Over the next year Cloudflare will make nearly every feature we offer available to any customer who wants to buy and use it regardless of whether they are an enterprise account. No need to pick up a phone and talk to a sales team member. No requirement to find time with a solutions engineer in our team to turn on a feature. No contract necessary. We believe that if you want to use something we offer, you should just be able to buy it.
Today’s launch starts by bringing Single Sign-On (SSO) into our dashboard out of our enterprise plan and making it available to any user. That capability is the first of many. We will be sharing updates over the next few months as more and more features become available for purchase on any plan.
We are also making a commitment to ensuring that all future releases will follow this model. The goal is not to restrict new tools to the enterprise tier for some amount of time before making them widely available. We believe helping build a better Internet means making sure the best tools are available to anyone who needs them.
Enterprise grade for everyone
It’s not enough to build the best tools on the web. At Cloudflare our mission is to help build a better Internet and that means making the tools we build accessible. We believe the best way to make the Internet faster and more secure is to put powerful features into the hands of as many people as possible.
We first launched an Enterprise tier years ago when larger customers came to us looking to scale their usage of Cloudflare in new ways. They needed procurement options beyond a credit card, like invoices, custom contracts, and dedicated support. This offering was a necessary and important step to bring the benefits of our network and tools to large organizations with complex needs.
This created an unintended side effect in how we shipped products. Some of our most powerful and innovative features were launched within an enterprise-only tier. This created a gap, a two-tiered system where some of the most advanced features were reserved only for the largest companies.
It also created a divergence in our product development. Features built for our self-service customers had to be incredibly simple and intuitive from day-one. Features designated “enterprise-only” didn’t always face that same pressure to scale – we could instead rely on our solutions teams or partners to help set up and support.
It’s time to fix that. Starting today, we are doing away with the concept of “enterprise-only” features. Over the coming months and quarters, we will make many of our most advanced capabilities available to all of our customers.
The change will help build a more secure Internet by removing barriers to the adoption of the most advanced tools available. The change improves the experience for all customers. Smaller teams on our self-service plans will have access to the most powerful configuration options we offer. Existing enterprise teams will have easier pathways to adopt new tools without calling their account manager. And our own Product teams have even more reason to continue to make all features we ship easy to use.
Today we are beginning with dashboard SSO with instructions on how to begin setting that up right now below. It is the first of many though and capabilities like apex proxying and expanded upload limits, along with many others of our most requested enterprise features, will follow.
Starting with how you sign in to Cloudflare
One example of a feature we launched only to enterprise customers because of the complexity in setting it up is SSO. Enterprise teams maintain their own identity provider where they can manage internal employee accounts and how their team members log into different services.
They integrate these identity providers with the tools their employees need so that team members do not need to create and remember a username and password for each and every service. More importantly, the management of identity in a single place gives enterprises the ability to control authentication policies, onboard and offboard users, and hand out licenses for tools.
We first launched our own SSO support way back in 2018. In the last seven years we have been helping thousands of enterprise customers manually set this up, but we know that teams of all sizes rely on the security and convenience of an identity provider. As part of this announcement, the first enterprise feature we are making available to everyone is dashboard SSO.
The functionality is available immediately to anyone on any plan. To get started, follow the instructions here to integrate your identity provider with Cloudflare and to then connect your domain with your account. By setting up your identity provider for dashboard SSO you will also be able to begin using the vast majority of our Zero Trust security features, as well, which are available at no cost for up to 50 users.
We also know that some teams are too early or distributed to have a full-fledged identity provider but want the convenience and security of managing logins in one place. To that end, we are also excited to launch support for GitHub as a social login provider to the Cloudflare dashboard as part of today’s announcement.
And extending to almost everything else over the next year
We prioritized dashboard SSO because just about every team that uses Cloudflare wants it. This one change helps make nearly every customer safer by allowing them to centrally manage team access. As we burn down the list of previously enterprise-only features, we will continue targeting those that have similar broad impact.
Some capabilities, like Magic Transit, have less broad appeal. The organizations that maintain their own networks and want to deploy Magic Transit tend to already want to be enterprise customers for account management reasons. That said, we still can improve their experience by making tools like Magic Transit available to all plans because we will have to remove some of the friction in the setup that we have historically just solved with people hours from our solution engineers and partners.
We also realize that the way some of these features are priced only made sense with an invoice or enterprise license agreement model. To make this work, we need to revisit how some of our usage metering and billing functions. That will continue to be a priority for us, and we are excited about how this will push us to continue making our packaging and billing even simpler for all customers.
There are some features that we can’t make available to everyone because of non-technical reasons. For example, using our China Network has complicated legal requirements in China that are impossible for us to manage for millions of customers.
Self-service by default going forward
One thing we are not announcing today is a strategy to continue to release “enterprise-only” features for a while before they eventually make it to the self-service plans. Going forward, to launch something at Cloudflare the team will need to make sure that any customer can buy it off the shelf without talking to someone.
We expect that requirement to improve how all products are built here, not just the more advanced capabilities. We also consider it mission-critical. We have a long history of making the kinds of tools that only the largest businesses could buy available to anyone, from universal SSL over a decade ago to newer features this week that were available for self-service plans immediately like per-customer bot detection IDs and security of data in transit between SaaS applications. We are excited to continue this tradition.
What’s next?
You can get started right now setting up dashboard SSO in your Cloudflare account using the documentation available here. We will continue to share updates as previously enterprise-only features are made available to any plan.
In June, we experienced two incidents that resulted in degraded performance across GitHub services.
June 05 17:05 UTC (lasting 142 minutes)
On June 5, between 17:05 UTC and 19:27 UTC, the GitHub Issues service was degraded. During that time, events related to projects were not displayed on issue timelines. These events indicate when an issue was added to or removed from a project and when their status changed within a project. A misconfiguration of the service backing these events prevented the data from being loaded.
We determined the root cause to be a scheduled secret rotation that resulted in one of the configured services using old expired secrets. Specifically, as a part of our continual improvement, we had an initiative to cleanup, streamline, and simplify our service configurations for improved automation. A bug in the implementation resulted in a misconfiguration that resulted in the degradation.
We mitigated the incident by remediating the service configuration and we believe the simplified configuration will help avoid similar incidents in the future.
June 27 20:39 UTC (lasting 58 minutes)
On June 27, between 20:39 UTC and 21:37 UTC, the GitHub Migration service saw all in-progress migrations fail. Once the increased failures were detected, we paused new migrations so they could resume when the issue was mitigated. This resulted in longer migration times, but prevented further failures.
We attributed the root cause of this incident to an invalid infrastructure credential that required us to manually intervene.
Once identified, the incident was mitigated by the active involvement of our first responders at which time we unpaused queued migrations and continued processing them with an expected level of success.
To prevent recurrence of similar incidents in the future, we are mitigating specific gaps in our monitoring and alerting for infrastructure credentials.
Please follow our status page for real-time updates on status changes and post-incident recaps. To learn more about what we’re working on, check out the GitHub Engineering Blog.
In March, we experienced two incidents that resulted in degraded performance across GitHub services.
March 15 19:42 UTC (lasting 42 minutes)
On March 15, GitHub experienced service degradation from 19:42 to 20:24 UTC due to a regression in the permissions system. This regression caused failures in GitHub Codespaces, GitHub Actions, and GitHub Pages. The problem stemmed from a framework upgrade that introduced MySQL query syntax that is incompatible with the database proxy service used in some production clusters. GitHub responded by rolling back the deployment and fixing a misconfiguration in development and CI environments to prevent similar issues in the future.
March 11 22:45 UTC (lasting 2 hours and 3 minutes)
On March 11, GitHub experienced service degradation from 22:45 to 00:48 UTC due to an inadvertent deployment of network configuration to the wrong environment. This led to intermittent errors in various services, including API requests, GitHub Copilot, GitHub secret scanning, and 2FA using GitHub Mobile. The issue was detected within 4 minutes, and a rollback was initiated immediately. The majority of impact was mitigated by 22:54 UTC. However, the rollback failed in one data center due to system-created configuration records missing a required field, causing 0.4% of requests to continue failing. Full rollback was successful after manual intervention to correct the configuration data, enabling full service restoration by 00:48 UTC. GitHub has implemented measures for safer configuration changes, such as prevention and automatic cleanup of obsolete configuration and faster issue detection, to prevent similar issues in the future.
Please follow our status page for real-time updates on status changes and post-incident recaps. To learn more about what we’re working on, check out the GitHub Engineering Blog.
In January, we experienced three incidents that resulted in degraded performance across GitHub services.
January 09 12:20 UTC (lasting 140 minutes)
On January 9 between 12:20 and 14:40 UTC, services in one of our three sites experienced elevated latency for connections. This led to a sustained period of timed-out requests across a number of services, including but not limited to our Git backend. An average of 5% and max of 10% of requests failed with a 5xx response or timed out during this period.
This was caused by an upgrade of hosts, which led to temporarily reduced capacity as the upgrade rolled through the fleet. While these hosts had plenty of capacity to handle the increased load, we found that the configured connection limit was lower than it should have been. We have increased that limit to prevent this from recurring. We have also identified improvements to our monitoring of connection limits and behavior and changes to reduce the risk of host upgrades leading to reduced capacity.
January 21 02:01 UTC (lasting 7 hours 3 minutes)
On January 21 at 2:01 UTC, we experienced an incident that affected customers using GitHub Codespaces. Customers encountered issues creating and resuming Codespaces in multiple regions due to operational issues with compute and storage resources.
Around 25% of customers were impacted, primarily in East US and West Europe. We re-routed traffic for Codespace creations to less impacted regions, but existing Codespaces in these regions may have been unable to resume during the incident.
By 7:30 UTC, we had recovered connectivity to all regions except West Europe, which had an extended recovery time due to increased load in that particular region. The incident was resolved on January 21 at 9:34 UTC once Codespace creations and resumes were working normally in all regions.
We are working to improve our alerting and resiliency to reduce the duration and impact of region-specific outages.
January 31 12:30 UTC (lasting 147 minutes)
On January 31, we deployed an infrastructure change to our load balancers in preparation towards our longer term goal of IPv6 enablement at GitHub.com. This change was deployed to a subset of our global edge sites. The change had the unintended consequence of causing IPv4 addresses to start being passed as an IPv4-mapped IPv6-compatible address (for example, 10.1.2.3 became ::ffff:10.1.2.3) to our IP Allow List functionality. While our IP Allow List functionality was developed with IPv6 in mind, it wasn’t developed to handle these mapped addresses, and hence, started blocking requests as it deemed these to be not in the defined list of allowed addresses. Request error rates peaked at 0.23% of all requests.
In addition to changes deployed to remediate the issues, we have taken steps to improve testing and monitoring to better catch these issues in the future.
Please follow our status page for real-time updates on status changes and post-incident recaps. To learn more about what we’re working on, check out the GitHub Engineering Blog.
In December, we experienced three incidents that resulted in degraded performance across GitHub services. All three are related to a broad secret rotation initiative in late December. While we have investigated and identified improvements from each of these individual incidents, we are also reviewing broader opportunities to reduce availability risk in our broader secrets management.
December 27 02:30 UTC (lasting 90 minutes)
While rotating HMAC secrets between GitHub’s frontend service and an internal service, we triggered a bug in how we fetch keys from Azure Key Vault. API calls between the two services started failing when we disabled a key in Key Vault while rolling back a rotation in response to an alert.
This resulted in all codespace creations failing between 02:30 and 04:00 UTC on December 27 and approximately 15% of resumes to fail as well as other background functions. We temporarily re-enabled the key in Key Vault to mitigate the impact before deploying a change to continue the secret rotation. The original alert turned out to be a separate issue that was not customer-impacting and was fixed immediately after the incident.
Learning from this, the team has improved the existing playbooks for HMAC key rotation and documentation of our Azure Key Vault implementation.
December 28 05:52 UTC (lasting 65 minutes)
Between 5:52 UTC and 6:47 UTC on December 28, certain GitHub email notifications were not sent due to failed authentication between backend services that generate notifications and a subset of our SMTP servers. This primarily impacted CI activity and Gist email notifications.
This was caused by the rotation of authentication credentials between frontend and internal services that resulted in the SMTP servers not being correctly updated with the new credentials. This triggered an alert for one of the two impacted notifications services within minutes of the secret rotation. On-call engineers discovered the incorrect authentication update on the SMTP servers and applied changes to update it, which mitigated the impact.
Repair items have already been completed to update the relevant secrets rotation playbooks and documentation. While the monitor that did fire was sufficient in this case to engage on-call engineers and remediate the incident, we’ve completed an additional repair item to provide earlier alerting across all services moving forward.
December 29 00:34 UTC (lasting 68 minutes)
Users were unable to sign in or sign up for new accounts between 00:34 and 1:42 UTC on December 29. Existing sessions were not impacted.
This was caused by a credential rotation that was not mirrored in our frontend caches, causing the mismatch in behavior between signed in and signed out users. We resolved the incident by deploying the updated credentials to our cache service.
