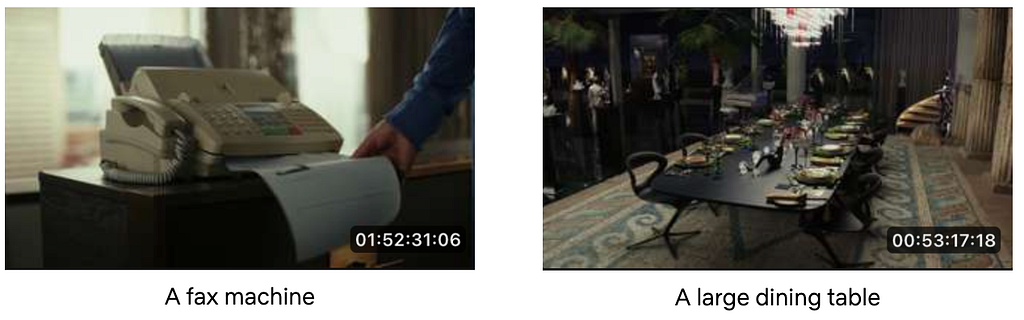Today we’re going to take a look at the behind the scenes technology behind how Netflix creates great trailers, Instagram reels, video shorts and other promotional videos.
Suppose you’re trying to create the trailer for the action thriller The Gray Man, and you know you want to use a shot of a car exploding. You don’t know if that shot exists or where it is in the film, and you have to look for it it by scrubbing through the whole film.
Or suppose it’s Christmas, and you want to create a great instagram piece out all the best scenes across Netflix films of people shouting “Merry Christmas”! Or suppose it’s Anya Taylor Joy’s birthday, and you want to create a highlight reel of all her most iconic and dramatic shots.
Making these comes down to finding the right video clips amongst hundreds of thousands movies and TV shows to find the right line of dialogue or the right visual elements (objects, scenes, emotions, actions, etc.). We have built an internal system that allows someone to perform in-video search across the entire Netflix video catalog, and we’d like to share our experience in building this system.
Building in-video search
To build such a visual search engine, we needed a machine learning system that can understand visual elements. Our early attempts included object detection, but found that general labels were both too limiting and too specific, yet not specific enough. Every show has special objects that are important (e.g. Demogorgon in Stranger Things) that don’t translate to other shows. The same was true for action recognition, and other common image and video tasks.
The Approach
We found that contrastive learning between images and text pairs work well for our goals because these models are able to learn joint embedding spaces between the two modalities. This approach is also able to learn about objects, scenes, emotions, actions, and more in a single model. We also found that extending contrastive learning to videos and text provided a substantial improvement over frame-level models.
In order to train the model on internal training data (video clips with aligned text descriptions), we implemented a scalable version on Ray Train and switched to a more performant video decoding library. Lastly, the embeddings from the video encoder exhibit strong zero or few-shot performance on multiple video and content understanding tasks at Netflix and are used as a starting point in those applications.
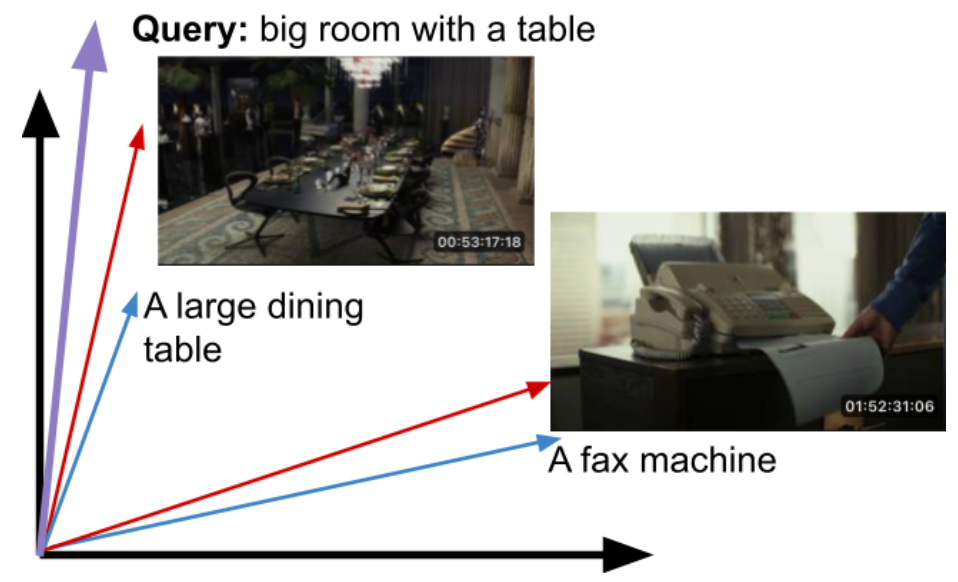
The recent success of large-scale models that jointly train image and text embeddings has enabled new use cases around multimodal retrieval. These models are trained on large amounts of image-caption pairs via in-batch contrastive learning. For a (large) batch of N examples, we wish to maximize the embedding (cosine) similarity of the N correct image-text pairs, while minimizing the similarity of the other N²-N paired embeddings. This is done by treating the similarities as logits and minimizing the symmetric cross-entropy loss, which gives equal weighting to the two settings (treating the captions as labels to the images and vice versa).
Once properly trained, the embeddings for the corresponding images and text (i.e. captions) will be close to each other and farther away from unrelated pairs.
Typically embedding spaces are hundred/thousand dimensional.
At query time, the input text query can be mapped into this embedding space, and we can return the closest matching images.
The query may have not existed in the training set. Cosine similarity can be used as a similarity measure.
