Post Syndicated from Ryan Timken original https://blog.cloudflare.com/improving-the-resiliency-of-our-infrastructure-dns-zone/
In this blog post we will discuss how we made our infrastructure DNS zone more reliable by using multiple primary nameservers to leverage our own DNS product running on our edge as well as a third-party DNS provider.
Authoritative Nameservers
You can think of an authoritative nameserver as the source of truth for the records of a given DNS zone. When a recursive resolver wants to look up a record, it will eventually need to talk to the authoritative nameserver(s) for the zone in question. If you’d like to read more on the topic, our learning center provides some additional information.
Here’s an example of our authoritative nameservers (replacing our actual domain with example.com):
~$ dig NS example.com +short
ns1.example.com.
ns2.example.com.
ns3.example.com.
As you can see, there are three nameservers listed. You’ll notice that the nameservers happen to reside in the same zone, but they don’t have to. Those three nameservers point to six anycasted IP addresses (3 x IPv4, 3 x IPv6) announced from our edge, comprising data centers from 200+ cities around the world.
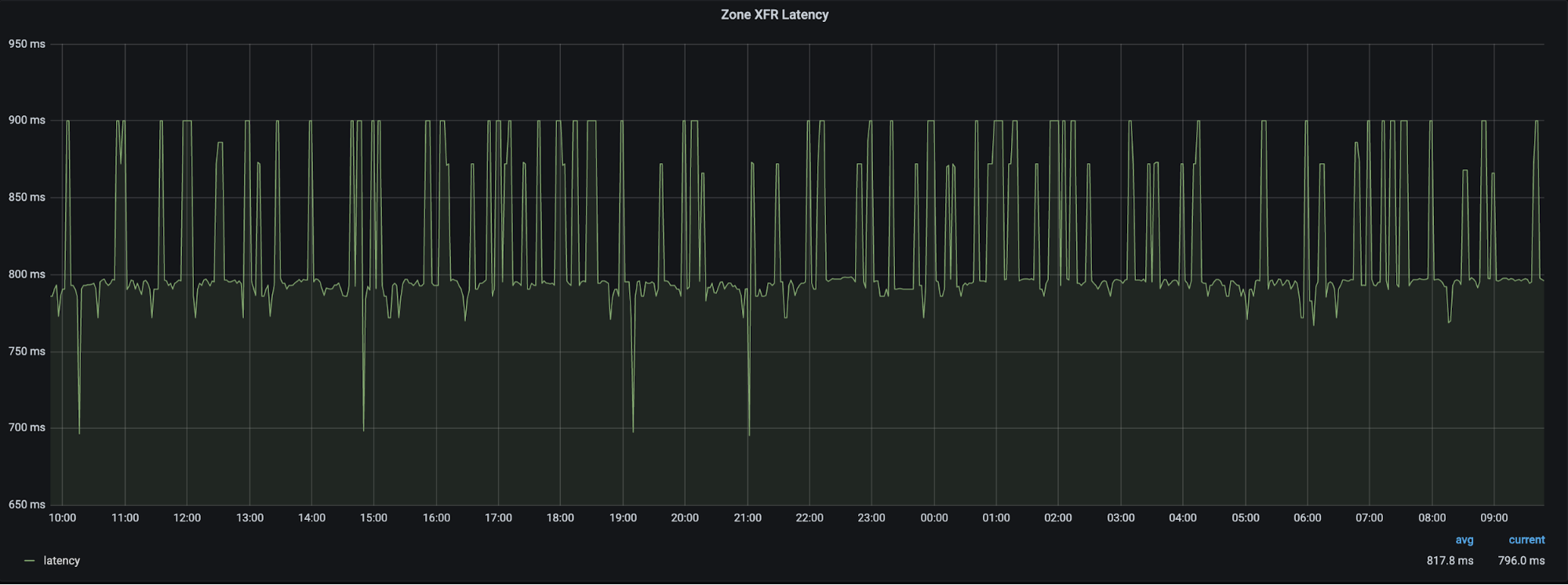
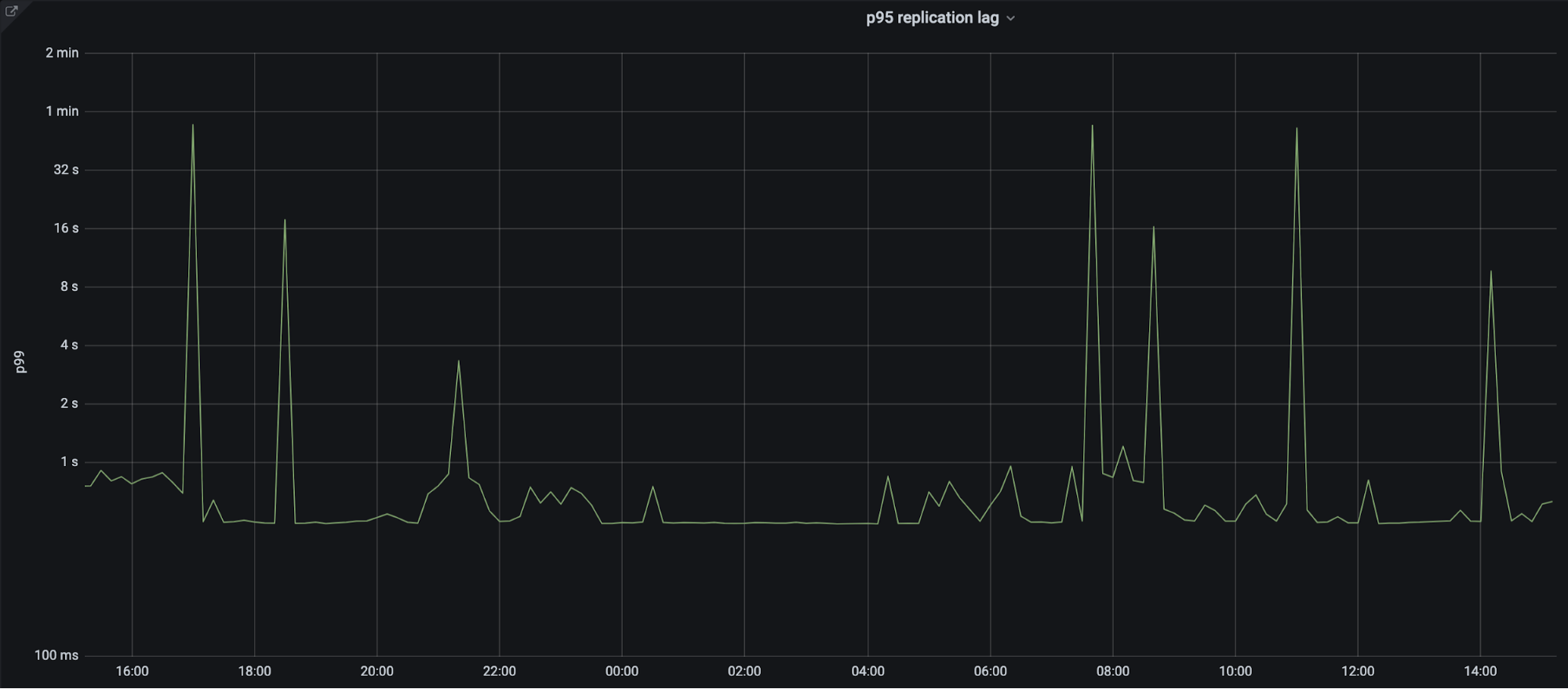
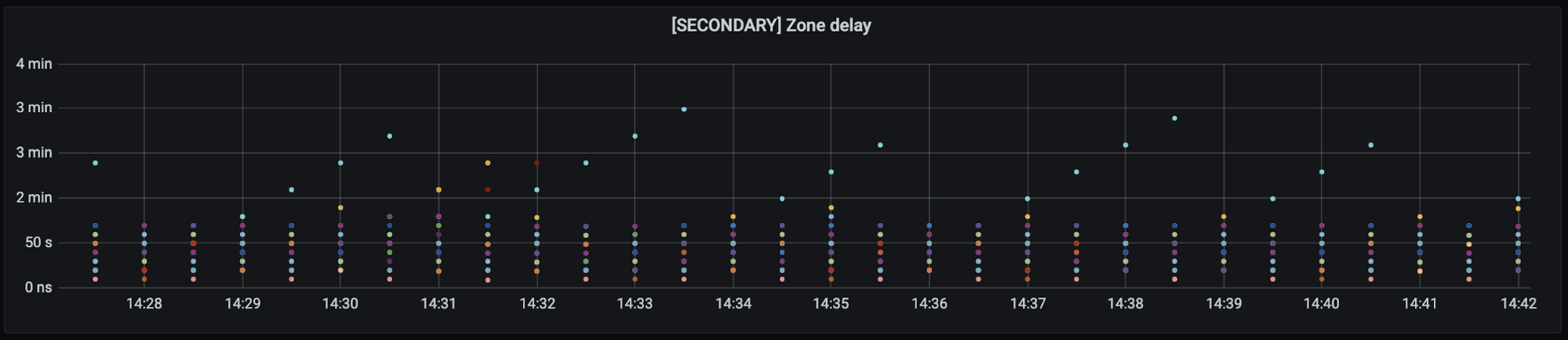
The Problem
We store the hostnames for all of our machines, both the ones at the edge and the ones at core data centers, in a DNS zone we refer to as our infrastructure zone. By using our own DNS product to run our infrastructure zone, we get the reliability and performance of our Global Anycast Network. However, what would happen if those nameservers became unavailable due to an issue on our edge? Eventually DNS lookups would fail, as resolvers would not be able to connect to the only authoritative nameservers configured on the zone: the ones hosted on our edge. This is the main problem we set out to solve.
