Post Syndicated from Kevin Yung original https://aws.amazon.com/blogs/devops/automate-mainframe-tests-on-aws-with-micro-focus/
Micro Focus – AWS Advanced Technology Parnter, they are a global infrastructure software company with 40 years of experience in delivering and supporting enterprise software.
We have seen mainframe customers often encounter scalability constraints, and they can’t support their development and test workforce to the scale required to support business requirements. These constraints can lead to delays, reduce product or feature releases, and make them unable to respond to market requirements. Furthermore, limits in capacity and scale often affect the quality of changes deployed, and are linked to unplanned or unexpected downtime in products or services.
The conventional approach to address these constraints is to scale up, meaning to increase MIPS/MSU capacity of the mainframe hardware available for development and testing. The cost of this approach, however, is excessively high, and to ensure time to market, you may reject this approach at the expense of quality and functionality. If you’re wrestling with these challenges, this post is written specifically for you.
To accompany this post, we developed an AWS prescriptive guidance (APG) pattern for developer instances and CI/CD pipelines: Mainframe Modernization: DevOps on AWS with Micro Focus.
Overview of solution
In the APG, we introduce DevOps automation and AWS CI/CD architecture to support mainframe application development. Our solution enables you to embrace both Test Driven Development (TDD) and Behavior Driven Development (BDD). Mainframe developers and testers can automate the tests in CI/CD pipelines so they’re repeatable and scalable. To speed up automated mainframe application tests, the solution uses team pipelines to run functional and integration tests frequently, and uses systems test pipelines to run comprehensive regression tests on demand. For more information about the pipelines, see Mainframe Modernization: DevOps on AWS with Micro Focus.
In this post, we focus on how to automate and scale mainframe application tests in AWS. We show you how to use AWS services and Micro Focus products to automate mainframe application tests with best practices. The solution can scale your mainframe application CI/CD pipeline to run thousands of tests in AWS within minutes, and you only pay a fraction of your current on-premises cost.
The following diagram illustrates the solution architecture.

Figure: Mainframe DevOps On AWS Architecture Overview
Best practices
Before we get into the details of the solution, let’s recap the following mainframe application testing best practices:
- Create a “test first” culture by writing tests for mainframe application code changes
- Automate preparing and running tests in the CI/CD pipelines
- Provide fast and quality feedback to project management throughout the SDLC
- Assess and increase test coverage
- Scale your test’s capacity and speed in line with your project schedule and requirements
Automated smoke test
In this architecture, mainframe developers can automate running functional smoke tests for new changes. This testing phase typically “smokes out” regression of core and critical business functions. You can achieve these tests using tools such as py3270 with x3270 or Robot Framework Mainframe 3270 Library.
The following code shows a feature test written in Behave and test step using py3270:
# home_loan_calculator.feature
Feature: calculate home loan monthly repayment
the bankdemo application provides a monthly home loan repayment caculator
User need to input into transaction of home loan amount, interest rate and how many years of the loan maturity.
User will be provided an output of home loan monthly repayment amount
Scenario Outline: As a customer I want to calculate my monthly home loan repayment via a transaction
Given home loan amount is <amount>, interest rate is <interest rate> and maturity date is <maturity date in months> months
When the transaction is submitted to the home loan calculator
Then it shall show the monthly repayment of <monthly repayment>
Examples: Homeloan
| amount | interest rate | maturity date in months | monthly repayment |
| 1000000 | 3.29 | 300 | $4894.31 |
# home_loan_calculator_steps.py
import sys, os
from py3270 import Emulator
from behave import *
@given("home loan amount is {amount}, interest rate is {rate} and maturity date is {maturity_date} months")
def step_impl(context, amount, rate, maturity_date):
context.home_loan_amount = amount
context.interest_rate = rate
context.maturity_date_in_months = maturity_date
@when("the transaction is submitted to the home loan calculator")
def step_impl(context):
# Setup connection parameters
tn3270_host = os.getenv('TN3270_HOST')
tn3270_port = os.getenv('TN3270_PORT')
# Setup TN3270 connection
em = Emulator(visible=False, timeout=120)
em.connect(tn3270_host + ':' + tn3270_port)
em.wait_for_field()
# Screen login
em.fill_field(10, 44, 'b0001', 5)
em.send_enter()
# Input screen fields for home loan calculator
em.wait_for_field()
em.fill_field(8, 46, context.home_loan_amount, 7)
em.fill_field(10, 46, context.interest_rate, 7)
em.fill_field(12, 46, context.maturity_date_in_months, 7)
em.send_enter()
em.wait_for_field()
# collect monthly replayment output from screen
context.monthly_repayment = em.string_get(14, 46, 9)
em.terminate()
@then("it shall show the monthly repayment of {amount}")
def step_impl(context, amount):
print("expected amount is " + amount.strip() + ", and the result from screen is " + context.monthly_repayment.strip())
assert amount.strip() == context.monthly_repayment.strip()
To run this functional test in Micro Focus Enterprise Test Server (ETS), we use AWS CodeBuild.
