Post Syndicated from Damian Brady original https://github.blog/2023-04-14-how-generative-ai-is-changing-the-way-developers-work/
During a time when computers were solely used for computation, the engineer, Douglas Engelbart, gave the “mother of all demos,” where he reframed the computer as a collaboration tool capable of solving humanity’s most complex problems. At the start of his demo, he asked audience members how much value they would derive from a computer that could instantly respond to their actions.
You can ask the same question of generative AI models. If you had a highly responsive generative AI coding tool to brainstorm new ideas, break big ideas into smaller tasks, and suggest new solutions to problems, how much more creative and productive could you be?
This isn’t a hypothetical question. AI-assisted engineering workflows are quickly emerging with new generative AI coding tools that offer code suggestions and entire functions in response to natural language prompts and existing code. These tools, and what they can help developers accomplish, are changing fast. That makes it important for every developer to understand what’s happening now—and the implications for how software is and will be built.
In this article, we’ll give a rundown of what generative AI in software development looks like today by exploring:
- The unique value generative AI brings to the developer workflow
- How generative AI coding tools are designed and built
- Why developers should care about large language models
- How developers are using generative AI coding tools
The unique value generative AI brings to the developer workflow
AI and automation have been a part of the developer workflow for some time now. From machine learning-powered security checks to CI/CD pipelines, developers already use a variety of automation and AI tools, like CodeQL on GitHub, for example.
While there’s overlap between all of these categories, here’s what makes generative AI distinct from automation and other AI coding tools:
Automation:  You know what needs to be done, and you know of a reliable way to get there every time. |
Rules-based logic:  You know the end goal, but there’s more than one way to achieve it. |
Machine learning:  You know the end goal, but the amount of ways to achieve it scales exponentially. |
Generative AI:  You have big coding dreams, and want the freedom to bring them to life. |
| You want to make sure that any new code pushed to your repository follows formatting specifications before it’s merged to the main branch. Instead of manually validating the code, you use a CI/CD tool like GitHub Actions to trigger an automated workflow on the event of your choosing (like a commit or pull request). | You know some patterns of SQL injections, but it’s time consuming to manually scan for them in your code. A tool like Code QL uses a system of rules to sort through your code and find those patterns, so you don’t have to do it by hand. | You want to stay on top of security vulnerabilities, but the list of SQL injections continues to grow. A coding tool that uses a machine learning (ML) model, like Code QL, is trained to not only detect known injections, but also patterns similar to those injections in data it hasn’t seen before. This can help you increase recognition of confirmed vulnerabilities and predict new ones. | Generative AI coding tools leverage ML to generate novel answers and predict coding sequences. A tool like GitHub Copilot can reduce the amount of times you switch out of your IDE to look up boilerplate code or help you brainstorm coding solutions. Shifting your role from rote writing to strategic decision making, generative AI can help you reflect on your code at a higher, more abstract level—so you can focus more on what you want to build and spend less time worrying about how. |
How are generative AI coding tools designed and built?
Building a generative AI coding tool requires training AI models on large amounts of code across programming languages via deep learning. (Deep learning is a way to train computers to process data like we do—by recognizing patterns, making connections, and drawing inferences with limited guidance.)
To emulate the way humans learn patterns, these AI models use vast networks of nodes, which process and weigh input data, and are designed to function like neurons. Once trained on large amounts of data and able to produce useful code, they’re built into tools and applications. The models can then be plugged into coding editors and IDEs where they respond to natural language prompts or code to suggest new code, functions, and phrases.
Before we talk about how generative AI coding tools are made, let’s define what they are first. It starts with LLMs, or large language models, which are sets of algorithms trained on large amounts of code and human language. Like we mentioned above, they can predict coding sequences and generate novel content using existing code or natural language prompts.
Today’s state-of-the-art LLMs are transformers. That means they use something called an attention mechanism to make flexible connections between different tokens in a user’s input and the output that the model has already generated. This allows them to provide responses that are more contextually relevant than previous AI models because they’re good at connecting the dots and big-picture thinking.
