We’re not burying the lede on this one: you can now connect Cloudflare Workers to your PlanetScale databases directly and ship full-stack applications backed by Postgres or MySQL.
We’ve teamed up with PlanetScale because we wanted to partner with a database provider that we could confidently recommend to our users: one that shares our obsession with performance, reliability and developer experience. These are all critical factors for any development team building a serious application.
Now, when connecting to PlanetScale databases, your connections are automatically configured for optimal performance with Hyperdrive, ensuring that you have the fastest access from your Workers to your databases, regardless of where your Workers are running.
Building full-stack
As Workers has matured into a full-stack platform, we’ve introduced more options to facilitate your connectivity to data. With Workers KV, we made it easy to store configuration and cache unstructured data on the edge. With D1 and Durable Objects, we made it possible to build multi-tenant apps with simple, isolated SQL databases. And with Hyperdrive, we made connecting to external databases fast and scalable from Workers.
Today, we’re introducing a new choice for building on Cloudflare: Postgres and MySQL PlanetScale databases, directly accessible from within the Cloudflare dashboard. Link your Cloudflare and PlanetScale accounts, stop manually copying API keys back-and-forth, and connect Workers to any of your PlanetScale databases (production or otherwise!).
Connect to a PlanetScale database — no figuring things out on your own
Postgres and MySQL are the most popular options for building applications, and with good reason. Many large companies have built and scaled on these databases, providing for a robust ecosystem (like Cloudflare!). And you may want to have access to the power, familiarity, and functionality that these databases provide.
Importantly, all of this builds on Hyperdrive, our distributed connection pooler and query caching infrastructure. Hyperdrive keeps connections to your databases warm to avoid incurring latency penalties for every new request, reduces the CPU load on your database by managing a connection pool, and can cache the results of your most frequent queries, removing load from your database altogether. Given that about 80% of queries for a typical transactional database are read-only, this can be substantial — we’ve observed this in reality!
No more copying credentials around
Starting today, you can connect to your PlanetScale databases from the Cloudflare dashboard in just a few clicks. Connecting is now secure by default with a one-click password rotation option, without needing to copy and manage credentials back and forth. A Hyperdrive configuration will be created for your PlanetScale database, providing you with the optimal setup to start building on Workers.
And the experience spans both Cloudflare and PlanetScale dashboards: you can also create and view attached Hyperdrive configurations for your databases from the PlanetScale dashboard.
By automatically integrating with Hyperdrive, your PlanetScale databases are optimally configured for access from Workers. When you connect your database via Hyperdrive, Hyperdrive’s Placement system automatically determines the location of the database and places its pool of database connections in Cloudflare data centers with the lowest possible latency.
When one of your Workers connects to your Hyperdrive configuration for your PlanetScale database, Hyperdrive will ensure the fastest access to your database by eliminating the unnecessary roundtrips included in a typical database connection setup. Hyperdrive will resolve connection setup within the Hyperdrive client and use existing connections from the pool to quickly serve your queries. Better yet, Hyperdrive allows you to cache your query results in case you need to scale for high-read workloads.
This is a peek under the hood of how Hyperdrive makes access to PlanetScale as fast as possible. We’ve previously blogged about Hyperdrive’s technical underpinnings — it’s worth a read. And with this integration with Hyperdrive, you can easily connect to your databases across different Workers applications or environments, without having to reconfigure your credentials. All in all, a perfect match.
Get started with PlanetScale and Workers
With this partnership, we’re making it trivially easy to build on Workers with PlanetScale. Want to build a new application on Workers that connects to your existing PlanetScale cluster? With just a few clicks, you can create a globally deployed app that can query your database, cache your hottest queries, and keep your database connections warmed for fast access from Workers.
Connect directly to your PlanetScale MySQL or Postgres databases from the Cloudflare dashboard, for optimal configuration with Hyperdrive.
Today, we’re announcing support for MySQL in Cloudflare Workers and Hyperdrive. You can now build applications on Workers that connect to your MySQL databases directly, no matter where they’re hosted, with native MySQL drivers, and with optimal performance.
Connecting to MySQL databases from Workers has been an area we’ve been focusing on for quite some time. We want you to build your apps on Workers with your existing data, even if that data exists in a SQL database in us-east-1. But connecting to traditional SQL databases from Workers has been challenging: it requires making stateful connections to regional databases with drivers that haven’t been designed for the Workers runtime.
After multiple attempts at solving this problem for Postgres, Hyperdrive emerged as our solution that provides the best of both worlds: it supports existing database drivers and libraries while also providing best-in-class performance. And it’s such a critical part of connecting to databases from Workers that we’re making it free (check out the Hyperdrive free tier announcement).
With new Node.js compatibility improvements and Hyperdrive support for the MySQL wire protocol, we’re happy to say MySQL support for Cloudflare Workers has been achieved. If you want to jump into the code and have a MySQL database on hand, this “Deploy to Cloudflare” button will get you setup with a deployed project and will create a repository so you can dig into the code.
Read on to learn more about how we got MySQL to work on Workers, and why Hyperdrive is critical to making connectivity to MySQL databases fast.
Getting MySQL to work on Workers
Until recently, connecting to MySQL databases from Workers was not straightforward. While it’s been possible to make TCP connections from Workers for some time, MySQL drivers had many dependencies on Node.js that weren’t available on the Workers runtime, and that prevented their use.
This led to workarounds being developed. PlanetScale provided a serverless driver for JavaScript, which communicates with PlanetScale servers using HTTP instead of TCP to relay database messages. In a separate effort, a fork of the mysql package was created to polyfill the missing Node.js dependencies and modify the mysql package to work on Workers.
These solutions weren’t perfect. They required using new libraries that either did not provide the level of support expected for production applications, or provided solutions that were limited to certain MySQL hosting providers. They also did not integrate with existing codebases and tooling that depended on the popular MySQL drivers (mysql and mysql2). In our effort to enable all JavaScript developers to build on Workers, we knew that we had to support these drivers.
Improving our Node.js compatibility story was critical to get these MySQL drivers working on our platform. We first identified net and stream as APIs that were needed by both drivers. This, complemented by Workers’ nodejs_compat to resolve unused Node.js dependencies with unenv, enabled the mysql package to work on Workers:
Further work was required to get mysql2 working: dependencies on Node.js timers and the JavaScript eval API remained. While we were able to land support for timers in the Workers runtime, eval was not an API that we could securely enable in the Workers runtime at this time.
mysql2 uses eval to optimize the parsing of MySQL results containing large rows with more than 100 columns (see benchmarks). This blocked the driver from working on Workers, since the Workers runtime does not support this module. Luckily, prior effort existed to get mysql2 working on Workers using static parsers for handling text and binary MySQL data types without using eval(), which provides similar performance for a majority of scenarios.
In mysql2 version 3.13.0, a new option to disable the use of eval() was released to make it possible to use the driver in Cloudflare Workers:
import { createConnection } from 'mysql2/promise';
export default {
async fetch(request, env, ctx): Promise<Response> {
const connection = await createConnection({
host: env.DB_HOST,
user: env.DB_USER,
password: env.DB_PASSWORD,
database: env.DB_NAME,
port: env.DB_PORT
// The following line is needed for mysql2 to work on Workers (as explained above)
// mysql2 uses eval() to optimize result parsing for rows with > 100 columns
// eval() is not available in Workers due to runtime limitations
// Configure mysql2 to use static parsing with disableEval
disableEval: true
});
const [results, fields] = await connection.query(
'SHOW tables;'
);
return new Response(JSON.stringify({ results, fields }), {
headers: {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*',
},
});
},
} satisfies ExportedHandler<Env>;
So, with these efforts, it is now possible to connect to MySQL from Workers. But, getting the MySQL drivers working on Workers was only half of the battle. To make MySQL on Workers performant for production uses, we needed to make it possible to connect to MySQL databases with Hyperdrive.
Supporting MySQL in Hyperdrive
If you’re a MySQL developer, Hyperdrive may be new to you. Hyperdrive solves a core problem: connecting from Workers to regional SQL databases is slow. Database drivers require many roundtrips to establish a connection to a database. Without the ability to reuse these connections between Worker invocations, a lot of unnecessary latency is added to your application.
Hyperdrive solves this problem by pooling connections to your database globally and eliminating unnecessary roundtrips for connection setup. As a plus, Hyperdrive also provides integrated caching to offload popular queries from your database. We wrote an entire deep dive on how Hyperdrive does this, which you should definitely check out.
Getting Hyperdrive to support MySQL was critical for us to be able to say “Connect from Workers to MySQL databases”. That’s easier said than done. To support a new database type, Hyperdrive needs to be able to parse the wire protocol of the database in question, in this case, the MySQL protocol. Once this is accomplished, Hyperdrive can extract queries from protocol messages, cache results across Cloudflare locations, relay messages to a datacenter close to your database, and pool connections reliably close to your origin database.
Adapting Hyperdrive to parse a new language, MySQL protocol, is a challenge in its own right. But it also presented some notable differences with Postgres. While the intricacies are beyond the scope of this post, the differences in MySQL’s authentication plugins across providers and how MySQL’s connection handshake uses capability flags required some adaptation of Hyperdrive. In the end, we leveraged the experience we gained in building Hyperdrive for Postgres to iterate on our support for MySQL. And we’re happy to announce MySQL support is available for Hyperdrive, with all of the performanceimprovements we’ve made to Hyperdrive available from the get-go!
Now, you can create new Hyperdrive configurations for MySQL databases hosted anywhere (we’ve tested MySQL and MariaDB databases from AWS (including AWS Aurora), GCP, Azure, PlanetScale, and self-hosted databases). You can create Hyperdrive configurations for your MySQL databases from the dashboard or the Wrangler CLI:
In your Wrangler configuration file, you’ll need to set your Hyperdrive binding to the ID of the newly created Hyperdrive configuration as well as set Node.js compatibility flags:
From your Cloudflare Worker, the Hyperdrive binding provides you with custom connection credentials that connect to your Hyperdrive configuration. From there onward, all of your queries and database messages will be routed to your origin database by Hyperdrive, leveraging Cloudflare’s network to speed up routing.
import { createConnection } from 'mysql2/promise';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request, env, ctx): Promise<Response> {
// Hyperdrive provides new connection credentials to use with your existing drivers
const connection = await createConnection({
host: env.HYPERDRIVE.host,
user: env.HYPERDRIVE.user,
password: env.HYPERDRIVE.password,
database: env.HYPERDRIVE.database,
port: env.HYPERDRIVE.port,
// Configure mysql2 to use static parsing (as explained above in Part 1)
disableEval: true
});
const [results, fields] = await connection.query(
'SHOW tables;'
);
return new Response(JSON.stringify({ results, fields }), {
headers: {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*',
},
});
},
} satisfies ExportedHandler<Env>;
As you can see from this code snippet, you only need to swap the credentials in your JavaScript code for those provided by Hyperdrive to migrate your existing code to Workers. No need to change the ORMs or drivers you’re using!
Get started building with MySQL and Hyperdrive
MySQL support for Workers and Hyperdrive has been long overdue and we’re excited to see what you build. We published a template for you to get started building your MySQL applications on Workers with Hyperdrive:
As for what’s next, we’re going to continue iterating on our support for MySQL during the beta to support more of the MySQL protocol and MySQL-compatible databases. We’re also going to continue to expand the feature set of Hyperdrive to make it more flexible for your full-stack workloads and more performant for building full-stack global apps on Workers.
Finally, whether you’re using MySQL, PostgreSQL, or any of the other compatible databases, we think you should be using Hyperdrive to get the best performance. And because we want to enable you to build on Workers regardless of your preferred database, we’re making Hyperdrive available to the Workers free plan.
We want to hear your feedback on MySQL, Hyperdrive, and building global applications with Workers. Join the #hyperdrive channel in our Developer Discord to ask questions, share what you’re building, and talk to our Product & Engineering teams directly.
In September 2024, we introduced beta support for hosting, storing, and serving static assets for free on Cloudflare Workers — something that was previously only possible on Cloudflare Pages. Being able to host these assets — your client-side JavaScript, HTML, CSS, fonts, and images — was a critical missing piece for developers looking to build a full-stack application within a single Worker.
Today we’re announcing ten big improvements to building apps on Cloudflare. All together, these new additions allow you to build and host projects ranging from simple static sites to full-stack applications, all on Cloudflare Workers:
You can build complete full-stack apps on Workers without a framework: you can “just use Vite” and React together, and build a backend API in the same Worker. See our Vite + React template for an example.
The Cloudflare Vite plugin is now v1.0 and generally available. The Vite plugin allows you to run Vite’s development server in the Workers runtime (workerd), meaning you get all the benefits of Vite, including Hot Module Replacement, while still being able to use features that are exclusive to Workers (like Durable Objects).
You can now use static _headers and _redirects configuration files for your applications on Workers, something that was previously only available on Pages. These files allow you to add simple headers and configure redirects without executing any Worker code.
In addition to PostgreSQL, you can now connect to MySQL databases in addition from Cloudflare Workers, via Hyperdrive. Bring your existing Planetscale, AWS, GCP, Azure, or other MySQL database, and Hyperdrive will take care of pooling connections to your database and eliminating unnecessary roundtrips by caching queries.
More Node.js APIs are available in the Workers Runtime — including APIs from the crypto, tls, net, and dns modules. We’ve also increased the maximum CPU time for a Workers request from 30 seconds to 5 minutes.
The Images binding in Workers is generally available, allowing you to build more flexible, programmatic workflows.
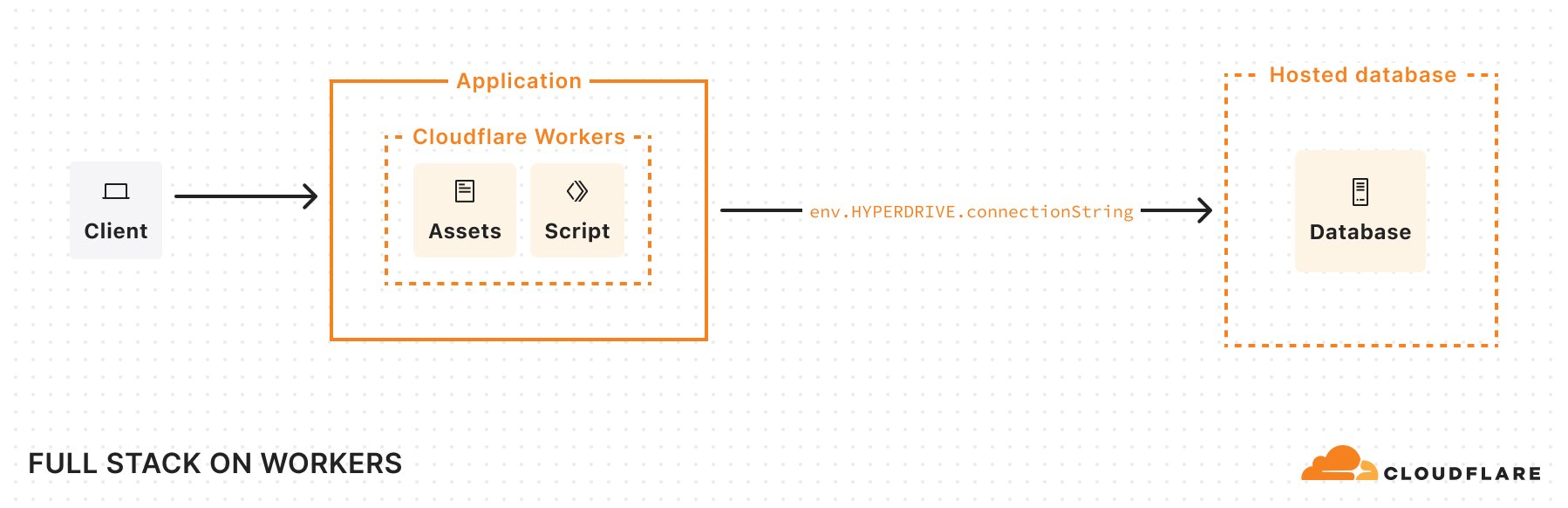
These improvements allow you to build both simple static sites and more complex server-side rendered applications. Like Pages, you only get charged when your Worker code runs, meaning you can host and serve static sites for free. When you want to do any rendering on the server or need to build an API, simply add a Worker to handle your backend. And when you need to read or write data in your app, you can connect to an existing database with Hyperdrive, or use any of our storage solutions: Workers KV, R2, Durable Objects, or D1.
