Post Syndicated from Alex Fattouche original https://blog.cloudflare.com/migrating-billions-of-records-moving-our-active-dns-database-while-in-use
According to a survey done by W3Techs, as of October 2024, Cloudflare is used as an authoritative DNS provider by 14.5% of all websites. As an authoritative DNS provider, we are responsible for managing and serving all the DNS records for our clients’ domains. This means we have an enormous responsibility to provide the best service possible, starting at the data plane. As such, we are constantly investing in our infrastructure to ensure the reliability and performance of our systems.
DNS is often referred to as the phone book of the Internet, and is a key component of the Internet. If you have ever used a phone book, you know that they can become extremely large depending on the size of the physical area it covers. A zone file in DNS is no different from a phone book. It has a list of records that provide details about a domain, usually including critical information like what IP address(es) each hostname is associated with. For example:
example.com 59 IN A 198.51.100.0
blog.example.com 59 IN A 198.51.100.1
ask.example.com 59 IN A 198.51.100.2It is not unusual for these zone files to reach millions of records in size, just for a single domain. The biggest single zone on Cloudflare holds roughly 4 million DNS records, but the vast majority of zones hold fewer than 100 DNS records. Given our scale according to W3Techs, you can imagine how much DNS data alone Cloudflare is responsible for. Given this volume of data, and all the complexities that come at that scale, there needs to be a very good reason to move it from one database cluster to another.
