“A penny for your thoughts” is a common boomer expression (so says my 23 year old). Instead, how about “a penny for a gigabyte of hard disk”? That’s new, tech-y, and, well, it’s almost true.
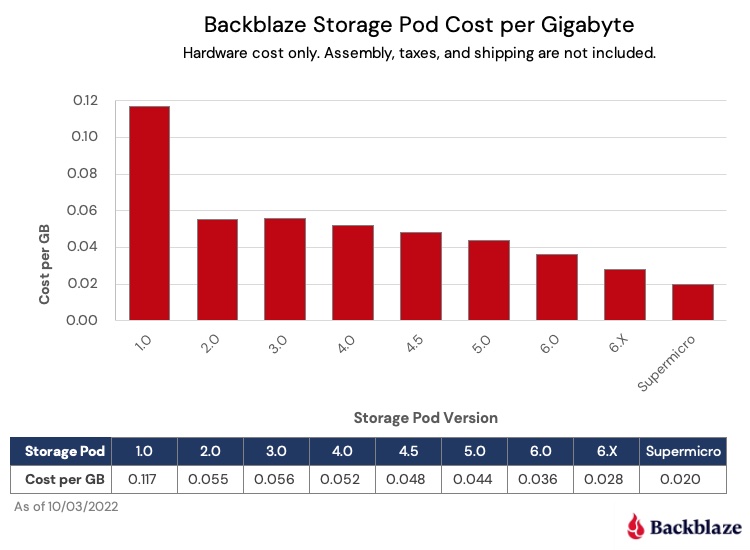
When Backblaze purchased hard drives back in 2009, we paid over $0.11 per gigabyte. In 2017, when we did a review of the cost of hard drives, the cost per gigabyte had fallen to just below $0.03 per gigabyte. Today, we can get 16TB hard drives for about $0.014 per gigabyte on average. That’s not quite a penny, but we think we’ll get there soon enough. In the meantime, let’s look at our hard drive purchases over the years and see what we can learn about the cost per gigabyte of hard drive storage.
How Many Drives?
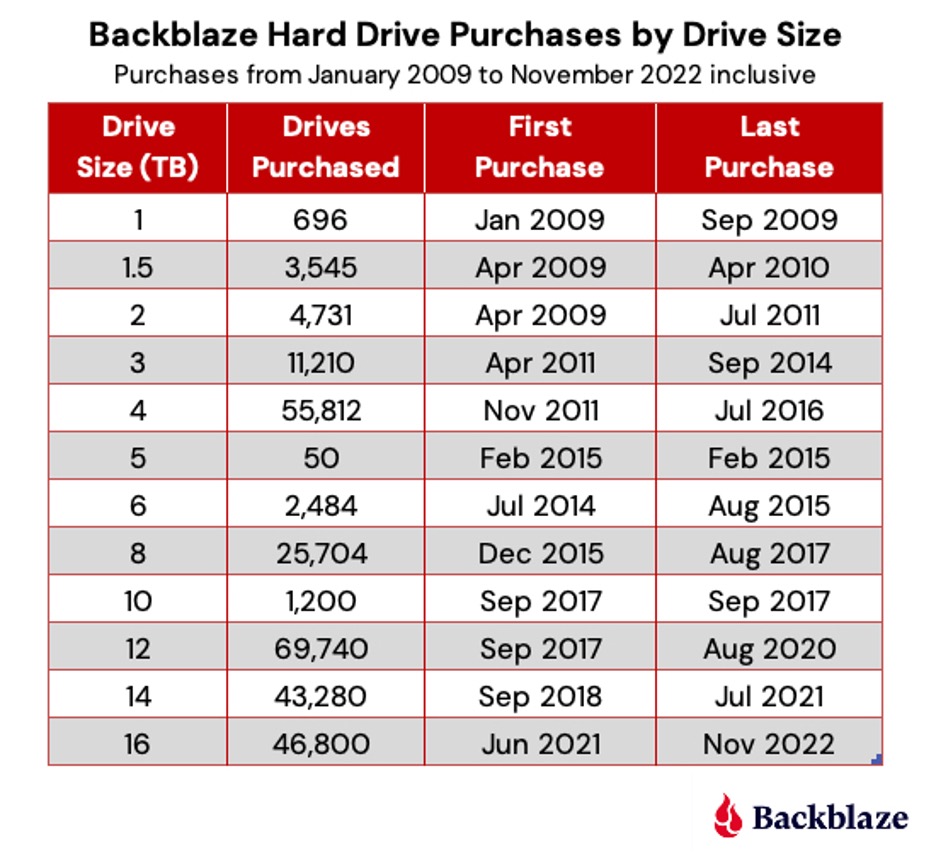
Backblaze has purchase records going back to 2009. In that time, we’ve purchased 265,332 hard drives. We even recorded each of the hundreds of hard drives purchased during our drive farming days in 2011 and our crowdsourcing days in 2012. Thank you, Cecilia! The 265,322 number is not precise—some drives were purchased before 2009, some drives were purchased and never put into service, and, occasionally, we received a small number of test drives from manufacturers. Still, the 265,332 number is close. The breakdown in drives purchased by drive size is shown below.
The 16TB drives are the only drive size we are currently purchasing. It is possible we could purchase a small group of spares for one of the other drive sizes. Unlikely at this point, but possible. In addition, the 16TB count does not include 12,000 drives purchased and scheduled for delivery over the next few months.
In 2023 we expect to qualify 18TB, 20TB, and potentially 22TB drives. Of course, we will wait a bit before purchasing in bulk to ensure the qualified drive models are stable over time and the price per gigabyte meets our expectations. Speaking of expectations, look for those drives to show up in the quarterly Drive Stats reports starting about mid-2023.
Drive Type
All of the drives we purchase use Perpendicular Magnetic Recording (PMR), also known as Conventional Magnetic Recording (CMR). We do not use Shingled Magnetic Recording (SMR) drives. SMR drives are sometimes less expensive but are demonstrably slower with random writes and when they are reusing space made available from previous file deletes. In most data backup use cases, where variable length writes and file deletions are the norm, the minimal cost savings of SMR drives is negated by the storage inefficiencies introduced by having to perform multiple writes to store data in tracks where data had been previously deleted.
The Cost Per Gigabyte
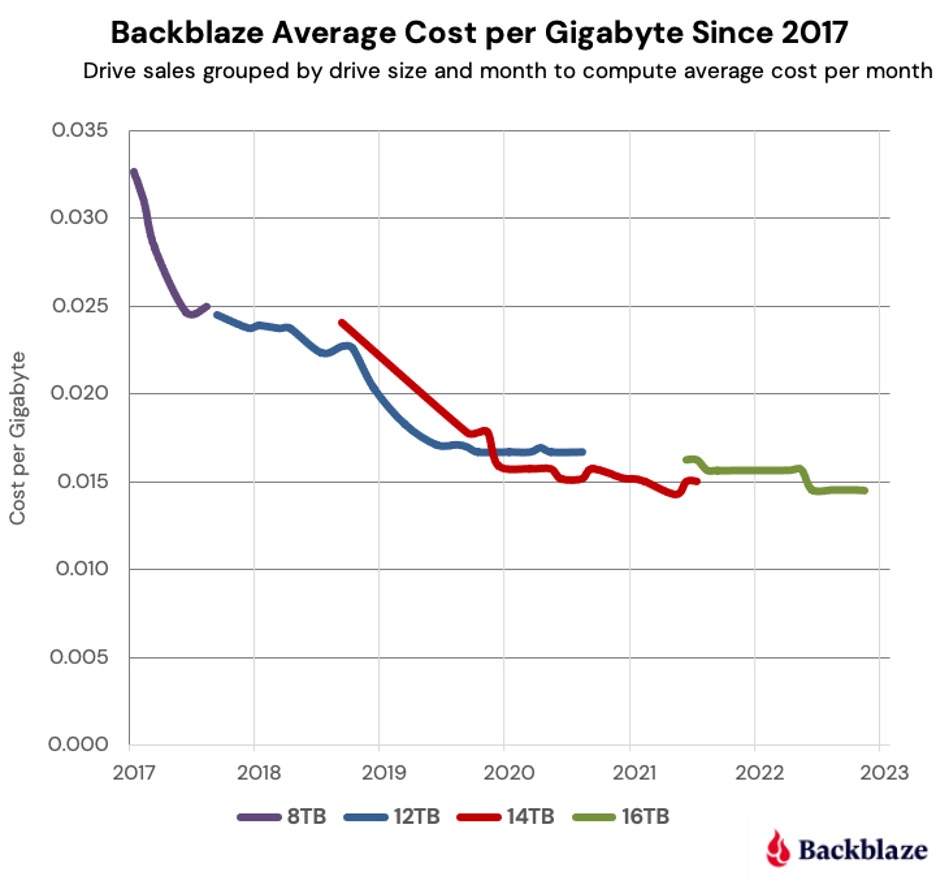
As noted earlier, our hard drive cost per gigabyte had fallen to a little over $0.03 by the end of 2017. At that point 8TB drives were our primary drives. Over the next few years we added 12TB, 14TB, and 16TB drives to the mix and the average cost per gigabyte continued to decrease as shown in the chart below.
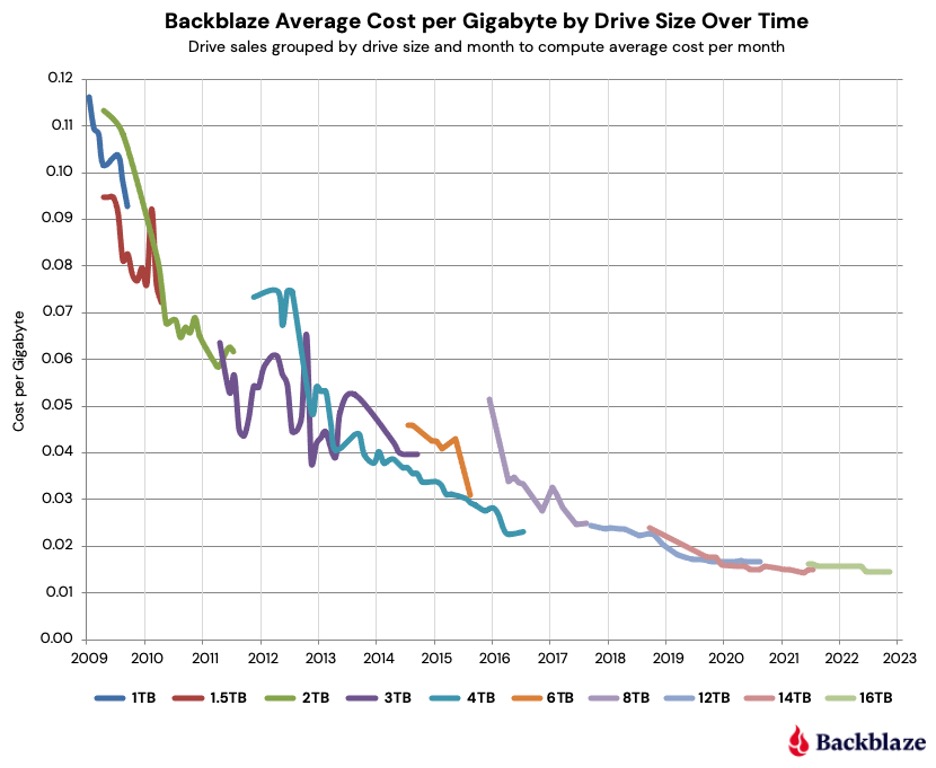
From 2017 to November 2022, the average cost per gigabyte decreased by 56.36% for all of the drives ($0.033 down to $0.0144). That’s over 9% per year on average across the four drive sizes. To put that data in context, below is the complete chart from 2009 through November 2022 for all drives sizes we have used as data drives during that period.
You can observe the overall down and to the right trend over the period, although the 3TB and 4TB drives make that drop messy. This was due primarily to the Thailand drive crisis which began in the second half of 2011 and continued to affect the market into 2013 before things got back to normal.
Overall, the drop in the average price per gigabyte was from $0.114 in 2009 to just $0.014 as of November 2022. That’s a difference of $0.100 (one thin dime) over the period. That equates to an 87.4% decrease in the average cost per terabyte since 2009. If we calculate the average decrease per month over that period, we get the cost per gigabyte of the hard drives we use decreasing 0.52% per month since January 2009.
During that time drive technology hardly stood still as drive manufacturers crammed more platters in the same basic 3 ½ inch chassis, dramatically increased areal media density, figured out how to use helium inside the drives, started using glass substrates for their platters, and other improvements and innovations. Regardless of what you may think of a given drive manufacturer, that’s pretty awesome for the industry as a whole.
At this point, a fair question would be why the cost we charge for storage hasn’t decreased 87% since 2009? Our friends at IDC (source: Figure 10; IDC Thought Leadership Practice Case Study) have calculated that in 2009, there was about 0.3 zettabytes of data stored on hard drives worldwide, and they estimated that by the end of 2022 there would be 1.8 zettabytes. That’s an increase of 500% for the amount of data stored on hard drives over the period. Let’s just say the global population is storing a lot more data and leave it at that.
Dollars and Sense
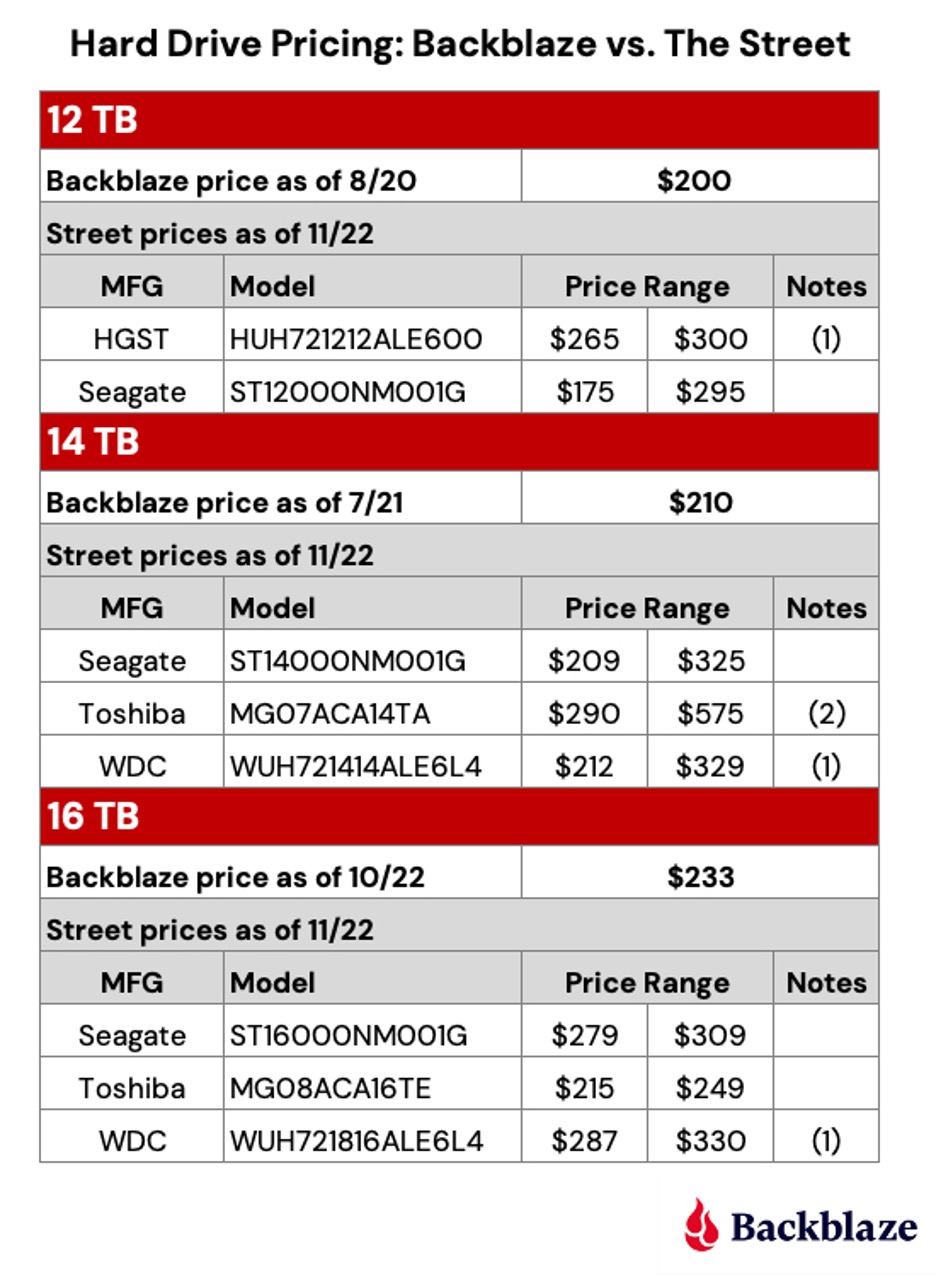
Of course, you don’t buy hard drives using percentages, you use dollars (or pesos, or pounds, or euros, and so on.) Let’s take a minute to see what price you would have to pay versus what we have paid. We’ve listed the best street price we could find for some of the 12TB, 14TB, and 16TB drives we use.
Notes:
As Western Digital continues to assimilate the HGST drive business, the model numbers of these drives are changing to WDC standards.
This model is sold as a server-based drive, similar models such as the MG07ACA14TE are less expensive.
Remember, we buy drives in bulk quantity and on contract with guaranteed pricing, delivery dates, and such. It’s not quite the same thing as buying a drive from a shrink wrapped pallet at Costco or from a Cyber Monday deal on Amazon. You may be able to buy a couple of drives at a great price, but when you need 12,000 drives delivered to your front door on a certain date, Amazon Prime isn’t going to cut it. As a result, it may cost a dollar or two more per drive to ensure we have what we need when we need it.
Lessons Learned
The cost per gigabyte has continued to fall over the past 13 years we’ve been tracking our drive purchases. This was in spite of the Thailand drive crisis which started in 2011, as well as the Coronavirus and the continuing supply chain problems it caused.
Drive manufacturer consolidation hasn’t stopped the cost per gigabyte from decreasing from 2009 through 2022. That said, it is impossible to say what the cost per gigabyte would be without consolidation.
On average, the cost per gigabyte of a drive will fall on average about 0.5% per month over time, slowly at first, then accelerating for some period before bottoming out.
In nearly every case, the cost per gigabyte of each new drive size introduced will eventually fall below that of its predecessor. For example, the cost per gigabyte for a 14TB drive will be less than a 12TB, and the cost per gigabyte for the 16TB drive will be less than the 14TB.
Where Is the Bottom?
When we published our 2017 report on this topic, we proclaimed the race to the bottom was over, implying that the cost per gigabyte could not go much (if any) lower. We were wrong.
So where is the bottom? There’s an expression that goes something like, “We have done so much for so long with so little that we can now do practically anything with nothing.” There are probably folks at the drive manufacturers mumbling that expression to themselves on a daily basis as they try to cram more bits in less space on increasingly thin sheets of coated glass racing by at 5,400/7,200/15,000 revolutions per minute.