Repair items are underway to improve our monitoring of signed out user experiences and to better manage updates to shared credentials in our systems moving forward.
Please follow our status page for real-time updates on status changes and post-incident recaps. To learn more about what we’re working on, check out the GitHub Engineering Blog.
In November, we experienced one incident that resulted in degraded performance across GitHub services.
November 3 18:42 UTC (lasting 38 minutes)
Between 18:42 and 19:20 UTC on November 3, the GitHub authorization service experienced excessive application memory use, leading to failed authorization requests and users getting 404 or error responses on most page and API requests.
A performance and resilience optimization to the authorization microservice contained a memory leak that was exposed under high traffic. Testing did not expose the service to sufficient traffic to discover the leak, allowing it to graduate to production at 18:37 UTC. The memory leak under high load caused pods to crash repeatedly starting at 18:42 UTC, failing authorization checks in their default closed state. These failures started triggering alerts at 18:44 UTC. Rolling back the authorization service change was delayed as parts of the deployment infrastructure relied on the authorization service and required manual intervention to complete. Rollback completed at 19:08 UTC and all impacted GitHub features recovered after pods came back online.
To reduce the risk of future deployments, we implemented changes to our rollout strategy by including additional monitoring and checks, which automatically block a deployment from proceeding if key metrics are not satisfactory. To reduce our time to recover in the future, we have removed dependencies between the authorization service and the tools needed to roll back changes.
Please follow our status page for real-time updates on status changes and post-incident recaps. To learn more about what we’re working on, check out the GitHub Engineering Blog.
In July, we experienced one incident that resulted in degraded performance across GitHub services.
July 21 13:07 UTC (lasting 59 minutes)
On July 21 at 13:07 UTC, GitHub experienced a partial power outage in one of our redundant data centers, which resulted in a loss of compute capacity. GitHub updated the status of six services to yellow at 13:12 UTC. The vast majority of customer impact occurred in the first 10 minutes up to 13:17 UTC as requests were internally rerouted to other nodes in the data center, but we elected to keep status at yellow until full capacity was restored out of an abundance of caution. As a result of this incident, we are conducting reviews of all power feeds with each of our datacenter partners. We have also identified improvements to reduce recovery time after power was restored and are evaluating ways to reduce the time to fail over all traffic.
Please follow our status page for real-time updates on status changes. To learn more about what we’re working on, check out the GitHub Engineering Blog.
In June, we experienced two incidents that resulted in degraded performance across GitHub services.
June 7 16:11 UTC (lasting 2 hours 28 minutes)
On June 7 at 16:11 UTC, GitHub started experiencing increasing delays in an internal job queue used to process Git pushes. Our monitoring systems alerted our first responders after 19 minutes. During this incident, customers experienced GitHub Actions workflow run and webhook delays as long as 55 minutes, and pull requests did not accurately reflect new commits.
We immediately began investigating and found that the delays were caused by a customer making a large number of pushes to a repository with a specific data shape. The jobs processing these pushes became throttled when communicating with the Git backend, leading to increased job execution times. These slow jobs exhausted a worker pool, starving the processing of pushes for other repositories. Once the source was identified and temporarily disabled, the system gradually recovered as the backlog of jobs was completed. To prevent a recurrence, we updated the Git backend’s throttling behavior to fail faster and reduced the Git client timeout within the job to prevent it from hanging. We have additional repair items in place to reduce the times to detect, diagnose, and recover.
June 29 14:50 UTC (lasting 32 minutes)
On June 29, starting from 17:39 UTC, GitHub was down in parts of North America, particularly the US East coast and South America, for approximately 32 minutes.
GitHub takes measures to ensure that we have redundancy in our system for various disaster scenarios. We have been working on building redundancy to an earlier single point of failure in our network architecture at a second Internet edge facility. This facility was completed in January and has been actively routing production traffic since then in a high availability (HA) architecture alongside the first edge facility. As part of the facility validation steps, we performed a live failover test in order to verify that we could use this second Internet edge facility if the primary were to fail. Unfortunately, during this failover test we inadvertently caused a production outage.
The test exposed a network path configuration issue in the secondary side that prevented it from properly functioning as a primary, which resulted in the outage. This has since been fixed. We were immediately notified of the issue and within two minutes of being alerted we reverted the change and brought the primary facility back online. Once online it took time for traffic to be rebalanced and for our border routers to reconverge restoring public connectivity to GitHub systems.
This failover test helped expose the configuration issue, and we are addressing the gaps in both configuration and our failover testing, which will help make GitHub more resilient. We recognize the severity of this outage and the importance of keeping GitHub available. Moving forward, we will continue our commitment to high availability, improving these tests and scheduling them in a way where potential customer impact is minimized as much as possible.
Please follow our status page for real-time updates on status changes. To learn more about what we’re working on, check out the GitHub Engineering Blog.
In May, we experienced four incidents that resulted in degraded performance across GitHub services. This report also sheds light into three April incidents that resulted in degraded performance across GitHub services.
April 26 23:11 UTC (lasting 51 minutes)
On April 25 at 23:11 UTC, a subset of users began to see a degraded experience with GitHub Copilot code completions. We publicly statused GitHub Copilot to yellow at 23:26 UTC, and to red at 23:41 UTC. As engineers identified the impact to be a subset of requests, we statused back to yellow at 23:48 UTC. The incident was fully resolved on April 26 at 00:02 UTC, and we publicly statused green at 00:30 UTC.
The degradation consisted of a rolling partial outage across all three GitHub Copilot regions: US Central, US East, and Switzerland North. Each of these regions experienced approximately 15-20 minutes of degraded service during the global incident. At the peak, 6% of GitHub Copilot code completion requests failed.
We identified the root cause to be a faulty configuration change by an automated maintenance process. The process was initiated across all regions sequentially, and placed a subset of faulty nodes in service before the rollout was halted by operators. Automated traffic rollover from the failed nodes and regions helped to mitigate the issue.
Our efforts to prevent a similar incident in the future include both reducing the batch size and iteration speed of the automated maintenance process, and lowering our time to detection by adjusting our alerting thresholds.
April 27 08:59 UTC (lasting 57 minutes)
On April 26 at 08:59 UTC, our internal monitors notified us of degraded availability with GitHub Packages. Users would have noticed slow or failed GitHub Packages upload and download requests. Our investigation revealed a spike in connection errors to our primary database node. We quickly took action to resolve the issue by manually restarting the database. At 09:56 UTC, all errors were cleared and users experienced a complete recovery of the GitHub Packages service. A planned migration of GitHub Packages database to a more robust platform was completed on May 2, 2023 to prevent this issue from recurring.
April 28 12:26 UTC (lasting 19 minutes)
On April 28 at 12:26 UTC, we were notified of degraded availability for GitHub Codespaces. Users in the East US region experienced failures when creating and resuming codespaces. At 12:45 UTC, we used regional failover to redirect East US codespace creates and resumes to the nearest healthy region, East US 2, and users experienced a complete and nearly immediate recovery of GitHub Codespaces.
Our investigation indicated our cloud provider had experienced an outage in the East US region, with virtual machines in that region experiencing internal operation errors. Virtual machines in the East US 2 region (and all other regions) were healthy, which enabled us to use regional failover to successfully recover GitHub Codespaces for our East US users. When our cloud provider’s outage was resolved, we were able to seamlessly direct all of our East US GitHub Codespaces uses back with no downtime.
Long-term mitigation is focused on reducing our time to detection for outages such as this by improving our monitors and alerts, as well as reducing our time to mitigate by making our regional failover tooling and documentation more accessible.
May 4th 15:53 UTC (lasting 30 minutes)
On May 4th at 15:23 UTC, our monitors detected degraded performance for Git Operations, GitHub APIs, GitHub Issues, GitHub Pull Requests, GitHub Webhooks, GitHub Actions, GitHub Pages, GitHub Codespaces, and GitHub Copilot. After troubleshooting we were able to mitigate the issue by performing a primary failover on our repositories database cluster. Further investigation indicated the root cause was connection pool exhaustion on our proxy layer. Prior updates to this configuration were inconsistently applied. We audited and fixed our proxy layer connection pool configurations during this incident, and updated our configuration automation to dynamically apply config changes without disruption to ensure consistent configuration of database proxies moving forward.
May 09 11:27 UTC (lasting 10 hours and 44 minutes)
On May 9 at 11:27 UTC, users began to see failures to read or write Git data. These failures continued until 12:33 UTC, affecting Git Operations, GitHub Issues, GitHub Actions, GitHub Codespaces, GitHub Pull Requests, GitHub Web Hooks, and GitHub APIs. Repositories and GitHub Pull Requests required additional time to fully recover job results and search capabilities, with recovery completing at 21:20 UTC. On May 11 at 13:33 UTC, similar failures occurred affecting the same services until 14:40 UTC. Again, GitHub Pull Requests required additional time to fully recover search capabilities, with recovery completing at 18:54 UTC. We discussed both of these events in a previous blog post and can confirm they share the same root cause.
Based on our investigation we determined that the cause of this crash is due to a bug in the database version we are running, and the conditions causing this bug were more likely to happen in a custom configuration on this data cluster. We updated our configuration to match the rest of our database clusters, and this cluster is no longer vulnerable to this kind of failover.
The bug has since been reported to the database maintainers, accepted as a private bug, and fixed. The fix is slated for a release expected in July.
There have been several directions of work in response to these incidents to avoid reoccurrence. We have focused on removing special case configurations of our database clusters to avoid unpredictable behavior from custom configurations. Across feature areas, we have also expanded tooling around graceful degradation of web pages when dependencies are unavailable.
May 10 12:38 UTC (lasting 11 hours and 56 minutes)
On May 10 at 12:38 UTC, issuance of auth tokens for GitHub Apps started failing, impacting GitHub Actions, GitHub API Requests, GitHub Codespaces, Git Operations, GitHub Pages, and GitHub Pull Requests. We identified the cause of these failures to be a significant increase in write latency on a shared permissions database cluster. First responders mitigated the incident by identifying the data shape in new API calls that was causing very expensive database write transactions and timeouts in a loop and blocking the source. We shared additional details on this incident in a previous blog post, but we wanted to share an update on our follow-up actions. Beyond the immediate work to address the expensive query pattern that caused this incident, we completed an audit of other endpoints to identify and correct any similar patterns. We completed improvements to the observability of API errors and have further work in progress to improve diagnosis of unhealthy MySQL write patterns. We also completed improvements to tools, documentation and playbooks, and training for both the technical diagnosis and our general incident response to address issues encountered while mitigating this issue and to reduce the time to mitigate similar incidents in the future.
May 16 21:07 UTC (lasting 25 minutes)
On May 16 at 21:08 UTC, we were alerted to degradation of multiple services. GitHub Issues, GitHub Pull Requests, and Git Ops were unavailable while GitHub API, GitHub Actions, GitHub Pages, and GitHub Codespaces were all partially unavailable. Alerts indicated that the primary database of a cluster supporting key-value data had experienced a hardware crash. The cluster was left in such a state that our failover automation was unable to select a new primary to promote due to the risk of data loss. Our first responder evaluated the cluster, determined it was safe to proceed, and then manually triggered a failover to a new primary host 11 minutes after the server crash. We aspire to reduce our response time moving forward and are looking into improving our alerting for cases like this. Long-term mitigation is focused on reducing dependency on this cluster as a single point of failure for much of the site.
Please follow our status page for real-time updates on status changes. To learn more about what we’re working on, check out the GitHub Engineering Blog.
Last week, GitHub experienced several availability incidents, both long running and shorter duration. We have since mitigated these incidents and all systems are now operating normally. The root causes for these incidents were unrelated but in aggregate, they negatively impacted the services that organizations and developers trust GitHub to deliver. This is not acceptable nor the standard we hold ourselves to. We took immediate and direct action to remedy the situation, and we want to be very transparent about what caused these incidents and what we’re doing to mitigate in the future. Read on for more details.
Date: May 9, 2023 Incident: Git Databases degraded due to configuration change Impact: 8 of 10 main services degraded
Details:
On May 9, we had an incident that caused 8 of the 10 services on the status portal to be impacted by a major (status red) outage. The majority of downtime lasted just over an hour. During that hour-long period, many services could not read newly-written Git data, causing widespread failures. Following this outage, there was an extended timeline for post-incident recovery of some pull request and push data.
This incident was triggered by a configuration change to the internal service serving Git data. The change was intended to prevent connection saturation, and had been previously introduced successfully elsewhere in the Git backend.
Shortly after the rollout began, the cluster experienced a failover. We reverted the config change and attempted a rollback within a few minutes, but the rollback failed due to an internal infrastructure error.
Once we completed a gradual failover, write operations were restored to the database and broad impact ended. Additional time was needed to get Git data, website-visible contents, and pull requests consistent for pushes received during the outage to achieve a full resolution.