While these models are trained on image-text pairs, we have found that they are an excellent starting point to learning representations of video units like shots and scenes. As videos are a sequence of images (frames), additional parameters may need to be introduced to compute embeddings for these video units, although we have found that for shorter units like shots, an unparameterized aggregation like averaging (mean-pooling) can be more effective. To train these parameters as well as fine-tune the pretrained image-text model weights, we leverage in-house datasets that pair shots of varying durations with rich textual descriptions of their content. This additional adaptation step improves performance by 15–25% on video retrieval tasks (given a text prompt), depending on the starting model used and metric evaluated.
On top of video retrieval, there are a wide variety of video clip classifiers within Netflix that are trained specifically to find a particular attribute (e.g. closeup shots, caution elements). Instead of training from scratch, we have found that using the shot-level embeddings can give us a significant head start, even beyond the baseline image-text models that they were built on top of.
Lastly, shot embeddings can also be used for video-to-video search, a particularly useful application in the context of trailer and promotional asset creation.
Engineering and Infrastructure
Our trained model gives us a text encoder and a video encoder. Video embeddings are precomputed on the shot level, stored in our media feature store, and replicated to an elastic search cluster for real-time nearest neighbor queries. Our media feature management system automatically triggers the video embedding computation whenever new video assets are added, ensuring that we can search through the latest video assets.
The embedding computation is based on a large neural network model and has to be run on GPUs for optimal throughput. However, shot segmentation from a full-length movie is CPU-intensive. To fully utilize the GPUs in the cloud environment, we first run shot segmentation in parallel on multi-core CPU machines, store the result shots in S3 object storage encoded in video formats such as mp4. During GPU computation, we stream mp4 video shots from S3 directly to the GPUs using a data loader that performs prefetching and preprocessing. This approach ensures that the GPUs are efficiently utilized during inference, thereby increasing the overall throughput and cost-efficiency of our system.
At query time, a user submits a text string representing what they want to search for. For visual search queries, we use the text encoder from the trained model to extract an text embedding, which is then used to perform appropriate nearest neighbor search. Users can also select a subset of shows to search over, or perform a catalog wide search, which we also support.
Finding a needle in a haystack is hard. We learned from talking to video creatives who make trailers and social media videos that being able to find needles was key, and a big pain point. The solution we described has been fruitful, works well in practice, and is relatively simple to maintain. Our search system allows our creatives to iterate faster, try more ideas, and make more engaging videos for our viewers to enjoy.
We hope this post has been interesting to you. If you are interested in working on problems like this, Netflix is always hiring great researchers, engineers and creators.
Building In-Video Search was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Netflix leverages machine learning to create the best media for our members. Earlier we shared the details of one of these algorithms, introduced how our platform team is evolving the media-specific machine learning ecosystem, and discussed how data from these algorithms gets stored in our annotation service.
Much of the ML literature focuses on model training, evaluation, and scoring. In this post, we will explore an understudied aspect of the ML lifecycle: integration of model outputs into applications.
An example of using Machine Learning to find shots of Eleven in Stranger Things and surfacing the results in studio application for the consumption of Netflix video editors.
Specifically, we will dive into the architecture that powers search capabilities for studio applications at Netflix. We discuss specific problems that we have solved using Machine Learning (ML) algorithms, review different pain points that we addressed, and provide a technical overview of our new platform.
Overview
At Netflix, we aim to bring joy to our members by providing them with the opportunity to experience outstanding content. There are two components to this experience. First, we must provide the content that will bring them joy. Second, we must make it effortless and intuitive to choose from our library. We must quickly surface the most stand-out highlights from the titles available on our service in the form of images and videos in the member experience.
These multimedia assets, or “supplemental” assets, don’t just come into existence. Artists and video editors must create them. We build creator tooling to enable these colleagues to focus their time and energy on creativity. Unfortunately, much of their energy goes into labor-intensive pre-work. A key opportunity is to automate these mundane tasks.
Use cases
Use case #1: Dialogue search
Dialogue is a central aspect of storytelling. One of the best ways to tell an engaging story is through the mouths of the characters. Punchy or memorable lines are a prime target for trailer editors. The manual method for identifying such lines is a watchdown (aka breakdown).
An editor watches the title start-to-finish, transcribes memorable words and phrases with a timecode, and retrieves the snippet later if the quote is needed. An editor can choose to do this quickly and only jot down the most memorable moments, but will have to rewatch the content if they miss something they need later. Or, they can do it thoroughly and transcribe the entire piece of content ahead of time. In the words of one of our editors:
Watchdowns / breakdown are very repetitive and waste countless hours of creative time!
Scrubbing through hours of footage (or dozens of hours if working on a series) to find a single line of dialogue is profoundly tedious. In some cases editors need to search across many shows and manually doing it is not feasible. But what if scrubbing and transcribing dialogue is not needed at all?
Ideally, we want to enable dialogue search that supports the following features:
Search across one title, a subset of titles (e.g. all dramas), or the entire catalog
Search by character or talent
Multilingual search
Use case #2: Visual search
A picture is worth a thousand words. Visual storytelling can help make complex stories easier to understand, and as a result, deliver a more impactful message.
Artists and video editors routinely need specific visual elements to include in artworks and trailers. They may scrub for frames, shots, or scenes of specific characters, locations, objects, events (e.g. a car chasing scene in an action movie), or attributes (e.g. a close-up shot). What if we could enable users to find visual elements using natural language?