Getting back to reality, the next milestone we can see is $0.01 per gigabyte for a hard drive—that’s not a sale price, but a stable street price. Let’s go out on a limb and say that we will reach that in mid-2025 with 22TB or 24TB drives. That would mean you could buy a 22TB drive at Costco or on Amazon for about $220, or a 24TB for $240.
Is $0.01 per gigabyte the bottom? At the risk of having boomers shout “How low can you go?” and throw their backs out doing the limbo, we’ll ask: How low can the cost per gigabyte go? Tell us what you think.
This post has been updated since it was originally published in 2017.
Programs, processes, and threads are all terms that relate to software execution, but you may not know what they really mean. Whether you’re a seasoned developer, an aspiring enthusiast, or you’re just wondering what you’re looking at when you open Task Manager on a PC or Activity Monitor on a Mac, learning these terms is essential for understanding how a computer works.
This post explains the technical concepts behind computer programs, processes, and threads to give you a better understanding of the functionality of your digital devices. With this knowledge, you can quickly diagnose problems and come up with solutions, like knowing if you need to install more memory for better performance. If you care about having a fast, efficient computer, it is worth taking the time to understand these key terms.
What Is a Computer Program?
A program is a sequence of coded commands that tells a computer to perform a given task. There are many types of programs, including programs built into the operating system (OS) and ones to complete specific tasks. Generally, task-specific programs are called applications (or apps). For example, you are probably reading this post using a web browser application like Google Chrome, Mozilla Firefox, or Apple Safari. Other common applications include email clients, word processors, and games.
The process of creating a computer program involves designing algorithms, writing code in a programming language, and then compiling or interpreting that code to transform it into machine-readable instructions that the computer can execute.
What Are Programming Languages?
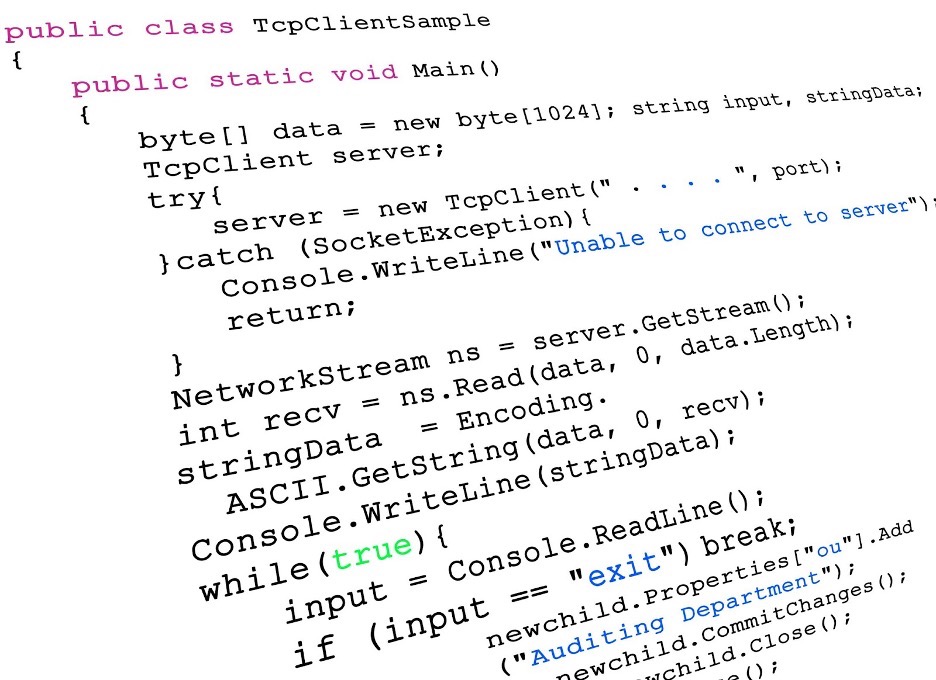
Programming languages are the way that humans and computers talk to each other. They are formalized sets of rules and syntax.
C# example of program code.
Compiled vs. Interpreted Programs
Many programs are written in a compiled language and created using programming languages like C, C++, C#. The end result is a text file of code that is compiled into binary form in order to run on the computer (more on binary form in a few paragraphs). The text file speaks directly to your computer. While they’re typically fast, they are also fixed compared to interpreted programs. That has positives and negatives: you have more control over things like memory management, but you’re platform dependent and, if you have to change something in your code, it typically takes longer to build and test.
There is another kind of program called an interpreted program. They require an additional program to take your program instructions and translate that to code for your computer. Compared with compiled languages, these types of programs are platform-independent (you just have to find a different interpreter, instead of writing a whole new program) and they typically take up less space. Some of the most common interpreted programming languages are Python, PHP, JavaScript, and Ruby.
Ultimately, both kinds of programs are run and loaded into memory in binary form. Programs have to run in binary because your computer’s CPU understands only binary instructions.
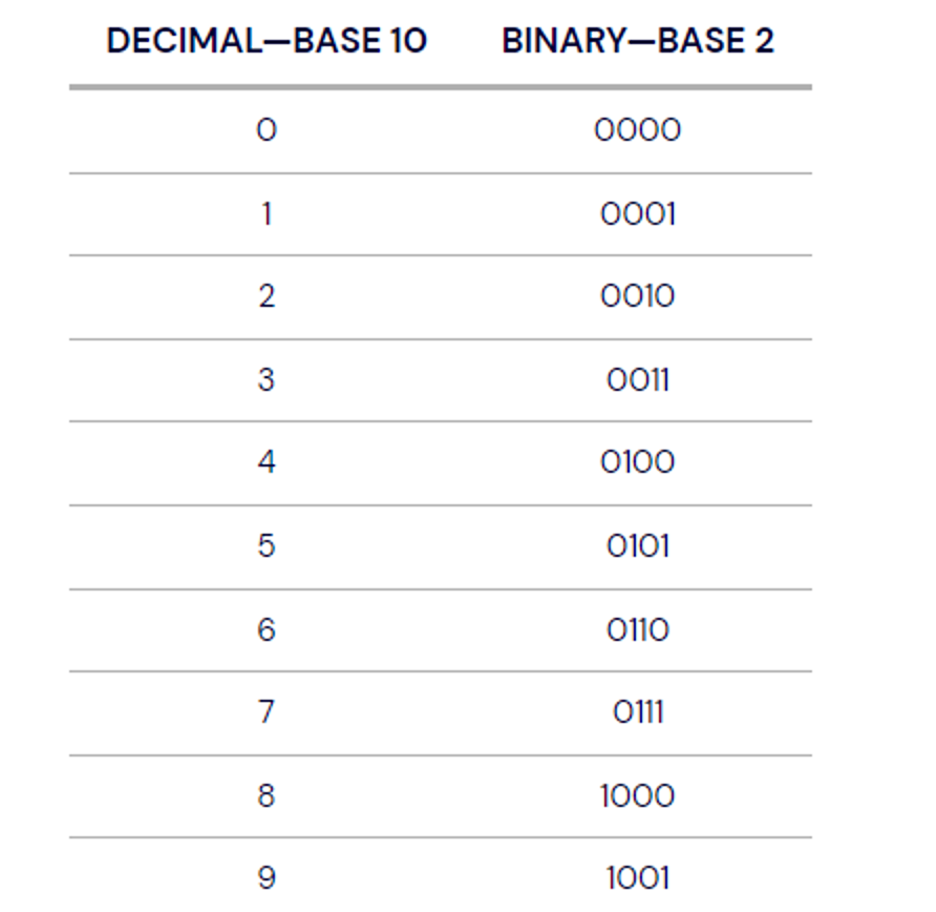
What Is Binary Code?
Binary is the native language of computers. At their most basic level, computers use only two states of electrical current—on and off. The on state is represented by 1 and the off state is represented by 0. Binary is different from the number system—base 10—that we use in daily life. In base 10, each digit position can be anything from 0 to 9. In the binary system, also known as base 2, each position is either a 0 or a 1.
Perhaps you’ve heard the programmer’s joke, “There are only 10 types of people in the world, those who understand binary, and those who don’t.”
How Are Computer Programs Stored and Run?
Programs are typically stored on a disk or in nonvolatile memory in executable format. Let’s break that down to understand why.
In this context, we’ll talk about your computer having two types of memory: volatile and nonvolatile. Volatile memory is temporary and processes in real time. It’s faster, easily accessible, and increases the efficiency of your computer. However, it’s not permanent. When your computer turns off, this type of memory resets.
Nonvolatile memory, on the other hand, is permanent unless deleted. While it’s slower to access, it can store more information. So, that makes it a better place to store programs. A file in an executable format is simply one that runs a program. It can be run directly by your CPU (that’s your processor). Examples of these file types are .exe in Windows and .app in Mac.
What Resources Does a Program Need to Run?
Once a program has been loaded into memory in binary form, what happens next?
Your executing program needs resources from the OS and memory to run. Without these resources, you can’t use the program. Fortunately, your OS manages the work of allocating resources to your programs automatically. Whether you use Microsoft Windows, macOS, Linux, Android, or something else, your OS is always hard at work directing your computer’s resources needed to turn your program into a running process.
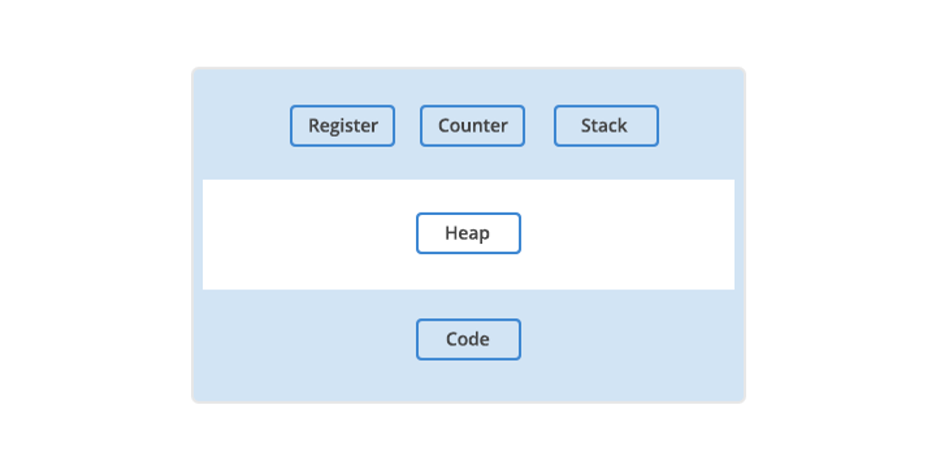
In addition to OS and memory resources, there are a few essential resources that every program needs.
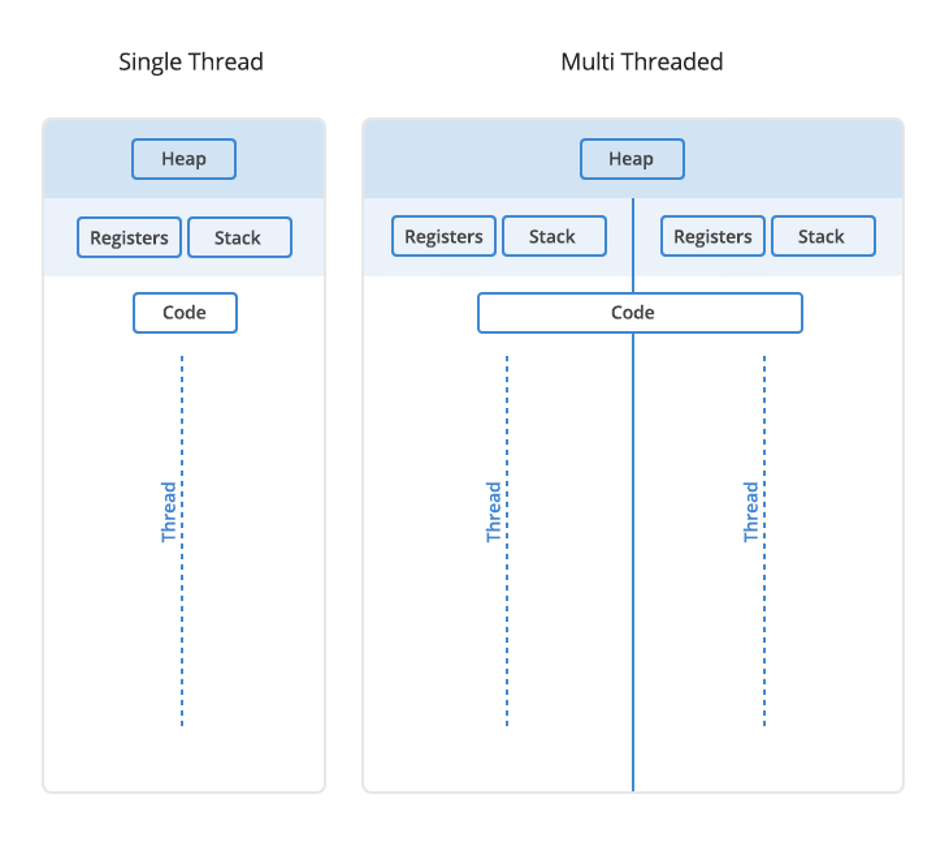
Register. Think of a register as a holding pen that contains data that may be needed by a process like instructions, storage addresses, or other data.
Program counter. Also known as an instruction pointer, the program counter plays an organizational role. It keeps track of where a computer is in its program sequence.
Stack. A stack is a data structure that stores information about the active subroutines of a computer program. It is used as scratch space for the process. It is distinguished from dynamically allocated memory for the process that is known as the “heap.”
The main resources a program needs to run.
What Is a Computer Process?
When a program is loaded into memory along with all the resources it needs to operate, it is called a process. You might have multiple instances of a single program. In that situation, each instance of that running program is a process.
Each process has a separate memory address space. That separate memory address is helpful because it means that a process runs independently and is isolated from other processes. However, processes cannot directly access shared data in other processes. Switching from one process to another requires some amount of time (relatively speaking) for saving and loading registers, memory maps, and other resources.
Having independent processes matters for users because it means one process won’t corrupt or wreak havoc on other processes. If a single process has a problem, you can close that program and keep using your computer. Practically, that means you can end a malfunctioning program and keep working with minimal disruptions.
What Are Threads?
The final piece of the puzzle is threads. A thread is the unit of execution within a process.
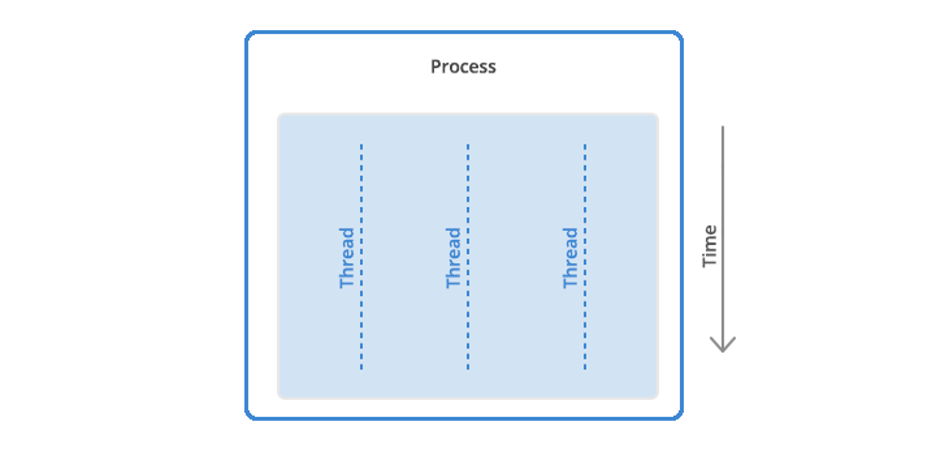
A process can have anywhere from one thread to many.
When a process starts, it receives an assignment of memory and other computing resources. Each thread in the process shares that memory and resources. With single-threaded processes, the process contains one thread.
The difference between single thread and multi-thread processes.
In multi-threaded processes, the process contains more than one thread, and the process is accomplishing a number of things at the same time (to be more accurate, we should say “virtually” the same time—you can read more about that in the section below on concurrency).
Earlier, we talked about the stack and the heap, the two kinds of memory available to a thread or process. Distinguishing between these kinds of memory matters because each thread will have its own stack. However, all the threads in a process will share the heap.
Some people call threads lightweight processes because they have their own stack but can access shared data. Since threads share the same address space as the process and other threads within the process, it is easy to communicate between the threads. The disadvantage is that one malfunctioning thread in a process can impact the viability of the process itself.
How Threads and Processes Work Step By Step
Here’s what happens when you open an application on your computer.
The program starts out as a text file of programming code.
The program is compiled or interpreted into binary form.
The program is loaded into memory.
The program becomes one or more running processes. Processes are typically independent of one another.
Threads exist as the subset of a process.
Threads can communicate with each other more easily than processes can.
Threads are more vulnerable to problems caused by other threads in the same process.
Computer Process vs. Threads
Aspect
Processes
Threads
Definition
Independent programs with their own memory space.
Lightweight, smaller units of a process, share memory.
Creation Overhead
Higher overhead due to separate memory space.
Lower overhead as they share the same memory space.
Isolation
Processes are isolated from each other.
Threads share the same memory space.
Resource Allocation
Each process has its own set of system resources.
Threads share resources within the same process.
Independence
Processes are more independent of each other.
Threads are dependent on each other within a process.
Failure Impact
A failure in one process does not directly affect others.
A failure in one thread can affect others in the same process.
Sychronization
Less need from synchronization, as processes are isolated.
Requires careful synchronization due to shared resources.
Example Use Cases
Running multiple independent applications.
Multithreading within a single application for parallelism.
Memory Usage
Typically consumes more memory.
Consumes less memory compared to processes.
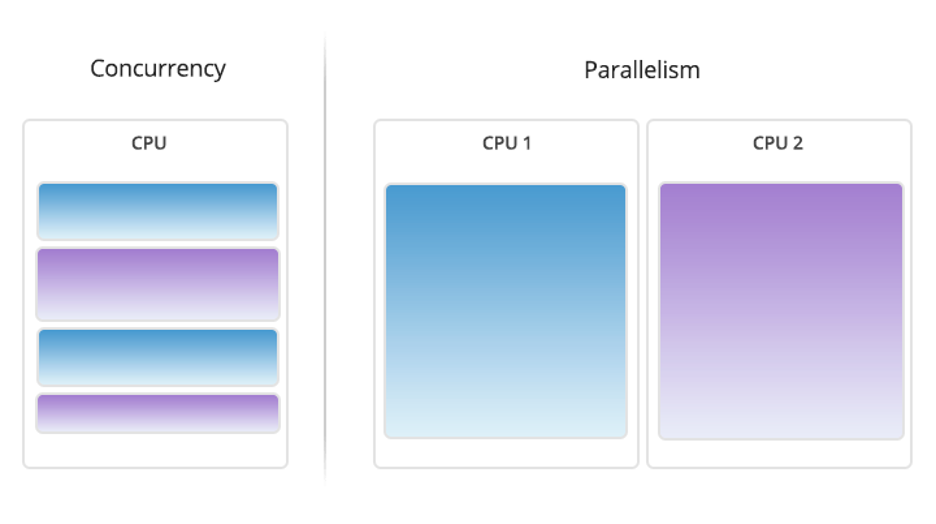
What About Concurrency and Parallelism?
