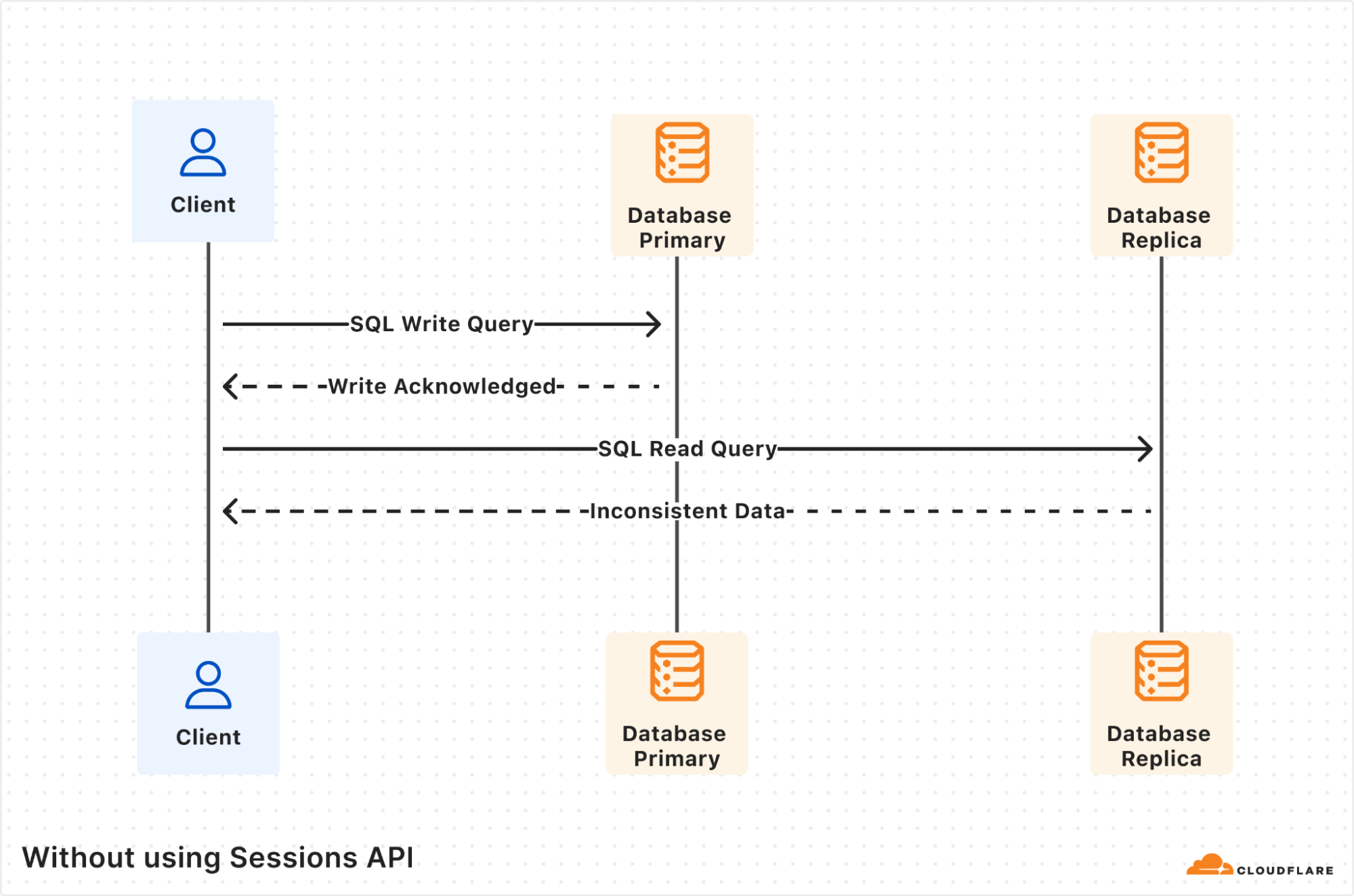
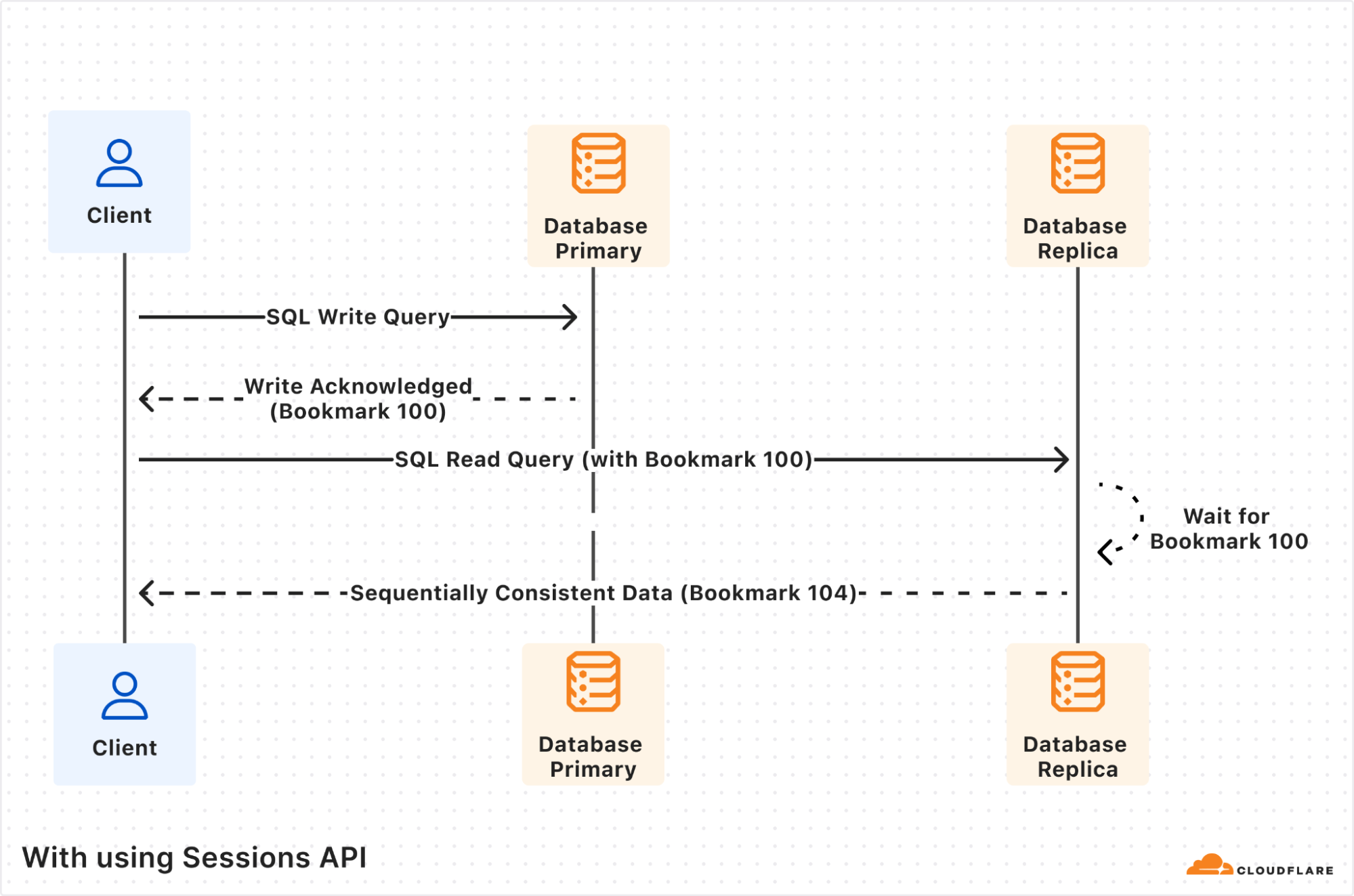
Post Syndicated from Yevgen Safronov original https://blog.cloudflare.com/r2-sql-deep-dive/
How do you run SQL queries over petabytes of data… without a server?
