Post Syndicated from Brendan Irvine-Broque original https://blog.cloudflare.com/cloudflare-developer-platform-keeps-getting-better-faster-and-more-powerful/
When you build on Cloudflare, we consider it our job to do the heavy lifting for you. That’s been true since we introduced Cloudflare Workers in 2017, when we first provided a runtime for you where you could just focus on building.
That commitment is still true today, and many of today’s announcements are focused on just that — removing friction where possible to free you up to build something great.
There are only so many blog posts we can write (and that you can read)! We have been busy on a much longer list of new improvements, and many of them we’ve been rolling out consistently over the course of the year. Today’s announcement breaks down all the new capabilities in detail, in one single post. The features being released today include:
-
Use more APIs from Node.js — including node:fs and node:https
-
Use models from different providers in AI Search (formerly AutoRAG)
-
Deploy larger container instances and more concurrent instances to our Containers platform
-
Run 30 concurrent headless web browsers (previously 10), via the Browser Rendering API
-
Use the Playwright browser automation library with the Browser Rendering API — now fully supported and GA
-
Use 4 vCPUs (prev 2) and 20GB of disk (prev 8GB) with Workers Builds — now GA
-
Connect to production services and resources from local development with Remote Bindings — now GA
-
R2 Infrequent Access GA – lower-cost storage class for backups, logs, and long-tail content
-
Resize, clip and reformat video files on-demand with Media Transformations — now GA
Alongside that, we’re constantly adding new building blocks, to make sure you have all the tools you need to build what you set out to. Those launches (that also went out today, but require a bit more explanation) include:
-
Connect to Postgres databases running on Planetscale
-
Send transactional emails via the new Cloudflare Email Service
-
Run distributed SQL queries with the new Cloudflare Data Platform
-
Deploy your own AI vibe coding platform to Cloudflare with VibeSDK
AutoRAG is now AI Search! The new name marks a new and bigger mission: to make world-class search infrastructure available to every developer and business. AI Search is no longer just about retrieval for LLM apps: it’s about giving you a fast, flexible index for your content that is ready to power any AI experience. With recent additions like NLWeb support, we are expanding beyond simple retrieval to provide a foundation for top quality search experiences that are open and built for the future of the web.
With AI Search you can now use models from different providers like OpenAI and Anthropic. Last month during AI Week we announced BYO Provider Keys for AI Gateway. That capability now extends to AI Search. By attaching your keys to the AI Gateway linked to your AI Search instance, you can use many more models for both embedding and inference.

Once configured, your AI Search instance will be able to reference models available through your AI Gateway when making a /ai-search request:
export default {
async fetch(request, env) {
// Query your AI Search instance with a natural language question to an OpenAI model
const result = await env.AI.autorag("my-ai-search").aiSearch({
query: "What's new for Cloudflare Birthday Week?",
model: "openai/gpt-5"
});
// Return only the generated answer as plain text
return new Response(result.response, {
headers: { "Content-Type": "text/plain" },
});
},
};In the coming weeks we will also roll out updates to align the APIs with the new name. The existing APIs will continue to be supported for the time being. Stay tuned to the AI Search Changelog and Discord for more updates!
Remote bindings for local development are generally available, supported in Wrangler v4.37.0, the Cloudflare Vite plugin, and the @cloudflare/vitest-pool-workers package. Remote bindings are bindings that are configured to connect to a deployed resource on your Cloudflare account instead of the locally simulated resource.
For example, here’s how you can instruct Wrangler or Vite to send all requests to env.MY_BUCKET to hit the real, deployed R2 bucket instead of a locally simulated one:
{
"name": "my-worker",
"compatibility_date": "2025-09-25",
"r2_buckets": [
{
"bucket_name": "my-bucket",
"binding": "MY_BUCKET",
"remote": true
},
],
}With the above configuration, all requests to env.MY_BUCKET will be proxied to the remote resource, but the Worker code will still execute locally. This means you get all the benefits of local development like faster execution times – without having to seed local databases with data.
You can pair remote bindings with environments, so that you can use staging data during local development and leave production data untouched.
For example, here’s how you could point Wrangler or Vite to send all requests to env.MY_BUCKET to staging-storage-bucket when you run wrangler dev --env staging (CLOUDFLARE_ENV=staging vite dev if using Vite).