If you’d like to dive straight into code, you can deploy a single-page application built with Vite and React, with the option to connect to a hosted database with Hyperdrive, by clicking this “Deploy to Cloudflare” button:
Start with Workers
Previously, you needed to choose between building on Cloudflare Pages or Workers (or use Pages for one part of your app, and Workers for another) just to get started. This meant figuring out what your app needed from the start, and hoping that if your project evolved, you wouldn’t be stuck with the wrong platform and architecture. Workers was designed to be a flexible platform, allowing developers to evolve projects as needed — and so, we’ve worked to bring pieces of Pages into Workers over the years.
Now that Workers supports both serving static assets and server-side rendering, you should start with Workers. Cloudflare Pages will continue to be supported, but, going forward, all of our investment, optimizations, and feature work will be dedicated to improving Workers. We aim to make Workers the best platform for building full-stack apps, building upon your feedback of what went well with Pages and what we could improve.
Before, building an app on Pages meant you got a really easy, opinionated on-ramp, but you’d eventually hit a wall if your application got more complex. If you wanted to use Durable Objects to manage state, you would need to set up an entirely separate Worker to do so, ending up with a complicated deployment and more overhead. You also were limited to real-time logs, and could only roll out changes all in one go.
When you build on Workers, you can immediately bind to any other Developer Platform service (including Durable Objects, Email Workers, and more), and manage both your front end and back end in a single project — all with a single deployment. You also get the whole suite of Workers observability tooling built into the platform, such as Workers Logs. And if you want to rollout changes to only a certain percentage of traffic, you can do so with Gradual Deployments.
These latest improvements are part of our goal to bring the best parts of Pages into Workers. For example, we now support static _headers and _redirects config files, so that you can easily take an existing project from Pages (or another platform) and move it over to Workers, without needing to change your project. We also directly integrate with GitHub and GitLab with Workers Builds, providing automatic builds and deployments. And starting today, Preview URLs are posted back to your repository as a comment, with feature branch aliases and environments coming soon.
To learn how to migrate an existing project from Pages to Workers, read our migration guide.
Next, let’s talk about how you can build applications with different rendering modes on Workers.
Building static sites, SPAs, and SSR on Workers
As a quick primer, here are all the architectures and rendering modes we’ll be discussing that are supported on Workers:
Static sites: When you visit a static site, the server immediately returns pre-built static assets — HTML, CSS, JavaScript, images, and fonts. There’s no dynamic rendering happening on the server at request-time. Static assets are typically generated at build-time and served directly from a CDN, making static sites fast and easily cacheable. This approach works well for sites with content that rarely changes.
Single-Page Applications (SPAs): When you load an SPA, the server initially sends a minimal HTML shell and a JavaScript bundle (served as static assets). Your browser downloads this JavaScript, which then takes over to render the entire user interface client-side. After the initial load, all navigation occurs without full-page refreshes, typically via client-side routing. This creates a fast, app-like experience.
Server-Side Rendered (SSR) applications: When you first visit a site that uses SSR, the server generates a fully-rendered HTML page on-demand for that request. Your browser immediately displays this complete HTML, resulting in a fast first page load. Once loaded, JavaScript “hydrates” the page, adding interactivity. Subsequent navigations can either trigger new server-rendered pages or, in many modern frameworks, transition into client-side rendering similar to an SPA.
Next, we’ll dive into how you can build these kinds of applications on Workers, starting with setting up your development environment.
Setup: build and dev
Before uploading your application, you need to bundle all of your client-side code into a directory of static assets. Wrangler bundles and builds your code when you run wrangler dev, but we also now support Vite with our new Vite plugin. This is a great option for those already using Vite’s build tooling and development server — you can continue developing (and testing with Vitest) using Vite’s development server, all using the Workers runtime.
To get started using the Cloudflare Vite plugin, you can scaffold a React application using Vite and our plugin, by running:
The Vite plugin informs Wrangler that this /dist directory contains the project’s built static assets — which, in this case, includes client-side code, some CSS files, and images.
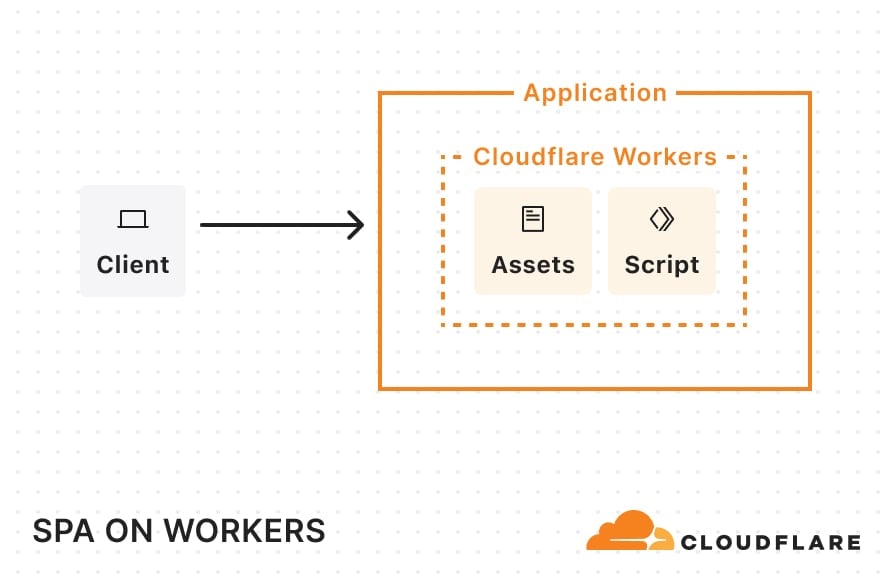
Once deployed, this single-page application (SPA) architecture will look something like this:
When a request comes in, Cloudflare looks at the pathname and automatically serves any static assets that match that pathname. For example, if your static assets directory includes a blog.html file, requests for example.com/blog get that file.
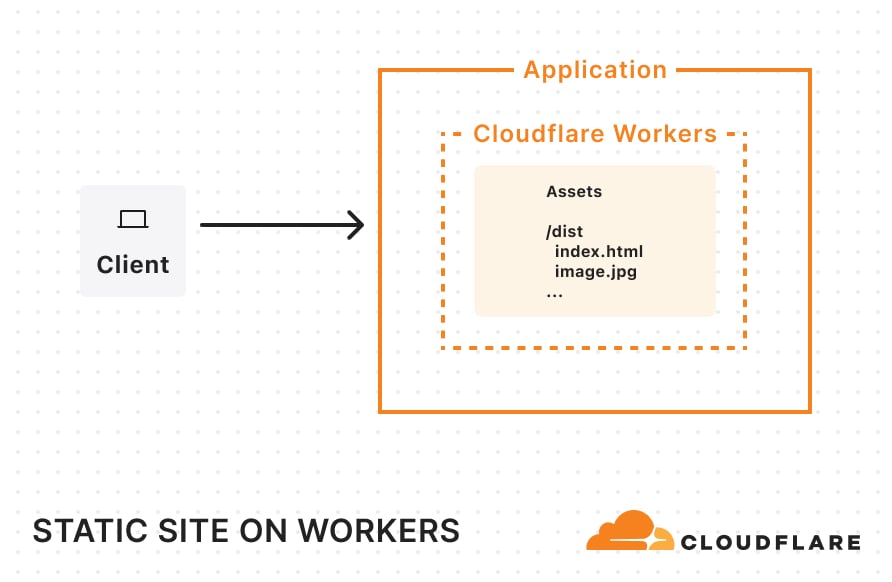
Static sites
If you have a static site created by a static site generator (SSG) like Astro, all you need to do is create a wrangler.jsonc file (or wrangler.toml) and tell Cloudflare where to find your built assets:
Once you’ve added this configuration, you can simply build your project and run wrangler deploy. Your entire site will then be uploaded and ready for traffic on Workers. Once deployed and requests start flowing in, your static site will be cached across Cloudflare’s network.
You can try starting a fresh Astro project on Workers today by running:
By enabling this, the platform assumes that any navigation request (requests which include a Sec-Fetch-Mode: navigate header) are intended for static assets and will serve up index.html whenever a matching static asset match cannot be found. For non-navigation requests (such as requests for data) that don’t match a static asset, Cloudflare will invoke the Worker script. With this setup, you can render the frontend with React, use a Worker to handle back-end operations, and use Vite to help stitch the two together. This is a great option for porting over older SPAs built with create-react-app, which was recently sunset.
Another thing to note in this Wrangler configuration file: we’ve defined a Hyperdrive binding and enabled Smart Placement. Hyperdrive lets us use an existing database and handles connection pooling. This solves a long-standing challenge of connecting Workers (which run in a highly distributed, serverless environment) directly to traditional databases. By design, Workers operate in lightweight V8 isolates with no persistent TCP sockets and a strict CPU/memory limit. This isolation is great for security and speed, but it makes it difficult to hold open database connections. Hyperdrive addresses these constraints by acting as a “bridge” between Cloudflare’s network and your database, taking care of the heavy lifting of maintaining stable connections or pools so that Workers can reuse them. By turning on Smart Placement, we also ensure that if requests to our Worker originate far from the database (causing latency), Cloudflare can choose to relocate both the Worker—which handles the database connection—and the Hyperdrive “bridge” to a location closer to the database, reducing round-trip times.
SPA example: Worker code
Let’s look at the “Deploy to Cloudflare” example at the top of this blog. In api/index.js, we’ve defined an API (using Hono) which connects to a hosted database through Hyperdrive.
import { Hono } from "hono";
import postgres from "postgres";
import booksRouter from "./routes/books";
import bookRelatedRouter from "./routes/book-related";
const app = new Hono();
// Setup SQL client middleware
app.use("*", async (c, next) => {
// Create SQL client
const sql = postgres(c.env.HYPERDRIVE.connectionString, {
max: 5,
fetch_types: false,
});
c.env.SQL = sql;
// Process the request
await next();
// Close the SQL connection after the response is sent
c.executionCtx.waitUntil(sql.end());
});
app.route("/api/books", booksRouter);
app.route("/api/books/:id/related", bookRelatedRouter);
export default {
fetch: app.fetch,
};
When deployed, our app’s architecture looks something like this:
If Smart Placement moves the placement of my Worker to run closer to my database, it could look like this:
Server-Side Rendering (SSR)
If you want to handle rendering on the server, we support a number of popular full-stack frameworks.
Here’s a version of our previous example, now using React Router v7’s server-side rendering:
Deploy to Workers, with as few changes as possible
Node.js compatibility
We’ve also continued to make progress supporting Node.js APIs, recently adding support for the crypto, tls, net, and dns modules. This allows existing applications and libraries that rely on these Node.js modules to run on Workers. Let’s take a look at an example:
Previously, if you tried to use the mongodb package, you encountered the following error:
Error: [unenv] dns.resolveTxt is not implemented yet!
This occurred when mongodb used the node:dns module to do a DNS lookup of a hostname. Even if you avoided that issue, you would have encountered another error when mongodb tried to use node:tls to securely connect to a database.
Now, you can use mongodb as expected because node:dns and node:tls are supported. The same can be said for libraries relying on node:crypto and node:net.
Additionally, Workers now expose environment variables and secrets on the process.env object when the nodejs_compat compatibility flag is on and the compatibility date is set to 2025-04-01 or beyond. Some libraries (and developers) assume that this object will be populated with variables, and rely on it for top-level configuration. Without the tweak, libraries may have previously broken unexpectedly and developers had to write additional logic to handle variables on Cloudflare Workers.
Now, you can just access your variables as you would in Node.js.
We have also raised the maximum CPU time per Worker request from 30 seconds to 5 minutes. This allows for compute-intensive operations to run for longer without timing out. Say you want to use the newly supported node:crypto module to hash a very large file, you can now do this on Workers without having to rely on external compute for CPU-intensive operations.
Workers Builds
We’ve also made improvements to Workers Builds, which allows you to connect a Git repository to your Worker, so that you can have automatic builds and deployments on every pushed change. Workers Builds was introduced during Builder Day 2024, and initially only allowed you to connect a repository to an existing Worker. Now, you can bring a repository and immediately deploy it as a new Worker, reducing the amount of setup and button clicking needed to bring a project over. We’ve improved the performance of Workers Builds by reducing the latency of build starts by 6 seconds — they now start within 10 seconds on average. We also boosted API responsiveness, achieving a 7x latency improvement thanks to Smart Placement.
Note: On April 2, 2025, Workers Builds transitioned to a new pricing model, as announced during Builder Day 2024. Free plan users are now capped at 3,000 minutes of build time, and Workers Paid subscription users will have a new usage-based model with 6,000 free minutes included and $0.005 per build minute pricing after. To better support concurrent builds, Paid plans will also now get six (6) concurrent builds, making it easier to work across multiple projects and monorepos. For more information on pricing, see the documentation.
Last week, we wrote a blog post that covers how the Images binding enables more flexible, programmatic workflows for image optimization.
Previously, you could access image optimization features by calling fetch() in your Worker. This method requires the original image to be retrievable by URL. However, you may have cases where images aren’t accessible from a URL, like when you want to compress user-uploaded images before they are uploaded to your storage. With the Images binding, you can directly optimize an image by operating on its body as a stream of bytes.
We’re excited to see what you’ll build, and are focused on new features and improvements to make it easier to create any application on Workers. Much of this work was made even better by community feedback, and we encourage everyone to join our Discord to participate in the discussion.
In acknowledgement of its pivotal role in building distributed applications that rely on regional databases, we’re making Hyperdrive available on the free plan of Cloudflare Workers!
Hyperdrive enables you to build performant, global apps on Workers with your existing SQL databases. Tell it your database connection string, bring your existing drivers, and Hyperdrive will make connecting to your database faster. No major refactors or convoluted configuration required.
Over the past year, Hyperdrive has become a key service for teams that want to build their applications on Workers and connect to SQL databases. This includes our own engineering teams, with Hyperdrive serving as the tool of choice to connect from Workers to our own Postgres clusters for many of the control-plane actions of our billing, D1, R2, and Workers KV teams (just to name a few).
This has highlighted for us that Hyperdrive is a fundamental building block, and it solves a common class of problems for which there isn’t a great alternative. We want to make it possible for everyone building on Workers to connect to their database of choice with the best performance possible, using the drivers and frameworks they already know and love.
Performance is a feature
To illustrate how much Hyperdrive can improve your application’s performance, let’s write the world’s simplest benchmark. This is obviously not production code, but is meant to be reflective of a common application you’d bring to the Workers platform. We’re going to use a simple table, a very popular OSS driver (postgres.js), and run a standard OLTP workload from a Worker. We’re going to keep our origin database in London, and query it from Chicago (those locations will come back up later, so keep them in mind).
// This is the test table we're using
// CREATE TABLE IF NOT EXISTS test_data(userId bigint, userText text, isActive bool);
import postgres from 'postgres';
let direct_conn = '<direct connection string here!>';
let hyperdrive_conn = env.HYPERDRIVE.connectionString;
async function measureLatency(connString: string) {
let beginTime = Date.now();
let sql = postgres(connString);
await sql`INSERT INTO test_data VALUES (${999}, 'lorem_ipsum', ${true})`;
await sql`SELECT userId, userText, isActive FROM test_data WHERE userId = ${999}`;
let latency = Date.now() - beginTime;
ctx.waitUntil(sql.end());
return latency;
}
let directLatency = await measureLatency(direct_conn);
let hyperdriveLatency = await measureLatency(hyperdrive_conn);
The code above
Takes a standard database connection string, and uses it to create a database connection.
