Interesting summary of various ways to derive the public key from digitally signed files.
Normally, with a signature scheme, you have the public key and want to know whether a given signature is valid. But what if we instead have a message and a signature, assume the signature is valid, and want to know which public key signed it? A rather delightful property if you want to attack anonymity in some proposed “everybody just uses cryptographic signatures for everything” scheme.
For the first time, researchers have demonstrated that a large portion of cryptographic keys used to protect data in computer-to-server SSH traffic are vulnerable to complete compromise when naturally occurring computational errors occur while the connection is being established.
[…]
The vulnerability occurs when there are errors during the signature generation that takes place when a client and server are establishing a connection. It affects only keys using the RSA cryptographic algorithm, which the researchers found in roughly a third of the SSH signatures they examined. That translates to roughly 1 billion signatures out of the 3.2 billion signatures examined. Of the roughly 1 billion RSA signatures, about one in a million exposed the private key of the host.
Abstract: We demonstrate that a passive network attacker can opportunistically obtain private RSA host keys from an SSH server that experiences a naturally arising fault during signature computation. In prior work, this was not believed to be possible for the SSH protocol because the signature included information like the shared Diffie-Hellman secret that would not be available to a passive network observer. We show that for the signature parameters commonly in use for SSH, there is an efficient lattice attack to recover the private key in case of a signature fault. We provide a security analysis of the SSH, IKEv1, and IKEv2 protocols in this scenario, and use our attack to discover hundreds of compromised keys in the wild from several independently vulnerable implementations.
Micro-Star International—aka MSI—had its UEFI signing key stolen last month.
This raises the possibility that the leaked key could push out updates that would infect a computer’s most nether regions without triggering a warning. To make matters worse, Matrosov said, MSI doesn’t have an automated patching process the way Dell, HP, and many larger hardware makers do. Consequently, MSI doesn’t provide the same kind of key revocation capabilities.
Delivering a signed payload isn’t as easy as all that. “Gaining the kind of control required to compromise a software build system is generally a non-trivial event that requires a great deal of skill and possibly some luck.” But it just got a whole lot easier.
ECDSA signatures rely on a pseudo-random number, typically notated as K, that’s used to derive two additional numbers, R and S. To verify a signature as valid, a party must check the equation involving R and S, the signer’s public key, and a cryptographic hash of the message. When both sides of the equation are equal, the signature is valid.
[…]
For the process to work correctly, neither R nor S can ever be a zero. That’s because one side of the equation is R, and the other is multiplied by R and a value from S. If the values are both 0, the verification check translates to 0 = 0 X (other values from the private key and hash), which will be true regardless of the additional values. That means an adversary only needs to submit a blank signature to pass the verification check successfully.
Madden wrote:
Guess which check Java forgot?
That’s right. Java’s implementation of ECDSA signature verification didn’t check if R or S were zero, so you could produce a signature value in which they are both 0 (appropriately encoded) and Java would accept it as a valid signature for any message and for any public key. The digital equivalent of a blank ID card.
The Transport Layer Security protocol (TLS), which secures most Internet connections, has mainly been a protocol consisting of a key exchange authenticated by digital signatures used to encrypt data at transport[1]. Even though it has undergone major changes since 1994, when SSL 1.0 was introduced by Netscape, its main mechanism has remained the same. The key exchange was first based on RSA, and later on traditional Diffie-Hellman (DH) and Elliptic-curve Diffie-Hellman (ECDH). The signatures used for authentication have almost always been RSA-based, though in recent years other kinds of signatures have been adopted, mainly ECDSA and Ed25519. This recent change to elliptic curve cryptography in both at the key exchange and at the signature level has resulted in considerable speed and bandwidth benefits in comparison to traditional Diffie-Hellman and RSA.
