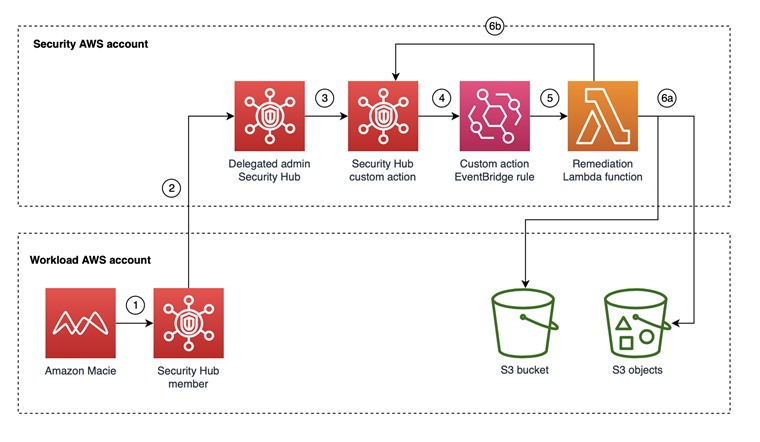
Post Syndicated from Jason Stone original https://aws.amazon.com/blogs/security/proof-of-concept-for-automated-discovery-using-amazon-macie/
Amazon Web Services (AWS) customers of various sizes across different industries are pursuing initiatives to better classify and protect the data they store in Amazon Simple Storage Service (Amazon S3). Amazon Macie helps customers identify, discover, monitor, and protect sensitive data stored in Amazon S3. However, it’s important that customers evaluate and test the capabilities of Macie to verify that they can meet their specific data identification and protection goals. In this post, we show you how to define and run a proof of concept (POC) to validate using Macie and automated discovery to enhance your current data protection strategies. The POC steps demonstrate how you can use Macie to detect and alert you to sensitive data discovered in your AWS environment and help you determine the value of using Macie to enhance your current data protection strategies.
Note: This POC uses some features that offer a 30-day free trial and other features that will incur minimal charges during the POC phase. We highlight and summarize these throughout this post.
Data security business challenges
Data security is a broad concept that revolves around protecting digital information from unauthorized access, corruption, theft, and other forms of malicious activity throughout its lifecycle. There’s an exponential growth of digital data and organizations are grappling with not only managing it but also determining where their sensitive data exists. Additionally, many organizations have compliance requirements from government regulators and industry standards, such as PCI DSS or HIPAA. Organizations want to move fast, which means giving developers the tools to build quickly to stay ahead, while making sure that the correct data classification policies are defined and enforced.
Macie features
Amazon Macie is a data security service that discovers sensitive data using machine learning and pattern matching, provides visibility into data security risks, and enables automated protection against those risks. The following is a summary of the key features of Macie, many of which will be used in this POC. The core capabilities of Macie are focused on the security of your S3 buckets and helping to identify sensitive data including financial data, personal data, and credentials as well as sensitive data that’s unique to your organization, such as intellectual property.
S3 bucket security
Customers use Amazon S3 for a variety of use cases and store various types of data in S3 buckets, including sensitive data. Continuously monitoring these buckets for the presence of sensitive data is a vital part of a data protection strategy. Macie gives you visibility into your S3 bucket inventory and the security and access controls associated with your buckets. This visibility includes if the bucket is publicly accessible, the encryption level of the bucket, and if the bucket is shared with other accounts. Whenever the security posture of one of your buckets is reduced, Macie generates a finding about the change, enabling you to respond. These findings are consumable through the AWS Management Console for Macie, through Macie APIs, as Amazon EventBridge messages, or through AWS Security Hub.
Sensitive data discovery jobs
Sensitive data discovery jobs provide a way to target a specific S3 bucket or group of buckets to do a deep analysis of the objects in those buckets and identify if sensitive data is present in the objects and if so, the type of data. These jobs can run on a daily, weekly, or monthly basis for new or changed data or once for on-demand analysis.
Automated data discovery
Macie offers an automated data discovery feature that can continually discover sensitive data within your S3 buckets. This feature is intended to help customers who have large amounts of S3 buckets and data better understand where sensitive data might be stored without having to scan all their data. By using automated data discovery, you can focus your resources on deeper investigations of the security of buckets identified to have sensitive data. Macie selects samples of the objects within S3 buckets and inspects them for the presence of sensitive data daily, providing insight into where sensitive data might reside in your overall Amazon S3 data estate.