Date: May 10, 2023 Incident: GitHub App authentication token issuance degradation due to load Impact: 6 of 10 main services degraded
Details:
On May 10, the database cluster serving GitHub App auth tokens saw a 7x increase in write latency for GitHub App permissions (status yellow). The failure rate of these auth token requests was 8-15% for the majority of this incident, but did peak at 76% percent for a short time.
Total LatencyFetch Latency
We determined that an API for managing GitHub App permissions had an inefficient implementation. When invoked under specific circumstances, it results in very large writes and a timeout failure. This API was invoked by a new caller that retried on timeouts, triggering the incident. While working to identify root cause, improve the data access pattern, and address the source of the new call pattern, we also took steps to reduce load from both internal and external paths, reducing impact to critical paths like GitHub Actions workflows. After recovery, we re-enabled all suspended sources before statusing green.
While we update the backing data model to avoid this pattern entirely, we are updating the API to check for the shift in installation state and will fail the request if it would trigger these large writes as a temporary measure.
Beyond the problem with the query performance, much of our observability is optimized for identifying high-volume patterns, not low-volume high-cost ones, which made it difficult to identify the specific circumstances that were causing degraded cluster health. Moving forward, we are prioritizing work to apply the experiences of our investigations during this incident to ensure we have quick and clear answers for similar cases in the future.
Date: May 11, 2023 Incident: Git database degraded due to loss of read replicas Impact: 8 of 10 main services degraded
Details:
On May 11, a database cluster serving git data crashed, triggering an automated failover. The failover of the primary was successful, but in this instance read replicas were not attached. The primary cannot handle full read/write load, so an average of 15% of requests for Git data were failed or slow, with peak impact of 26% at the start of the incident. We mitigated this by reattaching the read replicas and the core scenarios recovered. Similar to the May 9 incident, additional work was required to recover pull request push updates, but we were eventually able to achieve full resolution.
Beyond the immediate mitigation work, the top workstreams underway are focused on determining and resolving what caused the cluster to crash and why the failure didn’t leave the cluster in a good state. We want to clarify that the team was already working to understand and address a previous cluster crash as part of a repair item from a different recent incident. This failover replica failure is new.
Why did these incidents impact other GitHub services?
We expect our services to be as resilient as possible to failure. Failure in a distributed system is inevitable, but it shouldn’t result in significant outages across multiple services. We saw widespread degradation in all three of these incidents. In the Git database incidents, Git reads and writes are at the core of many GitHub scenarios, so increased latency and failures resulted in GitHub Actions workflows unable to pull data or pull requests not updating.
In the GitHub Apps incident, the impact on the token issuance also impacted GitHub features that rely on tokens for operation. This is the source of each GITHUB_TOKEN in GitHub Actions, as well as the tokens used to give GitHub Codespaces access to your repositories. They’re also how access to private GitHub Pages are secured. When token issuance fails, GitHub Actions and GitHub Codespaces are unable to access the data they need to run, and fail to launch as a result.
What actions are we taking?
We are carefully reviewing our internal processes and making adjustments to ensure changes are always deployed safely moving forward. Not all of these incidents were caused by production changes, but we recognize this as an area of improvement.
In addition to the standard post-incident analysis and review, we are analyzing the breadth of impact these incidents had across services to identify where we can reduce the impact of future similar failures.
We are working to improve observability of high-cost, low-volume query patterns and general ability to diagnose and mitigate this class of issue quickly.
We are addressing the Git database crash that has caused more than one incident at this point. This work was already in progress and we will continue to prioritize it.
We are addressing the database failover issues to ensure that failovers always recover fully without intervention.
As part of our commitment to transparency, we publish summaries of all incidents that result in degraded performance of GitHub services in our monthly availability report. Given the scope and duration of these recent incidents we felt it was important to address them with the community now. The May report will include these incidents and any further detail we have on them, along with a general update on progress towards increasing the availability of GitHub. We are deeply committed to improving site reliability moving forward and will continue to hold ourselves accountable for delivering on that commitment.
While it’s still in its infancy, generative AI coding tools are already changing the way developers and companies build software. Generative AI can boost developer and business productivity by automating tasks, improving communication and collaboration, and providing insights that can inform better decision-making.
In this post, we’ll explore the full story of how companies are adopting generative AI to ship software faster, including:
Generative AI refers to a class of artificial intelligence (AI) systems designed to create new content similar to what humans produce. These systems are trained on large datasets of content that include text, images, audio, music, or code.
Generative AI is an extension of traditional machine learning, which trains models to predict or classify data based on existing patterns. But instead of simply predicting the outcome, generative AI models are designed to identify underlying patterns and structures of the data, and then use that knowledge to quickly generate new content. However, the main difference between the two is one of magnitude and the size of the prediction or generation. Machine learning typically predicts the next word. Generative AI can generate the next paragraph.
AI-generated image from Shutterstack of a developer using a generative AI tool to code faster.
Generative AI tools have attracted particular interest in the business world. From marketing to software development, organizational leaders are increasingly curious about the benefits of the new generative AI applications and products.
“I do think that all companies will adopt generative AI tools in the near future, at least indirectly,” said Albert Ziegler, principal machine learning engineer at GitHub. “The bakery around the corner might have a logo that the designer made using a generative transformer. The neighbor selling knitted socks might have asked Bing where to buy a certain kind of wool. My taxi driver might do their taxes with a certain Excel plugin. This adoption will only increase over time.”
What are some business uses of generative AI tools?
Software development: generative AI tools can assist engineers with building, editing, and testing code.
Content creation: writers can use generative AI tools to help personalize product descriptions and write ad copy.
Design creation: from generating layouts to assisting with graphics, generative AI design tools can help designers create entirely new designs.
Video creation: generative AI tools can help videographers with building, editing, or enhancing videos and images.
Language translation: translators can use generative AI tools to create communications in different languages.
Personalization: generative AI tools can assist businesses with personalizing products and services to meet the needs of individual customers.
Operations: from supply chain management to pricing, generative AI tools can help operations professionals drive efficiency.
How generative AI coding tools are changing the developer experience
Generative AI has big implications for developers, as the tools can enable them to code and ship software faster.
How is generative AI affecting software development?
Check out our guide to learn what generative AI coding tools are, what developers are using them for, and how they’re impacting the future of development.
GitHub Copilot is only continuing to improve. When the tool was first launched for individuals in June 2022, more than 27% of developers’ code was generated by GitHub Copilot, on average. Today, that number is 46% across all programming languages—and in Java, that jumps to 61%.
How can generative AI tools help you build software?
These tools can help:
Write boilerplate code for various programming languages and frameworks.
Find information in documentation to understand what the code does.
Identify security vulnerabilities and implement fixes.
Streamline code reviews before merging new or edited code.
Like all technologies, responsibility and ethics are important with generative AI.
In February 2023, a group of 10 companies including OpenAI, Adobe, the BBC, and others agreed upon a new set of recommendations on how to use generative AI content in a responsible way.
The recommendations were put together by the Partnership on AI (PAI), an AI research nonprofit, in consultation with more than 50 organizations. The guidelines call for creators and distributors of generative AI to be transparent about what the technology can and can’t do and disclose when users might be interacting with this type of content (by using watermarks, disclaimers, or traceable elements in an AI model’s training data).
Businesses should be aware that while generative AI tools can speed up the creation of content, they should not be solely relied upon as a source of truth. A recent study suggests that people can identify whether AI-generated content is real or fake only 50% of the time. Here at GitHub, we named our generative AI tool “GitHub Copilot” to signify just this—the tool can help, but at the end of the day, it’s just a copilot. The developer needs to take responsibility for ensuring that the finished code is accurate and complete.
How companies are using generative AI
Even as generative AI models and tools continue to rapidly advance, businesses are already exploring how to incorporate these into their day-to-day operations.
This is particularly true for software development teams.
“Going forward, tech companies that don’t adopt generative AI tools will have a significant productivity disadvantage,” Ziegler said. “Given how much faster this technology can help developers build, organizations that don’t adopt these tools or create their own will have a harder time in the marketplace.”
3 primary generative AI business models for organizations
Enterprises all over the world are using generative AI tools to transform how work gets done. Three of the business models organizations use include:
Model as a Service (MaaS): Companies access generative AI models through the cloud and use them to create new content. OpenAI employs this model, which licenses its GPT-3 AI model, the platform behind ChatGPT. This option offers low-risk, low-cost access to generative AI, with limited upfront investment and high flexibility.
Built-in apps: Companies build new—or existing—apps on top of generative AI models to create new experiences. GitHub Copilot uses this model, which relies on Codex to analyze the context of the code to provide intelligent suggestions on how to complete it. This option offers high customization and specialized solutions with scalability.
Vertical integration: Vertical integration leverages existing systems to enhance the offerings. For instance, companies may use generative AI models to analyze large amounts of data and make predictions about prices or improve the accuracy of their services.
Duolingo, one of the largest language-learning apps in the world, is one company that recently adopted generative AI capabilities. They chose GitHub’s generative AI tool, GitHub Copilot, to help their developers write and ship code faster, while improving test coverage. Duolingo’s CTO Severin Hacker said GitHub Copilot delivered immediate benefits to the team, enabling them to code quickly and deliver their best work.
”[The tool] stops you from getting distracted when you’re doing deep work that requires a lot of your brain power,” Hacker noted. “You spend less time on routine work and more time on the hard stuff. With GitHub Copilot, our developers stay in the flow state and keep momentum instead of clawing through code libraries or documentation.”
After adopting GitHub Copilot and the GitHub platform, Duolingo saw a:
25% increase in developer speed for those who are new to working with a specific repository
10% increase in developer speed for those who are familiar with the respective codebase
67% decrease in median code review turnaround time
“I don’t know of anything available today that’s remotely close to what we can get with GitHub Copilot,” Hacker said.
Looking forward
Generative AI is changing the world of software development. And it’s just getting started. The technology is quickly improving and more use cases are being identified across the software development lifecycle. With the announcement of GitHub Copilot X, our vision for the future of AI-powered software development, we’re committed to installing AI capabilities into every step of the developer workflow. There’s no better time to get started with generative AI at your company.
In April, we experienced four incidents that resulted in degraded performance across GitHub services. This report also sheds light into three March incidents that resulted in degraded performance across GitHub services.
March 27 12:25 UTC (lasting 1 hour and 33 minutes)
On March 27 at 12:14 UTC, users began to see degraded experience with Git Operations, GitHub Issues, pull requests, GitHub Actions, GitHub API requests, GitHub Codespaces, and GitHub Pages. We publicly statused Git Operations 11 minutes later, initially to yellow, followed by red for other impacted services. Full functionality was restored at 13:17 UTC.
The cause was traced to a change in a frequently-used database query. The query alteration was part of a larger infrastructure change that had been rolled out gradually, starting in October 2022, then more quickly beginning February 2023, completing on March 20, 2023. The change increased the chance of lock contention, leading to increased query times and eventual resource exhaustion during brief load spikes, which caused the database to crash. An initial automatic failover solved this seamlessly, but the slow query continued to cause lock contention and resource exhaustion, leading to a second failover that did not complete. Mitigation took longer than usual because manual intervention was required to fully recover.
The query causing lock tension was disabled via feature flag, and then refactored. We have added additional monitoring of relevant database resources so as not to reach resource exhaustion, and detect similar issues earlier in our staged rollout process. Additionally, we have enhanced our query evaluation procedures related to database lock contention, along with improved documentation and training material.
March 29 14:21 UTC (lasting 4 hour and 57 minutes)
On March 29 at 14:10 UTC, users began to see a degraded experience with GitHub Actions with their workflows not progressing. Engineers initially statused GitHub Actions nine minutes later. GitHub Actions started recovering between 14:57 UTC and 16:47 UTC before degrading again. GitHub Actions fully recovered the queue of backlogged workflows at 19:03 UTC.
We determined the cause of the impact to be a degraded database cluster. Contributing factors included a new load source from a background job querying that database cluster, maxed out database transaction pools, and underprovisioning of vtgate proxy instances that are responsible for query routing, load balancing, and sharding. The incident was mitigated through throttling of job processing and adding capacity, including overprovisioning to speed processing of the backlogged jobs.
After the incident, we identified that the pool, found_rows_pool managed by the vtgate layer, was overwhelmed and unresponsive. This pool became flooded and stuck due to contention between inserting data into and reading data from the tables in the database. This contention led to us being unable to progress any new queries across our database cluster.
The health of our database clusters is a top priority for us and we have taken steps to reduce contentious queries on our cluster over the last few weeks. We also have taken multiple actions from what we learned in this incident to improve our telemetry and alerting to allow us to identify and act on blocking queries faster. We are carefully monitoring the cluster health and are taking a close look into each component to identify any additional repair items or adjustments we can make to improve long-term stability.
March 31 01:07 UTC (lasting 2 hours)
On March 31 at 00:06 UTC, a small percentage of users started to receive consistent 500 error responses on pull request files pages. At 01:07 UTC, the support team escalated reports from customers to engineering who identified the cause and statused yellow nine minutes later. The fix was deployed to all production hosts by 02:07 UTC.