We have an answer for that: R2 SQL, a serverless query engine that can sift through enormous datasets and return results in seconds.
This post details the architecture and techniques that make this possible. We’ll walk through our Query Planner, which uses R2 Data Catalog to prune terabytes of data before reading a single byte, and explain how we distribute the work across Cloudflare’s global network, Workers and R2 for massively parallel execution.
During Developer Week 2025, we launched R2 Data Catalog, a managed Apache Iceberg catalog built directly into your Cloudflare R2 bucket. Iceberg is an open table format that provides critical database features like transactions and schema evolution for petabyte-scale object storage. It gives you a reliable catalog of your data, but it doesn’t provide a way to query it.
Until now, reading your R2 Data Catalog required setting up a separate service like Apache Spark or Trino. Operating these engines at scale is not easy: you need to provision clusters, manage resource usage, and be responsible for their availability, none of which contributes to the primary goal of getting value from your data.
R2 SQL removes that step entirely. It’s a serverless query engine that executes retrieval SQL queries against your Iceberg tables, right where your data lives.
Object storage is fundamentally different from a traditional database’s storage. A database is structured by design; R2 is an ocean of objects, where a single logical table can be composed of potentially millions of individual files, large and small, with more arriving every second.
Apache Iceberg provides a powerful layer of logical organization on top of this reality. It works by managing the table’s state as an immutable series of snapshots, creating a reliable, structured view of the table by manipulating lightweight metadata files instead of rewriting the data files themselves.
However, this logical structure doesn’t change the underlying physical challenge: an efficient query engine must still find the specific data it needs within that vast collection of files, and this requires overcoming two major technical hurdles:
The I/O problem: A core challenge for query efficiency is minimizing the amount of data read from storage. A brute-force approach of reading every object is simply not viable. The primary goal is to read only the data that is absolutely necessary.
The Compute problem: The amount of data that does need to be read can still be enormous. We need a way to give the right amount of compute power to a query, which might be massive, for just a few seconds, and then scale it down to zero instantly to avoid waste.
Our architecture for R2 SQL is designed to solve these two problems with a two-phase approach: a Query Planner that uses metadata to intelligently prune the search space, and a Query Execution system that distributes the work across Cloudflare’s global network to process the data in parallel.
The most efficient way to process data is to avoid reading it in the first place. This is the core strategy of the R2 SQL Query Planner. Instead of exhaustively scanning every file, the planner makes use of the metadata structure provided by R2 Data Catalog to prune the search space, that is, to avoid reading huge swathes of data irrelevant to a query.
This is a top-down investigation where the planner navigates the hierarchy of Iceberg metadata layers, using stats at each level to build a fast plan, specifying exactly which byte ranges the query engine needs to read.
When we say the planner uses “stats” we are referring to summary metadata that Iceberg stores about the contents of the data files. These statistics create a coarse map of the data, allowing the planner to make decisions about which files to read, and which to ignore, without opening them.
There are two primary levels of statistics the planner uses for pruning:
Partition-level stats: Stored in the Iceberg manifest list, these stats describe the range of partition values for all the data in a given Iceberg manifest file. For a partition on day(event_timestamp), this would be the earliest and latest day present in the files tracked by that manifest.
Column-level stats: Stored in the manifest files, these are more granular stats about each individual data file. Data files in R2 Data Catalog are formatted using the Apache Parquet. For every column of a Parquet file, the manifest stores key information like:
-
The minimum and maximum values. If a query asks for
http_status = 500, and a file’s stats show itshttp_statuscolumn has a min of 200 and a max of 404, that entire file can be skipped. -
A count of null values. This allows the planner to skip files when a query specifically looks for non-null values (e.g.,
WHERE error_code IS NOT NULL) and the file’s metadata reports that all values forerror_codeare null.