We first need to build an Enterprise Test Server Docker image and push it to an Amazon Elastic Container Registry (Amazon ECR) registry. For instructions, see Using Enterprise Test Server with Docker.
Next, we create a CodeBuild project and uses the Enterprise Test Server Docker image in its configuration.
The following is an example AWS CloudFormation code snippet of a CodeBuild project that uses Windows Container and Enterprise Test Server:
BddTestBankDemoStage:
Type: AWS::CodeBuild::Project
Properties:
Name: !Sub '${AWS::StackName}BddTestBankDemo'
LogsConfig:
CloudWatchLogs:
Status: ENABLED
Artifacts:
Type: CODEPIPELINE
EncryptionDisabled: true
Environment:
ComputeType: BUILD_GENERAL1_LARGE
Image: !Sub "${EnterpriseTestServerDockerImage}:latest"
ImagePullCredentialsType: SERVICE_ROLE
Type: WINDOWS_SERVER_2019_CONTAINER
ServiceRole: !Ref CodeBuildRole
Source:
Type: CODEPIPELINE
BuildSpec: bdd-test-bankdemo-buildspec.yaml
In the CodeBuild project, we need to create a buildspec to orchestrate the commands for preparing the Micro Focus Enterprise Test Server CICS environment and issue the test command. In the buildspec, we define the location for CodeBuild to look for test reports and upload them into the CodeBuild report group. The following buildspec code uses custom scripts DeployES.ps1 and StartAndWait.ps1 to start your CICS region, and runs Python Behave BDD tests:
version: 0.2
phases:
build:
commands:
- |
# Run Command to start Enterprise Test Server
CD C:\
.\DeployES.ps1
.\StartAndWait.ps1
py -m pip install behave
Write-Host "waiting for server to be ready ..."
do {
Write-Host "..."
sleep 3
} until(Test-NetConnection 127.0.0.1 -Port 9270 | ? { $_.TcpTestSucceeded } )
CD C:\tests\features
MD C:\tests\reports
$Env:Path += ";c:\wc3270"
$address=(Get-NetIPAddress -AddressFamily Ipv4 | where { $_.IPAddress -Match "172\.*" })
$Env:TN3270_HOST = $address.IPAddress
$Env:TN3270_PORT = "9270"
behave.exe --color --junit --junit-directory C:\tests\reports
reports:
bankdemo-bdd-test-report:
files:
- '**/*'
base-directory: "C:\\tests\\reports"
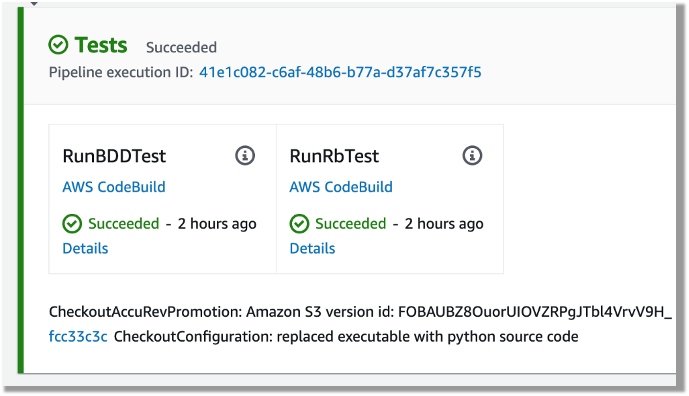
In the smoke test, the team may run both unit tests and functional tests. Ideally, these tests are better to run in parallel to speed up the pipeline. In AWS CodePipeline, we can set up a stage to run multiple steps in parallel. In our example, the pipeline runs both BDD tests and Robot Framework (RPA) tests.
The following CloudFormation code snippet runs two different tests. You use the same RunOrder value to indicate the actions run in parallel.
#...