Loads a user record into the database.
Queries all records for that user.
Measures how long this takes to do with a direct connection, and with Hyperdrive.
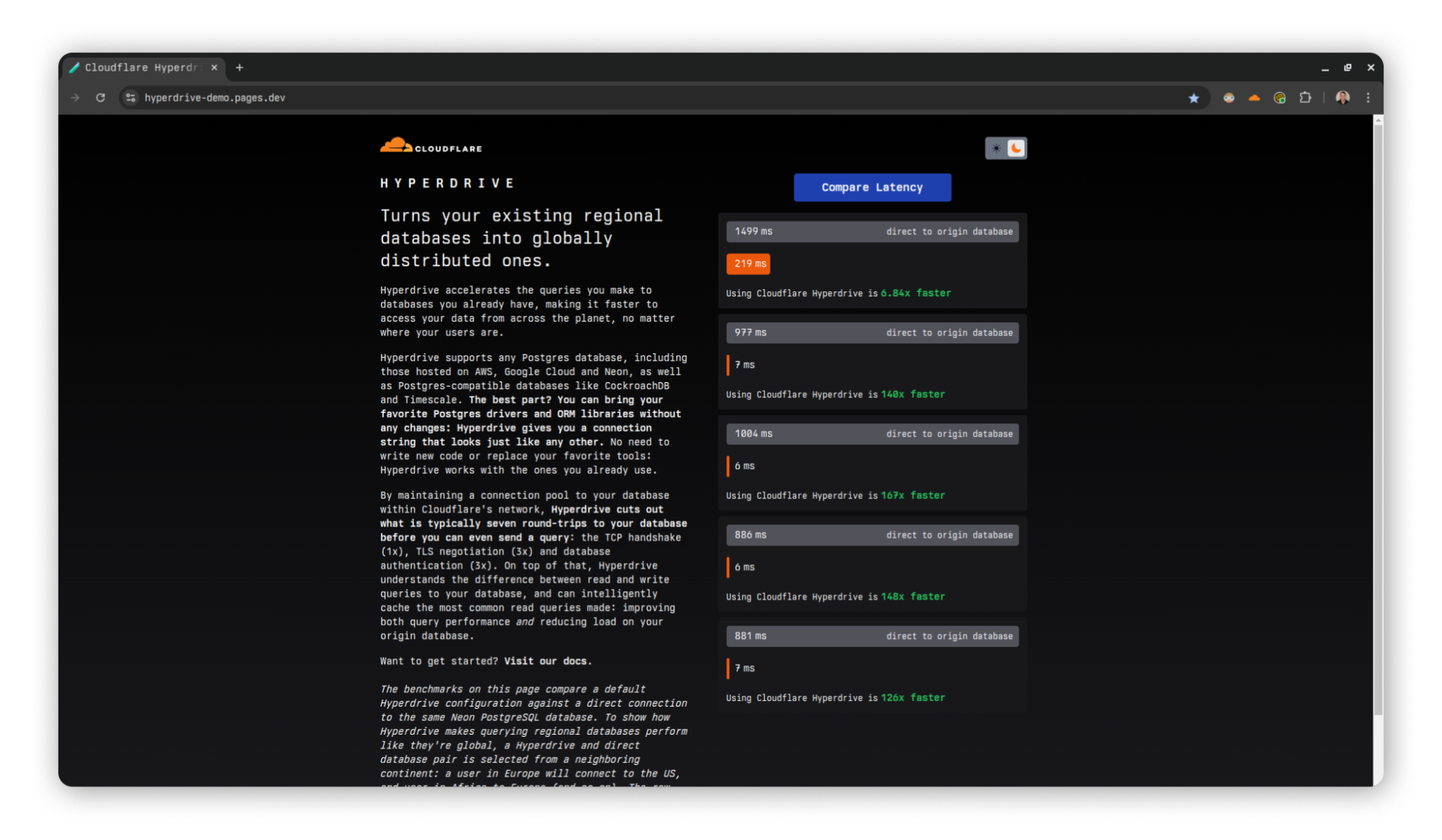
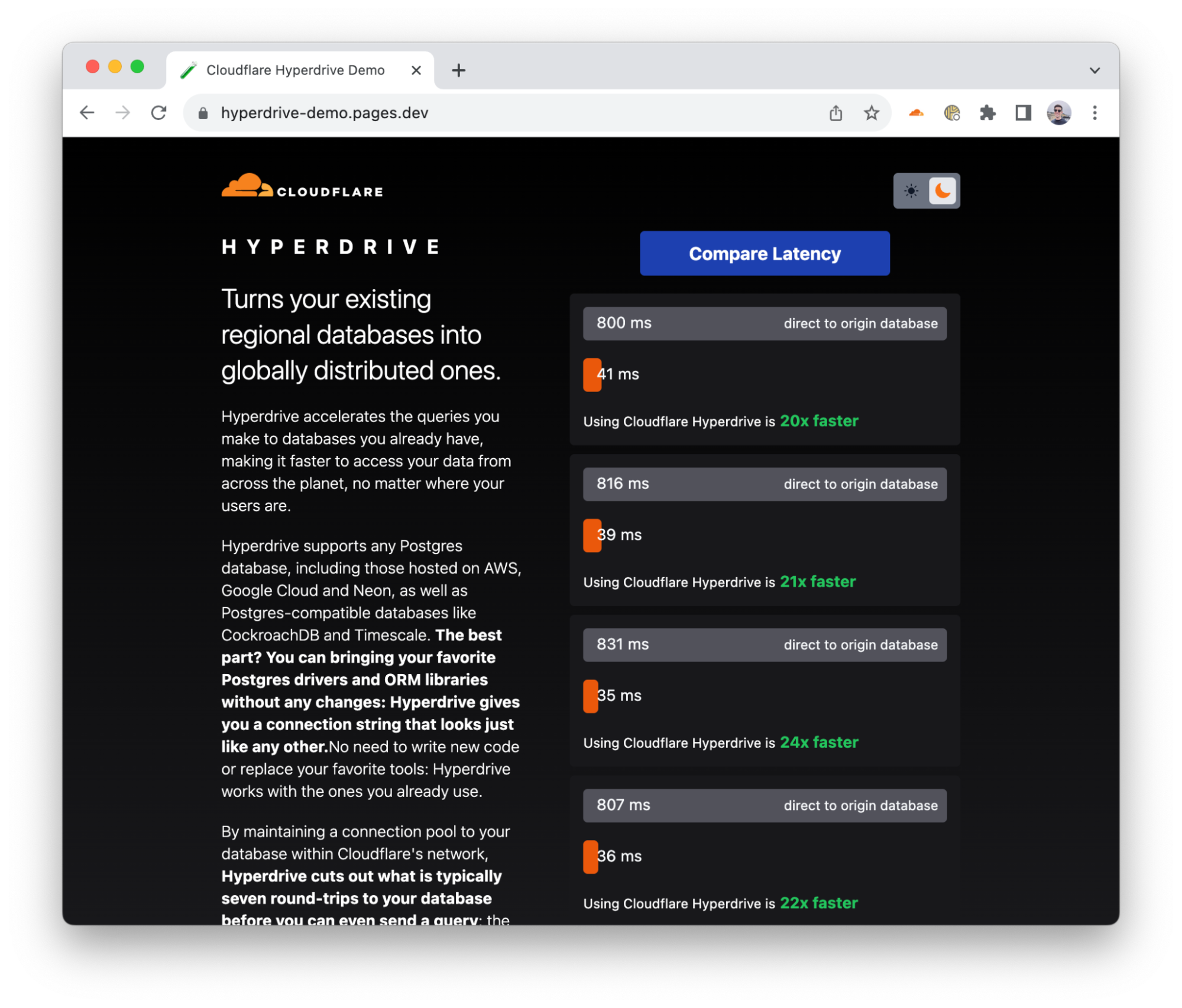
When connecting directly to the origin database, this set of queries takes an average of 1200 ms. With absolutely no other changes, just swapping out the connection string for env.HYPERDRIVE.connectionString, this number is cut down to 500 ms (an almost 60% reduction). If you enable Hyperdrive’s caching, so that the SELECT query is served from cache, this takes only 320 ms. With this one-line change, Hyperdrive will reduce the latency of this Worker by almost 75%! In addition to this speedup, you also get secure auth and transport, as well as a connection pool to help protect your database from being overwhelmed when your usage scales up. See it for yourself using our demo application.
A demo application comparing latencies between Hyperdrive and direct-to-database connections.
Traditional SQL databases are familiar and powerful, but they are designed to be colocated with long-running compute. They were not conceived in the era of modern serverless applications, and have connection models that don’t take the constraints of such an environment into account. Instead, they require highly stateful connections that do not play well with Workers’ global and stateless model. Hyperdrive solves this problem by maintaining database connections across Cloudflare’s network ready to be used at a moment’s notice, caching your queries for fast access, and eliminating round trips to minimize network latency.
With this announcement, many developers are going to be taking a look at Hyperdrive for the first time over the coming weeks and months. To help people dive in and try it out, we think it’s time to talk about how Hyperdrive actually works.
Staying warm in the pool
Let’s talk a bit about database connection poolers, how they work, and what problems they already solve. They are hardly a new technology, after all.
The point of any connection pooler, Hyperdrive or others, is to minimize the overhead of establishing and coordinating database connections. Every new database connection requires additional memory and CPU time from the database server, and this can only scale just so well as the number of concurrent connections climbs. So the question becomes, how should database connections be shared across clients?
Session mode: whenever a client connects, it is assigned a connection of its own until it disconnects. This dramatically reduces the available concurrency, in exchange for much simpler implementation and a broader selection of supported features
Transaction mode: when a client is ready to send a query or open a transaction, it is assigned a connection on which to do so. This connection will be returned to the pool when the query or transaction concludes. Subsequent queries during the same client session may (or may not) be assigned a different connection.
Statement mode: Like transaction mode, but a connection is given out and returned for each statement. Multi-statement transactions are disallowed.
When building Hyperdrive, we had to decide which of these modes we wanted to use. Each of the approaches implies some fairly serious tradeoffs, so what’s the right choice? For a service intended to make using a database from Workers as pleasant as possible we went with the choice that balances features and performance, and designed Hyperdrive as a transaction-mode pooler. This best serves the goals of supporting a large number of short-lived clients (and therefore very high concurrency), while still supporting the transactional semantics that cause so many people to reach for an RDBMS in the first place.
In terms of this part of its design, Hyperdrive takes its cues from many pre-existing popular connection poolers, and manages operations to allow our users to focus on designing their full-stack applications. There is a configured limit to the number of connections the pool will give out, limits to how long a connection will be held idle until it is allowed to drop and return resources to the database, bookkeeping around prepared statements being shared across pooled connections, and other traditional concerns of the management of these resources to help ensure the origin database is able to run smoothly. These are all described in our documentation.
Round and round we go
Ok, so why build Hyperdrive then? Other poolers that solve these problems already exist — couldn’t developers using Workers just run one of those and call it a day? It turns out that connecting to regional poolers from Workers has the same major downside as connecting to regional databases: network latency and round trips.
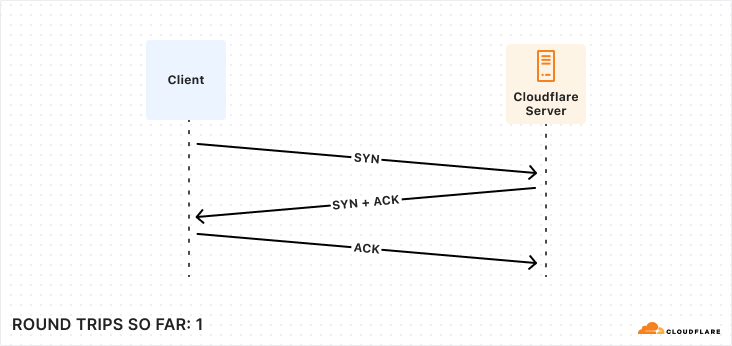
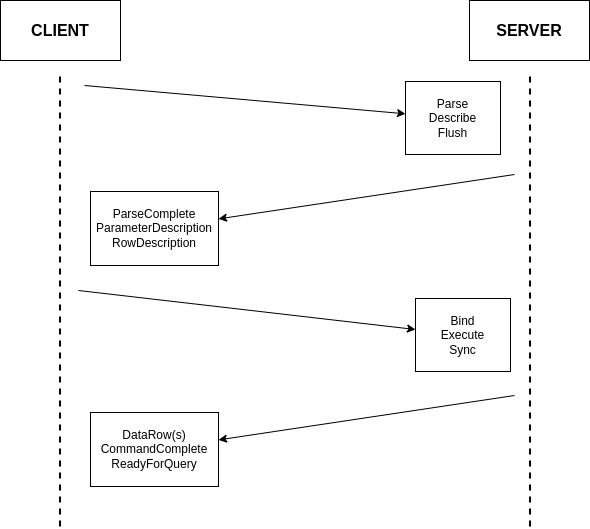
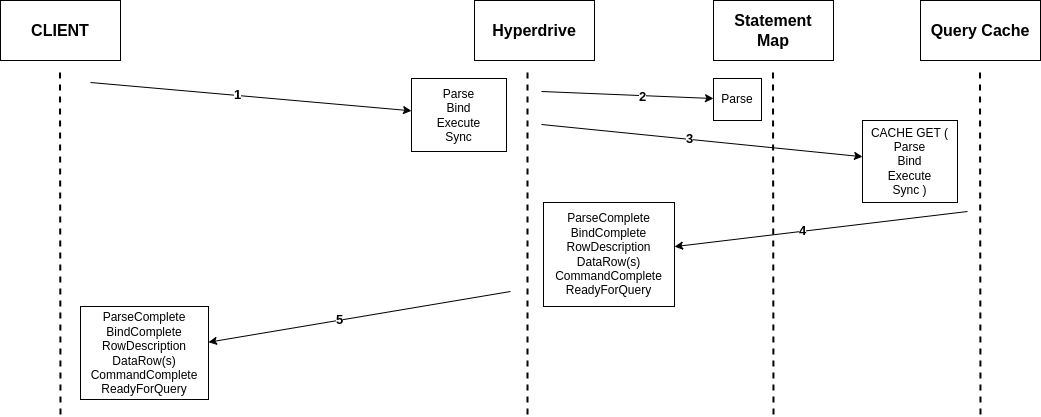
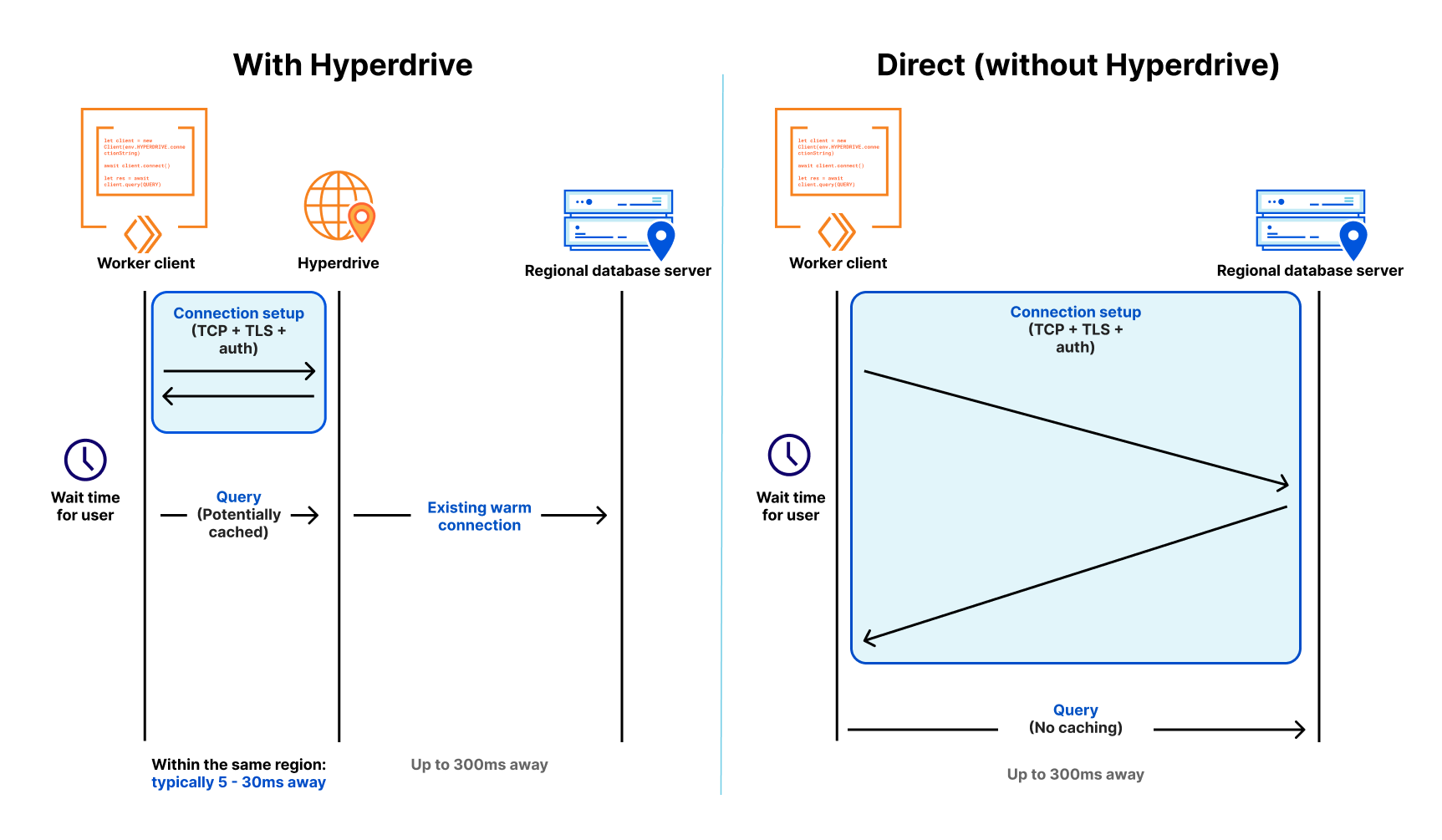
Establishing a connection, whether to a database or a pool, requires many exchanges between the client and server. While this is true for all fully-fledged client-server databases (e.g. MySQL, MongoDB), we are going to focus on the PostgreSQL connection protocol flow in this post. As we work through all of the steps involved, what we most want to keep track of is how many round trips it takes to accomplish. Note that we’re mostly concerned about having to wait around while these happen, so “half” round trips such as in the first diagram are not counted. This is because we can send off the message and then proceed without waiting.