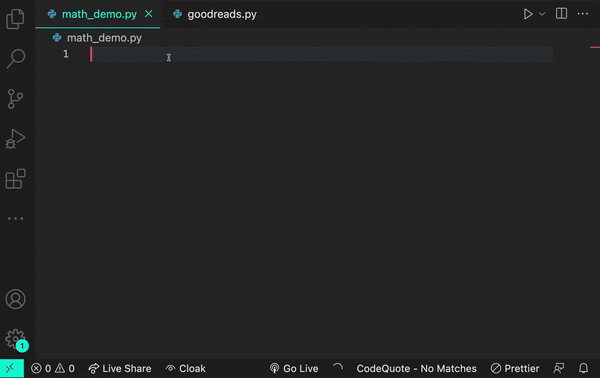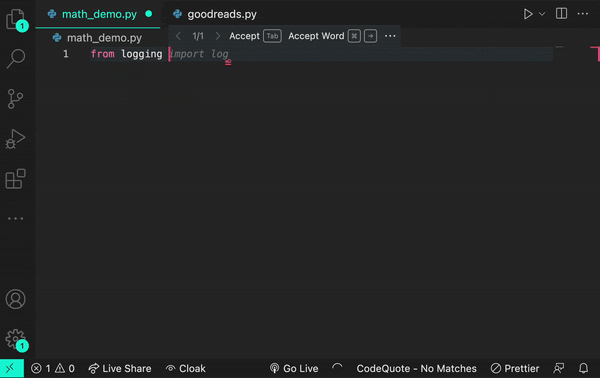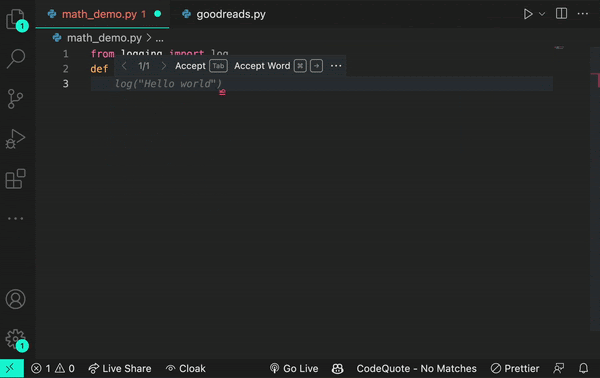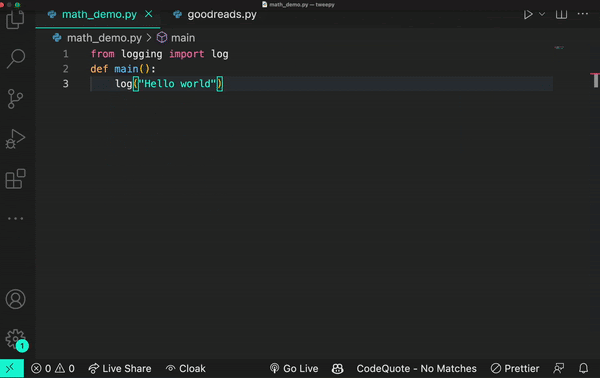
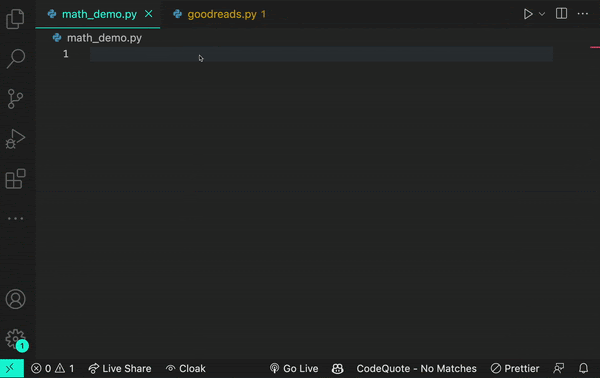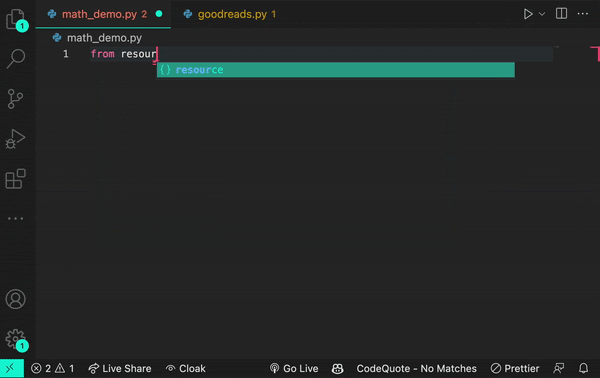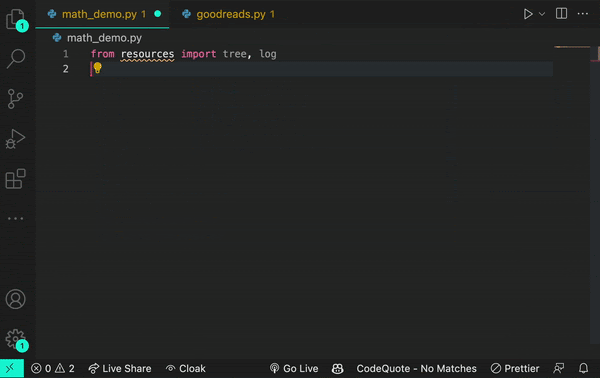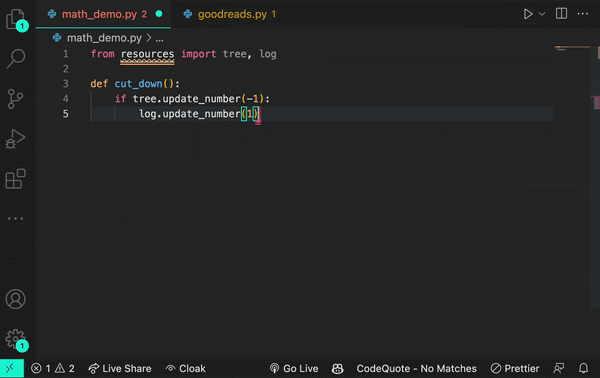
Here’s an example of how a transformer works. Let’s say you encounter the word log in your code. The transformer node at that place would use the attention mechanism to contextually predict what kind of log would come next in the sequence.
Let’s say, in the example below, you input the statement from math import log. A generative AI model would then infer you mean a logarithmic function.

And if you add the prompt from logging import log, it would infer that you’re using a logging function.
Though sometimes a log is just a log.
LLMs can be built using frameworks besides transformers. But LLMs using frameworks, like a recurrent neural network or long short-term memory, struggle with processing long sentences and paragraphs. They also typically require training on labeled data (making training a labor-intensive process). This limits the complexity and relevance of their outputs, and the data they can learn from.
Transformer LLMs, on the other hand, can train themselves on unlabeled data. Once they’re given basic learning objectives, LLMs take a part of the new input data and use it to practice their learning goals. Once they’ve achieved these goals on that portion of the input, they apply what they’ve learned to understand the rest of the input. This self-supervised learning process is what allows transformer LLMs to analyze massive amounts of unlabeled data—and the larger the dataset an LLM is trained on, the more they scale by processing that data.
Why should developers care about transformers and LLMs?
LLMs like OpenAI’s GPT-3, GPT-4, and Codex models are trained on an enormous amount of natural language data and publicly available source code. This is part of the reason why tools like ChatGPT and GitHub Copilot, which are built on these models, can produce contextually accurate outputs.
Here’s how GitHub Copilot produces coding suggestions:
- All of the code you’ve written so far, or the code that comes before the cursor in an IDE, is fed to a series of algorithms that decide what parts of the code will be processed by GitHub Copilot.
- Since it’s powered by a transformer-based LLM, GitHub Copilot will apply the patterns it’s abstracted from training data and apply those patterns to your input code.
- The result: contextually relevant, original coding suggestions. GitHub Copilot will even filter out known security vulnerabilities, vulnerable code patterns, and code that matches other projects.
Keep in mind: creating new content such as text, code, and images is at the heart of generative AI. LLMs are adept at abstracting patterns from their training data, applying those patterns to existing language, and then producing language or a line of code that follows those patterns. Given the sheer scale of LLMs, they might generate a language or code sequence that doesn’t even exist yet. Just as you would review a colleague’s code, you should assess and validate AI-generated code, too.
