Post Syndicated from Hood Chatham original https://blog.cloudflare.com/python-workers

Starting today, in open beta, you can now write Cloudflare Workers in Python.
This new support for Python is different from how Workers have historically supported languages beyond JavaScript — in this case, we have directly integrated a Python implementation into workerd, the open-source Workers runtime. All bindings, including bindings to Vectorize, Workers AI, R2, Durable Objects, and more are supported on day one. Python Workers can import a subset of popular Python packages including FastAPI, Langchain, Numpy and more. There are no extra build steps or external toolchains.
To do this, we’ve had to push the bounds of all of our systems, from the runtime itself, to our deployment system, to the contents of the Worker bundle that is published across our network. You can read the docs, and start using it today.
We want to use this post to pull back the curtain on the internal lifecycle of a Python Worker, share what we’ve learned in the process, and highlight where we’re going next.
Beyond “Just compile to WebAssembly”
Cloudflare Workers have supported WebAssembly since 2018 — each Worker is a V8 isolate, powered by the same JavaScript engine as the Chrome web browser. In principle, it’s been possible for years to write Workers in any language — including Python — so long as it first compiles to WebAssembly or to JavaScript.
In practice, just because something is possible doesn’t mean it’s simple. And just because “hello world” works doesn’t mean you can reliably build an application. Building full applications requires supporting an ecosystem of packages that developers are used to building with. For a platform to truly support a programming language, it’s necessary to go much further than showing how to compile code using external toolchains.
Python Workers are different from what we’ve done in the past. It’s early, and still in beta, but we think it shows what providing first-class support for programming languages beyond JavaScript can look like on Workers.
The lifecycle of a Python Worker
With Pyodide now built into workerd, you can write a Worker like this:
from js import Response
async def on_fetch(request, env):
return Response.new("Hello world!")…with a wrangler.toml file that points to a .py file:
name = "hello-world-python-worker"
main = "src/entry.py"
compatibility_date = "2024-03-18"…and when you run npx wrangler@latest dev, the Workers runtime will:
- Determine which version of Pyodide is required, based on your compatibility date
- Create an isolate for your Worker, and automatically inject Pyodide
- Serve your Python code using Pyodide
This all happens under the hood — no extra toolchain or precompilation steps needed. The Python execution environment is provided for you, mirroring how Workers written in JavaScript already work.
A Python interpreter built into the Workers runtime
Just as JavaScript has many engines, Python has many implementations that can execute Python code. CPython is the reference implementation of Python. If you’ve used Python before, this is almost certainly what you’ve used, and is commonly referred to as just “Python”.
Pyodide is a port of CPython to WebAssembly. It interprets Python code, without any need to precompile the Python code itself to any other format. It runs in a web browser — check out this REPL. It is true to the CPython that Python developers know and expect, providing most of the Python Standard Library. It provides a foreign function interface (FFI) to JavaScript, allowing you to call JavaScript APIs directly from Python — more on this below. It provides popular open-source packages, and can import pure Python packages directly from PyPI.
Pyodide struck us as the perfect fit for Workers. It is designed to allow the core interpreter and each native Python module to be built as separate WebAssembly modules, dynamically linked at runtime. This allows the code footprint for these modules to be shared among all Workers running on the same machine, rather than requiring each Worker to bring its own copy. This is essential to making WebAssembly work well in the Workers environment, where we often run thousands of Workers per machine — we need Workers using the same programming language to share their runtime code footprint. Running thousands of Workers on every machine is what makes it possible for us to deploy every application in every location at a reasonable price.