The first step to establishing a connection between Postgres client and server is very familiar ground to anyone who’s worked much with networks: a TCP startup handshake. Postgres uses TCP for its underlying transport, and so we must have that connection before anything else can happen on top of it.
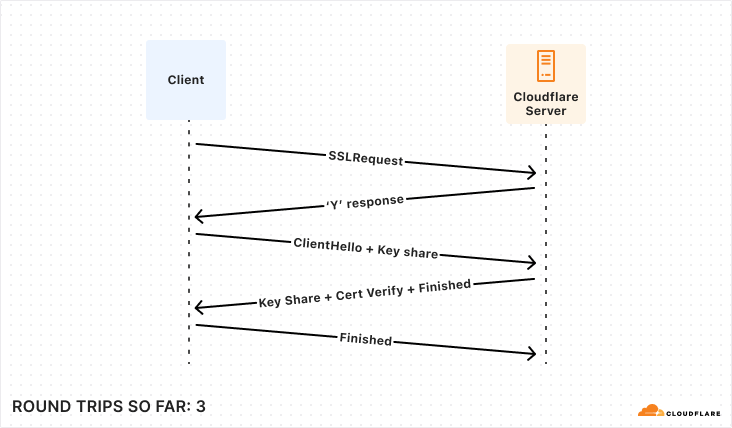
With our transport layer in place, the next step is to encrypt the connection. The TLS Handshake involves some back-and-forth in its own right, though this has been reduced to just one round trip for TLS 1.3. Below is the simplest and fastest version of this exchange, but there are certainly scenarios where it can be much more complex.
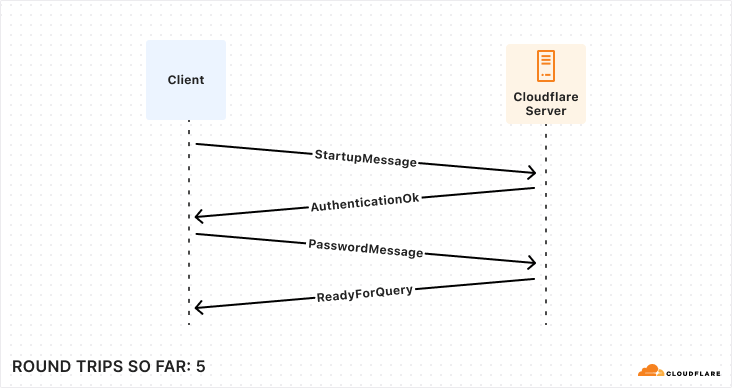
After the underlying transport is established and secured, the application-level traffic can actually start! However, we’re not quite ready for queries, the client still needs to authenticate to a specific user and database. Again, there are multiple supported approaches that offer varying levels of speed and security. To make this comparison as fair as possible, we’re again going to consider the version that offers the fastest startup (password-based authentication).
So, for those keeping score, establishing a new connection to your database takes a bare minimum of 5 round trips, and can very quickly climb from there.
While the latency of any given network round trip is going to vary based on so many factors that “it depends” is the only meaningful measurement available, some quick benchmarking during the writing of this post shows ~125 ms from Chicago to London. Now multiply that number by 5 round trips and the problem becomes evident: 625 ms to start up a connection is not viable in a distributed serverless environment. So how does Hyperdrive solve it? What if I told you the trick is that we do it all twice? To understand Hyperdrive’s secret sauce, we need to dive into Hyperdrive’s architecture.
Impersonating a database server
The rest of this post is a deep dive into answering the question of how Hyperdrive does what it does. To give the clearest picture, we’re going to talk about some internal subsystems by name. To help keep everything straight, let’s start with a short glossary that you can refer back to if needed. These descriptions may not make sense yet, but they will by the end of the article.
Hyperdrive subsystem name
Brief description
Client
Lives on the same server as your Worker, talks directly to your database driver. This caches query results and sends queries to Endpoint if needed.
Endpoint
Lives in the data center nearest to your origin database, talks to your origin database. This caches query results and houses a pool of connections to your origin database.
Edge Validator
Sends a request to a Cloudflare data center to validate that Hyperdrive can connect to your origin database at time of creation.
Placement
Builds on top of Edge Validator to connect to your origin database from all eligible data centers, to identify which have the fastest connections.
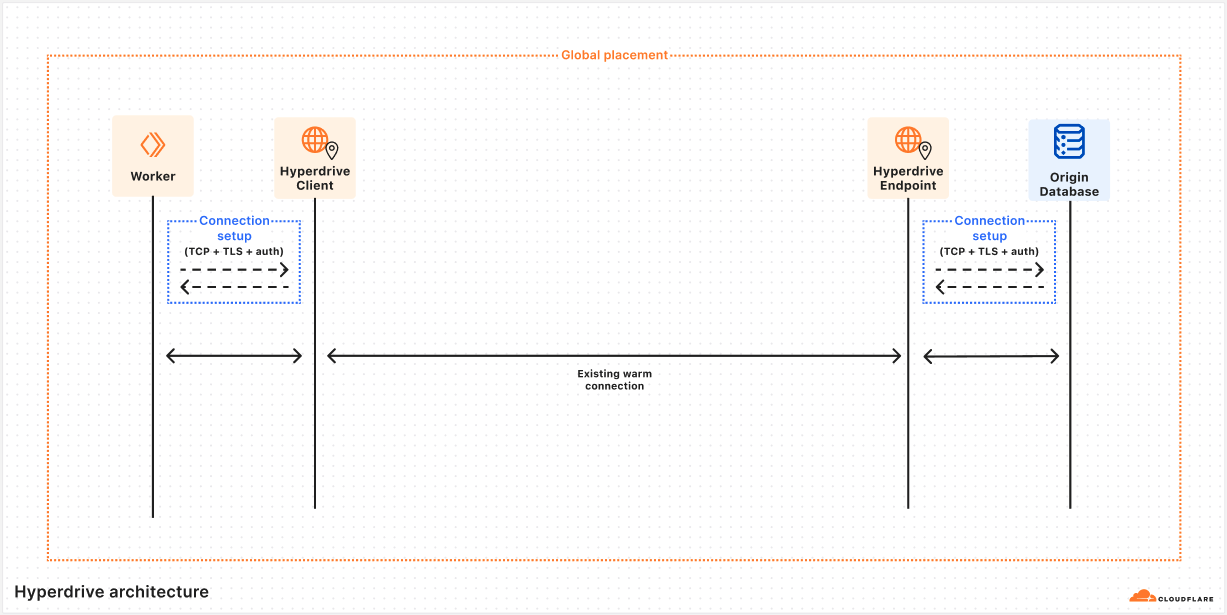
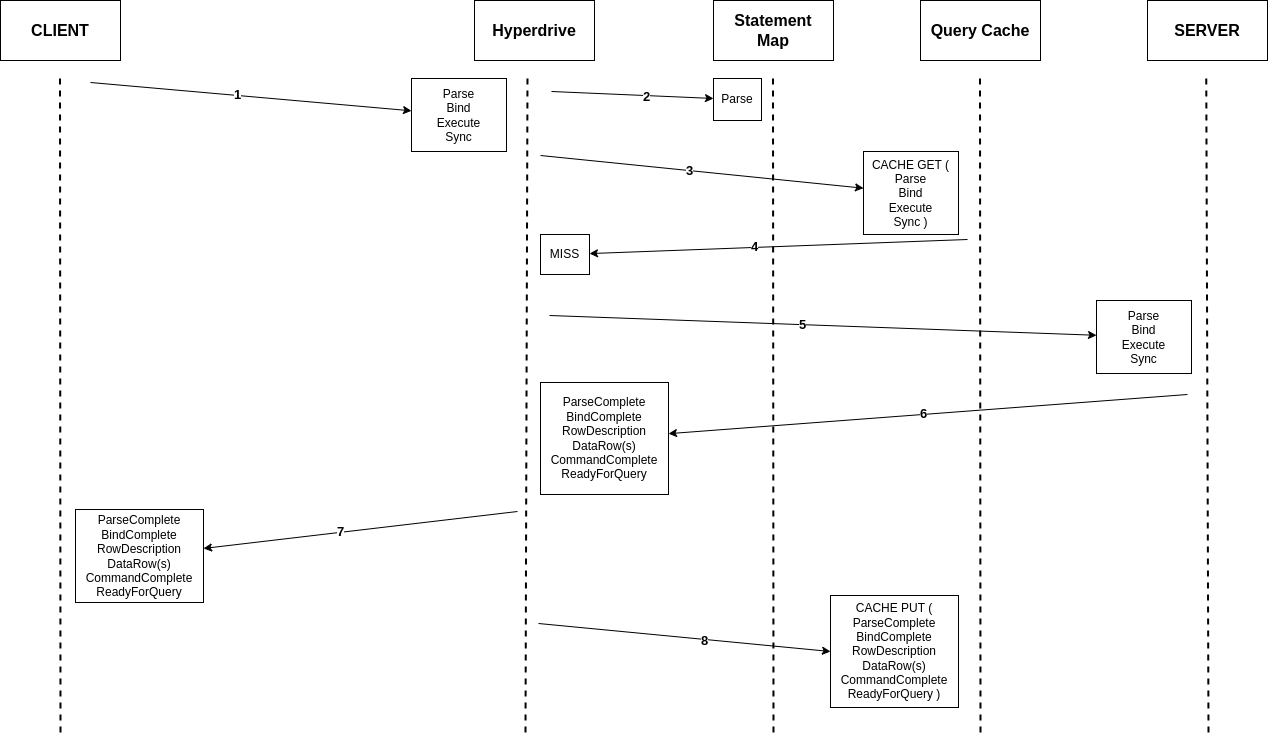
The first subsystem we want to dig into is named Client. Client’s first job is to pretend to be a database server. When a user’s Worker wants to connect to their database via Hyperdrive, they use a special connection string that the Worker runtime generates on the fly. This tells the Worker to reach out to a Hyperdrive process running on the same Cloudflare server, and direct all traffic to and from the database client to it.
import postgres from "postgres";
// Connect to Hyperdrive
const sql = postgres(env.HYPERDRIVE.connectionString);
// sql will now talk over an RPC channel to Hyperdrive, instead of via TCP to Postgres
Once this connection is established, the database driver will perform the usual handshake expected of it, with our Client playing the role of a database server and sending the appropriate responses. All of this happens on the same Cloudflare server running the Worker, and we observe that the p90 for all this is 4 ms (p50 is 2 ms). Quite a bit better than 625 ms, but how does that help? The query still needs to get to the database, right?
Client’s second main job is to inspect the queries sent from a Worker, and decide whether they can be served from Cloudflare’s cache. We’ll talk more about that later on. Assuming that there are no cached query results available, Client will need to reach out to our second important subsystem, which we call Endpoint.
In for the long haul
Before we dig into the role Endpoint plays, it’s worth talking more about how the Client→Endpoint connection works, because it’s a key piece of our solution. We have already talked a lot about the price of network round trips, and how a Worker might be quite far away from the origin database, so how does Hyperdrive handle the long trip from the Client running alongside their Worker to the Endpoint running near their database without expensive round trips?
This is accomplished with a very handy bit of Cloudflare’s networking infrastructure. When Client gets a cache miss, it will submit a request to our networking platform for a connection to whichever data center Endpoint is running on. This platform keeps a pool of ready TCP connections between all of Cloudflare’s data centers, such that we don’t need to do any preliminary handshakes to begin sending application-level traffic. You might say we put a connection pooler in our connection pooler.
Over this TCP connection, we send an initialization message that includes all of the buffered query messages the Worker has sent to Client (the mental model would be something like a SYN and a payload all bundled together). Endpoint will do its job processing this query, and respond by streaming the response back to Client, leaving the streaming channel open for any followup queries until Client disconnects. This approach allows us to send queries around the world with zero wasted round trips.
Impersonating a database client
Endpoint has a couple different jobs it has to do. Its first job is to pretend to be a database client, and to do the client half of the handshake shown above. Second, it must also do the same query processing that Client does with query messages. Finally, Endpoint will make the same determination on when it needs to reach out to the origin database to get uncached query results.
When Endpoint needs to query the origin database, it will attempt to take a connection out of a limited-size pool of database connections that it keeps. If there is an unused connection available, it is handed out from the pool and used to ferry the query to the origin database, and the results back to Endpoint. Once Endpoint has these results, the connection is immediately returned to the pool so that another Client can use it. These warm connections are usable in a matter of microseconds, which is obviously a dramatic improvement over the round trips from one region to another that a cold startup handshake would require.
If there are no currently unused connections sitting in the pool, it may start up a new one (assuming the pool has not already given out as many connections as it is allowed to). This set of handshakes looks exactly the same as the one Client does, but it happens across the network between a Cloudflare data center and wherever the origin database happens to be. These are the same 5 round trips as our original example, but instead of a full Chicago→London path on every single trip, perhaps it’s Virginia→London, or even London→London. Latency here will depend on which data center Endpoint is being housed in.
Distributed choreography
Earlier, we mentioned that Hyperdrive is a transaction-mode pooler. This means that when a driver is ready to send a query or open a transaction it must get a connection from the pool to use. The core challenge for a transaction-mode pooler is in aligning the state of the driver with the state of the connection checked out from the pool. For example, if the driver thinks it’s in a transaction, but the database doesn’t, then you might get errors or even corrupted results.