A question you might ask is whether processes or threads can run at the same time. The answer is: it depends. In environments with multiple processors or CPU cores, simultaneous execution of multiple processes or threads is feasible. However, on a single processor system, true simultaneous execution isn’t possible. In these cases, a process scheduling algorithm is employed to share the CPU among running processes or threads, creating the illusion of parallel execution. Each task is allocated a “time slice,” and the swift switching between tasks occurs seamlessly, typically imperceptible to users. The terms “parallelism” (denoting genuine simultaneous execution) and “concurrency” (indicating the interleaving of processes over time to simulate simultaneous execution) distinguish between the two modes of operation, whether truly simultaneous or approximated.
How Google Chrome Uses Processes and Threads
To illustrate the impact of processes and threads, let’s consider a real-world example with a program that many of us use, Google Chrome.
When Google designed the Chrome browser, they faced several important decisions. For instance, how should Chrome handle the fact that many different tasks often happen at the same time when using a browser? Every browser window (or tab) may communicate with several servers on the internet to download audio, video, text, and other resources. In addition, many users have 10 to 20 browser tabs (or more…) open most of the time, and each of these tabs may perform multiple tasks.
Google had to decide how to handle all of these tasks. They chose to run each browser window in Chrome as a separate process rather than a thread or many threads. That approach brought several benefits.
Running each window as a process protects the overall application from bugs and glitches.
Isolating a JavaScript program in a process prevents it from using too much CPU time and memory and making the entire browser unresponsive.
That said, there is a trade-off cost to Google’s design decision. Starting a new process for each browser window has a higher fixed cost in memory and resources compared to using threads. They were betting that their approach would end up with less memory bloat overall.
Using processes instead of threads provides better memory usage when memory is low. In practice, an inactive browser window is treated as a lower priority. That means the operating system may swap it to disk when memory is needed for other processes. If the windows were threaded, it would be more difficult to allocate memory efficiently which ultimately leads to lost computer performance.
The screen capture below shows the Google Chrome processes running on a MacBook Air with many tabs open. You can see that some Chrome processes are using a fair amount of CPU time and resources (e.g., the one at the top is using 44 threads) while others are using fewer.
Mac Activity Monitor displaying Google Chrome threads.
The Activity Monitor on the Mac (or Task Manager in Windows) on your system can be a valuable ally in fine-tuning your computer or troubleshooting problems. If your computer is running slowly or a program or browser window isn’t responding for a while, you can check its status using the system monitor.
In some cases, you’ll see a process marked as “Not Responding.” Try quitting that process and see if your system runs better. If an application is a memory hog, you might consider choosing a different application that will accomplish the same task.
Made It This Far?
We hope this Tron-like dive into the fascinating world of computer programs, processes, and threads has cleared up some questions.
At the start, we promised clarity on using these terms to improve performance. You can use Activity Monitor on the Mac or Task Manager on Windows to close applications and processes that are malfunctioning. That’s beneficial because it means you can end a malfunctioning program without the hassle of turning off your computer.
Still have questions? We’d love to hear from you in the comments.
FAQ
1. What are computer programs?
Computer programs are sets of coded instructions written in programming languages to direct computers in performing specific tasks or functions. Ranging from simple scripts to complex applications, computer programs enable users to interact with and leverage the capabilities of computing devices.
2. What are computer processes?
Computer processes are instances of executing computer programs. They represent the active state of a running application or task. Each process operates independently, with its own memory space and system resources, ensuring isolation from other processes. Processes are managed by the operating system, and they facilitate multitasking and parallel execution.
3. What are computer threads?
Computer threads are smaller units within computer processes, enabling parallel execution of tasks. Threads share the same memory space and resources within a process, allowing for more efficient communication and coordination. Unlike processes, threads operate in a cooperative manner, sharing data and context, making them suitable for tasks requiring simultaneous execution.
4. What’s the difference between computer processes and threads?
Computer processes are independent program instances with their own memory space and resources, operating in isolation. In contrast, threads are smaller units within processes that share the same memory, making communication easier but requiring careful synchronization. Processes are more independent, while threads enable concurrent execution and resource sharing within a process. The choice depends on the application’s requirements, balancing isolation with the benefits of parallelism and resource efficiency.
5. What’s the difference between concurrency and parallel processing?
Concurrency involves the execution of multiple tasks during overlapping time periods, enhancing system responsiveness. It doesn’t necessarily imply true simultaneous execution but rather the interleaving of processes to create an appearance of parallelism. Parallel processing, on the other hand, refers to the simultaneous execution of multiple tasks using multiple processors or cores, achieving genuine parallelism. Concurrency emphasizes efficient task management, while parallel processing focuses on concurrent tasks executing simultaneously for improved performance in tasks that can be divided into independent subtasks.
For schools and universities, data storage is paramount. Staff, administrators, and educators, not to mention students, need a secure place to store files. Add to that the legacy accounts of alumni storing irreplaceable files from their education, and you have a massive need for storage.
For a long time, Google was happy to oblige. In 2006, the company launched Google Apps for Education (later G Suite for Education; now Google Workplace for Education), offering free unlimited storage for qualifying schools and districts. But when they’d reached market penetration—somewhere in the neighborhood of 83% of school districts according to EdWeek Research Center—they ended the unlimited storage policy many schools had come to rely on.
If you already know about Google’s policy change and are looking for a solution to save your data and your budget, getting started with Backblaze B2 is easy. Otherwise, read on to learn more about the change, what it may mean for you in the long-term, and a Backblaze partnership with Carahsoft that eases purchasing through local, state, and federal buying programs.
Office Hours Are Over—Google Ends Unlimited Storage for Educational Institutions
Google’s policy change took effect in July 2022, and many schools and universities had to find alternative storage solutions or change their internal storage policies to stay within the new limits. Under the terms of the new policy, Google offers a baseline of 100TB of pooled storage shared across all users.
The policy shift was spurred, Google says, because “as we’ve grown to serve more schools and universities each year, storage consumption has also rapidly accelerated. Storage is not being consumed equitably across—nor within—institutions, and school leaders often don’t have the tools they need to manage this.”
For some school districts, colleges, and universities, this policy shift meant having to reach out to alumni with the request that they back up all their own data. It also hit some already-strapped IT budgets particularly hard. Estimates vary, but depending on the size of the school and their data needs, they could be looking at anywhere up to an extra $70,000 a year in storage costs.
That’s a non-negligible fee for a service that has become increasingly vital for schools. We’ve written about how important cloud storage is for schools, but it’s worth reiterating here.
School is in Session
Not only will a secure cloud storage solution help protect school districts from threats of ransomware, it can also help maintain predictable operating expenses and create opportunities for collaboration through remote learning. In cases like Kansas’ Pittsburg State University, it helped keep data safe from natural disasters that abound in places like Tornado Alley. Pittsburg State implemented Backblaze B2 as their off-site backup in the event of disaster and used Object Lock functionality to safeguard data from ransomware.
Photo Credit: Pittsburg State University
The academic world is still adjusting to Google’s policy change. Stories have emerged of schools simply dropping Google and being forced to move data out of thousands of alumni accounts. A quick-fix solution to avoid Google’s new fee structure, this strategy is being undertaken without a clear answer to the question of how alumni can access their own data after the move. After all, how up to date are those alumni email lists?
A Google Alternative for Schools
School districts, colleges, and universities need to find a new, budget-friendly way forward. If you’re still struggling to find an alternative storage solution now that the bell has rung and Google has dismissed its free storage, Backblaze can help you find a new home on the cloud.
Backblaze B2 offers schools unlimited, pay-as-you-go storage at a fraction of the price of Google, enabling you to continue offering students and alumni the storage space they’ve come to expect. For colleges, universities, and school districts not buying through government purchasing programs, you can sign up for Backblaze B2 directly. We offer 10TB of storage free so that you can see if it works for you, but if you want to do a larger or customized proof of concept, reach out to our Sales team.
Accessing Backblaze Through Your Local, State, or Federal Buying Program
As we revealed during this year’s Educause conference, Backblaze has recently rolled out a partnership with Carahsoft aimed squarely at budget-conscious educational institutions. The partnership brings Backblaze services to educational institutions with a capacity-based pricing model that’s a fraction of the price of traditional cloud providers like Google. And it can be purchased through local, state, or federal buying programs. If you buy IT services for your district through a distributor, this solution could work for you. Visit the partnership announcement to learn more.
Streamlining your digital media workflow can make all the difference when it comes to your productivity—not to mention your budget. For folks in media, entertainment, post-production, corporate, education, government, or content creation, media workflows just got a little easier thanks to a partnership between Backblaze and Telestream.
Now joint customers can store transcoded media files on Backblaze B2 Cloud Storage as their origin store for delivery via Telestream’s Vantage CloudPort product. Read on to learn more about the partnership and what it means for you.
What Does Telestream Do?
Telestream, a Backblaze alliance partner, specializes in products that make it possible to get video content to any audience regardless of how it is created, distributed, or viewed. Throughout the entire digital media lifecycle, from capture to viewing, for consumers through high-end professionals, Telestream products range from desktop components and cross-platform applications to fully-automated, enterprise-class digital media transcoding, and workflow systems. Telestream enables users in a broad range of business environments to leverage the value of their video content.
How Does This Partnership Benefit Joint Customers?
Content is king, as they say, and being able to efficiently and effectively produce content and make it available to the audiences that are going to consume it is critical. This partnership benefits joint customers in a few key ways:
Customers can benefit from cost savings in the cloud: Backblaze is a fraction of the cost of diversified cloud providers.
By storing transcoded media files in the cloud, customers can leverage other services like QC in the cloud to ensure quality is up to their high standards.
Customers can leave on-premises storage in the past and move to the cloud to leverage the cloud’s infinite scalability and parallelism.
Making the move to the cloud also reduces the risk of having a single point of failure on premises.
“Telestream and Backblaze are driven by a shared mission to empower our customers and help them make their businesses more efficient. With this collaboration, we can meet our customers where their content is stored and apply Telestream’s best in class media processing tools.”
—Tim MacGregor, Senior Director, Head of Strategy and Product Development, Telestream Cloud
Support from our partners is part of what makes Backblaze so easy to use for so many folks, and today we’re continuing our efforts to make working with us even easier with the launch of our new Partner Program.
For businesses, it cuts through the complexity and cost that may have stopped them from adopting cloud storage and backup. For partners—including resellers, integrators, managed service providers, and more—it boosts their array of cloud solutions and brings even more value to their clients. The program builds on our long commitment to develop new solutions for partners and help them grow their businesses.
Partner Program Offerings
The program provides new opportunities for four key partner groups: Channel Partners, Technology Partners, Managed Service Providers (MSPs), and Affiliates.
As part of this new program, Channel Partners can take advantage of special capacity-based pricing with B2 Reserve, as well as a self-service resource providing discounts, deal registration, and in-house support. It also offers training and education resources.
Technology Partners can enjoy complimentary solution expertise and joint go-to-market and co-branding opportunities. MSPs will notice the ease of the new admin console and the utility of in-house support, digital assets, training materials, and data sheets, not to mention the recurring 10% commissions on computer backup. And of course, Affiliates, too, can enjoy recurring 10% commissions.
With the launch of the program, Backblaze is doubling down on its commitment to its partners, proving why Backblaze has built its reputation on easy-to-use, affordable cloud storage.
“Ease of use and accessibility can have a significant impact for our partners and their business. We are continuously looking for ways to innovate and develop for our partners. Offering this easy, accessible, and efficient resource will strengthen our relationship with our customers.”
—Nilay Patel, Vice President of Sales, Backblaze
Visit our Partner page to learn more about the Partner Program, visit the Partner Portal, or get started as a new partner.
Last week, we published Backblaze Drive Stats for Q3 2022, sharing the metrics we’ve gathered on our fleet of over 230,000 hard drives. In this blog post, I’ll explain how we’re now using the Trino open source SQL query engine in ensuring the integrity of Drive Stats data, and how we plan to use Trino in future to generate the Drive Stats result set for publication.
Converting Zipped CSV Files into Parquet
In his blog post Storing and Querying Analytical Data in Backblaze B2, my colleague Greg Hamer explained how we started using Trino to analyze Drive Stats data earlier this year. We quickly discovered that formatting the data set as Apache Parquet minimized the amount of data that Trino needed to download from Backblaze B2 Cloud Storage to process queries, resulting in a dramatic improvement in query performance over the original CSV-formatted data.
As Greg mentioned in the earlier post, Drive Stats data is published quarterly to Backblaze B2 as a single .zip file containing a CSV file for each day of the quarter. Each CSV file contains a record for each drive that was operational on that day (see this list of the fields in each record).
When Greg and I started working with the Parquet-formatted Drive Stats data, we took a simple, but somewhat inefficient, approach to converting the data from zipped CSV to Parquet:
Download the existing zip files to local storage.
Unzip them.
Run a Python script to read the CSV files and write Parquet-formatted data back to local storage.
Upload the Parquet files to Backblaze B2.
We were keen to automate this process, so we reworked the script to use the Python ZipFile module to read the zipped CSV data directly from its Backblaze B2 Bucket and write Parquet back to another bucket. We’ve shared the script in this GitHub gist.
After running the script, the drivestats table now contains data up until the end of Q3 2022:
trino:ds> SELECT DISTINCT year, month, day
FROM drivestats ORDER BY year DESC, month DESC, day DESC LIMIT 1;
year | month | day
------+-------+-----
2022 | 9 | 30
(1 row)
In the last article, we were working with data running until the end of Q1 2022. On March 31, 2022, the Drive Stats dataset comprised 296 million records, and there were 211,732 drives in operation. Let’s see what the current situation is:
trino:ds> SELECT COUNT(*) FROM drivestats;
_col0
-----------
346006813
(1 row)
trino:ds> SELECT COUNT(*) FROM drivestats
WHERE year = 2022 AND month = 9 AND day = 30;
_col0
--------
230897
(1 row)
So, since the end of March, we’ve added 50 million rows to the dataset, and Backblaze is now spinning nearly 231,000 drives—over 19,000 more than at the end of March 2022. Put another way, we’ve added more than 100 drives per day to the Backblaze Cloud Storage Platform in the past six months. Finally, how many exabytes of raw data storage does Backblaze now manage?
trino:ds> SELECT ROUND(SUM(CAST(capacity_bytes AS bigint))/1e+18, 2)
FROM drivestats WHERE year = 2022 AND month = 9 AND day = 30;
_col0
-------
2.62
(1 row)
Will we cross the three exabyte mark this year? Stay tuned to find out.
Ensuring the Integrity of Drive Stats Data
As Andy Klein, the Drive Stats supremo, collates each quarter’s data, he looks for instances of healthy drives being removed and then returned to service. This can happen for a variety of operational reasons, but it shows up in the data as the drive having failed, then later revived. This subset of data shows the phenomenon:
trino:ds> SELECT year, month, day, failure FROM drivestats WHERE
serial_number = 'ZHZ4VLNV' AND year >= 2021 ORDER BY year, month,
day;
year | month | day | failure
------+-------+-----+---------
...
2021 | 12 | 26 | 0
2021 | 12 | 27 | 0
2021 | 12 | 28 | 0
2021 | 12 | 29 | 1
2022 | 1 | 3 | 0
2022 | 1 | 4 | 0
2022 | 1 | 5 | 0
...
This drive appears to have failed on Dec 29, 2021, but was returned to service on Jan 3, 2022.
Since these spurious “failures” would skew the reliability statistics, Andy searches for and removes them from each quarter’s data. However, even Andy can’t see into the future, so, when a drive is taken offline at the end of one quarter and then returned to service in the next quarter, as in the above case, there is a bit of a manual process to find anomalies and clean up past data.
With the entire dataset in a single location, we can now write a SQL query to find drives that were removed, then returned to service, no matter when it occurred. Let’s build that query up in stages.
We start by finding the serial numbers and failure dates for each drive failure:
trino:ds> SELECT serial_number, DATE(FORMAT('%04d-%02d-%02d', year,
month, day)) AS date
FROM drivestats
WHERE failure = 1;
serial_number | date
-----------------+------------
ZHZ3KMX4 | 2021-04-01
ZA12RBBM | 2021-04-01
S300Z52X | 2017-03-01
Z3051FWK | 2017-03-01
Z304JQAE | 2017-03-02
...
(17092 rows)
Now we find the most recent record for each drive:
trino:ds> SELECT serial_number, MAX(DATE(FORMAT('%04d-%02d-%02d',
year, month, day))) AS date
FROM drivestats
GROUP BY serial_number;
serial_number | date
------------------+------------
ZHZ65F2W | 2022-09-30
ZLW0GQ82 | 2022-09-30
ZLW0GQ86 | 2022-09-30
Z8A0A057F97G | 2022-09-30
ZHZ62XAR | 2022-09-30
...
(329908 rows)
We then join the two result sets to find spurious failures; that is, failures where the drive was later returned to service. Note the join condition—we select records whose serial numbers match and where the most recent record is later than the failure:
trino:ds> SELECT f.serial_number, f.failure_date
FROM (
SELECT serial_number, DATE(FORMAT('%04d-%02d-%02d', year, month,
day)) AS failure_date
FROM drivestats
WHERE failure = 1
) AS f
INNER JOIN (
SELECT serial_number, MAX(DATE(FORMAT('%04d-%02d-%02d', year,
month, day))) AS last_date
FROM drivestats
GROUP BY serial_number
) AS l
ON f.serial_number = l.serial_number AND l.last_date > f.failure_date;
serial_number | failure_date
-----------------+--------------
2003261ED34D | 2022-06-09
W300STQ5 | 2022-06-11
ZHZ61JMQ | 2022-06-17
ZHZ4VL2P | 2022-06-21
WD-WX31A2464044 | 2015-06-23
(864 rows)
As you can see, the current schema makes date comparisons a little awkward, pointing the way to optimizing the schema by adding a DATE-typed column to the existing year, month, and day. This kind of denormalization is common in analytical data.
Calculating the Quarterly Failure Rates
In calculating failure rates per drive model for each quarter, Andy loads the quarter’s data into MySQL and defines a set of views. We additionally define the current_quarter view to restrict the failure rate calculation to data in July, August, and September 2022:
CREATE VIEW current_quarter AS
SELECT * FROM drivestats
WHERE year = 2022 AND month in (7, 8, 9);
CREATE VIEW drive_days AS
SELECT model, COUNT(*) AS drive_days
FROM current_quarter
GROUP BY model;
CREATE VIEW failures AS
SELECT model, COUNT(*) AS failures
FROM current_quarter
WHERE failure = 1
GROUP BY model
UNION
SELECT DISTINCT(model), 0 AS failures
FROM current_quarter
WHERE model NOT IN
(
SELECT model
FROM current_quarter
WHERE failure = 1
GROUP BY model
);
CREATE VIEW failure_rates AS
SELECT drive_days.model AS model,
drive_days.drive_days AS drive_days,
failures.failures AS failures,
100.0 * (1.0 * failures) / (drive_days / 365.0) AS
annual_failure_rate
FROM drive_days, failures
WHERE drive_days.model = failures.model;
Running the above statements in Trino, then querying the failure_rates view, yields a superset of the data that we published in the Q3 2022 Drive Stats report. The difference is that this result set includes drives that Andy excludes from the Drive Stats report: SSD boot drives, drives that were used for testing purposes, and drive models which did not have at least 60 drives in service:
Now that we have shown that we can derive the required statistics by querying the Parquet-formatted data with Trino, we can streamline the Drive Stats process. Starting with the Q4 2022 report, rather than wrangling each quarter’s data with a mixture of tools on his laptop, Andy will use Trino to both clean up the raw data and produce the Drive Stats result set for publication.