Just like with JavaScript Workers, with Python Workers we provide the runtime for you:
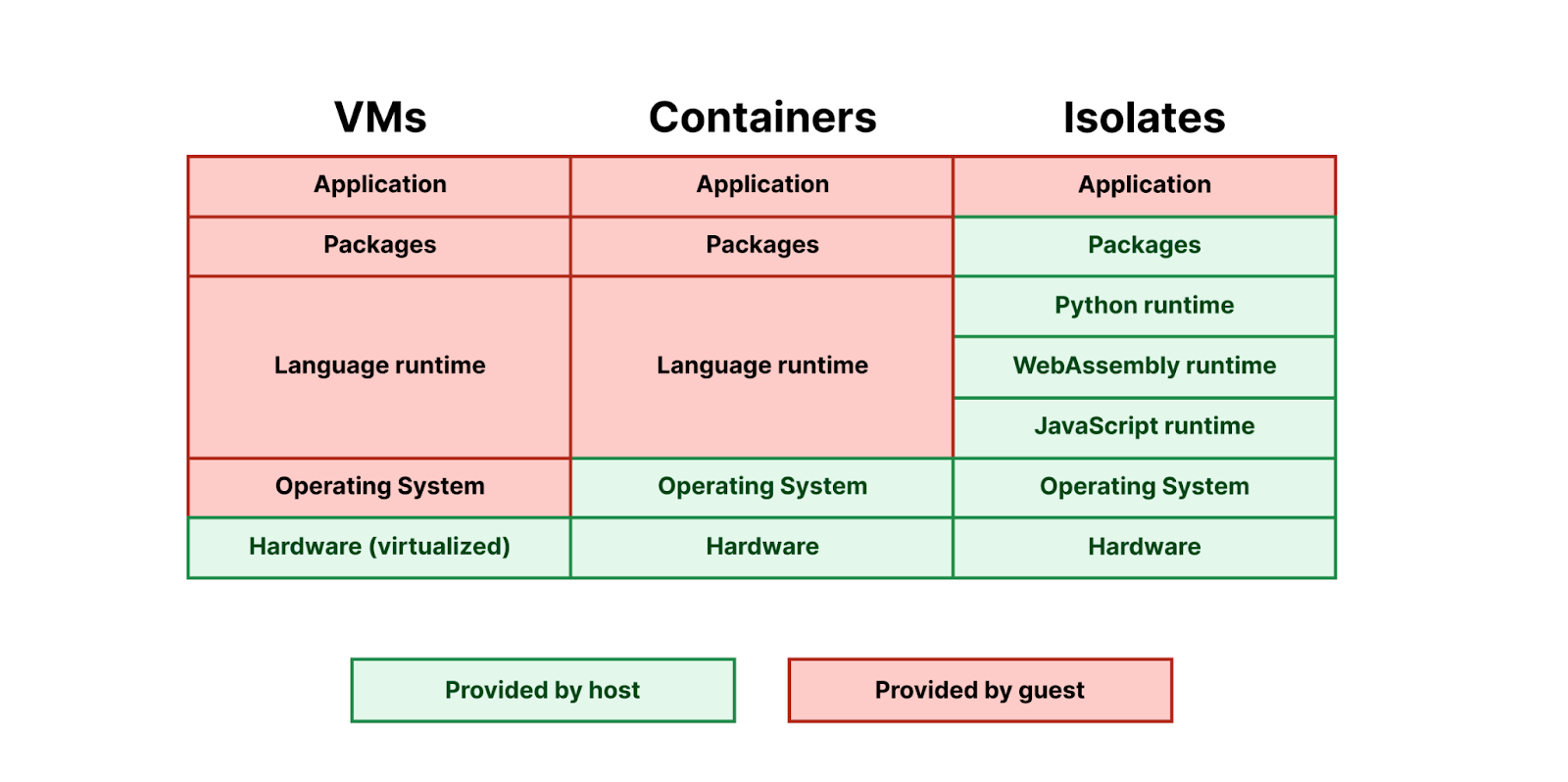
Pyodide is currently the exception — most languages that target WebAssembly do not yet support dynamic linking, so each application ends up bringing its own copy of its language runtime. We hope to see more languages support dynamic linking in the future, so that we can more effectively bring them to Workers.
How Pyodide works
Pyodide executes Python code in WebAssembly, which is a sandboxed environment, separated from the host runtime. Unlike running native code, all operations outside of pure computation (such as file reads) must be provided by a runtime environment, then imported by the WebAssembly module.
LLVM provides three target triples for WebAssembly:
- wasm32-unknown-unknown – this backend provides no C standard library or system call interface; to support this backend, we would need to manually rewrite every system or library call to make use of imports we would define ourselves in the runtime.
