Post Syndicated from Jeimy Ruiz original https://github.blog/engineering/engineering-principles/the-ultimate-guide-to-developer-happiness/
In today’s rapidly evolving landscape, where AI is reshaping industries and transforming workflows, the role of developers has never been more critical. As business leaders, fostering an environment where developers feel valued, motivated, and empowered is essential to harnessing their full potential and keeping your business profitable and innovative.
In this blog post, we’ll explore actionable tips and strategies to supercharge developer happiness, ensuring your team remains productive, engaged, and ahead of the AI curve. We’ll walk you through ways to secure your code with AI, how to increase productivity with a strong developer experience, and, of course, invite you to join us at GitHub Universe 2024 to see the very best of the latest AI tooling in action.
Boost productivity with a great developer experience
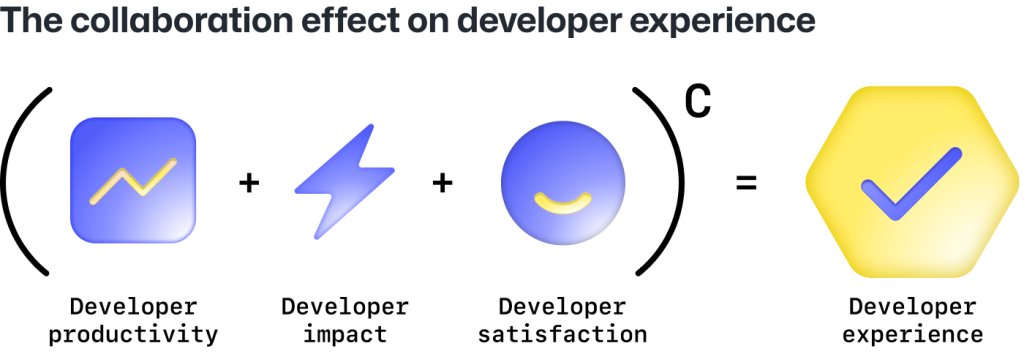
Developer experience is more than just a buzzword—it’s a critical factor in driving productivity and collaboration within software development teams. A seamless developer experience allows developers to get into the flow state more easily, where their productivity and creativity can peak. This flow state—characterized by uninterrupted concentration and a deep sense of involvement in the task—is crucial for tackling complex coding challenges.
