Post Syndicated from Oleksiy Volkov original https://aws.amazon.com/blogs/architecture/implementing-lightweight-on-premises-api-connectivity-using-inverting-traffic-proxy/
This post will explore the use of lightweight application inversion proxy as a solution for multi-point hybrid or multi-cloud, API-level connectivity for cases where AWS Direct Connect or VPN may not be practical. Then, we will present a sample solution and explain how it addresses typical challenges involved in this space.
Defining the issue
Large ISV providers and integration vendors often need to have API-level integration between a central cloud-based system and a number of on-premises APIs. Use cases can range from refactoring/modernization initiatives to interfacing with legacy on-premises applications, which have no direct migration path to the cloud.
The typical approach is to use VPN or Direct Connect, as they can provide significant benefits in terms of latency and security. However, they are not always practical in situations involving multi-source systems deployed by various groups or organizations that may have significant budget, process, or timeline constraints.
Conceptual solution
An option that addresses the connectivity need is an inverting application proxy, which can be deployed as a lightweight executable on an on-premises backend. The locally deployed agent can communicate with the proxy server on AWS using an inverted communication pattern. This means that the agent will establish outbound connection to the proxy, and it will use the connection to receive inbound requests, too. Figure 1 describes a sample architecture using inverting proxy pattern using Amazon API Gateway façade.
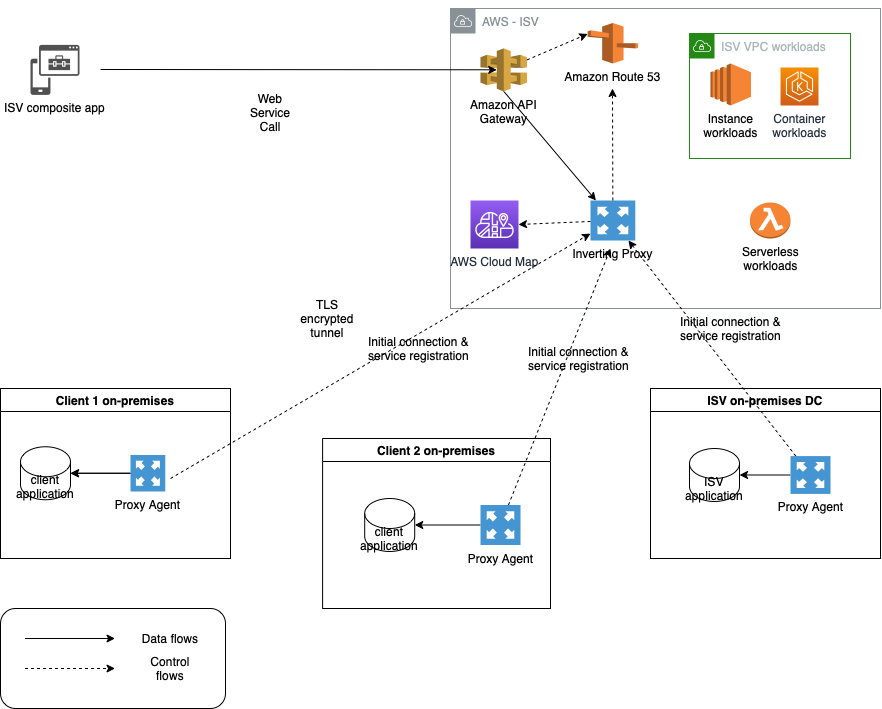
Figure 1. Inverting application proxy
The advantages of this approach include ease-of-deployment (drop-in executable agent) and -configuration. As the proxy inverts the direction of application connectivity to originate from on-premises servers, the local firewall does not need to be reconfigured to open additional ports needed for traditional proxy deployment.
Realizing the solution on AWS
We have built a sample traffic routing solution based on the original open-source Inverting Proxy and Agent by Ian Maddox, Jason Cooke, and Omar Janjur. The solution is written in Go and leverages multiple AWS services to provide additional telemetry, security, and discoverability capabilities that address the common needs of enterprise customers.
The solution is comprised of an inverting proxy and a forwarding agent. The inverting proxy is deployed on AWS as a stand-alone executable running on Amazon Elastic Compute Cloud (EC2) and responsible for forwarding traffic to the agent. The agent can be deployed as a binary or container within the target on-premises system.
Upon starting, the agent will establish an outbound connection with the proxy and local sever application. Once established, the proxy will use it in reverse to forward all incoming client requests through the agent and to the backend application. The connection is secured by Transport Layer Security (TLS) to protect communications between client and proxy and between agent and backend application.