- wasm32-wasi – WASI is a standardized system interface, and defines a standard set of imports that are implemented in WASI runtimes such as wasmtime.
- wasm32-unknown-emscripten – Like WASI, Emscripten defines the imports that a WebAssembly program needs to execute, but also outputs an accompanying JavaScript library that implements these imported functions.
Pyodide uses Emscripten, and provides three things:
- A distribution of the CPython interpreter, compiled using Emscripten
- A foreign function interface (FFI) between Python and JavaScript
- A set of third-party Python packages, compiled using Emscripten’s compiler to WebAssembly.
Of these targets, only Emscripten currently supports dynamic linking, which, as we noted above, is essential to providing a shared language runtime for Python that is shared across isolates. Emscripten does this by providing implementations of dlopen and dlsym, which use the accompanying JavaScript library to modify the WebAssembly program’s table to link additional WebAssembly-compiled modules at runtime. WASI does not yet support the dlopen/dlsym dynamic linking abstractions used by CPython.
Pyodide and the magic of foreign function interfaces (FFI)
You might have noticed that in our Hello World Python Worker, we import Response from the js module:
from js import Response
async def on_fetch(request, env):
return Response.new("Hello world!")Why is that?
Most Workers are written in JavaScript, and most of our engineering effort on the Workers runtime goes into improving JavaScript Workers. There is a risk in adding a second language that it might never reach feature parity with the first language and always be a second class citizen. Pyodide’s foreign function interface (FFI) is critical to avoiding this by providing access to all JavaScript functionality from Python. This can be used by the Worker author directly, and it is also used to make packages like FastAPI and Langchain work out-of-the-box, as we’ll show later in this post.
An FFI is a system for calling functions in one language that are implemented in another language. In most cases, an FFI is defined by a “higher-level” language in order to call functions implemented in a systems language, often C. Python’s ctypes module is such a system. These sorts of foreign function interfaces are often difficult to use because of the nature of C APIs.
Pyodide’s foreign function interface is an interface between Python and JavaScript, which are two high level object-oriented languages with a lot of design similarities. When passed from one language to another, immutable types such as strings and numbers are transparently translated. All mutable objects are wrapped in an appropriate proxy.
When a JavaScript object is passed into Python, Pyodide determines which JavaScript protocols the object supports and dynamically constructs an appropriate Python class that implements the corresponding Python protocols. For example, if the JavaScript object supports the JavaScript iteration protocol then the proxy will support the Python iteration protocol. If the JavaScript object is a Promise or other thenable, the Python object will be an awaitable.
from js import JSON
js_array = JSON.parse("[1,2,3]")
for entry in js_array:
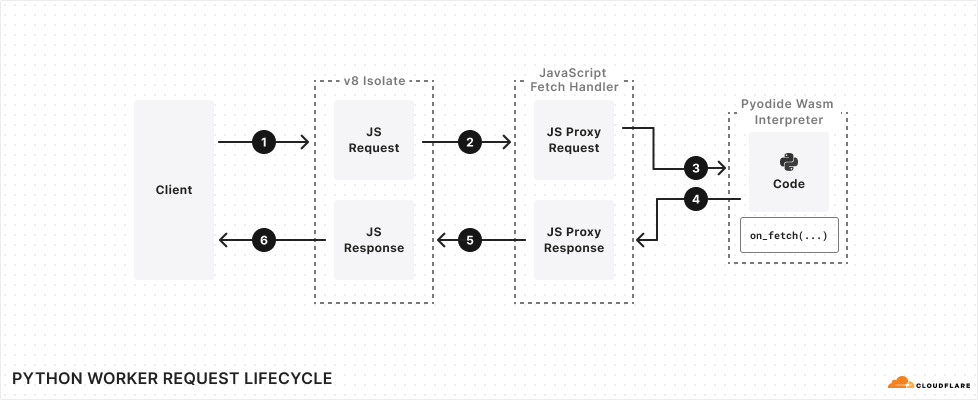
print(entry)The lifecycle of a request to a Python Worker makes use of Pyodide’s FFI, wrapping the incoming JavaScript Request object in a JsProxy object that is accessible in your Python code. It then converts the value returned by the Python Worker’s handler into a JavaScript Response object that can be delivered back to the client:
Why dynamic linking is essential, and static linking isn’t enough
Python comes with a C FFI, and many Python packages use this FFI to import native libraries. These libraries are typically written in C, so they must first be compiled down to WebAssembly in order to work on the Workers runtime. As we noted above, Pyodide is built with Emscripten, which overrides Python’s C FFI — any time a package tries to load a native library, it is instead loaded from a WebAssembly module that is provided by the Workers runtime. Dynamic linking is what makes this possible — it is what lets us override Python’s C FFI, allowing Pyodide to support many Python packages that have native library dependencies.
