consumers’ future behavior—rather than as a means of uncovering our past. Although commercial data is highly intimate—such as knowledge of your precise location over the course of a year, or the contents of every Facebook post you have ever created—it’s not the same thing as tax returns, police records, unemployment insurance applications, or medical history.
The U.S. government holds extensive data about everyone living inside its borders, some of it very sensitive—and there’s not much that can be done about it. This information consists largely of facts that people are legally obligated to tell the government. The IRS has a lot of very sensitive data about personal finances. The Treasury Department has data about any money received from the government. The Office of Personnel Management has an enormous amount of detailed information about government employees—including the very personal form required to get a security clearance. The Census Bureau possesses vast data about everyone living in the U.S., including, for example, a database of real estate ownership in the country. The Department of Defense and the Bureau of Veterans Affairs have data about present and former members of the military, the Department of Homeland Security has travel information, and various agencies possess health records. And so on.
It is safe to assume that the government has—or will soon have—access to all of this government data. This sounds like a tautology, but in the past, the U.S. government largely followed the many laws limiting how those databases were used, especially regarding how they were shared, combined, and correlated. Under the second Trump administration, this no longer seems to be the case.
Augmenting Government Data with Corporate Data
The mechanisms of corporate surveillance haven’t gone away. Compute technology is constantly spying on its users—and that data is being used to influence us. Companies like Google and Meta are vast surveillance machines, and they use that data to fuel advertising. A smartphone is a portable surveillance device, constantly recording things like location and communication. Cars, and many other Internet of Things devices, do the same. Credit card companies, health insurers, internet retailers, and social media sites all have detailed data about you—and there is a vast industry that buys and sells this intimate data.
This isn’t news. What’s different in a techno-authoritarian regime is that this data is also shared with the government, either as a paid service or as demanded by local law. Amazon shares Ring doorbell data with the police. Flock, a company that collects license plate data from cars around the country, shares data with the police as well. And just as Chinese corporations share user data with the government and companies like Verizon shared calling records with the National Security Agency (NSA) after the Sept. 11 terrorist attacks, an authoritarian government will use this data as well.
Personal Targeting Using Data
The government has vast capabilities for targeted surveillance, both technically and legally. If a high-level figure is targeted by name, it is almost certain that the government can access their data. The government will use its investigatory powers to the fullest: It will go through government data, remotely hack phones and computers, spy on communications, and raid a home. It will compel third parties, like banks, cell providers, email providers, cloud storage services, and social media companies, to turn over data. To the extent those companies keep backups, the government will even be able to obtain deleted data.
This data can be used for prosecution—possibly selectively. This has been made evident in recent weeks, as the Trump administration personally targeted perceived enemies for “mortgage fraud.” This was a clear example of weaponization of data. Given all the data the government requires people to divulge, there will be something there to prosecute.
Although alarming, this sort of targeted attack doesn’t scale. As vast as the government’s information is and as powerful as its capabilities are, they are not infinite. They can be deployed against only a limited number of people. And most people will never be that high on the priorities list.
The Risks of Mass Surveillance
Mass surveillance is surveillance without specific targets. For most people, this is where the primary risks lie. Even if we’re not targeted by name, personal data could raise red flags, drawing unwanted scrutiny.
The risks here are twofold. First, mass surveillance could be used to singleout people to harass or arrest: when they cross the border, show up at immigration hearings, attend a protest, are stopped by the police for speeding, or just as they’re living their normal lives. Second, mass surveillance could be used to threaten or blackmail. In the first case, the government is using that database to find a plausible excuse for its actions. In the second, it is looking for an actual infraction that it could selectively prosecute—or not.
Mitigating these risks is difficult, because it would require not interacting with either the government or corporations in everyday life—and living in the woods without any electronics isn’t realistic for most of us. Additionally, this strategy protects only future information; it does nothing to protect the information generated in the past. That said, going back and scrubbing social media accounts and cloud storage does have some value. Whether it’s right for you depends on your personal situation.
Opportunistic Use of Data
Beyond data given to third parties—either corporations or the government—there is also data users keep in their possession.This data may be stored on personal devices such as computers and phones or, more likely today, in some cloud service and accessible from those devices. Here, the risks are different: Some authority could confiscate your device and look through it.
This is not just speculative. There are many stories of ICE agents examining people’s phones and computers when they attempt to enter the U.S.: their emails, contact lists, documents, photos, browser history, and social media posts.
There are several different defenses you can deploy, presented from least to most extreme. First, you can scrub devices of potentially incriminating information, either as a matter of course or before entering a higher-risk situation. Second, you could consider deleting—even temporarily—social media and other apps so that someone with access to a device doesn’t get access to those accounts—this includes your contacts list. If a phone is swept up in a government raid, your contacts become their next targets.
Third, you could choose not to carry your device with you at all, opting instead for a burner phone without contacts, email access, and accounts, or go electronics-free entirely. This may sound extreme—and getting it right is hard—but I know many people today who have stripped-down computers and sanitized phones for international travel. At the same time, there are also stories of people being denied entry to the U.S. because they are carrying what is obviously a burner phone—or no phone at all.
Encryption Isn’t a Magic Bullet—But Use It Anyway
Encryption protects your data while it’s not being used, and your devices when they’re turned off. This doesn’t help if a border agent forces you to turn on your phone and computer. And it doesn’t protect metadata, which needs to be unencrypted for the system to function. This metadata can be extremely valuable. For example, Signal, WhatsApp, and iMessage all encrypt the contents of your text messages—the data—but information about who you are texting and when must remain unencrypted.
Also, if the NSA wants access to someone’s phone, it can get it. Encryption is no help against that sort of sophisticated targeted attack. But, again, most of us aren’t that important and even the NSA can target only so many people. What encryption safeguards against is mass surveillance.
I recommend Signal for text messages above all other apps. But if you are in a country where having Signal on a device is in itself incriminating, then use WhatsApp. Signal is better, but everyone has WhatsApp installed on their phones, so it doesn’t raise the same suspicion. Also, it’s a no-brainer to turn on your computer’s built-in encryption: BitLocker for Windows and FileVault for Macs.
On the subject of data and metadata, it’s worth noting that data poisoning doesn’t help nearly as much as you might think. That is, it doesn’t do much good to add hundreds of random strangers to an address book or bogus internet searches to a browser history to hide the real ones. Modern analysis tools can see through all of that.
Shifting Risks of Decentralization
This notion of individual targeting, and the inability of the government to do that at scale, starts to fail as the authoritarian system becomes more decentralized. After all, if repression comes from the top, it affects only senior government officials and people who people in power personally dislike. If it comes from the bottom, it affects everybody. But decentralization looks much like the events playing out with ICE harassing, detaining, and disappearing people—everyone has to fear it.
This can go much further. Imagine there is a government official assigned to your neighborhood, or your block, or your apartment building. It’s worth that person’s time to scrutinize everybody’s social media posts, email, and chat logs. For anyone in that situation, limiting what you do online is the only defense.
Being Innocent Won’t Protect You
This is vital to understand. Surveillance systems and sorting algorithms make mistakes. This is apparent in the fact that we are routinely served advertisements for products that don’t interest us at all. Those mistakes are relatively harmless—who cares about a poorly targeted ad?—but a similar mistake at an immigration hearing can get someone deported.
An authoritarian government doesn’t care. Mistakes are a feature and not a bug of authoritarian surveillance. If ICE targets only people it can go after legally, then everyone knows whether or not they need to fear ICE. If ICE occasionally makes mistakes by arresting Americans and deporting innocents, then everyone has to fear it. This is by design.
Effective Opposition Requires Being Online
For most people, phones are an essential part of daily life. If you leave yours at home when you attend a protest, you won’t be able to film police violence. Or coordinate with your friends and figure out where to meet. Or use a navigation app to get to the protest in the first place.
Threat modeling is all about trade-offs. Understanding yours depends not only on the technology and its capabilities but also on your personal goals. Are you trying to keep your head down and survive—or get out? Are you wanting to protest legally? Are you doing more, maybe throwing sand into the gears of an authoritarian government, or even engaging in active resistance? The more you are doing, the more technology you need—and the more technology will be used against you. There are no simple answers, only choices.
The Internet is in constant motion. Sites scale, traffic shifts, and attackers adapt. Security that worked yesterday may not be enough tomorrow. That’s why the technologies that protect the web — such as Transport Layer Security (TLS) and emerging post-quantum cryptography (PQC) — must also continue to evolve. We want to make sure that everyone benefits from this evolution automatically, so we enabled the strongest protections by default.
During Birthday Week 2024, we announced Automatic SSL/TLS: a service that scans origin server configurations of domains behind Cloudflare, and automatically upgrades them to the most secure encryption mode they support. In the past year, this system has quietly strengthened security for more than 6 million domains — ensuring Cloudflare can always connect to origin servers over the safest possible channel, without customers lifting a finger.
Now, a year after we started enabling Automatic SSL/TLS, we want to talk about these results, why they matter, and how we’re preparing for the next leap in Internet security.
The Basics: TLS protocol
Before diving in, let’s review the basics of Transport Layer Security (TLS). The protocol allows two strangers (like a client and server) to communicate securely.
Every secure web session begins with a TLS handshake. Before a single byte of your data moves across the Internet, servers and clients need to agree on a shared secret key that will protect the confidentiality and integrity of your data. The key agreement handshake kicks off with a TLS ClientHello message. This message is the browser/client announcing, “Here’s who I want to talk to (via SNI), and here are the key agreement methods I understand.” The server then proves who it is with its own credentials in the form of a certificate, and together they establish a shared secret key that will protect everything that follows.
