Post Syndicated from Jonathan Nguyen original https://aws.amazon.com/blogs/security/use-amazon-macie-for-automatic-continual-and-cost-effective-discovery-of-sensitive-data-in-s3/
Customers have an increasing need to collect, store, and process data within their AWS environments for application modernization, reporting, and predictive analytics. AWS Well-Architected security pillar, general data privacy and compliance regulations require that you appropriately identify and secure sensitive information. Knowing where your data is allows you to implement the appropriate security controls which help support meeting a range of objectives including compliance & data privacy.
With Amazon Macie, you can detect sensitive information stored in your organization’s Amazon Simple Storage Service (Amazon S3) storage. Macie provides sensitive data findings and additional metadata to help you protect your data in Amazon S3.
If you have many accounts with a lot of S3 buckets and data, you might find it complex, expensive, and time consuming to discover sensitive data in each bucket and account, and to evaluate the large number of findings. As your applications continue to scale you want to have confidence that you continue to understand where the data is in your environment.
To help discover sensitive data across your entire S3 storage, you can now use a new feature in Macie—automated sensitive data discovery—to automatically build sensitive data profiles on S3 buckets and uncover the presence of sensitive data. The new feature continually and cost-efficiently samples data across your S3 storage. This reduces the data scanning needed to locate sensitive data so that you can focus your time, effort, and resources on additional investigation and remediation if sensitive data is found. This broad visibility can help you develop scalable, repeatable processes for ongoing and proactive protection of data.
In this blog post, we show you how to set up Macie automated sensitive data discovery in your AWS environment and walk you through the insights that it generates. We also share some common patterns on how you can use the findings to improve your data security posture.
Prerequisites
To get started, you’ll need the following prerequisites:
- Activate Amazon Macie in your accounts for the AWS Regions of your choosing. Macie is a regional service, so it scans S3 buckets only in the Regions where it’s turned on.
- Set up a delegated Macie administrator account, also referred to as the Macie admin account, for these Regions. A Macie admin account has visibility into the S3 buckets of member accounts. It also allows you to restrict access to automated sensitive data discovery results to the appropriate teams, without providing access into the management account.
To set up the delegated Macie administrator to centrally manage multiple Macie accounts, do one of the following:
- Option 1 (Recommended) – Add member accounts using AWS Organizations. Make sure to review best practices for setting up Macie for your organizations.
- Option 2 – Add member accounts by using Macie membership invitations.
For steps on how to implement these options, see Considerations and recommendations for invitation-based organizations in Amazon Macie.
- Make sure that a Macie service-linked IAM role has appropriate permissions to read and decrypt S3 objects. For S3 objects that are server-side encrypted with AWS Key Management Service (AWS KMS), update the associated KMS key policies to grant the required permission for the Macie service-linked role to decrypt existing and future S3 objects.
- Configure a S3 bucket for sensitive data results in the Macie admin account to access the results and allow for long-term storage and retention.
Activate automated sensitive data discovery in the delegated Macie administrator account
In this section, we walk you through how to activate automated sensitive data discovery in Macie.
For new Macie admin accounts, automated sensitive data discovery is turned on by default. For existing Macie accounts, you need to activate automated sensitive data discovery in the existing Macie admin accounts.
To activate automated sensitive data discovery in the existing Macie admin accounts
- Navigate to the Amazon Macie console.
- Under Settings, choose Automated discovery.
- For Status, choose Enable, and then edit the following sections according to your needs:
- S3 buckets – By default, Macie selects and inspects samples of objects across all S3 buckets in your organization. For example, you might want to exclude an S3 bucket that stores AWS CloudTrail logs.
- Managed data identifiers – You can select managed data identifiers to include or exclude during automated sensitivity data discovery. By default, Macie inspects and samples objects by using a set of managed data identifiers that AWS recommends. This includes most of the managed data identifiers that AWS supports, but excludes some that can potentially cause a high volume of alerts in buckets where you might not expect them. If you know specific data types that could exist within your environment, you can add those managed data identifiers specifically. If you want Macie to exclude detections that aren’t sensitive in your deployment, you can exclude them. For more details, see the Macie administrator user guide.
- Custom data identifiers – You can select custom data identifiers to include or exclude during automated sensitive data discovery.
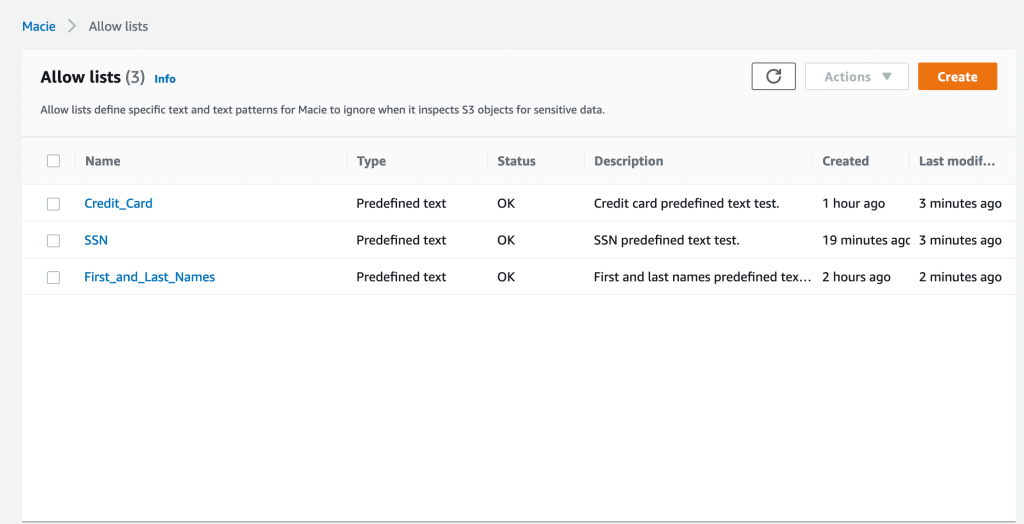
- Allow lists – You can select allow lists to define specific text or a text pattern that you want Macie to exclude from automated sensitive data discovery.