Dynamic linking is “pay as you go”, while static linking is “pay upfront” — if code is statically linked into your binary, it must be loaded upfront in order for the binary to run, even if this code is never used.
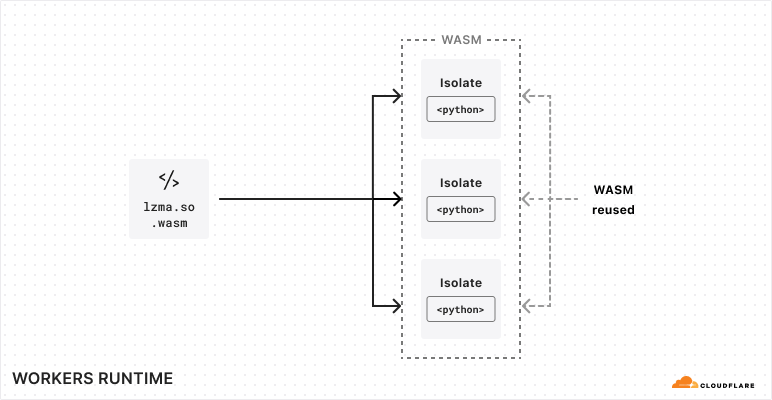
Dynamic linking enables the Workers runtime to share the underlying WebAssembly modules of packages across different Workers that are running on the same machine.
We won’t go too much into detail on how dynamic linking works in Emscripten, but the main takeaway is that the Emscripten runtime fetches WebAssembly modules from a filesystem abstraction provided in JavaScript. For each Worker, we generate a filesystem at runtime, whose structure mimics a Python distribution that has the Worker’s dependencies installed, but whose underlying files are shared between Workers. This makes it possible to share Python and WebAssembly files between multiple Workers that import the same dependency. Today, we’re able to share these files across Workers, but copy them into each new isolate. We think we can go even further, by employing copy-on-write techniques to share the underlying resource across many Workers.
Supporting Server and Client libraries
Python has a wide variety of popular HTTP client libraries, including httpx, urllib3, requests and more. Unfortunately, none of them work out of the box in Pyodide. Adding support for these has been one of the longest running user requests for the Pyodide project. The Python HTTP client libraries all work with raw sockets, and the browser security model and CORS do not allow this, so we needed another way to make them work in the Workers runtime.
Async Client libraries
For libraries that can make requests asynchronously, including aiohttp and httpx, we can use the Fetch API to make requests. We do this by patching the library, instructing it to use the Fetch API from JavaScript — taking advantage of Pyodide’s FFI. The httpx patch ends up quite simple —fewer than 100 lines of code. Simplified even further, it looks like this:
from js import Headers, Request, fetch
def py_request_to_js_request(py_request):
js_headers = Headers.new(py_request.headers)
return Request.new(py_request.url, method=py_request.method, headers=js_headers)
def js_response_to_py_response(js_response):
... # omitted
async def do_request(py_request):
js_request = py_request_to_js_request(py_request)
js_response = await fetch(js_request)
py_response = js_response_to_py_response(js_response)
return py_responseSynchronous Client libraries
Another challenge in supporting Python HTTP client libraries is that many Python APIs are synchronous. For these libraries, we cannot use the fetch API directly because it is asynchronous.