{
"name": "my-worker",
"compatibility_date": "2025-09-25",
"env": {
"staging": {
"r2_buckets": [
{
"binding": "MY_BUCKET",
"bucket_name": "staging-storage-bucket",
"remote": true
}
]
},
"production": {
"r2_buckets": [
{
"binding": "MY_BUCKET",
"bucket_name": "production-storage-bucket"
}
]
}
}
}Over the past year, we have been hard at work to make Workers more compatible with Node.js packages and APIs.
Several weeks ago, we shared how node:http and node:https APIs are now supported on Workers. This means that you can run backend Express and Koa.js work with only a few additional lines of code:
import { httpServerHandler } from 'cloudflare:node';
import express from 'express';
const app = express();
app.get('/', (req, res) => {
res.json({ message: 'Express.js running on Cloudflare Workers!' });
});
app.listen(3000);
export default httpServerHandler({ port: 3000 });And there’s much, much more. You can now:
-
Read and write temporary files in Workers, using
node:fs -
Do DNS looking using 1.1.1.1 with
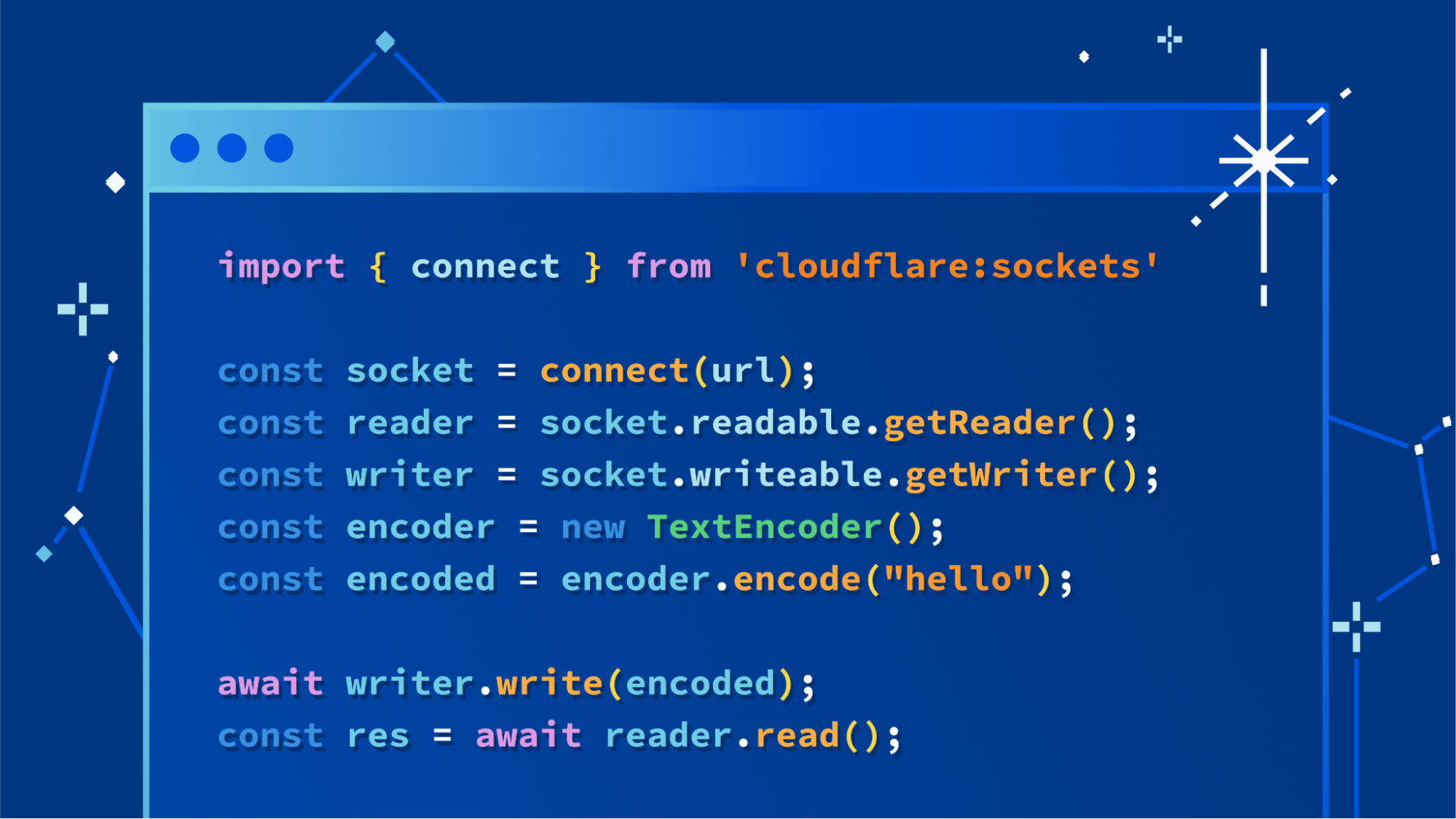
node:dns -
Use
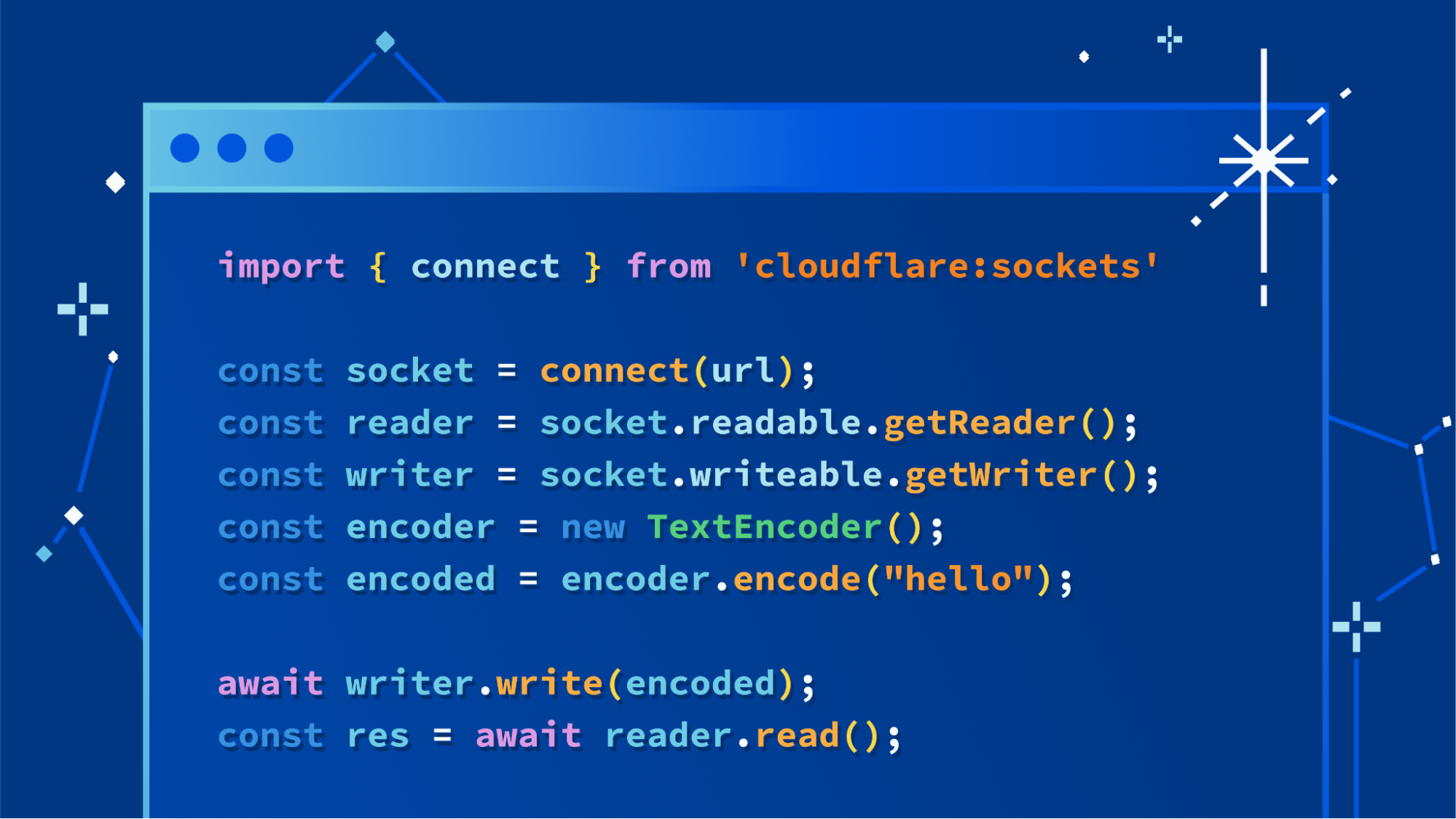
node:netandnode:tlsfor first class Socket support -
Use common hashing libraries with
node:crypto -
Access environment variables in a Node-like fashion on
process.env
Read our full recap of the last year’s Node.js-related changes for all the details.
