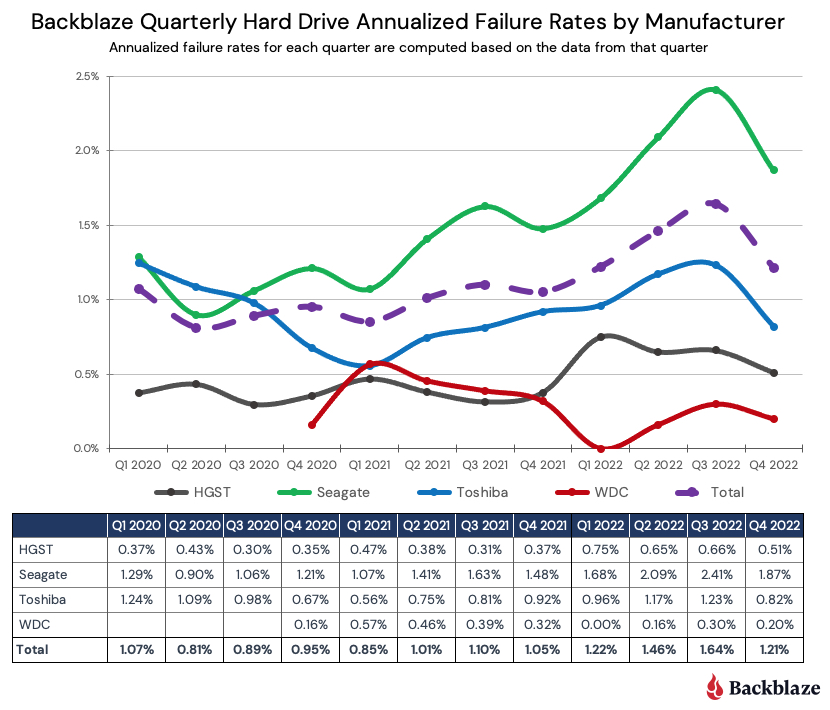
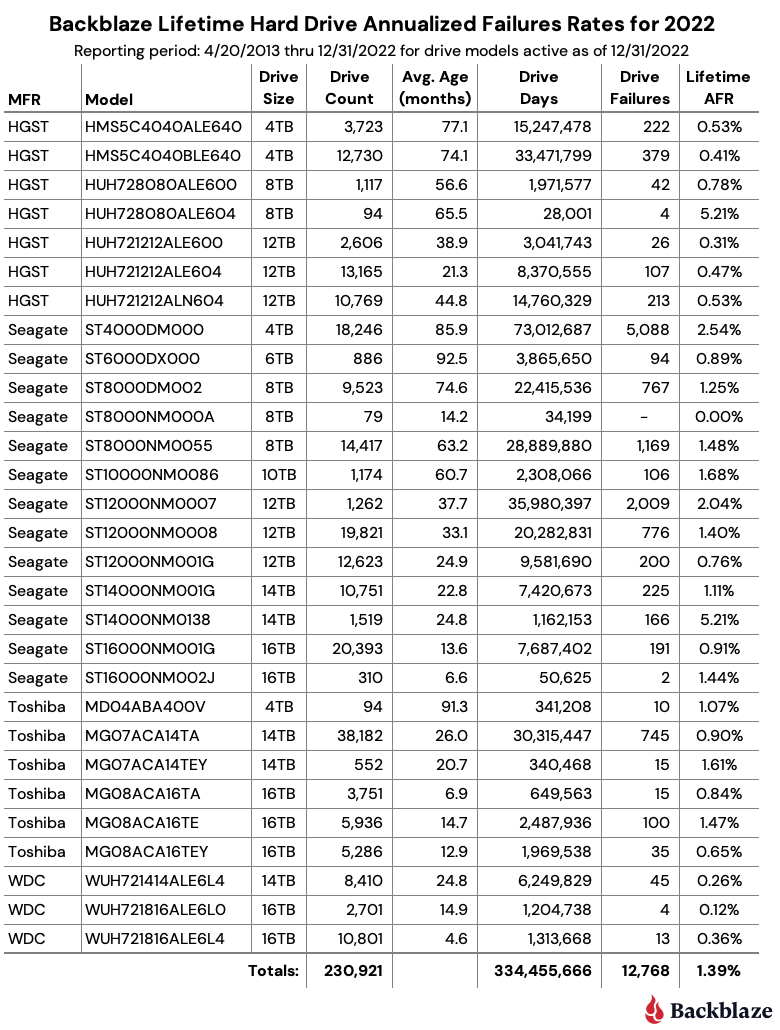
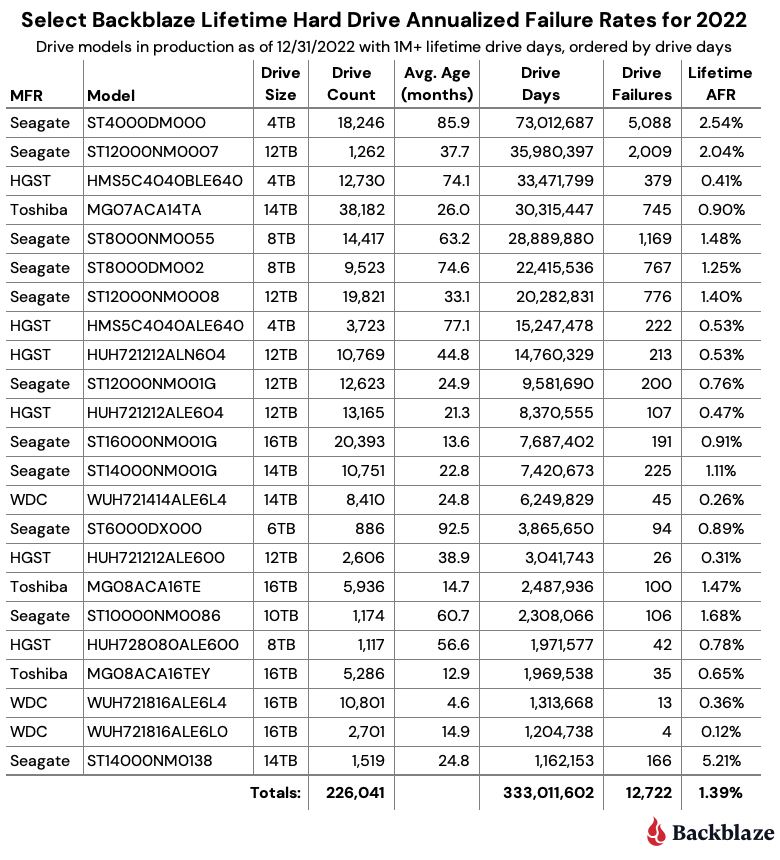
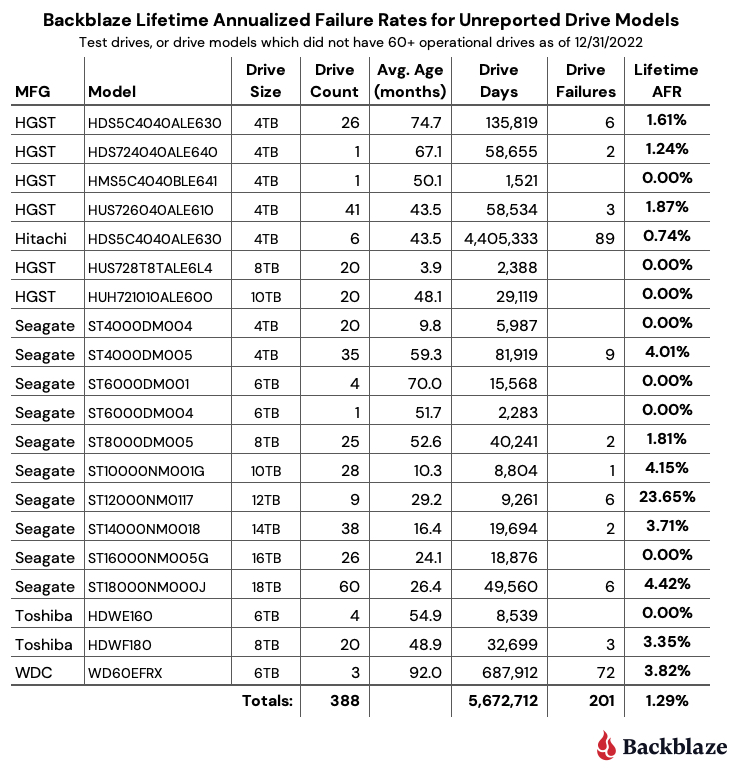
Post Syndicated from Molly Clancy original https://www.backblaze.com/blog/what-is-the-cjis-security-policy/

It’s always been the case that specific industries are subject to their own security standards when it comes to protecting sensitive data. You’ve probably heard of the complex rules and regulations around personal health information and credit card data, for example. Law enforcement agencies do some of the most specialized work possible, so the entire world of criminal justice is subject to its own policies and procedures. Here’s what you need to know about Criminal Justice Information Services and the CJIS Security Policy.
The History of Criminal Justice Information Services
Criminal Justice Information Services (CJIS) is the largest division of the FBI. It was originally established in 1992 to give law enforcement agencies, national security teams, and the intelligence community shared access to a huge repository of highly sensitive data like fingerprints and active case reports. The CJIS Security Policy exists to safeguard that information by defining protocols for the entire data life cycle wherever it exists, both at rest and in transit. It’s easy to see how important it is for law enforcement agencies to need quick and secure access to this case critical data, but it’s also clear just how detrimental that data could be if it got into the wrong hands.
What Is Criminal Justice Information?
To get a better sense of the CJIS Security Policy and how it works, let’s start by looking at the data it covers. These are the five types of data that qualify as criminal justice information (CJI):
- Biometric data: Data points that can be used to identify a unique individual, like fingerprints, palm prints, iris scans, and facial recognition data.
- Identity history data: A text record of an individual’s civil or criminal history that can be tied to the biometric data that identifies them.