Now, let’s see how the planner uses these stats as it walks through the metadata layers.
The pruning process is a top-down investigation that happens in three main steps:
-
Table metadata and the current snapshot
The planner begins by asking the catalog for the location of the current table metadata. This is a JSON file containing the table’s current schema, partition specs, and a log of all historical snapshots. The planner then fetches the latest snapshot to work with.
2. Manifest list and partition pruning
The current snapshot points to a single Iceberg manifest list. The planner reads this file and uses the partition-level stats for each entry to perform the first, most powerful pruning step, discarding any manifests whose partition value ranges don’t satisfy the query. For a table partitioned by day(event_timestamp), the planner can use the min/max values in the manifest list to immediately discard any manifests that don’t contain data for the days relevant to the query.
3. Manifests and file-level pruning
For the remaining manifests, the planner reads each one to get a list of the actual Parquet data files. These manifest files contain more granular, column-level stats for each individual data file they track. This allows for a second pruning step, discarding entire data files that cannot possibly contain rows matching the query’s filters.
4. File row-group pruning
Finally, for the specific data files that are still candidates, the Query Planner uses statistics stored inside Parquet file’s footers to skip over entire row groups.
The result of this multi-layer pruning is a precise list of Parquet files, and of row groups within those Parquet files. These become the query work units that are dispatched to the Query Execution system for processing.

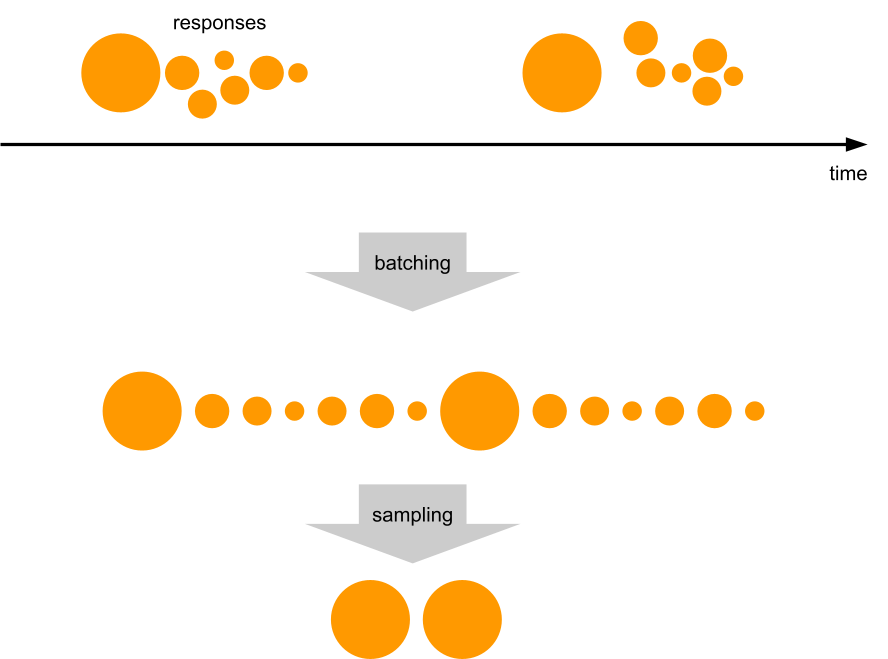
In R2 SQL, the multi-layer pruning we’ve described so far isn’t a monolithic process. For a table with millions of files, the metadata can be too large to process before starting any real work. Waiting for a complete plan would introduce significant latency.
Instead, R2 SQL treats planning and execution together as a concurrent pipeline. The planner’s job is to produce a stream of work units for the executor to consume as soon as they are available.
The planner’s investigation begins with two fetches to get a map of the table’s structure: one for the table’s snapshot and another for the manifest list.