- Name: Tests
Actions:
- Name: RunBDDTest
ActionTypeId:
Category: Build
Owner: AWS
Provider: CodeBuild
Version: 1
Configuration:
ProjectName: !Ref BddTestBankDemoStage
PrimarySource: Config
InputArtifacts:
- Name: DemoBin
- Name: Config
RunOrder: 1
- Name: RunRbTest
ActionTypeId:
Category: Build
Owner: AWS
Provider: CodeBuild
Version: 1
Configuration:
ProjectName : !Ref RpaTestBankDemoStage
PrimarySource: Config
InputArtifacts:
- Name: DemoBin
- Name: Config
RunOrder: 1
#...
The following screenshot shows the example actions on the CodePipeline console that use the preceding code.

Figure – Screenshot of CodePipeine parallel execution tests
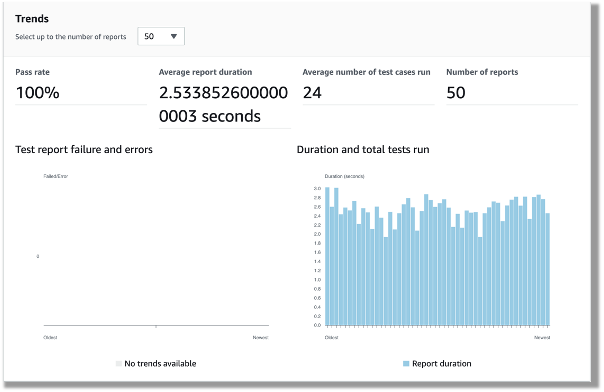
Both DBB and RPA tests produce jUnit format reports, which CodeBuild can ingest and show on the CodeBuild console. This is a great way for project management and business users to track the quality trend of an application. The following screenshot shows the CodeBuild report generated from the BDD tests.

Figure – CodeBuild report generated from the BDD tests
Automated regression tests
After you test the changes in the project team pipeline, you can automatically promote them to another stream with other team members’ changes for further testing. The scope of this testing stream is significantly more comprehensive, with a greater number and wider range of tests and higher volume of test data. The changes promoted to this stream by each team member are tested in this environment at the end of each day throughout the life of the project. This provides a high-quality delivery to production, with new code and changes to existing code tested together with hundreds or thousands of tests.
In enterprise architecture, it’s commonplace to see an application client consuming web services APIs exposed from a mainframe CICS application. One approach to do regression tests for mainframe applications is to use Micro Focus Verastream Host Integrator (VHI) to record and capture 3270 data stream processing and encapsulate these 3270 data streams as business functions, which in turn are packaged as web services. When these web services are available, they can be consumed by a test automation product, which in our environment is Micro Focus UFT One. This uses the Verastream server as the orchestration engine that translates the web service requests into 3270 data streams that integrate with the mainframe CICS application. The application is deployed in Micro Focus Enterprise Test Server.
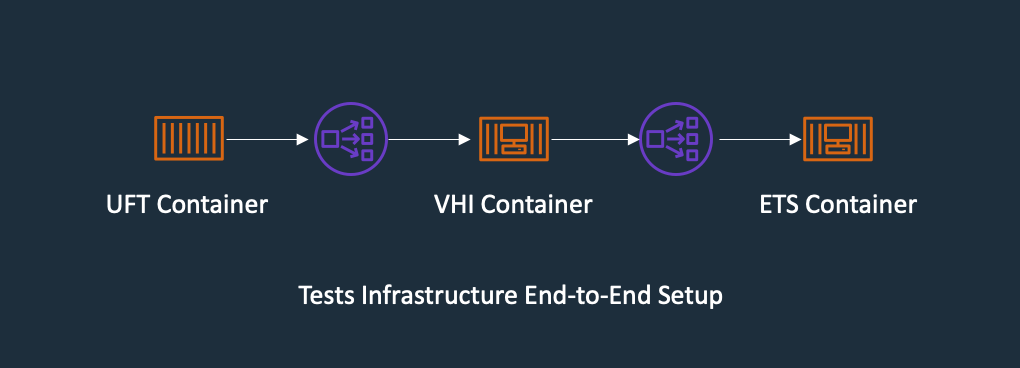
The following diagram shows the end-to-end testing components.

Figure – Regression Test Infrastructure end-to-end Setup
To ensure we have the coverage required for large mainframe applications, we sometimes need to run thousands of tests against very large production volumes of test data. We want the tests to run faster and complete as soon as possible so we reduce AWS costs—we only pay for the infrastructure when consuming resources for the life of the test environment when provisioning and running tests.
