Post Syndicated from Sean M. Tracey original https://aws.amazon.com/blogs/aws/announcing-amazon-sagemaker-ground-truth-plus/
Today, we’re pleased to announce the latest service in the Amazon SageMaker suite that will make labeling datasets easier than ever before. Ground Truth Plus is a turn-key service that uses an expert workforce to deliver high-quality training datasets fast, and reduces costs by up to 40 percent.
The Challenges of Machine Learning Model Creation
One of the biggest challenges in building and training machine learning (ML) models is sourcing enough high-quality, labeled data at scale to feed into and train those models so that they can make an accurate prediction.
On the face of it, labeling data might seem like a fairly straightforward task…
- Step 1: Get data
- Step 2: Label it
…but this is far from the reality.
Even before you have labelers begin annotations, you need a custom labeling workflow and user interface specific to your project so that you get a high-quality dataset. This relies on a combination of robust tooling and skilled workers, and the effort spent can be significant.
Once the data labeling workflow and user interface has been constructed, a workforce to use those systems must be organized and trained – and this is all before a single point of data has been labeled!
Finally, once the labeling systems have been built, the workflows designed, and the workforce trained and deployed, the process of passing data through that system must be monitored and checked to ensure a consistent, high-quality output. After enough data has been passed through and labeled by the system, you have arrived at the point you’ve been trying to get to all along: you finally have enough data to train the ML model.
Each of these steps represents a significant investment in time, costs, and energy. You could be spending these resources building ML models instead of labeling and managing data, and using Ground Truth Plus can help free you up to do just that.
Introducing Amazon SageMaker Ground Truth Plus
Amazon SageMaker Ground Truth Plus enables you to easily create high-quality training datasets without having to build labeling applications and manage the labeling workforce on your own. Which means you don’t even need to have deep ML expertise or extensive knowledge of workflow design and quality management. You simply provide data along with labeling requirements and Ground Truth Plus sets up the data labeling workflows and manages them on your behalf in accordance with your requirements.
For example, if you need medical experts to label radiology images, you can specify that in the guidelines you provide to Ground Truth Plus. The service will then automatically select labelers trained in radiology to label your data, and from there an expert workforce that is trained on a variety of ML tasks will start labeling the data. Ground Truth Plus brings ML-powered automation to data labeling, which increases the quality of the output dataset and decreases the data labeling costs.
Amazon SageMaker Ground Truth Plus uses a multi-step labeling workflow including ML techniques for active learning, pre-labeling, and machine validation. This reduces the time required to label datasets for a variety of use cases including computer vision and natural language processing. Finally, Ground Truth Plus provides transparency into data labeling operations and quality management through interactive dashboards and user interfaces. This lets you monitor the progress of training datasets across multiple projects, track project metrics such as daily throughput, inspect labels for quality, and provide feedback on the labeled data.
How Does It Work?
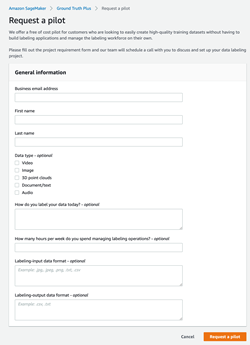
 First, let’s head to the new Ground Truth Plus console and fill out a form outlining the requirements for the data labeling project. Following that, our team of AWS Experts will schedule a call to discuss your data labeling project.
First, let’s head to the new Ground Truth Plus console and fill out a form outlining the requirements for the data labeling project. Following that, our team of AWS Experts will schedule a call to discuss your data labeling project.
After the call, you simply upload data in an Amazon Simple Storage Service (Amazon S3) bucket for labeling.
Once the data has been uploaded, our experts will set-up the data labeling workflow per your requirements and create a team of labelers with the expertise necessary to label your data effectively. This helps make sure that you have the best people possible working on your projects.
These expert labelers use the Ground Truth Plus tools we’ve built to label these datasets quickly and effectively.