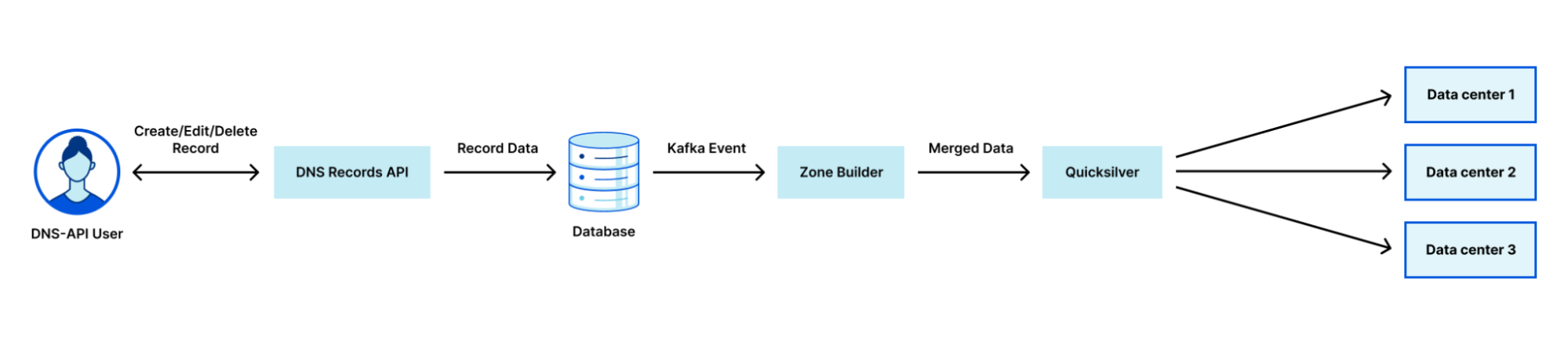
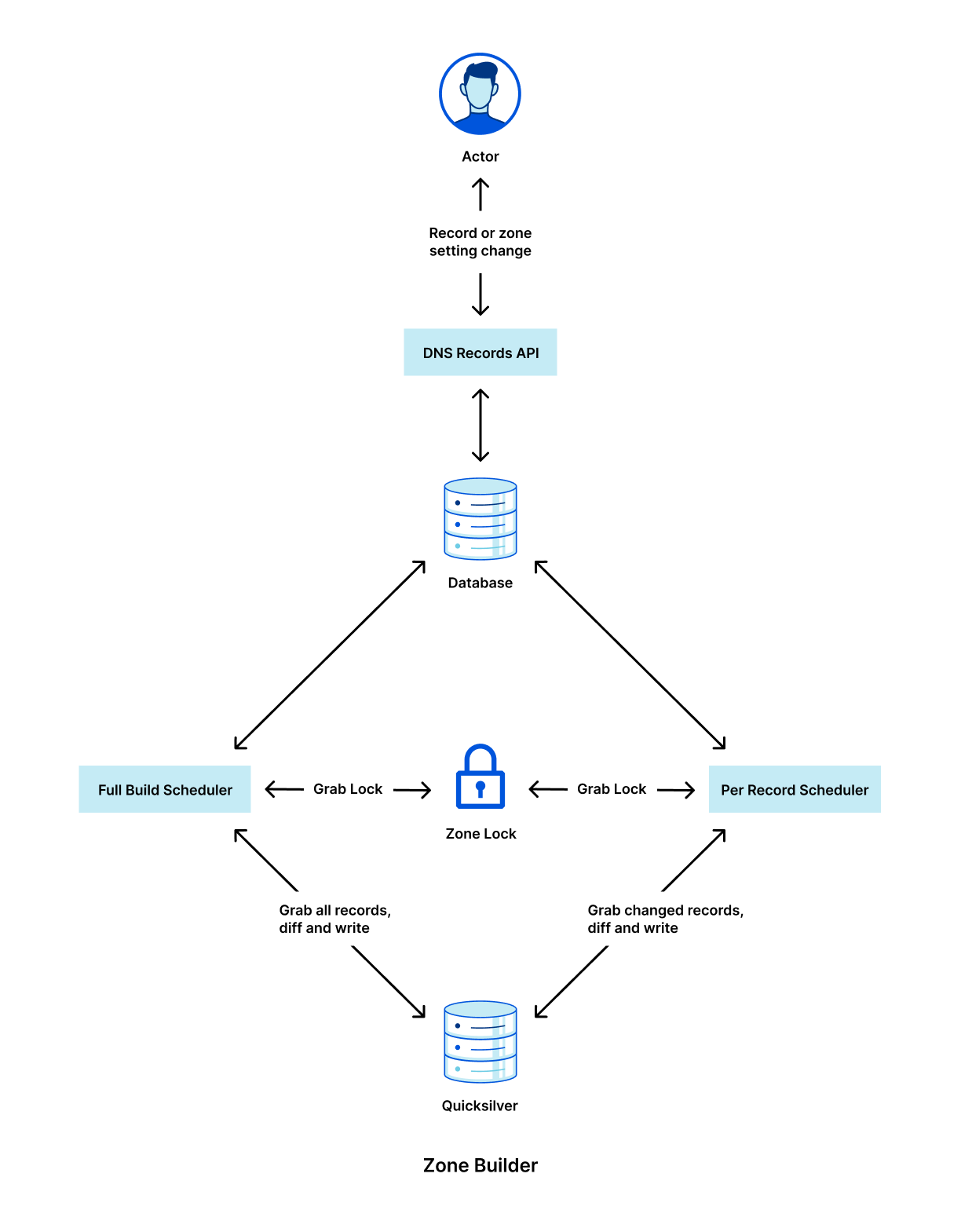
When initially measured in 2022, DNS data took up approximately 40% of the storage capacity in Cloudflare’s main database cluster (cfdb). This database cluster, consisting of a primary system and multiple replicas, is responsible for storing DNS zones, propagated to our data centers in over 330 cities via our distributed KV store Quicksilver. cfdb is accessed by most of Cloudflare’s APIs, including the DNS Records API. Today, the DNS Records API is the API most used by our customers, with each request resulting in a query to the database. As such, it’s always been important to optimize the DNS Records API and its surrounding infrastructure to ensure we can successfully serve every request that comes in.
As Cloudflare scaled, cfdb was becoming increasingly strained under the pressures of several services, many unrelated to DNS. During spikes of requests to our DNS systems, other Cloudflare services experienced degradation in the database performance. It was understood that in order to properly scale, we needed to optimize our database access and improve the systems that interact with it. However, it was evident that system level improvements could only be just so useful, and the growing pains were becoming unbearable. In late 2022, the DNS team decided, along with the help of 25 other teams, to detach itself from cfdb and move our DNS records data to another database cluster.
