Post Syndicated from Andrew Repp original https://blog.cloudflare.com/how-hyperdrive-speeds-up-database-access/
In acknowledgement of its pivotal role in building distributed applications that rely on regional databases, we’re making Hyperdrive available on the free plan of Cloudflare Workers!
Hyperdrive enables you to build performant, global apps on Workers with your existing SQL databases. Tell it your database connection string, bring your existing drivers, and Hyperdrive will make connecting to your database faster. No major refactors or convoluted configuration required.
Over the past year, Hyperdrive has become a key service for teams that want to build their applications on Workers and connect to SQL databases. This includes our own engineering teams, with Hyperdrive serving as the tool of choice to connect from Workers to our own Postgres clusters for many of the control-plane actions of our billing, D1, R2, and Workers KV teams (just to name a few).
This has highlighted for us that Hyperdrive is a fundamental building block, and it solves a common class of problems for which there isn’t a great alternative. We want to make it possible for everyone building on Workers to connect to their database of choice with the best performance possible, using the drivers and frameworks they already know and love.
To illustrate how much Hyperdrive can improve your application’s performance, let’s write the world’s simplest benchmark. This is obviously not production code, but is meant to be reflective of a common application you’d bring to the Workers platform. We’re going to use a simple table, a very popular OSS driver (postgres.js), and run a standard OLTP workload from a Worker. We’re going to keep our origin database in London, and query it from Chicago (those locations will come back up later, so keep them in mind).
// This is the test table we're using
// CREATE TABLE IF NOT EXISTS test_data(userId bigint, userText text, isActive bool);
import postgres from 'postgres';
let direct_conn = '<direct connection string here!>';
let hyperdrive_conn = env.HYPERDRIVE.connectionString;
async function measureLatency(connString: string) {
let beginTime = Date.now();
let sql = postgres(connString);
await sql`INSERT INTO test_data VALUES (${999}, 'lorem_ipsum', ${true})`;
await sql`SELECT userId, userText, isActive FROM test_data WHERE userId = ${999}`;
let latency = Date.now() - beginTime;
ctx.waitUntil(sql.end());
return latency;
}
let directLatency = await measureLatency(direct_conn);
let hyperdriveLatency = await measureLatency(hyperdrive_conn);The code above
-
Takes a standard database connection string, and uses it to create a database connection.
-
Loads a user record into the database.
-
Queries all records for that user.
-
Measures how long this takes to do with a direct connection, and with Hyperdrive.
When connecting directly to the origin database, this set of queries takes an average of 1200 ms. With absolutely no other changes, just swapping out the connection string for env.HYPERDRIVE.connectionString, this number is cut down to 500 ms (an almost 60% reduction). If you enable Hyperdrive’s caching, so that the SELECT query is served from cache, this takes only 320 ms. With this one-line change, Hyperdrive will reduce the latency of this Worker by almost 75%! In addition to this speedup, you also get secure auth and transport, as well as a connection pool to help protect your database from being overwhelmed when your usage scales up. See it for yourself using our demo application.
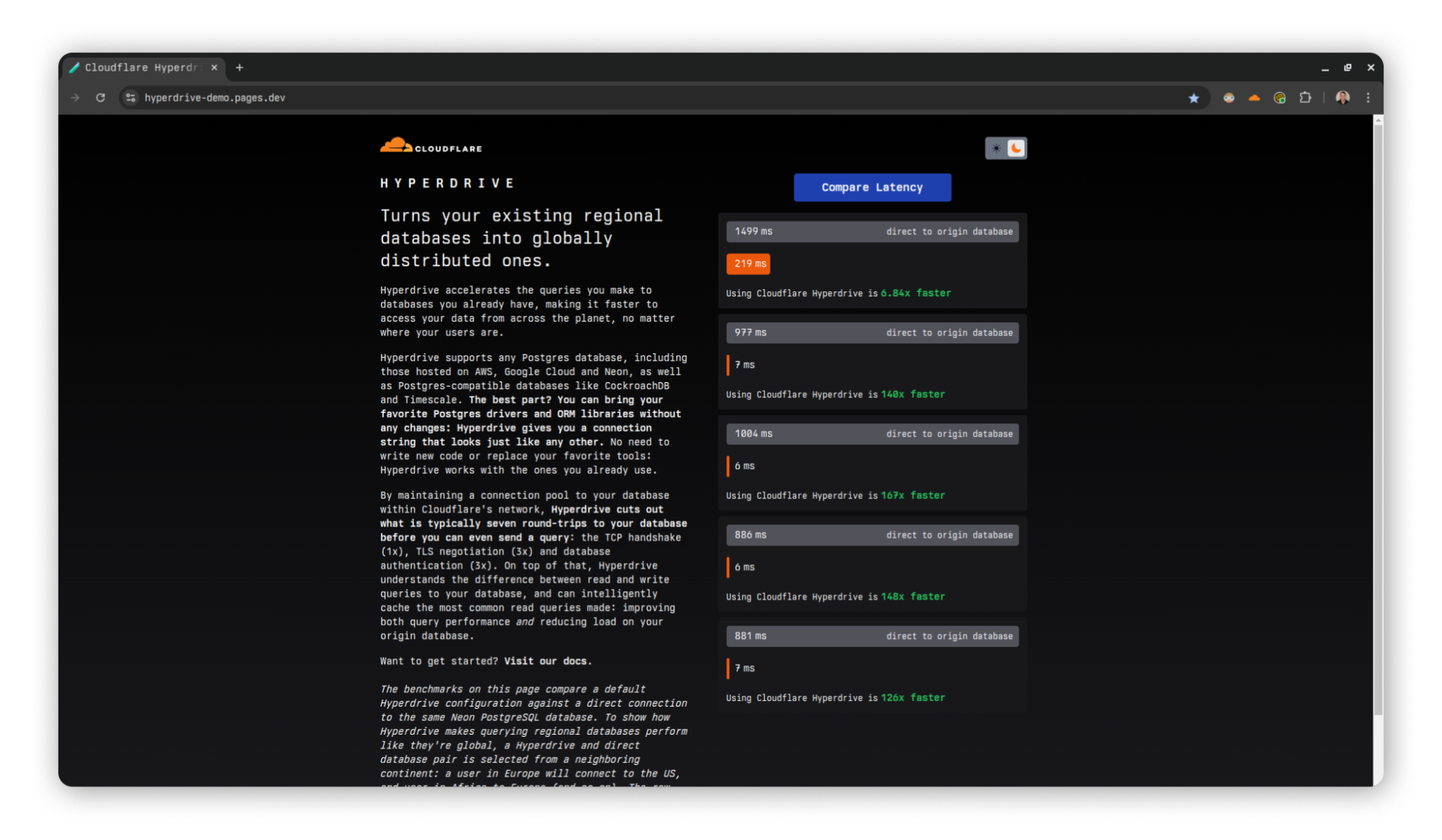
A demo application comparing latencies between Hyperdrive and direct-to-database connections.