TLS is the main protocol that protects the connections we use everyday. It’s everywhere: we use it when we buy products online, when we register for a newsletter — when we access any kind of website, IoT device, API for mobile apps and more, really. But with the imminent threat of the arrival of quantum computers (a threat that seems to be getting closer and closer), we need to reconsider the future of TLS once again. A wide-scale post-quantum experiment was carried out by Cloudflare and Google: two post-quantum key exchanges were integrated into our TLS stack and deployed at our edge servers as well as in Chrome Canary clients. The goal of that experiment was to evaluate the performance and feasibility of deployment of two post-quantum key exchanges in TLS.
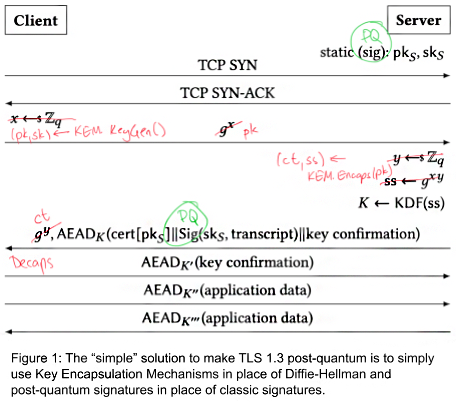
Similar experiments have been proposed for introducing post-quantum algorithms into the TLS handshake itself. Unfortunately, it seems infeasible to replace both the key exchange and signature with post-quantum primitives, because post-quantum cryptographic primitives are bigger, or slower (or both), than their predecessors. The proposed algorithms under consideration in the NIST post-quantum standardization process use mathematical objects that are larger than the ones used for elliptic curves, traditional Diffie-Hellman, or RSA. As a result, the overall size of public keys, signatures and key exchange material is much bigger than those from elliptic curves, Diffie-Hellman, or RSA.
How can we solve this problem? How can we use post-quantum algorithms as part of the TLS handshake without making the material too big to be transmitted? In this blogpost, we will introduce a new mechanism for making this happen. We’ll explain how it can be integrated into the handshake and we’ll cover implementation details. The key observation in this mechanism is that, while post-quantum algorithms have bigger communication size than their predecessors, post-quantum key exchanges have somewhat smaller sizes than post-quantum signatures, so we can try to replace signatures with key exchanges in some places to save space. We will only focus on the TLS 1.3 handshake as it is the TLS version that should be currently used.
Past experiments: making the TLS 1.3 handshake post-quantum
TLS 1.3 was introduced in August 2018, and it brought many security and performance improvements (notably, having only one round-trip to complete the handshake). But TLS 1.3 is designed for a world with classical computers, and some of its functionality will be broken by quantum computers when they do arrive.
The primary goal of TLS 1.3 is to provide authentication (the server side of the channel is always authenticated, the client side is optionally authenticated), confidentiality, and integrity by using a handshake protocol and a record protocol. The handshake protocol, the one of interest for us today, establishes the cryptographic parameters for securing and authenticating a connection. It can be thought of as having three main phases, as defined in RFC8446:
– The Parameter Negotiation phase (referred to as ‘Server Parameters’ in RFC8446), which establishes other handshake parameters (whether the client is authenticated, application-layer protocol support, etc).
– The Key Exchange phase, which establishes shared keying material and selects the cryptographic parameters to be used. Everything after this phase will be encrypted.
– The Authentication phase, which authenticates the server (and, optionally, the client) and provides key confirmation and handshake integrity.
The main idea of past experiments that introduced post-quantum algorithms into the handshake of TLS 1.3 was to use them in place of classical algorithms by advertising them as part of the supported groups[2] and key share[3] extensions, and, therefore, establishing with them the negotiated connection parameters. Key encapsulation mechanisms (KEMs) are an abstraction of the basic key exchange primitive, and were used to generate the shared secrets. When using a pre-shared key, its symmetric algorithms can be easily replaced by post-quantum KEMs as well; and, in the case of password-authenticated TLS, some ideas have been proposed on how to use post-quantum algorithms with them.