From a DNS perspective, this migration to an improved database cluster was in the works for several years. Cloudflare initially relied on a single Postgres database cluster, cfdb. At Cloudflare’s inception, cfdb was responsible for storing information about zones and accounts and the majority of services on the Cloudflare control plane depended on it. Since around 2017, as Cloudflare grew, many services moved their data out of cfdb to be served by a microservice. Unfortunately, the difficulty of these migrations are directly proportional to the amount of services that depend on the data being migrated, and in this case, most services require knowledge of both zones and DNS records.
Although the term “zone” was born from the DNS point of view, it has since evolved into something more. Today, zones on Cloudflare store many different types of non-DNS related settings and help link several non-DNS related products to customers’ websites. Therefore, it didn’t make sense to move both zone data and DNS record data together. This separation of two historically tightly coupled DNS concepts proved to be an incredibly challenging problem, involving many engineers and systems. In addition, it was clear that if we were going to dedicate the resources to solving this problem, we should also remove some of the legacy issues that came along with the original solution.
One of the main issues with the legacy database was that the DNS team had little control over which systems accessed exactly what data and at what rate. Moving to a new database gave us the opportunity to create a more tightly controlled interface to the DNS data. This was manifested as an internal DNS Records gRPC API which allows us to make sweeping changes to our data while only requiring a single change to the API, rather than coordinating with other systems. For example, the DNS team can alter access logic and auditing procedures under the hood. In addition, it allows us to appropriately rate-limit and cache data depending on our needs. The move to this new API itself was no small feat, and with the help of several teams, we managed to migrate over 20 services, using 5 different programming languages, from direct database access to using our managed gRPC API. Many of these services touch very important areas such as DNSSEC, TLS, Email, Tunnels, Workers, Spectrum, and R2 storage. Therefore, it was important to get it right.
One of the last issues to tackle was the logical decoupling of common DNS database functions from zone data. Many of these functions expect to be able to access both DNS record data and DNS zone data at the same time. For example, at record creation time, our API needs to check that the zone is not over its maximum record allowance. Originally this check occurred at the SQL level by verifying that the record count was lower than the record limit for the zone. However, once you remove access to the zone itself, you are no longer able to confirm this. Our DNS Records API also made use of SQL functions to audit record changes, which requires access to both DNS record and zone data. Luckily, over the past several years, we have migrated this functionality out of our monolithic API and into separate microservices. This allowed us to move the auditing and zone setting logic to the application level rather than the database level. Ultimately, we are still taking advantage of SQL functions in the new database cluster, but they are fully independent of any other legacy systems, and are able to take advantage of the latest Postgres version.
Now that Cloudflare DNS was mostly decoupled from the zones database, it was time to proceed with the data migration. For this, we built what would become our Change Data Capture and Transfer Service (CDCTS).
The Database team is responsible for all Postgres clusters within Cloudflare, and were tasked with executing the data migration of two tables that store DNS data: cf_rec and cf_archived_rec, from the original cfdb cluster to a new cluster we called dnsdb. We had several key requirements that drove our design:
-
Don’t lose data. This is the number one priority when handling any sort of data. Losing data means losing trust, and it is incredibly difficult to regain that trust once it’s lost. Important in this is the ability to prove no data had been lost. The migration process would, ideally, be easily auditable.
-
Minimize downtime. We wanted a solution with less than a minute of downtime during the migration, and ideally with just a few seconds of delay.
These two requirements meant that we had to be able to migrate data changes in near real-time, meaning we either needed to implement logical replication, or some custom method to capture changes, migrate them, and apply them in a table in a separate Postgres cluster.
We first looked at using Postgres logical replication using pgLogical, but had concerns about its performance and our ability to audit its correctness. Then some additional requirements emerged that made a pgLogical implementation of logical replication impossible:
-
The ability to move data must be bidirectional. We had to have the ability to switch back to cfdb without significant downtime in case of unforeseen problems with the new implementation.
-
Partition the cf_rec table in the new database. This was a long-desired improvement and since most access to cf_rec is by zone_id, it was decided that mod(zone_id, num_partitions) would be the partition key.
-
Transferred data accessible from original database. In case we had functionality that still needed access to data, a foreign table pointing to dnsdb would be available in cfdb. This could be used as emergency access to avoid needing to roll back the entire migration for a single missed process.
-
Only allow writes in one database. Applications should know where the primary database is, and should be blocked from writing to both databases at the same time.
