Post Syndicated from Daniele Molteni original https://blog.cloudflare.com/unmetered-ratelimiting/


In 2017, we made unmetered DDoS protection available to all our customers, regardless of their size or whether they were on a Free or paid plan. Today we are doing the same for Rate Limiting, one of the most successful products of the WAF family.
Rate Limiting is a very effective tool to manage targeted volumetric attacks, takeover attempts, bots scraping sensitive data, attempts to overload computationally expensive API endpoints and more. To manage these threats, customers deploy rules that limit the maximum rate of requests from individual visitors on specific paths or portions of their applications.
Until today, customers on a Free, Pro or Business plan were able to purchase Rate Limiting as an add-on with usage-based cost of $5 per million requests. However, we believe that an essential security tool like Rate Limiting should be available to all customers without restrictions.
Since we launched unmetered DDoS, we have mitigated huge attacks, like a 2 Tbps multi-vector attack or the most recent 26 million requests per second attack. We believe that releasing an unmetered version of Rate Limiting will increase the overall security posture of millions of applications protected by Cloudflare.
Today, we are announcing that Free, Pro and Business plans include Rate Limiting rules without extra charges.
…and we are not just dropping any Rate Limiting extra charges, we are also releasing an updated version of the product which is built on the powerful ruleset engine and allows building rules like in Custom Rules. This is the same engine which powers the enterprise-grade Advanced Rate Limiting. The new ‘Rate limiting rules’ will appear in your dashboard starting this week.
No more usage-based charges, just rate limiting when you need and how much you need it.
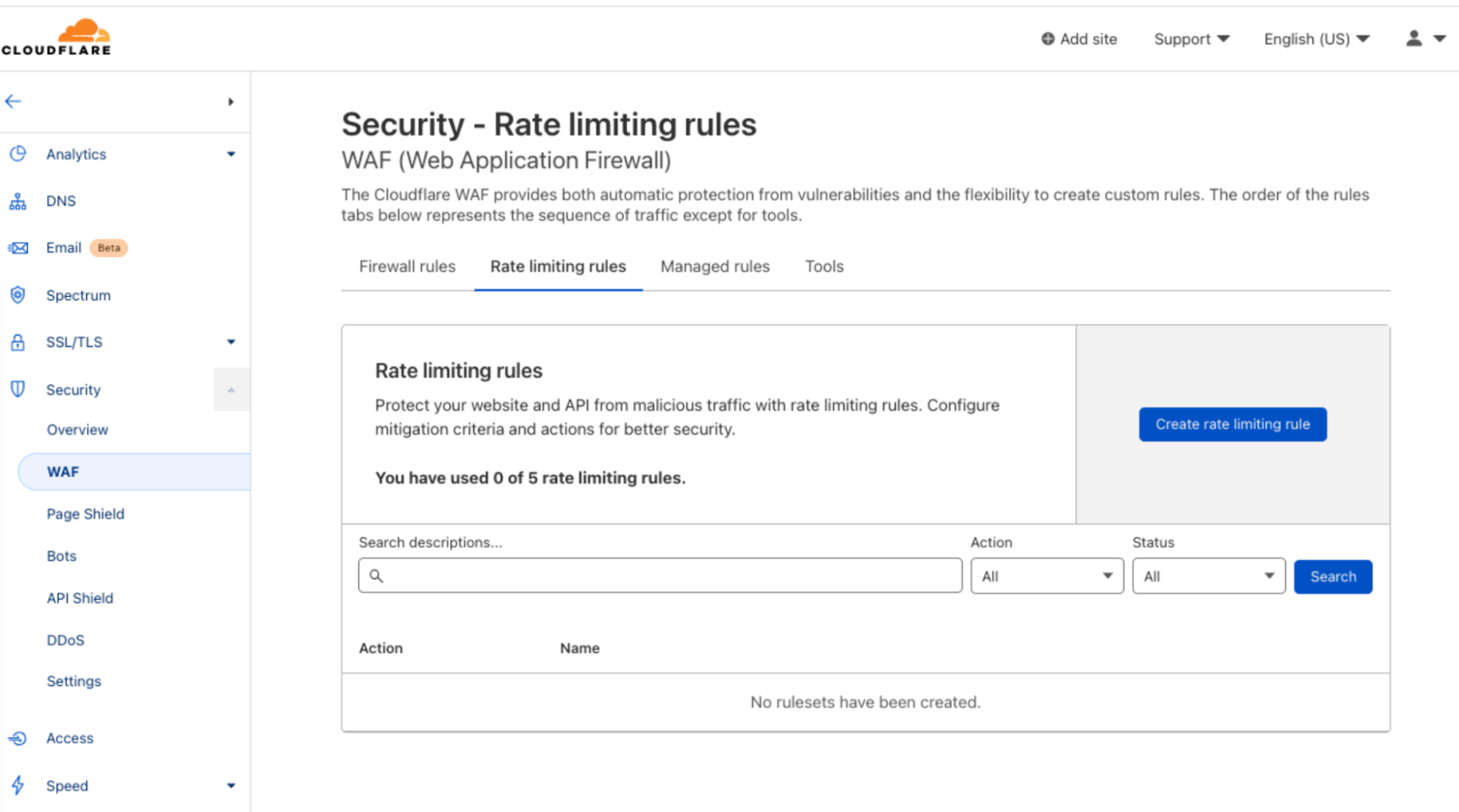
Note: starting today, September 29th, Pro and Business customers have the new product available in their dashboard. Free customers will get their rules enabled during the week starting on October 3rd 2022.