From that point on, the query is processed in a streaming fashion. As the Query Planner reads through the manifest files and subsequently the data files they point to and prunes them, it immediately emits any matching data files/row groups as work units to the execution queue.
This pipeline structure ensures the compute nodes can begin the expensive work of data I/O almost instantly, long before the planner has finished its full investigation.
On top of this pipeline model, the planner adds a crucial optimization: deliberate ordering. The manifest files are not streamed in an arbitrary sequence. Instead, the planner processes them in an order matching by the query’s ORDER BY clause, guided by the metadata stats. This ensures that the data most likely to contain the desired results is processed first.
These two concepts work together to address query latency from both ends of the query pipeline.
The streamed planning pipeline lets us start crunching data as soon as possible, minimizing the delay before the first byte is processed. At the other end of the pipeline, the deliberate ordering of that work lets us finish early by finding a definitive result without scanning the entire dataset.
The next section explains the mechanics behind this “finish early” strategy.
Thanks to the Query Planner streaming work units in an order matching the ORDER BY clause, the Query Execution system first processes the data that is most likely to be in the final result set.
This prioritization happens at two levels of the metadata hierarchy:
Manifest ordering: The planner first inspects the manifest list. Using the partition stats for each manifest (e.g., the latest timestamp in that group of files), it decides which entire manifest files to stream first.
Parquet file ordering: As it reads each manifest, it then uses the more granular column-level stats to decide the processing order of the individual Parquet files within that manifest.
This ensures a constantly prioritized stream of work units is sent to the execution engine. This prioritized stream is what allows us to stop the query early.
For instance, with a query like … ORDER BY timestamp DESC LIMIT 5, as the execution engine processes work units and sends back results, the planner does two things concurrently:
It maintains a bounded heap of the best 5 results seen so far, constantly comparing new results to the oldest timestamp in the heap.
It keeps a “high-water mark” on the stream itself. Thanks to the metadata, it always knows the absolute latest timestamp of any data file that has not yet been processed.
The planner is constantly comparing the state of the heap to the water mark of the remaining stream. The moment the oldest timestamp in our Top 5 heap is newer than the high-water mark of the remaining stream, the entire query can be stopped.
At that point, we can prove no remaining work unit could possibly contain a result that would make it into the top 5. The pipeline is halted, and a complete, correct result is returned to the user, often after reading only a fraction of the potentially matching data.
Currently, R2 SQL supports ordering on columns that are part of the table’s partition key only. This is a limitation we are working on lifting in the future.


Query Planner streams the query work in bite-sized pieces called row groups. A single Parquet file usually contains multiple row groups, but most of the time only a few of them contain relevant data. Splitting query work into row groups allows R2 SQL to only read small parts of potentially multi-GB Parquet files.