Hyperdrive achieves this by ensuring all connections are in the same state when they’re checked out of the pool: idle and ready for a query. Where Hyperdrive differs from other transaction-mode poolers is that it does this dance of matching up the states of two different connections across machines, such that there’s no need to share state between Client and Endpoint! Hyperdrive can terminate the incoming connection in Client on the same machine running the Worker, and pool the connections to the origin database wherever makes the most sense.
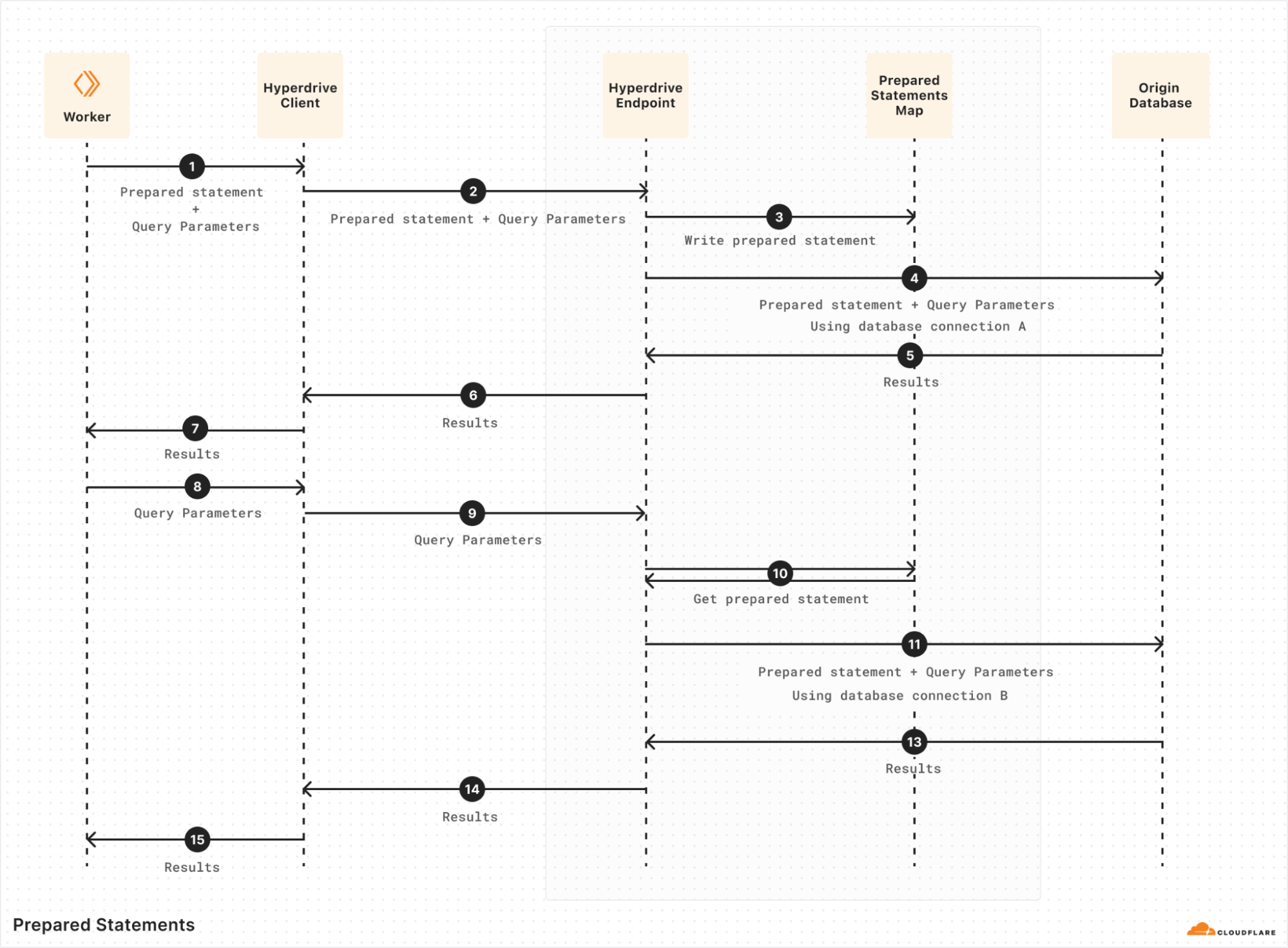
The job of a transaction-mode pooler is a hard one. Database connections are fundamentally stateful and keeping track of that state is important to maintain our guise when impersonating either a database client or a server. As an example, one of the trickier pieces of state to manage are prepared statements. When a user creates a new prepared statement, the prepared statement is only created on whichever database connection happened to be checked out at that time. Once the user finishes the transaction or query they are processing, the connection holding that statement is returned to the pool. From the user’s perspective they’re still connected using the same database connection, so a new query or transaction can reasonably expect to use that previously prepared statement. If a different connection is handed out for the next query and the query wants to make use of this resource, the pooler has to do something about it. We went into some depth on this topic in a previous blog post when we released this feature, but in sum, the process looks like this:
Hyperdrive implements this by keeping track of what statements have been prepared by a given client, as well as what statements have been prepared on each origin connection in the pool. When a query comes in expecting to re-use a particular prepared statement (#8 above), Hyperdrive checks if it’s been prepared on the checked-out origin connection. If it hasn’t, Hyperdrive will replay the wire-protocol message sequence to prepare it on the newly-checked-out origin connection (#10 above) before sending the query over it. Many little corrections like this are necessary to keep the client’s connection to Hyperdrive and Hyperdrive’s connection to the origin database lined up so that both sides see what they expect.
Better, faster, smarter, closer
This “split connection” approach is the founding innovation of Hyperdrive, and one of the most vital aspects of it is how it affects starting up new connections. While the same 5+ round trips must always happen on startup, the actual time spent on the round trips can be dramatically reduced by conducting them over the smallest possible distances. This impact of distance can be so big that there is still a huge latency reduction even though the startup round trips must now happen twice (once each between the Worker and Client, and Endpoint and your origin database). So how do we decide where to run everything, to lean into that advantage as much as possible?
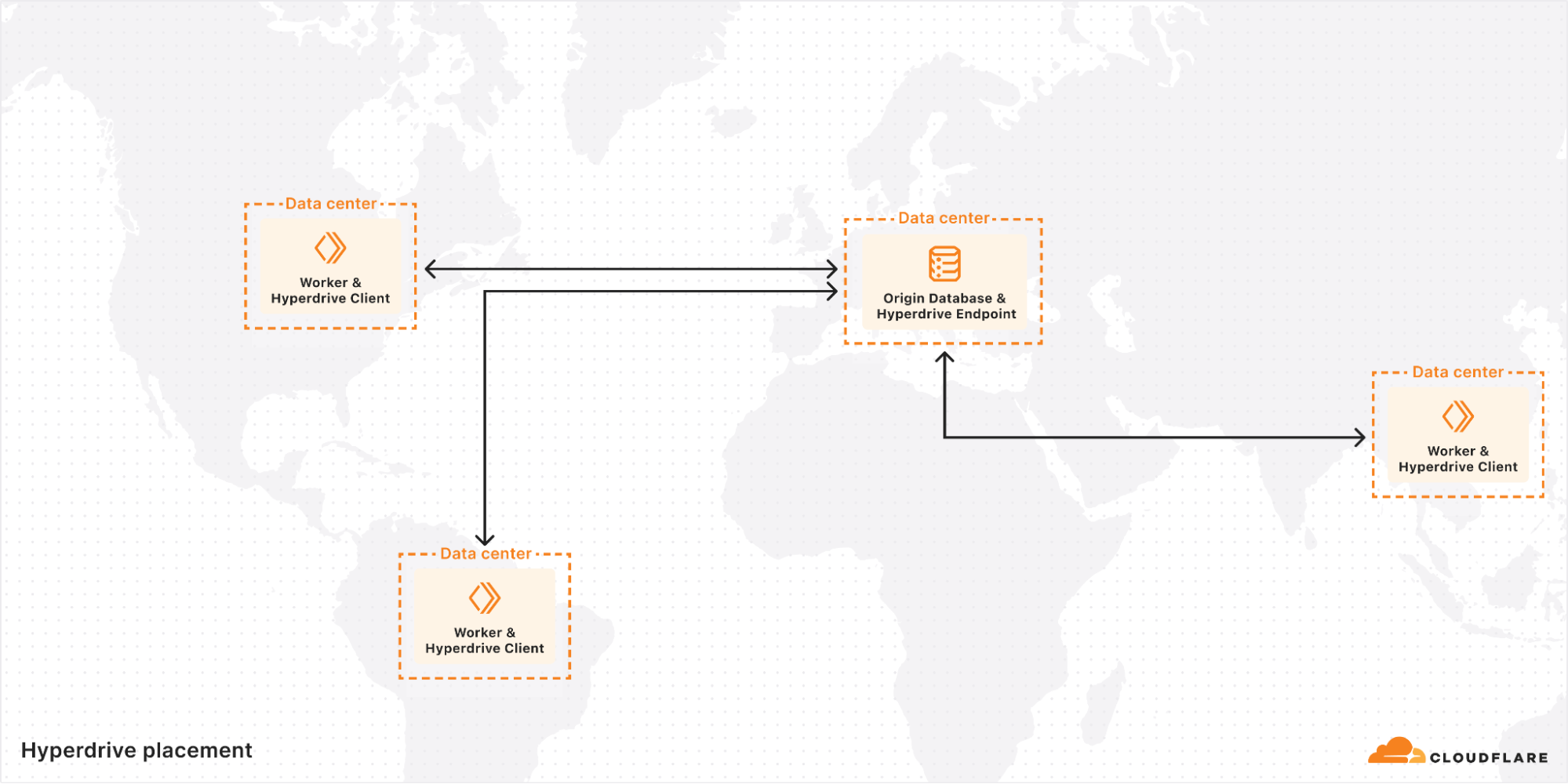
The placement of Client has not really changed since the original design of Hyperdrive. Sharing a server with the Worker sending the queries means that the Worker runtime can connect directly to Hyperdrive with no network hop needed. While there is always room for microoptimizations, it’s hard to do much better than that from an architecture perspective. By far the bigger piece of the latency puzzle is where to run Endpoint.
Hyperdrive keeps a list of data centers that are eligible to house Endpoints, requiring that they have sufficient capacity and the best routes available for pooled connections to use. The key challenge to overcome here is that a database connection string does not tell you where in the world a database actually is. The reality is that reliably going from a hostname to a precise (enough) geographic location is a hard problem, even leaving aside the additional complexity of doing so within a private network. So how do we pick from that list of eligible data centers?
For much of the time since its launch, Hyperdrive solved this with a regional pool approach. When a Worker connected to Hyperdrive, the location of the Worker was used to infer what region the end user was connecting from (e.g. ENAM, WEUR, APAC, etc. — see a rough breakdown here). Data centers to house Endpoints for any given Hyperdrive were deterministically selected from that region’s list of eligible options using rendezvous hashing, resulting in one pool of connections per region.
This approach worked well enough, but it had some severe shortcomings. The first and most obvious is that there’s no guarantee that the data center selected for a given region is actually closer to the origin database than the user making the request. This means that, while you’re getting the benefit of the excellent routing available on Cloudflare’s network, you may be going significantly out of your way to do so. The second downside is that, in the scenario where a new connection must be created, the round trips to do so may be happening over a significantly larger distance than is necessary if the origin database is in a different region than the Endpoint housing the regional connection pool. This increases latency and reduces throughput for the query that needs to instantiate the connection.
The final key downside here is an unfortunate interaction with Smart Placement, a feature of Cloudflare Workers that analyzes the duration of your Worker requests to identify the data center to run your Worker in. With regional Endpoints, the best Smart Placement can possibly do is to put your requests close to the Endpoint for whichever region the origin database is in. Again, there may be other data centers that are closer, but Smart Placement has no way to do better than where the Endpoint is because all Hyperdrive queries must route through it.
We recently shipped some improvements to this system that significantly enhanced performance. The new system discards the concept of regional pools entirely, in favor of a single global Endpoint for each Hyperdrive that is in the eligible data center as close as possible to the origin database.
The way we solved locating the origin database such that we can accomplish this was ultimately very straightforward. We already had a subsystem to confirm, at the time of creation, that Hyperdrive could connect to an origin database using the provided information. We call this subsystem our Edge Validator.
It’s bad user experience to allow someone to create a Hyperdrive, and then find out when they go to use it that they mistyped their password or something. Now they’re stuck trying to debug with extra layers in the way, with a Hyperdrive that can’t possibly work. Instead, whenever a Hyperdrive is created, the Edge Validator will send a request to an arbitrary data center to use its instance of Hyperdrive to connect to the origin database. If this connection fails, the creation of the Hyperdrive will also fail, giving immediate feedback to the user at the time it is most helpful.
With our new subsystem, affectionately called Placement, we now have a solution to the geolocation problem. After Edge Validator has confirmed that the provided information works and the Hyperdrive is created, an extra step is run in the background. Placement will perform the exact same connection routine, except instead of being done once from an arbitrary data center, it is run a handful of times from every single data center that is eligible to house Endpoints. The latency of establishing these connections is collected, and the average is sent back to a central instance of Placement. The data centers that can connect to the origin database the fastest are, by definition, where we want to run Endpoint for this Hyperdrive. The list of these is saved, and at runtime is used to select the Endpoint best suited to housing the pool of connections to the origin database.
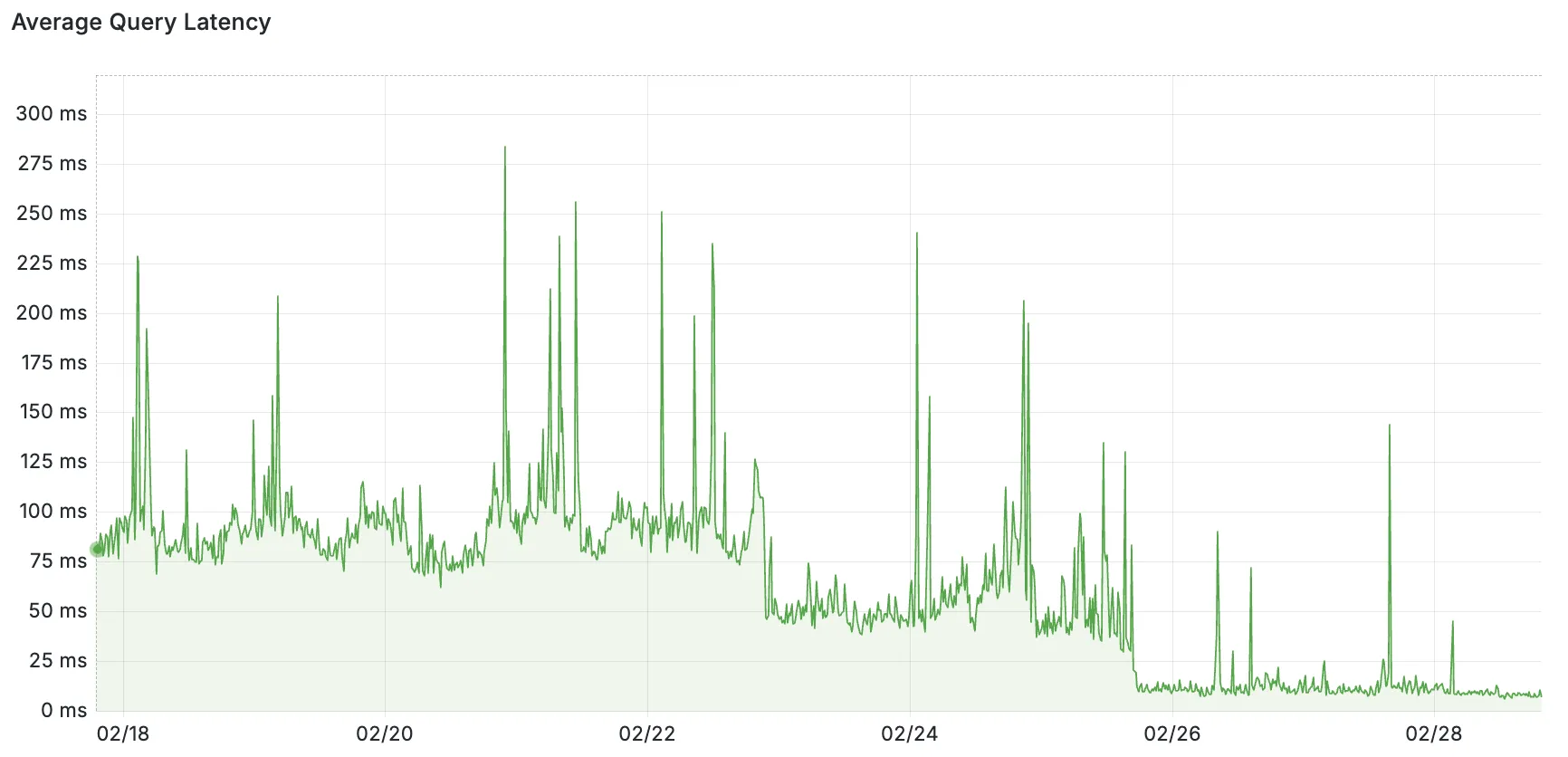
Given that the secret sauce of Hyperdrive is in managing and minimizing the latency of establishing these connections, moving Endpoints right next to their origin databases proved to be pretty impactful.