This solution uses a unique backend ID and IAM user/role tags to identify different backend servers and control access to proxies. The backend ID is passed as a command-line parameter to the agent. The agent checks the IAM account or IAM role Amazon EC2 is running under for tag “AllowedBackends”. The tag contains coma-separated list of backend IDs that the agent is allowed to access. The connectivity is established only if the provided backend ID matches one of the values in the coma-separated list.
The solution supports native integration with AWS Cloud Map to enable automatic discoverability of remote API endpoints. Upon start and once the IAM access control checks are successfully validated, the agent can register the backend endpoints within AWS Cloud Map using a provided service name and service namespace ID.
Inverting proxy agent can collect telemetry and automatically publish it to Amazon CloudWatch using a custom namespace. This includes HTTP response codes and counts from server application aggregated by the backend ID.
For full list of options, features, and supported configurations, use --help command-line parameter with both agent and proxy executables.
Enabling highly resilient proxy deployment
For production scenarios that require high availability, deploy a pair of inverting proxies connecting to a pair of agents deployed on separate EC2 instances. The entire configuration is then placed behind Application Load Balancer to provide a single point of ingress, load-balancing, and health-checking functionality. Figure 2 demonstrates a highly resilient setup for critical workloads.

Figure 2. Highly resilient deployment diagram for inverting proxy
Additionally, for real-life production workloads dealing with sensitive data, we recommend following security and resilience best practices for Amazon EC2.
Deploying and running the solution
The solution includes a simple demo Node.js server application to simulate connectivity with an inverting proxy. A restrictive security group will be used to simulate on-premises data center.
Steps to deployment:
1. Create a “backend” Amazon EC2 server using Linux 2, free-tier AMI. Ensure that Port 443 (inbound port for sample server application) is blocked from external access via appropriate security group.
2. Connect by using SSH into target server run updates.
sudo yum update -y
3. Install development tools and dependencies:
sudo yum groupinstall "Development Tools" -y
4. Install Golang:
sudo yum install golang -y
5. Install node.js.
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash
. ~/.nvm/nvm.sh
nvm install 16
6. Clone the inverting proxy GitHub repository to the “backend” EC2 instance.
7. From inverting-proxy folder, build the application by running:
mkdir /home/ec2-user/inverting-proxy/bin
export GOPATH=/home/ec2-user/inverting-proxy/bin
make
8. From /simple-server folder, run the sample appTLS application in the background (see instructions below). Note: to enable SSL you will need to generate encryption key and certificate files (server.crt and server.key) and place them in simple-server folder.
npm install
node appTLS &
Example app listening at https://localhost:443
Confirm that the application is running by using ps -ef | grep node:
ec2-user 1700 30669 0 19:45 pts/0 00:00:00 node appTLS
ec2-user 1708 30669 0 19:45 pts/0 00:00:00 grep --color=auto node
9. For backend Amazon EC2 server, navigate to Amazon EC2 security settings and create an IAM role for the instance. Keep default permissions and add “AllowedBackends” tag with the backend ID as a tag value (the backend ID can be any string that matches the backend ID parameter in Step 13).
10. Create a proxy Amazon EC2 server using Linux AMI in a public subnet and connect by using SSH in an Amazon EC2 once online. Copy the contents of the bin folder from the agent EC2 or clone the repository and follow build instructions above (Steps 2-7).
Note: the agent will be establishing outbound connectivity to the proxy; open the appropriate port (443) in the proxy Amazon EC2 security group. The proxy server needs to be accessible by the backend Amazon EC2 and your client workstation, as you will use your local browser to test the application.
11. To enable TLS encryption on incoming connections to proxy, you will need to generate and upload the certificate and private key (server.crt and server.key) to the bin folder of the proxy deployment.
12. Navigate to /bin folder of the inverting proxy and start the proxy by running:
sudo ./proxy –port 443 -tls
2021/12/19 19:56:46 Listening on [::]:443
13. Use the SSH to connect into the backend Amazon EC2 server and configure the inverting proxy agent. Navigate to /bin folder in the cloned repository and run the command below, replacing uppercase strings with the appropriate values. Note: the required trailing slash after the proxy DNS URL.
./proxy-forwarding-agent -proxy https://YOUR_PROXYSERVER_PUBLIC_DNS/ -backend SampleBackend-host localhost:443 -scheme https
14. Use your local browser to navigate to proxy server public DNS name (https://YOUR_PROXYSERVER_PUBLIC_DNS). You should see the following response from your sample backend application:
Hello World!
Conclusion
Inverting proxy is a flexible, lightweight pattern that can be used for routing API traffic in non-trivial hybrid and multi-cloud scenarios that do not require low-latency connectivity. It can also be used for securing existing endpoints, refactoring legacy applications, and enabling visibility into legacy backends. The sample solution we have detailed can be customized to create unique implementations and provides out-of-the-box baseline integration with multiple AWS services.