Traditional SQL databases are familiar and powerful, but they are designed to be colocated with long-running compute. They were not conceived in the era of modern serverless applications, and have connection models that don’t take the constraints of such an environment into account. Instead, they require highly stateful connections that do not play well with Workers’ global and stateless model. Hyperdrive solves this problem by maintaining database connections across Cloudflare’s network ready to be used at a moment’s notice, caching your queries for fast access, and eliminating round trips to minimize network latency.
With this announcement, many developers are going to be taking a look at Hyperdrive for the first time over the coming weeks and months. To help people dive in and try it out, we think it’s time to talk about how Hyperdrive actually works.
Let’s talk a bit about database connection poolers, how they work, and what problems they already solve. They are hardly a new technology, after all.
The point of any connection pooler, Hyperdrive or others, is to minimize the overhead of establishing and coordinating database connections. Every new database connection requires additional memory and CPU time from the database server, and this can only scale just so well as the number of concurrent connections climbs. So the question becomes, how should database connections be shared across clients?
There are three commonly-used approaches for doing so. These are:
-
Session mode: whenever a client connects, it is assigned a connection of its own until it disconnects. This dramatically reduces the available concurrency, in exchange for much simpler implementation and a broader selection of supported features
-
Transaction mode: when a client is ready to send a query or open a transaction, it is assigned a connection on which to do so. This connection will be returned to the pool when the query or transaction concludes. Subsequent queries during the same client session may (or may not) be assigned a different connection.
-
Statement mode: Like transaction mode, but a connection is given out and returned for each statement. Multi-statement transactions are disallowed.
When building Hyperdrive, we had to decide which of these modes we wanted to use. Each of the approaches implies some fairly serious tradeoffs, so what’s the right choice? For a service intended to make using a database from Workers as pleasant as possible we went with the choice that balances features and performance, and designed Hyperdrive as a transaction-mode pooler. This best serves the goals of supporting a large number of short-lived clients (and therefore very high concurrency), while still supporting the transactional semantics that cause so many people to reach for an RDBMS in the first place.
In terms of this part of its design, Hyperdrive takes its cues from many pre-existing popular connection poolers, and manages operations to allow our users to focus on designing their full-stack applications. There is a configured limit to the number of connections the pool will give out, limits to how long a connection will be held idle until it is allowed to drop and return resources to the database, bookkeeping around prepared statements being shared across pooled connections, and other traditional concerns of the management of these resources to help ensure the origin database is able to run smoothly. These are all described in our documentation.
Ok, so why build Hyperdrive then? Other poolers that solve these problems already exist — couldn’t developers using Workers just run one of those and call it a day? It turns out that connecting to regional poolers from Workers has the same major downside as connecting to regional databases: network latency and round trips.
Establishing a connection, whether to a database or a pool, requires many exchanges between the client and server. While this is true for all fully-fledged client-server databases (e.g. MySQL, MongoDB), we are going to focus on the PostgreSQL connection protocol flow in this post. As we work through all of the steps involved, what we most want to keep track of is how many round trips it takes to accomplish. Note that we’re mostly concerned about having to wait around while these happen, so “half” round trips such as in the first diagram are not counted. This is because we can send off the message and then proceed without waiting.
The first step to establishing a connection between Postgres client and server is very familiar ground to anyone who’s worked much with networks: a TCP startup handshake. Postgres uses TCP for its underlying transport, and so we must have that connection before anything else can happen on top of it.