TLS 1.3 added a clever shortcut: instead of waiting to be told which method to use for the shared key agreement, the browser can guess what key agreement the server supports, and include one or more keyshares right away. If the guess is correct, the handshake skips an extra round trip and the secure connection is established more quickly. If the guess is wrong, the server responds with a HelloRetryRequest (HRR), telling the browser which key agreement method to retry with. This speculative guessing is a major reason TLS 1.3 is so much faster than TLS 1.2.
Once both sides agree, the chosen keyshare is used to create a shared secret that encrypts the messages they exchange and allows only the right parties to decrypt them.
The nitty-gritty details of key agreement
Up until recently, most of these handshakes have relied on elliptic curve cryptography (ECC) using a curve known as X25519. But looming on the horizon are quantum computers, which could one day break ECC algorithms like X25519 and others. To prepare, the industry is shifting toward post-quantum key agreement with MLKEM, deployed in a hybrid mode (X25519 + MLKEM). This ensures that even if quantum machines arrive, harvested traffic today can’t be decrypted tomorrow. X25519 + MLKEM is steadily rising to become the most popular key agreement for connections to Cloudflare.
The TLS handshake model is the foundation for how we encrypt web communications today. The history of TLS is really the story of iteration under pressure. It’s a protocol that had to keep evolving, so trust on the web could keep pace with how Internet traffic has changed. It’s also what makes technologies like Cloudflare’s Automatic SSL/TLS possible, by abstracting decades of protocol battles and crypto engineering into a single click, so customer websites can be secured by default without requiring every operator to be a cryptography expert.
History Lesson: Stumbles and Standards
Early versions of TLS (then called SSL) in the 1990s suffered from weak keys, limited protection against attacks like man-in-the-middle, and low adoption on the Internet. To stabilize things, the IETF stepped in and released TLS 1.0, followed by TLS 1.1 and 1.2 through the 2000s. These versions added stronger ciphers and patched new attack vectors, but years of fixes and extensions left the protocol bloated and hard to evolve.
The early 2010s marked a turning point. After the Snowden disclosures, the Internet doubled down on encryption by default. Initiatives like Let’s Encrypt, the mass adoption of HTTPS, and Cloudflare’s own commitment to offer SSL/TLS for free turned encryption from optional, expensive, and complex into an easy baseline requirement for a safer Internet.
All of this momentum led to TLS 1.3 (2018), which cut away legacy baggage, locked in modern cipher suites, and made encrypted connections nearly as fast as the underlying transport protocols like TCP—and sometimes even faster with QUIC.
The CDN Twist
As Content Delivery Networks (CDNs) rose to prominence, they reshaped how TLS was deployed. Instead of a browser talking directly to a distant server hosting content (what Cloudflare calls an origin), it now spoke to the nearest edge data center, which may in-turn speak to an origin server on the client’s behalf.
This created two distinct TLS layers:
Edge ↔ Browser TLS: The front door, built to quickly take on new improvements in security and performance. Edges and browsers adopt modern protocols (TLS 1.3, QUIC, session resumption) to cut down on latency.
Edge ↔ Origin TLS: The backhaul, which must be more flexible. Origins might be older, more poorly maintained, run legacy TLS stacks, or require custom certificate handling.
In practice, CDNs became translators: modernizing encryption at the edge while still bridging to legacy origins. It’s why you can have a blazing-fast TLS 1.3 session from your phone, even if the origin server behind the CDN hasn’t been upgraded in years.
This is where Automatic SSL/TLS sits in the story of how we secure Internet communications.
Automatic SSL/TLS
Automatic SSL/TLS grew out of Cloudflare’s mission to ensure the web was as encrypted as possible. While we had initially spent an incredibly long time developing secure connections for the “front door” (from browsers to Cloudflare’s edge) with Universal SSL, we knew that the “back door” (from Cloudflare’s edge to origin servers) would be slower and harder to upgrade.
One option we offered was Cloudflare Tunnel, where a lightweight agent runs near the origin server and tunnels traffic securely back to Cloudflare. This approach ensures the connection always uses modern encryption, without requiring changes on the origin itself.
But not every customer uses Tunnel. Many connect origins directly to Cloudflare’s edge, where encryption depends on the origin server’s configuration. Traditionally this meant customers had to either manually select an encryption mode that worked for their origin server or rely on the default chosen by Cloudflare.
To improve the experience of choosing an encryption mode, we introduced our SSL/TLS Recommender in 2021.
The Recommender scanned customer origin servers and then provided recommendations for their most secure encryption mode. For example, if the Recommender detected that an origin server was using a certificate signed by a trusted Certificate Authority (CA) such as Let’s Encrypt, rather than a self-signed certificate, it would recommend upgrading from Full encryption mode to Full (Strict) encryption mode.
Based on how the origin responded, Recommender would tell customers if they could improve their SSL/TLS encryption mode to be more secure. The following encryption modes represent what the SSL/TLS Recommender could recommend to customers based on their origin responses:
However, in the three years after launching our Recommender we discovered something troubling: of the over two million domains using Recommender, only 30% of the recommendations that the system provided were followed. A significant number of users would not complete the next step of pushing the button to inform Cloudflare that we could communicate with their origin over a more secure setting.
We were seeing sub-optimal settings that our customers could upgrade from without risk of breaking their site, but for various reasons, our users did not follow through with the recommendations. So we pushed forward by building a system that worked with Recommender and actioned the recommendations by default.
How does Automatic SSL/TLS work?
Automatic SSL/TLSworks by crawling websites, looking for content over both HTTP and HTTPS, then comparing the results for compatibility. It also performs checks against the TLS certificate presented by the origin and looks at the type of content that is served to ensure it matches. If the downloaded content matches, Automatic SSL/TLS elevates the encryption level for the domain to the compatible and stronger mode, without risk of breaking the site.
More specifically, these are the steps that Automatic SSL/TLS takes to upgrade domain’s security:
Each domain is scheduled for a scan once per month (or until it reaches the maximum supported encryption mode).
The scan evaluates the current encryption mode for the domain. If it’s lower than what the Recommender thinks the domain can support based on the results of its probes and content scans, the system begins a gradual upgrade.
Automatic SSL/TLS begins to upgrade the domain by connecting with origins over the more secure mode starting with just 1% of its traffic.
If connections to the origin succeed, the result is logged as successful.
If they fail, the system records the failure to Cloudflare’s control plane and aborts the upgrade. Traffic is immediately downgraded back to the previous SSL/TLS setting to ensure seamless operation.
If no issues are found, the new SSL/TLS encryption mode is applied to traffic in 10% increments until 100% of traffic uses the recommended mode.
Once 100% of traffic has been successfully upgraded with no TLS-related errors, the domain’s SSL/TLS setting is permanently updated.
Special handling for Flexible → Full/Strict: These upgrades are more cautious because customers’ cache keys are changed (from http to https origin scheme).
In this situation, traffic ramps up from 1% to 10% in 1% increments, allowing customers’ cache to warm-up.
After 10%, the system resumes the standard 10% increments until 100%.
We know that transparency and visibility are critical, especially when automated systems make changes. To keep customers informed, Automatic SSL/TLS sends a weekly digest to account Super Administrators whenever updates are made to domain encryption modes. This way, you always have visibility into what changed and when.
In short, Automatic SSL/TLS automates what used to be trial and error: finding the strongest SSL/TLS mode your site can support while keeping everything working smoothly.
How are we doing so far?
So far we have onboarded all Free, Pro, and Business domains to use Automatic SSL/TLS. We also have enabled this for all new domains that will onboard onto Cloudflare regardless of plantype. Soon, we will start onboarding Enterprise customers as well. If you already have an Enterprise domain and want to try out Automatic SSL/TLS we encourage you to enable it in the SSL/TLS section of the dashboard or via the API.
As of the publishing of this blog, we’ve upgraded over 6 million domains to be more secure without the website operators needing to manually configure anything on Cloudflare.
Previous Encryption Mode
Upgraded Encryption Mode
Number of domains
Flexible
Full
~ 2,200,000
Flexible
Full (strict)
~ 2,000,000
Full
Full (strict)
~ 1,800,000
Off
Full
~ 7,000
Off
Full (strict)
~ 5,000
We’re most excited about the over 4 million domains that moved from Flexible or Off, which uses HTTP to origin servers, to Full or Strict, which uses HTTPS.
If you have a reason to use a particular encryption mode (e.g., on a test domain that isn’t production ready) you can always disable Automatic SSL/TLS and manually set the encryption mode that works best for your use case.
Today, SSL/TLS mode works on a domain-wide level, which can feel blunt. This means that one suboptimal subdomain can keep the entire domain in a less secure TLS setting, to ensure availability. Our long-term goal is to make these controls more precise, so that Automatic SSL/TLS and encryption modes can optimize security per origin or subdomain, rather than treating every hostname the same.
Impact on origin-facing connections
Since we began onboarding domains to Automatic SSL/TLS in late 2024 and early 2025, we’ve been able to measure how origin connections across our network are shifting toward stronger security. Looking at the ratios across all origin requests, the trends are clear:
Encryption is rising. Plaintext connections are steadily declining, a reflection of Automatic SSL/TLS helping millions of domains move to HTTPS by default. We’ve seen a correlated 7-8% reduction in plaintext origin-bound connections. Still, some origins remain on outdated configurations, and these should be upgraded to keep pace with modern security expectations.
TLS 1.3 is surging. Since late 2024, TLS 1.3 adoption has climbed sharply, now making up the majority of encrypted origin traffic (almost 60%). While Automatic SSL/TLS doesn’t control which TLS version an origin supports, this shift is an encouraging sign for both performance and security.
Older versions are fading. Month after month, TLS 1.2 continues to shrink, while TLS 1.0 and 1.1 are now so rare they barely register.
The decline in plaintext connections is encouraging, but it also highlights a long tail of servers still relying on outdated packages or configurations. Sites like SSL Labs can be used, for instance, to check a server’s TLS configuration. However, simply copy-pasting settings to achieve a high rating can be risky, so we encourage customers to review their origin TLS configurations carefully. In addition, Cloudflare origin CA or Cloudflare Tunnel can help provide guidance for upgrading origin security.
