Forrester Research has recognized Cloudflare as a Leader in it’s The Forrester Wave™: Web Application Firewall Solutions, Q1 2025 report. This market analysis helps security and risk professionals select the right solution for their needs. According to Forrester:
“Cloudflare is a strong option for customers that want to manage an easy-to-use, unified web application protection platform that will continue to innovate.”
In this evaluation, Forrester assessed 10 Web Application Firewall (WAF) vendors across 22 criteria, including product security and vision. We believe this recognition is due to our continued investment in our product offering. Get a complimentary copy of the report here.
Since introducing our first WAF in 2013, Cloudflare has transformed it into a robust, enterprise-grade Application Security platform. Our fully integrated suite includes WAF, bot mitigation, API security, client-side protection, and DDoS mitigation, all built on our expansive global network. By leveraging AI and machine learning, we deliver industry-leading security while enhancing application performance through our content delivery and optimization solutions.
According to the Forrester report, “Cloudflare stands out with features that help customers work more efficiently.” Unlike other solutions in the market, Cloudflare’s WAF, API Security, bot detection, client-side security, and DDoS protection are natively integrated within a single platform, running on a unified engine. Our integrated solution empowers a seamless user experience and enables advanced threat detection across multiple vectors to meet the most demanding security requirements.
Cloudflare: a standout in Application Security
Forrester’s evaluation of Web Application Firewall solutions is one of the most comprehensive assessments in the industry. We believe this report highlights Cloudflare’s integrated global cloud platform and our ability to deliver enterprise-grade security without added complexity. We don’t just offer a WAF — we provide a flexible, customizable security toolkit designed to address your unique application security challenges.
Cloudflare continuously leads the WAF market through our strategic vision and the breadth of our capabilities. We center our approach on relentless innovation, delivering industry-leading security features, and ensuring a seamless management experience with enterprise processes and tools such as Infrastructure as Code (IaC) and DevOps. Our predictable cadence of major feature releases, powered by annual initiatives like Security Week and Birthday Week, ensures that customers always have access to the latest security advancements.
We believe Forrester also highlighted Cloudflare’s extensive security capabilities, with particular recognition of the significant improvements in our API security offerings.
Cloudflare’s top-ranked criteria
In the report, Cloudflare received the highest possible scores in 15 out of 22 criteria, reinforcing, in our opinion, our commitment to delivering the most advanced, flexible and easy-to-use web application protection in the industry. Some of the key criteria include:
Detection models: Advanced AI and machine learning models that continuously evolve to detect new threats.
Layer 7 DDoS protection: Industry-leading mitigation of sophisticated application-layer attacks.
Rule creation and modification: Simple, easy to use rule creation experience, propagating within seconds globally.
Management UI: An intuitive and efficient user interface that simplifies security management.
Product security: A robust architecture that ensures enterprise-grade security.
Infrastructure-as-code support: Seamless integration with DevOps workflows for automated security policy enforcement.
Innovation: A forward-thinking approach to security, consistently pushing the boundaries of what’s possible.
What sets Cloudflare apart?
First, Cloudflare’s WAF goes beyond traditional rule-based protections, offering a comprehensive suite of detection mechanisms to identify attacks and vulnerabilities across web and API traffic while also safeguarding client environments. We leverage AI and machine learning to detect threats such as attacks, automated traffic, anomalies, and compromised JavaScript, among others. Our industry-leading application-layer DDoS protection makes volumetric attacks a thing of the past.
Second, Cloudflare has also made significant strides in API security. Our WAF can be supercharged with features such as: API discovery, schema validation & sequence mitigation, volumetric detection, and JWT authentication.
Third, Cloudflare simplifies security management with an intuitive dashboard that is easy to use while still offering powerful configurations for advanced practitioners. All features are Terraform-supported, allowing teams to manage the entire Cloudflare platform as code. With Security Analytics, customers gain a comprehensive view of all traffic, whether mitigated or not, and can run what-if scenarios to test new rules before deployment. This analytic capability ensures that businesses can dynamically adapt their security posture while maintaining high performance. To make security management even more seamless, our AI agent, powered by Natural Language Processing (NLP), helps users craft and refine custom rules and create powerful visualizations within our analytics engine.
Cloudflare: the clear choice for modern security
We are confident that Forrester’s report validates what our customers already know: Cloudflare is a leading WAF vendor, offering unmatched security, innovation, and ease of use. As threats continue to evolve, we remain committed to pushing the boundaries of web security to protect organizations worldwide.
If you’re looking for a powerful, scalable, and easy-to-manage web application firewall, Cloudflare is the best choice for securing your applications, APIs, and infrastructure.
Ready to enhance your security?
Learn more about Cloudflare WAF by creating an account today and see why Forrester has recognized us as a leader in the market.
Forrester does not endorse any company, product, brand, or service included in its research publications and does not advise any person to select the products or services of any company or brand based on the ratings included in such publications. Information is based on the best available resources. Opinions reflect judgment at the time and are subject to change. For more information, read about Forrester’s objectivity here .
In today’s fast-paced digital landscape, companies are managing an increasingly complex mix of environments — from SaaS applications and public cloud platforms to on-prem data centers and hybrid setups. This diverse infrastructure offers flexibility and scalability, but also opens up new attack surfaces.
To support both business continuity and security needs, “security must evolve from being reactive to predictive”. Maintaining a healthy security posture entails monitoring and strengthening your security defenses to identify risks, ensure compliance, and protect against evolving threats. With our newest capabilities, you can now use Cloudflare to achieve a healthy posture across your SaaS and web applications. This addresses any security team’s ultimate (daily) question: How well are our assets and documents protected?
A predictive security posture relies on the following key components:
Real-time discovery and inventory of all your assets and documents
Continuous asset-aware threat detection and risk assessment
Prioritised remediation suggestions to increase your protection
Today, we are sharing how we have built these key components across SaaS and web applications, and how you can use them to manage your business’s security posture.
Your security posture at a glance
Regardless of the applications you have connected to Cloudflare’s global network, Cloudflare actively scans for risks and misconfigurations associated with each one of them on a regular cadence. Identified risks and misconfigurations are surfaced in the dashboard under Security Center as insights.
Insights are grouped by their severity, type of risks, and corresponding Cloudflare solution, providing various angles for you to zoom in to what you want to focus on. When applicable, a one-click resolution is provided for selected insight types, such as setting minimum TLS version to 1.2 which is recommended by PCI DSS. This simplicity is highly appreciated by customers that are managing a growing set of assets being deployed across the organization.
To help shorten the time to resolution even further, we have recently added role-based access control (RBAC) to Security Insights in the Cloudflare dashboard. Now for individual security practitioners, they have access to a distilled view of the insights that are relevant for their role. A user with an administrator role (a CSO, for example) has access to, and visibility into, all insights.
In addition to account-wide Security Insights, we also provide posture overviews that are closer to the corresponding security configurations of your SaaS and web applications. Let’s dive into each of them.
Securing your SaaS applications
Without centralized posture management, SaaS applications can feel like the security wild west. They contain a wealth of sensitive information – files, databases, workspaces, designs, invoices, or anything your company needs to operate, but control is limited to the vendor’s settings, leaving you with less visibility and fewer customization options. Moreover, team members are constantly creating, updating, and deleting content that can cause configuration drift and data exposure, such as sharing files publicly, adding PII to non-compliant databases, or giving access to third party integrations. With Cloudflare, you have visibility across your SaaS application fleet in one dashboard.
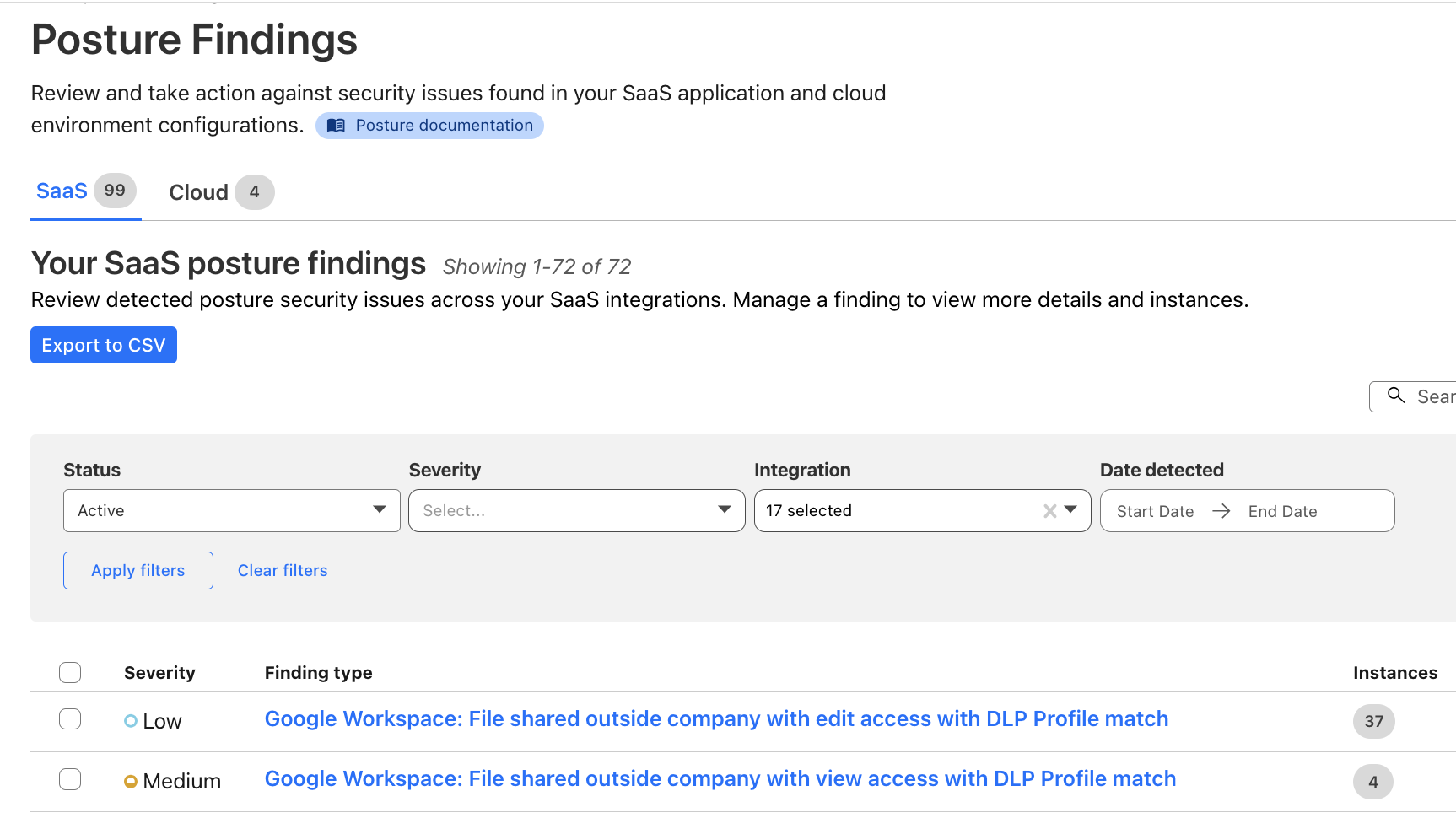
Posture findings across your SaaS fleet
From the account-wide Security Insights, you can review insights for potential SaaS security issues:
You can choose to dig further with Cloud Access Security Broker (CASB) for a thorough review of the misconfigurations, risks, and failures to meet best practices across your SaaS fleet. You can identify a wealth of security information including, but not limited to:
Publicly available or externally shared files
Third-party applications with read or edit access
Unknown or anonymous user access
Databases with exposed credentials
Users without two-factor authentication
Inactive user accounts
You can also explore the Posture Findings page, which provides easy searching and navigation across documents that are stored within the SaaS applications.
Additionally, you can create policies to prevent configuration drift in your environment. Prevention-based policies help maintain a secure configuration and compliance standards, while reducing alert fatigue for Security Operations teams, and these policies can prevent the inappropriate movement or exfiltration of sensitive data. Unifying controls and visibility across environments makes it easier to lock down regulated data classes, maintain detailed audit trails via logs, and improve your security posture to reduce the risk of breaches.
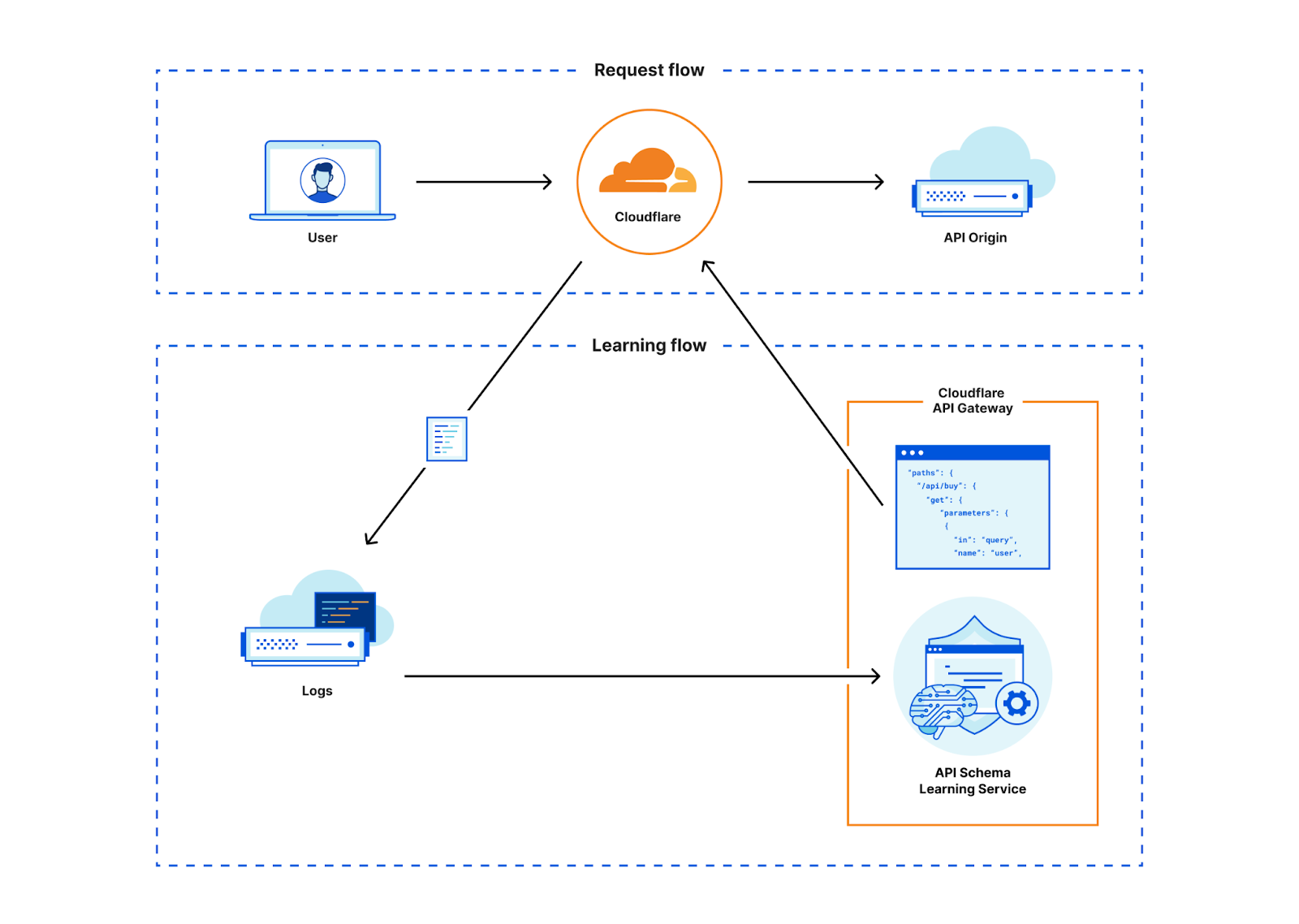
How it works: new, real-time SaaS documents discovery
Delivering SaaS security posture information to our customers requires collecting vast amounts of data from a wide range of platforms. In order to ensure that all the documents living in your SaaS apps (files, designs, etc.) are secure, we need to collect information about their configuration — are they publicly shared, do third-party apps have access, is multi-factor authentication (MFA) enabled?
We previously did this with crawlers, which would pull data from the SaaS APIs. However, we were plagued with rate limits from the SaaS vendors when working with larger datasets. This forced us to work in batches and ramp scanning up and down as the vendors permitted. This led to stale findings and would make remediation cumbersome and unclear – for example, Cloudflare would be reporting that a file is still shared publicly for a short period after the permissions were removed, leading to customer confusion.
To fix this, we upgraded our data collection pipeline to be dynamic and real-time, reacting to changes in your environment as they occur, whether it’s a new security finding, an updated asset, or a critical alert from a vendor. We started with our Microsoft asset discovery and posture findings, providing you real-time insight into your Microsoft Admin Center, OneDrive, Outlook, and SharePoint configurations. We will be rapidly expanding support to additional SaaS vendors going forward.
Listening for update events from Cloudflare Workers
Cloudflare Workers serve as the entry point for vendor webhooks, handling asset change notifications from external services. The workflow unfolds as follows:
Webhook listener: An initial Worker acts as the webhook listener, receiving asset change messages from vendors.
Data storage & queuing: Upon receiving a message, the Worker uploads the raw payload of the change notification to Cloudflare R2 for persistence, and publishes it to a Cloudflare Queue dedicated to raw asset changes.
Transformation Worker: A second Worker, bound as a consumer to the raw asset change queue, processes the incoming messages. This Worker transforms the raw vendor-specific data into a generic format suitable for CASB. The transformed data is then:
Stored in Cloudflare R2 for future reference.
Published on another Cloudflare Queue, designated for transformed messages.
CASB Processing: Consumers & Crawlers
Once the transformed messages reach the CASB layer, they undergo further processing:
Polling consumer: CASB has a consumer that polls the transformed message queue. Upon receiving a message, it determines the relevant handler required for processing.
Crawler execution: The handler then maps the message to an appropriate crawler, which interacts with the vendor API to fetch the most up-to-date asset details.
Data storage: The retrieved asset data is stored in the CASB database, ensuring it is accessible for security and compliance checks.
With this improvement, we are now processing 10 to 20 Microsoft updates per second, or 864,000 to 1.72 million updates daily, giving customers incredibly fast visibility into their environment. Look out for expansion to other SaaS vendors in the coming months.
Securing your web applications
A unique challenge of securing web applications is that no one size fits all. An asset-aware posture management bridges the gap between a universal security solution and unique business needs, offering tailored recommendations for security teams to protect what matters.
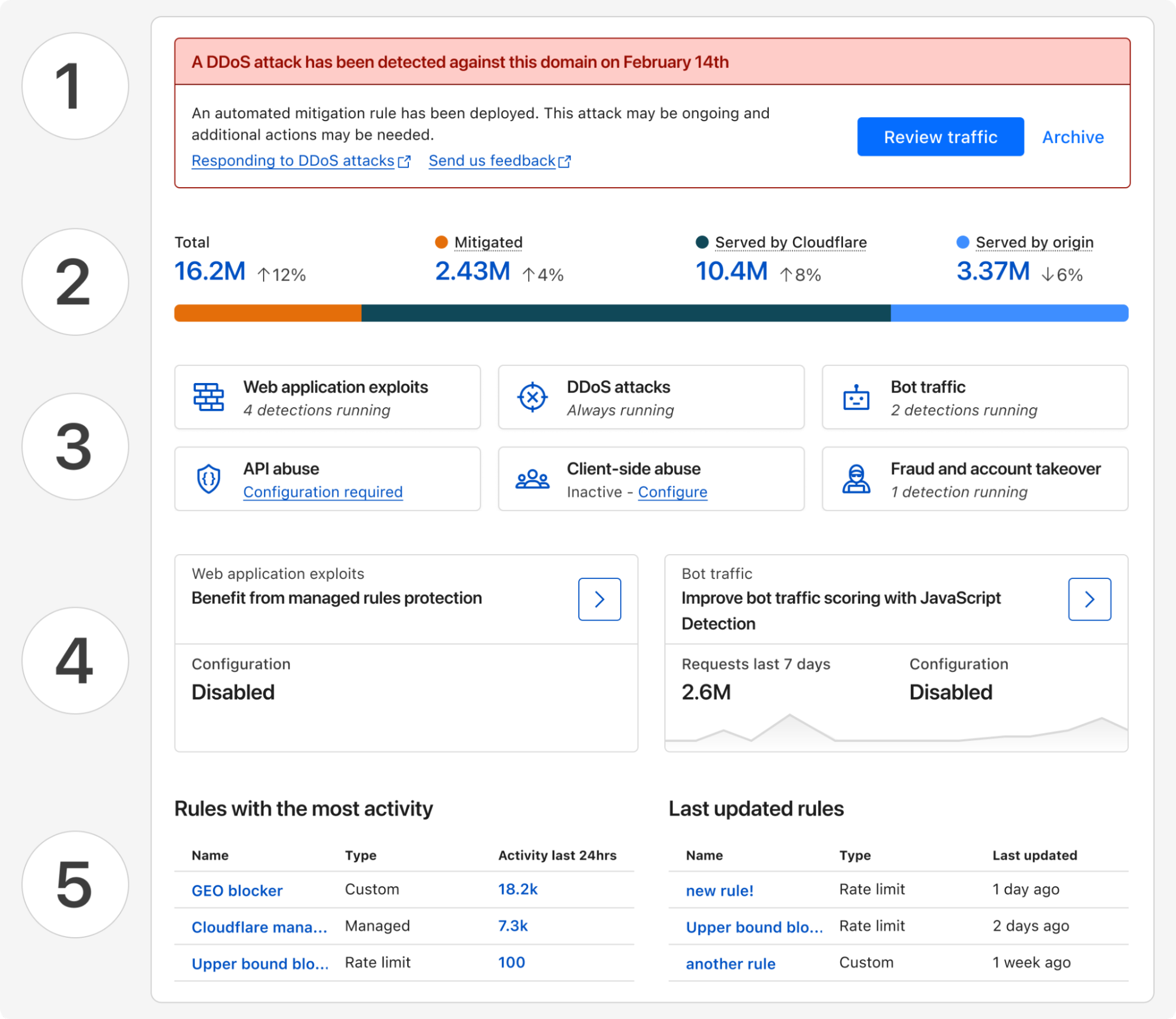
Posture overview from attacks to threats and risks
Starting today, all Cloudflare customers have access to Security Overview, a new landing page customized for each of your onboarded domains. This page aggregates and prioritizes security suggestions across all your web applications:
Any (ongoing) attacks detected that require immediate attention
Disposition (mitigated, served by Cloudflare, served by origin) of all proxied traffic over the last 7 days
Summary of currently active security modules that are detecting threats
Suggestions of how to improve your security posture with a step-by-step guide
And a glimpse of your most active and lately updated security rules
These tailored security suggestions are surfaced based on your traffic profile and business needs, which is made possible by discovering your proxied web assets.
Discovery of web assets
Many web applications, regardless of their industry or use case, require similar functionality: user identification, accepting payment information, etc. By discovering the assets serving this functionality, we can build and run targeted threat detection to protect them in depth.
As an example, bot traffic towards marketing pages versus login pages have different business impacts. Content scraping may be happening targeting your marketing materials, which you may or may not want to allow, while credential stuffing on your login page deserves immediate attention.
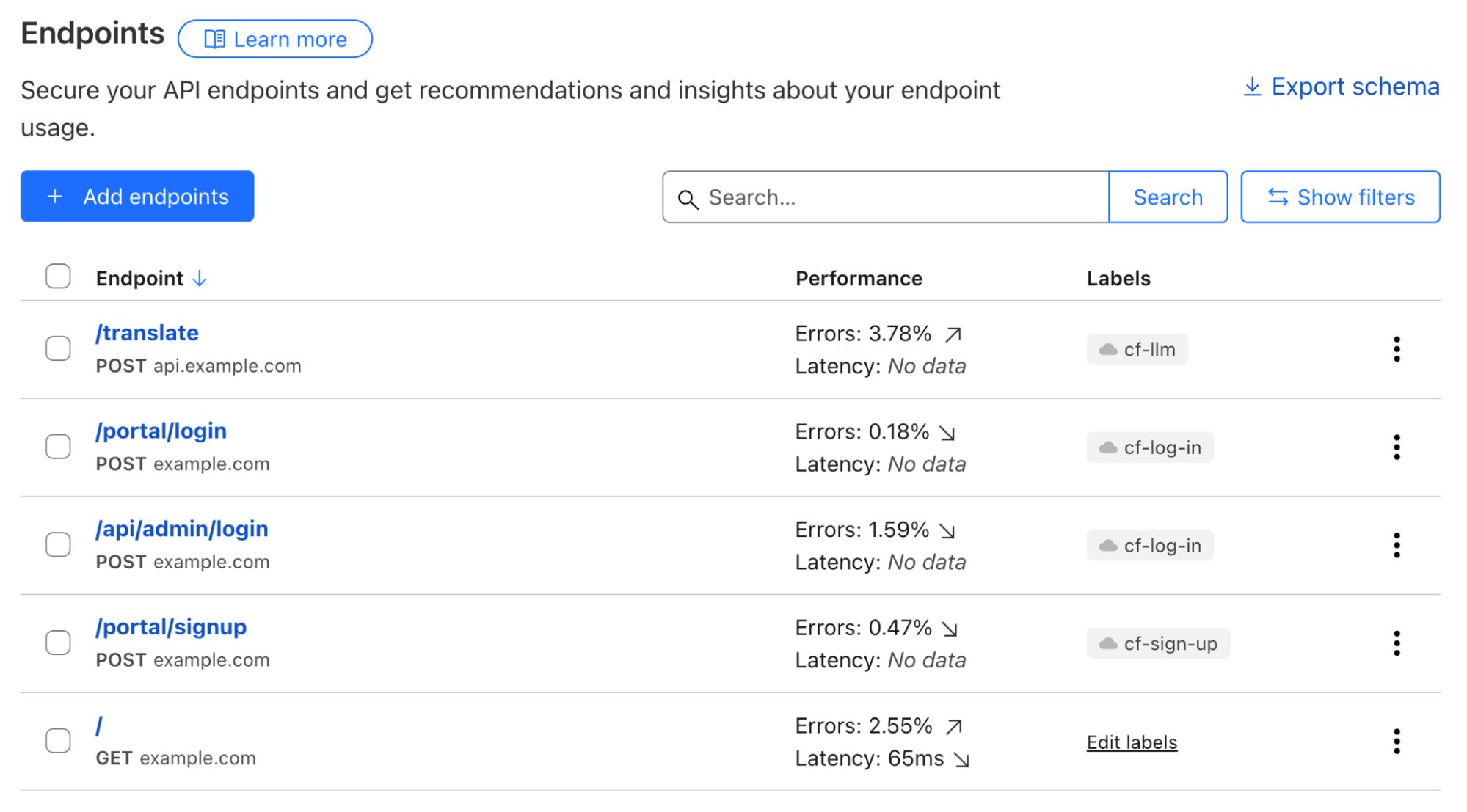
Web assets are described by a list of endpoints; and labelling each of them defines their business goals. A simple example can be POST requests to path /portal/login, which likely describes an API for user authentication. While the GET requests to path /portal/login denote the actual login webpage.
To describe business goals of endpoints, labels come into play. POST requests to the /portal/login endpoint serving end users and to the /api/admin/login endpoint used by employees can both can be labelled using the same cf-log-inmanaged label, letting Cloudflare know that usernames and passwords would be expected to be sent to these endpoints.
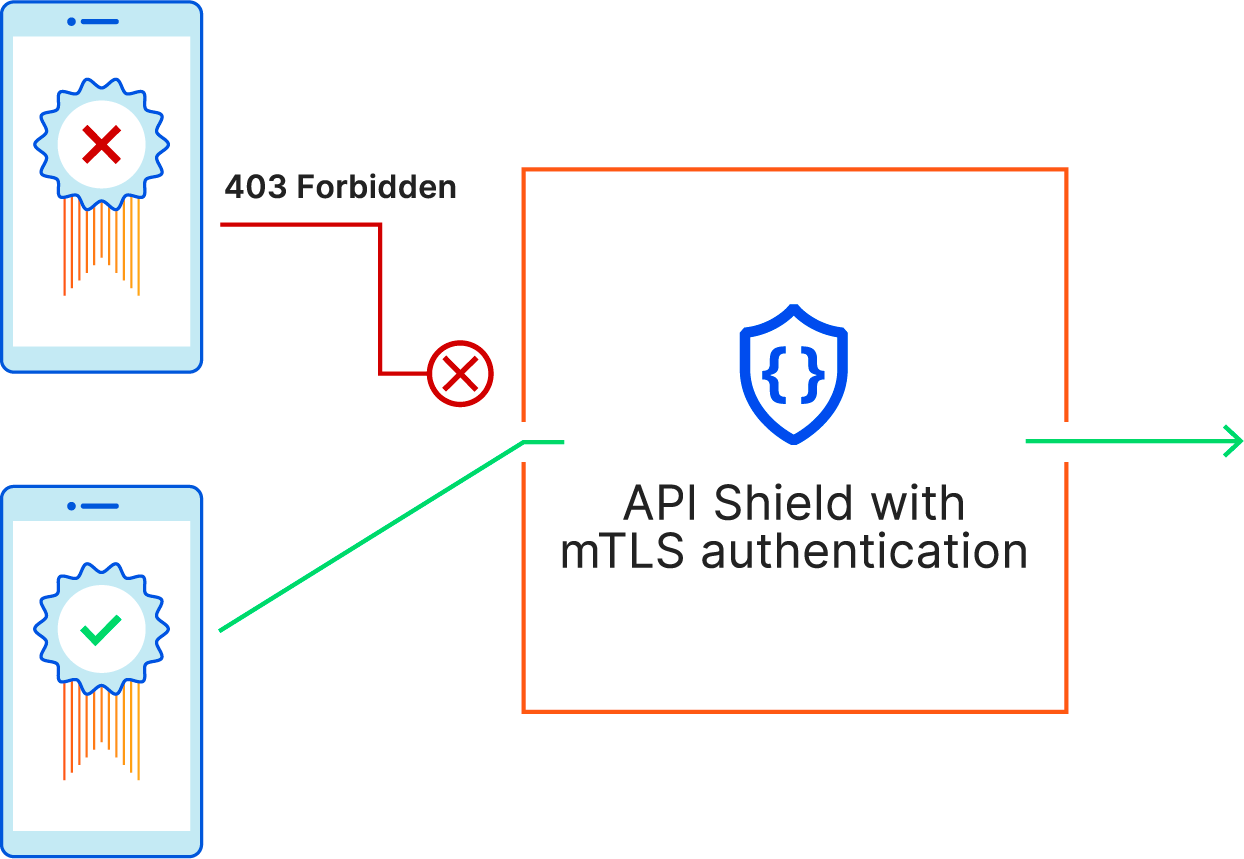
API Shield customers can already make use of endpoint labelling. In early Q2 2025, we are adding label discovery and suggestion capabilities, starting with three labels, cf-log-in, cf-sign-up, and cf-rss-feed. All other customers can manually add these labels to the saved endpoints. One example, explained below, is preventing disposable emails from being used during sign-ups.
Always-on threat detection and risk assessment
Use-case driven threat detection
Customers told us that, with the growing excitement around generative AI, they need support to secure this new technology while not hindering innovation. Being able to discover LLM-powered services allows fine-tuning security controls that are relevant for this particular technology, such as inspecting prompts, limit prompting rates based on token usage, etc. In a separate Security Week blog post, we will share how we build Cloudflare Firewall for AI, and how you can easily protect your generative AI workloads.
Account fraud detection, which encompasses multiple attack vectors, is another key area that we are focusing on in 2025.
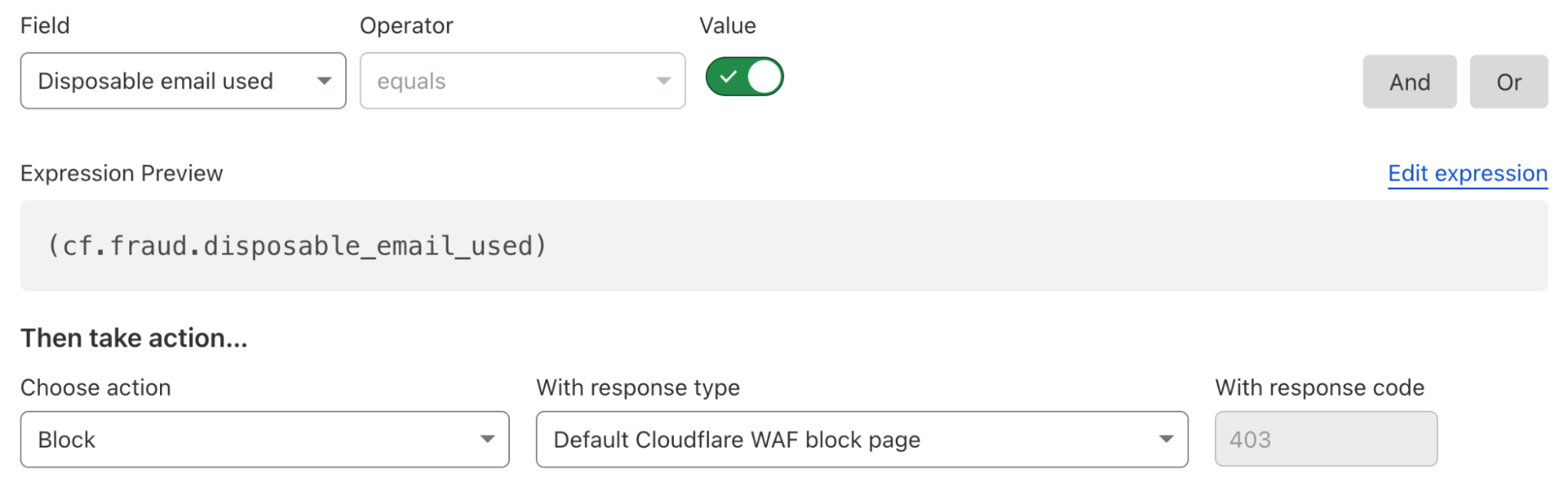
On many login and signup pages, a CAPTCHA solution is commonly used to only allow human beings through, assuming only bots perform undesirable actions. Put aside that most visual CAPTCHA puzzles can be easily solved by AI nowadays, such an approach cannot effectively solve the root cause of most account fraud vectors. For example, human beings using disposable emails to sign up single-use accounts to take advantage of signup promotions.
To solve this fraudulent sign up issue, a security rule currently under development could be deployed as below to block all attempts that use disposable emails as a user identifier, regardless of whether the requester was automated or not. All existing or future cf-log-in and cf-sign-up labelled endpoints are protected by this single rule, as they both require user identification.
Our fast expanding use-case driven threat detections are all running by default, from the first moment you onboarded your traffic to Cloudflare. The instant available detection results can be reviewed through security analytics, helping you make swift informed decisions.
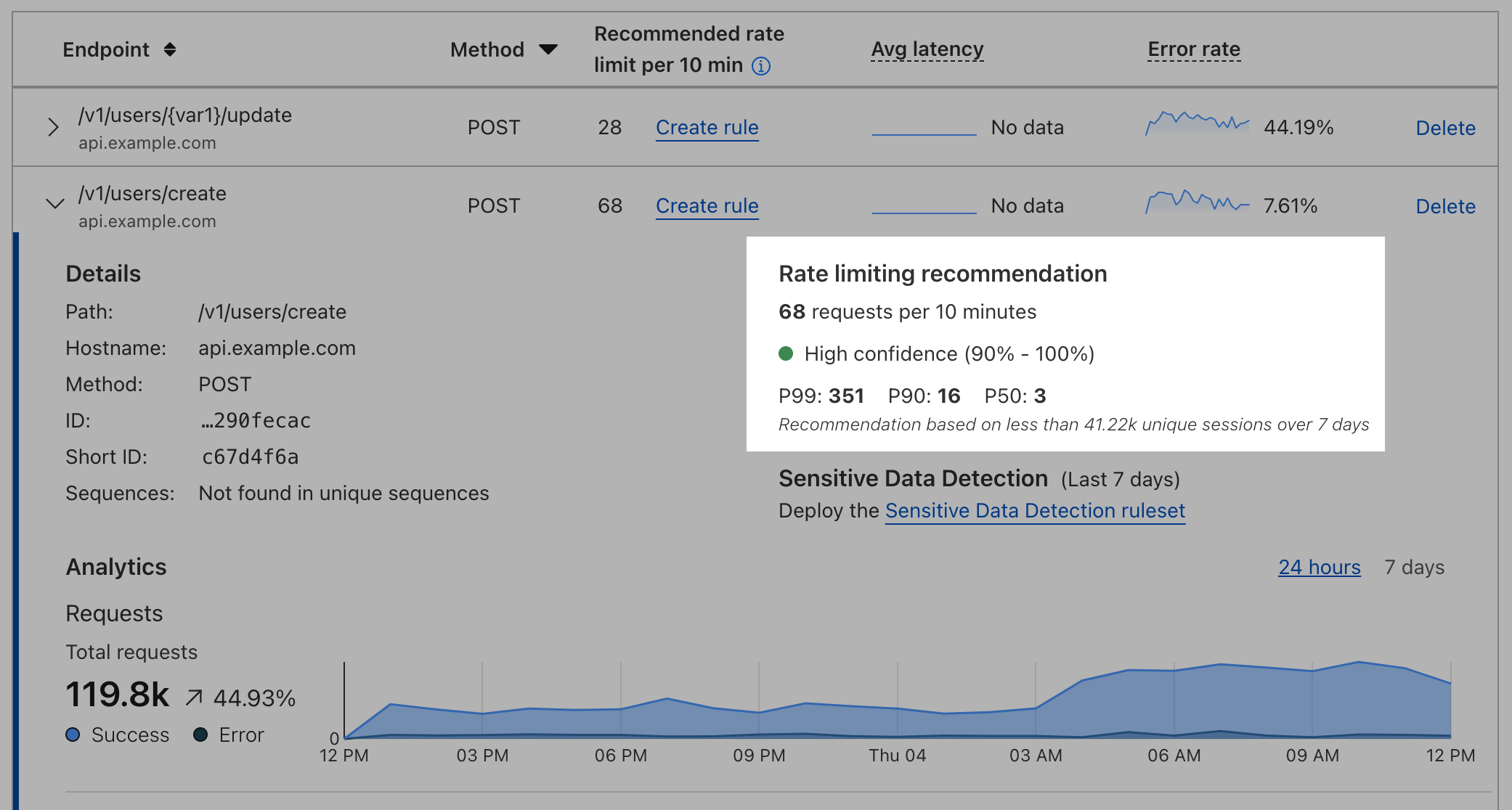
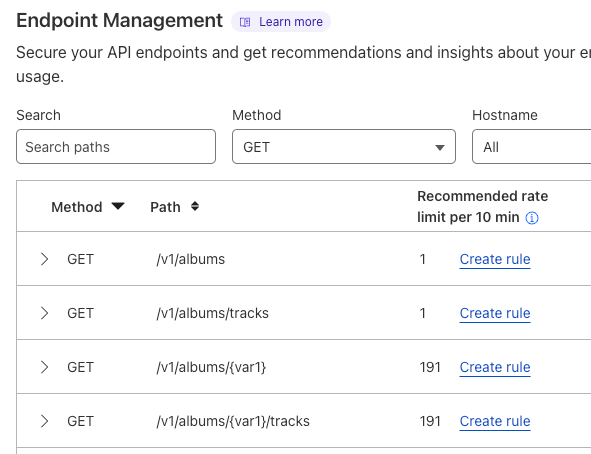
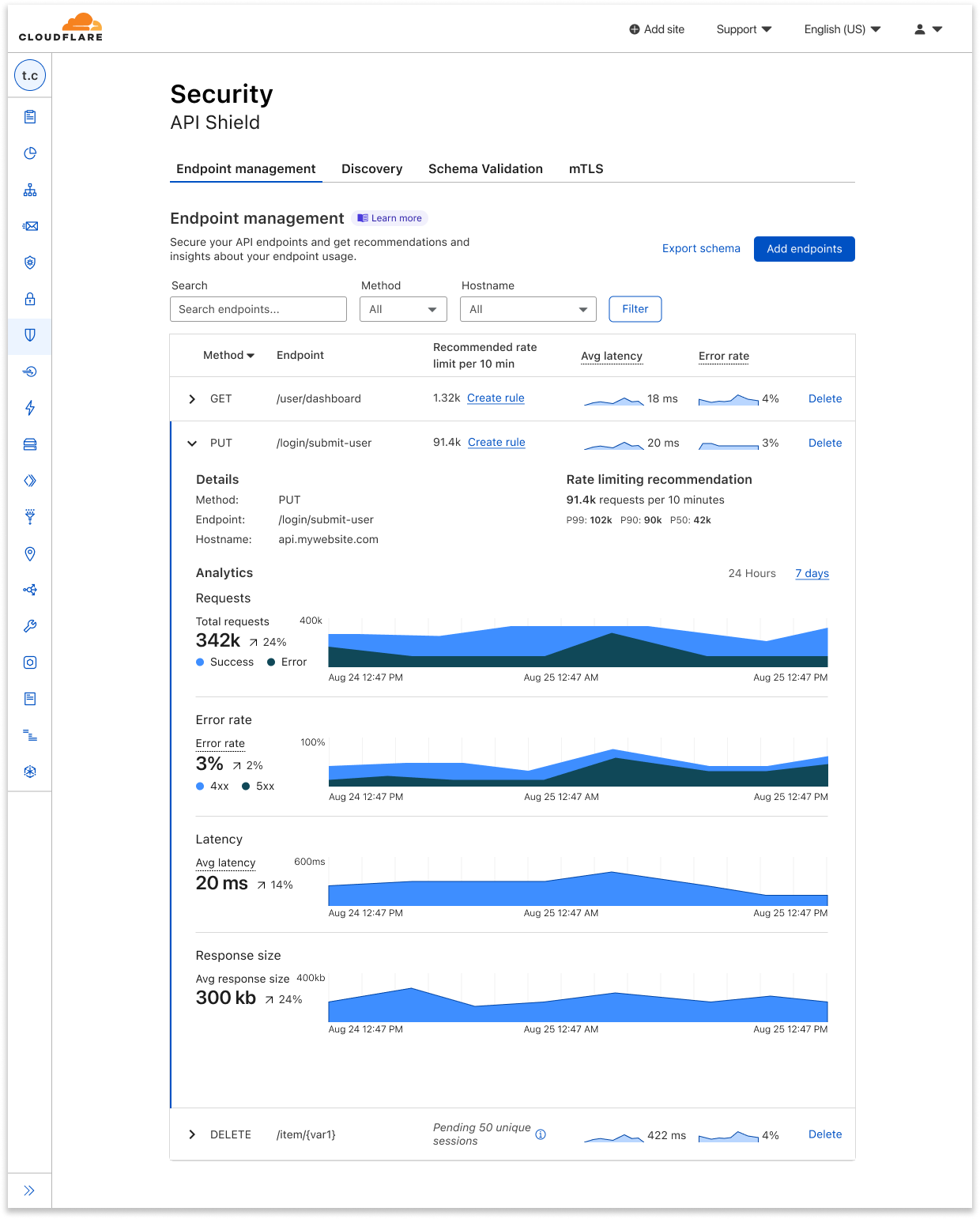
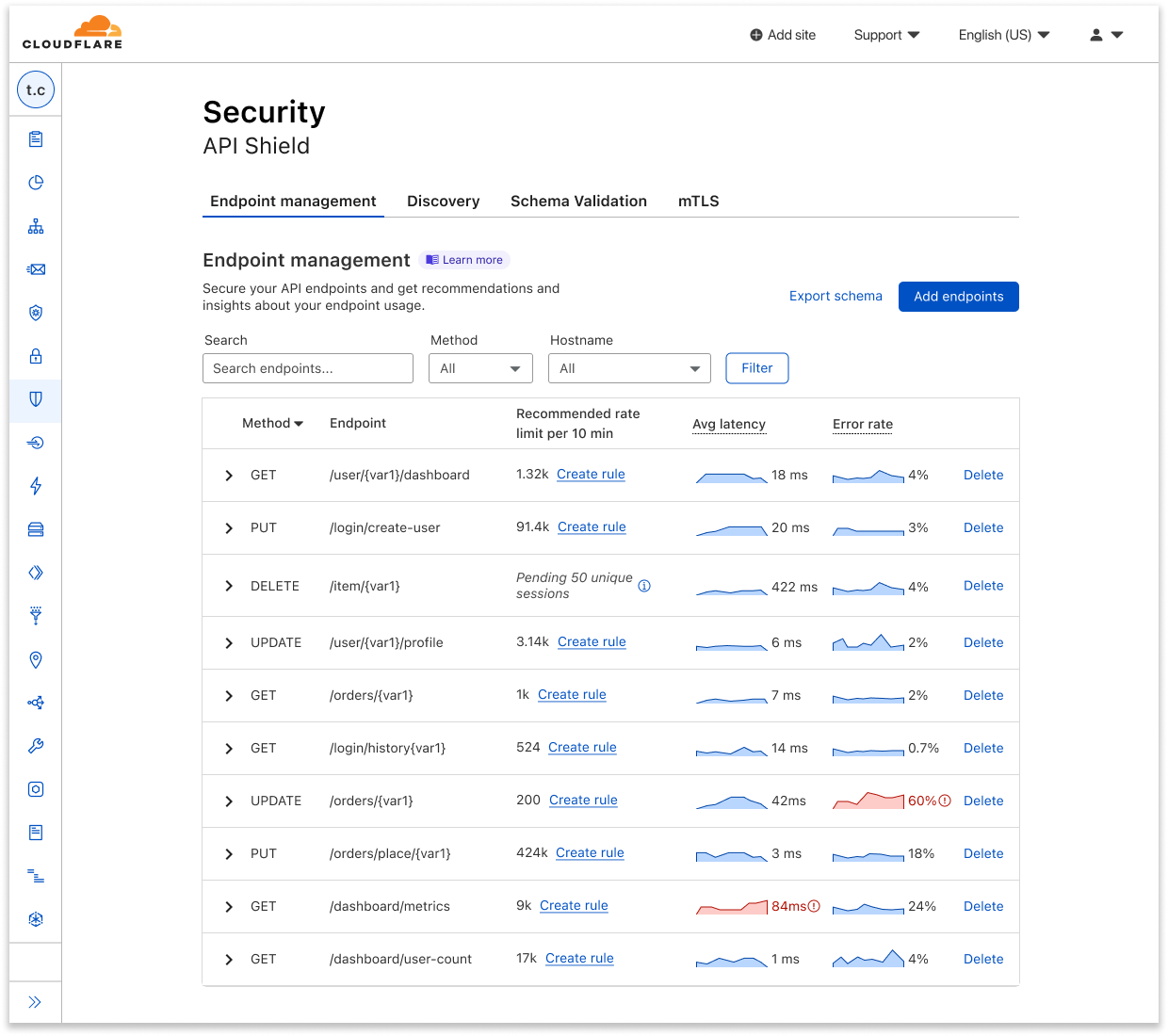
API endpoint risk assessment
APIs have their own set of risks and vulnerabilities, and today Cloudflare is delivering seven new risk scans through API Posture Management. This new capability of API Shield helps reduce risk by identifying security issues and fixing them early, before APIs are attacked. Because APIs are typically made up of many different backend services, security teams need to pinpoint which backend service is vulnerable so that development teams may remediate the identified issues.
Our new API posture management risk scans do exactly that: users can quickly identify which API endpoints are at risk to a number of vulnerabilities, including sensitive data exposure, authentication status, Broken Object Level Authorization (BOLA) attacks, and more.
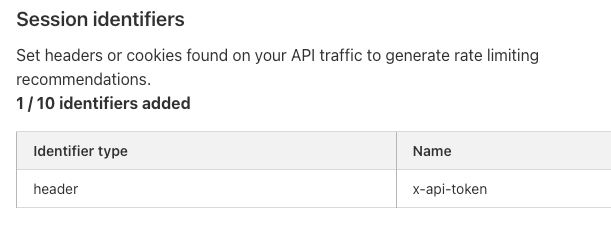
Authentication Posture is one risk scan you’ll see in the new system. We focused on it to start with because sensitive data is at risk when API authentication is assumed to be enforced but is actually broken. Authentication Posture helps customers identify authentication misconfigurations for APIs and alerts of their presence. This is achieved by scanning for successful requests against the API and noting their authentication status. API Shield scans traffic daily and labels API endpoints that have missing and mixed authentication for further review.
For customers that have configured session IDs in API Shield, you can find the new risk scan labels and authentication details per endpoint in API Shield. Security teams can take this detail to their development teams to fix the broken authentication.
We’re launching today with scans for authentication posture, sensitive data, underprotected APIs, BOLA attacks, and anomaly scanning for API performance across errors, latency, and response size.
Simplify maintaining a good security posture with Cloudflare
Achieving a good security posture in a fast-moving environment requires innovative solutions that can transform complexity into simplicity. Bringing together the ability to continuously assess threats and risks across both public and private IT environments through a single platform is our first step in supporting our customers’ efforts to maintain a healthy security posture.
To further enhance the relevance of security insights and suggestions provided and help you better prioritize your actions, we are looking into integrating Cloudflare’s global view of threat landscapes. With this, you gain additional perspectives, such as what the biggest threats to your industry are, and what attackers are targeting at the current moment. Stay tuned for more updates later this year.
If you haven’t done so yet, onboard your SaaS and web applications to Cloudflare today to gain instant insights into how to improve your business’s security posture.
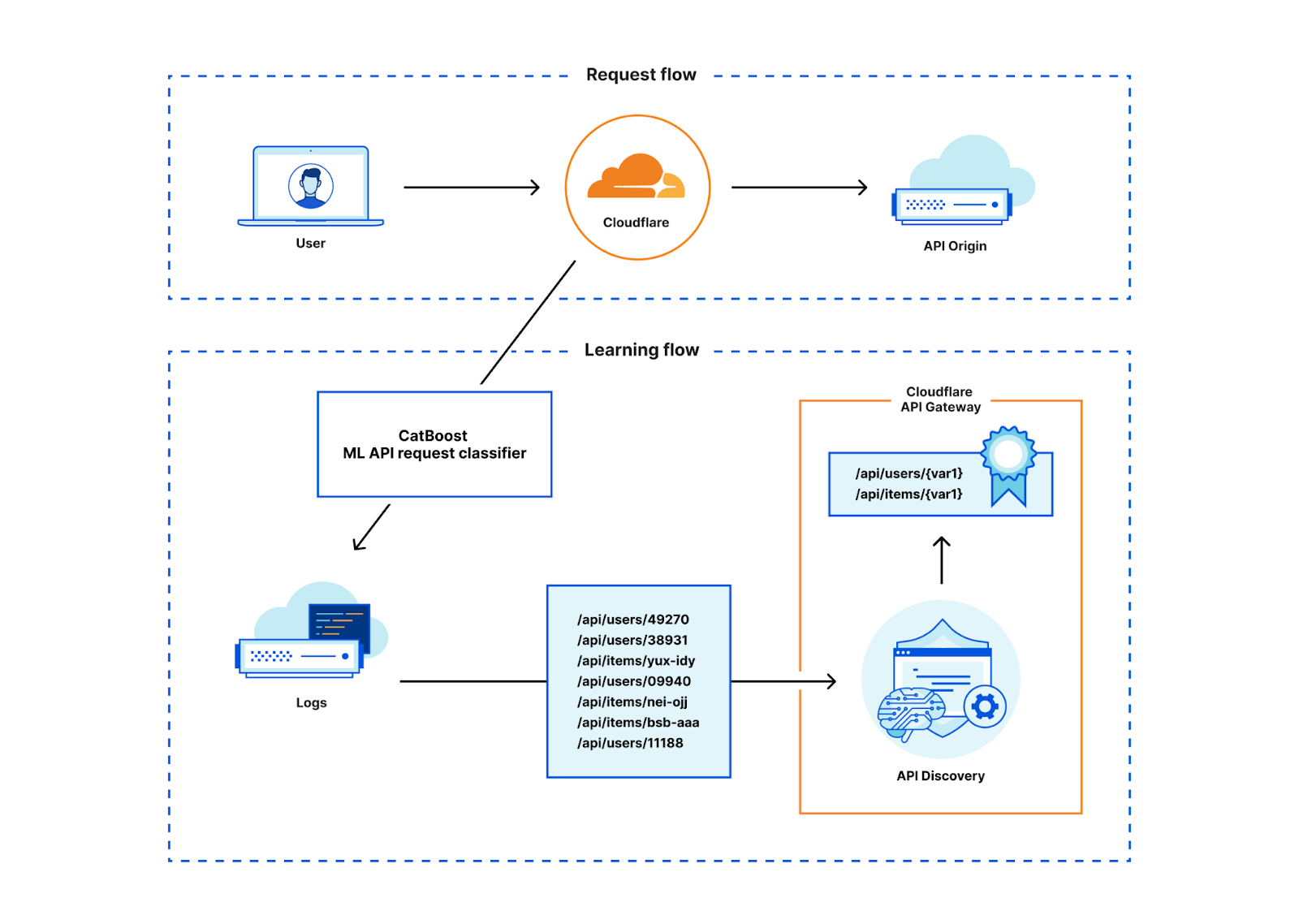
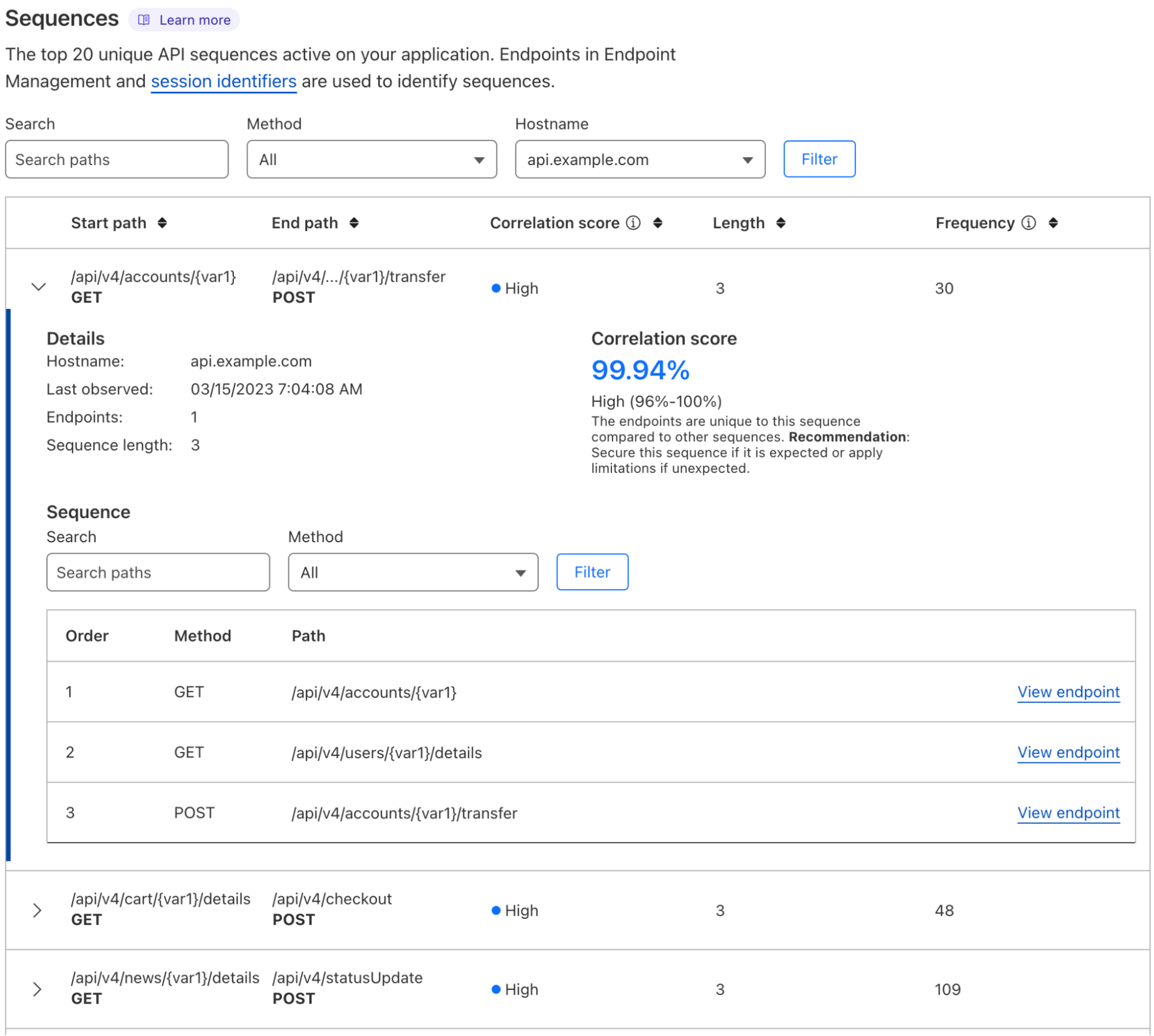
Consider the case of a malicious actor attempting to inject, scrape, harvest, or exfiltrate data via an API. Such malicious activities are often characterized by the particular order in which the actor initiates requests to API endpoints. Moreover, the malicious activity is often not readily detectable using volumetric techniques alone, because the actor may intentionally execute API requests slowly, in an attempt to thwart volumetric abuse protection. To reliably prevent such malicious activity, we therefore need to consider the sequential order of API requests. We use the term sequential abuse to refer to malicious API request behavior. Our fundamental goal thus involves distinguishing malicious from benign API request sequences.
In this blog post, you’ll learn about how we address the challenge of helping customers protect their APIs against sequential abuse. To this end, we’ll unmask the statistical machine learning (ML) techniques currently underpinning our Sequence Analytics product. We’ll build on the high-level introduction to Sequence Analytics provided in a previous blog post.
API sessions
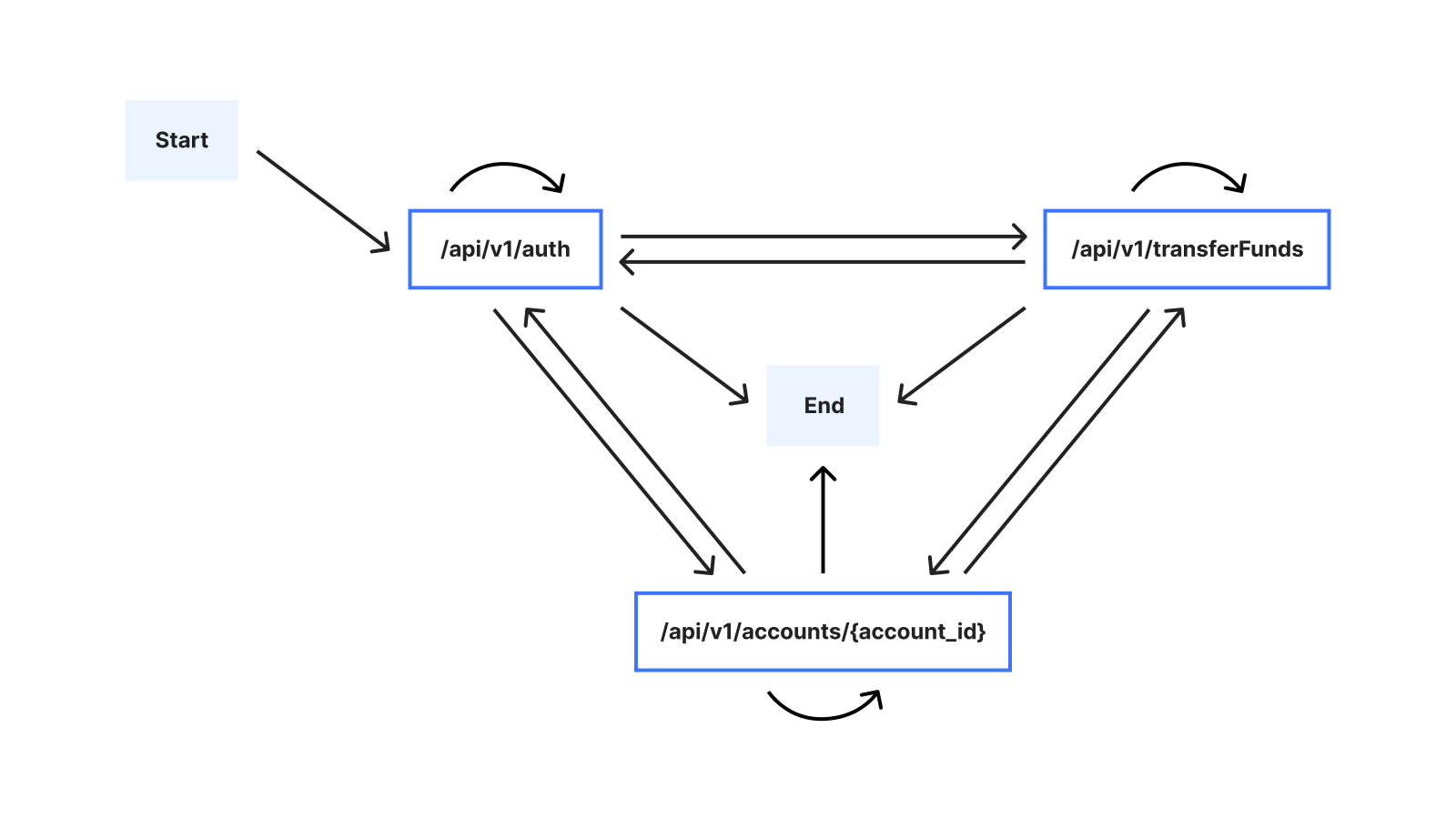
Introduced in the previous blog post, let’s consider the idea of a time-ordered series of HTTP API requests initiated by a specific user. These occur as the user interacts with a service, such as while browsing a website or using a mobile app. We refer to the user’s time-ordered series of API requests as a session. Choosing a familiar example, the session for a customer interacting with a banking service might look like:
Time Order
Method
Path
Description
1
POST
/api/v1/auth
Authenticates a user
2
GET
/api/v1/accounts/{account_id}
Displays account balance, where account_id is an account belonging to the user
3
POST
/api/v1/transferFunds
Containing a request body detailing an account to transfer funds from, an account to transfer funds to, and an amount of money to transfer
One of our aims is to enable our customers to secure their APIs by automatically suggesting rules applicable to our Sequence Mitigation product for enforcing desired sequential behavior. If we enforce the expected behavior, we can prevent unwanted sequential behavior. In our example, desired sequential behavior might entail that /api/v1/auth must always precede /api/v1/accounts/{account_id}.
One important challenge we had to address is that the number of possible sessions grows rapidly as the session length increases. To see why, we can consider the alternative ways in which a user might interact with the example banking service: The user may, for example, execute multiple transfers, and/or check the balance of multiple accounts, in any order. Assuming that there are 3 possible endpoints, the following graph illustrates possible sessions when the user interacts with the banking service:
Because of this large number of possible sessions, suggesting mitigation rules requires that we address the challenge of summarizing sequential behavior from past session data as an intermediate step. We’ll refer to a series of consecutive endpoints in a session (for example /api/v1/accounts/{account_id} → /api/v1/transferFunds) in our example as a sequence. Specifically, a challenge we needed to address is that the sequential behavior relevant for creating rules isn’t necessarily apparent from volume alone: Consider for example that /api/transferFunds might nearly always be preceded by /api/v1/accounts/{account_id}, but also that the sequence /api/v1/transferFunds → /api/v1/accounts/{account_id} might occur relatively rarely, compared to the sequence /api/v1/auth → /api/v1/accounts/{account_id}. It is therefore conceivable that if we were to summarize based on volume alone, we might potentially deem the sequence /api/v1/accounts/{account_id} → /api/v1/transferFunds as unimportant, when in fact we ought to surface it as a potential rule.
Learning important sequences from API sessions
A widely-applied modeling approach applicable to sequential data is the Markov chain, in which the probability of each endpoint in our session data depends only on a fixed number of preceding endpoints. First, we’ll show how standard Markov chains can be applied to our session data, while pointing out some of their limitations. Second, we’ll show how we use a less well-known, but powerful, type of Markov chain to determine important sequences.
For illustrative purposes, let’s assume that there are 3 possible endpoints in our session data. We’ll represent these endpoints using the letters a, b and c:
a: /api/v1/auth
b: /api/v1/accounts/{account_id}
c: /api/v1/transferFunds
In its simplest form, a Markov chain is nothing more than a table which tells us the probability of the next letter, given knowledge of the immediately preceding letter. If we were to model past session data using the simplest kind of Markov chain, we might end up with a table like this one:
Known preceding endpoint in the session
Estimated probability of next endpoint in the session
a
b
c
a
0.10 (1555)
0.89 (13718)
0.01 (169)
b
0.03 (9618)
0.63 (205084)
0.35 (113382)
c
0.02 (3340)
0.67 (109896)
0.31 (51553)
Table 1
Table 1 lists the parameters of the Markov chain, namely the estimated probabilities of observing a, b or c as the next endpoint in a session, given knowledge of the immediately preceding endpoint in the session. For example, the 3rd row cell with value 0.67 means that given knowledge of immediately preceding endpoint c, the estimated probability of observing b as the next endpoint in a session is 67%, regardless of whether c was preceded by any endpoints. Thus, each entry in the table corresponds to a sequence of two endpoints. The values in brackets are the number of times we saw each two-endpoint sequence in past session data and are used to compute the probabilities in the table. For example, the value 0.01 is the result of evaluating the fraction 169 / (1555+13718+169). This method of estimating probabilities is known as maximum likelihood estimation.
To determine important sequences, we rely on credible intervals for estimating probabilities instead of maximum likelihood estimation. Instead of producing a single point estimate (as described above), credible intervals represent a plausible range of probabilities. This range reflects the amount of data available, i.e. the total number of sequence occurrences in each row. More data produces narrower credible intervals (reflecting a greater degree of certainty) and conversely less data produces wider credible intervals (reflecting a lesser degree of certainty). Based on the values in brackets in the table above, we thus might obtain the following credible intervals (entries in boldface will be explained further on):
Known preceding endpoint in the session
Estimated probability of next endpoint in the session
a
b
c
a
0.09-0.11 (1555)
0.88-0.89 (13718)
0.01-0.01 (169)
b
0.03-0.03 (9618)
0.62-0.63 (205084)
0.34-0.35 (113382)
c
0.02-0.02 (3340)
0.66-0.67 (109896)
0.31-0.32 (51553)
Table 2
For brevity, we won’t demonstrate here how to work out the credible intervals by hand (they involve evaluating the quantile function of a beta distribution). Notwithstanding, the revised table indicates how more data causes credible intervals to shrink: note the first row with a total of 15442 occurrences in comparison to the second row with a total of 328084 occurrences.
To determine important sequences, we use slightly more complex Markov chains than those described above. As an intermediate step, let’s first consider the case where each table entry corresponds to a sequence of 3 endpoints (instead of 2 as above), exemplified by the following table:
Known preceding endpoints in the session
Estimated probability of next endpoint in the session
a
b
c
aa
0.09-0.13 (173)
0.86-0.90 (1367)
0.00-0.02 (13)
ba
0.09-0.11 (940)
0.88-0.90 (8552)
0.01-0.01 (109)
ca
0.09-0.12 (357)
0.87-0.90 (2945)
0.01-0.02 (35)
ab
0.02-0.02 (272)
0.56-0.58 (7823)
0.40-0.42 (5604)
bb
0.03-0.03 (6067)
0.60-0.60 (122796)
0.37-0.37 (75801)
cb
0.03-0.03 (3279)
0.68-0.68 (74449)
0.29-0.29 (31960)
ac
0.01-0.09 (6)
0.77-0.91 (144)
0.06-0.19 (19)
bc
0.02-0.02 (2326)
0.77-0.77 (87215)
0.21-0.21 (23612)
cc
0.02-0.02 (1008)
0.43-0.44 (22527)
0.54-0.55 (27919)
Table 3
Table 3 again lists the estimated probabilities of observing a, b or c as the next endpoint in a session, but given knowledge of 2 immediately preceding endpoints in the session (instead of 1 immediately preceding endpoint as before). That is, the 3rd row cell with interval 0.09-0.13 means that given knowledge of immediately preceding endpoints ca, the probability of observing a as the next endpoint has a credible interval spanning 9% and 13%, regardless of whether ca was preceded by any endpoints. In parlance, we say that the above table represents a Markov chain of order 2. This is because the entries in the table represent probabilities of observing the next endpoint, given knowledge of 2 immediately preceding endpoints as context.
As a special case, the Markov chain of order 0 simply represents the distribution over endpoints in a session. We can tabulate the probabilities as follows, in relation to a single row corresponding to an ‘empty context’:
Known preceding endpoints in the session
Estimated probability of next endpoint in the session
a
b
c
0.03-0.03 (15466)
0.64-0.65 (328732)
0.32-0.33 (165117)
Table 4
Note that the probabilities in Table 4 do not solely represent the case where there were no preceding endpoints in the session. Rather, the probabilities are for the occurrence of endpoints in the session, for the general case where we have no knowledge of the preceding endpoints and regardless of how many endpoints previously occurred.
Returning to our task of identifying important sequences, one possible approach might be to simply use a Markov chain of some fixed order N. For example, if we were to apply a threshold of 0.85 to the lower bounds of credible intervals in Table 3, we’d retain 3 sequences in total. On the other hand, this approach comes with two noteworthy limitations:
We need a way to select a suitable value for the model order N.
Since the model order remains fixed, identified sequences all have the same length N+1.
Variable order Markov chains
Variable order Markov chains (VOMCs) are a more powerful extension of the described fixed-order Markov chains which address the preceding limitations. VOMCs make use of the fact that for some chosen value of the Markov chain of fixed order N, the probability table might include statistically redundant information: Let’s compare Tables 3 and 2 above and consider in Table 3 the rows in boldface corresponding to contexts aa, ba, ca (these 3 contexts all share a as their suffix).
For all the 3 possible next endpoints a, b, c, these rows specify credible intervals which overlap with their respective estimates in Table 2 corresponding to context a (also indicated in boldface). We can interpret these overlapping intervals as representing no discernible difference between probability estimates, given knowledge of a as the preceding endpoint. With no discernible effect of what preceded a on the probability of the next endpoint, we can consider these 3 rows in Table 3 redundant: We may ‘collapse’ them by replacing them with the row in Table 2 corresponding to context a.
The result of revising Table 3 as described looks as follows (with the new row indicated in boldface):
Known preceding endpoints in the session
Estimated probability of next endpoint in the session
a
b
c
a
0.09-0.11 (1555)
0.88-0.89 (13718)
0.01-0.01 (169)
ab
0.02-0.02 (272)
0.56-0.58 (7823)
0.40-0.42 (5604)
ac
0.03-0.03 (6067)
0.60-0.60 (122796)
0.37-0.37 (75801)
bb
0.03-0.03 (3279)
0.68-0.68 (74449)
0.29-0.29 (31960)
bc
0.01-0.09 (6)
0.77-0.91 (144)
0.06-0.19 (19)
cb
0.02-0.02 (2326)
0.77-0.77 (87215)
0.21-0.21 (23612)
cc
0.02-0.02 (1008)
0.43-0.44 (22527)
0.54-0.55 (27919)
Table 5
Table 5 represents a VOMC, because the context length varies: In the example, we have context lengths 1 and 2. It follows that entries in the table represent sequences of length varying between 2 and 3 endpoints, depending on context length. Generalizing the described approach of collapsing contexts leads to the following algorithm sketch for learning a VOMC in an offline setting:
(1) Define the table T containing the estimated probability of the next endpoint in a session, given alternatively 0, 1, 2, …, N_max preceding endpoints in the session. That is, form a single table by concatenating the rows corresponding to Markov chains of fixed orders 0, 1, 2, …, N_max.
(2) is_modified := true
(3) DO WHILE is_modified
(4) D := all contexts in T which are not suffixes of at least 1 other context in T
(5) is_modified = false
(6) FOR ctx IN C
(7) IF length(ctx) > 0
(8) parent_ctx := the context obtained by deleting the leftmost endpoint in ctx
(9) IF is_collapsible(ctx, parent_ctx)
(10) Modify T by discarding ctx
(11) is_modified = true
In the pseudo-code, length(ctx) is the length of context ctx. On line 9, is_collapsible() involves comparing credible intervals for the contexts ctx and parent_ctx in the manner described for generating Table 5: is_collapsible() evaluates to true, if and only if we observe that all credible intervals overlap, when comparing contexts ctx and parent_ctx separately for each of the possible next endpoints. The maximum sequence length is N_max+1, where N_max is some constant. On line 4, we say that context q is a suffix of another context p if we can form p by prepending zero or more endpoints to q. (According to this definition, the ‘empty context’ mentioned above for the order 0 model is a suffix of all contexts in T.) The above algorithm sketch is a variant of the ideas first introduced by Rissanen [1], Ron et al. [2].
Finally, we take the entries in the resulting table T as our important sequences. Thus, the result of applying VOMCs is a set of sequences that we deem important. For Sequence Analytics however, we believe that it is additionally useful to rank sequences. We do this by computing a ‘precedence score’ between 0.0 and 1.0, which is the number of occurrences of the sequence divided by the number of occurrences of the last endpoint in the sequence. Thus, precedence scores close to 1.0 indicate that a given endpoint is nearly always preceded by the remaining endpoints in the sequence. In this way, manual inspection of the highest-scoring sequences is a semi-automated heuristic for creating precedence rules in our Sequence Mitigation product.
Learning sequences at scale
The preceding represents a very high-level overview of the statistical ML techniques that we use in Sequence Analytics. In practice, we have devised an efficient algorithm which does not require an upfront training step, but rather updates the model continuously as the data arrive and generates a frequently-updating summary of important sequences. This approach allows us to overcome additional challenges around memory cost not touched on in this blog post. Most significantly, a straightforward implementation of the algorithm sketch above would still result in the number of table rows (contexts) exploding with increasing maximum sequence length. A further challenge we had to address is how to ensure that our system is able to deal with high-volume APIs, without adversely impacting CPU load. We use a horizontally scalable adaptive sampling strategy upfront, such that more aggressive sampling is applied to high-volume APIs. Our algorithm then consumes the sampled streams of API requests. After a customer onboards, sequences are assembled and learned over time, so that the current summary of important sequences represents a sliding window with a look-back interval of approximately 24 hours. Sequence Analytics further stores sequences in Clickhouse and exposes them via a GraphQL API and via the Cloudflare dashboard. Customers who would like to enforce sequence rules can do so using Sequence Mitigation. Sequence Mitigation is what is responsible for ensuring that rules are shared and matched in distributed fashion on Cloudflare’s global network — another exciting topic for a future blog post!
What’s next
Now that you have a better understanding of how we surface important API request sequences, stay tuned for a future blog post in this series, where we’ll describe how we find the anomalous API request sequences that customers may want to stop. For now, API Gateway customers can get started in two ways: with Sequence Analytics to explore important API request sequences and with Sequence Mitigation to enforce sequences of API requests. Enterprise customers that haven’t purchased API Gateway can get started by enabling the API Gateway trial inside the Cloudflare Dashboard or contacting their account manager.
Today, we are happy to announce that Cloudflare customers can protect their APIs from broken authentication attacks by validating incoming JSON Web Tokens (JWTs) with API Gateway. Developers and their security teams need to control who can communicate with their APIs. Using API Gateway’s JWT Validation, Cloudflare customers can ensure that their Identity Provider previously validated the user sending the request, and that the user’s authentication tokens have not expired or been tampered with.
What’s new in this release?
After our beta release in early 2023, we continued to gather feedback from customers on what they needed from JWT validation in API Gateway. We uncovered four main feature requests and shipped updates in this GA release to address them all:
Old, Beta limitation
New, GA release capability
Only supported validating the raw JWT
Support for the Bearer token format
Only supported one JWKS configuration
Create up to four different JWKS configs to support different environments per zone
Only supported validating JWTs sent in HTTP headers
Validate JWTs if they are sent in a cookie, not just an HTTP header
JWT validation ran on all requests to the entire zone
Exclude any number of managed endpoints in a JWT validation rule
What is the threat?
Broken authentication is the #1 threat on the OWASP Top 10 and the #2 threat on the OWASP API Top 10. We’ve written before about how flaws in API authentication and authorization at Optus led to a threat actor offering 10 million user records for sale, and government agencies have warned about these exact API attacks.
According to Gartner®1, “attacks and data breaches involving poorly secured application programming interfaces (APIs) are occurring frequently.” Getting authentication correct for your API users can be challenging, but there are best practices you can employ to cover your bases. JSON Web Token Validation in API Gateway fulfills one of these best practices by enforcing a positive security model for your authenticated API users.
A primer on authentication and authorization
Authentication establishes identity. Imagine you’re collaborating with multiple colleagues and writing a document in Google Docs. When you’re all authors of the document, you have the same privileges, and you can overwrite each other’s text. You can all see each other’s name next to your respective cursor while you’re typing. You’re all authenticated to Google Docs, so Docs can show all the users on a document who everyone is.
Authorization establishes ownership or permissions to objects. Imagine you’re collaborating with your colleague in Docs again, but this time they’ve written a document ahead of time and simply wish for you to review it and add comments without changing the document. As the owner of the document, your colleague sets an authorization policy to only allow you ‘comment’ access. As such, you cannot change their writing at all, but you can still view the document and leave comments.
While the words themselves might sound similar, the differences between them are hugely important for security. It’s not enough to simply check that a user logging in has the correct login credentials (authentication). If you never check their permissions (authorization), they would be free to overwrite, add, or delete other users’ content. When this happens for APIs, OWASP calls it a Broken Object Level Authorization attack.
A primer on API access tokens
Users authenticate to services in many different ways on the web today. Let’s take a look at the history of authentication with username and password authentication, API key authentication, and JWT authentication before we mention how JWTs can help stop API attacks.
In the early days, the web used HTTP Basic Authentication, where browsers transmitted username and password pairs as an HTTP header, posing significant security risks and making credentials visible to any observer when the application failed to adopt SSL/TLS certificates. Basic authentication also complicated API access, requiring hard-coded credentials and potentially giving broad authorization policies to a single user.
The introduction of API access keys improved security by detaching authentication from user credentials and instead sending secret text strings along with requests. This approach allowed for more nuanced access control by key instead of by user ID, though API keys still faced risks from man-in-the-middle attacks and problematic storage of secrets in source code.
JSON Web Tokens (JWTs) address these issues by removing the need to send long-lived secrets on every request, introducing cryptographically verifiable, auto-expiring, short-lived sessions. Think of a JWT like a tamper-evident seal on a bottle of medication. Along with the seal, medication also has an expiration date printed on it. Users notice when the seal is tampered with or missing altogether, and when the medication expires.
These attributes enhance security any time a JWT is used instead of a long-lived shared secret. JWTs are not an end-all-be-all solution, but they do represent an evolution in authentication technology and are widely used for authentication and authorization on the Internet today.
What’s the structure of a JWT?
JWTs are composed of three fields separated by periods. The first field is a header, the second a payload, and the third a signature:
If we base64 decode the first two sections, we arrive at the following structure (comments added for clarity):
{
"alg": "RS256", // JWT signature algorithm
"typ": "JWT" // JWT type
}
{
"iss": "MyDemoIDP", // Which identity provider issued this JWT
"sub": "johndoe", // Which user this JWT identifies
"aud": "MyApp", // Which app this JWT is destined for
"iat": 1708985601, // When this JWT was issued
"exp": 1709986201, // When this JWT expires
"class": "admin" // Extra, customer-defined metadata
}
We can then use the algorithm mentioned in the header (RS256) as well as the Identity Provider’s public key (example below) to check the last segment in the JWT, the signature (code not shown).
-----BEGIN PUBLIC KEY-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA3exXmNOELAnrtejo3jb2
S6p+GFR5FFlO0AqC4lA4HjNX9stgxX8tcbzv1yl5CT6VWl4kpnBweJzdBsNOauPz
uiCFQ0PtTfS0wDZm3inRPR1bTvJEuqsRTbsCxw/nRLU2+Dvu0zF41Wo4OkAbuKGS
3FwfdKOY/rX5tzjhnTe7uhWTarJG3nVnwmuD03INeNI+fbTgbUrOaVFT06Ussb9L
NNe6BHGQjs6NfG037Jk36dGY1Yiy/rutj6nJ7WkEK5ktQgWrvMMoXW9TfpYHi6sC
mnSEdaxNS8jtFodqpURUaLDIdTOGGgpUZsvzv3jDMYo5IxQK+6y+HUV8eRyDYd/o
rQIDAQAB
-----END PUBLIC KEY-----
The signature is what makes a JWT special. The token issuer, taking into account the claims, generates a signature based on a private secret or a public/private key pair. The public key can be published online, allowing anyone to check if a JWT was legitimately issued by an organization.
Proper authentication and authorization stop API attacks
No developer wants to release an insecure application, and no security team wants their developers to skip secure coding practices, but we know both happen. In the Enterprise Strategy Group report “Securing the API Attack Surface”2, a survey found that 39% of developers skip security processes due to the faster development cycles of continuous integration and continuous delivery (CI/CD). The same survey found more than half (57%) of responding organizations faced multiple security incidents related to insecure APIs in the last 12 months, and 35% of responding organizations faced at least one incident within the last year.
Along with its accompanying database, permissions, and user roles, your origin application is the ultimate security backstop of your API. However, Cloudflare can assist in keeping attacks away from your origin when you configure API Gateway with the correct context. Let’s examine three different API attacks and how to protect against them.
Missing or broken authentication
The ability for a user to send or receive data to an API and entirely bypass authentication falls into ‘broken authentication’. It’s easy to think of the expected use cases your users will take with your application. You may assume that just because a user logs in and your application is written so that users can only access their own data in their dashboard, that all users are logged in and would only access their own data. This assumption fails to account for a user making an HTTP request outside your application requesting or modifying another user’s data and there being nothing in the way to stop your API from replying. In the worst case, a lack of authorization policy checks can enable an API client to change data without an authentication token at all!
Ensuring that incoming requests have an authentication token attached to them and dropping the requests that don’t is a great way to stop the simplest API attacks.
Expired token reuse
Maybe your application already uses JWTs for user authentication. Your application decodes the JWT and looks for user claims for group membership, and you validate the claims before allowing customers access to your API. But are you checking the JWT expiration time?
Imagine a user pays for your service, but they secretly know they will soon downgrade to a free account. If the user’s tier is stored within the JWT and the application or gateway doesn’t validate the expiration time of the JWT, the user could save an old JWT and replay it to continue their access to their paid benefits. Validating JWT expiration time can prevent this type of replay attack.
Let’s say you’re using JWTs for authentication, validating the claims inside them, and also validating expiration time. But do you verify the JWT signature? Practically every JWT is signed by its issuer such that API admins and security teams that know the issuer’s signing key can verify that the JWT hasn’t been tampered with. Without the API Gateway or application checking the JWT signature, a malicious user could change their JWT claims, elevating their privileges to assume an administrator role in an application by starting with a normal, non-privileged user account.
JWT Validation from API Gateway safeguards your API from broken authentication and authorization attacks by checking that JWT signatures are intact, expiry times haven’t yet passed, and that authentication tokens are present to begin with.
Don’t other Cloudflare products do this?
Other Cloudflare products also use JWTs. Cloudflare Access is part of our suite of Zero Trust products, and is meant to tie into your Identity Provider. As a best practice, customers should validate the JWT that Access creates and sends to the origin.
Conversely, JWT Validation for API Gateway is a security layer compatible with any API without changing the setup, management, or expectation of the existing user flow. API Gateway’s JWT Validation is meant to validate pre-existing JWTs that may be used by any number of services at your API origin. You really need both: Access for your internal users or employees and API Gateway for your external users.
In addition, some customers use a custom Cloudflare Worker to validate JWTs, which is a great use case for the Workers platform. However, for straightforward use cases customers may find the JWT Validation experience of API Gateway easier to interact with and manage over the lifecycle of their application. If you are validating JWTs with a Worker and today’s release of JWT Validation isn’t yet at feature parity for your custom Worker, let your account representative know. We’re interested in expanding our capabilities to meet your requirements.
What’s next?
In a future release, we will go beyond checking pre-existing JWTs, and customers will be able to generate and enforce authorization policies entirely within API Gateway. We’ll also upgrade our on-demand developer portal creation with the ability to issue keys and authentication tokens to your development team directly, streamlining API management with Cloudflare.
In addition, stay tuned for future API Gateway feature launches where we’ll use our knowledge of API traffic norms to automatically suggest security policies that highlight and stop Broken Object/Function Level Authorization attacks outside the JWT Validation use case.
Existing API Gateway customers can try the new feature now. Enterprise customers without API Gateway should sign up for the trial to try the latest from API Gateway.
—
1Gartner, “API Security: What You Need to Do to Protect Your APIs”, Analyst(s) Mark O’Neill, Dionisio Zumerle, Jeremy D’Hoinne, January 13, 2023 2Enterprise Strategy Group, “Securing the API Attack Surface”, Analyst, Melinda Marks, May 2023
The United States Cybersecurity and Infrastructure Agency (CISA) and seventeen international partners are helping shape best practices for the technology industry with their ‘Secure by Design’ principles. The aim is to encourage software manufacturers to not only make security an integral part of their products’ development, but to also design products with strong security capabilities that are configured by default.
As a cybersecurity company, Cloudflare considers product security an integral part of its DNA. We strongly believe in CISA’s principles and will continue to uphold them in the work we do. We’re excited to share stories about how Cloudflare has baked secure by design principles into the products we build and into the services we make available to all of our customers.
What do “secure by design” and “secure by default” mean?
Secure by design describes a product where the security is ‘baked in’ rather than ‘bolted on’. Rather than manufacturers addressing security measures reactively, they take actions to mitigate any risk beforehand by building products in a way that reasonably protects against attackers successfully gaining access to them.
Secure by default means products are built to have the necessary security configurations come as a default, without additional charges.
CISA outlines the following three software product security principles:
Take ownership of customer security outcomes
Embrace radical transparency and accountability
Lead from the top
In its documentation, CISA provides comprehensive guidance on how to achieve its principles and what security measures a manufacturer should follow. Adhering to these guidelines not only enhances security benefits to customers and boosts the developer’s brand reputation, it also reduces long term maintenance and patching costs for manufacturers.
Why does it matter?
Technology undeniably plays a significant role in our lives, automating numerous everyday tasks. The world’s dependence on technology and Internet-connected devices has significantly increased in the last few years, in large part due to Covid-19. During the outbreak, individuals and companies moved online as they complied with the public health measures that limited physical interactions.
While Internet connectivity makes our lives easier, bringing opportunities for online learning and remote work, it also creates an opportunity for attackers to benefit from such activities. Without proper safeguards, sensitive data such as user information, financial records, and login credentials can all be compromised and used for malicious activities.
Systems vulnerabilities can also impact entire industries and economies. In 2023, hackers from North Korea were suspected of being responsible for over 20% of crypto losses, exploiting software vulnerabilities and stealing more than $300 million from individuals and companies around the world.
Despite the potentially devastating consequences of insecure software, too many vendors place the onus of security on their customers — a fact that CISA underscores in their guidelines. While a level of care from customers is expected, the majority of risks should be handled by manufacturers and their products. Only then can we have more secure and trusting online interactions. The ‘Secure by Design’ principles are essential to bridge that gap and change the industry.
How does Cloudflare support secure by design principles?
Taking ownership of customer security outcomes
CISA explains that in order to take ownership of customer security outcomes, software manufacturers should invest in product security efforts that include application hardening, application features, and application default settings. At Cloudflare, we always have these product security efforts top of mind and a few examples are shared below.
Application hardening
At Cloudflare, our developers follow a defined software development life cycle (SDLC) management process with checkpoints from our security team. We proactively address known vulnerabilities before they can be exploited and fix any exploited vulnerabilities for all of our customers. For example, we are committed to memory safe programming languages and use them where possible. Back in 2021, Cloudflare rewrote the Cloudflare WAF from Lua into the memory safe Rust. More recently, Cloudflare introduced a new in-house built HTTP proxy named Pingora, that moved us from memory unsafe C to memory safe Rust as well. Both of these projects were extra large undertakings that would not have been possible without executive support from our technical leadership team.
Zero Trust Security
By default, we align with CISA’s Zero Trust Maturity Model through the use of Cloudflare’s Zero Trust Security suite of services, to prevent unauthorized access to Cloudflare data, development resources, and other services. We minimize trust assumptions and require strict identity verification for every person and device trying to access any Cloudflare resources, whether self-hosted or in the cloud.
At Cloudflare, we believe that Zero Trust Security is a must-have security architecture in today’s environment, where cyber security attacks are rampant and hybrid work environments are the new normal. To help protect small businesses today, we have a Zero Trust plan that provides the essential security controls needed to keep employees and apps protected online available free of charge for up to 50 users.
Application features
We not only provide users with many essential security tools for free, but we have helped push the entire industry to provide better security features by default since our early days.
Back in 2014, during Cloudflare’s birthday week, we announced that we were making encryption free for all our customers by introducing Universal SSL. Then in 2015, we went one step further and provided full encryption of all data from the browser to the origin, for free. Now, the rest of the industry has followed our lead and encryption by default has become the standard for Internet applications.
During Cloudflare’s seventh Birthday Week in 2017, we were incredibly proud to announce unmetered DDoS mitigation. The service absorbs and mitigates large-scale DDoS attacks without charging customers for the excess bandwidth consumed during an attack. With such announcement we eliminated the industry standard of ‘surge pricing’ for DDoS attacks
In 2021, we announced a protocol called MIGP (“Might I Get Pwned”) that allows users to check whether their credentials have been compromised without exposing any unnecessary information in the process. Aside from a bucket ID derived from a prefix of the hash of your email, your credentials stay on your device and are never sent (even encrypted) over the Internet. Before that, using credential checking services could turn out to be a vulnerability in itself, leaking sensitive information while you are checking whether or not your credentials have been compromised.
A year later, in 2022, Cloudflare again disrupted the industry when we announced WAF (Web Application Firewall) Managed Rulesets free of charge for all Cloudflare plans. WAF is a service responsible for protecting web applications from malicious attacks. Such attacks have a major impact across the Internet regardless of the size of an organization. By making WAF free, we are making the Internet safe for everyone.
Finally, at the end of 2023, we were excited to help lead the industry by making post-quantum cryptography available free of charge to all of our customers irrespective of plan levels.
Application default settings
To further protect our customers, we ensure our default settings provide a robust security posture right from the start. Once users are comfortable, they can change and configure any settings the way they prefer. For example, Cloudflare automatically deploys the Free Cloudflare Managed Ruleset to any new Cloudflare zone. The managed ruleset includes Log4j rules, Shellshock rules, rules matching very common WordPress exploits, and others. Customers are able to disable the ruleset, if necessary, or configure the traffic filter or individual rules. To provide an even more secure-by-default system, we also created the ML-computed WAF Attack Score that uses AI to detect bypasses of existing managed rules and can detect software exploits before they are made public.
As another example, all Cloudflare accounts come with unmetered DDoS mitigation services to protect applications from many of the Internet’s most common and hard to handle attacks, by default.
As yet another example, when customers use our R2 storage, all the stored objects are encrypted at rest. Both encryption and decryption is automatic, does not require user configuration to enable, and does not impact the performance of R2.
Cloudflare also provides all of our customers with robust audit logs. Audit logs summarize the history of changes made within your Cloudflare account. Audit logs include account level actions like login, as well as zone configuration changes. Audit Logs are available on all plan types and are captured for both individual users and for multi-user organizations. Our audit logs are available across all plan levels for 18 months.
Embracing radical transparency and accountability
To embrace radical transparency and accountability means taking pride in delivering safe and secure products. Transparency and sharing information are crucial for improving and evolving the security industry, fostering an environment where companies learn from each other and make the online world safer. Cloudflare shows transparency in multiple ways, as outlined below.
The Cloudflare blog
On the Cloudflare blog, you can find the latest information about our features and improvements, but also about zero-day attacks that are relevant to the entire industry, like the historic HTTP/2 Rapid Reset attacks detected last year. We are transparent and write about important security incidents, such as the Thanksgiving 2023 security incident, where we go in detail about what happened, why it happened, and the steps we took to resolve it. We have also made a conscious effort to embrace radical transparency from Cloudflare’s inception about incidents impacting our services, and continue to embrace this important principle as one of our core values. We hope that the information we share can assist others in enhancing their software practices.
Cloudflare System Status
Cloudflare System Status is a page to inform website owners about the status of Cloudflare services. It provides information about the current status of services and whether they are operating as expected. If there are any ongoing incidents, the status page notes which services were affected, as well as details about the issue. Users can also find information about scheduled maintenance that may affect the availability of some services.
Technical transparency for code integrity
We believe in the importance of using cryptography as a technical means for transparently verifying identity and data integrity. For example, in 2022, we partnered with WhatsApp to provide a system for WhatsApp that assures users they are running the correct, untampered code when visiting the web version of the service by enabling the code verify extension to confirm hash integrity automatically. It’s this process, and the fact that is automated on behalf of the user, that helps provide transparency in a scalable way. If users had to manually fetch, compute, and compare the hashes themselves, detecting tampering would likely only be done by a small fraction of technical users.
Transparency report and warrant canaries
We also believe that an essential part of earning and maintaining the trust of our customers is being transparent about the requests we receive from law enforcement and other governmental entities. To this end, Cloudflare publishes semi-annual updates to our Transparency Report on the requests we have received to disclose information about our customers.
An important part of Cloudflare’s transparency report is our warrant canaries. Warrant canaries are a method to implicitly inform users that we have not taken certain actions or received certain requests from government or law enforcement authorities, such as turning over our encryption or authentication keys or our customers’ encryption or authentication keys to anyone. Through these means we are able to let our users know just how private and secure their data is while adhering to orders from law enforcement that prohibit disclosing some of their requests. You can read Cloudflare’s warrant canaries here.
While transparency reports and warrant canaries are not explicitly mentioned in CISA’s secure by design principles, we think they are an important aspect in a technology company being transparent about their practices.
Public bug bounties
We invite you to contribute to our security efforts by participating in our public bug bounty hosted by HackerOne, where you can report Cloudflare vulnerabilities and receive financial compensation in return for your help.
Leading from the top
With this principle, security is deeply rooted inside Cloudflare’s business goals. Because of the tight relationship of security and quality, by improving a product’s default security, the quality of the overall product also improves.
At Cloudflare, our dedication to security is reflected in the company’s structure. Our Chief Security Officer reports directly to our CEO, and presents at every board meeting. That allows for board members well-informed about the current cybersecurity landscape and emphasizes the importance of the company’s initiatives to improve security.
Additionally, our security engineers are a part of the main R&D organization, with their work being as integral to our products as that of our system engineers. This means that our security engineers can bake security into the SDLC instead of bolting it on as an afterthought.
How can you help?
If you are a software manufacturer, we encourage you to familiarize yourself with CISA’s ‘Secure by Design’ principles and create a plan to implement them in your company.
As an individual, we encourage you to participate in bug bounty programs (such as Cloudflare’s HackerOne public bounty) and promote cybersecurity awareness in your community.
Email continues to be the largest attack vector that attackers use to try to compromise or extort organizations. Given the frequency with which email is used for business communication, phishing attacks have remained ubiquitous. As tools available to attackers have evolved, so have the ways in which attackers have targeted users while skirting security protections. The release of several artificial intelligence (AI) large language models (LLMs) has created a mad scramble to discover novel applications of generative AI capabilities and has consumed the minds of security researchers. One application of this capability is creating phishing attack content.
Phishing relies on the attacker seeming authentic. Over the years, we’ve observed that there are two distinct forms of authenticity: visual and organizational. Visually authentic attacks use logos, images, and the like to establish trust, while organizationally authentic campaigns use business dynamics and social relationships to drive their success. LLMs can be employed by attackers to make their emails seem more authentic in several ways. A common technique is for attackers to use LLMs to translate and revise emails they’ve written into messages that are more superficially convincing. More sophisticated attacks pair LLMs with personal data harvested from compromised accounts to write personalized, organizationally-authentic messages.
For example, WormGPT has the ability to take a poorly written email and recreate it to have better use of grammar, flow, and voice. The output is a fluent, well-written message that can more easily pass as authentic. Threat actors within discussion forums are encouraged to create rough drafts in their native language and let the LLM do its work.
One form of phishing attack that benefits from LLMs, which can have devastating financial impact, are Business Email Compromise (BEC) attacks. During these attacks, malicious actors attempt to dupe their victims into sending payment for fraudulent invoices; LLMs can help make these messages sound more organizationally authentic. And while BEC attacks are top of mind for organizations who wish to stop the unauthorized egress of funds from their organization, LLMs can be used to craft other types of phishing messages as well.
Yet these LLM-crafted messages still rely on the user performing an action, like reading a fraudulent invoice or interacting with a link, which can’t be spoofed so easily. And every LLM-written email is still an email, containing an array of other signals like sender reputation, correspondence patterns, and metadata bundled with each message. With the right mitigation strategy and tools in place, LLM-enhanced attacks can be reliably stopped.
While the popularity of ChatGPT has thrust LLMs into the recent spotlight, these kinds of models are not new; Cloudflare has been training its models to defend against LLM-enhanced attacks for years. Our models’ ability to look at all components of an email ensures that Cloudflare customers are already protected and will continue to be in the future — because the machine learning systems our threat research teams have developed through analyzing billions of messages aren’t deceived by nicely-worded emails.
Generative AI threats and trade offs
The riskiest of AI generated attacks are personalized based on data harvested prior to the attack. Threat actors collect this information during more traditional account compromise operations against their victims and iterate through this process. Once they have sufficient information to conduct their attack they proceed. It’s highly targeted and highly specific. The benefit of AI is scale of operations; however, mass data collection is necessary to create messages that accurately impersonate who the attacker is pretending to be.
While AI-generated attacks can have advantages in personalization and scalability, their effectiveness hinges on having sufficient samples for authenticity. Traditional threat actors can also employ social engineering tactics to achieve similar results, albeit without the efficiency and scalability of AI. The fundamental limitations of opportunity and timing, as we will discuss in the next section, still apply to all attackers — regardless of the technology used.
To defend against such attacks, organizations must adopt a multi-layer approach to cybersecurity. This includes employee awareness training, employing advanced threat detection systems that utilize AI and traditional techniques, and constantly updating security practices to protect against both AI and traditional phishing attacks.
Threat actors can utilize AI to generate attacks, but they come with tradeoffs. The bottleneck in the number of attacks they can successfully conduct is directly proportional to the number of opportunities they have at their disposal, and the data they have available to craft convincing messages. They require access and opportunity, and without both the attacks are not very likely to succeed.
BEC attacks and LLMs
BEC attacks are top of mind for organizations because they can allow attackers to steal a significant amount of funds from the target. Since BEC attacks are primarily based on text, it may seem like LLMs are about to open the floodgates. However, the reality is much different. The major obstacle limiting this proposition is opportunity. We define opportunity as a window in time when events align to allow for an exploitable condition and for that condition to be exploited — for example, an attacker might use data from a breach to identify an opportunity in a company’s vendor payment schedule. A threat actor can have motive, means, and resources to pull off an authentic looking BEC attack, but without opportunity their attacks will fall flat. While we have observed threat actors attempt a volumetric attack by essentially cold calling on targets, such attacks are unsuccessful the vast majority of the time. This is in line with the premise of BECs, as there is some component of social engineering at play for these attacks.
As an analogy, if someone were to walk into your business’ front door and demand you pay them \$20,000 without any context, a reasonable, logical person would not pay. A successful BEC attack would need to bypass this step of validation and verification, which LLMs can offer little assistance in. While LLMs can generate text that appears convincingly authentic, they cannot establish a business relationship with a company or manufacture an invoice that is authentic in appearance and style, matching those in use. The largest BEC payments are a product of not only account compromise, but invoice compromise, the latter of which are necessary for the attacker in order to provide convincing, fraudulent invoices to victims.
At Cloudflare, we are uniquely situated to provide this analysis, as our email security products scrutinize hundreds of millions of messages every month. In analyzing these attacks, we have found that there are other trends besides text which constitute a BEC attack, with our data suggesting that the vast majority of BEC attacks use compromised accounts. Attackers with access to a compromised account can harvest data to craft more authentic messages that can bypass most security checks because they are coming from a valid email address. Over the last year, 80% of BEC attacks involving \$10K or more involved compromised accounts. Out of that, 75% conducted thread hijacking and redirected the thread to newly registered domains. This is in keeping with observations that the vast majority of “successful” attacks, meaning the threat actor successfully compromised their target, leverages a lookalike domain. This fraudulent domain is almost always recently registered. We also see that 55% of these messages involving over $10K in payment attempted to change ACH payment details.
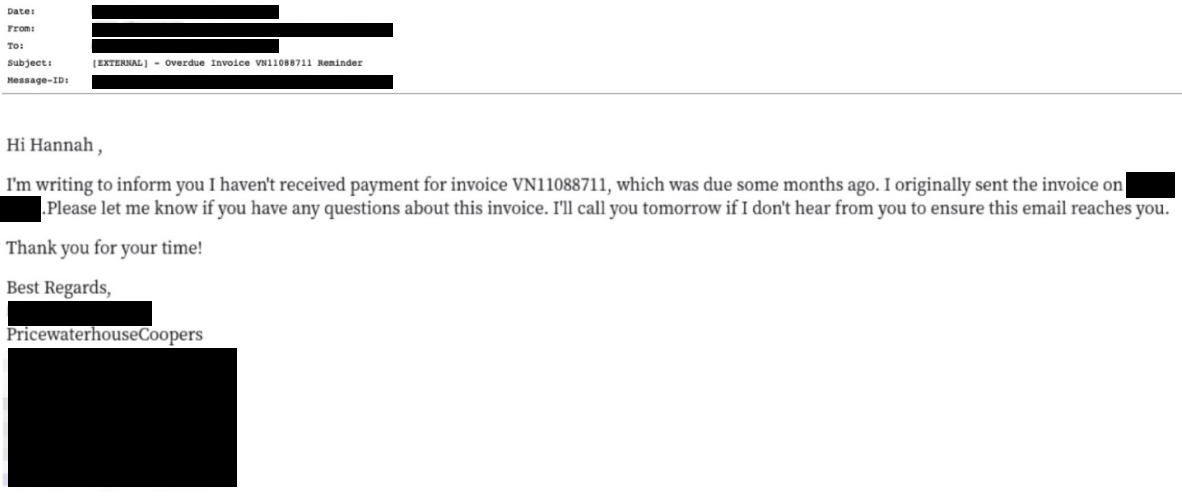
We can see an example of how this may accumulate in a BEC attack below.
The text within the message does not contain any grammatical errors and is easily readable, yet our sentiment models triggered on the text, detecting that there was a sense of urgency in the sentiment in combination with an invoice — a common pattern employed by attackers. However, there are many other things in this message that triggered different models. For example, the attacker is pretending to be from PricewaterhouseCoopers, but there is a mismatch in the domain from which this email was sent. We also noticed that the sending domain was recently registered, alerting us that this message may not be legitimate. Finally, one of our models generates a social graph unique to each customer based on their communication patterns. This graph provides information about whom each user communicates with and about what. This model flagged that, given the fresh history of this communication, this message was not business as usual. All the signals above plus the outputs of our sentiment models led our analysis engine to conclude that this was a malicious message and to not allow the recipient of this message to interact with it.
Generative AI is continuing to change and improve, so there’s still a lot to be discovered in this arena. While the advent of AI-created BEC attacks may cause an ultimate increase in the number of attacks seen in the wild, we do not expect their success rate to rise for organizations with robust security solutions and processes in place.
Phishing attack trends
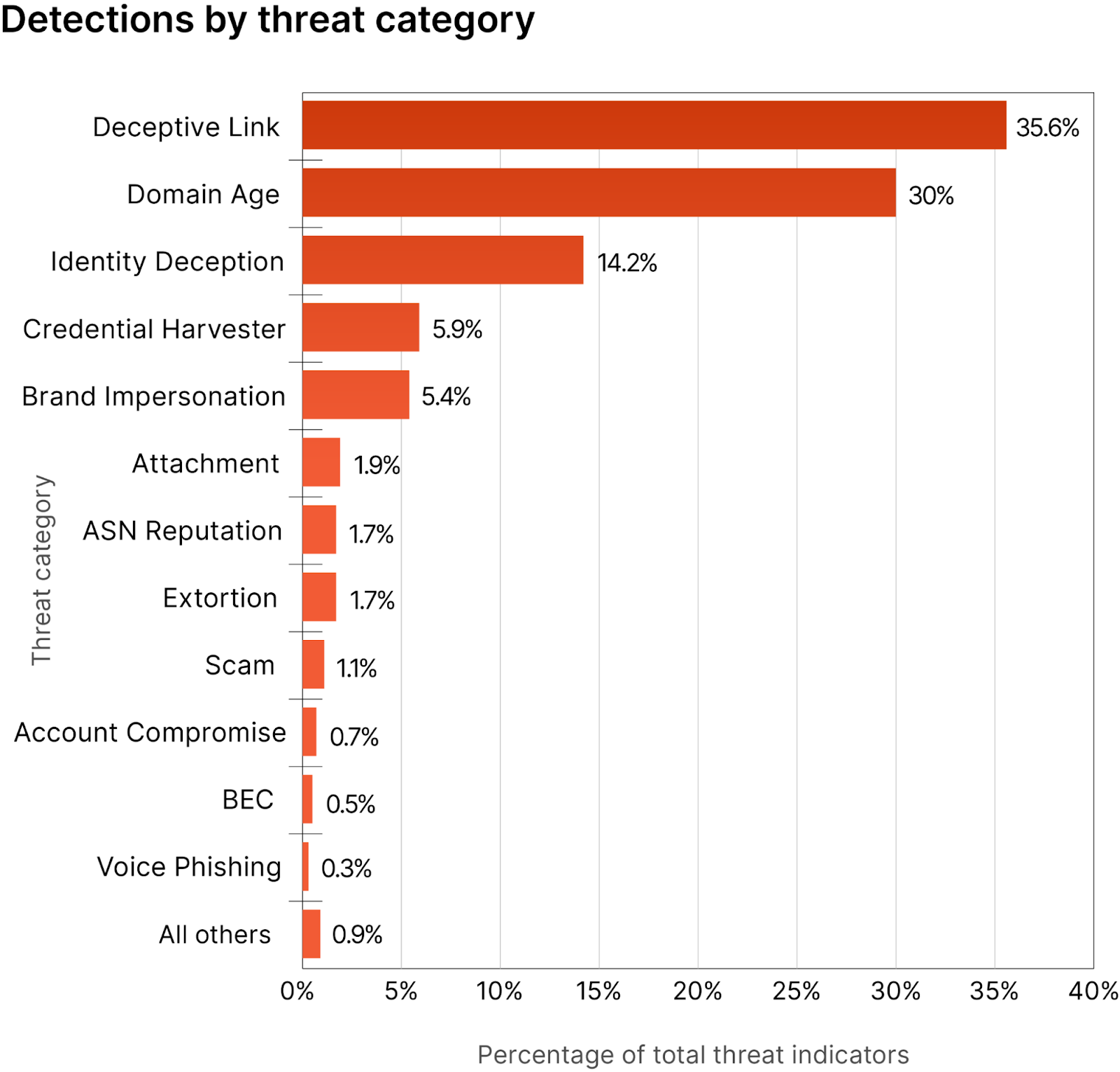
In August of last year, we published our 2023 Phishing Report. That year, Cloudflare processed approximately 13 billion emails, which included blocking approximately 250 million malicious messages from reaching customers’ inboxes. Even though it was the year of ChatGPT, our analysis saw that attacks still revolved around long-standing vectors like malicious links.
Most attackers were still trying to get users to either click on a link or download a malicious file. And as discussed earlier, while Generative AI can help with making a readable and convincing message, it cannot help attackers with obfuscating these aspects of their attack.
Cloudflare’s email security models take a sophisticated approach to examining each link and attachment they encounter. Links are crawled and scrutinized based on information about the domain itself as well as on–page elements and branding. Our crawlers also check for input fields in order to see if the link is a potential credential harvester. And for attackers who put their weaponized links behind redirects or geographical locks, our crawlers can leverage the Cloudflare network to bypass any roadblocks thrown our way.
Our detection systems are similarly rigorous in handling attachments. For example, our systems know that some parts of an attachment can be easily faked, while others are not. So our systems deconstruct attachments into their primitive components and check for abnormalities there. This allows us to scan for malicious files more accurately than traditional sandboxes which can be bypassed by attackers.
Attackers can use LLMs to craft a more convincing message to get users to take certain actions, but our scanning abilities catch malicious content and prevent the user from interacting with it.
Anatomy of an email
Emails contain information beyond the body and subject of the message. When building detections, we like to think of emails as having both mutable and immutable properties. Mutable properties like the body text can be easily faked while other mutable properties like sender IP address require more effort to fake. However, there are immutable properties like domain age of the sender and similarity of the domain to known brands that cannot be altered at all. For example, let’s take a look at a message that I received.
Example email content
While the message above is what the user sees, it is a small part of the larger content of the email. Below is a snippet of the message headers. This information is typically useless to a recipient (and most of it isn’t displayed by default) but it contains a treasure trove of information for us as defenders. For example, our detections can see all the preliminary checks for DMARC, SPF, and DKIM. These let us know whether this email was allowed to be sent on behalf of the purported sender and if it was altered before reaching our inbox. Our models can also see the client IP address of the sender and use this to check their reputation. We can also see which domain the email was sent from and check if it matches the branding included in the message.
Example email headers
As you can see, the body and subject of a message are a small portion of what makes an email to be an email. When performing analysis on emails, our models holistically look at every aspect of a message to make an assessment of its safety. Some of our models do focus their analysis on the body of the message for indicators like sentiment, but the ultimate assessment of the message’s risk is performed in concert with models evaluating every aspect of the email. All this information is surfaced to the security practitioners that are using our products.
Cloudflare’s email security models
Our philosophy of using multiple models trained on different properties of messages culminates in what we call our SPARSE engine. In the 2023 Forrester Wave™ for Enterprise Email Security report, the analysts mentioned our ability to catch phishing emails using our SPARSE engine saying “Cloudflare uses its preemptive crawling approach to discover phishing campaign infrastructure as it’s being built. Its Small Pattern Analytics Engine (SPARSE) combines multiple machine learning models, including natural language modeling, sentiment and structural analysis, and trust graphs”. 1
Our SPARSE engine is continually updated using messages we observe. Given our ability to analyze billions of messages a year, we are able to detect trends earlier and feed these into our models to improve their efficacy. A recent example of this is when we noticed in late 2023 a rise in QR code attacks. Attackers deployed different techniques to obfuscate the QR code so that OCR scanners could not scan the image but cellphone cameras would direct the user to the malicious link. These techniques included making the image incredibly small so that it was not clear for scanners or pixel shifting images. However, feeding these messages into our models trained them to look at all the qualities about the emails sent from those campaigns. With this combination of data, we were able to create detections to catch these campaigns before they hit customers’ inboxes.
Our approach to preemptive scanning makes us resistant to oscillations of threat actor behavior. Even though the use of LLMs is a tool that attackers are deploying more frequently today, there will be others in the future, and we will be able to defend our customers from those threats as well.
Future of email phishing
Securing email inboxes is a difficult task given the creative ways attackers try to phish users. This field is ever evolving and will continue to change dramatically as new technologies become accessible to the public. Trends like the use of generative AI will continue to change, but our methodology and approach to building email detections keeps our customers protected.
If you are interested in how Cloudflare’s Cloud Email Security works to protect your organization against phishing threats please reach out to your Cloudflare contact and set up a free Phishing Risk Assessment. For Microsoft 365 customers, you can also run our complementary retro scan to see what phishing emails your current solution has missed. More information on that can be found in our recent blog post.
[1] Source: The Forrester Wave™: Enterprise Email Security, Q2, 2023
The Forrester Wave™ is copyrighted by Forrester Research, Inc. Forrester and Forrester Wave are trademarks of Forrester Research, Inc. The Forrester Wave is a graphical representation of Forrester’s call on a market and is plotted using a detailed spreadsheet with exposed scores, weightings, and comments. Forrester does not endorse any vendor, product, or service depicted in the Forrester Wave. Information is based on best available resources. Opinions reflect judgment at the time and are subject to change.
Generative AI has captured the imagination of the world by being able to produce poetry, screenplays, or imagery. These tools can be used to improve human productivity for good causes, but they can also be employed by malicious actors to carry out sophisticated attacks.
We are witnessing phishing attacks and social engineering becoming more sophisticated as attackers tap into powerful new tools to generate credible content or interact with humans as if it was a real person. Attackers can use AI to build boutique tooling made for attacking specific sites with the intent of harvesting proprietary data and taking over user accounts.
To protect against these new challenges, we need new and more sophisticated security tools: this is how Defensive AI was born. Defensive AI is the framework Cloudflare uses when thinking about how intelligent systems can improve the effectiveness of our security solutions. The key to Defensive AI is data generated by Cloudflare’s vast network, whether generally across our entire network or specific to individual customer traffic.
At Cloudflare, we use AI to increase the level of protection across all security areas, ranging from application security to email security and our Zero Trust platform. This includes creating customized protection for every customer for API or email security, or using our huge amount of attack data to train models to detect application attacks that haven’t been discovered yet.
In the following sections, we will provide examples of how we designed the latest generation of security products that leverage AI to secure against AI-powered attacks.
Protecting APIs with anomaly detection
APIs power the modern Web, comprising 57% of dynamic traffic across the Cloudflare network, up from 52% in 2021. While APIs aren’t a new technology, securing them differs from securing a traditional web application. Because APIs offer easy programmatic access by design and are growing in popularity, fraudsters and threat actors have pivoted to targeting APIs. Security teams must now counter this rising threat. Importantly, each API is usually unique in its purpose and usage, and therefore securing APIs can take an inordinate amount of time.
Cloudflare is announcing the development of API Anomaly Detection for API Gateway to protect APIs from attacks designed to damage applications, take over accounts, or exfiltrate data. API Gateway provides a layer of protection between your hosted APIs and every device that interfaces with them, giving you the visibility, control, and security tools you need to manage your APIs.
API Anomaly Detection is an upcoming, ML-powered feature in our API Gateway product suite and a natural successor to Sequence Analytics. In order to protect APIs at scale, API Anomaly Detection learns an application’s business logic by analyzing client API request sequences. It then builds a model of what a sequence of expected requests looks like for that application. The resulting traffic model is used to identify attacks that deviate from the expected client behavior. As a result, API Gateway can use its Sequence Mitigation functionality to enforce the learned model of the application’s intended business logic, stopping attacks.
While we’re still developing API Anomaly Detection, API Gateway customers can sign up here to be included in the beta for API Anomaly Detection. Today, customers can get started with Sequence Analytics and Sequence Mitigation by reviewing the docs. Enterprise customers that haven’t purchased API Gateway can self-start a trial in the Cloudflare Dashboard, or contact their account manager for more information.
Identifying unknown application vulnerabilities
Another area where AI improves security is in our Web Application Firewall (WAF). Cloudflare processes 55 million HTTP requests per second on average and has an unparalleled visibility into attacks and exploits across the world targeting a wide range of applications.
One of the big challenges with the WAF is adding protections for new vulnerabilities and false positives. A WAF is a collection of rules designed to identify attacks directed at web applications. New vulnerabilities are discovered daily and at Cloudflare we have a team of security analysts that create new rules when vulnerabilities are discovered. However, manually creating rules takes time — usually hours — leaving applications potentially vulnerable until a protection is in place. The other problem is that attackers continuously evolve and mutate existing attack payloads that can potentially bypass existing rules.
This is why Cloudflare has, for years, leveraged machine learning models that constantly learn from the latest attacks, deploying mitigations without the need for manual rule creation. This can be seen, for example, in our WAF Attack Score solution. WAF Attack Score is based on an ML model trained on attack traffic identified on the Cloudflare network. The resulting classifier allows us to identify variations and bypasses of existing attacks as well as extending the protection to new and undiscovered attacks. Recently, we have made Attack Score available to all Enterprise and Business plans.
Attack Score uses AI to classify each HTTP request based on the likelihood that it’s malicious
While the contribution of security analysts is indispensable, in the era of AI and rapidly evolving attack payloads, a robust security posture demands solutions that do not rely on human operators to write rules for each novel threat. Combining Attack Score with traditional signature-based rules is an example of how intelligent systems can support tasks carried out by humans. Attack Score identifies new malicious payloads which can be used by analysts to optimize rules that, in turn, provide better training data for our AI models. This creates a reinforcing positive feedback loop improving the overall protection and response time of our WAF.
Long term, we will adapt the AI model to account for customer-specific traffic characteristics to better identify deviations from normal and benign traffic.
Using AI to fight phishing
Email is one of the most effective vectors leveraged by bad actors with the US Cybersecurity and Infrastructure Security Agency (CISA) reporting that 90% of cyber attacks start with phishing and Cloudflare Email Security marking 2.6% of 2023’s emails as malicious. The rise of AI-enhanced attacks are making traditional email security providers obsolete, as threat actors can now craft phishing emails that are more credible than ever with little to no language errors.
Cloudflare Email Security is a cloud-native service that stops phishing attacks across all threat vectors. Cloudflare’s email security product continues to protect customers with its AI models, even as trends like Generative AI continue to evolve. Cloudflare’s models analyze all parts of a phishing attack to determine the risk posed to the end user. Some of our AI models are personalized for each customer while others are trained holistically. Privacy is paramount at Cloudflare, so only non-personally identifiable information is used by our tools for training. In 2023, Cloudflare processed approximately 13 billion, and blocked 3.4 billion, emails, providing the email security product a rich dataset that can be used to train AI models.
Two detections that are part of our portfolio are Honeycomb and Labyrinth.
Honeycomb is a patented email sender domain reputation model. This service builds a graph of who is sending messages and builds a model to determine risk. Models are trained on specific customer traffic patterns, so every customer has AI models trained on what their good traffic looks like.
Labyrinth uses ML to protect on a per-customer basis. Actors attempt to spoof emails from our clients’ valid partner companies. We can gather a list with statistics of known & good email senders for each of our clients. We can then detect the spoof attempts when the email is sent by someone from an unverified domain, but the domain mentioned in the email itself is a reference/verified domain.
AI remains at the core of our email security product, and we are constantly improving the ways we leverage it within our product. If you want to get more information about how we are using our AI models to stop AI enhanced phishing attacks check out our blog post here.
Zero-Trust security protected and powered by AI
Cloudflare Zero Trust provides administrators the tools to protect access to their IT infrastructure by enforcing strict identity verification for every person and device regardless of whether they are sitting within or outside the network perimeter.
One of the big challenges is to enforce strict access control while reducing the friction introduced by frequent verifications. Existing solutions also put pressure on IT teams that need to analyze log data to track how risk is evolving within their infrastructure. Sifting through a huge amount of data to find rare attacks requires large teams and substantial budgets.
Cloudflare simplifies this process by introducing behavior-based user risk scoring. Leveraging AI, we analyze real-time data to identify anomalies in the users’ behavior and signals that could lead to harms to the organization. This provides administrators with recommendations on how to tailor the security posture based on user behavior.
Zero Trust user risk scoring detects user activity and behaviors that could introduce risk to your organizations, systems, and data and assigns a score of Low, Medium, or High to the user involved. This approach is sometimes referred to as user and entity behavior analytics (UEBA) and enables teams to detect and remediate possible account compromise, company policy violations, and other risky activity.
The first contextual behavior we are launching is “impossible travel”, which helps identify if a user’s credentials are being used in two locations that the user could not have traveled to in that period of time. These risk scores can be further extended in the future to highlight personalized behavior risks based on contextual information such as time of day usage patterns and access patterns to flag any anomalous behavior. Since all traffic would be proxying through your SWG, this can also be extended to resources which are being accessed, like an internal company repo.
From application and email security to network security and Zero Trust, we are witnessing attackers leveraging new technologies to be more effective in achieving their goals. In the last few years, multiple Cloudflare product and engineering teams have adopted intelligent systems to better identify abuses and increase protection.
Besides the generative AI craze, AI is already a crucial part of how we defend digital assets against attacks and how we discourage bad actors.
You may know Cloudflare as the company powering nearly 20% of the web. But powering and protecting websites and static content is only a fraction of what we do. In fact, well over half of the dynamic traffic on our network consists not of web pages, but of Application Programming Interface (API) traffic — the plumbing that makes technology work. This blog introduces and is a supplement to the API Security Report for 2024 where we detail exactly how we’re protecting our customers, and what it means for the future of API security. Unlike other industry API reports, our report isn’t based on user surveys — but instead, based on real traffic data.
If there’s only one thing you take away from our report this year, it’s this: many organizations lack accurate API inventories, even when they believe they can correctly identify API traffic. Cloudflare helps organizations discover all of their public-facing APIs using two approaches. First, customers configure our API discovery tool to monitor for identifying tokens present in their known API traffic. We then use a machine learning model that scans not just these known API calls, but all HTTP requests, identifying API traffic that may be going unaccounted for. The difference between these approaches is striking: we found 30.7% more API endpoints through machine learning-based discovery than the self-reported approach, suggesting that nearly a third of APIs are “Shadow APIs” — and may not be properly inventoried and secured.
Read on for extras and highlights from our inaugural API security report. In the full report, you’ll find updated statistics about the threats we see and prevent, along with our predictions for 2024. We predict that a lack of API security focus at organizations will lead to increased complexity and loss of control, and increased access to generative AI will lead to more API risk. We also anticipate an increase in API business logic attacks in 2024. Lastly, all of the above risks will necessitate growing governance around API security.
Hidden attack surfaces
How are web pages and APIs different? APIs are a quick and easy way for applications to retrieve data in the background, or ask that work be done from other applications. For example, anyone can write a weather app without being a meteorologist: a developer can write the structure of the page or mobile application and ask a weather API for the forecast using the user’s location. Critically, most end users don’t know that the data was provided by the weather API and not the app’s owner.
While APIs are the critical plumbing of the Internet, they’re also ripe for abuse. For example, flaws in API authentication and authorization at Optus led to a threat actor offering 10 million user records for sale, and government agencies have warned about these exact API attacks. Developers in an organization will often create Internet-facing APIs, used by their own applications to function more efficiently, but it’s on the security team to protect these new public interfaces. If the process of documenting APIs and bringing them to the attention of the security team isn’t clear, they become Shadow APIs — operating in production but without the organization’s knowledge. This is where the security challenge begins to emerge.
To help customers solve this problem, we shipped API Discovery. When we introduced our latest release, we mentioned how few organizations have accurate API inventories. Security teams sometimes are forced to adopt an “email and ask” approach to build an inventory, and in doing so responses are immediately stale upon the next application release when APIs change. Better is to track API changes by code base changes, keeping up with new releases. However, this still has a drawback of only inventorying actively maintained code. Legacy applications may not see new releases, despite receiving production traffic.
Cloudflare’s approach to API management involves creating a comprehensive, accurate API inventory using a blend of machine learning-based API discovery and network traffic inspection. This is integral to our API Gateway product, where customers can manage their Internet-facing endpoints and monitor API health. The API Gateway also allows customers to identify their API traffic using session identifiers (typically a header or cookie), which aids in specifically identifying API traffic for the discovery process.
As noted earlier, our analysis reveals that even knowledgeable customers often overlook significant portions of their API traffic. By comparing session-based API discovery (using API sessions to pinpoint traffic) with our machine learning-based API discovery (analyzing all incoming traffic), we found that the latter uncovers on average 30.7% more endpoints! Without broad traffic analysis, you may be missing almost a third of your API inventory.
If you aren’t a Cloudflare customer, you can still get started building an API inventory. APIs are typically cataloged in a standardized format called OpenAPI, and many development tools can build OpenAPI formatted schema files. If you have a file with that format, you can start to build an API inventory yourself by collecting these schemas. Here is an example of how you can pull the endpoints out of a schema file, assuming your have an OpenAPI v3 formatted file named my_schema.json:
import json
import csv
from io import StringIO
# Load the OpenAPI schema from a file
with open("my_schema.json", "r") as file:
schema = json.load(file)
# Prepare CSV output
output = StringIO()
writer = csv.writer(output)
# Write CSV header
writer.writerow(["Server", "Path", "Method"])
# Extract and write data to CSV
servers = schema.get("servers", [])
for server in servers:
url = server['url']
for path, methods in schema['paths'].items():
for method in methods.keys():
writer.writerow([url, path, method])
# Get and print CSV string
csv_output = output.getvalue().strip()
print(csv_output)
Unless you have been generating OpenAPI schemas and tracking API inventory from the beginning of your application’s development process, you’re probably missing some endpoints across your production application API inventory.
Precise rate limits minimize attack potential
When it comes to stopping abuse, most practitioners’ thoughts first come to rate limiting. Implementing limits on your API is a valuable tool to keep abuse in check and prevent accidental overload of the origin. But how do you know if you’ve chosen the correct rate limiting approach? Approaches can vary, but they generally come down to the error code chosen, and the basis for the limit value itself.
For some APIs, practitioners configure rate limiting errors to respond with an HTTP 403 (forbidden), while others will respond with HTTP 429 (too many requests). Using HTTP 403 sounds innocent enough until you realize that other security tools are also responding with 403 codes. When you’re under attack, it can be hard to decipher which tools are responsible for which errors / blocking.
Alternatively, if you utilize HTTP 429 for your rate limits, attackers will instantly know that they’ve been rate limited and can “surf” right under the limit without being detected. This can be OK if you’re only limiting requests to ensure your back-end stays alive, but it can tip your cards to attackers. In addition, attackers can “scale out” to more API clients to effectively request above the rate limit.
There are pros and cons to both approaches, but we find that by far most APIs respond with HTTP 429 out of all the 4xx and 5xx error messages (almost 52%).
What about the logic of the rate limit rule itself, not just the response code? Implementing request limits on IP addresses can be tempting, but we recommend you base the limit on a session ID as a best practice and only fall back to IP address (or IP + JA3 fingerprint) when session IDs aren’t available. Setting rate limits on user sessions instead of IPs will reliably identify your real users and minimize false positives due to shared IP space. Cloudflare’s Advanced Rate Limiting and API Gateway’s volumetric abuse protection make it easy to enforce these limits by profiling session traffic on each API endpoint and giving one-click solutions to set up the per-endpoint rate limits.
To find values for your rate limits, Cloudflare API Gateway computes session request statistics for you. We suggest a limit by looking at the distribution of requests per session across all sessions to your API as identified by the customer-configured API session identifier. We then compute statistical p-levels — which describe the request rates for different cohorts of traffic — for p50, p90, and p99 on this distribution and use the variance of the distribution to come up with a recommended threshold for every single endpoint in your API inventory. The recommendation might not match the p-levels, which is an important distinction and a reason not to use p-levels alone. Along with the recommendation, API Gateway informs users of our confidence in the recommendation. Generally, the more API sessions we’re able to collect, the more confident we’ll be in the recommendation.
Activating a rate limit is as easy as clicking the ‘create rule’ link, and API Gateway will automatically bring your session identifier over to the advanced rate limit rule creation page, ensuring your rules have pinpoint accuracy to defend against attacks and minimize false positives compared to traditional, overly broad limits.
APIs are also victim to web application attacks
APIs aren’t immune from normal OWASP Top 10 style attacks like SQL injection. The body of API requests can also find its way as a database input just like a web page form input or URL argument. It’s important to ensure that you have a web application firewall (WAF) also protecting your API traffic to defend against these styles of attacks.
In fact, when we looked at Cloudflare’s WAF managed rules, injection attacks were the second most common threat vector Cloudflare saw carried out on APIs. The most common threat was HTTP Anomaly. Examples of HTTP anomalies include malformed method names, null byte characters in headers, non-standard ports or content length of zero with a POST request. Here are the stats on the other top threats we saw against APIs:
Absent from the chart is broken authentication and authorization. Broken authentication and authorization occur when an API fails to check whether the entity sending requests for information to an API actually has the permission to request that data or not. It can also happen when attacks try to forge credentials and insert less restricted permissions into their existing (valid) credentials that have more restricted permissions. OWASP categorizes these attacks in a few different ways, but the main categories are Broken Object Level Authorization (BOLA) and Broken Function Level Authorization (BFLA) attacks.
The root cause of a successful BOLA / BFLA attack lies in an origin API not checking proper ownership of database records against the identity requesting those records. Tracking these specific attacks can be difficult, as the permission structure may be simply absent, inadequate, or improperly implemented. Can you see the chicken-and-egg problem here? It would be easy to stop these attacks if we knew the proper permission structure, but if we or our customers knew the proper permission structure or could guarantee its enforcement, the attacks would be unsuccessful to begin with. Stay tuned for future API Gateway feature launches where we’ll use our knowledge of API traffic norms to automatically suggest security policies that highlight and stop BOLA / BFLA attacks.
Here are four ways to plug authentication loopholes that may exist for your APIs, even if you don’t have a fine-grained authorization policy available:
First, enforce authentication on each publicly accessible API unless there’s a business approved exception. Look to technologies like mTLS and JSON Web Tokens.
Limit the speed of API requests to your servers to slow down potential attackers.
Block abnormal volumes of sensitive data outflow.
Block attackers from skipping legitimate sequences of API requests.
APIs are surprisingly human driven, not machine driven anymore
If you’ve been around technology since the pre-smartphone days when fewer people were habitually online, it can be tempting to think of APIs as only used for machine-to-machine communication in something like an overnight batch job process. However, the truth couldn’t be more different. As we’ve discussed, many web and mobile applications are powered by APIs, which facilitate everything from authentication to transactions to serving media files. As people use these applications, there is a corresponding increase in API traffic volume.
We can illustrate this by looking at the API traffic patterns observed during holidays, when people gather around friends and family and spend more time socializing in person and less time online. We’ve annotated the following Worldwide API traffic graph with common holidays and promotions. Notice how traffic peaks around Black Friday and Cyber Monday around the +10% level when people shop online, but then traffic drops off for the festivities of Christmas and New Years days.
This pattern closely resembles what we observe in regular HTTP traffic. It’s clear that APIs are no longer just the realm of automated processes but are intricately linked with human behaviors and social trends.
Recommendations
There is no silver bullet for holistic API security. For the best effect, Cloudflare recommends four strategies for increasing API security posture:
Combine API application development, visibility, performance, and security with a unified control plane that can keep an up-to-date API inventory.
Use security tools that utilize machine learning technologies to free up human resources and reduce costs.
Adopt a positive security model for your APIs (see below for an explanation on positive and negative security models).
Measure and improve your organization’s API maturity level over time (also see below for an explanation of an API maturity level).
What do we mean by a ‘positive’ or ‘negative’ security model? In a negative model, security tools look for known signs of attack and take action to stop those attacks. In a positive model, security tools look for known good requests and only let those through, blocking all else. APIs are often so structured that positive security models make sense for the highest levels of security. You can also combine security models, such as using a WAF in a negative model sense, and using API Schema Validation in a positive model sense.
Here’s a quick way to gauge your organization’s API security maturity level over time: Novice organizations will get started by assembling their first API inventory, no matter how incomplete. More mature organizations will strive for API inventory accuracy and automatic updates. The most mature organizations will actively enforce security checks in a positive security model on their APIs, enforcing API schema, valid authentication, and checking behavior for signs of abuse.
Predictions
In closing, our top four predictions for 2024 and beyond:
Increased loss of control and complexity: we surveyed practitioners in the API Security and Management field and 73% responded that security requirements interfere with their productivity and innovation. Coupled with increasingly sprawling applications and inaccurate inventories, API risks and complexity will rise.
Easier access to AI leading to more API risks: the rise in generative AI brings potential risks, including AI models’ APIs being vulnerable to attack, but also developers shipping buggy, AI-written code. Forrester predicts that, in 2024, without proper guardrails, “at least three data breaches will be publicly blamed on insecure AI-generated code – either due to security flaws in the generated code itself or vulnerabilities in AI-suggested dependencies.”
Increase in business logic-based fraud attacks: professional fraudsters run their operations just like a business, and they have costs like any other. We anticipate attackers will run fraud bots efficiently against APIs even more than in previous years.
Growing governance: The first version of PCI DSS that directly addresses API security will go into effect in March 2024. Check your industry’s specific requirements with your audit department to be ready for requirements as they come into effect.
If you’re interested in the full report, you can download the 2024 API Security Report here, which includes full detail on our recommendations.
Cloudflare API Gateway is our API security solution, and it is available for all Enterprise customers. If you aren’t subscribed to API Gateway, click here to view your initial API Discovery results and start a trial in the Cloudflare dashboard. To learn how to use API Gateway to secure your traffic, click here to view our development docs and here for our getting started guide.
APIs account for more than half of the total traffic of the Internet. They are the building blocks of many modern web applications. As API usage grows, so does the number of API attacks. And so now, more than ever, it’s important to keep these API endpoints secure. Cloudflare’s API Shield solution offers a comprehensive suite of products to safeguard your API endpoints and now we’re excited to give our customers one more tool to keep their endpoints safe. We’re excited to announce that customers can now bring their own Certificate Authority (CA) to use for mutual TLS client authentication. This gives customers more security, while allowing them to maintain control around their Mutual TLS configuration.
The power of Mutual TLS (mTLS)
Traditionally, when we refer to TLS certificates, we talk about the publicly trusted certificates that are presented by servers to prove their identity to the connecting client. With Mutual TLS, both the client and the server present a certificate to establish a two-way channel of trust. Doing this allows the server to check who the connecting client is and whether or not they’re allowed to make a request. The certificate presented by the client – the client certificate – doesn’t need to come from a publicly trusted CA. In fact, it usually comes from a private or self-signed CA. That’s because the only party that needs to be able to trust it is the connecting server. As long as the connecting server has the client certificate and can check its validity, it doesn’t need to be public.
Securing API endpoints with Mutual TLS
Mutual TLS plays a crucial role in protecting API endpoints. When it comes to safeguarding these endpoints, it's important to have a security model in place that only allows authorized clients to make requests and keeps everyone else out.
That’s why when we launched API Shield in 2020 – a product that’s centered around securing API endpoints – we included mutual TLS client certificate validation as a part of the offering. We knew that mTLS was the best way for our customers to identify and authorize their connecting clients.
When we launched mutual TLS for API Shield, we gave each of our customers a dedicated self-signed CA that they could use to issue client certificates. Once the certificates are installed on devices and mTLS is set up, administrators can enforce that connections can only be made if they present a client certificate issued from that self-signed CA.
This feature has been paramount in securing thousands of endpoints, but it does require our customer to install new client certificates on their devices, which isn’t always possible. Some customers have been using mutual TLS for years with their own CA, which means that the client certificates are already in the wild. Unless the application owner has direct control over the clients, it’s usually arduous, if not impossible, to replace the client certificates with ones issued from Cloudflare’s CA. Other customers may be required to use a CA issued from an approved third party in order to meet regulatory requirements.
To help all of our customers keep their endpoints secure, we’re extending API Shield’s mTLS capability to allow customers to bring their own CA.
Get started today
To simplify the management of private PKI at Cloudflare, we created one account level endpoint that enables customers to upload self-signed CAs to use across different Cloudflare products. Today, this endpoint can be used for API shield CAs and for Gateway CAs that are used for traffic inspection.
If you’re an Enterprise customer, you can upload up to five CAs to your account. Once you’ve uploaded the CA, you can use the API Shield hostname association API to associate the CA with the mTLS enabled hostnames. That will tell Cloudflare to start validating the client certificate against the uploaded CA for requests that come in on that hostname. Before you enforce the client certificate validation, you can create a Firewall rule that logs an event when a valid or invalid certificate is served. That will help you determine if you’ve set things up correctly before you enforce the client certificate validation and drop unauthorized requests.
Starting today, Cloudflare’s API Gateway can protect GraphQL APIs against malicious requests that may cause a denial of service to the origin. In particular, API Gateway will now protect against two of the most common GraphQL abuse vectors: deeply nested queries and queries that request more information than they should.
Typical RESTful HTTP APIs contain tens or hundreds of endpoints. GraphQL APIs differ by typically only providing a single endpoint for clients to communicate with and offering highly flexible queries that can return variable amounts of data. While GraphQL’s power and usefulness rests on the flexibility to query an API about only the specific data you need, that same flexibility adds an increased risk of abuse. Abusive requests to a single GraphQL API can place disproportional load on the origin, abuse the N+1 problem, or exploit a recursive relationship between data dimensions. In order to add GraphQL security features to API Gateway, we needed to obtain visibility inside the requests so that we could apply different security settings based on request parameters. To achieve that visibility, we built our own GraphQL query parser. Read on to learn about how we built the parser and the security features it enabled.
The power of GraphQL
Unlike a REST API, where the API’s users are limited to what data they can query and change on a per-endpoint basis, a GraphQL API offers users the ability to query and change any data they wish with an open-ended, yet structured request to a single endpoint. This open-endedness makes GraphQL APIs very powerful. Each user can query for a completely custom set of data and receive their custom response in a single HTTP request. Here are two example queries and their responses. These requests are typically sent via HTTP POST methods to an endpoint at /graphql.
# A query asking for multiple nested subfields of the "hero" object. This query has a depth level of 2.
{
hero {
name
friends {
name
}
}
}
# The corresponding response.
{
"data": {
"hero": {
"name": "R2-D2",
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}
# A query asking for just one subfield on the same "hero" object. This query has a depth level of 1.
{
hero {
name
}
}
# The corresponding response.
{
"data": {
"hero": {
"name": "R2-D2"
}
}
}
These custom queries give GraphQL endpoints more flexibility than conventional REST endpoints. But this flexibility also means GraphQL APIs can be subject to very different load or security risks based on the requests that they are receiving. For example, an attacker can request the exact same, valid data as a benevolent user would, but exploit the data’s self-referencing structure and ask that an origin return hundreds of thousands of rows replicated over and over again. Let’s consider an example, in which we operate a petitioning platform where our data model contains petitions and signers objects. With GraphQL, an attacker can, in a single request, query for a single petition, then for all people who signed that petition, then for all petitions each of those people have signed, then for all people that signed any of those petitions, then for all petitions that… you see where this is going!
A rate limit won’t protect against such an attack because the entire query fits into a single request.
So how can we secure GraphQL APIs? There is little agreement in the industry around what makes a GraphQL endpoint secure. For some, this means rejecting invalid queries. Normally, an invalid query refers to a query that would fail to compile by a GraphQL server and not cause any substantial load on the origin, but would still add noise and error logs and reduce operational visibility. For others, this means creating complexity-based rate limits or perhaps flagging broken object-level authorization. Still others want deeper visibility into query behavior and an ability to validate queries against a predefined schema.
When creating new features in API Gateway, we often start by providing deeper visibility for customers into their traffic behavior related to the feature in question. This way we create value from the large amount of data we see in the Cloudflare network, and can have conversations with customers where we ask: “Now that you have these data insights, what actions would you like to take with them?”. This process puts us in a good position to build a second, more actionable iteration of the feature.
We decided to follow the same process with GraphQL protection, with parsing GraphQL requests and gathering data as our first goal.
Parsing GraphQL quickly
As a starting point, we wanted to collect request query size and depth attributes. These attributes offer a surprising amount of insight into the query – if the query is requesting a single field at depth level 15, is it really innocuous or is it exploiting some recursive data relationship? if the query is asking for hundreds of fields at depth level 3, why wouldn’t it just ask for the entire object at level 2 instead?
To do this, we needed to parse queries without adding latency to incoming requests. We evaluated multiple open source GraphQL parsers and quickly realized that their performance would put us at the risk of adding hundreds of microseconds of latency to the request duration. Our goal was to have a p95 parsing time of under 50 microseconds. Additionally, the infrastructure we were planning to use to ship this functionality has a strict no-heap-allocation policy – this means that any memory allocated by a parser to process a request has to be amortized by being reused when parsing any subsequent requests. Parsing GraphQL in a no-allocation manner is not a fundamental technical requirement for us over the long-term, but it was a necessity if we wanted to build something quickly with confidence that the proof of concept will meet our performance expectations.
Meeting the latency and memory allocation constraints meant that we had to write a parser of our own. Building an entire abstract syntax tree of unpredictable structure requires allocating memory on the heap, and that’s what made conventional parsers unfit for our requirements. What if instead of building a tree, we processed the query in a streaming fashion, token by token? We realized that if we were to write our own GraphQL lexer that produces a list of GraphQL tokens (“comment”, “string”, “variable name”, “opening parenthesis”, etc.), we could use a number of heuristics to infer the query depth and size without actually building a tree or fully validating the query. Using this approach meant that we could deliver the new feature fast, both in engineering time and wall clock time – and, most importantly, visualize data insights for our customers.
To start, we needed to prepare GraphQL queries for parsing. Most of the time, GraphQL queries are delivered as HTTP POST requests with application/json or application/graphql Content-Type. Requests with application/graphql content type are easy to work with – they contain the raw query you can just parse. However, JSON-encoded queries present a challenge since JSON objects contain escaped characters – normally, any deserialization library will allocate new memory into which the raw string is copied with escape sequences removed, but we committed to allocating no memory, remember? So to parse GraphQL queries encoded in JSON fields, we used serde RawValue to locate the JSON field in which the escaped query was placed and then iterated over the constituent bytes one-by-one, feeding them into our tokenizer and removing escape sequences on the fly.
Once we had our query input ready, we built a simple Rust program that converts raw GraphQL input into a list of lexical tokens according to the GraphQL grammar. Tokenization is the first step in any parser – our insight was that this step was all we needed for what we wanted to achieve in the MVP.
mutation CreateMessage($input: MessageInput) {
createMessage(input: $input) {
id
}
}
For example, the mutation operation above gets converted into the following list of tokens:
name
name
punctuator (
punctuator $
name
punctuator :
name
punctuator )
punctuator {
name
punctuator (
name
punctuator :
punctuator $
name
punctuator )
punctuator {
name
punctuator }
punctuator }
With this list of tokens available to us, we built our validation engine and added the ability to calculate query depth and size. Again, everything is done one-the-fly in a single pass. A limitation of this approach is that we can’t parse 100% of the requests – there are some syntactic features of GraphQL that we have to fail open on; however, a major advantage of this approach is its performance – in our initial trial run against a stream of 10s of thousands of requests per second, we achieved a p95 parsing time of 25 microseconds. This is a good starting point to collect some data and to prototype our first GraphQL security features.
Getting started
Today, any API Gateway customer can use the Cloudflare GraphQL API to retrieve information about depth and size of GraphQL queries we see for them on the edge.
As an example, we’ve run the analysis below visualizing over 400,000 data points for query sizes and depths for a production domain utilizing API Gateway.
First let’s look at query sizes in our sample:
It looks like queries almost never request more than 60 fields. Let’s also look at query depths:
It looks like queries are never more than seven levels deep.
These two insights can be converted into security rules: we added three new Wirefilter fields that API Gateway customers can use to protect their GraphQL endpoints:
For now, we recommend the use of cf.api_gateway.graphql.parsed_successfully in all rules. Rules created with the use of this field will be backwards compatible with future GraphQL protection releases.
If a customer feels that there is nothing out of the ordinary with the traffic sample and that it represents a meaningful amount of normal usage, they can manually create and deploy the following custom rule to log all queries that were parsed by Cloudflare and that look like outliers:
cf.api_gateway.graphql.parsed_successfully and
(cf.api_gateway.graphql.query_depth > 7 or
cf.api_gateway.graphql.query_size > 60)
Learn more and run your own analysis with our documentation.
What’s next?
We are already receiving feedback from our first customers and are planning out the next iteration of this feature. These are the features we will build next:
Integrating GraphQL security with complexity-based rate limiting such that we automatically calculate query cost and let customers rate limit eyeballs based on the total query execution cost the eyeballs use during their entire session.
Allowing customers to configure specifically which endpoints GraphQL security features run on.
Creating data insights on the relationship between query complexity and the time it takes the customer origin to respond to the query.
Creating automatic GraphQL threshold recommendations based on historical trends.
If you’re an Enterprise customer that hasn't purchased API Gateway and you’re interested in protecting your GraphQL APIs today, you can get started by enabling the API Gateway trial inside the Cloudflare Dashboard or by contacting your account manager. Check out our documentation on the feature to get started once you have access.
I remember when the first iPhone was announced in 2007. This was NOT an iPhone as we think of one today. It had warts. A lot of warts. It couldn’t do MMS for example. But I remember the possibility it brought to mind. No product before had seemed like anything more than a product. The iPhone, or more the potential that the iPhone hinted at, had an actual impact on me. It changed my thinking about what could be.
In the years since no other product came close to matching that level of awe and wonder. That changed in March of this year. The release of GPT-4 had the same impact I remember from the iPhone launch. It’s still early, but it's opened the imagination, and fears, of millions of developers in a way I haven’t seen since that iPhone announcement.
That excitement has led to an explosion of development and hundreds of new tools broadly grouped into a category we call generative AI. Generative AI systems create content mimicking a particular style. New images that look like Banksy or lyrics that sound like Taylor Swift. All of these Generative AI tools, whether built on top of GPT-4 or something else, use the same basic model technique: a transformer.
Attention is all you need
GPT-4 (Generative Pretrained Transformer) is the most advanced version of a transformer model. Transformer models all emerged from a seminal paper written in 2017 by researchers at the University of Toronto and the team at Google Brain, titled Attention is all you need. The key insight from the paper is the self-attention mechanism. This mechanism replaced recurrent and convolutional layers, allowing for faster training and better performance.
The secret power of transformer models is their ability to efficiently process large amounts of data in parallel. It's the transformers' gargantuan scale and extensive training that makes them so appealing and versatile, turning them into the Swiss Army knife of natural language processing. At a high level, Large Language Models (LLMs) are just transformer models that use an incredibly large number of parameters (billions), and are trained on incredibly large amounts of unsupervised text (the Internet). Hence large, and language.
Unleashing the potential of LLMs in consumer-facing AI tools has opened a world of possibilities. But possibility also means new risk: developers must now navigate the unique security challenges that arise from making powerful new tools widely available to the masses.
First and foremost, consumer-facing applications inherently expose the underlying AI systems to millions of users, vastly increasing the potential attack surface. Since developers are targeting a consumer audience, they can't rely on trusted customers or limit access based on geographic location. Any security measure that makes it too difficult for consumers to use defeats the purpose of the application. Consequently, developers must strike a delicate balance between security and usability, which can be challenging.
The current popularity of AI tools makes explosive takeoff more likely than in the past. This is great! Explosive takeoff is what you want! But, that explosion can also lead to exponential growth in costs, as the computational requirements for serving a rapidly growing user base can become overwhelming.
In addition to being popular, Generative AI apps are unique in that calls to them are incredibly resource intensive, and therefore expensive for the owner. In comparison, think about a more traditional API that Cloudflare has protected for years. A product API. Sites don’t want competitors calling their product API and scraping data. This has an obvious negative business impact. However, it doesn’t have a direct infrastructure cost. A product list API returns a small amount of text. An attacker calling it 4 million times will have a negligible cost to an infrastructure bill. But generative models can cost cents, or in the case of image generation even tens of cents per call. An attacker gaining access and generating millions of calls has a real cost impact to the developers providing those APIs.
Not only are the costs for generating content high, but the value that end users are willing to pay is high as well. Customers tell us that they have seen multiple instances of bad actors accessing an API without paying, then reselling the content they generate for 50 cents or more per call. The huge monetary opportunity of exploitation means attackers are highly motivated to come back again and again, refactoring their approach each time.
Last, consumer-facing LLM applications are generally designed as a single entry point for customers, almost always accepting query text as input. The open-text nature of these calls makes it difficult to predict the potential impact of a single request. For example, a complex query might consume significant resources or trigger unexpected behavior. While these APIs are not GraphQL based, the challenges are similar. When you accept unstructured submissions, it's harder to create any type of rule to prevent abuse.
Tips for protecting your Generative AI application
So you've built the latest generative AI sensation, and the world is about to be taken by storm. But that success is also about to make you a target. What's the trick to stopping all those attacks you’re about to see? Well, unfortunately there isn’t one. For all the reasons above, this is a hard, persistent problem with no simple solution. But, we’ve been fortunate to work with many customers who have had that target on their back for months, and we’ve learned a lot from that experience. Here are some recommendations that will give you a good foundation for making sure that you, and only you, reap the rewards of your hard work.
1. Enforce tokens for each user. Enforcing usage based on a specific user or user session is straightforward. But sometimes you want to allow anonymous usage. While anonymous usage is great for demos and testing, it can lead to abuse. If you must allow anonymous usage, create a “stickier” identification scheme that persists browser restarts and incognito mode. Your goal isn’t to track specific users, but instead to understand how much an anonymous user has already used your service so far in demo / free mode.
2. Manage quotas carefully. Your service likely incurs costs and charges users per API call, so it likely makes sense to set a limit on the number of times any user can call your API. You may not ever intend for the average user to hit this limit, but having limits in place will protect against that user’s API key becoming compromised and shared amongst many users. It also protects against programming errors that could result in 100x or 1000x expected usage, and a large unexpected bill to the end user.
3. Block certain ASNs (autonomous system numbers) wholesale. Blocking ASNs, or even IPs wholesale is an incredibly blunt tool. In general Cloudflare rarely recommends this approach to customers. However, when tools are as popular as some generative AI applications, attackers are highly motivated to send as much traffic as possible to those applications. The fastest and cheapest way to accomplish this is through data centers that usually share a common ASN. Some ASNs belong to ISPs, and source traffic from people browsing the Internet. But other ASNs belong to cloud compute providers, and mainly source outbound traffic from virtual servers. Traffic from these servers can be overwhelmingly malicious. For example, several of our customers have found ASNs where 88-90% of the traffic turns out to be automated, while this number is usually only 30% for average traffic. In cases this extreme, blocking entire ASNs can make sense.
4. Implement smart rate limits. Counting not only requests per minute and requests per session, but also IPs per token and tokens per IP can guard against abuse. Tracking how many different IPs are using a particular token at any one time can alert you to a user's token being leaked. Similarly, if one IP is rotating through tokens, looking at each token’s session traffic would not alert you to the abuse. You’d need to look at how many tokens that single IP is generating in order to pinpoint that specific abusive behavior.
5. Rate limit on something other than the user. Similar to enforcing tokens on each user, your real time rate limits should also be set on your sticky identifier.
6. Have an option to slow down attackers. Customers often think about stopping abuse in terms of blocking traffic from abusers. But blocking isn’t the only option. Attacks not only need to be successful, they also need to be economically feasible. If you can make requests more difficult or time-consuming for abusers, you can ruin their economics. You can do this by implementing a waiting room, or by challenging users. We recommend a challenge option that doesn’t give real users an awful experience. Challenging users can also be quickly enabled or disabled as you see abuse spike or recede.
7. Map and analyze sequences. By sampling user sessions that you suspect of abuse, you can inspect their requests path-by-path in your SIEM. Are they using your app as expected? Or are they circumventing intended usage? You might benefit from enforcing a user flow between endpoints.
8. Build and validate an API schema. Many API breaches happen due to permissive schemas. Users are allowed to send in extra fields in requests that grant them too many privileges or allow access to other users’ data. Make sure you build a verbose schema that outlines what intended usage is by identifying and cataloging all API endpoints, then making sure all specific parameters are listed as required and have type limits to them.
We recently went through the transition to an OpenAPI schema ourselves for api.cloudflare.com. You can read more about how we did it here. Our schema looks like this:
/zones:
get:
description: List, search, sort, and filter your zones.
operationId: zone-list-zones
responses:
4xx:
content:
application/json:
schema:
allOf:
- $ref: '#/components/schemas/components-schemas-response_collection'
- $ref: '#/components/schemas/api-response-common-failure'
description: List Zones response failure
"200":
content:
application/json:
schema:
$ref: '#/components/schemas/components-schemas-response_collection'
description: List Zones response
security:
- api_email: []
api_key: []
summary: List Zones
tags:
- Zone
x-cfPermissionsRequired:
enum:
- '#zone:read'
x-cfPlanAvailability:
business: true
enterprise: true
free: true
pro: true
9. Analyze the depth and complexity of queries. Are your APIs driven by GraphQL? GraphQL queries can be a source of abuse since they allow such free-form requests. Large, complex queries can grow to overwhelm origins if limits aren’t in place. Limits help guard against outright DoS attacks as well as developer error, keeping your origin healthy and serving requests to your users as expected.
For example, if you have statistics about your GraphQL queries by depth and query size, you could execute this TypeScript function to analyze them by quantile:
import * as ss from 'simple-statistics';
function calculateQuantiles(data: number[], quantiles: number[]): {[key: number]: string} {
let result: {[key: number]: string} = {};
for (let q of quantiles) {
// Calculate quantile, convert to fixed-point notation with 2 decimal places
result[q] = ss.quantile(data, q).toFixed(2);
}
return result;
}
// Example usage:
let queryDepths = [2, 2, 2, 2, 2, 2, 2, 4, 4, 4, 4, 4, 1, 1, 1, 1, 1, 1, 1, 1];
let querySizes = [11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2];
console.log(calculateQuantiles(queryDepths, [0.5, 0.75, 0.95, 0.99]));
console.log(calculateQuantiles(querySizes, [0.5, 0.75, 0.95, 0.99]));
The results give you a sense for the depth of the average query hitting your endpoint, grouped by quantile:
Actual data from your production environment would provide a threshold to start an investigation into which queries to further log or limit. A simpler option is to use a query analysis tool, like Cloudflare’s, to make the process automatic.
10. Use short-lived access tokens and long-lived refresh tokens upon successful authentication of your users. Implement token validation in a middleware layer or API Gateway, and be sure to have a dedicated token renewal endpoint in your API. JSON Web Tokens (JWTs) are popular choices for these short-lived tokens. When access tokens expire, allow users to obtain new ones using their refresh tokens. Revoke refresh tokens when necessary to maintain system security. Adopting this approach enhances your API's security and user experience by effectively managing access and mitigating the risks associated with compromised tokens.
11. Communicate directly with your users. All of the above recommendations are going to make it a bit more cumbersome for some of your customers to use your product. You are going to get complaints. You can reduce these by first, giving clear communication to your users explaining why you put these measures in place. Write a blog about what security measures you did and did not decide to implement and have dev docs explaining troubleshooting steps to resolve. Second, give your users concrete steps they can take if they are having trouble, and a clear way to contact you directly. Feeling inconvenienced can be frustrating, but feeling stuck can lose you a customer.
Conclusion: this is the beginning
Generative AI, like the first iPhone, has sparked a surge of excitement and innovation. But that excitement also brings risk, and innovation brings new security holes and attack vectors. The broadness and uniqueness of generative AI applications in particular make securing them particularly challenging. But as every scout knows, being prepared ahead of time means less stress and worry during the journey. Implementing the tips we've shared can establish a solid foundation that will let you sit back and enjoy the thrill of building something special, rather than worrying what might be lurking around the corner.
Security Week 2023 is officially in the books. In our welcome post last Saturday, I talked about Cloudflare’s years-long evolution from protecting websites, to protecting applications, to protecting people. Our goal this week was to help our customers solve a broader range of problems, reduce external points of vulnerability, and make their jobs easier.
We announced 34 new tools and integrations that will do just that. Combined, these announcement will help you do five key things faster and easier:
Making it easier to deploy and manage Zero Trust everywhere
Reducing the number of third parties customers must use
Leverage machine learning to let humans focus on critical thinking
Opening up more proprietary Cloudflare threat intelligence to our customers
Making it harder for humans to make mistakes
And to help you respond to the most current attacks in real time, we reported on how we’re seeing scammers use the Silicon Valley Bank news to phish new victims, and what you can do to protect yourself.
In case you missed any of the announcements, take a look at the summary and navigation guide below.
Today we have released insights from our global network on the top 50 brands used in phishing attacks coupled with the tools customers need to stay safer. Our new phishing and brand protection capabilities, part of Security Center, let customers better preserve brand trust by detecting and even blocking “confusable” and lookalike domains involved in phishing campaigns.
Phishing attacks come in all sorts of ways to fool people. Email is definitely the most common, but there are others. Following up on our Top 50 brands in phishing attacks post, here are some tips to help you catch these scams before you fall for them.
Page Shield now ensures only vetted and secure JavaScript is being executed by browsers to stop unwanted or malicious JavaScript from loading to keep end user data safer.
With Aegis, customers can now get dedicated IPs from Cloudflare we use to send them traffic. This allows customers to lock down services and applications at an IP level and build a protected environment that is application, protocol, and even IP-aware.
mTLS support for Workers allows for communication with resources that enforce an mTLS connection. mTLS provides greater security for those building on Workers so they can identify and authenticate both the client and the server helps protect sensitive data.
We have introduced an innovative new approach to secure hosted applications via Cloudflare Access without the need for any installed software or custom code on application servers.
Cloudflare is excited to launch the Descaler Program, a frictionless path to migrate existing Zscaler customers to Cloudflare One. With this announcement, Cloudflare is making it even easier for enterprise customers to make the switch to a faster, simpler, and more agile foundation for security and network transformation.
Today we’re excited to announce the expansion of support for automated normalization and correlation of Zero Trust logs for Logpush in Sumo Logic’s Cloud SIEM. Joint customers will reduce alert fatigue and accelerate the triage process by converging security and network data into high-fidelity insights.
Cloudflare One now offers Data Loss Prevention (DLP) detections for Microsoft Purview Information Protection labels. This extends the power of Microsoft’s labels to any of your corporate traffic in just a few clicks.
We are unveiling two new integrations for Cloudflare CASB: one for Atlassian Confluence and the other for Atlassian Jira. Security teams can begin scanning for Atlassian- and Confluence-specific security issues that may be leaving sensitive corporate data at risk.
Cloudflare Access and Ping Identity offer a powerful solution for organizations looking to implement Zero Trust security controls to protect their applications and data. Cloudflare is now offering full integration support, so Ping Identity customers can easily integrate their identity management solutions with Cloudflare Access to provide a comprehensive security solution for their applications
We are excited to announce Cloudflare Fraud Detection that will provide precise, easy to use tools that can be deployed in seconds to detect and categorize fraud such as fake account creation or card testing and fraudulent transactions. Fraud Detection will be in early access later this year, those interested can sign up here.
Customers can use these new features to enforce a positive security model on their API endpoints even if they have little-to-no information about their existing APIs today.
With our new Cloudflare Sequence Analytics for APIs, organizations can view the most important sequences of API requests to their endpoints to better understand potential abuse and where to apply protections first.
Read our post on how we keep users and organizations safer with machine learning models that detect attackers attempting to evade detection with DNS tunneling and domain generation algorithms.
We are making the machine learning empowered WAF and Security analytics view available to our Business plan customers, to help detect and stop attacks before they are known.
We have made Cloudflare Radar’s newest free tool available, URL Scanner, providing an under-the-hood look at any webpage to make the Internet more transparent and secure for all.
One of our core beliefs is that privacy is a human right. To achieve that right, we are announcing that our implementations of post-quantum cryptography will be available to everyone, free of charge, forever.
The recent news reports of AI cracking post-quantum cryptography are greatly exaggerated. In this blog, we take a deep dive into the world of side-channel attacks and how AI has been used for more than a decade already to aid it.
IBM and Cloudflare continue to partner together to help customers meet the unique security, performance, resiliency and compliance needs of their customers through the addition of exciting new product and service offerings.
Customers will now be able to use our Cloudflare Tunnels product to send traffic to the key server through a secure channel, without publicly exposing it to the rest of the Internet.
Brand impersonation continues to be a big problem globally. Setting SPF, DKIM and DMARC policies is a great way to reduce that risk, and protect your domains from being used in spoofing emails. But maintaining a correct SPF configuration can be very costly and time consuming, and that’s why we’re launching Cloudflare DMARC Management.
At Cloudflare, we use the Workers platform and our product stack to build new services. Read how we made the new DMARC Management solution entirely on top of our APIs.
Cloudflare’s cloud email security solution now integrates with KnowBe4, allowing mutual customers to offer real-time coaching to employees when a phishing campaign is detected by Cloudflare.
We are excited to announce new options to customize user experience in Access, including customizable pages including login, blocks and the application launcher.
Cloudflare Access is 75% faster than Netskope and 50% faster than Zscaler, and our network is faster than other providers in 48% of last mile networks.
Cloudflare announces one-click ISO certified region, a super easy way for customers to limit where traffic is serviced to ISO 27001 certified data centers inside the European Union.
All WAF customers will benefit fromAccount Security Analytics and Events. This allows organizations to new eyes on your account in Cloudflare dashboard to give holistic visibility. No matter how many zones you manage, they are all there!
We are thrilled to announce the full support of wildcard and multi-hostname application definitions in Cloudflare Access. Until now, Access had limitations that restricted it to a single hostname or a limited set of wildcards
While that’s it for Security Week 2023, you all know by now that Innovation weeks never end for Cloudflare. Stay tuned for a week full of new developer tools coming soon, and a week dedicated to making the Internet faster later in the year.
Cloudflare now automatically discovers all API endpoints and learns API schemas for all of our API Gateway customers. Customers can use these new features to enforce a positive security model on their API endpoints even if they have little-to-no information about their existing APIs today.
The first step in securing your APIs is knowing your API hostnames and endpoints. We often hear that customers are forced to start their API cataloging and management efforts with something along the lines of “we email around a spreadsheet and ask developers to list all their endpoints”.
Can you imagine the problems with this approach? Maybe you have seen them first hand. The “email and ask” approach creates a point-in-time inventory that is likely to change with the next code release. It relies on tribal knowledge that may disappear with people leaving the organization. Last but not least, it is susceptible to human error.
Even if you had an accurate API inventory collected by group effort, validating that API was being used as intended by enforcing an API schema would require even more collective knowledge to build that schema. Now, API Gateway’s new API Discovery and Schema Learning features combine to automatically protect APIs across the Cloudflare global network and remove the need for manual API discovery and schema building.
API Gateway discovers and protects APIs
API Gateway discovers APIs through a feature called API Discovery. Previously, API Discovery used customer-specific session identifiers (HTTP headers or cookies) to identify API endpoints and display their analytics to our customers.
Doing discovery in this way worked, but it presented three drawbacks:
Customers had to know which header or cookie they used in order to delineate sessions. While session identifiers are common, finding the proper token to use can take time.
Needing a session identifier for API Discovery precluded us from monitoring and reporting on completely unauthenticated APIs. Customers today still want visibility into session-less traffic to ensure all API endpoints are documented and that abuse is at a minimum.
Once the session identifier was input into the dashboard, customers had to wait up to 24 hours for the Discovery process to complete. Nobody likes to wait.
While this approach had drawbacks, we knew we could quickly deliver value to customers by starting with a session-based product. As we gained customers and passed more traffic through the system, we knew our new labeled data would be extremely useful to further build out our product. If we could train a machine learning model with our existing API metadata and the new labeled data, we would no longer need a session identifier to pinpoint which endpoints were for APIs. So we decided to build this new approach.
We took what we learned from the session identifier-based data and built a machine learning model to uncover all API traffic to a domain, regardless of session identifier. With our new Machine Learning-based API Discovery, Cloudflare continually discovers all API traffic routed through our network without any prerequisite customer input. With this release, API Gateway customers will be able to get started with API Discovery faster than ever, and they’ll uncover unauthenticated APIs that they could not discover before.
Session identifiers are still important to API Gateway, as they form the basis of our volumetric abuse prevention rate limits as well as our Sequence Analytics. See more about how the new approach performs in the “How it works” section below.
API Protection starting from nothing
Now that you’ve found new APIs using API Discovery, how do you protect them? To defend against attacks, API developers must know exactly how they expect their APIs to be used. Luckily, developers can programmatically generate an API schema file which codifies acceptable input to an API and upload that into API Gateway’s Schema Validation.
However, we already talked about how many customers can’t find their APIs as fast as their developers build them. When they do find APIs, it’s very difficult to accurately build a unique OpenAPI schema for each of potentially hundreds of API endpoints, given that security teams seldom see more than the HTTP request method and path in their logs.
When we looked at API Gateway’s usage patterns, we saw that customers would discover APIs but almost never enforce a schema. When we ask them ‘why not?’ the answer was simple: “Even when I know an API exists, it takes so much time to track down who owns each API so that they can provide a schema. I have trouble prioritizing those tasks higher than other must-do security items.” The lack of time and expertise was the biggest gap in our customers enabling protections.
So we decided to close that gap. We found that the same learning process we used to discover API endpoints could then be applied to endpoints once they were discovered in order to automatically learn a schema. Using this method we can now generate an OpenAPI formatted schema for every single endpoint we discover, in real time. We call this new feature Schema Learning. Customers can then upload that Cloudflare-generated schema into Schema Validation to enforce a positive security model.
How it works
Machine learning-based API discovery
With RESTful APIs, requests are made up of different HTTP methods and paths. Take for example the Cloudflare API. You’ll notice a common trend with the paths that might make requests to this API stand out amongst requests to this blog: API requests all start with /client/v4 and continue with the service name, a unique identifier, and sometimes service feature names and further identifiers.
How could we easily identify API requests? At first glance, these requests seem easy to programmatically discover with a heuristic like “path starts with /client”, but the core of our new Discovery contains a machine-learned model that powers a classifier that scores HTTP transactions. If API paths are so structured, why does one need machine-learning for this and can’t one just use some simple heuristic?
The answer boils down to the question: what actually constitutes an API request and how does it differ from a non-API request? Let’s look at two examples.
Like the Cloudflare API, many of our customers’ APIs follow patterns such as prefixing the path of their API request with an “api” identifier and a version, for example: /api/v2/user/7f577081-7003-451e-9abe-eb2e8a0f103d.
So just looking for “api” or a version in the path is already a pretty good heuristic that tells us this is very likely part of an API, but it is unfortunately not always as easy.
Let’s consider two further examples, /users/7f577081-7003-451e-9abe-eb2e8a0f103d.jpg and /users/7f577081-7003-451e-9abe-eb2e8a0f103d, both just differ in a .jpg extension. The first path could just be a static resource like the thumbnail of a user. The second path does not give us a lot of clues just from the path alone.
Manually crafting such heuristics quickly becomes difficult. While humans are great at finding patterns, building heuristics is challenging considering the scale of the data that Cloudflare sees each day. As such, we use machine learning to automatically derive these heuristics such that we know that they are reproducible and adhere to a certain accuracy.
Input to the training are features of HTTP request/response samples such as the content-type or file extension that we collected through the session identifiers-based Discovery mentioned earlier. Unfortunately, not everything that we have in this data is clearly an API. Additionally, we also need samples that represent non-API traffic. As such, we started out with the session-identifier Discovery data, manually cleaned it up and derived further samples of non-API traffic. We took great care in trying to not overfit the model to the data. That is, we want that the model generalizes beyond the training data.
To train the model, we’ve used the CatBoost library for which we already have a good chunk of expertise as it also powers our Bot Management ML-models. In a simplification, one can regard the resulting model as a flow chart that tells us which conditions we should check after another, for example: if the path contains “api” then also check if there is no file extension and so forth. At the end of this flowchart is a score that tells us the likelihood that a HTTP transaction belongs to an API.
Given the trained model, we can thus input features of HTTP request/responses that run through the Cloudflare network and calculate the likelihood that this HTTP transaction belongs to an API or not. Feature extraction and model scoring is done in Rust and takes only a couple of microseconds on our global network. Since Discovery sources data from our powerful data pipeline, it is not actually necessary to score each transaction. We can reduce the load on our servers by only scoring those transactions that we know will end up in our data pipeline to begin with thus saving CPU time and allowing the feature to be cost effective.
With the classification results in our data pipeline, we can use the same API Discovery mechanism that we’ve been using for the session identifier-based discovery. This existing system works great and allows us to reuse code efficiently. It also aided us when comparing our results with the session identifier-based Discovery, as the systems are directly comparable.
For API Discovery results to be useful, Discovery’s first task is to simplify the unique paths we see into variables. We’ve talked about this before. It is not trivial to deduce the various different identifier schemes that we see across the global network, especially when sites use custom identifiers beyond a straightforward GUID or integer format. API Discovery aptly normalizes paths containing variables with the help of a few different variable classifiers and supervised learning.
Only after normalizing paths are the Discovery results ready for our users to use in a straightforward fashion.
The results: hundreds of found endpoints per customer
So, how does ML Discovery compare to the session identifier-based Discovery which relies on headers or cookies to tag API traffic?
Our expectation is that it detects a very similar set of endpoints. However, in our data we knew there would be two gaps. First, we sometimes see that customers are not able to cleanly dissect only API traffic using session identifiers. When this happens, Discovery surfaces non-API traffic. Second, since we required session identifiers in the first version of API Discovery, endpoints that are not part of a session (e.g. login endpoints or unauthenticated endpoints) were conceptually not discoverable.
The following graph shows a histogram of the number of endpoints detected on customer domains for both discovery variants.
From a bird’s eye perspective, the results look very similar, which is a good indicator that ML Discovery performs as it is supposed to. There are some differences already visible in this plot, which is also expected since we’ll also discover endpoints that are conceptually not discoverable with just a session identifier. In fact, if we take a closer look at a domain-by-domain comparison we see that there is no change for roughly ~46% of the domains. The next graph compares the difference (by percent of endpoints) between session-based and ML-based discovery:
For ~15% of the domains, we see an increase in endpoints between 1 and 50, and for ~9%, we see a similar reduction. For ~28% of the domains, we find more than 50 additional endpoints.
These results highlight that ML Discovery is able to surface additional endpoints that have previously been flying under the radar, and thus expands the set tools API Gateway offers to help bring order to your API landscape.
On-the-fly API protection through API schema learning
With API Discovery taken care of, how can a practitioner protect the newly discovered endpoints? We already looked at the API request metadata, so now let’s look at the API request body. The compilation of all expected formats for all API endpoints of an API is known as an API schema. API Gateway’s Schema Validation is a great way to protect against OWASP Top 10 API attacks, ensuring the body, path, and query string of a request contains the expected information for that API endpoint in an expected format. But what if you don’t know the expected format?
Even if the schema of a specific API is not known to a customer, the clients using this API will have been programmed to mostly send requests that conform to this unknown schema (or they would not be able to successfully query the endpoint). Schema Learning makes use of this fact and will look at successful requests to this API to reconstruct the input schema automatically for the customer. As an example, an API might expect the user-ID parameter in a request to have the form id12345-a. Even if this expectation is not explicitly stated, clients that want to have a successful interaction with the API will send user-IDs in this format.
Schema Learning first identifies all recent successful requests to an API-endpoint, and then parses the different input parameters for each request according to their position and type. After parsing all requests, Schema Learning looks at the different input values for each position and identifies which characteristics they have in common. After verifying that all observed requests share these commonalities, Schema Learning creates an input schema that restricts input to comply with these commonalities and that can directly be used for Schema Validation.
To allow for more accurate input schemas, Schema Learning identifies when a parameter can receive different types of input. Let’s say you wanted to write an OpenAPIv3 schema file and manually observe in a small sample of requests that a query parameter is a unix timestamp. You write an API schema that forces that query parameter to be an integer greater than the start of last year’s unix epoch. If your API also allowed that parameter in ISO 8601 format, your new rule would create false positives when the differently formatted (yet valid) parameter hit the API. Schema Learning automatically does all this heavy lifting for you and catches what manual inspection can’t.
To prevent false positives, Schema Learning performs a statistical test on the distribution of these values and only writes the schema when the distribution is bounded with high confidence.
So how well does it work? Below are some statistics about the parameter types and values we see:
Parameter learning classifies slightly more than half of all parameters as strings, followed by integers which make up almost a third. The remaining 17% are made up of arrays, booleans, and number (float) parameters, while object parameters are seen more rarely in the path and query.
The number of parameters in the path is usually very low, with 94% of all endpoints seeing at most one parameter in their path.
For the query, we do see a lot more parameters, sometimes reaching 50 different parameters for one endpoint!
Parameter learning is able to estimate numeric constraints with 99.9% confidence for the majority of parameters observed. These constraints can either be a maximum/minimum on the value, length, or size of the parameter, or a limited set of unique values that a parameter has to take.
Protect your APIs in minutes
Starting today, all API Gateway customers can now discover and protect APIs in just a few clicks, even if you’re starting with no previous information. In the Cloudflare dash, click into API Gateway and on to the Discovery tab to observe your discovered endpoints. These endpoints will be immediately available with no action required from you. Then, add relevant endpoints from Discovery into Endpoint Management. Schema Learning runs automatically for all endpoints added to Endpoint Management. After 24 hours, export your learned schema and upload it into Schema Validation.
Pro, Biz, and Enterprise customers that haven’t purchased API Gateway can get started by enabling the API Gateway trial inside the Cloudflare Dashboard or contacting their account manager.
What’s next
We plan to enhance Schema Learning by supporting more learned parameters in more formats, like POST body parameters with both JSON and URL-encoded formats as well as header and cookie schemas. In the future, Schema Learning will also notify customers when it detects changes in the identified API schema and present a refreshed schema.
We’d like to hear your feedback on these new features. Please direct your feedback to your account team so that we can prioritize the right areas of improvement. We look forward to hearing from you!
Today, we’re announcing Cloudflare Sequence Analytics for APIs. Using Sequence Analytics, Customers subscribed to API Gateway can view the most important sequences of API requests to their endpoints. This new feature helps customers to apply protection to the most important endpoints first.
What is a sequence? It is simply a time-ordered list of HTTP API requests made by a specific visitor as they browse a website, use a mobile app, or interact with a B2B partner via API. For example, a portion of a sequence made during a bank funds transfer could look like:
Order
Method
Path
Description
1
GET
/api/v1/users/{user_id}/accounts
user_id is the active user
2
GET
/api/v1/accounts/{account_id}/balance
account_id is one of the user’s accounts
3
GET
/api/v1/accounts/{account_id}/balance
account_id is a different account belonging to the user
4
POST
/api/v1/transferFunds
Containing a request body detailing an account to transfer funds from, an account to transfer funds to, and an amount of money to transfer
Why is it important to pay attention to sequences for API security? If the above API received requests for POST /api/v1/transferFunds without any of the prior requests, it would seem suspicious. Think about it: how would the API client know what the relevant account IDs are without listing them for the user? How would the API client know how much money is available to transfer? While this example may be obvious, the sheer number of API requests to any given production API can make it hard for human analysts to spot suspicious usage.
In security, one approach to defending against an untold number of threats that are impossible to screen by a team of humans is to create a positive security model. Instead of trying to block everything that could potentially be a threat, you allow all known good or benign traffic and block everything else by default.
Customers could already create positive security models with API Gateway in two main areas: volumetric abuse protection and schema validation. Sequences will form the third pillar of a positive security model for API traffic. API Gateway will be able to enforce the precedence of endpoints in any given API sequence. By establishing precedence within an API sequence, API Gateway will log or block any traffic that doesn’t match expectations, reducing abusive traffic.
Detecting abuse by sequence
When attackers attempt to exfiltrate data in an abusive way, they rarely follow the patterns of expected API traffic. Attacks often use special software to ‘fuzz’ the API, sending several requests with different request parameters hoping to find unexpected responses from the API indicating opportunities to exfiltrate data. Attackers can also manually send requests to APIs that attempt to trick the API in performing unauthorized actions, like granting an attacker elevated privileges or access to data through a Broken Object Level Authentication attack. Protecting APIs with rate limits is a common best practice; however, in both of the above examples attackers may deliberately execute request sequences slowly, in an attempt to thwart volumetric abuse detection.
Think of the sequence of requests above again, but this time imagine an attacker copying the legitimate funds transfer request and modifying the request payload in an attempt to trick the system:
Order
Method
Path
Description
1
GET
/api/v1/users/{user_id}/accounts
user_id is the active user
2
GET
/api/v1/accounts/{account_id}/balance
account_id is one of the user’s accounts
3
GET
/api/v1/accounts/{account_id}/balance
account_id is a different account belonging to the user
4
POST
/api/v1/transferFunds
Containing a request body detailing an account to transfer funds from, an account to transfer funds to, and an amount of money to transfer
… attacker copies the request to a debugging tool like Postman …
5
POST
/api/v1/transferFunds
Attacker has modified the POST body to try and trick the API
6
POST
/api/v1/transferFunds
A further modified POST body to try and trick the API
7
POST
/api/v1/transferFunds
Another, further modified POST body to try and trick the API
If the customer knew beforehand that the funds transfer endpoint was critical to protect and only occurred once during a sequence, they could write a rule to ensure that it was never called twice in a row and a GET /balance always preceded a POST /transferFunds. But without prior knowledge of which endpoint sequences are critical to protect, how would the customer know which rules to define? A low rate limit is too risky, since an API user might legitimately have a few funds transfer requests to perform in a short amount of time. In the present reality there are few tools to prevent this type of abuse, and most customers are left with reactive efforts to clean up abuse with their application teams and fraud departments after it’s happened.
Ultimately, we believe that providing our customers with the ability to define positive security models on API request sequences requires a three-pronged approach:
Sequence Analytics: Determining which sequences of API requests occurred and when, as well as summarizing the data into readily understandable form.
Sequence Abuse Detection: Identifying which sequences of API requests are likely of benign or malicious origin.
Sequence Mitigation: Identifying relevant rules on sequences of API requests for deciding which traffic to allow or block.
Challenges of sequence creation
Sequence Analytics presents some difficult technical challenges, because sessions may be long-lived and may consist of many requests. As a result, it is not sufficient to define sequences by session identifier alone. Instead, it was necessary for us to develop a solution capable of automatically identifying multiple sequences which occur within a given session. Additionally, since important sequences are not necessarily characterized by volume alone and the set of possible sequences is large, it was necessary to develop a solution capable of identifying important sequences, as opposed to simply surfacing frequent sequences.
To help illustrate these challenges for the example of api.cloudflare.com, we can group API requests by session and plot the number of distinct sequences versus sequence length:
The plot is based on a one hour snapshot comprising approximately 88,000 sessions and 300 million API requests, with 302 distinct API endpoints. We process the data by applying a fixed-length sliding window to each session, then we count the total number of different fixed-length sequences (‘n-grams’) that we observe as a result of applying the sliding window. The plot displays results for a window size (‘n-gram length’) varying between 1 and 10 requests. Based on the plot, we observe a large number of possible sequences which grows with sequence length: As we increase the sliding window size, we see an increasingly large amount of different sequences in the sample. The smooth trend can be explained by the fact that we apply a sliding window (sessions may themselves contain many sequences) in combination with many long sessions relative to the sequence length.
Given the large number of possible sequences, trying to find abusive sequences is a ‘needles in a haystack’ situation.
Introducing Sequence Analytics
Here is a screenshot from the API Gateway dashboard highlighting Sequence Analytics:
Let’s break down the new functionality seen in the screenshot.
API Gateway intelligently determines sequences of requests made by your API consumers using the methods described earlier in this article. API Gateway scores sequences by a metric we call Correlation Score. Sequence Analytics displays the top 20 sequences by highest correlation score, and we refer to these as your most important sequences. High-importance sequences contain API requests which are likely to occur together in order.
You should inspect each of your sequences to understand their correlation scores. High correlation score sequences may consist of rarely used endpoints (potentially anomalous user behavior) as well as commonly used endpoints (likely benign user behavior). Since the endpoints found in these sequences commonly occur together, they represent true usage patterns of your API. You should apply all possible API Gateway protections to these endpoints (rate limiting suggestions, Schema Validation, JWT Validation, and mTLS) and check their specific endpoint order with your development team.
We know customers want to explicitly set allowable behavior on their APIs beyond the active protections offered by API Gateway today. Coming soon, we’re releasing sequence precedence rules and enabling the ability to block requests based on those rules. The new sequence precedence rules will allow customers to specify the exact order of allowable API requests, bringing yet another way of establishing a positive security model to protect your API against unknown threats.
How to get started
All API Gateway customers now have access to Sequence Analytics. Navigate to a zone in the Cloudflare dashboard, then click the Security tab > API Gateway tab > Sequences tab. You’ll see the most important sequences that your API consumers request.
Pro, Biz, and Enterprise customers that haven’t purchased API Gateway can get started by enabling the API Gateway trial inside the Cloudflare Dashboard or contacting their account manager.
What’s next
Sequence-based detection is a powerful and unique capability that unlocks many new opportunities to identify and stop attacks. As we fine-tune the methods of identifying these sequences and shipping them to our global network, we will release custom sequence matching and real-time mitigation features at a future date. We will also ensure you have the actionable intelligence to take back to your team on who the API users were that attempted to request sequences that don’t match your policy.
Last month I had the chance to attend a dinner with 56 CISOs and CSOs across a range of banking, gaming, ecommerce, and retail companies. We rotated between tables of eight people and talked about the biggest challenges those in the group were facing, and what they were most worried about around the corner. We talk to customers every day at Cloudflare, but this was a unique opportunity to listen to customers (and non-customers) talk to each other. It was a fascinating evening and a few things stood out.
The common thread that dominated the discussions was “how do I convince my business and product teams to do the things I want them to”. Surprisingly little time was spent on specific technical challenges. No one brought up a concern about recent advanced mage cart skimmers, or about protecting their new GraphQL APIs, or how to secure two different cloud vendors at once, or about the size of DDoS attacks consistently getting larger. Over and over again the conversation came back to struggles with getting humans to do the secure thing, or to not do the insecure thing.
This instantly brought to mind a major phishing attack that Cloudflare was able to thwart last August. The attack was extremely sophisticated, using targeted text messages and an extremely professional impersonation of our Okta login page. Cloudflare did have individual employees fall for the phishing messages, because we are made up of a team of humans who are human. But we were able to thwart the attack through our own use of Cloudflare One products, and physical security keys issued to every employee that are required to access all our applications. The attacker was able to obtain compromised username and password credentials, but they could not get past the hard key requirement to log in. In 2023 phishing attacks are only getting more frequent.
Today’s security challenges are often a case of having the right tools deployed to prevent people from making mistakes. Last year when we kicked off Security Week, we talked about making a shift from protecting websites, to protecting applications. Today, the shift is from protecting applications, to protecting employees, and making sure they are protected everywhere. Just a few weeks ago, the White House released a new national cybersecurity strategy directing all agencies to “implement multi-factor authentication, gain visibility into their entire attack surface, manage authorization and access, and adopt cloud security tools”. Over the next six days you’ll read more than 30 announcements that will make it as easy as possible to do just that.
Welcome to Security Week 2023.
“The more tools you use the less secure you are”
This was a direct quote from the CISO of a large online gaming platform. Adding more vendors might seem like you are adding layers of security, but you do also open up avenues for risk. First, every third party you add by definition adds another potential vulnerability. The recent LastPass breach is a perfect example. Attackers gained access to a cloud storage service, which gave them information they used in a secondary attack to phish an employee. Second, more tools means more complexity. More systems to log into, more dashboards to check. If information is spread across multiple systems you are more likely to miss important changes. Third, the more tools you use, the less likely it is that anyone is able to master them all. If you need the person who knows the application security tool, and the person who knows the SIEM, and the person who knows the access tool to coordinate on every potential vulnerability, things will get lost in translation. Complexity is the enemy of security. Fourth, adding more tools can add a false sense of security. Simply adding a new tool can give the impression you’ve added defense in depth. But that tool only adds protection if it works, if it’s configured properly, and if people actually use it.
This week, you will hear about all of the initiatives we’ve been working on to help you solve this problem. We will announce multiple integrations that make it easier for you to deploy and manage Zero Trust anywhere, across multiple platforms, but all within the Cloudflare dashboard. We’re also extending our proven detection capabilities into new areas that will help you solve problems you couldn’t solve before, and thus allow you to get rid of additional vendors. And we’ll announce a brand new migration tool that makes it dead simple to move from those other vendors to Cloudflare.
Leverage machine learning to let humans focus on critical thinking
We all hear machine learning thrown around as a buzzword too often, but it boils down to this: computers are really good at finding patterns. When we train them on what a good pattern looks like, they can spot them really well, and spot the outliers. Humans are great at finding patterns too. But it takes us a long time, and any time we spend finding patterns distracts us from the thing that even the best AI or ML model still can’t do: critical thinking. By using machine learning to find these good and bad patterns, you can optimize the time of your most valuable people. Rather than searching for exceptions, they can focus on only those exceptions, and use their wisdom to make the hard decisions about what to do next.
Cloudflare has used machine learning to catch DDoS attacks, malicious bots, and malicious web traffic. We were able to do this differently from others because we built a unique network where we run all of our code at every single data center, on every single machine. Since we have a massive global network that is close to end users, we can run machine learning close to those users, unlike competitors who have to use centralized data centers. The result is a machine learning pipeline that runs inference in a few microseconds. That unique speed is an advantage for our customers, one we now use to run inference more than 40 million times every second.
This week, we have an entire day focused on how we are using that machine learning pipeline to build new models that will allow you to find new patterns, like fraud and API endpoints.
Our intelligence is your intelligence
In June we announced Cloudforce One, the first step in our threat operations team dedicated to turning the intelligence we gather from handling nearly 20% of Internet traffic into actionable insights. Since that launch, we’ve heard customers ask us to do more with those insights and give them easy buttons and products to take the appropriate action on their behalf. This week you’ll read multiple announcements on new ways that you can view and take action on unique Cloudflare threat intelligence. We’ll also be announcing multiple new reporting views, like being able to view more data at an account level so you can have one single lens into security trends across your entire organization.
Make it harder for humans to make mistakes
Each product, development, or business team wants to use their own tools, and wants to move as quickly as possible. For good reason! Any security that comes after the fact, and creates additional work for those teams, will be difficult to get internal buy on for. Which can lead to situations like the recent T-mobile hack where an API that was not intended to be public was exposed, discovered, and exploited. You need to meet teams where they are by making the tools they already use more secure, and preventing them from making mistakes, rather than giving them additional tasks.
In addition to making it easier to deploy our Application Security and Zero Trust products to a wider scope, you’ll also read about how we are adding new features that prevent humans from making the mistakes they always do. You’ll hear about how you can make it impossible to click on a phishing link by automatically blocking the domains that host them, prevent data from leaving regions it should never leave, give your users security alerts directly in the tools they already use, and automatically detect shadow APIs without making your developers change their development process. All of this without having to convince internal teams to make any changes to their behavior.
If you’re reading this and any part of your job involves securing an organization, I think that by the end of the week we’ll have made your job easier. With the new tools and integrations we release, you’ll be able to protect more of your infrastructure from a wider range of threats, but reduce the number of third parties you rely on. More importantly, you’ll be able to reduce the number of mistakes that the incredible humans you work with can make. I hope that helps you rest a bit easier!
Over the last few years the topic of cyber security has moved from the IT department to the board room. The current climate of geopolitical and economic uncertainty has made the threat of cyber attacks all the more pressing, with businesses of all sizes and across all industries feeling the impact. From the potential for a crippling ransomware attack to a data breach that could compromise sensitive consumer information, the risks are real and potentially catastrophic. Organizations are recognizing the need for better resilience and preparation regarding cybersecurity. It is not enough to simply react to attacks as they happen; companies must proactively prepare for the inevitable in their approach to cybersecurity.
The security approach that has gained the most traction in recent years is the concept of Zero Trust. The basic principle behind Zero Trust is simple: don’t trust anything; verify everything. The impetus for a modern Zero Trust architecture is that traditional perimeter-based (castle-and-moat) security models are no longer sufficient in today’s digitally distributed landscape. Organizations must adopt a holistic approach to security based on verifying the identity and trustworthiness of all users, devices, and systems that access their networks and data.
Zero Trust has been on the radar of business leaders and board members for some time now. However, Zero Trust is no longer just a concept being discussed; it’s now a mandate. With remote or hybrid work now the norm and cyber-attacks continuing to escalate, businesses realize they must take a fundamentally different approach to security. But as with any significant shift in strategy, implementation can be challenging, and efforts can sometimes stall. Although many firms have begun implementing Zero Trust methods and technologies, only some have fully implemented them throughout the organization. For many large companies, this is the current status of their Zero Trust initiatives – stuck in the implementation phase.
A new leadership role emerges
But what if there was a missing piece in the cybersecurity puzzle that could change everything? Enter the role of “Chief Zero Trust Officer” (CZTO) – a new position that we believe will become increasingly common in large organizations over the next year.
The idea of companies potentially creating the role of Chief Zero Trust Officer evolved from conversations last year between Cloudflare’s Field CTO team members and US federal government agencies. A similar job function was first noted in the White House memorandum directing federal agencies to “move toward Zero Trust cybersecurity principles” and requiring agencies “designate and identify a Zero Trust strategy implementation lead for their organization” within 30 days. In government, a role like this is often called a “czar,” but the title “chief” is more appropriate within a business.
Large organizations need strong leaders to efficiently get things done. Businesses assign the ultimate leadership responsibility to people with titles that begin with the word chief, such as Chief Executive Officer (CEO) or Chief Financial Officer (CFO). These positions exist to provide direction, set strategy, make critical decisions, and manage day-to-day operations and they are often accountable to the board for overall performance and success.
Why a C-level for Zero Trust, and why now?
An old saying goes, “when everyone is responsible, no one is responsible.” As we consider the challenges in implementing Zero Trust within an enterprise, it appears that a lack of clear leadership and accountability is a significant issue. The question remains, who *exactly* is responsible for driving the adoption and execution of Zero Trust within the organization?
Large enterprises need a single person responsible for driving the Zero Trust journey. This leader should be empowered with a clear mandate and have a singular focus: getting the enterprise to Zero Trust. This is where the idea of the Chief Zero Trust Officer was born. “Chief Zero Trust Officer” may seem like just a title, but it holds a lot of weight. It commands attention and can overcome many obstacles to Zero Trust.
Barriers to adoption
Implementing Zero Trust can be hindered by various technological challenges. Understanding and implementing the complex architecture of some vendors can take time, demand extensive training, or require a professional services engagement to acquire the necessary expertise. Identifying and verifying users and devices in a Zero Trust environment can also be a challenge. It requires an accurate inventory of the organization’s user base, groups they’re a part of, and their applications and devices.
On the organizational side, coordination between different teams is crucial for effectively implementing Zero Trust. Breaking down the silos between IT, cybersecurity, and networking groups, establishing clear communication channels, and regular meetings between team members can help achieve a cohesive security strategy. General resistance to change can also be a significant obstacle. Leaders should use techniques such as leading by example, transparent communication, and involving employees in the change process to mitigate it. Proactively addressing concerns, providing support, and creating employee training opportunities can also help ease the transition.
Responsibility and accountability – no matter what you call it
But why does an organization need a CZTO? Is another C-level role essential? Why not assign someone already managing security within the CISO organization? Of course, these are all valid questions. Think about it this way – companies should assign the title based on the level of strategic importance to the company. So, whether it’s Chief Zero Trust Officer, Head of Zero Trust, VP of Zero Trust, or something else, the title must command attention and come with the power to break down silos and cut through bureaucracy.
New C-level titles aren’t without precedent. In recent years, we’ve seen the emergence of titles such as Chief Digital Transformation Officer, Chief eXperience Officer, Chief Customer Officer, and Chief Data Scientist. The Chief Zero Trust Officer title is likely not even a permanent role. What’s crucial is that the person holding the role has the authority and vision to drive the Zero Trust initiative forward, with the support of company leadership and the board of directors.
Getting to Zero Trust in 2023
Getting to Zero Trust security is now a mandate for many companies, as the traditional perimeter-based security model is no longer enough to protect against today’s sophisticated threats. To navigate the technical and organizational challenges that come with Zero Trust implementation, the leadership of a CZTO is crucial. The CZTO will lead the Zero Trust initiative, align teams and break down barriers to achieve a smooth rollout. The role of CZTO in the C-suite emphasizes the importance of Zero Trust in the company. It ensures that the Zero Trust initiative is given the necessary attention and resources to succeed. Organizations that appoint a CZTO now will be the ones that come out on top in the future.
Cloudflare One for Zero Trust
Cloudflare One is Cloudflare’s Zero Trust platform that is easy to deploy and integrates seamlessly with existing tools and vendors. It is built on the principle of Zero Trust and provides organizations with a comprehensive security solution that works globally. Cloudflare One is delivered on Cloudflare’s global network, which means that it works seamlessly across multiple geographies, countries, network providers, and devices. With Cloudflare’s massive global presence, traffic is secured, routed, and filtered over an optimized backbone that uses real-time Internet intelligence to protect against the latest threats and route traffic around bad Internet weather and outages. Additionally, Cloudflare One integrates with best-of-breed identity management and endpoint device security solutions, creating a complete solution that encompasses the entire corporate network of today and tomorrow. If you’d like to know more, let us know here, and we’ll reach out.
Do you prefer to avoid talking to someone just yet? Nearly every feature in Cloudflare One is available at no cost for up to 50 users. Many of our largest enterprise customers start by exploring our Zero Trust products themselves on our free plan, and we invite you to do so by following the link here.
Working with another Zero Trust vendor?
Cloudflare’s security experts have built a vendor-neutral roadmap to provide a Zero Trust architecture and an example implementation timeline. The Zero Trust Roadmap https://zerotrustroadmap.org/ is an excellent resource for organizations that want to learn more about the benefits and best practices of implementing Zero Trust. And if you feel stuck on your current Zero Trust journey, have your chief Zero Trust officer give us a call at Cloudflare!
Forester has recognised Cloudflare as a Leader in The Forrester Wave™: Web Application Firewalls, Q3 2022 report. The report evaluated 12 Web Application Firewall (WAF) providers on 24 criteria across current offering, strategy and market presence.
You can register for a complimentary copy of the report here. The report helps security and risk professionals select the correct offering for their needs.
We believe this achievement, along with recent WAF developments, reinforces our commitment and continued investment in the Cloudflare Web Application Firewall (WAF), one of our core product offerings.
The WAF, along with our DDoS Mitigation and CDN services, has in fact been an offering since Cloudflare’s founding, and we could not think of a better time to receive this recognition: Birthday Week.
We’d also like to take this opportunity to thank Forrester.
Leading WAF in strategy
Cloudflare received the highest score of all assessed vendors in the strategy category. We also received the highest possible scores in 10 criteria, including:
Innovation
Management UI
Rule creation and modification
Log4Shell response
Incident investigation
Security operations feedback loops
According to Forrester, “Cloudflare Web Application Firewall shines in configuration and rule creation”, “Cloudflare stands out for its active online user community and its associated response time metrics”, and “Cloudflare is a top choice for those prioritizing usability and looking for a unified application security platform.”
Protecting web applications
The core value of any WAF is to keep web applications safe from external attacks by stopping any compromise attempt. Compromises can in fact lead to complete application take over and data exfiltration resulting in financial and reputational damage to the targeted organization.
The Log4Shell criterion in the Forrester Wave report is an excellent example of a real world use case to demonstrate this value.
Log4Shell was a high severity vulnerability discovered in December 2021 that affected the popular Apache Log4J software commonly used by applications to implement logging functionality. The vulnerability, when exploited, allows an attacker to perform remote code execution and consequently take over the target application.
Due to the popularity of this software component, many organizations worldwide were potentially at risk after the immediate public announcement of the vulnerability on December 9, 2021.
We believe that we scored the highest possible score in the Log4Shell criterion due to our fast response to the announcement, by ensuring that all customers using the Cloudflare WAF were protected against the exploit in less than 17 hours globally.
We did this by deploying new managed rules (virtual patching) that were made available to all customers. The rules were deployed with a block action ensuring exploit attempts never reached customer applications.
The Cloudflare WAF ultimately “bought” valuable time for our customers to patch their back end systems before attackers may have been able to find and attempt compromise of vulnerable applications.
You can read about our response and our actions following the Log4Shell announcement in great detail on our blog.
Use the Cloudflare WAF today
Cloudflare WAF keeps organizations safer while they focus on improving their applications and APIs. We integrate leading application security capabilities into a single console to protect applications with our WAF while also securing APIs, stopping DDoS attacks, blocking unwanted bots, and monitoring for 3rd party JavaScript attacks.
The Internet is an endless flow of conversations between computers. These conversations, the constant exchange of information from one computer to another, are what allow us to interact with the Internet as we know it. Application Programming Interfaces (APIs) are the vital channels that carry these conversations, and their usage is quickly growing: in fact, more than half of the traffic handled by Cloudflare is for APIs, and this is increasing twice as fast as traditional web traffic.
In March, we announced that we’re expanding our API Shield into a full API Gateway to make it easy for our customers to protect and manage those conversations. We already offer several features that allow you to secure your endpoints, but there’s more to endpoints than their security. It can be difficult to keep track of many endpoints over time and understand how they’re performing. Customers deserve to see what’s going on with their API-driven domains and have the ability to manage their endpoints.
Today, we’re excited to announce that the ability to save, update, and monitor the performance of all your API endpoints is now generally available to API Shield customers. This includes key performance metrics like latency, error rate, and response size that give you insights into the overall health of your API endpoints.
A Refresher on APIs
The bar for what we expect an application to do for us has risen tremendously over the past few years. When we open a browser, app, or IoT device, we expect to be able to connect to data instantly, compare dozens of flights within seconds, choose a menu item from a food delivery app, or see the weather for ten locations at once.
How are applications able to provide this kind of dynamic engagement for their users? They rely on APIs, which provide access to data and services—either from the application developer or from another company. APIs are fundamental in how computers (or services) talk to each other and exchange information.
You can think of an API as a waiter: say a customer orders a delicious bowl of Mac n Cheese. The waiter accepts this order from the customer, communicates the request to the chef in a format the chef can understand, and then delivers the Mac n Cheese back to the customer (assuming the chef has the ingredients in stock). The waiter is the crucial channel of communication, which is exactly what the API does.
Managing API Endpoints
The first step in managing APIs is to get a complete list of all the endpoints exposed to the internet. API Discovery automatically does this for any traffic flowing through Cloudflare. Undiscovered APIs can’t be monitored by security teams (since they don’t know about them) and they’re thus less likely to have proper security policies and best practices applied. However, customers have told us they also want the ability to manually add and manage APIs that are not yet deployed, or they want to ignore certain endpoints (for example those in the process of deprecation). Now, API Shield customers can choose to save endpoints found by Discovery or manually add endpoints to API Shield.
But security vulnerabilities aren’t the only risk or area of concern with APIs – they can be painfully slow or connections can be unsuccessful. We heard questions from our customers such as: what are my most popular endpoints? Is this endpoint significantly slower than it was yesterday? Are any endpoints returning errors that may indicate a problem with the application?
That’s why we built Performance Metrics into API Shield, which allows our customers to quickly answer these questions themselves with real-time data.
Prioritizing Performance
Once you’ve discovered, saved, or removed endpoints, you want to know what’s going well and what’s not. To end-users, a huge part of what defines the experience as “going well” is good performance. Poor performance can lead to a frustrating experience: when you’re shopping online and press a button to check out, you don’t want to wait around for minutes for the page to load. And you certainly never want to see a dreaded error symbol telling you that you can’t get what you came for.
Exposing performance metrics of API endpoints puts concrete numerical data into your developers’ hands to tell you how things are going. When things are going poorly, these dashboard metrics will point out exactly which aspect of performance is causing concern: maybe you expected to see a spike in requests, but find out that request count is normal and latency is just higher than usual.
Empowering our customers to make data-driven decisions to better manage their APIs ends up being a win for our customers and our customers’ customers, who expect to seamlessly engage with the domain’s APIs and get exactly what they came for.
Management and Performance Metrics in the Dashboard
So, what’s available today? Log onto your Cloudflare dashboard, go to the domain-level Security tab, and open up the API Shield page. Here, you’ll see the Endpoint Management tab, which shows you all the API endpoints that you’ve saved, alongside placeholders for metrics that will soon be gathered.
Here you can easily delete endpoints you no longer want to track, or click manually add additional endpoints. You can also export schemas for each host to share internally or externally.
Once you’ve saved the endpoints that you want to keep tabs on, Cloudflare will start collecting data on its performance and make it available to you as soon as possible.
In Endpoint Management, you can see a few summary metrics in the collapsed view of each endpoint, including recommended rate limits, average latency, and error rate. It can be difficult to tell whether things are going well or not just from seeing a value alone, so we added sparklines that show relative performance, comparing an endpoint’s current metrics with its usual or previous data.
If you want to view further details about a given endpoint, you can expand it for additional metrics such as response size and errors separated by 4xx and 5xx. The expanded view also allows you to view all metrics at a single timestamp by hovering over the charts.
For each saved endpoint, customers can see the following metrics:
Request count: total number of requests to the endpoint over time.
Rate limiting recommendation per 10 minutes, which is guided by the request count.
Latency: average origin response time, in milliseconds (ms). How long does it take from the moment a visitor makes a request to the moment the visitor gets a response back from the origin?
Error rate vs. overall traffic: grouped by 4xx, 5xx, and their sum.
Response size: average size of the response (in bytes) returned to the request.
You can toggle between viewing these metrics on a 24-hour period or a 7-day period, depending on the scale on which you’d like to view your data. And in the expanded view, we provide a percentage difference between the averages of the current vs. the previous period. For example, say I’m viewing my metrics on a 24-hour timeline. My average latency yesterday was 10 ms, and my average latency today is 30 ms, so the dashboard shows a 200% increase. We also use anomaly detection to bring attention to endpoints that have concerning performance changes.
Additional improvements to Discovery and Schema Validation
As part of making endpoint management GA, we’re also adding two additional enhancements to API Shield.
First, API Discovery now accepts cookies — in addition to authorization headers — to discover endpoints and suggest rate limiting thresholds. Previously, you could only identify an API session with HTTP headers, which didn’t allow customers to protect endpoints that use cookies as session identifiers. Now these endpoints can be protected as well. Simply go to the API Shield tab in the dashboard, choose edit session identifiers, and either change the type, or click Add additional identifier.
Second, we added the ability to validate the body of requests via Schema Validation for all customers. Schema Validation allows you to provide an OpenAPI schema (a template for your API traffic) and have Cloudflare block non-conformant requests as they arrive at our edge. Previously, you provided specific headers, cookies, and other features to validate. Now that we can validate the body of requests, you can use Schema Validation to confirm every element of a request matches what is expected. If a request contains strange information in the payload, we’ll notice. Note: customers who have already uploaded schemas will need to re-upload to take advantage of body validation.
Endpoint Management, performance metrics, schema exporting, discovery via cookies, and schema body validation are all available now for all API Shield customers. To use them, log into the Cloudflare dashboard, click on Security in the navigation bar, and choose API Shield. Once API Shield is enabled, you’ll be able to start discovering endpoints immediately. You can also use all features through our API.
If you aren’t yet protecting a website with Cloudflare, it only takes a few minutes to sign up.
The step-up authentication solution discussed in Part 1 uses a reference implementation that you can use for demonstration and learning purposes. You can also review the implementation code in the step-up-auth GitHub repository. The reference implementation includes a web application that you can use in the following sections to test the step-up implementation. Additionally, the implementation contains a sample privileged API action /transfer and a non-privileged API action /info, and two step-up authentication solution API operations /initiate-auth, and /respond-to-challenge. The web application invokes these API operations to demonstrate how to perform step-up authentication.
You must have AWS credentials files that contain a profile with your account secret key and access key to perform the deployment. Make sure that your account has enough privileges to create, update, or delete the following resources:
A two-factor authentication (2FA) mobile application, such as Google Authenticator, is installed on your mobile device.
Deploy the step-up solution
You can deploy the solution by using the AWS CDK, which will create a working reference implementation of the step-up authentication solution.
To deploy the solution
Build the necessary resources by using the build.sh script in the deployment folder. Run the build script from a terminal window, using the following command: cd deployment && ./build.sh
Deploy the solution by using the deploy.sh script that is present in the deployment folder, using the following command. Be sure to replace the required environment variables with your own values. export AWS_REGION=<your AWS Region of choice, for example us-east-2> export AWS_ACCOUNT=<your account number> export AWS_PROFILE=<a valid profile in .aws/credentials that contains the secret/access key to your account> export NODE_ENV=development export ENV_PREFIX=dev
The account you specify in the AWS_ACCOUNT environment variable is used to bootstrap the AWS CDK deployment. Set AWS_PROFILE to point to your profile. Make sure that your account has sufficient privileges, as described in the prerequisites.
The NODE_ENV environment variable can be set to development or production. This variable controls the log output that the Lambda functions generate. The ENV_PREFIX environment variable allows you to prefix all resources with a tag, which enables a multi-tenant deployment of this solution.
Still in the deployment folder, deploy the stack by using the following command: ./deploy.sh
Make note of the CloudFront distribution URL that follows Sample Web App URL, as shown in Figure 1. In the next section, you will use this CloudFront distribution URL to load the sample web app in a web browser and test the step-up solution
Figure 1: The output of the deployment process
After the deployment script deploy.sh completes successfully, the AWS CDK creates the following resources in your account:
An Amazon Cognito user pool that is used as a user registry.
An Amazon API Gateway API that contains three resources:
A protected resource that requires step-up authentication.
An initiate-auth resource to start the step-up challenge response.
A respond-to-challenge resource to complete the step-up challenge.
An API Gateway Lambda authorizer that is used to protect API actions.
The following Amazon DynamoDB tables:
A setting table that holds the configuration mapping of the API operations that require elevated privileges.
A session table that holds temporary, user-initiated step-up sessions and their current status.
A React web UI that demonstrates how to invoke a privileged API action and go through step-up authentication.
Test the step-up solution
In order to test the step-up solution, you’ll use the sample web application that you deployed in the previous section. Here’s an overview of the actions you’ll perform to test the flow:
In the AWS Management Console, create items in the setting DynamoDB table that point to privileged API actions. After the solution deployment, the setting DynamoDB table is called step-up-auth-setting-<ENV_PREFIX>. For more information about ENV_PREFIX variable usage in a multi-tenant environment, see Deploy the step-up solution earlier in this post.
As discussed, in the Data design section in Part 1 of this series, the Lambda authorizer treats all API invocations as non-privileged (that is, they don’t require step-up authentication) unless there is a matching entry for the API action in the setting table. Additionally, you can switch a privileged API action to a non-privileged API action by simply changing the stepUpState attribute in the setting table. Create an item in the DynamoDB table for the sample /transfer API action and for the sample /info API action. The /transfer API action will require step-up authentication, whereas the /info API action will be a non-privileged invocation that does not require step-up authentication. Note that there is no need to define a non-privileged API action in the table; it is there for illustration purposes only.
If you haven’t already, install Google Authenticator or a similar two-factor authentication (2FA) application on your mobile device.
Using the sample web application, register a new user in Amazon Cognito.
Log in to the sample web application by using the registered new user.
Configure the preferred multi-factor authentication (MFA) settings for the logged in user in the application. This step is necessary so that Amazon Cognito can challenge the user with a one-time password (OTP).
Using the sample web application, invoke the sample /transfer privileged API action that requires step-up authentication.
The Lambda authorizer will intercept the API request and return a 401 Unauthorized response status code that the sample web application will handle. The application will perform step-up authentication by prompting you to provide additional security credentials, specifically the OTP. To complete the step-up authentication, enter the OTP, which is sent through short service message (SMS) or by using an authenticator mobile app.
Invoke the sample /transfer privileged API action again in the sample web application, and verify that the API invocation is successful.
The following instructions assume that you’ve installed a 2FA mobile application, such as Google Authenticator, on your mobile device. You will configure the 2FA application in the following steps and use the OTP from this mobile application when prompted to enter the step-up challenge. You can configure Amazon Cognito to send you an SMS with the OTP. However, you must be aware of the Amazon Cognito throttling limits. See the Additional considerations section in Part 1 of this series. Read these limits carefully, especially if you set the user’s preferred MFA setting to SMS.
On the left nav pane, under Tables, choose Explore items. In the right pane, choose the table named step-up-auth-setting* and choose Create item, as shown in Figure 2.
Figure 2: Choose the step-up-auth-setting* table and choose Create item button
In the Edit item screen as shown in Figure 3, ensure that JSON is selected, and the Attributes button for View DynamoDB JSON is off.
Figure 3: Edit an item in the table – select JSON and turn off View DynamoDB JSON button
To create an entry for the /info API action, copy the following JSON text:
Paste the copied JSON text for the /transfer API action in the Attributes text area, as shown in Figure 4, and choose Create item.
Figure 5: Create an entry for the /transfer API action
Open your web browser and load the CloudFront URL that you made note of in step 4 of the Deploy the step-up solution procedure.
On the login screen of the sample web application, enter the information for a new user. Make sure that the email address and phone numbers are valid. Choose Register. You will be prompted to enter a verification code. Check your email for the verification code, and enter it at the sample web application prompt.
You will be sent back to the login screen. Log in as the user that you just registered. You will see the welcome screen, as shown in Figure 6.
Figure 6: Welcome screen of the sample web application
In the left nav pane choose Setting, choose the Configure button to the right of Software Token, as shown in Figure 7. Use your mobile device camera to capture the QR code on the screen in your 2FA application, for example Google Authenticator.
Figure 7: Configure Software Token screen with QR code
Enter the temporary code from the 2FA application into the web application and choose Submit. You will see the message Software Token successfully configured!
Still in the Setting menu, next to Select Preferred MFA, choose Software Token. You will see the message User preferred MFA set to Software Token, as shown in Figure 8.
Figure 8: Completed Software Token setup
In the left nav pane choose StepUp Auth. In the right pane, choose Invoke Transfer API. You should see Response: 401 authorization challenge, as shown in Figure 9.
Figure 9: The step-up API invocation returns an authorization challenge
On your mobile device, open the 2FA application, copy the OTP code from the 2FA application, and enter the code into the Enter OTP field, as shown in Figure 9. Choose Submit.
This sends the OTP to the respond-to-challenge endpoint. After the OTP is verified, the endpoint will return a success or failure message. Figure 10 shows a successful OTP verification. You are prompted to invoke the /transfer privileged API action again.
Figure 10: The OTP prompt during step-up API invocation
Invoke the transfer API action again by choosing Invoke Transfer API. You should see a success message as shown in Figure 11.
Figure 11: A successful step-up API invocation
Congratulations! You’ve successfully performed step-up authentication.
Conclusion
In the previous post in this series, Implement step-up authentication with Amazon Cognito, Part 1: Solution overview, you learned about the architecture and implementation details for the step-up authentication solution. In this blog post, you learned how to deploy and test the step-up authentication solution in your AWS account. You deployed the solution by using scripts from the step-up-auth GitHub repository that use the AWS CDK to create resources in your account for Amazon Cognito, Amazon API Gateway, a Lambda authorizer, and Amazon DynamoDB. Finally, you tested the end-to-end solution on a sample web application by invoking a privileged API action that required step-up authentication. Using the 2FA application, you were able to pass in an OTP to complete the step-up authentication and subsequently successfully invoke the privileged API action.
If you have feedback about this post, submit comments in the Comments section below. If you have any questions about this post, start a thread on the Amazon Cognito forum.
Want more AWS Security news? Follow us on Twitter.
In this blog post, you’ll learn how to protect privileged business transactions that are exposed as APIs by using multi-factor authentication (MFA) or security challenges. These challenges have two components: what you know (such as passwords), and what you have (such as a one-time password token). By using these multi-factor security controls, you can implement step-up authentication to obtain a higher level of security when you perform critical transactions. In this post, we show you how you can use AWS services such as Amazon API Gateway, Amazon Cognito, Amazon DynamoDB, and AWS Lambda functions to implement step-up authentication by using a simple rule-based security model for your API resources.
Previously, identity and access management solutions have attempted to deliver step-up authentication by retrofitting their runtimes with stateful server-side management, which doesn’t scale in the modern-day stateless cloud-centered application architecture. We’ll show you how to use a pluggable, stateless authentication implementation that integrates into your existing infrastructure without compromising your security or performance. The Amazon API Gateway Lambda authorizer is a pluggable serverless function that acts as an intermediary step before an API action is invoked. This Lambda authorizer, coupled with a small SDK library that runs in the authorizer, will provide step-up authentication.
The reference architecture in this post uses a purpose-built step-up authorization workflow engine, which uses a custom SDK. The custom SDK uses the DynamoDB service as a persistent layer. This workflow engine is generic and can be used across any API serving layers, such as API Gateway or Elastic Load Balancing (ELB) Application Load Balancer, as long as the API serving layers can intercept API requests to perform additional actions. The step-up workflow engine also relies on an identity provider that is capable of issuing an OAuth 2.0 access token.
There are three parts to the step-up authentication solution:
An API serving layer with the capability to apply custom logic before applying business logic.
An OAuth 2.0–capable identity provider system.
A purpose-built step-up workflow engine.
The solution in this post uses Amazon Cognito as the identity provider, with an API Gateway Lambda authorizer to invoke the step-up workflow engine, and DynamoDB as a persistent layer used by the step-up workflow engine. You can see a reference implementation of the API Gateway Lambda authorizer in the step-up-auth GitHub repository. Additionally, the purpose-built step-up workflow engine provides two API endpoints (or API actions), /initiate-auth and /respond-to-challenge, which are realized using the API Gateway Lambda authorizer, to drive the API invocation step-up state.
Note: If you decide to use an API serving layer other than API Gateway, or use an OAuth 2.0 identity provider besides Amazon Cognito, you will have to make changes to the accompanying sample code in the step-up-auth GitHub repository.
Solution architecture
Figure 1 shows the high-level reference architecture.
First, let’s talk about the core components in the step-up authentication reference architecture in Figure 1.
Identity provider
In order for a client application or user to invoke a protected backend API action, they must first obtain a valid OAuth token or JSON web token (JWT) from an identity provider. The step-up authentication solution uses Amazon Cognito as the identity provider. The step-up authentication solution and the accompanying step-up API operations use the access token to make the step-up authorization decision.
Protected backend
The step-up authentication solution uses API Gateway to protect backend resources. API Gateway supports several different API integration types, and you can use any one of the supported API Gateway integration types. For this solution, the accompanying sample code in the step-up-auth GitHub repository uses Lambda proxy integration to simulate a protected backend resource.
Data design
The step-up authentication solution relies on two DynamoDB tables, a session table and a setting table. The session table contains the user’s step-up session information, and the setting table contains an API step-up configuration. The API Gateway Lambda authorizer (described in the next section) checks the setting table to determine whether the API request requires a step-up session. For more information about table structure and sample values, see the Step-up authentication data design section in the accompanying GitHub repository.
The session table has the DynamoDB Time to Live (TTL) feature enabled. An item stays in the session table until the TTL time expires, when DynamoDB automatically deletes the item. The TTL value can be controlled by using the environment variable SESSION_TABLE_ITEM_TTL. Later in this post, we’ll cover where to define this environment variable in the Step-up solution design details section; and we’ll cover how to set the optimal value for this environment variable in the Additional considerations section.
Authorizer
The step-up authentication solution uses a purpose-built request parameter-based Lambda authorizer (also called a REQUEST authorizer). This REQUEST authorizer helps protect privileged API operations that require a step-up session.
The authorizer verifies that the API request contains a valid access token in the HTTP Authorization header. Using the access token’s JSON web token ID (JTI) claim as a key, the authorizer then attempts to retrieve a step-up session from the session table. If a session exists and its state is set to either STEP_UP_COMPLETED or STEP_UP_NOT_REQUIRED, then the authorizer lets the API call through by generating an allow API Gateway Lambda authorizer policy. If the set-up state is set to STEP_UP_REQUIRED, then the authorizer returns a 401 Unauthorized response status code to the caller.
If a step-up session does not exist in the session table for the incoming API request, then the authorizer attempts to create a session. It first looks up the setting table for the API configuration. If an API configuration is found and the configuration status is set to STEP_UP_REQUIRED, it indicates that the user must provide additional authentication in order to call this API action. In this case, the authorizer will create a new session in the session table by using the access token’s JTI claim as a session key, and it will return a 401 Unauthorized response status code to the caller. If the API configuration in the setting table is set to STEP_UP_DENY, then the authorizer will return a deny API Gateway Lambda authorizer policy, therefore blocking the API invocation. The caller will receive a 403 Forbidden response status code.
The authorizer uses the purpose-built auth-sdk library to interface with both the session and setting DynamoDB tables. The auth-sdk library provides convenient methods to create, update, or delete items in tables. Internally, auth-sdk uses the DynamoDB v3 Client SDK.
Initiate auth endpoint
When you deploy the step-up authentication solution, you will get the following two API endpoints:
The initiate step-up authentication endpoint (described in this section).
The respond to step-up authentication challenge endpoint (described in the next section).
When a client receives a 401 Unauthorized response status code from API Gateway after invoking a privileged API operation, the client can start the step-up authentication flow by invoking the initiate step-up authentication endpoint (/initiate-auth).
The /initiate-auth endpoint does not require any extra parameters, it only requires the Amazon Cognito access_token to be passed in the Authorization header of the request. The /initiate-auth endpoint uses the access token to call the Amazon Cognito API actions GetUser and GetUserAttributeVerificationCode on behalf of the user.
After the /initiate-auth endpoint has determined the proper multi-factor authentication (MFA) method to use, it returns the MFA method to the client. There are three possible values for the MFA methods:
MAYBE_SOFTWARE_TOKEN_STEP_UP, which is used when the MFA method cannot be determined.
SOFTWARE_TOKEN_STEP_UP, which is used when the user prefers software token MFA.
SMS_STEP_UP, which is used when the user prefers short message service (SMS) MFA.
Let’s take a closer look at how /initiate-auth endpoint determines the type of MFA methods to return to the client. The endpoint calls Amazon Cognito GetUser API action to check for user preferences, and it takes the following actions:
Determines what method of MFA the user prefers, either software token or SMS.
If the user’s preferred method is set to software token, the endpoint returns SOFTWARE_TOKEN_STEP_UP code to the client.
If the user’s preferred method is set to SMS, the endpoint sends an SMS message with a code to the user’s mobile device. It uses the Amazon Cognito GetUserAttributeVerificationCode API action to send the SMS message. After the Amazon Cognito API action returns success, the endpoint returns SMS_STEP_UP code to the client.
When the user preferences don’t include either a software token or SMS, the endpoint checks if the response from Amazon Cognito GetUser API action contains UserMFASetting response attribute list with either SOFTWARE_TOKEN_MFA or SMS_MFA keywords. If the UserMFASetting response attribute list contains SOFTWARE_TOKEN_MFA, then the endpoint returns SOFTWARE_TOKEN_STEP_UP code to the client. If it contains SMS_MFA keyword, then the endpoint invokes the Amazon Cognito GetUserAttributeVerificationCode API action to send the SMS message (as in step 3). Upon successful response from the Amazon Cognito API action, the endpoint returns SMS_STEP_UP code to the client.
If the UserMFASetting response attribute list from Amazon Cognito GetUser API action does not contain SOFTWARE_TOKEN_MFA or SMS_MFA keywords, then the endpoint looks for phone_number_verified attribute. If found, then the endpoint sends an SMS message with a code to the user’s mobile device with verified phone number. The endpoint uses the Amazon Cognito GetUserAttributeVerificationCode API action to send the SMS message (as in step 3). Otherwise, when no verified phone is found, the endpoint returns MAYBE_SOFTWARE_TOKEN_STEP_UP code to the client.
The flowchart shown in Figure 2 illustrates the full decision logic.
Figure 2: MFA decision flow chart
Respond to challenge endpoint
The respond to challenge endpoint (/respond-to-challenge) is called by the client after it receives an appropriate MFA method from the /initiate-auth endpoint. The user must respond to the challenge appropriately by invoking /respond-to-challenge with a code and an MFA method.
The /respond-to-challenge endpoint receives two parameters in the POST body, one indicating the MFA method and the other containing the challenge response. Additionally, this endpoint requires the Amazon Cognito access token to be passed in the Authorization header of the request.
If the MFA method is SMS_STEP_UP, the /respond-to-challenge endpoint invokes the Amazon Cognito API action VerifyUserAttribute to verify the user-provided challenge response, which is the code that was sent by using SMS.
If the MFA method is SOFTWARE_TOKEN_STEP_UP or MAYBE_SOFTWARE_TOKEN_STEP_UP, the /respond-to-challenge endpoint invokes the Amazon Cognito API action VerifySoftwareToken to verify the challenge response that was sent in the endpoint payload.
After the user-provided challenge response is verified, the /respond-to-challenge endpoint updates the session table with the step-up session state STEP_UP_COMPLETED by using the access_token JTI. If the challenge response verification step fails, no changes are made to the session table. As explained earlier in the Data design section, the step-up session stays in the session table until the TTL time expires, when DynamoDB will automatically delete the item.
Deploy and test the step-up authentication solution
Otherwise, you can continue reading the rest of this post to review the details and code behind the step-up authentication solution.
Step-up solution design details
Now let’s dig deeper into the step-up authentication solution. Figure 3 expands on the high-level solution design in the previous section and highlights the sequence of events that must take place to perform step-up authentication. In this section, we’ll break down these sequences into smaller parts and discuss each by going over a detailed sequence diagram.
Let’s group the step-up authentication flow in Figure 3 into three parts:
Create a step-up session (steps 1-6 in Figure 3)
Initiate step-up authentication (steps 7-8 in Figure 3)
Respond to the step-up challenge (steps 9-12 in Figure 3)
In the next sections, you’ll learn how the user’s API requests are handled by the step-up authentication solution, and how the user state is elevated by going through an additional challenge.
Create a step-up session
After the user successfully logs in, they create a step-up session when invoking a privileged API action that is protected with the step-up Lambda authorizer. This authorizer determines whether to start a step-up challenge based on the configuration within the DynamoDB setting table, which might create a step-up session in the DynamoDB session table. Let’s go over steps 1–6, shown in the architecture diagram in Figure 3, in more detail:
Step 1 – It’s important to note that the user must authenticate with Amazon Cognito initially. As a result, they must have a valid access token generated by the Amazon Cognito user pool.
Step 2 – The user then invokes a privileged API action and passes the access token in the Authorization header.
Step 3 – The API action is protected by using a Lambda authorizer. The authorizer first validates the token by invoking the Amazon Cognito user pool public key. If the token is invalid, a 401 Unauthorized response status code can be sent immediately, prompting the client to present a valid token.
Step 4 – The authorizer performs a lookup in the DynamoDB setting table to check whether the current request needs elevated privilege (also known as step-up privilege). In the setting table, you can define which API actions require elevated privilege. You can additionally bundle API operations into a group by defining the group attribute. This allows you to further isolate privileged API operations, especially in a large-scale deployment.
Step 5 – If an API action requires elevated privilege, the authorizer will check for an existing step-up session for this specific user in the session table. If a step-up session does not exist, the authorizer will create a new entry in the session table. The key for this table will be the JTI claim of the access_token (which can be obtained after token verification).
Step 6 – If a valid session exists, then authorization will be given. Otherwise an unauthorized access response (401 HTTP code) will be sent back from the Lambda authorizer, indicating that the user requires elevated privilege.
Figure 4 highlights these steps in a sequence diagram.
Figure 4: Sequence diagram for creating a step-up session
Initiate step-up authentication
After the user receives a 401 Unauthorized response status code from invoking the privileged API action in the previous step, the user must call the /initiate-auth endpoint to start step-up authentication. The endpoint will return the response to the user or the client application to supply the temporary code. Let’s go over steps 7 and 8, shown in the architecture diagram in Figure 3, in more detail:
Step 7 – The client application initiates a step-up action by calling the /initiate-auth endpoint. This action is protected by the API Gateway built-in Amazon Cognito authorizer, and the client needs to pass a valid access_token in the Authorization header.
Step 8 – The call is forwarded to a Lambda function that will initiate the step-up action with the end user. The function first calls the Amazon Cognito API action GetUser to find out the user’s MFA settings. Depending on which MFA type is enabled for the user, the function uses different Amazon Cognito API operations to start the MFA challenge. For more details, see the Initiate auth endpoint section earlier in this post.
Figure 5 shows these steps in a sequence diagram.
Figure 5: Sequence diagram for invoking /initiate-auth to start step-up authentication
Respond to the step-up challenge
In the previous step, the user receives a challenge code from the /initiate-auth endpoint. Depending on the type of challenge code, user must respond by sending a one-time password (OTP) to the /respond-to-challenge endpoint. The /respond-to-challenge endpoint invokes an Amazon Cognito API action to verify the OTP. Upon successful verification, the /respond-to-challenge endpoint marks the step-up session in the session table to STEP_UP_COMPLETED, indicating that the user now has elevated privilege. At this point, the user can invoke the privileged API action again to perform the elevated business operation. Let’s go over steps 9–12, shown in the architecture diagram in Figure 3, in more detail:
Step 9 – The client application presents an appropriate screen to the user to collect a response to the step-up challenge. The client application calls the /respond-to-challenge endpoint that contains the following:
An access_token in the Authorization header.
A step-up challenge type.
A response provided by the user to the step-up challenge.
This endpoint is protected by the API Gateway built-in Amazon Cognito authorizer.
Step 10 – The call is forwarded to the Lambda function, which verifies the response by calling the Amazon Cognito API action VerifyUserAttribute (in the case of SMS_STEP_UP) or VerifySoftwareToken (in the case of SOFTWARE_TOKEN_STEP_UP), depending on the type of step-up action that was returned from the /initiate-auth API action. The Amazon Cognito response will indicate whether verification was successful.
Step 11 – If the Amazon Cognito response in the previous step was successful, the Lambda function associated with the /respond-to-challenge endpoint inserts a record in the session table by using the access_token JTI as key. This record indicates that the user has completed step-up authentication. The record is inserted with a time to live (TTL) equal to the lesser of these values: the remaining period in the access_token timeout, or the default TTL value that is set in the Lambda function as a configurable environment variable, SESSION_TABLE_ITEM_TTL. The /respond-to-challenge endpoint returns a 200 status code after successfully updating the session table. It returns a 401 Unauthorized response status code if the operation failed or if the Amazon Cognito API calls in the previous step failed. For more information about the optimal value for the SESSION_TABLE_ITEM_TTL variable, see the Additional considerations section later in this post.
Step 12 – The client application can re-try the original call (using the same access token) to the privileged API operations, and this call should now succeed because an active step-up session exists for the user. Calls to other privileged API operations that require step-up should also succeed, as long as the step-up session hasn’t expired.
Figure 6 shows these steps in a sequence diagram.
Figure 6: Invoke the /respond-to-challenge endpoint to complete step-up authentication
Additional considerations
This solution uses several Amazon Cognito API operations to provide step-up authentication functionality. Amazon Cognito applies rate limiting on all API operations categories, and rapid calls that exceed the assigned quota will be throttled.
The step-up flow for a single user can include multiple Amazon Cognito API operations such as GetUser, GetUserAttributeVerificationCode, VerifyUserAttribute, and VerifySoftwareToken. These Amazon Cognito API operations have different rate limits. The effective rate, in requests per second (RPS), that your privileged and protected API action can achieve will be equivalent to the lowest category rate limit among these API operations. When you use the default quota, your application can achieve 25 SMS_STEP_UP RPS or up to 50 SOFTWARE_TOKEN_STEP_UP RPS.
Certain Amazon Cognito API operations have additional security rate limits per user per hour. For example, the GetUserAttributeVerificationCode API action has a limit of five calls per user per hour. For that reason, we recommend 15 minutes as the minimum value for SESSION_TABLE_ITEM_TTL, as this will allow a single user to have up to four step-up sessions per hour if needed.
Conclusion
In this blog post, you learned about the architecture of our step-up authentication solution and how to implement this architecture to protect privileged API operations by using AWS services. You learned how to use Amazon Cognito as the identity provider to authenticate users with multi-factor security and API Gateway with an authorizer Lambda function to enforce access to API actions by using a step-up authentication workflow engine. This solution uses DynamoDB as a persistent layer to manage the security rules for the step-up authentication workflow engine, which helps you to efficiently manage your rules.
If you have feedback about this post, submit comments in the Comments section below. If you have any questions about this post, start a thread on the Amazon Cognito forum.
Want more AWS Security news? Follow us on Twitter.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.