End of usage-based charges
New customers get new Rate Limiting by default while existing customers will be able to run both products in parallel: new and previous version.
For new customers, new Rate Limiting rules will be included in each plan according to the following table:
| FREE | PRO | BUSINESS | |
|---|---|---|---|
| Number of rules | 1 | 2 | 5 |
When using these rules, no additional charges will be added to your account. No matter how much traffic these rules handle.
Existing customers will be granted the same amount of rules in the new, unmetered, system as the rules they’re currently using in the previous version (as of September 20, 2022). For example, if you are a Business customer with nine active rules in the previous version, you will get nine rules in the new system as well.
The previous version of Rate Limiting will still be subject to charges when in use. If you want to take advantage of the unmetered option, we recommend rewriting your rules in the new engine. As outlined below, new Rate Limiting offers all the capabilities of the previous version of Rate Limiting and more. In the future, the previous version of Rate Limiting will be deprecated, however we will give plenty of time to self-migrate rules.
New rate limiting engine for all
A couple of weeks ago, we announced that Cloudflare was named a Leader in the Gartner® Magic Quadrant™ for Web Application and API Protection (WAAP). One of the key services offered in our WAAP portfolio is Advanced Rate Limiting.
The recent Advanced Rate Limiting has shown great success among our Enterprise customers. Advanced Rate Limiting allows an unprecedented level of control on how to manage incoming traffic rate. We decided to give the same rule-building experience to all of our customers as well as some of its new features.
A summary of the feature set is outlined in the following table:
| FREE | PRO | BUSINESS | ENT with WAF Essential |
ENT with Advanced Rate Limiting |
|
|---|---|---|---|---|---|
| Fields available (request) | Path | Host URI Path Full URI Query |
Host URI Path Full URI Query Method Source IP User Agent |
All fields available in Custom Rules: Including request metadata(1). | Same WAF Essential. Request Bot score(1) and body fields(2) |
| Counting expression | Not available | Not available | Available with access to response headers and response status code | Available with access to response headers and response status code | Available with access to response headers and response status code |
| Counting characteristics | IP | IP | IP | IP IP with NAT awareness |
IP IP with NAT awareness Query Host Headers Cookie ASN Country Path JA3(2) JSON field (New!) |
| Max Counting period | 10 seconds | 60 seconds | 10 minutes | 10 minutes | 1 hour |
| Price | Free | Included in monthly subscription | Included in monthly subscription | Included in contracted plan | Included in contracted plan |
(1): Requires Bots Management add-on
(2): Requires specific plan
Leveraging the ruleset engine. Previous version of Rate Limiting allows customers to scope the rule based on a single path and method of the request. Thanks to the ruleset engine, customers can now write rules like they do in Custom Rules and combine multiple parameters of the HTTP request.
For example, Pro domains can combine multiple paths in the same rule using the OR or AND operators. Business domains can also write rules using Source IP or User Agent. This allows enforcing different rates for specific User Agents. Furthermore, Business customers can now scope Rate Limiting to specific IPs (using IP List, for example) or exclude IPs where no attack is expected.