Upgraded domain results
Instead of focusing on the entire network of origin-facing connections from Cloudflare, we’re now going to drill into specific changes that we’ve seen from domains that have been upgraded by Automatic SSL/TLS.
By January 2025, most domains had been enrolled in Automatic SSL/TLS, and the results were dramatic: a near 180-degree shift from plaintext to encrypted communication with origins. After that milestone, traffic patterns leveled off into a steady plateau, reflecting a more stable baseline of secure connections across the network. There is some drop in encrypted traffic which may represent some of the originally upgraded domains manually turning off Automatic SSL/TLS.
But the story doesn’t end there. In the past two months (July and August 2025), we’ve observed another noticeable uptick in encrypted origin traffic. This likely reflects customers upgrading outdated origin packages and enabling stronger TLS support—evidence that Automatic SSL/TLS not only raised the floor on encryption but continues nudging the long tail of domains toward better security.
To further explore the “encrypted” line above, we wanted to see what the delta was between TLS 1.2 and 1.3. Originally we wanted to include all TLS versions we support but the levels of 1.0 and 1.1 were so small that they skewed the graph and were taken out. We see a noticeable rise in the support for both TLS 1.2 and 1.3 between Cloudflare and origin servers. What is also interesting to note here is the network-wide decrease in TLS 1.2 but for the domains that have been automatically upgraded a generalized increase, potentially also signifying origin TLS stacks that could be updated further.
Finally, for Full (Strict) mode,we wanted to investigate the number of successful certificate validations we performed. This line shows a dramatic, approximately 40%, increase in successful certificate validations performed for customers upgraded by Automatic SSL/TLS.
We’ve seen a largely successful rollout of Automatic SSL/TLS so far, with millions of domains upgraded to stronger encryption by default. We’ve seen help Automatic SSL/TLS improve origin-facing security, safely pushing connections to stronger modes whenever possible, without risking site breakage. Looking ahead, we’ll continue to expand this capability to more customer use cases as we help to build a more encrypted Internet.
What will we build next for Automatic SSL/TLS?
We’re expanding Automatic SSL/TLS with new features that give customers more visibility and control, while keeping the system safe by default. First, we’re building an ad-hoc scan option that lets you rescan your origin earlier than the standard monthly cadence. This means if you’ve just rotated certificates, upgraded your origin’s TLS configuration, or otherwise changed how your server handles encryption, you won’t need to wait for the next scheduled pass—Cloudflare will be able to re-evaluate and move you to a stronger mode right away.
In addition, we’re working on error surfacing that will highlight origin connection problems directly in the dashboard and provide actionable guidance for remediation. Instead of discovering after the fact that an upgrade failed, or a change on the origin resulted in a less secure setting than what was set previously, customers will be able to see where the issue lies and how to fix it.
Finally, for newly onboarded domains, we plan to add clearer guidance on when to finish configuring the origin before Cloudflare runs its first scan and sets an encryption mode. Together, these improvements are designed to reduce surprises, give customers more agency, and ensure smoother upgrades. We expect all three features to roll out by June 2026.
Post Quantum Era
Looking ahead, quantum computers introduce a serious risk: data encrypted today can be harvested and decrypted years later once quantum attacks become practical. To counter this harvest-now, decrypt-later threat, the industry is moving towards post-quantum cryptography (PQC)—algorithms designed to withstand quantum attacks. We have extensively written on this subject in our previous blogs.
In August 2024, NIST finalized its PQC standards: ML-KEM for key agreement, and ML-DSA and SLH-DSA for digital signatures. In collaboration with industry partners, Cloudflare has helped drive the development and deployment of PQC. We have deployed the hybrid key agreement, combining ML-KEM (post-quantum secure) and X25519 (classical), to secure TLS 1.3 traffic to our servers and internal systems. As of mid-September 2025, around 43% of human-generated connections to Cloudflare are already protected with the hybrid post-quantum secure key agreement – a huge milestone in preparing the Internet for the quantum era.
But things look different on the other side of the network. When Cloudflare connects to origins, we act as the client, navigating a fragmented landscape of hosting providers, software stacks, and middleboxes. Each origin may support a different set of cryptographic features, and not all are ready for hybrid post-quantum handshakes.
To manage this diversity without the risk of breaking connections, we relied on HelloRetryRequest. Instead of sending post-quantum keyshare immediately in the ClientHello, we only advertise support for it. If the origin server supports the post-quantum key agreement, it uses HelloRetryRequest to request it from Cloudflare, and creates the post-quantum connection. The downside is this extra round trip (from the retry) cancels out the performance gains of TLS 1.3 and makes the connection feel closer to TLS 1.2 for uncached requests.
Back in 2023, we launched an API endpoint, so customers could manually opt their origins into preferring post-quantum connections. If set, we avoid the extra roundtrip and try to create a post-quantum connection at the start of the TLS session. Similarly, we extended post-quantum protection to Cloudflare tunnel, making it one of the easiest ways to get origin-facing PQ today.
Starting Q4 2025, we’re taking the next step – making it automatic. Just as we’ve done with SSL/TLS upgrades, Automatic SSL/TLS will begin testing, ramping, and enabling post-quantum handshakes with origins—without requiring customers to change a thing, as long as their origins support post-quantum key agreement.
Behind the scenes, we’re already scanning active origins about every 24 hours to test support and preferences for both classical and post-quantum key agreements. We’ve worked directly with vendors and customers to identify compatibility issues, and this new scanning system will be fully integrated into Automatic SSL/TLS.
And the benefits won’t stop at post-quantum. Even for classical handshakes, optimization matters. Today, the X25519 algorithm is used by default, but our scanning data shows that more than 6% of origins currently prefer a different key agreement algorithm, which leads to unnecessary HelloRetryRequests and wasted round trips. By folding this scanning data into Automatic SSL/TLS, we’ll improve connection establishment for classical TLS as well—squeezing out extra speed and reliability across the board.
As enterprises and hosting providers adopt PQC, our preliminary scanning pipeline has already found that around 4% of origins could benefit from a post-quantum-preferred key agreement even today, as shown below. This is an 8x increase since we started our scans in 2023. We expect this number to grow at a steady pace as the industry continues to migrate to post-quantum protocols.
As part of this change, we will also phase out support for the pre-standard version X25519Kyber768 to support the final ML-KEM standard, again using a hybrid, from edge to origin connections.
With Automatic SSL/TLS, we will soon by default scan your origins proactively to directly send the most preferred keyshare to your origin removing the need for any extra roundtrip, improving both security and performance of your origin connections collectively.
At Cloudflare, we’ve always believed security is a right, not a privilege. From Universal SSL to post-quantum cryptography, our mission has been to make the strongest protections free and available to everyone. Automatic SSL/TLS is the next step—upgrading every domain to the best protocols automatically. Check the SSL/TLS section of your dashboard to ensure it’s enabled and join the millions of sites already secured for today and ready for tomorrow.
Three Dutch security analysts discovered the vulnerabilities—five in total—in a European radio standard called TETRA (Terrestrial Trunked Radio), which is used in radios made by Motorola, Damm, Hytera, and others. The standard has been used in radios since the ’90s, but the flaws remained unknown because encryption algorithms used in TETRA were kept secret until now.
In 2023, Carlo Meijer, Wouter Bokslag, and Jos Wetzels of security firm Midnight Blue, based in the Netherlands, discovered vulnerabilities in encryption algorithms that are part of a European radio standard created by ETSI called TETRA (Terrestrial Trunked Radio), which has been baked into radio systems made by Motorola, Damm, Sepura, and others since the ’90s. The flaws remained unknown publicly until their disclosure, because ETSI refused for decades to let anyone examine the proprietary algorithms.
[…]
But now the same researchers have found that at least one implementation of the end-to-end encryption solution endorsed by ETSI has a similar issue that makes it equally vulnerable to eavesdropping. The encryption algorithm used for the device they examined starts with a 128-bit key, but this gets compressed to 56 bits before it encrypts traffic, making it easier to crack. It’s not clear who is using this implementation of the end-to-end encryption algorithm, nor if anyone using devices with the end-to-end encryption is aware of the security vulnerability in them.
[…]
The end-to-end encryption the researchers examined recently is designed to run on top of TETRA encryption algorithms.
The researchers found the issue with the end-to-end encryption (E2EE) only after extracting and reverse-engineering the E2EE algorithm used in a radio made by Sepura.
These seem to be deliberately implemented backdoors.
The auction, which will include other items related to cryptology, will be held Nov. 20. RR Auction, the company arranging the sale, estimates a winning bid between $300,000 and $500,000.
Along with the original handwritten plain text of K4 and other papers related to the coding, Mr. Sanborn will also be providing a 12-by-18-inch copper plate that has three lines of alphabetic characters cut through with a jigsaw, which he calls “my proof-of-concept piece” and which he kept on a table for inspiration during the two years he and helpers hand-cut the letters for the project. The process was grueling, exacting and nerve wracking. “You could not make any mistake with 1,800 letters,” he said. “It could not be repaired.”
Mr. Sanborn’s ideal winning bidder is someone who will hold on to that secret. He also hopes that person is willing to take over the system of verifying possible solutions and reviewing those unending emails, possibly through an automated system.