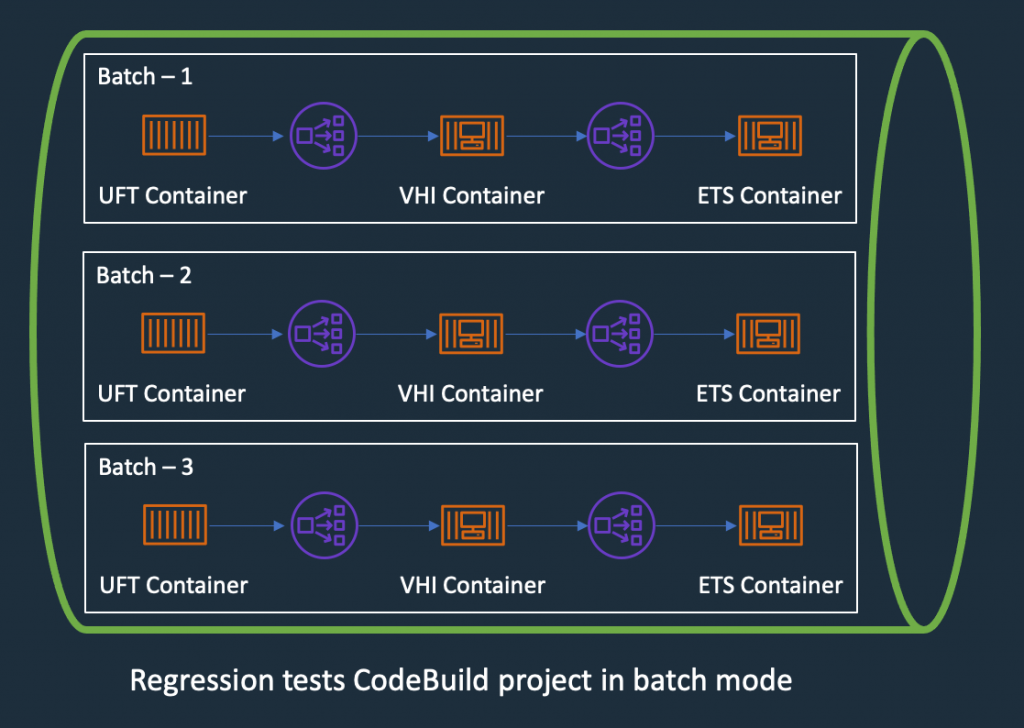
Therefore, the design of the test environment needs to scale out. The batch feature in CodeBuild allows you to run tests in batches and in parallel rather than serially. Furthermore, our solution needs to minimize interference between batches, a failure in one batch doesn’t affect another running in parallel. The following diagram depicts the high-level design, with each batch build running in its own independent infrastructure. Each infrastructure is launched as part of test preparation, and then torn down in the post-test phase.

Figure – Regression Tests in CodeBuoild Project setup to use batch mode
Building and deploying regression test components
Following the design of the parallel regression test environment, let’s look at how we build each component and how they are deployed. The followings steps to build our regression tests use a working backward approach, starting from deployment in the Enterprise Test Server:
- Create a batch build in CodeBuild.
- Deploy to Enterprise Test Server.
- Deploy the VHI model.
- Deploy UFT One Tests.
- Integrate UFT One into CodeBuild and CodePipeline and test the application.
Creating a batch build in CodeBuild
We update two components to enable a batch build. First, in the CodePipeline CloudFormation resource, we set BatchEnabled to be true for the test stage. The UFT One test preparation stage uses the CloudFormation template to create the test infrastructure. The following code is an example of the AWS CloudFormation snippet with batch build enabled:
#...
- Name: SystemsTest
Actions:
- Name: Uft-Tests
ActionTypeId:
Category: Build
Owner: AWS
Provider: CodeBuild
Version: 1
Configuration:
ProjectName : !Ref UftTestBankDemoProject
PrimarySource: Config
BatchEnabled: true
CombineArtifacts: true
InputArtifacts:
- Name: Config
- Name: DemoSrc
OutputArtifacts:
- Name: TestReport
RunOrder: 1
#...
