Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/08/poor-password-choices.html
Look at this: McDonald’s chose the password “123456” for a major corporate system.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/08/poor-password-choices.html
Look at this: McDonald’s chose the password “123456” for a major corporate system.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/06/new-linux-vulnerabilities.html
They’re interesting:
Tracked as CVE-2025-5054 and CVE-2025-4598, both vulnerabilities are race condition bugs that could enable a local attacker to obtain access to access sensitive information. Tools like Apport and systemd-coredump are designed to handle crash reporting and core dumps in Linux systems.
[…]
“This means that if a local attacker manages to induce a crash in a privileged process and quickly replaces it with another one with the same process ID that resides inside a mount and pid namespace, apport will attempt to forward the core dump (which might contain sensitive information belonging to the original, privileged process) into the namespace.”
Moderate severity, but definitely worth fixing.
Slashdot thread.
Post Syndicated from David Belson original https://blog.cloudflare.com/cloudflare-radar-ddos-leaked-credentials-bots/
Security and attacks continues to be a very active environment, and the visibility that Cloudflare Radar provides on this dynamic landscape has evolved and expanded over time. To that end, during 2023’s Security Week, we launched our URL Scanner, which enables users to safely scan any URL to determine if it is safe to view or interact with. During 2024’s Security Week, we launched an Email Security page, which provides a unique perspective on the threats posed by malicious emails, spam volume, the adoption of email authentication methods like SPF, DMARC, and DKIM, and the use of IPv4/IPv6 and TLS by email servers. For Security Week 2025, we are adding several new DDoS-focused graphs, new insights into leaked credential trends, and a new Bots page to Cloudflare Radar. We are also taking this opportunity to refactor Radar’s Security & Attacks page, breaking it out into Application Layer and Network Layer sections.
Below, we review all of these changes and additions to Radar.
Since Cloudflare Radar launched in 2020, it has included both network layer (Layers 3 & 4) and application layer (Layer 7) attack traffic insights on a single Security & Attacks page. Over the last four-plus years, we have evolved some of the existing data sets on the page, as well as adding new ones. As the page has grown and improved over time, it risked becoming unwieldy to navigate, making it hard to find the graphs and data of interest. To help address that, the Security section on Radar now features separate Application Layer and Network Layer pages. The Application Layer page is the default, and includes insights from analysis of HTTP-based malicious and attack traffic. The Network Layer page includes insights from analysis of network and transport layer attacks, as well as observed TCP resets and timeouts. Future security and attack-related data sets will be added to the relevant page. Email Security remains on its own dedicated page.

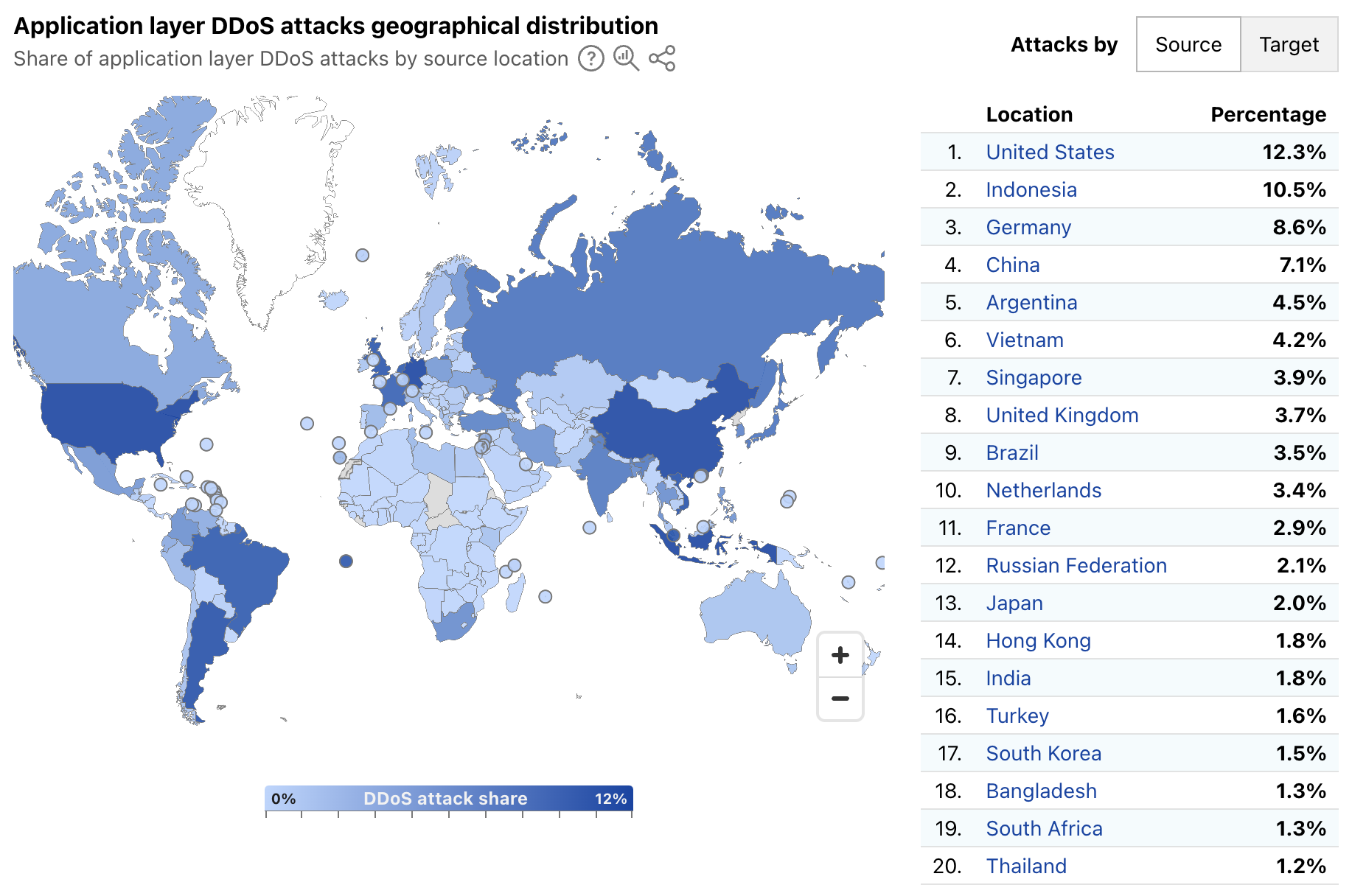
Radar’s quarterly DDoS threat reports have historically provided insights, aggregated on a quarterly basis, into the top source and target locations of application layer DDoS attacks. A new map and table on Radar’s Application Layer Security page now provide more timely insights, with a global choropleth map showing a geographical distribution of source and target locations, and an accompanying list of the top 20 locations by share of all DDoS requests. Source location attribution continues to rely on the geolocation of the IP address originating the blocked request, while target location remains the billing location of the account that owns the site being attacked.
Over the first week of March 2025, the United States, Indonesia, and Germany were the top sources of application layer DDoS attacks, together accounting for over 30% of such attacks as shown below. The concentration across the top targeted locations was quite different, with customers from Canada, the United States, and Singapore attracting 56% of application layer DDoS attacks.