Accessing the Drive Stats Parquet Dataset
When Greg and I started experimenting with Trino, our starting point was Brian Olsen’s Trino Getting Started GitHub repository, in particular, the Hive connector over MinIO file storage tutorial. Since MinIO and Backblaze B2 both have S3-compatible APIs, it was easy to adapt the tutorial’s configuration to target the Drive Stats data in Backblaze B2, and Brian was kind enough to accept my contribution of a new tutorial showing how to use the Hive connector over Backblaze B2 Cloud Storage. This tutorial will get you started using Trino with data stored in Backblaze B2 Buckets, and includes a section on accessing the Drive Stats dataset.
You might be interested to know that Backblaze is sponsoring this year’s Trino Summit, taking place virtually and in person in San Francisco, on November 10. Registration is free; if you do attend, come say hi to Greg and me at the Backblaze booth and see Trino in action, querying data stored in Backblaze B2.
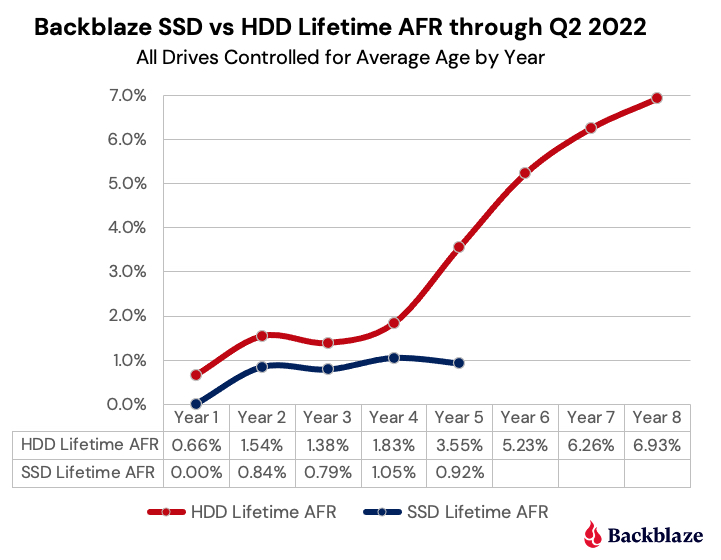
As of the end of Q3 2022, Backblaze was monitoring 230,897 hard drives and SSDs in our data centers around the world. Of that number, 4,200 are boot drives, with 2,778 SSDs and 1,422 HDDs. The SSDs were previously covered in our recently published Midyear SSD Report. Today, we’ll focus on the 226,697 data drives under management as we review their quarterly and lifetime failure rates as of the end of Q3 2022.
We’ll also take a look at the relationship between hard drive failure rates and hard drive cost. Along the way, we’ll share our observations and insights on the data presented, and, as always, we look forward to you doing the same in the comments section at the end of the post.
Q3 2022 Hard Drive Failure Rates
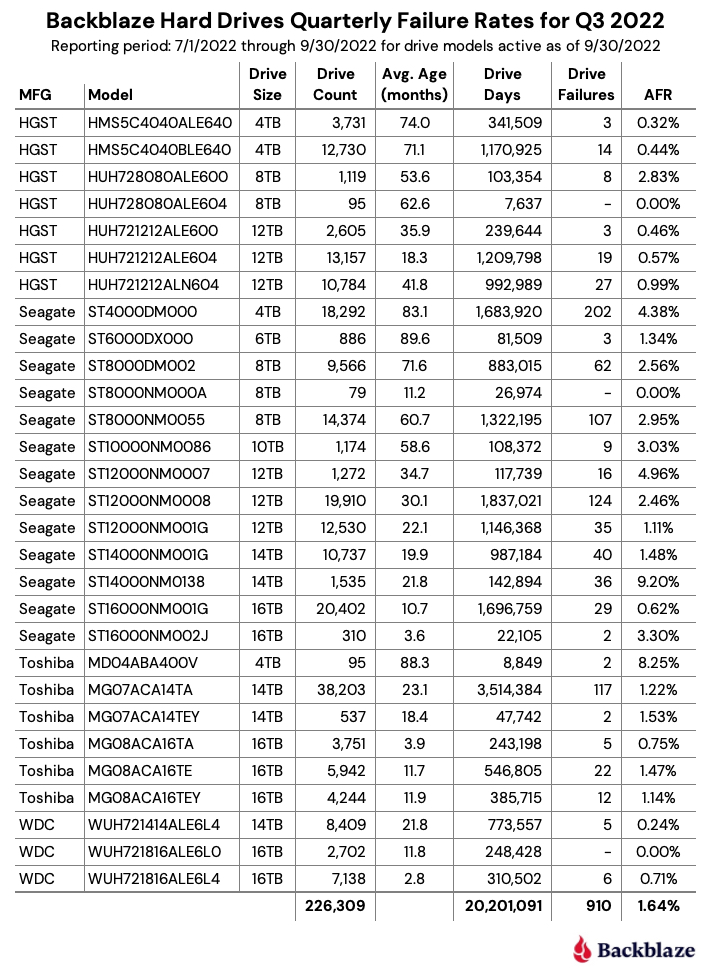
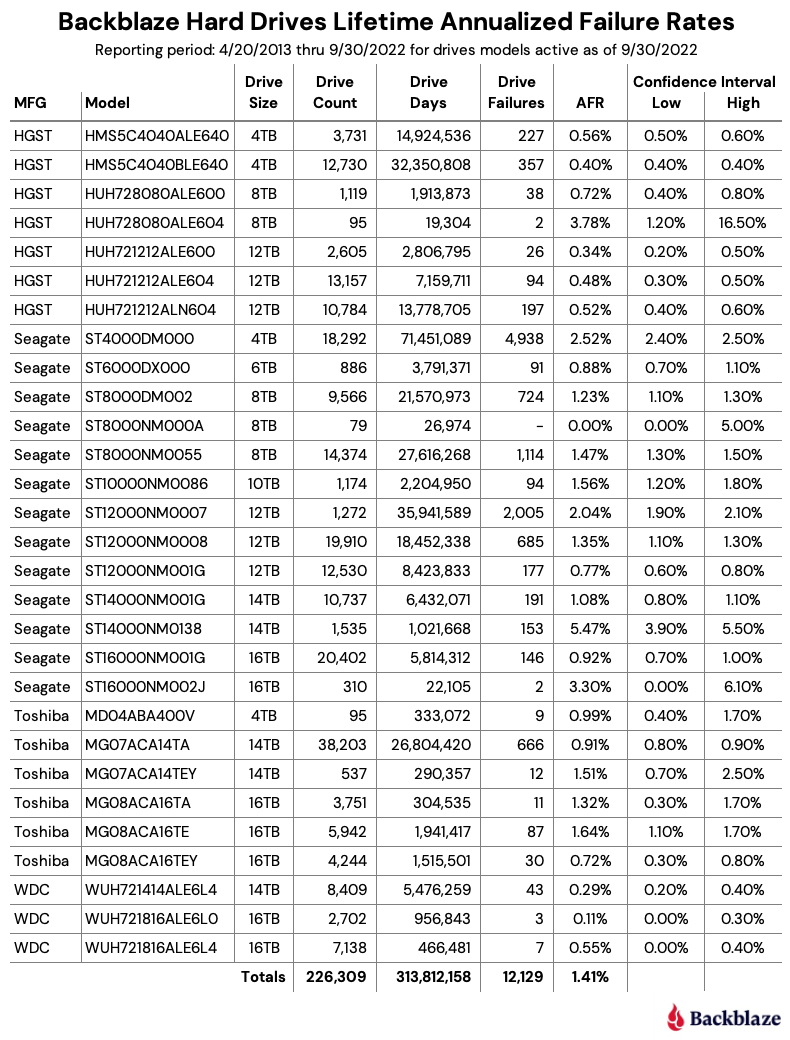
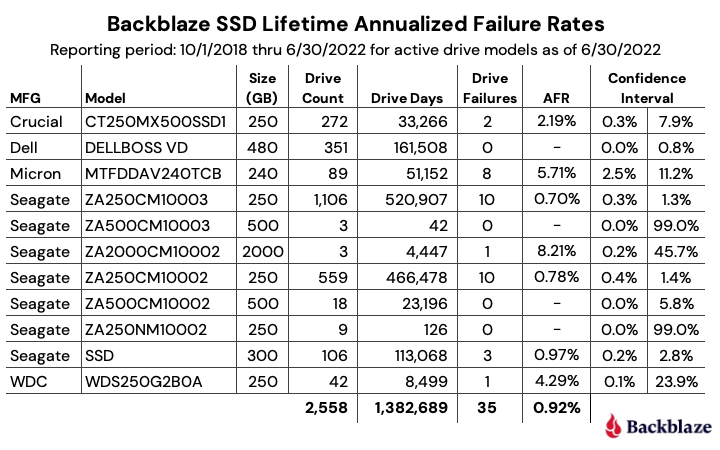
Let’s start with reviewing our data for the Q3 2022 period. In that quarter, we tracked 226,697 hard drives used to store data. For our evaluation, we removed 388 drives from consideration as they were used for testing purposes or drive models which did not have at least 60 drives. This leaves us with 226,309 hard drives grouped into 29 different models to analyze.
Notes and Observations on the Q2 2022 Stats
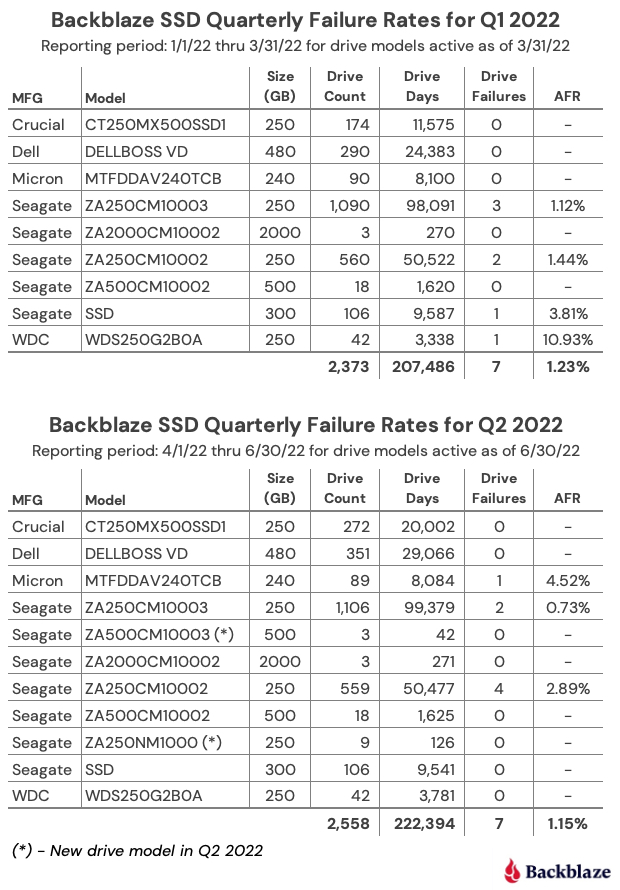
Zero failures for Q3: Three drives had zero failures this quarter: the 8TB HGST (model: HUH728080ALE604), the 8TB Seagate (model: ST8000NM000A), and the 16TB WDC (model: WUH721816ALE6L0). For the 8TB HGST, that was the second quarter in a row with zero failures. Of the three, only the WDC model has enough lifetime data (drive days) to be comfortable with the calculated annualized failure rate (AFR). As we will see later in this review, this 14TB WDC model has a lifetime AFR of 0.11% with the confidence interval range of just 0.30 at a 95% confidence level.
The new disks in town: There are two new models in this quarter’s data: the 8TB Seagate (model: ST8000NM000A) and the 16TB Seagate (model: ST16000NM002J). Neither has enough data to be interesting yet, but as noted above, the 8TB Seagate had zero failures in its first quarter in operation. These additions give us 29 different models we are tracking, up from 27 in the previous quarter.
The 29 models break down by manufacturer as:
HGST: 7 models
Seagate: 13 models
Toshiba: 6 models
WDC: 3 models
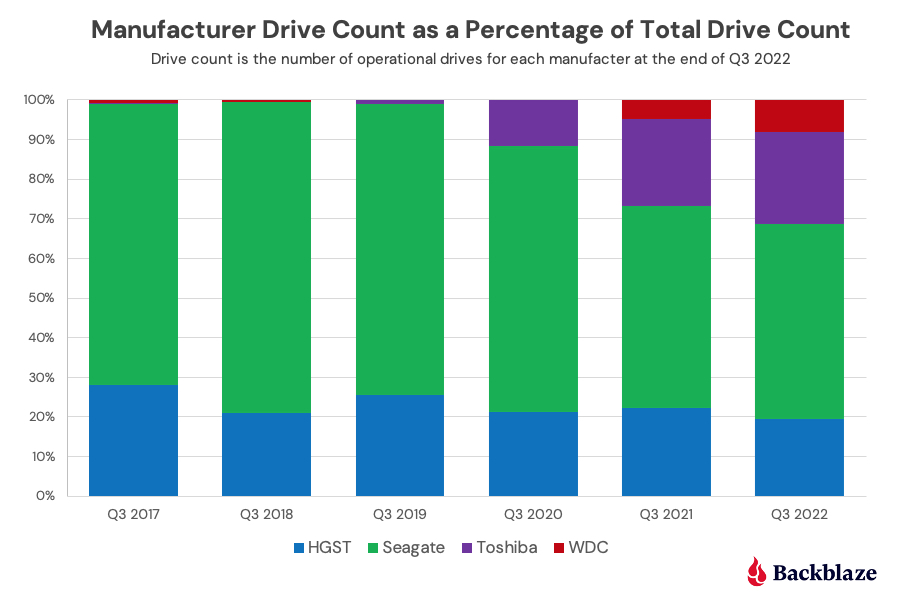
The chart below shows, by manufacturer, how our drive fleet has changed over the past six years.
The old guard is feeling old: All three of the oldest drives we currently use are showing signs of their age as each experienced an increase in AFR from Q2 to Q3 2022 as shown below.
MFG
Model
Size
Q3 2022 Avg Age
Q2 AFR
Q3 AFR
Seagate
ST4000DM000
4TB
83.1
3.42%
4.38%
Seagate
ST6000DX000
6TB
89.6
0.91%
1.34%
TOSHIBA
MD04ABA400V
4TB
88.3
0.00%
8.25%
Note that the 4TB Toshiba only had two failures in Q3 2022. The high AFR (8.25%) is due to the limited number of drive days in the quarter (8,849) from only 95 drives. For all three, it seems their spindles, actuators, and media are starting to wear out after seven years or so of constant spinning.
The Quarterly AFR continues to rise: The AFR for Q3 2022 was 1.64%, increasing from 1.46% in Q2 2022 and from 1.10% a year ago. As noted previously, this is related to the aging of the entire drive fleet and we would expect this number to go down as older drives are retired and replaced over the next year. A possible harbinger of what is to come can be seen in the 16TB models which as a group had an 0.80% AFR in Q3 2022. As these drives are used to replace the aging 4TB drives, the quarterly AFR should decrease.
Hard Drive Failure Versus Hard Drive Cost
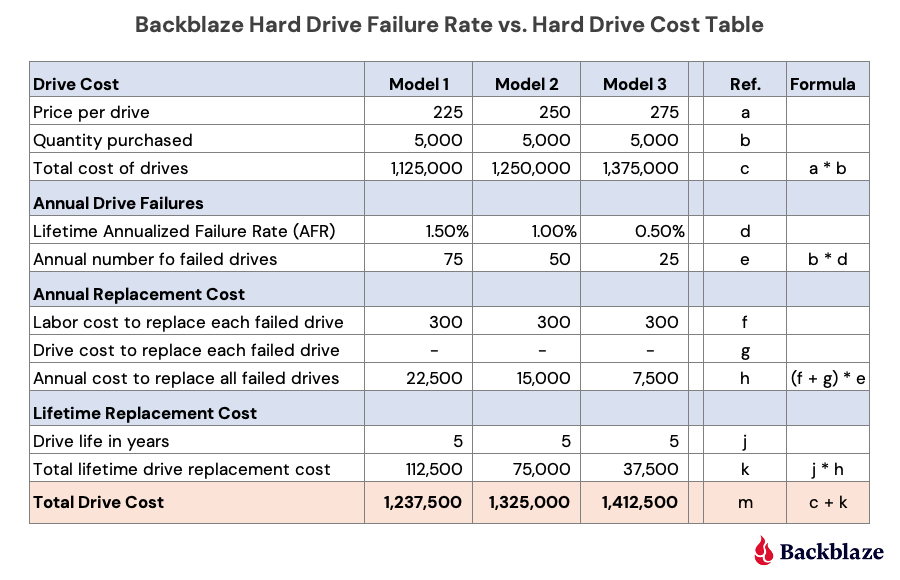
One question that comes up is why we would continue to buy a drive model that has a higher annualized failure rate versus a comparably sized, but more expensive, model. Two primary reasons: First, we are able to do so as our cloud storage Backblaze Vault architecture is designed for drive failure. Second, by studying data like drive stats and such, we work hard to understand our environment from the inside out. Understanding the relationship between cost and drive failure is one of those learnings. Here’s a simple example below using three fictitious models of 14TB drives, Model 1, Model 2, and Model 3.
Let’s take a look at the different sections (i.e. blue rows) of this table.
Drive Cost: Each model has a different price: low ($225), medium ($250), and high ($275). We would buy the same number of drives (5,000) of each model and we get the cost of each model.
Annual Drive Failures: This is the AFR of each drive model. For this example, we assigned the lowest price model to the highest failure rate, the highest price model to the lowest failure rate, and so on. In practice, we would use our own AFR numbers for a given model that we are considering purchasing. Regardless, we get the annual number of failed drives for each model.
Annual Replacement Cost: Labor cost covers the human cost involved from identifying the failure to returning and replacing the drive. Drive cost is zero here as the assumption is that all drives are returned for credit or replacement to the manufacturer or their agent. A zero value here may not always be the case; hence the line item. In either case, the annual cost to replace the failed drives for each model is computed.
