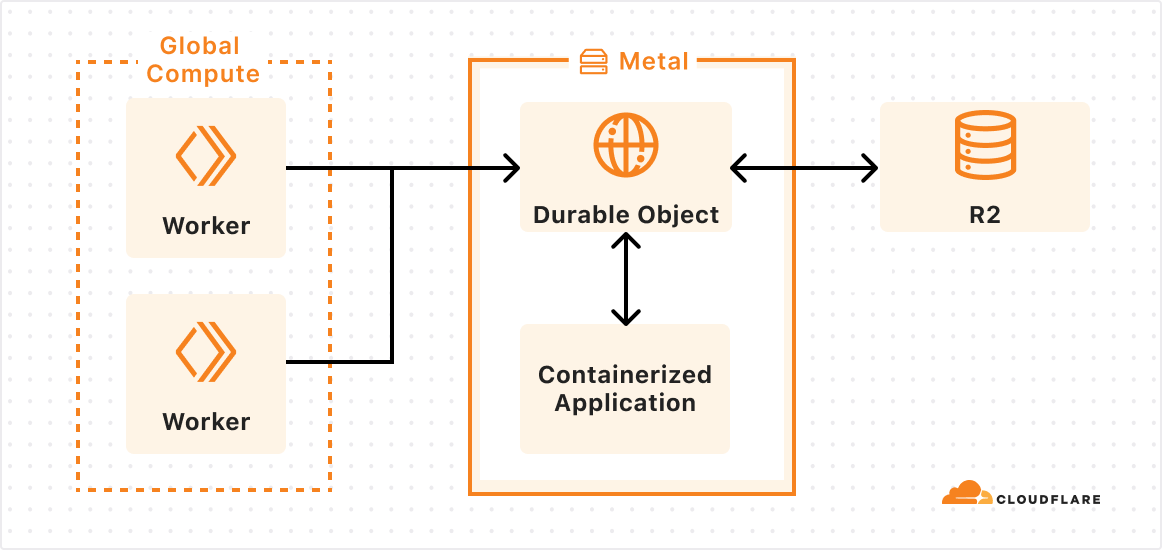
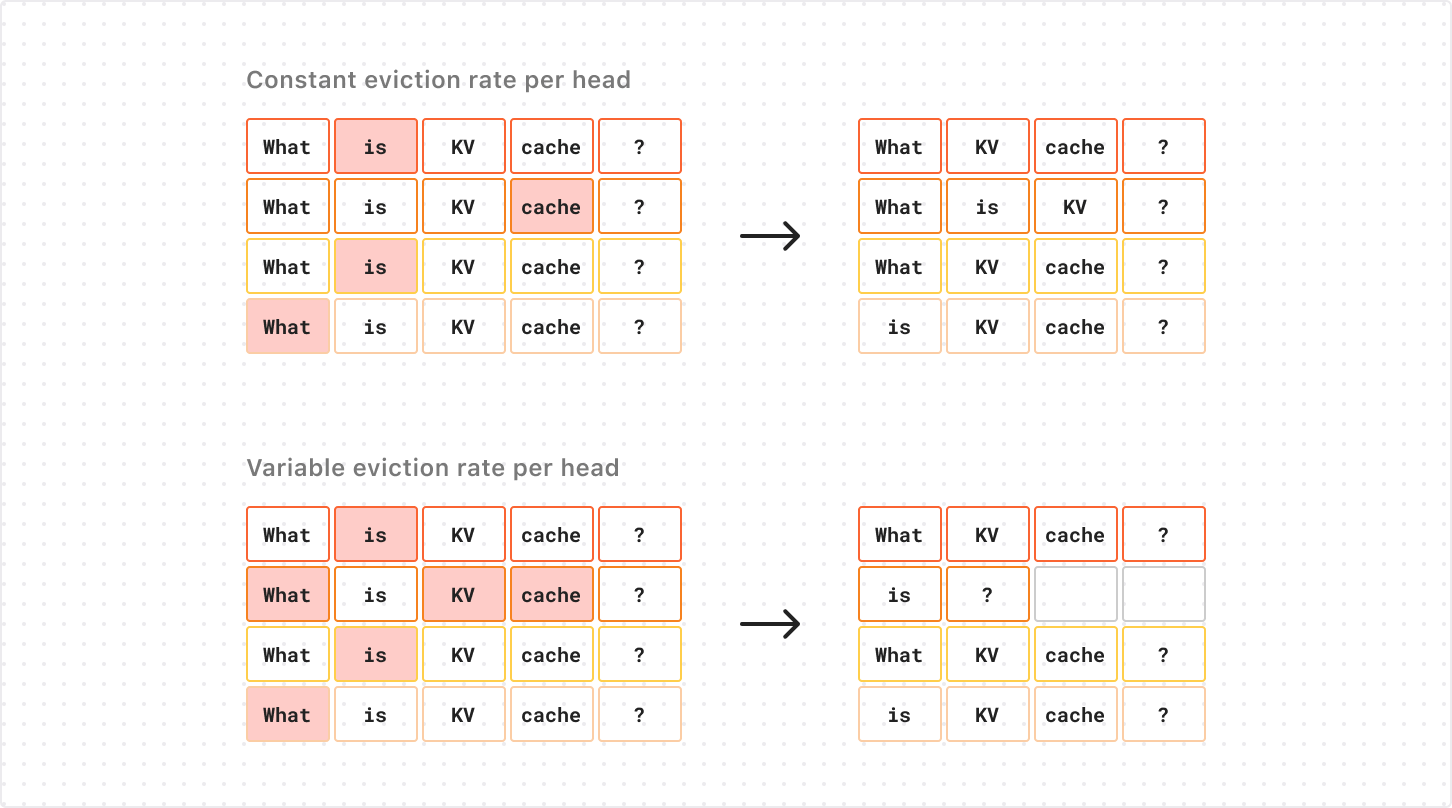
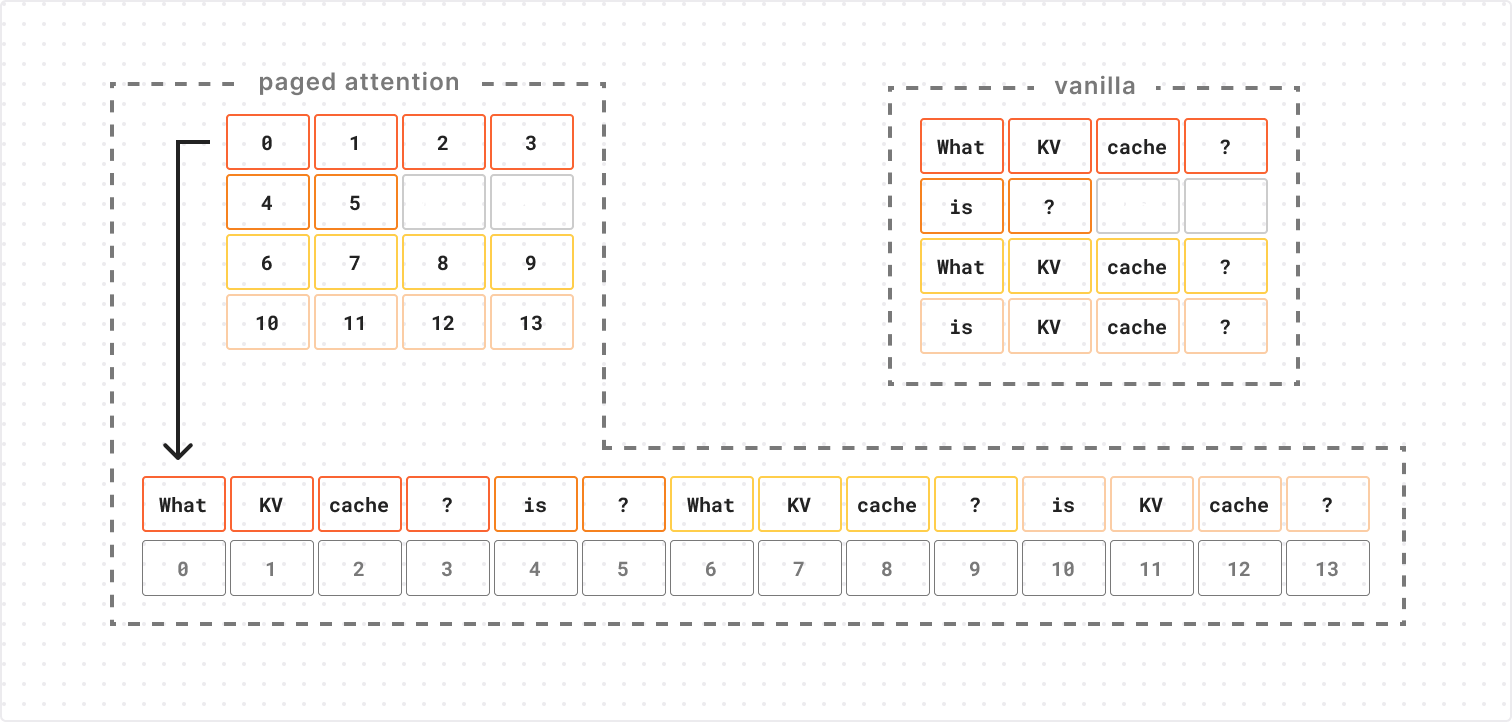
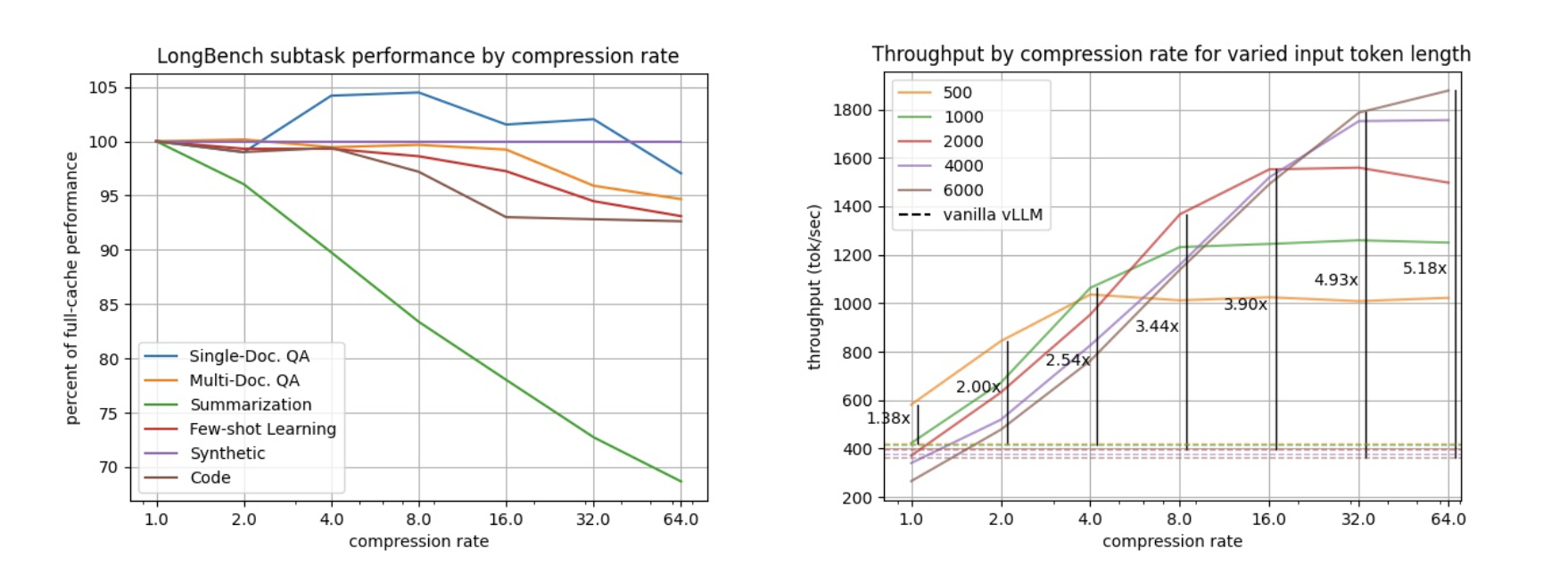
In October 2024, we talked about storing billions of logs from your AI application using AI Gateway, and how we used Cloudflare’s Developer Platform to do this.
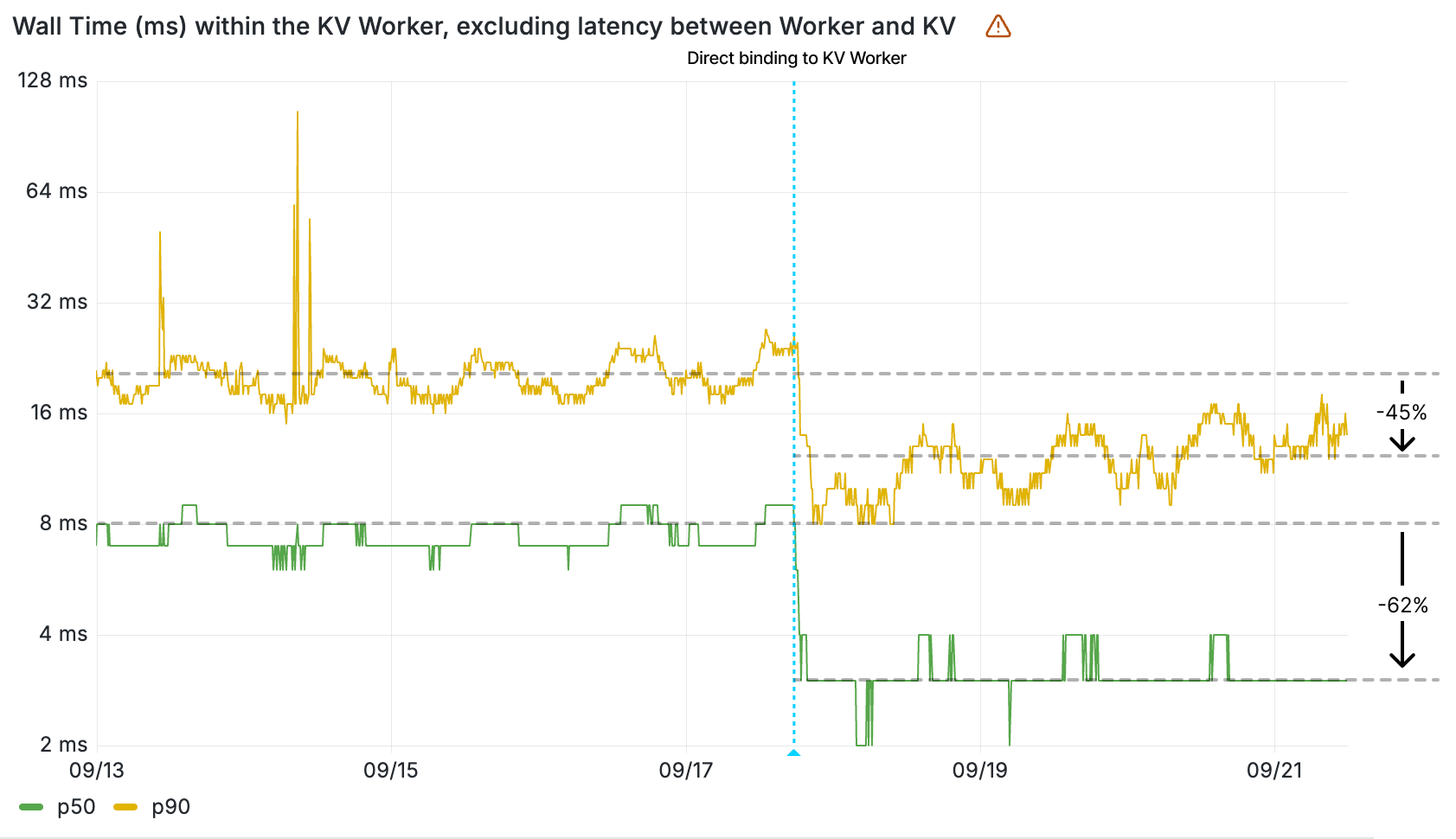
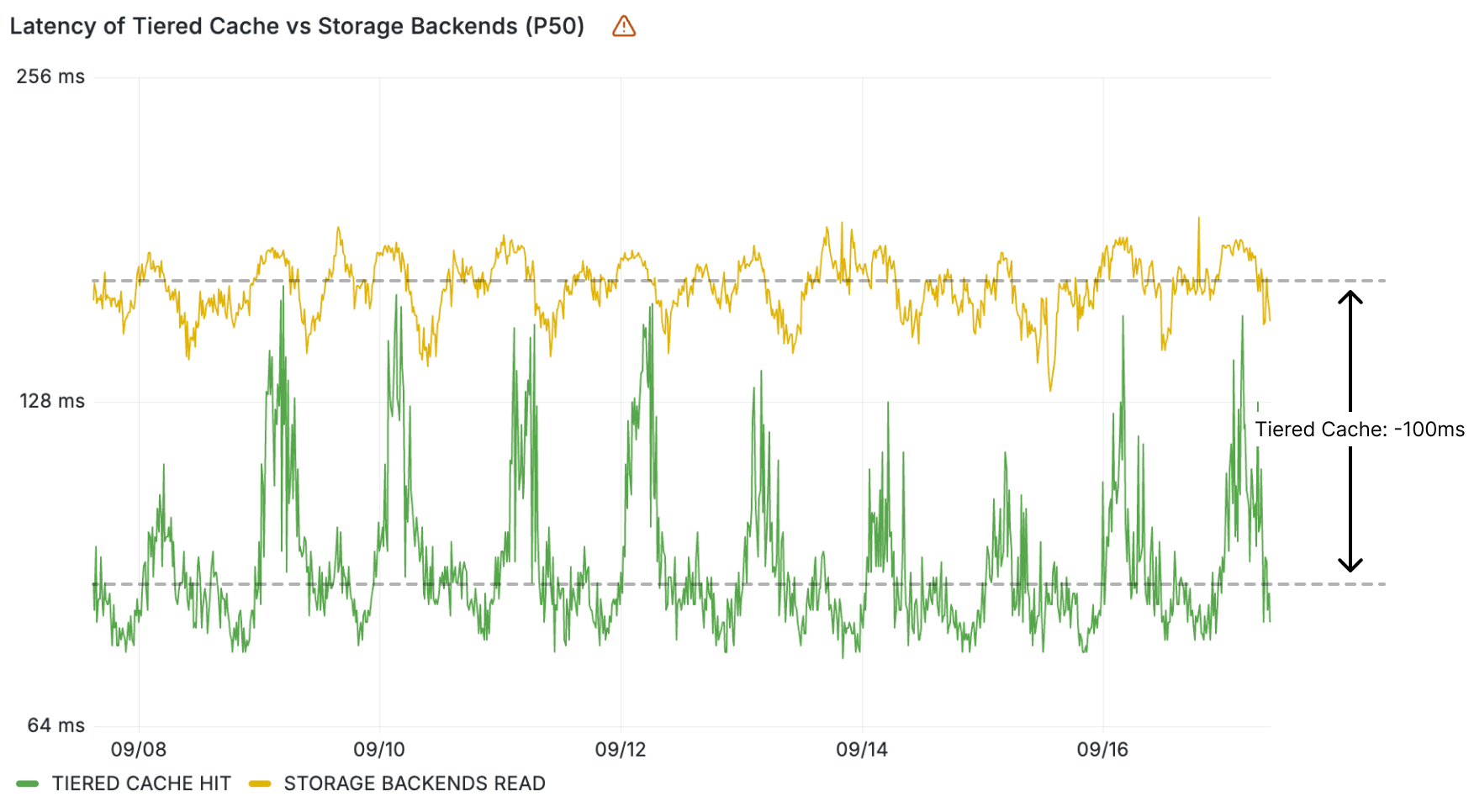
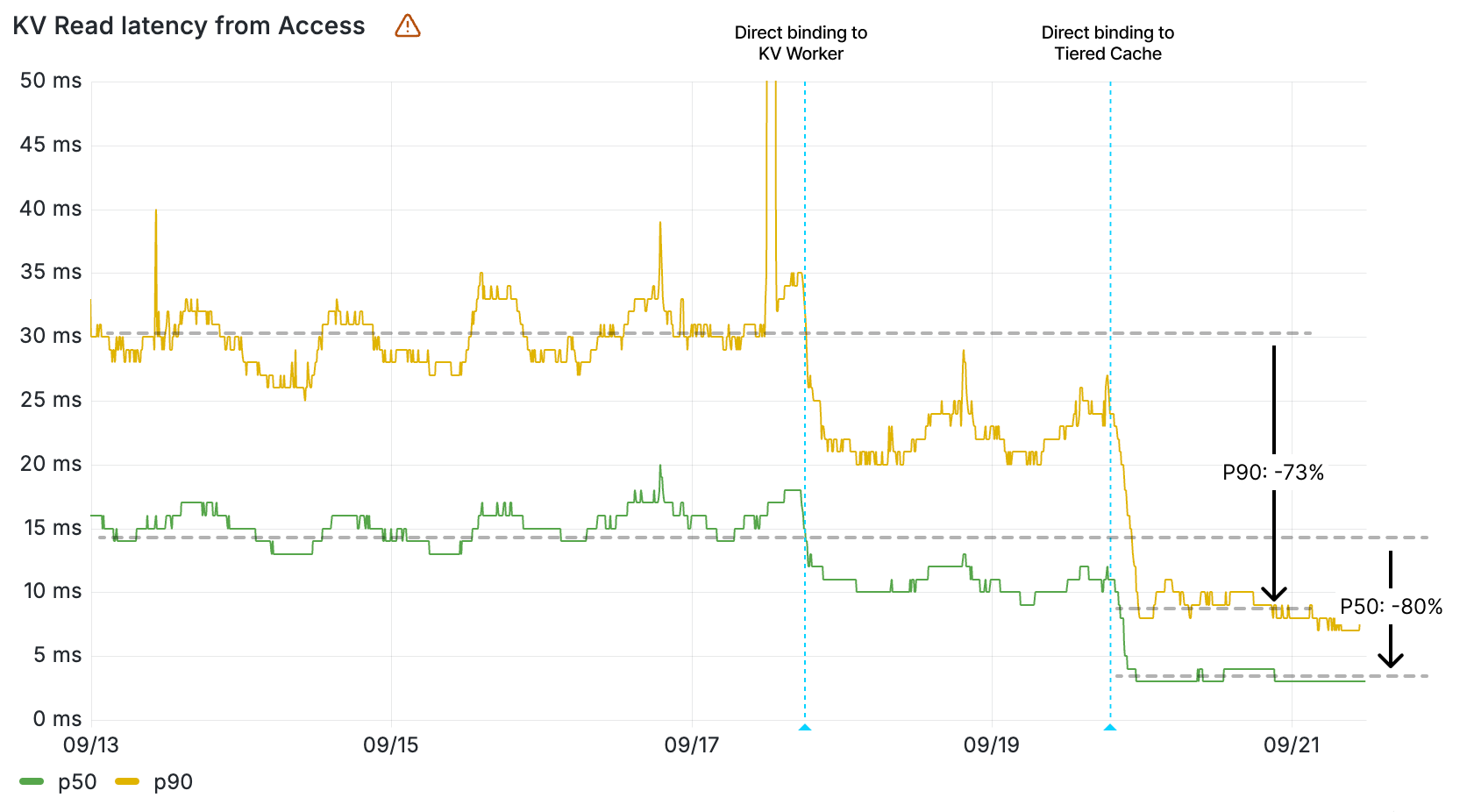
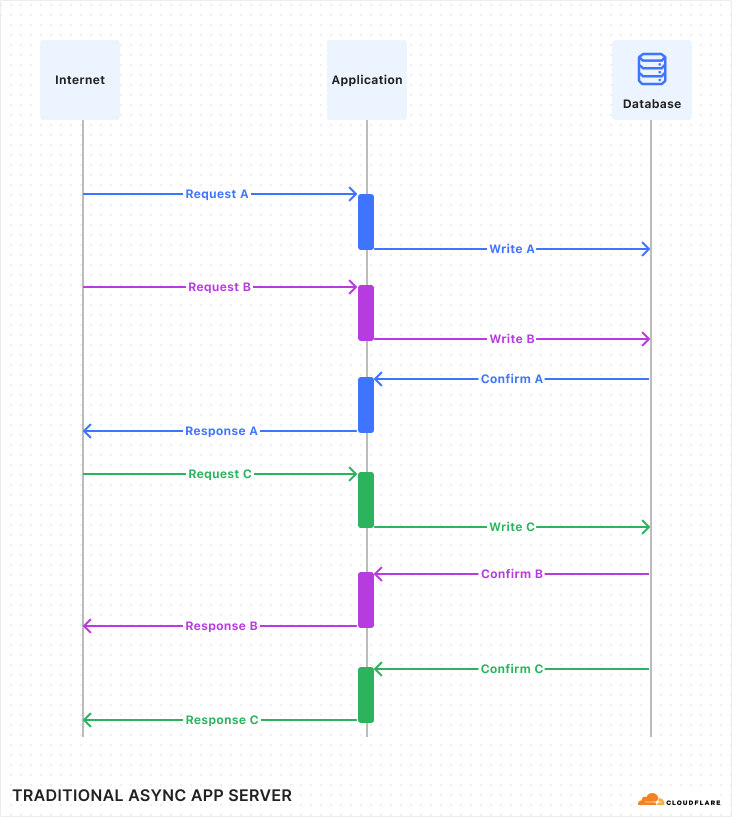
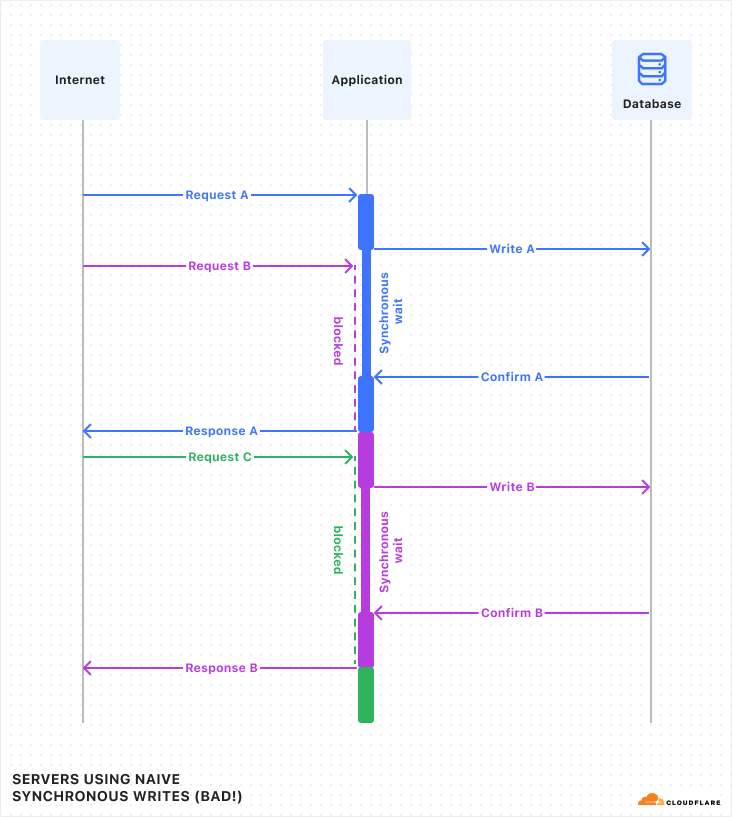
With AI Gateway already processing over 3 billion logs and experiencing rapid growth, the number of connections to the platform continues to increase steadily. To help developers manage this scale more effectively, we wanted to offer an alternative to implementing HTTP/2 keep-alive to maintain persistent HTTP(S) connections, thereby avoiding the overhead of repeated handshakes and TLS negotiations with each new HTTP connection to AI Gateway. We understand that implementing HTTP/2 can present challenges, particularly when many libraries and tools may not support it by default and most modern programming languages have well-established WebSocket libraries available.
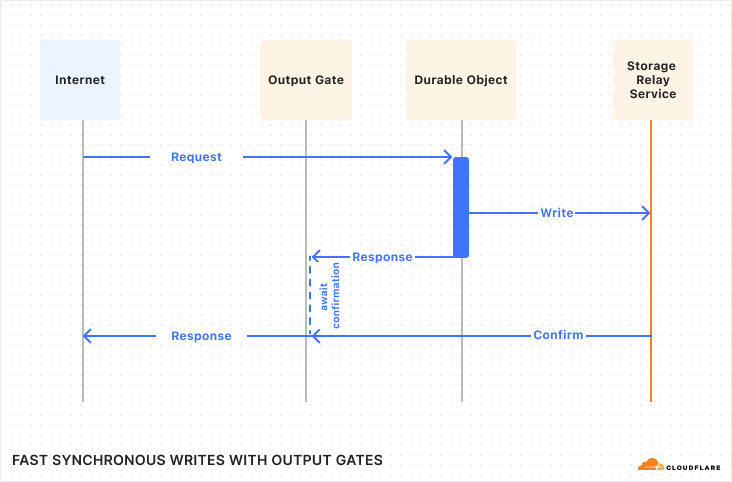
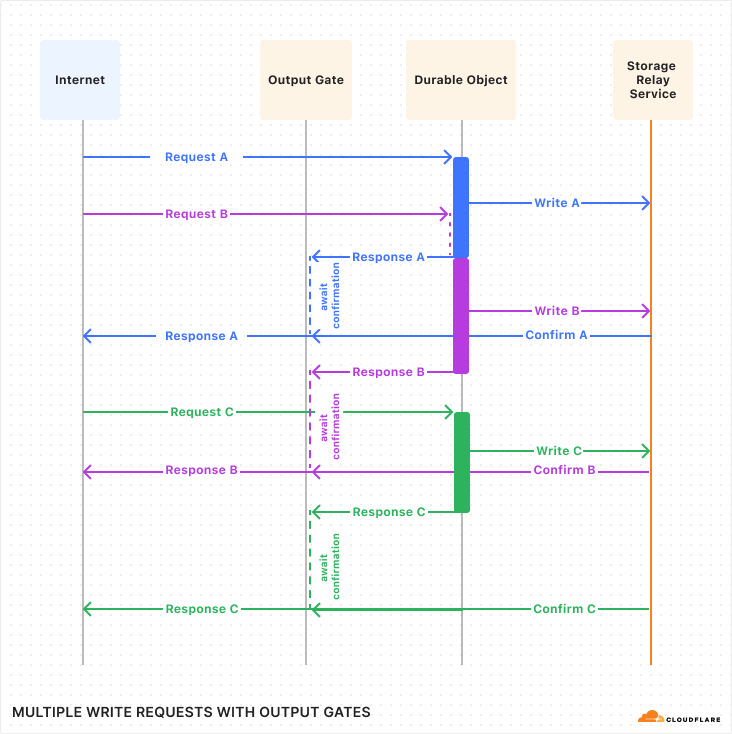
With this in mind, we used Cloudflare’s Developer Platform and Durable Objects (yes, again!) to build a WebSockets API that establishes a single, persistent connection, enabling continuous communication.
Through this API, all AI providers supported by AI Gateway can be accessed via WebSocket, allowing you to maintain a single TCP connection between your client or server application and the AI Gateway. The best part? Even if your chosen provider doesn’t support WebSockets, we handle it for you, managing the requests to your preferred AI provider.