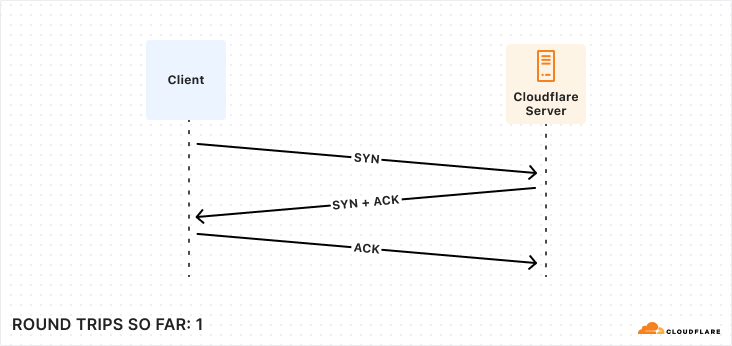
With our transport layer in place, the next step is to encrypt the connection. The TLS Handshake involves some back-and-forth in its own right, though this has been reduced to just one round trip for TLS 1.3. Below is the simplest and fastest version of this exchange, but there are certainly scenarios where it can be much more complex.
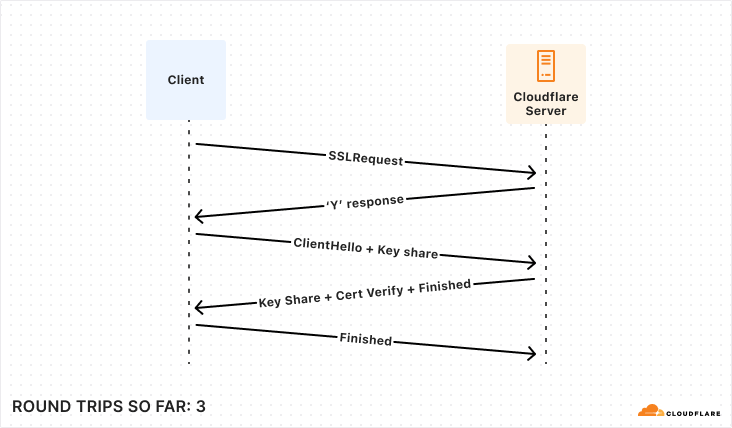
After the underlying transport is established and secured, the application-level traffic can actually start! However, we’re not quite ready for queries, the client still needs to authenticate to a specific user and database. Again, there are multiple supported approaches that offer varying levels of speed and security. To make this comparison as fair as possible, we’re again going to consider the version that offers the fastest startup (password-based authentication).
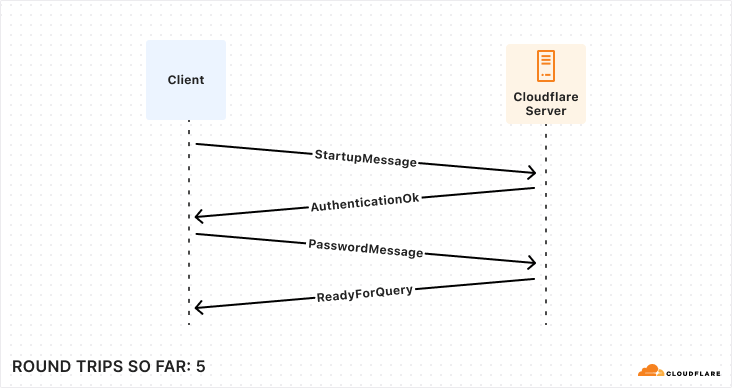
So, for those keeping score, establishing a new connection to your database takes a bare minimum of 5 round trips, and can very quickly climb from there.
While the latency of any given network round trip is going to vary based on so many factors that “it depends” is the only meaningful measurement available, some quick benchmarking during the writing of this post shows ~125 ms from Chicago to London. Now multiply that number by 5 round trips and the problem becomes evident: 625 ms to start up a connection is not viable in a distributed serverless environment. So how does Hyperdrive solve it? What if I told you the trick is that we do it all twice? To understand Hyperdrive’s secret sauce, we need to dive into Hyperdrive’s architecture.
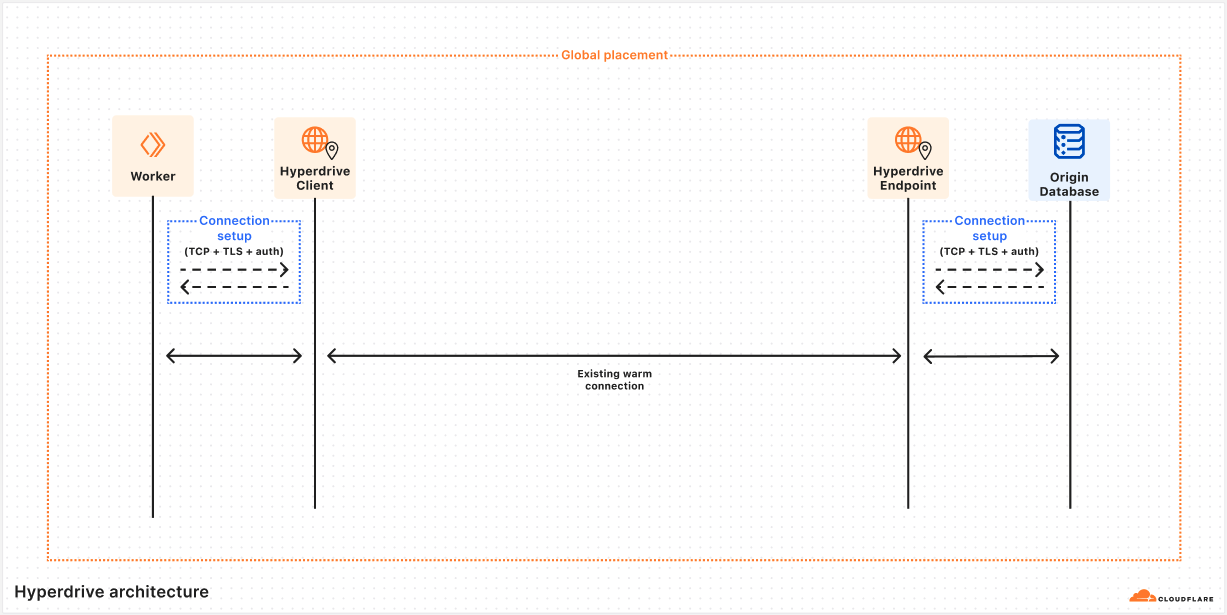
The rest of this post is a deep dive into answering the question of how Hyperdrive does what it does. To give the clearest picture, we’re going to talk about some internal subsystems by name. To help keep everything straight, let’s start with a short glossary that you can refer back to if needed. These descriptions may not make sense yet, but they will by the end of the article.