We determined the source of the bug to be a notification to promote a new feature. Only repository admins who had not enabled the new feature or dismissed the notification were impacted. An expiry date in the configuration of this notification was set incorrectly, which caused a constant that was still referenced in code to no longer be available.
We have taken steps to avoid similar issues in the future by auditing the expiry dates of existing notices, preventing future invalid configurations, and improving test coverage.
April 18 09:28 UTC (lasting 11 minutes)
On April 18 at 09:22 UTC, users accessing any issues or pull request related entities experienced consistent 5xx responses. Engineers publicly statused pull requests to red and issues six minutes later. At 09:33 UTC, the root cause self-healed and traffic recovered. The impact resulted in an 11 minute outage of access to issues and pull request related artifacts. After fully validating traffic recovery, we statused green for issues at 09:42 UTC.
The root cause of this incident was a planned change in our database infrastructure to minimize the impact of unsuccessful deployments. As part of the progressive rollout of this change, we deleted nodes that were taking live traffic. When these nodes were deleted, there was an 11 minute window where requests to this database cluster failed. The incident was resolved when traffic automatically switched back to the existing nodes.
This planned rollout was a rare event. In order to avoid similar incidents, we have taken steps to review and improve our change management process. We are updating our monitoring and observability guidelines to check for traffic patterns prior to disruptive actions. Furthermore, we’re adding additional review steps for disruptive actions. We have also implemented a new checklist for change management for these types of infrequent administrative changes that will prompt the primary operator to document the change and associated risks along with mitigation strategies.
April 26 23:26 UTC (lasting 1 hour and 04 minutes)
On April 26 at 23:26 UTC, we were notified of an outage with GitHub Copilot. We resolved the incident at 00:29 UTC.
Due to the recency of this incident, we are still investigating the contributing factors and will provide a more detailed update in next month’s report.
April 27 08:59 UTC (lasting 57 minutes)
On April 26 at 08:59 UTC, we were notified of an outage with GitHub Packages. We resolved the incident at 09:56 UTC.
Due to the recency of this incident, we are still investigating the contributing factors and will provide a more detailed update in next month’s report.
April 28 12:26 UTC (lasting 19 minutes)
On April 28 at 12:26 UTC, we were notified of degraded availability for GitHub Codespaces. We resolved the incident at 12:45 UTC.
Due to the recency of this incident, we are still investigating the contributing factors and will provide a more detailed update in next month’s report.
Please follow our status page for real-time updates on status changes. To learn more about what we’re working on, check out the GitHub Engineering Blog.
In a previous blog on consolidating your toolkit, we shared strategies to help you simplify your tech stack, which ultimately helps developers be more productive. In fact, developers are almost 60% more likely to feel equipped to do their job when they can easily find what they need.
But there are other benefits of consolidating and simplifying your toolkit that may be surprising–especially when migrating your source code and collaboration history to GitHub.
Today, we’ll explore three benefits that will support enterprises in a business climate where everyone is being asked to do more with less, as well as some resources to help get started on the migration journey.
1. Enable developer self-service culture
Some of the benefits enterprises can achieve with DevOps are improved productivity, security, and collaboration. Silos should be broken down and traditionally separated teams should be working in a cohesive and cloud native way.
Another benefit that DevOps enables, which is a key part of the Platform Engineering technology approach, is the ability for development teams to self-service workflows, processes, and controls which traditionally have either been manual, or tightly-coupled with other teams. A great example of this was covered in a previous blog where we described how to build consistent and shared IaC workflows. IaC workflows can be created by operations teams, if your enterprise separation of duties governance policies require this, but self-serviced when needed by development teams.
But this type of consistent, managed, and governable, self-service culture would not be possible if you have multiple source code management tools in your enterprise. If development teams have to spend time figuring out which tool has the source of truth for the workflow they need to execute, the benefits of DevOps and Platform Engineering quickly deteriorate.
There is no better place to migrate the core of your self-service culture to than GitHub–which is the home to 100 million developers and counting. Your source code management tool should be an enabler for developer productivity and happiness or else they will be reluctant to use it. And if they don’t use it, you won’t have a self-service culture within your enterprise.
2. Save time and money during audits
The latest Forrester report on the economic impact of GitHub Enterprise Cloud and GitHub Advanced Security, determined a 75% improvement in time spent managing tools and code infrastructure. But one of the potentially surprising benefits is related to implementing DevOps and cloud native processes that would both help developers and auditors save time and money.
If your tech stack includes multiple source code tools, and other development tools which may not be integrated our have overlapping capabilities, each time your security, compliance, and audit teams need to review the source of truth for your delivery artifacts, you will need to gather artifacts and setup walkthroughs for each of the tools. This can lead to days and even weeks of lost time and money on simply preparing and executing audits–taking your delivery teams away from creating business value.
Working with GitHub customers, Forrester identified and quantified key benefits of investing in GitHub Enterprise Cloud and GitHub Advanced Security. The corresponding GitHub Ent ROI Estimate Calculator includes factors for time saving on IT Audit preparations related to the number of non-development security or audit staff involved in software development. This itself can lead to hundreds of thousands if not millions of dollars of time savings.
What is not factored into the calculator is the potential time savings for development teams who have a single source of truth for their code and collaboration history. A simplified and centrally auditable tech stack with a single developer-friendly core source code management platform will enable consistent productivity even during traditionally time-consuming audit and compliance reviews–for both developers and non-developers.
3. Keep up with innovation
If you are using another source code platform besides GitHub, or if GitHub is one of several tools that are providing the overlapping functionality, some of your teams may be missing out on the amazing innovations that have been happening lately.
Generative AI is enabling some amazing capabilities and GitHub is at the forefront with our AI pair-programmer, GitHub Copilot. The improvements to developer productivity are truly amazing and continue to improve.
A graphic showing how many developers and companies have already used GitHub Copilot and how it’s helping improve productivity and happiness.
GitHub continues to innovate with the news about GitHub Copilot X, which is not only adopting OpenAI’s new GPT-4 model, but introducing chat and voice for GitHub Copilot, and bringing GitHub Copilot to pull requests, the command line, and docs to answer questions on your projects.
Innovations like this need to be rolled-out in a controlled and governable manner within many enterprises. But if your techstack is overly complex and you have several source code management tools, the roll-out may take a long time or may be stalled while security and compliance reviews take place.
However, if your development core is GitHub, security and compliance reviews can happen once, on a centrally managed platform that is well understood and secure. And you’ll be front row for all of the amazing new innovations that GitHub will be releasing down the road.
Get started today
If you are planning on migrating your source code and collaboration history to GitHub and have questions, thankfully, many other enterprises have done this already with great success and there are resources to help you through the process.
If you want to learn more about how GitHub can benefit your business, while increasing developer velocity and collaboration, see how GitHub Enterprise can help.
During a time when computers were solely used for computation, the engineer, Douglas Engelbart, gave the “mother of all demos,” where he reframed the computer as a collaboration tool capable of solving humanity’s most complex problems. At the start of his demo, he asked audience members how much value they would derive from a computer that could instantly respond to their actions.
You can ask the same question of generative AI models. If you had a highly responsive generative AI coding tool to brainstorm new ideas, break big ideas into smaller tasks, and suggest new solutions to problems, how much more creative and productive could you be?
This isn’t a hypothetical question. AI-assisted engineering workflows are quickly emerging with new generative AI coding tools that offer code suggestions and entire functions in response to natural language prompts and existing code. These tools, and what they can help developers accomplish, are changing fast. That makes it important for every developer to understand what’s happening now—and the implications for how software is and will be built.
In this article, we’ll give a rundown of what generative AI in software development looks like today by exploring:
The unique value generative AI brings to the developer workflow
AI and automation have been a part of the developer workflow for some time now. From machine learning-powered security checks to CI/CD pipelines, developers already use a variety of automation and AI tools, like CodeQL on GitHub, for example.
While there’s overlap between all of these categories, here’s what makes generative AI distinct from automation and other AI coding tools:
Automation: You know what needs to be done, and you know of a reliable way to get there every time.
Rules-based logic: You know the end goal, but there’s more than one way to achieve it.
Machine learning:
You know the end goal, but the amount of ways to achieve it scales exponentially.
Generative AI: You have big coding dreams, and want the freedom to bring them to life.
You want to make sure that any new code pushed to your repository follows formatting specifications before it’s merged to the main branch. Instead of manually validating the code, you use a CI/CD tool like GitHub Actions to trigger an automated workflow on the event of your choosing (like a commit or pull request).
You know some patterns of SQL injections, but it’s time consuming to manually scan for them in your code. A tool like Code QL uses a system of rules to sort through your code and find those patterns, so you don’t have to do it by hand.
You want to stay on top of security vulnerabilities, but the list of SQL injections continues to grow. A coding tool that uses a machine learning (ML) model, like Code QL, is trained to not only detect known injections, but also patterns similar to those injections in data it hasn’t seen before. This can help you increase recognition of confirmed vulnerabilities and predict new ones.
Generative AI coding tools leverage ML to generate novel answers and predict coding sequences. A tool like GitHub Copilot can reduce the amount of times you switch out of your IDE to look up boilerplate code or help you brainstorm coding solutions. Shifting your role from rote writing to strategic decision making, generative AI can help you reflect on your code at a higher, more abstract level—so you can focus more on what you want to build and spend less time worrying about how.
How are generative AI coding tools designed and built?
Building a generative AI coding tool requires training AI models on large amounts of code across programming languages via deep learning. (Deep learning is a way to train computers to process data like we do—by recognizing patterns, making connections, and drawing inferences with limited guidance.)
To emulate the way humans learn patterns, these AI models use vast networks of nodes, which process and weigh input data, and are designed to function like neurons. Once trained on large amounts of data and able to produce useful code, they’re built into tools and applications. The models can then be plugged into coding editors and IDEs where they respond to natural language prompts or code to suggest new code, functions, and phrases.
Before we talk about how generative AI coding tools are made, let’s define what they are first. It starts with LLMs, or large language models, which are sets of algorithms trained on large amounts of code and human language. Like we mentioned above, they can predict coding sequences and generate novel content using existing code or natural language prompts.
Today’s state-of-the-art LLMs are transformers. That means they use something called an attention mechanism to make flexible connections between different tokens in a user’s input and the output that the model has already generated. This allows them to provide responses that are more contextually relevant than previous AI models because they’re good at connecting the dots and big-picture thinking.
Here’s an example of how a transformer works. Let’s say you encounter the word log in your code. The transformer node at that place would use the attention mechanism to contextually predict what kind of log would come next in the sequence.
Let’s say, in the example below, you input the statement from math import log. A generative AI model would then infer you mean a logarithmic function.
And if you add the prompt from logging import log, it would infer that you’re using a logging function.
Though sometimes a log is just a log.
LLMs can be built using frameworks besides transformers. But LLMs using frameworks, like a recurrent neural network or long short-term memory, struggle with processing long sentences and paragraphs. They also typically require training on labeled data (making training a labor-intensive process). This limits the complexity and relevance of their outputs, and the data they can learn from.
Transformer LLMs, on the other hand, can train themselves on unlabeled data. Once they’re given basic learning objectives, LLMs take a part of the new input data and use it to practice their learning goals. Once they’ve achieved these goals on that portion of the input, they apply what they’ve learned to understand the rest of the input. This self-supervised learning process is what allows transformer LLMs to analyze massive amounts of unlabeled data—and the larger the dataset an LLM is trained on, the more they scale by processing that data.
Why should developers care about transformers and LLMs?
LLMs like OpenAI’s GPT-3, GPT-4, and Codex models are trained on an enormous amount of natural language data and publicly available source code. This is part of the reason why tools like ChatGPT and GitHub Copilot, which are built on these models, can produce contextually accurate outputs.
Here’s how GitHub Copilot produces coding suggestions:
All of the code you’ve written so far, or the code that comes before the cursor in an IDE, is fed to a series of algorithms that decide what parts of the code will be processed by GitHub Copilot.
Since it’s powered by a transformer-based LLM, GitHub Copilot will apply the patterns it’s abstracted from training data and apply those patterns to your input code.
The result: contextually relevant, original coding suggestions. GitHub Copilot will even filter out known security vulnerabilities, vulnerable code patterns, and code that matches other projects.
Keep in mind: creating new content such as text, code, and images is at the heart of generative AI. LLMs are adept at abstracting patterns from their training data, applying those patterns to existing language, and then producing language or a line of code that follows those patterns. Given the sheer scale of LLMs, they might generate a language or code sequence that doesn’t even exist yet. Just as you would review a colleague’s code, you should assess and validate AI-generated code, too.
Why context matters for AI coding tools
Developing good prompt crafting techniques is important because input code passes through something called a context window, which is present in all transformer-based LLMs. The context window represents the capacity of data an LLM can process. Though it can’t process an infinite amount of data, it can grow larger. Right now, the Codex model has a context window that allows it to process a couple of hundred lines of code, which has already advanced and accelerated coding tasks like code completion and code change summarization.