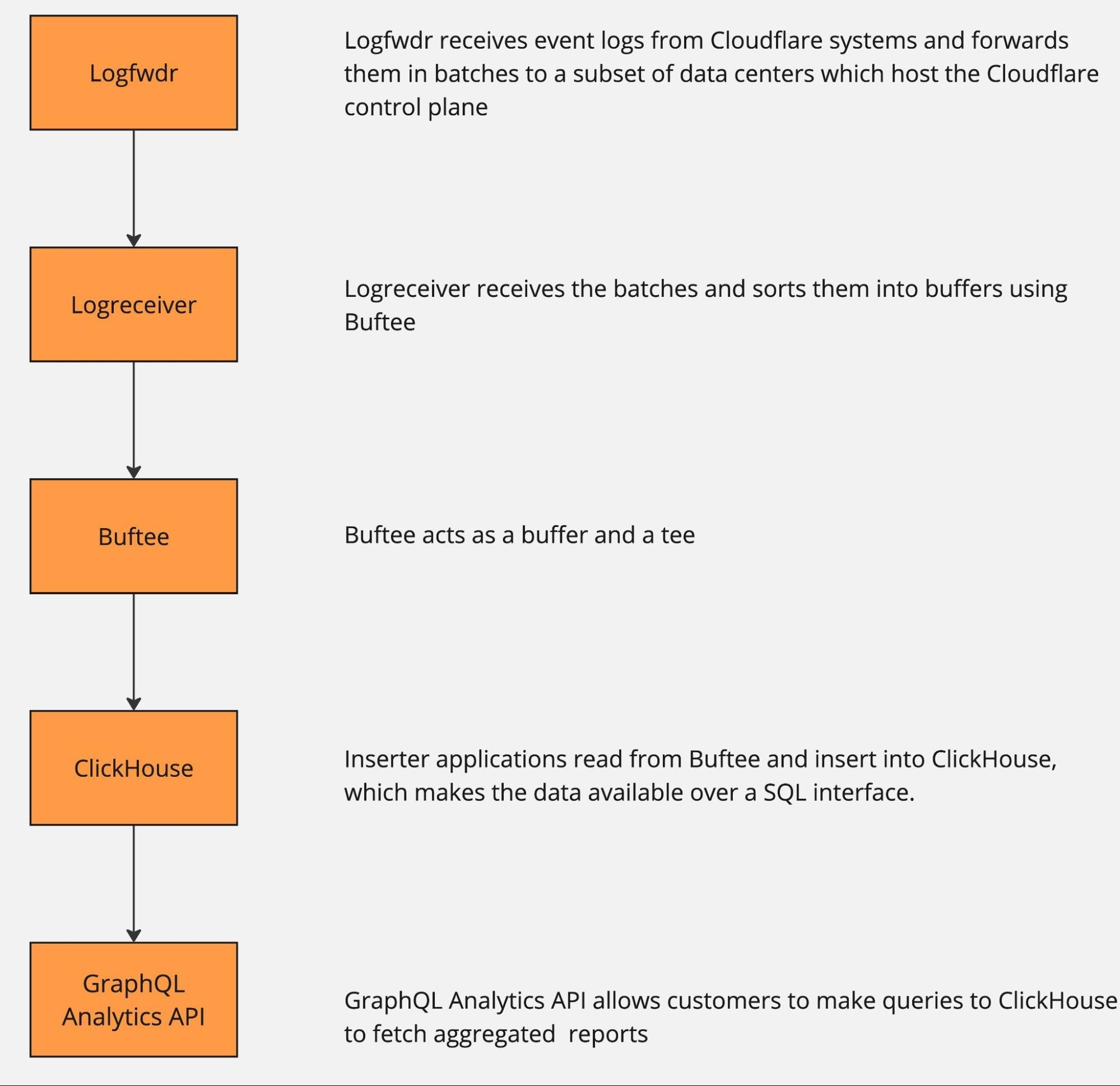
The server that receives the user’s request and performs query planning assumes the role of query coordinator. It distributes the work across query workers and aggregates results before returning them to the user.
Cloudflare’s network is vast, and many servers can be in maintenance at the same time. The query coordinator contacts Cloudflare’s internal API to make sure only healthy, fully functioning servers are picked for query execution. Connections between coordinator and query worker go through Cloudflare Argo Smart Routing to ensure fast, reliable connectivity.
Servers that receive query execution requests from the coordinator assume the role of query workers. Query workers serve as a point of horizontal scalability in R2 SQL. With a higher number of query workers, R2 SQL can process queries faster by distributing the work among many servers. That’s especially true for queries covering large amounts of files.
Both the coordinator and query workers run on Cloudflare’s distributed network, ensuring R2 SQL has plenty of compute power and I/O throughput to handle analytical workloads.
Each query worker receives a batch of row groups from the coordinator as well as an SQL query to run on it. Additionally, the coordinator sends serialized metadata about Parquet files containing the row groups. Thanks to that, query workers know exact byte offsets where each row group is located in the Parquet file without the need to read this information from R2.