Pictured: query latency as measured from Endpoint to origin databases. The backfill of Placement to existing customers was done in stages on 02/22 and 02/25.
Serverless drivers exist, though?
While we went in a different direction, it’s worth acknowledging that other teams have solved this same problem with a very different approach. Custom database drivers, usually called “serverless drivers”, have made several optimization efforts to reduce both the number of round trips and how quickly they can be conducted, while still connecting directly from your client to your database in the traditional way. While these drivers are impressive, we chose not to go this route for a couple of reasons.
First off, a big part of the appeal of using Postgres is its vibrant ecosystem. Odds are good you’ve used Postgres before, and it can probably help solve whichever problem you’re tackling with your newest project. This familiarity and shared knowledge across projects is an absolute superpower. We wanted to lean into this advantage by supporting the most popular drivers already in this ecosystem, instead of fragmenting it by adding a competing one.
Second, Hyperdrive also functions as a cache for individual queries (a bit of trivia: its name while still in Alpha was actually sql-query-cache). Doing this as effectively as possible for distributed users requires some clever positioning of where exactly the query results should be cached. One of the unique advantages of running a distributed service on Cloudflare’s network is that we have a lot of flexibility on where to run things, and can confidently surmount challenges like those. If we’re going to be playing three-card monte with where things are happening anyway, it makes the most sense to favor that route for solving the other problems we’re trying to tackle too.
Pick your favorite cache pun
As we’ve talked about in the past, Hyperdrive buffers protocol messages until it has enough information to know whether a query can be served from cache. In a post about how Hyperdrive works it would be a shame to skip talking about how exactly we cache query results, so let’s close by diving into that.
First and foremost, Hyperdrive uses Cloudflare’s cache, because when you have technology like that already available to you, it’d be silly not to use it. This has some implications for our architecture that are worth exploring.
The cache exists in each of Cloudflare’s data centers, and by default these are separate instances. That means that a Client operating close to the user has one, and an Endpoint operating close to the origin database has one. However, historically we weren’t able to take full advantage of that, because the logic for interacting with cache was tightly bound to the logic for managing the pool of connections.
Part of our recent architecture refactoring effort, where we switched to global Endpoints, was to split up this logic such that we can take advantage of Client’s cache too. This was necessary because, with Endpoint moving to a single location for each Hyperdrive, users from other regions would otherwise have gotten cache hits served from almost as far away as the origin.
With the new architecture, the role of Client during active query handling transitioned from that of a “dumb pipe” to more like what Endpoint had always been doing. It now buffers protocol messages, and serves results from cache if possible. In those scenarios, Hyperdrive’s traffic never leaves the data center that the Worker is running in, reducing query latencies from 20-70 ms to an average of around 4 ms. As a side benefit, it also substantially reduces the network bandwidth Hyperdrive uses to serve these queries. A win-win!
In the scenarios where query results can’t be served from the cache in Client’s data center, all is still not lost. Endpoint may also have cached results for this query, because it can field traffic from many different Clients around the world. If so, it will provide these results back to Client, along with how much time is remaining before they expire, such that Client can both return them and store them correctly into its own cache. Likewise, if Endpoint does need to go to the origin database for results, they will be stored into both Client and Endpoint caches. This ensures that followup queries from that same Client data center will get the happy path with single-digit ms response times, and also reduce load on the origin database from any other Client’s queries. This functions similarly to how Cloudflare’s Tiered Cache works, with Endpoint’s cache functioning as a final layer of shielding for the origin database.
Come on in, the water’s fine!
With this announcement of a Free Plan for Hyperdrive, and newly armed with the knowledge of how it works under the hood, we hope you’ll enjoy building your next project with it! You can get started with a single Wrangler command (or using the dashboard):
We’ve also included a Deploy to Cloudflare button below to let you get started with a sample Worker app using Hyperdrive, just bring your existing Postgres database! If you have any questions or ideas for future improvements, please feel free to visit our Discord channel!
With September’s announcement of Hyperdrive’s ability to send database traffic from Workers over Cloudflare Tunnels, we wanted to dive into the details of what it took to make this happen.
Hyper-who?
Accessing your data from anywhere in Region Earth can be hard. Traditional databases are powerful, familiar, and feature-rich, but your users can be thousands of miles away from your database. This can cause slower connection startup times, slower queries, and connection exhaustion as everything takes longer to accomplish.
Cloudflare Workers is an incredibly lightweight runtime, which enables our customers to deploy their applications globally by default and renders the cold start problem almost irrelevant. The trade-off for these light, ephemeral execution contexts is the lack of persistence for things like database connections. Database connections are also notoriously expensive to spin up, with many round trips required between client and server before any query or result bytes can be exchanged.
Hyperdrive is designed to make the centralized databases you already have feel like they’re global while keeping connections to those databases hot. We use our global network to get faster routes to your database, keep connection pools primed, and cache your most frequently run queries as close to users as possible.
Why a Tunnel?
For something as sensitive as your database, exposing access to the public Internet can be uncomfortable. It is common to instead host your database on a private network, and allowlist known-safe IP addresses or configure GRE tunnels to permit traffic to it. This is complex, toilsome, and error-prone.
On Cloudflare’s Developer Platform, we strive for simplicity and ease-of-use. We cannot expect all of our customers to be experts in configuring networking solutions, and so we went in search of a simpler solution. Being your own customer is rarely a bad choice, and it so happens that Cloudflare offers an excellent option for this scenario: Tunnels.
Integrating with Tunnels to support sending Postgres directly through them was a bit of a new challenge for us. Most of the time, when we use Tunnels internally (more on that later!), we rely on the excellent job cloudflared does of handling all of the mechanics, and we just treat them as pipes. That wouldn’t work for Hyperdrive, though, so we had to dig into how Tunnels actually ingress traffic to build a solution.
Hyperdrive handles Postgres traffic using an entirely custom implementation of the Postgres message protocol. This is necessary, because we sometimes have to alter the specific type or content of messages sent from client to server, or vice versa. Handling individual bytes gives us the flexibility to implement whatever logic any new feature might need.
An additional, perhaps less obvious, benefit of handling Postgres message traffic as just bytes is that we are not bound to the transport layer choices of some ORM or library. One of the nuances of running services in Cloudflare is that we may want to egress traffic over different services or protocols, for a variety of different reasons. In this case, being able to egress traffic via a Tunnel would be pretty challenging if we were stuck with whatever raw TCP socket a library had established for us.
The way we accomplish this relies on a mainstay of Rust: traits (which are how Rust lets developers apply logic across generic functions and types). In the Rust ecosystem, there are two traits that define the behavior Hyperdrive wants out of its transport layers: AsyncRead and AsyncWrite. There are a couple of others we also need, but we’re going to focus on just these two. These traits enable us to code our entire custom handler against a generic stream of data, without the handler needing to know anything about the underlying protocol used to implement the stream. So, we can pass around a WebSocket connection as a generic I/O stream, wherever it might be needed.
As an example, the code to create a generic TCP stream and send a Postgres startup message across it might look like this:
/// Send a startup message to a Postgres server, in the role of a PG client.
/// https://www.postgresql.org/docs/current/protocol-message-formats.html#PROTOCOL-MESSAGE-FORMATS-STARTUPMESSAGE
pub async fn send_startup<S>(stream: &mut S, user_name: &str, db_name: &str, app_name: &str) -> Result<(), ConnectionError>
where
S: AsyncWrite + Unpin,
{
let protocol_number = 196608 as i32;
let user_str = &b"user\0"[..];
let user_bytes = user_name.as_bytes();
let db_str = &b"database\0"[..];
let db_bytes = db_name.as_bytes();
let app_str = &b"application_name\0"[..];
let app_bytes = app_name.as_bytes();
let len = 4 + 4
+ user_str.len() + user_bytes.len() + 1
+ db_str.len() + db_bytes.len() + 1
+ app_str.len() + app_bytes.len() + 1 + 1;
// Construct a BytesMut of our startup message, then send it
let mut startup_message = BytesMut::with_capacity(len as usize);
startup_message.put_i32(len as i32);
startup_message.put_i32(protocol_number);
startup_message.put(user_str);
startup_message.put_slice(user_bytes);
startup_message.put_u8(0);
startup_message.put(db_str);
startup_message.put_slice(db_bytes);
startup_message.put_u8(0);
startup_message.put(app_str);
startup_message.put_slice(app_bytes);
startup_message.put_u8(0);
startup_message.put_u8(0);
match stream.write_all(&startup_message).await {
Ok(_) => Ok(()),
Err(err) => {
error!("Error writing startup to server: {}", err.to_string());
ConnectionError::InternalError
}
}
}
/// Connect to a TCP socket
let stream = match TcpStream::connect(("localhost", 5432)).await {
Ok(s) => s,
Err(err) => {
error!("Error connecting to address: {}", err.to_string());
return ConnectionError::InternalError;
}
};
let _ = send_startup(&mut stream, "db_user", "my_db").await;
With this approach, if we wanted to encrypt the stream using TLS before we write to it (upgrading our existing TcpStream connection in-place, to an SslStream), we would only have to change the code we use to create the stream, while generating and sending the traffic would remain unchanged. This is because SslStream also implements AsyncWrite!
/// We're handwaving the SSL setup here. You're welcome.
let conn_config = new_tls_client_config()?;
/// Encrypt the TcpStream, returning an SslStream
let ssl_stream = match tokio_boring::connect(conn_config, domain, stream).await {
Ok(s) => s,
Err(err) => {
error!("Error during websocket TLS handshake: {}", err.to_string());
return ConnectionError::InternalError;
}
};
let _ = send_startup(&mut ssl_stream, "db_user", "my_db").await;
Whence WebSocket
WebSocket is an application layer protocol that enables bidirectional communication between a client and server. Typically, to establish a WebSocket connection, a client initiates an HTTP request and indicates they wish to upgrade the connection to WebSocket via the “Upgrade” header. Then, once the client and server complete the handshake, both parties can send messages over the connection until one of them terminates it.
Now, it turns out that the way Cloudflare Tunnels work under the hood is that both ends of the tunnel want to speak WebSocket, and rely on a translation layer to convert all traffic to or from WebSocket. The cloudflared daemon you spin up within your private network handles this for us! For Hyperdrive, however, we did not have a suitable translation layer to send Postgres messages across WebSocket, and had to write one.
One of the (many) fantastic things about Rust traits is that the contract they present is very clear. To be AsyncRead, you just need to implement poll_read. To be AsyncWrite, you need to implement only three functions (poll_write, poll_flush, and poll_shutdown). Further, there is excellent support for WebSocket in Rust built on top of the tungstenite-rs library.
Thus, building our custom WebSocket stream such that it can share the same machinery as all our other generic streams just means translating the existing WebSocket support into these poll functions. There are some existing OSS projects that do this, but for multiple reasons we could not use the existing options. The primary reason is that Hyperdrive operates across multiple threads (thanks to the tokio runtime), and so we rely on our connections to also handle Send, Sync, and Unpin. None of the available solutions had all five traits handled. It turns out that most of them went with the paradigm of Sink and Stream, which provide a solid base from which to translate to AsyncRead and AsyncWrite. In fact some of the functions overlap, and can be passed through almost unchanged. For example, poll_flush and poll_shutdown have 1-to-1 analogs, and require almost no engineering effort to convert from Sink to AsyncWrite.
/// We use this struct to implement the traits we need on top of a WebSocketStream
pub struct HyperSocket<S>
where
S: AsyncRead + AsyncWrite + Send + Sync + Unpin,
{
inner: WebSocketStream<S>,
read_state: Option<ReadState>,
write_err: Option<Error>,
}
impl<S> AsyncWrite for HyperSocket<S>
where
S: AsyncRead + AsyncWrite + Send + Sync + Unpin,
{
fn poll_flush(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<io::Result<()>> {
match ready!(Pin::new(&mut self.inner).poll_flush(cx)) {
Ok(_) => Poll::Ready(Ok(())),
Err(err) => Poll::Ready(Err(Error::new(ErrorKind::Other, err))),
}
}
fn poll_shutdown(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<io::Result<()>> {
match ready!(Pin::new(&mut self.inner).poll_close(cx)) {
Ok(_) => Poll::Ready(Ok(())),
Err(err) => Poll::Ready(Err(Error::new(ErrorKind::Other, err))),
}
}
}
With that translation done, we can use an existing WebSocket library to upgrade our SslStream connection to a Cloudflare Tunnel, and wrap the result in our AsyncRead/AsyncWrite implementation. The result can then be used anywhere that our other transport streams would work, without any changes needed to the rest of our codebase!
That would look something like this:
let websocket = match tokio_tungstenite::client_async(request, ssl_stream).await {
Ok(ws) => Ok(ws),
Err(err) => {
error!("Error during websocket conn setup: {}", err.to_string());
return ConnectionError::InternalError;
}
};
let websocket_stream = HyperSocket::new(websocket));
let _ = send_startup(&mut websocket_stream, "db_user", "my_db").await;
Access granted
An observant reader might have noticed that in the code example above we snuck in a variable named request that we passed in when upgrading from an SslStream to a WebSocketStream. This is for multiple reasons. The first reason is that Tunnels are assigned a hostname and use this hostname for routing. The second and more interesting reason is that (as mentioned above) when negotiating an upgrade from HTTP to WebSocket, a request must be sent to the server hosting the ingress side of the Tunnel to perform the upgrade. This is pretty universal, but we also add in an extra piece here.
At Cloudflare, we believe that secure defaults and defense in depth are the correct ways to build a better Internet. This is why traffic across Tunnels is encrypted, for example. However, that does not necessarily prevent unwanted traffic from being sent into your Tunnel, and therefore egressing out to your database. While Postgres offers a robust set of access control options for protecting your database, wouldn’t it be best if unwanted traffic never got into your private network in the first place?
To that end, all Tunnels set up for use with Hyperdrive should have a Zero Trust Access Application configured to protect them. These applications should use a Service Token to authorize connections. When setting up a new Hyperdrive, you have the option to provide the token’s ID and Secret, which will be encrypted and stored alongside the rest of your configuration. These will be presented as part of the WebSocket upgrade request to authorize the connection, allowing your database traffic through while preventing unwanted access.