POC overview
This POC is intended to help you gain an understanding of what Macie is capable of and how you can use it to achieve your data discovery goals. The POC in this post includes the following tasks in Macie:
- Reviewing managed data identifiers
- Defining custom data identifiers
- Staging POC data
- Running a sensitive data discovery job
- Reviewing the output of the discovery job
- Enabling and reviewing the output of automated data discovery
Note: The amount of time required for each task depends on your preparation and analysis for each stage. Note that, in the automated data discovery phase, it will take 24–48 hours for Macie to perform the first scan after the feature is enabled.
Enable Macie
Macie must be enabled before you can proceed with the POC. If you haven’t yet enabled Macie, see Enable Macie for instructions.
Note: When you enable Macie and the 30-day free trial for S3, monitoring S3 bucket security and privacy is automatically enabled. There’s also a 30-day free trial for automated data discovery, which is covered later in this post. There is no free trial for running targeted data discovery jobs. Review the Macie pricing page for details.
Review managed data identifiers
A successful POC of Macie includes understanding what data Macie can detect. Macie comes with over 150 managed data identifiers that are designed to identify sensitive data in your S3 objects. It’s important to first understand the available managed data identifiers and which ones align with the use cases you want to address. Examples of Macie managed data identifiers include credit card numbers, AWS secret access keys, and national identification numbers. Macie offers a default collection of recommend managed data identifiers to use for detecting general categories and types of sensitive data while optimizing data discovery results and reducing noise.
Keywords are an important component for Macie to be able to detect sensitive data. Many managed data identifiers require keywords to be in proximity of the data for Macie to be able to detect findings. Understanding the keywords that are used as part of sensitive data detection is important when it comes to building test data for a POC.
Prior to beginning your POC, review the list of managed data identifiers and determine which ones you feel will be necessary to use for your data discovery requirements. Additionally, identify which managed data identifiers, which are applicable to your POC, fall outside of the default list of identifiers.
Define custom data identifiers
Macie covers a wide number of use cases with its managed data identifiers, but some use cases need custom data identifiers for data types that aren’t included in the managed data identifiers. For example, customers might need to identify sensitive data that’s specific to their company, such as an employee ID or project number. Other customers might operate in industries that have data types unique to that industry, such as a known traveler number in the airline industry. If your requirements for identifying sensitive data include detecting sensitive data that isn’t part of the current list of managed data identifiers, then you can create custom data identifiers for those data types. For a POC, you might not want to create a custom data identifier for every additional detection. Instead, you can create a few to help confirm that you can use custom data identifiers for sensitive data detection and that Macie can support your data discovery goals. Building custom data identifiers has a thorough explanation of how to define a custom data identifier. Similar to managed data identifiers, custom data identifiers have keyword requirements. Defining detection criteria for custom data identifiers provides details for the types of data that require keywords.
Stage POC data
After reviewing the managed data identifiers provided by Macie and creating the custom data identifiers needed for your POC, it’s time to stage data sets that will help demonstrate the capabilities of these identifiers and better understand how Macie identifies sensitive data. We recommend that you stage data sets that contain sensitive data as well as data sets that do not to gain a full understanding of how Macie detects and reports on each of these situations. You can stage a variety of data sets to use for your POC using just a few GB of data to help keep your initial POC scans’ cost low. Staged data must be in file formats that Macie supports.
When preparing data to stage, keep in mind the keyword requirements for many of the Macie managed data identifiers. To determine which managed data identifiers have keyword requirements, see Managed data identifiers by type. When you’re staging your data, reference the keywords that are supported for the managed data identifiers you are using to help ensure that the data can be identified in your POC tests.
We recommend staging the data in one S3 bucket that’s dedicated to the POC and to use S3 server-side encryption on the bucket. If you want to use a customer managed AWS KMS key to encrypt the S3 data at rest, follow the instructions in Allowing Macie to use a customer managed AWS KMS key to give Macie access to decrypt the data in the bucket. You should also follow best practices for the S3 bucket related to not allowing public access and implementing least privilege access.
You can use one or more of the following approaches to identify and stage data for your POC:
- Stage data files created by synthetic data generator tools with sensitive data included. There are many tools available for generating sensitive data. The following are two that you can use to generate test data.
