Last week, multiple organizations issued warnings that a ransomware campaign dubbed “ESXiArgs” was targeting VMware ESXi servers by leveraging CVE-2021-21974—a nearly two-year-old heap overflow vulnerability. Two years. And yet, Rapid7 research has found that a significant number of ESXi servers likely remain vulnerable. We believe, with high confidence, that there are at least 18,581 vulnerable internet-facing ESXi servers at the time of this writing.
That 18,581 number is based on Project Sonar telemetry. We leverage the TLS certificate Recog signature to determine that a particular server is a legitimate ESXi server. Then, after removing likely honeypots from the results, we checked the build ids of the scanned servers against a list of vulnerable build ids.
Project Sonar is a Rapid7 research effort aimed at improving security through the active analysis of public networks. As part of the project, we conduct internet-wide surveys across more than 70 different services and protocols to gain insights into global exposure to common vulnerabilities.
We have also observed additional incidents targeting ESXi servers, unrelated to the ESXiArgs campaign, that may also leverage CVE-2021-21974. RansomExx2—a relatively new strain of ransomware written in Rust and targeting Linux has been observed exploiting vulnerable ESXi servers. According to a recent IBM Security X-Force report, ransomware written in Rust has lower antivirus detection rates compared to those written in more common languages.
CISA issues fix, sort of
The U.S. Cybersecurity and Infrastructure Security Agency (CISA) on Wednesday released a ransomware decryptor to help victims recover from ESXiArgs attacks. However, it’s important to note the script is not a cure all and requires additional tools for a full recovery. Moreover, reporting suggests that the threat actor behind the campaign has modified their attack to mitigate the decryptor.
The script works by allowing users to unregister virtual machines that have been encrypted by the ransomware and re-register them with a new configuration file. However, you still need to have a backup of the encrypted parts of the VM to make a full restore.
The main benefit of the decryptor script is that it enables users to bring virtual machines back to a working state while data restore from backup occurs in the background. This is particularly useful for users of traditional backup tools without virtualization-based disaster recovery capabilities.
Rapid7 recommends
Deny access to servers. Unless a service absolutely needs to be on the internet, do not expose it to the internet. Some victims of these attacks had these servers exposed to the open internet, but could have gotten just as much business value out of them by restricting access to allowlisted IP addresses. If you are running an ESXi server, or any server, default to denying access to that server except from trusted IP space.
Patch vulnerable ESXi Servers. VMware issued a patch for CVE-2021-21974 nearly two years ago. If you have unpatched ESXi servers in your environment, click on that link and patch them now.
Develop and adhere to a patching strategy. Patching undoubtedly has challenges. However, this event illustrates perfectly why it’s essential to have a patching strategy in place and stick to it.
Back up virtual machines. Make sure you have a backup solution in place, even for virtual machines. As noted above, the decryptor script issued by the CIA is only a partial fix. The only way to completely recover from attacks associated with CVE-2021-21974 is via operational backups. There are a wide variety of backup solutions available to protect virtual machines today.
On November 30, 2022, a Google apvi report from Łukasz Siewierski initially filed on November 11, 2022 was made public. The report contained 10 different platform certificates and malware sample SHA256 sums where the malware sample had been signed by a platform certificate — the application signing certificate used to sign the “Android” application on the system image. Applications signed with platform certificates can therefore run with the same level of privileges as the “Android” application, yielding system privileges on the operating system without user input. Google has recommended that affected parties should rotate their platform certificate. However, platform certificates are considered very sensitive, and the source of these certificates is unknown at this time.
Impact and Remediation
This use of platform certificates to sign malware indicates that a sophisticated adversary has gained privileged access to very sensitive code signing certificates. Any application signed by these certificates could gain complete control over the victim device. Rapid7 does not have any information that would indicate a particular threat actor group as being responsible, but historically, these types of techniques have been preferred by state-sponsored actors. That said, a triage-level analysis of the malicious applications reported shows that the signed applications are adware — a malware type generally considered less sophisticated. This finding suggests that these platform certificates may have been widely available, as state-sponsored actors tend to be more subtle in their approach to highly privileged malware.
We note that although these platform certificates are very sensitive, the over-the-air update certificates are different, and so these cannot be used to push malicious updates.
In cases where the malware can be detected on user devices, it should be remediated immediately. The Google apvi report contains the relevant hashes and we have also listed them at the bottom of this post.
CVE-2022-42889, which some have begun calling “Text4Shell,” is a vulnerability in the popular Apache Commons Text library that can result in code execution when processing malicious input. The vulnerability was announced on October 13, 2022 on the Apache dev list. CVE-2022-42889 arises from insecure implementation of Commons Text’s variable interpolation functionality—more specifically, some default lookup strings could potentially accept untrusted input from remote attackers, such as DNS requests, URLs, or inline scripts.
CVE-2022-42889 affects Apache Commons Text versions 1.5 through 1.9. It has been patched as of Commons Text version 1.10.
The vulnerability has been compared to Log4Shell since it is an open-source library-level vulnerability that is likely to impact a wide variety of software applications that use the relevant object. However, initial analysis indicates that this is a bad comparison. The nature of the vulnerability means that unlike Log4Shell, it will be rare that an application uses the vulnerable component of Commons Text to process untrusted, potentially malicious input. Additionally, JDK version matters for exploitability. Our team tested their proof-of-concept exploit across the following JDK versions:
JDK 1.8.0_341 – PoC works
JDK 9.0.4 – PoC works
JDK 10.0.2 – PoC works
JDK 11.0.16.1 – warning but works
JDK 12.0.2 – warning but works
JDK 13.0.2 – warning but works
JDK 14.0.2 – warning but works
JDK 15.0.2 – fails
JDK 16.0.2 – fails
JDK 17.0.4.1 – fails
JDK 18.0.2.1 – fails
JDK 19 – fails
Results were identical for OpenJDK.
In summary, much like with Spring4Shell, there are significant caveats to practical exploitability for CVE-2022-42889. With that said, we still recommend patching any relevant impacted software according to your normal, hair-not-on-fire patch cycle.
Technical analysis
The vulnerability exists in the StringSubstitutor interpolator object. An interpolator is created by the StringSubstitutor.createInterpolator() method and will allow for string lookups as defined in the StringLookupFactory. This can be used by passing a string “${prefix:name}” where the prefix is the aforementioned lookup. Using the “script”, “dns”, or “url” lookups would allow a crafted string to execute arbitrary scripts when passed to the interpolator object.
Since Commons Text is a library, the specific usage of the interpolator will dictate the impact of this vulnerability. As a toy proof of concept, consider:
While this specific code fragment is unlikely to exist in production applications, the concern is that in some applications, the `pocstring` variable may be attacker-controlled. In this sense, the vulnerability echoes Log4Shell. However, the StringSubstitutor interpolator is considerably less widely used than the vulnerable string substitution in Log4j and the nature of such an interpolator means that getting crafted input to the vulnerable object is less likely than merely interacting with such a crafted string as in Log4Shell.
Mitigation guidance
Organizations who have direct dependencies on Apache Commons Text should upgrade to the fixed version (1.10.0). As with most library vulnerabilities, we will see the usual tail of follow-on vendor advisories with upgrades for products that package vulnerable implementations of the library. We recommend that you install these patches as they become available, and prioritize any where the vendor indicates that their implementation may be remotely exploitable.
Rapid7 customers
Our engineering team is evaluating the feasibility of a vulnerability check.