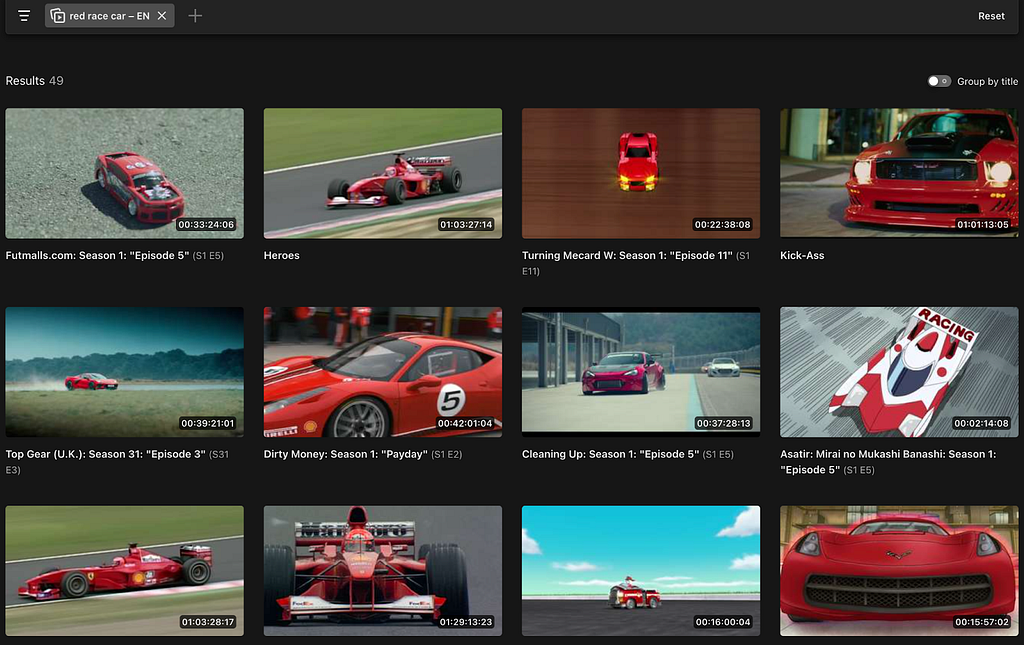
Here is an example of the desired output when the user searches for “red race car” across the entire content library.
User searching for “red race car”
Use case #3: Reverse shot search
Natural-language visual search offers editors a powerful tool. But what if they already have a shot in mind, and they want to find something that just looks similar? For instance, let’s say that an editor has found a visually stunning shot of a plate of food from Chef’s Table, and she’s interested in finding similar shots across the entire show.
User provides a sample image to find other similar images
Prior engineering work
Approach #1: on-demand batch processing
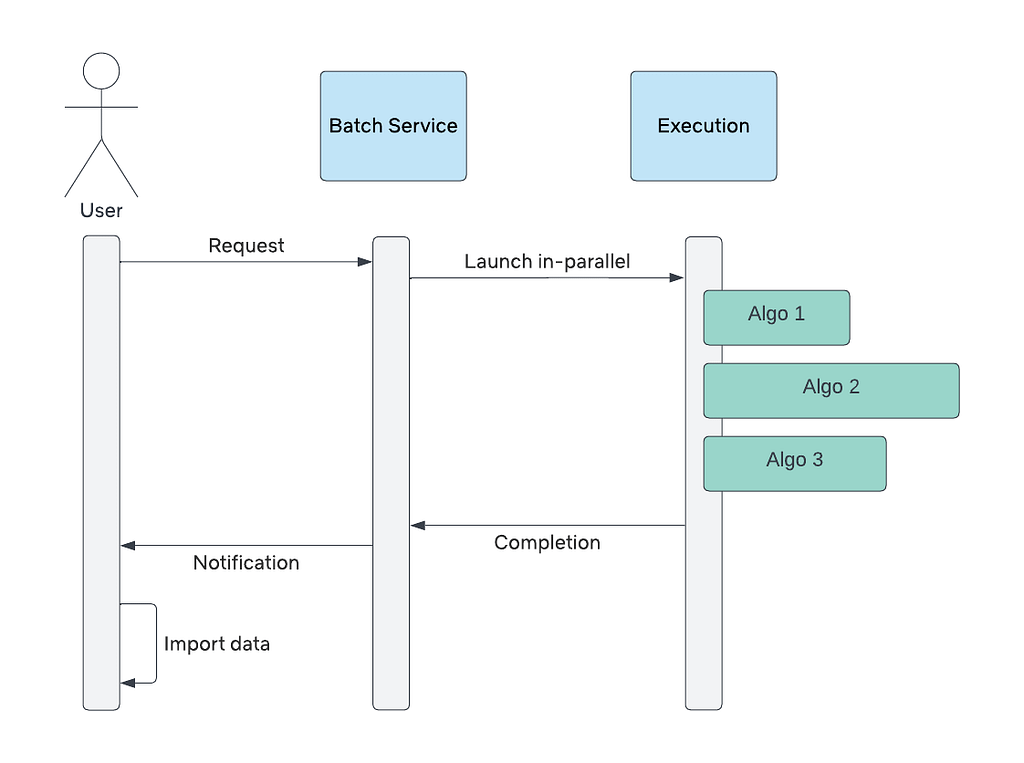
Our first approach to surface these innovations was a tool to trigger these algorithms on-demand and on a per-show basis. We implemented a batch processing system for users to submit their requests and wait for the system to generate the output. Processing took several hours to complete. Some ML algorithms are computationally intensive. Many of the samples provided had a significant number of frames to process. A typical 1 hour video could contain over 80,000 frames!
After waiting for processing, users downloaded the generated algo outputs for offline consumption. This limited pilot system greatly reduced the time spent by our users to manually analyze the content. Here is a visualization of this flow.
On-demand batch processing system flow
Approach #2: enabling online request with pre-computation
After the success of this approach we decided to add online support for a couple of algorithms. For the first time, users were able to discover matches across the entire catalog, oftentimes finding moments they never knew even existed. They didn’t need any time-consuming local setup and there was no delays since the data was already pre-computed.