- Stage data files from public data repositories. There are various repositories staged with information that could be used for sensitive data detection. These repositories are often comprised of publicly available data sets or were created to help with testing machine learning models or sensitive data detection.
- Stage data files of your own data with sensitive information. Because the goal is to use Macie to identify sensitive information in your S3 buckets, including examples of your own data that contains sensitive information can be helpful to test the capabilities of Macie.
- Stage data files that don’t contain sensitive information. This can help you understand how Macie handles data that you believe doesn’t contain sensitive information. With the managed data identifiers that Macie offers, you should stage data files that you believe don’t contain information that aligns to the managed data identifiers. The staged data files could be log files, documents, or data sets that meet the criteria of this step.
- Stage data that contains information that’s representative of data that you would want to detect using custom data identifiers.
Run a data classification job
Now that you’ve reviewed the managed data identifiers, defined custom data identifiers, and staged sample data, it’s time to run a sensitive data discovery job. When configuring the job scope, we recommend the following:
- A specific S3 bucket where the POC data is staged.
- The scope is set to be a one-time job.
- Leave the sampling depth at 100 percent. Most customers leave this value at 100 percent, but some will lower it if they want a smaller random sample scan of their data. Most customers use automated data discovery to get sample scans instead of adjusting the sampling depth for individual jobs.
- Select the recommended managed data identifiers. If your testing requires that Macie identify additional sensitive data types that are offered as managed data identifiers but aren’t part of the recommended list, choose the Custom option and select the managed data identifiers that you need. Make sure that the recommended managed data identifiers are part of the custom list that you construct.
- Choose the custom data identifiers that you want to be used in the job.
After you configure your job, give it a name, review the final configuration, and then submit the job to run. A job that uses a data set of a few GB should complete within 30 minutes.
Review the findings from your job
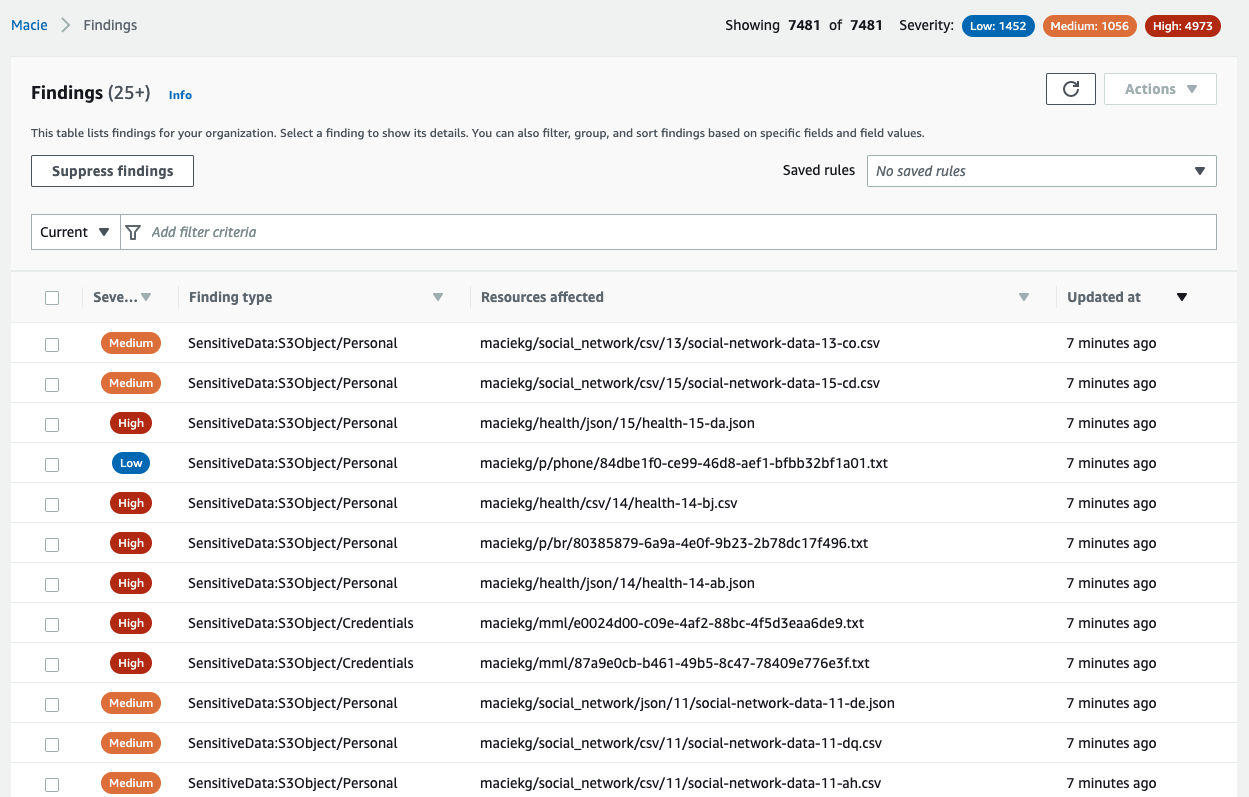
After the job completes, it’s time to review what Macie found in the data. Objects that Macie found with sensitive data will be presented as Findings in the Macie console. From the Jobs screen, choose the job you submitted. In the right-hand window, you will see the overview information for the job. From the overview window you can choose Show results menu and then select Show findings to view a list of the findings that were generated by the job.