The primary table, cf_rec, stores DNS record information, and its rows are regularly inserted, updated, and deleted. At the time of the migration, this table had 1.7 billion records, and with several indexes took up 1.5 TB of disk. Typical daily usage would observe 3-5 million inserts, 1 million updates, and 3-5 million deletes.
The second table, cf_archived_rec, stores copies of cf_rec that are obsolete — this table generally only has records inserted and is never updated or deleted. As such, it would see roughly 3-5 million inserts per day, corresponding to the records deleted from cf_rec. At the time of the migration, this table had roughly 4.3 billion records.
Fortunately, neither table made use of database triggers or foreign keys, which meant that we could insert/update/delete records in this table without triggering changes or worrying about dependencies on other tables.
Ultimately, both of these tables are highly active and are the source of truth for many highly critical systems at Cloudflare.
There were two main parts to this database migration:
-
Initial copy: Take all the data from cfdb and put it in dnsdb.
-
Change copy: Take all the changes in cfdb since the initial copy and update dnsdb to reflect them. This is the more involved part of the process.
Normally, logical replication replays every insert, update, and delete on a copy of the data in the same transaction order, making a single-threaded pipeline. We considered using a queue-based system but again, speed and auditability were both concerns as any queue would typically replay one change at a time. We wanted to be able to apply large sets of changes, so that after an initial dump and restore, we could quickly catch up with the changed data. For the rest of the blog, we will only speak about cf_rec for simplicity, but the process for cf_archived_rec is the same.
What we decided on was a simple change capture table. Rows from this capture table would be loaded in real-time by a database trigger, with a transfer service that could migrate and apply thousands of changed records to dnsdb in each batch. Lastly, we added some auditing logic on top to ensure that we could easily verify that all data was safely transferred without downtime.
For cf_rec to be migrated, we would create a change logging table, along with a trigger function and a table trigger to capture the new state of the record after any insert/update/delete.
The change logging table named log_cf_rec had the same columns as cf_rec, as well as four new columns:
-
change_id: a sequence generated unique identifier of the record
-
action: a single character indicating whether this record represents an [i]nsert, [u]pdate, or [d]elete
-
change_timestamp: the date/time when the change record was created
-
change_user: the database user that made the change.
A trigger was placed on the cf_rec table so that each insert/update would copy the new values of the record into the change table, and for deletes, create a ‘D’ record with the primary key value.
Here is an example of the change logging where we delete, re-insert, update, and finally select from the log_cf_rec table. Note that the actual cf_rec and log_cf_rec tables have many more columns, but have been edited for simplicity.
dns_records=# DELETE FROM cf_rec WHERE rec_id = 13;
dns_records=# SELECT * from log_cf_rec;
Change_id | action | rec_id | zone_id | name
----------------------------------------------
1 | D | 13 | |
dns_records=# INSERT INTO cf_rec VALUES(13,299,'cloudflare.example.com');
dns_records=# UPDATE cf_rec SET name = 'test.example.com' WHERE rec_id = 13;
dns_records=# SELECT * from log_cf_rec;
Change_id | action | rec_id | zone_id | name
----------------------------------------------
1 | D | 13 | |
2 | I | 13 | 299 | cloudflare.example.com
3 | U | 13 | 299 | test.example.com In addition to log_cf_rec, we also introduced 2 more tables in cfdb and 3 more tables in dnsdb:
cfdb
-
transferred_log_cf_rec: Responsible for auditing the batches transferred to dnsdb.
-
log_change_action: Responsible for summarizing the transfer size in order to compare with the log_change_action in dnsdb.
dnsdb
-
migrate_log_cf_rec: Responsible for collecting batch changes in dnsdb, which would later be applied to cf_rec in dnsdb.
-
applied_migrate_log_cf_rec: Responsible for auditing the batches that had been successfully applied to cf_rec in dnsdb.
-
log_change_action: Responsible for summarizing the transfer size in order to compare with the log_change_action in cfdb.