Interactive system with pre-computed data flow
The following quote exemplifies the positive reception by our users:
“We wanted to find all the shots of the dining room in a show. In seconds, we had what normally would have taken 1–2 people hours/a full day to do, look through all the shots of the dining room from all 10 episodes of the show. Incredible!” Dawn Chenette, Design Lead
This approach had several benefits for product engineering. It allowed us to transparently update the algo data without users knowing about it. It also provided insights into query patterns and algorithms that were gaining traction among users. In addition, we were able to perform a handful of A/B tests to validate or negate our hypotheses for tuning the search experience.
Pain points
Our early efforts to deliver ML insights to creative professionals proved valuable. At the same time we experienced growing engineering pains that limited our ability to scale.
Maintaining disparate systems posed a challenge. They were first built by different teams on different stacks, so maintenance was expensive. Whenever ML researchers finished a new algorithm they had to integrate it separately into each system. We were near the breaking point with just two systems and a handful of algorithms. We knew this would only worsen as we expanded to more use cases and more researchers.
The online application unlocked the interactivity for our users and validated our direction. However, it was not scaling well. Adding new algos and onboarding new use cases was still time consuming and required the effort of too many engineers. These investments in one-to-one integrations were volatile with implementation timelines varying from a few weeks to several months. Due to the bespoke nature of the implementation, we lacked catalog wide searches for all available ML sources.
In summary, this model was a tightly-coupled application-to-data architecture, where machine learning algos were mixed with the backend and UI/UX software code stack. To address the variance in the implementation timelines we needed to standardize how different algorithms were integrated — starting from how they were executed to making the data available to all consumers consistently. As we developed more media understanding algos and wanted to expand to additional use cases, we needed to invest in system architecture redesign to enable researchers and engineers from different teams to innovate independently and collaboratively. Media Search Platform (MSP) is the initiative to address these requirements.
Although we were just getting started with media-search, search itself is not new to Netflix. We have a mature and robust search and recommendation functionality exposed to millions of our subscribers. We knew we could leverage learnings from our colleagues who are responsible for building and innovating in this space. In keeping with our “highly aligned, loosely coupled” culture, we wanted to enable engineers to onboard and improve algos quickly and independently, while making it easy for Studio and product applications to integrate with the media understanding algo capabilities.
Making the platform modular, pluggable and configurable was key to our success. This approach allowed us to keep the distributed ownership of the platform. It simultaneously provided different specialized teams to contribute relevant components of the platform. We used services already available for other use cases and extended their capabilities to support new requirements.
Next we will discuss the system architecture and describe how different modules interact with each other for end-to-end flow.
Architecture
System Architecture
Netflix engineers strive to iterate rapidly and prefer the “MVP” (minimum viable product) approach to receive early feedback and minimize the upfront investment costs. Thus, we didn’t build all the modules completely. We scoped the pilot implementation to ensure immediate functionalities were unblocked. At the same time, we kept the design open enough to allow future extensibility. We will highlight a few examples below as we discuss each component separately.
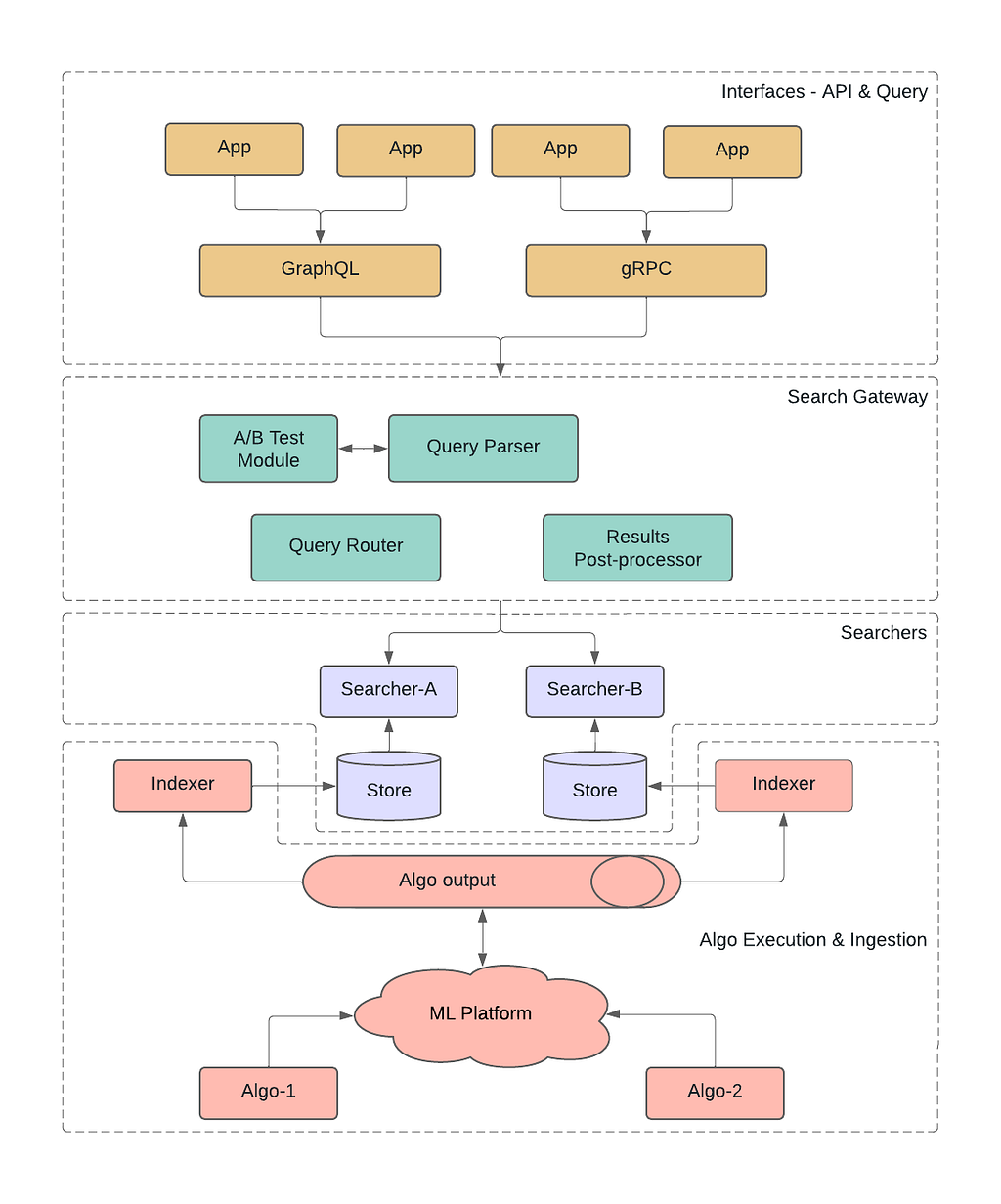
Interfaces – API & Query
Starting at the top of the diagram, the platform allows apps to interact with it using either gRPC or GraphQL interfaces. Having diversity in the interfaces is essential to meet the app-developers where they are. At Netflix, gRPC is predominantly used in backend-to-backend communication. With active GraphQL tooling provided by our developer productivity teams, GraphQL has become a de-facto choice for UI — backend integration. You can find more about what the team has built and how it is getting used in these blog posts. In particular, we have been relying on Domain Graph Service Framework for this project.