With these changes, Workers become even more powerful and easier to adopt, regardless of where you’re coming from. The APIs that you are familiar with are there, and more packages you need will just work.
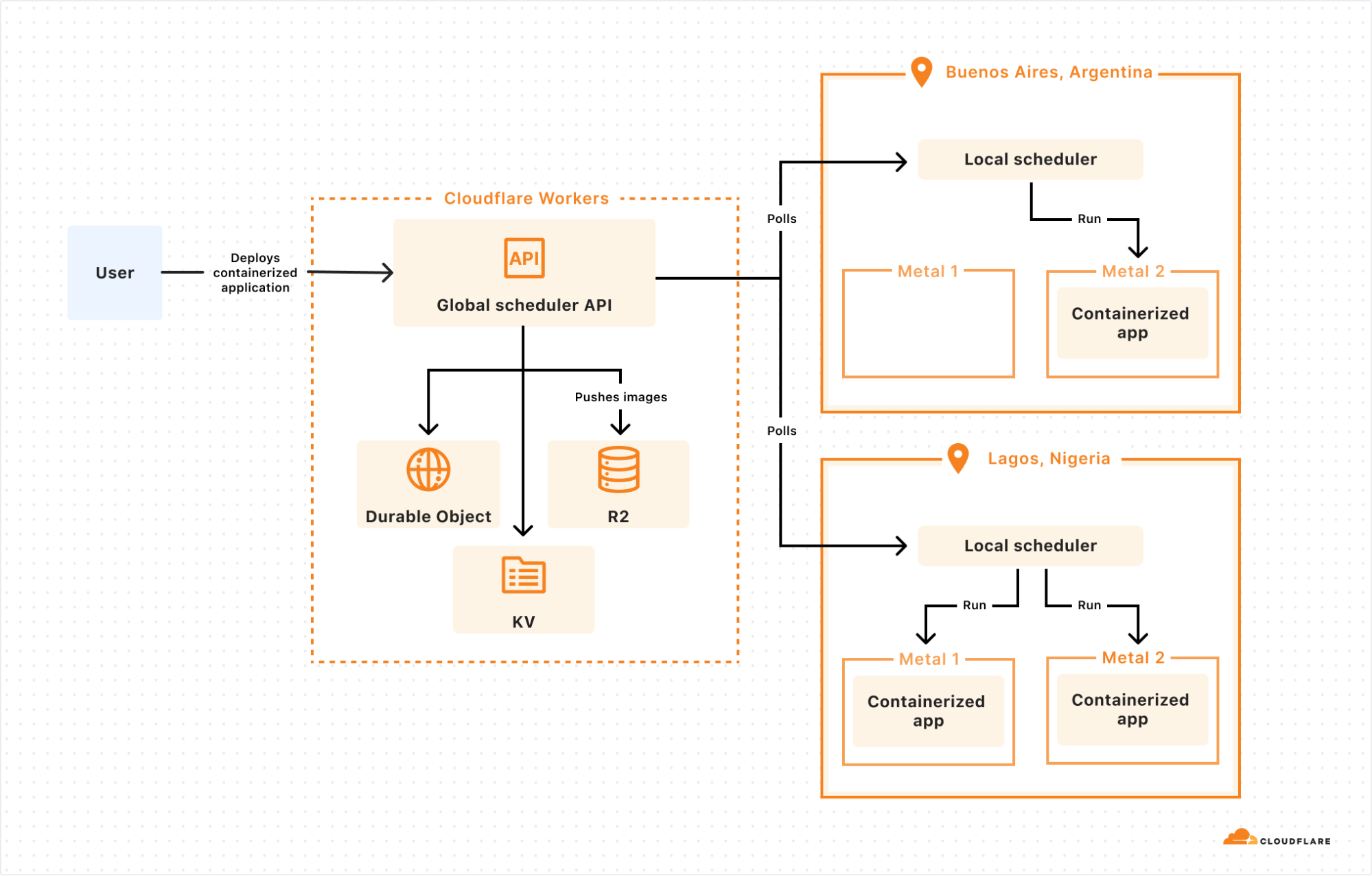
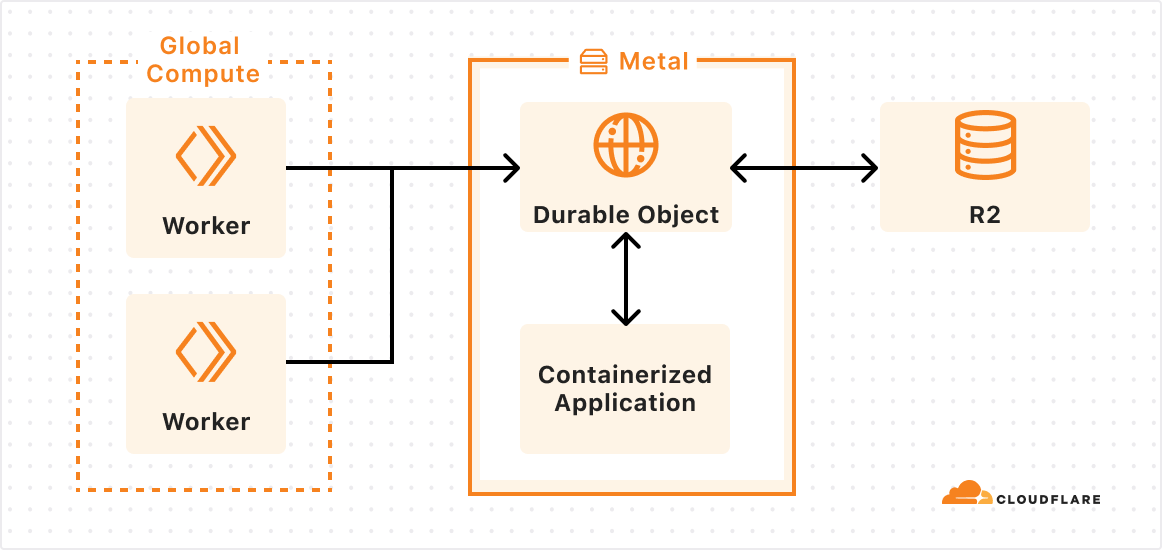
Cloudflare Containers now has higher limits on concurrent instances and an upcoming new, larger instance type.
Previously you could run 50 instances of the dev instance type or 25 instances of the basic instance type concurrently. Now you can run concurrent containers with up to 400 GiB of memory, 100 vCPUs, and 2 TB of disk. This allows you to run up to 1000 dev instances or 400 basic instances concurrently. Enterprise customers can push far beyond these limits — contact us if you need more. If you are using Containers to power your app and it goes viral, you’ll have the ability to scale on Cloudflare.
Cloudflare Containers also now has a new instance type coming soon — standard-2 which includes 8 GiB of memory, 1 vCPU, and 12 GB of disk. This new instance type is an ideal default for workloads that need more resources, from AI Sandboxes to data processing jobs.
Last Birthday Week, we announced the launch of our integrated CI/CD pipeline, Workers Builds, in open beta. We also gave you a detailed look into how we built this system on our Workers platform using Containers, Durable Objects, Hyperdrive, Workers Logs, and Smart Placement.
This year, we are excited to announce that Workers Builds is now Generally Available. Here’s what’s new:
-
Increased disk space for all plans: We’ve increased the disk size from 8 GB to 20 GB for both free and paid plans, giving you more space for your projects and dependencies
-
More compute for paid plans: We’ve doubled the CPU power for paid plans from 2 vCPU to 4 vCPU, making your builds significantly faster
-
Faster single-core and multi-core performance: To ensure consistent, high performance builds, we now run your builds on the fastest available CPUs at the time your build runs
Haven’t used Workers Builds yet? You can try it by connecting a Git repository to an existing Worker, or try it out on a fresh new project by clicking any Deploy to Cloudflare button, like the one below that deploys a blog built with Astro to your Cloudflare account:

Durable Objects, R2, and Workers now all have a more consistent look with the rest of our developer platform. As you explore these pages you’ll find that things should load faster, feel smoother and are easier to use.