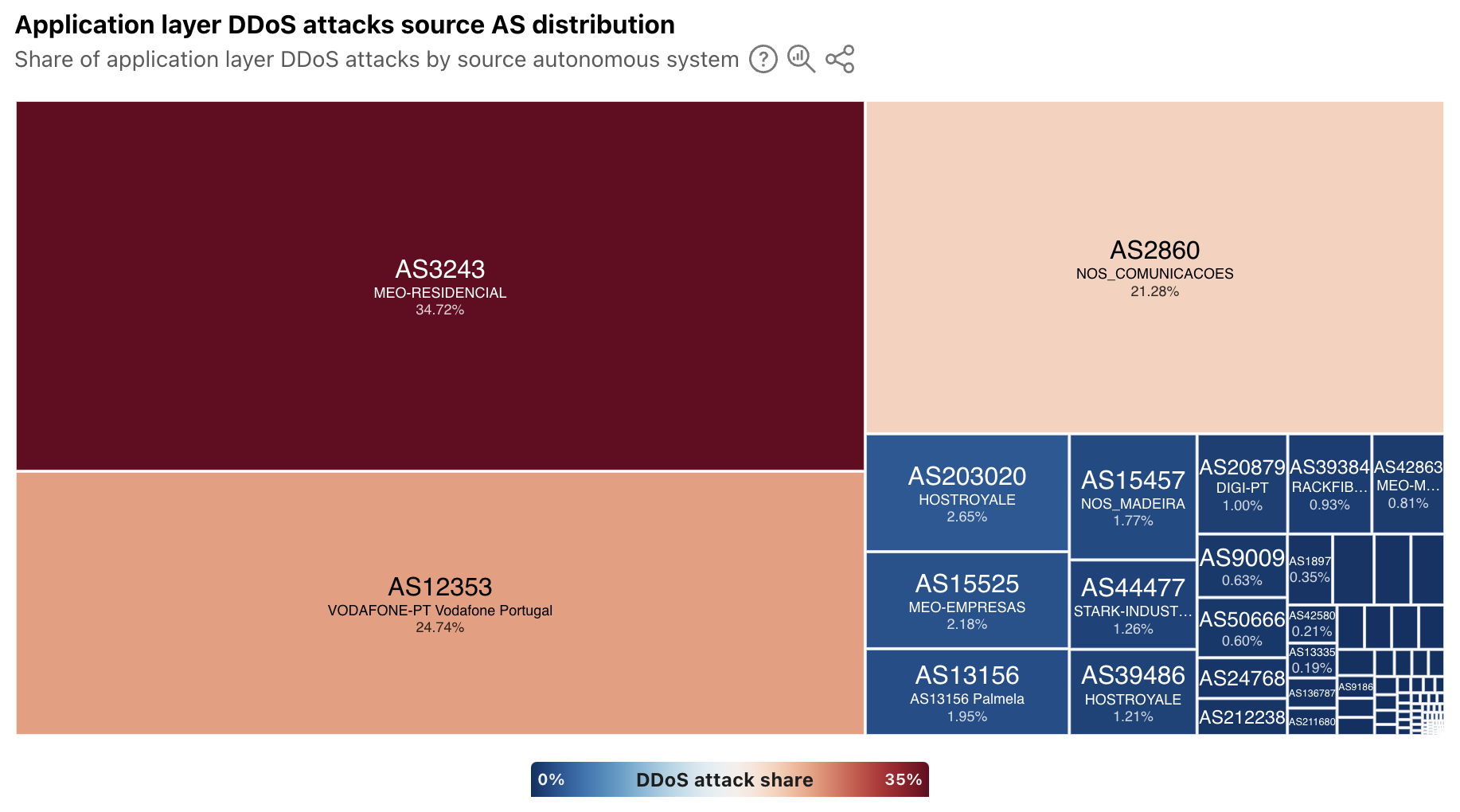
In addition to extended visibility into the geographic source of application layer DDoS attacks, we have also added autonomous system (AS)-level visibility. A new treemap view shows the distribution of these attacks by source AS. At a global level, the largest sources include cloud/hosting providers in Germany, the United States, China, and Vietnam.

For a selected country/region, the treemap displays a source AS distribution for attacks observed to be originating from that location. In some, the sources of attack traffic are heavily concentrated in consumer/business network providers, such as in Portugal, shown below. However, in other countries/regions that have a large cloud provider presence, such as Ireland, Singapore, and the United States, ASNs associated with these types of providers are the dominant sources. To that end, Singapore was listed as being among the top sources of application layer DDoS attacks in each of the quarterly DDoS threat reports in 2024.
Every week, it seems like there’s another headline about a data breach, talking about thousands or millions of usernames and passwords being stolen. Or maybe you get an email from an identity monitoring service that your username and password were found on the “dark web”. (Of course, you’re getting those alerts thanks to a complementary subscription to the service offered as penance from another data breach…)
This credential theft is especially problematic because people often reuse passwords, despite best practices advising the use of strong, unique passwords for each site or application. To help mitigate this risk, starting in 2024, Cloudflare began enabling customers to scan authentication requests for their websites and applications using a privacy-preserving compromised credential checker implementation to detect known-leaked usernames and passwords. Today, we’re using aggregated data to display trends in how often these leaked and stolen credentials are observed across Cloudflare’s network. (Here, we are defining “leaked credentials” as usernames or passwords being found in a public dataset, or the username and password detected as being similar.)
Leaked credentials detection scans incoming HTTP requests for known authentication patterns from common web apps and any custom detection locations that were configured. The service uses a privacy-preserving compromised credential checking protocol to compare a hash of the detected passwords to hashes of compromised passwords found in databases of leaked credentials. A new Radar graph on the worldwide Application Layer Security page provides visibility into aggregate trends around the detection of leaked credentials in authentication requests. Filterable by authentication requests from human users, bots, or all (human + bot), the graph shows the distribution requests classified as “clean” (no leaked credentials detected) and “compromised” (leaked credentials, as defined above, were used). At a worldwide level, we found that for the first week of March 2025, leaked credentials were used in 64% of all, over 65% of bot, and over 44% of human authorization requests.
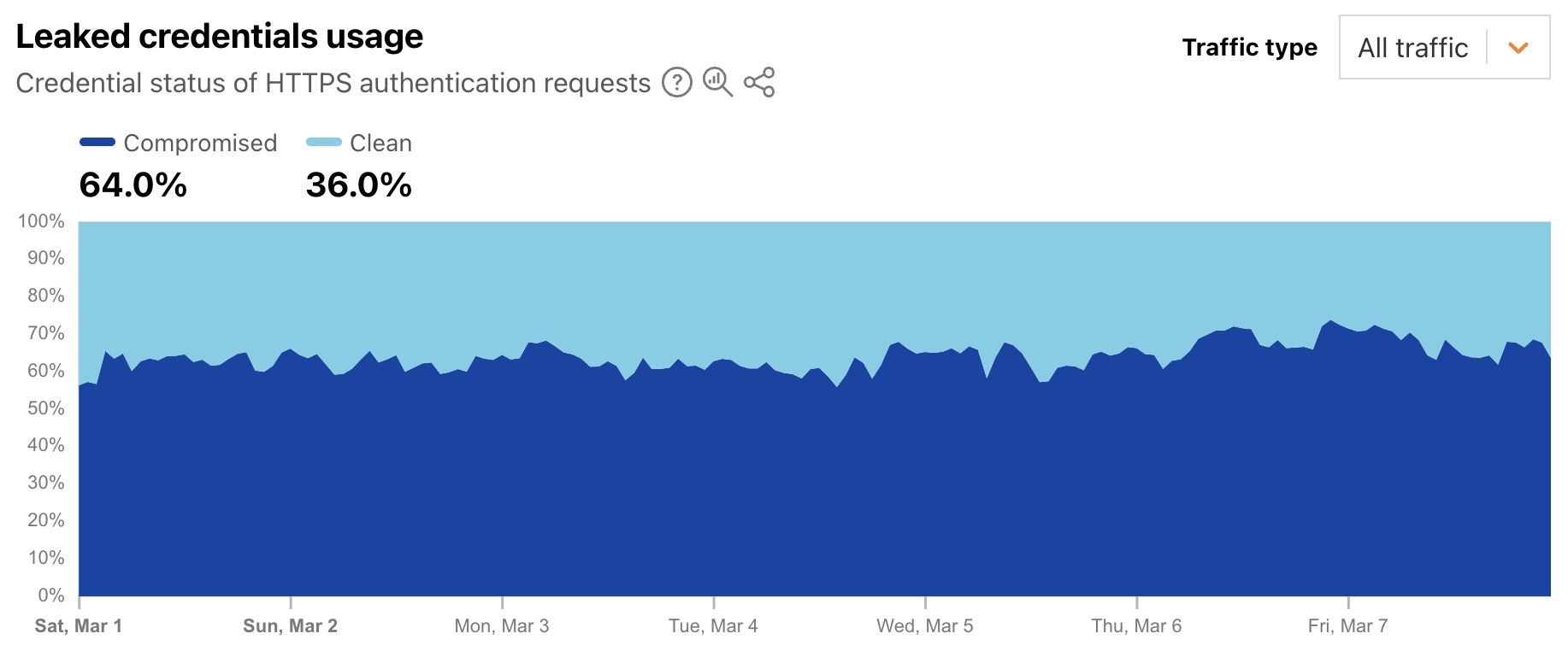
This suggests that from a human perspective, password reuse is still a problem, as is users not taking immediate actions to change passwords when notified of a breach. And from a bot perspective, this suggests that attackers know that there is a good chance that leaked credentials for one website or application will enable them to access that same user’s account elsewhere.