During the query schema design, we accounted for future use cases and ensured that it will allow future extensions. We aimed to keep the schema generic enough so that it hides implementation details of the actual search systems that are used to execute the query. Additionally it is intuitive and easy to understand yet feature rich so that it can be used to express complex queries. Users have flexibility to perform multimodal search with input being a simple text term, image or short video. As discussed earlier, search could be performed against the entire Netflix catalog, or it could be limited to specific titles. Users may prefer results that are organized in some way such as group by a movie, sorted by timestamp. When there are a large number of matches, we allow users to paginate the results (with configurable page size) instead of fetching all or a fixed number of results.
Search Gateway
The client generated input query is first given to the Query processing system. Since most of our users are performing targeted queries such as — search for dialogue “friends don’t lie” (from the above example), today this stage performs lightweight processing and provides a hook to integrate A/B testing. In the future we plan to evolve it into a “query understanding system” to support free-form searches to reduce the burden on users and simplify client side query generation.
The query processing modifies queries to match the target data set. This includes “embedding” transformation and translation. For queries against embedding based data sources it transforms the input such as text or image to corresponding vector representation. Each data source or algorithm could use a different encoding technique so, this stage ensures that the corresponding encoding is also applied to the provided query. One example why we need different encoding techniques per algorithm is because there is different processing for an image — which has a single frame while video — which contains a sequence of multiple frames.
With global expansion we have users where English is not a primary language. All of the text-based models in the platform are trained using English language so we translate non-English text to English. Although the translation is not always perfect it has worked well in our case and has expanded the eligible user base for our tool to non-English speakers.
Once the query is transformed and ready for execution, we delegate search execution to one or more of the searcher systems. First we need to federate which query should be routed to which system. This is handled by the Query router and Searcher-proxy module. For the initial implementation we have relied on a single searcher for executing all the queries. Our extensible approach meant the platform could support additional searchers, which have already been used to prototype new algorithms and experiments.
A search may intersect or aggregate the data from multiple algorithms so this layer can fan out a single query into multiple search executions. We have implemented a “searcher-proxy” inside this layer for each supported searcher. Each proxy is responsible for mapping input query to one expected by the corresponding searcher. It then consumes the raw response from the searcher before handing it over to the Results post-processor component.
The Results post-processor works on the results returned by one or more searchers. It can rank results by applying custom scoring, populate search recommendations based on other similar searches. Another functionality we are evaluating with this layer is to dynamically create different views from the same underlying data.
For ease of coordination and maintenance we abstracted the query processing and response handling in a module called — Search Gateway.
Searchers
As mentioned above, query execution is handled by the searcher system. The primary searcher used in the current implementation is called Marken — scalable annotation service built at Netflix. It supports different categories of searches including full text and embedding vector based similarity searches. It can store and retrieve temporal (timestamp) as well as spatial (coordinates) data. This service leverages Cassandra and Elasticsearch for data storage and retrieval. When onboarding embedding vector data we performed an extensive benchmarking to evaluate the available datastores. One takeaway here is that even if there is a datastore that specializes in a particular query pattern, for ease of maintainability and consistency we decided to not introduce it.
We have identified a handful of common schema types and standardized how data from different algorithms is stored. Each algorithm still has the flexibility to define a custom schema type. We are actively innovating in this space and recently added capability to intersect data from different algorithms. This is going to unlock creative ways of how the data from multiple algorithms can be superimposed on each other to quickly get to the desired results.
Algo Execution & Ingestion
So far we have focused on how the data is queried but, there is an equally complex machinery powering algorithm execution and the generation of the data. This is handled by our dedicated media ML Platform team. The team specializes in building a suite of media-specific machine learning tooling. It facilitates seamless access to media assets (audio, video, image and text) in addition to media-centric feature storage and compute orchestration.
For this project we developed a custom sink that indexes the generated data into Marken according to predefined schemas. Special care is taken when the data is backfilled for the first time so as to avoid overwhelming the system with huge amounts of writes.
Last but not the least, our UI team has built a configurable, extensible library to simplify integrating this platform with end user applications. Configurable UI makes it easy to customize query generation and response handling as per the needs of individual applications and algorithms. The future work involves building native widgets to minimize the UI work even further.
Summary
The media understanding platform serves as an abstraction layer between machine learning algos and various applications and features. The platform has already allowed us to seamlessly integrate search and discovery capabilities in several applications. We believe future work in maturing different parts will unlock value for more use cases and applications. We hope this post has offered insights into how we approached its evolution. We will continue to share our work in this space, so stay tuned.