Lifetime Replacement Cost: Take the number of years you expect the drive model to be in service times the annual cost to replace the failed drives. All of this gets us the total cost of each drive model—the peach section. In our example, the most expensive model (Model 3) is the most expensive drive over the five-year life expectancy and the lowest cost drive model (Model 1) is the least expensive over the same period, even with a higher annualized failure rate.
But we’re not done. The next question is: What would the annualized failure rate for the least expensive choice, Model 1, need to be such that the total cost after five years would be the same as Model 2 and then Model 3? In other words, how much failure can we tolerate before our original purchase decision is wrong? When we crunch the numbers we come out with the following:
Model 1 and Model 2 have the same total drive cost ($1,325,000) when the annualized failure rate for Model 1 is 2.67%.
Model 1 and Model 3 have the same total drive cost ($1,412,500) when the annualized failure rate for Model 1 is 3.83%.
The model presented is a simplified version of how we think about drive purchase decisions using annualized drive failure rates as part of the equation. You can make this model more accurate, and complicated, by adding in the drive failure rate changes over time (the bathtub curve) and prorating the cost of returning failed drives over the years. Whether that is needed is up to you.
The need for such a model is important in our business if you are interested in optimizing the efficiency of your cloud storage platform. Otherwise, just robotically buying the most expensive, or least expensive, drives is turning a blind eye to the expense side of the ledger.
On an individual or small office/home office level, your drive purchasing decision requires a lot less math, and often comes down to what drive can you afford. Even so, you should still try to do some research. Our drive stats can help, but in all cases you should have a solid backup plan in place as no drive you can buy is failure proof.
Lifetime Hard Drive Failure Rates
As of September 30, 2022, Backblaze was monitoring 226,697 hard drives used to store data. For our evaluation, we removed 388 drives from consideration as they were used for testing purposes or drive models which did not have at least 60 drives. This leaves us with 226,309 hard drives grouped into 29 different models to analyze for the lifetime report.
Notes and Observations About the Lifetime Stats
The lifetime annualized failure rate for all the drives listed above is 1.41%. That is a slight increase from the previous quarter of 1.39%, but lower than one year ago (Q3 2021) which was 1.45%.
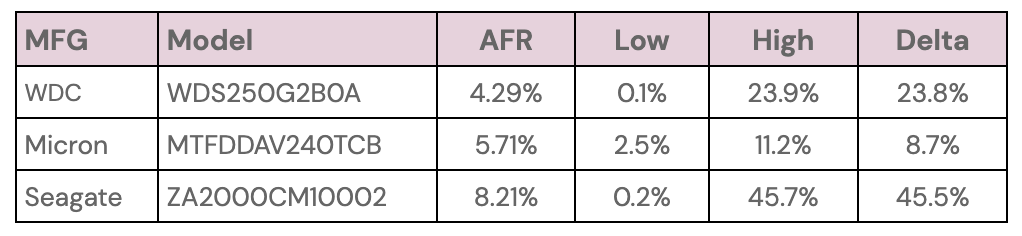
The usual caution should be applied to those drive models that have wide confidence intervals, one percent or greater. Such a gap indicates there is not enough data or that the data we do have is not readily predictable.
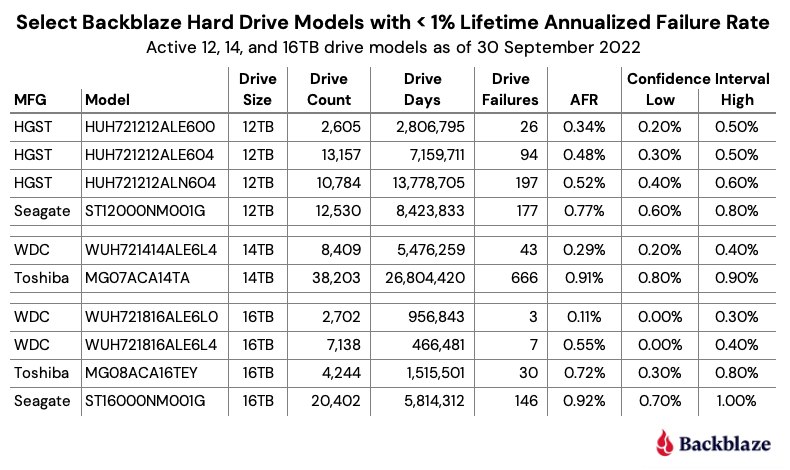
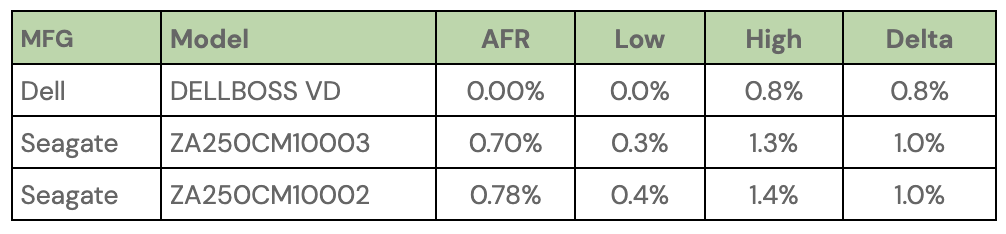
That said, we do have plenty of drive models for which we have solid data. Below we’ve extracted the 12TB, 14TB, and 16TB models from the lifetime table above that have a Lifetime AFR of less than 1% and have a confidence interval of 0.5% or less. These are hard drives which, up to this point, have shown solid reliability in our environment.
The Hard Drive Stats Data
The complete data set used to create the information in this review is available on our Hard Drive Test Data page. You can download and use this data for free for your own purpose. All we ask are three things: 1) you cite Backblaze as the source if you use the data, 2) you accept that you are solely responsible for how you use the data, and 3) you do not sell this data to anyone; it is free.
If you want the tables and charts used in this report, you can download the .zip file from Backblaze B2 Cloud Storage which contains the .jpg and/or .xlsx files as applicable.
Good luck, and let us know if you find anything interesting.
No matter which way war, the global economy, or superstorms are headed, one thing remains constant: ransomware threats continue to persist and evolve. That’s not new information, of course, but understanding the sophistication of emerging attacks is useful for anyone responsible for defending vulnerable infrastructure. Cybercriminals continue to target more industries such as healthcare and education that might not be as well-equipped to defend themselves. New strategies have allowed them to do more damage.
The landscape continues to change, but staying informed is one of the best ways to protect your organization against the ever-present threat of ransomware. It’s no substitute for comprehensive training for your team and a safely object-locked backup solution, but it never hurts to know too much. Here are a few of the biggest stories in ransomware from Q3.
This post is a part of our ongoing series on ransomware. Take a look at our other posts for more information on how businesses can defend themselves against a ransomware attack, and more.
With businesses ramping up their ransomware protection, cybercriminals have begun shifting toward more so-called “soft targets” including hospitals and small municipal governments. This has proven dangerous, as not only do these targets have fewer resources to devote to cybersecurity, but a compromise of their systems can lead to real-world disaster.
Three different hospitals around the country—CHI Memorial Hospital in Tennessee, hospitals in the St. Luke’s system within Texas, and Virginia Mason Franciscan Health in Seattle—were all recently hit with ransomware attacks, causing widespread delays in patient care. This has become a sadly common story, as attacks continue on healthcare targets.
Ransomware groups have increasingly been targeting school systems as well. One such group, The Vice Society, were recently the subject of an FBI warning, identifying their activity as “disproportionately targeting the education sector” and that those attacks against school districts “may increase as the 2022/2023 school year begins and criminal ransomware groups perceive opportunities for successful attacks.”
Key Takeaway: No vertical is safe from the threat of ransomware, but the rise of these threats has led to greater protections specifically for soft target sectors. Cybersecurity and Infrastructure Security Agency (CISA) has provided a wealth of tools for education, and companies have begun pivoting to create budget-friendly options for cash-strapped public sector CIOs.
2. Ransomware Gangs May Now Be Deploying “Triple Extortion”
This past quarter saw several high-profile attacks against larger businesses, including Cisco, Uber, and Rockstar Games, but it also saw signs that the ongoing war between black hat and white hat hackers may be entering a new realm.
In June, LockBit Ransomware was able to infect systems at Entrust, giving the ransomware gang access to nearly 300GB of data which they threatened to publish if their demands were not met. Entrust did not pay the ransom, and while the company did not claim credit for it, someone shortly after launched a DDoS attack against the site that LockBit was going to use to publish the data.
In retaliation, the Lockbit ransomware gang began actively recruiting DDoSers to begin executing a “triple extortion” tactic, layering the possibility of a DDoS attack on top of attacks via ransomware. In a post to a popular forum for black hat hackers, LockBit’s public face LockBitSupp wrote, “have felt the power of dudos [DDoS] and how it invigorates and makes life more interesting.”
Key Takeaway: Time and time again we see hackers creating new tactics, and simple non-negotiation doesn’t protect your business or solve for operational downtime. We’ve seen that paying ransoms doesn’t stop attacks, and engaging in counterattacks rarely has the desired outcome. Strong defensive strategies, like object lock capability, can’t block cybercriminals from accessing and publishing information, but it does ensure that you have everything you need to bring your business back online as quickly as possible.
3. The Geopolitical Landscape is Impacting Cybercrime
The Council on Foreign Relations recently released a bombshell report titled, “Confronting Reality in Cyberspace: Foreign Policy for a Fragmented Internet” that outlined the extent to which state-sponsored hackers have begun undermining American sovereignty through attacks. This dovetails with recent reports of the information wars between Russia and Ukraine spilling out beyond the battlefield. A report from Wired showed how pro-Russia group Killnet has launched cyberattacks against 10 different countries for supporting Ukraine.
This isn’t necessarily new information: the 2020 Homeland Security Threat Assessment calls out several nations, including Russia, China, North Korea, and Iran, as likely to employ cybersecurity attacks against the U.S. What is new is that the Senate voted $45 million in support of cybertools that are specifically earmarked to protect the U.S. power grid. Some groups—including the U.S. Government Accountability Office—don’t think that we’re doing enough. The impact here is that we’re not just talking about ransomware attacks exposing private data; we’ve evaluated as likely, and have started protecting ourselves against, attacks that will functionally shut down basic utilities.
Key Takeaway: As the lines blur between malicious hacking and state-sponsored attacks, the sophistication of the threats faced by most businesses and individuals will only grow. New laws and policies may eventually emerge to combat this trend, but until then it will be on you to ensure your infrastructure is safe.
The Bottom Line
The threat of cybercrime will only continue to expand in coming years. No matter what industry you’re in or what size organization’s infrastructure you have been tasked with protecting, continuous vigilance is crucial.
Like many industries, higher education has spent the last decade discovering the transformative power of the cloud and moving into the next century. The cost savings of running a more efficient tech stack and easier access to the vital data it contains have allowed those institutions to pursue the practical and academic discoveries they were built for.
Graduating to Cloud Storage
Across the board, colleges and universities are pushing the boundaries of what cloud storage can do—and their creativity is paying huge dividends for their efficiency and security. We’ve included a few examples below that show just how these institutions have been able to maximize their cloud storage capabilities to reduce costs, modernize outdated operations, protect sensitive student and research data, and extend their ability to provide knowledge to a wider audience.
Citing Our Work
Pittsburg State: Located in Kansas, this university found themselves with nearly five decades of data in harm’s way due to the constant threat of tornadoes. Adding off-premises storage with Backblaze B2 not only gave them the geographical separation they needed, but the addition of a virtual air gap through Object Lock quadrupled their protection against ransomware.
Coast Community College District: CCCD aiming to update its data management system and eliminate costly delays from tape backups. Their existing tapes needed to be physically chauffeured between the three colleges in the district—Coastline Community College, Golden West College, and Orange Coast College—in friendly L.A. traffic. Backblaze B2’s S3 Compatible APIs made for a seamless integration with Cohesity backup.
UCSC–Silicon Valley: A 22-person video production team at the university’s online learning program, UC–Scout had quickly reached their storage capacity after archiving thousands of videos. By leveraging Backblaze B2, their IT team was able to streamline the entire production process, saving money and unleashing the team’s full creative potential.
Kanopy: The “Netflix for libraries” overhauled its tech stack in order to share its massive selection of more than 25,000 videos with thousands of schools and public libraries. After migrating to Backblaze B2, Kanopy was able to scale efficiently and rapidly accelerate content onboarding.
Gladstone Institutes: Gladstone Institutes needed an affordable, reliable backup system that would allow their researchers to focus on the life-saving developments they were pursuing in the lab. Cloud storage’s increased reliability allowed them to move away from LTO, and off-premise storage shielded their findings from the potential for natural disasters.
Office Hours—No Lectures
If you’re planning to attend EduCause ’22, you can learn more about the many possibilities Backblaze opens up in higher education. Through a new partnership between Backblaze and Carahsoft, public sector customers can now leverage their existing state, local, and federal buying programs to access Backblaze B2 Cloud Storage.
In addition to a live demo of Instant Recovery in the Veeam booth, we’re proud to sponsor the Carahsoft Happy Hour Reception. With special cocktails you won’t find anywhere else (try the “Backblaze Special;” you’ll love it), this is a great opportunity to network with fellow educators and learn more about how Backblaze can help you leverage your tech stack.
If you’ve ever told an IT professional that you’re using Dropbox to back up files and were greeted with a side eye and a stifled “well, actually…” it’s because Dropbox isn’t actually a backup. It’s for syncing data. The distinction is subtle, but critical.
If you’re reading this post, you probably already know that data is always at risk of loss to accidental deletion, system updates, or even if you forget your password and get locked out of your account. The difference between backing up and syncing is that syncing your data will not protect it from these risks.
It’s easy to accidentally lose access to a sync service where you might be keeping files or images that no longer live on your computer. Many colleges and universities now even offer file hosting service subscriptions to students for free—until they graduate. After students earn their diplomas and leave the dorms, these services graduate, too, and students either get locked out of their accounts or have to choose between switching to a free tier and compromising on storage space or paying the fees to keep their existing subscription tier.
To make sure your data stays safe and secure, you’ll want to make sure you have a copy of it on your local device as well as a copy backed up to the cloud. A 3-2-1 backup strategy is always your best bet for securely storing your data. In this post, we’ll walk you through downloading your data from Dropbox and some strategies for backing up your downloaded files.
To help you save your synced computer data, we’re developing a series of guides to downloading and backing up your data across different sync services, like OneDrive. Comment below to let us know what other sync services you’d like to see us cover.
How to Download Files From Dropbox
Note: If you are using the Dropbox client to sync the files that are on your computer, the option to download your files may be replaced by an option to open them, instead. Clicking on “Open” will open up the files directly from the file on your computer where they are saved.
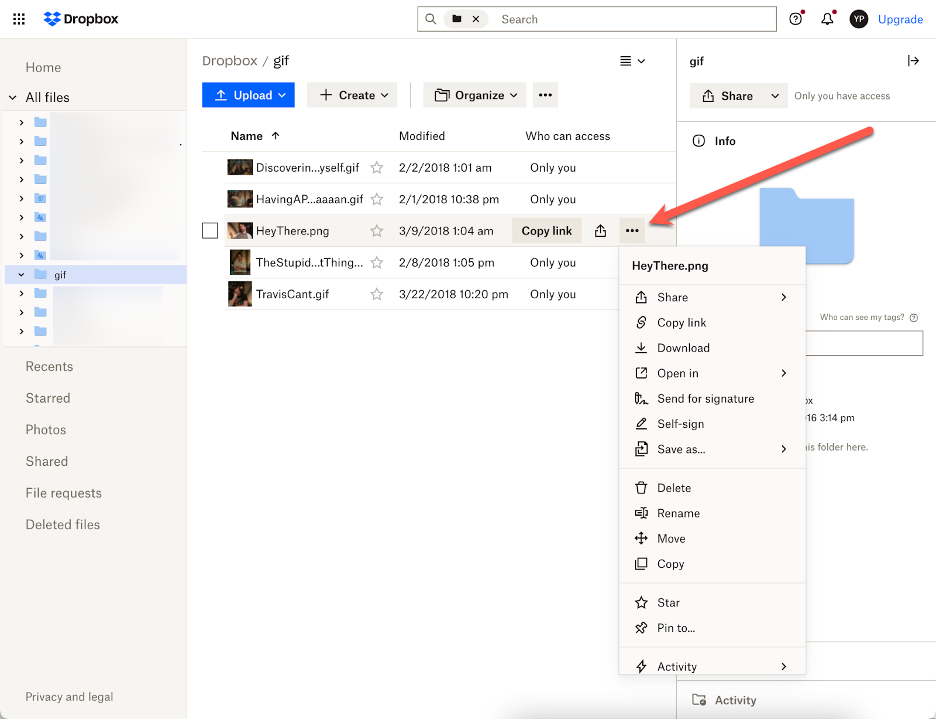
To download a file or folder from Dropbox, follow these steps:
Sign in to your Dropbox account. (We know, this is pretty self-evident. We’re just trying to be thorough here).
Find the file or folder you’d like to download and hover your cursor over it.
Click on the three dots.
Select Download. Your files will appear in the Downloads folder on your computer, and folders will be downloaded as .zip files.
It’s also important to note that Dropbox only supports downloads of folders that are less than 20GB and contain fewer than 10,000 total files.
How to Back Up Your Dropbox Data
Now that you have all of your Dropbox files downloaded to your computer, you’ll want to follow through with the next steps of the 3-2-1 backup strategy. By saving a copy of your data on an external or secondary device (like a hard drive), and a third copy in an off-site location (like the cloud) your data will be protected from any number of possible risks. Backblaze Personal Backup automatically and continuously backs up a copy of all of the data on your computer to the cloud, making it that much easier to fulfill the 3-2-1 backup strategy.
Bonus: How to Export a File From Dropbox to an App on Your Phone or Mobile Device
If you want to send a portion of your files elsewhere for safekeeping, or to share with another app, you can follow the set of instructions below. Just remember that downloading your files to your phone or emailing them to yourself isn’t the same as keeping a full copy of your data on an external device—your data is still susceptible to damage or loss.
First, you’ll need to download the Dropbox mobile app to access your synced files on your mobile device.
Open the app and select the three dots next to the file or folder you’d like to export. On an iPhone or iPad, the dots will appear horizontal, and on an Android device they’ll be vertical.
Select Share.
Select Export file, which will show a list of apps that can open the file. Choose the app you’d like to open the file. Note: once you export the file, if you make any changes to that file in the other app, those changes may not be saved back to your Dropbox account unless the app integrates with Dropbox.
Back Up Your Dropbox Before It’s Too Late
Have a lot of Dropbox data you don’t want to take up space on your computer? Upload and store your data in Backblaze B2 Cloud Storage as a part of your 3-2-1 approach. Also, let us know in the comments if you’d like to see more guides to downloading and backing up the data saved to other sync services.
You can send media in milliseconds to just about every corner of the earth with an origin store at your favorite cloud storage company and a snappy CDN. Sadly, delivering people across continents is a touch more complicated and time intensive. Nevertheless, the Backblaze team is saddling up planes, trains, and automobiles to bring the latest on media workflows to the attendees of NAB Show New York. Whether you’re there in person or virtually, we’ll be discussing and demo-ing all the newest Backblaze B2 Cloud Storage solutions that will ensure your data can travel with ease—no mass transit needed—everywhere you need it to be.