As a complement to the leaked credentials data, Radar is also now providing a worldwide view into the share of authentication requests originating from bots. Note that not all of these requests are necessarily malicious — while some may be associated with credential stuffing-style attacks, others may be from automated scripts or other benign applications accessing an authentication endpoint. (Having said that, automated malicious attack request volume far exceeds legitimate automated login attempts.) During the first week of March 2025, we found that over 94% of authentication requests came from bots (were automated), with the balance coming from humans. Over that same period, bot traffic only accounted for 30% of overall requests. So although bots don’t represent a majority of request traffic, authentication requests appear to comprise a significant portion of their activity.
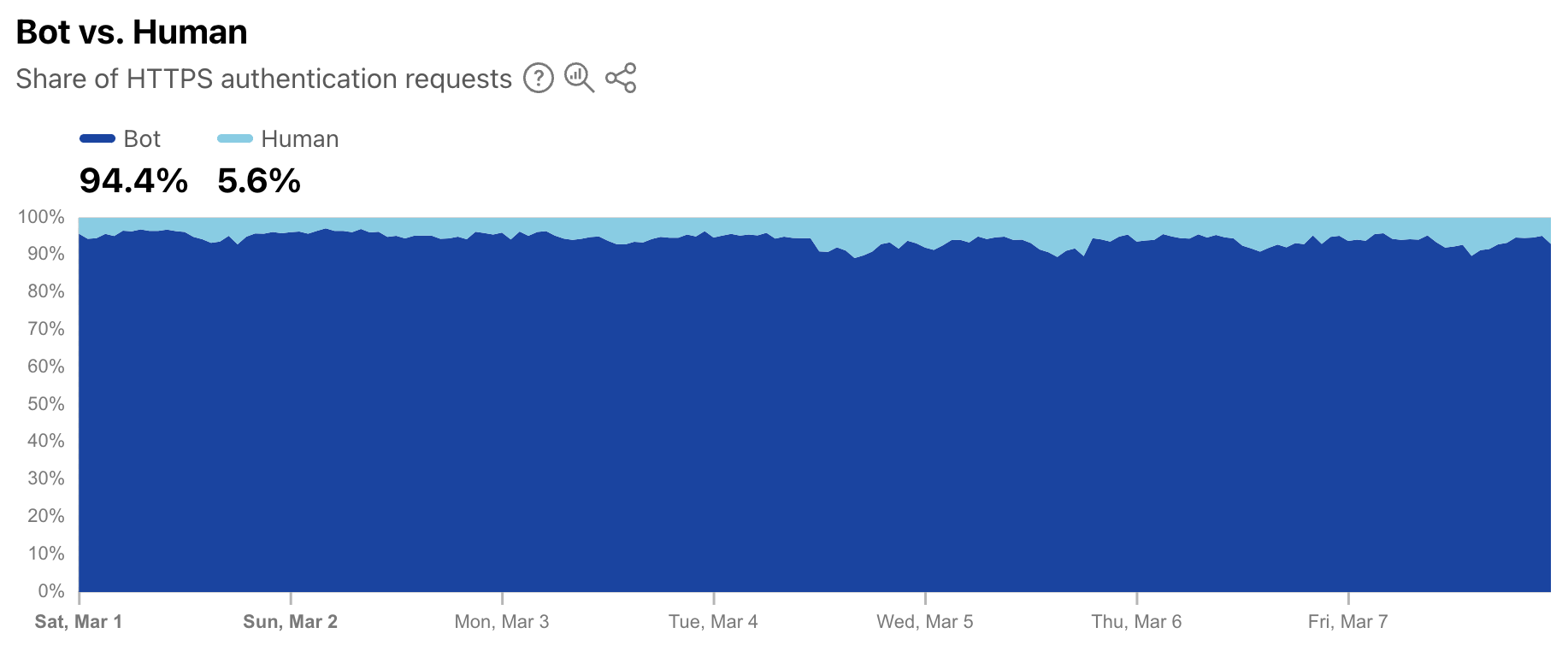
As a reminder, bot traffic describes any non-human Internet traffic, and monitoring bot levels can help spot potential malicious activities. Of course, bots can be helpful too, and Cloudflare maintains a list of verified bots to help keep the Internet healthy. Given the importance of monitoring bot activity, we have launched a new dedicated Bots page in the Traffic section of Cloudflare Radar to support these efforts. For both worldwide and location views over the selected time period, the page shows the distribution of bot (automated) vs. human HTTP requests, as well as a graph showing bot traffic trends. (Our bot score, combining machine learning, heuristics, and other techniques, is used to identify automated requests likely to be coming from bots.)
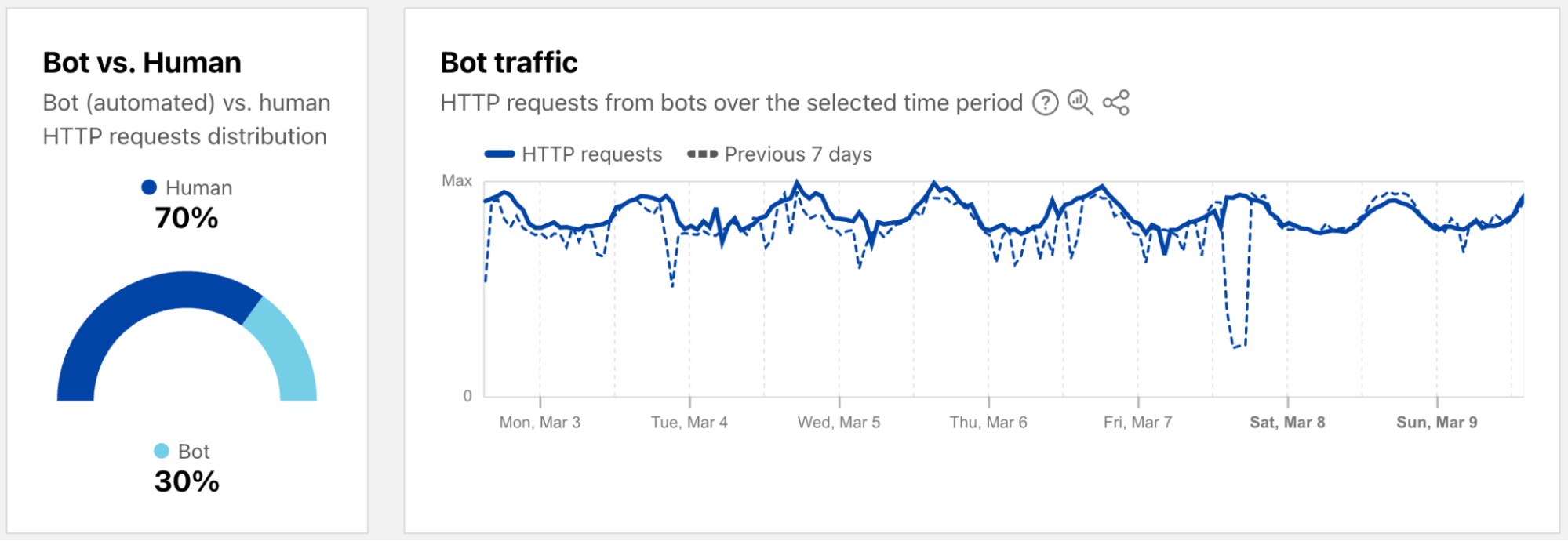
Both the 2023 and 2024 Cloudflare Radar Year in Review microsites included a “Bot Traffic Sources” section, showing the locations and networks that Cloudflare determined that the largest shares of automated/likely automated traffic was originating from. However, these traffic shares were published just once a year, aggregating traffic from January through the end of November.