Thankfully, Joe Marshall recently landed a contribution to urllib3 that adds Pyodide support in web browsers by:
- Checking if blocking with
Atomics.wait()is possible
a. If so, start a fetch worker thread
b. Delegate the fetch operation to the worker thread and serialize the response into a SharedArrayBuffer
c. In the Python thread, use Atomics.wait to block for the response in the SharedArrayBuffer - If
Atomics.wait()doesn’t work, fall back to a synchronous XMLHttpRequest
Despite this, today Cloudflare Workers do not support worker threads or synchronous XMLHttpRequest, so neither of these two approaches will work in Python Workers. We do not support synchronous requests today, but there is a way forward…
WebAssembly Stack Switching
There is an approach which will allow us to support synchronous requests. WebAssembly has a stage 3 proposal adding support for stack switching, which v8 has an implementation of. Pyodide contributors have been working on adding support for stack switching to Pyodide since September of 2022, and it is almost ready.
With this support, Pyodide exposes a function called run_sync which can block for completion of an awaitable:
from pyodide.ffi import run_sync
def sync_fetch(py_request):
js_request = py_request_to_js_request(py_request)
js_response = run_sync(fetch(js_request))
return js_response_to_py_response(js_response)FastAPI and Python’s Asynchronous Server Gateway Interface
FastAPI is one of the most popular libraries for defining Python servers. FastAPI applications use a protocol called the Asynchronous Server Gateway Interface (ASGI). This means that FastAPI never reads from or writes to a socket itself. An ASGI application expects to be hooked up to an ASGI server, typically uvicorn. The ASGI server handles all of the raw sockets on the application’s behalf.
Conveniently for us, this means that FastAPI works in Cloudflare Workers without any patches or changes to FastAPI itself. We simply need to replace uvicorn with an appropriate ASGI server that can run within a Worker. Our initial implementation lives here, in the fork of Pyodide that we maintain. We hope to add a more comprehensive feature set, add test coverage, and then upstream this implementation into Pyodide.
You can try this yourself by cloning cloudflare/python-workers-examples, and running npx wrangler@latest dev in the directory of the FastAPI example.
Importing Python Packages
Python Workers support a subset of Python packages, which are provided directly by Pyodide, including numpy, httpx, FastAPI, Langchain, and more. This ensures compatibility with the Pyodide runtime by pinning package versions to Pyodide versions, and allows Pyodide to patch internal implementations, as we showed above in the case of httpx.
To import a package, simply add it to your requirements.txt file, without adding a version number. A specific version of the package is provided directly by Pyodide. Today, you can use packages in local development, and in the coming weeks, you will be able to deploy Workers that define dependencies in a requirements.txt file. Later in this post, we’ll show how we’re thinking about managing new versions of Pyodide and packages.
We maintain our own fork of Pyodide, which allows us to provide patches specific to the Workers runtime, and to quickly expand our support for packages in Python Workers, while also committing to upstreaming our changes back to Pyodide, so that the whole ecosystem of developers can benefit.
Python packages are often big and memory hungry though, and they can do a lot of work at import time. How can we ensure that you can bring in the packages you need, while mitigating long cold start times?
Making cold starts faster with memory snapshots
In the example at the start of this post, in local development, we mentioned injecting Pyodide into your Worker. Pyodide itself is 6.4MB — and Python packages can also be quite large.
If we simply shoved Pyodide into your Worker and uploaded it to Cloudflare, that’d be quite a large Worker to load into a new isolate — cold starts would be slow. On a fast computer with a good network connection, Pyodide takes about two seconds to initialize in a web browser, one second of network time and one second of cpu time. It wouldn’t be acceptable to initialize it every time you update your code for every isolate your Worker runs in across Cloudflare’s network.