Learn More LIVE in NYC
If you’re attending the NAB Show New York, join us in booth 1239 to learn about integrating B2 Cloud Storage into your workflow. Stop by anytime or you can schedule a meeting here. We’d love to see you.
NAB Show New York Preview: What’s New for Backblaze B2 Media Workflow Solutions
Our booth will have all the goodness you’d expect of us: partners, friendly faces, spots to take a load off and talk about making your data work harder, and, of course, some next-level SWAG. Let’s get into what you can expect.
New Pricing Models and Migration Tools
Our team is on hand to talk you through two new offerings that have been generating a lot of excitement among teams across media organizations:
Backblaze B2 Reserve: You can now purchase the Backblaze service many know and love in capacity-based bundles through resellers. If your team seeks 100% budget predictability with transaction fees and premium support included, you should check out this new offering. Check it out here.
Universal Data Migration: Recently an International Broadcasting Convention (IBC) 2022 Best of Show nominee, the service makes it easy and FREE to move data into Backblaze from legacy cloud, on-premises, and LTO/tape origins. If your current data storage is holding your team or your budget back, we’ll pay to free your media and move it to B2 Cloud Storage. Learn more here.
Six Flavors of Media Workflow Deep Dives
We’ve gathered materials and expertise to discuss or demo our six most asked about workflow improvements. We’re happy to talk about many other tools and improvements, but here are the six areas we expect to talk about the most:
Moving more (or all) media production to the cloud. Ensuring everyone—clients, collaborators, employers, everyone—has easy real-time access to content is essential for the inevitable geographical distribution of modern media workflows.
Reducing costs. Cloud workflows don’t need to come with costly gotchas, minimum retention penalties, and/or high costs when you actually want to use your content. We’ll explain how the right partners will unlock your budget so you can save on cloud services and spend more on creative projects.
Streamlining delivery. Pairing cloud storage with the right CDN is essential to making sure your media is consumable and monetizable at the edge. From streaming services to ecommerce outlets to legacy media outlets, we’ve helped every type of media organization do more with their content.
Freeing storage. Empty your expensive on-prem storage and stop adding HDs and tapes to the pile by moving finished projects to always-hot cloud storage. This doesn’t just free up space and money: Instantly accessible archives means you can work with and monetize older content with little friction in your creative process.
Safeguarding content. All those tapes or HDs on a shelf, in the closet, or wherever you keep them are hard to manage and harder to access and use. Parking everything safely and securely in the cloud means all that data is centrally accessible, protected, and available for more use.
Backing up (better!). Yes, we’ve got roots in backup going back >15 years—so when it comes to making sure your precious media is protected with easy access for speedy recovery, we’ve got a few thoughts (and solutions).
Partners, Partners, and More Partners…
“The more we get together, the happier we’ll be,” might as well be the theme lyric of cloud workflows. Combining best of breed platforms unlocks better value and functionality, and offers you the ability to build your cloud stack exactly how you need it for your business. We’ve got a large ecosystem of Alliance Partners, and we’re happy to get deep into your needs and demo how you can combine Backblaze B2 Cloud Storage with one or more partners including iconik, LucidLink, Synology (who will also be right next to us in the Javits Center!), and Fastly to best achieve your objectives.
Hoping to visit NAB Show New York but not yet registered? All good. You can register free on the NAB site with promo code NY4429.
Hoping We Can Help You Soon
Whether it’s in person at NAB Show New York or virtually when it works for you, we’d love to walk you through any of the solutions we can serve for hardworking media teams. If you will be in Manhattan, schedule a meeting to ensure you’ll get the right expert on our team, then stick around for the swag and good times. This invitation applies to you too, Channel Partners and Resellers—whether you have active projects or just want to learn more, let’s meet up and chat about ways to deliver more value together. If you’re not making the trip, not a problem. Just contact us here so we can arrange to help virtually.
For those looking to build and grow blazing applications and do more with their data, we’d like to welcome you to this year’s Tech Day ‘22. We have a great community that works with Backblaze B2 Cloud Storage, including our internal team, IT professionals, developers, tech decision makers, cloud partners and more—and we felt it was high time to bring you all together again to share ideas, discuss upcoming changes, win some swag, and network.
Join our Technical Evangelists in live interactive sessions, demos, and tech talks that help you unlock your cloud potential and put B2 Cloud Storage to work for you. Whatever your role in the tech world—or if you’re simply curious about leveraging the Backblaze B2 platform—we invite you to join us!
Here’s What to Expect at Tech Day ’22
Tech Day ’22 is happening October 31, 10 a.m. PT. Can’t make it? Sign up anyway and we’ll share the event recording straight to your inbox.
IaaS Unboxed
A live chat about leveraging the independent cloud ecosystem for storage, compute, delivery, and backup, along with a customer showcase.
Sneak Peek
An early look at the Q3 2022 Drive Stats data with Andy Klein as he walks through the latest learnings to inform your thinking and purchase decisions.
Hands-On Demos
Pat Patterson (Chief Technical Evangelist), and Greg Hamer (Senior Developer Evangelist) team up to facilitate an action-packed set of interactive sessions aimed at helping you do more in the cloud. If you don’t have an account already, you’ll definitely want to create a free Backblaze B2 account so you can follow along. All you need to do is sign up with your email and create a password—it’s really that easy.
Scaling a Social App with Appwrite: Appwrite is a self-hosted backend-as-a-service platform that provides developers with all the core APIs required to build any application. Appwrite’s storage abstraction allows developers to store project files in a range of devices, including Backblaze B2. In this session, you’ll learn how to get started with Appwrite, and quickly build a social app that stores user-generated content in a Backblaze B2 Bucket.
Go Serverless with Fastly Compute@Edge: Fastly has long been a Backblaze partner—mutual customers are able to serve assets stored in Backblaze B2 Buckets via Fastly’s global content delivery network with zero download charges from Backblaze B2. Compute@Edge leverages Fastly’s network to enable developers to create high-scale, globally-distributed applications, and execute code at the edge. Discover how to build a simple serverless application in JavaScript and deploy it globally with a single command.
Provisioning Resources with the Backblaze B2 Terraform Provider: Hashicorp Terraform is an open-source infrastructure-as-code software tool that enables you to safely and predictably create, change, and improve infrastructure. Learn how our Terraform Provider unlocks Backblaze B2’s capabilities for DevOps engineers, allowing you to create, list, and delete Buckets and application keys, as well as upload and download objects.
Storing and Querying Analytical Data with Trino: Trino is a SQL-compliant query engine that supports a wide range of business intelligence and analytical tools, allowing you to write queries against structured and semi-structured data in a variety of formats and storage locations. We’ll share how we optimized Backblaze’s Drive Stats data for queries and used Trino to gain new insights into nine years of real-world data.
And So Much More
Join the live Q&A and our user community of tech leaders, IT pros, and developers like you. Register for free to grab your spot (and swag) and we’ll see you on October 31.
It has been over six years since we released Storage Pod 6.0. Yes, we have improved that system since then, several times. We’ve added more memory, upgraded the CPU, and of course deployed larger disks. I suppose we could have written blog posts about those improvements, a Storage Pod 6.X post or two or three, but somehow that felt a bit hollow.
About 18 months ago, we talked about The Next Backblaze Storage Pod. We had started using Dell servers in our Amsterdam data center, although we were still building and deploying the version 6.X storage pods in our U.S. data centers. That changed about six months ago and we haven’t built or deployed a Backblaze Storage Pod since that time. Here’s what we’ve done instead.
A Backblaze-Worthy Storage Server
In September of 2019, we wrote a blog post to celebrate the 10 year anniversary of open sourcing our Storage Pod design. In that post we mused about the build/buy decision and stated the criteria we needed to consider if we were going to buy storage servers from someone else: cost, ease of maintenance, the use of commodity parts, ability to scale production, and so on. Also in that post, we compiled a list of storage servers on the market at the time which were similar to our Storage Pod design.
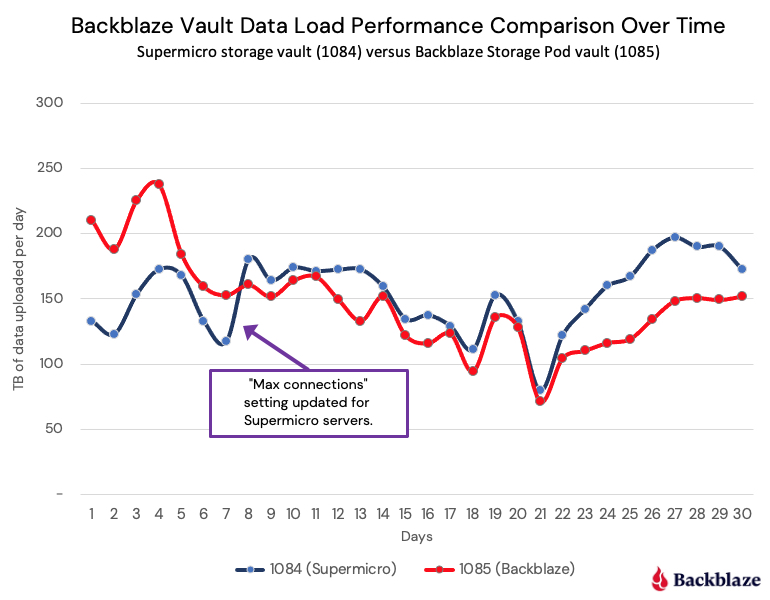
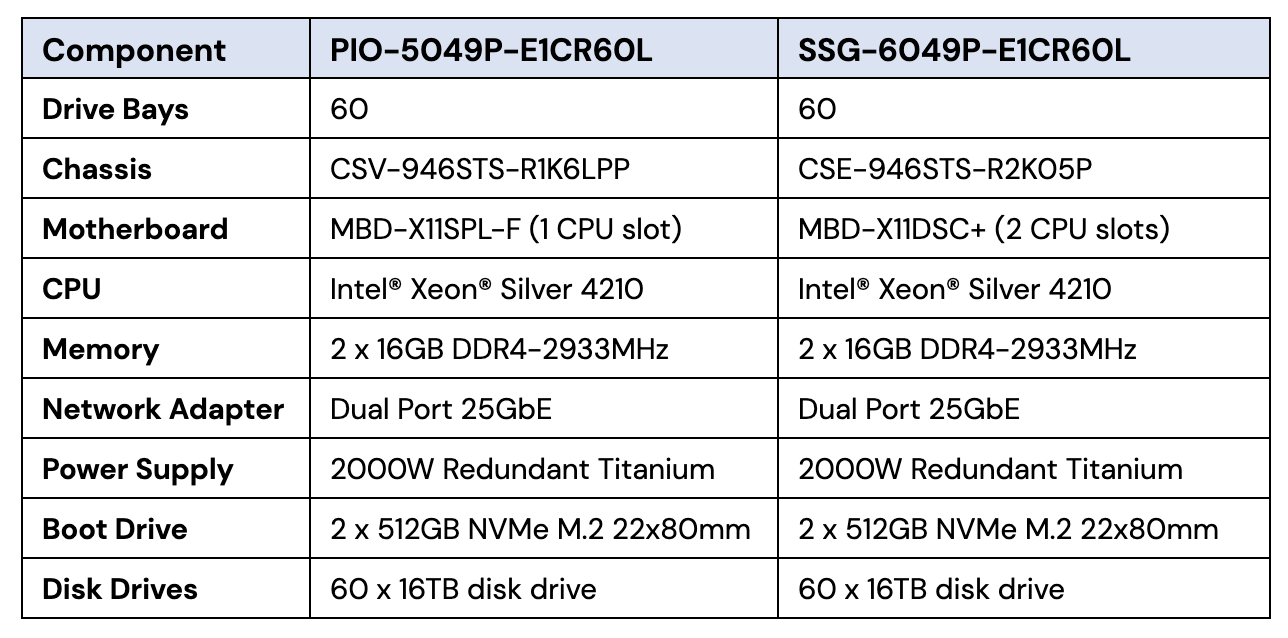
We then proceeded to test several different storage servers from the list and elsewhere. The testing was done over a period of about a year using the criteria noted earlier. The process progressed and one server, a 60-drive Supermicro server, was selected to move on to the next stage, production performance testing.
Here we would observe the server’s performance and test its compatibility with our operational architecture. We built a vault of 20 Supermicro servers and placed it into production, and at the same time we placed a standard Storage Pod vault into production. The two vaults ran the same software and we would track each vault’s performance throughout.
When a Backblaze Vault enters production, 60 tomes of storage come online at the same time joining thousands of other tomes ready to receive data. Each vault has the same opportunity to load data, but this will vary depending on the performance of the vault to process the requests received. In general, the more performant the vault, the more data it can upload each day.
The comparison of how much data each vault uploaded each day is shown below. Vault 1084 is composed of 20 Supermicro servers and Vault 1085 is composed of 20 Backblaze Storage Pods.
The Supermicro vault (1084) started with a limit of 2,500 simultaneous connections allowed for the first seven days. Once that limit was lifted and both vaults were set to 5,000 simultaneous connections, the Supermicro vault generally outperformed the Backblaze vault over the remainder of the observation period.
What happened to the data once the test was over? It stayed in the Supermicro vault and that vault became a permanent part of our production environment. It is still in operation today, joined by over 1,100 additional Supermicro servers. Safe to say, we moved ahead with using the Supermicro servers in our environment in place of building new Storage Pods.
The Server Model We Use
The Supermicro model we order from Supermicro is the PIO-5049P-E1CR60L (PIO-5049). That model is not sold via the Supermicro website. That said, model SSG-6049P-E1CR60L (SSG-6049) is similar and is widely available. Both models have 60 drives, but the chassis is slightly different, and the motherboards are different with the PIO-5049 model having a single CPU slot, and the SSG-6049 model having two CPU slots. Let’s compare the basics of the two models below.
In practice, the Supermicro SSG-6049 model supports newer components such as the latest CPUs and allows more memory versus the Supermicro PIO-5049 model, but the latter is more than capable of supporting our needs.
Can You Build It?
A little over 13 years ago, we wrote the Petabytes on a Budget blog post introducing Backblaze Storage Pods to the world and open sourcing the design. Since then, many individuals, organizations, and businesses have taken the various storage pod designs we published over the years and built their own storage servers. That’s awesome.
We know building a Storage Pod was not easy. Oh, the assembly was simple enough, but getting all the parts you needed was a challenge: searching endlessly for 5-port backplanes (minimum order quantity 1,000-ouch, sorry) or having to build your own power supply cables. While many of you enjoyed the challenge; many didn’t.
For the Supermicro system, let’s work with the Supermicro SSG-6049 model as it is available to everyone and see what it would take for you to acquire/assemble/build a single Supermicro storage server.
Option One: Go Standard
The easiest thing to do is to order a pre-configured SSG-6049 model from Supermicro or you can try one of their online reseller sites such as Canada Computers & Electronics or ComputerLink, which offer the same “complete system”. In these cases, the ability to customize the server is minimal and requires direct contact with the vendor for most changes. If that works for you, then you’re all set.
Option Two: Configure
If you want to design your own system you can try Supermicro resellers such as IT Creations (US) and Server Simply (EU) which have configurators that allow you to select your CPU, motherboard, network cards, memory, and various other components. This is a great option but given the number of different options and the possibility of incompatibilities between components, you need to be careful here. Don’t rely on the configurator to catch a component mismatch.
Option Three: Create
Here you might buy the most stripped-down server you can find and replace nearly everything inside—motherboard, CPU, fans, switches, cables and so on. You’ll probably void any warranty you had on the system, but we suspect you knew that already. Regardless, you can take the base system and stuff it full of smoking-fast everything so that your copy of “Ferris Buellers Day Off” downloads in picoseconds. That’s the fun part of building your own storage server, when you are done it is uniquely yours.
Which option you choose is, of course, your choice, and while ordering a standard system from Supermicro may not be as satisfying as soldering heat sinks to the motherboard or neatly tying off your SATA cable runs, it will give you more time to watch Ferris, so there’s that.
FYI, Supermicro has an extensive network of resellers around the world. While the options above fall neatly into three categories, each reseller has their own way of working with their clients. If you are going to buy or build your own Supermicro storage server or have already done so, share your experience with your colleagues in the comments below or on your favorite forum or community site.
What About Pricing
Supermicro does not publish prices and we are not going to out them here, but we wanted to see if we could determine the street price for the Supermicro SSG-6049 system by surveying reseller websites. It was not pretty. In our research, we saw prices for the Supermicro SSG-6049 model range from $6K to 40K on different reseller sites. On the website with the $6K price they started with a fictitious base system that you could not order, and then listed the various components you were required to add, such as CPU, memory, hard drives, etc. At the $40K website the reseller didn’t bother to list any of the components; it just had the model and the price—no specs or technical information. Classic buyer beware scenarios in both cases.
The other variable that made the street price hard to determine was that resellers often bundled other services into the price of the system such as installation, annual maintenance, and even shipping. All are reasonable services for a reseller to offer, but they cloud the picture when trying to determine the actual cost of the product you are trying to buy. At best, we can say that the street price is somewhere between $20K and $30K, but we are not very confident with that range.
Storage Server Pricing Over Time
Since 2009 we have tracked the cost per GB of each Storage Pod version we have produced. We’ve updated the chart below to add both Storage Pod version 6.X, our most current Storage Pod configuration, and the Supermicro storage server we are buying, model PIO-5049.
The cost per GB is computed by taking the total hardware cost of a storage server, including the hard drives, and dividing by the total storage in the server at the time. When Storage Pod 1.0 was released in September 2009, the system cost was about $0.12/GB, and as you can see that has decreased over time to $0.02/GB in the Supermicro systems.
One point to note is that both the Storage Pod 6.X ($0.028/GB) and Supermicro ($0.020/GB) servers use the same 16TB hard drive models. We believe the difference between the cost per GB of the two cohorts ($0.008) is primarily based on the operational efficiency obtained by Supermicro in making and selling tens of thousands of units a month versus Backblaze assembling a hundred 6.X Storage Pods on our own. In other words, Supermicro’s scale of production has enabled us to get performant systems for less than if we continued to build them ourselves.
What’s Next for Storage Pods
No one here at Backblaze is ready to write the obituary for our beloved red Backblaze Storage Pods. Afterall, the innovation that was the Storage Pod created the opportunity for Backblaze to change the dynamics of the storage market. Now that the Storage Pod hardware has been commoditized, our cloud storage software platform is what enables us to continue to deliver value to businesses and individuals alike.
All that means is that our next Storage Pod probably won’t be an incremental change, but instead something completely new, at least for us. It may not even be a Storage Pod—who knows? That said, we will continue to upgrade our existing Storage Pods with new CPUs, memory, and such, and they’ll be around for years to come. At which point we may give them away or crush them (again). In the meantime, we’ll probably do another blog post or two so we can post a few pictures and tell a few stories. Or maybe we’ll just move on. Hard to say right now.
Thanks to all our Storage Pod readers for your comments and suggestions over the years. You’ve made us better along the way and we look forward to continuing to hear from you as our journey continues.