In 2007, Netflix started offering streaming alongside its DVD shipping services. As the catalog grew and users adopted streaming, so did the opportunities for creating and improving our recommendations. With a catalog spanning thousands of shows and a diverse member base spanning millions of accounts, recommending the right show to our members is crucial.
Why should members care about any particular show that we recommend? Trailers and artworks provide a glimpse of what to expect in that show. We have been leveraging machine learning (ML) models to personalize artwork and to help our creatives create promotional content efficiently.
Our goal in building a media-focused ML infrastructure is to reduce the time from ideation to productization for our media ML practitioners. We accomplish this by paving the path to:
Accessing and processing media data (e.g. video, image, audio, and text)
Training large-scale models efficiently
Productizing models in a self-serve fashion in order to execute on existing and newly arriving assets
Storing and serving model outputs for consumption in promotional content creation
In this post, we will describe some of the challenges of applying machine learning to media assets, and the infrastructure components that we have built to address them. We will then present a case study of using these components in order to optimize, scale, and solidify an existing pipeline. Finally, we’ll conclude with a brief discussion of the opportunities on the horizon.
Infrastructure challenges and components
In this section, we highlight some of the unique challenges faced by media ML practitioners, along with the infrastructure components that we have devised to address them.
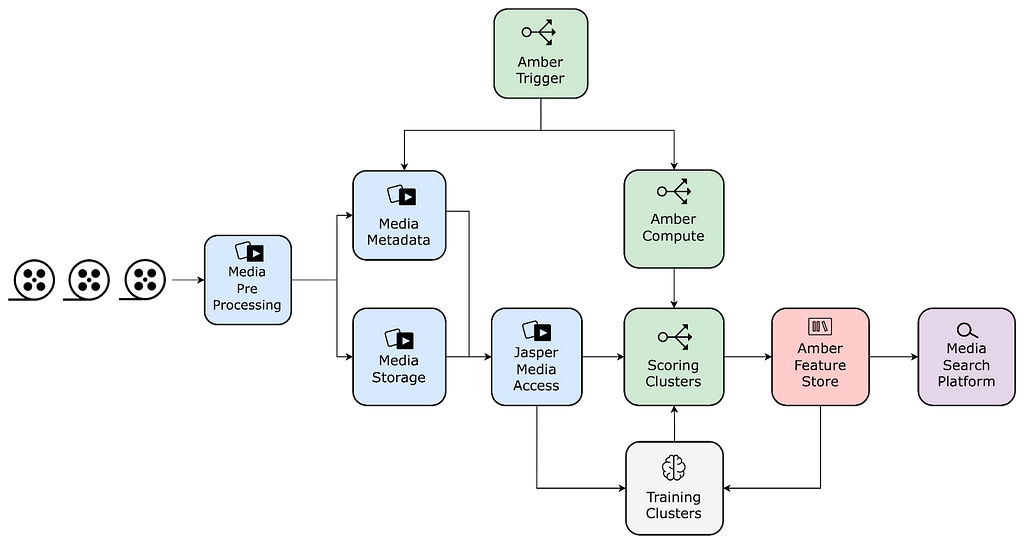
Media Access: Jasper
In the early days of media ML efforts, it was very hard for researchers to access media data. Even after gaining access, one needed to deal with the challenges of homogeneity across different assets in terms of decoding performance, size, metadata, and general formatting.
To streamline this process, westandardized media assets with pre-processing steps that create and store dedicated quality-controlled derivatives with associated snapshotted metadata. In addition, we provide a unified library that enables ML practitioners to seamlessly access video, audio, image, and various text-based assets.
Media Feature Storage: Amber Storage
Media feature computation tends to be expensive and time-consuming. Many ML practitioners independently computed identical features against the same asset in their ML pipelines.
To reduce costs and promote reuse, we have built a feature store in order to memoize features/embeddings tied to media entities. This feature store is equipped with a data replication system that enables copying data to different storage solutions depending on the required access patterns.
Compute Triggering and Orchestration: Amber Orchestration
Productized models must run over newly arriving assets for scoring. In order to satisfy this requirement, ML practitioners had to develop bespoke triggering and orchestration components per pipeline. Over time, these bespoke components became the source of many downstream errors and were difficult to maintain.
Amber is a suite of multiple infrastructure components that offers triggering capabilities to initiate the computation of algorithms with recursive dependency resolution.
Training Performance
Media model training poses multiple system challenges in storage, network, and GPUs. We have developed a large-scale GPU training cluster based on Ray, which supports multi-GPU / multi-node distributed training. We precompute the datasets, offload the preprocessing to CPU instances, optimize model operators within the framework, and utilize a high-performance file system to resolve the data loading bottleneck, increasing the entire training system throughput 3–5 times.
Serving and Searching
Media feature values can be optionally synchronized to other systems depending on necessary query patterns. One of these systems is Marken, a scalable service used to persist feature values as annotations, which are versioned and strongly typed constructs associated with Netflix media entities such as videos and artwork.
This service provides a user-friendly query DSL for applications to perform search operations over these annotations with specific filtering and grouping. Marken provides unique search capabilities on temporal and spatial data by time frames or region coordinates, as well as vector searches that are able to scale up to the entire catalog.
ML practitioners interact with this infrastructure mostly using Python, but there is a plethora of tools and platforms being used in the systems behind the scenes. These include, but are not limited to, Conductor, Dagobah, Metaflow, Titus, Iceberg, Trino, Cassandra, Elastic Search, Spark, Ray, MezzFS, S3, Baggins, FSx, and Java/Scala-based applications with Spring Boot.
Case study: scaling match cutting using the media ML infra
The Media Machine Learning Infrastructure is empowering various scenarios across Netflix, and some of them are described here. In this section, we showcase the use of this infrastructure through the case study of Match Cutting.