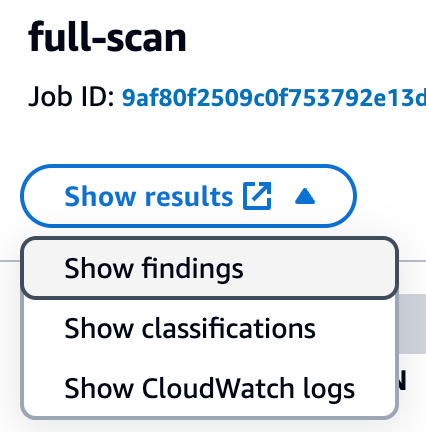
Figure 1: Viewing Macie job findings
Each object where Macie found sensitive data will be listed as a single finding. If there were multiple types of sensitive data found in the object, each type of sensitive data and a count will be included in the details. Choose each of the findings that was produced and review the details to confirm what sensitive data was identified and if the sensitive data was discovered as you expected. Additionally, confirm that you don’t have findings for objects that you staged that were not supposed to have sensitive data so that you can confirm how Macie handles these types of objects. If you created custom data identifiers, review findings for the objects that included the custom data that you detect to confirm that the data was detected.
Enable automated discovery
Now that you understand how to use Macie to discover sensitive data, the next step in the POC is to enable automated discovery and use Macie to discover sensitive data across a larger collection of your existing S3 data.
You will be enabling automated discovery in Macie as a 30-day free trial. For the free trial, the scope of total data storage to be evaluated will be 150 GB. Use the following steps to guide your setup of the automated discovery feature:
- To use automated discovery, ensure that you have a delegated administrator account defined for Macie. See Integrating and configuring an organization in Macie for steps on how to configure your delegated administrator account for Macie.
- After your delegated administrator account is configured, enable automated discovery. As part of enabling automated discovery, pay extra attention to the following items:
- Set managed data identifiers. Ideally, choose the recommended data identifiers to help reduce noise. If there are specific managed data identifiers that you really want to see, then choose Custom to choose the ones you want.
- Include custom data identifiers that you want to be used to evaluate your sensitive data.
- Exclude buckets that you don’t want included in the scope for identifying sensitive data.
- Include or exclude specific accounts that should be part of the POC. Step 5 of Enable automated discovery covers how to enable it for specific accounts.
You will see the first set of results 24 to 48 hours after you enable automated discovery. After that, you will see updates to the automated discovery results every 24 hours.
After automated discovery starts producing results, you will start seeing data in the Automated Discovery section of the Macie summary page in the console. The summary includes metrics for the total number of buckets eligible for discovery, counts for the number of buckets where sensitive data was or was not found, and how many of these buckets are public.