Last month, the Institute for Security and Technology’s (IST) Ransomware Task Force (RTF) launched the Blueprint for Ransomware Defense, a mitigation, response, and recovery plan for small- and medium-sized enterprises. This action plan is a cross-industry document that targets business leaders and protectors to ensure that even resource-strapped organizations can defend against the continued threat of extortion attacks, including ransomware.
Crucially, the RTF understands that most teams are strapped for resources, including time. So while it can be incredibly insightful — and great fun — to sketch out taxonomies of ransomware actors and their TTPs, or do graph analysis on communications networks for cybercrime groups, the blueprint considers what they call “essential cyber hygiene,” the foundational capabilities needed to successfully combat ransomware and other extortion threats.
A note on terminology
The term “ransomware” refers to a type of malware that encrypts files and demands payment for the key necessary to decrypt the files. A trend pioneered by the Maze ransomware group in 2020, double extortion, adds a second layer to this by also exfiltrating files and threatening to leak them if the ransom is not paid. We’ve also begun to see a broader trend of hack-and-leak extortion operations typified by the now-defunct LAPSU$ group, where rather than performing double extortion, the attacker simply skips the ransomware step of the operation.
While the Ransomware Task Force — as its name suggests — has prioritized ransomware, and the blueprint is called the Blueprint for Ransomware Defense, the overwhelming majority of the safeguards are useful against a variety of attacks. Thus, when we say “ransomware,” we specifically mean “an attack in which your files are encrypted and a ransom is demanded” and “extortion” for the broader class of operations.
How to use the blueprint
The blueprint outlines 40 safeguards: 14 foundational and 26 actionable. The foundational safeguards are the well-trod security advice that protectors are familiar with: Have an asset inventory, have a vulnerability management process, establish a security awareness program, etc.
Readers who wish to review these safeguards should consult the RTF blueprint directly and particularly consider printing out Appendix A, which nicely lists the category and type of each safeguard while also mapping it to the National Institute of Standards and Technology (NIST) cybersecurity framework function and the Center for Internet Security (CIS) safeguard number. There is also a helpful tools and resources spreadsheet linked in the PDF.
Safeguards to start implementing today
All of the safeguards chosen by the RTF are designed to be easy to implement and offer good “bang for your buck.” The controls that RTF has identified as important have also been identified by CIS as crucial for stopping ransomware attacks. However, some items, such as having a detailed asset inventory, are easier said than done. Of these, a handful are uniquely impactful or easy to implement, so they offer a good starting point.
1. Require MFA for externally exposed applications, remote network access, and administrative access
OK, technically this recommendation is three safeguards, but since they’re related, we’re lumping them into one. Lumping these together does not mean that implementation is a one-stop shop. Indeed, each one of these will require its own configuration to get working. However, as our incident response analysts and pentesters can both attest, the number one headache for attackers is multi-factor authentication (MFA).
MFA may not be a panacea, but it can serve as a roadblock for initial access or lateral movement, and it can provide an early warning that someone is in your environment who does not belong. If your organization is not pushing MFA everywhere, they should be, as most enterprise applications today support it natively or via single sign-on. A variety of free and paid authenticators exist and can be implemented in a straightforward manner.
2. Restrict administrator privileges to dedicated administrator accounts
Separation of duties is a longstanding core tenet of information security, but between remote work, the increased speed of communications and development, and the general expectation that things Get Done Right Now, we have systematically over-privileged user accounts. Even if global administrators remain rare, users are often local administrators on their machines, permitting the installation of unauthorized software that can be used by attackers and access brokers to establish persistence. This persistence can be leveraged into higher-level access through the use of tools like Mimikatz or techniques like Kerberoasting, and that higher-level access exposes the enterprise to significant risk.
By restricting administrator privileges to dedicated accounts, we develop some very clear indicators that something is wrong – no administrator account should ever be logged in multiple places at the same time, and there are some functions that simply should never be performed from a dedicated administrator account. This may add some friction to your IT management, but it’s good friction.
3. Use DNS filtering services
Unlike the two previous suggestions, this is something that not only could you start implementing today – you could probably finish implementing it today. Domain Name System (DNS) filtering services replace the default DNS configuration in your environment. Free options like Quad9 and OpenDNS offer security-friendly domain name lookups, which can defeat phishing attempts, malvertising, and malware command and control beaconing.
CIS also offers malicious domain blocking and reporting to members of some organizations. In general, this is a simple configuration update that can be pushed to all computers and will instantly improve your security posture.
Safeguards for tomorrow
While the three action items for today will offer the greatest return on investment for your time, all of the safeguards in the guide are important. Many are well-understood but can take time to implement. For some controls that aren’t “table stakes” in the way that deploying anti-malware software, establishing a security awareness program, and collecting audit logs are, we offer a bit of advice.
1. Manage default accounts on enterprise assets and software
As Rapid7’s own Curt Barnard demonstrated with Defaultinator this year at Black Hat, applications and hardware are still rife with default credentials that never get changed. Defaultinator is one tool that can help evaluate devices that may have default credentials in use. Finding these default accounts can be challenging, but once you have a good asset inventory, managing these default accounts is important to keeping attackers out and your data in.
2. Use unique passwords
Continuing with the notion of credentials, using unique passwords is incredibly important. Password reuse is a common way for attackers to move from a single, potentially unrelated account to your crown jewels. Today, there are myriad password management tools that will even generate unique passwords for users and many of them offer enterprise subscriptions. Of these, nearly all allow for the secure sharing of passwords – if for some reason that is necessary. (Hint: It’s almost never actually necessary, but merely a bad habit.) Easily guessable (or easily shareable) passwords often fall victim to brute-force or password-spraying attacks, and with an enterprise password management tool, no user should need to use passwords that aren’t both strong and unique.
3. Establish and maintain a data management process
While we all know the power, benefit, and value of backups – especially when it comes to ransomware – data management is a bit more nuanced. We know that attackers in double extortion or leak-and-extort operations choose the files they steal and leak carefully to put maximum pressure on victims. Thus, the data management process is of increased importance for this category of attack. Categorizing and classifying your data will help inform the particular restrictions that need to be put around that data. Since attackers are targeting and leaking different sorts of data across industries, it’s imperative to know what data is most important to you and most likely to be targeted by attackers, and to have a plan to protect it.
While extortion attacks are on the rise and ransomware remains an expensive threat to organizations, action plans like the RTF’s Blueprint for Ransomware Defense serve as great tools to help decision makers, technical leaders, and other protectors mitigate extortion attacks. The safeguards in the report and the details in this blog post can help prioritize and contextualize what needs to be done. After all, we’re all targets, but we don’t all have to be victims.
On Monday, June 14, 2022, Citrix published an advisory on CVE-2022-27511, a critical improper access control vulnerability affecting their Application Delivery Management (ADM) product.
A remote, unauthenticated attacker can leverage CVE-2022-27511 to reset administrator credentials to the default value at the next reboot. This allows the attacker to use SSH and the default administrator credentials to access the affected management console. The vulnerability has been patched in Citrix ADM 13.1-21.53 and ADM 13.0-85.19 and should be applied as soon as possible. Versions of Citrix ADM before 13.0 and 13.1 are end of life, so Citrix will not make patches available for these versions. Users still on version 12.x are encouraged to upgrade to a supported version.
At the time of this writing, no exploitation has been observed, and no exploits have been made publicly available. However, given the nature of the vulnerability and the footprint of Citrix ADM, we anticipate that exploitation will happen as soon as an exploit is made available.