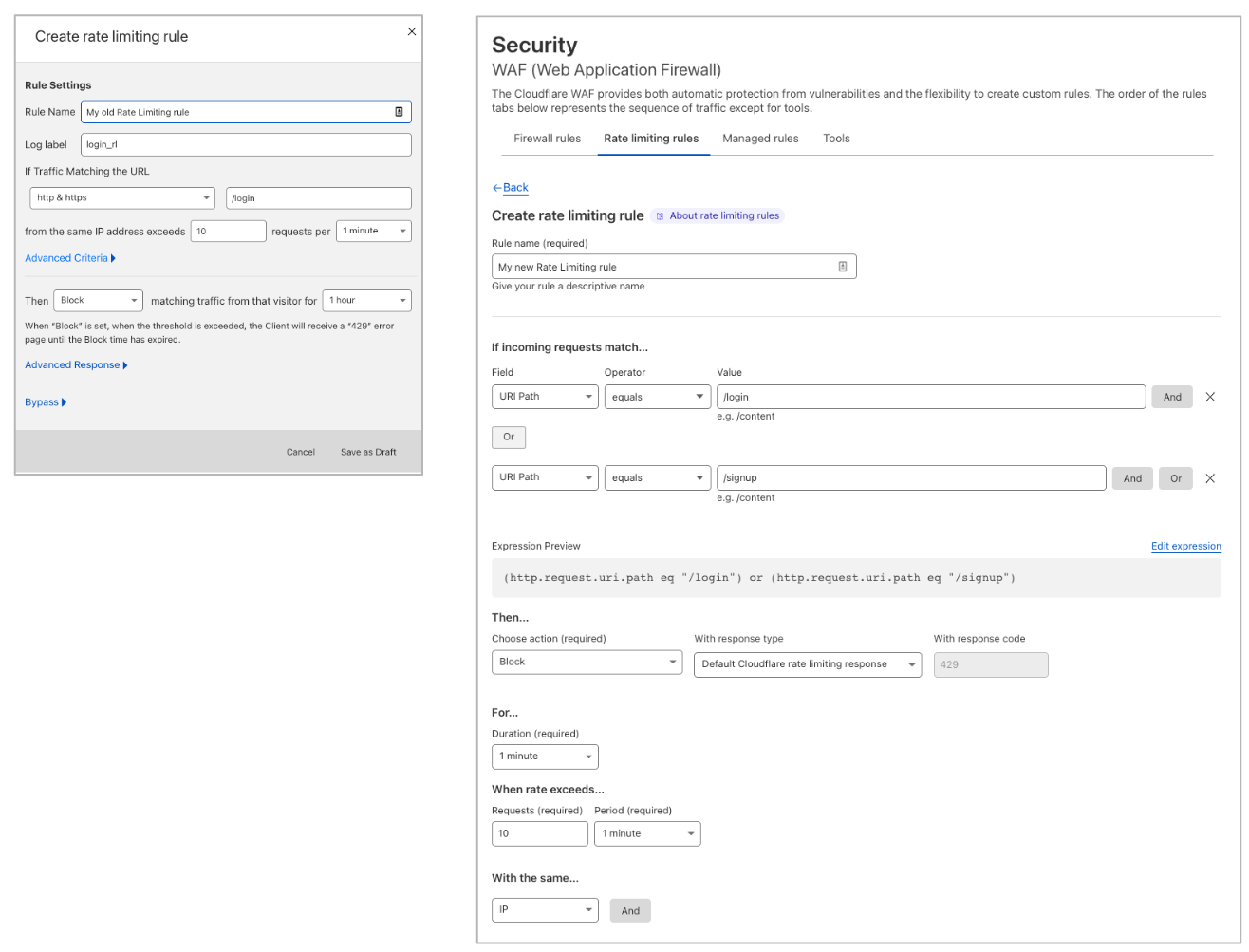
Counting and mitigation expressions are now separate. A feature request we often heard about was the ability to track the rate of requests on a specific path (such as ‘/login’) and, when an IP exceeds the threshold, block every request from the same IP hitting anywhere on your domain. Business and Enterprise customers can now achieve this by using the counting expression which is separate from the mitigation. The former defines what requests are used to compute the rate while the letter defines what requests are mitigated once the threshold has been reached.
Another use case for using the counting expression is when you need to use Origin Status Code or HTTP Response Headers. If you need to use these fields, we recommend creating a counting expression that includes response parameters and explicitly writing a filter that defines what the request parameters that will trigger a block action.
