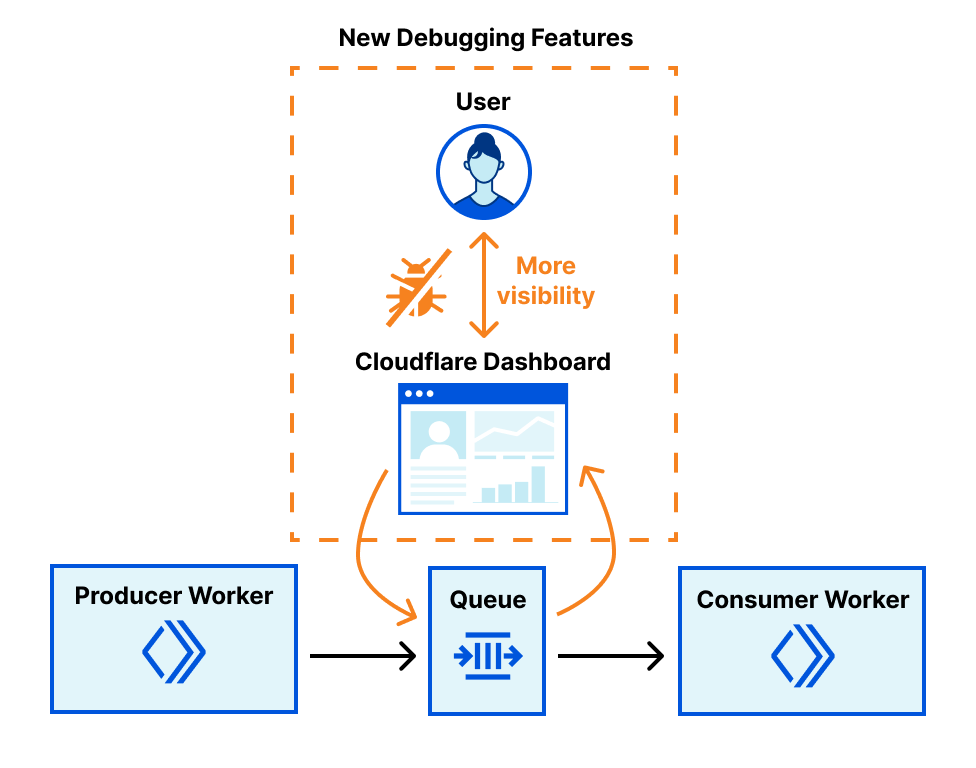
Post Syndicated from Pakhi Sinha original https://blog.cloudflare.com/extract-audio-from-your-videos-with-cloudflare-stream/
Cloudflare Stream loves video. But we know not every workflow needs the full picture, and the popularity of podcasts highlights how compelling stand-alone audio can be. For developers, processing a video just to access audio is slow, costly, and complex.
What makes video so expensive? A video file is a dense stack of high-resolution images, stitched together over time. As such, it is not just “one file” — it’s a container of high-dimensional data such as frames per second, resolution, codecs. Analyzing video means traversing time resolution frame rate.
By comparison, an audio file is far simpler. If an audio file consists of only one channel, it is defined as a single waveform. The technical characteristics of this waveform are defined by the sample rate (the number of audio samples taken per second), and the bit depth (the precision of each sample).
With the rise of computationally intensive AI inference pipelines, many of our customers want to perform downstream workflows that require only analyzing the audio. For example:
-
Power AI and Machine Learning: In addition to translation and transcription, you can feed the audio into Voice-to-Text models for speech recognition or analysis, or AI-powered summaries.
-
Improve content moderation: Analyze the audio within your videos to ensure the content is safe and compliant.
Using video data in such cases is expensive and unnecessary.
That’s why we’re introducing audio extraction. Through this feature, with just a single API call or click in the dashboard, you can now extract a lightweight M4A audio track from any video.
We’re introducing two flexible methods to extract audio from your videos.
Media Transformations is perfect for processing and transforming short-form videos, like social media clips, that you store anywhere you’d like. It works by fetching your media directly from its source, optimizing it at our edge, and delivering it efficiently.
We extended this workflow to include audio. By simply adding mode=audio to the transformation URL, you can now extract audio on-the-fly from a video file stored anywhere.
Once Media Transformations is enabled for your domain, you can extract audio from any source video. You can even clip specific sections by specifying time and duration.
For example:
https://example.com/cdn-cgi/media/mode=audio,time=5s,duration=10s/<SOURCE-VIDEO>The above request generates a 10 second M4A audio clip from the source video, beginning at the 5-second mark. You can learn more about setup and other options in the Media Transformations documentation.