Mitigation guidance
Citrix ADM customers should upgrade their versions of both ADM server and agents as soon as possible. Citrix notes in their advisory that they strongly recommend that network traffic to the Citrix ADM’s IP address be segmented, either physically or logically, from standard network traffic.
Rapid7 customers
We are investigating the feasibility of a vulnerability check for InsightVM and Nexpose customers.
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
“At this particular mobile army hospital, we’re not concerned with the ultimate reconstruction of the patient. We only care about getting the kid out of here alive enough for someone else to put on the fine touches. We work fast and we’re not dainty, because a lot of these kids who can stand 2 hours on the table just can’t stand one second more. We try to play par surgery on this course. Par is a live patient.” – Hawkeye, M*A*S*H
Recently, CISA released their Shields Up guidance around reducing the likelihood and impact of a cyber intrusion in response to increased risk around the Russia-Ukraine conflict. This week, the White House echoed those sentiments and released a statement about potential impact to Western companies from Russian threat actors. The White House guidance also included a fact sheet identifying urgent steps to take.
Given the urgency of these warnings, many information security teams find themselves scrambling to prioritize mitigation actions and protect their networks. We may not have time to make our networks less flat, patch all the vulnerabilities, set up a backup plan, encrypt all the data at rest, and practice our incident response scenarios before disaster strikes. To that end, we’ve put together 8 tips for “emergency field security” that defenders can take right now to protect themselves.
1. Familiarize yourself with CISA’s KEV, and prioritize those patches
CISA’s Known Exploited Vulnerabilities (KEV) catalog enumerates vulnerabilities that are, as the name implies, known to be exploited in the wild. This should be your first stop for patch remediation.
These vulns are known to be weaponized and effective — thus, they’re likely to be exploited if your organization is targeted and attackers expose one of them in your environment. CISA regularly updates this catalog, so it’s important to subscribe to their update notices and prioritize patching vulnerabilities included in future releases.
2. Keep an eye on egress
Systems, especially those that serve customers or live in a DMZ, are going to see tons of inbound requests – probably too many to keep track of. On the other hand, those systems are going to initiate very few outbound requests, and those are the ones that are far more likely to be command and control.
If you’re conducting hunting, look for signs that the calls may be coming from inside your network. Start keeping track of the outbound requests, and implement a default deny-all outbound rule with exceptions for the known-good domains. This is especially important for cloud environments, as they tend to be dynamic and suffer from “policy drift” far more than internal environments.
3. Review your active directory groups
Now is the perfect time to review active directory group memberships and permissions. Making sure that users are granted access to the minimum set of assets required to do their jobs is critical to making life hard for attackers.
Ideally, even your most privileged users should have regular accounts that they use for the majority of their job, logging into administrator accounts only when it’s absolutely necessary to complete a task. This way, it’s much easier to track privileged users and spot anomalous behavior for global or domain administrators. Consider using tools such as Bloodhound to get a handle on existing group membership and permissions structure.
4. Don’t laugh off LOL
Living off the land (LOL) is a technique in which threat actors use legitimate system tools in attacks. These tools are frequently installed by default and used by systems administrators to do their jobs. That means they’re often ignored or even explicitly allowed by antivirus and endpoint protection software.
You can help protect systems against LOL attacks by configuring logging for Powershell and adding recommended block rules for these binaries unless they are necessary. Refer to the regularly updated (but not comprehensive, as this is a constantly evolving space) list of these at LOLBAS.
5. Don’t push it
If your organization hasn’t mandated multi-factor authentication (MFA) yet, now would be a very good time to require it. Even if you already require MFA, you may need to let users know to immediately report any notifications they did not initiate.
Nobelium, a likely Russian-state sponsored threat actor, has been observed repeatedly sending MFA push notifications to users’ smartphones. Though push notifications are considered more secure than email or SMS notifications due to the need for physical access, it turns out that sending enough requests means many users eventually – either due to annoyance or accident – approve the request, effectively defeating the two-factor authentication.
When you do enable MFA, be sure to regularly review the authentication logs, keeping an eye out for accounts being placed in “recovery” mode, especially for extended periods of time or repeatedly. Also consider using tools or services that monitor the MFA configuration status of your environment to ensure configuration drift (or attackers) have not disabled MFA.
6. Stick to the script
Often, your enterprise’s first line of defense is the help desk. Over the next few days, it’s important that these people feel empowered to enforce your security policies.
Sometimes, people lose their phone and can’t perform their MFA. Other times, their company laptop just up and dies, and they can’t get at their presentation materials on the shared drive. Or maybe they’re sure what their password should be, but today, it just isn’t. It happens. Any number of regular disasters can befall your users, and they’ll turn to your help desk to get them back up and running. Most of the time, these aren’t devious social engineering attacks. They just need help.
Of course, the point of a help desk is to help people. Sometimes, however, the “users” are attackers in disguise, looking for a quick path around your security controls. It can be hard to tell when someone calling in to the help desk is a legitimate user who is pressed for time or an attacker trying to scale the walls. Your help desk folks should be extra wary of these requests — and, more importantly, know they won’t be fired, reprimanded, or retaliated against for following the standard, agreed-upon procedures. It might be a key executive or customer who’s having trouble, and it might not be.
You already have a procedure for resets and re-enrollments, and exceptions to that procedure need to be accompanied by exceptional evidence.
Now is the time to make sure you have solid offline backups of:
Business-critical data
Active Directory (or your equivalent identity store)
All network configurations (down to the device level)
All cloud service configurations
Continue to refresh these backups moving forward. In addition, make sure your backups are integrity-tested and that you can (quickly) recover them, especially for the duration of this conflict.
8. Practice good posture
While humans will be targeted with phishing attacks, your internet-facing components will also be in the sights of attackers. There are numerous attack surface profiling tools and services out there that help provide an attacker’s-eye view of what you’re exposing and identify any problematic services and configurations — we have one that is free to all Rapid7 customers, and CISA provides a free service to any US organization that signs up. You should review your attack surface regularly to ensure there are no unseen gaps.
While security is a daunting task, especially when faced with guidance from the highest levels of the US government, we don’t necessarily need to check all the boxes today. These 8 steps are a good start on “field security” to help your organization stabilize and prepare ahead of any impending attack.
During the British rule of India, the British government became concerned about the number of cobras in the city of Delhi. The ambitious bureaucrats came up with what they thought was the perfect solution, and they issued a bounty for cobra skins. The plan worked wonderfully at first, as cobra skins poured in and reports of cobras in Delhi declined.
However, it wasn’t long before some of the Indian people began breeding these snakes for their lucrative scales. Once the British discovered this scheme, they immediately cancelled the bounty program, and the Indian snake farmers promptly released their now-worthless cobras into the wild.
Now, the cobra conundrum was even worse than before the bounty was offered, giving rise to the term “the cobra effect.” Later, the economist Charles Goodhart coined the closely related Goodhart’s Law, widely paraphrased as, “When a measure becomes a target, it ceases to be a good measure.”
Creating metrics in cybersecurity is hard enough, but creating metrics that matter is a harder challenge still. Any business-minded person can tell you that effective metrics (in any field) need to meet these 5 criteria:
Cheap to create
Consistently measured
Quantifiable
Significant to someone
Tied to a business need
If your proposed metrics don’t meet any one of the above criteria, you are setting yourself up for a fantastic failure. Yet if they do meet those criteria, you aren’t totally out of the woods yet. You must still avoid the cobra effect.