Second, in the buildspec configuration of the test stage, we provide a build matrix setting. We use the custom environment variable TEST_BATCH_NUMBER to indicate which set of tests runs in each batch. See the following code:
version: 0.2
batch:
fast-fail: true
build-matrix:
static:
ignore-failure: false
dynamic:
env:
variables:
TEST_BATCH_NUMBER:
- 1
- 2
- 3
phases:
pre_build:
commands:
#...
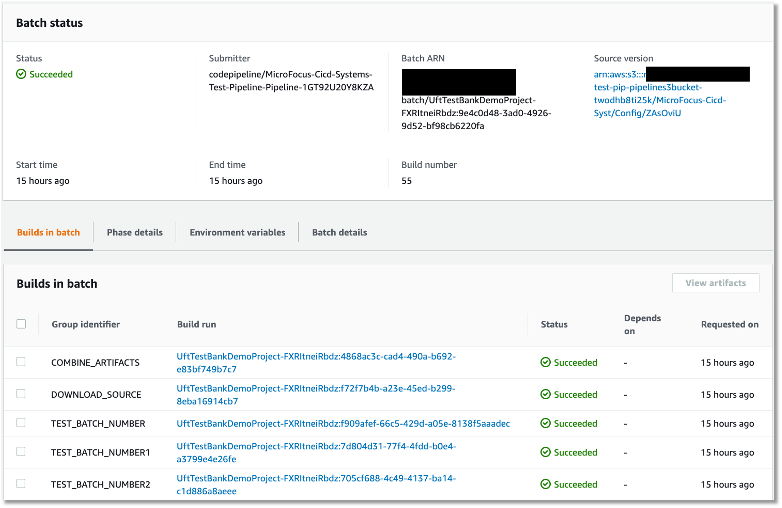
After setting up the batch build, CodeBuild creates multiple batches when the build starts. The following screenshot shows the batches on the CodeBuild console.

Figure – Regression tests Codebuild project ran in batch mode
Deploying to Enterprise Test Server
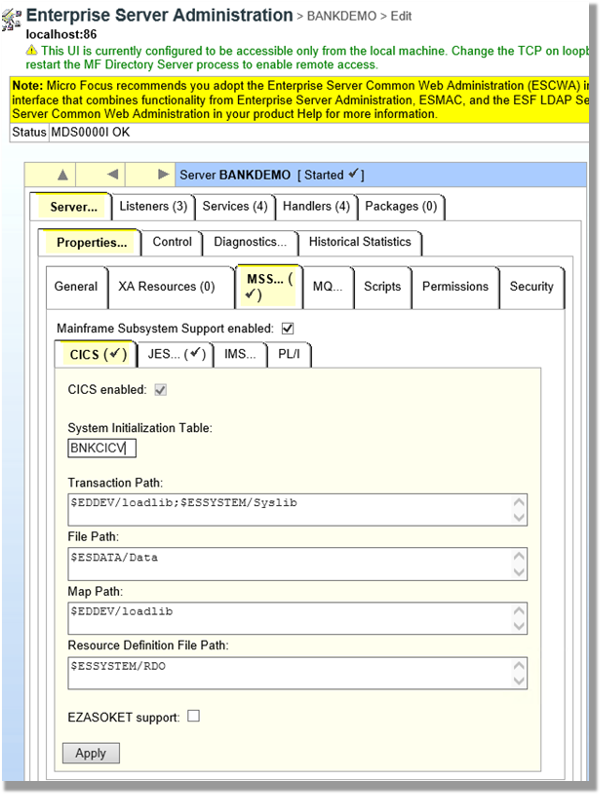
ETS is the transaction engine that processes all the online (and batch) requests that are initiated through external clients, such as 3270 terminals, web services, and websphere MQ. This engine provides support for various mainframe subsystems, such as CICS, IMS TM and JES, as well as code-level support for COBOL and PL/I. The following screenshot shows the Enterprise Test Server administration page.

Figure – Enterprise Server Administrator window
In this mainframe application testing use case, the regression tests are CICS transactions, initiated from 3270 requests (encapsulated in a web service). For more information about Enterprise Test Server, see the Enterprise Test Server and Micro Focus websites.
In the regression pipeline, after the stage of mainframe artifact compiling, we bake in the artifact into an ETS Docker container and upload the image to an Amazon ECR repository. This way, we have an immutable artifact for all the tests.
During each batch’s test preparation stage, a CloudFormation stack is deployed to create an Amazon ECS service on Windows EC2. The stack uses a Network Load Balancer as an integration point for the VHI’s integration.
The following code is an example of the CloudFormation snippet to create an Amazon ECS service using an Enterprise Test Server Docker image:
#...