Abstract: The National Security Agency (NSA) reportedly paid and pressured technology companies to trick their customers into using vulnerable encryption products. This Article examines whether any of three theories removed the Fourth Amendment’s requirement that this be reasonable. The first is that a challenge to the encryption backdoor might fail for want of a search or seizure. The Article rejects this both because the Amendment reaches some vulnerabilities apart from the searches and seizures they enable and because the creation of this vulnerability was itself a search or seizure. The second is that the role of the technology companies might have brought this backdoor within the private-search doctrine. The Article criticizes the doctrine particularly its origins in Burdeau v. McDowelland argues that if it ever should apply, it should not here. The last is that the customers might have waived their Fourth Amendment rights under the third-party doctrine. The Article rejects this both because the customers were not on notice of the backdoor and because historical understandings of the Amendment would not have tolerated it. The Article concludes that none of these theories removed the Amendment’s reasonableness requirement.
Developing a new video conferencing application often begins with a peer-to-peer setup using WebRTC, facilitating direct data exchange between clients. While effective for small demonstrations, this method encounters scalability hurdles with increased participants. The data transmission load for each client escalates significantly in proportion to the number of users, as each client is required to send data to every other client except themselves (n-1).
In the scaling of video conferencing applications, Selective Forwarding Units (SFUs) are essential. Essentially a media stream routing hub, an SFU receives media and data flows from participants and intelligently determines which streams to forward. By strategically distributing media based on network conditions and participant needs, this mechanism minimizes bandwidth usage and greatly enhances scalability. Nearly every video conferencing application today uses SFUs.
In 2024, we announced Cloudflare Realtime (then called Cloudflare Calls), our suite of WebRTC products, and we also released Orange Meets, an open source video chat application built on top of our SFU.
We also realized that use of an SFU often comes with a privacy cost, as there is now a centralized hub that could see and listen to all the media contents, even though its sole job is to forward media bytes between clients as a data plane.
We believe end-to-end encryption should be the industry standard for secure communication and that’s why today we’re excited to share that we’ve implemented and open sourced end-to-end encryption in Orange Meets. Our generic implementation is client-only, so it can be used with any WebRTC infrastructure. Finally, our new designated committer distributed algorithm is verified in a bounded model checker to verify this algorithm handles edge cases gracefully.
End-to-end encryption for video conferencing is different than for text messaging
End-to-end encryption describes a secure communication channel whereby only the intended participants can read, see, or listen to the contents of the conversation, not anybody else. WhatsApp and iMessage, for example, are end-to-end-encrypted, which means that the companies that operate those apps or any other infrastructure can’t see the contents of your messages.
Whereas encrypted group chats are usually long-lived, highly asynchronous, and low bandwidth sessions, video and audio calls are short-lived, highly synchronous, and require high bandwidth. This difference comes with plenty of interesting tradeoffs, which influenced the design of our system.
We had to consider how factors like the ephemeral nature of calls, compared to the persistent nature of group text messages, also influenced the way we designed E2EE for Orange Meets. In chat messages, users must be able to decrypt messages sent to them while they were offline (e.g. while taking a flight). This is not a problem for real-time communication.
The bandwidth limitations around audio/video communication and the use of an SFU prevented us from using some of the E2EE technologies already available for text messages. Apple’s iMessage, for example, encrypts a message N-1 times for an N-user group chat. We can’t encrypt the video for each recipient, as that could saturate the upload capacity of Internet connections as well as slow down the client. Media has to be encrypted once and decrypted by each client while preserving secrecy around only the current participants of the call.
Messaging Layer Security (MLS)
Around the same time we were working on Orange Meets, we saw a lot of excitement around new apps being built with Messaging Layer Security (MLS), an IETF-standardized protocol that describes how you can do a group key exchange in order to establish end-to-end-encryption for group communication.
Previously, the only way to achieve these properties was to essentially run your own fork of the Signal protocol, which itself is more of a living protocol than a solidified standard. Since MLS is standardized, we’ve now seen multiple high-quality implementations appear, and we’re able to use them to achieve Signal-level security with far less effort.
Implementing MLS here wasn’t easy: it required a moderate amount of client modification, and the development and verification of an encrypted room-joining protocol. Nonetheless, we’re excited to be pioneering a standards-based approach that any customer can run on our network, and to share more details about how our implementation works.
We did not have to make any changes to the SFU to get end-to-end encryption working. Cloudflare’s SFU doesn’t care about the contents of the data forwarded on our data plane and whether it’s encrypted or not.
Orange Meets: the basics
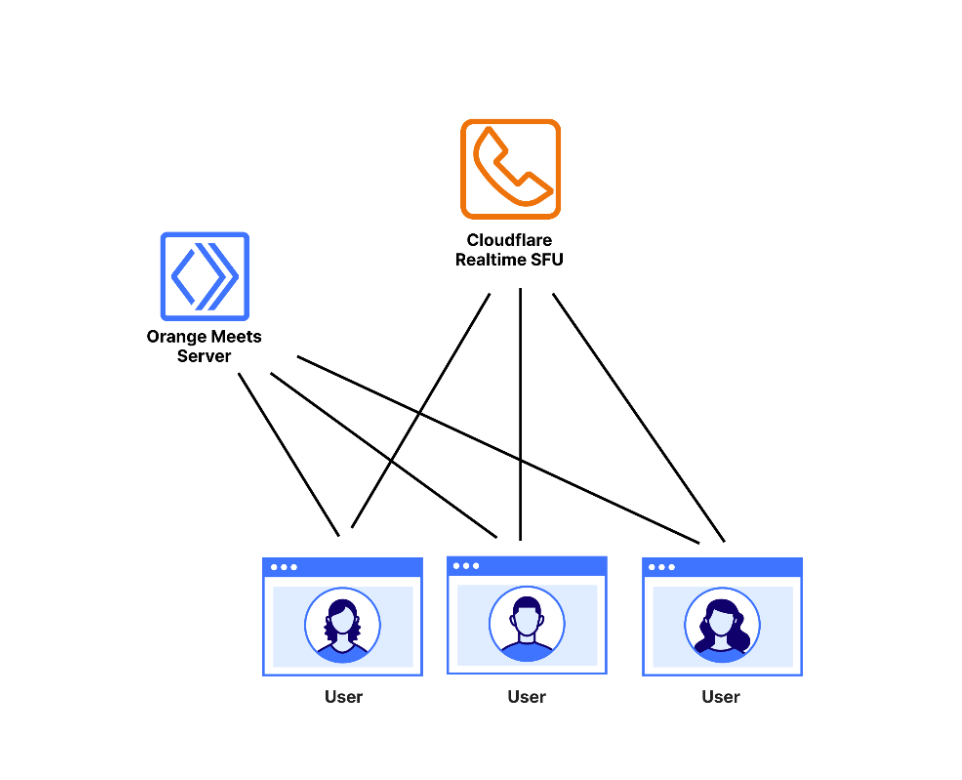
Orange Meets is a video calling application built on Cloudflare Workers that uses the Cloudflare Realtime SFU service as the data plane. The roles played by the three main entities in the application are as follows:
The user is a participant in the video call. They connect to the Orange Meets server and SFU, described below.
The Orange Meets Server is a simple service run on a Cloudflare Worker that runs the small-scale coordination logic of Orange Meets, which is concerned with which user is in which video call — called a room — and what the state of the room is. Whenever something in the room changes, like a participant joining or leaving, or someone muting themselves, the app server broadcasts the change to all room participants. You can use any backend server for this component, we just chose Cloudflare Workers for its convenience.
Cloudflare Realtime Selective Forwarding Unit (SFU) is a service that Cloudflare runs, which takes everyone’s audio and video and broadcasts it to everyone else. These connections are potentially lossy, using UDP for transmission. This is done because a dropped video frame from five seconds ago is not very important in the context of a video call, and so should not be re-sent, as it would be in a TCP connection.
The network topology of Orange Meets
Next, we have to define what we mean by end-to-end encryption in the context of video chat.
End-to-end encrypting Orange Meets
The most immediate way to end-to-end encrypt Orange Meets is to simply have the initial users agree on a symmetric encryption/decryption key at the beginning of a call, and just encrypt every video frame using that key. This is sufficient to hide calls from Cloudflare’s SFU. Some source-encrypted video conferencing implementations, such as Jitsi Meet, work this way.
The issue, however, is that kicking a malicious user from a call does not invalidate their key, since the keys are negotiated just once. A joining user learns the key that was used to encrypt video from before they joined. These failures are more formally referred to as failures of post-compromise security and perfect forward secrecy. When a protocol successfully implements these in a group setting, we call the protocol a continuous group key agreement protocol.
Fortunately for us, MLS is a continuous group key agreement protocol that works out of the box, and the nice folks at Phoenix R&D and Cryspen have a well-documented open-source Rust implementation of most of the MLS protocol.
All we needed to do was write an MLS client and compile it to WASM, so we could decrypt video streams in-browser. We’re using WASM since that’s one way of running Rust code in the browser. If you’re running a video conferencing application on a desktop or mobile native environment, there are other MLS implementations in your preferred programming language.
Our setup for encryption is as follows:
Make a web worker for encryption. We wrote a web worker in Rust that accepts a WebRTC video stream, broken into individual frames, and encrypts each frame. This code is quite simple, as it’s just an MLS encryption:
Postprocess outgoing audio/video. We take our normal stream and, using some newer features of the WebRTC API, add a transform step to it. This transform step simply sends the stream to the worker:
Once we do this for both audio and video streams, we’re done.
Handling different codec behaviors
The streams are now encrypted before sending and decrypted before rendering, but the browser doesn’t know this. To the browser, the stream is still an ordinary video or audio stream. This can cause errors to occur in the browser’s depacketizing logic, which expects to see certain bytes in certain places, depending on the codec. This results in some extremely cypherpunk artifacts every dozen seconds or so:
Fortunately, this exact issue was discovered by engineers at Discord, who handily documented it in their DAVE E2EE videocalling protocol. For the VP8 codec, which we use by default, the solution is simple: split off the first 1–10 bytes of each packet, and send them unencrypted:
fn split_vp8_header(frame: &[u8]) -> Option<(&[u8], &[u8])> {
// If this is a keyframe, keep 10 bytes unencrypted. Otherwise, 1 is enough
let is_keyframe = frame[0] >> 7 == 0;
let unencrypted_prefix_size = if is_keyframe { 10 } else { 1 };
frame.split_at_checked(unencrypted_prefix_size)
}
These bytes are not particularly important to encrypt, since they only contain versioning info, whether or not this frame is a keyframe, some constants, and the width and height of the video.