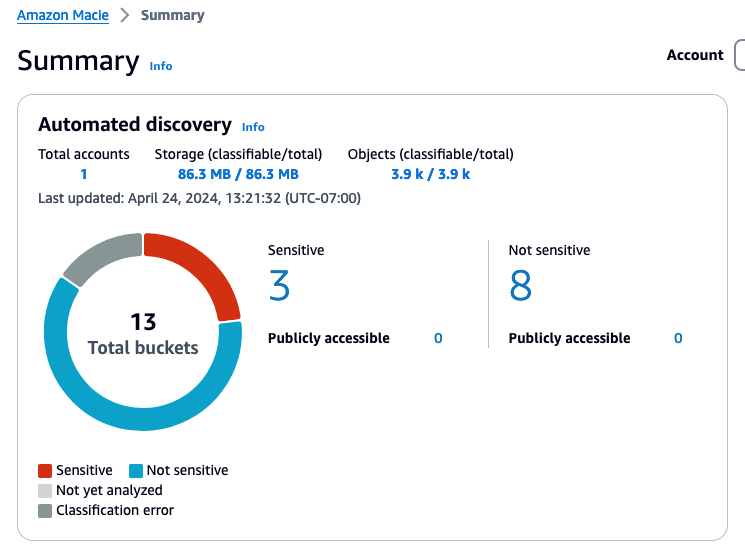
Figure 2: Example automated discovery summary metrics
Choosing a link for one of the counts will take you to the S3 buckets view with the appropriate filters applied.
After reviewing the summary screen, choose S3 buckets from the navigation pane to see a heatmap that shows each account and the buckets within each account.
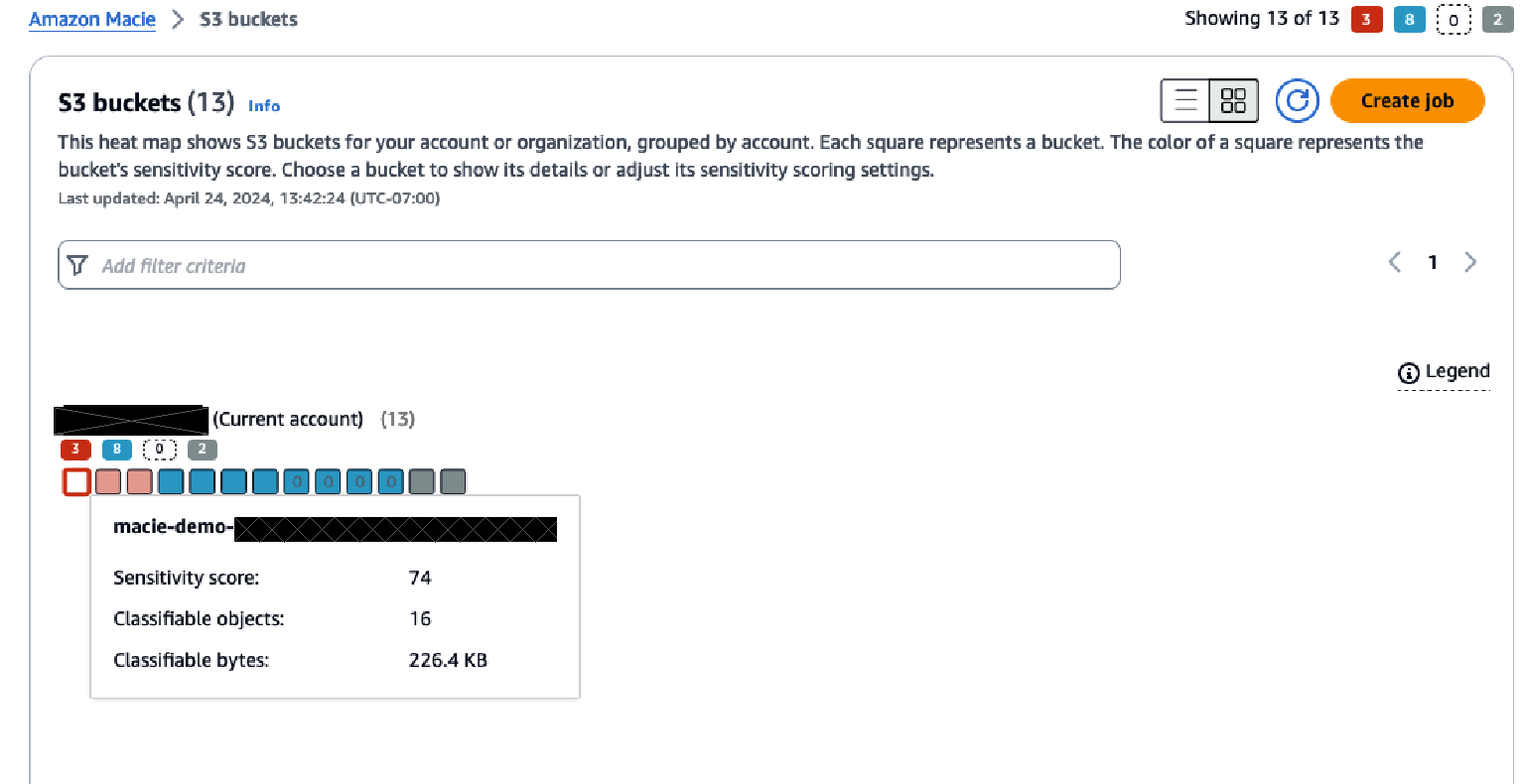
Figure 3: S3 bucket heatmap view in Macie
The heatmap provides point-in-time insights into the data that Macie has scanned, and in which buckets sensitive data has been identified or no sensitive data has been found.