Figure 1: Settings page for Macie automated sensitive data discovery
Note: When you make changes to the inclusion or exclusion of managed or custom data identifiers for S3 buckets managed by the Macie admin account, those changes apply only to new S3 objects that are discovered. The changes do not apply to detections for existing S3 objects that were previously scanned with automated sensitive data discovery.
How Macie samples data and assigns scores
Macie automated sensitive data discovery analyzes objects in the S3 buckets in your accounts where Macie is turned on. It organizes objects with similar S3 metadata, such as bucket names, object-key prefixes, file-type extensions, and storage class, into groups that are likely to have similar content. It then selects small, but representative, samples from each identified group of objects and scans them to detect the presence of sensitive data. Macie has a feedback loop that uses the results of previously scanned samples to prioritize the next set of samples to inspect.
This systematic exploration of your S3 storage can help identify the presence of unknown sensitive data for a fraction of the cost of targeted sensitive data discovery jobs. A single sample might not be conclusive, so Macie continues sampling to build a security-relevant, interactive map of your S3 buckets. It automatically detects new buckets in your accounts, and keeps track of the previously scanned objects that get deleted from existing buckets to make sure that your map stays up to date.
Review data sensitivity scoring
When you first activate automated sensitive data discovery, Macie assigns each of your S3 buckets a sensitivity score of 50. Then, Macie begins to continually select and scan a sample of objects in your S3 buckets across each member account. Based on the results, Macie adjusts the sensitivity score for each bucket, assigning new scores that range from 1–99. Macie increases the score if sensitive data is found, and decreases the score if sensitive data isn’t found.
Macie calculates this score based on the amount of data inspected, number of sensitive data types discovered, number of occurrences of each sensitive data type, and the nature of the sensitive data. The score can help you identify potential security risks, but it does not indicate the criticality that a given bucket, and its contents, might have for your organization.
Figure 2 shows an example Summary page for the delegated Macie administrator. This page summarizes the results of automated sensitive data discovery for the delegated administrator account and each member account.

Figure 2: Macie summary page showing S3 bucket metadata
From the Summary page, you can choose statistics, such as Publicly accessible or Sensitive, to investigate. When you choose a statistic, you will be redirected to the S3 buckets page that displays a filtered view based on the selected data.
On the S3 buckets page shown in Figure 3, Macie displays a heat map of consolidated information, grouped by account, on whether a bucket is sensitive, not sensitive, or not analyzed yet. Each square in the heat map represents an S3 bucket. In the figure, account 111122223333 has 79 buckets, including 4 buckets with sensitive data findings, 34 buckets that were scanned with no sensitive data found, and 41 buckets that are pending scanning.