In order to provide a more timely perspective, these insights are now available on the new Radar Bots page. Similar to the new DDoS attacks content discussed above, the worldwide view includes a choropleth map and table illustrating the locations originating the largest shares of all bot traffic. (Note that a similar Traffic Characteristics map and table on the Traffic Overview page ranks locations by the bot traffic share of the location’s total traffic.) Similar to Year in Review data linked above, the United States continues to originate the largest share of bot traffic.
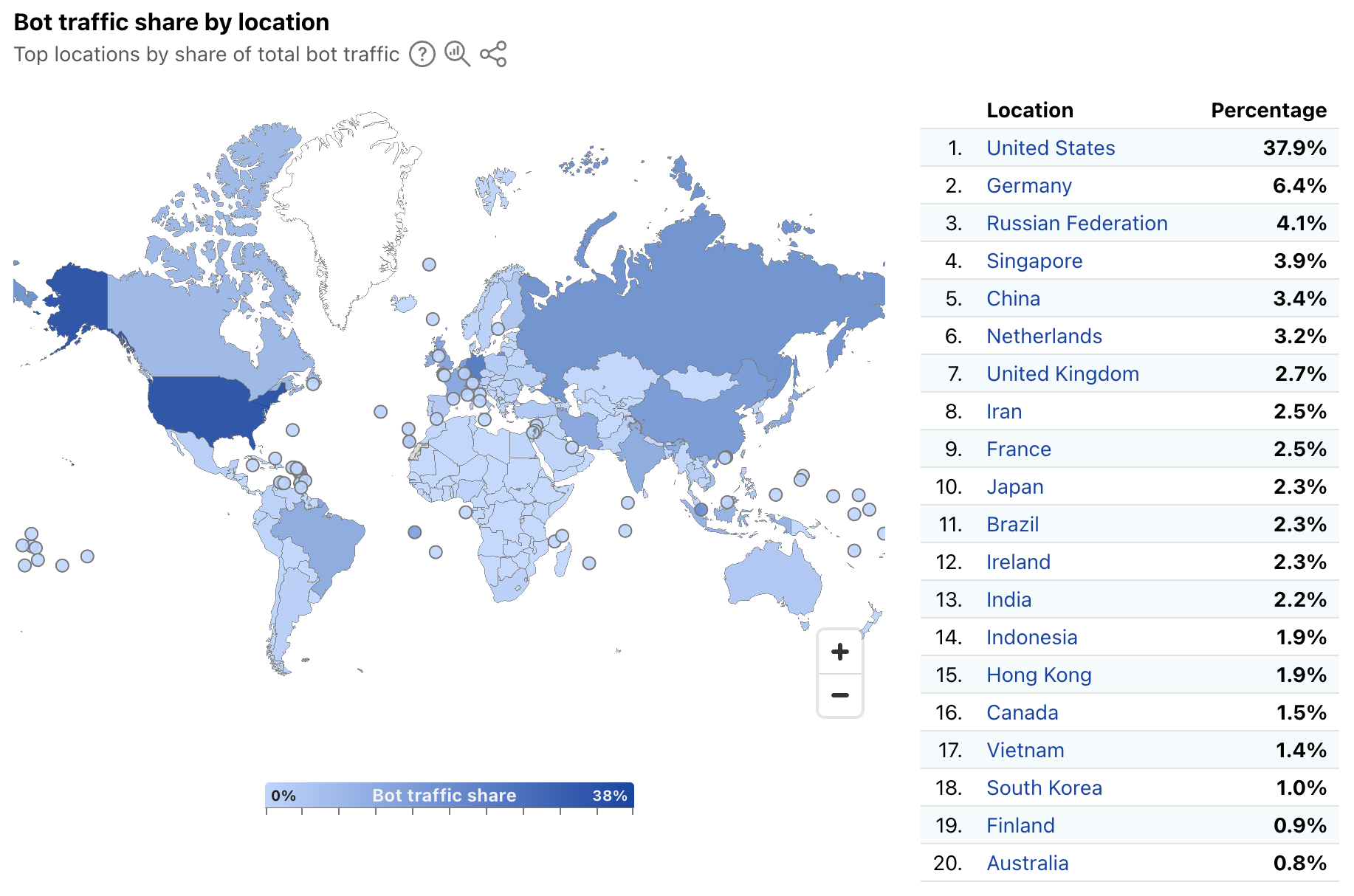
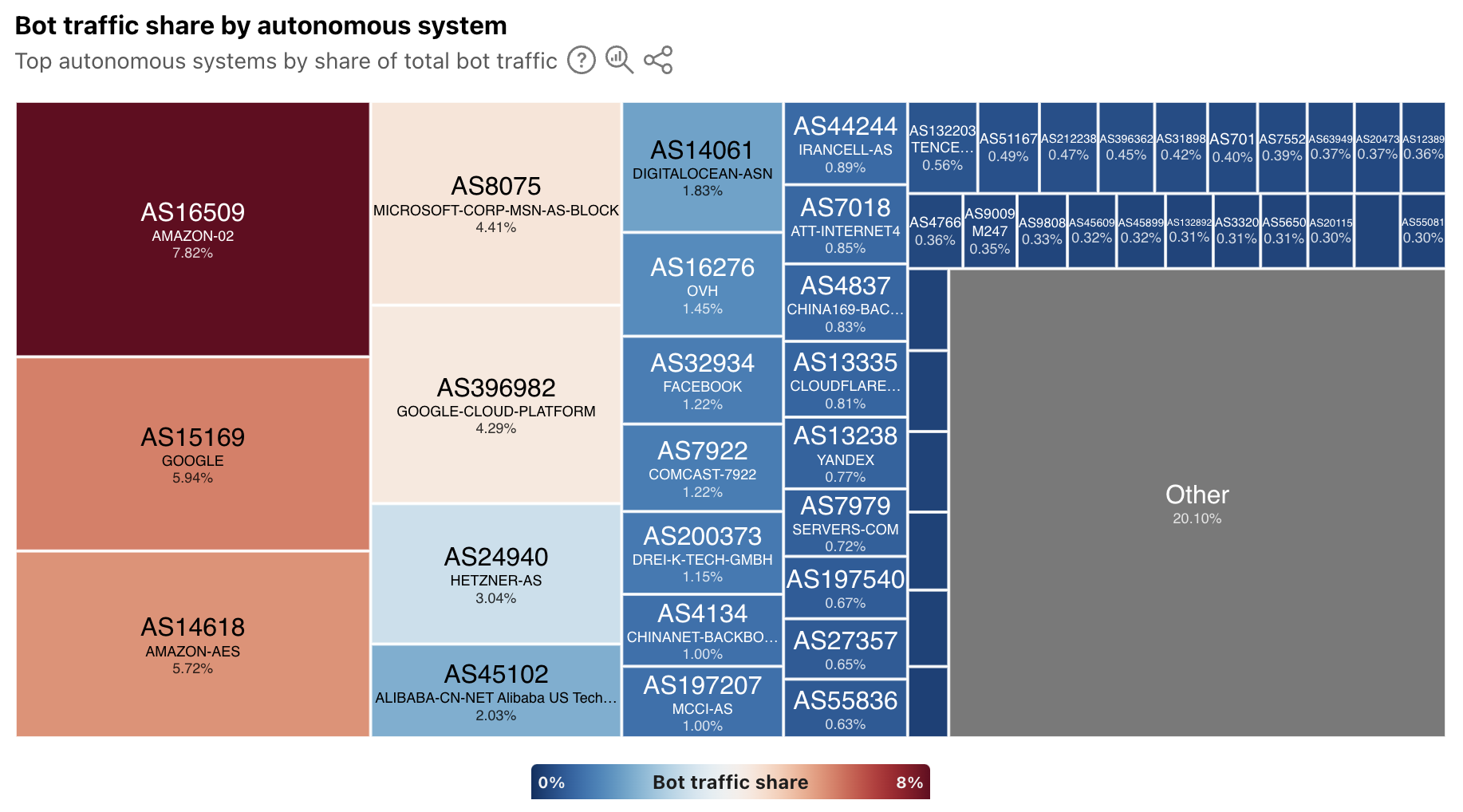
In addition, the worldwide view also breaks out bot traffic share by AS, mirroring the treemap shown in the Year in Review. As we have noted previously, cloud platform providers account for a significant amount of bot traffic.