By connecting via WebSocket to AI Gateway, we make the requests to the inference service for you using the provider’s supported protocols (HTTPS, WebSocket, etc.), and you can keep the connection open to execute as many inference requests as you would like.
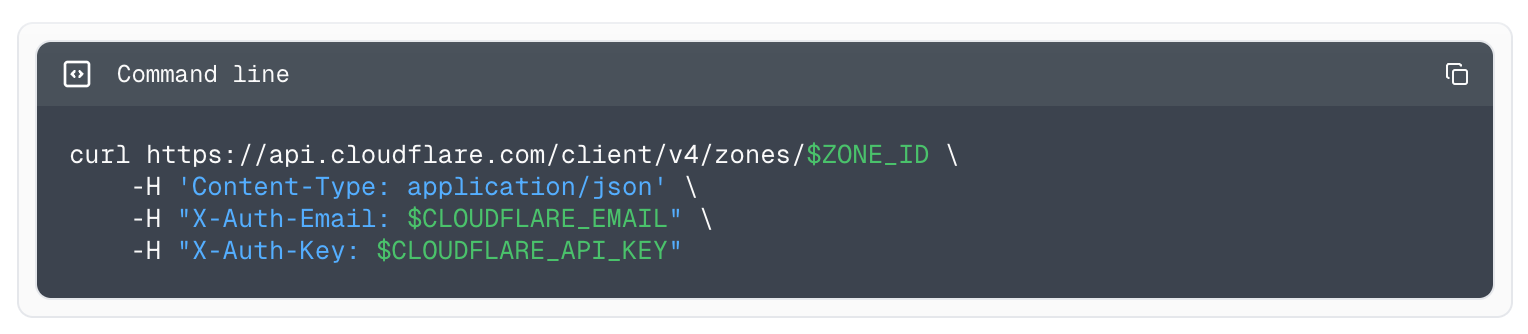
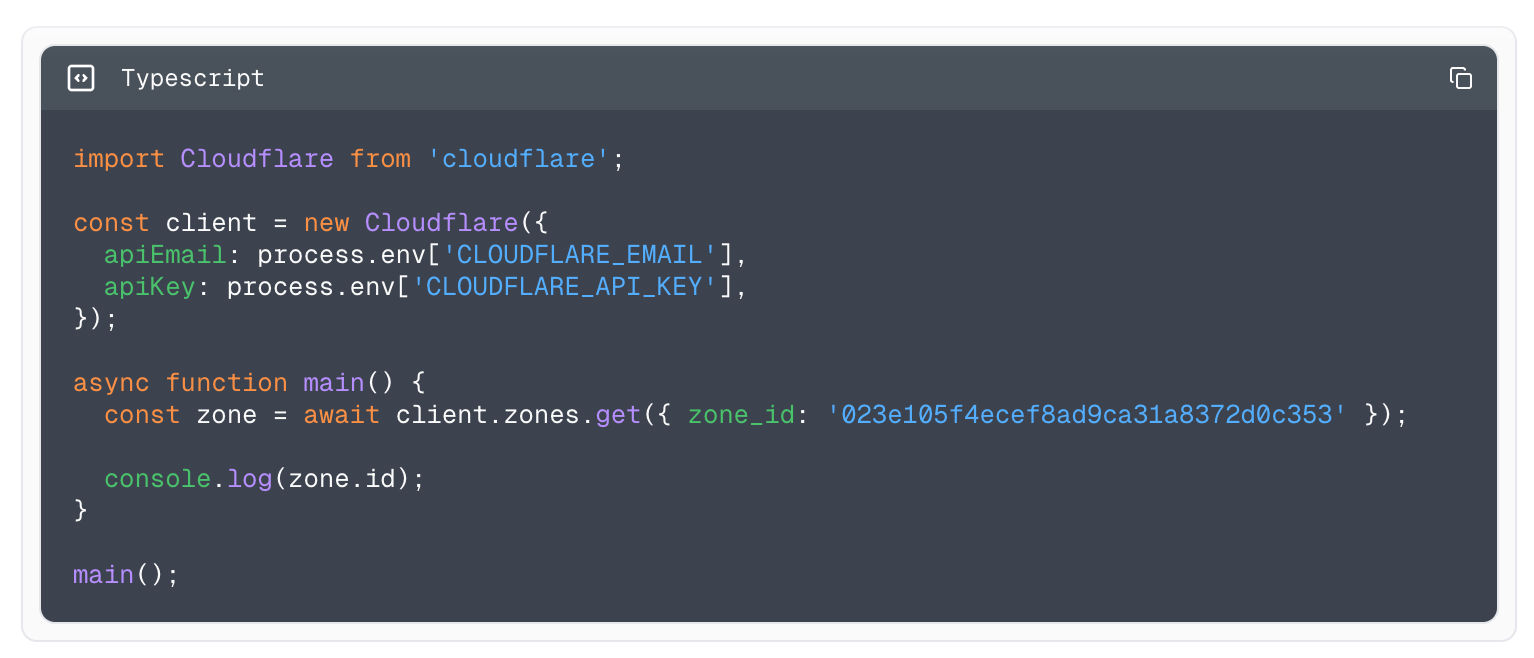
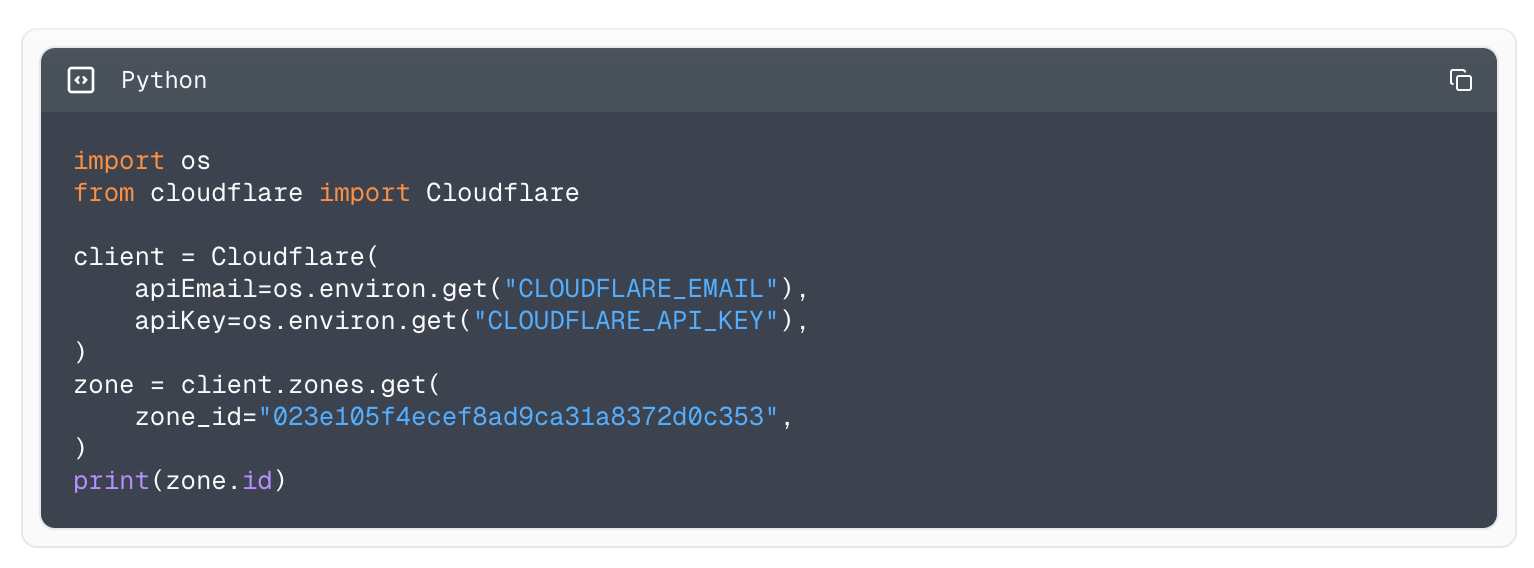
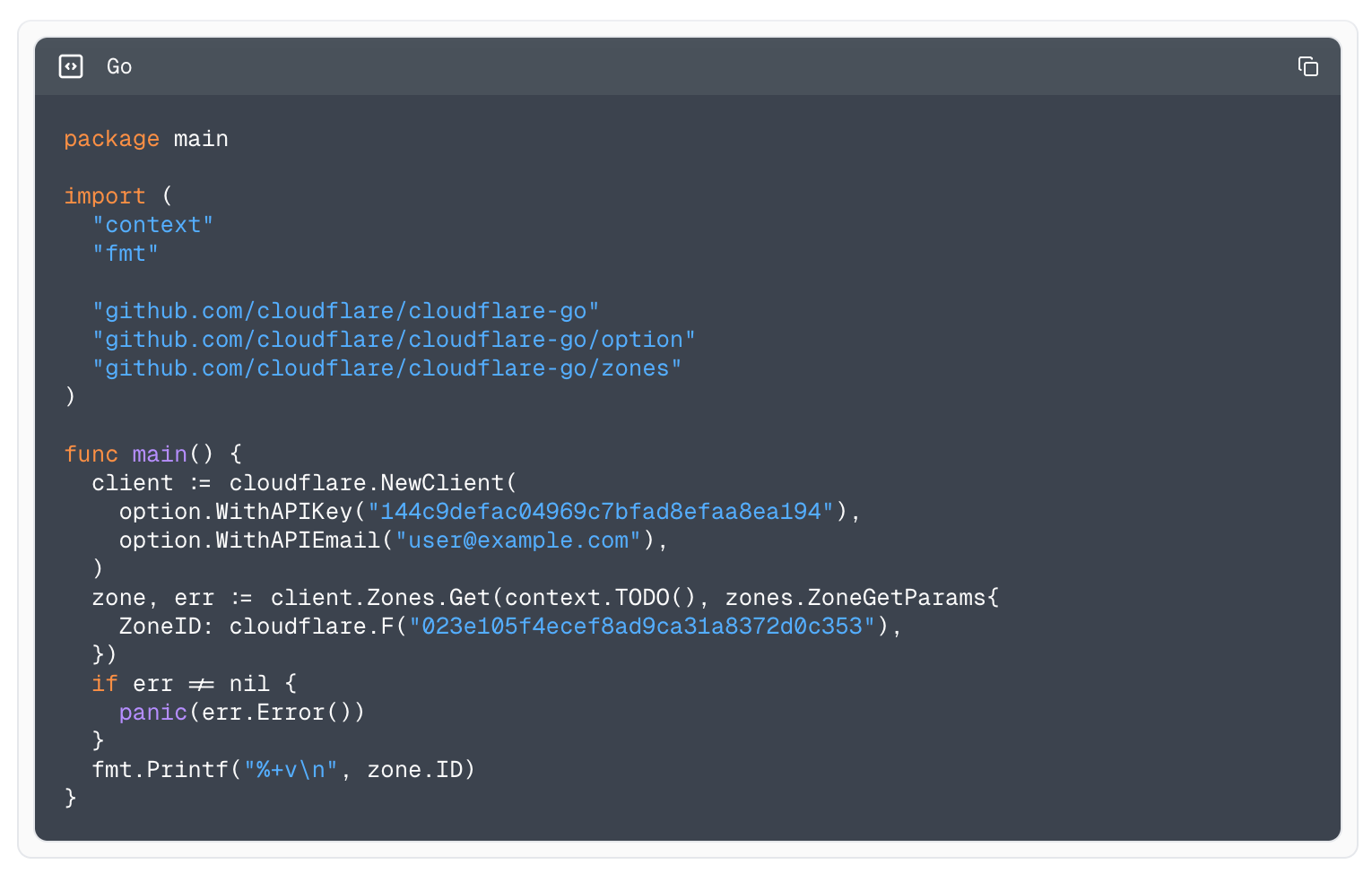
To make your connection to AI Gateway more secure, we are also introducing authentication for AI Gateway. The new WebSockets API will require authentication. All you need to do is create a Cloudflare API token with the permission “AI Gateway: Run” and send that in the cf-aig-authorization header.
In the flow diagram above:
1️⃣ When Authenticated Gateway is enabled and a valid token is included, requests will pass successfully.
2️⃣ If Authenticated Gateway is enabled, but a request does not contain the required cf-aig-authorization header with a valid token, the request will fail. This ensures only verified requests pass through the gateway.
3️⃣ When Authenticated Gateway is disabled, the cf-aig-authorization header is bypassed entirely, and any token — whether valid or invalid — is ignored.
How we built it
We recently used Durable Objects (DOs) to scale our logging solution for AI Gateway, so using WebSockets within the same DOs was a natural fit.
When a new WebSocket connection is received by our Cloudflare Workers, we implement authentication in two ways to support the diverse capabilities of WebSocket clients. The primary method involves validating a Cloudflare API token through the cf-aig-authorization header, ensuring the token is valid for the connecting account and gateway.
However, due to limitations in browser WebSocket implementations, we also support authentication via the “sec-websocket-protocol” header. Browser WebSocket clients don’t allow for custom headers in their standard API, complicating the addition of authentication tokens in requests. While we don’t recommend that you store API keys in a browser, we decided to add this method to add more flexibility to all WebSocket clients.
// Built-in WebSocket client in browsers
const socket = new WebSocket("wss://gateway.ai.cloudflare.com/v1/my-account-id/my-gateway/", [
"cf-aig-authorization.${AI_GATEWAY_TOKEN}"
]);
// ws npm package
import WebSocket from "ws";
const ws = new WebSocket("wss://gateway.ai.cloudflare.com/v1/my-account-id/my-gateway/",{
headers: {
"cf-aig-authorization": "Bearer AI_GATEWAY_TOKEN",
},
});
After this initial verification step, we upgrade the connection to the Durable Object, meaning that it will now handle all the messages for the connection. Before the new connection is fully accepted, we generate a random UUID, so this connection is identifiable among all the messages received by the Durable Object. During an open connection, any AI Gateway settings passed via headers — such as cf-aig-skip-cache (which bypasses caching when set to true) — are stored and applied to all requests in the session. However, these headers can still be overridden on a per-request basis, just like with the Universal Endpoint today.
How it works
Once the connection is established, the Durable Object begins listening for incoming messages. From this point on, users can send messages in the AI Gateway universal format via WebSocket, simplifying the transition of your application from an existing HTTP setup to WebSockets-based communication.
When a new message reaches the Durable Object, it’s processed using the same code that powers the HTTP Universal Endpoint, enabling seamless code reuse across Workers and Durable Objects — one of the key benefits of building on Cloudflare.
For non-streaming requests, the response is wrapped in a JSON envelope, allowing us to include additional information beyond the AI inference itself, such as the AI Gateway log ID for that request.
Here’s an example response for the request above:
{
"type":"universal.created",
"metadata":{
"cacheStatus":"MISS",
"eventId":"my-request",
"logId":"01JC3R94FRD97JBCBX3S0ZAXKW",
"step":"0",
"contentType":"application/json"
},
"response":{
"result":{
"response":"Why was the math book sad? Because it had too many problems. Would you like to hear another one?"
},
"success":true,
"errors":[],
"messages":[]
}
}
For streaming requests, AI Gateway sends an initial message with request metadata telling the developer the stream is starting.
After this initial message, all streaming chunks are relayed in real-time to the WebSocket connection as they arrive from the inference provider. Note that only the eventId field is included in the metadata for these streaming chunks (more info on what this new field is below).
This approach serves two purposes: first, all request metadata is already provided in the initial message. Second, it addresses the concurrency challenge of handling multiple streaming requests simultaneously.
Handling asynchronous events
With WebSocket connections, client and server can send messages asynchronously at any time. This means the client doesn’t need to wait for a server response before sending another message. But what happens if a client sends multiple streaming inference requests immediately after the WebSocket connection opens?
In this case, the server streams all the inference responses simultaneously to the client. Since everything occurs asynchronously, the client has no built-in way to identify which response corresponds to each request.
To address this, we introduced a new field in the Universal format called eventId, which allows AI Gateway to include a client-defined ID with each message, even in a streaming WebSocket environment.
So, to fully answer the question above: the server streams both responses in parallel chunks, and the client can accurately identify which request each message belongs to based on the eventId.
Once all chunks for a request have been streamed, AI Gateway sends a final message to signal the request’s completion. For added flexibility, this message includes all the metadata again, even though it was also provided at the start of the streaming process.
Then open a WebSocket connection using your Universal Endpoint, and guarantee that it is authenticated with a Cloudflare token with the AI Gateway Run permission.
In Q1 2025, we plan to support WebSocket-to-WebSocket connections (using DOs), allowing you to connect to OpenAI’s new real-time API directly through our platform. In the meantime, you can deploy this Worker in your account to proxy the requests yourself.
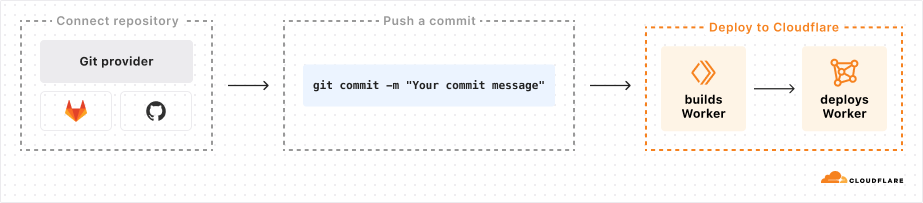
During 2024’s Birthday Week, we launched Workers Builds in open beta — an integrated Continuous Integration and Delivery (CI/CD) workflow you can use to build and deploy everything from full-stack applications built with the most popular frameworks to simple static websites onto the Workers platform. With Workers Builds, you can connect a GitHub or GitLab repository to a Worker, and Cloudflare will automatically build and deploy your changes each time you push a commit.
Workers Builds is intended to bridge the gap between the developer experiences for Workers and Pages, the latter of which launched with an integrated CI/CD system in 2020. As we continue to merge the experiences of Pages and Workers, we wanted to bring one of the best features of Pages to Workers: the ability to tie deployments to existing development workflows in GitHub and GitLab with minimal developer overhead.
The core problem for Workers Builds is how to pick up a commit from GitHub or GitLab and start a containerized job that can clone the repo, build the project, and deploy a Worker.
Pages solves a similar problem, and we were initially inclined to expand our existing architecture and tech stack, which includes a centralized configuration plane built on Go in Kubernetes. We also considered the ways in which the Workers ecosystem has evolved in the four years since Pages launched — we have since launched so many more tools built for use cases just like this!
The distributed nature of Workers offers some advantages over a centralized stack — we can spend less time configuring Kubernetes because Workers automatically handles failover and scaling. Ultimately, we decided to keep using what required no additional work to re-use from Pages (namely, the system for connecting GitHub/GitLab accounts to Cloudflare, and ingesting push events from them), and for the rest build out a new architecture on the Workers platform, with reliability and minimal latency in mind.
The Workers Builds system
We didn’t need to make any changes to the system that handles connections from GitHub/GitLab to Cloudflare and ingesting push events from them. That left us with two systems to build: the configuration plane for users to connect a Worker to a repo, and a build management system to run and monitor builds.
Client Worker
We can begin with our configuration plane, which consists of a simple Client Worker that implements a RESTful API (using Hono) and connects to a PostgreSQL database. It’s in this database that we store build configurations for our users, and through this Worker that users can view and manage their builds.
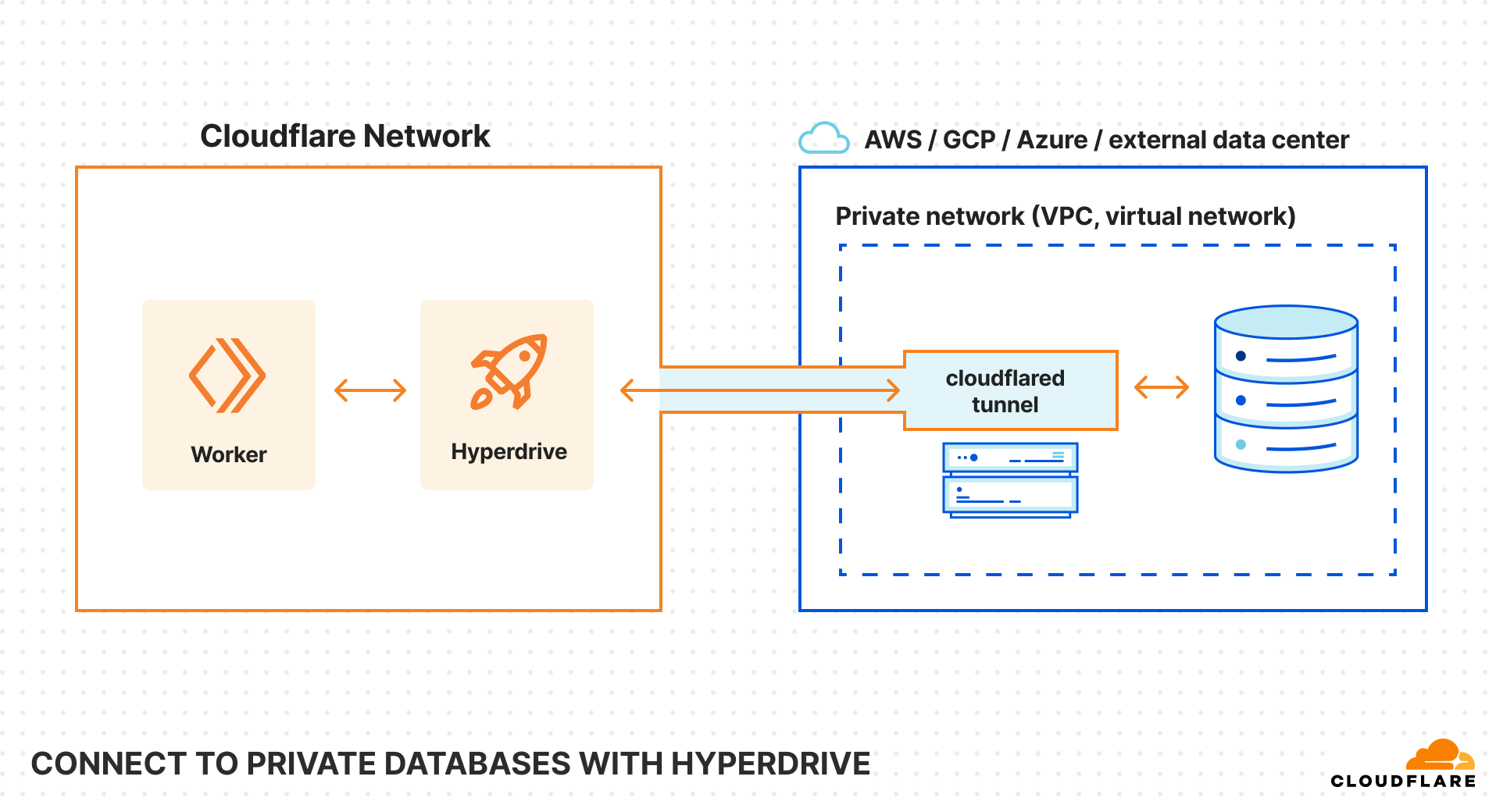
We considered a more distributed data model (like D1, sharded by account), but ultimately decided that keeping our database in a datacenter more easily fit our use-case. The Workers Builds data model is relational — Workers belong to Cloudflare Accounts, and Builds belong to Workers — and build metadata must be consistent in order to properly manage build queues. We chose to keep our failover-ready database in a centralized datacenter and take advantage of two other Workers products, Smart Placement and Hyperdrive, in order to keep the benefits of a distributed control plane.
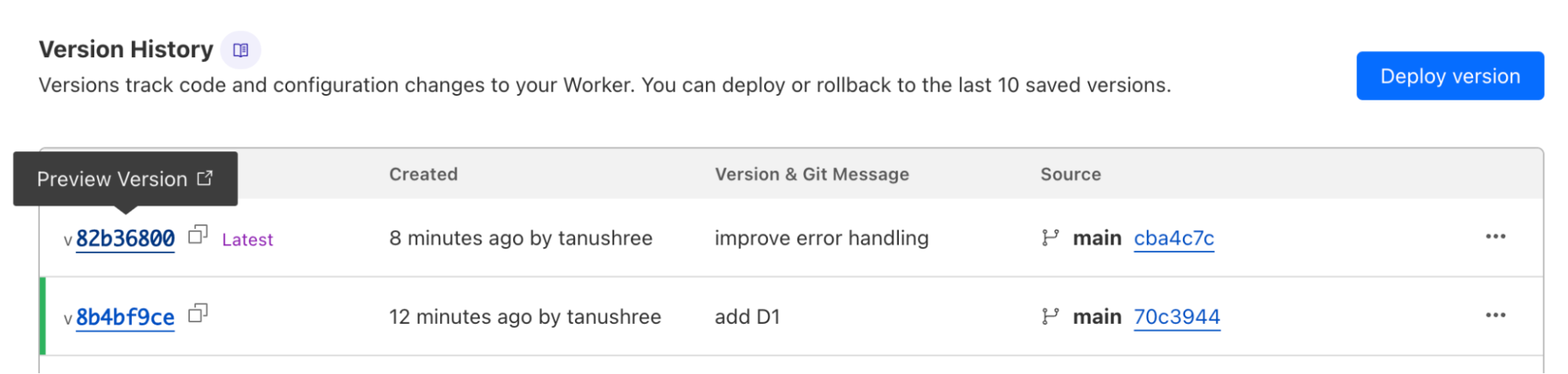
Everything that you see in the Cloudflare Dashboard related to Workers Builds is served by this Worker.
Build Management Worker
The more challenging problem we faced was how to run and manage user builds effectively. We wanted to support the same experience that we had achieved with Pages, which led to these key requirements:
Builds should be initiated with minimal latency.
The status of a build should be tracked and displayed through its entire lifecycle, starting when a user pushes a commit.
Customer build logs should be stored in a secure, private, and long-lived way.
To solve these problems, we leaned heavily into the technology of Durable Objects (DO).
We created a Build Management Worker with two DO classes: A Scheduler class to manage the scheduling of builds, and a class called BuildBuddy to manage individual builds. We chose to design our system this way for an efficient and scalable system. Since each build is assigned its own build manager DO, its operation won’t ever block other builds or the scheduler, meaning we can start up builds with minimal latency. Below, we dive into each of these Durable Objects classes.
Scheduler DO
The Scheduler DO class is relatively simple. Using Durable Objects Alarms, it is triggered every second to pull up a list of user build configurations that are ready to be started. For each of those builds, the Scheduler creates an instance of our other DO Class, the Build Buddy.
import { DurableObject } from 'cloudflare:workers'
export class BuildScheduler extends DurableObject {
state: DurableObjectState
env: Bindings
constructor(ctx: DurableObjectState, env: Bindings) {
super(ctx, env)
}
// The DO alarm handler will be called every second to fetch builds
async alarm(): Promise<void> {
// set alarm to run again in 1 second
await this.updateAlarm()
const builds = await this.getBuildsToSchedule()
await this.scheduleBuilds(builds)
}
async scheduleBuilds(builds: Builds[]): Promise<void> {
// Don't schedule builds, if no builds to schedule
if (builds.length === 0) return
const queue = new PQueue({ concurrency: 6 })
// Begin running builds
builds.forEach((build) =>
queue.add(async () => {
// The BuildBuddy is another DO described more in the next section!
const bb = getBuildBuddy(this.env, build.build_id)
await bb.startBuild(build)
})
)
await queue.onIdle()
}
async getBuildsToSchedule(): Promise<Builds[]> {
// returns list of builds to schedule
}
async updateAlarm(): Promise<void> {
// We want to ensure we aren't running multiple alarms at once, so we only set the next alarm if there isn’t already one set.
const existingAlarm = await this.ctx.storage.getAlarm()
if (existingAlarm === null) {
this.ctx.storage.setAlarm(Date.now() + 1000)
}
}
}
Build Buddy DO
The Build Buddy DO class is what we use to manage each individual build from the time it begins initializing to when it is stopped. Every build has a buddy for life!
Upon creation of a Build Buddy DO instance, the Scheduler immediately calls startBuild() on the instance. The startBuild() method is responsible for fetching all metadata and secrets needed to run a build, and then kicking off a build on Cloudflare’s container platform (not public yet, but coming soon!).
As the containerized build runs, it reports back to the Build Buddy, sending status updates and logs for the Build Buddy to deal with.
Build status
As a build progresses, it reports its own status back to Build Buddy, sending updates when it has finished initializing, has completed successfully, or been terminated by the user. The Build Buddy is responsible for handling this incoming information from the containerized build, writing status updates to the database (via a Hyperdrive binding) so that users can see the status of their build in the Cloudflare dashboard.
Build logs
A running build generates output logs that are important to store and surface to the user. The containerized build flushes these logs to the Build Buddy every second, which, in turn, stores those logs in DO storage.
The decision to use Durable Object storage here makes it easy to multicast logs to multiple clients efficiently, and allows us to use the same API for both streaming logs and viewing historical logs.
// build-management-app.ts
// We created a Hono app to for use by our Client Worker API
const app = new Hono<HonoContext>()
.post(
'/api/builds/:build_uuid/status',
async (c) => {
const buildStatus = await c.req.json()
// fetch build metadata
const build = ...
const bb = getBuildBuddy(c.env, build.build_id)
return await bb.handleStatusUpdate(build, statusUpdate)
}
)
.post(
'/api/builds/:build_uuid/logs',
async (c) => {
const logs = await c.req.json()
// fetch build metadata
const build = ...
const bb = getBuildBuddy(c.env, build.build_id)
return await bb.addLogLines(logs.lines)
}
)
export default {
fetch: app.fetch
}
// build-buddy.ts
import { DurableObject } from 'cloudflare:workers'
export class BuildBuddy extends DurableObject {
compute: WorkersBuildsCompute
constructor(ctx: DurableObjectState, env: Bindings) {
super(ctx, env)
this.compute = new ComputeClient({
// ...
})
}
// The Scheduler DO calls startBuild upon creating a BuildBuddy instance
startBuild(build: Build): void {
this.startBuildAsync(build)
}
async startBuildAsync(build: Build): Promise<void> {
// fetch all necessary metadata build, including
// environment variables, secrets, build tokens, repo credentials,
// build image URI, etc
// ...
// start a containerized build
const computeBuild = await this.compute.createBuild({
// ...
})
}
// The Build Management worker calls handleStatusUpdate when it receives an update
// from the containerized build
async handleStatusUpdate(
build: Build,
buildStatusUpdatePayload: Payload
): Promise<void> {
// Write status updates to the database
}
// The Build Management worker calls addLogLines when it receives flushed logs
// from the containerized build
async addLogLines(logs: LogLines): Promise<void> {
// Generate nextLogsKey to store logs under
this.ctx.storage.put(nextLogsKey, logs)
}
// The Client Worker can call methods on a Build Buddy via RPC, using a service binding to the Build Management Worker.