Most of the above ideas only provide what is often defined as ‘transitional security’, because its main focus is to provide quantum-resistant confidentiality, and not to take quantum-resistant authentication into account. It is possible to use post-quantum signatures for TLS authentication, but the post-quantum signatures are larger than traditional ones. Furthermore, it is worth noting that using post-quantum signatures is much more expensive than using post-quantum KEMs.
We can estimate the impact of such a replacement on network traffic by simply looking at the sum of the cryptographic objects that are transmitted during the handshake. A typical TLS 1.3 handshake using elliptic curve X25519 and RSA-2048 would transmit 1,376 bytes, which would correspond to the public keys for key exchange, the certificate, the signature of the handshake, and the certificate chain. If we were to replace X25519 by the post-quantum KEM Kyber512 and RSA by the post-quantum signature Dilithium II, two of the more efficient proposals, the size transmitted data would increase to 10,036 bytes[4]. The increase is mostly due to the size of the post-quantum signature algorithm.
The question then is: how can we achieve full post-quantum security and give a handshake that is efficient to be used?
A more efficient proposal: KEMTLS
There is a long history of other mechanisms, besides signatures, being used for authentication. Modern protocols, such as the Signal protocol, the Noise framework, or WireGuard, rely on key exchange mechanisms for authentication; but they are unsuitable for the TLS 1.3 case as they expect the long-term key material to be known in advance by the interested parties.
The OPTLS proposal by Krawczyk and Wee authenticates the TLS handshake without signatures by using a non-interactive key exchange (NIKE). However, the only somewhat efficient construction for a post-quantum NIKE is CSIDH, the security of which is the subject of an ongoing debate. But we can build on this idea, and use KEMs for authentication. KEMTLS, the current proposed experiment, replaces the handshake signature by a post-quantum KEM key exchange. It was designed and introduced by Peter Schwabe, Douglas Stebila and Thom Wiggers in the publication ‘Post-Quantum TLS Without Handshake Signatures’.
KEMTLS, therefore, achieves the same goals as TLS 1.3 (authentication, confidentiality and integrity) in the face of quantum computers. But there’s one small difference compared to the TLS 1.3 handshake. KEMTLS allows the client to send encrypted application data in the second client-to-server TLS message flow when client authentication is not required, and in the third client-to-server TLS message flow when mutual authentication is required. Note that with TLS 1.3, the server is able to send encrypted and authenticated application data in its first response message (although, in most uses of TLS 1.3, this feature is not actually used). With KEMTLS, when client authentication is not required, the client is able to send its first encrypted application data after the same number of handshake round trips as in TLS 1.3.
Intuitively, the handshake signature in TLS 1.3 proves possession of the private key corresponding to the public key certified in the TLS 1.3 server certificate. For these signature schemes, this is the straightforward way to prove possession; another way to prove possession is through key exchanges. By carefully considering the key derivation sequence, a server can decrypt any messages sent by the client only if it holds the private key corresponding to the certified public key. Therefore, implicit authentication is fulfilled. It is worth noting that KEMTLS still relies on signatures by certificate authorities to authenticate the long-term KEM keys.
With KEMTLS, application data transmitted during the handshake is implicitly authenticated rather than explicitly (as in TLS 1.3), and has slightly weaker downgrade resilience and forward secrecy; but full downgrade resilience and forward secrecy are achieved once the KEMTLS handshake completes.
By replacing the handshake signature by a KEM key exchange, we reduce the size of the data transmitted in the example handshake to 8,344 bytes, using Kyber512 and Dilithium II — a significant reduction. We can reduce the handshake size even for algorithms such as the NTRU-assumption based KEM NTRU and signature algorithm Falcon, which have a less-pronounced size gap. Typically, KEM operations are computationally much lighter than signing operations, which makes the reduction even more significant.