When an incident occurs, our engineering teams are busy investigating, debugging, and fixing the issue at hand. If they cannot resolve the hostnames of the infrastructure they need to use, it will lead to confusion and delays in resolving the incident.
Imagine you are part of a team tackling an incident. As you quickly begin to investigate, you try to connect to a specific machine to gather some debugging information, but you get a DNS resolution error. What now? You know you are using the right hostname. Is this a result of the incident at hand, some side effect, or is this completely unrelated? You need to keep investigating, so you try another way. Maybe you have memorized the IP address of the machine and you can connect. More likely, you ask another resolver which still has the answer in its cache and resolve the IP that way. One thing is certain, the extra “mini-debug” step costs you precious time and detracts from debugging the real root cause.
Unavailable nameservers and the problems they cause are not unique to Cloudflare, and are not specific to our use case. Even if we hosted our authoritative nameservers with a single external provider, they could also experience their own issues causing the nameservers to fail.
Within the DNS community it is always understood that the more diversity, the better. Some common methods include diversifying network/routing configurations and software choices between a standard primary/secondary setup. However, no matter how resilient the network or software stack is, a single authority is still responsible for the zone. Luckily, there are ways to solve this problem!
Our Solution: Multiple Primary Nameservers
Our solution was to set up our infrastructure zone with multiple primary nameservers. This type of setup is referred to as split authority, multi-primary, or primary/primary. This way, instead of using just one provider for our authoritative nameservers, we use two.
We added three nameservers from our additional provider to our zone at our registrar. Using multiple primaries allows changes to our zone at each provider, to be controlled separately and completely by us. Instead of using zone transfers to keep our zone in sync, we use OctoDNS to independently and simultaneously manage the zone at both providers. We’ll talk more about our use of OctoDNS in a bit.
This setup is similar to using a primary and secondary server. The main difference is that the nameservers operate independently from one another, and do not use the usual DNS AXFR/IXFR method to keep the zone up to date. If you’d like to learn more about this type of solution, here is a great blog post by Dina Kozlov, our Product Manager for DNS, about Secondary DNS.
The nameservers in our zone after adding an additional provider would look something like:
~$ dig NS example.com +short
ns1.example.com.
ns2.example.com.
ns3.example.com.
ns1.additional-provider.net.
ns2.additional-provider.net.
ns3.additional-provider.net.
Predictable Query Routing
Currently, we cannot coordinate which provider should be used when querying a record within the zone. Recursive resolvers have different methods of choosing which nameserver should be used when presented with multiple NS records. A popular choice is to use the server with the lowest RTT (round trip time). A great blog post from APNIC on recursive resolver authoritative nameserver selection can be consulted for a detailed explanation.
We needed to enforce specific routing decisions between the two authorities. Our requirement was for a weighted routing policy preferring Cloudflare based on availability checks for requests originating from our infrastructure servers. This reduces RTT, since the queries originate from the same servers hosting our nameservers in the same data center, and do not need to travel further to the external provider when all is well.
Our edge infrastructure servers are configured to use DNSDist as their primary system resolver. DNSDist load balances queries using multiple upstream recursive DNS servers (Unbound) in each data center to provide DNS resolution. This setup is used for internal DNS resolution only, and as such, it is independent from our authoritative DNS and public resolver 1.1.1.1 service.