Why context matters for AI coding tools
Developing good prompt crafting techniques is important because input code passes through something called a context window, which is present in all transformer-based LLMs. The context window represents the capacity of data an LLM can process. Though it can’t process an infinite amount of data, it can grow larger. Right now, the Codex model has a context window that allows it to process a couple of hundred lines of code, which has already advanced and accelerated coding tasks like code completion and code change summarization.
Developers use details from pull requests, a folder in a project, open issues—and the list goes on—to contextualize their code. So, when it comes to a coding tool with a limited context window, the challenge is to figure out what data, in addition to code, will lead to the best suggestions.
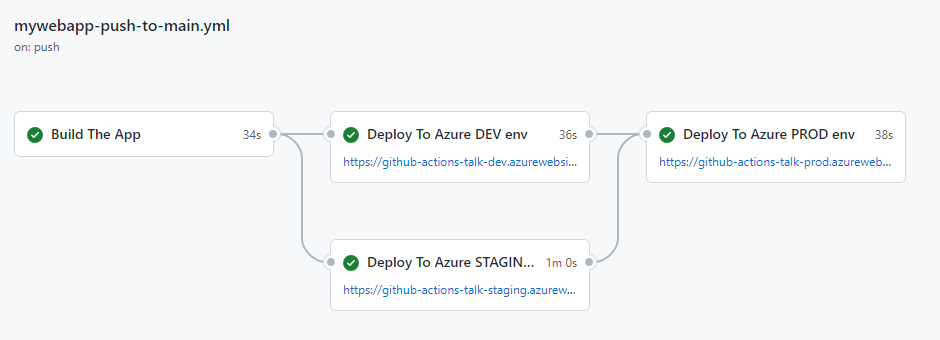
The order of the data also impacts a model’s contextual understanding. Recently, GitHub made updates to its pair programmer so that it considers not only the code immediately before the cursor, but also some of the code after the cursor. The paradigm—which is called Fill-In-the-Middle (FIM)—leaves a gap in the middle of the code for GitHub Copilot to fill, providing the tool with more context about the developer’s intended code and how it should align with the rest of the program. This helps produce higher quality code suggestions without any added latency.
Visuals can also contextualize code. Multimodal LLMs (MMLLMs) scale transformer LLMs so they process images and videos, as well as text. OpenAI recently released its new GPT-4 model—and Microsoft revealed its own MMLLM called Kosmos-1. These models are designed to respond to natural language and images, like alternating text and images, image-caption pairs, and text data.
GitHub’s senior developer advocate Christina Warren shares the latest on GPT-4 and the creative potential it holds for developers:
| Our R&D team at GitHub Next has been working to move AI past the editor with GitHub Copilot X. With this new vision for the future of AI-powered software development, we’re not only adopting OpenAI’s new GPT-4 model, but also introducing chat and voice, and bringing GitHub Copilot to pull requests, the command line, and docs. See how we’re investigating the future of AI-powered software development > |
How developers are using generative AI coding tools
The field of generative AI is filled with experiments and explorations to uncover the technology’s full capabilities—and how they can enable effective developer workflows. Generative AI tools are already changing how developers write code and build software, from improving productivity to helping developers focus on bigger problems.
While generative AI applications in software development are still being actively defined, today, developers are using generative AI coding tools to:
- Get a head start on complex code translation tasks. A study presented at the 2021 International Conference on Intelligent User Interfaces found that generative AI provided developers with a skeletal framework to translate legacy source code into Python. Even if the suggestions weren’t always correct, developers found it easier to assess and fix those mistakes than manually translate the source code from scratch. They also noted that this process of reviewing and correcting was similar to what they already do when working with code produced by their colleagues.
With GitHub Copilot Labs, developers can use the companion VS Code extension (that’s separate from but dependent on the GitHub Copilot extension) to translate code into different programming languages. Watch how GitHub Developer Advocate, Michelle Mannering, uses GitHub Copilot Labs to translate her Python code into Ruby in just a few steps.