A case study
I’d like to take a moment to recount a story from one of the more effective security operations centers (SOCs) I’ve had the pleasure of working with. They had a quite well-oiled 24/7 operation going. There was a dedicated team of data scientists who spent their time writing custom tooling and detections, as well as a wholly separate team of traditional SOC analysts, who were responsible for responding to the generated alerts. The data scientists were judged by the number of new threat detections they were able to come up with. The analysts were judged by the number of alerts they were able to triage, and they were bound by a (rather rapid) service-level agreement (SLA).
This largely worked well, with one fairly substantial caveat. The team of analysts had to sign off on any new detection that entered the production alerting system. These analysts, however, were largely motivated by being able to triage a new issue quickly.
I’m not here to say that I believe they were doing anything morally ambiguous, but the organizational incentive encouraged them to accept detections that could quickly and easily be marked as false positives and reject detections that took more time to investigate, even if they were more densely populated with true positives. The end effect was a system structured to create a success condition that was a massive number of false-positive alerts that could be quickly clicked away.
Avoiding common pitfalls
The most common metrics used by SOCs are number of issues closed and mean time to close.
While I personally am not in love with these particular quantifiers, there is a very obvious reason these are the go-to data points. They very easily fit all 5 criteria listed above. But on their own, they can lead you down a path of negative incentivization.
So how can we take metrics like this, and make them effective? Ideally, we could use these in conjunction with some analysis on false/true positivity rate to arrive at an efficacy rate that will maximize your true positive detections per dollar.
Arriving at efficacy
Before we get started, let’s make some assumptions. We are going to talk about SOC alerts that must be responded to by a human being. The ideal state is for high-fidelity alerting with automated response, but there is always a state where human intervention is necessary to make a disposition. We are also going to assume that there are a variety of types of detections that have different false-positive and true-positive rates, and for the sheer sake of brevity, we are going to pretend that false negatives incur no cost (an obvious absurdity, but my college physics professor taught me that this is fine for demonstration purposes). We are also going to assume, safely, I imagine, that reviewing these alerts takes time and that time incurs a dollars-and-cents cost.
For any alert type, you would want to establish the number of expected true positives, which is the alert rate multiplied by the true-positive rate (which you must be somehow tracking, by the way). This will give you the expected number of true positives over the alert rate period.
Great! So we know how many true positives to expect in a big bucket of alerts. Now what? Well, we need to know how much it costs to look through the alerts in that bucket! Take the alert rate, multiply by the alert review time, and if you are feeling up to it, multiply by the cost of the manpower, and you’ll arrive at the expected cost to review all the alerts in that bucket.
But the real question you want to know is, is the juice worth the squeeze? The detection efficacy will tell you the cost of each true positive and can be calculated by dividing the number of expected true positives by the expected cost. Or to simplify the whole process, divine the true-positive rate by the average alert review time, and multiply by the manpower cost.
If you capture detection efficacy this way, you can effectively discover which detections are costing you the most and which are most effective.
Dragging down distributions
Another important option to consider is the use of distributions in your metric calculation. We all remember mean, median, and mode from grade school — these and other statistics are tools we can use to tell us how effective we are. In particular, we want to ask whether our measure should be sensitive to outliers — data points that don’t look typical. We should also consider whether our mean and median are being dragged down by our distribution.
As a quick numerical example, assume we have 100 alerts come in, and we bulk-close 75 of them based on some heuristic. The other 25 alerts are all reviewed, taking 15 minutes each, and handed off as true positives. Then our median time to close is 0 minutes, and our mean time to close is 3 minutes and 45 seconds.
Those numbers are great, right? Well, not exactly. They tell us what “normal” looks like but give us no insight into what is actually happening.
To that end, we have two options. Firstly, we can remove zero values from our data! This is typical in data science as a way to clean data, since in most cases, zeros are values that are either useless or erroneous. This gives us a better idea of what “normal” looks like.
Second, we can use a value like the upper quartile to see that the 75th-percentile time to close is 15 minutes, which in this case is a much more representative example of how long an analyst would expect to spend on events. In particular, it’s easy to drag down the average — just close false positives quickly! But it’s much harder to drag down the upper quartile without making some real improvements.
3 keys to keep in mind
When creating metrics for your security program, there are a lot of available options. When choosing your metrics, there are a few keys:
Watch out for the cobra effect. Your metrics should describe something meaningful, but they should be hard to game. When in doubt, remember Goodhart’s Law — if it’s a target, it’s not a good metric.
Remember efficacy.In general, we are aiming to get high-quality responses to alerts that require human expertise. To that point, we want our analysts to be as efficient and our detections to be as effective as possible. Efficacy gives us a powerful metric that is tailor-made for this purpose.
When in doubt, spread it out.A single number is rarely able to give a truly representative measure of what is happening in your environment. However, having two or more metrics — such as mean time to response and upper-quartile time to response — can make those metrics more robust to outliers and against being gamed, ensuring you get better information.
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
Editor’s note: We had planned to publish our Hacky Holidays blog series throughout December 2021 – but then Log4Shell happened, and we dropped everything to focus on this major vulnerability that impacted the entire cybersecurity community worldwide. Now that it’s 2022, we’re feeling in need of some holiday cheer, and we hope you’re still in the spirit of the season, too. Throughout January, we’ll be publishing Hacky Holidays content (with a few tweaks, of course) to give the new year a festive start. So, grab an eggnog latte, line up the carols on Spotify, and let’s pick up where we left off.
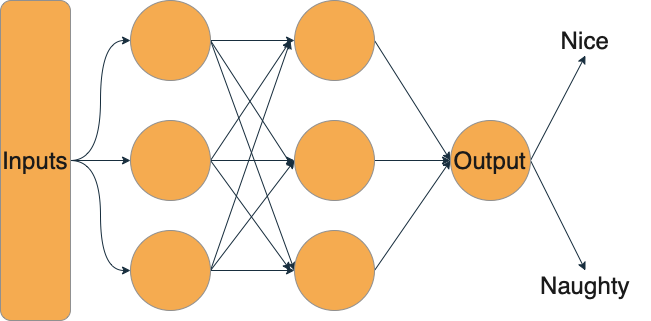
Santa’s task of making the nice and naughty list has gotten a lot harder over time. According to estimates, there are around 2.2 billion children in the world. That’s a lot of children to make a list of, much less check it twice! So like many organizations with big data problems, Santa has turned to machine learning to help him solve the issue and built a classifier using historical naughty and nice lists. This makes it easy to let the algorithm decide whether they’ll be getting the gifts they’ve asked for or a lump of coal.
Santa’s lists have long been a jealously guarded secret. After all, being on the naughty list can turn one into a social pariah. Thus, Santa has very carefully protected his training data — it’s locked up tight. Santa has, however, made his model’s API available to anyone who wants it. That way, a parent can check whether their child is on the nice or naughty list.
Santa, being a just and equitable person, has already asked his data elves to tackle issues of algorithmic bias. Unfortunately, these data elves have overlooked some issues in machine learning security. Specifically, the issues of membership inference and model inversion.
Membership inference attacks
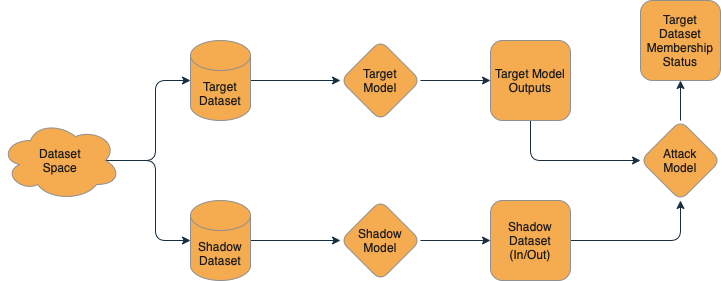
Membership inference is a class of machine learning attacks that allows a naughty attacker to query a model and ask, in effect, “Was this example in your training data?” Using the techniques of Salem et al. or a tool like PrivacyRaven, an attacker can train a model that figures out whether or not a model has seen an example before.