And that’s truly it for the stream encryption part! The only thing remaining is to figure out how we will let new users join a room.
“Join my Orange Meet”
Usually, the only way to join the call is to click a link. And since the protocol is encrypted, a joining user needs to have some cryptographic information in order to decrypt any messages. How do they receive this information, though? There are a few options.
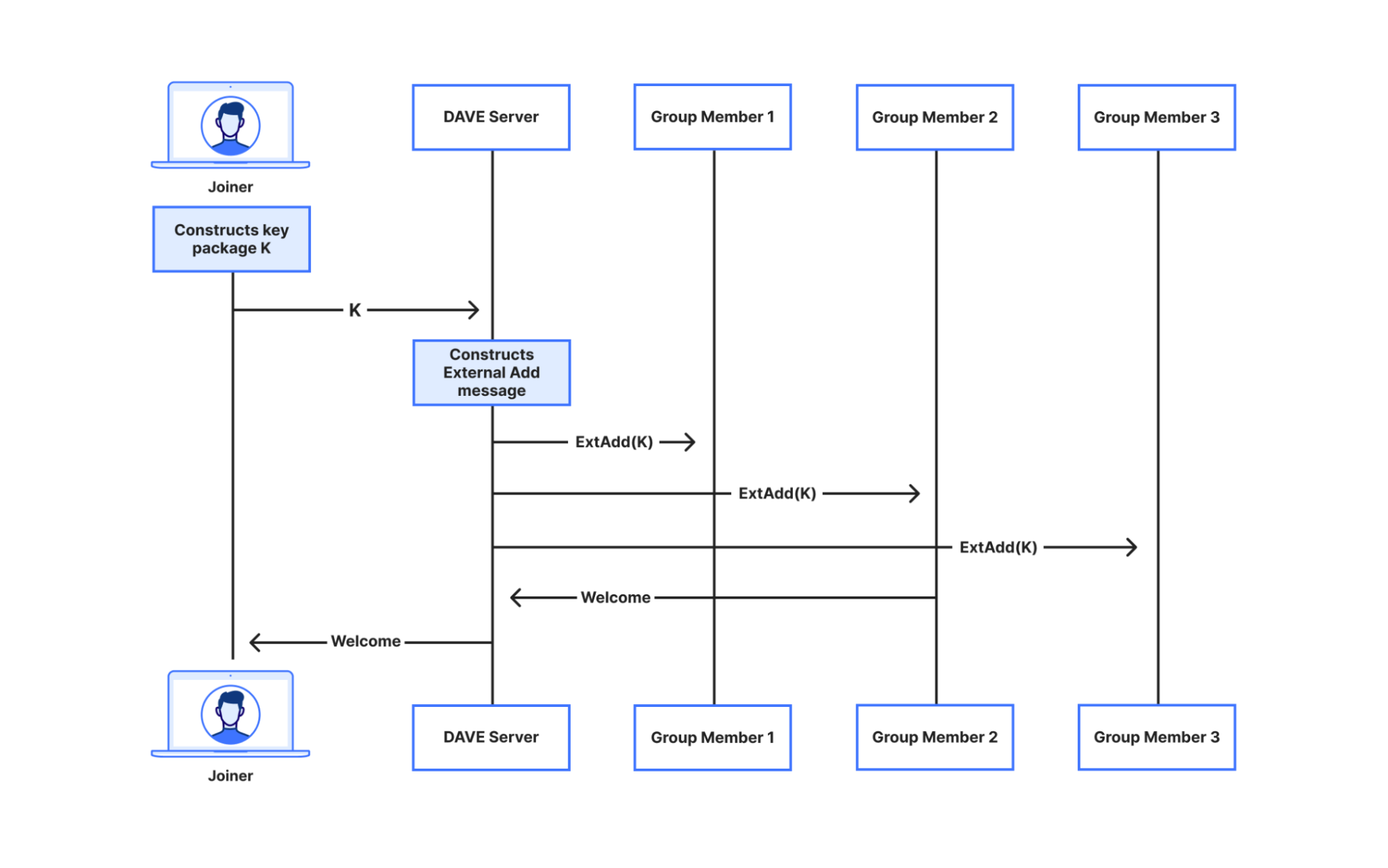
DAVE does it by using an MLS feature called external proposals. In short, the Discord server registers itself as an external sender, i.e., a party that can send administrative messages to the group, but cannot receive any. When a user wants to join a room, they provide their own cryptographic material, called a key package, and the server constructs and sends an MLS External Add message to the group to let them know about the new user joining. Eventually, a group member will commit this External Add, sending the joiner a Welcome message containing all information necessary to send and receive video.
A user joining a group via MLS external proposals. Recall the Orange Meets app server functions as a broadcast channel for the whole group. We consider a group of 3 members. We write member #2 as the one committing to the proposal, but this can be done by any member. Member #2 also sends a Commit message to the other members, but we omit this for space.
This is a perfectly viable way to implement room joining, but implementing it would require us to extend the Orange Meets server logic to have some concept of MLS. Since part of our goal is to keep things as simple as possible, we would like to do all our cryptography client-side.
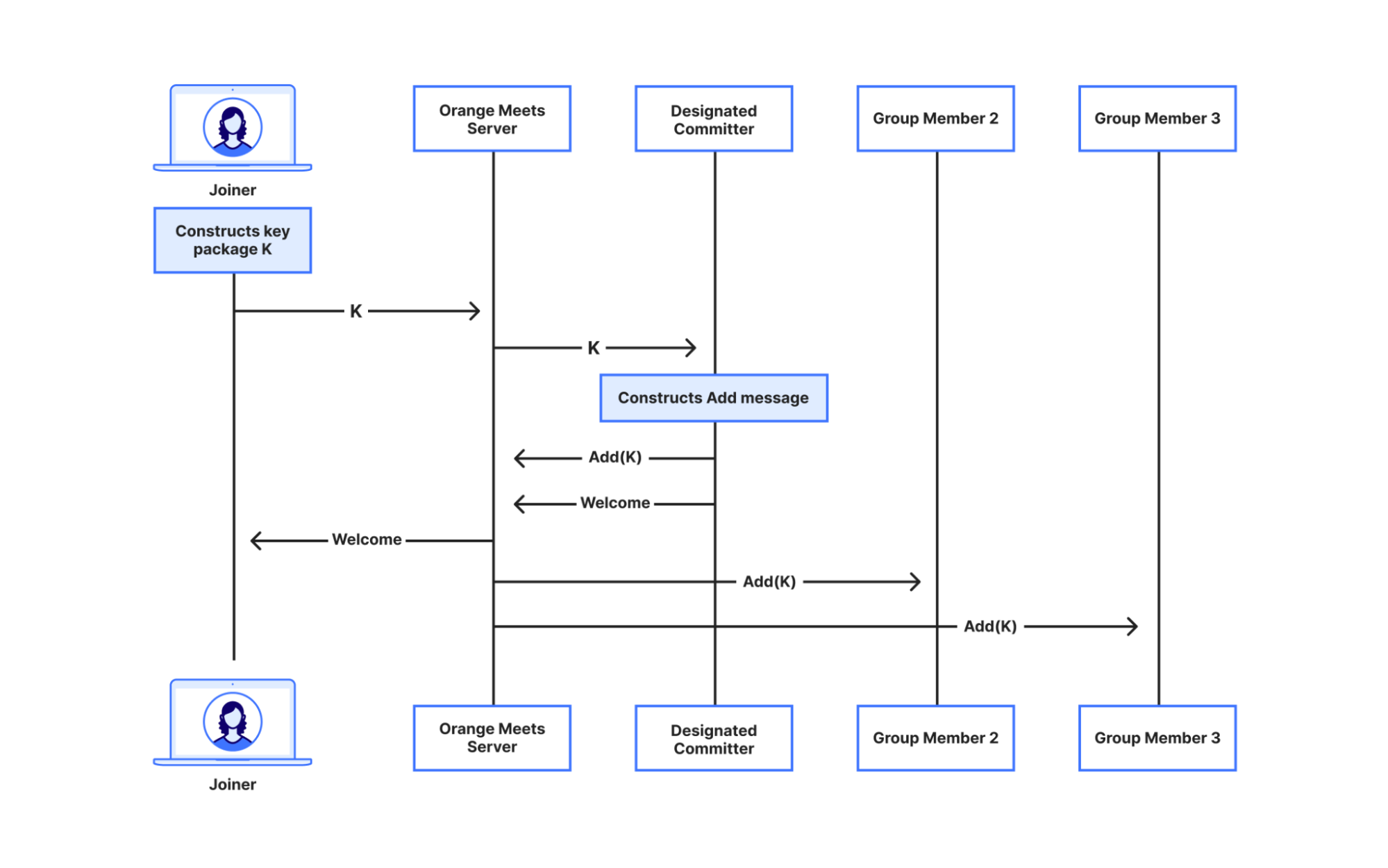
So instead we do what we call the designated committer algorithm. When a user joins a group, they send their cryptographic material to one group member, the designated committer, who then constructs and sends the Add message to the rest of the group. Similarly, when notified of a user’s exit, the designated committer constructs and sends a Remove message to the rest of the group. With this setup, the server’s job remains nothing more than broadcasting messages! It’s quite simple too—the full implementation of the designated committer state machine comes out to 300 lines of Rust, including the MLS boilerplate, and it’s about as efficient.
A user joining a group via the designated committer algorithm.
