Post Syndicated from Sheila Busser original https://aws.amazon.com/blogs/compute/quick-restoration-through-replacing-the-root-volumes-of-amazon-ec2/
This blog post is written by Katja-Maja Krödel, IoT Specialist Solutions Architect, and Benjamin Meyer, Senior Solutions Architect, Game Tech.
Customers use Amazon Elastic Compute Cloud (Amazon EC2) instances to develop, deploy, and test applications. To use those instances most effectively, customers have expressed the need to set back their instance to a previous state within minutes or even seconds. They want to find a quick and automated way to manage setting back their instances at scale.
The feature of replacing Root Volumes of Amazon EC2 instances enables customers to replace the root volumes of running EC2 instances to a specific snapshot or its launch state. Without stopping the instance, this allows customers to fix issues while retaining the instance store data, networking, and AWS Identity and Access Management (IAM) configuration. Customers can resume their operations with their instance store data intact. This works for all virtualized EC2 instances and bare metal EC2 Mac instances today.
In this post, we show you how to design your architecture for automated Root Volume Replacement using this Amazon EC2 feature. We start with the automated snapshot creation, continue with automatically replacing the root volume, and finish with how to keep your environment clean after your replacement job succeeds.
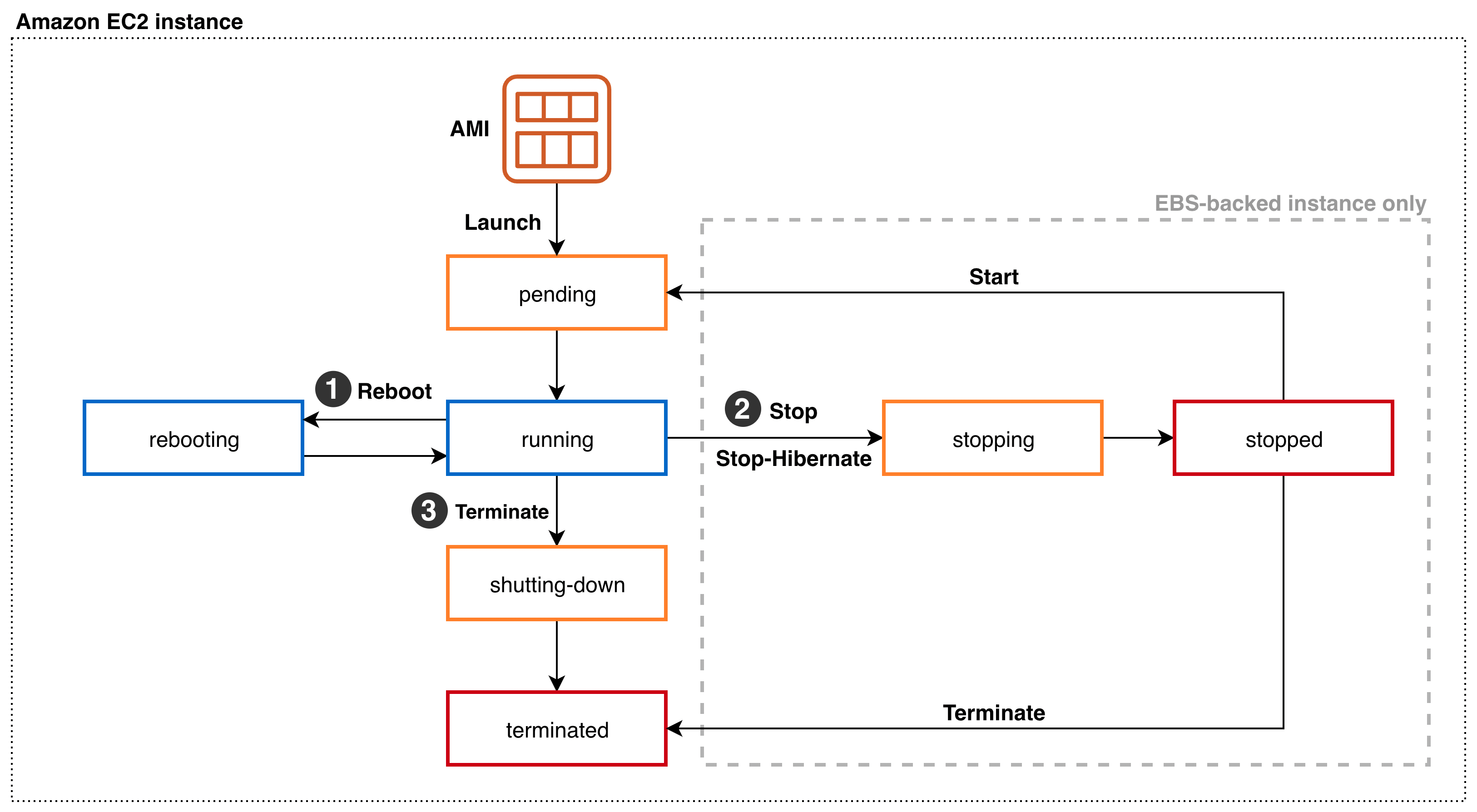
What is Root Volume Replacement?
Amazon EC2 enables customers to replace the root Amazon Elastic Block Store (Amazon EBS) volume for an instance without stopping the instance to which it’s attached. An Amazon EBS root volume is replaced to the launch state, or any snapshot taken from the EBS volume itself. This allows issues to be fixed, such as root volume corruption or guest OS networking errors. Replacing the root volume of an instance includes the following steps:
- A new EBS volume is created from a previously taken snapshot or the launch state
- Reboot of the instance
- While rebooting, the current root volume is detached and the new root volume is attached
The previous EBS root volume isn’t deleted and can be attached to an instance for later investigation of the volume. If replacing to a different state of the EBS than the launch state, then a snapshot of the current root volume is used.