From a technical perspective, we know that there is some amount of memorization in models, and so when they make their predictions, they are more likely to be confident on items that they have seen before — in some ways, “memorizing” examples that have already been seen. We can then create a dataset for our “shadow” model — a model that approximates Santa’s nice/naughty system, trained on data that we’ve collected and labeled ourselves.
We can then take the training data and label the outputs of this model with a “True” value — it was in the training dataset. Then, we can run some additional data through the model for inference and collect the outputs and label it with a “False” value — it was not in the training dataset. It doesn’t matter if these in-training and out-of-training data points are nice or naughty — just that we know if they were in the “shadow” training dataset or not. Using this “shadow” dataset, we train a simple model to answer the yes or no question: “Was this in the training data?” Then, we can turn our naughty algorithm against Santa’s model — “Dear Santa, was this in your training dataset?” This lets us take real inputs to Santa’s model and find out if the model was trained on that data — effectively letting us de-anonymize the historical nice and naughty lists!
Model inversion
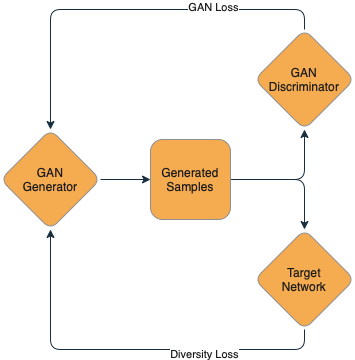
Now being able to take some inputs and de-anonymize them is fun, but what if we could get the model to just tell us all its secrets? That’s where model inversion comes in! Fredrikson et al. proposed model inversion in 2015 and really opened up the realm of possibilities for extracting data from models. Model inversion seeks to take a model and, as the name implies, turn the output we can see into the training inputs. Today, extracting data from models has been done at scale by the likes of Carlini et al., who have managed to extract data from large language models like GPT-2.
In model inversion, we aim to extract memorized training data from the model. This is easier with generative models than with classifiers, but a classifier can be used as part of a larger model called a Generative Adversarial Network (GAN). We then sample the generator, requesting text or images from the model. Then, we use the membership inference attack mentioned above to identify outputs that are more likely to belong to the training set. We can iterate this process over and over to generate progressively more training set-like outputs. In time, this will provide us with memorized training data.
Note that model inversion is a much heavier lift than membership inference and can’t be done against all models all the time — but for models like Santa’s, where the training data is so sensitive, it’s worth considering how much we might expose! To date, model inversion has only been conducted in lab settings on models for text generation and image classification, so whether or not it could work on a binary classifier like Santa’s list remains an open question.
Mitigating model mayhem
Now, if you’re on the other side of this equation and want to help Santa secure his models, there are a few things we can do. First and foremost, we want to log, log, log! In order to carry out the attacks, the model — or a very good approximation — needs to be available to the attacker. If you see a suspicious number of queries, you can filter IP addresses or rate limit. Additionally, limiting the return values to merely “naughty” or “nice” instead of returning the probabilities can make both attacks more difficult.
For extremely sensitive applications, the use of differential privacy or optimizing with DPSGD can also make it much more difficult for attackers to carry out their attacks, but be aware that these techniques come with some accuracy loss. As a result, you may end up with some nice children on the naughty list and a naughty hacker on your nice list.
Santa making his list into a model will save him a whole lot of time, but if he’s not careful about how the model can be queried, it could also lead to some less-than-jolly times for his data. Membership inference and model inversion are two types of privacy-related attacks that models like this may be susceptible to. As a best practice, Santa should:
Log information about queries like:
IP address
Input value
Output value
Time
Consider differentially private model training
Limit API access
Limit the information returned from the model to label-only
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
Much ado has been made (by this very author on this very blog!) about the incentives for attackers and defenders around ransomware. There is also a wealth of information on the internet about how to protect yourself from ransomware. One thing we want to avoid losing sight of, however, is just how we go from a machine that is working perfectly fine to one that is completely inoperable due to ransomware. We’ll use MITRE’s ATT&CK as a vague guide, but we don’t follow it exactly.
If you’re running an Exchange server, please stop reading this blog and go patch right away.
When a widely exploitable vulnerability is available, ransomware actors will target it — no matter who you are.
Highly targeted attacks have certainly leveraged ransomware, but for nearly all of these actors, the goal is profit. That means widespread scanning for and exploitation of server-side vulnerabilities that allow for initial access, coupled with tools for privilege escalation and lateral movement. It also means the use of watering hole attacks, exploit kits, and spam campaigns.
That is to say, there are a few ways the initial access to a particular machine can come about, including through:
Server-side vulnerability
Lateral movement
Watering hole or exploit kit
Spam or phishing
The particular method tends to be subject to the availability of widely exploitable vulnerabilities and the preferences of the cybercrime group in question.
Droppers
The overwhelming majority of ransomware operators don’t directly drop the ransomware payload on a victim machine. Instead, the first stage tends to be something like TrickBot, Qbot, Dridex, Ursnif, BazarLoader, or some other dropper. Upon execution, the dropper will often disable detection and response software, extract credentials for lateral movement, and — crucially — download the second-stage payload.
This all happens quietly, and the second-stage payload may not be dropped immediately. In some cases, the dropper will drop a second-stage payload which is not ransomware — something like Cobalt Strike. This tends to happen more frequently in larger organizations, where the potential payoff is much greater. When something that appears to be a home computer is infected, actors will typically quickly encrypt the machine, demand a payment that they expect to be paid, and move on with their day.
Once the attacker has compromised to their heart’s content — one machine, one subnet, or every machine at an organization — they pull the trigger on the ransomware.
How ransomware works
By this point, nearly every security practitioner and many laypeople have a conceptual understanding of the mechanics of ransomware: A program encrypts some or all of your files, displays a message demanding payment, and (usually) sends a decryption key when the ransom is paid. But under the hood, how do these things happen? Once the dropper executes the ransomware, how does it work?
Launching the executable
The dropper will launch the executable. Typically, once it has achieved persistence and escalated privileges, the ransomware will either be injected into a running process or executed as a DLL. After successful injection or execution, the ransomware will build its imports and kill processes that could stop it. Many ransomware families will also delete all shadow copies and possible backups to maximize the damage.
The key
The first step of the encryption process is getting a key to actually encrypt the files with. Older and less advanced ransomware families will first reach out to a command and control server to request a key. Others come with built-in secret keys — these are typically easy to decrypt, with the right decrypter. Others still will use RSA or some other public key encryption so that no key needs to be imported. Many advanced families of ransomware today use both symmetric key encryption for speed and public key encryption to prevent defenders from intercepting the symmetric key.
For these modern families, an RSA public key is embedded in the executable, and an AES key is generated on the victim machine. Then, the files are encrypted using AES, and the key is encrypted using the RSA public key. Therefore, if a victim pays the ransom, they’re paying for the private key to decrypt the key that was used to encrypt all of their files.
Encryption
Once the right key is in place, the ransomware begins encryption of the filesystem. Sometimes, this is file-by-file. In other cases, they encrypt blocks of bytes on the system directly. In both cases, the end result is the same — an encrypted filesystem and a ransom note requesting payment for the decryption key.