EtsService:
DependsOn:
- EtsTaskDefinition
- EtsContainerSecurityGroup
- EtsLoadBalancerListener
Properties:
Cluster: !Ref 'WindowsEcsClusterArn'
DesiredCount: 1
LoadBalancers:
-
ContainerName: !Sub "ets-${AWS::StackName}"
ContainerPort: 9270
TargetGroupArn: !Ref EtsPort9270TargetGroup
HealthCheckGracePeriodSeconds: 300
TaskDefinition: !Ref 'EtsTaskDefinition'
Type: "AWS::ECS::Service"
EtsTaskDefinition:
Properties:
ContainerDefinitions:
-
Image: !Sub "${AWS::AccountId}.dkr.ecr.us-east-1.amazonaws.com/systems-test/ets:latest"
LogConfiguration:
LogDriver: awslogs
Options:
awslogs-group: !Ref 'SystemsTestLogGroup'
awslogs-region: !Ref 'AWS::Region'
awslogs-stream-prefix: ets
Name: !Sub "ets-${AWS::StackName}"
cpu: 4096
memory: 8192
PortMappings:
-
ContainerPort: 9270
EntryPoint:
- "powershell.exe"
Command:
- '-F'
- .\StartAndWait.ps1
- 'bankdemo'
- C:\bankdemo\
- 'wait'
Family: systems-test-ets
Type: "AWS::ECS::TaskDefinition"
#...
Deploying the VHI model
In this architecture, the VHI is a bridge between mainframe and clients.
We use the VHI designer to capture the 3270 data streams and encapsulate the relevant data streams into a business function. We can then deliver this function as a web service that can be consumed by a test management solution, such as Micro Focus UFT One.
The following screenshot shows the setup for getCheckingDetails in VHI. Along with this procedure we can also see other procedures (eg calcCostLoan) defined that get generated as a web service. The properties associated with this procedure are available on this screen to allow for the defining of the mapping of the fields between the associated 3270 screens and exposed web service.

Figure – Setup for getCheckingDetails in VHI
The following screenshot shows the editor for this procedure and is initiated by the selection of the Procedure Editor. This screen presents the 3270 screens that are involved in the business function that will be generated as a web service.

Figure – VHI designer Procedure Editor shows the procedure
After you define the required functional web services in VHI designer, the resultant model is saved and deployed into a VHI Docker image. We use this image and the associated model (from VHI designer) in the pipeline outlined in this post.
For more information about VHI, see the VHI website.
The pipeline contains two steps to deploy a VHI service. First, it installs and sets up the VHI models into a VHI Docker image, and it’s pushed into Amazon ECR. Second, a CloudFormation stack is deployed to create an Amazon ECS Fargate service, which uses the latest built Docker image. In AWS CloudFormation, the VHI ECS task definition defines an environment variable for the ETS Network Load Balancer’s DNS name. Therefore, the VHI can bootstrap and point to an ETS service. In the VHI stack, it uses a Network Load Balancer as an integration point for UFT One test integration.
The following code is an example of a ECS Task Definition CloudFormation snippet that creates a VHI service in Amazon ECS Fargate and integrates it with an ETS server:
#...
VhiTaskDefinition:
DependsOn:
- EtsService
Type: AWS::ECS::TaskDefinition
Properties:
Family: systems-test-vhi
NetworkMode: awsvpc
RequiresCompatibilities:
- FARGATE
ExecutionRoleArn: !Ref FargateEcsTaskExecutionRoleArn
Cpu: 2048
Memory: 4096
ContainerDefinitions:
- Cpu: 2048
Name: !Sub "vhi-${AWS::StackName}"
Memory: 4096
Environment:
- Name: esHostName
Value: !GetAtt EtsInternalLoadBalancer.DNSName
- Name: esPort
Value: 9270
Image: !Ref "${AWS::AccountId}.dkr.ecr.us-east-1.amazonaws.com/systems-test/vhi:latest"
PortMappings:
- ContainerPort: 9680
LogConfiguration:
LogDriver: awslogs
Options:
awslogs-group: !Ref 'SystemsTestLogGroup'
awslogs-region: !Ref 'AWS::Region'
awslogs-stream-prefix: vhi
#...
Deploying UFT One Tests
UFT One is a test client that uses each of the web services created by the VHI designer to orchestrate running each of the associated business functions. Parameter data is supplied to each function, and validations are configured against the data returned. Multiple test suites are configured with different business functions with the associated data.