// The getLogs method retrieves logs for the user, and the cancelBuild method forwards a request from the user to terminate a build.
async getLogs(cursor: string){
const decodedCursor = cursor !== undefined ? decodeLogsCursor(cursor) : undefined
return await this.getLogs(decodedCursor)
}
async cancelBuild(compute_id: string, build_id: string): void{
await this.terminateBuild(build_id, compute_id)
}
async terminateBuild(build_id: number, compute_id: string): Promise<void> {
await this.compute.stopBuild(compute_id)
}
}
export function getBuildBuddy(
env: Pick<Bindings, 'BUILD_BUDDY'>,
build_id: number
): DurableObjectStub<BuildBuddy> {
const id = env.BUILD_BUDDY.idFromName(build_id.toString())
return env.BUILD_BUDDY.get(id)
}
Alarms
We utilize alarms in the Build Buddy to check that a build has a healthy startup and to terminate any builds that run longer than 20 minutes.
How else have we leveraged the Developer Platform?
Now that we’ve gone over the core behavior of the Workers Builds control plane, we’d like to detail a few other features of the Workers platform that we use to improve performance, monitor system health, and troubleshoot customer issues.
Smart Placement and location hints
While our control plane is distributed in the sense that it can be run across multiple datacenters, to reduce latency costs, we want most requests to be served from locations close to our primary database in the western US.
While a build is running, Build Buddy, a Durable Object, is continuously writing status updates to our database. For the Client and the Build Management API Workers, we enabled Smart Placement with location hints to ensure requests run close to the database.
This graph shows the reduction in round trip time (RTT) observed for our Worker with Smart Placement turned on.
Workers Logs
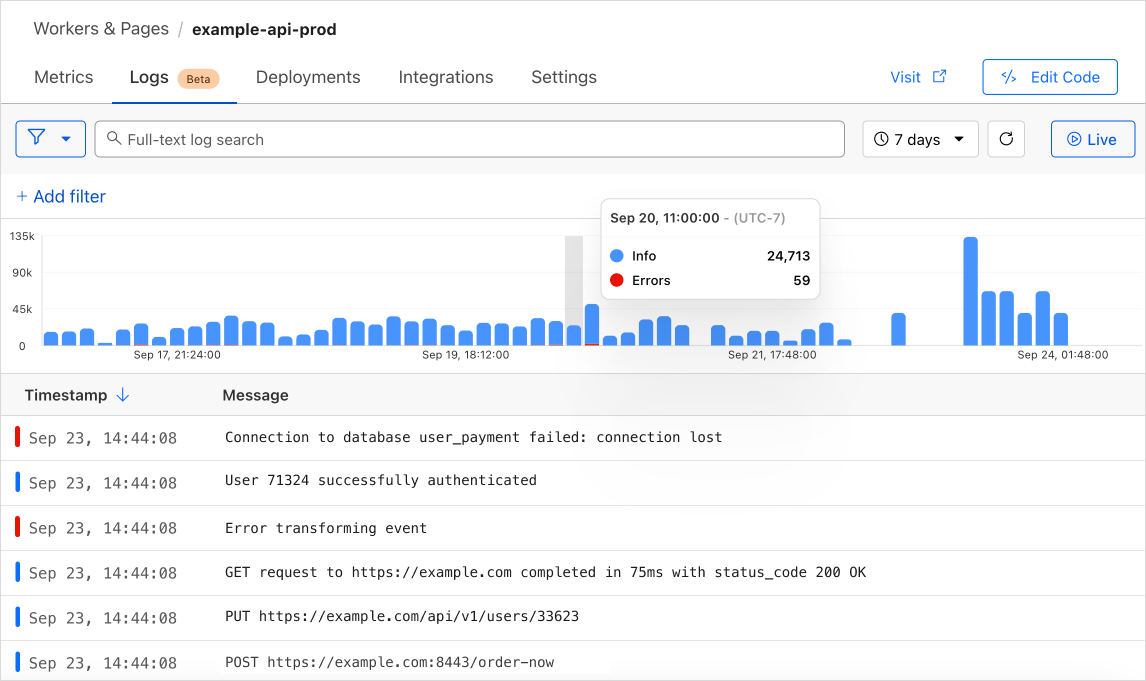
We needed a logging tool that allows us to aggregate and search across persistent operational logs from our Workers to assist with identifying and troubleshooting issues. We worked with the Workers Observability team to become early adopters of Workers Logs.
Workers Logs worked out of the box, giving us fast and easy to use logs directly within the Cloudflare dashboard. To improve our ability to search logs, we created a tagging library that allows us to easily add metadata like the git tag of the deployed worker that the log comes from, allowing us to filter logs by release.
See a shortened example below for how we handle and log errors on the Client Worker.
// client-worker-app.ts
// The Client Worker is a RESTful API built with Hono
const app = new Hono<HonoContext>()
// This is from the workers-tagged-logger library - first we register the logger
.use(useWorkersLogger('client-worker-app'))
// If any error happens during execution, this middleware will ensure we log the error
.onError(useOnError)
// routes
.get(
'/apiv4/builds',
async (c) => {
const { ids } = c.req.query()
return await getBuildsByIds(c, ids)
}
)
function useOnError(e: Error, c: Context<HonoContext>): Response {
// Set the project identifier n the error
logger.setTags({ release: c.env.GIT_TAG })
// Write a log at level 'error'. Can also log 'info', 'log', 'warn', and 'debug'
logger.error(e)
return c.json(internal_error.toJSON(), internal_error.statusCode)
}
This setup can lead to the following sample log message from our Workers Log dashboard. You can see the release tag is set on the log.
We can get a better sense of the impact of the error by adding filters to the Workers Logs view, as shown below. We are able to filter on any of the fields since we’re logging with structured JSON.
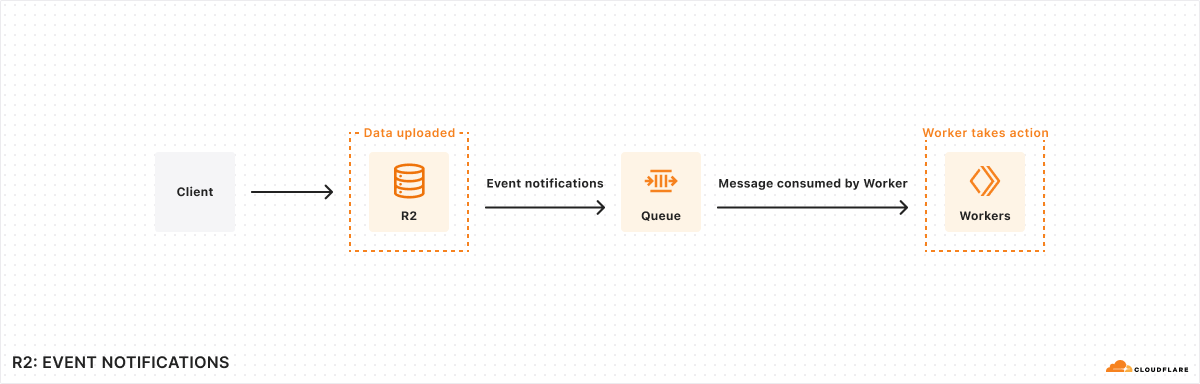
R2
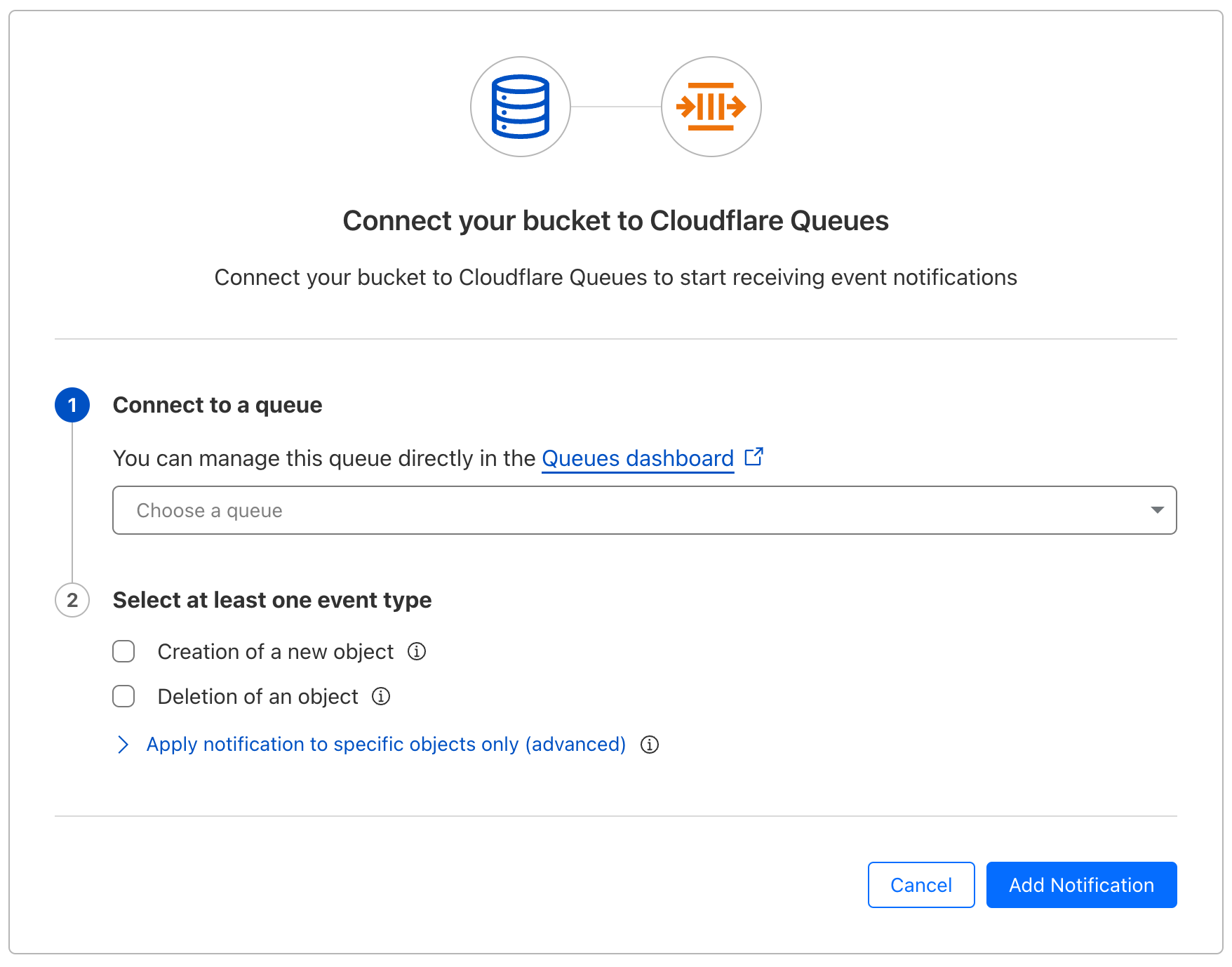
Coming soon to Workers Builds is build caching, used to store artifacts of a build for subsequent builds to reuse, such as package dependencies and build outputs. Build caching can speed up customer builds by avoiding the need to redownload dependencies from NPM or to rebuild projects from scratch. The cache itself will be backed by R2 storage.
Testing
We were able to build up a great testing story using Vitest and workerd — unit tests, cross-worker integration tests, the works. In the example below, we make use of the runInDurableObject stub from cloudflare:test to test instance methods on the Scheduler DO directly.
// scheduler.spec.ts
import { env, runInDurableObject } from 'cloudflare:test'
import { expect, test } from 'vitest'
import { BuildScheduler } from './scheduler'
test('getBuildsToSchedule() runs a queued build', async () => {
// Our test harness creates a single build for our scheduler to pick up
const { build } = await harness.createBuild()
// We create a scheduler DO instance
const id = env.BUILD_SCHEDULER.idFromName(crypto.randomUUID())
const stub = env.BUILD_SCHEDULER.get(id)
await runInDurableObject(stub, async (instance: BuildScheduler) => {
expect(instance).toBeInstanceOf(BuildScheduler)
// We check that the scheduler picks up 1 build
const builds = await instance.getBuildsToSchedule()
expect(builds.length).toBe(1)
// We start the build, which should mark it as running
await instance.scheduleBuilds(builds)
})
// Check that there are no more builds to schedule
const queuedBuilds = ...
expect(queuedBuilds.length).toBe(0)
})
We use SELF.fetch() from cloudflare:test to run integration tests on our Client Worker, as shown below. This integration test covers our Hono endpoint and database queries made by the Client Worker in retrieving the metadata of a build.
// builds_api.test.ts
import { env, SELF } from 'cloudflare:test'
it('correctly selects a single build', async () => {
// Our test harness creates a randomized build to test with
const { build } = await harness.createBuild()
// We send a request to the Client Worker itself to fetch the build metadata
const getBuild = await SELF.fetch(
`https://example.com/builds/${build1.build_uuid}`,
{
method: 'GET',
headers: new Headers({
Authorization: `Bearer JWT`,
'content-type': 'application/json',
}),
}
)
// We expect to receive a 200 response from our request and for the
// build metadata returned to match that of the random build that we created
expect(getBuild.status).toBe(200)
const getBuildV4Resp = await getBuild.json()
const buildResp = getBuildV4Resp.result
expect(buildResp).toBeTruthy()
expect(buildResp).toEqual(build)
})
These tests run on the same runtime that Workers run on in production, meaning we have greater confidence that any code changes will behave as expected when they go live.
Analytics
We use the technology underlying the Workers Analytics Engine to collect all of the metrics for our system. We set up Grafana dashboards to display these metrics.
JavaScript-native RPC
JavaScript-native RPC was added to Workers in April of 2024, and it’s pretty magical. In the scheduler code example above, we call startBuild() on the BuildBuddy DO from the Scheduler DO. Without RPC, we would need to stand up routes on the BuildBuddy fetch() handler for the Scheduler to trigger with a fetch request. With RPC, there is almost no boilerplate — all we need to do is call a method on a class.
const bb = getBuildBuddy(this.env, build.build_id)
// Starting a build without RPC 😢
await bb.fetch('http://do/api/start_build', {
method: 'POST',
body: JSON.stringify(build),
})
// Starting a build with RPC 😸
await bb.startBuild(build)
Conclusion
By using Workers and Durable Objects, we were able to build a complex and distributed system that is easy to understand and is easily scalable.
It’s been a blast for our team to build on top of the very platform that we work on, something that would have been much harder to achieve on Workers just a few years ago. We believe in being Customer Zero for our own products — to identify pain points firsthand and to continuously improve the developer experience by applying them to our own use cases. It was fulfilling to have our needs as developers met by other teams and then see those tools quickly become available to the rest of the world — we were collaborators and internal testers for Workers Logs and private network support for Hyperdrive (both released on Birthday Week), and the soon to be released container platform.
Opportunities to build complex applications on the Developer Platform have increased in recent years as the platform has matured and expanded product offerings for more use cases. We hope that Workers Builds will be yet another tool in the Workers toolbox that enables developers to spend less time thinking about configuration and more time writing code.
Want to try it out? Check out the docs to learn more about how to deploy your first project with Workers Builds.
With the rapid advancements occurring in the AI space, developers face significant challenges in keeping up with the ever-changing landscape. New models and providers are continuously emerging, and understandably, developers want to experiment and test these options to find the best fit for their use cases. This creates the need for a streamlined approach to managing multiple models and providers, as well as a centralized platform to efficiently monitor usage, implement controls, and gather data for optimization.
AI Gateway is specifically designed to address these pain points. Since its launch in September 2023, AI Gateway has empowered developers and organizations by successfully proxying over 2 billion requests in just one year, as we highlighted during September’s Birthday Week. With AI Gateway, developers can easily store, analyze, and optimize their AI inference requests and responses in real time.
With our initial architecture, AI Gateway faced a significant challenge: the logs, those critical trails of data interactions between applications and AI models, could only be retained for 30 minutes. This limitation was not just a minor inconvenience; it posed a substantial barrier for developers and businesses needing to analyze long-term patterns, ensure compliance, or simply debug over more extended periods.
In this post, we’ll explore the technical challenges and strategic decisions behind extending our log storage capabilities from 30 minutes to being able to store billions of logs indefinitely. We’ll discuss the challenges of scale, the intricacies of data management, and how we’ve engineered a system that not only meets the demands of today, but is also scalable for the future of AI development.
Background
AI Gateway is built on Cloudflare Workers, a serverless platform that runs on the Cloudflare network, allowing developers to write small JavaScript functions that can execute at the point of need, near the user, on Cloudflare’s vast network of data centers, without worrying about platform scalability.
Our customers use multiple providers and models and are always looking to optimize the way they do inference. And, of course, in order to evaluate their prompts, performance, cost, and to troubleshoot what’s going on, AI Gateway’s customers need to store requests and responses. New requests show up within 15 seconds and customers can check a request’s cost, duration, number of tokens, and provide their feedback (thumbs up or down).
This scales in a way where an account can have multiple gateways and each gateway has its own settings. In our first implementation, a backend worker was responsible for storing Real Time Logs and other background tasks. However, in the rapidly evolving domain of artificial intelligence, where real-time data is as precious as the insights it provides, managing log data efficiently becomes paramount. We recognized that to truly empower our users, we needed to offer a solution where logs weren’t just transient records but could be stored permanently. Permanent log storage means developers can now track the performance, security, and operational insights of their AI applications over time, enabling not only immediate troubleshooting but also longitudinal studies of AI behavior, usage trends, and system health.
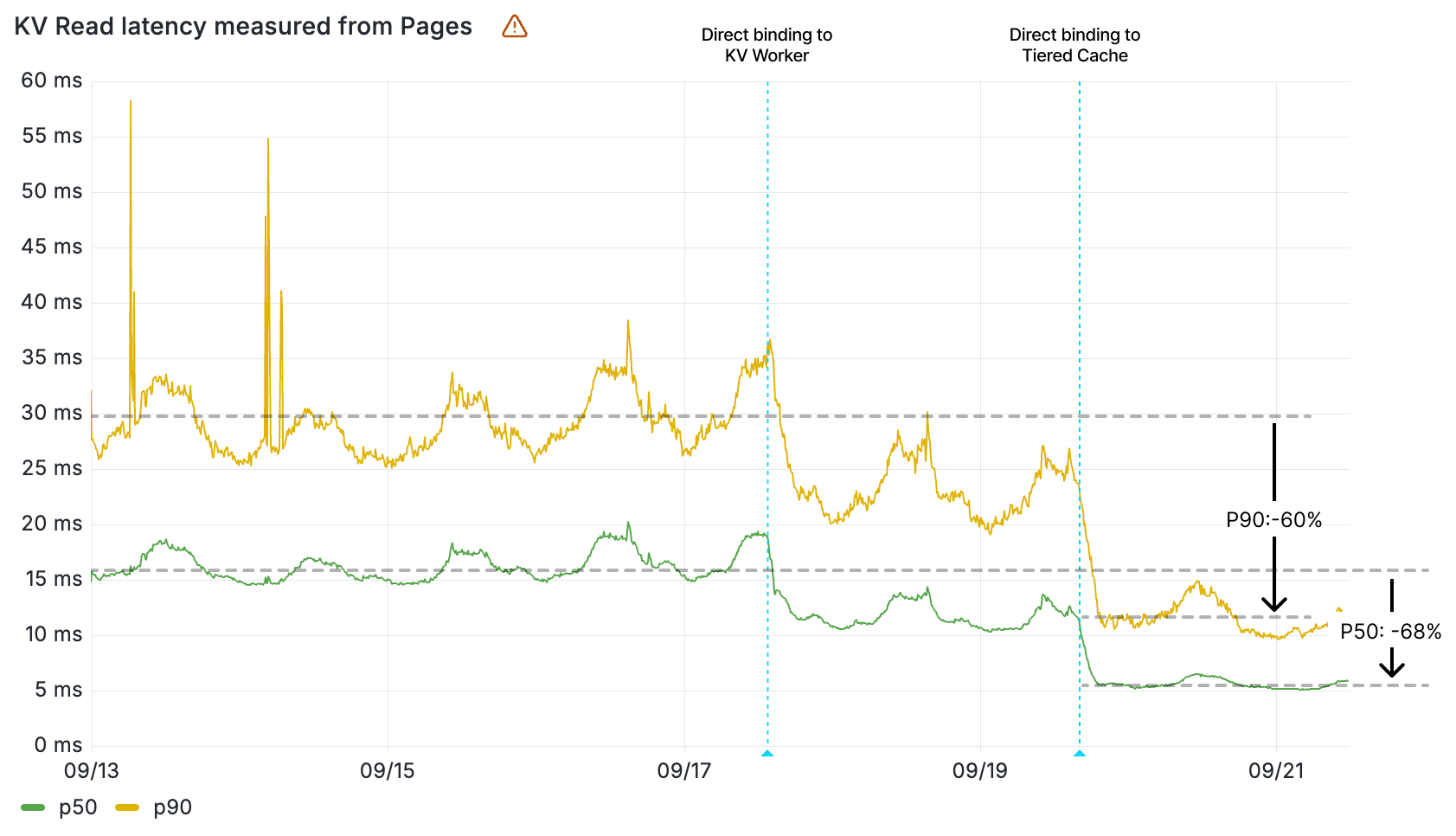
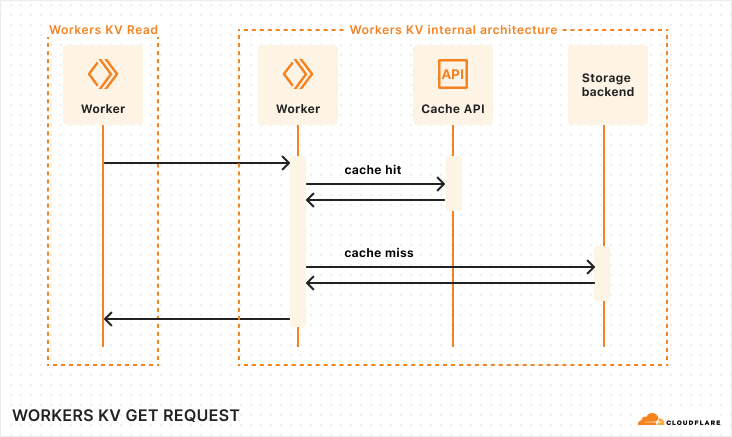
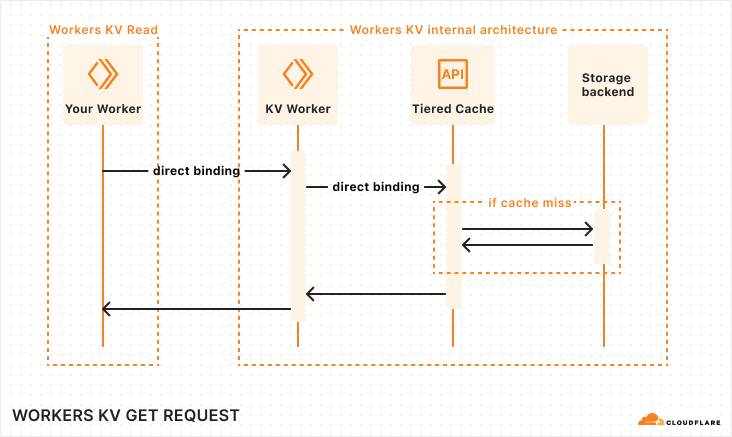
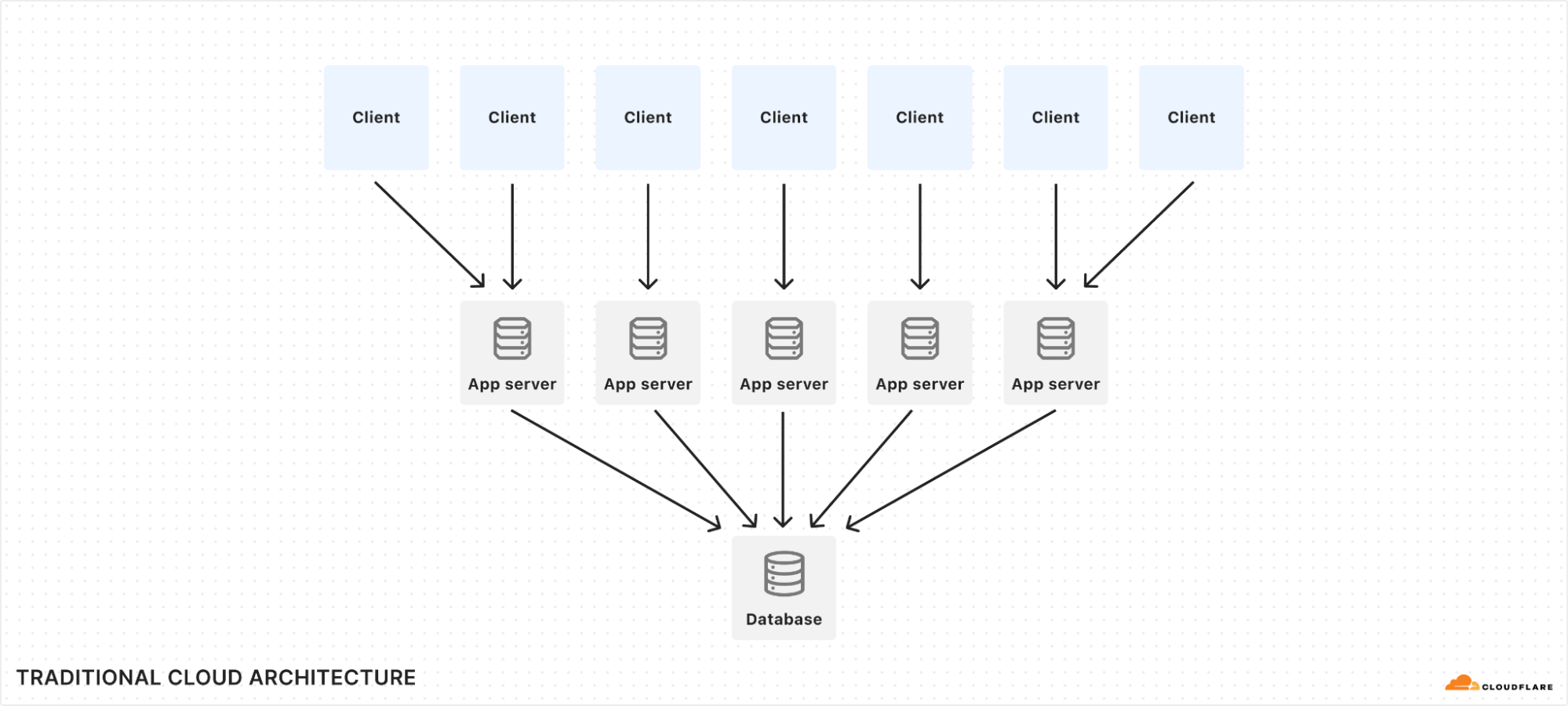
The diagram above describes our old architecture, which could only store 30 minutes of data.
Tracing the path of a request through the AI Gateway, as depicted in the sequence above:
A developer sends a new inference request, which is first received by our Gateway Worker.
The Gateway Worker then performs several checks: it looks for cached results, enforces rate limits, and verifies any other configurations set by the user for their gateway. Provided all conditions are met, it forwards the request to the selected inference provider (in this diagram, OpenAI).
The inference provider processes the request and sends back the response.
Simultaneously, as the response is relayed back to the developer, the request and response details are also dispatched to our Backend Worker. This worker’s role is to manage and store the log of this transaction.
The challenge: Store two billion logs
First step: real-time logs
Initially, the AI Gateway project stored both request metadata and the actual request bodies in a D1 database. This approach facilitated rapid development in the project’s infancy. However, as customer engagement grew, the D1 database began to fill at an accelerating rate, eventually retaining logs for only 30 minutes at a time.
To mitigate this, we first optimized the database schema, which extended the log retention to one hour. However, we soon encountered diminishing returns due to the sheer volume of byte data from the request bodies. Post-launch, it became clear that a more scalable solution was necessary. We decided to migrate the request bodies to R2 storage, significantly alleviating the data load on D1. This adjustment allowed us to incrementally extend log retention to 24 hours.
Consequently, D1 functioned primarily as a log index, enabling users to search and filter logs efficiently. When users needed to view details or download a log, these actions were seamlessly proxied through to R2.
This dual-system approach provided us with the breathing room to contemplate and develop more sophisticated storage solutions for the future.
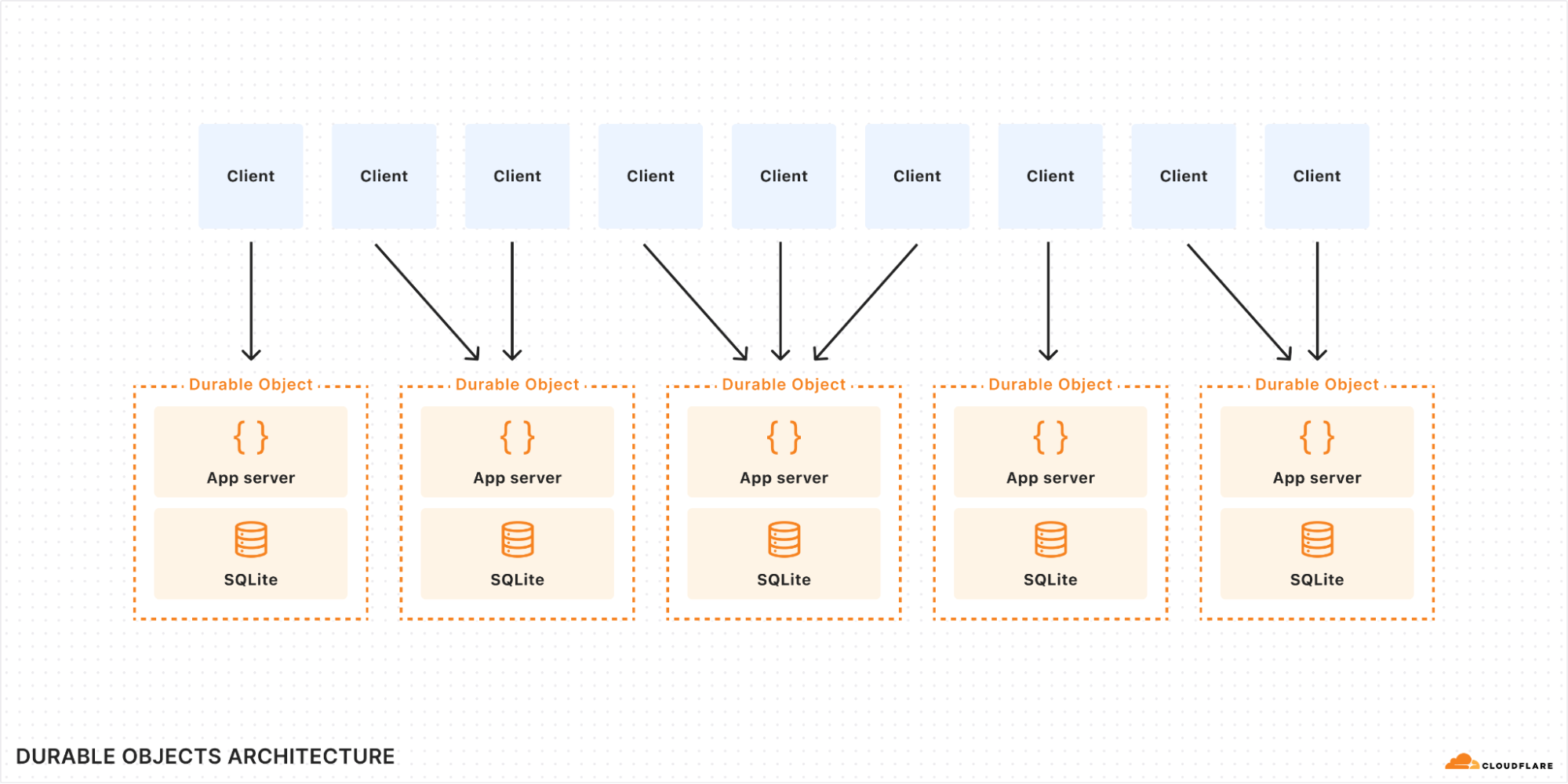
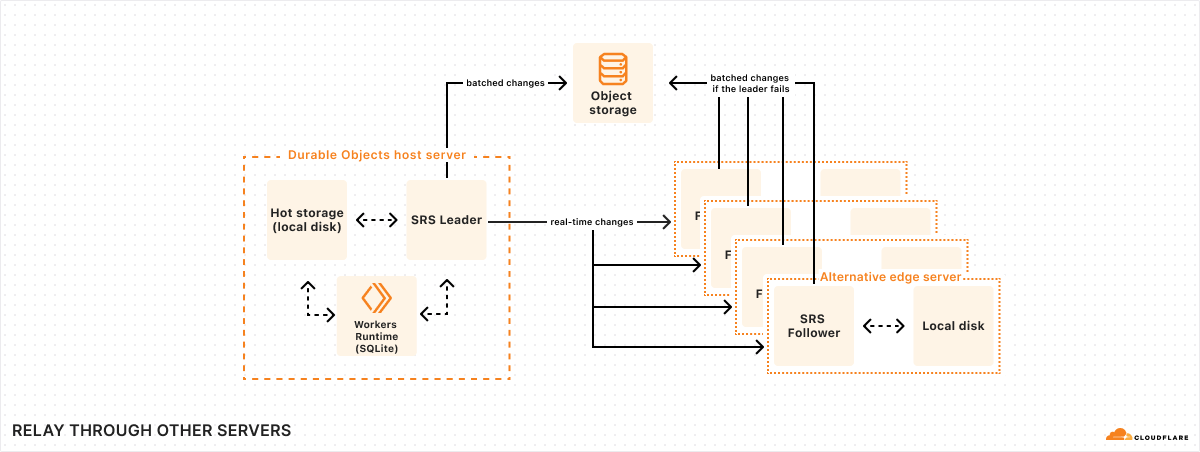
Second step: persistent logs and Durable Object transactional storage
As our traffic surged, we encountered a growing number of requests from customers wanting to access and compare older logs.