|
Hyperdrive subsystem name |
Brief description |
|
Client |
Lives on the same server as your Worker, talks directly to your database driver. This caches query results and sends queries to Endpoint if needed. |
|
Endpoint |
Lives in the data center nearest to your origin database, talks to your origin database. This caches query results and houses a pool of connections to your origin database. |
|
Edge Validator |
Sends a request to a Cloudflare data center to validate that Hyperdrive can connect to your origin database at time of creation. |
|
Placement |
Builds on top of Edge Validator to connect to your origin database from all eligible data centers, to identify which have the fastest connections. |
The first subsystem we want to dig into is named Client. Client’s first job is to pretend to be a database server. When a user’s Worker wants to connect to their database via Hyperdrive, they use a special connection string that the Worker runtime generates on the fly. This tells the Worker to reach out to a Hyperdrive process running on the same Cloudflare server, and direct all traffic to and from the database client to it.
import postgres from "postgres";
// Connect to Hyperdrive
const sql = postgres(env.HYPERDRIVE.connectionString);
// sql will now talk over an RPC channel to Hyperdrive, instead of via TCP to PostgresOnce this connection is established, the database driver will perform the usual handshake expected of it, with our Client playing the role of a database server and sending the appropriate responses. All of this happens on the same Cloudflare server running the Worker, and we observe that the p90 for all this is 4 ms (p50 is 2 ms). Quite a bit better than 625 ms, but how does that help? The query still needs to get to the database, right?
Client’s second main job is to inspect the queries sent from a Worker, and decide whether they can be served from Cloudflare’s cache. We’ll talk more about that later on. Assuming that there are no cached query results available, Client will need to reach out to our second important subsystem, which we call Endpoint.
Before we dig into the role Endpoint plays, it’s worth talking more about how the Client→Endpoint connection works, because it’s a key piece of our solution. We have already talked a lot about the price of network round trips, and how a Worker might be quite far away from the origin database, so how does Hyperdrive handle the long trip from the Client running alongside their Worker to the Endpoint running near their database without expensive round trips?
This is accomplished with a very handy bit of Cloudflare’s networking infrastructure. When Client gets a cache miss, it will submit a request to our networking platform for a connection to whichever data center Endpoint is running on. This platform keeps a pool of ready TCP connections between all of Cloudflare’s data centers, such that we don’t need to do any preliminary handshakes to begin sending application-level traffic. You might say we put a connection pooler in our connection pooler.
Over this TCP connection, we send an initialization message that includes all of the buffered query messages the Worker has sent to Client (the mental model would be something like a SYN and a payload all bundled together). Endpoint will do its job processing this query, and respond by streaming the response back to Client, leaving the streaming channel open for any followup queries until Client disconnects. This approach allows us to send queries around the world with zero wasted round trips.
Endpoint has a couple different jobs it has to do. Its first job is to pretend to be a database client, and to do the client half of the handshake shown above. Second, it must also do the same query processing that Client does with query messages. Finally, Endpoint will make the same determination on when it needs to reach out to the origin database to get uncached query results.
When Endpoint needs to query the origin database, it will attempt to take a connection out of a limited-size pool of database connections that it keeps. If there is an unused connection available, it is handed out from the pool and used to ferry the query to the origin database, and the results back to Endpoint. Once Endpoint has these results, the connection is immediately returned to the pool so that another Client can use it. These warm connections are usable in a matter of microseconds, which is obviously a dramatic improvement over the round trips from one region to another that a cold startup handshake would require.
If there are no currently unused connections sitting in the pool, it may start up a new one (assuming the pool has not already given out as many connections as it is allowed to). This set of handshakes looks exactly the same as the one Client does, but it happens across the network between a Cloudflare data center and wherever the origin database happens to be. These are the same 5 round trips as our original example, but instead of a full Chicago→London path on every single trip, perhaps it’s Virginia→London, or even London→London. Latency here will depend on which data center Endpoint is being housed in.
Earlier, we mentioned that Hyperdrive is a transaction-mode pooler. This means that when a driver is ready to send a query or open a transaction it must get a connection from the pool to use. The core challenge for a transaction-mode pooler is in aligning the state of the driver with the state of the connection checked out from the pool. For example, if the driver thinks it’s in a transaction, but the database doesn’t, then you might get errors or even corrupted results.