An example use case is a continuous integration/continuous deployment (CI/CD) System that builds on EC2 instances to build artifacts. Within this system, you could alter the installed tools on the host and may cause failing builds on the same machine. To prevent any unclean builds, the introduced architecture is used to clean up the machine by replacing the root volume to a previously known good state. This is especially interesting for EC2 Mac Instances, as their Dedicated Host won’t undergo the scrubbing process, and the instance is more quickly restored than launching a fresh EC2 Mac instance on the same host.
Overview
The feature of replacing Root Volumes was introduced in April 2021 and has just been <TBD> extended to work for Bare Metal EC2 Mac Instances. This means that EC2 Mac Instances are included. If you want to reset an EC2 instance to a previously known good state, then you can create Snapshots of your EBS volumes. To reset the root volume to its launch state, no snapshot is needed. For non-root volumes, you can use these Snapshots to create new EBS volumes, and then attach those to your instance as well as detach them. To automate the process of replacing your root volume not only once, but also in a repeatable manner, we’re introducing you to an architecture that can fully-automate this process.
In the case that you use a snapshot to create a new root volume, you must take a new snapshot of that volume to be able to get back to that state later on. You can’t use a snapshot of a different volume to restore to, which is the reason that the architecture includes the automatic snapshot creation of a fresh root volume.
The architecture is built in three steps:
- Automation of Snapshot Creation for new EBS volumes
- Automation of replacing your Root Volume
- Preparation of the environment for the next Root Volume Replacement
The following diagram illustrates the architecture of this solution.

In the next sections, we go through these concepts to design the automatic Root Volume Replacement Task.
Automation of Snapshot Creation for new EBS volumes

The figure above illustrates the architecture for automatically creating a snapshot of an existing EBS volume. In this architecture, we focus on the automation of creating a snapshot whenever a new EBS root volume is created.