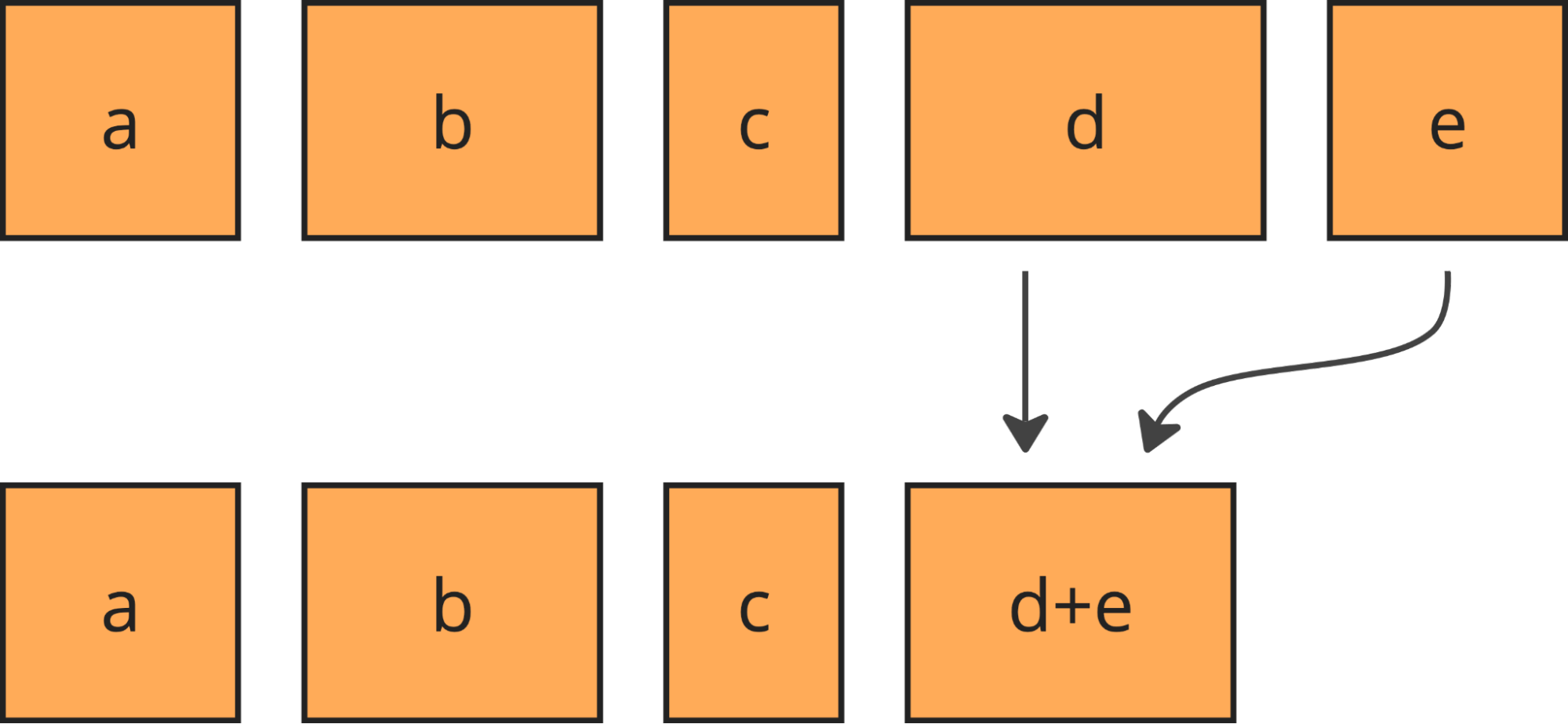
Internally, each query worker uses Apache DataFusion to run SQL queries against row groups. DataFusion is an open-source analytical query engine written in Rust. It is built around the concept of partitions. A query is split into multiple concurrent independent streams, each working on its own partition of data.