Additionally, we modified our DNSDist configuration by adding two server pools for our infrastructure zone authoritative servers, and set up active checks with weighted routes to always use the Cloudflare pool when available. With the active checking and weighted routing in place, our queries are always routed internally when available. In the event of a Cloudflare authoritative DNS failure, DNSDist will route all requests for the zone to our external provider.
Maintaining Our Infrastructure DNS Zone
In addition to a more reliable infrastructure zone, we also wanted to further automate the provisioning of DNS records. We had been relying on an older manual tool that became quite slow handling our growing number of DNS records. In a nutshell, this tool queried our provisioning database to gather all of the machine names, and then created, deleted, or updated the required DNS records using the Cloudflare API. We had to run this tool whenever we provisioned or decommissioned machines that serve our customers’ requests.
Part of the procedure for running this tool was to first run it in dry-run mode, and then paste the results for review in our team chat room. This review step ensured the changes the tool found were expected and safe to run, and it is something we want to keep as part of our plan to automate the process.
Here’s what the old tool looked like:
$ cf-provision update-example -l ${USER}@cloudflare.com -u
Running update-example.sh -t /var/tmp/cf-provision -l [email protected] -u
* Loading up possible records …
deleting: {"name":"node44.example.com","ttl":300, "type":"A","content":"192.0.2.2","proxied":false}
rec_id:abcdefg
updating: { "name":"build-ts.example.com", "ttl":120, "type":"TXT", "content":"1596722274"} rec_id:123456 previous content: 1596712896
Result : SUCCESS
Task : BUILD
Dest dir :
Started : Thu, 06 Aug 2020 13:57:40 +0000
Finished : Thu, 06 Aug 2020 13:58:16 +0000
Elapsed : 36 secs
Records Changed In API : 1 record(s) changed
Records Deleted In API : 1 record(s) deleted
Zone Management with OctoDNS
As we mentioned earlier, when using a multi-primary setup for our infrastructure zone, we are required to maintain the zone data outside of traditional DNS replication. Before rolling out our own solution we wanted to see what was out there, and we stumbled upon OctoDNS, a project from GitHub. OctoDNS provides a set of tools that make it easy to manage your DNS records across multiple providers.
OctoDNS uses a pluggable architecture. This means we can rewrite our old script as a plugin (which is called a ‘source’), and use other existing provider plugins (called ‘providers’) to interact with both the Cloudflare and our other provider’s APIs. Should we decide to sync to more external DNS providers in the future, we would just need to add them to our OctoDNS configuration. This allows our records to stay up to date, and, as an added benefit, records OctoDNS doesn’t know about will be removed during operation (for example, changes made outside of OctoDNS). This ensures that manual changes do not diverge from what is present in the provisioning database.
Our goal was to keep the zone management workflow as simple as possible. At Cloudflare, we use TeamCity for CI/CD, and we realized that it could not only facilitate code builds of our OctoDNS implementation, but it could also be used to deploy the zone.
There are a number of benefits to using our existing TeamCity infrastructure.