- Code more efficiently. While autocompletion has been in modern IDEs for years, LLMs can generate longer suggestions—sometimes multiple lines of code—that are often more relevant. A 2022 study published in the Proceedings of the Association for Computing Machinery on Programming Languages (PACMPL) observed 20 programmers who interacted with GitHub Copilot. They found that thanks to end-of-line suggestions for function calls and argument completions, developers were able to code faster and stay in the flow longer.
Our own research supports these findings, too. As we mentioned earlier, we found that developers who used GitHub Copilot coded up to 55% faster than those who didn’t. But productivity gains went beyond speed with 74% of developers reporting that they felt less frustrated when coding and were able to focus on more satisfying work.
- Tackle new problems and get creative. The PACMPL study also found that developers used GitHub Copilot to find creative solutions when they were unsure of how to move forward. These developers searched for next possible steps and relied on the generative AI coding tool to assist with unfamiliar syntax, look up the right API, or discover the correct algorithm.
I was one of the developers who wrote GitHub Copilot, but prior to that work, I had never written a single line of TypeScript. That wasn’t a problem because I used the first prototype of GitHub Copilot to learn the language and, eventually, help ship the world’s first at-scale generative AI coding tool.
- Find answers without leaving their IDEs. Some participants in the PACMPL study also treated GitHub Copilot’s multi-suggestion pane like StackOverflow. Since they were able to describe their goals in natural language, participants could directly prompt GitHub Copilot to generate ideas for implementing their goals, and press Ctrl/Cmd + Enter to see a list of 10 suggestions. Even though this kind of exploration didn’t lead to deep knowledge, it helped one developer to effectively use an unfamiliar API.
A 2023 study published by GitHub in the Association for Computing Machinery’s Queue magazine also found that generative AI coding tools save developers the effort of searching for answers online. This provides them with more straightful forward answers, reduces context switching, and conserves mental energy.
Part of GitHub’s new vision for the future of AI-powered software development is a ChatGPT-like experience directly in your editor. Watch how Martin Woodward, GitHub’s Vice President of Developer Relations, uses GitHub Copilot Chat to find and fix bugs in his code.
- Build better test coverage. Some generative AI coding tools excel in pattern recognition and completion. Developers are using these tools to build unit and functional tests—and even security tests—via natural language prompts. Some tools also offer security vulnerability filtering, so a developer will be alerted if they unknowingly introduce a vulnerability in their code.
Want to see some examples in action? Check out how Rizel Scarlett, a developer advocate at GitHub, uses GitHub Copilot to develop tests for her codebase:
- Discover tricks and solutions they didn’t know they needed. Scarlett also wrote about eight unexpected ways developers can use GitHub Copilot—from prompting it to create a dictionary of two-letter ISO country codes and their contributing country name, to helping developers exit Vim, an editor with a sometimes finicky closing process. Want to learn more? Check out the full guide >
The bottom line
Generative AI provides humans with a new mode of interaction—and it doesn’t just alleviate the tedious parts of software development. It also inspires developers to be more creative, feel empowered to tackle big problems, and model large, complex solutions in ways they couldn’t before. From increasing productivity and offering alternative solutions, to helping you build new skills—like learning a new language or framework, or even writing clear comments and documentation—there are so many reasons to be excited about the next wave of software development. This is only the beginning.

.](https://github.blog/wp-content/uploads/2023/04/image3.gif)
 האדם-החושב on wikipedia](https://github.blog/wp-content/uploads/2023/04/image4-1.png?w=1024&fit=1024%2C1024)
 using VAEs trained on the CelebA dataset.](https://github.blog/wp-content/uploads/2023/04/image6.jpg?w=539&fit=1024%2C1024)
 ) by generating new characters, storylines, design components, and more. Case in point: The developer behind the game,
) by generating new characters, storylines, design components, and more. Case in point: The developer behind the game,  ). Artists and designers alike are using these AI tools as a source of inspiration. For example, architects can quickly create 3D models of objects or environments and artists can breathe new life into their portraits by using AI to apply different styles, like adding a Cubist style to their original image. Need proof? Designers are already starting to use AI image generators, such as
). Artists and designers alike are using these AI tools as a source of inspiration. For example, architects can quickly create 3D models of objects or environments and artists can breathe new life into their portraits by using AI to apply different styles, like adding a Cubist style to their original image. Need proof? Designers are already starting to use AI image generators, such as