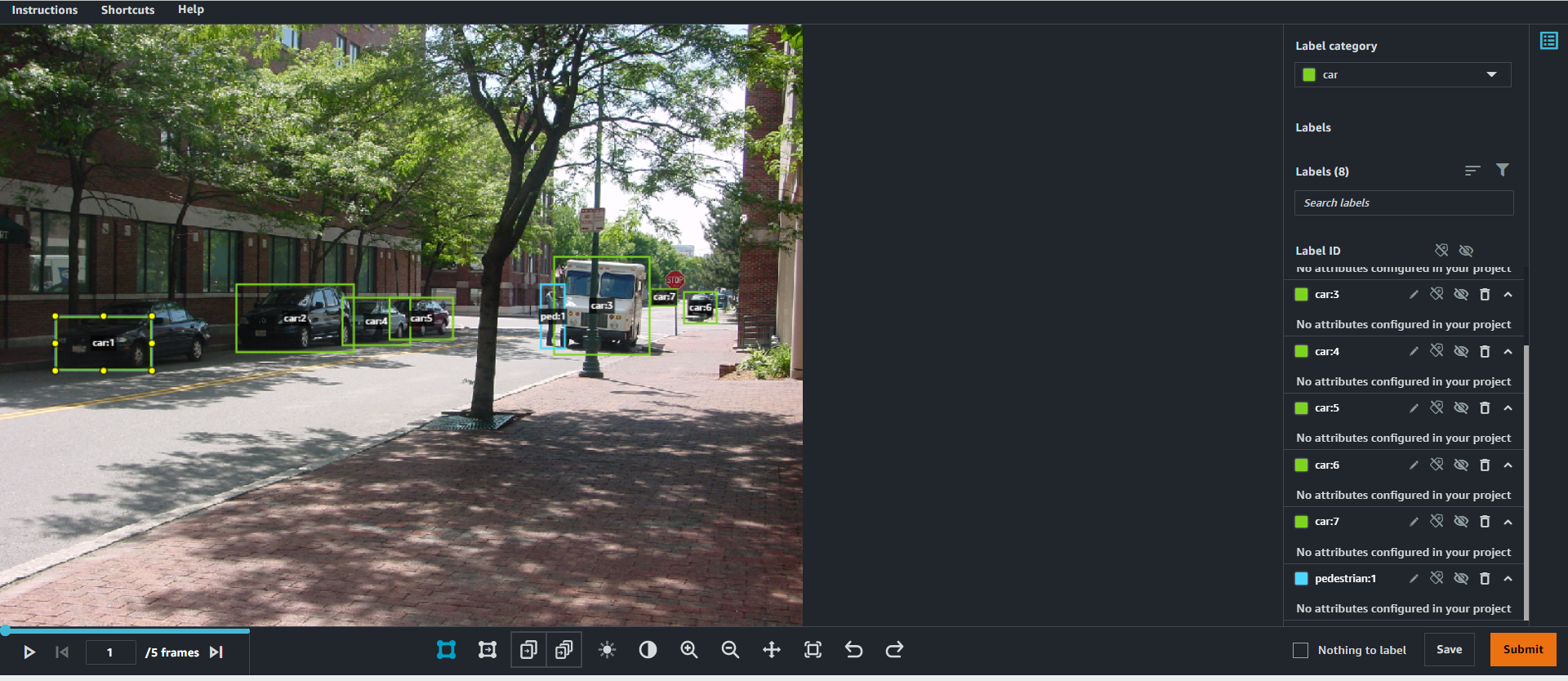
Initially, labelers will annotate the data you’ve uploaded, much like the following example image that we’ve uploaded from the CBCL StreetScenes dataset. However, as the labelers start to submit examples of labeled data, something cool begins happening: our ML systems kick in and start to pre-label the images on behalf of the expert workforce!

As more and more data is labeled by the expert workforce, the ML model becomes better at pre-labeling those images. This means that there’s less need for a human to spend as much time creating each individual label for every object of interest in a dataset. Less time spent on labeling means lower costs for you, and it also means a quicker turnaround in creating a dataset that can be used for training a model – all without sacrificing quality.