KEMTLS was presented at ACM CCS 2020. You can read more about its details in the paper. It was initially implemented in the RustTLS library by Thom Wiggers using optimized C/assembly implementations of the post-quantum algorithms provided by the PQClean and Open Quantum Safe projects.
Cloudflare and KEMTLS: the implementation
As part of our effort to show that TLS can be completely post-quantum safe, we implemented the full KEMTLS handshake in Golang’s TLS 1.3 suite. The implementation was done in several steps:
We first needed to clone our own version of Golang, so we could add different post-quantum algorithms to it. You can find our own version here. This code gets constantly updated with every release of Golang, following these steps.
We needed to implement post-quantum algorithms in Golang, which we did on our own cryptographic library, CIRCL.
As we cannot force certificate authorities to use certificates with long-term post-quantum KEM keys, we decided to use Delegated Credentials. A delegated credential is a short-lasting key that the certificate’s owner has delegated for use in TLS. Therefore, they can be used for post-quantum KEM keys. See its implementation in our Golang code here.
We implemented mutual auth (client and server authentication) KEMTLS by using Delegated Credentials for the authentication process. See its implementation in our Golang code here. You can also check its test for an overview of how it works.
Implementing KEMTLS was a straightforward process, although it did require changes to the way Golang handles a TLS 1.3 handshake and how the key schedule works.
A “regular” TLS 1.3 handshake in Golang (from the server perspective) looks like this:
func (hs *serverHandshakeStateTLS13) handshake() error {
c := hs.c
// For an overview of the TLS 1.3 handshake, see RFC 8446, Section 2.
if err := hs.processClientHello(); err != nil {
return err
}
if err := hs.checkForResumption(); err != nil {
return err
}
if err := hs.pickCertificate(); err != nil {
return err
}
c.buffering = true
if err := hs.sendServerParameters(); err != nil {
return err
}
if err := hs.sendServerCertificate(); err != nil {
return err
}
if err := hs.sendServerFinished(); err != nil {
return err
}
// Note that at this point we could start sending application data without
// waiting for the client's second flight, but the application might not
// expect the lack of replay protection of the ClientHello parameters.
if _, err := c.flush(); err != nil {
return err
}
if err := hs.readClientCertificate(); err != nil {
return err
}
if err := hs.readClientFinished(); err != nil {
return err
}
atomic.StoreUint32(&c.handshakeStatus, 1)
return nil
}
We had to interrupt the process when the server sends the Certificate (sendServerCertificate()) in order to send the KEMTLS specific messages. In the same way, we had to add the appropriate KEM TLS messages to the client’s handshake. And, as we didn’t want to change so much the way Golang handles TLS 1.3, we only added one new constant to the configuration that can be used by a server in order to ask for the Client’s Certificate (the constant is serverConfig.ClientAuth = RequestClientKEMCert).
The implementation is easy to work with: if a delegated credential or a certificate has a public key of a supported post-quantum KEM algorithm, the handshake will proceed with KEMTLS. If the server requests a Client KEMTLS Certificate, the handshake will use client KEMTLS authentication.
Running the Experiment
So, what’s next? We’ll take the code we have produced and run it on actual Cloudflare infrastructure to measure how efficiently it works.
Thanks
Many thanks to everyone involved in the project: Chris Wood, Armando Faz-Hernández, Thom Wiggers, Bas Westerbaan, Peter Wu, Peter Schwabe, Goutam Tamvada, Douglas Stebila, Thibault Meunier, and the whole Cloudflare Research team.
1It is worth noting that the RSA key transport in TLS ≤1.2 has the server only authenticated by RSA public key encryption, although the server’s RSA public key is certified using RSA signatures by Certificate Authorities. 2An extension used by the client to indicate which named groups -Elliptic Curve Groups, Finite Field Groups- it supports for key exchange. 3An extension which contains the endpoint’s cryptographic parameters. 4These numbers, as it is noted in the paper, are based on the round-2 submissions.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.