Payment and decryption
The typical “business” transaction involves sending a certain amount of bitcoin to a specified wallet and proof of payment. Then, the hackers provide their private key and a decryption utility to the victim. In most cases, the attackers actually do follow through on giving decryption keys, though we have recently seen a rise in double encryption, where two payments need to be made.
Once the ransom is paid and the files are decrypted, the real work begins.
Recovery
Recovering encrypted files is an important part of the ransomware recovery process, and whether you pay for decryption, use an available decrypter, or some other method, there’s a catch to all of it. The attackers can still be in your environment.
As mentioned, in all but the least interesting cases (one machine on one home network), attackers are looking for lateral movement, and they’re looking to establish persistence. That means that even after the files have been decrypted, you will need to scour your entire environment for residual backdoors, cobalt strike deployments, stolen credentials, and so on. A full-scale incident response is warranted.
Even beyond the cost of paying the ransom, this can be an extremely expensive endeavor. Reimaging systems, resetting passwords throughout an organization, and performing threat hunting is a lot of work, but it’s necessary. Ultimately, failing to expunge the attacker from all of your systems means that if they want to double dip on your willingness to pay (especially if you paid them!), they just have to walk through the back door.
Proactive ransomware defense
Ransomware is a popular tactic for cybercrime organizations and shows no signs of slowing down. Unlike intellectual property theft or other forms of cybercrime, ransomware is typically an attack of opportunity and is therefore a threat to organizations of all sizes and industries. By understanding the different parts of the ransomware killchain, we can identify places to plug into the process and mitigate the issue.
Patching vulnerable systems and knowing your attack surface is a good first step in this process. Educating your staff on phishing emails, the threats of enabling macros, and other security knowledge can also help prevent the initial access.
The use of two-factor authentication, disabling of unnecessary or known-insecure services, and other standard hardening measures can help limit the spread of lateral movement. Additionally, having a security program that identifies and responds to threats in your environment is crucial for controlling the movement of attackers.
Having off-site backups is a really important step in this process as well. Between double extortion and the possibility that the group that attacked your organization and encrypted your files just isn’t an honest broker, there are many ways that things could go wrong after you’ve decided to pay the ransom. This can also make the incident response process easier, since the backup images themselves can be checked for signs of intrusion.
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
The casino floor at Bally’s is a thrilling place, one that loads of hackers are familiar with from our time at DEF CON. One feature of these casinos is the unmistakable song of slots being played. Imagine a slot machine that costs a dollar to play, and pays out $75 if you win — what probability of winning would it take for you to play?
Naively, I’d guess most people’s answers are around “1 in 75” or maybe “1 in 74” if they want to turn a profit. One in 74 is a payout probability of about 1.37%. Now, at 1.37%, you turn a profit, on average, of $1 for 74 games — so how many times do you play? Probably not that many. You’re basically playing for free — but you’re not pulling much off $1 profit per 74 pulls. At least on average.
But what if that slot machine paid out about half the time, giving you $75 every other time you played? How many times would you play?
This is the game that ransomware operators are playing.
Playing Against the Profiteers
Between Wannacry, the Colonial Pipeline hack, and the recent Kaseya incident, everyone is now familiar with supply chain attacks — particularly those that use ransomware. As a result, ransomware has entered the public consciousness, and a natural question is: why ransomware? From an attacker’s perspective, the answer is simple: why not?
For the uninitiated, ransomware is a family of malware that encrypts files on a system and demands a payment to decrypt the files. Proof-of-concept ransomware has existed since at least 1996, but the attack vector really hit its stride with CryptoLocker’s innovative use of Bitcoin as a payment method. This allowed ransomware operators to perpetuate increasingly sophisticated attacks, including the 2017 WannaCry attack — the effects of which, according to the ransomware payment tracker Ransomwhere, are still being felt today.
Between the watering hole attacks and exploit kits of the Angler EK era and the recent spate of ransomware attacks targeting high-profile companies, the devastation of ransomware is being felt even by those outside of infosec. The topic of whether or not to pay ransoms — and whether or not to ban them — has sparked heated debate and commentary from folks like Tarah Wheeler and Ciaran Martin at the Brookings Institute, the FBI, and others in both industrial and academic circles. One noteworthy academic paper by Cartwright, Castro, and Cartwright uses game theory to ask the question of whether or not to pay.
Ransomware operators aren’t typically strategic actors with a long-term plan; rather, they’re profiteers who seek targets of opportunity. No target is too big or too small for these groups. Although these analyses differ in the details, they get the message right — if the ransomware operators don’t get paid, they won’t want to play the game anymore.
Warning: Math Ahead
According to Kaspersky, 56% of ransomware victims pay the ransom. Most other analyses put it around 50%, so we’ll use Kaspersky’s. In truth, it’s unlikely we have an accurate number for this, as many organizations specifically choose to pay the ransom in order to avoid public exposure of the incident.
If a ransomware attack costs some amount of money to launch and is successful some percentage of the time, the amount of money made from each attack is:
We call this the expected value of an attack.
It’s hard to know how many attacks are launched — and how many of those launched attacks actually land. Attackers use phishing, RDP exploits, and all kinds of other methods to gain initial access. For the moment, let’s ignore that problem and assume that every attack that gets launched lands. Ransomware that lands on a machine is successful about 54% of the time, and the probability of payment is 56%. Together, this means that the expected value of an attack is:
Given the average ransom payment is up to $312,493 as of 2020 — or using Sophos’s more conservative estimate, $170,404 — that means ransomware authors are turning a profit as long as the cost of an attack is less than $127,747.14 (or the more conservative $51,530.17). Based on some of the research that’s been done on the cost of attacks, where high-end estimates put it at around $4,200, we can start to see how a payout of almost 75 times the cost to play becomes an incentive.
In fact, because expected values are linear and the expected value is only for one play, we can see pretty quickly that in general, two attacks will give us double the value of one, and three will triple it. This means that if we let our payout be a random variable X, a ransomware operator’s expected value over an infinite number of attacks is… infinite.
Obviously, an infinite number of ransomware attacks is not reasonable, and there is a limit to the amount that any individual or business can pay over time before they just give up. But from an ideal market standpoint, the message is clear: While ransoms are being paid at these rates and sizes, the problem is only going to grow. Just like you’d happily play a slot machine that paid out almost half the time, attackers are happy to play a game that gets them paid more than 40% of the time, especially because the profits are so large.
Removing Incentives
So why would ransomware operators ever stop if, in an idealized model, there’s potentially infinite incentive to keep playing? A few reasons:
The value of payments is lower
The cost becomes prohibitive
The attacks don’t work
Nobody is paying
Out of the gate, we can more or less dismiss the notion that payment values will get lower. The only way to lower the value of the payment is to lower the value of Bitcoin to nearly zero. We’ve seen attempts to ban and regulate cryptocurrencies, but none of those have been successful.
In terms of the monetary cost, this is also pretty much a dead end for us. Even if we could remove all of the efficiencies and resilience of darknet markets, that would only remove the lowest-skill attackers from the equation. Other groups would still be capable of developing their own exploits and ransomware.
Ultimately, what our first two options have in common is that they deal, in a pretty direct way, with adversary capabilities. They leave room for adversaries to adapt and respond, ultimately trying to affect things that are in the control of attackers. This makes them much less desirable avenues for response.
So let’s look at the things that victims have control over: defenses and payments.