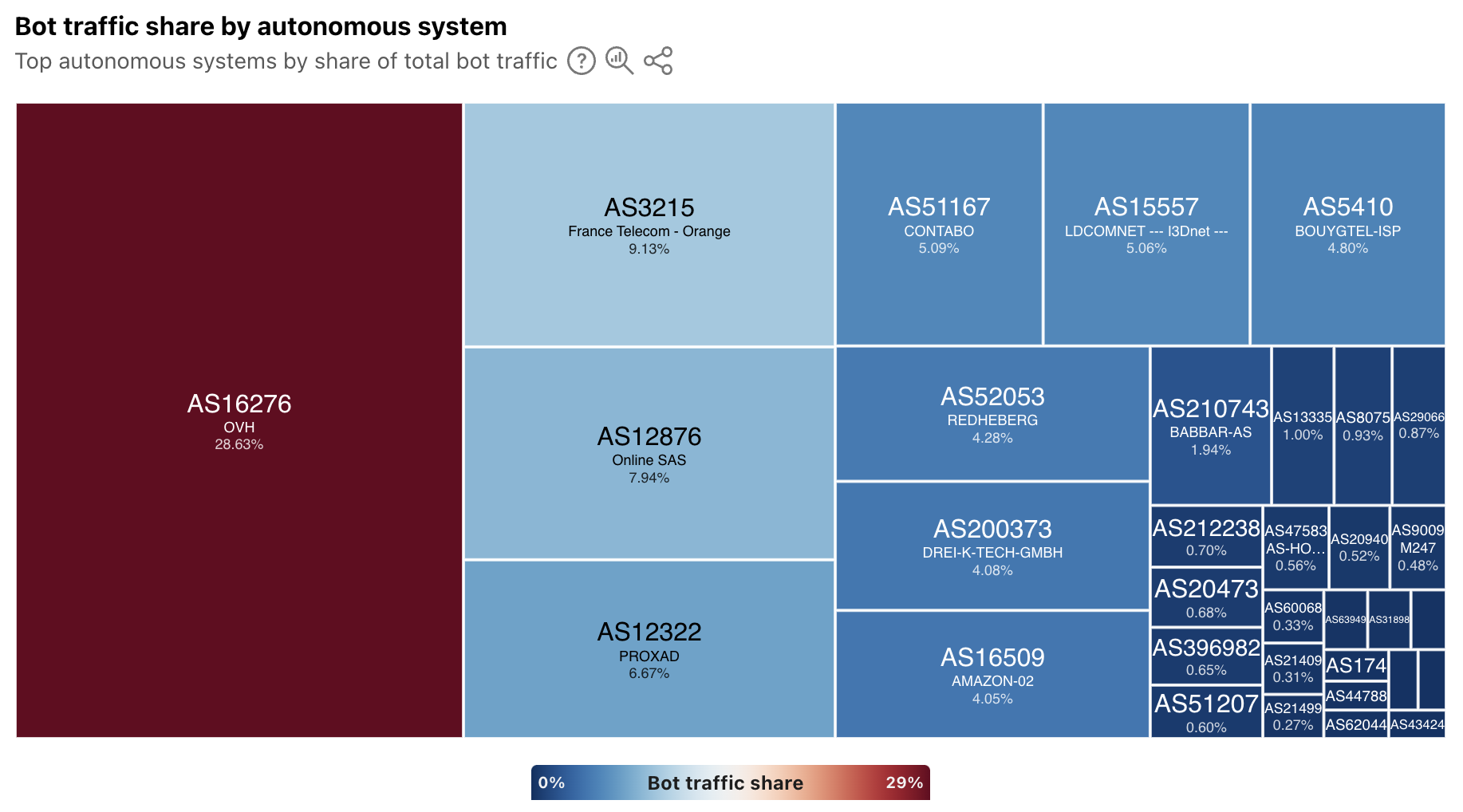
At a location level, depending on the country/region selected, the top sources of bot traffic may be cloud/hosting providers, consumer/business network providers, or a mix. For instance, France’s distribution is shown below, and four ASNs account for just over half of the country’s bot traffic. Of these ASNs, two (AS16276 and AS12876) belong to cloud/hosting providers, and two (AS3215 and AS12322) belong to network providers.
In addition, the Verified Bots list has been moved to the new Bots page on Radar. The data shown and functionality remains unchanged, and links to the old location will automatically be redirected to the new one.
The Cloudflare dashboard provides customers with specific views of security trends, application and network layer attacks, and bot activity across their sites and applications. While these views are useful at an individual customer level, aggregated views at a worldwide, location, and network level provide a macro-level perspective on trends and activity. These aggregated views available on Cloudflare Radar not only help customers understand how their observations compare to the larger whole, but they also help the industry understand emerging threats that may require action.
The underlying data for the graphs and data discussed above is available via the Radar API (Application Layer, Network Layer, Bots, Leaked Credentials). The data can also be interactively explored in more detail across locations, networks, and time periods using Radar’s Data Explorer and AI Assistant. And as always, Radar and Data Explorer charts and graphs are downloadable for sharing, and embeddable for use in your own blog posts, websites, or dashboards.
If you share our security, attacks, or bots graphs on social media, be sure to tag us: @CloudflareRadar and @1111Resolver (X), noc.social/@cloudflareradar (Mastodon), and radar.cloudflare.com (Bluesky). If you have questions or comments, you can reach out to us on social media, or contact us via email.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/01/the-first-password-on-the-internet.html
It was created in 1973 by Peter Kirstein:
So from the beginning I put password protection on my gateway. This had been done in such a way that even if UK users telephoned directly into the communications computer provided by Darpa in UCL, they would require a password.
In fact this was the first password on Arpanet. It proved invaluable in satisfying authorities on both sides of the Atlantic for the 15 years I ran the service during which no security breach occurred over my link. I also put in place a system of governance that any UK users had to be approved by a committee which I chaired but which also had UK government and British Post Office representation.
I wish he’d told us what that password was.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/11/good-essay-on-the-history-of-bad-password-policies.html
Stuart Schechter makes some good points on the history of bad password policies:
Morris and Thompson’s work brought much-needed data to highlight a problem that lots of people suspected was bad, but that had not been studied scientifically. Their work was a big step forward, if not for two mistakes that would impede future progress in improving passwords for decades.
First, was Morris and Thompson’s confidence that their solution, a password policy, would fix the underlying problem of weak passwords. They incorrectly assumed that if they prevented the specific categories of weakness that they had noted, that the result would be something strong. After implementing a requirement that password have multiple characters sets or more total characters, they wrote:
These improvements make it exceedingly difficult to find any individual password. The user is warned of the risks and if he cooperates, he is very safe indeed.
As should be obvious now, a user who chooses “p@ssword” to comply with policies such as those proposed by Morris and Thompson is not very safe indeed. Morris and Thompson assumed their intervention would be effective without testing its efficacy, considering its unintended consequences, or even defining a metric of success to test against. Not only did their hunch turn out to be wrong, but their second mistake prevented anyone from proving them wrong.
That second mistake was convincing sysadmins to hash passwords, so there was no way to evaluate how secure anyone’s password actually was. And it wasn’t until hackers started stealing and publishing large troves of actual passwords that we got the data: people are terrible at generating secure passwords, even with rules.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/11/iot-devices-in-password-spraying-botnet.html
Microsoft is warning Azure cloud users that a Chinese controlled botnet is engaging in “highly evasive” password spraying. Not sure about the “highly evasive” part; the techniques seem basically what you get in a distributed password-guessing attack:
“Any threat actor using the CovertNetwork-1658 infrastructure could conduct password spraying campaigns at a larger scale and greatly increase the likelihood of successful credential compromise and initial access to multiple organizations in a short amount of time,” Microsoft officials wrote. “This scale, combined with quick operational turnover of compromised credentials between CovertNetwork-1658 and Chinese threat actors, allows for the potential of account compromises across multiple sectors and geographic regions.”