Developers use details from pull requests, a folder in a project, open issues—and the list goes on—to contextualize their code. So, when it comes to a coding tool with a limited context window, the challenge is to figure out what data, in addition to code, will lead to the best suggestions.
The order of the data also impacts a model’s contextual understanding. Recently, GitHub made updates to its pair programmer so that it considers not only the code immediately before the cursor, but also some of the code after the cursor. The paradigm—which is called Fill-In-the-Middle (FIM)—leaves a gap in the middle of the code for GitHub Copilot to fill, providing the tool with more context about the developer’s intended code and how it should align with the rest of the program. This helps produce higher quality code suggestions without any added latency.
Visuals can also contextualize code. Multimodal LLMs (MMLLMs) scale transformer LLMs so they process images and videos, as well as text. OpenAI recently released its new GPT-4 model—and Microsoft revealed its own MMLLM called Kosmos-1. These models are designed to respond to natural language and images, like alternating text and images, image-caption pairs, and text data.
GitHub’s senior developer advocate Christina Warren shares the latest on GPT-4 and the creative potential it holds for developers:
How developers are using generative AI coding tools
The field of generative AI is filled with experiments and explorations to uncover the technology’s full capabilities—and how they can enable effective developer workflows. Generative AI tools are already changing how developers write code and build software, from improving productivity to helping developers focus on bigger problems.
While generative AI applications in software development are still being actively defined, today, developers are using generative AI coding tools to:
Get a head start on complex code translation tasks. A study presented at the 2021 International Conference on Intelligent User Interfaces found that generative AI provided developers with a skeletal framework to translate legacy source code into Python. Even if the suggestions weren’t always correct, developers found it easier to assess and fix those mistakes than manually translate the source code from scratch. They also noted that this process of reviewing and correcting was similar to what they already do when working with code produced by their colleagues.
With GitHub Copilot Labs, developers can use the companion VS Code extension (that’s separate from but dependent on the GitHub Copilot extension) to translate code into different programming languages. Watch how GitHub Developer Advocate, Michelle Mannering, uses GitHub Copilot Labs to translate her Python code into Ruby in just a few steps.
Code more efficiently. While autocompletion has been in modern IDEs for years, LLMs can generate longer suggestions—sometimes multiple lines of code—that are often more relevant. A 2022 study published in the Proceedings of the Association for Computing Machinery on Programming Languages (PACMPL) observed 20 programmers who interacted with GitHub Copilot. They found that thanks to end-of-line suggestions for function calls and argument completions, developers were able to code faster and stay in the flow longer.
Our own research supports these findings, too. As we mentioned earlier, we found that developers who used GitHub Copilot coded up to 55% faster than those who didn’t. But productivity gains went beyond speed with 74% of developers reporting that they felt less frustrated when coding and were able to focus on more satisfying work.
Tackle new problems and get creative. The PACMPL study also found that developers used GitHub Copilot to find creative solutions when they were unsure of how to move forward. These developers searched for next possible steps and relied on the generative AI coding tool to assist with unfamiliar syntax, look up the right API, or discover the correct algorithm.
I was one of the developers who wrote GitHub Copilot, but prior to that work, I had never written a single line of TypeScript. That wasn’t a problem because I used the first prototype of GitHub Copilot to learn the language and, eventually, help ship the world’s first at-scale generative AI coding tool.
– Albert Ziegler, Principal Machine Learning Engineer // GitHub
Find answers without leaving their IDEs. Some participants in the PACMPL study also treated GitHub Copilot’s multi-suggestion pane like StackOverflow. Since they were able to describe their goals in natural language, participants could directly prompt GitHub Copilot to generate ideas for implementing their goals, and press Ctrl/Cmd + Enter to see a list of 10 suggestions. Even though this kind of exploration didn’t lead to deep knowledge, it helped one developer to effectively use an unfamiliar API.
Build better test coverage. Some generative AI coding tools excel in pattern recognition and completion. Developers are using these tools to build unit and functional tests—and even security tests—via natural language prompts. Some tools also offer security vulnerability filtering, so a developer will be alerted if they unknowingly introduce a vulnerability in their code.
Discover tricks and solutions they didn’t know they needed. Scarlett also wrote about eight unexpected ways developers can use GitHub Copilot—from prompting it to create a dictionary of two-letter ISO country codes and their contributing country name, to helping developers exit Vim, an editor with a sometimes finicky closing process. Want to learn more? Check out the full guide >
The bottom line
Generative AI provides humans with a new mode of interaction—and it doesn’t just alleviate the tedious parts of software development. It also inspires developers to be more creative, feel empowered to tackle big problems, and model large, complex solutions in ways they couldn’t before. From increasing productivity and offering alternative solutions, to helping you build new skills—like learning a new language or framework, or even writing clear comments and documentation—there are so many reasons to be excited about the next wave of software development. This is only the beginning.
In our recent blog post announcing GitHub Copilot X, we mentioned that generative AI represents the future of software development. This amazing technology will enable developers to stay in the flow while helping enterprises meet their business goals.
But as we have also mentioned in our blog series on compliance, generative AI may soon act as an enabler for developer-focused compliance programs that will drive optimization and keep your development, compliance and audit teams productive and happy.
Today, we’ll explore the potential for generative AI to help enable teams to optimize and automate some of the foundational compliance components of separation of duties that many enterprises still often manage and review manually.
Generative AI has been dominating the news lately—but what exactly is it? Here’s what you need to know, and what it means for developers.
Separation of duties
The concept of “separation of duties,” long used in the accounting world as a check and balance approach, is also adopted in other scenarios, including technology architecture and workflows. While helpful to address compliance, it can lead to additional manual steps that can slow down delivery and innovation.
Fortunately, the PCI-DSS requirements guide provides a more DevOps, cloud native, and AI-enabled approach to separation of duties by focusing on functions and accounts, as opposed to people:
“The purpose of this requirement is to separate the development and test functions from the production functions. For example, a developer can use an administrator-level account with elevated privileges in the development environment and have a separate account with user-level access to the production environment.”
There are many parts of a software delivery workflow that need to have separation of duties in place—but one of the core components that is key for any compliance program is the code review. Having a separate set of objective eyes reviewing your code, whether it’s human or AI-powered, helps to ensure risks, tech debt, and security vulnerabilities are found and mitigated as early as possible.
Code reviews also help enable the concept of separation of duties since it prohibits a single person or a single function, account, or process from moving code to the next part of your delivery workflow. Additionally, code reviews help enable separation of duties for Infrastructure as Code (IaC) workflows, Policy-as-Code configurations, and even Kubernetes declarative deployments.
As we mentioned in our previous blog, GitHub makes code review easy, since pull requests are part of the existing workflow that millions of developers use daily. Having a foundational piece of compliance built-in to the platform that developers know and love keeps them in the flow, while keeping compliance and audit teams happy as well.
Generative AI and pull requests
Wouldn’t it be cool if one-day generative AI could be leveraged to enable more developer-friendly compliance programs which have traditionally been very labor and time intensive? Imagine if generative AI could help enable DevOps and cloud native approaches for separation of duties by automating tedious tasks and allowing humans to focus on key value-added tasks.
Bringing this back to compliance and separation of duties, wouldn’t it be great if a generative AI helper was available to provide an objective set of eyes on your pull requests? This is what the GitHub Next team has been working towards with GitHub Copilot for Pull Requests.
Suggestions for your pull request descriptions. AI-powered tags are embedded into a pull request description and automatically filled out by GitHub Copilot based on the code which the developers changed. Going one step further, the GitHub Next team is also looking at the creation of descriptive sentences and paragraphs as developers create pull requests.
Code reviews with AI. Taking pull requests and code reviews one step further, the GitHub Next team is looking at AI to help review the code and provide suggestions for changes. This will help enable human interactions and optimize existing processes. The AI would automate the creation of the descriptions, based on the code changes, as well as suggestions for improvements. The code reviewer will have everything they need to quickly review the change and decide to either move forward or send the change back.
When these capabilities are production ready, development teams and compliance programs will appreciate these features for a few reasons. First, the pull request and code review process would be driven by a conversation based on a neutral and independent description. Second, the description will be based on the actual code that was changed. Third, both development and compliance workflows will be optimized and allow humans to focus on value-added work.
While these capabilities are still a work in progress, there are features available now that may help enable compliance, audit, and security teams with GitHub Copilot for Business. The ability for developers to complete tasks faster and stay in the flow are truly amazing. But the ability for GitHub Copilot to provide AI-based security vulnerability filtering nowis a great place for compliance and audit teams within enterprises to get started on their journey to embracing generative AI into their day-to-day practices.
Next steps
Generative AI will enable developers and enterprises to achieve success by reducing manual tasks and enabling developers to focus their creativity on business value–all while staying in the flow.
I hope this blog will help drive positive discussions regarding this topic and has provided a forward looking view into what will be possible in the future. The future ability of generative AI to help enable teams by automating tedious tasks will help humans focus on more value-added work and could eventually be an important part of a robust and risk-based compliance posture.
Developers who feel more satisfied in their jobs are better positioned to be more productive. We also know developers can gain a sense of fulfillment by making an impact beyond the walls of their company and elevating their community. An opportunity exists, which developers can meet, to support those who lack access to the financial system. Many countries are working to drive financial inclusion through different motions—to which developers can contribute. GitHub provides a set of tools and services, which can support your developers working to address this need.
For example, in Australia, there is a huge opportunity to continue the work aimed at reaching those who are not currently included in the financial system. There are still a large number of people that don’t have access to important services that many of us take for granted—an opportunity that financial inclusion tries to solve.
Let’s explore these opportunities and how GitHub can help.
Financial inclusion explained
The World Bank defines financial inclusion as providing individuals and businesses access to affordable financial products to meet their needs. This includes products, such as checking accounts, credit cards, mortgages, and payments, which are still not available to over a billion unbanked people around the world. Many of these are women, people living in poverty, and those living outside of large cities.
Open Finance (or Open Banking) is an approach adopted by banks like NAB (National Australia Bank) to help include more individuals in the financial system by providing them access to the best products and services in a secure way that addresses their needs.
To enable financial inclusion and Open Finance, there needs to be a channel to exchange data and services between banks, customers, and trusted partners (fintechs, for example); that is where application programming interfaces (APIs) come in. The easiest way to understand an API is to think of it as a contract between two applications that need a standardized and secure way to talk to each other. Once the contract is created and secured, it can be used anywhere to share data or initiate a financial transaction.
This API-driven innovation lowers barriers for those individuals who may have limited physical access to banks, credit cards, or traditional financial products.
How GitHub can help
The tremendous opportunities for Australia, New Zealand, India, and other countries to enable financial inclusion to its population are dependent on the quality of the APIs. The quality and adoption of the APIs is dependent on creating a great developer experience because they are the ones building the APIs and applications that will leverage them.
GitHub is used by 100 million developers and is widely-recognized as the global home of open source. Developer experience is at the core of everything we do and it empowers developers to do their best work and be happy. But how does GitHub help enable financial inclusion and Open Finance?
The Open Bank Project released a report in 2020 highlighting how providing a great developer experience can drive growth of APIs that enable financial inclusion. Several topics which were highlighted and where GitHub can help are:
1. Create solutions to help people
This is an important motivator for developers. If developers create solutions that can help increase financial inclusion, they should make sure those solutions are available to as many people as possible through the open source community. Since we know that open source is the foundation of more than 90% of the world’s software, there is a great opportunity to collaborate globally and build on solutions that already exist.
Because GitHub is the home of open source and has 100 million developers, there is no better place for developers to create solutions that will make the biggest impact.
2. Running Hackathons
Hackathons, like the Global Open Finance Challenge, which NAB collaborated in and was won by an Aussie start-up, are important for developers to share ideas with other developers and large enterprises. They help developers see what APIs are currently available and enable innovation and collaboration with a global reach. To run a successful hackathon, developers will need to have access to code and documentation, which has been open sourced—and GitHub is a key component to enable this.
3. Recognition for developers
If a developer has worked on a solution that is helping enable financial inclusion, it’s important to ensure their effort is recognized and supported. The most important part of recognizing the awesome work developers do is to make sure there is a single platform where this work can be shared. Thankfully, that platform already exists and any developer, anywhere in the world, can access it for free—it’s GitHub!
At GitHub, we also know that sometimes recognition isn’t enough, and developers need support. This is why the GitHub Sponsors program was created. We also created our GitHub for Startups program which provides support to the startup community around the world—many of whom are important contributors to Open Banking.
4. Documentation
The success of an API is dependent on how easy it is for developers to understand and use. If developers are unable to quickly understand the context of the API, how to connect to it, or easily set it up to test it, then it probably won’t be successful.
The topic of API documentation and API Management is beyond the scope of this post, but it’s important to remember that open source is a key enabler of Open Finance and developers will need a platform to collaborate and share documentation and code. GitHub is the best platform for that, and we have seen at least a 50% increase in productivity when developers leverage documentation best practices enabled by GitHub.