Background
Match Cutting is a video editing technique. It’s a transition between two shots that uses similar visual framing, composition, or action to fluidly bring the viewer from one scene to the next. It is a powerful visual storytelling tool used to create a connection between two scenes.
Figure 2 – a series of frame match cuts from Wednesday.
In an earlier post, we described how we’ve used machine learning to find candidate pairs. In this post, we will focus on the engineering and infrastructure challenges of delivering this feature.
Where we started
Initially, we built Match Cutting to find matches across a single title (i.e. either a movie or an episode within a show). An average title has 2k shots, which means that we need to enumerate and process ~2M pairs.
Figure 3- The original Match Cutting pipeline before leveraging media ML infrastructure components.
This entire process was encapsulated in a single Metaflow flow. Each step was mapped to a Metaflow step, which allowed us to control the amount of resources used per step.
Step 1
We download a video file and produce shot boundary metadata. An example of this data is provided below:
SB = {0: [0, 20], 1: [20, 30], 2: [30, 85], …}
Each key in the SB dictionary is a shot index and each value represents the frame range corresponding to that shot index. For example, for the shot with index 1 (the second shot), the value captures the shot frame range [20, 30], where 20 is the start frame and 29 is the end frame (i.e. the end of the range is exclusive while the start is inclusive).
Using this data, we then materialized individual clip files (e.g. clip0.mp4, clip1.mp4, etc) corresponding to each shot so that they can be processed in Step 2.
Step 2
This step works with the individual files produced in Step 1 and the list of shot boundaries. We first extract a representation (aka embedding) of each file using a video encoder (i.e. an algorithm that converts a video to a fixed-size vector) and use that embedding to identify and remove duplicate shots.
In the following example SB_deduped is the result of deduplicating SB:
# the second shot (index 1) was removed and so was clip1.mp4 SB_deduped = {0: [0, 20], 2: [30, 85], …}
SB_deduped along with the surviving files are passed along to step 3.
Step 3
We compute another representation per shot, depending on the flavor of match cutting.
Step 4
We enumerate all pairs and compute a score for each pair of representations. These scores are stored along with the shot metadata:
[ # shots with indices 12 and 729 have a high matching score {shot1: 12, shot2: 729, score: 0.96}, # shots with indices 58 and 419 have a low matching score {shot1: 58, shot2: 410, score: 0.02}, … ]
Step 5
Finally, we sort the results by score in descending order and surface the top-K pairs, where K is a parameter.
The problems we faced
This pattern works well for a single flavor of match cutting and finding matches within the same title. As we started venturing beyond single-title and added more flavors, we quickly faced a few problems.
Lack of standardization
The representations we extract in Steps 2 and Step 3 are sensitive to the characteristics of the input video files. In some cases such as instance segmentation, the output representation in Step 3 is a function of the dimensions of the input file.
Not having a standardized input file format (e.g. same encoding recipes and dimensions) created matching quality issues when representations across titles with different input files needed to be processed together (e.g. multi-title match cutting).
Wasteful repeated computations
Segmentation at the shot level is a common task used across many media ML pipelines. Also, deduplicating similar shots is a common step that a subset of those pipelines shares.
We realized that memoizing these computations not only reduces waste but also allows for congruence between algo pipelines that share the same preprocessing step. In other words, having a single source of truth for shot boundaries helps us guarantee additional properties for the data generated downstream. As a concrete example, knowing that algo A and algoB both used the same shot boundary detection step, we know that shot index i has identical frame ranges in both. Without this knowledge, we’ll have to check if this is actually true.
Gaps in media-focused pipeline triggering and orchestration
Our stakeholders (i.e. video editors using match cutting) need to start working on titles as quickly as the video files land. Therefore, we built a mechanism to trigger the computation upon the landing of new video files. This triggering logic turned out to present two issues:
Lack of standardization meant that the computation was sometimes re-triggered for the same video file due to changes in metadata, without any content change.
Many pipelines independently developed similar bespoke components for triggering computation, which created inconsistencies.
Additionally, decomposing the pipeline into modular pieces and orchestrating computation with dependency semantics did not map to existing workflow orchestrators such as Conductor and Meson out of the box. The media machine learning domain needed to be mapped with some level of coupling between media assets metadata, media access, feature storage, feature compute and feature compute triggering, in a way that new algorithms could be easily plugged with predefined standards.
This is where Amber comes in, offering a Media Machine Learning Feature Development and Productization Suite, gluing all aspects of shipping algorithms while permitting the interdependency and composability of multiple smaller parts required to devise a complex system.
Each part is in itself an algorithm, which we call an Amber Feature, with its own scope of computation, storage, and triggering. Using dependency semantics, an Amber Feature can be plugged into other Amber Features, allowing for the composition of a complex mesh of interrelated algorithms.
Match Cutting across titles
Step 4 entails a computation that is quadratic in the number of shots. For instance, matching across a series with 10 episodes with an average of 2K shots per episode translates into 200M comparisons. Matching across 1,000 files (across multiple shows) would take approximately 200 trillion computations.
Setting aside the sheer number of computations required momentarily, editors may be interested in considering any subset of shows for matching. The naive approach is to pre-compute all possible subsets of shows. Even assuming that we only have 1,000 video files, this means that we have to pre-compute 2¹⁰⁰⁰ subsets, which is more than the number of atoms in the observable universe!
Ideally, we want to use an approach that avoids both issues.
Where we landed
The Media Machine Learning Infrastructure provided many of the building blocks required for overcoming these hurdles.
Standardized video encodes
The entire Netflix catalog is pre-processed and stored for reuse in machine learning scenarios. Match Cutting benefits from this standardization as it relies on homogeneity across videos for proper matching.