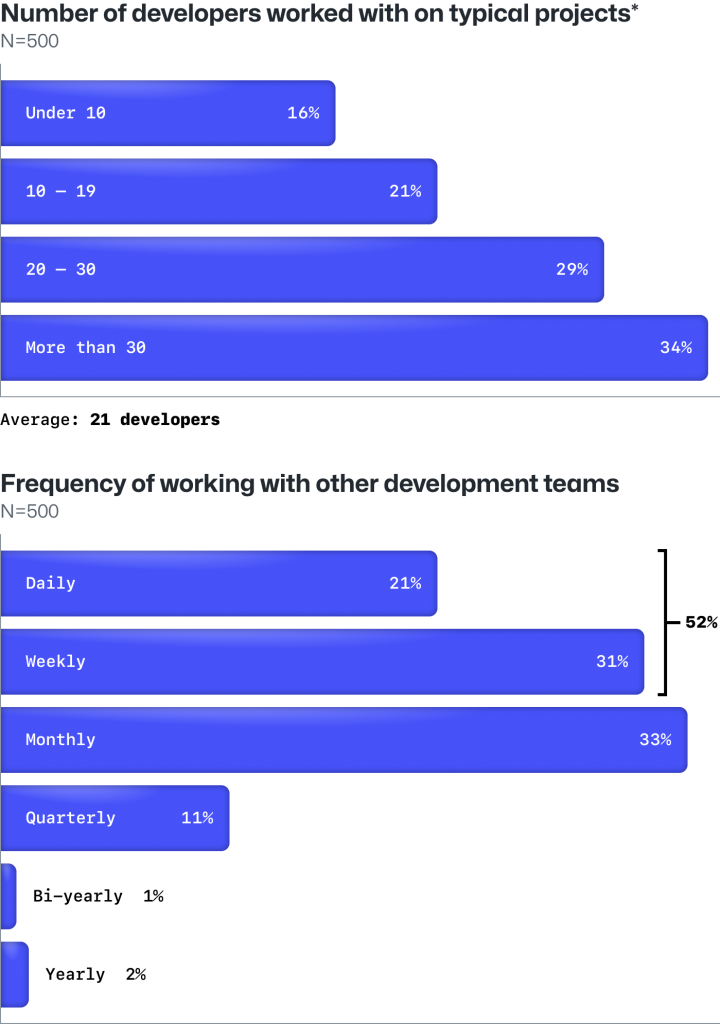
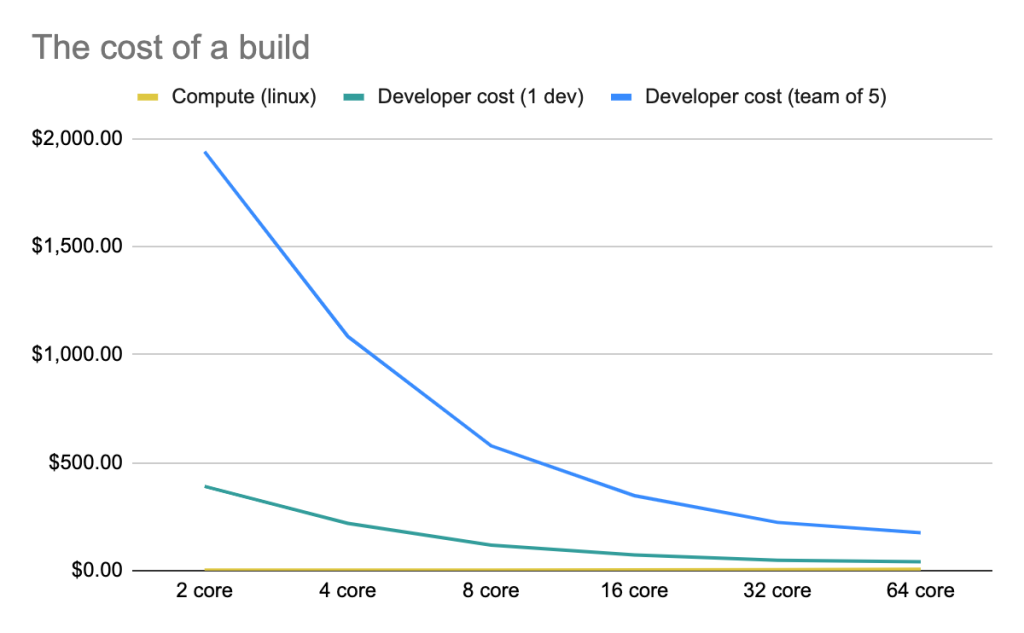
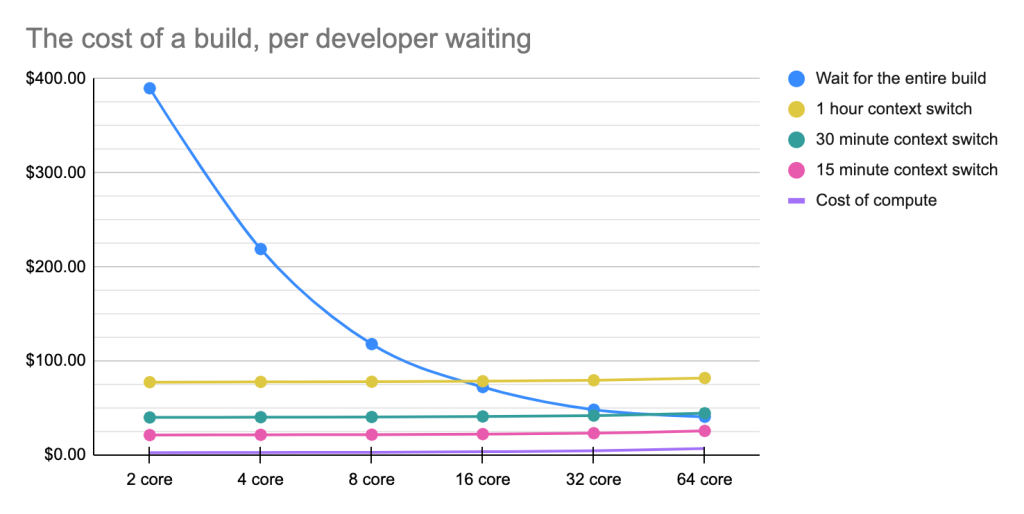
This work environment needs to be built intentionally, and the research backs it up. Developers who carve out time for deep work enjoy 50% more productivity, while those that get work they find engaging are 30% more productive.
How does this impact businesses? Well, because a developer that can significantly reduce their context-switching and mental load can also produce code faster and at a higher quality.
When developers understand their code, they’re 42% more productive. When developers are able to get faster turnaround times, they are 20% more innovative. These are tangible, individual benefits that in turn directly impact the output of developer teams.
Now is the time for leaders to invest in creating a great developer experience. By prioritizing the developer experience, you’re setting your team up to harness the full potential of the latest AI and platform engineering advances, ensuring your business stays ahead of the curve. Curious to learn more? Then dive into how a great developer experience fuels productivity with our latest research.