Hyperdrive achieves this by ensuring all connections are in the same state when they’re checked out of the pool: idle and ready for a query. Where Hyperdrive differs from other transaction-mode poolers is that it does this dance of matching up the states of two different connections across machines, such that there’s no need to share state between Client and Endpoint! Hyperdrive can terminate the incoming connection in Client on the same machine running the Worker, and pool the connections to the origin database wherever makes the most sense.
The job of a transaction-mode pooler is a hard one. Database connections are fundamentally stateful and keeping track of that state is important to maintain our guise when impersonating either a database client or a server. As an example, one of the trickier pieces of state to manage are prepared statements. When a user creates a new prepared statement, the prepared statement is only created on whichever database connection happened to be checked out at that time. Once the user finishes the transaction or query they are processing, the connection holding that statement is returned to the pool. From the user’s perspective they’re still connected using the same database connection, so a new query or transaction can reasonably expect to use that previously prepared statement. If a different connection is handed out for the next query and the query wants to make use of this resource, the pooler has to do something about it. We went into some depth on this topic in a previous blog post when we released this feature, but in sum, the process looks like this:
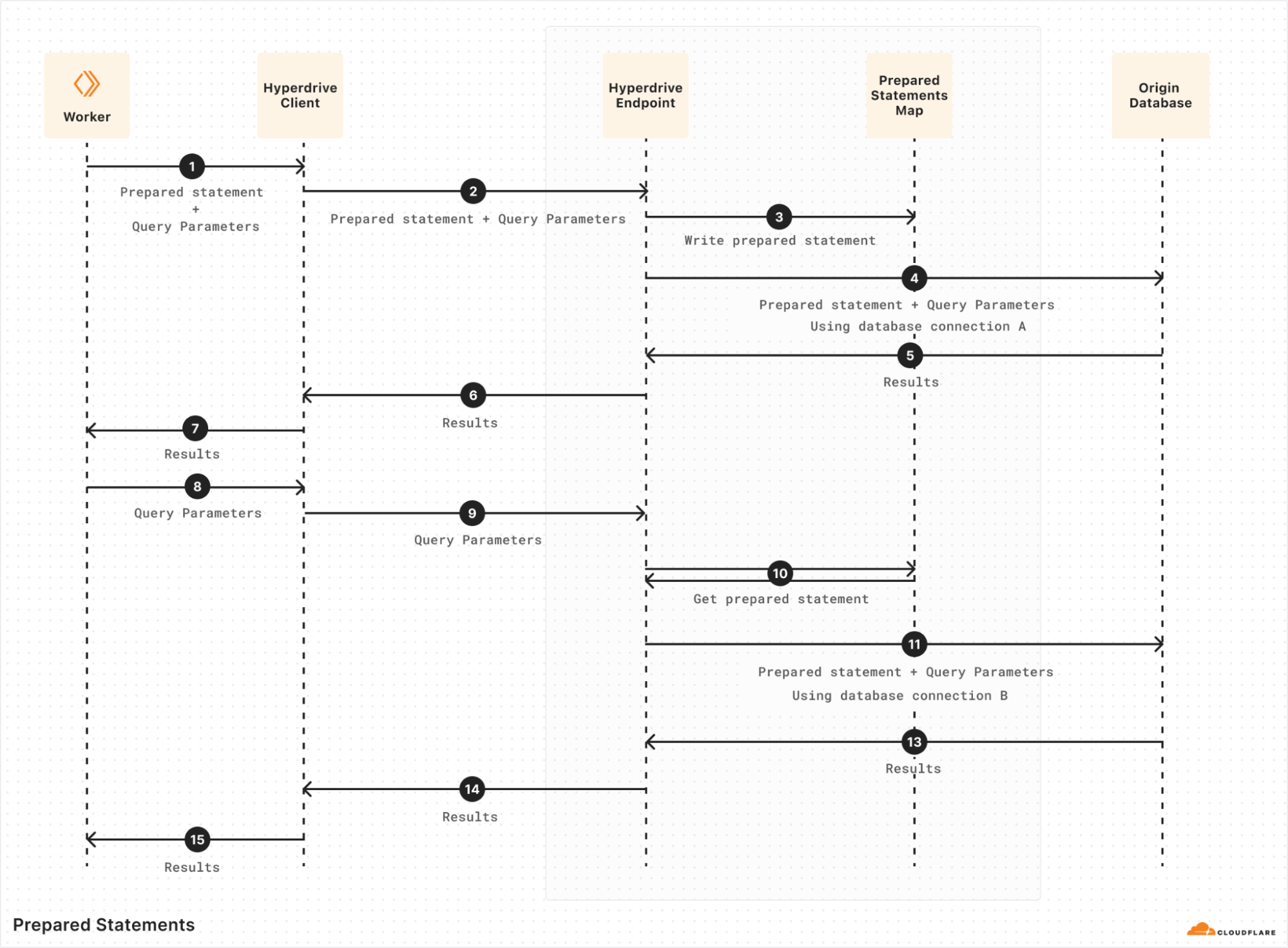
Hyperdrive implements this by keeping track of what statements have been prepared by a given client, as well as what statements have been prepared on each origin connection in the pool. When a query comes in expecting to re-use a particular prepared statement (#8 above), Hyperdrive checks if it’s been prepared on the checked-out origin connection. If it hasn’t, Hyperdrive will replay the wire-protocol message sequence to prepare it on the newly-checked-out origin connection (#10 above) before sending the query over it. Many little corrections like this are necessary to keep the client’s connection to Hyperdrive and Hyperdrive’s connection to the origin database lined up so that both sides see what they expect.