Upon learning that the Durable Objects team was seeking beta testers for their new Durable Objects with SQLite, we eagerly signed up.
Originally, we considered Durable Objects as the ideal solution for expanding our log storage capacity, which required us to shard the logs by a unique string. Initially, this string was the account ID, but during a mid-development load test, we hit a cap at 10 million logs per Durable Object. This limitation meant that each account could only support up to this number of logs.
Given our commitment to the DO migration, we saw an opportunity rather than a constraint. To overcome the 10 million log limit per account, we refined our approach to shard by both account ID and gateway name. This adjustment effectively raised the storage ceiling from 10 million logs per account to 10 million per gateway. With the default setting allowing each account up to 10 gateways, the potential storage for each account skyrocketed to 100 million logs.
This strategic pivot not only enabled us to store a significantly larger number of logs. But also enhanced our flexibility in gateway management. Now, when a gateway is deleted, we can simply remove the corresponding Durable Object.
Additionally, this sharding method isolates high-volume request scenarios. If one customer’s heavy usage slows down log insertion, it only impacts their specific Durable Object, thereby preserving performance for other customers.
Taking a glance at the revised architecture diagram, we replaced the Backend Worker with our newly integrated Durable Object. The rest of the request flow remains unchanged, including the concurrent response to the user and the interaction with the Durable Object, which occurs in the fourth step.
Leveraging Cloudflare’s network, our Gateway Worker operates near the user’s location, which in turn positions the user’s Durable Object close by. This proximity significantly enhances the speed of log insertion and query operations.
Third step: managing thousands of Durable Objects
As the number of users and requests on AI Gateway grows, managing each unique Durable Object (DO) becomes increasingly complex. New customers join continuously, and we needed an efficient method to track each DO, ensure users stay within their 10 gateway limit, and manage the storage capacity for free users.
To address these challenges, we introduced another layer of control with a new Durable Object we’ve named the Account Manager. The primary function of the Account Manager is straightforward yet crucial: it keeps user activities in check.
Here’s how it works: before any Gateway commits a new log to permanent storage, it consults the Account Manager. This check determines whether the gateway is allowed to insert the log based on the user’s current usage and entitlements. The Account Manager uses its own SQLite database to verify the total number of rows a user has and their service level. If all checks pass, it signals the Gateway that the log can be inserted. It was paramount to guarantee that this entire validation process occurred in the background, ensuring that the user experience remains seamless and uninterrupted.
The Account Manager stays updated by periodically receiving data from each Gateway’s Durable Object. Specifically, after every 1000 inference requests, the Gateway sends an update on its total rows to the Account Manager, which then updates its local records. This system ensures that the Account Manager has the most current data when making its decisions.
Additionally, the Account Manager is responsible for monitoring customer entitlements. It tracks whether an account is on a free or paid plan, how many gateways a user is permitted to create, and the log storage capacity allocated to each gateway.
Through these mechanisms, the Account Manager not only helps in maintaining system integrity but also ensures fair usage across all users of AI Gateway.
AI evaluations and Durable Objects sharding
As we continue to develop evaluations to fully automatic and, in the future, use Large Language Models (LLMs), we are now taking the first step towards this goal and launching the open beta phase of comprehensive AI evaluations, centered on Human-in-the-Loop feedback.
This feature empowers users to create bespoke datasets from their application logs, thereby enabling them to score and evaluate the performance, speed, and cost-effectiveness of their models, with a primary focus on LLMs and automated scoring, analyzing the performance of LLMs, providing developers with objective, data-driven insights to refine their models.
To do this, developers require a reliable logging mechanism that persists logs from multiple gateways, storing up to 100 million logs in total (10 million logs per gateway, across 10 gateways). This represents a significant volume of data, as each request made through the AI Gateway generates a log entry, with some log entries potentially exceeding 50 MB in size.
This necessity leads us to work on the expansion of log storage capabilities. Since log storage is limited to 10 million logs per gateway, in future iterations, we aim to scale this capacity by implementing sharded Durable Objects (DO), allowing multiple Durable Objects per gateway to handle and store logs. This scaling strategy will enable us to store significantly larger volumes of logs, providing richer data for evaluations (using LLMs as a judge or from user input), all through AI Gateway.
Coming Soon
We are working on improving our existing Universal Endpoint, the next step on an enhanced solution that builds on existing fallback mechanisms to offer greater resilience, flexibility, and intelligence in request management.
Currently, when a provider encounters an error or is unavailable, our system falls back to an alternative provider to ensure continuity. The improved Universal Endpoint takes this a step further by introducing automatic retry capabilities, allowing failed requests to be reattempted before fallback is triggered. This significantly improves reliability by handling transient errors and increasing the likelihood of successful request fulfillment. It will look something like this:
The request to the improved Universal Endpoint system demonstrates how it handles multiple providers with integrated retry mechanisms and fallback logic. In this example, the first request is sent to a provider like OpenAI, asking it to generate a text-to-image prompt. The “retry” option ensures that transient issues don’t result in immediate failure.
The system’s ability to seamlessly switch between providers while applying retry strategies ensures higher reliability and robustness in managing requests. By leveraging fallback logic, the Improved Universal Endpoint can dynamically adapt to provider failures, ensuring that tasks are completed successfully even in complex, multi-step workflows.
In addition to retry logic, we will have the ability to inspect requests and responses and make dynamic decisions based on the content of the result. This enables developers to create conditional workflows where the system can adapt its behavior depending on the nature of the response, creating a highly flexible and intelligent decision-making process.
If you haven’t yet used AI Gateway, check out our developer documentation on how to get started. If you have any questions, reach out on our Discord channel.
Failure is an expected state in production systems, and no predictable failure of either software or hardware components should result in a negative experience for users. The exact failure mode may vary, but certain remediation steps must be taken after detection. A common example is when an error occurs on a server, rendering it unfit for production workloads, and requiring action to recover.
When operating at Cloudflare’s scale, it is important to ensure that our platform is able to recover from faults seamlessly. It can be tempting to rely on the expertise of world-class engineers to remediate these faults, but this would be manual, repetitive, unlikely to produce enduring value, and not scaling. In one word: toil; not a viable solution at our scale and rate of growth.
In this post we discuss how we built the foundations to enable a more scalable future, and what problems it has immediately allowed us to solve.
Growing pains
The Cloudflare Site Reliability Engineering (SRE) team builds and manages the platform that helps product teams deliver our extensive suite of offerings to customers. One important component of this platform is the collection of servers that power critical products such as Durable Objects, Workers, and DDoS mitigation. We also build and maintain foundational software services that power our product offerings, such as configuration management, provisioning, and IP address allocation systems.
As part of tactical operations work, we are often required to respond to failures in any of these components to minimize impact to users. Impact can vary from lack of access to a specific product feature, to total unavailability. The level of response required is determined by the priority, which is usually a reflection of the severity of impact on users. Lower-priority failures are more common — a server may run too hot, or experience an unrecoverable hardware error. Higher-priority failures are rare and are typically resolved via a well-defined incident response process, requiring collaboration with multiple other teams.
The commonality of lower-priority failures makes it obvious when the response required, as defined in runbooks, is “toilsome”. To reduce this toil, we had previously implemented a plethora of solutions to automate runbook actions such as manually-invoked shell scripts, cron jobs, and ad-hoc software services. These had grown organically over time and provided solutions on a case-by-case basis, which led to duplication of work, tight coupling, and lack of context awareness across the solutions.
We also care about how long it takes to resolve any potential impact on users. A resolution process which involves the manual invocation of a script relies on human action, increasing the Mean-Time-To-Resolve (MTTR) and leaving room for human error. This risks increasing the amount of errors we serve to users and degrading trust.
These problems proved that we needed a way to automatically heal these platform components. This especially applies to our servers, for which failure can cause impact across multiple product offerings. While we have mechanisms to automatically steer traffic away from these degraded servers, in some rare cases the breakage is sudden enough to be visible.
Solving the problem
To provide a more reliable platform, we needed a new component that provides a common ground for remediation efforts. This would remove duplication of work, provide unified context-awareness and increase development speed, which ultimately saves hours of engineering time and effort.
A good solution would not allow only the SRE team to auto-remediate, it would empower the entire company. The key to adding self-healing capability was a generic interface for all teams to self-service and quickly remediate failures at various levels: machine, service, network, or dependencies.
A good way to think about auto-remediation is in terms of workflows. A workflow is a sequence of steps to get to a desired outcome. This is not dissimilar to a manual shell script which executes what a human would otherwise do via runbook instructions. Because of this logical fit with workflows, we decided to adopt Temporal.
Temporal is a durable execution platform which is useful to gracefully manage infrastructure failures such as network outages and transient failures in external service endpoints. This capability meant we only needed to build a way to schedule “workflow” tasks and have Temporal provide reliability guarantees. This allowed us to focus on building out the orchestration system to support the control and flow of workflow execution in our data centers.
How does Temporal work?
Before we discuss the system that provides our self-healing functions, let’s explore how the workflow execution engine works, as its native architecture provided numerous benefits that we took advantage of to build a more robust foundation.
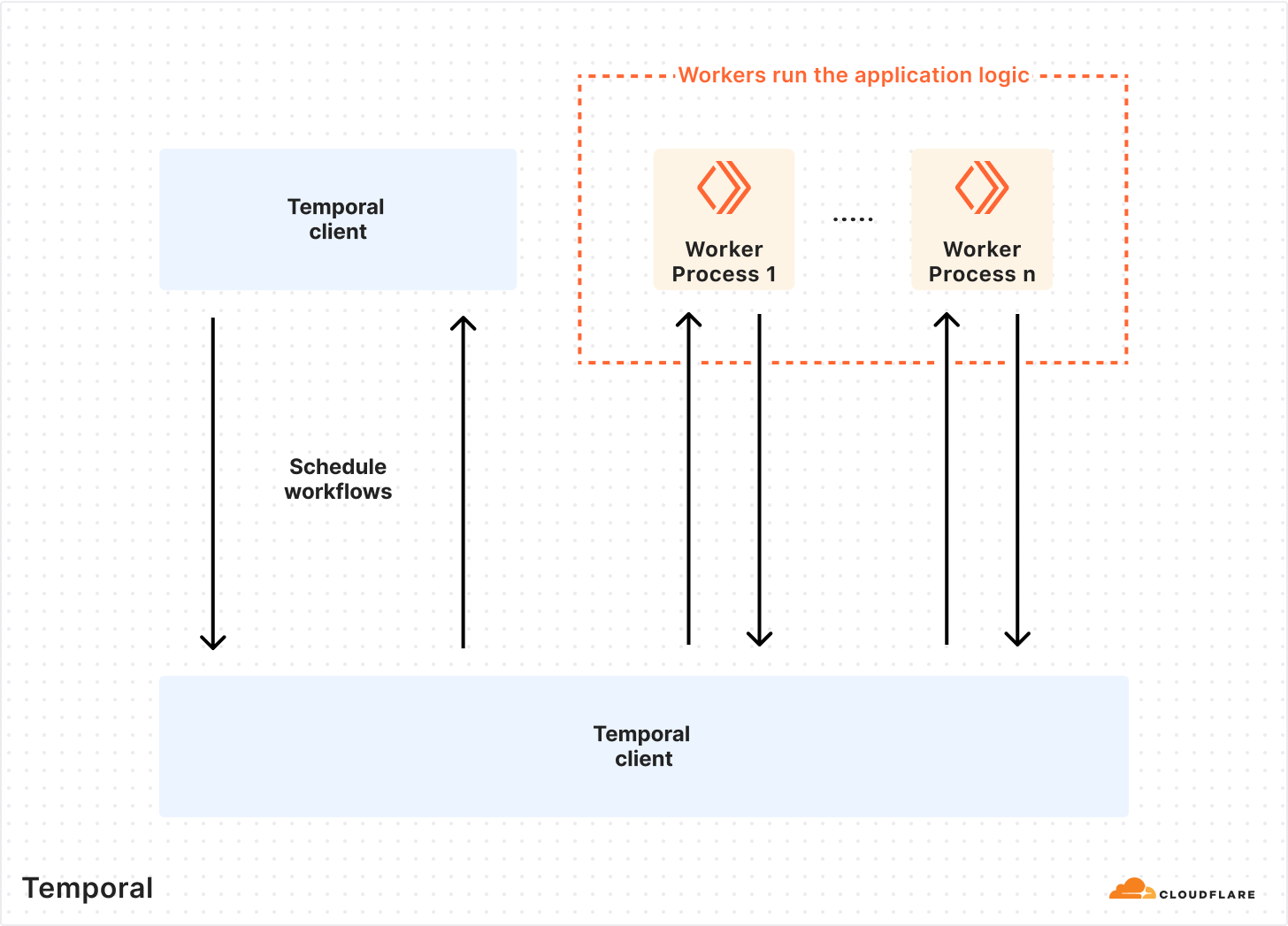
The most attractive feature Temporal offered us was the ability to write code that has reliability baked in. Some examples of these primitives are automatic retries, timeouts, rollbacks, and queueing. The Temporal Platform consists of the Temporal Cluster and Worker processes (application code that contains your custom logic).
This architecture allowed us to write our application logic as we normally would, with the added benefits of Temporal. Since Temporal Workers are external to the cluster, we can run tasks anywhere across our global network — a feature that made it easy to build an extensible, easy-to-understand framework for automating tasks.
In Temporal terms, control is provided by the basic principles used to provide workflow execution — Workflows and Activities. A Workflow is simply a sequence of Activities, which are functions that ideally do only ONE task, such as making a request to an external service or rebooting a machine.
Control of workflow behavior can be done using ActivityOptions. This is where you can define timeouts for workflow execution, retry policies, and task queues. Each worker can poll several task queues for both Workflow and Activity tasks. If no worker is polling the task queue in which a Workflow task is declared, nothing happens.
Below, we describe how our automatic remediation system works. It is essentially a way to schedule tasks across our global network with built-in reliability guarantees. With this system, teams can serve their customers more reliably. An unexpected failure mode can be recognized and immediately mitigated, while the root cause can be determined later via a more detailed analysis.
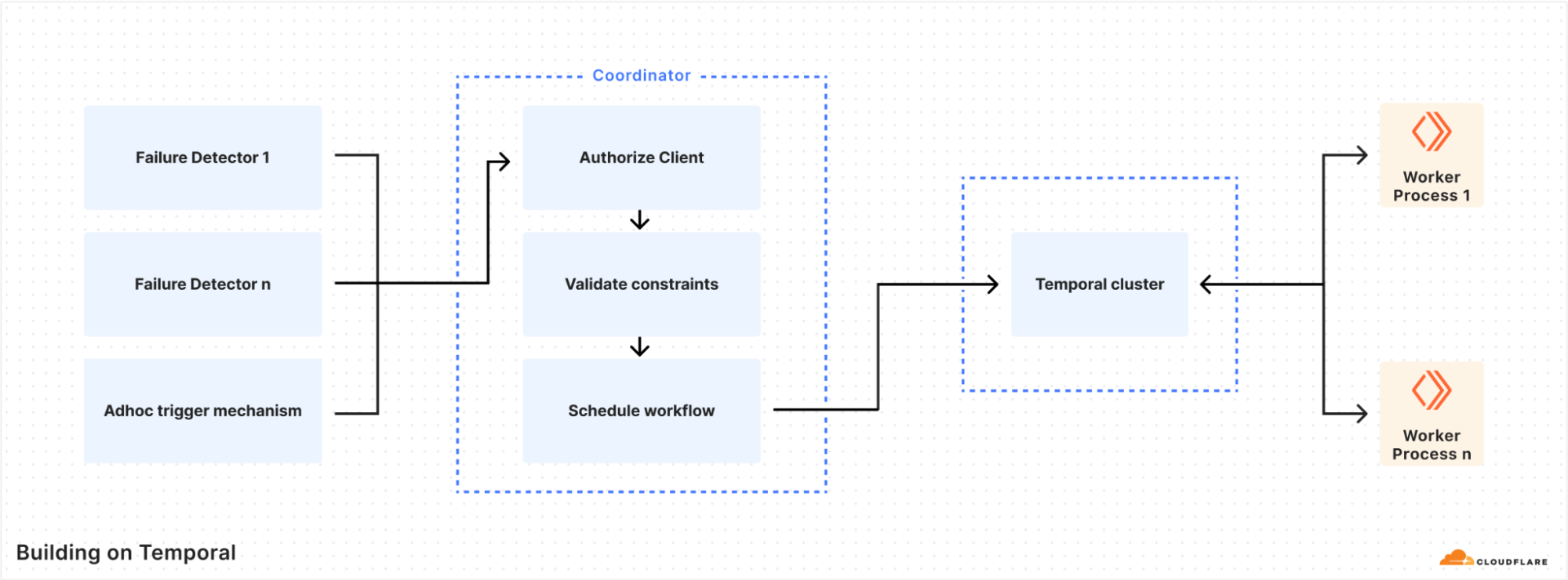
Step one: we need a coordinator
After our initial testing of Temporal, it was now possible to write workflows. But we needed a way to schedule workflow tasks from other internal services. The coordinator was built to serve this purpose, and became the primary mechanism for the authorisation and scheduling of workflows.
The most important roles of the coordinator are authorisation, workflow task routing, and safety constraints enforcement. Each consumer is authorized via mTLS authentication, and the coordinator uses an ACL to determine whether to permit the execution of a workflow. An ACL configuration looks like the following example.
Each workflow specifies two key characteristics: where to run the tasks and the safety constraints, using an HCL configuration file. Example constraints could be whether to run on only a specific node type (such as a database), or if multiple parallel executions are allowed: if a task has been triggered too many times, that is a sign of a wider problem that might require human intervention. The coordinator uses the Temporal Visibility API to determine the current state of the executions in the Temporal cluster.
An example of a configuration file is shown below:
task_queue_target = "<target>"
# The following entries will ensure that
# 1. This workflow is not run at the same time in a 15m window.
# 2. This workflow will not run more than once an hour.
# 3. This workflow will not run more than 3 times in one day.
#
constraint {
kind = "concurency"
value = "1"
period = "15m"
}
constraint {
kind = "maxExecution"
value = "1"
period = "1h"
}
constraint {
kind = "maxExecution"
value = "3"
period = "24h"
is_global = true
}
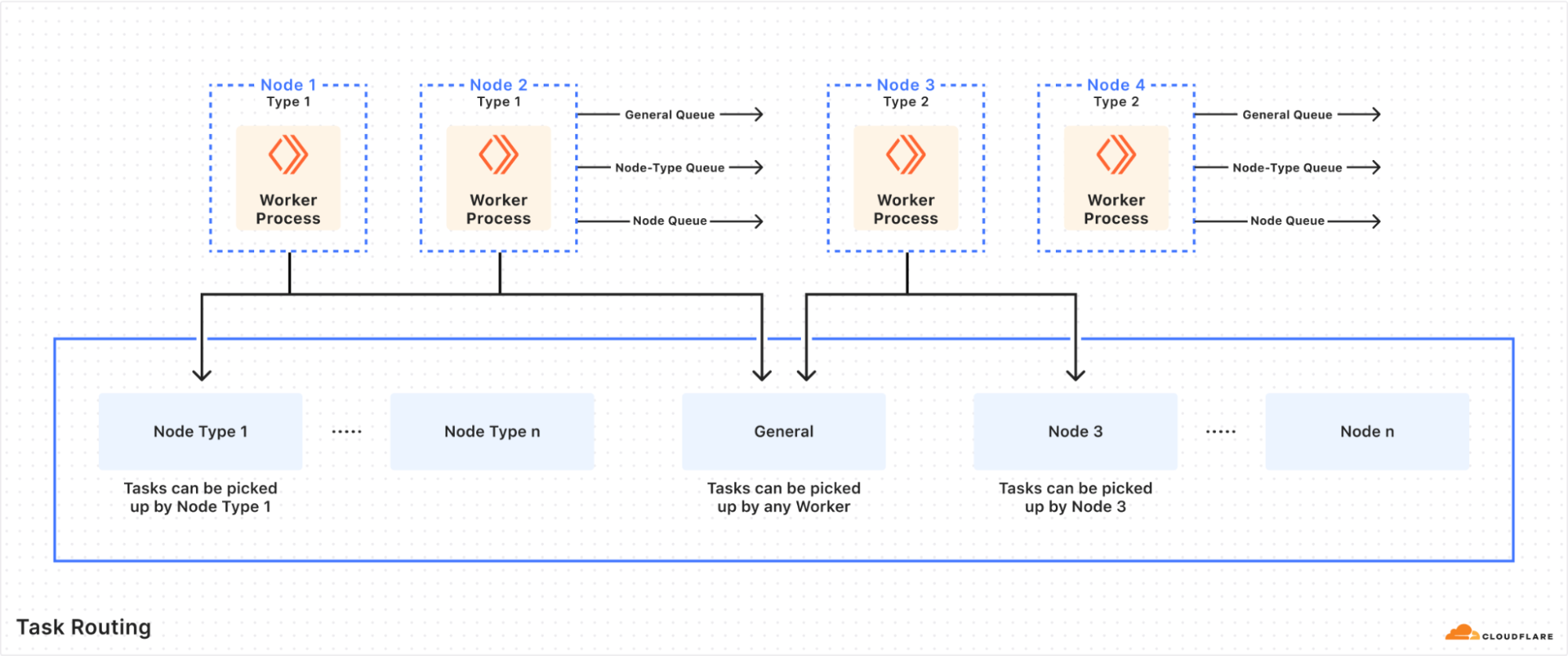
Step two: Task Routing is amazing
An unforeseen benefit of using a central Temporal cluster was the discovery of Task Routing. This feature allows us to schedule a Workflow/Activity on any server that has a running Temporal Worker, and further segment by the type of server, its location, etc. For this reason, we have three primary task queues — the general queue in which tasks can be executed by any worker in the datacenter, the node type queue in which tasks can only be executed by a specific node type in the datacenter, and the individual node queue where we target a specific node for task execution.
We rely on this heavily to ensure the speed and efficiency of automated remediation. Certain tasks can be run in datacenters with known low latency to an external resource, or a node type with better performance than others (due to differences in the underlying hardware). This reduces the amount of failure and latency we see overall in task executions. Sometimes we are also constrained by certain types of tasks that can only run on a certain node type, such as a database.
Task Routing also means that we can configure certain task queues to have a higher priority for execution, although this is not a feature we have needed so far. A drawback of task routing is that every Workflow/Activity needs to be registered to the target task queue, which is a common gotcha. Thankfully, it is possible to catch this failure condition with proper testing.
Step three: when/how to self-heal?
None of this would be relevant if we didn’t put it to good use. A primary design goal for the platform was to ensure we had easy, quick ways to trigger workflows on the most important failure conditions. The next step was to determine what the best sources to trigger the actions were. The answer to this was simple: we could trigger workflows from anywhere as long as they are properly authorized and detect the failure conditions accurately.
Example triggers are an alerting system, a log tailer, a health check daemon, or an authorized engineer via a chatbot. Such flexibility allows a high level of reuse, and permits to invest more in workflow quality and reliability.
As part of the solution, we built a daemon that is able to poll a signal source for any unwanted condition and trigger a configured workflow. We have initially found Prometheus useful as a source because it contains both service-level and hardware/system-level metrics. We are also exploring more event-based trigger mechanisms, which could eliminate the need to use precious system resources to poll for metrics.
We already had internal services that are able to detect widespread failure conditions for our customers, but were only able to page a human. With the adoption of auto-remediation, these systems are now able to react automatically. This ability to create an automatic feedback loop with our customers is the cornerstone of these self-healing capabilities and we continue to work on stronger signals, faster reaction times, and better prevention of future occurrences.
The most exciting part, however, is the future possibility. Every customer cares about any negative impact from Cloudflare. With this platform we can onboard several services (especially those that are foundational for the critical path) and ensure we react quickly to any failure conditions, even before there is any visible impact.
Step four: packaging and deployment
The whole system is written in golang, and a single binary can implement each role. We distribute it as an apt package or a container for maximum ease of deployment.
We deploy a Temporal-based worker to every server we intend to run tasks on, and a daemon in datacenters where we intend to automatically trigger workflows based on the local conditions. The coordinator is more nuanced since we rely on task routing and can trigger from a central coordinator, but we have also found value in running coordinators locally in the datacenters. This is especially useful in datacenters with less capacity or degraded performance, removing the need for a round-trip to schedule the workflows.
Step five: test, test, test
Temporal provides native mechanisms to test an entire workflow, via a comprehensive test suite that supports end-to-end, integration, and unit testing, which we used extensively to prevent regressions while developing. We also ensured proper test coverage for all the critical platform components, especially the coordinator.
Despite the ease of written tests, we quickly discovered that they were not enough. After writing workflows, engineers need an environment as close as possible to the target conditions. This is why we configured our staging environments to support quick and efficient testing. These environments receive the latest changes and point to a different (staging) Temporal cluster, which enables experimentation and easy validation of changes.
After a workflow is validated in the staging environment, we can then do a full release to production. It seems obvious, but catching simple configuration errors before releasing has saved us many hours in development/change-related-task time.
Deploying to production
As you can guess from the title of this post, we put this in production to automatically react to server-specific errors and unrecoverable failures. To this end, we have a set of services that are able to detect single-server failure conditions based on analyzed traffic data. After deployment, we have successfully mitigated potential impact by taking any errant single sources of failure out of production.
We have also created a set of workflows to reduce internal toil and improve efficiency. These workflows can automatically test pull requests on target machines, wipe and reset servers after experiments are concluded, and take away manual processes that cost many hours in toil.
Building a system that is maintained by several SRE teams has allowed us to iterate faster, and rapidly tackle long-standing problems. We have set ambitious goals regarding toil elimination and are on course to achieve them, which will allow us to scale faster by eliminating the human bottleneck.
Looking to the future
Our immediate plans are to leverage this system to provide a more reliable platform for our customers and drastically reduce operational toil, freeing up engineering resources to tackle larger-scale problems. We also intend to leverage more Temporal features such as Workflow Versioning, which will simplify the process of making changes to workflows by ensuring that triggered workflows run expected versions.
We are also interested in how others are solving problems using durable execution platforms such as Temporal, and general strategies to eliminate toil. If you would like to discuss this further, feel free to reach out on the Cloudflare Community and start a conversation!
The continued growth of AI has fundamentally changed the Internet over the past 24 months. AI is increasingly ubiquitous, and Cloudflare is leaning into the new opportunities and challenges it presents in a big way. This year for Cloudflare’s birthday, we’ve extended our AI Assistant capabilities to help you build new WAF rules, added AI bot traffic insights on Cloudflare Radar, and given customers new AI bot blocking capabilities.
AI Assistant for WAF Rule Builder
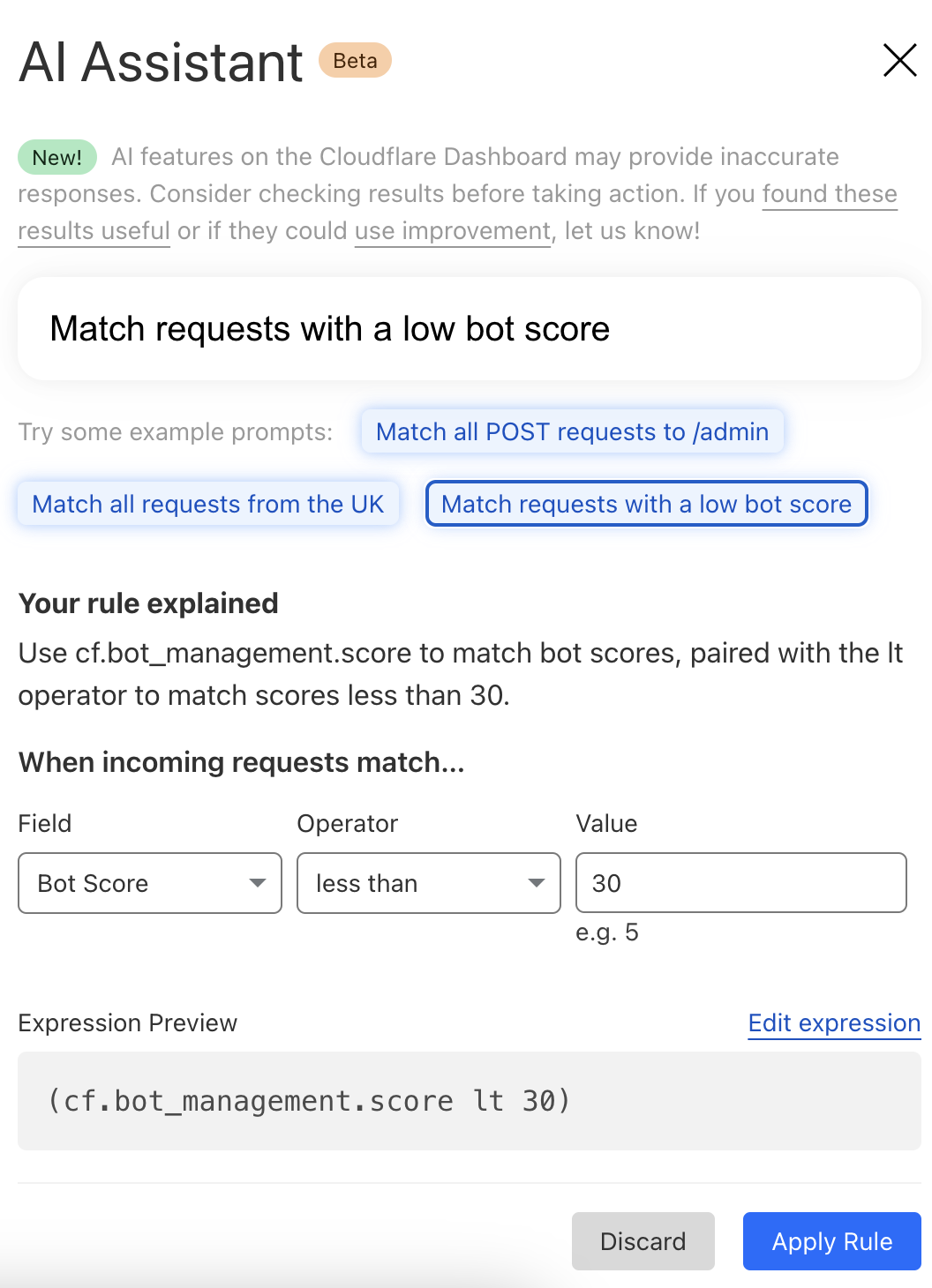
At Cloudflare, we’re always listening to your feedback and striving to make our products as user-friendly and powerful as possible. One area where we’ve heard your feedback loud and clear is in the complexity of creating custom and rate-limiting rules for our Web Application Firewall (WAF). With this in mind, we’re excited to introduce a new feature that will make rule creation easier and more intuitive: the AI Assistant for WAF Rule Builder.