- Our DevTools team can reliably manage it as a service
- It has granular permissions, which allow us to control who can deploy the changes
- It provides storage of the logs for auditing
- It allows easy rollback of zone revisions
- It integrates easily with our chat ops workflow via Google Chat webhooks
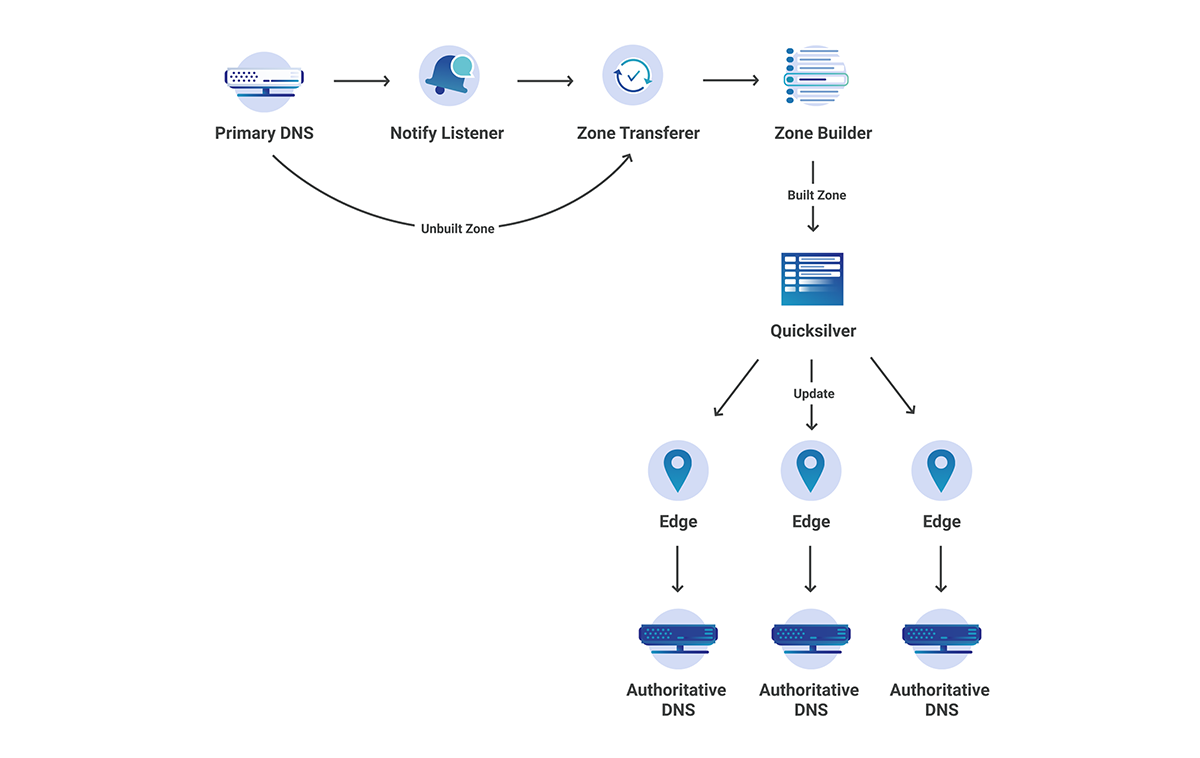
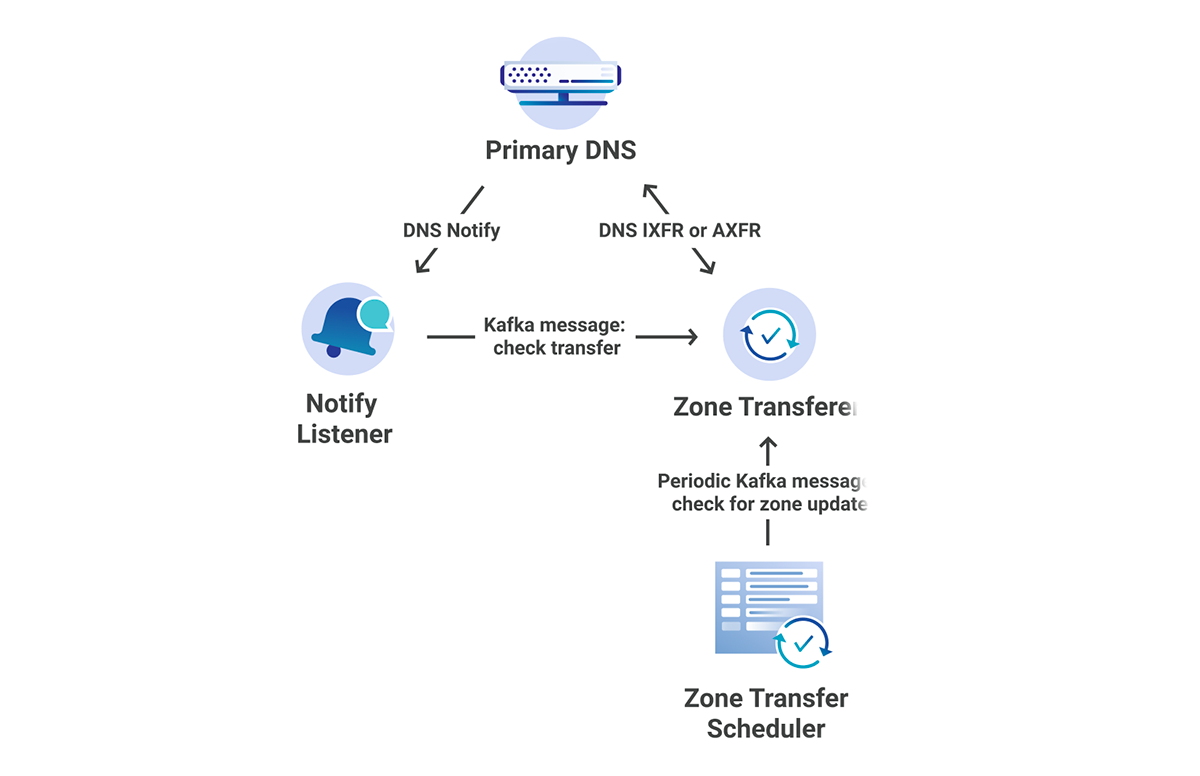
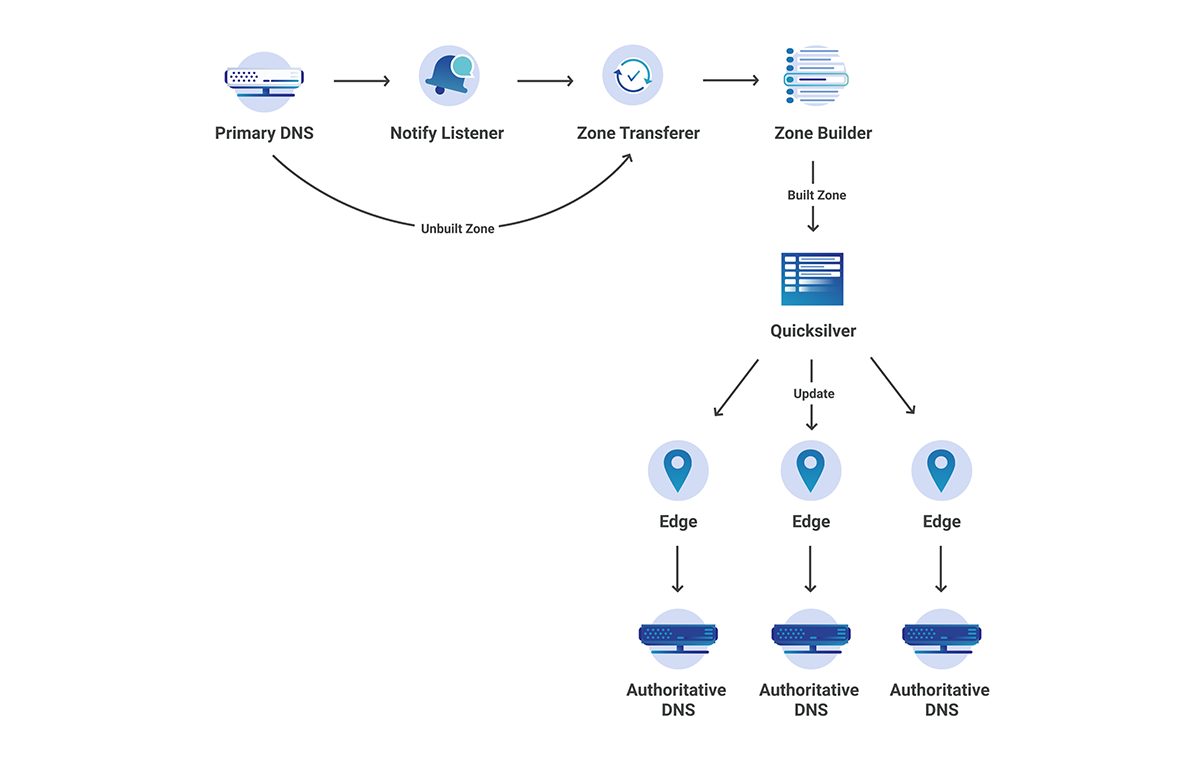
Below is a high-level overview of how we manage our zone through OctoDNS.