This “split connection” approach is the founding innovation of Hyperdrive, and one of the most vital aspects of it is how it affects starting up new connections. While the same 5+ round trips must always happen on startup, the actual time spent on the round trips can be dramatically reduced by conducting them over the smallest possible distances. This impact of distance can be so big that there is still a huge latency reduction even though the startup round trips must now happen twice (once each between the Worker and Client, and Endpoint and your origin database). So how do we decide where to run everything, to lean into that advantage as much as possible?
The placement of Client has not really changed since the original design of Hyperdrive. Sharing a server with the Worker sending the queries means that the Worker runtime can connect directly to Hyperdrive with no network hop needed. While there is always room for microoptimizations, it’s hard to do much better than that from an architecture perspective. By far the bigger piece of the latency puzzle is where to run Endpoint.
Hyperdrive keeps a list of data centers that are eligible to house Endpoints, requiring that they have sufficient capacity and the best routes available for pooled connections to use. The key challenge to overcome here is that a database connection string does not tell you where in the world a database actually is. The reality is that reliably going from a hostname to a precise (enough) geographic location is a hard problem, even leaving aside the additional complexity of doing so within a private network. So how do we pick from that list of eligible data centers?
For much of the time since its launch, Hyperdrive solved this with a regional pool approach. When a Worker connected to Hyperdrive, the location of the Worker was used to infer what region the end user was connecting from (e.g. ENAM, WEUR, APAC, etc. — see a rough breakdown here). Data centers to house Endpoints for any given Hyperdrive were deterministically selected from that region’s list of eligible options using rendezvous hashing, resulting in one pool of connections per region.
This approach worked well enough, but it had some severe shortcomings. The first and most obvious is that there’s no guarantee that the data center selected for a given region is actually closer to the origin database than the user making the request. This means that, while you’re getting the benefit of the excellent routing available on Cloudflare’s network, you may be going significantly out of your way to do so. The second downside is that, in the scenario where a new connection must be created, the round trips to do so may be happening over a significantly larger distance than is necessary if the origin database is in a different region than the Endpoint housing the regional connection pool. This increases latency and reduces throughput for the query that needs to instantiate the connection.
The final key downside here is an unfortunate interaction with Smart Placement, a feature of Cloudflare Workers that analyzes the duration of your Worker requests to identify the data center to run your Worker in. With regional Endpoints, the best Smart Placement can possibly do is to put your requests close to the Endpoint for whichever region the origin database is in. Again, there may be other data centers that are closer, but Smart Placement has no way to do better than where the Endpoint is because all Hyperdrive queries must route through it.
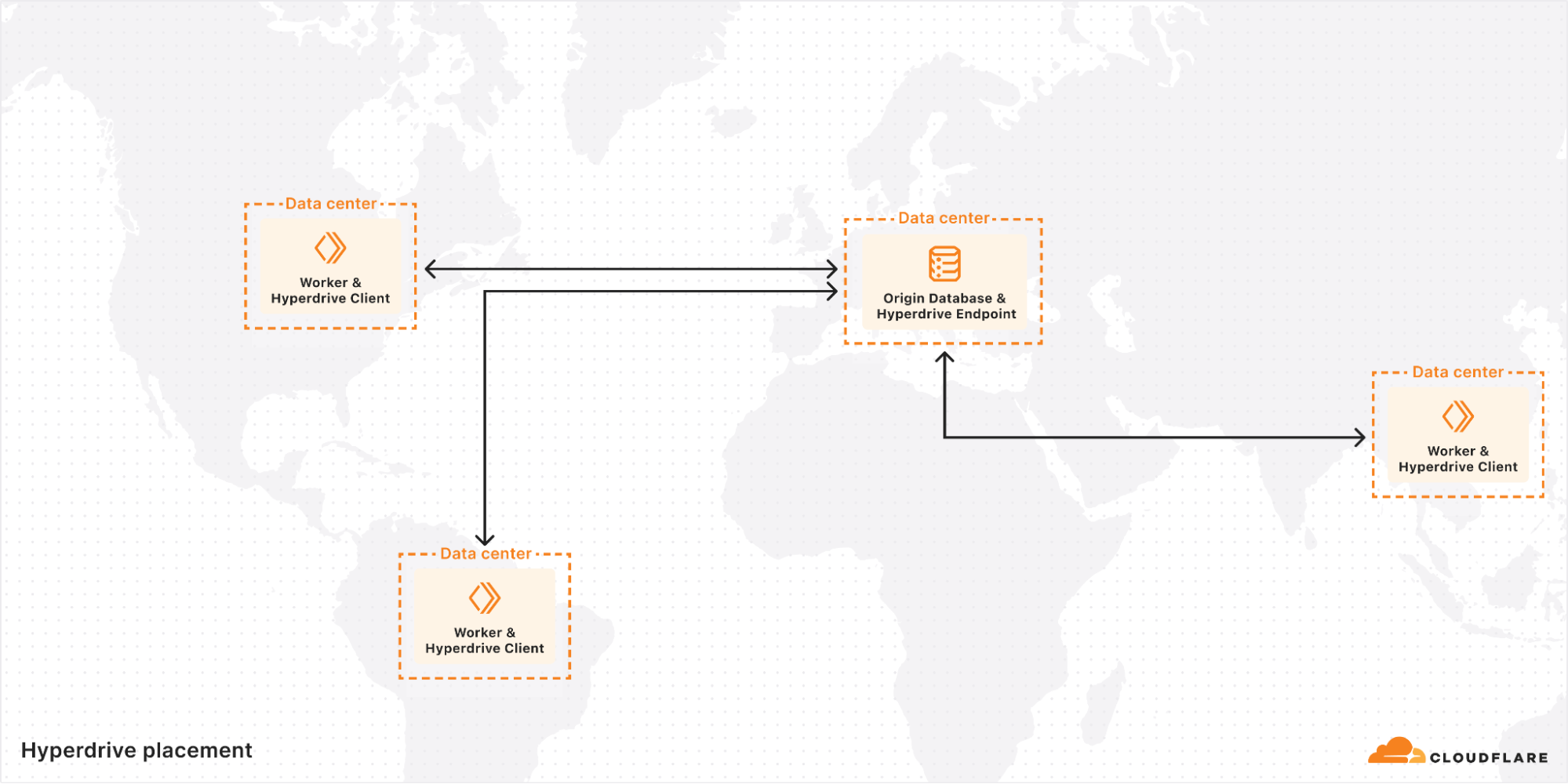
We recently shipped some improvements to this system that significantly enhanced performance. The new system discards the concept of regional pools entirely, in favor of a single global Endpoint for each Hyperdrive that is in the eligible data center as close as possible to the origin database.