By simply entering a natural language prompt, you can generate a custom or rate-limiting rule tailored to your needs. For example, instead of manually configuring a complex rule matching criteria, you can now type something like, “Match requests with low bot score,” and the assistant will generate the rule for you. It’s not about creating the perfect rule in one step, but giving you a strong foundation that you can build on.
The assistant will be available in the Custom and Rate Limit Rule Builder for all WAF users. We’re launching this feature in Beta for all customers, and we encourage you to give it a try. We’re looking forward to hearing your feedback (via the UI itself) as we continue to refine and enhance this tool to meet your needs.
AI bot traffic insights on Cloudflare Radar
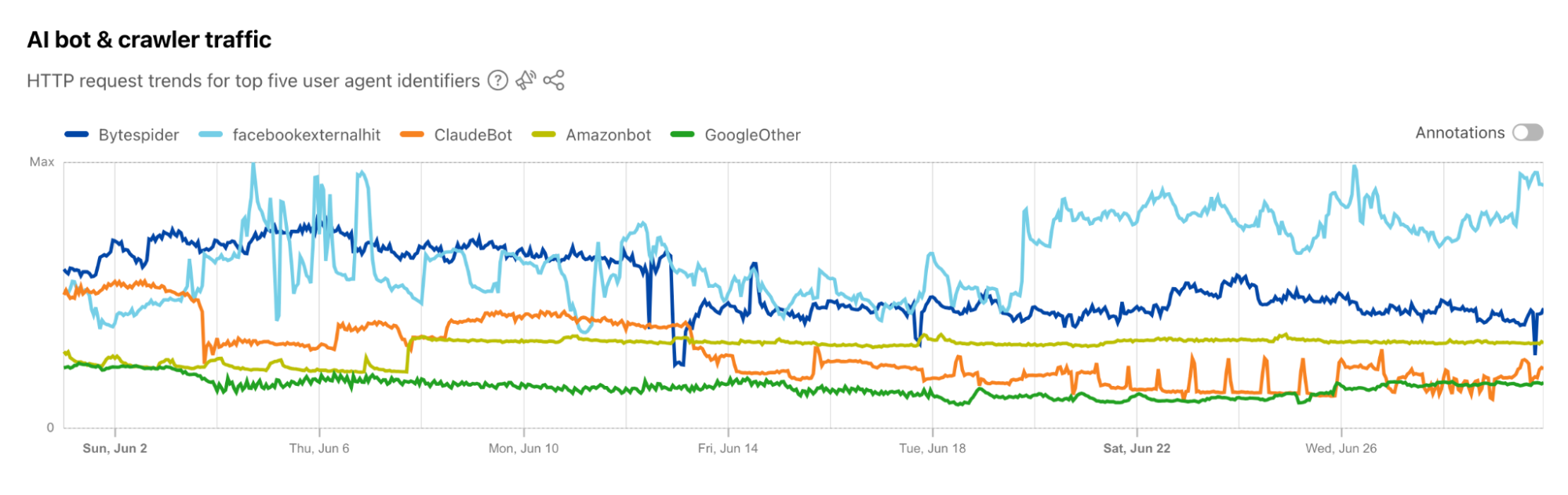
AI platform providers use bots to crawl and scrape websites, vacuuming up data to use for model training. This is frequently done without the permission of, or a business relationship with, the content owners and providers. In July, Cloudflare urged content owners and providers to “declare their AIndependence”, providing them with a way to block AI bots, scrapers, and crawlers with a single click. In addition to this so-called “easy button” approach, sites can provide more specific guidance to these bots about what they are and are not allowed to access through directives in a robots.txt file. Regardless of whether a customer chooses to block or allow requests from AI-related bots, Cloudflare has insight into request activity from these bots, and associated traffic trends over time.
Tracking traffic trends for AI bots can help us better understand their activity over time — which are the most aggressive and have the highest volume of requests, which launch crawls on a regular basis, etc. The new AI bot & crawler traffic graph on Radar’s Traffic page provides insight into these traffic trends gathered over the selected time period for the top known AI bots. The associated list of bots tracked here is based on the ai.robots.txt list, and will be updated with new bots as they are identified. Time series and summary data is available from the Radar API as well. (Traffic trends for the full set of AI bots & crawlers can be viewed in the new Data Explorer.)
Blocking more AI bots
For Cloudflare’s birthday, we’re following up on our previous blog post, Declaring Your AIndependence, with an update on the new detections we’ve added to stop AI bots. Customers who haven’t already done so can simply click the button to block AI bots to gain more protection for their website.
Enabling dynamic updates for the AI bot rule
The old button allowed customers to block verified AI crawlers, those that respect robots.txt and crawl rate, and don’t try to hide their behavior. We’ve added new crawlers to that list, but we’ve also expanded the previous rule to include 27 signatures (and counting) of AI bots that don’t follow the rules. We want to take time to say “thank you” to everyone who took the time to use our “tip line” to point us towards new AI bots. These tips have been extremely helpful in finding some bots that would not have been on our radar so quickly.
For each bot we’ve added, we’re also adding them to our “Definitely automated” definition as well. So, if you’re a self-service plan customer using Super Bot Fight Mode, you’re already protected. Enterprise Bot Management customers will see more requests shift from the “Likely Bot” range to the “Definitely automated” range, which we’ll discuss more below.
Under the hood, we’ve converted this rule logic to a Cloudflare managed rule (the same framework that powers our WAF). This enables our security analysts and engineers to safely push updates to the rule in real-time, similar to how new WAF rule changes are rapidly delivered to ensure our customers are protected against the latest CVEs. If you haven’t logged back into the Bots dashboard since the previous version of our AI bot protection was announced, click the button again to update to the latest protection.
The impact of new fingerprints on the model
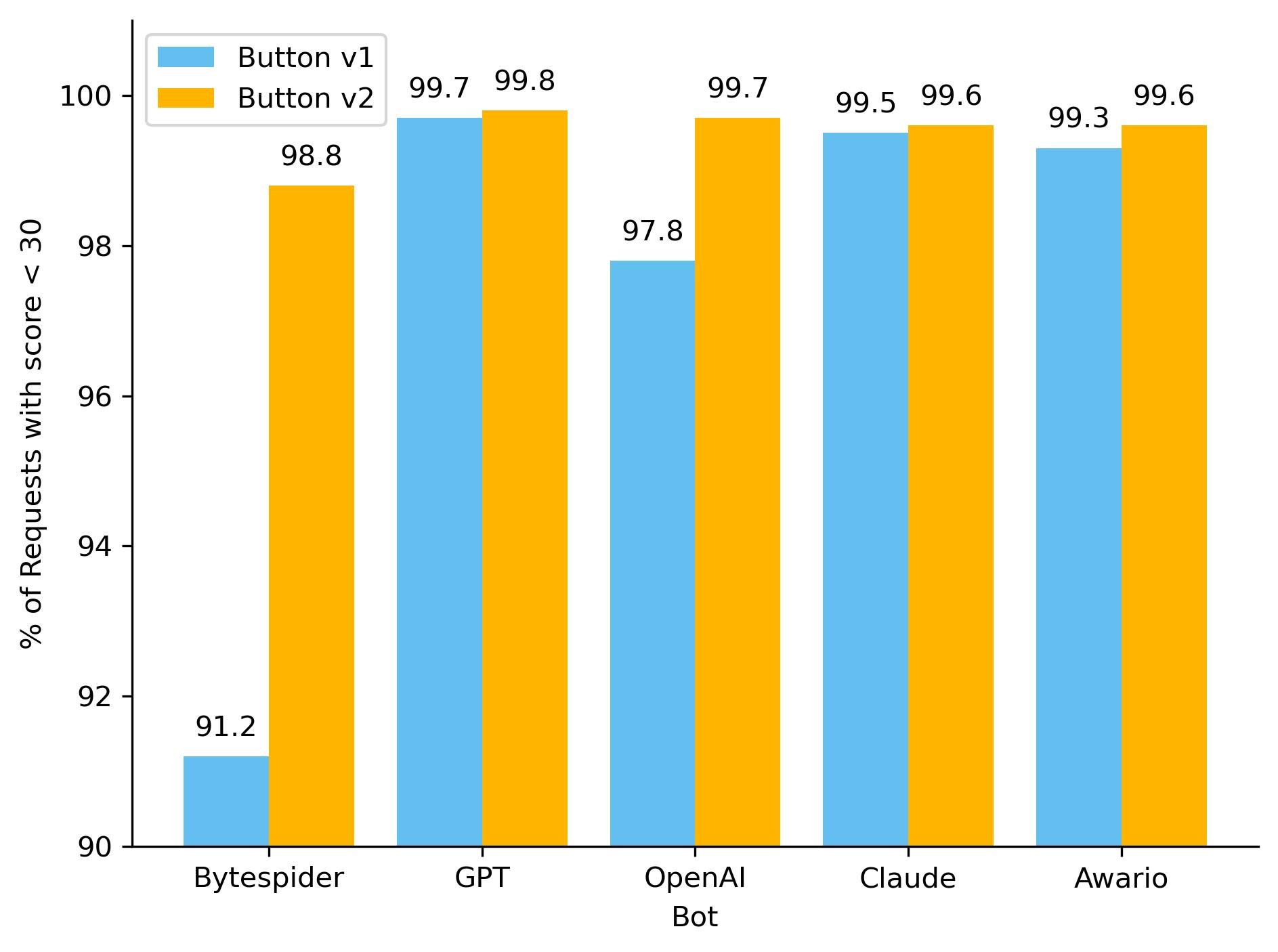
One hidden beneficiary of fingerprinting new AI bots is our ML model. As we’ve discussed before, our global ML model uses supervised machine learning and greatly benefits from more sources of labeled bot data. Below, you can see how well our ML model recognized these requests as automated, before and after we updated the button, adding new rules. To keep things simple, we have shown only the top 5 bots by the volume of requests on the chart. With the introduction of our new managed rule, we have observed an improvement in our detection capabilities for the majority of these AI bots. Button v1 represents the old option that let customers block only verified AI crawlers, while Button v2 is the newly introduced feature that includes managed rule detections.
So how did we make our detections more robust? As we have mentioned before, sometimes a single attribute can give a bot away. We developed a sophisticated set of heuristics tailored to these AI bots, enabling us to effortlessly and accurately classify them as such. Although our ML model was already detecting the vast majority of these requests, the integration of additional heuristics has resulted in a noticeable increase in detection rates for each bot, and ensuring we score every request correctly 100% of the time. Transitioning from a purely machine learning approach to incorporating heuristics offers several advantages, including faster detection times and greater certainty in classification. While deploying a machine learning model is complex and time-consuming, new heuristics can be created in minutes.
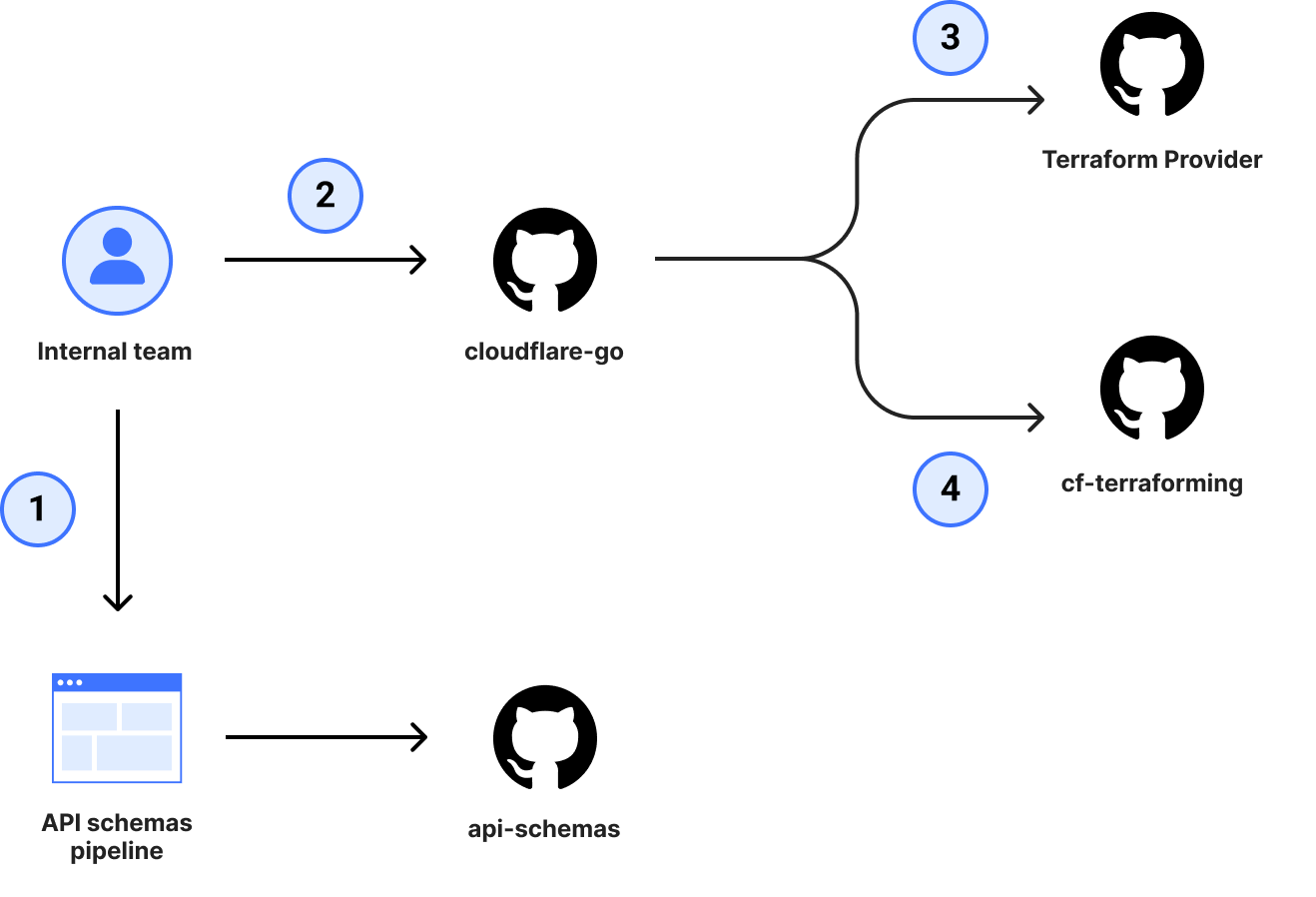
The initial launch of the AI bots block button was well-received and is now used by over 133,000 websites, with significant adoption even among our Free tier customers. The newly updated button, launched on August 20, 2024, is rapidly gaining traction. Over 90,000 zones have already adopted the new rule, with approximately 240 new sites integrating it every hour. Overall, we are now helping to protect the intellectual property of more than 146,000 sites from AI bots, and we are currently blocking 66 million requests daily with this new rule. Additionally, we’re excited to announce that support for configuring AI bots protection via Terraform will be available by the end of this year, providing even more flexibility and control for managing your bot protection settings.
Bot behavior
With the enhancements to our detection capabilities, it is essential to assess the impact of these changes to bot activity on the Internet. Since the launch of the updated AI bots block button, we have been closely monitoring for any shifts in bot activity and adaptation strategies. The most basic fingerprinting technique we use to identify AI bot looking for simple user-agent matches. User-agent matches are important to monitor because they indicate the bot is transparently announcing who they are when they’re crawling a website.
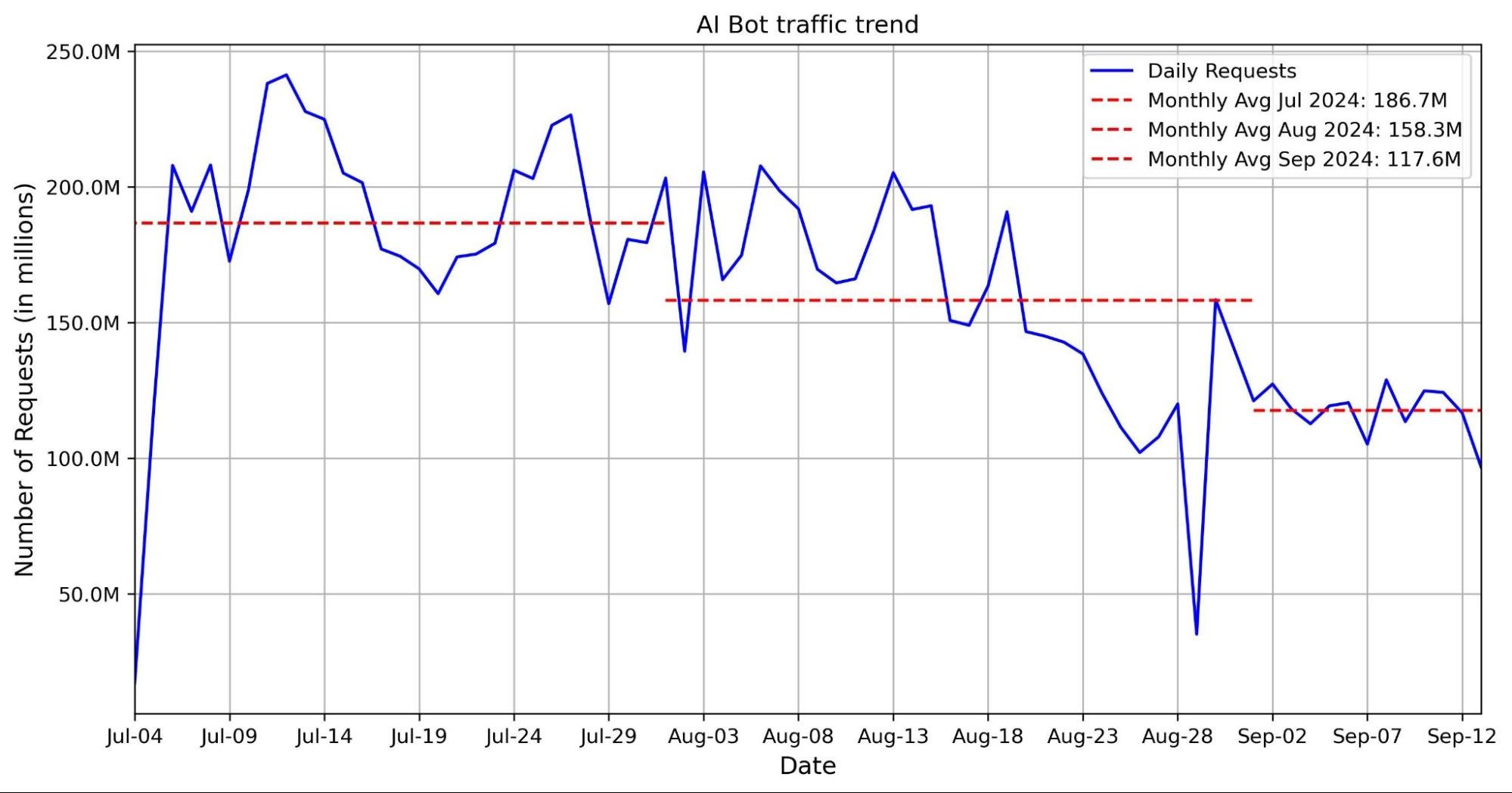
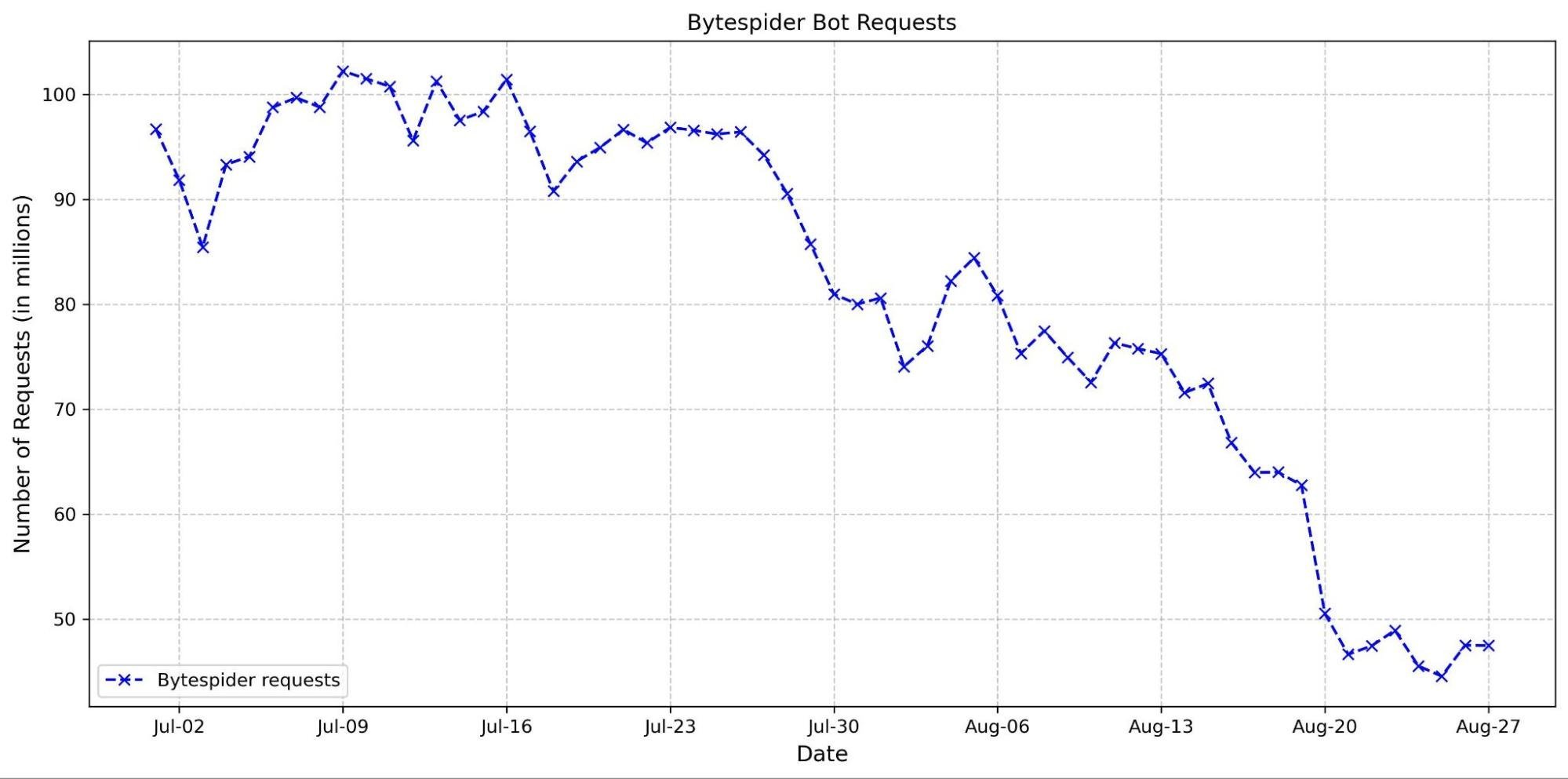
The graph below shows a volume of traffic we label as AI bot over the past two months. The blue line indicates the daily request count, while the red line represents the monthly average number of requests. In the past two months, we have seen an average reduction of nearly 30 million requests, with a decrease of 40 million in the most recent month.This decline coincides with the release of Button v1 and Button v2. Our hypothesis is that with the new AI bots blocking feature, Cloudflare is blocking a majority of these bots, which is discouraging them from crawling.
This hypothesis is supported by the observed decline in requests from several top AI crawlers. Specifically, the Bytespider bot reduced its daily requests from approximately 100 million to just 50 million between the end of June and the end of August (see graph below). This reduction could be attributed to several factors, including our new AI bots block button and changes in the crawler’s strategy.
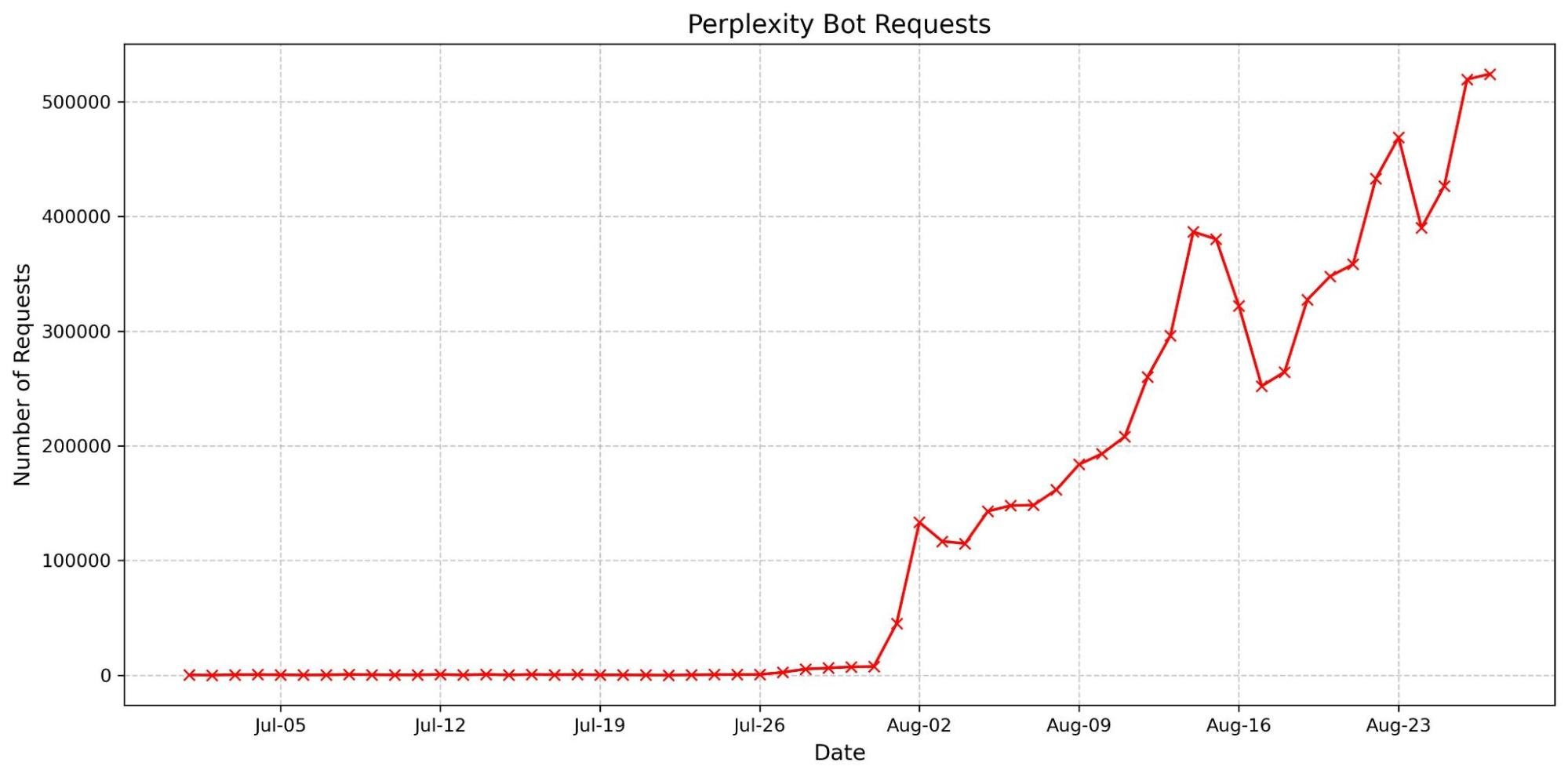
We have also observed an increase in the accountability of some AI crawlers. The most basic fingerprinting technique we use to identify AI bot looking for simple user-agent matches. User-agent matches are important to monitor because they indicate the bot is transparently announcing who they are when they’re crawling a website. These crawlers are now more frequently using their agents, reflecting a shift towards more transparent and responsible behavior. Notably, there has been a dramatic surge in the number of requests from the Perplexity user agent. This increase might be linked to previous accusationsthat Perplexity did not properly present its user agent, which could have prompted a shift in their approach to ensure better identification and compliance.
These trends suggest that our updates are likely affecting how AI crawlers interact with content. We will continue to monitor AI bot activity to help users control who accesses their content and how. By keeping a close watch on emerging patterns, we aim to provide users with the tools and insights needed to make informed decisions about managing their traffic.
Wrap up
We’re excited to continue to explore the AI landscape, whether we’re finding more ways to make the Cloudflare dashboard usable or new threats to guard against. Our AI insights on Radar update in near real-time, so please join us in watching as new trends emerge and discussing them in the Cloudflare Community.
We’ve been working on something new — a platform for running containers across Cloudflare’s network. We already use it in production for Workers AI, Workers Builds, Remote Browsing Isolation, and the Browser Rendering API. Today, we want to share an early look at how it’s built, why we built it, and how we use it ourselves.
In 2024, Cloudflare Workers celebrates its 7th birthday. When we first announced Workers, it was a completely new model for running compute in a multi-tenant way — on isolates, as opposed to containers. While, at the time, Workers was a pretty bare-bones functions-as-a-service product, we took a big bet that this was going to become the way software was going to be written going forward. Since introducing Workers, in addition to expanding our developer products in general to include storage and AI, we have been steadily adding more compute capabilities to Workers:
With each of these, we’ve faced a question — can we build this natively into the platform, in a way that removes, rather than adds complexity? Can we build it in a way that lets developers focus on building and shipping, rather than managing infrastructure, so that they don’t have to be a distributed systems engineer to build distributed systems?