Figure 3: Heat map of automated sensitive data discovery in Macie
For more information about an S3 bucket, select one of the squares in the heat map. This will show you the sensitivity score and other details, such as types of sensitive data, names of sensitive objects, and profiling statistics.
The following table summarizes Macie sensitivity score categories and how to interpret the heat map.
| Data sensitivity score | Data sensitivity status | Data sensitivity heat map |
| -1 | Unable to analyze | Macie was unable to analyze a S3 object(s) due to a permission issue. |
| 1-49 | Not sensitive | A darker shade of blue, and a lower sensitivity score, indicates that a greater proportion of objects in the bucket were scanned and fewer occurrences of sensitive data were found.
|
| 50 | Not analyzed | White shading indicates that Macie hasn’t analyzed objects yet. |
| 51-99 | Sensitive | A darker shade of red, and a higher sensitivity score, indicates that a greater proportion of objects in the bucket were scanned and more occurrences of sensitive data were found.
|
| 100 | Maximum score | A solid shade of red. Macie doesn’t assign this score, but you can manually assign it. |
Common use cases for Macie automated sensitive data discovery
In this section, we discuss how you can use automated sensitive data discovery in Macie to implement the following common patterns:
- Activate continuous monitoring for broad visibility into the presence of sensitive data in your S3 buckets, including existing buckets where sensitive data was not found before.
- Manually identify and prioritize a subset of S3 buckets so that you can conduct a full scan based on the sensitivity score.
- Build automation that scans S3 buckets by using the sensitivity score and takes actions, such as sending notifications or performing remediation, so that buckets with sensitive data have proper guardrails.
Continuous monitoring of S3 buckets for sensitive data
The dynamic nature of applications and the speed of innovation increases the type and amount of data generated, stored, and processed over time. While development teams work on developing new features for your applications, security teams help the application teams understand where they should take action to protect data.
Discovering sensitive data is an ongoing activity that requires a continuous search for sensitive data in S3 buckets in each account that the Macie admin accounts manage. Macie continually searches for sensitive data and updates the information found on the Summary and S3 buckets pages in the Macie admin accounts.
To help you gain visibility across your S3 storage at an affordable cost, automated sensitive data discovery establishes a baseline profile of the sensitivity of each bucket, while analyzing only a fraction of S3 data for each account in a given month. After you activate this feature in the Macie admin accounts, Macie starts constructing an S3 bucket baseline within 48 hours.
Macie continues to refine bucket profiles and prioritizes those that it has the least information on. For example, Macie might prioritize buckets that were recently created in the monitored accounts or existing buckets from a member account that recently joined your organization. This provides continual visibility that achieves greater fidelity over time while scanning data at a predictable monthly rate.
Automated discovery uses the results of the automated data inspection to create a profile for each bucket. It also tracks previously scanned objects to make sure that each bucket profile is up to date. This means that if a previously scanned object is removed, Macie updates the profile of the bucket to make sure that you have the most current information.
You can also include or exclude specific managed and custom data identifiers from specific S3 buckets or from each S3 bucket that the Macie admin accounts manages. For example, to make sure that the sensitivity score is as accurate as possible, you can exclude specific data identifiers on select S3 buckets where you expect those identifiers.
Let’s walk through an example of how to exclude specific data identifiers on an S3 bucket. Imagine that your company has an S3 bucket where data scientists store a test dataset of fictitious names and addresses. The appropriate teams have verified that the test dataset isn’t sensitive and can be used to create test data models. You want to exclude name and address detections for this bucket while keeping these detections for the rest of your S3 storage.
To exclude the name and address identifiers, navigate to the specific S3 bucket, choose the identifiers to exclude (in this case, NAME and ADDRESS), and choose Exclude from score, as shown in Figure 4. Macie automatically excludes these identifiers from the sensitivity score for that S3 bucket only, for existing and new objects.

Figure 4: Macie S3 bucket list view with sensitivity scores and detections
Note: When you change the included or excluded managed or custom data identifiers for an S3 bucket, Macie automatically updates existing detections and sensitivity scores. Macie also applies these changes to new S3 objects that it scans with automated sensitive data discovery.
You can prioritize S3 buckets that need additional review by manually assigning them a maximum sensitivity score. When you select Assign maximum score on an S3 bucket, Macie sets the score to 100, regardless of the sensitive data detections that it found through automated sensitive data discovery. Automated sensitive data discovery continues to scan the bucket and create sensitive data detections unless you select Exclude from automated discovery.
You might want to assign maximum scores for S3 buckets that are publicly accessible, shared across multiple internal or external customers, or part of an environment where sensitive data shouldn’t be present. By assigning a maximum score to an S3 bucket, you can help ensure that your security and privacy teams regularly review high-priority buckets. You can decide whether to assign maximum scores based on your organization’s use cases and security policies.
Identify a subset of S3 buckets to conduct a full scan based on the sensitivity score
You can use sensitivity scores to prioritize specific S3 buckets for full Macie scanning jobs. By running full scanning jobs on specific buckets, you can focus your efforts on buckets where sensitive data could have the greatest impact on your organization. Because full scanning occurs on only a subset of your buckets, this strategy can help lower your overall costs for Macie.
To create a Macie job that scans S3 buckets based on the sensitivity score
- Navigate to the Amazon Macie console.
- In the left navigation pane, choose S3 buckets.
- For Sensitivity, add a filter as follows:
- For To, enter a minimum sensitivity score.
- For From, enter a maximum sensitivity score.
If you leave the To field blank, Macie returns a list of buckets with a score greater than or equal to the value in the From field.
Note: Sensitivity scores can vary based on the objects analyzed and whether you have the settings configured for Assign maximum score, Automatically discover sensitive data, or both.
- After you add the filter, you will see the S3 bucket results for the Sensitivity values that you entered, grouped by account. To view the buckets in list view, choose the list view icon (
 ). To view the buckets in group view, choose the group view icon (
). To view the buckets in group view, choose the group view icon ( ).
).
Note: You can’t create Macie scan jobs from group view. To run Macie scan jobs, switch to list view.
- Make sure that you are in list view, select the specific S3 buckets that you want to scan based on the Sensitivity score, and then choose Create Jobs.