The way we solved locating the origin database such that we can accomplish this was ultimately very straightforward. We already had a subsystem to confirm, at the time of creation, that Hyperdrive could connect to an origin database using the provided information. We call this subsystem our Edge Validator.
It’s bad user experience to allow someone to create a Hyperdrive, and then find out when they go to use it that they mistyped their password or something. Now they’re stuck trying to debug with extra layers in the way, with a Hyperdrive that can’t possibly work. Instead, whenever a Hyperdrive is created, the Edge Validator will send a request to an arbitrary data center to use its instance of Hyperdrive to connect to the origin database. If this connection fails, the creation of the Hyperdrive will also fail, giving immediate feedback to the user at the time it is most helpful.
With our new subsystem, affectionately called Placement, we now have a solution to the geolocation problem. After Edge Validator has confirmed that the provided information works and the Hyperdrive is created, an extra step is run in the background. Placement will perform the exact same connection routine, except instead of being done once from an arbitrary data center, it is run a handful of times from every single data center that is eligible to house Endpoints. The latency of establishing these connections is collected, and the average is sent back to a central instance of Placement. The data centers that can connect to the origin database the fastest are, by definition, where we want to run Endpoint for this Hyperdrive. The list of these is saved, and at runtime is used to select the Endpoint best suited to housing the pool of connections to the origin database.
Given that the secret sauce of Hyperdrive is in managing and minimizing the latency of establishing these connections, moving Endpoints right next to their origin databases proved to be pretty impactful.
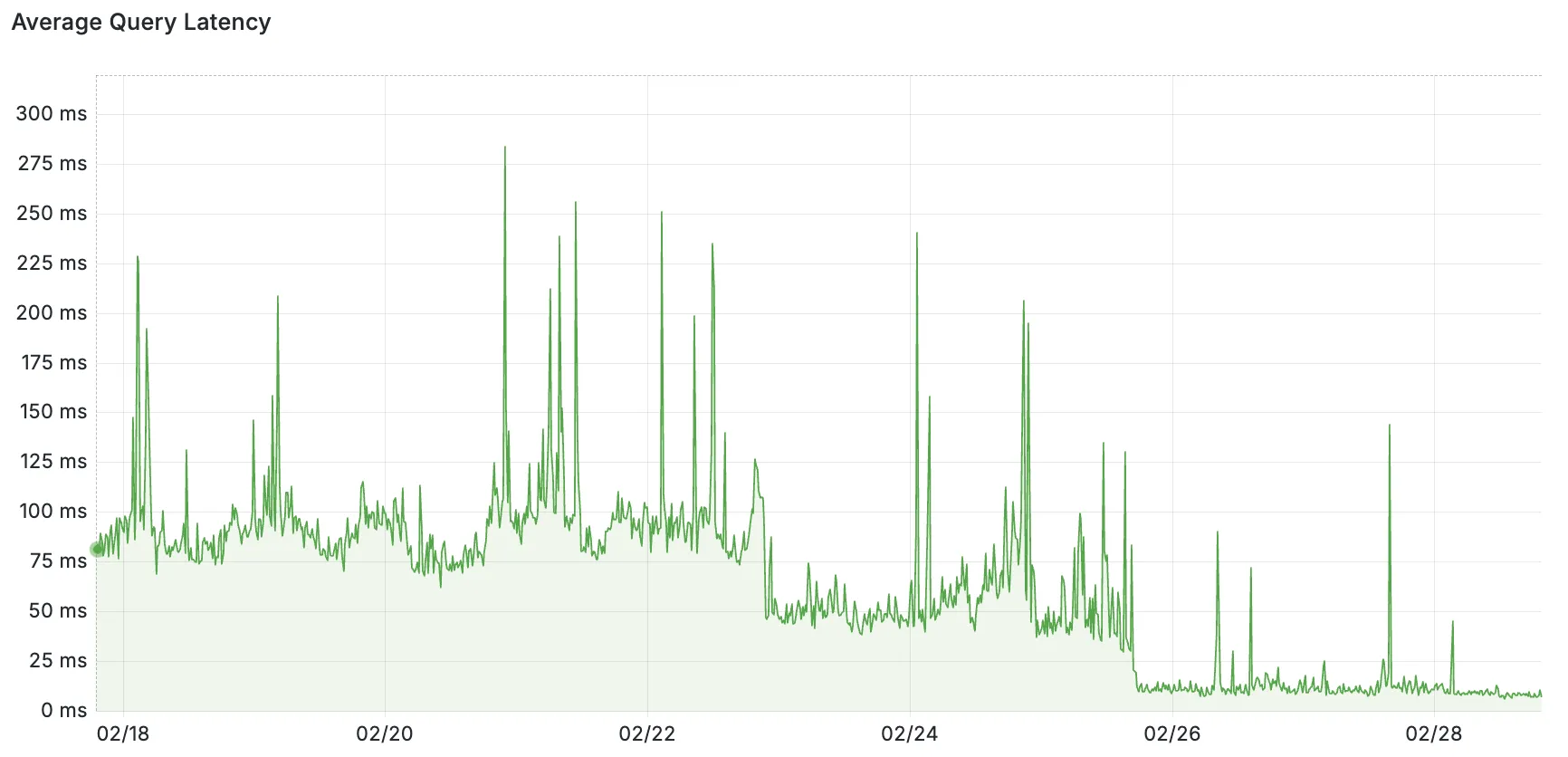
Pictured: query latency as measured from Endpoint to origin databases. The backfill of Placement to existing customers was done in stages on 02/22 and 02/25.