Defending Against Ransomware
Defending against ransomware is quite similar to defending against other attack types. In general, ransomware is not the first-stage payload delivered by an exploit; instead, it’s dropped by a loader. So the name of the game is to prevent code execution on endpoints. As security professionals, this is something we know quite well.
For ransomware, the majority of attacks come via a handful of vectors, which will be familiar to most security practitioners:
Phishing
Vulnerable services
Weak passwords, especially on Remote Desktop Protocol
Exploit kits
Many of these initial access vectors are things that can be kept in check with user training, vulnerability scans, and sound patching practices. Once initial access is established, many of these ransomware operators use software like WMI, PSExec, Powershell, and Cobalt Strike, in addition to commodity malware like Trickbot, to move laterally before hitting the entire network with ransomware.
Looking for these indicators of compromise is one way to limit the potential impact of ransomware. But of course, these techniques are hard to detect, and no organization is able to catch 100% of the bad things that are coming at them. So what do victims do when the worst happens?
Choosing Not to Pay
When ransomware attacks are successful, victims have two primary choices: pay or don’t. There are many follow-on decisions from each of these decisions, but the first and most critical decision (for the attacker) is whether or not to pay the ransom.
When people pay the ransom, they’re likely — though not guaranteed — to get their files back. However, because of the significant amounts of first stage implants and lateral movement associated with ransomware attacks, there’s still a lot of incident response work to be done beyond the return of the files. For many organizations, if they don’t have a suitable off-site backup in place, this may feel like an inevitable impact of this type of attack. As Tarah Wheeler pointed out, this is often something that can simply be written off as a business expense. Consequently, hackers get paid, companies get to write off the loss, and nobody learns a lesson.
As we discussed above, when you pay a ransom, you’re paying for the next attack, and according to reports from the UK’s NCSC, you may also be paying for human trafficking. None of us wants to be funding these attackers, but we want to protect our data. So how do we get away from paying?
As we mentioned before, preventing the attacks in the first place is the optimal outcome for us as defenders, but security solutions are never 100% effective. The easiest way not to pay is to have an off-site backup. That will let you invoke your normal incident response process but have your data intact. In many cases, this isn’t any more expensive than paying, and you’re guaranteed to get your data back.
In some cases, a decrypter is available for the ransomware. The decrypters can be used by victims to restore their files without paying the ransom. Organizations like No More Ransomware make decrypters available for free, saving organizations significant amounts of money paying for decryption keys.
Having a network configuration that makes lateral movement difficult will also reduce the “blast radius” of the attack and can help mitigate the spread. In these cases, you may be able to get away with reimaging a handful of employee laptops and accepting the loss. Ultimately, letting people write off their backups instead of their ransom payments encourages the switch to having sensible backup policies and discouraging these ransomware operators.
Why the Wheel Keeps Spinning
Ransomware remains a significant problem, and I hope we’ve demonstrated why: the incentives for everyone, including victims, are there to increase the number of ransomware attacks. Attackers who do more attacks will see more profits, which fund subsequent attacks. While victims can write off their payments, there’s no incentive to take steps to mitigate the impact of ransomware, so the problem will continue.
Crucially, ransomware attackers aren’t picky about their victims. They’re not nation-state actors who seek to target only the largest companies with the most intellectual property. Rather, they’re attackers of opportunity — their victim is anyone who lets their lever be pulled, and as long as the victims keep paying out often enough, attackers are happy to play.
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
“Estragon: I’m like that. Either I forget right away or I never forget.” – Samuel Beckett, Waiting for Godot
Hacking and Automation
As hackers, we spend a lot of time making things easier for ourselves.
For example, you might be aware of a tool called Metasploit, which can be used to make getting into a target easier. We’ve also built internet-scale scanning tools, allowing us to easily view data about open ports across the internet. Some of our less ethical comrades-in-arms build worms and botnets to automate the process of doing whatever they want to do.
If the heart of hacking is making things do what they shouldn’t, then perhaps the lungs are automation.
Over the years, we’ve seen security in general and vulnerability discovery in particular move from a risky, shady business to massive corporate-sponsored activities with open marketplaces for bug bounties. We’ve also seen a concomitant improvement in the techniques of hacking.
If hackers had known in 1996 that we’d go from Stack-based buffer overflows to chaining ROP gadgets, perhaps we’d have asserted “no free bugs” earlier on. This maturity has allowed us to find a number of bugs that would have been unbelievable in the early 2000s, and exploits for those bugs are quickly packaged into tools like Metasploit.
Now that we’ve automated the process of running our exploits once they’ve been written, why is it so hard to get machines to find the bugs for us?
This is, of course, not for lack of trying. Fuzzing is a powerful technique that turns up a ton of bugs in an automated way. In fact, fuzzing is powerful enough that loads of folks turn up 0-days while they’re learning how to do fuzzing!
However, the trouble with fuzzing is that you never know what you’re going to turn up, and once you get a crash, there is a lot of work left to be done to craft an exploit and understand how and why the crash occurred — and that’s on top of all the work needed to craft a reliable exploit.
Automated bug finding, like we saw in the DARPA Cyber Grand Challenge, takes this to another level by combining fuzzing and symbolic execution with other program analysis techniques, like reachability and input dependence. But fuzzers and SMT solvers — a program that solves particular types of logic problems — haven’t found all the bugs, so what are we missing?
As with many problems in the last few years, organizations are hoping the answer lies in artificial intelligence and machine learning. The trouble with this hope is that AI is good at some tasks, and bug finding may simply not be one of them — at least not yet.
Learning to Find Bugs
Academic literature is rich with papers aiming to find bugs with machine learning. A quick Google Scholar search turns up over 140,000 articles on the topic as of this writing, and many of these articles seem to promise that, any day now, machine learning algorithms will turn up bugs in your source code.
There are a number of developer tools that suggest this could be true. Tools like Codota, Tabnine, and Kite will help auto-complete your code and are quite good. In fact, Microsoft has used GPT-3 to write code from natural language.
But creating code and finding bugs is sadly an entirely different problem. A 2017 paper written by Chappell et al — a collaboration between Australia’s Queensland University of Technology and the technology giant Oracle — found that a variety of machine learning approaches vastly underperformed Oracle’s Parfait system, which uses more traditional symbolic analysis techniques on the intermediate representations used by the compiler.
Another paper, out of the University of Oslo in Norway, Simulated SQL injection using Q-Learning, a form of Reinforcement Learning. This paper caused a stir in the MLSec community and especially within the DEF CON AI village (full disclosure: I am an officer for the AI village and helped cause the stir). The possibility of using a roomba-like method to find bugs was deeply enticing, and Erdodi et al. did great work.
However, their method requires a very particular environment, and although the agent learned to exploit the specific simulation, the method does not seem to generalize well. So, what’s a hacker to do?
Blaming Our Boots
“Vladimir: There’s man all over for you, blaming on his boots the faults of his feet.” – Samuel Beckett, Waiting for Godot
One of the fundamental problems with throwing machine learning at security problems is that many ML techniques have been optimized for particular types of data. This is particularly important for deep learning techniques.
Images are tensors — a sort of matrix with not just height and width but also color channels — of rectangular bit maps with a range of possible values for each pixel. Natural language is tokenized, and those tokens are mapped into a word embedding, like GloVe or Word2Vec.
This is not to downplay the tremendous accomplishments of these machine learning techniques but to demonstrate that, in order for us to repurpose them, we must understand why they were built this way.