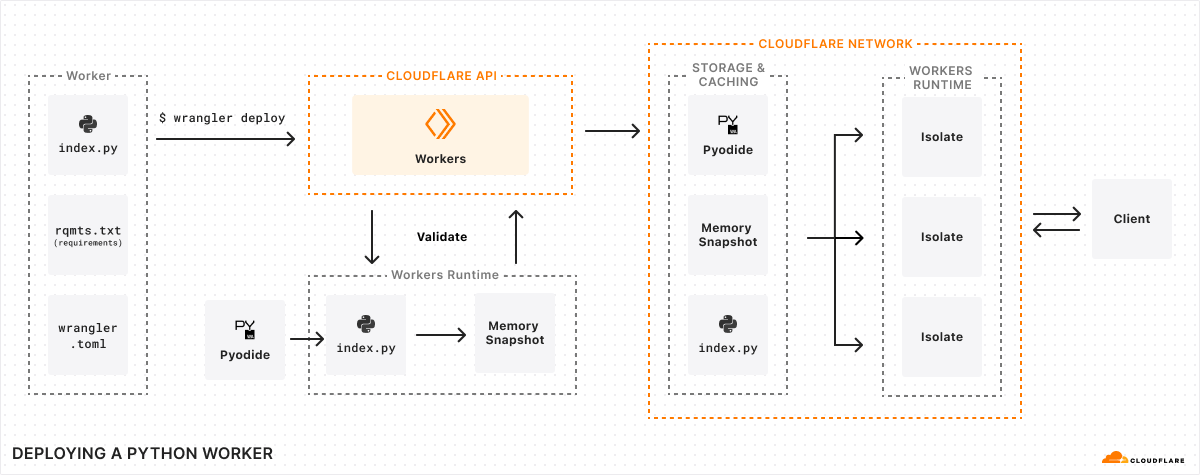
Instead, when you run npx wrangler@latest deploy, the following happens:
- Wrangler uploads your Python code and your
requirements.txtfile to the Workers API - We send your Python code, and your
requirements.txtfile to the Workers runtime to be validated - We create a new isolate for your Worker, and automatically inject Pyodide plus any packages you’ve specified in your
requirements.txtfile. - We scan the Worker’s code for import statements, execute them, and then take a snapshot of the Worker’s WebAssembly linear memory. Effectively, we perform the expensive work of importing packages at deploy time, rather than at runtime.
- We deploy this snapshot alongside your Worker’s Python code to Cloudflare’s network.
- Just like a JavaScript Worker, we execute the Worker’s top-level scope.
When a request comes in to your Worker, we load this snapshot and use it to bootstrap your Worker in an isolate, avoiding expensive initialization time:
This takes cold starts for a basic Python Worker down to below 1 second. We’re not yet satisfied with this though. We’re confident that we can drive this down much, much further. How? By reusing memory snapshots.
Reusing Memory Snapshots
When you upload a Python Worker, we generate a single memory snapshot of the Worker’s top-level imports, including both Pyodide and any dependencies. This snapshot is specific to your Worker. It can’t be shared, even though most of its contents are the same as other Python Workers.
Instead, we can create a single, shared snapshot ahead of time, and preload it into a pool of “pre-warmed” isolates. These isolates would already have the Pyodide runtime loaded and ready — making a Python Worker work just like a JavaScript Worker. In both cases, the underlying interpreter and execution environment is provided by the Workers runtime, and available on-demand without delay. The only difference is that with Python, the interpreter runs in WebAssembly, within the Worker.
Snapshots are a common pattern across runtimes and execution environments. Node.js uses V8 snapshots to speed up startup time. You can take snapshots of Firecracker microVMs and resume execution in a different process. There’s lots more we can do here — not just for Python Workers, but for Workers written in JavaScript as well, caching snapshots of compiled code from top-level scope and the state of the isolate itself. Workers are so fast and efficient that to-date we haven’t had to take snapshots in this way, but we think there are still big performance gains to be had.
This is our biggest lever towards driving cold start times down over the rest of 2024.
Future proofing compatibility with Pyodide versions and Compatibility Dates
When you deploy a Worker to Cloudflare, you expect it to keep running indefinitely, even if you never update it again. There are Workers deployed in 2018 that are still running just fine in production.
We achieve this using Compatibility Dates and Compatibility Flags, which provide explicit opt-in mechanisms for new behavior and potentially backwards-incompatible changes, without impacting existing Workers.