In the fast-moving consumer goods space, Daltix is a pioneer in providing complete, transparent, and high-quality retail data. With global industry leaders like GFK and Unilever depending on their pricing, product, promotion, and location data to build go-to market strategies and make critical decisions, maintaining a reliable data ecosystem is an imperative for Daltix.
As the company has grown since its founding in 2016, the amount of data Daltix is processing has increased exponentially. They’re currently managing around 250TB, but that amount is spread across billions of files, which soon created a massive drag on time and resources. With an infrastructure built almost entirely around AWS and billions of miniscule files to manage, Daltix started to outgrow AWS’ storage options in both scalability and cost efficiency.
The Daltix team in Belgium.
We got to chat with Charlie Orford, Principal Software Engineer for Daltix, about how Datix switched to Backblaze B2 Cloud Storage and their takeaways from that process. Here are some highlights:
They used a custom engine to migrate billions of files from AWS S3 to Backblaze B2.
Monthly costs reduced by $2,500 while increasing data portability and reliability.
Daltix established the infrastructure to automatically back up 8.4 million data objects every day.
Read on to learn how they did it.
A Complex Data Pipeline Built Around AWS
Most of the S3-based infrastructure Daltix built in the company’s early days is still intact. Historically, the data pipeline started with web-scraped resources written directly to Amazon S3, which were then standardized by Lamba-based extractors before being sent back to S3. Then AWS Batch picked up the resources to be augmented and enriched using other data sources.
All those steps took place before the data was ready for Daltix’s team of analysts. In order to optimize the pipeline and increase efficiency, Orford started absorbing pieces of that process into Kubernetes. But there was still a data storage problem; Daltix generates about 300GB of compressed data per day, and that figure was growing rapidly. “As we’d scaled up our data collection, we’d had to sharpen our focus on cost control, data portability, and reliability,” said Orford. “They’re obvious, but at scale, they’re extremely important.”
Cost Concerns Inspire The Search For Warm Archival Storage
By 2020, Daltix had started to realize the limitations of building so much of their infrastructure in AWS. For example, heavy customization around S3 metadata made the ability to move objects entirely dependent on the target system’s compatibility with S3. Orford was also concerned about the costs of permanently storing such a huge data lake in S3. As he puts it, “It was clear that there was no need to have everything in S3 forever. If we didn’t do anything about it, our S3 costs were going to continue to rise and eventually dwarf virtually all of our other AWS costs.”
Side-by-side comparison of server costs.
Because Daltix works with billions of tiny files, using Glacier was out of the question as its pricing model is based around retrieval fees. Even using Glacier Instant Retrieval, the sheer number of files Daltix works with would have forced them to rack up an additional $200,000 in fees per year. So Daltix’s data collection team—which produces more than 85% of the company’s overall data—pushed for an alternative solution that could address a number of competing concerns:
The sheer size of the data lake.
The need to store raw resources as discrete files (which means that batching is not an option).
Limitations on the team’s ability to invest time and effort.
A desire for simplicity to guarantee the solution’s reliability.
Daltix settled on using Amazon S3 for hot storage and moving warm storage into a new archival solution, which would reduce costs while keeping priority data accessible—even if the intention is to keep files stored away. “It was important to find something that would be very easy to integrate, have a low development risk, and start meaningfully eating into our costs,” said Orford. “For us, Backblaze really ticked all the boxes.”
Initial Migration Unlocks Immediate Savings of $2,000 Per Month
Before launching into a full migration, Orford and his team tested a proof of concept (POC) to make sure the solution addressed his key priorities:
Making sure the huge volume of data was migrated successfully.
Avoiding data corruption and checking for errors with audit logs.
Preserving custom metadata on each individual object.
“Early on, Backblaze worked with us hand-in-hand to come up with a custom migration tool that fit all our requirements,” said Orford. “That’s what gave us the confidence to proceed.” In partnership with Flexify, Backblaze delivered a tailor-made engine to ensure that the migration process would transfer the entire data lake reliably and with object-level metadata intact. After the initial POC bucket was migrated successfully, Daltix had everything they needed to start modeling and forecasting future costs. “As soon as we started interacting with Backblaze, we stopped looking at other options,” Orford said.
In August 2021, Daltix moved a 120TB bucket of 2.2 billion objects from standard storage in S3 to Backblaze B2 cloud storage. That initial migration alone unlocked an immediate cost savings of $2,000 per month, or $24,000 per year.
A peaceful data lake.
Quadruple the Data, Direct S3 Compatibility, and $100,000 Cumulative Savings
Today, Daltix is migrating about 3.2 million data objects (approximately 70GB of data) from Amazon S3 into Backblaze B2 every day. They keep 18 months of hot data in S3, and as soon as an object reaches 18 months and one day, it becomes eligible for archiving in B2. On the rare occasions that Daltix receives requests for data outside that 18-month window, they can pull data directly from Backblaze B2 into Amazon S3 thanks to Backblaze’s S3-compatible API and ever-available data.
Daily audit logs summarize how much data has been transferred, and the entire migration process happens automatically every day. “It runs in the background, there’s nothing to manage, we have full visibility, and it’s cost effective,” Orford said. “Backblaze B2 is an ideal solution for us.”
As daily data collection increases and more data ages out of the hot storage window, Orford expects more cost reductions. Orford expects it will take about a year and a half for daily migrations to nearly triple their current levels: that means Daltix will be backing up 9 million objects (about 450GB of data) to Backblaze B2 every day. Taking that long-term view, we see incredible cost savings for Daltix by switching from Amazon S3 to Backblaze B2. “By 2023, we forecast we will have realized a cumulative saving in the region of $75,000-$100,000 on our storage spend thanks to leveraging Backblaze B2, with expected ongoing savings of at least $30,000 per year,” said Orford.
“It runs in the background, there’s nothing to manage, we have full visibility, and it’s cost effective. B2 is an ideal solution for us.” —Charlie Orford, Principal Software Engineer, Daltix
Crunch the Numbers and See for Yourself
Want to find out what your business could do with an extra $30,000 a year? Check out our Cloud Storage Pricing Calculator to see what you could save switching to Backblaze B2.
Using Linear-Tape Open (LTO) backups has been a solid strategy used by companies with robust media libraries for a long time. The downside of LTO is, of course, the sheer volume of space dedicated to storing these vast piles of tapes, the laboriously slow process of accessing the data on them, and the fact that they can only be accessed where they’re stored—so if there’s a natural disaster or a break-in, your data is at risk. Anyone staring down a shelf sagging under the weight of years of data and picturing the extra editing bay you could put in its place is probably thinking about making a move to the cloud.
Once you have decided to migrate your data, you need a plan to move forward. The following article will give you the basic tools for migrating from LTO to the Cloud. Before we dive in, let’s talk about some of the vast benefits of migration (other than reclaiming your storage closet).
Benefits of Moving Your Data to the Cloud
Some pretty convincing benefits come with moving away from tape to cloud storage. First is the cost. Some people might think cloud storage is more expensive, but a closer crunching of the numbers proves that it actually saves you money. We’ve created a handy LTO to Cloud Storage calculator to figure out individual savings. If you’re concerned about migration/egress fees, utilizing a Universal Data Migration (UDM) service can help eliminate those costs. In addition, tape players and tapes need maintenance and eventually replacement, adding another budgetary benefit to migrating things to the cloud.
Another benefit is easy access to files. Rather than being hidden among the files on one particular tape in one particular area of one particular stack, files can be accessed, viewed and downloaded immediately from cloud storage. With many industries moving towards remote work, being able to access your files or archives from afar is increasingly important.
So much tape; so little time.
Cloud storage is also more secure than people think. Many cloud services providers offer products like Object Lock to keep files immutable (a huge concern for compliance-heavy industries like healthcare). In the case of a ransomware attack, off-site cloud storage data means that you’re safe from the threat and restore your data quickly and get back to normal.
With all those benefits, the only concern left is that anytime you make a change to your data infrastructure, you want it to be as easy as possible. Let’s walk through a typical LTO to cloud migration so you can explore how it aligns with your process.
Six Steps to Migrate from LTO to Cloud Storage (or a Hybrid Solution)
Migrating can feel like a daunting task, but breaking it down into bite-sized pieces will help a lot. Fears about data loss and team bandwidth will obviously play a factor in migration. Don’t worry: it’s much easier than you think, and the long-term benefits will outweigh the short-term migration considerations.
Follow the steps below for a seamless, successful migration.
Step One: Take Stock of Your Content
The first concern of migration: how do you ensure that all the data you need to move is there and will be there at the end of the process? Well, now is the time to take a complete content inventory. It may have been a long time since you reviewed what is stored on tape, where it is located, and if you even want to continue keeping it. You may have old, archived data that is safe to get rid of now.
In addition to an inventory, if there was ever a good time to clean out unused/unneeded files, now is the time. It’s also a good opportunity to eliminate any duplicates—that will ensure that you’re not wasting money on storage costs or time and confusion ensuring that you’re looking at the correct file.
Does data fold?
Instead of looking at it as a pain point or chore you dread, consider a content inventory as an opportunity to clean out old files, eliminate waste, and streamline your data to only what you need and want to keep. It’s like inviting Marie Kondo over to ask whether your files spark joy. It’s also a great time to reorganize your files. Consider renaming files and folders to make it easy to retrieve items once they are stored in the cloud. Bonus: this walk down memory lane might spark ideas for refreshing or repurposing old content.
Step Two: Update Your Tracking System
LTO backups involve rotating many tapes on different days and sorting them by type of data (what is stored on them) and on varying schedules. You will need to update your tracking system for your tape strategy to how you will use tape going forward. You can also formulate a plan for tracking your cloud-based backup data as well. It may be as simple as cataloging where files are located, what type of data needs to be on tape, how often they will be backed up, when files move from hot storage to archive, and so on.
Step Three: Plan for Your Migration
To ensure a successful migration, spend some time planning exactly how to execute the move. Here are a few common questions that come up:
Are you moving the data in phases or all at once? If you’re moving data in phases, what needs to move first and why?
How many personnel are you dedicating to work on the project? And what kind of support will they need from other stakeholders?
Are you planning on keeping any information on tape long-term (a hybrid solution)? Some companies like healthcare, government contractors, education, and accounting firms are subject to data retention and storage laws, so that might come into play here.
Document how you want to proceed so that everyone involved has their needs met. Planning ahead will help you feel like you have a good handle on things before jumping into the deep water.
Also, it’s important to evaluate your internet bandwidth and speed to ensure you don’t experience any bottlenecks. If you have to upgrade your internet package, do so before you begin migrating. Migrate using an Ethernet-connected device with a stable connection. Wi-Fi is much slower and less reliable. If you’re moving a significant amount of data at once, you may even want to consider something like Backblaze’s Fireball service.
Backblaze’s Fireball, ready to help you transfer data.
Another thing to consider is that the cloud will let you categorize and interact with your data in different ways. For example, with Backblaze B2 storage, you can create up to 1,000 buckets per account to categorize your data your way and keep files separate—how is that different from how you’re currently interacting with your data? Who will have access to your cloud storage backups? Do you need to employ Extended Version History or Object Lock to make sure that your backups aren’t unintentionally changed?
Step Four: Back Up Both Ways
For a short while, you might want to back up to both LTO and the cloud, keeping them in tandem while you ensure a smooth and successful data migration. Once all your critical files have been moved over, you can stop backing up to tape. (Unless your organization has decided that a hybrid model works for you.)
Again, keep in mind that you may want to keep some files archived on tape and stored away. It depends on your industry, compliance issues, and data infrastructure preferences.
Step Five: Execute the Migration
Now it’s time to take the plunge. You can use the Universal Data Migration (UDM) service to move your data over and absorb any egress fees. You can move your data in days, not weeks, streamlining this chore.
All roads lead to cloud.
Step Six: Review and Compare Cloud and LTO Backups
Before you stop running your backup systems concurrently (LTO and cloud), be sure to test your backups thoroughly. When you run those tests, you don’t want to just look at the files; you actually want to restore several files, just as if you’d had them deleted from your system. Run tests restoring individual files and whole folders to ensure data integrity and master the restore process. Make sure to run those tests for your servers and with files in both Mac and PC environments.
At the end of the day, cloud storage offers many benefits like secure storage, easy access, and cost-efficient backups. Once you get past the hurdle of migration, you’ll be glad you made the switch.
Let’s Talk Solutions in Person
If you’re attending the 2022 NAB Show New York, stop by the Backblaze booth for an opportunity to see how making the move from tape to the cloud could help streamline your workflow. If nothing else, you’ll get some great swag out of it! Stop by our booth or schedule a meeting to talk to the team.
Part 2 in a series covering the Frame.io/Backblaze B2 integration, covering the implementation. See Part 1 here, which covers the UI.
In Lights, Camera, Custom Action: Integrating Frame.io with Backblaze B2, we described a custom action for the Frame.io cloud-based media asset management (MAM) platform. The custom action allows users to export assets and projects from Frame.io to Backblaze B2 Cloud Storage and import them back from Backblaze B2 to Frame.io.
The custom action is implemented as a Node.js web service using the Express framework, and its complete source code is open-sourced under the MIT license in the backblaze-frameio GitHub repository. In this blog entry we’ll focus on how we secured the solution, how we made it deployable anywhere (including to options with free bandwidth), and how you can customize it to your needs.
What is a Custom Action?
Custom Actions are a way for you to build integrations directly into Frame.io as programmable UI components. This enables event-based workflows that can be triggered by users within the app, but controlled by an external system. You create custom actions in the Frame.io Developer Site, specifying a name (shown as a menu item in the Frame.io UI), URL, and Frame.io team, among other properties. The user sees the custom action in the contextual/right-click dropdown menu available on each asset:
When the user selects the custom action menu item, Frame.io sends an HTTP POST request to the custom action URL, containing the asset’s id. For example:
The custom action can optionally respond with a JSON description of a form to gather more information from the user. For example, our custom action needs to know whether the user wishes to export or import data, so its response is:
{
"title": "Import or Export?",
"description": "Import from Backblaze B2, or export to Backblaze B2?",
"fields": [
{
"type": "select",
"label": "Import or Export",
"name": "copytype",
"options": [
{
"name": "Export to Backblaze B2",
"value": "export"
},
{
"name": "Import from Backblaze B2",
"value": "import"
}
]
}
]
}
When the user submits the form, Frame.io sends another HTTP POST request to the custom action URL, containing the data entered by the user. The custom action can respond with a form as many times as necessary to gather the data it needs, at which point it responds with a suitable message. For example, when it has all the information it needs to export data, our custom action indicates that an asynchronous job has been initiated:
When you create a custom action in the Frame.io Developer Tools, a signing key is generated for it. The custom action code uses this key to verify that the request originates from Frame.io.
When Frame.io sends a POST request, it includes the following HTTP headers:
X-Frameio-Request-Timestamp
The time the custom action was triggered, in Epoch Epoch timetime (seconds since midnight UTC, Jan 1, 1970).
X-Frameio-Signature
The request signature.
The timestamp can be used to prevent replay attacks; Frame.io recommends that custom actions verify that this time is within five minutes of local time. The signature is an HMAC SHA-256 hash secured with the custom action’s signing key—a secret shared exclusively between Frame.io and the custom action. If the custom action is able to correctly verify the HMAC, then we know that the request came from Frame.io (message authentication) and it has not been changed in transit (message integrity).
The process for verifying the signature is:
Combine the signature version (currently “v0”), timestamp, and request body, separated by colons, into a string to be signed.
Compute the HMAC SHA256 signature using the signing key.
If the computed signature and signature header are not identical, then reject the request.
The custom action’s verify TimestampAndSignature() function implements the above logic, throwing an error if the timestamp is missing, outside the accepted range, or the signature is invalid. In all cases, 403 Forbidden is returned to the caller.
Custom Action Deployment Options
The root directory of the backblaze-frameio GitHub repository contains three directories, comprising two different deployment options and a directory containing common code:
node-docker—generic: Node.js deployment
node-risingcloud: Rising Cloud deployment
backblaze-frameio-common: common code
The node-docker directory contains a generic Node.js implementation suitable for deployment on any Internet-addressable machine–for example, an Optimized Cloud Compute VM on Vultr. The app comprises an Express web service that handles requests from Frame.io, providing form responses to gather information from the user, and a worker task that the web service executes as a separate process to actually copy files between Frame.io and Backblaze B2.
You might be wondering why the web service doesn’t just do the work itself, rather than spinning up a separate process to do so. Well, media projects can contain dozens or even hundreds of files, containing a terabyte or more of data. If the web service were to perform the import or export, it would tie up resources and ultimately be unable to respond to Frame.io. Spinning up a dedicated worker process frees the web service to respond to new requests while the work is being done.
The downside of this approach is that you have to deploy the custom action on a machine capable of handling the peak expected load. The node-risingcloud implementation works identically to the generic Node.js app, but takes advantage of Rising Cloud’s serverless platform to scale elastically. A web service handles the form responses, then starts a task to perform the work. The difference here is that the task isn’t a process on the same machine, but a separate job running in Rising Cloud’s infrastructure. Jobs can be queued and new task instances can be started dynamically in response to rising workloads.
Note that since both Vultr and Rising Cloud are Backblaze Compute Partners, apps deployed on those platforms enjoy zero-cost downloads from Backblaze B2.
Customizing the Custom Action
We published the source code for the custom action to GitHub under the permissive MIT license. You are free to “use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software” as long as you include the copyright notice and MIT permission notice when you do so.
At present, the user must supply the name of a file when importing an asset from Backblaze B2, but it would be straightforward to add code to browse the bucket and allow the user to navigate the file tree. Similarly, it would be straightforward to extend the custom action to allow the user to import a whole tree of files based on a prefix such as raw_footage/2022-09-07. Feel free to adapt the custom action to your needs; we welcome pull requests for fixes and new features!
Welcome to the midyear SSD edition of the Backblaze Drive Stats report. This report builds on the 2021 SSD report published previously and is based on data from the SSDs we use as storage server boot drives in our Backblaze Cloud Storage platform. We will review the quarterly and lifetime failure rates for these drives and, later in this report, we will also compare the performance of these SSDs to hard drives we also use as boot drives. Along the way, we’ll offer observations and insights to the data presented and, as always, we look forward to your questions and comments.
Overview
Boot drives in our environment do much more than boot the storage servers: they also store log files and temporary files produced by the storage server. Each day a boot drive will read, write, and delete files depending on the activity of the storage server itself. In our early storage servers, we used HDDs exclusively for boot drives. We began using SSDs in this capacity in Q4 2018. Since that time, all new storage servers, and any with failed HDD boot drives, have had SSDs installed.
Midyear SSD Results by Quarter
As of June 30, 2022, there were 2,558 SSDs in our storage servers. This compares to 2,200 SSDs we reported in our 2021 SSD report. We’ll start by presenting and discussing the quarterly data from each of the last two quarters (Q1 2022 and Q2 2022).
Notes and Observations
Form factors: All of the drives listed above are the standard 2.5” form factor, except the Dell (DELLVOSS VD) and Micron (MTFDDAV240TCB) models each of which are the M.2 form factor.