Call to action
Developers have an amazing opportunity to contribute to the financial inclusion work that is happening in Australia and across the world. GitHub can help support developers to address this opportunity by giving them the tools and services they need to be productive and successful.
We’ve recently launched our weekly livestream on LinkedIn Live, GitHub in my Day Job, for those who want to learn more about how GitHub empowers developers across the community while providing guardrails to govern, and remain compliant. So, join us at https://gh.io/dayjob—we can’t wait to have you with us.
By now, you’ve heard of generative artificial intelligence (AI) tools like ChatGPT, DALL-E, and GitHub Copilot, among others. They’re gaining widespread interest thanks to the fact that they allow anyone to create content from email subject lines to code functions to artwork in a matter of moments.
This potential to revolutionize content creation across various industries makes it important to understand what generative AI is, how it’s being used, and who it’s being used by. In this article, we’ll explore what generative AI is, how it works, some real-world applications, and how it’s already changing the way people (and developers) work.
What is generative AI used for?
You may have heard the buzz around new generative AI tools like ChatGPT or the new Bing, but there’s a lot more to generative AI than any one single framework, project, or application.
Traditional AI systems are trained on large amounts of data to identify patterns, and they’re capable of performing specific tasks that can help people and organizations. But generative AI goes one step further by using complex systems and models to generate new, or novel, outputs in the form of an image, text, or audio based on natural language prompts.
Generative AI models and applications can, for example, be used for:
Text generation. Text generation, as a field, with AI tools has been in development since the 1970s—but more recently, AI researchers have been able to train generative adversarial networks (GANs) to produce text that models human-like speech. A prime example is OpenAI’s application ChatGPT, which has been trained on thousands of texts, books, articles, and code repositories, and can respond with full answers to natural language prompts and questions.
An example of text generation in ChatGPT
Image generation. Generative AI models can be used to create new images with natural language prompts, which is one of the most popular techniques with current tools and applications. The goal with text-to-image generation is to create an image that accurately represents the content of a given prompt. For example, when we give the text prompt, “impressionist style oil painting of a Shiba Inu dog giving a tarot card reading,” to the popular AI image generator DALL-E 2 we get something that looks like this (and yes, it’s a gem):
An AI-generated image from DALL-E 2 of a Shiba Inu dog giving a tarot card reading
Video generation. Generative AI models, like Stable Diffusion, are creating new videos from existing videos by applying specified styles through a text prompt or image reference. One project on GitHub, stable-diffusion-videos, offers helpful examples and tips on how to create music videos and videos that can morph between text prompts with Stable Diffusion.
Programming code generation. Rather than scouring the internet or developer community groups for help with code examples, generative AI models can be used to help generate new programming code with natural language prompts, complete partially written code with suggestions, or even translate code from one programming language to another. This is how, at a simple level, GitHub Copilot works: it uses OpenAI’sCodex model to offer code suggestions right from a developer’s editor. However, as you would with any software development tool, we encourage you to review generated code before merging into production.
Data generation. Creating new data—which is called synthetic data—and augmenting existing data sets is another common use case for generative AI. This involves generating new samples from an existing dataset to increase the dataset’s size and improve machine learning models trained on it, all while providing a layer of privacy since real user data is not being utilized to power models. Synthetic data generation provides a way to create useful, meaningful data for more than just ML training though—a number of self-driving car companies like Cruise and Waymoutilize AI-generated synthetic data for training perception systems to prepare vehicles for real-world situations while in operation.
Language translation. Natural-language understanding (NLU) models combined with generative AI have become increasingly popular to provide language translations on-the-fly. These types of tools help companies break language barriers and increase their scope of accessibility for customer bases by being able to provide things like support or documentation in their native language. Through complex, deep learning algorithms, generative AI is able to understand the context of a source text and linguistically construct those sentences in another language. This practice can also apply to coding languages, for example, translating a desired function from Python to Java.
The bottom line: Even though generative AI is a relatively new technology, it’s already being used in consumer and business applications. The use cases, as well as the quantity of applications created with it, will continue evolving to meet more distinct and specific needs.
How does generative AI work?
Generative AI models work by using neural networks to identify patterns from large sets of data, then generate new and original data or content.
But what are neural networks? In simple terms, they use interconnected nodes that are inspired by neurons in the human brain. These networks are the foundation of machine learning and deep learning models, which use a complex structure of algorithms to process large amounts of data such as text, code, or images. Training these neural networks involves adjusting the weights or parameters of the connections between neurons to minimize the difference between predicted and desired outputs, which allows the network to learn from mistakes and make more accurate predictions based on the data.
Algorithms are a key component of machine learning and generative AI models. But beyond helping machines learn from data, algorithms are also used to optimize accuracy of outputs and make decisions, or recommendations, based on input data.
While algorithms help automate these processes, building a generative AI model is incredibly complex due to the massive amounts of data and compute resources they require. People and organizations need large datasets to train these models, and generating high-quality data can be time-consuming and expensive.
To restate the obvious, these models are complicated. Need proof? Here are some common generative AI models and how they work:
Large language models (LLM): LLMs are a type of machine learning model that process and generate natural language text. One of the most significant advancements in the development of large language models has been the availability of vast amounts of text data, such as books, websites, and social media posts. This data can be used to train models that are capable of predicting and generating natural language responses in a variety of contexts. As a result, large language models have multiple practical applications, such as virtual assistants, chatbots, or text generators, like ChatGPT.
Generative adversarial networks (GAN): GANs are one of the most used models for generative AI, and they employ two different neural networks. GANs consist of two different types of neural networks: a generator and a discriminator. The generator network generates new data, such as images or audio, from a random noise signal while the discriminator is trained to distinguish between real data from the training set and the data produced by the generator.
During training, the generator tries to create data that can trick the discriminator network into thinking it’s real. This “adversarial” process will continue until the generator can produce data that is totally indistinguishable from real data in the training set. This process helps both networks improve at their respective tasks, which ultimately results in more realistic and higher-quality generated data.
A diagram illustrating how a generative adversarial network works. Image [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/deed.en) האדם-החושב on wikipedia
Transformer-based models: A transformer-based model’s neural networks operate by learning context and meaning through tracking relationships of sequential data, which means these models are really good at natural language processing tasks like machine translation, language modeling, and answering questions. These models have been used in popular language models, such as GPT-4 (which stands for Generative Pre-trained Transformer 4), and have also been adapted for other such tasks that require the modeling of sequential data such as image recognition.
Variational autoencoder models (VAEs): These models are similar to GANs in that they work with two different neural networks: encoders and decoders. VAEs can take a large amount of data and compress it into a smaller representation, which can be used to create new data that is similar to the original data. VAEs are often used in image, video, and audio generation—and here’s a fun fact: you can train a VAE on datasets like CelebA, which contains over 200,000 images of celebrities, to create completely new portraits of people that don’t exist.
The smile vector, a concept vector discovered by Tom White using VAEs trained on the CelebA dataset.
The real-world applications of generative AI
The impact of generative AI is quickly becoming apparent—but it’s still in its early days. Despite this, we’re already seeing a proliferation of applications, products, and open source projects that are using generative AI models to achieve specific outcomes for people and organizations (and yes, developers, too).
Though generative AI is constantly evolving, it already has some solid real world applications. Here’s just a few of them:
Coding
New and seasoned developers alike can utilize generative AI to improve their coding processes. Generative AI coding tools can help automate some of the more repetitive tasks, like testing, as well as complete code or even generate brand new code. GitHub has its own AI-powered pair programmer, GitHub Copilot, which uses generative AI to provide developers with code suggestions. And GitHub also has announced GitHub Copilot X, which brings generative AI to more of the developer experience across the editor, pull requests, documentation, CLI, and more.
Accessibility
Generative AI has the potential to greatly impact and improve accessibility for folks with disabilities through a variety of modalities, such as speech-to-text transcription, text-to-speech audio generation, or assistive technologies. One of the most exciting facets of our GitHub Copilot tool is its voice-activated capabilities that allow developers with difficulties using a keyboard to code with their voice. By leveraging the power of generative AI, these types of tools are paving the way for a more inclusive and accessible future in technology.
Gaming
Generative AI can take gaming to the next level (get it? ) by generating new characters, storylines, design components, and more. Case in point: The developer behind the game, This Girl Does Not Exist, has said that every component of the game—from the storyline to the art and even the music—was generated entirely by AI. This use of generative AI can enable gaming studios to create new and exciting content for their users, all without increasing the developer workload, which frees them up to work on other aspects of the game, such as story development.
Web design
Designers can utilize generative AI tools to automate the design process and save significant time and resources, which allows for a more streamlined and efficient workflow. Additionally, incorporating these tools into the development process can lead to the creation of highly customized designs and logos, enhancing the overall user experience and engagement with the website or application. Generative AI tools can also be used to do some of the more tedious work, such as creating design layouts that are optimized and adaptable across devices. For example, designers can use tools like designs.ai to quickly generate logos, banners, or mockups for their websites.
Web search
Microsoft and other industry players are increasingly utilizing generative AI models in search to create more personalized experiences. This includes query expansion, which generates relevant keywords to reduce the number of searches. So, rather than the search engine returning a list of links, generative AI can help these new and improved models return search results in the form of natural language responses. Bing now includes AI-powered features in partnership with OpenAI that provide answers to complex questions and allow users to ask follow-up questions in a chatbox for more refined responses.
Healthcare
Interest has emerged around the potential applications of generative AI in the healthcare field to improve disease detection and diagnosis, advance medical research, and accelerate progress in the pharmaceutical space. Potentially, generative AI could be used to analyze large amounts of data to simulate chemical structures and predict new compounds will be the most effective for new drug discoveries. NVIDIA Clara is one example of a generative AI model specifically designed for medical imaging and healthcare research. (Plus, Gartner suggests more than 30 percent of new pharmaceutical drugs and materials will be discovered via generative AI models by 2025.)
In marketing, content is king—and generative AI is making it easier than ever to quickly create large amounts of it. A number of companies, agencies, and creators are already turning to generative AI tools to create images for social posts or write captions, product descriptions, blog posts, email subject lines, and more. Generative AI can also help companies personalize ad experiences by creating custom, engaging content for individuals at speed. Writers, marketers, and creators can leverage tools like Jasper to generate copy, Surfer SEO to optimize organic search, or albert.ai to personalize digital advertising content.
Art and design
As we’ve seen above, the power of AI can be harnessed to create some incredible portraits in a matter of moments (re: the future-telling Shiba ). Artists and designers alike are using these AI tools as a source of inspiration. For example, architects can quickly create 3D models of objects or environments and artists can breathe new life into their portraits by using AI to apply different styles, like adding a Cubist style to their original image. Need proof? Designers are already starting to use AI image generators, such as Midjourney and Microsoft Designer, to create high-quality images by simply typing out Discord commands.
Finance
In a recent discussion about tech trends and how they’ll affect the finance sector, Michael Schrage, a research fellow at the MIT Sloan School Initiative on the Digital Economy, said, “I think, increasingly, we’re going to be seeing generative AI used for financial forecasts and scenario generation.” This is a likely path forward—generative AI can be used to analyze large amounts of data to detect fraud, manage risk, and inform decision making. And that has obvious applications in the financial services industry.
Manufacturing
Manufacturers are starting to turn to generative AI solutions to help with product design, quality control, and predictive maintenance. Generative AI can be used to analyze historical data to improve machine failure predictions and help manufacturers with maintenance planning. According to research conducted by Capgemini, more than half of European manufacturers are implementing some AI solutions (although so far, these aren’t generative AI solutions). This is largely because the sheer amount of manufacturing data is easier for machines to analyze at speed than humans.
AI as a partner: Generative AI models and tools are narrow in focus, and work best at generating content, code, and images. In research at GitHub, we’ve found that GitHub Copilot helps developers code up to 55% faster, underscoring how generative AI models and tools can improve overall productivity and boost efficiency. Metrics like these show how generative AI tools are already changing how people and teams work—but they also underscore how these tools act as complement to human efforts.
Take this with you
Whether it’s creating visual assets for an ad campaign or augmenting medical images to help diagnose diseases, generative AI is helping us solve complex problems at speed. And the emergence of generative AI-based programming tools has revolutionized the way developers approach writing code.
While these models aren’t perfect yet, they’re getting better by the day—and that’s creating an exciting immediate future for developers and generative AI.
In March, we experienced six incidents that resulted in degraded performance across GitHub services. This report also sheds light into a February incident that resulted in degraded performance for GitHub Codespaces.
February 28 15:42 UTC (lasting 1 hour and 26 minutes)
On February 28 at 15:42 UTC, our monitors detected a higher than normal failure rate for creating and starting GitHub Codespaces in the East US region, caused by slower than normal VM allocation time from our cloud provider. To reduce impact to our customers during this time, we redirected codespace creations to a secondary region. Codespaces in other regions were not impacted during this incident.