Partitions in DataFusion are similar to partitions in Iceberg, but serve a different purpose. In Iceberg, partitions are a way to physically organize data on object storage. In DataFusion, partitions organize in-memory data for query processing. While logically they are similar – rows grouped together based on some logic – in practice, a partition in Iceberg doesn’t always correspond to a partition in DataFusion.
DataFusion partitions map perfectly to the R2 SQL query worker’s data model because each row group can be considered its own independent partition. Thanks to that, each row group is processed in parallel.
At the same time, since row groups usually contain at least 1000 rows, R2 SQL benefits from vectorized execution. Each DataFusion partition stream can execute the SQL query on multiple rows in one go, amortizing the overhead of query interpretation.
There are two ends of the spectrum when it comes to query execution: processing all rows sequentially in one big batch and processing each individual row in parallel. Sequential processing creates a so-called “tight loop”, which is usually more CPU cache friendly. In addition to that, we can significantly reduce interpretation overhead, as processing a large number of rows at a time in batches means that we go through the query plan less often. Completely parallel processing doesn’t allow us to do these things, but makes use of multiple CPU cores to finish the query faster.
DataFusion’s architecture allows us to achieve a balance on this scale, reaping benefits from both ends. For each data partition, we gain better CPU cache locality and amortized interpretation overhead. At the same time, since many partitions are processed in parallel, we distribute the workload between multiple CPUs, cutting the execution time further.

In addition to the smart query execution model, DataFusion also provides first-class Parquet support.
As a file format, Parquet has multiple optimizations designed specifically for query engines. Parquet is a column-based format, meaning that each column is physically separated from others. This separation allows better compression ratios, but it also allows the query engine to read columns selectively. If the query only ever uses five columns, we can only read them and skip reading the remaining fifty. This massively reduces the amount of data we need to read from R2 and the CPU time spent on decompression.
DataFusion does exactly that. Using R2 ranged reads, it is able to read parts of the Parquet files containing the requested columns, skipping the rest.
DataFusion’s optimizer also allows us to push down any filters to the lowest levels of the query plan. In other words, we can apply filters right as we are reading values from Parquet files. This allows us to skip materialization of results we know for sure won’t be returned to the user, cutting the query execution time further.
Once the query worker finishes computing results, it returns them to the coordinator through the gRPC protocol.
R2 SQL uses Apache Arrow for internal representation of query results. Arrow is an in-memory format that efficiently represents arrays of structured data. It is also used by DataFusion during query execution to represent partitions of data.
In addition to being an in-memory format, Arrow also defines the Arrow IPC serialization format. Arrow IPC isn’t designed for long-term storage of the data, but for inter-process communication, which is exactly what query workers and the coordinator do over the network. The query worker serializes all the results into the Arrow IPC format and embeds them into the gRPC response. The coordinator in turn deserializes results and can return to working on Arrow arrays.
While R2 SQL is currently quite good at executing filter queries, we also plan to rapidly add new capabilities over the coming months. This includes, but is not limited to, adding:
-
Support for complex aggregations in a distributed and scalable fashion;
-
Tools to help provide visibility in query execution to help developers improve performance;
-
Support for many of the configuration options Apache Iceberg supports.
In addition to that, we have plans to improve our developer experience by allowing users to query their R2 Data Catalogs using R2 SQL from the Cloudflare Dashboard.
Given Cloudflare’s distributed compute, network capabilities, and ecosystem of developer tools, we have the opportunity to build something truly unique here. We are exploring different kinds of indexes to make R2 SQL queries even faster and provide more functionality such as full text search, geospatial queries, and more.
It’s early days for R2 SQL, but we’re excited for users to get their hands on it. R2 SQL is available in open beta today! Head over to our getting started guide to learn how to create an end-to-end data pipeline that processes and delivers events to an R2 Data Catalog table, which can then be queried with R2 SQL.
We’re excited to see what you build! Come share your feedback with us on our Developer Discord.