Amazon EventBridge is used to invoke an AWS Lambda function on an emitted createVolume event. For automated reaction to the event, you can add a rule to the EventBridge which will forward the event to an AWS Lambda function whenever a new EBS volume is created. The rule within EventBridge looks like this:
{
"source": ["aws.ec2"],
"detail-type": ["EBS Volume Notification"],
"detail": {
"event": ["createVolume"]
}
}
An example event is emitted when an EBS root volume is created, which will then invoke the Lambda function to look like this:
{
"version": "0",
"id": "01234567-0123-0123-0123-012345678901",
"detail-type": "EBS Volume Notification",
"source": "aws.ec2",
"account": "012345678901",
"time": "yyyy-mm-ddThh:mm:ssZ",
"region": "us-east-1",
"resources": [
"arn:aws:ec2:us-east-1:012345678901:volume/vol-01234567"
],
"detail": {
"result": "available",
"cause": "",
"event": "createVolume",
"request-id": "01234567-0123-0123-0123-0123456789ab"
}
}
The code of the function uses the resource ARN within the received event and requests resource details about the EBS volume from the Amazon EC2 APIs. Since the event doesn’t include information if it’s a root volume, then you must verify this using the Amazon EC2 API.
The following is a summary of the tasks of the Lambda function:
- Extract the EBS ARN from the EventBridge Event
- Verify that it’s a root volume of an EC2 Instance
- Call the Amazon EC2 API
create-snapshotto create a snapshot of the root volume and add a tagreplace-snapshot=true
Then, the tag is used to clean up the environment and get rid of snapshots that aren’t needed.
As an alternative, you can emit your own event to EventBridge. This can be used to automatically create snapshots to which you can restore your volume. Instead of reacting to the createVolume event, you can use a customized approach for this architecture.
Automation of replacing your Root Volume

The figure above illustrates the procedure of replacing the EBS root volume. It starts with the event, which is created through the AWS Command Line Interface (AWS CLI), console, or usage of the API. This leads to creating a new volume from a snapshot or using the initial launch state. The EC2 instance is rebooted, and during that time the old root volume is detached and a new volume gets attached as the root volume.
To invoke the create-replace-root-volume-task, you can call the Amazon EC2 API with the following AWS CLI command:
aws ec2 create-replace-root-volume-task --instance-id <value> --snapshot <value> --tag-specifications ResourceType=string,Tags=[{Key=replaced-volume,Value=true}]If you want to restore to launch state, then omit the --snapshot parameter:
aws ec2 create-replace-root-volume-task --instance-id <value> --tag-specifications ResourceType=string,Tags=[{Key=delete-volume,Value=true}]After running this command, AWS will create a new EBS volume, add the tag to the old EBS replaced-volume=true, restart your instance, and attach the new volume to the instance as the root volume. The tag is used later to detect old root volumes and clean up the environment.
If this is combined with the earlier explained automation, then the automation will immediately take a snapshot from the new EBS volume. A restore operation can only be done to a snapshot of the current EBS root volume. Therefore, if no snapshot is taken from the freshly restored EBS volume, then no restore operation is possible except the restore to launch state.
Preparation of the Environment for the next Root Volume Replacement
After the task is completed, the old root volume isn’t removed. Additionally, snapshots of previous root volumes can’t be used to restore current root volumes. To clean up your environment, you can schedule a Lambda function which does the following steps:
- Delete detached EBS volumes with the tag
delete-volume=true - Delete snapshots with the tag
replace-snapshot=true, which aren’t associated with an existing EBS volume
Conclusion
In this post, we described an architecture to quickly restore EC2 instances through Root Volume Replacement. The feature of replacing Root Volumes of Amazon EC2 instances, now including Bare Metal EC2 Mac instances, enables customers to replace the root volumes of running EC2 instances to a specific snapshot or its launch state. Customers can resume their operations with their instance store data intact. We’ve split the process of doing this in an automated and quick manner into three steps: Create a snapshot, run the replacement task, and reset your environment to be prepared for a following replacement task. If you want to learn more about this feature, then see the Announcement of replacing Root Volumes, as well as the documentation for this feature. <TBD Announcement Bare Metal>