Shot segmentation and deduplication reuse
Videos are matched at the shot level. Since breaking videos into shots is a very common task across many algorithms, the infrastructure team provides this canonical feature that can be used as a dependency for other algorithms. With this, we were able to reuse memoized feature values, saving on compute costs and guaranteeing coherence of shot segments across algos.
Orchestrating embedding computations
We have used Amber’s feature dependency semantics to tie the computation of embeddings to shot deduplication. Leveraging Amber’s triggering, we automatically initiate scoring for new videos as soon as the standardized video encodes are ready. Amber handles the computation in the dependency chain recursively.
Feature value storage
We store embeddings in Amber, which guarantees immutability, versioning, auditing, and various metrics on top of the feature values. This also allows other algorithms to be built on top of the Match Cutting output as well as all the intermediate embeddings.
Compute pairs and sink to Marken
We have also used Amber’s synchronization mechanisms to replicate data from the main feature value copies to Marken, which is used for serving.
Media Search Platform
Used to serve high-scoring pairs to video editors in internal applications via Marken.
The following figure depicts the new pipeline using the above-mentioned components:
Figure 4 – Match cutting pipeline built using media ML infrastructure components. Interactions between algorithms are expressed as a feature mesh, and each Amber Feature encapsulates triggering and compute.
Conclusion and Future Work
The intersection of media and ML holds numerous prospects for innovation and impact. We examined some of the unique challenges that media ML practitioners face and presented some of our early efforts in building a platform that accommodates the scaling of ML solutions.
In addition to the promotional media use cases we discussed, we are extending the infrastructure to facilitate a growing set of use cases. Here are just a few examples:
ML-based VFX tooling
Improving recommendations using a suite of content understanding models
Enriching content understanding ML and creative tooling by leveraging personalization signals and insights
In future posts, we’ll dive deeper into more details about the solutions built for each of the components we have briefly described in this post.
Bivol has now been welcomed into the world’s largest family of investigative reporters and journalism nonprofits – the Global Investigative Jourmalism Network (GIJN). Joining GIJN is a great and unequivocal…
Welcome to the first post in our multi-part series on how Netflix is developing and using machine learning (ML) to help creators make better media — from TV shows to trailers to movies to promotional art and so much more.
Media is at the heart of Netflix. It’s our medium for delivering a range of emotions and experiences to our members. Through each engagement, media is how we bring our members continued joy.
This blog series will take you behind the scenes, showing you how we use the power of machine learning to create stunning media at a global scale.
At Netflix, we launch thousands of new TV shows and movies every year for our members across the globe. Each title is promoted with a custom set of artworks and video assets in support of helping each title find their audience of fans. Our goal is to empower creators with innovative tools that support them in effectively and efficiently create the best media possible.
With media-focused ML algorithms, we’ve brought science and art together to revolutionize how content is made. Here are just a few examples:
We maintain a growing suite of video understanding models that categorize characters, storylines, emotions, and cinematography. These timecode tags enable efficient discovery, freeing our creators from hours of categorizing footage so they can focus on creative decisions instead.
We arm our creators with rich insights derived from our personalization system, helping them better understand our members and gain knowledge to produce content that maximizes their joy.
We invest in novel algorithms for bringing hard-to-execute editorial techniques easily to creators’ fingertips, such as match cutting and automated rotoscoping/matting.
One of our competitive advantages is the instant feedback we get from our members and creator teams, like the success of assets for content choosing experiences and internal asset creation tools. We use these measurements to constantly refine our research, examining which algorithms and creative strategies we invest in. The feedback we collect from our members also powers our causal machine learning algorithms, providing invaluable creative insights on asset generation.
In this blog series, we will explore our media-focused ML research, development, and opportunities related to the following areas:
Computer vision: video understanding search and match cut tools
VFX and Computer graphics: matting/rotoscopy, volumetric capture to digitize actors/props/sets, animation, and relighting
Audio and Speech
Content: understanding, extraction, and knowledge graphs
Infrastructure and paradigms
We are continuously investing in the future of media-focused ML. One area we are expanding into is multimodal content understanding — a fundamental ML research that utilizes multiple sources of information or modality (e.g. video, audio, closed captions, scripts) to capture the full meaning of media content. Our teams have demonstrated value and observed success by modeling different combinations of modalities, such as video and text, video and audio, script alone, as well as video, audio and scripts together. Multimodal content understanding is expected to solve the most challenging problems in content production, VFX, promo asset creation, and personalization.
We are also using ML to transform the way we create Netflix TV shows and movies. Our filmmakers are embracing Virtual Production (filming on specialized light and MoCap stages while being able to view a virtual environment and characters). Netflix is building prototype stages and developing deep learning algorithms that will maximize cost efficiency and adoption of this transformational tech. With virtual production, we can digitize characters and sets as 3D models, estimate lighting, easily relight scenes, optimize color renditions, and replace in-camera backgrounds via semantic segmentation.
Most importantly, in close collaboration with creators, we are building human-centric approaches to creative tools, from VFX to trailer editing. Context, not control, guides the work for data scientists and algorithm engineers at Netflix. Contributors enjoy a tremendous amount of latitude to come up with experiments and new approaches, rapidly test them in production contexts, and scale the impact of their work. Our leadership in this space hinges on our reliance on each individual’s ideas and drive towards a common goal — making Netflix the home of the best content and creative experience in the world.
Working on media ML at Netflix is a unique opportunity to push the boundaries of what’s technically and creatively possible. It’s a cutting edge and quickly evolving research area. The progress we’ve made so far is just the beginning. Our goal is to research and develop machine learning and computer vision tools that put power into the hands of creators and support them in making the best media possible.
We look forward to sharing our work with you across this blog series and beyond.
If these types of challenges interest you, please let us know! We are always looking for great people who are inspired by machine learning and computer vision to join our team.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.