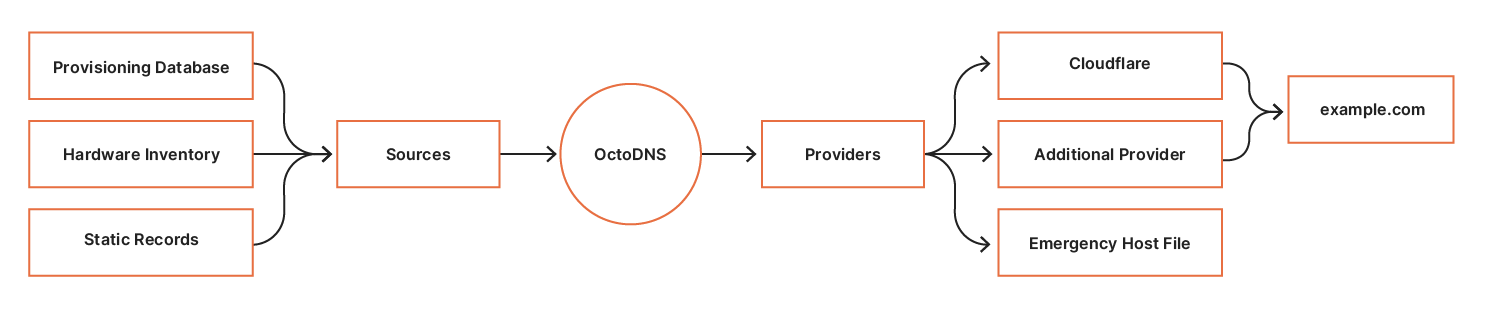
There are three steps in the workflow:
- Build – evaluate the sources and build the complete zone.
- Compare – parse the built zone and compare to the records on the providers. Changes found are sent to SRE for evaluation.
- Deploy – deploy the changes to the providers.
Step 1: Build
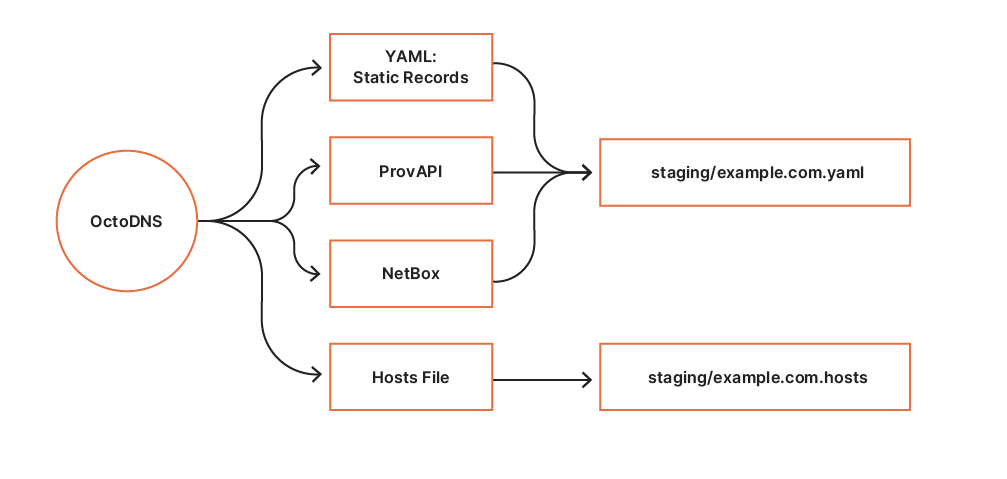
Sources
OctoDNS consumes data from our internal systems via custom source modules. So far, we have built two source modules for querying data:
- ProvAPI queries our internal provisioning API providing data center and node configuration.
- NetBox queries our internal NetBox deployment providing hardware metadata.
Additionally, static records are defined in a YAML file. These sources form the infrastructure zone source of truth.
Providers
The build process establishes a staging area per execution. The YAML provider builds a static YAML file containing the complete zone. The hosts file provider is used to generate an emergency hosts file for the zone. Contents from the staging area are revision controlled in CI, which allows us to easily deploy previous versions if required.
Step 2: Compare
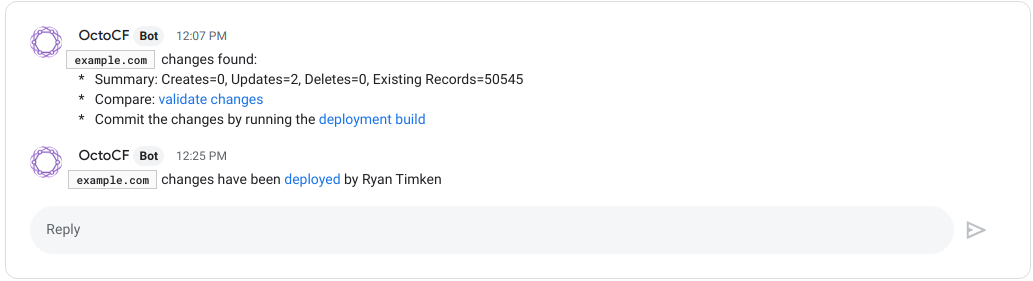
Following a successful zone build CI executes the compare build. During this phase, OctoDNS performs an octodns-sync in dry-run mode. The compare build consumes the staging YAML zone configuration, and compares the records against the records on our authoritative providers via their respective APIs. Any identified zone changes are parsed, and a summary line is generated and sent to the SRE Chat room for approval. SRE are automatically linked to the changes and associated CI build for deployment.