This works in part because it mirrors how the Internet and web browsers work. You publish a web page with some JavaScript, and rightly expect it to work forever. Web browsers and Cloudflare Workers have the same type of commitment of stability to developers.
There is a challenge with Python though — both Pyodide and CPython are versioned. Updated versions are published regularly and can contain breaking changes. And Pyodide provides a set of built-in packages, each with a pinned version number. This presents a question — how should we allow you to update your Worker to a newer version of Pyodide?
The answer is Compatibility Dates and Compatibility Flags.
A new version of Python is released every year in August, and a new version of Pyodide is released six (6) months later. When this new version of Pyodide is published, we will add it to Workers by gating it behind a Compatibility Flag, which is only enabled after a specified Compatibility Date. This lets us continually provide updates, without risk of breaking changes, extending the commitment we’ve made for JavaScript to Python.
Each Python release has a five (5) year support window. Once this support window has passed for a given version of Python, security patches are no longer applied, making this version unsafe to rely on. To mitigate this risk, while still trying to hold as true as possible to our commitment of stability and long-term support, after five years any Python Worker still on a Python release that is outside of the support window will be automatically moved forward to the next oldest Python release. Python is a mature and stable language, so we expect that in most cases, your Python Worker will continue running without issue. But we recommend updating the compatibility date of your Worker regularly, to stay within the support window.
In between Python releases, we also expect to update and add additional Python packages, using the same opt-in mechanism. A Compatibility Flag will be a combination of the Python version and the release date of a set of packages. For example, python_3.17_packages_2025_03_01.
How bindings work in Python Workers
We mentioned earlier that Pyodide provides a foreign function interface (FFI) to JavaScript — meaning that you can directly use JavaScript objects, methods, functions and more, directly from Python.
This means that from day one, all binding APIs to other Cloudflare resources are supported in Cloudflare Workers. The env object that is provided by handlers in Python Workers is a JavaScript object that Pyodide provides a proxy API to, handling type translations across languages automatically.
For example, to write to and read from a KV namespace from a Python Worker, you would write:
from js import Response
async def on_fetch(request, env):
await env.FOO.put("bar", "baz")
bar = await env.FOO.get("bar")
return Response.new(bar) # returns "baz"This works for Web APIs too — see how Response is imported from the js module? You can import any global from JavaScript this way.
Get this JavaScript out of my Python!
You’re probably reading this post because you want to write Python instead of JavaScript. from js import Response just isn’t Pythonic. We know — and we have actually tackled this challenge before for another language (Rust). And we think we can do this even better for Python.
We launched workers-rs in 2021 to make it possible to write Workers in Rust. For each JavaScript API in Workers, we, alongside open-source contributors, have written bindings that expose a more idiomatic Rust API.
We plan to do the same for Python Workers — starting with the bindings to Workers AI and Vectorize. But while workers-rs requires that you use and update an external dependency, the APIs we provide with Python Workers will be built into the Workers runtime directly. Just update your compatibility date, and get the latest, most Pythonic APIs.
This is about more than just making bindings to resources on Cloudflare more Pythonic though — it’s about compatibility with the ecosystem.
Similar to how we recently converted workers-rs to use types from the http crate, which makes it easy to use the axum crate for routing, we aim to do the same for Python Workers. For example, the Python standard library provides a raw socket API, which many Python packages depend on. Workers already provides connect(), a JavaScript API for working with raw sockets. We see ways to provide at least a subset of the Python standard library’s socket API in Workers, enabling a broader set of Python packages to work on Workers, with less of a need for patches.
But ultimately, we hope to kick start an effort to create a standardized serverless API for Python. One that is easy to use for any Python developer and offers the same capabilities as JavaScript.
We’re just getting started with Python Workers
Providing true support for a new programming language is a big investment that goes far beyond making “hello world” work. We chose Python very intentionally — it’s the second most popular programming language after JavaScript — and we are committed to continuing to improve performance and widen our support for Python packages.
We’re grateful to the Pyodide maintainers and the broader Python community — and we’d love to hear from you. Drop into the Python Workers channel in the Cloudflare Developers Discord, or start a discussion on Github about what you’d like to see next and which Python packages you’d like us to support.