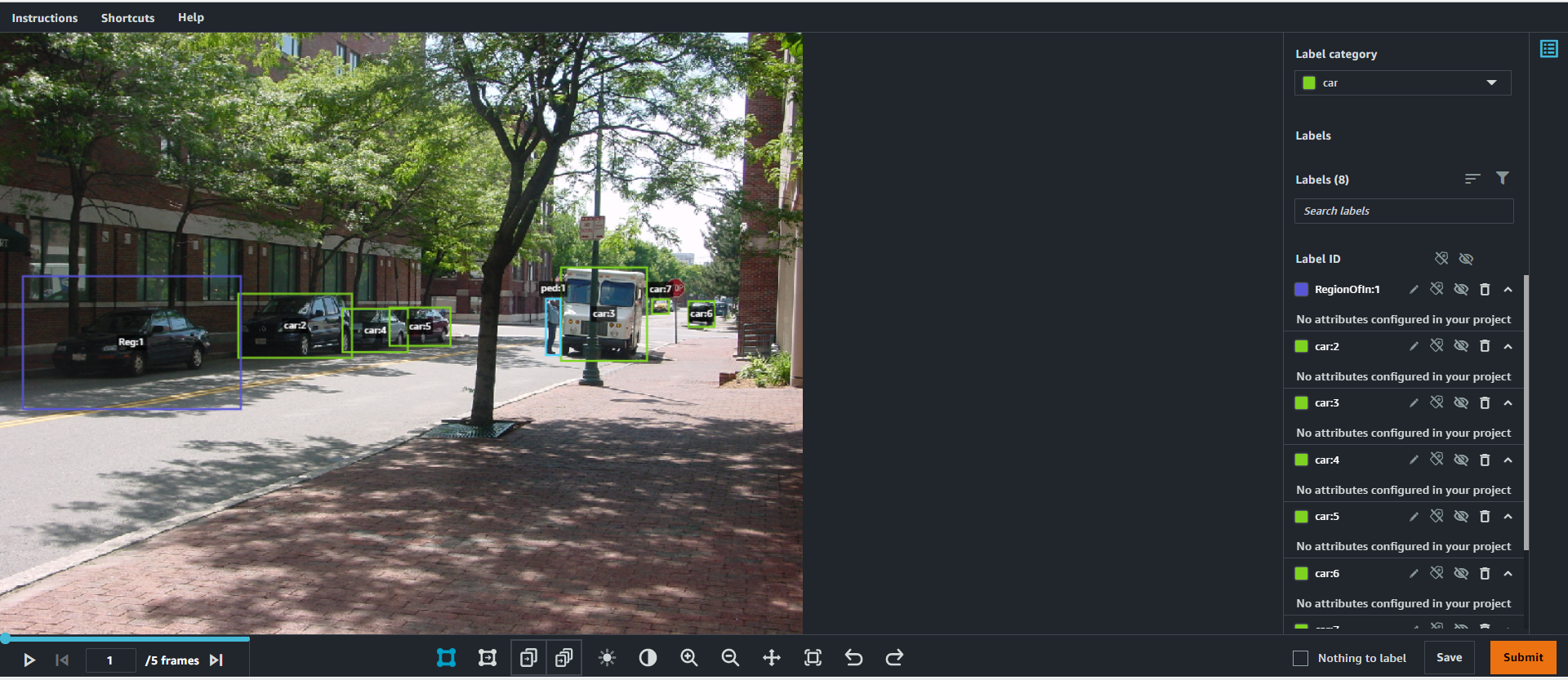
As the process continues, these ML models will also start to highlight potential areas of interest that the labeling workforce may have missed or incorrectly labeled through machine validation (indicated below by the purple box). Once an area of interest has been highlighted, a human labeler can view and either confirm or delete the suggestion that the model has made. This iteratively improves the pre-labeling and machine validation stages, further reducing the time needed by a labeler to manually label the data, and ensures a high-quality output throughout the process.