To help reduce the impact of similar incidents in the future, we tuned our monitors to allow for quicker detection. We are also making architectural changes to enable failover for existing codespaces and to initiate failover automatically without human intervention.
March 01 12:01 UTC (lasting 3 hour and 06 minutes)
On March 1 at 12:01 UTC, our monitors detected a higher than normal latency for requests to Container, NPM, Nuget, and RubyGems Packages registries. Initial impact was 5xx responses to 0.5% of requests, peaking at 10% during this incident. We determined the root cause to be an unhealthy disk on a VM node hosting our database, which caused significant performance degradation at the OS level. All MySQL servers on this problematic node experienced connection delays and slow query execution, leading to the high failure rate.
We mitigated this with a failover of the database. We recognize this incident lasted too long and have updated our runbooks for quicker mitigation short term. To address the reliability issue, we have architectural changes in progress to migrate the application backend to a new MySQL infrastructure. This includes improved observability and auto-recovery tooling, thereby increasing application availability.
March 02 23:37 UTC (lasting 2 hour and 18 minutes)
On March 2 at 23:37 UTC, our monitors detected an elevated amount of failed requests for GitHub Actions workflows, which appeared to be caused by TLS verification failures due to an unexpected SSL certificate bound to our CDN IP address. We immediately engaged our CDN provider to help investigate. The root cause was determined to be a configuration change on the provider’s side that unintentionally changed the SSL certificate binding to some of our GitHub Actions production IP addresses. We remediated the issue by removing the certificate binding.
Our team is now evaluating onboarding multiple DNS/CDN providers to ensure we can maintain consistent networking even when issues arise that are out of our control.
March 15 14:07 UTC (lasting 1 hour and 20 minutes)
On March 15 at 14:07 UTC, our monitors detected increased latency for requests to Container, NPM, Nuget, RubyGems package registries. This was caused by an operation on the primary database host that was performed as part of routine maintenance. During the maintenance, a slow running query that was not properly drained blocked all database resources. We remediated this issue by killing the slow running query and restarting the database.
To prevent future incidents, we have paused maintenance until we investigate and address the draining of long running queries. We have also updated our maintenance process to perform additional safety checks on long running queries and blocking processes before proceeding with production changes.
March 27 12:25 UTC (lasting 1 hour and 33 minutes)
On March 27 at 12:25 UTC, we were notified of impact to pages, codespaces and issues. We resolved the incident at 13:29 UTC.
Due to the recency of this incident, we are still investigating the contributing factors and will provide a more detailed update in next month’s report.
March 29 14:21 UTC (lasting 4 hour and 29 minutes)
On March 29 at 14:21 UTC, we were notified of impact to pages, codespaces and actions. We resolved the incident at 18:50 UTC.
Due to the recency of this incident, we are still investigating the contributing factors and will provide a more detailed update in next month’s report.
March 31 01:16 UTC (lasting 52 minutes)
On March 31 at 01:16 UTC, we were notified of impact to Git operations, issues and pull requests. We resolved the incident at 02:08 UTC.
Due to the recency of this incident, we are still investigating the contributing factors and will provide a more detailed update in next month’s report.
Please follow our status page for real-time updates on status changes. To learn more about what we’re working on, check out the GitHub Engineering Blog.
In February, we experienced three incidents that resulted in degraded performance across GitHub services. This report also sheds light into a January incident that resulted in degraded performance for GitHub Packages and GitHub Pages and another January incident that impacted Git users.
January 30 21:31 UTC (lasting 35 minutes)
On January 30 at 21:36 UTC, our alerting system detected a 500 error response increase in requests made to the Container registry. As a result, most builds on GitHub Pages and requests to GitHub Packages failed during the incident.
Upon investigation, we found that a change was made to the Container registry Redis configuration at 21:30 UTC to enforce authentication on Redis connections. There was an issue with the Container registry production deployment file where client connections were unable to authenticate due to a hard coded connection string, resulting in errors and preventing successful connections.
At 22:12 UTC, we reverted the configuration change for Redis authentication. Container registry began recovering two minutes later, and GitHub Pages was considered healthy again by 22:21 UTC.
To help prevent future incidents, we improved management of secrets in the Container registry’s Redis deployment configurations and added extra test coverage for authenticated Redis connections.
January 30 18:35 UTC (lasting 7 hours)
On January 30 at 18:35 UTC, GitHub deployed a change which slightly altered the compression settings on source code downloads. This change altered the checksums of the resulting archive files, resulting in unforeseen consequences for a number of communities. The contents of these files were unchanged, but many communities had come to rely on the precise layout of bytes also being unchanged. When we realized the impact we reverted the change and communicated with affected communities.
We did not anticipate the broad impact this change would have on a number of communities and are implementing new procedures to prevent future incidents. This includes working through several improvements in our deployment of Git throughout GitHub and adding a checksum validation to our workflow.
February 7 21:30 UTC (lasting 20 hours and 35 minutes)
On February 7 at 21:30 UTC, our monitors detected failures creating, starting, and connecting to GitHub Codespaces in the Southeast Asia region, caused by a datacenter outage of our cloud provider. To reduce the impact to our customers during this time, we redirected codespace creations to a secondary location, allowing new codespaces to be used. Codespaces in that region recovered automatically when the datacenter recovered, allowing existing codespaces in the region to be restarted. Codespaces in other regions were not impacted during this incident.
Based on learnings from this incident, we are evaluating expanding our regional redundancy and have started making architectural changes to better handle temporary regional and datacenter outages, including more regularly exercising our failover capabilities.
February 18 02:36 UTC (lasting 2 hours and 26 minutes)
On February 18 at 02:36 UTC, we became aware of errors in our application code pointing to connectivity issues to our MySQL databases. Upon investigation, we believe these errors were due to a few unhealthy deployments of our sharding middleware. At 03:30 UTC, we performed a re-deployment of the database infrastructure in an effort to remediate. Unfortunately, this propagated the issue to all Kubernetes pods, leading to system-wide errors. As a result, multiple services returned 500 error responses and GitHub users were experiencing issues signing in to GitHub.com.
At 04:30 UTC, we found that the database topology in 30% of our deployments was corrupted, which prevented applications from connecting to the database. We applied a copy of the correct database topology to all deployments, which resolved the errors across services by 05:00 UTC. Users were then able to sign in to GitHub.com.
To help prevent future incidents, we added a monitor to detect database topology errors so we can identify this well in advance of these changes impacting production systems. We have also improved our observability around topology reloads, both successful and erroneous ones. We are also doing a deeper review of the contributing factors to this incident to learn and improve both our architecture and operations to prevent a recurrence.
February 28 16:05 UTC (lasting 1 hour and 26 minutes)
On February 28 at 16:05 UTC, we were notified of degraded performance for GitHub Codespaces. We resolved the incident at 17:31 UTC.
Due to the recency of this incident, we are still investigating the contributing factors and will provide a more detailed update in next month’s report.
Please follow our status page for real-time updates on status changes. To learn more about what we’re working on, check out the GitHub Engineering Blog.
In GitHub’s recent 2022 State of the Octoverse report, HashiCorp Configuration Language (HCL) was the fastest growing programming language on GitHub. HashiCorp is a leading provider of Infrastructure as Code (IaC) automation for cloud computing. HCL is HashiCorp’s configuration language used with tools like Terraform and Vault to deliver IaC capabilities in a human-readable configuration file across multi-cloud and on-premises environments.
HCL’s growth shows the importance of bringing together the worlds of infrastructure, operations, and developers. This was always the goal of DevOps. But in reality, these worlds remain siloed for many enterprises.
In this post we’ll look at the business and cultural influences that bring development and operations together, as well as security, governance, and networking teams. Then, we’ll explore how GitHub and HashiCorp can enable consistent workflows and guardrails throughout the entire CI/CD pipeline.
The traditional world of operations (Ops)
Armon Dadgar, co-founder of HashiCorp, uses the analogy of a tree to explain the traditional world of Ops. The trunk includes all of the shared and consistent services you need in an enterprise to get stuff done. Think of things like security requirements, Active Directory, and networking configurations. A branch represents the different lines of business within an enterprise, providing services and products internally or externally. The leaves represent the different environments and technologies where your software or services are deployed: cloud, on-premises, and container environment, among others.
In many enterprises, the communication channels and processes between these different business areas can be cumbersome and expensive. If there is a significant change to the infrastructure or architecture, multiple tickets are typically submitted to multiple teams for reviews and approvals across different parts of the enterprise. Change Advisory Boards are commonly used to protect the organization. The change is usually unable to proceed unless the documentation is complete. Commonly, there’s a set of governance logs and auditable artifacts which are required for future audits.
Wouldn’t it be more beneficial for companies if teams had an optimized, automated workflow that could be used to speed up delivery and empower teams to get the work done in a set of secure guardrails? This could result in significant time and cost savings, leading to added business value.
After all, a recent Forrester report found that over three years, using GitHub drove 433% ROI for a composite organization simply with the combined power of all GitHub’s enterprise products. Not to mention the potential for time savings and efficiency increase, along with other qualitative benefits that come with consistency and streamlining work.
Your products and services would be deployed through an optimized path with security and governance built-in, rather than a sluggish, manual and error-prone process. After all, isn’t that the dream of DevOps, GitOps, and Cloud Native?
Introducing IaC
Let’s use a different analogy. Think of IaC as the blueprint for resources (such as servers, databases, networking components, or PaaS services) that host our software and services.
If you were architecting a hospital or a school, you wouldn’t use the same overall blueprint for both scenarios as they serve entirely different purposes with significantly different requirements. But there are likely building blocks or foundations that can be reused across the two designs.
IaC solutions, such as HCL, allow us to define and reuse these building blocks, similarly to how we reuse methods, modules, and package libraries in software development. With it being IaC, we can start adopting the same recommended practices for infrastructure that we use when collaborating and deploying on applications.
After all, we know that teams that adopt DevOps methodologies will see improved productivity, cloud-enabled scalability, collaboration, and security.
A better way to deliver
With that context, let’s explore the tangible benefits that we gain in codifying our infrastructure and how they can help us transform our traditional Ops culture.
Storing code in repositories
Let’s start with the lowest-hanging fruit. With it being IaC, we can start storing infrastructure and architectural patterns in source code repositories such as GitHub. This gives us a single source of truth with a complete version history. This allows us to easily rollback changes if needed, or deploy a specific version of the truth from history.
Teams across the enterprise can collaborate in separate branches in a Git repository. Branches allow teams and individuals to be productive in “their own space” and not have to worry about negatively impacting the in-progress work of other teams, away from the “production” source of truth (typically, the main branch).
Terraform modules, the reusable building blocks mentioned in the last section, are also stored and versioned in Git repositories. From there, modules can be imported to the private registry in Terraform Cloud to make them easily discoverable by all teams. When a new release version is tagged in GitHub, it is automatically updated in the registry.
Collaborate early and often
As we discussed above, teams can make changes in separate branches to not impact the current state. But what happens when you want to bring those changes to the production codebase? If you’re unfamiliar with Git, then you may not have heard of a pull request before. As the name implies, we can “pull” changes from one branch into another.
Pull requests in GitHub are a great way to collaborate with other users in the team, being able to get peer reviews so feedback can be incorporated into your work. The pull request process is deliberately very social, to foster collaboration across the team.
In GitHub, you could consider setting branch protection rules so that direct changes to your main branch are not allowed. That way, all users must go through a pull request to get their code into production. You can even specify the minimum number of reviewers needed in branch protection rules.
Tip: you could use a special type of file, the CODEOWNERS file in GitHub, to automatically add reviewers to a pull request based on the files being edited. For example, all HCL files may need a review by the core infrastructure team. Or IaC configurations for line of business core banking systems might require review by a compliance team.
Unlike Change Advisory Boards, which typically take place on a specified cadence, pull requests become a natural part of the process to bring code into production. The quality of the decisions and discussions also evolves. Rather than being a “yes/no” decision with recommendations in an external system, the context and recommendations can be viewed directly in the pull request.
Collaboration is also critical in the provisioning process, and GitHub’s integrations with Terraform Cloud will help you scale these processes across multiple teams. Terraform Cloud offers workflow features like secure storage for your Terraform state and direct integration with your GitHub repositories for a turnkey experience around the pull request and merge lifecycle.
Bringing automated quality reviews into the process
Building on from the previous section, pull requests also allow us to automatically check the quality of the changes that are being proposed. It is common in software to check that the application still compiles correctly, that unit tests pass, that no security vulnerabilities are introduced, and more.
From an IaC perspective, we can bring similar automated checks into our process. This is achieved by using GitHub status checks and gives us a clear understanding of whether certain criteria has been met or not.
GitHub Actions are commonly used to execute some of these automated checks in pull requests on GitHub. To determine the quality of IaC, you could include checks such as:
Validating that the code is syntactically correct (for example, Terraform validate).
Linting the code to ensure a certain set of standards are being followed (for example, TFLint or Terraform format).