You can now download the audio track directly for any content that you manage within Stream. Alongside the ability to generate a downloadable MP4 for offline viewing, you can also now create and store a persistent M4A audio file.
Here, you can see a sample piece of code that demonstrates how to use Media Transformations with one of Cloudflare’s own products — Workers AI. The following code creates a two-step process: first transcribing the video’s audio to English, then translating it into Spanish.
export default {
async fetch(request, env, ctx) {
// 1. Use Media Transformations to fetch only the audio track
const res = await fetch( "https://blog.cloudflare.com/cdn-cgi/media/mode=audio/https://pub-d9fcbc1abcd244c1821f38b99017347f.r2.dev/announcing-audio-mode.mp4" );
const blob = await res.arrayBuffer();
// 2. Transcribe the audio to text using Whisper
const transcript_response = await env.AI.run(
"@cf/openai/whisper-large-v3-turbo",
{
audio: base64Encode(blob), // A base64 encoded string is required by @cf/openai/whisper-large-v3-turbo
}
);
// Check if transcription was successful and text exists
if (!transcript_response.text) {
return Response.json({ error: "Failed to transcribe audio." }, { status: 500 });
}
// 3. Translate the transcribed text using the M2M100 model
const translation_response = await env.AI.run(
'@cf/meta/m2m100-1.2b',
{
text: transcript_response.text,
source_lang: 'en', // The source language (English)
target_lang: 'es' // The target language (Spanish)
}
);
// 4. Return both the original transcription and the translation
return Response.json({
transcription: transcript_response.text,
translation: translation_response.translated_text
});
}
};
export function base64Encode(buf) {
let string = '';
(new Uint8Array(buf)).forEach(
(byte) => { string += String.fromCharCode(byte) }
)
return btoa(string)
}After running, the worker returns a clean JSON response. Shown below is a snippet of the transcribed and then translated response the worker returned.
Transcription:
{
"transcription": "I'm excited to announce that Media Transformations from Cloudflare has added audio-only mode. Now you can quickly extract and deliver just the audio from your short form video. And from there, you can transcribe it or summarize it on Worker's AI or run moderation or inference tasks easily.",
"translation": "Estoy encantado de anunciar que Media Transformations de Cloudflare ha añadido el modo solo de audio. Ahora puede extraer y entregar rápidamente sólo el audio de su vídeo de forma corta. Y desde allí, puede transcribirlo o resumirlo en la IA de Worker o ejecutar tareas de moderación o inferencia fácilmente."
}As a summer intern on the Stream team, I worked on shipping this long-requested feature. My first step was to understand the complex architecture of Stream’s media pipelines.
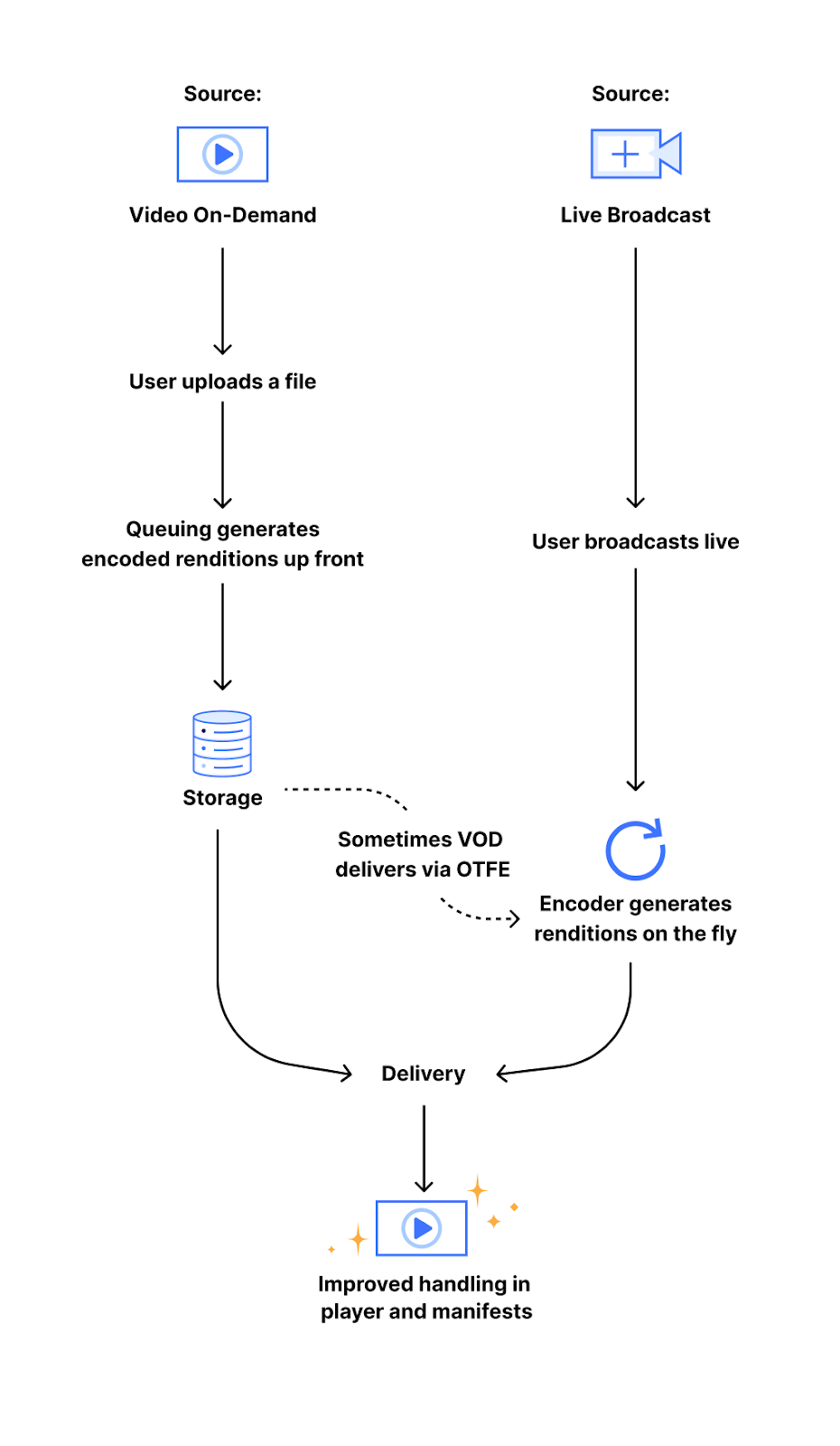
When a video is processed by Stream, it can follow one of two paths. The first is our video-on-demand (VOD) pipeline, which handles videos directly uploaded to Stream. It generates and stores a set of encoded video segments for adaptive bitrate streaming that can be streamed via HLS/DASH. The other path is our on-the-fly-encoding (or OTFE) pipeline, that drives the Stream Live and Media Transformations service. Instead of pre-processing and storing files, OTFE fetches media from a customer’s own website and performs transformations at the edge.