One cool property of the designated committer algorithm is that something like this isn’t possible in a text group chat setting, since any given user (in particular, the designated committer) may be offline for an arbitrary period of time. Our method works because it leverages the fact that video calls are an inherently synchronous medium.
Verifying the Designated Committer Algorithm with TLA+
The designated committer algorithm is a pretty neat simplification, but it comes with some non-trivial edge cases that we need to make sure we handle, such as:
How do we make sure there is only one designated committer at a time? The designated committer is the alive user with the smallest index in the MLS group state, which all users share.
What happens if the designated committer exits? Then the next user will take its place. Every user keeps track of pending Adds and Removes, so it can continue where the previous designated committer left off.
If a user has not caught up to all messages, could they think they’re the designated committer? No, they have to believe first that all prior eligible designated committers are disconnected.
To make extra sure that this algorithm was correct, we formally modeled it and put it through the TLA+ model checker. To our surprise, it caught some low-level bugs! In particular, it found that, if the designated committer dies while adding a user, the protocol does not recover. We fixed these by breaking up MLS operations and enforcing a strict ordering on messages locally (e.g., a Welcome is always sent before its corresponding Add).
You can find an explainer, lessons learned, and the full PlusCal program (a high-level language that compiles to TLA+) here. The caveat, as with any use of a bounded model checker, is that the checking is, well, bounded. We verified that no invalid protocol states are possible in a group of up to five users. We think this is good evidence that the protocol is correct for an arbitrary number of users. Because there are only two distinct roles in the protocol (designated committer and other group member), any weird behavior ought to be reproducible with two or three users, max.
Preventing Man-in-the-Middle attacks
One important concern to address in any end-to-end encryption setup is how to prevent the service provider from replacing users’ key packages with their own. If the Orange Meets app server did this, and colluded with a malicious SFU to decrypt and re-encrypt video frames on the fly, then the SFU could see all the video sent through the network, and nobody would know.
To resolve this, like DAVE, we include a safety number in the corner of the screen for all calls. This number uniquely represents the cryptographic state of the group. If you check out-of-band (e.g., in a Signal group chat) that everyone agrees on the safety number, then you can be sure nobody’s key material has been secretly replaced.
In fact, you could also read the safety number aloud in the video call itself, but doing this is not provably secure. Reading a safety number aloud is an in-band verification mechanism, i.e., one where a party authenticates a channel within that channel. If a malicious app server colluding with a malicious SFU were able to construct believable video and audio of the user reading the safety number aloud, it could bypass this safety mechanism. So if your threat model includes adversaries that are able to break into a Worker and Cloudflare’s SFU, and simultaneously generate real-time deep-fakes, you should use out-of-band verification 😄.
Future work
There are some areas we could improve on:
There is another attack vector for a malicious app server: it is possible to simply serve users malicious Javascript. This problem, more generally called the Javascript Cryptography Problem, affects any in-browser application where the client wants to hide data from the server. Fortunately, we are working on a standard to address this, called Web Application Manifest Consistency, Integrity, and Transparency. In short, like our Code Verify solution for WhatsApp, this would allow every website to commit to the Javascript it serves, and have a third party create an auditable log of the code. With transparency, malicious Javascript can still be distributed, but at least now there is a log that records the code.
We can make out-of-band authentication easier by placing trust in an identity provider. Using OpenPubkey, it would be possible for a user to get the identity provider to sign their cryptographic material, and then present that. Then all the users would check the signature before using the material. Transparency would also help here to ensure no signatures were made in secret.
Conclusion
We built end-to-end encryption into the Orange Meets video chat app without a lot of engineering time, and by modifying just the client code. To do so, we built a WASM (compiled from Rust) service worker that sets up an MLS group and does stream encryption and decryption, and designed a new joining protocol for groups, called the designated committer algorithm, and formally modeled it in TLA+. We made comments for all kinds of optimizations that are left to do, so please send us a PR if you’re so inclined!
Last month, I wrote about the UK forcing Apple to break its Advanced Data Protection encryption in iCloud. More recently, both Sweden and France are contemplating mandating backdoors. Both initiatives are attempting to scare people into supporting backdoors, which are—of course—are terrible idea.
Last month, the UK government demanded that Apple weaken the security of iCloud for users worldwide. On Friday, Apple took steps to comply for users in the United Kingdom. But the British law is written in a way that requires Apple to give its government access to anyone, anywhere in the world. If the government demands Apple weaken its security worldwide, it would increase everyone’s cyber-risk in an already dangerous world.
If you’re an iCloud user, you have the option of turning on something called “advanced data protection,” or ADP. In that mode, a majority of your data is end-to-end encrypted. This means that no one, not even anyone at Apple, can read that data. It’s a restriction enforced by mathematics—cryptography—and not policy. Even if someone successfully hacks iCloud, they can’t read ADP-protected data.
Using a controversial power in its 2016 Investigatory Powers Act, the UK government wants Apple to re-engineer iCloud to add a “backdoor” to ADP. This is so that if, sometime in the future, UK police wanted Apple to eavesdrop on a user, it could. Rather than add such a backdoor, Apple disabled ADP in the UK market.
Should the UK government persist in its demands, the ramifications will be profound in two ways. First, Apple can’t limit this capability to the UK government, or even only to governments whose politics it agrees with. If Apple is able to turn over users’ data in response to government demand, every other country will expect the same compliance. China, for example, will likely demand that Apple out dissidents. Apple, already dependent on China for both sales and manufacturing, won’t be able to refuse.
Second: Once the backdoor exists, others will attempt to surreptitiously use it. A technical means of access can’t be limited to only people with proper legal authority. Its very existence invites others to try. In 2004, hackers—we don’t know who—breached a backdoor access capability in a major Greek cellphone network to spy on users, including the prime minister of Greece and other elected officials. Just last year, China hacked U.S. telecoms and gained access to their systems that provide eavesdropping on cellphone users, possibly including the presidential campaigns of both Donald Trump and Kamala Harris. That operation resulted in the FBI and the Cybersecurity and Infrastructure Security Agency recommendingthat everyone use end-to-end encrypted messaging for their own security.
Apple isn’t the only company that offers end-to-end encryption. Google offers the feature as well. WhatsApp, iMessage, Signal, and Facebook Messenger offer the same level of security. There are other end-to-end encrypted cloud storage providers. Similar levels of security are available for phones and laptops. Once the UK forces Apple to break its security, actions against these other systems are sure to follow.
It seems unlikely that the UK is not coordinating its actions with the other “Five Eyes” countries of the United States, Canada, Australia, and New Zealand: the rich English-language-speaking spying club. Australia passed a similar law in 2018, giving it authority to demand that companies weaken their security features. As far as we know, it has never been used to force a company to re-engineer its security—but since the law allows for a gag order we might never know. The UK law has a gag order as well; we only know about the Apple action because a whistleblower leaked it to the Washington Post. For all we know, they may have demanded this of other companies as well. In the United States, the FBI has long advocated for the same powers. Having the UK make this demand now, when the world is distracted by the foreign-policy turmoil of the Trump administration, might be what it’s been waiting for.
The companies need to resist, and—more importantly—we need to demand they do. The UK government, like the Australians and the FBI in years past, argues that this type of access is necessary for law enforcement—that it is “going dark” and that the internet is a lawless place. We’ve heard this kind of talk since the 1990s, but its scant evidence doesn’t hold water. Decades of court cases with electronic evidence show again and again the police collect evidence through a variety of means, most of them—like traffic analysis or informants—having nothing to do with encrypted data. What police departments need are better computer investigative and forensics capabilities, not backdoors.
We can all help. If you’re an iCloud user, consider turning this feature on. The more of us who use it, the harder it is for Apple to turn it off for those who need it to stay out of jail. This also puts pressure on other companies to offer similar security. And it helps those who need it to survive, because enabling the feature couldn’t be used as a de facto admission of guilt. (This is a benefit of using WhatsApp over Signal. Since so many people in the world use WhatsApp, having it on your phone isn’t in itself suspicious.)
On the policy front, we have two choices. Wecan’tbuild security systems that work for some people and not others. We can either make our communications and devices as secure as possible against everyone who wants access, including foreign intelligence agencies and our own law enforcement, which protects everyone, including (unfortunately) criminals. Or we can weaken security—the criminals’ as well as everyone else’s.
It’s a question of security vs. security. Yes, we are all more secure if the police are able to investigate and solve crimes. But we are also more secure if our data and communications are safe from eavesdropping. A backdoor in Apple’s security is not just harmful on a personal level, it’s harmful to national security. We live in a world where everyone communicates electronically and stores their important data on a computer. These computers and phones are used by every national leader, member of a legislature, police officer, judge, CEO, journalist, dissident, political operative, and citizen. They need to be as secure as possible: from account takeovers, from ransomware, from foreign spying and manipulation. Remember that the FBI recommended that we all use backdoor-free end-to-end encryption for messaging just a few months ago.
Securing digital systems is hard. Defenders must defeat every attack, while eavesdroppers need one attack that works. Given how essential these devices are, we need to adopt a defense-dominant strategy. To do anything else makes us all less safe.
February 12, 2025: This post was republished to include new services and features that have launched since the original publication date of June 11, 2020.
Encryption is a critical component of a defense-in-depth security strategy that uses multiple defensive mechanisms to protect workloads, data, and assets. As organizations look to innovate while building trust with customers, they need to meet critical compliance requirements and improve data security. Encryption, when used correctly, adds a layer of protection against unauthorized access that can help you strengthen data protection, adhere to regulations and standards, and enhance the security of communications.
How and why does encryption work?