Over time, this heatmap might change as automated data discovery continues sampling the data in each bucket. The heatmap view provides information on each organizational member account and insight about sensitive data within each bucket in the account.
The console displays the results as a set of colored squares for each account. Each square represents a bucket in that account and the color of the square indicates whether sensitive data was discovered in that bucket. Red indicates that some type of sensitive data has been found in the bucket, while blue indicates no sensitive data has been identified. If a bucket is blue, that means only that automated data discovery hasn’t identified sensitive data up to the point in time of the last scan, not that there is no sensitive data in the bucket.
Hover over each bucket to see a summary of the sensitivity score of the bucket along with statistics about the data in the bucket. Choosing a bucket in the heatmap will open a window that provides more information about the bucket. This information includes the sensitivity score of the bucket, a summary of the types of sensitive data found in the bucket, which objects within the bucket have been sampled, statistics related to the data that has been scanned and data that is still to be scanned, and other information about the bucket.
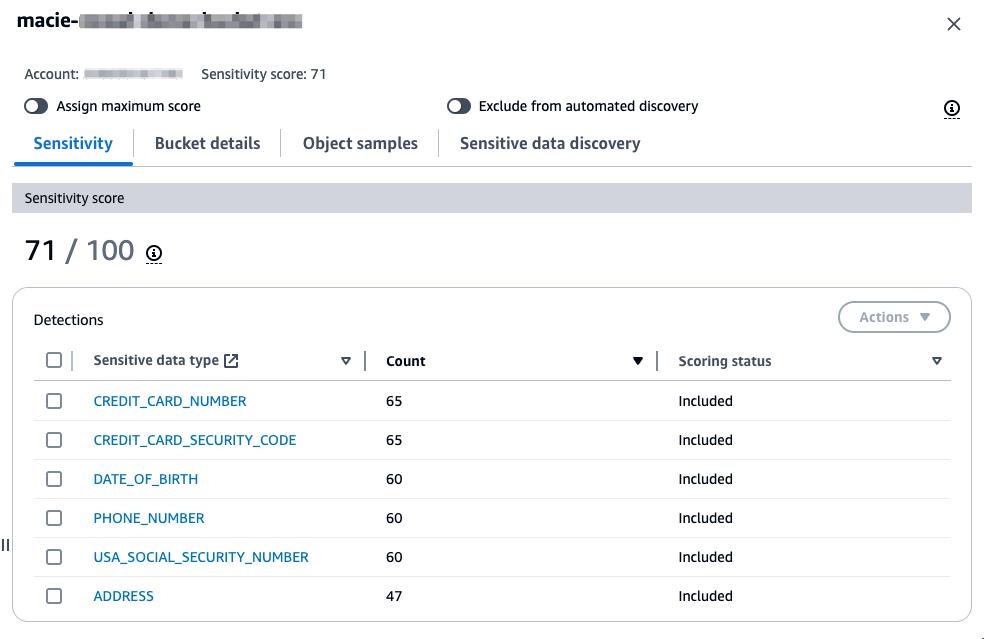
Figure 4: S3 bucket sensitivity information in Macie
As part of your POC, it’s recommended that you investigate buckets that are reported to contain sensitive data. For your investigation, validate if the data identified is sensitive based on your organization’s data classification policy. Each Macie finding contains not only the details on the types of sensitive data identified, but also the location within the file where the sensitive data is located so that you can confirm the identified data is sensitive. The following is an example of a Macie finding in an Excel file where bank account numbers were found. This example shows the row and column where the sensitive data was found.
Investigating sensitive data with findings has detailed guidance around locating sensitive data from Macie findings, retrieving the sensitive data, and the schema for sensitive data locations. If the findings are true positives, make sure that the bucket has the right level of security configurations and permissions based on the data stored in the bucket.