Unfortunately, the properties we find important for computer vision — shift invariance and orientation invariance — are not properties that are important for tasks like vulnerability detection or malware analysis. There is, likewise, a heavy dependence in log analysis and similar tasks on tokens that are unlikely to be in our vocabulary — oddly encoded strings, weird file names, and unusual commands. This makes these techniques unsuitable for many of our defensive tasks and, for similar reasons, mostly useless for generating net-new exploits.
Why doesn’t this work? A few issues are at play here. First, the machine does not understand what it is learning. Machine learning algorithms are ultimately function approximators — systems that see some inputs and some outputs, and figure out what function generated them.
For example, if our dataset is:
X = {1, 3, 7, 11, 2}
Y = {3, 7, 15, 23, 5}
Our algorithm might see the first input and output: 3 = f(1) and guess that f(x) = 3x.
By the second input, it would probably be able to figure out that y = f(x) = 2x + 1.
By the fifth, there would be a lot of good evidence that f(x) = 2x + 1. But this is a simple linear model, with one weight term and one bias term. Once we have to account for a large number of dimensions and a function that turns a label like “cat” into a 32 x 32 image with 3 color channels, approximating that function becomes much harder.
It stands to reason then that the function which maps a few dozen lines of code that spread across several files into a particular class of vulnerability will be harder still to approximate.
Ultimately, the problem is neither the technology on its own nor the data representation on its own. It is that we are trying to use the data we have to solve a hard problem without addressing the underlying difficulties of that problem.
In our case, the challenge is not identifying vulnerabilities that look like others we’ve found before. The challenge is in capturing the semantic meaning of the code and the code flow at a point, and using that information to generate an output that tells us whether or not a certain condition is met.
This is what SAT solvers are trying to do. It is worth noting then that, from a purely theoretical perspective, this is the problem SAT, the canonical NP-Complete problem. It explains why the problem is so hard — we’re trying to solve one of the most challenging problems in computer science!
Waiting for Godot
The Samuel Beckett play, Waiting for Godot, centers around the characters of Vladimir and Estragon. The two characters are, as the title suggests, waiting for a character named Godot. To spoil a roughly 70-year-old play, I’ll give away the punchline: Godot never comes.
Today, security researchers who are interested in using artificial intelligence and machine learning to move the ball forward are in a similar position. We sit or stand by the leafless tree, waiting for our AI Godot. Like Vladimir and Estragon, our Godot will never come if we wait.
If we want to see more automation and applications of machine learning to vulnerability discovery, it will not suffice to repurpose convolutional neural networks, gradient-boosted decision trees, and transformers. Instead, we need to think about the way we represent data and how to capture the relevant details of that data. Then, we need to develop algorithms that can capture, learn, and retain that information.
We cannot wait for Godot — we have to find him ourselves.
On July 12, 2021, SolarWinds confirmed an actively exploited zero-day vulnerability, CVE-2021-35211, in the Serv-U FTP and Managed File Transfer component of SolarWinds15.2.3 HF1 (released May 5, 2021) and all prior versions. Successful exploitation of CVE-2021-35211 could enable an attacker to gain remote code execution on a vulnerable target system. The vulnerability only exists when SSH is enabled in the Serv-U environment.
A hotfix for the vulnerability is available, and we recommend all customers of SolarWinds Serv-U FTP and Managed File Transfer install this hotfix immediately (or, at minimum, disable SSH for a temporary mitigation). SolarWinds has emphasized that CVE-2021-35211 only affects Serv-U Managed File Transfer and Serv-U Secure FTP and does not affect any other SolarWinds or N-able (formerly SolarWinds MSP) products. For further details, see SolarWinds’s advisory.
Details
The SolarWinds advisory cites threat intelligence provided by Microsoft. According to Microsoft, a single threat actor unrelated to this year’s earlier SUNBURST intrusions has exploited the vulnerability against a limited, targeted population of SolarWinds customers. The vulnerability exists in all versions of Serv-U 15.2.3 HF1 and earlier. Though Microsoft provided a proof-of-concept exploit to SolarWinds, there are no public proofs-of-concept as of July 12, 2021.
The vulnerability appears to be in the exception handling functionality in a portion of the software related to processing connections on open sockets. Successful exploitation of the vulnerability will cause the Serv-U product to throw an exception, then will overwrite the exception handler with the attacker’s code, causing remote code execution.
Detection
Since the vulnerability is in the exception handler, looking for exceptions in the DebugSocketLog.txt file may help identify exploitation attempts. Note, however, that exceptions can be thrown for many reasons and the presence of an exception in the log does not guarantee that there has been an exploitation attempt.
IP addresses used by the threat actor include:
98.176.196.89
68.235.178.32
208.113.35.58
Rapid7 does not use SolarWinds Serv-U FTP products anywhere in our environment and is not affected by CVE-2021-35211.
Vulnerability note: Members of the community including Will Dormann of CERT/CC have noted that the publicly available exploits which purport to exploit CVE-2021-1675 may in fact target a new vulnerability in the same function as CVE-2021-1675. Thus, the advisory update published by Microsoft on June 21 does not address these exploits and defenders should be on the look out for a new patch from Microsoft in the future.
On June 8, 2021, Microsoft released an advisory and patch for CVE-2021-1675 (“PrintNightmare”), a critical vulnerability in the Windows Print Spooler. Although originally classified as a privilege escalation vulnerability, security researchers have demonstrated that the vulnerability allows authenticated users to gain remote code execution with SYSTEM-level privileges. On June 29, 2021, as proof-of-concept exploits for the vulnerability began circulating, security researchers discovered that CVE-2021-1675 is still exploitable on some systems that have been patched. As of this writing, at least 3 different proof-of-concept exploits have been made public.
Rapid7 researchers have confirmed that public exploits work against fully patched Windows Server 2019 installations. The vulnerable service is enabled by default on Windows Server, with the exception of Windows Server Core. Therefore, it is expected that in the vast majority of enterprise environments, all domain controllers, even those that are fully patched, are vulnerable to remote code execution by authenticated attackers.
The vulnerability is in the RpcAddPrinterDriver call of the Windows Print Spooler. A client uses the RPC call to add a driver to the server, storing the desired driver in a local directory or on the server via SMB. The client then allocates a DRIVER_INFO_2 object and initializes a DRIVER_CONTAINER object that contains the allocated DRIVER_INFO_2 object. The DRIVER_CONTAINER object is then used within the call to RpcAddPrinterDriver to load the driver. This driver may contain arbitrary code that will be executed with SYSTEM privileges on the victim server. This command can be executed by any user who can authenticate to the Spooler service.
Mitigation Guidance
Since the patch is currently not effective against the vulnerability, the most effective mitigation strategy is to disable the print spooler service itself. This should be done on all endpoints, servers, and especially domain controllers. Dedicated print servers may still be vulnerable if the spooler is not stopped. Microsoft security guidelines do not recommend disabling the service across all domain controllers, since the active directory has no way to remove old queues that no longer exist unless the spooler service is running on at least one domain controller in each site. However, until this vulnerability is effectively patched, this should have limited impact compared to the risk.
The following PowerShell command can be used to help find exploitation attempts:
Get-WinEvent -LogName 'Microsoft-Windows-PrintService/Admin' | Select-String -InputObject {$_.message} -Pattern 'The print spooler failed to load a plug-in module'
Rapid7 Customers
We strongly recommend that all customers disable the Windows Print Spooler service on an emergency basis to mitigate the immediate risk of exploitation. While InsightVM and Nexpose checks for CVE-2021-1675 were released earlier in June, we are currently investigating the feasibility of additional checks to determine whether the print spooler service has been disabled in customer environments.
We will update this blog as further information comes to light.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.