Encryption works by using an algorithm with a key to convert data into unreadable data (ciphertext) that can only become readable again with the right key. For example, a simple phrase like “Hello World!” may look like “1c28df2b595b4e30b7b07500963dc7c” when encrypted. There are several different types of encryption algorithms, all using different types of keys. A strong encryption algorithm relies on mathematical properties to produce ciphertext that can’t be decrypted using any practically available amount of computing power without also having the necessary key. Therefore, protecting and managing the keys becomes a critical part of any encryption solution.
Encryption as part of your security strategy
An effective security strategy begins with stringent access control and continuous work to define the least privilege necessary for persons or systems accessing data. When using the AWS Cloud, you adopt the model of shared responsibility. You are responsible for managing your own access control policies. Encryption is a critical component of a defense-in-depth strategy because it can mitigate weaknesses in your primary access control mechanism. What if an access control mechanism fails and allows access to the raw data on disk or traveling along a network link? If the data is encrypted using a strong key, as long as the decryption key is not on the same system as your data, it is computationally infeasible for a bad actor to decrypt your data.
To show how infeasible this is, let’s consider the Advanced Encryption Standard (AES) with 256-bit keys (AES-256). It’s the strongest industry-adopted and government-approved algorithm for encrypting data. AES-256 is the technology we use to encrypt data in AWS, including Amazon Simple Storage Service (S3) server-side encryption. It would take at least a trillion years to break using current (and foreseeable future) computing technology. Current research suggests that even the future availability of quantum-based computing won’t sufficiently reduce the time it would take to break AES-256 encryption.
But what if you mistakenly create overly permissive access policies on your data? A well-designed encryption and key management system can also help prevent this from becoming an issue, because it separates access to the decryption key from access to your data.
Requirements for an encryption solution
To get the most from an encryption solution, you need to think about two things:
Protecting keys at rest: Are the systems using encryption keys secured so the keys can never be used outside the system? In addition, do these systems implement encryption algorithms correctly to produce strong ciphertexts that cannot be decrypted without access to the right keys?
Independent key management: Is the authorization to use encryption independent from how access to the underlying data is controlled?
There are third-party solutions that you can bring to AWS to help meet these requirements. However, these systems can be difficult and expensive to operate at scale. AWS offers a range of options to simplify encryption and key management.
Protecting keys at rest
When you use third-party key management solutions, it can be difficult to gauge the risk of your plaintext keys leaking and being used outside the solution. The keys have to be stored somewhere, and you can’t always know or audit all the ways those storage systems are secured from unauthorized access. The combination of technical complexity and the necessity of making the encryption usable without degrading performance or availability means that choosing and operating a key management solution can present difficult tradeoffs. The best practice to maximize key security is using a hardware security module (HSM). This is a specialized computing device that has several security controls built into it to help prevent encryption keys from leaving the device in a way that could allow an adversary to access and use those keys.
One such control in modern HSMs is tamper response, in which the device detects physical or logical attempts to access plaintext keys without authorization, and destroys the keys before the attack succeeds. Because you can’t install and operate your own hardware in AWS datacenters, AWS offers two services using HSMs with tamper response to protect customers’ keys: AWS Key Management Service (AWS KMS), which manages a fleet of HSMs on the customer’s behalf, and AWS CloudHSM, which gives customers the ability to manage their own HSMs. Each service can create keys on your behalf, or you can import keys from your on-premises systems to be used by each service.
The keys in AWS KMS or AWS CloudHSM can be used to encrypt data directly, or to protect other keys that are distributed to applications that directly encrypt data. The technique of encrypting encryption keys is called envelope encryption, and it enables encryption and decryption to happen on the computer where the plaintext customer data exists, rather than sending the data to the HSM each time. For very large data sets (e.g., a database), it’s not practical to move gigabytes of data between the data set and the HSM for every read/write operation. Instead, envelope encryption allows a data encryption key to be distributed to the application when it’s needed. The “master” keys in the HSM are used to encrypt a copy of the data key so the application can store the encrypted key alongside the data encrypted under that key. Once the application encrypts the data, the plaintext copy of data key can be deleted from its memory. The only way for the data to be decrypted is if the encrypted data key, which is only a few hundred bytes in size, is sent back to the HSM and decrypted.
The process of envelope encryption is used in AWS services in which data is encrypted on a customer’s behalf (which is known as server-side encryption) to minimize performance degradation. If you want to encrypt data in your own applications (client-side encryption), you’re encouraged to use envelope encryption with AWS KMS or AWS CloudHSM. Both services offer client libraries and SDKs to add encryption functionality to their application code and use the cryptographic functionality of each service. The AWS Encryption SDK is an example of a tool that can be used anywhere, not just in applications running in AWS. To make it easier for customers to encrypt data in databases like Amazon DynamoDB, we built the AWS Database Encryption SDK. The AWS Database Encryption SDK is a set of software libraries that enable you to use client-side encryption in your database design, including record-level encryption of database items. Today, the AWS Database Encryption SDK supports Amazon DynamoDB with attribute-level encryption.
Because implementing encryption algorithms and HSMs is critical to get right, all vendors of HSMs should have their products validated by a trusted third party. HSMs in both AWS KMS and AWS CloudHSM are validated under the National Institute of Standards and Technology’s FIPS 140 program, the standard for evaluating cryptographic modules. This validates the secure design and implementation of cryptographic modules, including functions related to ports and interfaces, authentication mechanisms, physical security and tamper response, operational environments, cryptographic key management, and electromagnetic interference/electromagnetic compatibility (EMI/EMC). Encryption using a FIPS 140 level 3 validated cryptographic module is often a requirement for other security-related compliance schemes like FedRamp and HIPAA-HITECH in the U.S., or the international payment card industry standard (PCI-DSS).
Independent key management
While AWS KMS and AWS CloudHSM can protect plaintext master keys on your behalf, you are still responsible for managing access controls to determine who can cause which encryption keys to be used under which conditions. One advantage of using AWS KMS is that the policy language you use to define access controls on keys is the same one you use to define access to all other AWS resources. Note that the language is the same, not the actual authorization controls. You need a mechanism for managing access to keys that is different from the one you use for managing access to your data. AWS KMS provides that mechanism by allowing you to assign one set of administrators who can only manage keys and a different set of administrators who can only manage access to the underlying encrypted data. Configuring your key management process in this way helps provide separation of duties you need to avoid accidentally escalating privilege to decrypt data to unauthorized users. For even further separation of control, AWS CloudHSM offers an independent policy mechanism to define access to keys.
In 2022, AWS KMS launched support for external key stores (XKS), a feature that allows you to store AWS KMS customer managed keys on an HSM that you operate on premises or at a location of your choice. At a high level, AWS KMS forwards requests for encryption and decryption to your HSM. Your key material never leaves your HSM. This can help you unblock use cases for a small portion of highly regulated workloads where encryption keys should be stored and used outside of an AWS data center. However, XKS forces a significant shift in the shared responsibility model—you now have responsibility for the durability, throughput, latency, and availability of your KMS key. If that key is lost or destroyed, you could permanently lose access to data, and if an XKS key becomes unavailable, all workloads in AWS that are dependent on that XKS key will be inaccessible.
Even with the ability to separate key management from data management, you can still verify that you have configured access to encryption keys correctly. AWS KMS is integrated with AWS CloudTrail so you can audit who used which keys, for which resources, and when. This provides granular vision into your encryption management processes, which is typically much more in-depth than on-premises audit mechanisms. Audit events from AWS CloudHSM can be sent to Amazon CloudWatch, the AWS service for monitoring and alarming third-party solutions you operate in AWS.
Encrypting data at rest and in transit
AWS services that handle customer data, encrypt data that is sent from one system to another—known as data in transit—provide options to encrypt data at rest. AWS services that offer encryption at rest using AWS KMS or AWS CloudHSM use AES-256. None of these services store plaintext encryption keys at rest—that’s a function that only AWS KMS and AWS CloudHSM may perform using their FIPS 140 level 3 validated HSMs. This architecture helps minimize the unauthorized use of keys.
When encrypting data in transit, AWS services use the Transport Layer Security (TLS) protocol to provide encryption between your application and the AWS service. Most commercial solutions use an open source project called OpenSSL for their TLS needs. OpenSSL has roughly 500,000 lines of code with at least 70,000 of those implementing TLS. The code base is large, complex, and difficult to audit. Moreover, when OpenSSL has bugs, the global developer community is challenged to not only fix and test the changes, but also to make sure that the resulting fixes themselves do not introduce new flaws.
AWS’s response to challenges with the TLS implementation in OpenSSL was to develop our own implementation of TLS, known as s2n, or signal to noise. We released s2n in June 2015, which we designed to be small and fast. The goal of s2n is to provide you with network encryption that is easier to understand and that is fully auditable. We released and licensed it under the Apache 2.0 license and hosted it on GitHub.
We also designed s2n to be analyzed using automated reasoning to test for safety and correctness using mathematical logic. Through this process, known as formal methods, we verify the correctness of the s2n code base every time we change the code. We also automated these mathematical proofs, which we regularly re-run to ensure the desired security properties are unchanged with new releases of the code. Automated mathematical proofs of correctness are an emerging trend in the security industry, and AWS uses this approach for a wide variety of our mission-critical software.
Similarly, in 2022, we released s2n-quic, an open-source Rust implementation of the QUIC protocol that was added to our set of AWS encryption open source libraries. QUIC is an encrypted transport protocol designed for performance and is the foundation of HTTP/3. It is specified in a set of IETF standards that were ratified in May 2021. Amazon CloudFront HTTP/3 support is built on top of s2n-quic, due to its emphasis on performance and efficiency. You can learn more about s2n-quic in this Security Blog post.
Implementing TLS requires using encryption keys and digital certificates that assert the ownership of those keys. AWS Certificate Manager and AWS Private Certificate Authority are two services that can simplify the issuance and rotation of digital certificates across your infrastructure that needs to offer TLS endpoints. Both services use a combination of AWS KMS and AWS CloudHSM to generate and/or protect the keys used in the digital certificates they issue.