In each instance, the answer has been YES. We try to solve problems in a way that simplifies things for developers in the long run, even if that is the harder path for us to take ourselves. If we didn’t, you’d be right to ask — why not self-host and manage all of this myself? What’s the point of the cloud if I’m still provisioning and managing infrastructure? These are the questions many are asking today about the earlier generation of cloud providers.
Pushing ourselves to build platform-native products and features helped us answer this question. Particularly because some of these actually use containers behind the scenes, even though as a developer you never interact with or think about containers yourself.
If you’ve used AI inference on GPUs with Workers AI, spun up headless browsers with Browser Rendering, or enqueued build jobs with the new Workers Builds, you’ve run containers on our network, without even knowing it. But to do so, we needed to be able to run untrusted code across Cloudflare’s network, outside a v8 isolate, in a way that fits what we promise:
You shouldn’t have to think about regions or data centers. Routing, scaling, load balancing, scheduling, and capacity are our problem to solve, not yours, with tools like Smart Placement.
You should be able to build distributed systems without being a distributed systems engineer.
Every millisecond matters — Cloudflare has to be fast.
There wasn’t an off-the-shelf container platform that solved for what we needed, so we built it ourselves — from scheduling to IP address management, pulling and caching images, to improving startup times and more. Our container platform powers many of our newest products, so we wanted to share how we built it, optimized it, and well, you can probably guess what’s next.
Global scheduling — “The Network is the Computer”
Cloudflare serves the entire world — region: earth. Rather than asking developers to provision resources in specific regions, data centers and availability zones, we think “The Network is the Computer”. When you build on Cloudflare, you build software that runs on the Internet, not just in a data center.
When we started working on this, Cloudflare’s architecture was to just run every service via systemd on every server (we call them “metals” — we run our own hardware), allowing all services to take advantage of new capacity we add to our network. That fits running NGINX and a few dozen other services, but cannot fit a world where we need to run many thousands of different compute heavy, resource hungry workloads. We’d run out of space just trying to load all of them! Consider a canonical AI workload — deploying Llama 3.1 8B to an inference server. If we simply ran a Llama 3.1 8B service on every Cloudflare metal, we’d have no flexibility to use GPUs for the many other models that Workers AI supports.
We needed something that would allow us to still take advantage of the full capacity of Cloudflare’s entire network, not just the capacity of individual machines. And ideally not put that burden on the developer.
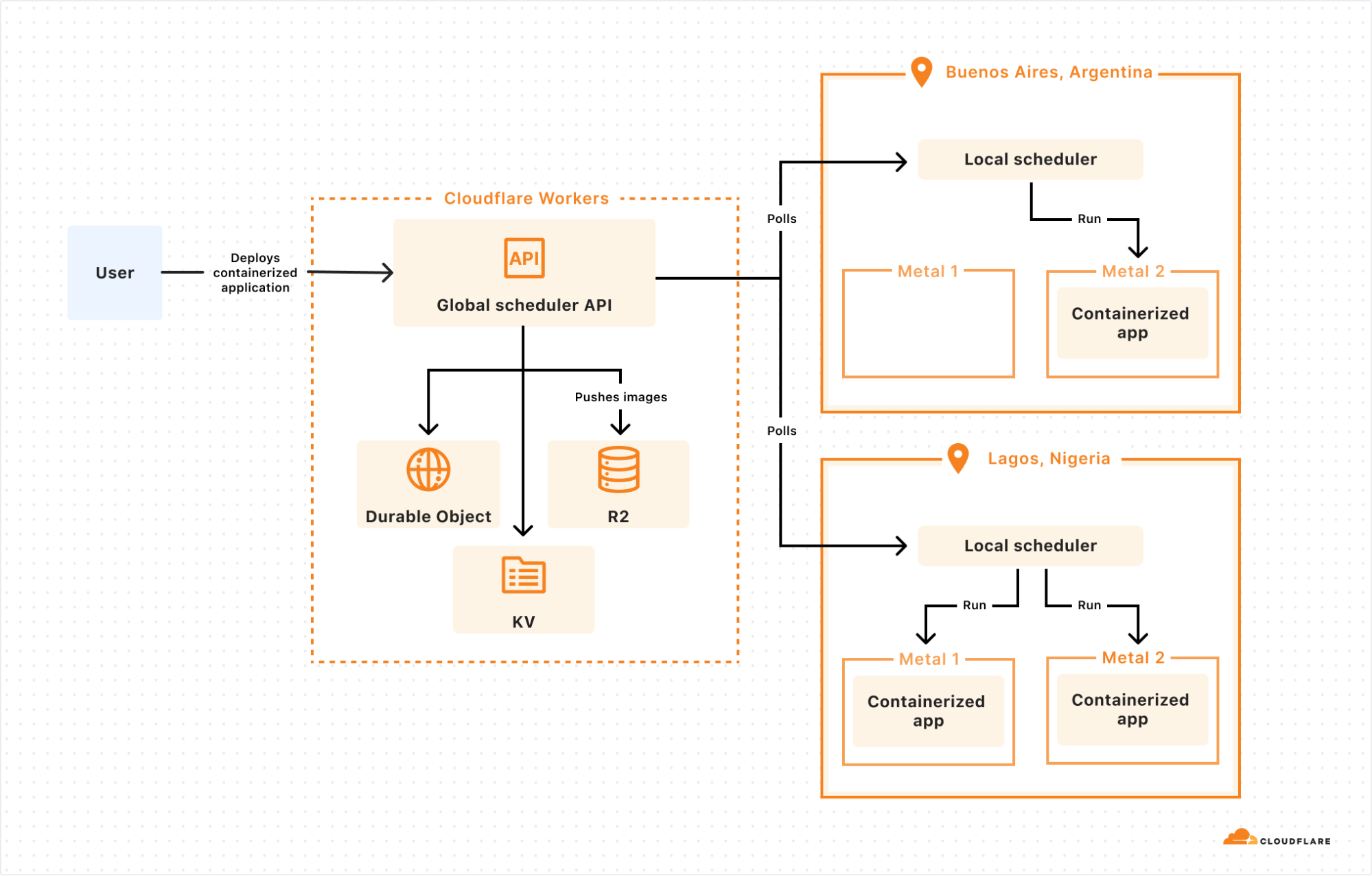
The answer: we built a control plane on our own Developer Platform that lets us schedule a container anywhere on Cloudflare’s Network:
The global scheduler is built on Cloudflare Workers, Durable Objects, and KV, and decides which Cloudflare location to schedule the container to run in. Each location then runs its own scheduler, which decides which metals within that location to schedule the container to run on. Location schedulers monitor compute capacity, and expose this to the global scheduler. This allows Cloudflare to dynamically place workloads based on capacity and hardware availability (e.g. multiple types of GPUs) across our network.
Why does global scheduling matter?
When you run compute on a first generation cloud, the “contract” between the developer and the platform is that the developer must specify what runs where. This is regional scheduling, the status quo.
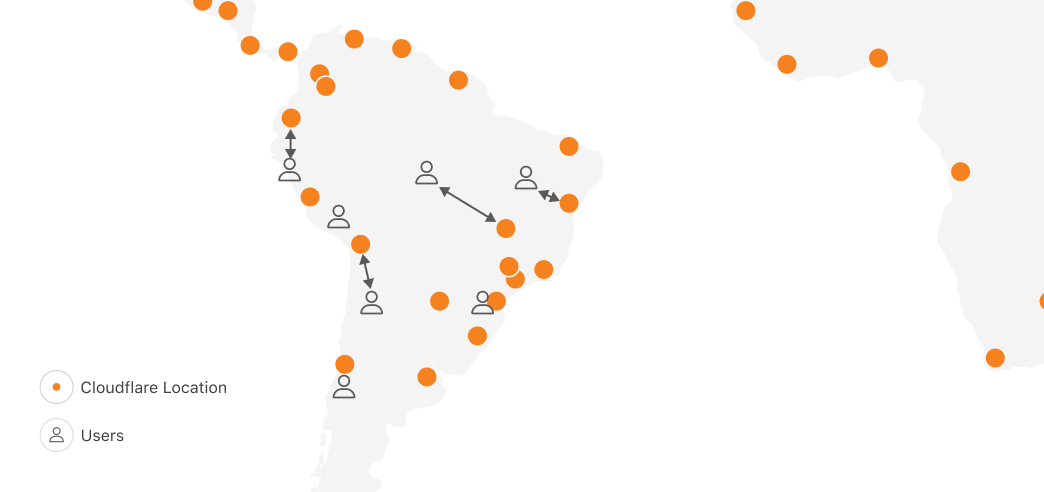
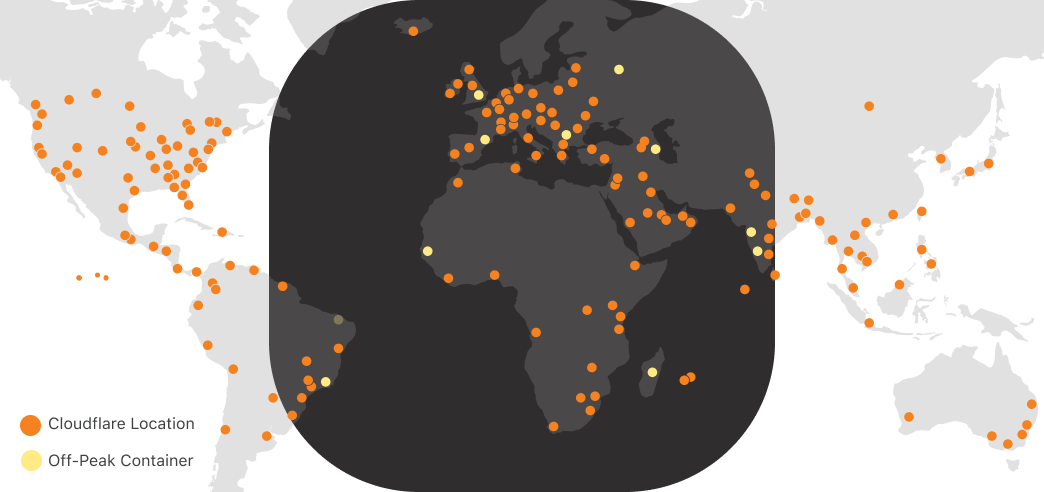
Let’s imagine for a second if we applied regional scheduling to running compute on Cloudflare’s network, with locations in 330+ cities, across 120+ countries. One of the obvious reasons people tell us they want to run on Cloudflare is because we have compute in places where others don’t, within 50ms of 95% of the world’s Internet-connected population. In South America, other clouds have one region in one city. Cloudflare has 19:
Running anywhere means you can be faster, highly available, and have more control over data location. But with regional scheduling, the more locations you run in, the more work you have to do. You configure and manage load balancing, routing, auto-scaling policies and more. Balancing performance and cost in a multi-region setup is literally a full-time job (or more) at most companies who have reached meaningful scale on traditional clouds.
But most importantly, no matter what tools you bring, you were the one who told the cloud provider, “run this container over here”. The cloud platform can’t move it for you, even if moving it would make your workload faster. This prevents the platform from adding locations, because for each location, it has to convince developers to take action themselves to move their compute workloads to the new location. Each new location carries a risk that developers won’t migrate workloads to it, or migrate too slowly, delaying the return on investment.
Global scheduling means Cloudflare can add capacity and use it immediately, letting you benefit from it. The “contract” between us and our customers isn’t tied to a specific datacenter or region, so we have permission to move workloads around to benefit customers. This flexibility plays an essential role in all of our own uses of our container platform, starting with GPUs and AI.
GPUs everywhere: Scheduling large images with Workers AI
In late 2023, we launched Workers AI, which provides fast, easy to use, and affordable GPU-backed AI inference.
The more efficiently we can use our capacity, the better pricing we can offer. And the faster we can make changes to which models run in which Cloudflare locations, the closer we can move AI inference to the application, lowering Time to First Token (TTFT). This also allows us to be more resilient to spikes in inference requests.
AI models that rely on GPUs present three challenges though:
Models have different GPU memory needs. GPU memory is the most scarce resource, and different GPUs have different amounts of memory.
Not all container runtimes, such as Firecracker, support GPU drivers and other dependencies.
AI models, particularly LLMs, are very large. Even a smaller parameter model, like @cf/meta/llama-3.1-8b-instruct, is at least 5 GB. The larger the model, the more bytes we need to pull across the network when scheduling a model to run in a new location.
Let’s dive into how we solved each of these…
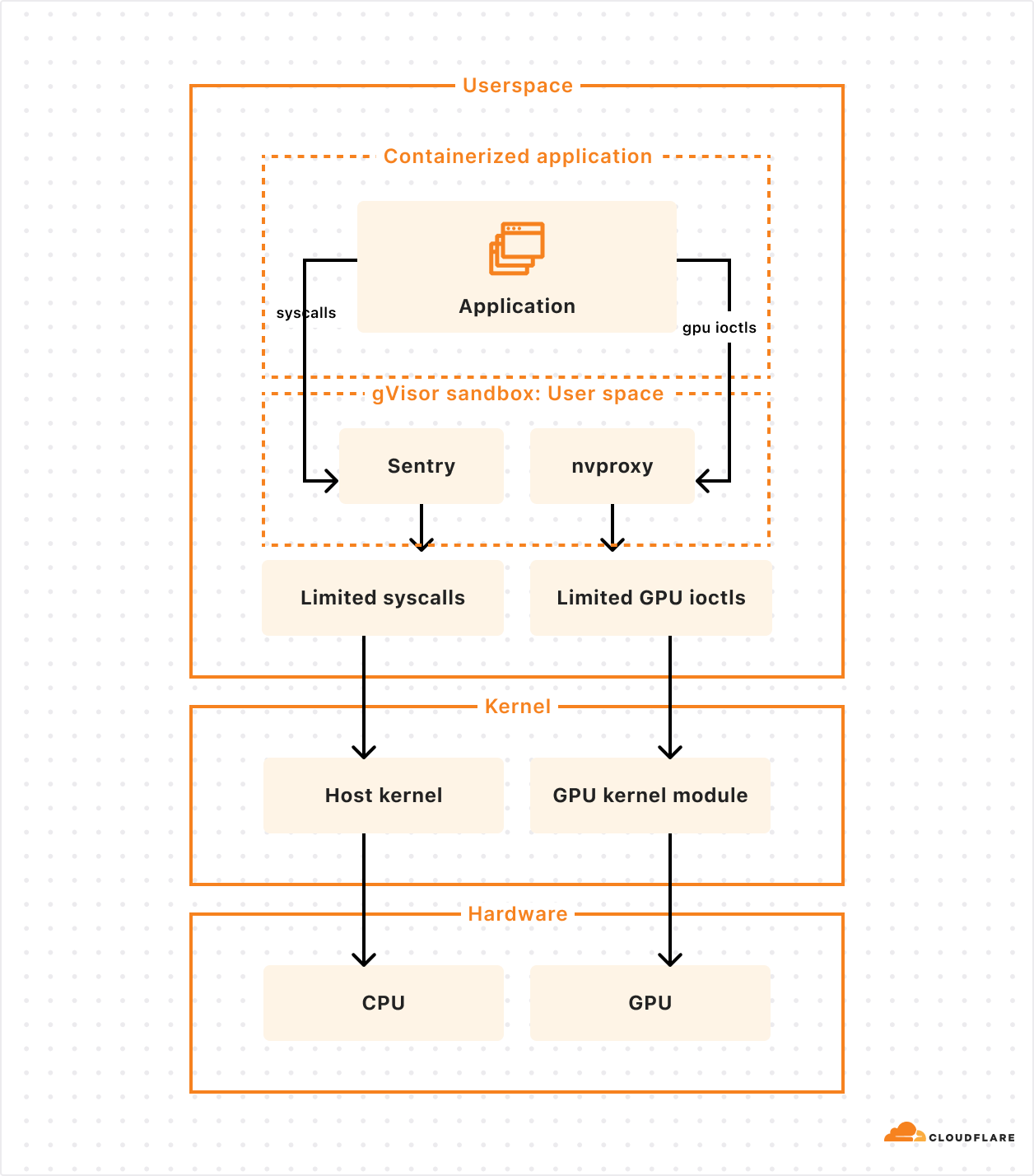
First, GPU memory needs. The global scheduler knows which Cloudflare locations have blocks of GPU memory available, and then delegates scheduling the workload on a specific metal to the local scheduler. This allows us to prioritize placement of AI models that use a large amount of GPU memory, and then move smaller models to other machines in the same location. By doing this, we maximize the overall number of locations that we run AI models in, and maximize our efficiency.
Second, container runtimes and GPU support. Thankfully, from day one we built our container platform to be runtime agnostic. Using a runtime agnostic scheduler, we’re able to support gVisor, Firecracker microVMs, and traditional VMs with QEMU. We are also evaluating adding support for another one: cloud-hypervisor which is based on rust-vmm and has a few compelling advantages for our use case:
vhost-user-net support, enabling high throughput between the host network interface and the VM
vhost-user-blk support, adding flexibility to introduce novel network-based storage backed by other Cloudflare Workers products
all the while being a smaller codebase than QEMU and written in a memory-safe language
Our goal isn’t to build a platform that makes you as the developer choose between runtimes, and ask, “should I use Firecracker or gVisor”. We needed this flexibility in order to be able to run workloads with different needs efficiently, including workloads that depend on GPUs. gVisor has GPU support, while Firecracker microVMs currently does not.
gVisor’s main component is an application kernel (called Sentry) that implements a Linux-like interface but is written in a memory-safe language (Go) and runs in userspace. It works by intercepting application system calls and acting as the guest kernel, without the need for translation through virtualized hardware.
The resource footprint of a containerized application running on gVisor is lower than a VM because it does not require managing virtualized hardware and booting up a kernel instance. However, this comes at the price of reduced application compatibility and higher per-system call overhead.
To add GPU support, the Google team introduced nvproxy which works using the same principles as described above for syscalls: it intercepts ioctls destined to the GPU and proxies a subset to the GPU kernel module.
To solve the third challenge, and make scheduling fast with large models, we weren’t satisfied with the status quo. So we did something about it.
Docker pull was too slow, so we fixed it (and cut the time in half)
Many of the images we need to run for AI inference are over 15 GB. Specialized inference libraries and GPU drivers add up fast. For example, when we make a scheduling decision to run a fresh container in Tokyo, naively running docker pull to fetch the image from a storage bucket in Los Angeles would be unacceptably slow. And scheduling speed is critical to being able to scale up and down in new locations in response to changes in traffic.
We had 3 essential requirements:
Pulling and pushing very large images should be fast
We should not rely on a single point of failure
Our teams shouldn’t waste time managing image registries
We needed globally distributed storage, so we used R2. We needed the highest cache hit rate possible, so we used Cloudflare’s Cache, and will soon use Tiered Cache. And we needed a fast container image registry that we could run everywhere, in every Cloudflare location, so we built and open-sourced serverless-registry, which is built on Workers. You can deploy serverless-registry to your own Cloudflare account in about 5 minutes. We rely on it in production.
This is fast, but we can be faster. Our performance bottleneck was, somewhat surprisingly, docker push. Docker uses gzip to compress and decompress layers of images while pushing and pulling. So we started using Zstandard (zstd) instead, which compresses and decompresses faster, and results in smaller compressed files.
In order to build, chunk, and push these images to the R2 registry, we built a custom CLI tool that we use internally in lieu of running docker build and docker push. This makes it easy to use zstd and split layers into 500 MB chunks, which allows uploads to be processed by Workers while staying under body size limits.
Using our custom build and push tool doubled the speed of image pulls. Our 30 GB GPU images now pull in 4 minutes instead of 8. We plan on open sourcing this tool in the near future.
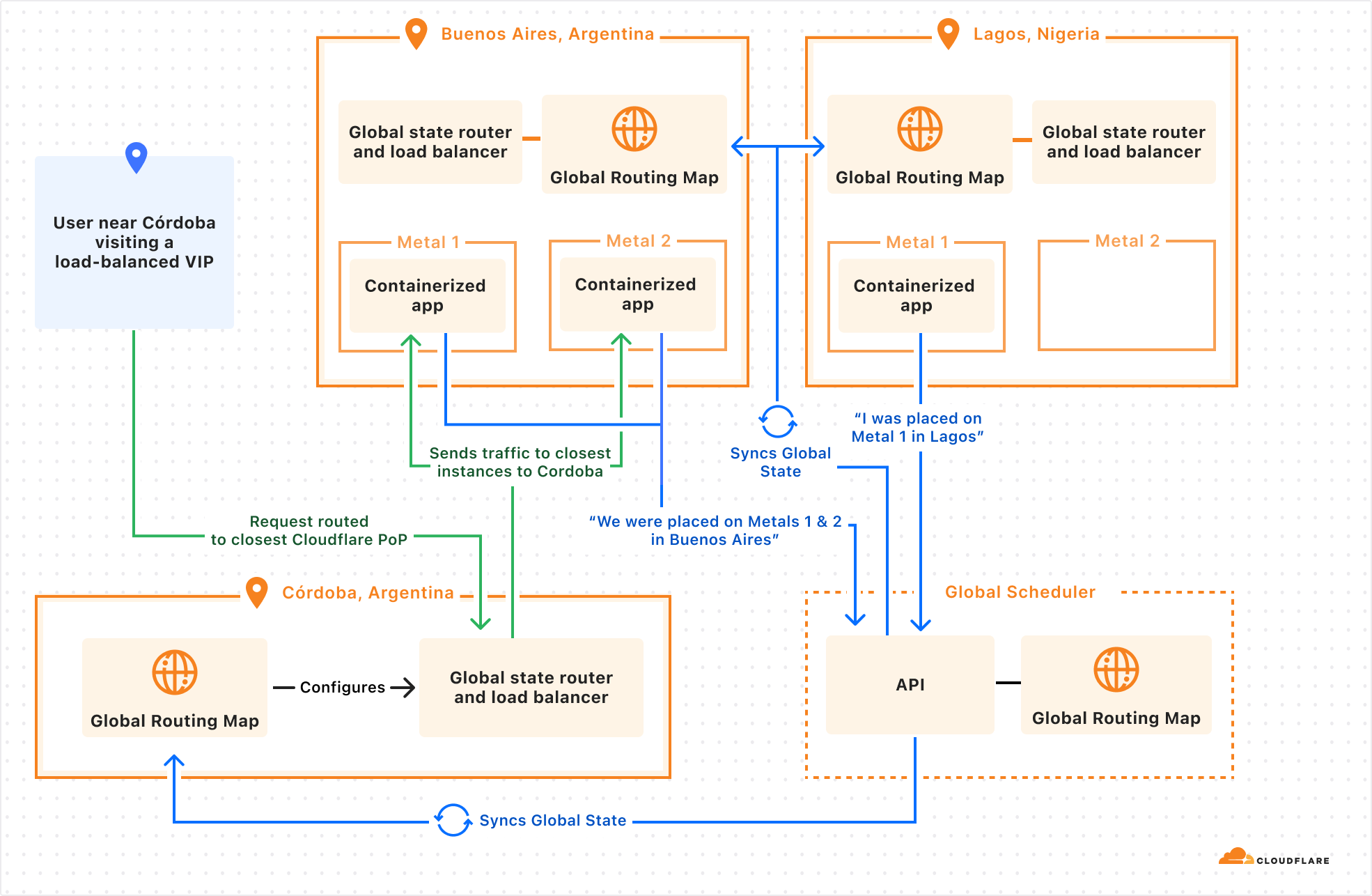
Anycast is the gift that keeps on simplifying — Virtual IPs and the Global State Router
We still had another challenge to solve. And yes, we solved it with anycast. We’re Cloudflare, did you expect anything else?
First, a refresher — Cloudflare operates Unimog, a Layer 4 load balancer that handles all incoming Cloudflare traffic. Cloudflare’s network uses anycast, which allows a single IP address to route requests to a variety of different locations. For most Cloudflare services with anycast, the given IP address will route to the nearest Cloudflare data center, reducing latency. Since Cloudflare runs almost every service in every data center, Unimog can simply route traffic to any Cloudflare metal that is online and has capacity, without needing to map traffic to a specific service that runs on specific metals, only in some locations.
The new compute-heavy, GPU-backed workloads we were taking on forced us to confront this fundamental “everything runs everywhere” assumption. If we run a containerized workflow in 20 Cloudflare locations, how does Unimog know which locations, and which metals, it runs in? You might say “just bring your own load balancer” — but then what happens when you make scheduling decisions to migrate a workload between locations, scale up, or scale down?
Anycast is foundational to how we build fast and simple products on our network, and we needed a way to keep building new types of products this way — where a team can deploy an application, get back a single IP address, and rely on the platform to balance traffic, taking load, container health, and latency into account, without extra configuration. We started letting teams use the container platform without solving this, and it was painfully clear that we needed to do something about it.
So we started integrating directly into our networking stack, building a sidecar service to Unimog. We’ll call this the Global State Router. Here’s how it works:
An eyeball makes a request to a virtual IP address issued by Cloudflare
Request sent to the best location as determined by BGP routing. This is anycast routing.
A small eBPF program sits on the main networking interface and ensures packets bound to a virtual IP address are handled by the Global State Router.
The main Global State Router program contains a mapping of all anycast IPs addresses to potential end destination container IP addresses. It updates this mapping based on container health, readiness, distance, and latency. Using this information, it picks a best-fit container.
Packets are forwarded at the L4 layer.
When a target container’s server receives a packet, its own Global State Router program intercepts the packet and routes it to the local container.
This might sound like just a lower level networking detail, disconnected from developer experience. But by integrating directly with Unimog, we can let developers:
Push a containerized application to Cloudflare.
Provide constraints, health checks, and load metrics that describe what the application needs.
Delegate scheduling and scaling many containers across Cloudflare’s network.
Get back a single IP address that can be used everywhere.
We’re actively working on this, and are excited to continue building on Cloudflare’s anycast capabilities, and pushing to keep the simplicity of running “everywhere” with new categories of workloads.
Our container platform actually started because of a very specific challenge, running Remote Browser Isolation across our network. Remote Browser Isolation provides Chromium browsers that run on Cloudflare, in containers, rather than on the end user’s own computer. Only the rendered output is sent to the end user. This provides a layer of protection against zero-day browser vulnerabilities, phishing attacks, and ransomware.
Location is critical — people expect their interactions with a remote browser to feel just as fast as if it ran locally. If the server is thousands of miles away, the remote browser will feel slow. Running across Cloudflare’s network of over 330 locations means the browser is nearly always as close to you as possible.
Imagine a user in Santiago, Chile, if they were to access a browser running in the same city, each interaction would incur negligible additional latency. Whereas a browser in Buenos Aires might add 21 ms, São Paulo might add 48 ms, Bogota might add 67 ms, and Raleigh, NC might add 128 ms. Where the container runs significantly impacts the latency of every user interaction with the browser, and therefore the experience as a whole.
It’s not just browser isolation that benefits from running near the user: WebRTC servers stream video better, multiplayer games have less lag, online advertisements can be served faster, financial transactions can be processed faster. Our container platform lets us run anything we need to near the user, no matter where they are in the world.
Using spare compute — “off-peak” jobs for Workers CI/CD builds
At any hour of the day, Cloudflare has many CPU cores that sit idle. This is compute power that could be used for something else.
Via anycast, most of Cloudflare’s traffic is handled as close as possible to the eyeball (person) that requested it. Most of our traffic originates from eyeballs. And the eyeballs of (most) people are closed and asleep between midnight and 5:00 AM local time. While we use our compute capacity very efficiently during the daytime in any part of the world, overnight we have spare cycles. Consider what a map of the world looks like at night-time in Europe and Africa:
As shown above, we can run containers during “off-peak” in Cloudflare locations receiving low traffic at night. During this time, the CPU utilization of a typical Cloudflare metal looks something like this:
We have many “background” compute workloads at Cloudflare. These are workloads that don’t actually need to run close to the eyeball because there is no eyeball waiting on the request. The challenge is that many of these workloads require running untrusted code — either a dependency on open-source code that we don’t trust enough to run outside of a sandboxed environment, or untrusted code that customers deploy themselves. And unlike Cron Triggers, which already make a best-effort attempt to use off-peak compute, these other workloads can’t run in v8 isolates.
On Builder Day 2024, we announced Workers Builds in open beta. You connect your Worker to a git repository, and Cloudflare builds and deploys your Worker each time you merge a pull request. Workers Builds run on our containers platform, using otherwise idle “off-peak” compute, allowing us to offer lower pricing, and hold more capacity for unexpected spikes in traffic in Cloudflare locations during daytime hours when load is highest. We preserve our ability to serve requests as close to the eyeball as possible where it matters, while using the full compute capacity of our network.
We developed a purpose-built API for these types of jobs. The Workers Builds service has zero knowledge of where Cloudflare has spare compute capacity on its network — it simply schedules an “off-peak” job to run on the containers platform, by defining a scheduling policy:
scheduling_policy: "off-peak"
Making off-peak jobs faster with prewarmed images
Just because a workload isn’t “eyeball-facing” doesn’t mean speed isn’t relevant. When a build job starts, you still want it to start as soon as possible.
Each new build requires a fresh container though, and we must avoid reusing containers to provide strong isolation between customers. How can we keep build job start times low, while using a new container for each job without over-provisioning?
We prewarm servers with the proper image.
Before a server becomes eligible to receive an “off peak” job, the container platform instructs it to download the correct image. Once the image is downloaded and cached locally, new containers can start quickly in a Firecracker VM after receiving a request for a new build. When a build completes, we throw away the container, and start the next build using a fresh container based on the prewarmed image.
Without prewarming, pulling and unpacking our Workers Build images would take roughly 75 seconds. With prewarming, we’re able to spin up a new container in under 10 seconds. We expect this to get even faster as we introduce optimizations like pre-booting images before new runs, or Firecracker snapshotting, which can restore a VM in under 200ms.
Workers and containers, better together
As more of our own engineering teams rely on our containers platform in production, we’ve noticed a pattern: they want a deeper integration with Workers.
We plan to give it to them.
Let’s take a look at a project deployed on our container platform already, Key Transparency. If the container platform were highly integrated with Workers, what would this team’s experience look like?
Cloudflare regularly audits changes to public keys used by WhatsApp for encrypting messages between users. Much of the architecture is built on Workers, but there are long-running compute-intensive tasks that are better suited for containers.
We don’t want our teams to have to jump through hoops to deploy a container and integrate with Workers. They shouldn’t have to pick specific regions to run in, figure out scaling, expose IPs and handle IP updates, or set up Worker-to-container auth.
We’re still exploring many different ideas and API designs, and we want your feedback. But let’s imagine what it might look like to use Workers, Durable Objects and Containers together.
In this case, an outer layer of Workers handles most business logic and ingress, a specialized Durable Object is configured to run alongside our new container, and the platform ensures the image is loaded on the right metals and can scale to meet demand.
I didn’t have to worry about placement, scaling, service discovery authorization, and I was able to leverage integrations into other services like KV and R2 with just a few lines of code. The container platform took care of routing, placement, and auth. If I needed more instances, I could call the binding with a new ID, and the platform would scale up containers for me.