With change logging in place, we were now ready to do the initial copy of the tables from cfdb to dnsdb. Because we were changing the structure of the tables in the destination database and because of network timeouts, we wanted to bring the data over in small pieces and validate that it was brought over accurately, rather than doing a single multi-hour copy or pg_dump. We also wanted to ensure a long-running read could not impact production and that the process could be paused and resumed at any time. The basic model to transfer data was done with a simple psql copy statement piped into another psql copy statement. No intermediate files were used.
psql_cfdb -c "COPY (SELECT * FROM cf_rec WHERE id BETWEEN n and n+1000000 TO STDOUT)" |
psql_dnsdb -c "COPY cf_rec FROM STDIN"
Prior to a batch being moved, the count of records to be moved was recorded in cfdb, and after each batch was moved, a count was recorded in dnsdb and compared to the count in cfdb to ensure that a network interruption or other unforeseen error did not cause data to be lost. The bash script to copy data looked like this, where we included files that could be touched to pause or end the copy (if they cause load on production or there was an incident). Once again, this code below has been heavily simplified.
#!/bin/bash
for i in "$@"; do
# Allow user to control whether this is paused or not via pause_copy file
while [ -f pause_copy ]; do
sleep 1
done
# Allow user to end migration by creating end_copy file
if [ ! -f end_copy ]; then
# Copy a batch of records from cfdb to dnsdb
# Get count of records from cfdb
# Get count of records from dnsdb
# Compare cfdb count with dnsdb count and alert if different
fi
done
Bash copy script
Once the initial copy was completed, we needed to update dnsdb with any changes that had occurred in cfdb since the start of the initial copy. To implement this change copy, we created a function fn_log_change_transfer_log_cf_rec that could be passed a batch_id and batch_size, and did 5 things, all of which were executed in a single database transaction:
-
Select a batch_size of records from log_cf_rec in cfdb.
-
Copy the batch to transferred_log_cf_rec in cfdb to mark it as transferred.
-
Delete the batch from log_cf_rec.
-
Write a summary of the action to log_change_action table. This will later be used to compare transferred records with cfdb.
-
Return the batch of records.
We then took the returned batch of records and copied them to migrate_log_cf_rec in dnsdb. We used the same bash script as above, except this time, the copy command looked like this:
psql_cfdb -c "COPY (SELECT * FROM fn_log_change_transfer_log_cf_rec(<batch_id>,<batch_size>) TO STDOUT" |
psql_dnsdb -c "COPY migrate_log_cf_rec FROM STDIN"
Now, with a batch of data in the migrate_log_cf_rec table, we called a newly created function log_change_apply to apply and audit the changes. Once again, this was all executed within a single database transaction. The function did the following:
-
Move a batch from the migrate_log_cf_rec table to a new temporary table.
-
Write the counts for the batch_id to the log_change_action table.
-
Delete from the temporary table all but the latest record for a unique id (last action). For example, an insert followed by 30 updates would have a single record left, the final update. There is no need to apply all the intermediate updates.
-
Delete any record from cf_rec that has any corresponding changes.
-
Insert any [i]nsert or [u]pdate records in cf_rec.
-
Copy the batch to applied_migrate_log_cf_rec for a full audit trail.
There were 4 distinct phases, each of which was part of a different database transaction:
-
Call fn_log_change_transfer_log_cf_rec in cfdb to get a batch of records.
-
Copy the batch of records to dnsdb.
-
Call log_change_apply in dnsdb to apply the batch of records.
-
Compare the log_change_action table in each respective database to ensure counts match.

This process was run every 3 seconds for several weeks before the migration to ensure that we could keep dnsdb in sync with cfdb.
The last major pre-migration task was the construction of the request locking system that would be used throughout the actual migration. The aim was to create a system that would allow the database to communicate with the DNS Records API, to allow the DNS Records API to handle HTTP connections more gracefully. If done correctly, this could reduce downtime for DNS Record API users to nearly zero.
In order to facilitate this, a new table called cf_migration_manager was created. The table would be periodically polled by the DNS Records API, communicating two critical pieces of information:
-
Which database was active. Here we just used a simple A or B naming convention.
-
If the database was locked for writing. In the event the database was locked for writing, the DNS Records API would hold HTTP requests until the lock was released by the database.
Both pieces of information would be controlled within a migration manager script.
The benefit of migrating the 20+ internal services from direct database access to using our internal DNS Records gRPC API is that we were able to control access to the database to ensure that no one else would be writing without going through the cf_migration_manager.