Some of the characteristics that make detection difficult are:
- The use of compromised SOHO IP addresses
- The use of a rotating set of IP addresses at any given time. The threat actors had thousands of available IP addresses at their disposal. The average uptime for a CovertNetwork-1658 node is approximately 90 days.
- The low-volume password spray process; for example, monitoring for multiple failed sign-in attempts from one IP address or to one account will not detect this activity.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/09/nist-recommends-some-common-sense-password-rules.html
NIST’s second draft of its “SP 800-63-4“—its digital identify guidelines—finally contains some really good rules about passwords:
The following requirements apply to passwords:
- lVerifiers and CSPs SHALL require passwords to be a minimum of eight characters in length and SHOULD require passwords to be a minimum of 15 characters in length.
- Verifiers and CSPs SHOULD permit a maximum password length of at least 64 characters.
- Verifiers and CSPs SHOULD accept all printing ASCII [RFC20] characters and the space character in passwords.
- Verifiers and CSPs SHOULD accept Unicode [ISO/ISC 10646] characters in passwords. Each Unicode code point SHALL be counted as a signgle character when evaluating password length.
- Verifiers and CSPs SHALL NOT impose other composition rules (e.g., requiring mixtures of different character types) for passwords.
- Verifiers and CSPs SHALL NOT require users to change passwords periodically. However, verifiers SHALL force a change if there is evidence of compromise of the authenticator.
- Verifiers and CSPs SHALL NOT permit the subscriber to store a hint that is accessible to an unauthenticated claimant.
- Verifiers and CSPs SHALL NOT prompt subscribers to use knowledge-based authentication (KBA) (e.g., “What was the name of your first pet?”) or security questions when choosing passwords.
- Verifiers SHALL verify the entire submitted password (i.e., not truncate it).
Hooray.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/07/compromising-the-secure-boot-process.html
This isn’t good:
On Thursday, researchers from security firm Binarly revealed that Secure Boot is completely compromised on more than 200 device models sold by Acer, Dell, Gigabyte, Intel, and Supermicro. The cause: a cryptographic key underpinning Secure Boot on those models that was compromised in 2022. In a public GitHub repository committed in December of that year, someone working for multiple US-based device manufacturers published what’s known as a platform key, the cryptographic key that forms the root-of-trust anchor between the hardware device and the firmware that runs on it. The repository was located at https://github.com/raywu-aaeon/Ryzen2000_4000.git, and it’s not clear when it was taken down.
The repository included the private portion of the platform key in encrypted form. The encrypted file, however, was protected by a four-character password, a decision that made it trivial for Binarly, and anyone else with even a passing curiosity, to crack the passcode and retrieve the corresponding plain text. The disclosure of the key went largely unnoticed until January 2023, when Binarly researchers found it while investigating a supply-chain incident. Now that the leak has come to light, security experts say it effectively torpedoes the security assurances offered by Secure Boot.
[…]
These keys were created by AMI, one of the three main providers of software developer kits that device makers use to customize their UEFI firmware so it will run on their specific hardware configurations. As the strings suggest, the keys were never intended to be used in production systems. Instead, AMI provided them to customers or prospective customers for testing. For reasons that aren’t clear, the test keys made their way into devices from a nearly inexhaustive roster of makers. In addition to the five makers mentioned earlier, they include Aopen, Foremelife, Fujitsu, HP, Lenovo, and Supermicro.
Post Syndicated from Garrett Galow original https://blog.cloudflare.com/helping-keep-customers-safe-with-leaked-password-notification
Password reuse is a real problem. When people use the same password across multiple services, it creates a risk that a breach of one service will give attackers access to a different, apparently unrelated, service. Attackers know people reuse passwords and build giant lists of known passwords and known usernames or email addresses.
If you got to the end of that paragraph and realized you’ve reused the same password multiple places, stop reading and go change those passwords. We’ll wait.
To help protect Cloudflare customers who have used a password attackers know about, we are releasing a feature to improve the security of the Cloudflare dashboard for all our customers by automatically checking whether their Cloudflare user password has appeared in an attacker’s list. Cloudflare will securely check a customer’s password against threat intelligence sources that monitor data breaches in other services.
If a customer logs in to Cloudflare with a password that was leaked in a breach elsewhere on the Internet, Cloudflare will alert them and ask them to choose a new password.
For some customers, the news that their password was known to hackers will come as a surprise – no one wants to intentionally use passwords that they know have been leaked elsewhere. To help customers avoid being locked out when they urgently need to use their Cloudflare dashboard, the leaked password check will provide a warning to the customer for the first three login attempts. After those three attempts, Cloudflare will require that the customer reset their password.
Resetting a leaked password is just the first step in Internet account security. The best way to protect your Cloudflare account, or any account, is to add two-factor authentication, such as using a hardware security key or an authenticator application, or to rely on a single sign-on integration. Cloudflare makes it easy for any user to add two-factor authentication security to their account through app-based codes, hardware keys, or passkeys. Cloudflare account Super Administrators can also require that all members enable two-factor authentication.
Whether or not a user has been impacted in a data breach, we encourage everyone to add two-factor authentication security to their Cloudflare account.
Each time you authenticate to a service on the Internet with a username and password, that service can take a range of steps to protect your credentials.
More secure providers will hash the passwords. Hashing uses a cryptographic algorithm to convert the password into a random string of characters. Some platforms will layer on additional safeguards like a salt mechanism that introduces a random value to each password before the hashing process to ensure that two identical passwords do not have identical hashes.
These protections, combined with rate limits on login attempts, prevent brute force attacks. However, even for providers that adopt these best practices, users can still become victims of determined attackers when bad actors gain access to breached password databases. Attackers can collect compromised email password pairs to gain access to user accounts elsewhere as part of targeted attacks.
When vendors discover these kinds of compromised accounts, in many cases they will quickly force a password reset. However, resetting a leaked password in one application can still leave you vulnerable in other applications if you reused that password in other places and do not change your credentials everywhere.
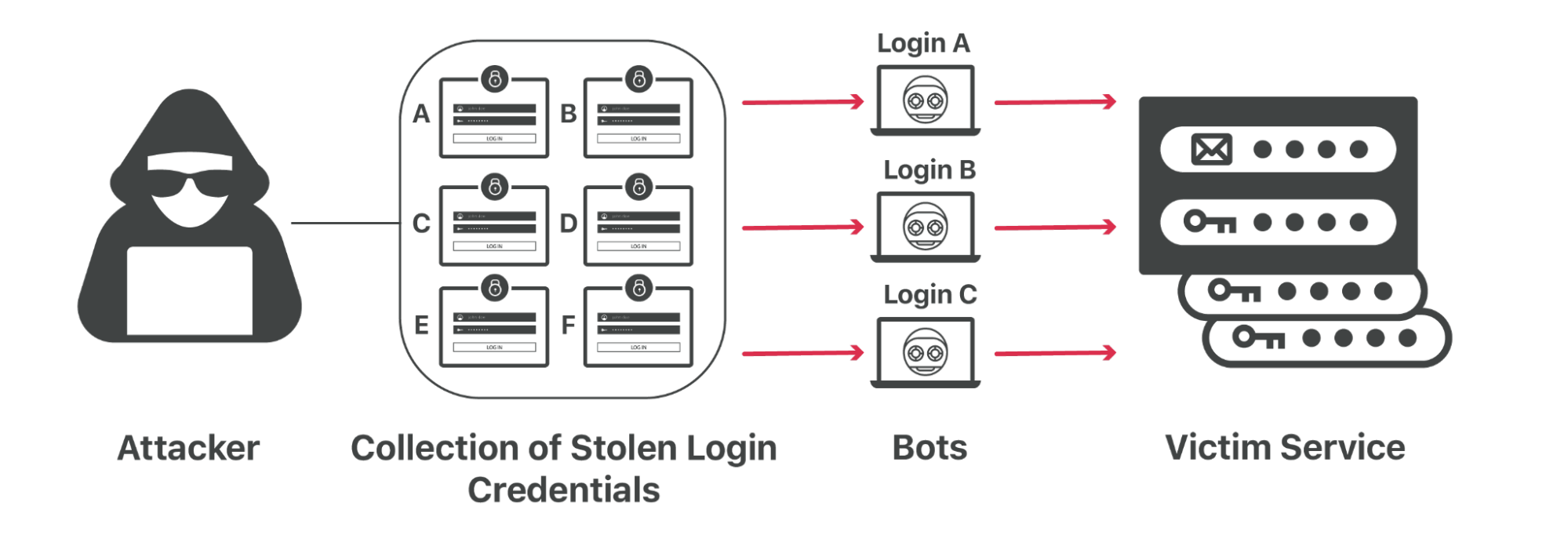
That kind of password reuse means that an attacker can steal your credentials from one Internet service and try them against dozens of other popular destinations to see where you reuse the same password.