The following screenshot shows the test suite API_Bankdemo3, which is used in this regression test process.

Figure – API_Bankdemo3 in UFT One Test Editor Console
For more information, see the UFT One website.
Integrating UFT One and testing the application
The last step is to integrate UFT One into CodeBuild and CodePipeline to test our mainframe application. First, we set up CodeBuild to use a UFT One container. The Docker image is available in Docker Hub. Then we author our buildspec. The buildspec has the following three phrases:
- Setting up a UFT One license and deploying the test infrastructure
- Starting the UFT One test suite to run regression tests
- Tearing down the test infrastructure after tests are complete
The following code is an example of a buildspec snippet in the pre_build stage. The snippet shows the command to activate the UFT One license:
version: 0.2
batch:
# . . .
phases:
pre_build:
commands:
- |
# Activate License
$process = Start-Process -NoNewWindow -RedirectStandardOutput LicenseInstall.log -Wait -File 'C:\Program Files (x86)\Micro Focus\Unified Functional Testing\bin\HP.UFT.LicenseInstall.exe' -ArgumentList @('concurrent', 10600, 1, ${env:AUTOPASS_LICENSE_SERVER})
Get-Content -Path LicenseInstall.log
if (Select-String -Path LicenseInstall.log -Pattern 'The installation was successful.' -Quiet) {
Write-Host 'Licensed Successfully'
} else {
Write-Host 'License Failed'
exit 1
}
#...
The following command in the buildspec deploys the test infrastructure using the AWS Command Line Interface (AWS CLI)
aws cloudformation deploy --stack-name $stack_name `
--template-file cicd-pipeline/systems-test-pipeline/systems-test-service.yaml `
--parameter-overrides EcsCluster=$cluster_arn `
--capabilities CAPABILITY_IAM
Because ETS and VHI are both deployed with a load balancer, the build detects when the load balancers become healthy before starting the tests. The following AWS CLI commands detect the load balancer’s target group health:
$vhi_health_state = (aws elbv2 describe-target-health --target-group-arn $vhi_target_group_arn --query 'TargetHealthDescriptions[0].TargetHealth.State' --output text)
$ets_health_state = (aws elbv2 describe-target-health --target-group-arn $ets_target_group_arn --query 'TargetHealthDescriptions[0].TargetHealth.State' --output text)
When the targets are healthy, the build moves into the build stage, and it uses the UFT One command line to start the tests. See the following code:
$process = Start-Process -Wait -NoNewWindow -RedirectStandardOutput UFTBatchRunnerCMD.log `
-FilePath "C:\Program Files (x86)\Micro Focus\Unified Functional Testing\bin\UFTBatchRunnerCMD.exe" `
-ArgumentList @("-source", "${env:CODEBUILD_SRC_DIR_DemoSrc}\bankdemo\tests\API_Bankdemo\API_Bankdemo${env:TEST_BATCH_NUMBER}")
The next release of Micro Focus UFT One (November or December 2020) will provide an exit status to indicate a test’s success or failure.
When the tests are complete, the post_build stage tears down the test infrastructure. The following AWS CLI command tears down the CloudFormation stack:
#...
post_build:
finally:
- |
Write-Host "Clean up ETS, VHI Stack"
#...
aws cloudformation delete-stack --stack-name $stack_name
aws cloudformation wait stack-delete-complete --stack-name $stack_name
At the end of the build, the buildspec is set up to upload UFT One test reports as an artifact into Amazon Simple Storage Service (Amazon S3). The following screenshot is the example of a test report in HTML format generated by UFT One in CodeBuild and CodePipeline.

Figure – UFT One HTML report
A new release of Micro Focus UFT One will provide test report formats supported by CodeBuild test report groups.
Conclusion
In this post, we introduced the solution to use Micro Focus Enterprise Suite, Micro Focus UFT One, Micro Focus VHI, AWS developer tools, and Amazon ECS containers to automate provisioning and running mainframe application tests in AWS at scale.
The on-demand model allows you to create the same test capacity infrastructure in minutes at a fraction of your current on-premises mainframe cost. It also significantly increases your testing and delivery capacity to increase quality and reduce production downtime.
A demo of the solution is available in AWS Partner Micro Focus website AWS Mainframe CI/CD Enterprise Solution. If you’re interested in modernizing your mainframe applications, please visit Micro Focus and contact AWS mainframe business development at [email protected].