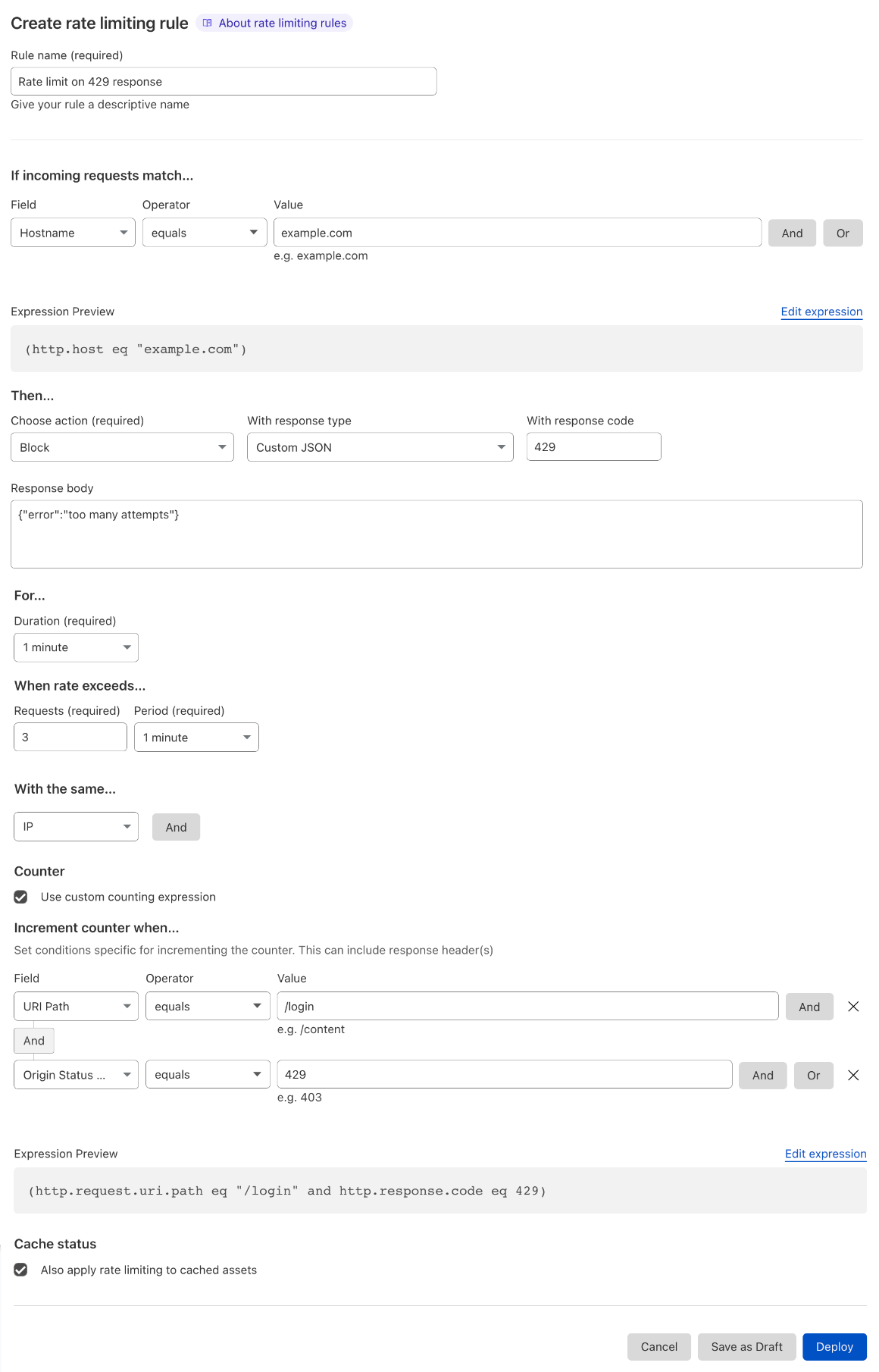
Counting dimensions. Similarly to the previous version, Free, Pro and Business customers will get the IP-based Rate Limiting. When we say IP-based we refer to the way we group (or count) requests. You can set a rule that enforces a maximum rate of request from the same IPs. If you set a rule to limit 10 requests over one minute, we will count requests from individual IPs until they reach the limit and then block for a period of time.
Advanced Rate Limiting users are able to group requests based on additional characteristics, such as API keys, cookies, session headers, ASN, query parameters, a JSON body field (e.g. the username value of a login request) and more.
What do Enterprise customers get? Enterprise customers can get Rate Limiting as part of their contract. When included in their contract, they get access to 100 rules, a more comprehensive list of fields available in the rule builder, and they get to upgrade to Advanced Rate Limiting. Please reach out to your account team to learn more.
More information on how to use new Rate Limiting can be found in the documentation.
Additional information for existing customers
If you are a Free, Pro or Business customer, you will automatically get the new product in the dashboard. We will entitle you with as many unmetered Rate Limiting rules as you are using in the previous version.
If you are an Enterprise customer using the previous version of Rate Limiting, please reach out to the account team to discuss the options to move to new Rate Limiting.
To take advantage of the unmetered functionality, you will need to migrate your rules to the new system. The previous version will keep working as usual, and you might be charged based on the traffic that its rules evaluate.
Long term, the previous version of Rate Limiting will be deprecated and when this happens all rules still running on the old system will cease to run.
What’s next?
The WAF team has plans to further expand our Rate Limiting capabilities. Features we are considering include better analytics to support the rule creation. Furthermore, new Rate Limiting can now benefit from new fields made available in the WAF as soon as they are released. For example, Enterprise customers can combine Bot Score or the new WAF Attack Score to create a more fine grain security posture.