We are still in the early stages of building these integrations, but we’re excited about everything that containers will bring to Workers and vice versa.
So, what do you want to build?
If you’ve read this far, there’s a non-zero chance you were hoping to get to run a container yourself on our network. While we’re not ready (quite yet) to open up the platform to everyone, now that we’ve built a few GA products on our container platform, we’re looking for a handful of engineering teams to start building, in advance of wider availability in 2025. And we’re continuing to hire engineers to work on this.
We’ve told you about our use cases for containers, and now it’s your turn. If you’re interested, tell us here what you want to build, and why it goes beyond what’s possible today in Workers and on our Developer Platform. What do you wish you could build on Cloudflare, but can’t yet today?
To celebrate Builder Day 2024, we’re shipping 18 updates inspired by direct feedback from developers building on Cloudflare. Choosing a platform isn’t just about current technologies and services — it’s about betting on a partner that will evolve with your needs as your project grows and the tech landscape shifts. We’re in it for the long haul with you.
Everything in this post is available for you to use today. Keep reading to learn more, and watch the Builder Day Live Stream for demos and more.
Persistent Logs for every Worker
Starting today in open beta, you can automatically retain logs from your Worker, with full search, query, and filtering capabilities available directly within the Cloudflare dashboard. All newly created Workers will have this setting automatically enabled. This marks the first step in the development of our observability platform, following Cloudflare’s acquisition of Baselime.
Getting started is easy – just add two lines to your Worker’s wrangler.toml and redeploy:
[observability]
enabled = true
Workers Logs allow you to view all logs emitted from your Worker. When enabled, each console.log message, error, and exception is published as a separate event. Every Worker invocation (i.e. requests, alarms, rpc, etc.) also publishes an enriched execution log that contains invocation metadata. You can view logs in the Logs tab of your Worker in the dashboard, where you can filter on any event field, such as time, error code, message, or your own custom field.
If you’ve ever had to piece together the puzzle of unusual metrics, such as a spike in errors or latency, you know how frustrating it is to connect metrics to traces and logs that often live in independent data silos. Workers Logs is the first piece of a new observability platform we are building that helps you easily correlate telemetry data, and surfaces insights to help you understand. We’ll structure your telemetry data so you have the full context to ask the right questions, and can quickly and easily analyze the behavior of your applications. This is just the beginning for observability tools for Workers. We are already working on automatically emitting distributed traces from Workers, with real time errors and wide, high dimensionality events coming soon as well.
Starting November 1, 2024, Workers Logs will cost $0.60 per million log lines written after the included volume, as shown in the table below. Querying your logs is free. This makes it easy to estimate and forecast your costs — we think you shouldn’t have to calculate the number of ‘Gigabytes Ingested’ to understand what you’ll pay.
Workers Free
Workers Paid
Included Volume
200,000 logs per day
20,000,000 logs per month
Additional Events
N/A
$0.60 per million logs
Retention
3 days
7 days
Try out Workers Logs today. You can learn more from our developer documentation, and give us feedback directly in the #workers-observability channel on Discord.
Connect to private databases from Workers
Starting today, you can now use Hyperdrive, Cloudflare Tunnels and Access together to securely connect to databases that are isolated in a private network.
Hyperdrive enables you to build on Workers with your existing regional databases. It accelerates database queries using Cloudflare’s network, caching data close to end users and pooling connections close to the database. But there’s been a major blocker preventing you from building with Hyperdrive: network isolation.
The majority of databases today aren’t publicly accessible on the Internet. Data is highly sensitive and placing databases within private networks like a virtual private cloud (VPC) keeps data secure. But to date, that has also meant that your data is held captive within your cloud provider, preventing you from building on Workers.
With this update, Hyperdrive makes it possible for you to build full-stack applications on Workers with your existing databases, network-isolated or not. Whether you’re using Amazon RDS, Amazon Aurora, Google Cloud SQL, Azure Database, or any other provider, Hyperdrive can connect to your databases and optimize your database connections to provide the fast performance you’ve come to expect with building on Workers.
Read the developer documentation to learn more about how to opt-in your Workers to try it today. If you encounter any bugs or want to report feedback, open an issue.
Build frontend applications on Workers with Static Asset Hosting
Starting today in open beta, you now can upload and serve HTML, CSS, and client-side JavaScript directly as part of your Worker. This means you can build dynamic, server-side rendered applications on Workers using popular frameworks such as Astro, Remix, Next.js and Svelte (full list here), with more coming soon.
If you’re wondering “What about Pages?” — rest assured, Pages will remain fully supported. We’ve heard from developers that as we’ve added new features to Workers and Pages, the choice of which product to use has become challenging. We’re closing this gap by bringing asset hosting, CI/CD and Preview URLs to Workers this Birthday Week.
To make the upfront choice Cloudflare Workers and Pages more transparent, we’ve created a compatibility matrix. Looking ahead, we plan to bridge the remaining gaps between Workers and Pages and provide ways to migrate your Pages projects to Workers.
Cloudflare joins OpenNext to deploy Next.js apps to Workers
Cloud providers shouldn’t lock you in. Like cloud compute and storage, open source frameworks should be portable — you should be able to deploy them to different cloud providers. The goal of the OpenNext project is to make sure you can deploy Next.js apps to any cloud platform, originally to AWS, and now Cloudflare. We’re excited to contribute to the OpenNext community, and give developers the freedom to run on the cloud that fits their applications needs (and budget) best.
Continuous Integration & Delivery (CI/CD) with Workers Builds
Now in open beta, you can connect a GitHub or GitLab repository to a Worker, and Cloudflare will automatically build and deploy your changes each time you push a commit. Workers Builds provides an integrated CI/CD workflow you can use to build and deploy everything from full-stack applications built with the most popular frameworks to simple static websites. Just add your build command and let Workers Builds take care of the rest.
While in open beta, Workers Builds is free to use, with a limit of one concurrent build per account, and unlimited build minutes per month. Once Workers Builds is Generally Available in early 2025, you will be billed based on the number of build minutes you use each month, and have a higher number of concurrent builds.
Workers Free
Workers Paid
Build minutes, open beta
Unlimited
Unlimited
Concurrent builds, open beta
1
1
Build minutes, general availability
3,000 minutes included per month
6,000 minutes included per month +$0.005 per additional build minute
Concurrent builds, general availability
1
6
Read the docs to learn more about how to deploy your first project with Workers Builds.
Workers preview URLs
Each newly uploaded version of a Worker now automatically generates a preview URL. Preview URLs make it easier for you to collaborate with your team during development, and can be used to test and identify issues in a preview environment before they are deployed to production.
When you upload a version of your Worker via the Wrangler CLI, Wrangler will display the preview URL once your upload succeeds. You can also find preview URLs for each version of your Worker in the Cloudflare dashboard:
Preview URLs for Workers are similar to Pages preview deployments — they run on your Worker’s workers.dev subdomain and allow you to view changes applied on a new version of your application before the changes are deployed.
Safely release to production with Gradual Deployments
At Developer Week, we launched Gradual Deployments for Workers and Durable Objects to make it safer and easier to deploy changes to your applications. Gradual Deployments is now GA — we have been using it ourselves at Cloudflare for mission-critical services built on Workers since early 2024.
Gradual deployments can help you stay on top of availability SLAs and minimize application downtime by surfacing issues early. Internally at Cloudflare, every single service built on Workers uses gradual deployments to roll out new changes. Each new version gets released in stages —– 0.05%, 0.5%, 3%, 10%, 25%, 50%, 75% and 100% with time to soak between each stage. Throughout the roll-out, we keep an eye on metrics (which are often instrumented with Workers Analytics Engine!) and we roll back if we encounter issues.
Using gradual deployments is as simple as swapping out the wrangler commands, API endpoints, and/or using “Save version” in the code editor that is built into the Workers dashboard. Read the developer documentation to learn more and get started.
Queues is GA, with higher throughput and concurrency limits
Queues let a developer decouple their Workers into event driven services. Producer Workers write events to a Queue, and consumer Workers are invoked to take actions on the events. For example, you can use a Queue to decouple an e-commerce website from a service which sends purchase confirmation emails to users.
Throughput and concurrency limits for Queues are now significantly higher, which means you can push more messages through a Queue, and consume them faster.
Throughput: Each queue can now process 5000 messages per second (previously 400 per second).
Concurrency: Each queue can now have up to 250 concurrent consumers (previously 20 concurrent consumers).
HTTP Pull consumers allow messages to be consumed outside Workers, with zero data egress costs.
Queues can be used by any developer on a Workers Paid plan. Head over to our getting startedguide to start building with Queues.
Event notifications for R2 is now GA
We’re excited to announce that event notifications for R2 is now generally available. Whether it’s kicking off image processing after a user uploads a file or triggering a sync to an external data warehouse when new analytics data is generated, many applications need to be able to reliably respond when events happen. Event notifications for Cloudflare R2 give you the ability to build event-driven applications and workflows that react to changes in your data.
Here’s how it works: When data in your R2 bucket changes, event notifications are sent to your queue. You can consume these notifications with a consumer Worker or pull them over HTTP from outside of Cloudflare Workers.
Since we introduced event notifications in open beta earlier this year, we’ve made significant improvements based on your feedback:
We increased reliability of event notifications with throughput improvements from Queues. R2 event notifications can now scale to thousands of writes per second.
You can now configure event notifications directly from the Cloudflare dashboard (in addition to Wrangler).
You can now set up multiple notification rules for a single queue on a bucket.
Visit our documentation to learn about how to set up event notifications for your R2 buckets.
Removing the serverless microservices tax: No more request fees for Service Bindings and Tail Workers
Earlier this year, we quietly changed Workers pricing to lower your costs. As of July 2024, you are no longer charged for requests between Workers on your account made via Service Bindings, or for invocations of Tail Workers. For example, let’s say you have the following chain of Workers:
Each request from a client results in three Workers invocations. Previously, we charged you for each of these invocations, plus the CPU time for each of these Workers. With this change, we only charge you for the first request from the client, plus the CPU time used by each Worker.
This eliminates the additional cost of breaking a monolithic serverless app into microservices. In 2023, we introduced new pricing based on CPU time, rather than duration, so you don’t have to worry about being billed for time spent waiting on I/O. This includes I/O to other Workers. With this change, you’re only billed for the first request in the chain, eliminating the other additional cost of using multiple Workers.
Image optimization is available to everyone for free — no subscription needed
Starting today, you can use Cloudflare Images for free to optimize your images with up to 5,000 transformations per month.
Large, oversized images can throttle your application speed and page load times. We built Cloudflare Images to let you dynamically optimize images in the correct dimensions and formats for each use case, all while storing only the original image.
In the spirit of Birthday Week, we’re making image optimization available to everyone with a Cloudflare account, no subscription needed. You’ll be able to use Images to transform images that are stored outside of Images, such as in R2.
Transformations are served from your zone through a specially formatted URL with parameters that specify how an image should be optimized. For example, the transformation URL below uses the format parameter to automatically serve the image in the most optimal format for the requesting browser:
This means that the original PNG image may be served as AVIF to one user and WebP to another. Without a subscription, transforming images from remote sources is free up to 5,000 unique transformations per month. Once you exceed this limit, any already cached transformations will continue to be served, but you’ll need a paid Images plan to request new transformations or to purchase storage within Images.
Dive deep into more announcements from Builder Day
We shipped so much that we couldn’t possibly fit it all in one blog post. These posts dive into the technical details of what we’re announcing at Builder Day:
Cloudflare is for builders, and everything we’re announcing at Builder Day, you can start building with right away. We’re now offering $250,000 in credits to use on our Developer Platform to qualified startups, so that you can get going even faster, and become the next company to reach hypergrowth scale with a small team, and not waste time provisioning infrastructure and doing undifferentiated heavy lifting. Focus on shipping, and we’ll take care of the rest.
Speed is a critical factor that dictates Internet behavior. Every additional millisecond a user spends waiting for your web page to load results in them abandoning your website. The old adage remains as true as ever: faster websites result in higher conversion rates. And with such outcomes tied to Internet speed, we believe a faster Internet is a better Internet.
Customers often use Workers KV to provide Workers with key-value data for configuration, routing, personalization, experimentation, or serving assets. Many of Cloudflare’s own products rely on KV for just this purpose: Pages stores static assets, Access stores authentication credentials, AI Gateway stores routing configuration, and Images stores configuration and assets, among others. So KV’s speed affects the latency of every request to an application, throughout the entire lifecycle of a user session.
Today, we’re announcing up to 3x faster KV hot reads, with all KV operations faster by up to 20ms. And we want to pull back the curtain and show you how we did it.
Workers KV read latency (ms) by percentile measured from Pages
Optimizing Workers KV’s architecture to minimize latency
At a high level, Workers KV is itself a Worker that makes requests to central storage backends, with many layers in between to properly cache and route requests across Cloudflare’s network. You can rely on Workers KV to support operations made by your Workers at any scale, and KV’s architecture will seamlessly handle your required throughput.
Sequence diagram of a Workers KV operation
When your Worker makes a read operation to Workers KV, your Worker establishes a network connection within its Cloudflare region to KV’s Worker. The KV Worker then accesses the Cache API, and in the event of a cache miss, retrieves the value from the storage backends.
Let’s look one level deeper at a simplified trace:
Simplified trace of a Workers KV operation
From the top, here are the operations completed for a KV read operation from your Worker:
Your Worker makes a connection to Cloudflare’s network in the same data center. This incurs ~5 ms of network latency.
Upon entering Cloudflare’s network, a service called Front Line (FL) is used to process the request. This incurs ~10 ms of operational latency.
FL proxies the request to the KV Worker. The KV Worker does a cache lookup for the key being accessed. This, once again, passes through the Front Line layer, incurring an additional ~10 ms of operational latency.
Cache is stored in various backends within each region of Cloudflare’s network. A service built upon Pingora, our open-sourced Rust framework for proxying HTTP requests, routes the cache lookup to the proper cache backend.
Finally, if the cache lookup is successful, the KV read operation is resolved. Otherwise, the request reaches our storage backends, where it gets its value.
Looking at these flame graphs, it became apparent that a major opportunity presented itself to us: reducing the FL overhead (or eliminating it altogether) and reducing the cache misses across the Cloudflare network would reduce the latency for KV operations.
Bypassing FL layers between Workers and services to save ~20ms
A request from your Worker to KV doesn’t need to go through FL. Much of FL’s responsibility is to process and route requests from outside of Cloudflare — that’s more than is needed to handle a request from the KV binding to the KV Worker. So we skipped the Front Line altogether in both layers.
Reducing latency in a Workers KV operation by removing FL layers
To bypass the FL layer from the KV binding in your Worker, we modified the KV binding to connect directly to the KV Worker within the same Cloudflare location. Within the Workers host, we configured a C++ subpipeline to allow code from bindings to establish a direct connection with the proper routing configuration and authorization loaded.
The KV Worker also passes through the FL layer on its way to our internal Pingora service. In this case, we were able to use an internal Worker binding that allows Workers for Cloudflare services to bind directly to non-Worker services within Cloudflare’s network. With this fix, the KV Worker sets the proper cache control headers and establishes its connection to Pingora without leaving the network.
Together, both of these changes reduced latency by ~20 ms for every KV operation.
Implementing tiered cache to minimize requests to storage backends
We also optimized KV’s architecture to reduce the amount of requests that need to reach our centralized storage backends. These storage backends are further away and incur network latency, so improving the cache hit rate in regions close to your Workers significantly improves read latency.
Workers KV uses Tiered Cache to resolve operations closer to your users
To accomplish this, we used Tiered Cache, and implemented a cache topology that is fine-tuned to the usage patterns of KV. With a tiered cache, requests to KV’s storage backends are cached in regional tiers in addition to local (lower) tiers. With this architecture, KV operations that may be cache misses locally may be resolved regionally, which is especially significant if you have traffic across an entire region spanning multiple Cloudflare data centers.
This significantly reduced the amount of requests that needed to hit the storage backends, with ~30% of requests resolved in tiered cache instead of storage backends.
KV’s new architecture
As a result of these optimizations, KV operations are now simplified:
When you read from KV in your Worker, the KV binding binds directly to KV’s Worker, saving 10 ms.
The KV Worker binds directly to the Tiered Cache service, saving another 10 ms.
Tiered Cache is used in front of storage backends, to resolve local cache misses regionally, closer to your users.
Sequence diagram of KV operations with new architecture
In aggregate, these changes significantly reduced KV’s latency.
The impact of the direct binding to cache is clearly seen in the wall time of the KV Worker, given this value measures the duration of a retrieval of a key-value pair from cache. The 90th percentile of all KV Worker invocations now resolve in less than 12 ms — before the direct binding to cache, that was 22 ms. That’s a 10 ms decrease in latency.
Wall time (ms) within the KV Worker by percentile
These KV read operations resolve quickly because the data is cached locally in the same Cloudflare location. But what about reads that aren’t resolved locally? ~30% of these resolve regionally within the tiered cache. Reads from tiered cache are up to 100 ms faster than when resolved at central storage backends, once again contributing to making KV reads faster in aggregate.
Wall time (ms) within the KV Worker for tiered cache vs. storage backends reads
These graphs demonstrate the impact of direct binding from the KV binding to cache, and tiered cache. To see the impact of the direct binding from a Worker to the KV Worker, we need to look at the latencies reported by Cloudflare products that use KV.
Cloudflare Pages, which serves static assets like HTML, CSS, and scripts from KV, saw load times for fetching assets improve by up to 68%. Workers asset hosting, which we also announced as part of today’s Builder Day announcements, gets this improved performance from day 1.
Workers KV read operation latency measured within Cloudflare Pages by percentile
Queues and Access also saw their latencies for KV operations drop, with their KV read operations now 2-5x faster. These services rely on Workers KV data for configuration and routing data, so KV’s performance improvement directly contributes to making them faster on each request.
Workers KV read operation latency measured within Cloudflare Queues by percentile
Workers KV read operation latency measured within Cloudflare Access by percentile
These are just some of the direct effects that a faster KV has had on other services. Across the board, requests are resolving faster thanks to KV’s faster response times.
And we have one more thing to make KV lightning fast.
Optimizing KV’s hottest keys with an in-memory cache
Less than 0.03% of keys account for nearly half of requests to the Workers KV service across all namespaces. These keys are read thousands of times per second, so making these faster has a disproportionate impact. Could these keys be resolved within the KV Worker without needing additional network hops?
Almost all of these keys are under 100 KB. At this size, it becomes possible to use the in-memory cache of the KV Worker — a limited amount of memory within the main runtime process of a Worker sandbox. And that’s exactly what we did. For the highest throughput keys across Workers KV, reads resolve without even needing to leave the Worker runtime process.
Sequence diagram of KV operations with the hottest keys resolved within an in-memory cache
As a result of these changes, KV reads for these keys, which represent over 40% of Workers KV requests globally, resolve in under a millisecond. We’re actively testing these changes internally and expect to roll this out during October to speed up the hottest key-value pairs on Workers KV.
A faster KV for all
Most of these speed gains are already enabled with no additional action needed from customers. Your websites that are using KV are already responding to requests faster for your users, as are the other Cloudflare services using KV under the hood and the countless websites that depend upon them.
And we’re not done: we’ll continue to chase performance throughout our stack to make your websites faster. That’s how we’re going to move the needle towards a faster Internet.
To see Workers KV’s recent speed gains for your own KV namespaces, head over to your dashboard and check out the new KV analytics, with latency and cache status detailed per namespace.
Traditional cloud storage is inherently slow, because it is normally accessed over a network and must carefully synchronize across many clients that could be accessing the same data. But what if we could instead put your application code deep into the storage layer, such that your code runs directly on the machine where the data is stored, and the database itself executes as a local library embedded inside your application?
Durable Objects (DO) are a novel approach to cloud computing which accomplishes just that: Your application code runs exactly where the data is stored. Not just on the same machine: your storage lives in the same thread as the application, requiring not even a context switch to access. With proper use of caching, storage latency is essentially zero, while nevertheless being durable and consistent.
Until today, DOs only offered key/value oriented storage. But now, they support a full SQL query interface with tables and indexes, through the power of SQLite.
SQLite is the most-used SQL database implementation in the world, with billions of installations. It’s on practically every phone and desktop computer, and many embedded devices use it as well. It’s known to be blazingly fast and rock solid. But it’s been less common on the server. This is because traditional cloud architecture favors large distributed databases that live separately from application servers, while SQLite is designed to run as an embedded library. In this post, we’ll show you how Durable Objects turn this architecture on its head and unlock the full power of SQLite in the cloud.
Refresher: what are Durable Objects?
Durable Objects (DOs) are a part of the Cloudflare Workers serverless platform. A DO is essentially a small server that can be addressed by a unique name and can keep state both in-memory and on-disk. Workers running anywhere on Cloudflare’s network can send messages to a DO by its name, and all messages addressed to the same name — from anywhere in the world — will find their way to the same DO instance.
DOs are intended to be small and numerous. A single application can create billions of DOs distributed across our global network. Cloudflare automatically decides where a DO should live based on where it is accessed, automatically starts it up as needed when requests arrive, and shuts it down when idle. A DO has in-memory state while running and can also optionally store long-lived durable state. Since there is exactly one DO for each name, a DO can be used to coordinate between operations on the same logical object.
For example, imagine a real-time collaborative document editor application. Many users may be editing the same document at the same time. Each user’s changes must be broadcast to other users in real time, and conflicts must be resolved. An application built on DOs would typically create one DO for each document. The DO would receive edits from users, resolve conflicts, broadcast the changes back out to other users, and keep the document content updated in its local storage.
DOs are especially good at real-time collaboration, but are by no means limited to this use case. They are general-purpose servers that can implement any logic you desire to serve requests. Even more generally, DOs are a basic building block for distributed systems.
When using Durable Objects, it’s important to remember that they are intended to scale out, not up. A single object is inherently limited in throughput since it runs on a single thread of a single machine. To handle more traffic, you create more objects. This is easiest when different objects can handle different logical units of state (like different documents, different users, or different “shards” of a database), where each unit of state has low enough traffic to be handled by a single object. But sometimes, a lot of traffic needs to modify the same state: consider a vote counter with a million users all trying to cast votes at once. To handle such cases with Durable Objects, you would need to create a set of objects that each handle a subset of traffic and then replicate state to each other. Perhaps they use CRDTs in a gossip network, or perhaps they implement a fan-in/fan-out approach to a single primary object. Whatever approach you take, Durable Objects make it fast and easy to create more stateful nodes as needed.
Why is SQLite-in-DO so fast?
In traditional cloud architecture, stateless application servers run business logic and communicate over the network to a database. Even if the network is local, database requests still incur latency, typically measured in milliseconds.
When a Durable Object uses SQLite, SQLite is invoked as a library. This means the database code runs not just on the same machine as the DO, not just in the same process, but in the very same thread. Latency is effectively zero, because there is no communication barrier between the application and SQLite. A query can complete in microseconds.
Reads and writes are synchronous
The SQL query API in DOs does not require you to await results — they are returned synchronously:
// No awaits!
let cursor = sql.exec("SELECT name, email FROM users");
for (let user of cursor) {
console.log(user.name, user.email);
}
This may come as a surprise to some. Querying a database is I/O, right? I/O should always be asynchronous, right? Isn’t this a violation of the natural order of JavaScript?
It’s OK! The database content is probably cached in memory already, and SQLite is being called as a library in the same thread as the application, so the query often actually won’t spend any time at all waiting for I/O. Even if it does have to go to disk, it’s a local SSD. You might as well consider the local disk as just another layer in the memory cache hierarchy: L5 cache, if you will. In any case, it will respond quickly.
Meanwhile, synchronous queries provide some big benefits. First, the logistics of asynchronous event loops have a cost, so in the common case where the data is already in memory, a synchronous query will actually complete faster than an async one.
More importantly, though, synchronous queries help you avoid subtle bugs. Any time your application awaits a promise, it’s possible that some other code executes while you wait. The state of the world may have changed by the time your await completes. Maybe even other SQL queries were executed. This can lead to subtle bugs that are hard to reproduce because they require events to happen at just the wrong time. With a synchronous API, though, none of that can happen. Your code always executes in the order you wrote it, uninterrupted.
Fast writes with Output Gates
Database experts might have a deeper objection to synchronous queries: Yes, caching may mean we can perform reads and writes very fast. However, in the case of a write, just writing to cache isn’t good enough. Before we return success to our client, we must confirm that the write is actually durable, that is, it has actually made it onto disk or network storage such that it cannot be lost if the power suddenly goes out.
Normally, a database would confirm all writes before returning to the application. So if the query is successful, it is confirmed. But confirming writes can be slow, because it requires waiting for the underlying storage medium to respond. Normally, this is OK because the write is performed asynchronously, so the program can go on and work on other things while it waits for the write to finish. It looks kind of like this:
But I just told you that in Durable Objects, writes are synchronous. While a synchronous call is running, no other code in the program can run (because JavaScript does not have threads). This is convenient, as mentioned above, because it means you don’t need to worry that the state of the world may have changed while you were waiting. However, if write queries have to wait a while, and the whole program must pause and wait for them, then throughput will suffer.
Luckily, in Durable Objects, writes do not have to wait, due to a little trick we call “Output Gates”.
In DOs, when the application issues a write, it continues executing without waiting for confirmation. However, when the DO then responds to the client, the response is blocked by the “Output Gate”. This system holds the response until all storage writes relevant to the response have been confirmed, then sends the response on its way. In the rare case that the write fails, the response will be replaced with an error and the Durable Object itself will restart. So, even though the application constructed a “success” response, nobody can ever see that this happened, and thus nobody can be misled into believing that the data was stored.
Let’s see what this looks like with multiple requests:
If you compare this against the first diagram above, you should notice a few things:
The timing of requests and confirmations are the same.
But, all responses were sent to the client sooner than in the first diagram. Latency was reduced! This is because the application is able to work on constructing the response in parallel with the storage layer confirming the write.
Request handling is no longer interleaved between the three requests. Instead, each request runs to completion before the next begins. The application does not need to worry, during the handling of one request, that its state might change unexpectedly due to a concurrent request.
With Output Gates, we get the ease-of-use of synchronous writes, while also getting lower latency and no loss of throughput.
N+1 selects? No problem.
Zero-latency queries aren’t just faster, they allow you to structure your code differently, often making it simpler. A classic example is the “N+1 selects” or “N+1 queries” problem. Let’s illustrate this problem with an example:
// N+1 SELECTs example
// Get the 100 most-recently-modified docs.
let docs = sql.exec(`
SELECT title, authorId FROM documents
ORDER BY lastModified DESC
LIMIT 100
`).toArray();
// For each returned document, get the author name from the users table.
for (let doc of docs) {
doc.authorName = sql.exec(
"SELECT name FROM users WHERE id = ?", doc.authorId).one().name;
}
If you are an experienced SQL user, you are probably cringing at this code, and for good reason: this code does 101 queries! If the application is talking to the database across a network with 5ms latency, this will take 505ms to run, which is slow enough for humans to notice.
// Do it all in one query with a join?
let docs = sql.exec(`
SELECT documents.title, users.name
FROM documents JOIN users ON documents.authorId = users.id
ORDER BY documents.lastModified DESC
LIMIT 100
`).toArray();
Here we’ve used SQL features to turn our 101 queries into one query. Great! Except, what does it mean? We used an inner join, which is not to be confused with a left, right, or cross join. What’s the difference? Honestly, I have no idea! I had to look up joins just to write this example and I’m already confused.
Well, good news: You don’t need to figure it out. Because when using SQLite as a library, the first example above works just fine. It’ll perform about the same as the second fancy version.
More generally, when using SQLite as a library, you don’t have to learn how to do fancy things in SQL syntax. Your logic can be in regular old application code in your programming language of choice, orchestrating the most basic SQL queries that are easy to learn. It’s fine. The creators of SQLite have made this point themselves.
Point-in-Time Recovery
While not necessarily related to speed, SQLite-backed Durable Objects offer another feature: any object can be reverted to the state it had at any point in time in the last 30 days. So if you accidentally execute a buggy query that corrupts all your data, don’t worry: you can recover. There’s no need to opt into this feature in advance; it’s on by default for all SQLite-backed DOs. See the docs for details.
How do I use it?
Let’s say we’re an airline, and we are implementing a way for users to choose their seats on a flight. We will create a new Durable Object for each flight. Within that DO, we will use a SQL table to track the assignments of seats to passengers. The code might look something like this:
import {DurableObject} from "cloudflare:workers";
// Manages seat assignment for a flight.
//
// This is an RPC interface. The methods can be called remotely by other Workers
// running anywhere in the world. All Workers that specify same object ID
// (probably based on the flight number and date) will reach the same instance of
// FlightSeating.
export class FlightSeating extends DurableObject {
sql = this.ctx.storage.sql;
// Application calls this when the flight is first created to set up the seat map.
initializeFlight(seatList) {
this.sql.exec(`
CREATE TABLE seats (
seatId TEXT PRIMARY KEY, -- e.g. "3B"
occupant TEXT -- null if available
)
`);
for (let seat of seatList) {
this.sql.exec(`INSERT INTO seats VALUES (?, null)`, seat);
}
}
// Get a list of available seats.
getAvailable() {
let results = [];
// Query returns a cursor.
let cursor = this.sql.exec(`SELECT seatId FROM seats WHERE occupant IS NULL`);
// Cursors are iterable.
for (let row of cursor) {
// Each row is an object with a property for each column.
results.push(row.seatId);
}
return results;
}
// Assign passenger to a seat.
assignSeat(seatId, occupant) {
// Check that seat isn't occupied.
let cursor = this.sql.exec(`SELECT occupant FROM seats WHERE seatId = ?`, seatId);
let result = [...cursor][0]; // Get the first result from the cursor.
if (!result) {
throw new Error("No such seat: " + seatId);
}
if (result.occupant !== null) {
throw new Error("Seat is occupied: " + seatId);
}
// If the occupant is already in a different seat, remove them.
this.sql.exec(`UPDATE seats SET occupant = null WHERE occupant = ?`, occupant);
// Assign the seat. Note: We don't have to worry that a concurrent request may
// have grabbed the seat between the two queries, because the code is synchronous
// (no `await`s) and the database is private to this Durable Object. Nothing else
// could have changed since we checked that the seat was available earlier!
this.sql.exec(`UPDATE seats SET occupant = ? WHERE seatId = ?`, occupant, seatId);
}
}
(With just a little more code, we could extend this example to allow clients to subscribe to seat changes with WebSockets, so that if multiple people are choosing their seats at the same time, they can see in real time as seats become unavailable. But, that’s outside the scope of this blog post, which is just about SQL storage.)
Then in wrangler.toml, define a migration setting up your DO class like usual, but instead of using new_classes, use new_sqlite_classes:
[[migrations]]
tag = "v1"
new_sqlite_classes = ["FlightSeating"]
SQLite-backed objects also support the existing key/value-based storage API: KV data is stored into a hidden table in the SQLite database. So, existing applications built on DOs will work when deployed using SQLite-backed objects.
However, because SQLite-backed objects are based on an all-new storage backend, it is currently not possible to switch an existing deployed DO class to use SQLite. You must ask for SQLite when initially deploying the new DO class; you cannot change it later. We plan to begin migrating existing DOs to the new storage backend in 2025.