In addition to reviewing the bucket level statistics that are generated by automated discovery, you can view the individual findings that were generated for each S3 object that was identified as having sensitive data. You can view the findings through the Findings tab in Macie or by choosing the sensitive data type when looking at the summary detections for a bucket.
Next steps
With the preceding POC, you should now have a more complete understanding of how Macie identifies sensitive data and how you can use the information that Macie provides about that data identified. As you complete your POC, there are a few next steps that other customers have taken after completing their POC with Macie.
Operationalize Macie output
In the POC steps, we outlined how to view the findings and the insights that the automated discovery provides. Before you proceed with Macie, you should have a plan for how you will operationalize the Macie output. This will help ensure that the remediation steps for identified sensitive data are directed to the correct parties.
Depending on what operational tools you have in place, the steps that you take to operationalize the output of Macie will vary. Many customers implement operational processes that cover the following areas:
- The privacy or security team that’s responsible for Macie does an initial triage on the findings to confirm if there are true positives.
- The privacy or security team defines their operational processes related to the summary dashboard and bucket sensitivity information that’s provided by automated discovery.
- The team that owns the bucket where the sensitive data is located is provided the information needed to investigate the identified data and provide a response. Responses will vary but could include removal of the data, correcting the application that is writing the data, or applying additional security to the bucket.
A key part of operationalizing Macie output is also how you are getting and reviewing the signals related to Macie findings. As outlined in this post, you can view and investigate findings in the Macie console. At a steady state, customers find it beneficial to consume Macie findings using Amazon EventBridge, through Macie APIs, or through the integration of Macie with AWS Security Hub. These options can be used to incorporate the findings that are reported by Macie into the operational workflows and tools that work best for your organization and allow you to consume and address findings at scale. Monitoring and processing findings provides more insight into these integration approaches.
Store and retain sensitive data discovery results
As you move forward with Macie, it’s important to enable logging for each of the S3 objects that Macie has scanned. Macie creates an analysis record for each S3 object that’s in scope for a data discovery job or an automated discovery scan. These records are an audit of every object that Macie attempted to scan, including objects that didn’t contain sensitive data. Data discovery results are written to an S3 bucket that you own and where you control the data retention. These data discovery results can assist with analysis of records over time or to get a broader sense of what data Macie has scanned and which objects had sensitive data and which did not.
The data discovery scan results are stored as JSON Lines files. You can use multiple approaches to analyze and query these log files. The Amazon Macie Results Analytics GitHub repository provides instructions on how to configure Amazon Athena with tables that allow you to query the results of Macie discovery scan files.
Define the scope for Macie use
After a POC with Macie, you can set the scope of how you will use Macie in production by deciding which buckets don’t need to be evaluated and so can be excluded, such as buckets used for AWS logs and buckets deemed not in scope for sensitive data identification.
You can also refine the managed data identifiers that are required for detecting sensitive data. Based on what they learned from the POC. You can create custom data identifiers to help meet your data detection needs if necessary.
As you identify the sensitive data discovery jobs to run as part of your production use of Macie, keep in mind that these jobs are immutable. To edit an existing scheduled job, you must create a copy of the job with the updated configuration and cancel the original job for changes to take effect. Depending on the updated criteria for your job, you must do one of the following to help avoid re-scanning objects that were covered by the previous job:
- Clear include existing objects when setting the scope. This will cause the new job to schedule only objects that were created between when it was first created and when it was run for the first time.
- When setting the job scope, set the object attributes so that the object last modified date is the date of the last time the previous job ran. This helps ensure that when the new scheduled job runs, it evaluates only objects that weren’t covered by the previous job.
Clean up
To avoid incurring additional charges, disable Macie while you evaluate the value of the additional data protection provided. If S3 buckets were created for this POC, those should also be deleted.
Call to action
After the POC is complete, evaluate the results to determine how much using Macie can strengthen your organization’s data protection program. Based on that evaluation, you can identify how and where to use Macie for maximum effectiveness. Also consider how the information provided can be factored into operational workflows to get additional value from Macie.
Conclusion
This post outlined how you can use a POC to better understand how Amazon Macie can help meet your data discovery and classification needs. A well thought-out and implemented POC can provide valuable early insights and help you develop a more thorough understanding of what your data discovery and classification strategy should be. Planning your POC using the guidance in this post can help you determine more quickly if Macie is a fit for your company.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.