Use AI to secure your code
Historically, developers and security teams have found themselves at odds due to competing business goals. Shifting security left incorporates security earlier in the software development lifecycle, but in practice it has primarily shifted responsibility to developers without necessarily giving them the required expertise.
This, combined with the context switching inherent in development work, makes addressing security concerns particularly challenging. With AI, developers now have powerful tools at their disposal to enhance code security. AI can:
- Improve detection rates
- Provide near-instant fixes with context
- Enable application security (AppSec) at scale
These three improvements make it easier for developers to integrate robust security measures without sacrificing productivity, and transform the relationship between developers and security teams into a collaborative partnership.
Introducing a new security tool doesn’t have to be a daunting task either. By following a few simple steps, organizations can ensure a smooth transition and broad adoption.
- Document the tool’s features and usage to set the foundation and set realistic expectations to help align goals across teams.
- Recognize and celebrate successes to showcase the value of the new tool.
- Adopt a go-with-the-flow approach and organize hackathons to further drive engagement and interest.
- Listen to developer feedback continuously improve and refine security practices.
AI-powered security tools not only enhance the efficiency and effectiveness of AppSec, but also empower developers to take a proactive role in securing their code. This shift not only improves overall security posture, but also fosters a culture of shared responsibility and continuous learning, ultimately leading to more secure and resilient applications.
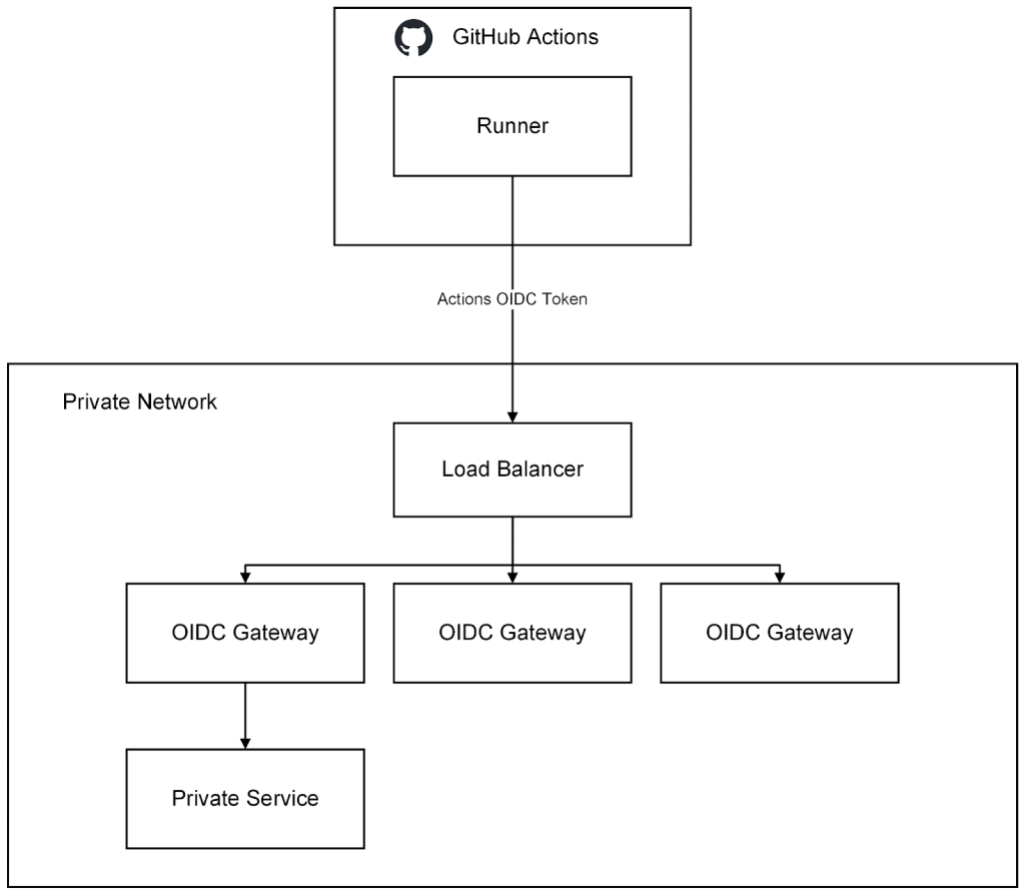
See exactly why security should be built into the developer workflow. 👇
Customize your LLMs
Organizations that take AI a step further and customize their AI tools are poised to lead the pack.