Although we aimed to complete this migration in a matter of seconds, we announced a DNS maintenance window that could last a couple of hours just to be safe. Now that everything was set up, and both cfdb and dnsdb were roughly in sync, it was time to proceed with the migration. The steps were as follows:
-
Lower the time between copies from 3s to 0.5s.
-
Lock cfdb for writes via cf_migration_manager. This would tell the DNS Records API to hold write connections.
-
Make cfdb read-only and migrate the last logged changes to dnsdb.
-
Enable writes to dnsdb.
-
Tell DNS Records API that dnsdb is the new primary database and that write connections can proceed via the cf_migration_manager.
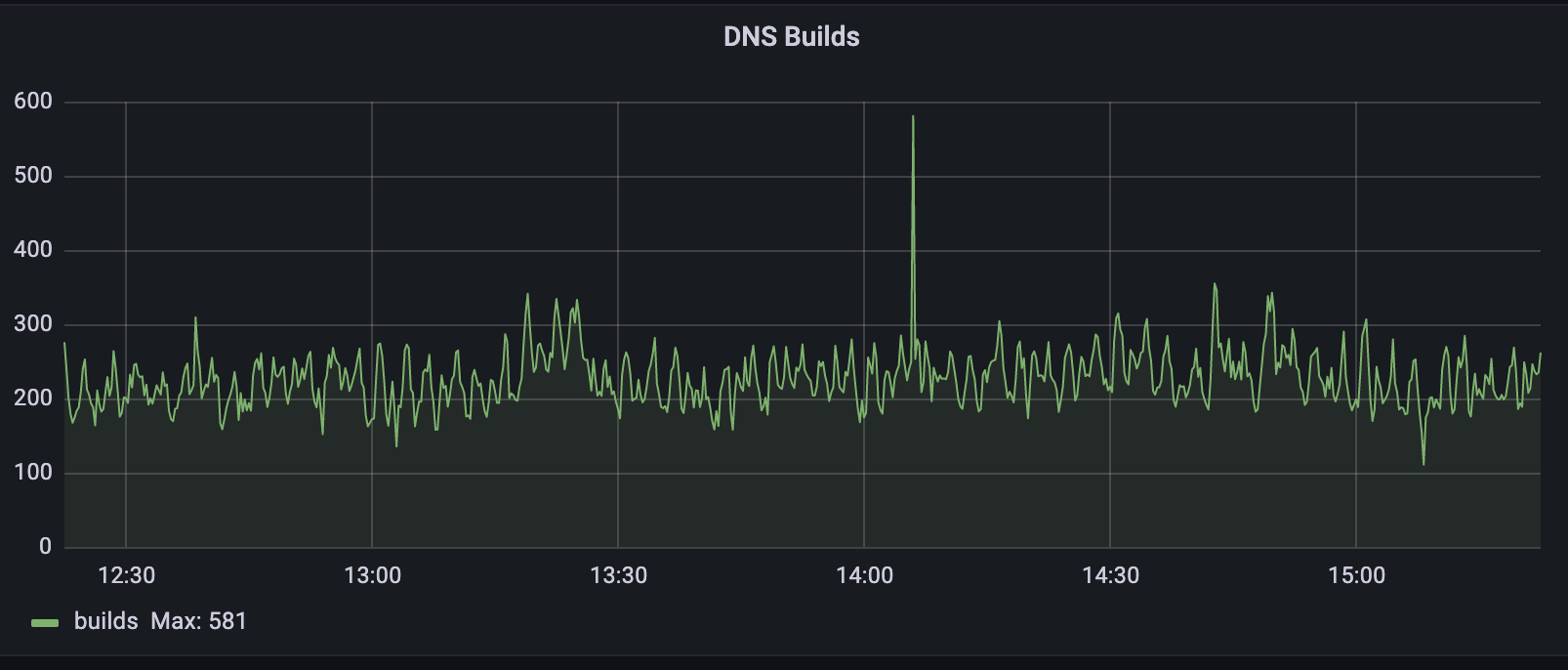
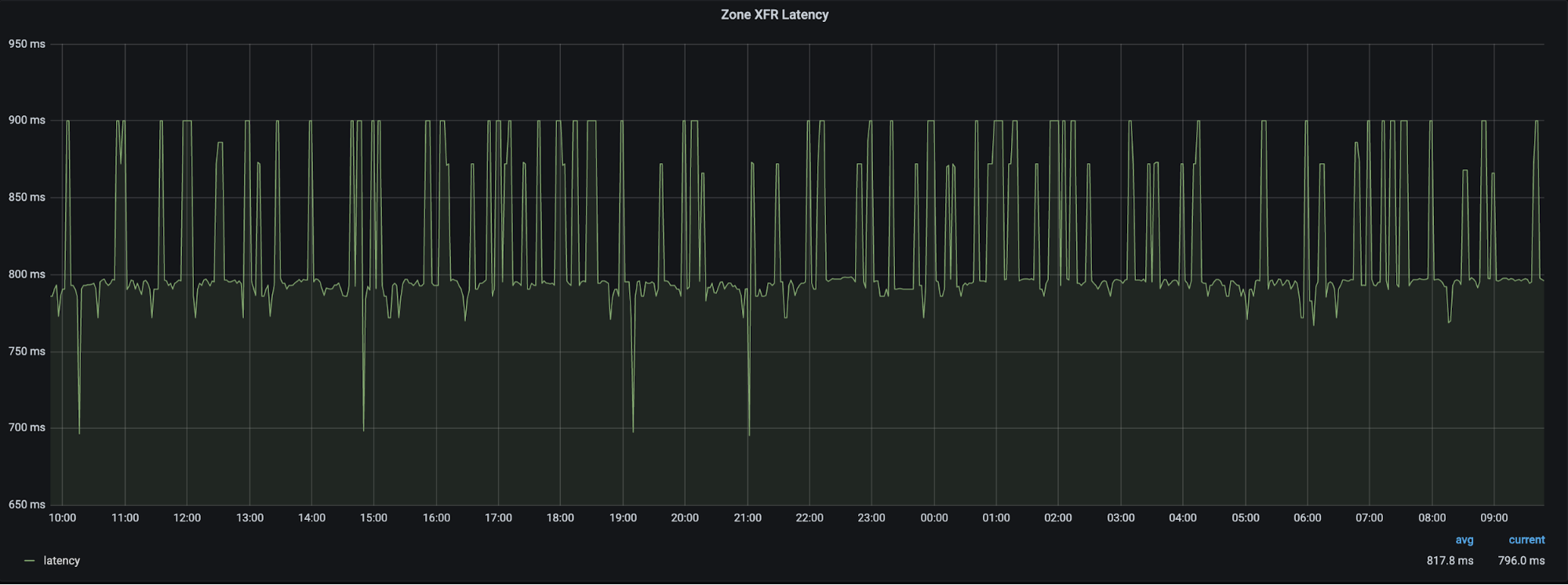
Since we needed to ensure that the last changes were copied to dnsdb before enabling writing, this entire process took no more than 2 seconds. During the migration we saw a spike of API latency as a result of the migration manager locking writes, and then dealing with a backlog of queries. However, we recovered back to normal latencies after several minutes.

DNS Records API Latency and Requests during migration
Unfortunately, due to the far-reaching impact that DNS has at Cloudflare, this was not the end of the migration. There were 3 lesser-used services that had slipped by in our scan of services accessing DNS records via cfdb. Fortunately, the setup of the foreign table meant that we could very quickly fix any residual issues by simply changing the table name.
Almost immediately, as expected, we saw a steep drop in usage across cfdb. This freed up a lot of resources for other services to take advantage of.

cfdb usage dropped significantly after the migration period.
Since the migration, the average requests per second to the DNS Records API has more than doubled. At the same time, our CPU usage across both cfdb and dnsdb has settled at below 10% as seen below, giving us room for spikes and future growth.


cfdb and dnsdb CPU usage now
As a result of this improved capacity, our database-related incident rate dropped dramatically.