These so-called credential stuffing attacks have become more prevalent as breaches pile up. Attackers can sit on large troves of credentials for months or years, waiting to sell them to another bad actor or to use them in targeted attacks. For customers who want to protect themselves from these and other attacks that can compromise their end customer’s accounts, Cloudflare has solutions like bot management, exposed credential checks, and rate limiting available to help defend against these kinds of attacks
If every password you use is unique, then a data breach in one vendor will be limited to just that particular system. For that reason, we encourage users to adopt a password manager that can create and remember unique passwords for each service that you use. Thankfully, the most popular operating systems now include password managers by default, and multiplatform third party options also make it easy for users to adopt this practice.
However, unique passwords are still vulnerable to phishing attacks. The best way to protect any Internet account is to add two-factor authentication (2FA). Two-factor authentication provides a comprehensive defense against credential stuffing attacks. When using two-factor authentication to log in, you must use your password and, for example, a one-time code from an app or a tap on a physical hardware key. The password alone is not enough to access your account.
Adoption of two-factor authentication, specifically hardware keys, has been shown to be able to eliminate 99.9% of account takeovers, since the attacker must also get access to your second factor in addition to your password. In the case of hardware keys, they need to physically obtain the key.
When a user attempts to log into Cloudflare, we will check if the password used has been leaked in a known data breach of another service or application on the Internet. We maintain data on breaches of Internet services that we can use to search against. Because we use password hashes, scrambled versions of the original password that can’t be easily reversed, we compare a hash of the password to hashes of compromised passwords found in these lists from other attacks. An additional benefit, beside the security of hashes, is the ability to perform fast lookups, much faster than plaintext searches. This means that we can perform these checks without adding significant latency to the login process for users.
Because of the potential impact of a Cloudflare account being compromised, we opt for a more secure approach of disallowing leaked credentials regardless of whether they were associated with the specific user’s email or not. Unfortunately, data breaches are likely to continue to happen. Therefore, being proactive helps reduce the risk of new breaches that contain the email and password pair allowing for an account to be compromised before the data is available to us.
If we detect a match, the user will be prompted with the following warning. We will also send an email notification with instructions on what to do and a unique link in order to reset the password.
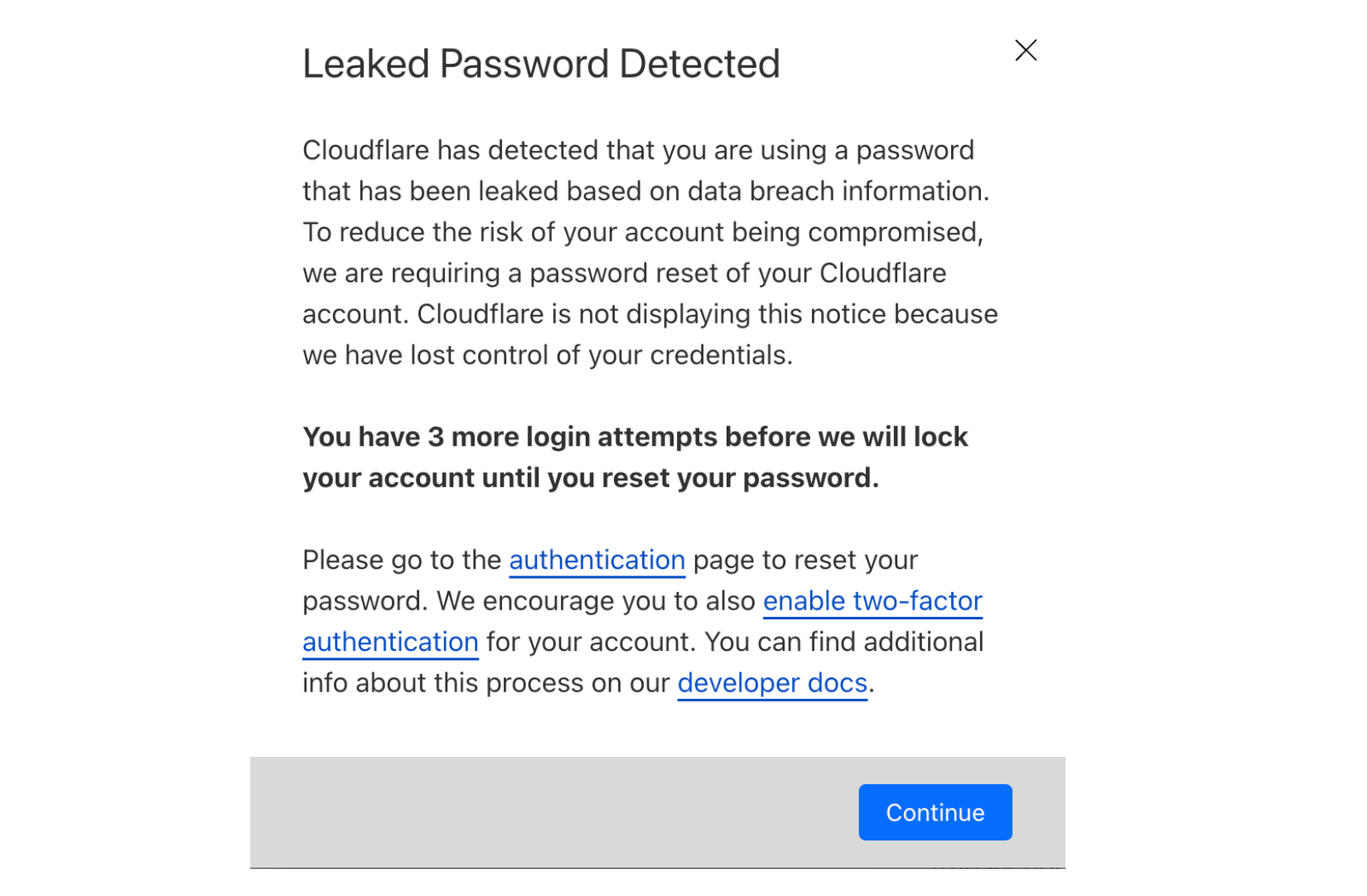
At this point, the user will still be able to log in to their Cloudflare account. We strongly encourage users to reset their password immediately. However, we know that in some cases you need to reach the Cloudflare dashboard immediately or do not have convenient access to the email used for the account. Cloudflare will allow two additional login attempts to succeed with the same compromised password before forcing the user to reset their password.
To reset a password in Cloudflare Dashboard, navigate to the Authentication page in My Profile. From here, select Change Password and enter both the current password to authenticate and a new, non-compromised password. Alternatively, for those whose password was leaked, upon login an email will be sent with a unique link to reset the password.
Forcing users to reset compromised credentials helps prevent attacks from spreading on the Internet, but it’s just a small piece of improved account security. We know that adding the next step, second factor authentication, can be cumbersome. We have committed to CISA’s Secure by Design Pledge, which includes working to increase 2FA adoption across the industry. We will share our plans on how we will be implementing the pledge by mid-2025.
Adding multifactor authentication to every one of your accounts on the Internet can still be a chore, no matter how much the experience is improved. It’s much easier if you can just do it with one account and use that account to authenticate into other services and applications – a single-sign on (SSO) flow. Right now, our SSO feature is limited to enterprise accounts, and we plan to change that. We will allow users to access Cloudflare through other providers like Google, GitHub, and more. Allowing users to reduce how many unique password and 2FA combinations they have to keep track of helps to reduce the likelihood of being impacted by future password breaches.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/06/breaking-a-password-manager.html
Interesting story of breaking the security of the RoboForm password manager in order to recover a cryptocurrency wallet password.