Large language models (LLMs) are trained on vast amounts of text data and can perform a variety of natural language processing tasks like translation, summarization, question-answering, and text generation. Customizing a pre-trained LLM goes beyond mere training—it involves adapting the model to perform specific tasks relevant to the organization’s needs. This level of customization helps developers maintain their flow state and significantly boost productivity and efficiency.
Customization techniques like retrieval-augmented generation (RAG), in-context learning, and fine-tuning enable LLMs to deliver more accurate and contextually appropriate responses:
- RAG combines retrieval-based and generation-based approaches in natural language processing. It enhances LLMs by integrating information retrieval techniques, where relevant documents or snippets are retrieved from a vector database to assist in generating more accurate and contextually appropriate responses. This approach allows the model to access and utilize external knowledge, making the generated output more informed and relevant to the user’s query.
- In-context learning refers to a model’s ability to adapt and respond to new tasks or inputs based on the context provided in the input prompt without requiring additional training. The model leverages its pre-trained knowledge and the context given in the input to perform tasks effectively.
- Fine-tuning, on the other hand, is a process in which an LLM is further trained on a specific dataset to adapt it to a particular task or domain. During fine-tuning, the model’s parameters are adjusted based on the new dataset, which typically involves supervised learning with labeled data. This process allows the model to specialize and improve its performance on specific tasks, (such as text classification, question answering, or machine translation), by leveraging the general knowledge acquired during its initial pre-training phase.
By implementing these customization strategies, businesses can unlock the full potential of their AI tools. Customized LLMs not only improve developer productivity—they also enhance the quality and relevance of AI-generated content.
Prepare your repository for teamwork
Fostering collaboration doesn’t just make software development faster, it also helps teams build better products and boost job satisfaction. By making your repository as collaborative as possible, you’ll optimize success. This includes focusing on:
- Repository settings: properly configuring repository settings to control visibility, access, and contribution workflows lays the foundation for collaboration.
- Repository contents: including essential files like README.md, LICENSE.md, CONTRIBUTING.md, CODEOWNERS, and CODE_OF_CONDUCT.md helps collaborators understand the project, its purpose, and how to contribute.
- Automation and checks: implementing automation tools such as linters, continuous integration (CI), and continuous deployment (CD) pipelines streamlines the development process, ensures code quality, and enables immediate feedback.
- Security practices: enforcing role-based access control, managing secrets securely, and scanning code for vulnerabilities can foster trust and protect the project from vulnerabilities.
- Issue templates: providing structured issue templates guides contributors in providing necessary information and context when reporting bugs.
- Community engagement: engaging with the project’s community through meetups, project blogs, discussions, and other channels fosters belonging and builds relationships.
Invest in your team’s learning opportunities
When you signal to your team that you value their career growth and exposure to learning opportunities, it can boost happiness and job satisfaction, leading to increased productivity, collaboration, and better problem solving.
Encouraging your developer teams to attend conferences like GitHub Universe 2024 is a strategic investment in their professional growth and your business’ success. Our global developer event provides an unparalleled platform for the best in software development to gather and expand their knowledge, stay updated on the latest AI-powered tools, and bring fresh ideas back to their teams.
Here are a few highlights of what you and your team can expect:
- Help your developers get in the flow and stay there with sessions, demos, panels, and more on the powerful tools and techniques that enhance productivity and satisfaction.
- Connect with other technical leaders to share experiences, challenges, and best practices. Expand your network with valuable industry contacts.
- Get a first look at GitHub’s product roadmap and see how upcoming features and enhancements can help you stay ahead in a competitive landscape.
- Gain technical skills with GitHub certifications and workshops designed to enhance your expertise in a rapidly evolving industry.
- Learn the latest on GitHub Copilot and stay ahead with the latest coding practices and techniques.
Get your tickets today. You can take advantage of our group discount and get four tickets for the price of three. (That’s a 25% savings!)
If you’re flying solo, you can also use our Early Bird discount and save 20% off one in-person ticket, only until September 3.
Reach new levels of creativity and efficiency
Incorporating these five business strategies can transform your development process and increase developer happiness. By investing in these areas, you empower your team, foster a culture of continuous learning, and position your organization for success in the rapidly evolving tech landscape.
- Get tickets to GitHub Universe 2024
- Read more about how DevEx boosts productivity and innovation
- Customize GitHub Copilot for your business
The post The ultimate guide to developer happiness appeared first on The GitHub Blog.


 Summarization is a core workflow for AI, and so far, while it’s not always perfect, it’s been working well. If you’re interested in the prompt we’re using (or want to help us improve it!), you can find it
Summarization is a core workflow for AI, and so far, while it’s not always perfect, it’s been working well. If you’re interested in the prompt we’re using (or want to help us improve it!), you can find it