Across storage products, you can now customize the table that lists the resources on your account, choose which data you want to see, sort by any column, and hide columns you don’t need. In the Workers and Pages dashboard, we’ve reduced clutter and have modernized the design to make it faster for you to get the data you need.

And when you create a new Pipeline or a Hyperdrive configuration, you’ll find a new interface that helps you get started and guides you through each step.

This work is ongoing, and we’re excited to continue improving with the help of your feedback, so keep it coming!
In March 2025 we announced Media Transformations in open beta, which brings the magic of Image transformations to short-form video files — including video files stored outside of Cloudflare. Since then, we have increased input and output limits, and added support for audio-only extraction. Media Transformations is now generally available.
Media Transformations is ideal if you have a large existing volume of short videos, such as generative AI output, e-commerce product videos, social media clips, or short marketing content. Content like this should be fetched from your existing storage like R2 or S3 directly, optimized by Cloudflare quickly, and delivered efficiently as small MP4 files or used to extract still images and audio.
https://example.com/cdn-cgi/media/<OPTIONS>/<SOURCE-VIDEO>
EXAMPLE, RESIZE:
EXAMPLE, STILL THUMBNAIL:
https://example.com/cdn-cgi/media/mode=frame,time=3s,width=120,height=120,fit=cover/https://pub-d9fcbc1abcd244c1821f38b99017347f.r2.dev/aus-mobile.mp4Media Transformations includes a free tier available to all customers and is included with Media Platform subscriptions. Check out the transform videos documentation for all the latest, then enable transformations for your zone today!
R2 Infrequent Access is now generally available. Last year, we introduced the Infrequent Access storage class designed for data that doesn’t need to be accessed frequently. It’s a great fit for use cases including long-tail user content, logs, or data backups.
Since launch, Infrequent Access has been proven in production by our customers running these types of workloads at scale. The results confirmed our goal: a storage class that reduces storage costs while maintaining performance and durability.
Pricing is simple. You pay less on data storage, while data retrievals are billed per GB to reflect the additional compute required to serve data from underlying storage optimized for less frequent access. And as with all of R2, there are no egress fees, so you don’t pay for the bandwidth to move data out.
Here’s how you can upload an object to R2 infrequent access class via Workers:
export default {
async fetch(request, env) {
// Upload the incoming request body to R2 in Infrequent Access class
await env.MY_BUCKET.put("my-object", request.body, {
storageClass: "InfrequentAccess",
});
return new Response("Object uploaded to Infrequent Access!", {
headers: { "Content-Type": "text/plain" },
});
},
};You can also monitor your Infrequent Access vs. Standard storage usage directly in your R2 dashboard for each bucket. Get started with R2 today!
We’re excited to announce three updates to Browser Rendering:
-
Our support for Playwright is now Generally Available, giving developers the stability and confidence to run critical browser tasks.
-
We’re introducing support for Stagehand, enabling developers to build AI agents using natural language, powered by Cloudflare Workers AI.
-
Finally, to help developers scale, we are tripling limits for paid plans, with more increases to come.
The browser is no longer only used by humans. AI agents need to be able to reliably navigate browsers in the same way a human would, whether that’s booking flights, filling in customer info, or scraping structured data. Playwright gives AI agents the ability to interact with web pages and perform complex tasks on behalf of humans. However, running browsers at scale is a significant infrastructure challenge. Cloudflare Browser Rendering solves this by providing headless browsers on-demand. By moving Playwright support to Generally Available, and now synced with the latest version v1.55, customers have a production-ready foundation to build reliable, scalable applications on.
To help AI agents better navigate the web, we’re introducing support for Stagehand, an open source browser automation framework. Rather than dictating exact steps or specifying selectors, Stagehand enables developers to build more reliably and flexibly by combining code with natural-language instructions powered by AI. This makes it possible for AI agents to navigate and adapt if a website changes – just like a human would.
To get started with Playwright and Stagehand, check our changelog with code examples and more.