Grand and Bruno spent months reverse engineering the version of the RoboForm program that they thought Michael had used in 2013 and found that the pseudo-random number generator used to generate passwords in that version—and subsequent versions until 2015—did indeed have a significant flaw that made the random number generator not so random. The RoboForm program unwisely tied the random passwords it generated to the date and time on the user’s computer—it determined the computer’s date and time, and then generated passwords that were predictable. If you knew the date and time and other parameters, you could compute any password that would have been generated on a certain date and time in the past.
If Michael knew the day or general time frame in 2013 when he generated it, as well as the parameters he used to generate the password (for example, the number of characters in the password, including lower- and upper-case letters, figures, and special characters), this would narrow the possible password guesses to a manageable number. Then they could hijack the RoboForm function responsible for checking the date and time on a computer and get it to travel back in time, believing the current date was a day in the 2013 time frame when Michael generated his password. RoboForm would then spit out the same passwords it generated on the days in 2013.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/05/the-uk-bans-default-passwords.html
The UK is the first country to ban default passwords on IoT devices.
On Monday, the United Kingdom became the first country in the world to ban default guessable usernames and passwords from these IoT devices. Unique passwords installed by default are still permitted.
The Product Security and Telecommunications Infrastructure Act 2022 (PSTI) introduces new minimum-security standards for manufacturers, and demands that these companies are open with consumers about how long their products will receive security updates for.
The UK may be the first country, but as far as I know, California is the first jurisdiction. It banned default passwords in 2018, the law taking effect in 2020.
This sort of thing benefits all of us everywhere. IoT manufacturers aren’t making two devices, one for California and one for the rest of the US. And they’re not going to make one for the UK and another for the rest of Europe, either. They’ll remove the default passwords and sell those devices everywhere.
Another news article.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/02/on-passkey-usability.html
Matt Burgess tries to only use passkeys. The results are mixed.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/01/canadian-citizen-gets-phone-back-from-police.html
After 175 million failed password guesses, a judge rules that the Canadian police must return a suspect’s phone.
[Judge] Carter said the investigation can continue without the phones, and he noted that Ottawa police have made a formal request to obtain more data from Google.
“This strikes me as a potentially more fruitful avenue of investigation than using brute force to enter the phones,” he said.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/10/cisco-cant-stop-using-hard-coded-passwords.html
There’s a new Cisco vulnerability in its Emergency Responder product:
This vulnerability is due to the presence of static user credentials for the root account that are typically reserved for use during development. An attacker could exploit this vulnerability by using the account to log in to an affected system. A successful exploit could allow the attacker to log in to the affected system and execute arbitrary commands as the root user.
This is not the first time Cisco products have had hard-coded passwords made public. You’d think it would learn.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/09/using-hacked-lastpass-keys-to-steal-cryptocurrency.html
Remember last November, when hackers broke into the network for LastPass—a password database—and stole password vaults with both encrypted and plaintext data for over 25 million users?
Well, they’re now using that data break into crypto wallets and drain them: $35 million and counting, all going into a single wallet.
That’s a really profitable hack. (It’s also bad opsec. The hackers need to move and launder all that money quickly.)
Look, I know that online password databases are more convenient. But they’re also risky. This is why my Password Safe is local only. (I know this sounds like a commercial, but Password Safe is not a commercial product.)
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/07/practice-your-security-prompting-skills.html
Gandalf is an interactive LLM game where the goal is to get the chatbot to reveal its password. There are eight levels of difficulty, as the chatbot gets increasingly restrictive instructions as to how it will answer. It’s a great teaching tool.
I am stuck on Level 7.
Feel free to give hints and discuss strategy in the comments below. I probably won’t look at them until I’ve cracked the last level.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/07/the-password-game.html
Amusing parody of password rules.
For example, at a certain level, your password must include today’s Wordle answer. And then there’s rule #27: “At least 50% of your password must be in the Wingdings font.”
EDITED TO ADD (7/13): Here are all the rules.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/03/dumb-password-rules.html
Examples of dumb password rules.
There are some pretty bad disasters out there.
My worst experiences are with sites that have artificial complexity requirements that cause my personal password-generation systems to fail. Some of the systems on the list are even worse: when they fail they don’t tell you why, so you just have to guess until you get it right.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/02/passwords-are-terrible-surprising-no-one.html
This is the result of a security audit:
More than a fifth of the passwords protecting network accounts at the US Department of the Interior—including Password1234, Password1234!, and ChangeItN0w!—were weak enough to be cracked using standard methods, a recently published security audit of the agency found.
[…]
The results weren’t encouraging. In all, the auditors cracked 18,174—or 21 percent—of the 85,944 cryptographic hashes they tested; 288 of the affected accounts had elevated privileges, and 362 of them belonged to senior government employees. In the first 90 minutes of testing, auditors cracked the hashes for 16 percent of the department’s user accounts.
The audit uncovered another security weakness—the failure to consistently implement multi-factor authentication (MFA). The failure extended to 25—or 89 percent—of 28 high-value assets (HVAs), which, when breached, have the potential to severely impact agency operations.
Original story:
To make their point, the watchdog spent less than $15,000 on building a password-cracking rig—a setup of a high-performance computer or several chained together - with the computing power designed to take on complex mathematical tasks, like recovering hashed passwords. Within the first 90 minutes, the watchdog was able to recover nearly 14,000 employee passwords, or about 16% of all department accounts, including passwords like ‘Polar_bear65’ and ‘Nationalparks2014!’.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/12/lastpass-breach.html
Last August, LastPass reported a security breach, saying that no customer information—or passwords—were compromised. Turns out the full story is worse:
While no customer data was accessed during the August 2022 incident, some source code and technical information were stolen from our development environment and used to target another employee, obtaining credentials and keys which were used to access and decrypt some storage volumes within the cloud-based storage service.
[…]
To date, we have determined that once the cloud storage access key and dual storage container decryption keys were obtained, the threat actor copied information from backup that contained basic customer account information and related metadata including company names, end-user names, billing addresses, email addresses, telephone numbers, and the IP addresses from which customers were accessing the LastPass service.
The threat actor was also able to copy a backup of customer vault data from the encrypted storage container which is stored in a proprietary binary format that contains both unencrypted data, such as website URLs, as well as fully-encrypted sensitive fields such as website usernames and passwords, secure notes, and form-filled data.
That’s bad. It’s not an epic disaster, though.
These encrypted fields remain secured with 256-bit AES encryption and can only be decrypted with a unique encryption key derived from each user’s master password using our Zero Knowledge architecture. As a reminder, the master password is never known to LastPass and is not stored or maintained by LastPass.
So, according to the company, if you chose a strong master password—here’s my advice on how to do it—your passwords are safe. That is, you are secure as long as your password is resilient to a brute-force attack. (That they lost customer data is another story….)
Fair enough, as far as it goes. My guess is that many LastPass users do not have strong master passwords, even though the compromise of your encrypted password file should be part of your threat model. But, even so, note this unverified tweet:
I think the situation at @LastPass may be worse than they are letting on. On Sunday the 18th, four of my wallets were compromised. The losses are not significant. Their seeds were kept, encrypted, in my lastpass vault, behind a 16 character password using all character types.
If that’s true, it means that LastPass has some backdoor—possibly unintentional—into the password databases that the hackers are accessing. (Or that @Cryptopathic’s “16 character password using all character types” is something like “P@ssw0rdP@ssw0rd.”)
My guess is that we’ll learn more during the coming days. But this should serve as a cautionary tale for anyone who is using the cloud: the cloud is another name for “someone else’s computer,” and you need to understand how much or how little you trust that computer.
If you’re changing password managers, look at my own Password Safe. Its main downside is that you can’t synch between devices, but that’s because I don’t use the cloud for anything.
News articles. Slashdot thread.
EDITED TO ADD: People choose lousy master passwords.