Most drives added: Since our last SSD report, ending in Q4 2021, the Crucial (model: CT250MX500SSD1) lead the way with 192 new drives added, followed by 101 new DELL drives (model: DELLBOSS VD) and 42 WDC drives (model: WDS250G2B0A).
New drive models: In Q2 2022 we added two new SSD models, both from Seagate, the 500GB model: ZA500CM10003 (3 drives), and the 250 GB model: ZA250NM1000 (18 drives). Neither has enough drives or drive days to reach any conclusions, although they each had zero failures, so nice start.
Crucial is not critical: In our previous SSD report, a few readers took exception to the high failure rate we reported for the Crucial SSD (model: CT250MX500SSD1) although we observed that it was with a very limited amount of data. Now that our Crucial drives have settled in, we’ve had no failures in either Q1 or Q2. Please call off the dogs.
One strike and you’re out: Three drives had only one failure in a given quarter, but the AFR they posted was noticeable: WDC model WDS250G2B0A – 10.93%, Micron – Model MTFDDAV240TCB – 4.52%, and the Seagate model: SSD – 3.81%. Of course if any of these models had 1 less failure their AFR would be zero, zip, bupkus, nada – you get it.
It’s all good man: For any given drive model in this cohort of SSDs, we like to see at least 100 drives and 10,000 drives-days in a given quarter as a minimum before we begin to consider the calculated AFR to be “reasonable”. That said, quarterly data can be volatile, so let’s next take a look at the data for each of these drives over their lifetime.
SSD Lifetime Annualized Failure Rates
As of the end of Q2 2022 there were 2,558 SSDs in our storage servers. The table below is based on the lifetime data for the drive models which were active as of the end of Q2 2022.
Notes and Observations
Lifetime annualized failure rate (AFR): The lifetime data is cumulative over the period noted, in this case from Q4 2018 through Q2 2022. As SSDs age, lifetime failure rates can be used to see trends over time. We’ll see how this works in the next section when we compare SSD and HDD lifetime annualized failure rates over time.
Falling failure rate?: The lifetime AFR for all of the SSDs for Q2 2022 was 0.92%. That was down from 1.04% at the end of 2021, but exactly the same as the Q2 2021 AFR of 0.92%.
Confidence Intervals: In general, the more data you have, and the more consistent that data is, the more confident you are in your predictions based on that data. For SSDs we like to see a confidence interval of 1.0% or less between the low and the high values before we are comfortable with the calculated AFR. This doesn’t mean that drive models with a confidence interval greater than 1.0% are wrong, it just means we’d like to get more data to be sure.
Speaking of Confidence Intervals: You’ll notice from the table above that the three drives with the highest lifetime annualized failure rates also have sizable confidence intervals.
Conversely, there are three drives with a confidence interval of 1% or less, as shown below:
Of these three, the Dell drive seems the best. It is a server-class drive in an M.2 form factor, but it might be out of the price range for many of us as it currently sells from Dell for $468.65. The two remaining drives are decidedly consumer focused and have the traditional SSD form factor. The Seagate model ZA250CM10003 is no longer available new, only refurbished, and the Seagate model ZA250CM10002 is currently available on Amazon for $45.00.
SSD Versus HDD Annualized Failure Rates
Last year we compared SSD and HDD failure rates when we asked: Are SSDs really more reliable than Hard Drives? At that time the answer was maybe. We now have a year’s worth of data available to help answer that question, but first, a little background to catch everyone up.
The SSDs and HDDs we are reporting on are all boot drives. They perform the same functions: booting the storage servers, recording log files, acting as temporary storage for SMART stats, and so on. In other words they perform the same tasks. As noted earlier, we used HDDs until late 2018, then switched to SSDs. This creates a situation where the two cohorts are at different places in their respective life expectancy curves.
To fairly compare the SSDs and HDDs, we controlled for average age of the two cohorts, so that SSDs that were on average one year old, were compared to HDDs that were on average one year old, and so on. The chart below shows the results through Q2 2021 as we controlled for the average age of the two cohorts.
Through Q2 2021 (Year 4 in the chart for SSDs) the SSDs followed the failure rate of the HDDs over time, albeit with a slightly lower AFR. But, it was not clear whether the failure rate of the SSD cohort would continue to follow that of the HDDs, flatten out, or fall somewhere in between.
Now that we have another year of data, the answer appears to be obvious as seen in the chart below, which is based on data through Q2 2022 data and gives us the SSD data for Year 5.
And the Winner Is…
At this point we can reasonably claim that SSDs are more reliable than HDDs, at least when used as boot drives in our environment. This supports the anecdotal stories and educated guesses made by our readers over the past year or so. Well done.
We’ll continue to collect and present the SSD data on a regular basis to confirm these findings and see what’s next. It is highly certain that the failure rate of SSDs will eventually start to rise. It is also possible that at some point the SSDs could hit the wall, perhaps when they start to reach their media wearout limits. To that point, over the coming months we’ll take a look at the SMART stats for our SSDs and see how they relate to drive failure. We also have some anecdotal information of our own that we’ll try to confirm on how far past the media wearout limits you can push an SSD. Stay tuned.
The SSD Stats Data
The data collected and analyzed for this review is available on our Hard Drive Test Data page. You’ll find SSD and HDD data in the same files and you’ll have to use the model number to locate the drives you want, as there is no field to designate a drive as SSD or HDD. You can download and use this data for free for your own purpose. All we ask are three things: 1) you cite Backblaze as the source if you use the data, 2) you accept that you are solely responsible for how you use the data, and 3) you do not sell this data to anyone—it is free.
You can also download the Backblaze Drive Stats data via SNIA IOTTA Trace Repository if desired. Same data; you’ll just need to comply with the license terms listed. Thanks to Geoff Kuenning and Manjari Senthilkumar for volunteering their time and brainpower to make this happen. Awesome work.
Good luck and let us know if you find anything interesting.
It’s the classic “tree falls in the woods” scenario: if your company experiences data loss, but your users never feel it, did it even happen? That’s the value proposition our friends over at Quest—an IT platform that solves complex problems with simple software solutions—present with their popular Rapid Recovery tool:
Back up and quickly recover anything — systems, apps, and data — anywhere, whether it’s physical, virtual, or in the cloud. This data recovery software allows you to run without restore, with zero impact on your users, and as if the outage or data loss never happened.
Quest Rapid Recovery Version 6.7 Adds Backblaze B2 in Cloud Tier
As of today—whether you’re a Quest customer or a Backblaze B2 Cloud Storage user—you can combine all this value with the astonishingly easy cloud storage we’re known for here at Backblaze. In Quest’s 6.7 release of Rapid Recovery, navigate to Cloud Accounts in the menu (see screenshot below for menu location), click Add New Account.
Enter a display name, select B2 Cloud Storage, and choose Amazon S3 as the cloud type. Then you just need to enter your Access key (keyID), Secret Key (applicationKey), and your service endpoint URL.
Your data will be safe, useful, and affordable at a quarter of the price of legacy cloud providers. Try it out today or contact our sales team to learn more.
So, What’s Changed?
If you’re already a Quest Rapid Recovery user, you may notice that setup hasn’t changed. What’s changed is actually in the code—Rapid Recovery will now work more seamlessly and more efficiently. Bug fixes have been baked into version 6.7 and their support will be more robust. We love a seamless partnership—and stay tuned for more integrations between Quest and Backblaze in the future!
More About Quest’s Rapid Recovery Tool
If you’re a Backblaze B2 Cloud Storage user who is in the market for a recovery solution for your business, you can dig into the details about Rapid Recovery here. Here’s a brief primer of the solutions capabilities:
Simplify backup and restore: One cloud-based management console allows you to restore lost or damaged systems and data with near-zero recovery time and no impact to users—an advanced, admin-friendly solution.
Address demanding recovery point objectives (RPO): Leverage image-based snapshots for RPOs and reduce risk of data loss and downtime with tracked change blocks to accelerate backups and reduce storage.
Wide application support: Lightning-fast recovery for file servers and applications on both Microsoft Windows and Linux systems gets business-critical applications online to keep your business rolling.
Cloud-based backup, archive, and disaster recovery: (This is where we come in…) Point-and-click cloud connectivity makes for easy replication of application backups for no-stress cloud backup.
Virtual environment protection: Agentless backup and recovery for Microsoft Exchange and SQL databases residing on your virtual machines and low-cost VM-only tiered licensing for on-premises and cloud virtual environments.
Data deduplication and replication: With B2 Cloud storage, you’ll already save upwards of 75% versus other cloud storage solutions, but you can reduce costs further by leveraging built-in compression and deduplication. Nice.
More about Backblaze B2 Cloud Storage
Backblaze B2 Cloud Storage is purpose-built for ease, instant access to files and data, and infinite scalability. Backblaze B2 is priced so users don’t have to choose between what matters and what doesn’t when it comes to backup, archive, data organization, workflow streamlining, and more. Signing up couldn’t be more simple: a few clicks and you’re storing data. The first 10GB is free, and if you need more capacity to run a proof of concept you can talk to our sales team. Otherwise, when you’re ready to store data, you can pay one of two ways:
Our per-byte consumption pricing: Only pay for what you store. It’s $5 TB/month, no hidden delete fees or gotchas. What you see is what you get.
Our B2 Reserve capacity pricing: If you’d like to by predictable blocks of storage, you can work with any of our reseller partners to unlock the following benefits:
Free egress up to the amount of storage purchased per month.
Free transaction calls.
Enhanced migration services.
No delete penalties.
Tera support.
The Answer to the Question
You all can debate the philosophical implications of trees falling in woods and the sound they make. But when it comes to Rapid Recovery, it seems like we can guarantee one thing: your users might not hear the data loss when it happens, but you can bet the sight of relief your IT team breathes when they rapidly recover will be audible.
On the outside and on the inside, our newest data center (DC) is more than a little different: there are no cooling towers chugging on the roof, no chillers, or coolants at all. No, we’re not doing a drive stats experiment on how well data centers run at 54° Celsius. This data center, owned and developed by Nautilus Data Technologies, is nice and cool inside. Built with a unique mix of proven maritime and industrial water-cooling technologies that use river water to cool everything inside—racks, servers, switches, and people—this new DC is innovative, environmentally awesome, secure, fascinating, and other such words and phrases, all rolled into one. And it just happens to be located on a barge on a river in California.
It’s a unique setup, one that might raise a few eyebrows. It certainly did for us. But once our team dug in, we didn’t just find room for another exabyte of data, we found an extremely resilient data center that supports our durability requirements and decreases our environmental impact of providing you cloud storage. You can do a deep dive into the Nautilus technology on their website, but of course I needed to make my own visit to look into this shiny new tech on my own. What follows is an overview of what I learned: how the technology works and why we decided to make the Nautilus data center part of our cloud storage platform.
In the Port of Stockton in California, an odd looking barge is moored next to the shore of the San Joaquin River. If you were able to get close enough, you might notice the massive mooring poles the barge is attached to. And if you were a student of such things, you might recognize these mooring poles as having the same rating as the mooring poles whose attached boats and barges survived hurricane Katrina. The barge isn’t going anywhere.
Above deck are the data center halls. Once inside, it feels like, well, a data center—almost. The power distribution units (PDUs) and other power-related equipment hum quietly and racks of servers and networking gear are lined up across the floor, but there are no hot and cold aisles, and no air conditioning grates or ductwork either. Instead the ceiling is lined with an orderly arrangement of pipes carrying water that’s been cooled by the river outside.
Upriver from the data center, water is collected from the river and filtered before running through the heat exchanger that cools water circulating in a closed loop inside the data center. River water never enters the data center hall.
The technology used to collect and filter the water has been used for decades in power plants, submarines, aircraft carriers, and so on. The entire collection system is marine wildlife-friendly and certified by multiple federal and state agencies, commissions, and water boards, including the California Department of Fish and Wildlife. One of the reasons Nautilus chose the Port of Stockton was the truism that, if you can get something certified for operation in the state of California, then you can typically get it certified pretty much anywhere.
Inside the data center, at specific intervals, water supply and return lines run down to the rear door on each rack. The server fans expel hot air through the rear door and the water inside the door removes the heat to deliver cool air into the room. We use ColdLogik Rear Door Coolers to perform the heat exchange process. The closed loop water system is under vacuum—meaning that it’s leak proof, so water will never touch the servers. A nice bit of innovation by the Nautilus designers and engineers.
Downriver from the data center, the water is discharged. The water can be up to 4° Fahrenheit warmer than when it started upriver. As we mentioned before, the various federal and state authorities worked with Nautilus engineers to select a discharge location which was marine wildlife-friendly. Within seconds of being discharged the water is back to river temperature and continues its journey to the Sacramento Delta. The water spends less than 15 seconds end-to-end in the system which operates with no additional water, uses no chemicals, and adds zero pollutants to the river.
Why Nautilus
For Backblaze, the process of choosing a data center location is a bit more rigorous than throwing a dart at a map and putting some servers there. Our due diligence checklist is long and thorough, taking into consideration redundancy, capacity, scalability, cost, network providers, power providers, stability of the data center owner, and so on. The Nautilus facility passed all of our tests and will enable us to store over an exabyte of data on-site to optimize our operational scalability. In addition, the Nautilus relationship brings us a few additional benefits not traditionally heard of when talking about data centers.
Innovation
Storage Pods, Drive Farming, Drive Stats, and even Backblaze B2 Cloud Storage are all innovations in their own way as they changed market dynamics or defined a different way to do things. They all have in common the trait of putting together proven ideas and technologies in a new way that adds value to the marketplace. In this case, Nautilus marries proven maritime and industrial water cooling and distribution technologies with a new approach to data center infrastructure. The result is an innovative way to use a precious resource to help meet the ever-increasing demand for data storage. This is the kind of engineering and innovation we admire and respect.
Environmental Awesomeness
We can appreciate the environmental impact of the Nautilus data center from two perspectives. The first is obvious: taking a precious resource, river water, and using it to not only lower the carbon footprint of the data center (Nautilus projects by up to 30%), but to also do so without permanently affecting the resource and ecosystem. That’s awesome. The world has been harnessing the power of Mother Nature for thousands of years, yet doing so responsibly has not always been top-of-mind in the process. In the case of Nautilus, the environmental impact is at the top of their list.
The second reason this is awesome is that Nautilus chose to do this in California, coming face-to-face with probably the most stringent environmental requirements in the United States. Almost anywhere else would have been easier, but if you are looking to show your environmental credibility and commitment, then California is the place to start. We commend them for their effort.
Unique Security
Like any well-run data center site, Nautilus has a multitude of industry standard security practices in place: a 24x7x365 security staff, cameras, biometric access, and so on. But the security doesn’t stop there. Being a data center on a barge also means that divers regularly inspect the underwater systems and the barge itself for maintenance and security purposes. In addition, by nature of being a data center on a barge in the Port of Stockton, the data center has additional security: the port itself is protected by the U.S. Department of Homeland Security (DHS) and the waterways are patrolled by the U.S. Coast Guard. This enhanced collection of protective resources is unique for data centers in the U.S., except possibly the kind of data centers we are not supposed to know anything about.
The Manatee in the River
Let’s get to the elephant in the room here: is there risk in putting a data center on a barge in a river? Yes—but no more so than putting one in a desert, or near any body of water, or near a forest, or in an abandoned mine, or near a mountain, or in a city. You get the idea: they all have some level of risk. We’d argue that this new data center—with its decreased reliance on energy and air conditioning and its protection by DHS, among other positives—is quite a bit more reliable than most places the world stores its data. As always, though, we continue to encourage folks to have their data in multiple places.
Still, putting a data center on a river is novel. We’re sure some people will make jokes, and probably pretty funny ones—we’re happy to laugh at our own expense. (It’s certainly happened before.) We are also sure some competitors will use this as part of their sales and marketing—FUD (fear, uncertainty and doubt) as it is called behind your back. We don’t play that game, and, as with our past innovations, we’re used to people sniping a bit when we move out ahead on technology. As always, we encourage you to dig in, get the facts, and be comfortable with the choice you make. Here at Backblaze, we won’t sell you up the river, but we may put your data there.
At Backblaze, we love hearing from our customers about their unique and varied storage needs. Our media and entertainment customers have some of the most interesting use cases and often tell us about their workflow needs moving assets at every stage of the process, from camera to post-production and everywhere in between.
The desire to have more flexibility controlling data movement in their media management systems is a consistent theme. In the interest of helping customers with not just storing their data, but using their data, today we are publishing a new open-source custom integration we have created for Frame.io. Read on to learn more about how to use Frame.io to streamline your media workflows.
What is Frame.io?
Frame.io, an Adobe company, has built a cloud-based media asset management (MAM) platform allowing creative professionals to collaborate at every step of the video production process. For example, videographers can upload footage from the set after each take; editors can work with proxy files transcoded by Frame.io to speed the editing process; and production staff can share sound reports, camera logs, and files like Color Decision Lists.
The Backblaze B2 Custom Action for Frame.io
Creative professionals who use Frame.io know that it can be a powerful tool for content collaboration. Many of those customers also leverage Backblaze B2 for long-term archive, and often already have large asset inventories in Backblaze B2 as well.
What our Backblaze B2 Custom Action for Frame.io does is quite simple: it allows you to quickly move data between Backblaze B2 and Frame.io. Media professionals can use the action to export selected assets or whole projects from Frame.io to B2 Cloud Storage, and then later import exported assets and projects from B2 Cloud Storage back to Frame.io.
How to Use the Backblaze B2 Custom Action for Frame.io
Let’s take a quick look at how to use the custom action:
As you can see, after enabling the Custom Action, a new option appears in the asset context dropdown. Once you select the action, you are presented with a dialog to select Import or Export of data:
After selecting Export, you can choose whether you want just the single selected asset, or the entire project sent to Backblaze B2.
Once you make a selection, that’s it! The custom action handles the movement for you behind the scenes. The export is a point-in-time snapshot of the data from Frame.io—which remains as it was—to Backblaze B2.
The Custom Action creates a new exports folder in your B2 bucket, and then uploads the asset(s) to the folder. If you opt to upload the entire Project, it will be structured the same way it is organized in Frame.io.
How to Get Started With Backblaze B2 and Frame.io
To get started using the Custom Action described above, you will need:
A Frame.io account.
Access to a compute resource to run the custom action code.
A Backblaze B2 account.
If you don’t have a Backblaze B2 account yet, you can sign up here and get 10GB free, or contact us here to run a proof of concept with more than 10GB.
What’s Next?
We’ve written previously about similar open-sourced custom integrations for other tools, and by releasing this one we are continuing in that same spirit. If you are interested in learning more about this integration, you can jump straight to the source code on GitHub.
Watch this space for a follow-up post diving into more of the technical details. We’ll discuss how we secured the solution, made it deployable anywhere (including to options with free bandwidth), and how you can customize it to your needs.
We would love to hear your feedback on this integration, and also any other integrations you would like to see from Backblaze. Feel free to reach out to us in the comments below or through our social channels. We’re particularly active on Twitter and Reddit—let’s chat!
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.