My project involved extending both of these pipelines to support audio extraction.
The OTFE pipeline is designed for real-time operations. The existing flow was engineered for visual tasks. When a customer with Media Transformations enabled makes a request on their own website, it’s routed to our edge servers, which acts as the entry point. The request is then validated, and per the user’s request, OTFE would fetch the video and generate a resized version or a still-frame thumbnail.
In order to support audio-only extraction, I built upon our existing workflow to add a new mode. This involved:
-
Extending the validation logic: Specifically for audio, a crucial validation step was to verify that the source video contained an audio track before attempting extraction. This was in addition to pre-existing validation steps that ensure the requested URL was correctly formatted.
-
Building a new transformation handler: This was the core of my project. I built a new handler within the OTFE platform that specifically discarded the visual tracks in order to deliver a high-quality M4A file.
Similar to my work on OTFE, this project involved extending our current MP4 downloads workflow to audio-only, M4A downloads. This presented a series of interesting technical decisions.
The typical flow for creating a video download begins with a POST request to our main API layer, which handles authentication and validation, and creates a corresponding database record. Which then enqueues a job in our asynchronous queue where workers perform the processing task. To enable audio downloads for VOD, I introduced new, type-specific API endpoints (POST /downloads/{type}) while preserving the legacy POST /downloads route as an alias for creating downloads of the default, or video, download type. This ensured full backward compatibility.
The core work, of creating a download, is performed by our asynchronous queue. Which included:
-
Adding logic to the consumer to detect the new audio download type
-
Pulling the ffmpeg template we define in our API layer to properly encode the audio stream into a high-quality M4A container
By extending each component of this pipeline– from the API routes to the media processing commands– I was able to deliver a new, highly-requested feature that unlocks audio-centric workflows for our customers!
We’re excited to announce that this feature is also available in the Stream dashboard. Simply navigate to any of your videos, and you’ll find the option to download the video or just the audio.

Once the download is ready, you will see the URL for the file, along with the option to disable it.

This project addressed a long-standing customer need, providing a simpler way to work with audio from video. I’m truly grateful for this entire journey, from understanding the problem to shipping the solution, and especially for the mentorship and guidance I received from my team along the way. We are excited to see how developers use this new capability to build more efficient and exciting applications on Cloudflare Stream.
You can try the audio extraction feature by uploading a video to Stream or using the API! If you’re interested in tackling these kinds of technical challenges yourself, explore our internship and early talent programs to start your own journey.