References
Micro Focus
Peter Woods
Peter has been with Micro Focus for almost 30 years, in a variety of roles and geographies including Technical Support, Channel Sales, Product Management, Strategic Alliances Management and Pre-Sales, primarily based in Europe but for the last four years in Australia and New Zealand. In his current role as Pre-Sales Manager, Peter is charged with driving and supporting sales activity within the Application Modernization and Connectivity team, based in Melbourne.
Leo Ervin
Leo Ervin is a Senior Solutions Architect working with Micro Focus Enterprise Solutions working with the ANZ team. After completing a Mathematics degree Leo started as a PL/1 programming with a local insurance company. The next step in Leo’s career involved consulting work in PL/1 and COBOL before he joined a start-up company as a technical director and partner. This company became the first distributor of Micro Focus software in the ANZ region in 1986. Leo’s involvement with Micro Focus technology has continued from this distributorship through to today with his current focus on cloud strategies for both DevOps and re-platform implementations.
Kevin Yung
Kevin is a Senior Modernization Architect in AWS Professional Services Global Mainframe and Midrange Modernization (GM3) team. Kevin currently is focusing on leading and delivering mainframe and midrange applications modernization for large enterprise customers.






























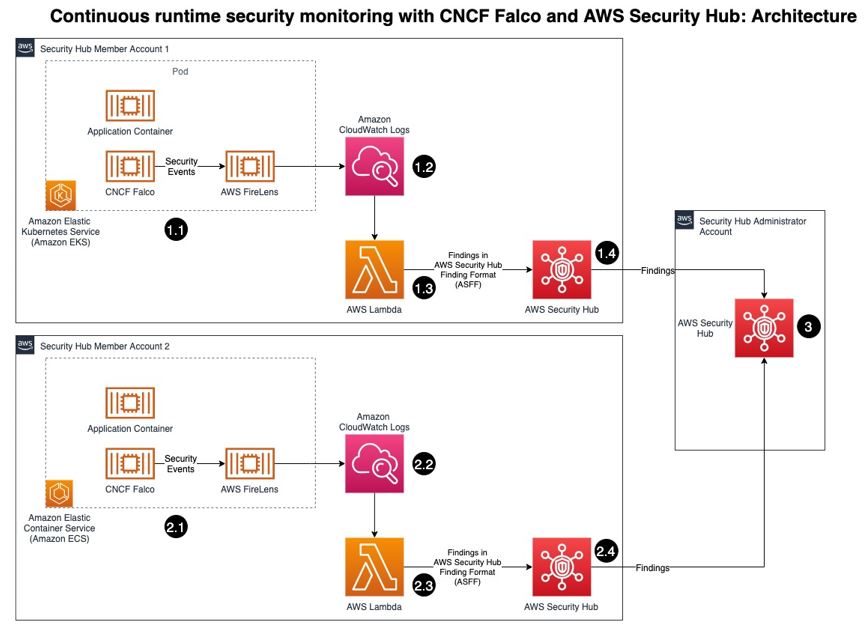






![Architecture Diagram showing the service “Test” using the container “brickwall-maker” with a desired count of two. The two ECS Task’s vended metrics are then processed by CloudWatch Container Insights. Both, CloudWatch Container Insights and CloudTrail, are ingested by Amazon DevOps Guru which then makes detected insights available to the user. [Image: DevOpsGuruBlog1.png]V1: DevOpsGuruBlog1.drawio (https://api.quip-amazon.com/2/blob/fbe9AAT37Ge/LdkTqbmlZ8uNj7A44pZbnw?name=DevOpsGuruBlog1.drawio&s=cVbmAWsXnynz) V2: DevOpsGuruBlog1.drawio (https://api.quip-amazon.com/2/blob/fbe9AAT37Ge/SvsNTJLEJOHHBls_kV7EwA?name=DevOpsGuruBlog1.drawio&s=cVbmAWsXnynz) V3: DevOpsGuruBlog1.drawio (https://api.quip-amazon.com/2/blob/fbe9AAT37Ge/DqKTxtQvmOLrzM3KcF_oTg?name=DevOpsGuruBlog1.drawio&s=cVbmAWsXnynz)](https://d2908q01vomqb2.cloudfront.net/7719a1c782a1ba91c031a682a0a2f8658209adbf/2021/10/29/DevOpsGuruBlog1-1-1.png)