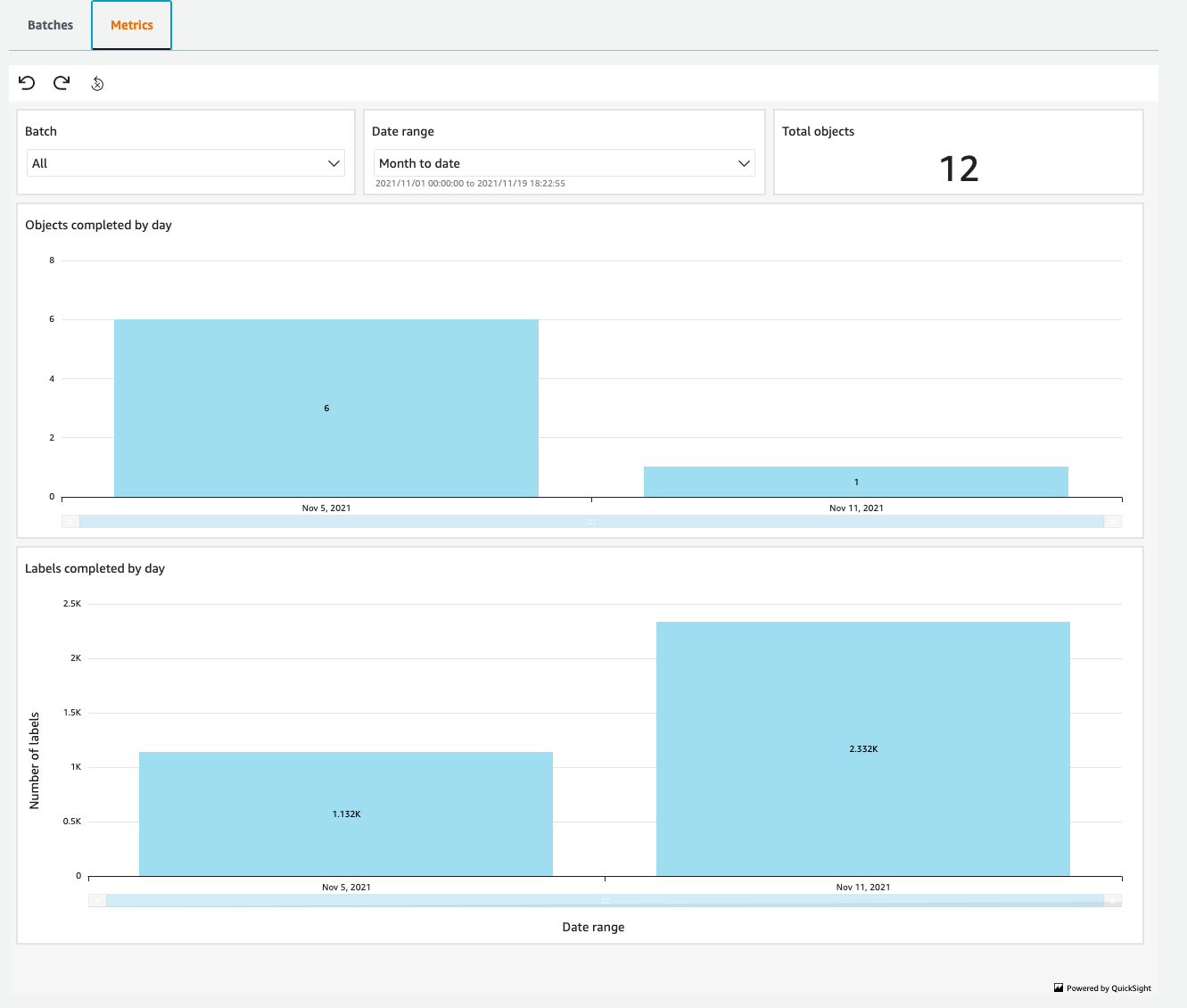
While this is all going on, you can monitor the progress and output of the project using the Ground Truth Plus Project Portal. Within this portal, you can track the amount of data labeled on a day-by-day basis, and make sure that the project is progressing at an acceptable rate.

With each batch of images uploaded and labeled, you can decide whether to accept them or send them back for relabeling if something has been missed.
Finally, when the labeling process has completed, you can retrieve the labeled data from a secure S3 bucket and get to the business of training models.
Find out more
Today, Amazon SageMaker Ground Truth Plus is available in the N. Virginia (us-east-1) region.
To learn more: