Post Syndicated from Jin-Hee Lee original https://blog.cloudflare.com/per-customer-bot-defenses/
Today, we are announcing a new approach to catching bots: using models to provide behavioral anomaly detection unique to each bot management customer and stop sophisticated bot attacks.
With this per-customer approach, we’re giving every bot management customer hyper-personalized security capabilities to stop even the sneakiest bots. We’re doing this by not only making a first-request judgement call, but also by tracking behavior of bots who play the long-game and continuously execute unwanted behavior on our customers’ websites. We want to share how this service works, and where we’re focused. Our new platform has the power to fuel hundreds of thousands of unique detection suites, and we’ve heard our first target loud and clear from site owners: protect websites from the explosion of sophisticated, AI-driven web scraping.
The battle against malicious bots used to be a simpler affair. Attackers used scripts that were fairly easy to identify through static, predictable signals: a request with a missing User-Agent header, a malformed method name, or traffic from a non-standard port was a clear indicator of malicious intent. However, the Internet is always evolving. As websites became more dynamic to create rich user experiences, attackers evolved their tools in response. The simple scripts of yesterday were replaced by headless browsers and automation frameworks, capable of rendering pages and mimicking human interaction with far greater fidelity.
AI has made this even trickier. The rise of Generative AI has fundamentally changed the capabilities and the motivations of attackers. The web scraping of today isn’t limited to competitive price intelligence or content aggregation, but driven by the voracious appetite of Large Language Models (LLMs) for training data.
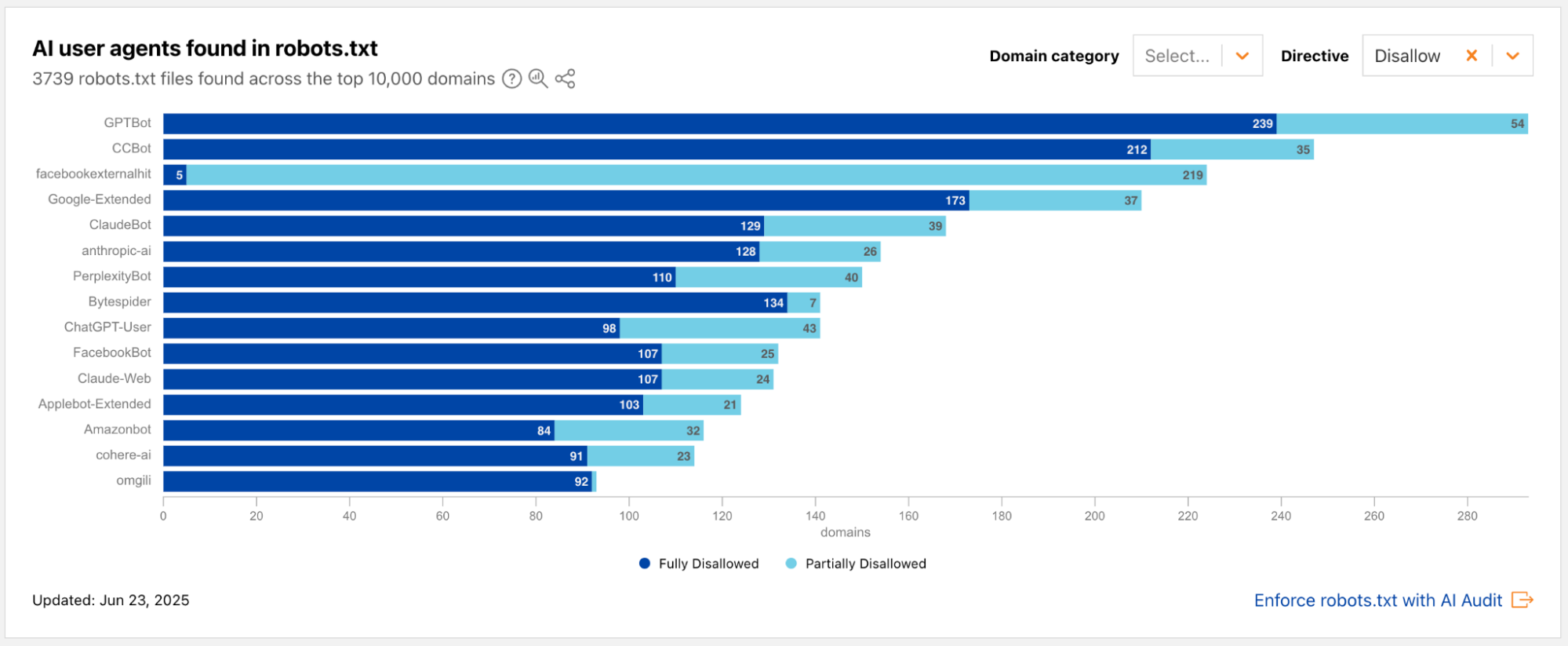
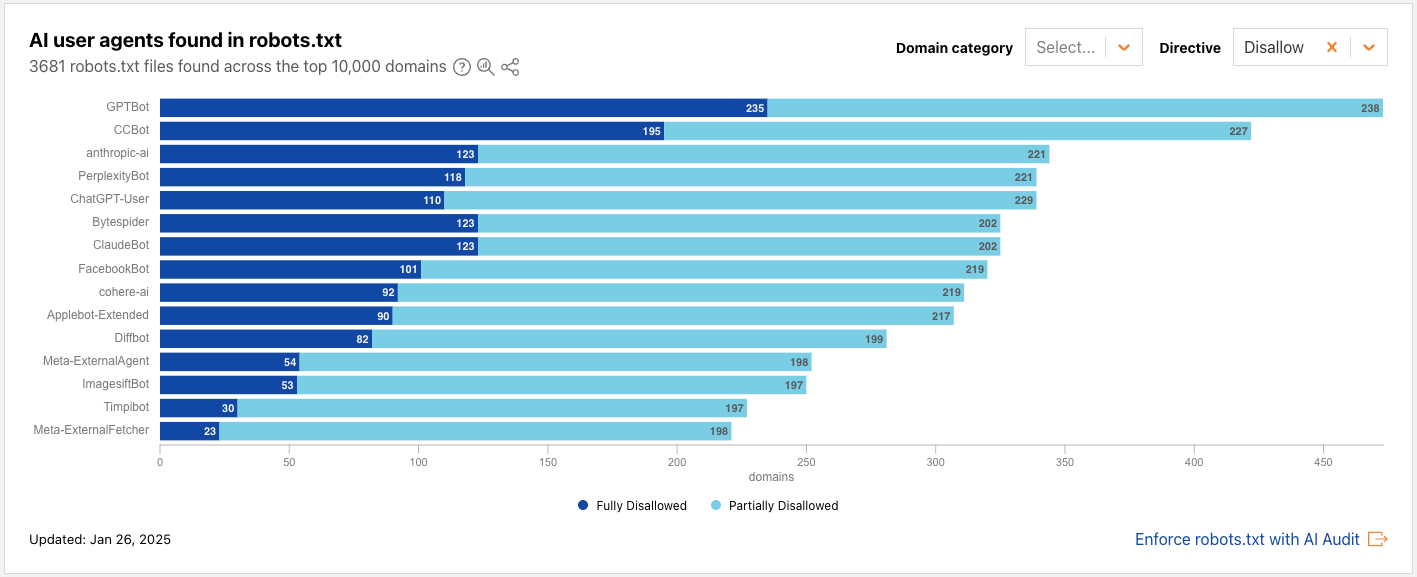
Cloudflare’s data shows this shift in stark terms. In mid-2025, crawling for the purpose of AI model training accounted for nearly 80% of all AI bot activity on our network, a significant increase from the year prior. Modern scraping tools are now AI-powered themselves. They leverage LLMs for semantic understanding of page content, use computer vision to solve visual challenges, and employ reinforcement learning to navigate complex websites they’ve never seen before. The evolution of these bots exposes critical vulnerability in the traditional, one-size-fits-all approach to security. While global threat intelligence is immensely powerful for stopping widespread attacks, these new AI-powered scrapers are designed to blend in. They can rotate IP addresses through residential proxies, generate human-like user agents, and mimic plausible browsing patterns. A request from one of these bots might not look anomalous when compared to the trillions of requests we see across the Cloudflare network, but would appear anomalous when compared to the established patterns of legitimate users on a specific website. This means we need to build defenses against these bots from every angle we have — from the global view to specific behavior on a single application.

To target specific well-known bots or bot actors, we leverage the Cloudflare network to fingerprint bots that we see behave similarly across millions of websites. Since June, Cloudflare’s bot detection security analysts have written 50 heuristics to catch bots using a variety of signals, including but not limited to HTTP/2 fingerprints and Client Hello extensions. By observing traffic on millions of websites, we establish a baseline of legitimate fingerprints of common browsers and benign devices. When a new, unique fingerprint suddenly appears across many different sites, it’s a tell-tale sign of a distributed botnet or a new automation tool, allowing our analysts to block the bot’s signature itself and neutralize the entire campaign, regardless of the thousands of different IP addresses it might use.
Recently, we also introduced detection improvements to tackle residential proxy networks and similar commercial proxies, which are used by attackers to make their bots appear as thousands of distinct real visitors, allowing them to bypass traditional security measures. The superpower of this detection improvement? Combining the vast amount of network data we see with particular client-side fingerprints obtained through the millions of challenge solves that happen across the Internet daily. Challenges have always served as an ideal mitigation action for customers who want to protect their applications without compromising real-user experience, but now they also serve as a gift that keeps on giving: in this case, feeding the Cloudflare threat detection teams a constant stream of client-side information that allows us to pattern match to determine IP addresses that are used by residential proxy networks.
This detection improvement is already ingesting data from the entire Cloudflare network, automatically catching more malicious traffic for all customers using Super Bot Fight Mode (bot protection included for Pro, Business, and all Enterprise customers) and Enterprise Bot Management. Examining 7 days of data from the time of authoring this post, we’ve observed 11 billion requests from millions of unique IP addresses that we’ve identified as connected to residential or commercial proxy networks. This is just one piece of the global detection puzzle; the existing residential proxy detection features in our ML already catch tens of millions of requests every hour.
The new arms race against AI-powered bots necessitates a closer look — something more precise. For instance, a script that systematically scrapes every user profile on a social media site, or every product listing on an e-commerce platform, is exhibiting behavior that is fundamentally abnormal for that application, even if a standalone request appears benign. This realization is at the heart of our new strategy: to win this new arms race, defenses must become as bespoke and adaptive as the attacks they face.
To meet this challenge, we built a new, foundational platform engineered to deploy custom machine learning models for every bot management customer. We’re creating a unique defense for every application. Because each website has different traffic, the traffic that we flag as anomalous will, of course, be different for each zone — for this system, we want to be clear that data from one customer’s zone won’t be used to train the model for another customer’s use.
Announcing this as a new platform capability, rather than a single feature, is a deliberate choice. It aligns with how we’ve approached our most significant innovations, from Cloudflare Workers changing how developers build applications, to AI Gateway creating a single control plane for AI observability and security. By focusing on the platform, we tackle the scraping problems our customers are seeing today and power future detections as bot attacks become increasingly sophisticated.
Our new generation of per-customer anomaly detection is a three-step process, designed to identify malicious behavior by first understanding what constitutes legitimate traffic for each individual website and API.
For each customer zone, our behavioral detections ingest traffic data to build a baseline of normal activity. Rather than taking a static snapshot, our new platform ingests data to make living, continuously updated calculations of what “normal” looks like on a specific website. This approach understands seasonality, recognizes traffic spikes from legitimate marketing campaigns, and maps the typical pathways users take through a site. This approach evolves the concept of Anomaly Detection already present in our Enterprise Bot Management suite, but applies it at a far more granular and dynamic per-customer level.
Once the baseline of “normal” is established, we begin the true work — identifying deviations. Because the baseline is specific to each website, the anomalies detected are highly contextual, perhaps even invisible to a global system. We can examine a few different types of websites to unpack this:
-
For a gaming company: A normal traffic baseline might show millions of users making frequent, rapid API calls to a matchmaking service or an in-game inventory system. A behavioral detection model trained on this baseline would immediately flag a single user making slow, methodical, sequential API calls to scrape the entire player leaderboard. This behavior, while low in volume, is a clear anomaly against the backdrop of normal gameplay patterns.
-
For a retail website: The normal baseline is a complex funnel of users browsing categories, viewing products, adding items to a cart, and proceeding to checkout. These detections would identify an actor that systematically visits every single product page in alphabetical order at a machine-like pace, without ever interacting with the cart or session cookies, as a significant anomaly indicative of content scraping.
-
For a media publisher: Normal user behavior involves reading a few articles, following internal links, and spending a measurable amount of time on each page. An anomaly would be a script that hits thousands of article URLs per minute, spending less than a second on each, purely to extract the text content for AI model training.
In each case, the malicious activity is defined not by a universal signature, but by its deviation from the application’s unique, established norm.
Detecting an anomaly is only half the battle. The power of bot management comes from its seamless integration into the Cloudflare security ecosystem you already use, turning detection into immediate, actionable findings. Customers can benefit from these behavioral detection improvements in two ways:
-
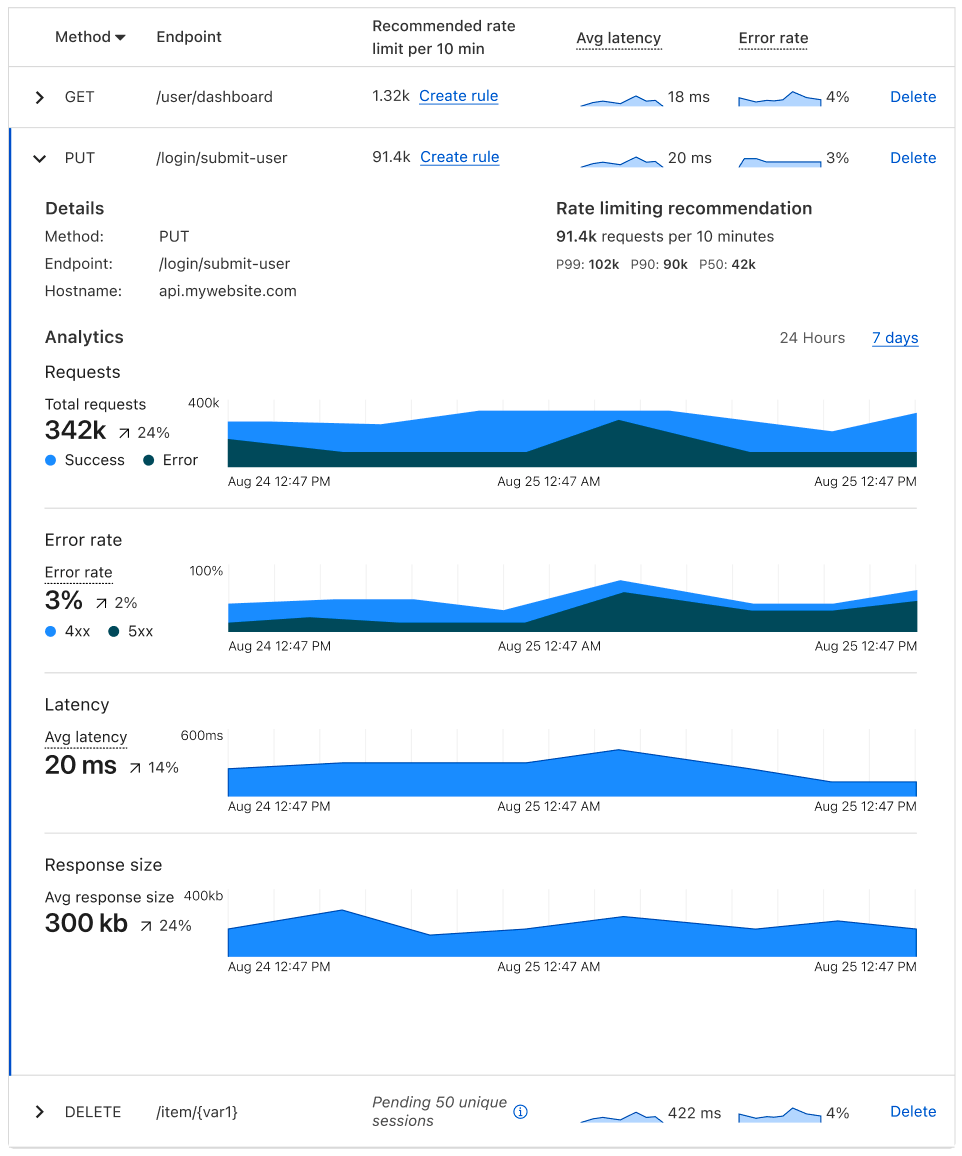
New Bot Detection IDs: For our Enterprise customers, we’re introducing a new set of Bot Detection IDs. Website owners and security teams can write WAF security rules to challenge, rate-limit, or block traffic based on the specific anomalies flagged by these detections. Since each detection type is tied to a unique ID, customers can see exactly what kind of behavior caused a request to be flagged as anomalous, offering a detailed, per-request view into stealthy malicious traffic. And for a wider view, customers can filter by Detection ID from their Security Analytics, to see the bigger picture of all traffic captured by that detection type.
-
Improving Bot Score: Another key output from these new, per-customer models will be to directly influence the Bot Score of a request. A request flagged as anomalous will have its score lowered, moving it into the “Likely Automated” (scores 2-29) or “Automated” (score 1) categories. This means that existing WAF custom rules based on Bot Score will automatically see impact and become more effective against bespoke attacks, with no changes required. This functionality update is available today for our latest account takeover detection, residential proxy detections and our recent enhancements, and will be implemented in the future for our behavioral scraping detection.
This three-step process is already in action with our behavioral detections to catch account takeover attacks. Taking bot detection ID 201326598 as an example: it (1) establishes a zone-level baseline that understands what normal traffic patterns look like for a specific website, (2) examines anomalous login failures to identify brute force and credential stuffing attacks, then (3) allows customers to mitigate these attacks by automatically influencing bot score and offering more visibility with the detection ID’s analytics.

This integration strategy creates a flywheel effect: the new intelligence from these improved detections immediately enhances the value of existing products like Super Bot Fight Mode, Bot Management, and the WAF, making the entire Cloudflare platform stronger for you.
The first challenge we’re tackling is sophisticated scraping. AI-driven scraping is one of the most pressing and rapidly evolving threats facing website owners today, and its adaptive nature makes it an ideal adversary for a system designed to fight an enemy that constantly changes its tactics.
The first generation of our improved behavioral detections are tuned specifically to detect scraping by analyzing signals that go beyond simple request headers. These include:
-
Behavioral Analysis: Looking at session traversal paths, the sequence of requests, and interaction (or lack thereof) with dynamic page elements.
-
Client Fingerprinting: Analyzing subtle signals from the client to identify signs of automation such as JA4 fingerprints in the context of the customer’s specific traffic baseline.
-
Content-Agnostic Detection: These models do not need to understand the content of a page, only the patterns of how it is being accessed. This makes them highly scalable and efficient, without actually using the unique content on a website to make judgement calls.
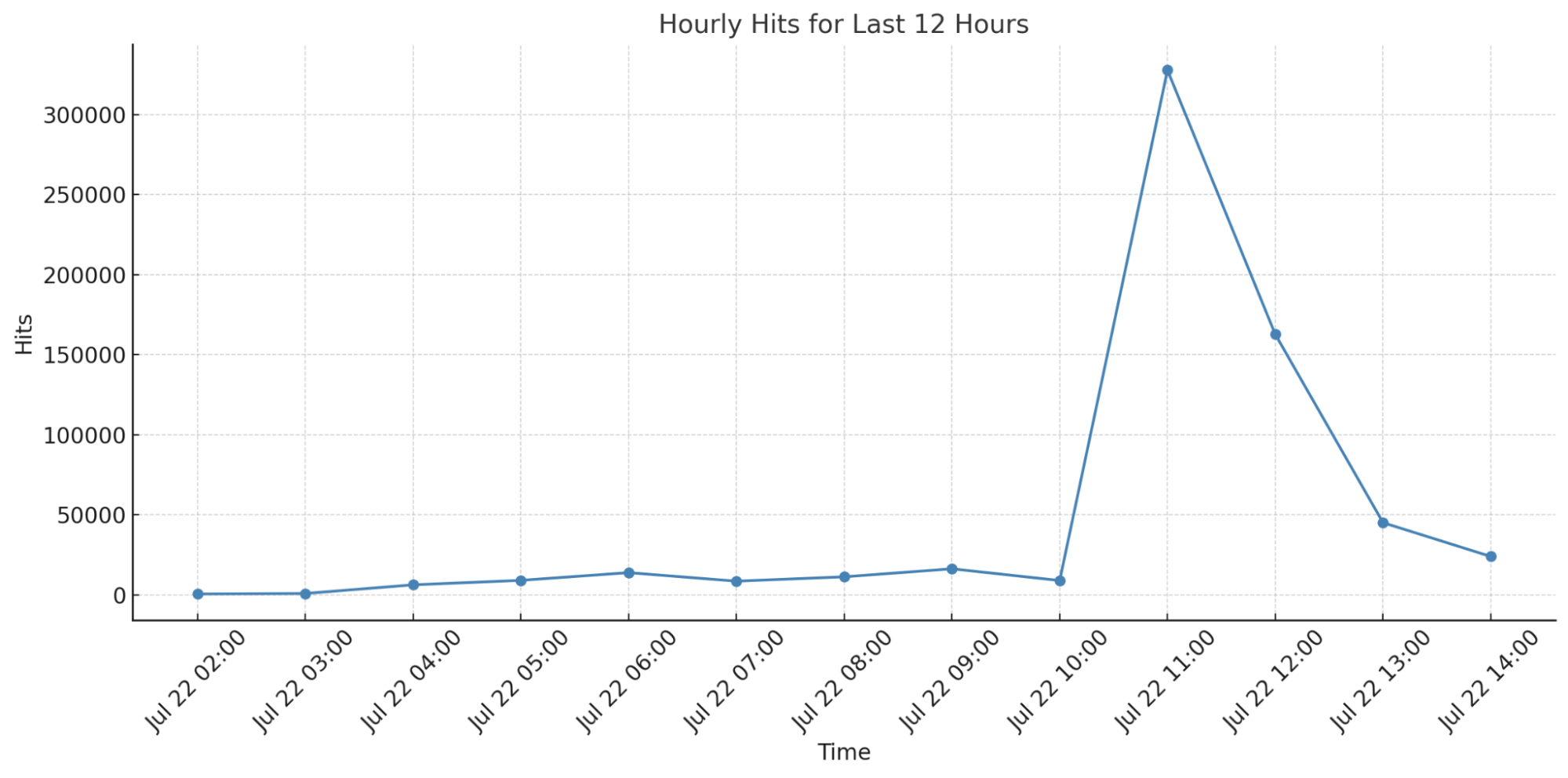
How do these scraping detections look, in practice? We validated our logic for detecting scraping with early adopters in a closed beta, in order to receive ground-truth feedback and tune our detections. As with any ideal detection, our goal is to capture as much malicious traffic as possible, without compromising the experience of legitimate website visitors. Looking at just a 24-hour period, our new scraping detections have caught hundreds of millions of requests, flagging 138 million scraping requests on just 5 of our early beta zones.

Naturally, we see an overlap with our existing system of bot scoring, but the numbers here show us concretely that our new method of behavioral detections have a completely new value add: 34% of the requests flagged by our new scraping detections would not have been detected by our existing bot score system, making us all the more eager to use these novel detections to inform the way we score automation.
Our mission to help build a better Internet means that when we develop powerful new defenses, we believe in democratizing access to them. Protecting the entire Internet from new and evolving threats requires raising the baseline of security for everyone.
In that spirit, we’re excited to announce that our enhanced behavioral detections will not only roll out to bot management customers, but will also benefit Cloudflare customers using our global Super Bot Fight Mode system. For our Enterprise Bot Management customers, we automatically tune our detections based on the exact traffic for each zone. Because these advanced models are trained on your zone’s specific traffic, they detect even the most evasive attacks: from account takeovers to web scraping to other attacks executed through residential proxy networks — and we consider this only the tip of the iceberg of behavioral bot profiling.
Our initial focus on scraping is just the beginning of a new wave of behavioral bot detections. The infrastructure we’ve built is a flexible, powerful foundation for tackling a wide range of malicious behavior on your websites; the same principles of establishing a per-customer baseline and detecting anomalies can be applied to other critical threats that are unique to an application’s logic, such as credential stuffing, inventory hoarding, carding attacks, and API abuse.
We are moving into an era where generic defenses are no longer enough. As threats become more personal, so must the defenses against them, and paving this path of behavioral detections is our latest gift to the Internet. Our first offering of scraping behavioral detections is just around the corner: customers will be able to turn on this new detection from the Security Overview page in their dashboard.

(We’re always looking for enthusiastic humans to help us in our mission against bots! If you’re interested in helping us build a better Internet, check out our open positions.)