This can be done within the request’s headers, and might look something like this:
let ws_url = format!("wss://{}", host);
let mut request = match ws_url.into_client_request() {
Ok(req) => req,
Err(err) => {
error!(
"Hostname {} could not be parsed into a valid request URL: {}",
host,
err.to_string()
);
return ConnectionError::InternalError;
}
};
request.headers_mut().insert(
"CF-Access-Client-Id",
http::header::HeaderValue::from_str(&client_id).unwrap(),
);
request.headers_mut().insert(
"CF-Access-Client-Secret",
http::header::HeaderValue::from_str(&client_secret).unwrap(),
);
Building for customer zero
If you’ve been reading the blog for a long time, some of this might sound a bit familiar. This isn’t the first time that we’ve sent Postgres traffic across a tunnel, it’s something most of us do from our laptops regularly. This works very well for interactive use cases with low traffic volume and a high tolerance for latency, but historically most of our products have not been able to employ the same approach.
Cloudflare operates many data centers around the world, and most services run in every one of those data centers. There are some tasks, however, that make the most sense to run in a more centralized fashion. These include tasks such as managing control plane operations, or storing configuration state. Nearly every Cloudflare product houses its control plane information in Postgres clusters run centrally in a handful of our data centers, and we use a variety of approaches for accessing that centralized data from elsewhere in our network. For example, many services currently use a push-based model to publish updates to Quicksilver, and work through the complexities implied by such a model. This has been a recurring challenge for any team looking to build a new product.
Hyperdrive’s entire reason for being is to make it easy to access such central databases from our global network. When we began exploring Tunnel integrations as a feature, many internal teams spoke up immediately and strongly suggested they’d be interested in using it themselves. This was an excellent opportunity for Cloudflare to scratch its own itch, while also getting a lot of traffic on a new feature before releasing it directly to the public. As always, being “customer zero” means that we get fast feedback, more reliability over time, stronger connections between teams, and an overall better suite of products. We jumped at the chance.
As we rolled out early versions of Tunnel integration, we worked closely with internal teams to get them access to it, and fixed any rough spots they encountered. We’re pleased to share that this first batch of teams have found great success building new or refactored products on Hyperdrive over Tunnels. For example: if you’ve already tried out Workers Builds, or recently submitted an abuse report, you’re among our first users! At the time of this writing, we have several more internal teams working to onboard, and we on the Hyperdrive team are very excited to see all the different ways in which fast and simple connections from Workers to a centralized database can help Cloudflare just as much as they’ve been helping our external customers.
Outro
Cloudflare is on a mission to make the Internet faster, safer, and more reliable. Hyperdrive was built to make connecting to centralized databases from the Workers runtime as quick and consistent as possible, and this latest development is designed to help all those who want to use Hyperdrive without directly exposing resources within their virtual private clouds (VPCs) on the public web.
To this end, we chose to build a solution around our suite of industry-leading Zero Trust tools, and were delighted to find how simple it was to implement in our runtime given the power and extensibility of the Rust trait system.
Without waiting for the ink to dry, multiple teams within Cloudflare have adopted this new feature to quickly and easily solve what have historically been complex challenges, and are happily operating it in production today.
Hyperdrive (Cloudflare’s globally distributed SQL connection pooler and cache) recently added support for Postgres protocol-level named prepared statements across pooled connections. Named prepared statements allow Postgres to cache query execution plans, providing potentially substantial performance improvements. Further, many popular drivers in the ecosystem use these by default, meaning that not having them is a bit of a footgun for developers. We are very excited that Hyperdrive’s users will now have access to better performance and a more seamless development experience, without needing to make any significant changes to their applications!
While we’re not the first connection pooler to add this support (PgBouncer got to it in October 2023 in version 1.21, for example), there were some unique challenges in how we implemented it. To that end, we wanted to do a deep dive on what it took for us to deliver this.
Hyper-what?
One of the classic problems of building on the web is that your users are everywhere, but your database tends to be in one spot. Combine that with pesky limitations like network routing, or the speed of light, and you can often run into situations where your users feel the pain of having your database so far away. This can look like slower queries, slower startup times, and connection exhaustion as everything takes longer to accomplish.
Hyperdrive is designed to make the centralized databases you already have feel like they’re global. We use our global network to get faster routes to your database, keep connection pools primed, and cache your most frequently run queries as close to users as possible.
Postgres Message Protocol
To understand exactly what the challenge with prepared statements is, it’s first necessary to dig in a bit to the Postgres Message Protocol. Specifically, we are going to take a look at the protocol for an “extended” query, which uses different message types and is a bit more complex than a “simple” query, but which is more powerful and thus more widely used.
A query using Hyperdrive might be coded something like this, but a lot goes on under the hood in order for Postgres to reliably return your response.
import postgres from "postgres";
// with Hyperdrive, we don't have to disable prepared statements anymore!
// const sql = postgres(env.HYPERDRIVE.connectionString, {prepare: false});
// make a connection, with the default postgres.js settings (prepare is set to true)
const sql = postgres(env.HYPERDRIVE.connectionString);
// This sends the query, and while it looks like a single action it contains several
// messages implied within it
let [{ a, b, c, id }] = await sql`SELECT a, b, c, id FROM hyper_test WHERE id = ${target_id}`;
To prepare a statement, a Postgres client begins by sending a Parse message. This includes the query string, the number of parameters to be interpolated, and the statement’s name. The name is a key piece of this puzzle. If it is empty, then Postgres uses a special “unnamed” prepared statement slot that gets overwritten on each new Parse. These are relatively easy to support, as most drivers will keep the entirety of a message sequence for unnamed statements together, and will not try to get too aggressive about reusing the prepared statement because it is overwritten so often.
If the statement has a name, however, then it is kept prepared for the remainder of the Postgres session (unless it is explicitly removed with DEALLOCATE). This is convenient because parsing a query string and preparing the statement costs bytes sent on the wire and CPU cycles to process, so reusing a statement is quite a nice optimization.
Once done with Parse, there are a few remaining steps to (the simplest form of) an extended query:
A Bind message, which provides the specific values to be passed for the parameters in the statement (if any).
An Execute message, which tells the Postgres server to actually perform the data retrieval and processing.
And finally a Sync message, which causes the server to close the implicit transaction, return results, and provides a synchronization point for error handling.
While that is the core pattern for accomplishing an extended protocol query, there are many more complexities possible (named Portal, ErrorResponse, etc.).
We will briefly mention one other complexity we often encounter in this protocol, which is Describe messages. Many drivers leverage Postgres’ built-in types to help with deserialization of the results into structs or classes. This is accomplished by sending a Parse-Describe-Flush/Sync sequence, which will send a statement to be prepared, and will expect back information about the types and data the query will return. This complicates bookkeeping around named prepared statements, as now there are two separate queries, with two separate kinds of responses, that must be kept track of. We won’t go into much depth on the tradeoffs of an additional round-trip in exchange for advanced information about the results’ format, but suffice it to say that it must be handled explicitly in order for the overall system to gracefully support prepared statements.
So the basic query from our code above looks like this from a message perspective:
The first challenge that Hyperdrive must solve (that many other connection poolers don’t have) is that it’s also a cache.
The happiest path for a query on Hyperdrive never travels far, and we are quite proud of the low latency of our cache hits. However, this presents a particular challenge in the case of an extended protocol query. A Parse by itself is insufficient as a cache key, both because the parameter values in the Bind messages can alter the expected results, and because it might be followed up with either a Describe or an Execute message which will invoke drastically different responses.
So Hyperdrive cannot simply pass each message to the origin database, as we must buffer them in a message log until we have enough information to reliably distinguish between cache keys. It turns out that receiving a Sync is quite a natural point at which to check whether you have enough information to serve a response. For most scenarios, we buffer until we receive a Sync, and then (assuming the scenario is cacheable) we determine whether we can serve the response from cache or we need to take a connection to the origin database.
Taking a Connection From the Pool
Assuming we aren’t serving a response from cache, for whatever reason, we’ll need to take an origin connection from our pool. One of the key advantages any connection pooler offers is in allowing many client connections to share few database connections, so minimizing how often and for how long these connections are held is crucial to making Hyperdrive performant.
To this end, Hyperdrive operates in what is traditionally called “transaction mode”. This means that a connection taken from the pool for any given transaction is returned once that transaction concludes. This is in contrast to what is often called “session mode”, where once a connection is taken from the pool it is held by the client until the client disconnects.
For Hyperdrive, allowing any client to take any database connection is vital. This is because if we “pin” a client to a given database connection then we have one fewer available for every other possible client. You can run yourself out of database connections very quickly once you start down that path, especially when your clients are many small Workers spread around the world.
The challenge prepared statements present to this scenario is that they exist at the “session” scope, which is to say, at the scope of one connection. If a client prepares a statement on connection A, but tries to reuse it and gets assigned connection B, Postgres will naturally throw an error claiming the statement doesn’t exist in the given session. No results will be returned, the client is unhappy, and all that’s left is to retry with a Parse message included. This causes extra round-trips between client and server, defeating the whole purpose of what is meant to be an optimization.
One of the goals of a connection pooler is to be as transparent to the client and server as possible. There are limitations, as Postgres will let you do some powerful things to session state that cannot be reasonably shared across arbitrary client connections, but to the extent possible the endpoints should not have to know or care about any multiplexing happening between them.
This means that when a client sends a Parse message on its connection, it should expect that the statement will be available for reuse when it wants to send a Bind-Execute-Sync sequence later on. It also means that the server should not get Bind messages for statements that only exist on some other session. Maintaining this illusion is the crux of providing support for this feature.
Putting it all together
So, what does the solution look like? If a client sends Parse-Bind-Execute-Sync with a named prepared statement, then later sends Bind-Execute-Sync to reuse it, how can we make sure that everything happens as expected? The solution, it turns out, needs just a few built-in Rust data structures for efficiently capturing what we need (a HashMap, some LruCaches and a VecDeque), and some straightforward business logic to keep track of when to intervene in the messages being passed back and forth.
Whenever a named Parse comes in, we store it in an in-memory HashMap on the server that handles message processing for that client’s connection. This persists until the client is disconnected. This means that whenever we see anything referencing the statement, we can go retrieve the complete message defining it. We’ll come back to this in a moment.
Once we’ve buffered all the messages we can and gotten to the point where it’s time to return results (let’s say because the client sent a Sync), we need to start applying some logic. For the sake of brevity we’re going to omit talking through error handling here, as it does add some significant complexity but is somewhat out of scope for this discussion.
There are two main questions that determine how we should proceed:
Does our message sequence include a Parse, or are we trying to reuse a pre-existing statement?
Do we have a cache hit or are we serving from the origin database?
This gives us four scenarios to consider:
Parse with cache hit
Parse with cache miss
Reuse with cache hit
Reuse with cache miss
A Parse with a cache hit is the easiest path to address, as we don’t need to do anything special. We use the messages sent as a cache key, and serve the results back to the client. We will still keep the Parse in our HashMap in case we want it later (#2 below), but otherwise we’re good to go.
A Parse with a cache miss is a bit more complicated, as now we need to send these messages to the origin server. We take a connection at random from our pool and do so, passing the results back to the client. With that, we’ve begun to make changes to session state such that all our database connections are no longer identical to each other. To keep track of what we’ve done to muddy up our state, we keep a LruCache on each connection of which statements it already has prepared. In the case where we need to evict from such a cache, we will also DEALLOCATE the statement on the connection to keep things tracked correctly.
Reuse with a cache hit is yet more tricky, but still straightforward enough. In the example below, we are sent a Bind with the same parameters twice (#1 and #9). We must identify that we received a Bind without a preceding Parse, we must go retrieve that Parse (#10), and we must use the information from it to build our cache key. Once all that is accomplished, we can serve our results from cache, needing only to trim out the ParseComplete within the cached results before returning them to the client.
Reuse with a cache miss is the hardest scenario, as it may require us to lie in both directions. In the example below, we cache results for one set of parameters (#8), but are sent a Bind with different parameters (#9). As in the cache hit scenario, we must identify that we were not sent a Parse as part of the current message sequence, retrieve it from our HashMap (#10), and build our cache key to GET from cache and confirm the miss (#11). Once we take a connection from the pool, though, we then need to check if it already has the statement we want prepared. If not, we must take our saved Parse and prepend it to our message log to be sent along to the origin database (#13). Thus, what the server receives looks like a perfectly valid Parse-Bind-Execute-Sync sequence. This is where our VecDeque (mentioned above) comes in, as converting our message log to that structure allowed us to very ergonomically make such changes without needing to rebuild the whole byte sequence. Once we receive the response from the server, all that’s needed is to trim out the initial ParseComplete response from the server, as a well-made client would likely be very confused receiving such a response to a Parse it didn’t send. With that message trimmed out, however, the client is in the position of getting exactly what it asked for, and both sides of the conversation are happy.
Dénouement
Now that we’ve got a working solution, where all parties are functioning well, let’s review! Our solution lets us share database connections across arbitrary clients with no “pinning”, no custom handling on either client or server, and supports reuse of prepared statements to reduce CPU load on re-parsing queries and reduce network traffic on re-sending Parse messages. Engineering always involves tradeoffs, so the cost of this is that we will sometimes still need to sneak in a Parse because a client got assigned a different connection on reuse, and in those scenarios there is a small amount of additional memory overhead because the same statement is prepared on multiple connections.
Today might be April Fools, and while we like to have fun as much as anyone else, we like to use this day for serious announcements. In fact, as of today, there are over 2 million developers building on top of Cloudflare’s platform — that’s no joke!
To kick off this Developer Week, we’re flipping the big “production ready” switch on three products: D1, our serverless SQL database; Hyperdrive, which makes your existing databases feel like they’re distributed (and faster!); and Workers Analytics Engine, our time-series database.
We’ve been on a mission to allow developers to bring their entire stack to Cloudflare for some time, but what might an application built on Cloudflare look like?
The diagram itself shouldn’t look too different from the tools you’re already familiar with: you want a database for your core user data. Object storage for assets and user content. Maybe a queue for background tasks, like email or upload processing. A fast key-value store for runtime configuration. Maybe even a time-series database for aggregating user events and/or performance data. And that’s before we get to AI, which is increasingly becoming a core part of many applications in search, recommendation and/or image analysis tasks (at the very least!).
Yet, without having to think about it, this architecture runs on Region: Earth, which means it’s scalable, reliable and fast — all out of the box.
D1: Production Ready
Your core database is one of the most critical pieces of your infrastructure. It needs to be ultra-reliable. It can’t lose data. It needs to scale. And so we’ve been heads down over the last year getting the pieces into place to make sure D1 is production-ready, and we’re extremely excited to say that D1 — our global, serverless SQL database — is now Generally Available.
The GA for D1 lands some of the most asked-for features, including:
Support for 10GB databases — and 50,000 databases per account;
New data export capabilities; and
Enhanced query debugging (we call it “D1 Insights”) — that allows you to understand what queries are consuming the most time, cost, or that are just plain inefficient…
… to empower developers to build production-ready applications with D1 to meet all their relational SQL needs. And importantly, in an era where the concept of a “free plan” or “hobby plan” is seemingly at risk, we have no intention of removing the free tier for D1 or reducing the 25 billion row reads included in the $5/mo Workers Paid plan:
Plan
Rows Read
Rows Written
Storage
WorkersPaid
First 25 billion / month included + $0.001 / million rows
First 50 million / month included + $1.00 / million rows
First 5 GB included
+ $0.75 / GB-mo
Workers Free
5 million / day
100,000 / day
5 GB (total)
For those who’ve been following D1 since the start: this is the same pricing we announced at open beta
But things don’t just stop at GA: we have some major new features lined up for D1, including global read replication, even larger databases, more Time Travel capabilities that will allow you to branch your database, and new APIs for dynamically querying and/or creating new databases-on-the-fly from within a Worker.
D1’s read replication will automatically deploy read replicas as needed to get data closer to your users: and without you having to spin up, manage scaling, or run into consistency (replication lag) issues. Here’s a sneak preview of what D1’s upcoming Replication API looks like:
export default {
async fetch(request: Request, env: Env) {
const {pathname} = new URL(request.url);
let resp = null;
let session = env.DB.withSession(token); // An optional commit token or mode
// Handle requests within the session.
if (pathname === "/api/orders/list") {
// This statement is a read query, so it will work against any
// replica that has a commit equal or later than `token`.
const { results } = await session.prepare("SELECT * FROM Orders");
resp = Response.json(results);
} else if (pathname === "/api/orders/add") {
order = await request.json();
// This statement is a write query, so D1 will send the query to
// the primary, which always has the latest commit token.
await session.prepare("INSERT INTO Orders VALUES (?, ?, ?)")