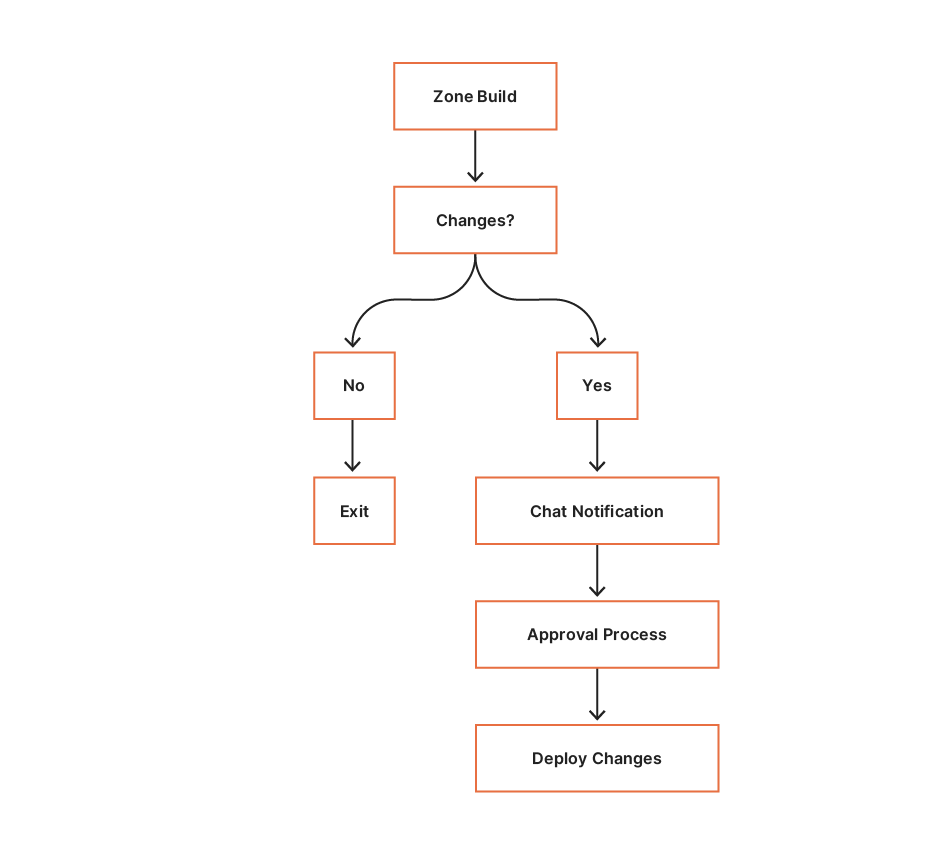
Step 3: Deploy
The deployment CI build is access-controlled and scoped to the SRE group using our single sign-on provider. Following successful approval and peer review, an SRE can deploy the changes by executing the deploy build.
The deployment process is simple; consume the YAML zone data from our staging area and deploy the changes to the zone’s authoritative providers via ‘octodns-sync –doit’. The hosts file generated for the zone is packaged and deployed, to be used in the event of complete DNS failure.
Here’s an example of how the message looks. When the deploy is finished, the thread is updated to indicate which user initiated it.
Future Improvements
In the future, we would like to automate the process further by reducing the need for approvals. There is usually no harm in adding new records, and it is done very often during the provisioning of new machines. Removing the need to approve those records would take out another step in the provisioning process, which is something we are always looking to optimize.
Introducing OctoDNS and an additional provider allowed us to make our infrastructure DNS zone more reliable and easier to manage. We can now easily include new sources of record data, with OctoDNS allowing us to focus more on new and exciting projects and less on managing DNS records.