Encrypting data in use
You might also have use cases for protecting data that is actively being used by federated learning models or other applications. Cryptographic computing—a set of technologies that allow computations to be performed on encrypted data, so that sensitive data is not exposed—is a methodology for protecting data in use.
Consider the example of an insurance company that works with other companies to develop machine learning models for insurance fraud detection. You might need to use sensitive data about your customers as training data for your models, but you don’t want to share your customer data in plaintext form with the other companies. Cryptographic computing gives organizations a way to train models collaboratively without exposing plaintext data about their customers to each other, or to a cloud provider like AWS. You can read more about cryptographic computing in this AWS Security Blog post.
Today, you can see cryptographic computing at work in AWS Clean Rooms, a service that helps companies and their partners more easily and securely analyze and collaborate on their collective datasets—all without sharing or copying one another’s underlying data. AWS Clean Rooms has a feature called Cryptographic Computing for AWS Clean Rooms (C3R) that cryptographically protects your data even while it is being processed by an AWS Clean Rooms collaboration.
The role of end-to-end encryption in secure communications
End-to-end encryption (E2EE) is a method of secure communication between two or more parties that combines encryption in transit and encryption at rest to protect data from unauthorized access, interception, or tampering. Decryption happens only on the parties you intend to communicate with, and no service providers in between. Every call, message, and file is encrypted with a unique private key and remains protected in transit. Unauthorized parties can’t access communication content, because they don’t have the private key required to decrypt the data.
AWS Wickr is an end-to-end encrypted messaging and collaboration service that protects one-to-one and group messaging, voice and video calling, file sharing, screen sharing, and location sharing with 256-bit encryption. With Wickr, each message gets a unique AES private encryption key and a unique Elliptic-curve Diffie–Hellman (ECDH) public key to negotiate the key exchange with recipients. Message content—including text, files, audio, or video—is encrypted on the sending device (your iPhone, for example) by using the message-specific AES key. This key is then exchanged by using the ECDH key exchange mechanism, so that only intended recipients can decrypt the message.
Quantum computing and post-quantum cryptography
Quantum computing is a field of technology that uses quantum mechanics to solve complex problems faster than on classical computers. Quantum computers are able to solve certain types of problems faster by taking advantage of quantum mechanical effects, such as superposition and quantum interference. For cryptography, this has implications that affect traditional encryption mechanisms such as asymmetric key encryption, which is often used for protecting data in transit (TLS) or creating hash-based signatures to verify the integrity and authenticity of a message or file. Quantum computers, if they are performant and stable enough, could theoretically compromise the security of asymmetric key algorithms like RSA, Elliptic Curve Cryptography (ECC), or Diffie-Hellman key agreement schemes. Based on current research, symmetric key algorithms like AES are not considered to be at risk from a quantum computer, because the key length of 256 bits is already sufficient to compensate for a decrease in cryptographic key strength posed by quantum algorithms.
AWS gives customers the option of evaluating post-quantum algorithms alongside traditional algorithms, using hybrid schemes that make use of both classic cryptography and newer post-quantum cryptographic (PQC) algorithms that are designed to be resistant to quantum computer threats. AWS has taken the first step in deploying PQC by implementing ML-KEM, a module lattice-based key encapsulation mechanism, within AWS-LC, our open source FIPS-140-3 validated cryptographic library. AWS-LC is the core cryptographic library used throughout AWS. Specifically, AWS-LC is used in s2n-tls, our open source TLS implementation used across AWS services with HTTPS-based endpoints.
AWS provides customers the ability to encrypt everything, everywhere. Customers can encrypt data at rest, in transit, and in memory, with a few clicks in the AWS Management Console, or an AWS API call. Services like Amazon Simple Storage Service (Amazon S3) encrypt new objects by default, and also support the use of customer managed AWS KMS keys to give customers more control over their encryption keys. Importantly, AWS KMS uses techniques like envelope encryption and highly scalable key management infrastructure to enable AWS services like Amazon S3 or Amazon Elastic Block Store (Amazon EBS) to encrypt data with minimal performance impact to customer applications.
AWS is also consistently working to improve the performance and security of our customers’ data as it moves between networks or devices. As of June 2024, all AWS API endpoints support TLS 1.3 and require at least TLS 1.2 or higher. By using TLS 1.3, you can decrease your connection time by removing one network round trip for every connection request, and can benefit from some of the most modern and secure cryptographic cipher suites available today.
Customers who require memory encryption can use AWS Graviton, our custom-built family of processors based on ARM. AWS Graviton2, AWS Graviton3, and AWS Graviton3E support always-on memory encryption. The encryption keys are securely generated within the host system, do not leave the host system, and are destroyed when the host is rebooted or powered down. Memory encryption is also supported for other instance types; see the EC2 documentation for more details.
As part of our AWS Digital Sovereignty Pledge, we commit to continue to innovate and invest in additional controls for encryption features so that our customers can encrypt everything, everywhere with encryption keys managed inside or outside the AWS Cloud.
Summary
At AWS, security is our top priority. We are committed to helping you control how your data is used, who has access to it, and how it is protected. By building and supporting encryption tools that work both on and off the cloud, we help you secure your data and enable compliance across your environment. We put security at the center of everything we do to make sure that you can protect your data using best-of-breed security technology in a cost-effective way.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS KMS forum or the AWS CloudHSM forum, or contact AWS Support.
The Washington Post is reporting that the UK government has served Apple with a “technical capability notice” as defined by the 2016 Investigatory Powers Act, requiring it to break the Advanced Data Protection encryption in iCloud for the benefit of law enforcement.
This is a big deal, and something we in the security community have worried was coming for a while now.
The law, known by critics as the Snoopers’ Charter, makes it a criminal offense to reveal that the government has even made such a demand. An Apple spokesman declined to comment.
Apple can appeal the U.K. capability notice to a secret technical panel, which would consider arguments about the expense of the requirement, and to a judge who would weigh whether the request was in proportion to the government’s needs. But the law does not permit Apple to delay complying during an appeal.
In March, when the company was on notice that such a requirement might be coming, it told Parliament: “There is no reason why the U.K. [government] should have the authority to decide for citizens of the world whether they can avail themselves of the proven security benefits that flow from end-to-end encryption.”
Apple is likely to turn the feature off for UK users rather than break it for everyone worldwide. Of course, UK users will be able to spoof their location. But this might not be enough. According to the law, Apple would not be able to offer the feature to anyone who is in the UK at any point: for example, a visitor from the US.
And what happens next? Australia has a law enabling it to ask for the same thing. Will it? Will even more countries follow?
Our longstanding offering won’t fundamentally change next year, but we are going to introduce a new offering that’s a big shift from anything we’ve done before—short-lived certificates. Specifically, certificates with a lifetime of six days. This is a big upgrade for the security of the TLS ecosystem because it minimizes exposure time during a key compromise event.
Because we’ve done so much to encourage automation over the past decade, most of our subscribers aren’t going to have to do much in order to switch to shorter lived certificates. We, on the other hand, are going to have to think about the possibility that we will need to issue 20x as many certificates as we do now. It’s not inconceivable that at some point in our next decade we may need to be prepared to issue 100,000,000 certificates per day.
That sounds sort of nuts to me today, but issuing 5,000,000 certificates per day would have sounded crazy to me ten years ago.
This debunking saved me the trouble of writing one. It all seems to have come from this news article, which wasn’t bad but was taken widely out of proportion.
In 2018, Australia passed the Assistance and Access Act, which—among other things—gave the government the power to force companies to break their own encryption.
The Assistance and Access Act includes key components that outline investigatory powers between government and industry. These components include:
Technical Assistance Requests (TARs): TARs are voluntary requests for assistance accessing encrypted data from law enforcement to teleco and technology companies. Companies are not legally obligated to comply with a TAR but law enforcement sends requests to solicit cooperation.
Technical Assistance Notices (TANs): TANS are compulsory notices (such as computer access warrants) that require companies to assist within their means with decrypting data or providing technical information that a law enforcement agency cannot access independently. Examples include certain source code, encryption, cryptography, and electronic hardware.
Technical Capability Notices (TCNs): TCNs are orders that require a company to build new capabilities that assist law enforcement agencies in accessing encrypted data. The Attorney-General must approve a TCN by confirming it is reasonable, proportionate, practical, and technically feasible.
It’s that final one that’s the real problem. The Australian government can force tech companies to build backdoors into their systems.
This is law, but near as anyone can tell the government has never used that third provision.
Now, the director of the Australian Security Intelligence Organisation (ASIO)—that’s basically their FBI or MI5—is threatening to do just that:
ASIO head, Mike Burgess, says he may soon use powers to compel tech companies to cooperate with warrants and unlock encrypted chats to aid in national security investigations.
[…]
But Mr Burgess says lawful access is all about targeted action against individuals under investigation.
“I understand there are people who really need it in some countries, but in this country, we’re subject to the rule of law, and if you’re doing nothing wrong, you’ve got privacy because no one’s looking at it,” Mr Burgess said.
“If there are suspicions, or we’ve got proof that we can justify you’re doing something wrong and you must be investigated, then actually we want lawful access to that data.”
Mr Burgess says tech companies could design apps in a way that allows law enforcement and security agencies access when they request it without comprising the integrity of encryption.
“I don’t accept that actually lawful access is a back door or systemic weakness, because that, in my mind, will be a bad design. I believe you can these are clever people design things that are secure, that give secure, lawful access,” he said.
We in the encryption space call that last one “nerd harder.” It, and the rest of his remarks, are the same tired talking points we’ve heard again and again.
It’s going to be an awfully big mess if Australia actually tries to make Apple, or Facebook’s WhatsApp, for that matter, break its own encryption for its “targeted actions” that put every other user at risk.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.