.bind(order.orderName, order.customer, order.value);
.run();
// In order for the application to be correct, this SELECT
// statement must see the results of the INSERT statement above.
//
// D1's new Session API keeps track of commit tokens for queries
// within the session and will ensure that we won't execute this
// query until whatever replica we're using has seen the results
// of the INSERT.
const { results } = await session.prepare("SELECT COUNT(*) FROM Orders")
.run();
resp = Response.json(results);
}
// Set the token so we can continue the session in another request.
resp.headers.set("x-d1-token", session.latestCommitToken);
return resp;
}
}
Importantly, we will give developers the ability to maintain session-based consistency, so that users still see their own changes reflected, whilst still benefiting from the performance and latency gains that replication can bring.
You can learn more about how D1’s read replication works under the hood in our deep-dive post, and if you want to start building on D1 today, head to our developer docs to create your first database.
Hyperdrive: GA
We launched Hyperdrive into open beta last September during Birthday Week, and it’s now Generally Available — or in other words, battle-tested and production-ready.
If you’re not caught up on what Hyperdrive is, it’s designed to make the centralized databases you already have feel like they’re global. We use our global network to get faster routes to your database, keep connection pools primed, and cache your most frequently run queries as close to users as possible.
Importantly, Hyperdrive supports the most popular drivers and ORM (Object Relational Mapper) libraries out of the box, so you don’t have to re-learn or re-write your queries:
// Use the popular 'pg' driver? Easy. Hyperdrive just exposes a connection string
// to your Worker.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
// Prefer using an ORM like Drizzle? Use it with Hyperdrive too.
// https://orm.drizzle.team/docs/get-started-postgresql#node-postgres
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
const db = drizzle(client);
But the work on Hyperdrive doesn’t stop just because it’s now “GA”. Over the next few months, we’ll be bringing support for the other most widely deployed database engine there is: MySQL. We’ll also be bringing support for connecting to databases inside private networks (including cloud VPC networks) via Cloudflare Tunnel and Magic WAN On top of that, we plan to bring more configurability around invalidation and caching strategies, so that you can make more fine-grained decisions around performance vs. data freshness.
As we thought about how we wanted to price Hyperdrive, we realized that it just didn’t seem right to charge for it. After all, the performance benefits from Hyperdrive are not only significant, but essential to connecting to traditional database engines. Without Hyperdrive, paying the latency overhead of 6+ round-trips to connect & query your database per request just isn’t right.
And so we’re happy to announce that for any developer on a Workers Paid plan, Hyperdrive is free. That includes both query caching and connection pooling, as well as the ability to create multiple Hyperdrives — to separate different applications, prod vs. staging, or to provide different configurations (cached vs. uncached, for example).
Plan
Price per query
Connection Pooling
WorkersPaid
$0
$0
To get started with Hyperdrive, head over to the docs to learn how to connect your existing database and start querying it from your Workers.
Queues: Pull From Anywhere
The task queue is an increasingly critical part of building a modern, full-stack application, and this is what we had in mind when we originally announced the open beta of Queues. We’ve since been working on several major Queues features, and we’re launching two of them this week: pull-based consumers and new message delivery controls.
Any HTTP-speaking client can now pull messages from a queue: call the new /pull endpoint on a queue to request a batch of messages, and call the /ack endpoint to acknowledge each message (or batch of messages) as you successfully process them:
// Pull and acknowledge messages from a Queue using any HTTP client
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/pull" -X POST --data '{"visibilityTimeout":10000,"batchSize":100}}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
// Ack the messages you processed successfully; mark others to be retried.
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/ack" -X POST --data '{"acks":["lease-id-1", "lease-id-2"],"retries":["lease-id-100"]}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
A pull-based consumer can run anywhere, allowing you to run queue consumers alongside your existing legacy cloud infrastructure. Teams inside Cloudflare adopted this early on, with one use-case focused on writing device telemetry to a queue from our 310+ data centers and consuming within some of our back-of-house infrastructure running on Kubernetes. Importantly, our globally distributed queue infrastructure means that messages are retained within the queue until the consumer is ready to process them.
Queues also now supports delaying messages, both when sending to a queue, as well as when marking a message for retry. This can be useful to queue (pun intended) tasks for the future, as well apply a backoff mechanism if an upstream API or infrastructure has rate limits that require you to pace how quickly you are processing messages.
// Apply a delay to a message when sending it
await env.YOUR_QUEUE.send(msg, { delaySeconds: 3600 })
// Delay a message (or a batch of messages) when marking it for retry
for (const msg of batch.messages) {
msg.retry({delaySeconds: 300})
}
We’ll also be bringing substantially increased per-queue throughput over the coming months on the path to getting Queues to GA. It’s important to us that Queues is extremely reliable: lost or dropped messages means that a user doesn’t get their order confirmation email, that password reset notification, and/or their uploads processed — each of those are user-impacting and hard to recover from.
Workers Analytics Engine
Workers Analytics Engine provides unlimited-cardinality analytics at scale, via a built-in API to write data points from Workers, and a SQL API to query that data.
Workers Analytics Engine is backed by the same ClickHouse-based system we have depended on for years at Cloudflare. We use it ourselves to observe the health of our own services, to capture product usage data for billing, and to answer questions about specific customers’ usage patterns. At least one data point is written to this system on nearly every request to Cloudflare’s network. Workers Analytics Engine lets you build your own custom analytics using this same infrastructure, while we manage the hard parts for you.
Since launching in beta, developers have started depending on Workers Analytics Engine for these same use cases and more, from large enterprises to open-source projects like Counterscale. Workers Analytics Engine has been operating at production scale with mission-critical workloads for years — but we hadn’t shared anything about pricing, until today.
We are keeping Workers Analytics Engine pricing simple, and based on two metrics:
Data points written — every time you call writeDataPoint() in a Worker, this counts as one data point written. Every data point costs the same amount — unlike other platforms, there is no penalty for adding dimensions or cardinality, and no need to predict what the size and cost of a compressed data point might be.
Read queries — every time you post to the Workers Analytics Engine SQL API, this counts as one read query. Every query costs the same amount — unlike other platforms, there is no penalty for query complexity, and no need to reason about the number of rows of data that will be read by each query.
Both the Workers Free and Workers Paid plans will include an allocation of data points written and read queries, with pricing for additional usage as follows:
Plan
Data points written
Read queries
WorkersPaid
10 million included per month
+$0.25 per additional million
1 million included per month
+$1.00 per additional million
Workers Free
100,000 included per day
10,000 included per day
With this pricing, you can answer, “how much will Workers Analytics Engine cost me?” by counting the number of times you call a function in your Worker, and how many times you make a request to a HTTP API endpoint. Napkin math, rather than spreadsheet math.
This pricing will be made available to everyone in coming months. Between now and then, Workers Analytics Engine continues to be available at no cost. You can start writing data points from your Worker today — it takes just a few minutes and less than 10 lines of code to start capturing data. We’d love to hear what you think.
The week is just getting started
Tune in to what we have in store for you tomorrow on our second day of Developer Week. If you have questions or want to show off something cool you already built, please join our developer Discord.
Hyperdrive makes accessing your existing databases from Cloudflare Workers, wherever they are running, hyper fast. You connect Hyperdrive to your database, change one line of code to connect through Hyperdrive, and voilà: connections and queries get faster (and spoiler: you can use it today).
In a nutshell, Hyperdrive uses our global network to speed up queries to your existing databases, whether they’re in a legacy cloud provider or with your favorite serverless database provider; dramatically reduces the latency incurred from repeatedly setting up new database connections; and caches the most popular read queries against your database, often avoiding the need to go back to your database at all.
Without Hyperdrive, that core database — the one with your user profiles, product inventory, or running your critical web app — sitting in the us-east1 region of a legacy cloud provider is going to be really slow to access for users in Paris, Singapore and Dubai and slower than it should be for users in Los Angeles or Vancouver. With each round trip taking up to 200ms, it’s easy to burn up to a second (or more!) on the multiple round-trips needed just to set up a connection, before you’ve even made the query for your data. Hyperdrive is designed to fix this.
To demonstrate Hyperdrive’s performance, we built a demo application that makes back-to-back queries against the same database: both with Hyperdrive and without Hyperdrive (directly). The app selects a database in a neighboring continent: if you’re in Europe, it selects a database in the US — an all-too-common experience for many European Internet users — and if you’re in Africa, it selects a database in Europe (and so on). It returns raw results from a straightforward SELECT query, with no carefully selected averages or cherry-picked metrics.
We built a demo app that makes real queries to a PostgreSQL database, with and without Hyperdrive
Throughout internal testing, initial user reports and the multiple runs in our benchmark, Hyperdrive delivers a 17 – 25x performance improvement vs. going direct to the database for cached queries, and a 6 – 8x improvement for uncached queries and writes. The cached latency might not surprise you, but we think that being 6 – 8x faster on uncached queries changes “I can’t query a centralized database from Cloudflare Workers” to “where has this been all my life?!”. We’re also continuing to work on performance improvements: we’ve already identified additional latency savings, and we’ll be pushing those out in the coming weeks.
We’ve been working on Hyperdrive in secret for a short while: but allowing developers to connect to databases they already have — with their existing data, queries and tooling — has been something on our minds for quite some time.
In a modern distributed cloud environment like Workers, where compute is globally distributed (so it’s close to users) and functions are short-lived (so you’re billed no more than is needed), connecting to traditional databases has been both slow and unscalable. Slow because it takes upwards of seven round-trips (TCP handshake; TLS negotiation; then auth) to establish the connection, and unscalable because databases like PostgreSQL have a high resource cost per connection. Even just a couple of hundred connections to a database can consume non-negligible memory, separate from any memory needed for queries.
Our friends over at Neon (a popular serverless Postgres provider) wrote about this, and even released a WebSocket proxy and driver to reduce the connection overhead, but are still fighting uphill in the snow: even with a custom driver, we’re down to 4 round-trips, each still potentially taking 50-200 milliseconds or more. When those connections are long-lived, that’s OK — it might happen once every few hours at best. But when they’re scoped to an individual function invocation, and are only useful for a few milliseconds to minutes at best — your code spends more time waiting. It’s effectively another kind of cold start: having to initiate a fresh connection to your database before making a query means that using a traditional database in a distributed or serverless environment is (to put it lightly) really slow.
To combat this, Hyperdrive does two things.
First, it maintains a set of regional database connection pools across Cloudflare’s network, so a Cloudflare Worker avoids making a fresh connection to a database on every request. Instead, the Worker can establish a connection to Hyperdrive (fast!), with Hyperdrive maintaining a pool of ready-to-go connections back to the database. Since a database can be anywhere from 30ms to (often) 300ms away over a single round-trip (let alone the seven or more you need for a new connection), having a pool of available connections dramatically reduces the latency issue that short-lived connections would otherwise suffer.
Second, it understands the difference between read (non-mutating) and write (mutating) queries and transactions, and can automatically cache your most popular read queries: which represent over 80% of most queries made to databases in typical web applications. That product listing page that tens of thousands of users visit every hour; open jobs on a major careers site; or even queries for config data that changes occasionally; a tremendous amount of what is queried does not change often, and caching it closer to where the user is querying it from can dramatically speed up access to that data for the next ten thousand users. Write queries, which can’t be safely cached, still get to benefit from both Hyperdrive’s connection pooling and Cloudflare’s global network: being able to take the fastest routes across the Internet across our backbone cuts down latency there, too.
Even if your database is on the other side of the country, 70ms x 6 round-trips is a lot of time for a user to be waiting for a query response.
Hyperdrive works not only with PostgreSQL databases — including Neon, Google Cloud SQL, AWS RDS, and Timescale, but also PostgreSQL-compatible databases like Materialize (a powerful stream-processing database), CockroachDB (a major distributed database), Google Cloud’s AlloyDB, and AWS Aurora Postgres.
We’re also working on bringing support for MySQL, including providers like PlanetScale, by the end of the year, with more database engines planned in the future.
The magic connection string
One of the major design goals for Hyperdrive was the need for developers to keep using their existing drivers, query builder and ORM (Object-Relational Mapper) libraries. It wouldn’t have mattered how fast Hyperdrive was if we required you to migrate away from your favorite ORM and/or rewrite hundreds (or more) lines of code & tests to benefit from Hyperdrive’s performance.
The magic behind Hyperdrive is that you can start using it in your existing Workers applications, with your existing queries, just by swapping out your connection string for the one Hyperdrive generates instead.
Creating a Hyperdrive
With an existing database ready to go — in this example, we’ll use a Postgres database from Neon — it takes less than a minute to get Hyperdrive running (yes, we timed it).
If you don’t have an existing Cloudflare Workers project, you can quickly create one:
$ npm create cloudflare@latest
# Call the application "hyperdrive-demo"
# Choose "Hello World Worker" as your template
From here, we just need the database connection string for our database and a quick wrangler command-line invocation to have Hyperdrive connect to it.
# Using wrangler v3.8.0 or above
wrangler hyperdrive databases create a-faster-database --connection-string="postgres://user:[email protected]/neondb"
# This will return an ID: we'll use this in the next step
[[hyperdrive]]
name = "HYPERDRIVE"
database_id = "cdb28782-0dfc-4aca-a445-a2c318fb26fd"
We can now write a Worker — or take an existing Worker script — and use Hyperdrive to speed up connections and queries to our existing database. We use node-postgres here, but we could just as easily use Drizzle ORM.
import { Client } from 'pg';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
console.log(JSON.stringify(env));
// Create a database client that connects to our database via Hyperdrive
//
// Hyperdrive generates a unique connection string you can pass to
// supported drivers, including node-postgres, Postgres.js, and the many
// ORMs and query builders that use these drivers.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
try {
// Connect to our database
await client.connect();
// A very simple test query
let result = await client.query({ text: 'SELECT * FROM pg_tables' });
// Return our result rows as JSON
return Response.json({ result: result });
} catch (e) {
console.log(e);
return Response.json({ error: JSON.stringify(e) }, { status: 500 });
}
},
};
The code above is intentionally simple, but hopefully you can see the magic: our database driver gets a connection string from Hyperdrive, and is none-the-wiser. It doesn’t need to know anything about Hyperdrive, we don’t have to toss out our favorite query builder library, and we can immediately realize the speed benefits when making queries.
Connections are automatically pooled and kept warm, our most popular queries are cached, and our entire application gets faster.
We think Hyperdrive is critical to accessing your existing databases when building on Cloudflare Workers: traditional databases were just never designed for a world where clients are globally distributed.
Hyperdrive’s connection pooling will always be free, for both database protocols we support today and new database protocols we add in the future. Just like DDoS protection and our global CDN, we think access to Hyperdrive’s core feature is too useful to hold back.
During the open beta, Hyperdrive itself will not incur any charges for usage, regardless of how you use it. We’ll be announcing more details on how Hyperdrive will be priced closer to GA (early in 2024), with plenty of notice.
Time to query
So where to from here for Hyperdrive?
We’re planning on bringing Hyperdrive to GA in early 2024 — and we’re focused on landing more controls over how we cache & automatically invalidate based on writes, detailed query and performance analytics (soon!), support for more database engines (including MySQL) as well as continuing to work on making it even faster.
We’re also working to enable private network connectivity via Magic WAN and Cloudflare Tunnel, so that you can connect to databases that aren’t (or can’t be) exposed to the public Internet.
To connect Hyperdrive to your existing database, visit our developer docs — it takes less than a minute to create a Hyperdrive and update existing code to use it. Join the #hyperdrive-beta channel in our Developer Discord to ask questions, surface bugs, and talk to our Product & Engineering teams directly.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.