- Biographic data: Information about individuals associated with a particular case, even without unique identifiers or biometric data attached.
- Property data: Information about vehicles or physical property associated with a particular case and accompanied by personally identifiable information.
- Case/Incident history: Data about the history of criminal incidents.
How Does CJIS Compliance Work?
The sensitivity of the types of data that qualify as CJI explains just how complicated the CJIS Security Policy is. To complicate matters further, CJIS (under the FBI and in turn the U.S. Department of Justice) issues regular updates to the Security Policy. The complexity inherent in the national policy, in combination with the pressure of keeping pace with constant changes, has meant that many law enforcement, national security, and intelligence agencies opt not to share data between agencies in lieu of taking the necessary steps to keep it safe in compliance with CJIS.
Each individual government agency is responsible for managing their own CJIS compliance. And the Security Policy applies to anyone interacting with that data, regardless of what system they use to do so or how they are associated with the agency that owns it. That means law enforcement representatives, lawyers, contractors, and private entities, for example, are all subject to the rules laid out in the CJIS Security Policy. What’s more, state governments and their respective CJIS Security Officers are responsible for managing the application of the Security Policy at the state level.

How To Achieve CJIS Compliance
Despite all this complexity, CJIS doesn’t issue any official compliance certifications. Instead, compliance with the Security Policy falls under the purview of each individual organization, agency, or government body. Having the right technical controls in place to satisfy all standardized areas of the policy—and managing those controls on an ongoing basis—is the best (and the only) way to achieve CJIS compliance. These are the 13 key areas listed in the Security Policy:
Area 1: Information Exchange Agreements
Before an agency or organization shares CJI with any other entity, both parties must establish and mutually sign a formal information exchange agreement to certify that everyone involved is in CJIS compliant.
Area 2: Awareness & Training
Any individuals interacting with CJI have to participate in annual specialized training about how they are expected to comply with the Security Policy.
Area 3: Incident Response
Every agency interacting with CJI must have an Incident Response Plan (IRP) in place to ensure their ability to identify security incidents when they occur. IRPs also outline plans to contain and remediate damage as quickly and efficiently as possible.
Area 4: Auditing & Accountability
Organizations have to monitor who accesses CJI, when they access it, and what they do with it. Establishing visibility into interactions like file access, login attempts, password changes, etc. helps dissuade bad actors from accessing data they shouldn’t and also gives agencies the forensic information they need to investigate incidents if breaches do occur.
Area 5: Access Control
Another way to ensure that only authorized users interact with CJI is to limit access based on specific attributes like job title, location, and IP address. Implementing role-based access controls helps limit the availability of CJI, so only the people who need to use that data can access it (and only when absolutely necessary).
Area 6: Identification & Authentication
Because of the rules around auditing & accountability and access control, the Security Policy also stipulates the importance of authenticating every user’s identity. CJIS’ identification & authentication rules include the use of multifactor authentication, regular password resets, and revoked credentials after five unsuccessful login attempts.
Area 7: Configuration Management
Only authorized users should be allowed to change the configuration of the systems that store CJI. This includes simple tasks like performing software updates, but it also extends to the hardware realm, for example when it comes to adding or removing devices from a network.
Area 8: Media Protection
Compliant agencies must establish policies to protect all forms of media, including putting procedures in place for the secure disposal of that media once it is no longer in use.
Area 9: Physical Protection
Any physical spaces (like on-premises server rooms, for example) should be locked, monitored by camera equipment, and equipped with alarms to prevent unauthorized access.

Area 10: System & Communications Protection
Cybersecurity best practices should be in place, including perimeter protection measures like Intrusion Prevention Systems, firewalls, and anti-virus solutions. In the category of encryption, FIPS 140-2 certification and a minimum of 128 bit strength are required.
Area 11: Formal Audits
Although the CJIS doesn’t issue compliance certifications, agencies still have to be available for formal audits by CJIS representatives (like the CJIS Audit Unit and the CJIS Systems Agency) at least once every three years.
Area 12: Personnel Security
Any personnel with access to CJI have to undergo a screening process and background checks (including fingerprinting) to ensure their fitness to handle sensitive data.
Area 13: Mobile Devices
In order to remain in compliance, organizations have to develop acceptable use policies that govern how mobile devices are used, how they connect to the internet, what applications they can have on them, and even what websites they can access. In this case, mobile devices include smartphones, tablets, and laptops that can access CJI. When representatives use mobile devices to access CJI, those devices (and that access) are subject to all the areas of the Security Policy.
How Backblaze Supports CJIS Compliance
For any organization to achieve CJIS compliance, any partner or vendor that accesses, interacts with, or stores their CJI also needs to comply with the same Security Policy standards. You guessed it: that means cloud storage providers too. It’s your job to ensure that your organization is CJIS-compliant before transmitting your data to any cloud storage provider. At Backblaze, we follow the same security standards outlined in the CJIS Security Policy so that you can trust that your CJI is protected and your agency is in compliance even while it’s being stored in Backblaze B2 Cloud Storage or via our Business Backup product.
The post What is the CJIS Security Policy? appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.