Static code analysis to identify any misconfigurations in your infrastructure at “design time” (for example, tfsec or terrascan).
Relevant unit or integration tests (using tools such as Terratest).
Deploying the infrastructure into a “smoke test”environment to verify that the infrastructure configuration (along with a known set of parameters) results deploy into a desired state.
We recently blogged about building compliance, security, and audit into your delivery pipelines and the benefits of this approach. When you add IaC to your existing development pipelines and workflows, you’ll have the ability to describe previously manual compliance testing and artifacts as code directly into your HCL configurations files.
A natural extension to IaC, policy as code allows your security and compliance teams to centralize the definitions of your organization’s requirements. Terraform Cloud’s built-in support for the HashiCorp Sentinel and Open Policy Agent (OPA) frameworks allows policy sets to be automatically ingested from GitHub repositories and applied consistently across all provisioning runs. This ensures policies are applied before misconfigurations have a chance to make it to production.
An added bonus mentioned in another recent blog is the ability to leverage AI-powered compliance solutions to optimize your delivery even more. Imagine a future where generative AI could create compliance-focused unit-tests across your entire development and infrastructure delivery pipeline with no manual effort.
With the checks complete, it’s now time for us to deploy our new infrastructure configuration! Branching and deployment strategies is beyond the scope of this post, so we’ll leave that for another discussion.
But you can take this even further! In Terraform, it is very common to use the command terraform plan to understand the impact of changes before you push them to production. terraform apply is then used to execute the changes.
Reviewing environment changes in a pull request
HashiCorp provides an example of automating Terraform with GitHub Actions. This example orchestrates a release through Terraform Cloud by using GitHub Actions. The example takes the output of the terraform plan command and copies the output into your pull request for approval (again, this depends on the development flow that you’ve chosen).
Reviewing environment changes using GitHub Actions environments
Let’s consider another example, based on the example from HashiCorp. GitHub Actions has a built-in concept of environments. Think of these environments as a logical mapping to a target deployment location. You can associate a protection rule with an environment so that an approval is given before deploying.
So, with that context, let’s create a GitHub Action workflow that has two environments—one which is used for planning purposes, and another which is used for deployment:
Before executing the workflow, we can create an environment in the GitHub repository and associate protection rules with the environment_a_deploy. This means that a review is required before a production deployment.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.

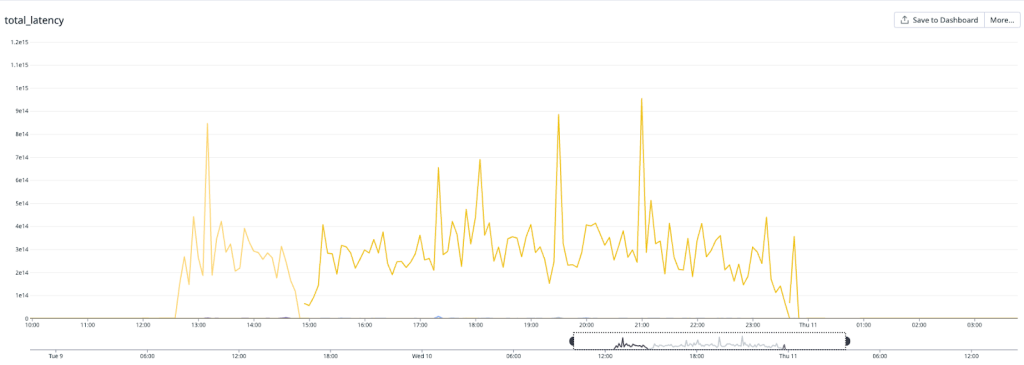
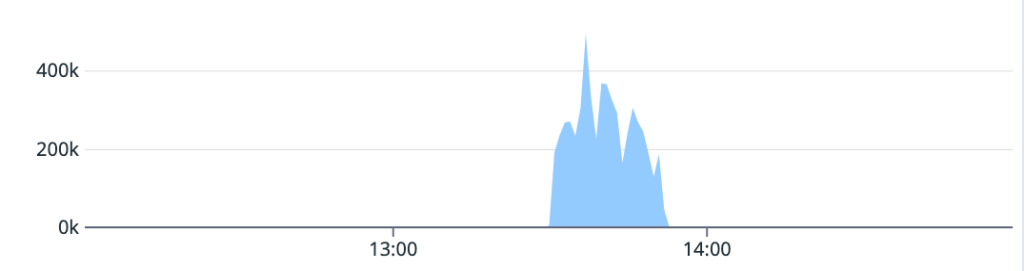















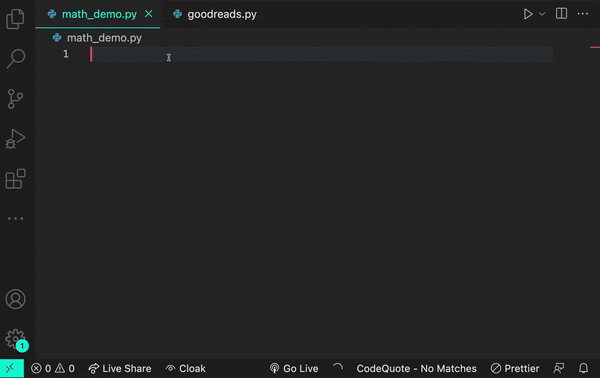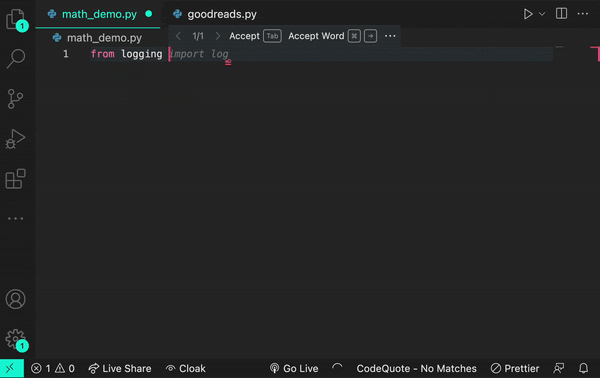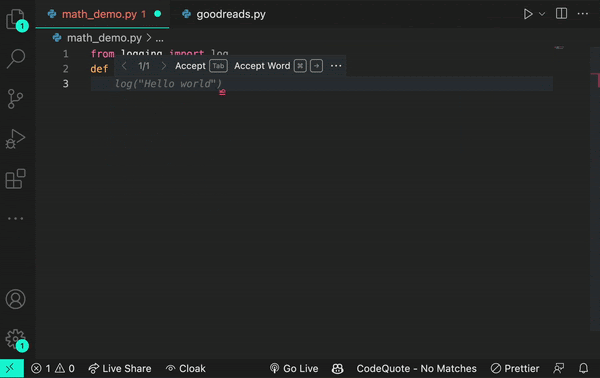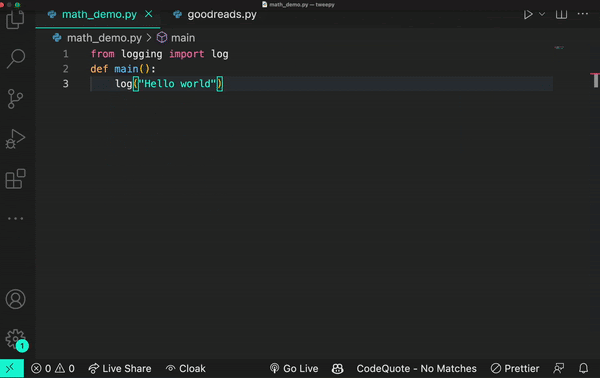
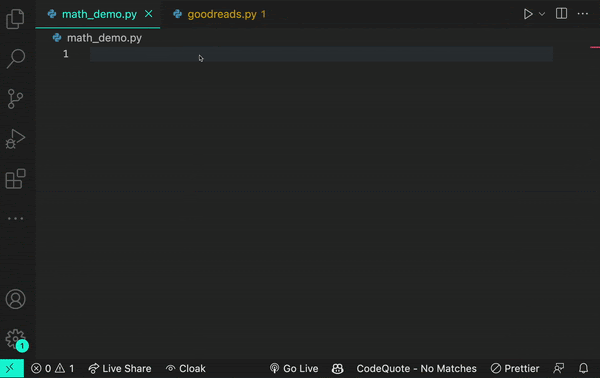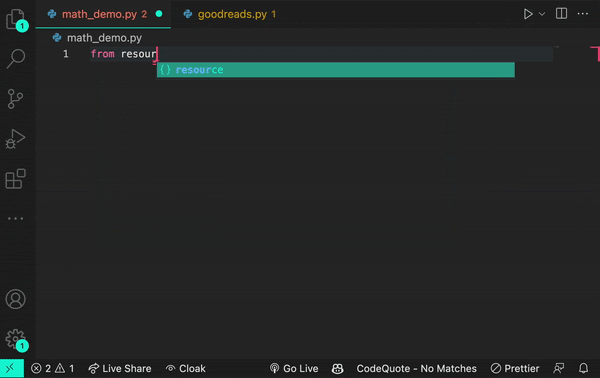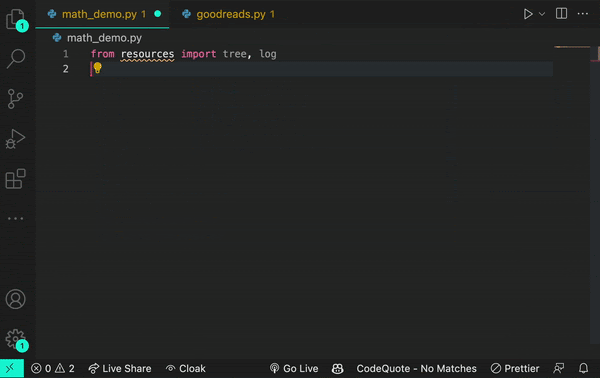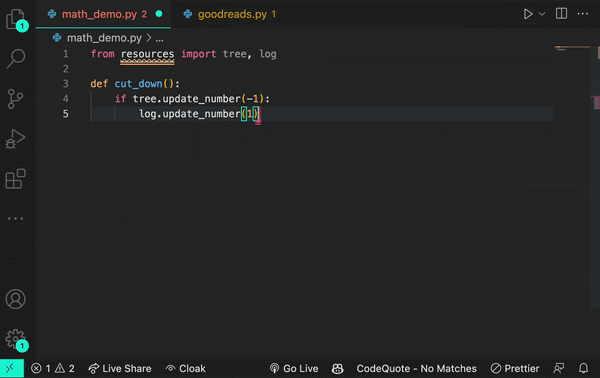
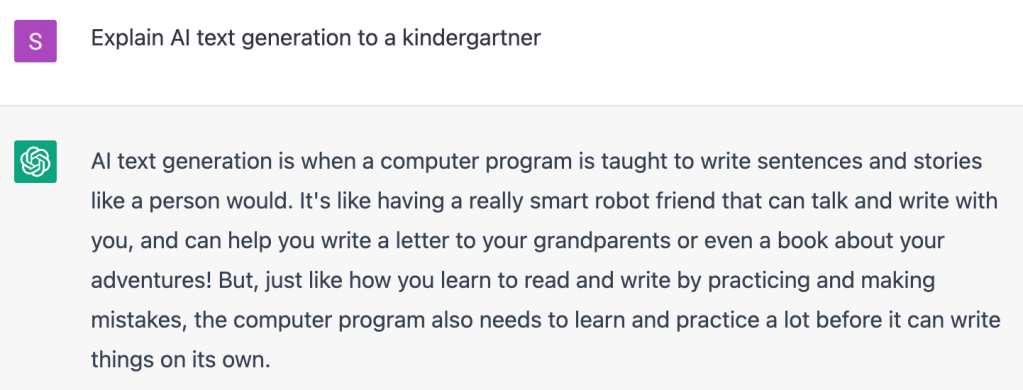

.](https://github.blog/wp-content/uploads/2023/04/image3.gif)
 האדם-החושב on wikipedia](https://github.blog/wp-content/uploads/2023/04/image4-1.png?w=1024&fit=1024%2C1024)
 using VAEs trained on the CelebA dataset.](https://github.blog/wp-content/uploads/2023/04/image6.jpg?w=539&fit=1024%2C1024)
 ) by generating new characters, storylines, design components, and more. Case in point: The developer behind the game,
) by generating new characters, storylines, design components, and more. Case in point: The developer behind the game,  ). Artists and designers alike are using these AI tools as a source of inspiration. For example, architects can quickly create 3D models of objects or environments and artists can breathe new life into their portraits by using AI to apply different styles, like adding a Cubist style to their original image. Need proof? Designers are already starting to use AI image generators, such as
). Artists and designers alike are using these AI tools as a source of inspiration. For example, architects can quickly create 3D models of objects or environments and artists can breathe new life into their portraits by using AI to apply different styles, like adding a Cubist style to their original image. Need proof? Designers are already starting to use AI image generators, such as