While we went in a different direction, it’s worth acknowledging that other teams have solved this same problem with a very different approach. Custom database drivers, usually called “serverless drivers”, have made several optimization efforts to reduce both the number of round trips and how quickly they can be conducted, while still connecting directly from your client to your database in the traditional way. While these drivers are impressive, we chose not to go this route for a couple of reasons.
First off, a big part of the appeal of using Postgres is its vibrant ecosystem. Odds are good you’ve used Postgres before, and it can probably help solve whichever problem you’re tackling with your newest project. This familiarity and shared knowledge across projects is an absolute superpower. We wanted to lean into this advantage by supporting the most popular drivers already in this ecosystem, instead of fragmenting it by adding a competing one.
Second, Hyperdrive also functions as a cache for individual queries (a bit of trivia: its name while still in Alpha was actually sql-query-cache). Doing this as effectively as possible for distributed users requires some clever positioning of where exactly the query results should be cached. One of the unique advantages of running a distributed service on Cloudflare’s network is that we have a lot of flexibility on where to run things, and can confidently surmount challenges like those. If we’re going to be playing three-card monte with where things are happening anyway, it makes the most sense to favor that route for solving the other problems we’re trying to tackle too.
As we’ve talked about in the past, Hyperdrive buffers protocol messages until it has enough information to know whether a query can be served from cache. In a post about how Hyperdrive works it would be a shame to skip talking about how exactly we cache query results, so let’s close by diving into that.
First and foremost, Hyperdrive uses Cloudflare’s cache, because when you have technology like that already available to you, it’d be silly not to use it. This has some implications for our architecture that are worth exploring.
The cache exists in each of Cloudflare’s data centers, and by default these are separate instances. That means that a Client operating close to the user has one, and an Endpoint operating close to the origin database has one. However, historically we weren’t able to take full advantage of that, because the logic for interacting with cache was tightly bound to the logic for managing the pool of connections.
Part of our recent architecture refactoring effort, where we switched to global Endpoints, was to split up this logic such that we can take advantage of Client’s cache too. This was necessary because, with Endpoint moving to a single location for each Hyperdrive, users from other regions would otherwise have gotten cache hits served from almost as far away as the origin.
With the new architecture, the role of Client during active query handling transitioned from that of a “dumb pipe” to more like what Endpoint had always been doing. It now buffers protocol messages, and serves results from cache if possible. In those scenarios, Hyperdrive’s traffic never leaves the data center that the Worker is running in, reducing query latencies from 20-70 ms to an average of around 4 ms. As a side benefit, it also substantially reduces the network bandwidth Hyperdrive uses to serve these queries. A win-win!
In the scenarios where query results can’t be served from the cache in Client’s data center, all is still not lost. Endpoint may also have cached results for this query, because it can field traffic from many different Clients around the world. If so, it will provide these results back to Client, along with how much time is remaining before they expire, such that Client can both return them and store them correctly into its own cache. Likewise, if Endpoint does need to go to the origin database for results, they will be stored into both Client and Endpoint caches. This ensures that followup queries from that same Client data center will get the happy path with single-digit ms response times, and also reduce load on the origin database from any other Client’s queries. This functions similarly to how Cloudflare’s Tiered Cache works, with Endpoint’s cache functioning as a final layer of shielding for the origin database.
With this announcement of a Free Plan for Hyperdrive, and newly armed with the knowledge of how it works under the hood, we hope you’ll enjoy building your next project with it! You can get started with a single Wrangler command (or using the dashboard):
wrangler hyperdrive create postgres-hyperdrive
--connection-string="postgres://user:[email protected]:5432/defaultdb"We’ve also included a Deploy to Cloudflare button below to let you get started with a sample Worker app using Hyperdrive, just bring your existing Postgres database! If you have any questions or ideas for future improvements, please feel free to visit our Discord channel!