Pricing
We’ve kept pricing for SQLite-in-DO similar to D1, Cloudflare’s serverless SQL database, by billing for SQL queries (based on rows) and SQL storage. SQL storage per object is limited to 1 GB during the beta period, and will be increased to 10 GB on general availability. DO requests and duration billing are unchanged and apply to all DOs regardless of storage backend.
During the initial beta, billing is not enabled for SQL queries (rows read and rows written) and SQL storage. SQLite-backed objects will incur charges for requests and duration. We plan to enable SQL billing in the first half of 2025 with advance notice.
Workers Paid
Rows read
First 25 billion / month included + $0.001 / million rows
Rows written
First 50 million / month included + $1.00 / million rows
SQL storage
5 GB-month + $0.20/ GB-month
For more on how to use SQLite-in-Durable Objects, check out the documentation.
What about D1?
Cloudflare Workers already offers another SQLite-backed database product: D1. In fact, D1 is itself built on SQLite-in-DO. So, what’s the difference? Why use one or the other?
In short, you should think of D1 as a more “managed” database product, while SQLite-in-DO is more of a lower-level “compute with storage” building block.
D1 fits into a more traditional cloud architecture, where stateless application servers talk to a separate database over the network. Those application servers are typically Workers, but could also be clients running outside of Cloudflare. D1 also comes with a pre-built HTTP API and managed observability features like query insights. With D1, where your application code and SQL database queries are not colocated like in SQLite-in-DO, Workers has Smart Placement to dynamically run your Worker in the best location to reduce total request latency, considering everything your Worker talks to, including D1. By the end of 2024, D1 will support automatic read replication for scalability and low-latency access around the world. If this managed model appeals to you, use D1.
Durable Objects require a bit more effort, but in return, give you more power. With DO, you have two pieces of code that run in different places: a front-end Worker which routes incoming requests from the Internet to the correct DO, and the DO itself, which runs on the same machine as the SQLite database. You may need to think carefully about which code to run where, and you may need to build some of your own tooling that exists out-of-the-box with D1. But because you are in full control, you can tailor the solution to your application’s needs and potentially achieve more.
Under the hood: Storage Relay Service
When Durable Objects first launched in 2020, it offered only a simple key/value-based interface for durable storage. Under the hood, these keys and values were stored in a well-known off-the-shelf database, with regional instances of this database deployed to locations in our data centers around the world. Durable Objects in each region would store their data to the regional database.
For SQLite-backed Durable Objects, we have completely replaced the persistence layer with a new system built from scratch, called Storage Relay Service, or SRS. SRS has already been powering D1 for over a year, and can now be used more directly by applications through Durable Objects.
SRS is based on a simple idea:
Local disk is fast and randomly-accessible, but expensive and prone to disk failures. Object storage (like R2) is cheap and durable, but much slower than local disk and not designed for database-like access patterns. Can we get the best of both worlds by using a local disk as a cache on top of object storage?
So, how does it work?
The mismatch in functionality between local disk and object storage
A SQLite database on disk tends to undergo many small changes in rapid succession. Any row of the database might be updated by any particular query, but the database is designed to avoid rewriting parts that didn’t change. Read queries may randomly access any part of the database. Assuming the right indexes exist to support the query, they should not require reading parts of the database that aren’t relevant to the results, and should complete in microseconds.
Object storage, on the other hand, is designed for an entirely different usage model: you upload an entire “object” (blob of bytes) at a time, and download an entire blob at a time. Each blob has a different name. For maximum efficiency, blobs should be fairly large, from hundreds of kilobytes to gigabytes in size. Latency is relatively high, measured in tens or hundreds of milliseconds.
So how do we back up our SQLite database to object storage? An obviously naive strategy would be to simply make a copy of the database files from time to time and upload it as a new “object”. But, uploading the database on every change — and making the application wait for the upload to complete — would obviously be way too slow. We could choose to upload the database only occasionally — say, every 10 minutes — but this means in the case of a disk failure, we could lose up to 10 minutes of changes. Data loss is, uh, bad! And even then, for most databases, it’s likely that most of the data doesn’t change every 10 minutes, so we’d be uploading the same data over and over again.
Trick one: Upload a log of changes
Instead of uploading the entire database, SRS records a log of changes, and uploads those.
Conveniently, SQLite itself already has a concept of a change log: the Write-Ahead Log, or WAL. SRS always configures SQLite to use WAL mode. In this mode, any changes made to the database are first written to a separate log file. From time to time, the database is “checkpointed”, merging the changes back into the main database file. The WAL format is well-documented and easy to understand: it’s just a sequence of “frames”, where each frame is an instruction to write some bytes to a particular offset in the database file.
SRS monitors changes to the WAL file (by hooking SQLite’s VFS to intercept file writes) to discover the changes being made to the database, and uploads those to object storage.
Unfortunately, SRS cannot simply upload every single change as a separate “object”, as this would result in too many objects, each of which would be inefficiently small. Instead, SRS batches changes over a period of up to 10 seconds, or up to 16 MB worth, whichever happens first, then uploads the whole batch as a single object.
When reconstructing a database from object storage, we must download the series of change batches and replay them in order. Of course, if the database has undergone many changes over a long period of time, this can get expensive. In order to limit how far back it needs to look, SRS also occasionally uploads a snapshot of the entire content of the database. SRS will decide to upload a snapshot any time that the total size of logs since the last snapshot exceeds the size of the database itself. This heuristic implies that the total amount of data that SRS must download to reconstruct a database is limited to no more than twice the size of the database. Since we can delete data from object storage that is older than the latest snapshot, this also means that our total stored data is capped to 2x the database size.
Credit where credit is due: This idea — uploading WAL batches and snapshots to object storage — was inspired by Litestream, although our implementation is different.
Trick two: Relay through other servers in our global network
Batches are only uploaded to object storage every 10 seconds. But obviously, we cannot make the application wait for 10 whole seconds just to confirm a write. So what happens if the application writes some data, returns a success message to the user, and then the machine fails 9 seconds later, losing the data?
To solve this problem, we take advantage of our global network. Every time SQLite commits a transaction, SRS will immediately forward the change log to five “follower” machines across our network. Once at least three of these followers respond that they have received the change, SRS informs the application that the write is confirmed. (As discussed earlier, the write confirmation opens the Durable Object’s “output gate”, unblocking network communications to the rest of the world.)
When a follower receives a change, it temporarily stores it in a buffer on local disk, and then awaits further instructions. Later on, once SRS has successfully uploaded the change to object storage as part of a batch, it informs each follower that the change has been persisted. At that point, the follower can simply delete the change from its buffer.
However, if the follower never receives the persisted notification, then, after some timeout, the follower itself will upload the change to object storage. Thus, if the machine running the database suddenly fails, as long as at least one follower is still running, it will ensure that all confirmed writes are safely persisted.
Each of a database’s five followers is located in a different physical data center. Cloudflare’s network consists of hundreds of data centers around the world, which means it is always easy for us to find four other data centers nearby any Durable Object (in addition to the one it is running in). In order for a confirmed write to be lost, then, at least four different machines in at least three different physical buildings would have to fail simultaneously (three of the five followers, plus the Durable Object’s host machine). Of course, anything can happen, but this is exceedingly unlikely.
Followers also come in handy when a Durable Object’s host machine is unresponsive. We may not know for sure if the machine has died completely, or if it is still running and responding to some clients but not others. We cannot start up a new instance of the DO until we know for sure that the previous instance is dead – or, at least, that it can no longer confirm writes, since the old and new instances could then confirm contradictory writes. To deal with this situation, if we can’t reach the DO’s host, we can instead try to contact its followers. If we can contact at least three of the five followers, and tell them to stop confirming writes for the unreachable DO instance, then we know that instance is unable to confirm any more writes going forward. We can then safely start up a new instance to replace the unreachable one.
Bonus feature: Point-in-Time Recovery
I mentioned earlier that SQLite-backed Durable Objects can be asked to revert their state to any time in the last 30 days. How does this work?
This was actually an accidental feature that fell out of SRS’s design. Since SRS stores a complete log of changes made to the database, we can restore to any point in time by replaying the change log from the last snapshot. The only thing we have to do is make sure we don’t delete those logs too soon.
Normally, whenever a snapshot is uploaded, all previous logs and snapshots can then be deleted. But instead of deleting them immediately, SRS merely marks them for deletion 30 days later. In the meantime, if a point-in-time recovery is requested, the data is still there to work from.
For a database with a high volume of writes, this may mean we store a lot of data for a lot longer than needed. As it turns out, though, once data has been written at all, keeping it around for an extra month is pretty cheap — typically cheaper, even, than writing it in the first place. It’s a small price to pay for always-on disaster recovery.
Get started with SQLite-in-DO
SQLite-backed DOs are available in beta starting today. You can start building with SQLite-in-DO by visiting developer documentation and provide beta feedback via the #durable-objects channel on our Developer Discord.
Do distributed systems like SRS excite you? Would you like to be part of building them at Cloudflare? We’re hiring!
During Birthday Week 2023, we launched Workers AI. Since then, we have been listening to your feedback, and one thing we’ve heard consistently is that our customers want Workers AI to be faster. In particular, we hear that large language model (LLM) generation needs to be faster. Users want their interactive chat and agents to go faster, developers want faster help, and users do not want to wait for applications and generated website content to load. Today, we’re announcing three upgrades we’ve made to Workers AI to bring faster and more efficient inference to our customers: upgraded hardware, KV cache compression, and speculative decoding.
Thanks to Cloudflare’s 12th generation compute servers, our network now supports a newer generation of GPUs capable of supporting larger models and faster inference. Customers can now use Meta Llama 3.2 11B, Meta’s newly released multi-modal model with vision support, as well as Meta Llama 3.1 70B on Workers AI. Depending on load and time of day, customers can expect to see two to three times the throughput for Llama 3.1 and 3.2 compared to our previous generation Workers AI hardware. More performance information for these models can be found in today’s post: Cloudflare’s Bigger, Better, Faster AI platform.
New KV cache compression methods, now open source
In our effort to deliver low-cost low-latency inference to the world, Workers AI has been developing novel methods to boost efficiency of LLM inference. Today, we’re excited to announce a technique for KV cache compression that can help increase throughput of an inference platform. And we’ve made it open source too, so that everyone can benefit from our research.
It’s all about memory
One of the main bottlenecks when running LLM inference is the amount of vRAM (memory) available. Every word that an LLM processes generates a set of vectors that encode the meaning of that word in the context of any earlier words in the input that are used to generate new tokens in the future. These vectors are stored in the KV cache, causing the memory required for inference to scale linearly with the total number of tokens of all sequences being processed. This makes memory a bottleneck for a lot of transformer-based models. Because of this, the amount of memory an instance has available limits the number of sequences it can generate concurrently, as well as the maximum token length of sequences it can generate.
So what is the KV cache anyway?
LLMs are made up of layers, with an attention operation occurring in each layer. Within each layer’s attention operation, information is collected from the representations of all previous tokens that are stored in cache. This means that vectors in the KV cache are organized into layers, so that the active layer’s attention operation can only query vectors from the corresponding layer of KV cache. Furthermore, since attention within each layer is parallelized across multiple attention “heads”, the KV cache vectors of a specific layer are further subdivided into groups corresponding to each attention head of that layer.
The diagram below shows the structure of an LLM’s KV cache for a single sequence being generated. Each cell represents a KV and the model’s representation for a token consists of all KV vectors for that token across all attention heads and layers. As you can see, the KV cache for a single layer is allocated as an M x N matrix of KV vectors where M is the number of attention heads and N is the sequence length. This will be important later!
Now that we know what the KV cache looks like, let’s dive into how we can shrink it!
The most common approach to compressing the KV cache involves identifying vectors within it that are unlikely to be queried by future attention operations and can therefore be removed without impacting the model’s outputs. This is commonly done by looking at the past attention weights for each pair of key and value vectors (a measure of the degree with which that KV’s representation has been queried during past attention operations) and selecting the KVs that have received the lowest total attention for eviction. This approach is conceptually similar to a LFU (least frequently used) cache management policy: the less a particular vector is queried, the more likely it is to be evicted in the future.
Different attention heads need different compression rates
As we saw earlier, the KV cache for each sequence in a particular layer is allocated on the GPU as a # attention heads X sequence length tensor. This means that the total memory allocation scales with the maximum sequence length for all attention heads of the KV cache. Usually this is not a problem, since each sequence generates the same number of KVs per attention head.
When we consider the problem of eviction-based KV cache compression, however, this forces us to remove an equal number of KVs from each attention head when doing the compression. If we remove more KVs from one attention head alone, those removed KVs won’t actually contribute to lowering the memory footprint of the KV cache on GPU, but will just add more empty “padding” to the corresponding rows of the tensor. You can see this in the diagram below (note the empty cells in the second row below):
The extra compression along the second head frees slots for two KVs, but the cache’s shape (and memory footprint) remains the same.
This forces us to use a fixed compression rate for all attention heads of KV cache, which is very limiting on the compression rates we can achieve before compromising performance.
Enter PagedAttention
The solution to this problem is to change how our KV cache is represented in physical memory. PagedAttention can represent N x M tensors with padding efficiently by using an N x M block table to index into a series of “blocks”.
This lets us retrieve the ith element of a row by taking the ith block number from that row in the block table and using the block number to lookup the corresponding block, so we avoid allocating space to padding elements in our physical memory representation. In our case, the elements in physical memory are the KV cache vectors, and the M and N that define the shape of our block table are the number of attention heads and sequence length, respectively. Since the block table is only storing integer indices (rather than high-dimensional KV vectors), its memory footprint is negligible in most cases.
Results
Using paged attention lets us apply different rates of compression to different heads in our KV cache, giving our compression strategy more flexibility than other methods. We tested our compression algorithm on LongBench (a collection of long-context LLM benchmarks) with Llama-3.1-8B and found that for most tasks we can retain over 95% task performance while reducing cache size by up to 8x (left figure below). Over 90% task performance can be retained while further compressing up to 64x. That means you have room in memory for 64 times as many tokens!
This lets us increase the number of requests we can process in parallel, increasing the total throughput (total tokens generated per second) by 3.44x and 5.18x for compression rates of 8x and 64x, respectively (right figure above).
Try it yourself!
If you’re interested in taking a deeper dive check out our vLLM fork and get compressing!!
Speculative decoding for faster throughput
A new inference strategy that we implemented is speculative decoding, which is a very popular way to get faster throughput (measured in tokens per second). LLMs work by predicting the next expected token (a token can be a word, word fragment or single character) in the sequence with each call to the model, based on everything that the model has seen before. For the first token generated, this means just the initial prompt, but after that each subsequent token is generated based on the prompt plus all other tokens that have been generated. Typically, this happens one token at a time, generating a single word, or even a single letter, depending on what comes next.
But what about this prompt:
Knock, knock!
If you are familiar with knock-knock jokes, you could very accurately predict more than one token ahead. For an English language speaker, what comes next is a very specific sequence that is four to five tokens long: “Who’s there?” or “Who is there?” Human language is full of these types of phrases where the next word has only one, or a few, high probability choices. Idioms, common expressions, and even basic grammar are all examples of this. So for each prediction the model makes, we can take it a step further with speculative decoding to predict the next n tokens. This allows us to speed up inference, as we’re not limited to predicting one token at a time.
There are several different implementations of speculative decoding, but each in some way uses a smaller, faster-to-run model to generate more than one token at a time. For Workers AI, we have applied prompt-lookup decoding to some of the LLMs we offer. This simple method matches the last n tokens of generated text against text in the prompt/output and predicts candidate tokens that continue these identified patterns as candidates for continuing the output. In the case of knock-knock jokes, it can predict all the tokens for “Who’s there” at once after seeing “Knock, knock!”, as long as this setup occurs somewhere in the prompt or previous dialogue already. Once these candidate tokens have been predicted, the model can verify them all with a single forward-pass and choose to either accept or reject them. This increases the generation speed of llama-3.1-8b-instruct by up to 40% and the 70B model by up to 70%.
Speculative decoding has tradeoffs, however. Typically, the results of a model using speculative decoding have a lower quality, both when measured using benchmarks like MMLU as well as when compared by humans. More aggressive speculation can speed up sequence generation, but generally comes with a greater impact to the quality of the result. Prompt lookup decoding offers one of the smallest overall quality impacts while still providing performance improvements, and we will be adding it to some language models on Workers AI including @cf/meta/llama-3.1-8b-instruct.
And, by the way, here is one of our favorite knock-knock jokes, can you guess the punchline?
Knock, knock!
Who’s there?
Figs!
Figs who?
Figs the doorbell, it’s broken!
Keep accelerating
As the AI industry continues to evolve, there will be new hardware and software that allows customers to get faster inference responses. Workers AI is committed to researching, implementing, and making upgrades to our services to help you get fast inference. As an Inference-as-a-Service platform, you’ll be able to benefit from all the optimizations we apply, without having to hire your own team of ML researchers and SREs to manage inference software and hardware deployments.
We’re excited for you to try out some of these new releases we have and let us know what you think! Check out our full-suite of AI announcements here and check out the developer docs to get started.
In November 2022, we announced the transition to OpenAPI Schemas for the Cloudflare API. Back then, we had an audacious goal to make the OpenAPI schemas the source of truth for our SDK ecosystem and reference documentation. During 2024’s Developer Week, we backed this up by announcing that our SDK libraries are now automatically generated from these OpenAPI schemas. Today, we’re excited to announce the latest pieces of the ecosystem to now be automatically generated — the Terraform provider and API reference documentation.
This means that the moment a new feature or attribute is added to our products and the team documents it, you’ll be able to see how it’s meant to be used across our SDK ecosystem and make use of it immediately. No more delays. No more lacking coverage of API endpoints.
For anyone who is unfamiliar with Terraform, it is a tool for managing your infrastructure as code, much like you would with your application code. Many of our customers (big and small) rely on Terraform to orchestrate their infrastructure in a technology-agnostic way. Under the hood, it is essentially an HTTP client with lifecycle management built in, which means it makes use of our publicly documented APIs in a way that understands how to create, read, update and delete for the life of the resource.
Keeping Terraform updated — the old way
Historically, Cloudflare has manually maintained a Terraform provider, but since the provider internals require their own unique way of doing things, responsibility for maintenance and support has landed on the shoulders of a handful of individuals. The service teams always had difficulties keeping up with the number of changes, due to the amount of cognitive overhead required to ship a single change in the provider. In order for a team to get a change to the provider, it took a minimum of 3 pull requests (4 if you were adding support to cf-terraforming).
Even with the 4 pull requests completed, it didn’t offer guarantees on coverage of all available attributes, which meant small yet important details could be forgotten and not exposed to customers, causing frustration when trying to configure a resource.
To address this, our Terraform provider needed to be relying on the same OpenAPI schemas that the rest of our SDK ecosystem was already benefiting from.
Updating Terraform automatically
The thing that differentiates Terraform from our SDKs is that it manages the lifecycle of resources. With that comes a new range of problems related to known values and managing differences in the request and response payloads. Let’s compare the two different approaches of creating a new DNS record and fetching it back.
With our Go SDK:
// Create the new record
record, _ := client.DNS.Records.New(context.TODO(), dns.RecordNewParams{
ZoneID: cloudflare.F("023e105f4ecef8ad9ca31a8372d0c353"),
Record: dns.RecordParam{
Name: cloudflare.String("@"),
Type: cloudflare.String("CNAME"),
Content: cloudflare.String("example.com"),
},
})
// Wasteful fetch, but shows the point
client.DNS.Records.Get(
context.Background(),
record.ID,
dns.RecordGetParams{
ZoneID: cloudflare.String("023e105f4ecef8ad9ca31a8372d0c353"),
},
)
And with Terraform:
resource "cloudflare_dns_record" "example" {
zone_id = "023e105f4ecef8ad9ca31a8372d0c353"
name = "@"
content = "example.com"
type = "CNAME"
}
On the surface, it looks like the Terraform approach is simpler, and you would be correct. The complexity of knowing how to create a new resource and maintain changes are handled for you. However, the problem is that for Terraform to offer this abstraction and data guarantee, all values must be known at apply time. That means that even if you’re not using the proxied value, Terraform needs to know what the value needs to be in order to save it in the state file and manage that attribute going forward. The error below is what Terraform operators commonly see from providers when the value isn’t known at apply time.
Error: Provider produced inconsistent result after apply
When applying changes to example_thing.foo, provider "provider[\"registry.terraform.io/example/example\"]"
produced an unexpected new value: .foo: was null, but now cty.StringVal("").
Whereas when using the SDKs, if you don’t need a field, you just omit it and never need to worry about maintaining known values.
Tackling this for our OpenAPI schemas was no small feat. Since introducing Terraform generation support, the quality of our schemas has improved by an order of magnitude. Now we are explicitly calling out all default values that are present, variable response properties based on the request payload, and any server-side computed attributes. All of this means a better experience for anyone that interacts with our APIs.
Making the jump from terraform-plugin-sdk to terraform-plugin-framework
To build a Terraform provider and expose resources or data sources to operators, you need two main things: a provider server and a provider.
The provider server takes care of exposing a gRPC server that Terraform core (via the CLI) uses to communicate when managing resources or reading data sources from the operator provided configuration.
The provider is responsible for wrapping the resources and data sources, communicating with the remote services, and managing the state file. To do this, you either rely on the terraform-plugin-sdk (commonly referred to as SDKv2) or terraform-plugin-framework, which includes all the interfaces and methods provided by Terraform in order to manage the internals correctly. The decision as to which plugin you use depends on the age of your provider. SDKv2 has been around longer and is what most Terraform providers use, but due to the age and complexity, it has many core unresolved issues that must remain in order to facilitate backwards compatibility for those who rely on it. terraform-plugin-framework is the new version that, while lacking the breadth of features SDKv2 has, provides a more Go-like approach to building providers and addresses many of the underlying bugs in SDKv2.
The majority of the Cloudflare Terraform provider is built using SDKv2, but at the beginning of 2023, we took the plunge to multiplex and offer both in our provider. To understand why this was needed, we have to understand a little about SDKv2. The way SDKv2 is structured isn’t really conducive to representing null or “unset” values consistently and reliably. You can use the experimental ResourceData.GetRawConfig to check whether the value is set, null, or unknown in the config, but writing it back as null isn’t really supported.
This caveat first popped up for us when the Edge Rules Engine (Rulesets) started onboarding new services and those services needed to support API responses that contained booleans in an unset (or missing), true, or false state each with their own reasoning and purpose. While this isn’t a conventional API design at Cloudflare, it is a valid way to do things that we should be able to work with. However, as mentioned above, the SDKv2 provider couldn’t. This is because when a value isn’t present in the response or read into state, it gets a Go-compatible zero value for the default. This showed up as the inability to unset values after they had been written to state as false values (and vice versa).
Once we started adding more functionality using terraform-plugin-framework in the old provider, it was clear that it was a better developer experience, so we added a ratchet to prevent SDKv2 usage going forward to get ahead of anyone unknowingly setting themselves up to hit this issue.
When we decided that we would be automatically generating the Terraform provider, it was only fitting that we also brought all the resources over to be based on the terraform-plugin-framework and leave the issues from SDKv2 behind for good. This did complicate the migration as with the improved internals came changes to major components like the schema and CRUD operations that we needed to familiarize ourselves with. However, it has been a worthwhile investment because by doing so, we’ve future-proofed the foundations of the provider and are now making fewer compromises on a great Terraform experience due to buggy, legacy internals.
Iteratively finding bugs
One of the common struggles with code generation pipelines is that unless you have existing tools that implement your new thing, it’s hard to know if it works or is reasonable to use. Sure, you can also generate your tests to exercise the new thing, but if there is a bug in the pipeline, you are very likely to not see it as a bug as you will be generating test assertions that show the bug is expected behavior.
One of the essential feedback loops we have had is the existing acceptance test suite. All resources within the existing provider had a mix of regression and functionality tests. Best of all, as the test suite is creating and managing real resources, it was very easy to know whether the outcome was a working implementation or not by looking at the HTTP traffic to see whether the API calls were accepted by the remote endpoints. Getting the test suite ported over was only a matter of copying over all the existing tests and checking for any type assertion differences (such as list to single nested list) before kicking off a test run to determine whether the resource was working correctly.
While the centralized schema pipeline was a huge quality of life improvement for having schema fixes propagate to the whole ecosystem almost instantly, it couldn’t help us solve the largest hurdle, which was surfacing bugs that hide other bugs. This was time-consuming because when fixing a problem in Terraform, you have three places where you can hit an error:
Before any API calls are made, Terraform implements logical schema validation and when it encounters validation errors, it will immediately halt.
If any API call fails, it will stop at the CRUD operation and return the diagnostics, immediately halting.
After the CRUD operation has run, Terraform then has checks in place to ensure all values are known.
That means that if we hit the bug at step 1 and then fixed the bug, there was no guarantee or way to tell that we didn’t have two more waiting for us. Not to mention that if we found a bug in step 2 and shipped a fix, that it wouldn’t then identify a bug in the first step on the next round of testing.
There is no silver bullet here and our workaround was instead to notice patterns of problems in the schema behaviors and apply CI lint rules within the OpenAPI schemas before it got into the code generation pipeline. Taking this approach incrementally cut down the number of bugs in step 1 and 2 until we were largely only dealing with the type in step 3.
A more reusable approach to model and struct conversion
Within Terraform provider CRUD operations, it is fairly common to see boilerplate like the following:
var plan ThingModel
diags := req.Plan.Get(ctx, &plan)
resp.Diagnostics.Append(diags...)
if resp.Diagnostics.HasError() {
return
}
out, err := r.client.UpdateThingModel(ctx, client.ThingModelRequest{
AttrA: plan.AttrA.ValueString(),
AttrB: plan.AttrB.ValueString(),
AttrC: plan.AttrC.ValueString(),
})
if err != nil {
resp.Diagnostics.AddError(
"Error updating project Thing",
"Could not update Thing, unexpected error: "+err.Error(),
)
return
}
result := convertResponseToThingModel(out)
tflog.Info(ctx, "created thing", map[string]interface{}{
"attr_a": result.AttrA.ValueString(),
"attr_b": result.AttrB.ValueString(),
"attr_c": result.AttrC.ValueString(),
})
diags = resp.State.Set(ctx, result)
resp.Diagnostics.Append(diags...)
if resp.Diagnostics.HasError() {
return
}
At a high level:
We fetch the proposed updates (known as a plan) using req.Plan.Get()
Perform the update API call with the new values
Manipulate the data from a Go type into a Terraform model (convertResponseToThingModel)
Set the state by calling resp.State.Set()
Initially, this doesn’t seem too problematic. However, the third step where we manipulate the Go type into the Terraform model quickly becomes cumbersome, error-prone, and complex because all of your resources need to do this in order to swap between the type and associated Terraform models.
To avoid generating more complex code than needed, one of the improvements featured in our provider is that all CRUD methods use unified apijson.Marshal, apijson.Unmarshal, and apijson.UnmarshalComputed methods that solve this problem by centralizing the conversion and handling logic based on the struct tags.
var data *ThingModel
resp.Diagnostics.Append(req.Plan.Get(ctx, &data)...)
if resp.Diagnostics.HasError() {
return
}
dataBytes, err := apijson.Marshal(data)
if err != nil {
resp.Diagnostics.AddError("failed to serialize http request", err.Error())
return
}
res := new(http.Response)
env := ThingResultEnvelope{*data}
_, err = r.client.Thing.Update(
// ...
)
if err != nil {
resp.Diagnostics.AddError("failed to make http request", err.Error())
return
}
bytes, _ := io.ReadAll(res.Body)
err = apijson.UnmarshalComputed(bytes, &env)
if err != nil {
resp.Diagnostics.AddError("failed to deserialize http request", err.Error())
return
}
data = &env.Result
resp.Diagnostics.Append(resp.State.Set(ctx, &data)...)
Instead of needing to generate hundreds of instances of type-to-model converter methods, we can instead decorate the Terraform model with the correct tags and handle marshaling and unmarshaling of the data consistently. It’s a minor change to the code that in the long run makes the generation more reusable and readable. As an added benefit, this approach is great for bug fixing as once you identify a bug with a particular type of field, fixing that in the unified interface fixes it for other occurrences you may not yet have found.
But wait, there’s more (docs)!
To top off our OpenAPI schema usage, we’re tightening the SDK integration with our new API documentation site. It’s using the same pipeline we’ve invested in for the last two years while addressing some of the common usage issues.
SDK aware
If you’ve used our API documentation site, you know we give you examples of interacting with the API using command line tools like curl. This is a great starting point, but if you’re using one of the SDK libraries, you need to do the mental gymnastics to convert it to the method or type definition you want to use. Now that we’re using the same pipeline to generate the SDKs and the documentation, we’re solving that by providing examples in all the libraries you could use — not just curl.
Example using cURL to fetch all zones.
Example using the Typescript library to fetch all zones.
Example using the Python library to fetch all zones.
Example using the Go library to fetch all zones.
With this improvement, we also remember the language selection so if you’ve selected to view the documentation using our Typescript library and keep clicking around, we keep showing you examples using Typescript until it is swapped out.
Best of all, when we introduce new attributes to existing endpoints or add SDK languages, this documentation site is automatically kept in sync with the pipeline. It is no longer a huge effort to keep it all up to date.
Faster and more efficient rendering
A problem we’ve always struggled with is the sheer number of API endpoints and how to represent them. As of this post, we have 1,330 endpoints, and for each of those endpoints, we have a request payload, a response payload, and multiple types associated with it. When it comes to rendering this much information, the solutions we’ve used in the past have had to make tradeoffs in order to make parts of the representation work.
This next iteration of the API documentation site addresses this is a couple of ways:
It’s implemented as a modern React application that pairs an interactive client-side experience with static pre-rendered content, resulting in a quick initial load and fast navigation. (Yes, it even works without JavaScript enabled!).
It fetches the underlying data incrementally as you navigate.
By solving this foundational issue, we’ve unlocked other planned improvements to the documentation site and SDK ecosystem to improve the user experience without making tradeoffs like we’ve needed to in the past.
Permissions
One of the most requested features to be re-implemented into the documentation site has been minimum required permissions for API endpoints. One of the previous iterations of the documentation site had this available. However, unknown to most who used it, the values were manually maintained and were regularly incorrect, causing support tickets to be raised and frustration for users.
Inside Cloudflare’s identity and access management system, answering the question “what do I need to access this endpoint” isn’t a simple one. The reason for this is that in the normal flow of a request to the control plane, we need two different systems to provide parts of the question, which can then be combined to give you the full answer. As we couldn’t initially automate this as part of the OpenAPI pipeline, we opted to leave it out instead of having it be incorrect with no way of verifying it.
Fast-forward to today, and we’re excited to say endpoint permissions are back! We built some new tooling that abstracts answering this question in a way that we can integrate into our code generation pipeline and have all endpoints automatically get this information. Much like the rest of the code generation platform, it is focused on having service teams own and maintain high quality schemas that can be reused with value adds introduced without any work on their behalf.
Stop waiting for updates
With these announcements, we’re putting an end to waiting for updates to land in the SDK ecosystem. These new improvements allow us to streamline the ability of new attributes and endpoints the moment teams document them. So what are you waiting for? Check out the Terraform provider and API documentation site today.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.