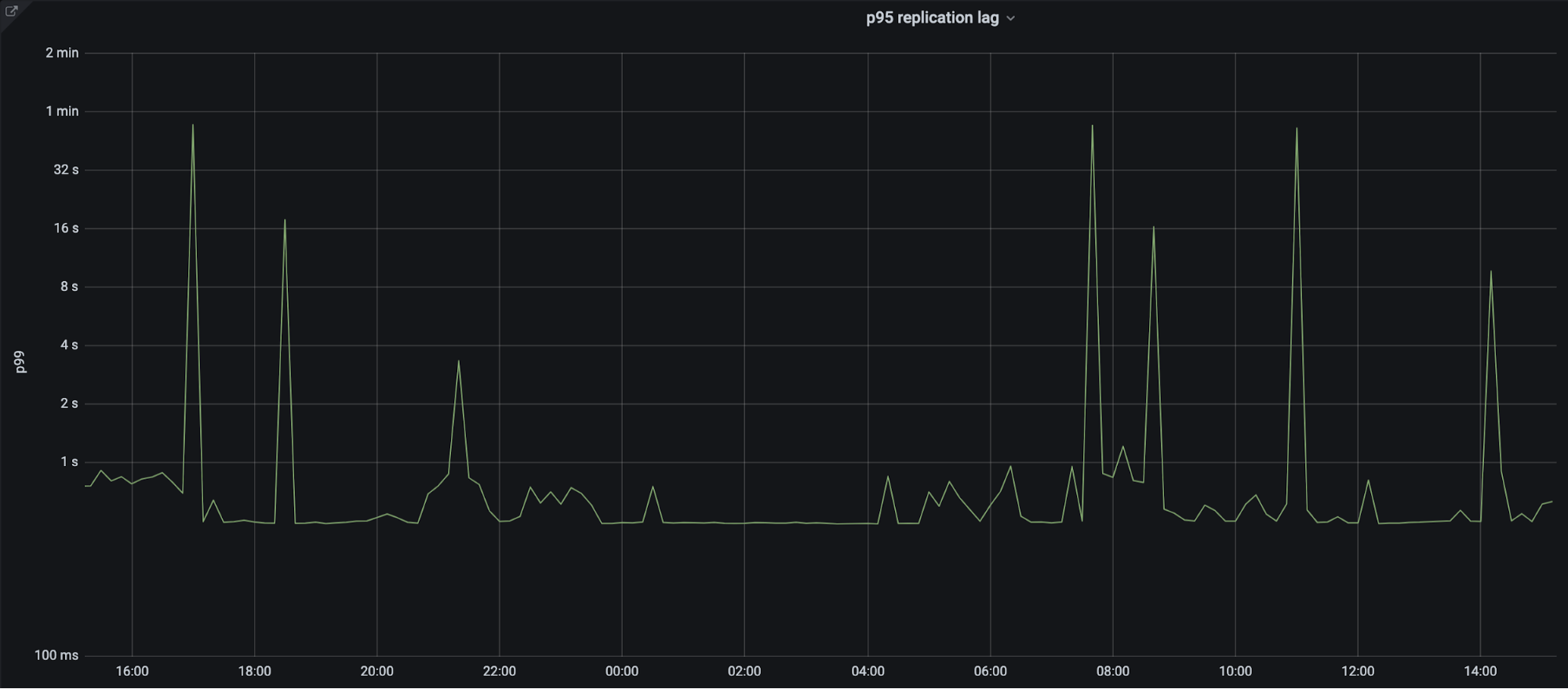
As for query latencies, our latency post-migration is slightly lower on average, with fewer sustained spikes above 500ms. However, the performance improvement is largely noticed during high load periods, when our database handles spikes without significant issues. Many of these spikes come as a result of clients making calls to collect a large amount of DNS records or making several changes to their zone in short bursts. Both of these actions are common use cases for large customers onboarding zones.
In addition to these improvements, the DNS team also has more granular control over dnsdb cluster-specific settings that can be tweaked for our needs rather than catering to all the other services. For example, we were able to make custom changes to replication lag limits to ensure that services using replicas were able to read with some amount of certainty that the data would exist in a consistent form. Measures like this reduce overall load on the primary because almost all read queries can now go to the replicas.
Although this migration was a resounding success, we are always working to improve our systems. As we grow, so do our customers, which means the need to scale never really ends. We have more exciting improvements on the roadmap, and we are looking forward to sharing more details in the future.
The DNS team at Cloudflare isn’t the only team solving challenging problems like the one above. If this sounds interesting to you, we have many more tech deep dives on our blog, and we are always looking for curious engineers to join our team — see open opportunities here.