Figure 5: List view of sensitivity scores for S3 buckets
- Review the S3 buckets that you selected. To exclude specific buckets, choose Remove for each bucket. After you review your selection, choose Next.
- Select a scheduled job or one-time job. If you select Scheduled job, select the update frequency and whether or not to include existing objects. Configure the sampling depth to be 100%. Optionally, you can configure additional object criteria.
- Select managed data identifiers, custom data identifiers, allow lists, and general settings according to your needs.
- Confirm the Macie job details and choose Submit to start scanning the S3 buckets based on the sensitivity score. When this job is complete, you will receive findings on sensitive data discovered from the job.

When you are considering whether to run a scheduled job or a one-time job, remember that S3 bucket sensitivity scores can change based on new objects, managed or custom identifiers, and allow lists used by Macie automated sensitive data discovery. If you run a scheduled job on buckets that meet certain sensitivity score criteria, the configurations for the job are immutable in order to support data privacy and protection audits or investigations. If a new bucket meets the sensitivity score criteria, you need to create a new scheduled job to include that bucket.
Use automation to scan S3 buckets by sensitivity score and take actions based on findings
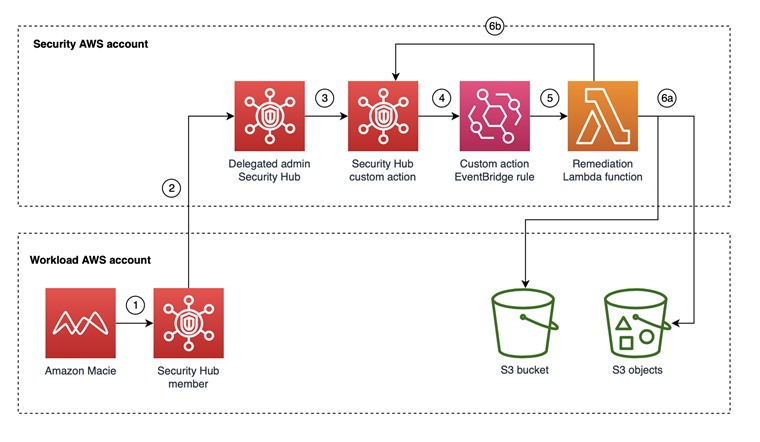
You can use the GetResourceProfile API to query specific S3 buckets and return sensitivity profiling information. With the information returned from the API, you can develop custom automation to take specific actions on buckets based on their sensitivity scores. For example, you can use Amazon EventBridge and AWS Lambda functions to create Macie jobs based on the sensitivity scores of the S3 buckets managed by Macie, as shown in the following architecture.

Figure 6: Example architecture for automated jobs based on sensitivity scores
This architecture has the following steps:
- An EventBridge rule runs periodically to invoke a Lambda function that invokes the GetResourceProfile API for S3 buckets managed by the Macie admin accounts.
- The Lambda function takes the following actions:
- Creates a list of S3 buckets with maximum sensitivity scores, or with automated sensitivity profiling scores that exceed a threshold value, and then stores the results in an Amazon DynamoDB table.
- Creates a Macie job by using items in the DynamoDB table to conduct a one-time scan with 100% sampling depth of those S3 buckets. Upon job submission, you can add a last-scanned date to the table for tracking purposes, to help avoid the creation of multiple one-time jobs on the same bucket.
- The delegated Macie administrator job starts scan jobs for S3 buckets in member accounts.
After you conduct your Macie scans either manually or with automation, you can implement semi- or fully automated response and remediation actions based on the sensitive data findings. The following are examples of automated response and remediation actions that you can take:
- You can deploy the solution to automatically send notifications to Slack if sensitive data is found for buckets with specific sensitivity scores.
- You can use AWS Security Hub custom actions to develop pre-determined response and remediation actions on Macie sensitive data findings.
Conclusion
In this blog post, we showed you how to turn on Macie automated sensitive data discovery in your AWS environment and how to use the findings to continually manage your data security posture. This new feature can help you prioritize your remediation efforts and identify buckets on which to run full scans for sensitive data discovery. We also shared a design pattern to build automation by using Macie APIs for automated remediation of Macie findings.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on Amazon Macie re:Post.
Want more AWS Security news? Follow us on Twitter.